9.17 学习记录
今天学习了RAG的流程,并了解了基本方法和当前的主流方法。
RAG工作机制
RAG 全称 Retrival-Augmented Generation 检索增强生成,顾名思义,先检索,再生成。
先从资料库里检索相关内容 ,再基于检索到的内容生成答案。
RAG的使用场景:
假设需要做一个智能客服,可以回答自己公司的产品问题。
那么首先,这个客服的内部要有一个大模型(比如GPT或者deepseek),但模型不知道自己公司的产品信息。
容易想到的方法是在问问题的时候同时将产品手册一起发给大模型,但产品手册可能太长,会带来若干问题,首先模型无法读取所有内容(超过模型上下文窗口),其次,模型的推理成本会很高,输入越多,模型的推理成本越高,而且每次回答问题的时候都要输入整个手册,模型的推理速度也会大幅减慢。所以需要将手册中与问题相关的内容发给模型,这就是RAG的作用。
RAG的基本运行流程
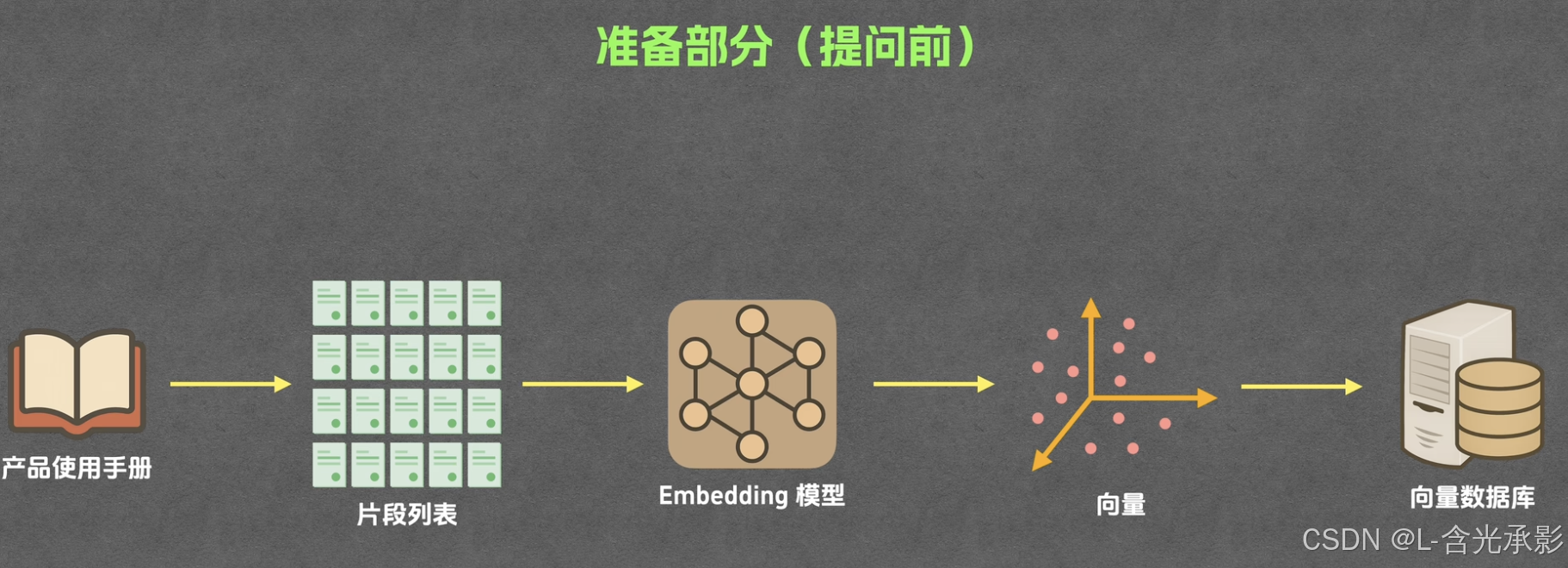
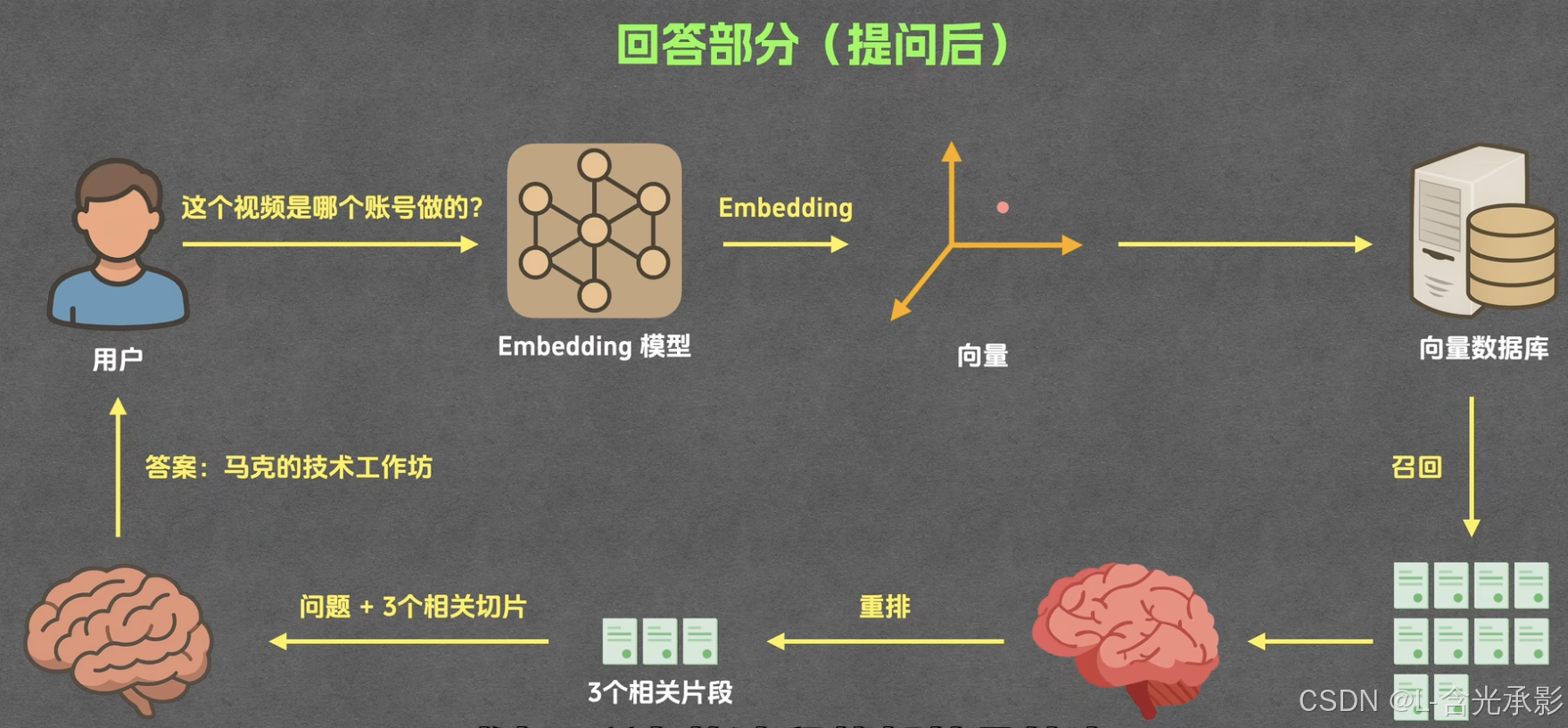
首先,RAG会将文档切分成多个片段,但用户提出问题后,就在分好的所有片段里找寻找相关内容,将高相关的片段和用户的问题一起发给大模型,从而解决输入过长的问题 ,但这只是一个简化的链路。RAG的具体工作流程包括两个部分:
- 准备(用户提问前):包括分片和索引
- 回答(提问后):包括召回、重排和生成
分片
将文档分成多个片段,分片的方式有很多种,比如按字数分、按照段落分、按章节分、按页码分等,具体的切分方式需要根据实际问题确定。
索引
通过embedding将每一个片段文本转化为向量,然后将片段文本和对应向量都存储在向量数据库中。embedding中,含义越相似的文本转化成的向量距离越小。常用的embedding模型如下图。
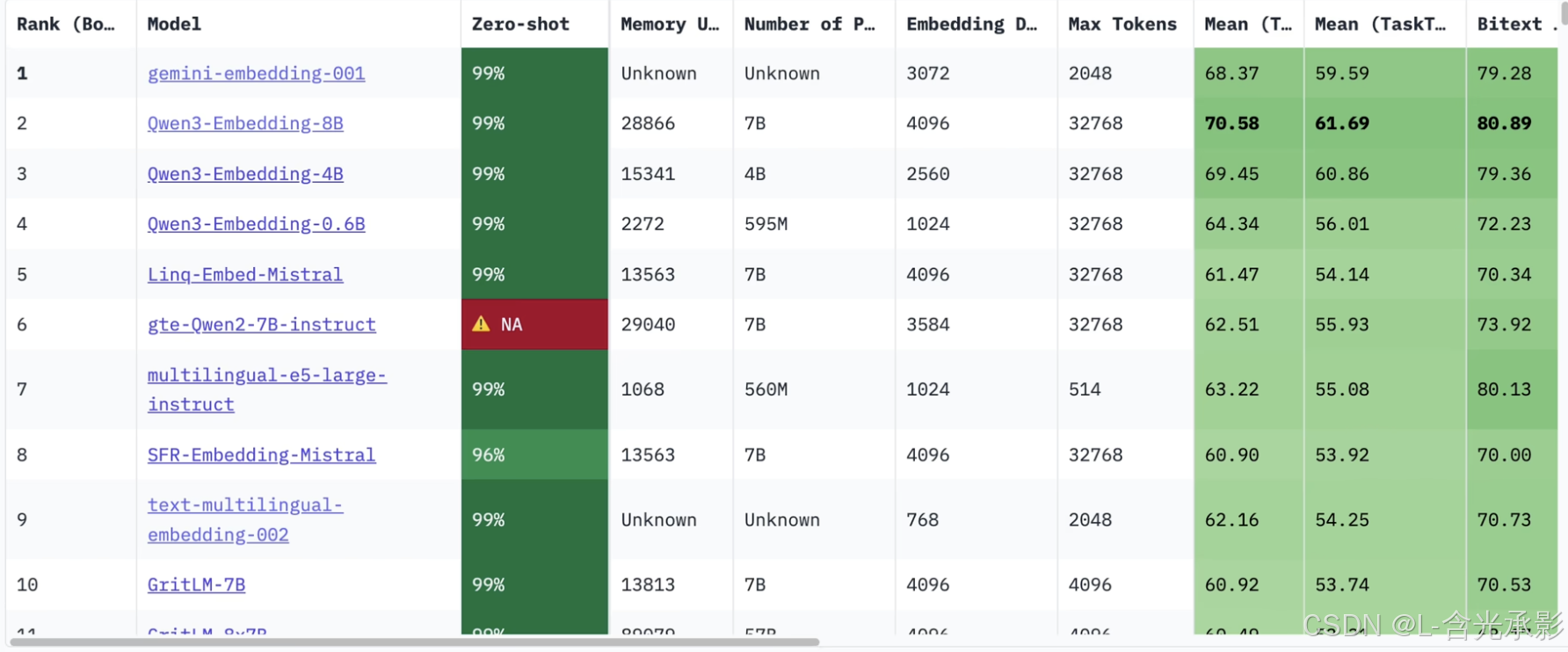
向量数据库用于查询和存储向量,并且提供了计算向量相似度的相关函数。 embedding后的向量需要存在向量数据库中,且对应的片段文本也要发给向量数据库,所以一般的向量数据库中有两种数据:片段文本和其对应的向量。
召回
搜索与用户问题相关的片段 。首先,用户的问题会发给embedding模型转化为向量,然后向量发给向量数据库,并在其中查找与其距离最小的n个向量(计算向量相似度),这n个向量对应的片段就是与问题最相关的n个片段,目前用的较多的向量相似度计算方法有:余弦相似度(夹角)、欧氏距离(向量的距离)、点积(同时考虑两向量的方向和长度关系)。
重排
从召回的n个片段中挑选m个,但重排与召回阶段使用的文本相似度计算逻辑不一样,召回阶段使用向量相似度,耗时短,成本低,但准确率也低,作为初步筛选,而重排阶段使用cross-encoder模型计算每个片段与用户问题的相似度,成本高,耗时长,但其准确率高,适合精选片段。
生成
经过前面几个阶段,得到了与用户问题相关的m个片段,此时将问题与m个片段一起送入大模型,让其根据片段内容回答问题。
综述理解
本小结是结合综述A Survey on Knowledge-Oriented Retrieval-Augmented Generation的学习对RAG理解。
知识融合
在 RAG 中,知识融合(常被称为增强)是将大模型的内部知识与检索到的外部知识相融合的关键过程。主要分为三种方法:
- 输入层融合:将检索到的文档与原始查询直接拼接后输入模型,使模型能够同时处理查询与外部知识。
- 输出层融合:在对数概率(logits)层面融入检索知识,校准模型的最终预测结果,对提升输出准确性效果显著。
- 中间层融合:在生成过程中将外部知识融入模型的隐藏状态,实现内部与外部知识表示之间更细致的交互。
RAG评估
传统评估指标(如ROUGE)主要通过将生成文本与参考输出进行比较,评估生成文本的质量。然而,这些指标无法充分衡量检索组件的有效性,而检索组件对生成内容的相关性与准确性起着至关重要的作用。
因此,全面的评估框架需整合评估检索准确性(如精度、召回率、F1 得分)与生成质量(如连贯性、流畅性、事实准确性)的指标。
基础RAG方法
基础 RAG 方法包含多个关键步骤:用户意图理解、知识源与解析、知识嵌入、知识索引、知识检索、知识融合、答案生成以及知识引用。
查询分解
查询分解现在已成为提升语言模型推理能力的有效方法,适用于需要多步推理或组合推理的复杂任务。例如,“由少到多提示”(least-to-most prompting)方法将复杂问题逐步分解为更简单的子问题,提高了模型对复杂任务的泛化能力。
“自我提问”(Self-ask) 采用类似思路,但通过让模型提出并回答后续问题进一步优化流程,缩小了组合推理差距,实现了更优的多跳推理效果。
另外,“验证链”(Chain-of-Verification,CoVe)通过让模型通过独立事实核查验证自身响应,提高了答案的可靠性,显著降低了列表式问题、长文本生成等任务中的幻觉现象。
还有一种有潜力的方法是 “链中搜索”(Search-in-the-Chain,SearChain),将信息检索(IR)融入推理过程。
知识源与解析
结构化数据:
知识图谱这种结构化信息的表示能力强,其结构化特性便于高效查询与检索,所捕获的语义关系有助于实现更细致的理解与推理。但其融入RAG的难度较大,目前也有很多方法将知识图谱融入到RAG,比如GRAG 跨多个文档检索文本子图,提升了 RAG 系统的信息检索效率;KG-RAG融入 “探索链”(Chain of Explorations,CoE)算法,优化知识图谱问答(KGQA)任务中的知识图谱导航过程;GNN-RAG 利用图神经网络(GNNs)从知识图谱中检索和处理信息,在与大模型交互前增强推理能力。
表格通过行与列的相互作用传递丰富信息,提高了数据密度。但将表格数据融入 RAG 也存在许多问题。一个问题是对表格内容的语义理解 —— 表格中可能包含不直观的隐含关系与上下文,另一个问题是不同领域表格结构的多样性,会导致开发通用表格解读模型的难度变大。
半结构化数据:
半结构化数据介于结构化与非结构化数据之间,具有一定的组织元素,但缺乏严格的模式。例如 JSON 文件、XML 文件、电子邮件,尤其是 HTML 文档。HTML 作为网页的基础,融合了标签、属性等结构化组件与自由文本等非结构化内容。这种混合特性使其能够以层级结构表示文本、图像、链接等复杂信息。但HTML 的灵活性可能导致数据不一致与不规则性,导致其难以进行数据提取及融入 RAG 。目前有多种技术与开源库,如Beautiful Soup、htmlparser2 、MyHTML 、Fast HTML Parser 等,实现 HTML 的有效解析。
非结构化数据:
非结构化知识涵盖多种缺乏统一结构的数据类型,如自由文本、PDF 文档等。非结构化数据格式多样,内容往往复杂,难以直接检索与解读。PDF 文档通常包含丰富信息,如文本、表格、嵌入式图像等,但由于其结构的固有可变性,提取信息并将其融入 RAG 还存在问题。
PDF 解析的难点在于需准确解读不同的布局、字体与嵌入式结构。要将 PDF 转换为 RAG 系统可处理的机器可读格式,需采用光学字符识别(OCR)技术提取文本、进行布局分析以理解空间关系,并运用先进方法解读表格、公式等复杂元素。
多模态知识的融合:
多模态知识(包括图像、音频、视频)提供了丰富的补充信息,能够显著增强 RAG 的能力,尤其在需要深度上下文理解的任务中效果突出。图像提供空间与视觉细节,音频传递时间与语音信息,视频则结合空间与时间维度,捕捉动态与复杂场景。
传统 RAG 主要针对文本数据设计,往往难以处理和检索这些模态的信息,导致当非文本内容至关重要时,生成的响应不够完整或缺乏深度。
知识嵌入
RAG 中分块(分片)的目标与挑战在于:确保分割后的块保留有意义的上下文,同时避免冗余与信息丢失。固定长度、基于规则或基于语义的传统分块方法相对简单,但缺乏捕捉复杂文本中细微结构的灵活性。
近期的优化策略致力于捕捉文本中的细粒度信息分布与语义结构。例如,“命题级” 分块将文本分解为单个事实的小单元,能够捕捉更丰富的信息。有些方法利用大模型实现动态分块,如 LumberChunker 方法,通过大型语言模型检测段落间的内容转移,生成符合上下文的块。另外,“延迟分块”(late chunking)先对整个文档进行嵌入,再进行分割,这种方法使模型能够保留完整上下文,尤其对于复杂或上下文密集型文本,检索效果显著提升。
嵌入模型
当前有不少通用和针对特定领域的文本嵌入模型,关键是选择合适的嵌入模型。
对于非文本形式的信息,如图像、音频、视频等,需要嵌入模型将来自不同模态的信息融合到统一的向量空间中。
知识索引
索引分为
- 结构化索引:结构化索引根据预定义的固定属性组织数据,通常采用表格或关系格式。
- 非结构化索引:与结构化索引不同,非结构化索引专为自由文本或半结构化数据设计,在现代 RAG 中应用更为广泛。
- 图索引:作为非结构化索引的一种形式,图索引利用图结构的固有优势表示和检索相互关联的数据。在图索引中,数据点表示为节点,数据点之间的关系表示为边。这种索引范式特别擅长捕捉语义关系与上下文信息,对 RAG 实现有效检索至关重要。
- 混合索引:在实际应用中,混合索引方法通常比单一索引方法表现更优,因为它结合了结构化与非结构化技术,优化了不同数据类型的检索效果。
知识检索
检索的目标是根据输入查询识别并提取最相关的知识。通过采用相似性函数,检索排名前 k 的最相关块。根据相似性函数的不同,检索策略可分为三类:稀疏检索、密集检索与混合检索。
- 稀疏检索:稀疏检索策略利用稀疏向量,通过术语分析与匹配检索文档或块。
- 密集检索:密集检索策略将查询与文档均编码到低维向量空间中,通过向量表示之间的点积或余弦相似性衡量相关性。
- 混合检索:混合检索策略结合稀疏检索与密集检索技术,旨在利用两种方法的优势优化性能。
知识融合
知识融合就是将检索到的外部知识与生成模型的内部知识相融合,以提升输出的准确性与连贯性。知识融合主要分为三类:输入层融合、中间层融合与输出层融合。
输入成融合又可分为文本级融合与特征级融合两类。
- 文本级融合:一种简单的文本级融合方法是将检索到的排名前 k 的文档与查询直接拼接。
- 特征级融合:特征级融合侧重于在特征层面将检索内容的编码形式与原始输入相融合。该方法 并非简单拼接原始文本,而是将输入查询与检索文档均转换为特征表示(如密集向量或稀疏向量)后,再输入模型。通过对特征表示(而非原始文本)进行操作,特征级融合使输入数据的处理更具灵活性。
中间层融合又分为基于集成的融合与基于校准的融合。 - 基于集成的融合:整合检索得到的对数概率,将最近邻的概率与模型预测相插值,以提升泛化能力与稳健性。
- 基于校准的融合:利用检索对数概率优化模型的预测置信度。