联邦学习论文分享:
摘要
1. 研究背景与问题
-
多机构协作可以提升深度 MRI 重建模型的训练效果,但跨站点共享成像数据会带来隐私风险。
-
联邦学习(FL)可以解决隐私问题,通过在各站点不传输原始数据的情况下进行分布式训练。
-
现有的 FL 方法通常使用条件重建模型(conditional reconstruction models)从欠采样数据映射到完全采样数据,这种方法泛化性差:
-
对不同加速率(acceleration rates)或采样密度(sampling densities)适应性弱;
-
训练和测试时需要固定成像算子(imaging operator),并且通常需要跨站点一致。
-
2. 提出的方法
-
提出 FedGIMP(Federated learning of Generative IMage Priors),目标是提高泛化能力和多机构协作的灵活性。
-
两阶段方法:
-
跨站点学习生成式 MRI 先验(generative MRI prior)
-
使用无条件对抗模型(unconditional adversarial model / GAN)生成高质量 MR 图像。
-
基于潜在变量(latent variables)生成图像。
-
-
个体化注入成像算子(subject-specific injection)
-
引入一个 mapper 子网络,生成站点特定的潜在变量,保持生成先验的特异性。
-
推断阶段,将先验与个体成像算子结合,进行 MRI 重建,并通过数据一致性损失(data-consistency loss)进行局部调整。
-
-
3. 实验与结果
-
在多机构数据集上的综合实验表明:
-
FedGIMP 的泛化性能优于基于条件模型的集中式(centralized)和联邦(federated)方法。
-
方法在不同采样密度和加速率下仍能保持较好重建效果。
-
引言
1. 背景与问题
-
MRI 优势与限制:MRI 无创且软组织对比度高,但低信噪比导致扫描时间长,影响临床使用。
-
加速 MRI:通过欠采样获取数据,并结合重建算法和先验信息恢复缺失数据,提高效率。
-
深度学习应用:深度模型可学习数据驱动的先验,用于从欠采样数据到全采样图像的条件映射(conditional mapping)。
-
数据获取难题:单一机构难以收集大量多样化数据,受成本和隐私限制。
2. 联邦学习(FL)的优势与挑战
-
FL 优势:允许多机构协作训练模型而无需共享原始数据,保护隐私。
-
FL 挑战:多机构数据存在分布异质性(不同组织的扫描仪、组织对比、采样率等差异),导致模型在不同站点或训练/测试集间可能性能下降。
-
现有方法局限:
-
多数基于条件模型,需要明确成像算子信息。
-
条件模型在成像算子变化时泛化能力差,训练和测试时加速率、采样密度必须一致,限制多机构灵活协作。
-
3. FedGIMP 方法提出
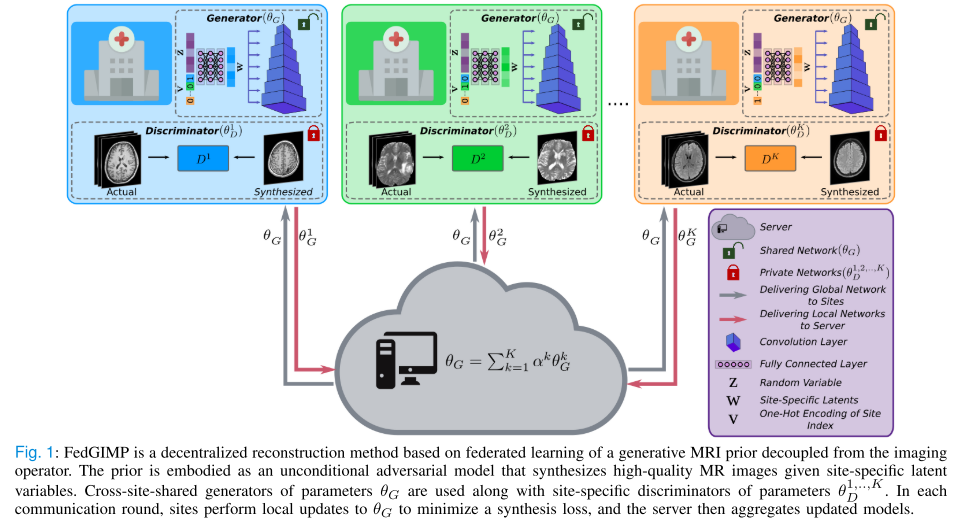
-
两阶段策略:
-
跨站点学习生成式 MRI 先验(generative MRI prior)
-
使用**无条件对抗模型(unconditional adversarial model)**生成高质量 MRI 图像。
-
引入 mapper 网络生成站点特定潜变量,保持先验特异性。
-
-
个体化注入成像算子
-
将全局 MRI 先验与可变的站点/个体成像算子结合,通过最小化 k-space 数据一致性损失进行局部适配,实现针对每个测试横截面的重建。
-
-
-
代码资源:FedGIMP 的实现开源于 GitHub
4. 主要贡献
-
提出一种从成像算子解耦的 FL MRI 重建方法,提升多站点协作灵活性和对成像算子变化的鲁棒性。
-
引入无条件生成模型 + 站点特定潜变量 + 跨站点共享生成器权重,同时捕捉站点特异性和站点通用的图像表示。
-
提出基于个体的 MRI 先验适配策略,提高模型在训练与测试数据分布差异下的可靠性。
补充
**MRI(Magnetic Resonance Imaging,磁共振成像)**是一种医学影像技术,用于在人体内部生成详细的组织和器官图像。它具有以下几个核心特点:
1. 原理
-
基于核磁共振现象:人体内的氢原子核在强磁场下会排列,并对射频脉冲产生响应。
-
MRI 扫描器检测这些响应信号,并通过计算机处理生成体内组织的图像。
2. 主要特点
-
无创:不需要手术或穿刺,也通常不使用电离辐射(不像 X 光或 CT)。
-
软组织对比度高:可以清晰显示脑、肌肉、关节、心脏、肝脏等组织,比 CT 更适合观察软组织结构。
-
可多方位成像:可以获取横断面、纵断面或任意方向的切片图像。
-
功能成像:不仅能看到结构,还可以测量血流、扩散、代谢等功能信息(如 fMRI 功能性 MRI)。
3. 局限
-
扫描时间较长:容易造成病人不适或运动伪影。
-
成本高:设备昂贵,运行和维护费用大。
-
对金属敏感:体内有金属植入物的患者可能无法做 MRI。
简单理解:MRI 就像是一台**“内部摄影机”**,通过磁场和射频信号拍摄人体内部的高分辨率图像,而无需开刀或使用放射线。
相关工作
1. 已有深度 MRI 重建方法
-
基于条件模型(conditional models):直接将欠采样数据映射为全采样图像,需要大量成对训练数据。
-
数据需求问题:单一站点很难收集足够大且多样化的数据集。
-
解决策略:
-
非配对学习(unpaired learning)
-
自监督学习(self-supervised learning)
-
迁移学习(transfer learning)
-
-
问题:这些方法通常需要将数据集中到单一位置进行训练,带来隐私风险。
2. 联邦学习(FL)的应用
-
优势:
-
多机构协作时只传递模型参数而非原始数据,保护隐私。
-
分摊数据收集与处理成本。
-
-
已有应用:在图像分割、分类等任务上效果良好。
-
挑战:跨机构数据存在域差异(domain shift),包括:
-
MR 图像分布差异(不同扫描仪、成像协议)
-
成像算子差异(加速率、采样密度不同)
-
-
已有方法:
-
数据统一化(data harmonization)
-
频域的 episodic learning
-
对抗对齐(adversarial alignment)和网络拆分(network splitting)
-
-
局限:大部分方法仍基于条件模型,需要明确成像算子信息,泛化能力受限;训练-测试或站点间算子不一致时性能下降。
3. FedGIMP 的创新
-
提出方法:在 FL 框架下学习生成式 MRI 先验(generative MRI prior),并在重建时结合个体化成像算子进行适配。
-
创新点:
-
先验与成像算子解耦:不同于传统条件模型,增强跨站点灵活性和泛化能力。
-
首次在 FL 下实现多线圈 MRI 重建(multi-coil MRI reconstruction)。
-
有效应对域差异:处理训练-测试集或不同站点间成像算子不匹配导致的性能下降。
-
算法
条件模型的MRI联邦学习
1. 加速 MRI 的基本问题
-
目标是从欠采样的 k 空间数据 y 重建 MRI 图像 m:

其中 A 是成像算子,包含线圈灵敏度和部分傅里叶变换等影响。
-
由于问题欠定(underdetermined),需要引入先验信息进行正则化:
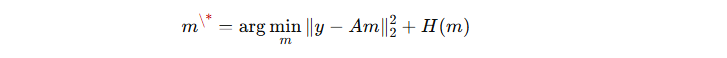
H(m) 表示先验约束,深度学习模型通过学习数据驱动的先验来解决这一问题。
2. 联邦学习训练流程
-
多个站点与中心服务器协作训练:
-
服务器保留全局模型
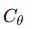
-
各站点保留相同架构的本地模型
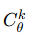
-
-
每轮通信:
-
本地模型初始化为全局模型参数:
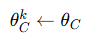
-
本地训练最小化重建损失:
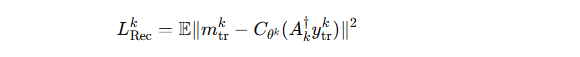
其中
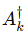 是成像算子的伴随操作(adjoint),
是成像算子的伴随操作(adjoint),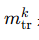 是参考全采样图像。
是参考全采样图像。 -
各站点更新的模型参数通过 FedAvg 聚合:
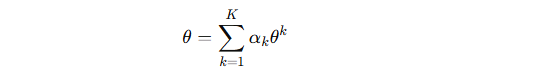
αk 是权重,一般按各站点样本数比例分配。
-
3. 推理阶段
-
聚合后的全局模型 Cθ\*C_{\theta^\*}Cθ\* 用于重建测试数据:
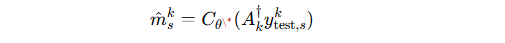
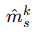 是第 k 站点第 s 个受试者的重建图像。
是第 k 站点第 s 个受试者的重建图像。
4. 局限
-
条件模型对**成像算子异质性(不同站点或训练-测试差异)**泛化能力差。
-
因此通常要求训练和测试数据、不同站点的成像算子一致。
基于生成 MRI 先验的联邦学习重建的模型架构
1. 核心思想
-
传统条件模型依赖成像算子,泛化能力有限。
-
FedGIMP 通过 训练一个生成型 MRI 先验(generative MRI prior),将全局 MRI 先验与受试者特定的成像算子分离,提高多站点协作的灵活性。
2. 模型架构
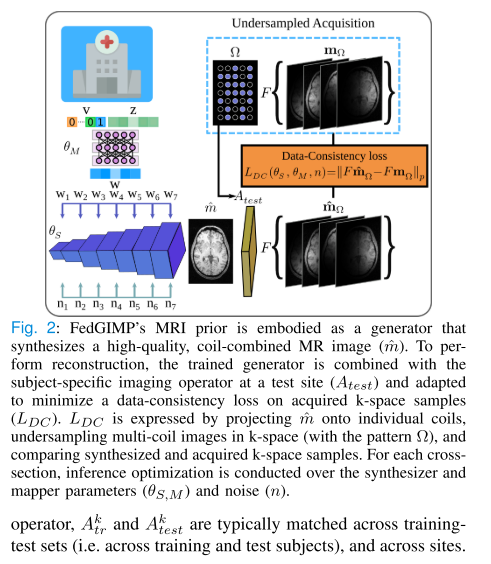
生成器(Generator, G)
-
由两部分组成:
-
Mapper(M):将低维随机向量 z 与站点索引 v(one-hot 编码)映射为 站点特异性潜变量 w

-
Synthesizer(S):将潜变量 w 逐层映射为高质量 MR 图像。每层包括:
-
卷积(Conv)
-
噪声注入(Noise Injection)控制低级结构细节
-
自适应实例归一化(AdaIN)控制高级风格特征
-
-
-
最终映射公式:
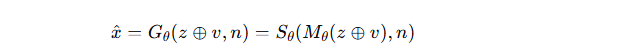
判别器(Discriminator, D)
-
输入真实或生成的 MR 图像,判别真假。
-
结构:多层卷积+下采样+全连接输出。
3. 联邦训练(Global MRI Prior)

-
共享生成器(G),每站点保留 本地判别器(Dk),判别器不交换以减少通信并增强隐私。
-
每轮通信:
-
本地生成器初始化为全局生成器参数
-
本地训练若干轮:
-
生成器最小化非饱和对抗损失 LGk
-
判别器最小化非饱和对抗损失 LDk + 梯度惩罚
-
-
本地生成器参数聚合回服务器形成全局生成器:
-
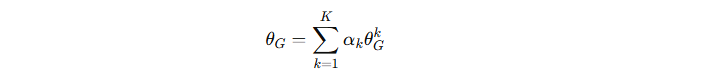
4. 推理阶段(Inference at Test Site)

-
全局生成器可以生成高质量 MR 图像,但不能直接映射欠采样数据。
-
将生成器与受试者特定成像算子
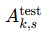 结合:
结合:-
通过最小化 数据一致性损失(data-consistency loss) 对生成器进行微调
-
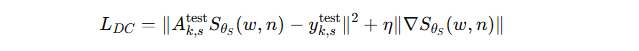
-
优化 Synthesizer、Mapper 参数和噪声变量,最终得到重建图像:
![]()
实验方法
FedGIMP 中无条件对抗模型(unconditional adversarial model)的具体架构和训练细节
1. Mapper
-
输入:标准正态向量 + 站点索引的 one-hot 编码向量
-
网络:8 层全连接层(FC)
-
输出:32 个中间潜变量(intermediate latent variables)
2. Synthesizer
-
网络:8 层
-
每层包含:
-
双线性上采样(bilinear upsampling)——特征图尺寸增加 2 倍
-
两个串联块:卷积(Conv)、噪声注入(NI)、自适应实例归一化(AdaIN)
-
-
输入:第一层为 4x4 的可学习常量值(初始化为 1)
-
噪声变量:随机初始化自标准正态分布
3. Discriminator
-
网络:8 层
-
每层包含:
-
双线性下采样(bilinear downsampling)——特征图尺寸减半
-
卷积块(卷积核 3x3)
-
-
激活函数:Leaky ReLU
4. 复数 MR 图像处理
-
生成器输出和判别器输入有两个通道,分别表示 MR 图像的实部和虚部
5. 训练和推理细节
-
训练时:图像零填充(zero-padding)以匹配输出层尺寸
-
推理时:合成图像按采集矩阵大小中央裁剪,用于计算数据一致性损失
-
Synthesizer 和 Discriminator 非渐进式训练(all layers intact)
实验细节
1. 对比方法
-
传统重建方法
-
LORAKS:自校准低秩矩阵重建
-
-
非联邦学习模型(centralized, privacy-violating)
-
GANcond:条件 GAN,从零填充(ZF)重建到完整图像
-
GIMP:无条件 GAN,基于 FedGIMP 架构
-
-
联邦学习条件模型(federated conditional models)
-
FL-MRCM:跨站点潜变量对齐的条件模型
-
FedGAN:共享编码器和解码器的条件模型
-
LG-Fed:站点特定编码器 + 共享解码器
-
FedMRI:共享编码器 + 站点特定解码器 + 对比损失
-
2. 训练和超参数设置
-
优化器:Adam
-
非联邦模型学习率:2×10⁻⁴,β₁=0.5, β₂=0.99
-
联邦模型学习率:10⁻³,β₁=0.0, β₂=0.99
-
-
训练轮数:
-
非联邦模型:100 epochs
-
联邦模型:100 轮通信(L=100)+ 每轮 1 epoch
-
-
FedGIMP 推理阶段:
-
学习率:10⁻²
-
数据一致性梯度权重 η=10⁻⁴
-
迭代次数 E=1200
-
-
损失权重:
-
GANcond、FedGAN、LG-Fed 等使用像素损失、对抗损失、感知损失(权重示例:100,1,100)
-
FedMRI 额外加入对比损失(权重 10)
-
FL-MRCM 还加入域对齐损失(权重 0.5)
-
3. 实现与硬件
-
LORAKS:Matlab
-
非联邦模型:TensorFlow
-
条件模型:PyTorch
-
硬件:四块 Nvidia RTX 3090 GPU
数据集
1. 数据集(Datasets)
-
内部数据集(In-House):Bilkent University,10 名受试者
-
扫描序列:T1、T2、PD 加权
-
扫描仪:3T Siemens Tim Trio,32 通道线圈
-
扫描参数详细说明(TE/TI/TR、翻转角、体素大小等)
-
遵守伦理,受试者签署知情同意
-
-
公共数据集:
-
IXI(脑部 MRI)
-
fastMRI(脑和膝盖 MRI)
-
BRATS(脑肿瘤 MRI)
-
-
采样:回溯性欠采样,使用可变密度(VD)和均匀密度(UD),加速比 R = 3x、6x
-
数据划分:训练、验证、测试集之间不重叠
2. 单线圈重建(Single-Coil Reconstruction)
-
数据集:IXI、fastMRI、BRATS
-
数据划分(训练/验证/测试):
-
IXI & BRATS: 40/10/5 名受试者
-
fastMRI: 40/10/5 名受试者
-
-
每个受试者随机选取 21 个切片
-
使用的扫描加权:T1、T2、PD(IXI/BRATS),T1c、T2、FLAIR(fastMRI)
-
总训练切片数:2520
3. 多线圈重建(Multi-Coil Reconstruction)
-
数据集:fastMRI 脑、fastMRI 膝、In-House 脑
-
数据划分:
-
fastMRI 脑:36/6/18 名受试者,每受试者随机 8 个切片
-
fastMRI 膝:48/7/24 名受试者,每受试者随机 9 个切片
-
In-House 脑:6/1/3 名受试者,每受试者随机 48 个切片
-
-
总训练切片数:2592
-
线圈压缩:压缩到 5 个虚拟线圈
-
模型处理方式:
-
条件模型:输入多线圈、复数零填充(ZF)数据,输出参考图像
-
GIMP & FedGIMP:训练阶段合成复数线圈组合 MR 图像
-
成像算子只在推理阶段注入,用于保持数据一致性
-
定量评估方法
-
比较对象:重建图像与参考图像(通过全采样傅里叶重建获得)
-
评估指标:
-
峰值信噪比(PSNR,单位 dB)
-
结构相似性指数(SSIM,单位 %)
-
-
处理方法:
-
先将图像归一化到 [0, 1]
-
在测试受试者上计算平均指标
-
-
统计分析:使用 Wilcoxon 符号秩检验评估不同方法之间的显著性差异
实验结果
单线圈
-
图像分布的域偏移(Domain shifts in MR image distribution)
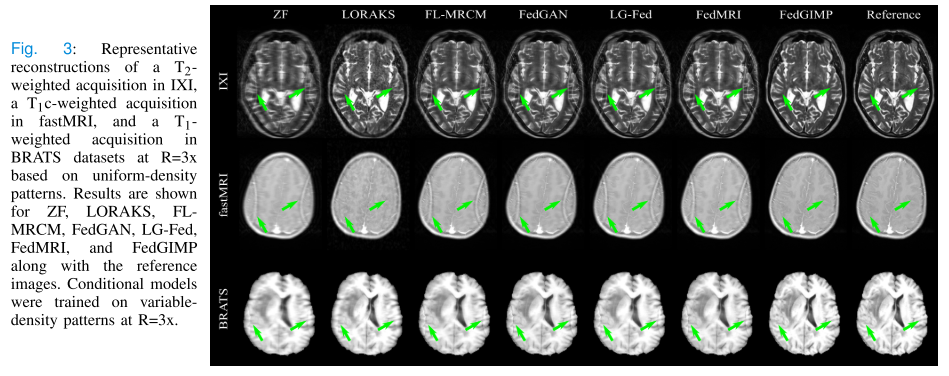
-
多站点多对比度MRI数据存在内在图像分布差异。
-
当成像算子在各站点及训练-测试集间匹配时,FedGIMP相比其他联邦学习(FL)方法表现更好(平均提升 3.66 dB PSNR 和 3.00% SSIM),说明其对图像分布异质性更鲁棒。
-
-
成像算子的域偏移(Domain shifts in the imaging operator)
-
考察了加速率(R)或采样密度(VD vs UD)在训练和测试集不匹配的情况。
-
FedGIMP仍为最优方法(PSNR提升 4.75 dB / 4.50 dB,SSIM提升 4.00% / 4.76%),明显优于其他联邦条件模型和传统方法(如LORAKS),可有效减少伪影和模糊。
-
-
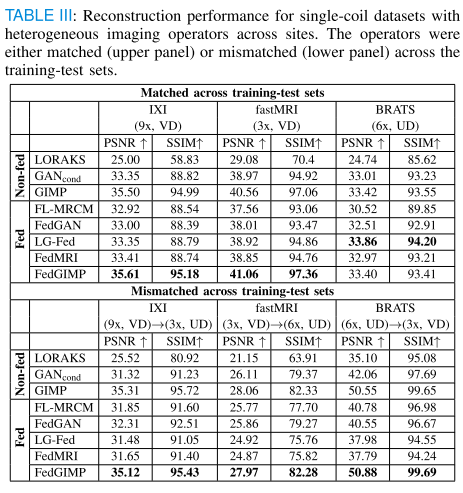
异构成像算子(Heterogeneous imaging operators across sites)
-
当各站点成像算子不一致时,无论训练-测试集算子是否匹配,FedGIMP表现最优(PSNR提升 1.31~5.08 dB,SSIM提升 2.70~2.98%),显示其在跨站点协作和算子不一致条件下具有更强的泛化能力。
-
总结:FedGIMP在单线圈MRI重建中对图像分布和成像算子的变化更鲁棒,能够显著提高重建质量和减少伪影,比现有联邦条件模型和传统方法表现更好。
多线圈
-
图像分布的域偏移(Domain shifts in the MR image distribution)
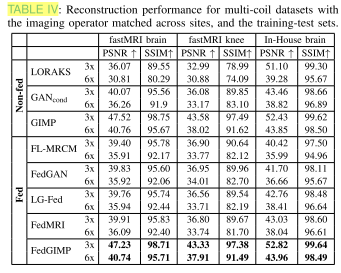
-
实验设置:成像算子在各站点和训练-测试集之间匹配,主要考察由于图像分布(解剖部位差异,如膝关节 vs 大脑)带来的域偏移。
-
结果:FedGIMP在这种情况下优于所有对比方法(除GIMP外相似),平均提升 6.26 dB PSNR 和 4.21% SSIM,说明其能有效应对解剖差异导致的图像分布异质性。
-
-
成像算子的域偏移(Domain shifts in the imaging operator)
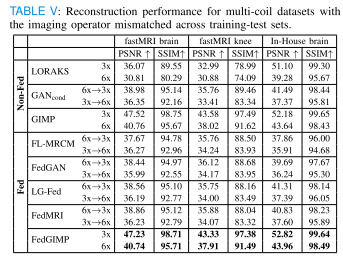
-
实验设置:训练集和测试集使用的加速率不同,即成像算子不匹配。
-
结果:FedGIMP依然是表现最好的方法(除GIMP外),比第二好的联邦学习方法提升 6.93 dB PSNR 和 4.45% SSIM。
-
对比表现:LORAKS出现噪声放大,条件模型有模糊和伪影,而FedGIMP能保持较高清晰度并减轻噪声放大。
-
总结:FedGIMP在多线圈MRI重建中,不论是因为解剖差异(图像分布域偏移),还是因为成像算子不匹配(算子域偏移),都显著优于其他联邦方法,表现出强大的泛化和鲁棒性。
消融实验
-
实验对比的三种变体
-
未训练生成器:推理时直接用随机初始化的生成器做适配,没有经过先前的联邦训练。
-
固定映射器(static mapper):虽然有训练过,但在推理时映射器参数固定不变,只适配合成器(synthesizer)。
-
站点无关映射器(site-general mapper):训练时不使用站点特定的潜在变量,映射器输出不包含站点差异。
-
-
结果
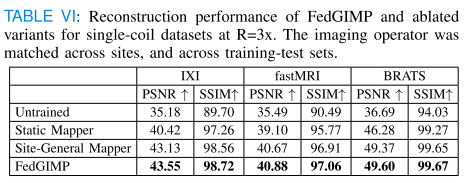
-
FedGIMP 在所有站点上的表现都优于这三种削弱版本。
-
这说明:
-
高质量的生成图像先验(通过联邦训练获得)对重建很重要;
-
推理阶段的 个体(subject-specific)适配 能有效提升结果;
-
站点特定(site-specific)的潜在变量分布 对于处理多站点异质性也非常关键。
-
-
总结
-
FedGIMP 的优势
-
现有基于条件模型的方法(如潜在空间对齐、分裂网络)容易受到 成像算子变化(加速率、采样密度差异) 的影响。
-
FedGIMP 将成像算子和图像先验解耦,因此在多站点数据存在异质性时表现更稳健。
-
实验表明 FedGIMP 在不同加速率、采样密度和跨站点情况下都优于现有的联邦条件模型。
-
这样提升了多站点协作的灵活性,即使协议和设备不一致也能合作。
-
-
计算成本对比
-
条件模型训练时需要针对不同加速率/采样密度反复训练,而 FedGIMP 只需训练一次通用的 MRI 先验,训练更简单。
-
但推理时,条件模型一次前向传播就能完成,速度快;FedGIMP 需要迭代优化,计算负担较大。
-
可通过 跨切片迁移优化参数 来加速 FedGIMP 的推理。
-
-
隐私与安全性
-
联邦学习降低了直接共享数据的风险,但仍可能受到 后门攻击(恶意更新破坏模型)或 推理攻击(模型泄露训练数据信息)。
-
FedGIMP 由于推理阶段有 个体适配机制,可能更能抵御模型腐败。
-
其 共享生成器 + 不共享的判别器 也减少了数据暴露风险。
-
未来可结合 差分隐私 提高安全性。
-
-
潜在扩展应用
-
FedGIMP 学到的 高质量 MRI 先验 可以迁移到其他任务,如:
-
MRI 超分辨率、合成
-
作为 plug-and-play 正则项 融入优化问题
-
-
通过修改成像算子,它还可能用于 CT、PET、超声 等其他医学成像模态。
-
-
结论
-
FedGIMP 是一种新颖的基于联邦学习的 MRI 重建方法,通过 生成先验 + 推理适配 实现。
-
在多站点实验中展现出更好的泛化性能和抗领域偏移能力。
-
未来有望成为多站点 MRI 协作的有效方案,并扩展到其他医学影像重建任务。
-