Datawhale 理工科-大模型入门实训课程 202509 第1次作业
💻 算力需求
算力配置
- 显卡:RTX 4090 24G显存/人
- 内存:16G以上
其他需求
- 操作系统:Linux服务器
- CPU:不要太低,否则处理速度太慢
- 硬盘:单个机器硬盘50G以上
- 环境:最好是有某LLM镜像的,至少需要有Pytorch 2.5.1、CUDA 12.4以上
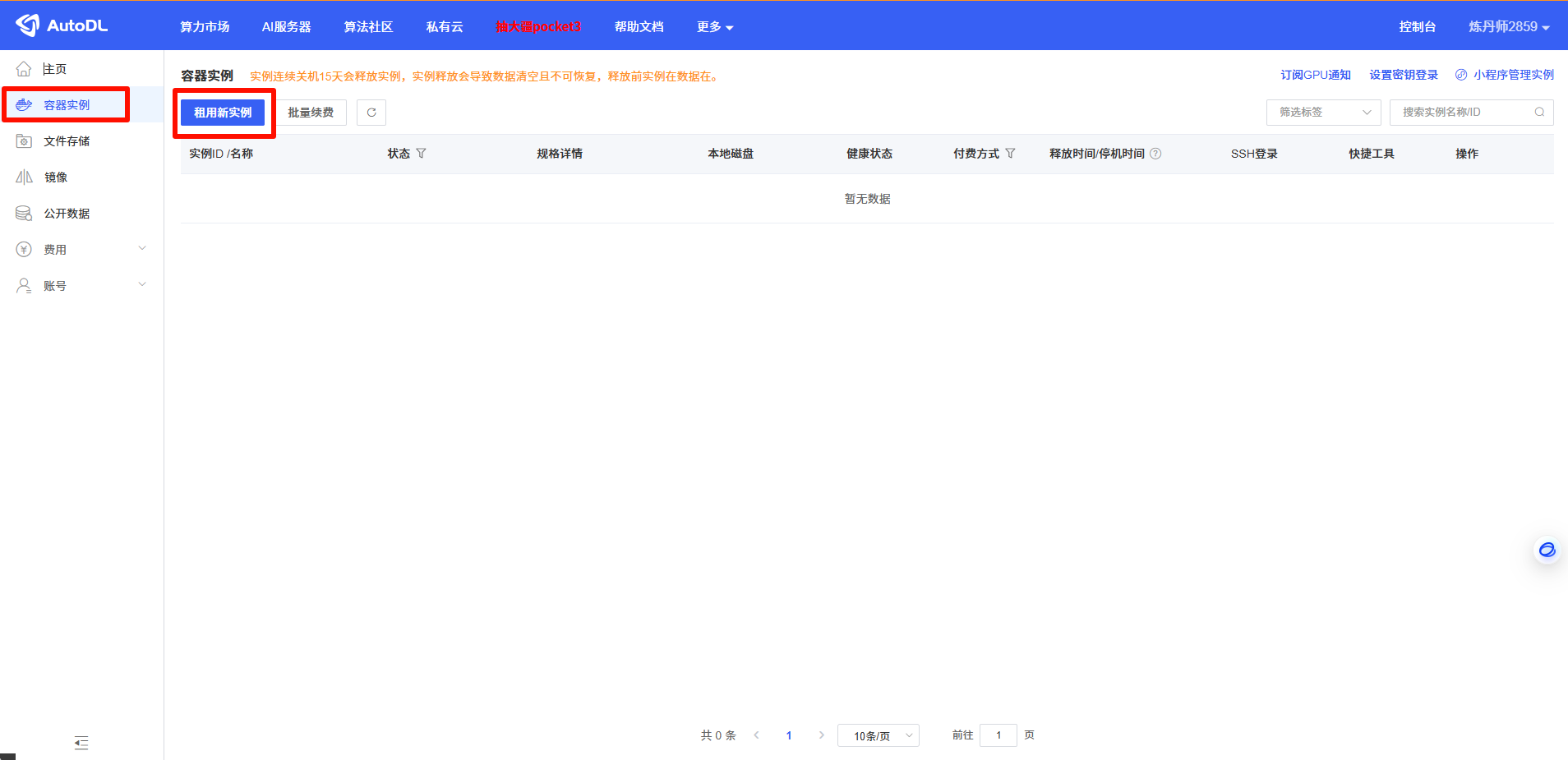
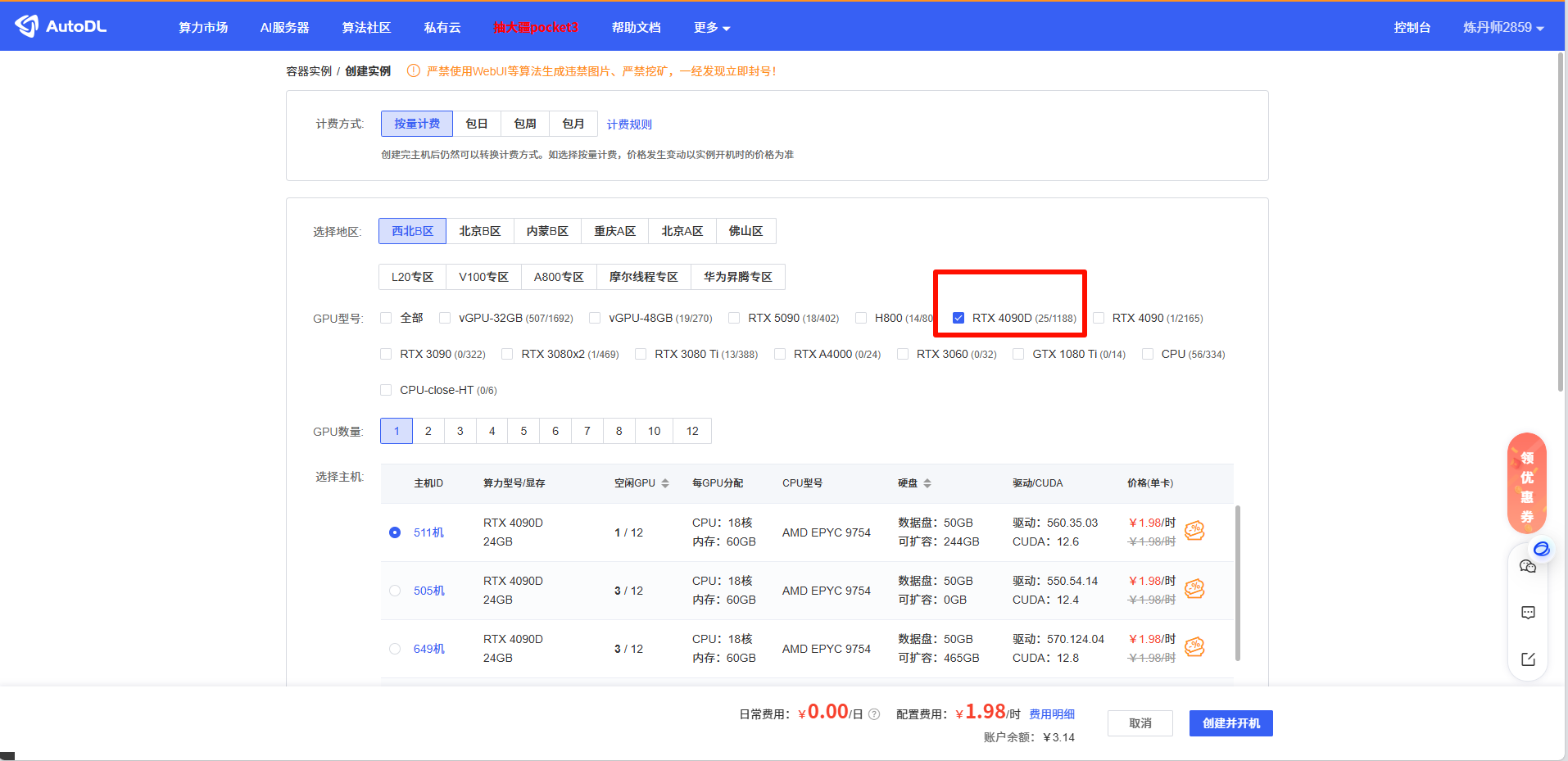
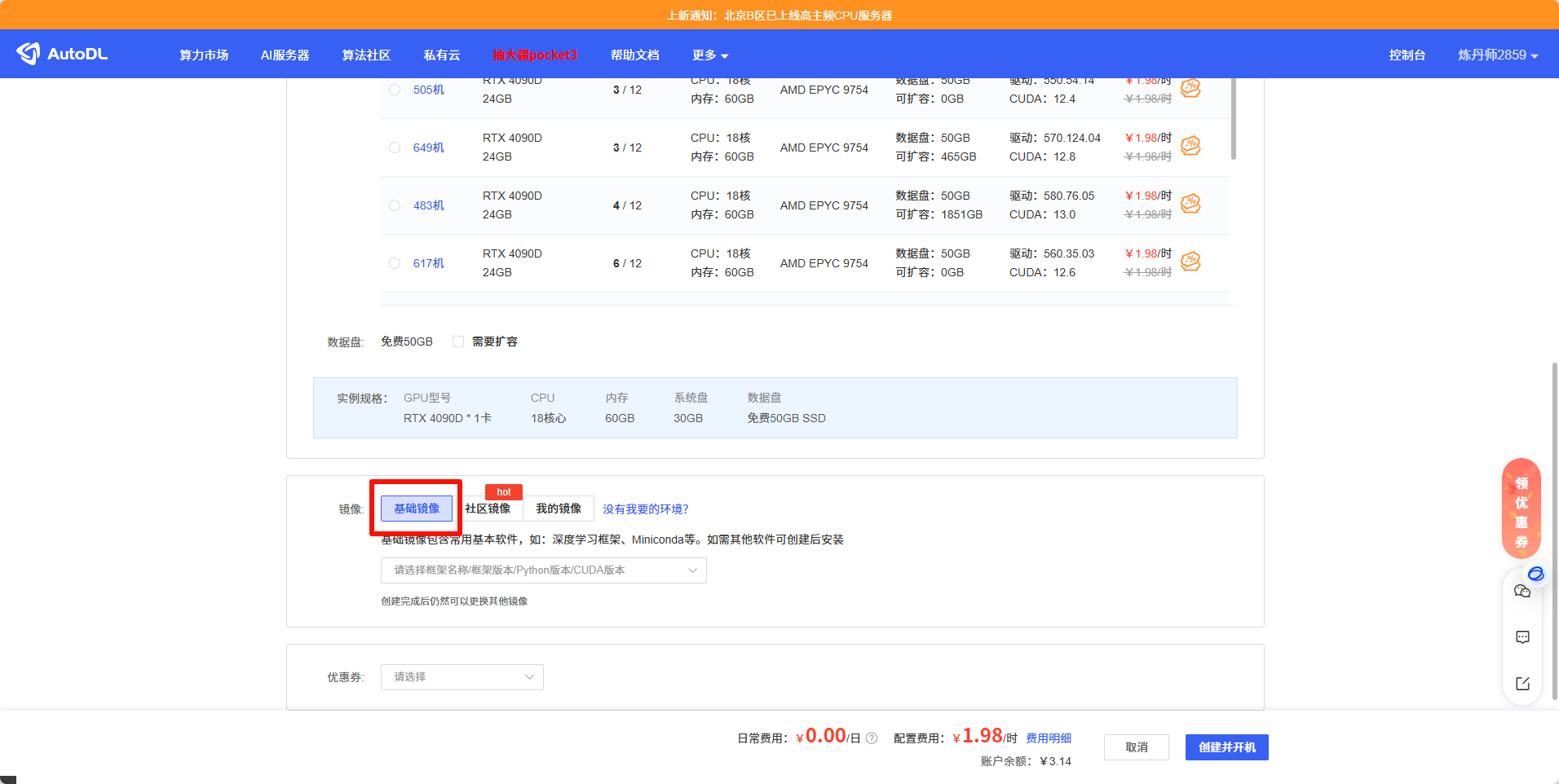
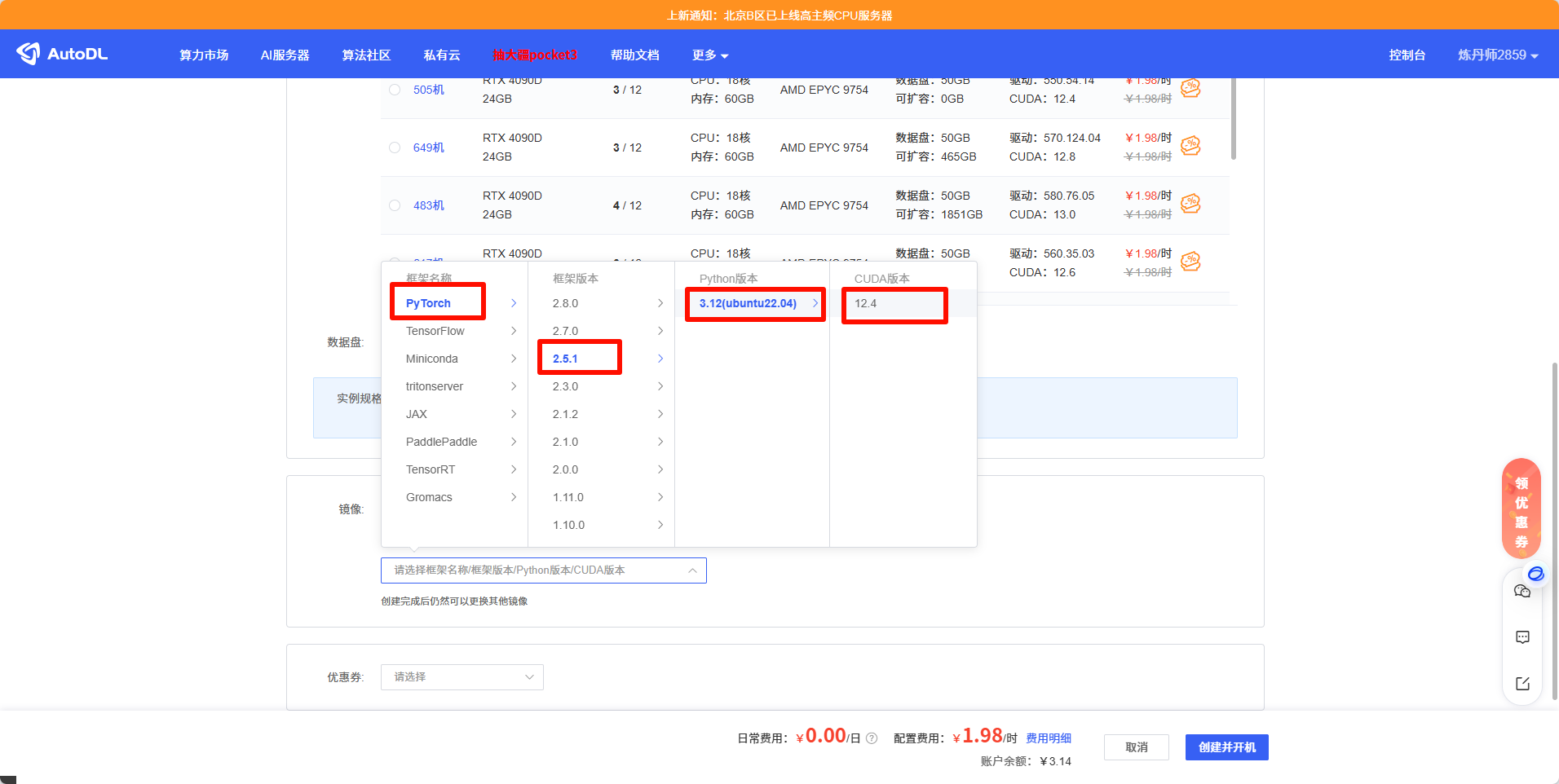
Autodl创建实例地址:
datawhalechina/llm-preview/llm-preview: llm-preview - CG![]() https://www.codewithgpu.com/i/datawhalechina/llm-preview/llm-previewshift+enter 可以运行
https://www.codewithgpu.com/i/datawhalechina/llm-preview/llm-previewshift+enter 可以运行
运行结果:

作业:
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-4B-Instruct-2507', cache_dir='/root/autodl-tmp/model', revision='master')全部代码是:
# 导入必要的transformers库组件
from transformers import AutoModelForCausalLM, AutoTokenizer# 设置模型本地路径
model_name = "/root/autodl-tmp/model/Qwen/Qwen3-0___6B"# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto", # 自动选择合适的数据类型device_map="auto", # 自动选择可用设备(CPU/GPU)trust_remote_code=True
)# 准备模型输入
prompt = "你好,你叫什么名字"
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # 选择是否打开深度推理模式
)
# 将输入文本转换为模型可处理的张量格式
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# 生成文本
generated_ids = model.generate(**model_inputs,max_new_tokens=32768 # 设置最大生成token数量
)
# 提取新生成的token ID
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # 解析思考内容
try:# rindex finding 151668 (</think>)# 查找结束标记"</think>"的位置index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0# 解码思考内容和最终回答
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")# 打印结果
print("thinking content:", thinking_content)
print("content:", content)显示结果:
thinking content: <think> 好的,用户问:“你好,你叫什么名字”。首先,我需要确认用户是否在测试我的名字,或者他们可能有其他意图。作为AI助手,我应该以友好和专业的态度回应。接下来,我需要考虑用户可能的背景。他们可能是第一次与我交谈,或者想了解我的身份。因此,回答应该简洁明了,同时保持亲切。然后,我需要检查是否有任何潜在的问题。例如,用户可能对我的角色或功能有疑问,或者希望确认我的身份。在这种情况下,提供明确的说明是必要的。最后,确保回答符合用户的需求。他们可能需要知道我的名字,或者希望得到更多的信息。因此,回答应该包含名字,并邀请进一步交流。 </think> content: 你好!我是你的AI助手,叫小明。有什么可以帮助你的吗?