Scikit-learn Python机器学习 - 分类算法 - 随机森林
锋哥原创的Scikit-learn Python机器学习视频教程:
https://www.bilibili.com/video/BV11reUzEEPH
课程介绍

本课程主要讲解基于Scikit-learn的Python机器学习知识,包括机器学习概述,特征工程(数据集,特征抽取,特征预处理,特征降维等),分类算法(K-临近算法,朴素贝叶斯算法,决策树等),回归与聚类算法(线性回归,欠拟合,逻辑回归与二分类,K-means算法)等。
Scikit-learn Python机器学习 - 分类算法 - 随机森林
随机森林算法核心思想
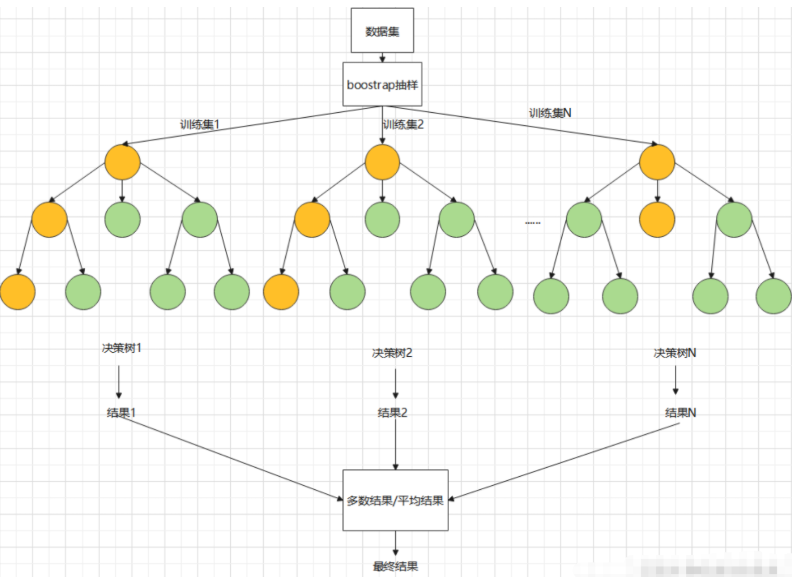
随机森林属于集成学习中的 Bagging 类型。
-
“森林”:由多棵决策树构成的“森林”,最终的预测结果由所有决策树共同决定(例如,通过投票)。
-
“随机”:主要体现在两个方面:
-
数据随机性 (Bootstrap Aggregating, Bagging): 每棵树训练时,不是使用全部数据集,而是有放回地随机抽取一个子集(Bootstrap Sample)。这意味着有些样本可能被多次抽取,而有些样本可能从未被选中(称为 Out-of-Bag,OOB)。
-
特征随机性: 每棵树在分裂节点时,不是从所有特征中选择最优特征,而是先随机选取一个特征子集,然后从这个子集中寻找最优分裂点。
-
这种双重随机性的设计,有效降低了模型的方差(Variance),避免了单棵决策树容易过拟合的问题,使得模型更具泛化能力,且不容易受噪声数据影响。
随机森林分类器的优势
-
高性能:通常能产生非常高的准确率,是许多数据科学竞赛中的“常胜将军”。
-
抗过拟合:通过集成多棵树和随机性,有效降低了过拟合风险。
-
处理高维数据:可以处理具有大量特征的数据集。
-
评估特征重要性:内置功能可以输出每个特征对预测的贡献程度。
-
无需大量预处理:对数据分布没有严格假设,不需要对数据进行标准化(但有时标准化会有帮助)。
-
处理缺失值:虽然有内置方法,但通常建议先自行处理缺失值。
关键超参数详解
sklearn.ensemble.RandomForestClassifier 有许多参数,以下是一些最常用的:
-
n_estimators:森林中树的数量。通常越大越好,但计算成本也会增加。默认=100。
-
criterion:分裂节点时使用的衡量标准。
‘gini’(基尼系数)或‘entropy’(信息增益)。默认=‘gini’。 -
max_depth:树的最大深度。限制树的深度,是防止过拟合的关键参数。默认=None(不限制)。
-
min_samples_split:分裂内部节点所需的最小样本数。默认=2。
-
min_samples_leaf:叶节点所需的最小样本数。默认=1。增大此值可以平滑模型。
-
max_features:寻找最佳分裂时考虑的特征数。
-
可设为整数、浮点数(
auto或sqrt->sqrt(n_features))、字符串(log2)。(‘auto’现等同于‘sqrt’)。 -
这是引入特征随机性的关键参数。
-
-
bootstrap:是否使用bootstrap样本。默认=True。如果设为False,则将使用整个数据集构建每棵树。
-
oob_score:是否使用袋外样本(OOB)来评估模型泛化精度。默认=False。设为True后,训练完成后可通过
model.oob_score_查看分数。
具体示例
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
# 1,加载数据
iris = load_iris()
X = iris.data # 特征矩阵 (150个样本,4个特征:萼长、萼宽、瓣长、瓣宽)
y = iris.target # 特征值 目标向量 (3类鸢尾花:0, 1, 2)
# 2,数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # 划分训练集和测试集
# 3,创建和训练模型
rfc_model = RandomForestClassifier(n_estimators=100, # 100棵树oob_score=True, # 启用OOB评估max_depth=3 # 控制树的深度,防止过拟合)
rfc_model.fit(X_train, y_train) # 训练模型
# 4,进行预测并评估模型
y_pred = rfc_model.predict(X_test) # 在测试集上进行预测
print('随机森林预测值:', y_pred)
print('正确值 :', y_test)
accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print(f'测试集准确率:{accuracy:.2f}')
print('分类报告:\n', classification_report(y_test, y_pred, target_names=iris.target_names))运行结果:
随机森林预测值: [2 2 1 0 0 1 2 0 0 2 0 1 1 0 0 2 0 0 0 2 1 2 1 0 1 0 2 1 2 0]
正确值 : [1 2 1 0 0 1 2 0 0 2 0 1 1 0 0 2 0 0 0 1 1 2 1 0 1 0 2 1 2 0]
测试集准确率:0.93
分类报告:precision recall f1-score support
setosa 1.00 1.00 1.00 13versicolor 1.00 0.80 0.89 10virginica 0.78 1.00 0.88 7
accuracy 0.93 30macro avg 0.93 0.93 0.92 30
weighted avg 0.95 0.93 0.93 30超参数调优建议
上面的例子使用了默认或手动设置的参数。在实际项目中,为了获得最佳性能,通常需要进行超参数调优。最常用的方法是 Grid Search(网格搜索) 或 Random Search(随机搜索)。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split, GridSearchCV
# 1,加载数据
iris = load_iris()
X = iris.data # 特征矩阵 (150个样本,4个特征:萼长、萼宽、瓣长、瓣宽)
y = iris.target # 特征值 目标向量 (3类鸢尾花:0, 1, 2)
# 2,数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # 划分训练集和测试集
# 定义要搜索的参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 5, 10, 15],'min_samples_split': [2, 5, 10],'max_features': ['sqrt', 'log2']
}
# 创建GridSearch对象
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42),param_grid=param_grid,cv=5, # 5折交叉验证scoring='accuracy',n_jobs=-1 # 使用所有CPU核心并行计算
)
# 在训练数据上执行网格搜索 (警告:这可能很耗时!)
grid_search.fit(X_train, y_train)
# 输出最佳参数和最佳分数
print("最佳参数: ", grid_search.best_params_)
print("最佳交叉验证分数: ", grid_search.best_score_)
# 使用最佳参数的模型进行预测
best_rf_model = grid_search.best_estimator_
y_pred_best = best_rf_model.predict(X_test)
print("调优后测试集准确率: ", accuracy_score(y_test, y_pred_best))运行结果:
最佳参数: {'max_depth': None, 'max_features': 'sqrt', 'min_samples_split': 5, 'n_estimators': 200}
最佳交叉验证分数: 0.9583333333333334
调优后测试集准确率: 0.9333333333333333