[Token剪枝]Token Cropr: 针对众多任务的更快ViT, CVPR2025
Token Cropr: Faster ViTs for Quite a Few Tasks
paper|code
Motivation
为了提高ViT的吞吐量,已经提出了许多token剪枝、合并的方法,这些方法通过减少token提高效率。但是设计一种快速、高性能并适用于各种视觉任务的token减少方法依然是值得探索的问题。
设计了token剪枝器,通过辅助预测头根据任务特点学习token的选择。这些辅助头可以在训练后移除。
在图像分类、语义分割、目标检测和实例分割上评估了该方法,有 1.5 – 4 倍的加速,性能略有下降。
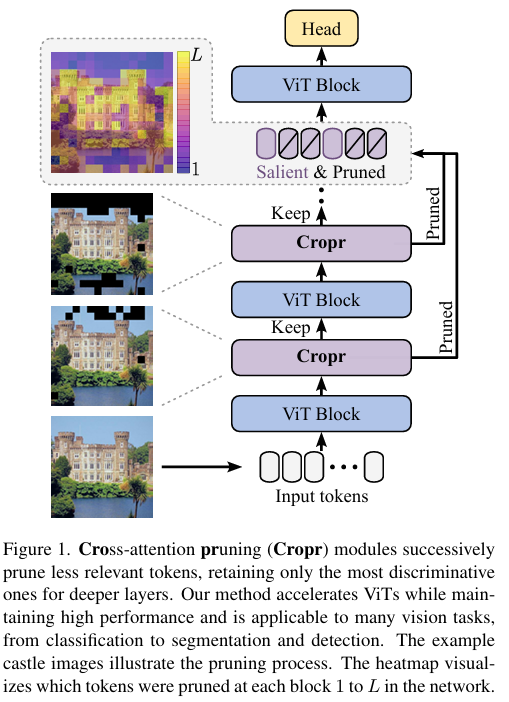
Related Work
如何有效评估图片中的token对给定任务的重要性?
启发式方法token剪枝和token merge等没有明确地将token针对给定任务重要性建模。归因方法,开销大。
语义分类等密集任务与token剪枝的想法本质上是冲突的。
Method
训练时的Cropr模块
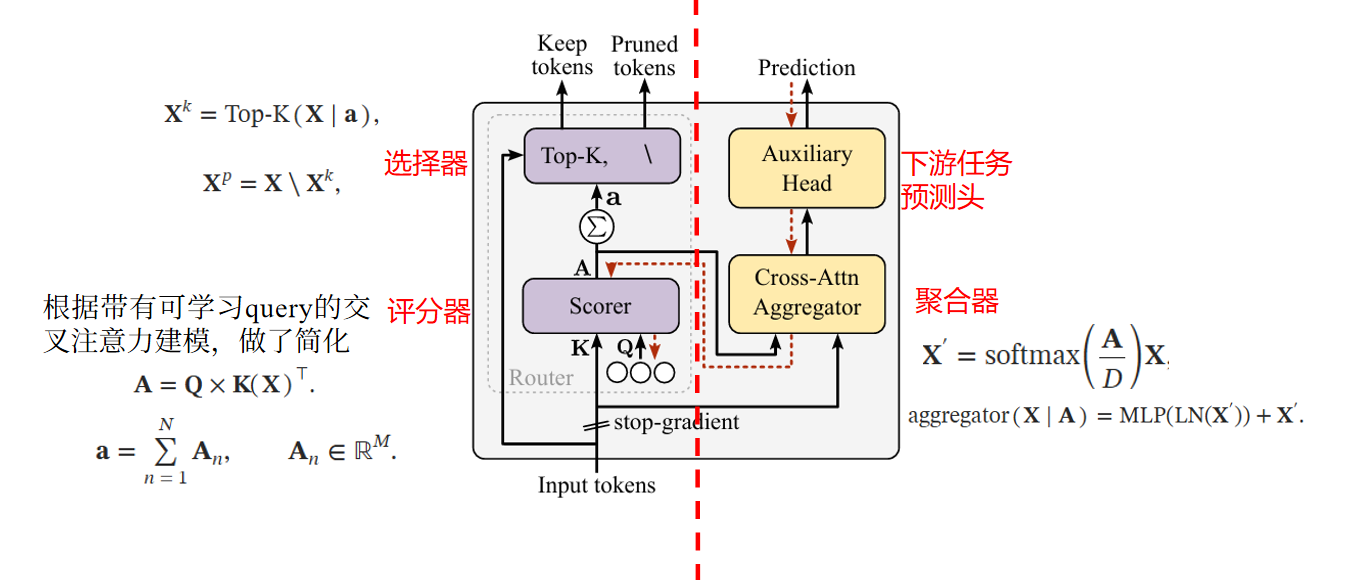
聚合的输出由特定于任务的头处理以进行中间预测,这反过来又为训练聚合器和打分器提供了梯度。
在打分和聚合块之间应用了停止梯度。将辅助头与主干隔离开,编码器不受辅助损失的冲突梯度的影响。 在训练期间保证效率,因为 Cropr 组件的梯度不会通过编码器反向传播。
推理时的Cropr模块
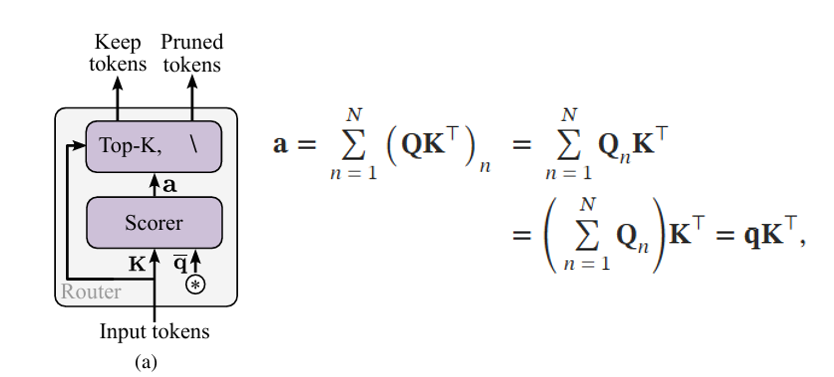
针对密集任务的最后一层融合LLF
来自所有 Cropr 模块的剪枝 token 会被插入到倒数第二个 ViT 块输出的保留 token 旁边 (图 1),位于它们各自的空间位置。最终的 ViT 块处理这个组合序列,允许先前剪枝的token关注保留token的深层特征。
应用于特定任务的预测头设计
语义分割
主头和辅助头都采用 Segmenter的线性头。评分器为每个 patch token 使用一个可学习查询,以获取网格结构表示。聚合器输出使用 LN 和线性投影处理,但独立于每个 patch 位置,然后是每个 patch 的 softmax 交叉熵损失。为了降低辅助头的计算复杂性,标签被下采样到特征图分辨率,然后可以在 Cropr 模块中重用下采样的标签。
举例
考虑一个 ViT-L,它有24个block,224×224的输入图像,每个patch块数为16,因此有196个patch token。(224/16)使用 LLF,剪枝在每两个块之后执行,这种逐块的修剪策略会每次修剪 R 个 Token。
Experiment
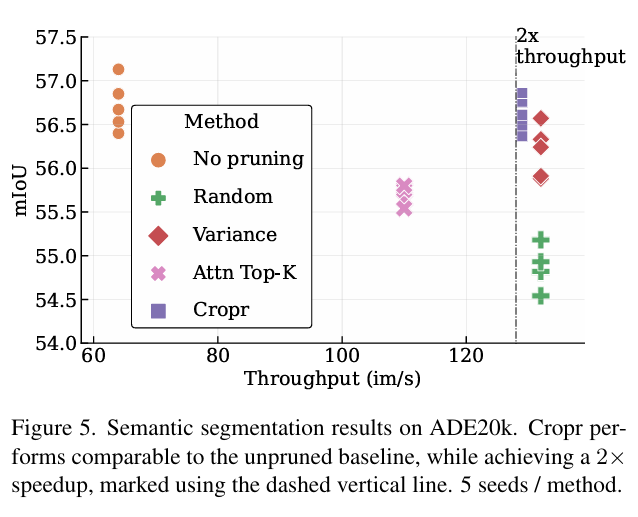
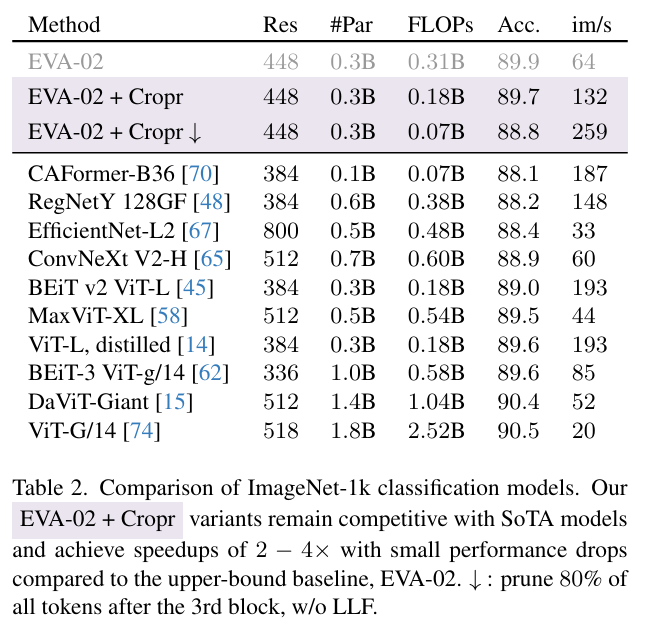
启发
- 参考设计训练和推理分开的模块加速推理过程。
- 根据超分特点,设计聚合模块和预测头。
- 做token merge但是不能每层都merge,可以参考这里安排的每两层或几层学习一次token相似度。