2025 AIME Benchmark:AI 在奥数领域的最新进展
2025 AIME Benchmark:AI 在奥数领域的最新进展
人工智能在许多领域都取得了惊人的成就,但在需要深度数学推理和解决复杂问题的领域,它的表现一直备受关注。一个名为 “2025 AIME Benchmark” 的新基准测试,为我们提供了一个了解顶尖 AI 模型在奥林匹克数学竞赛级别推理能力的机会。
什么是 AIME?
首先,让我们了解一下 AIME。AIME(American Invitational Mathematics Examination) 是一项享誉全球的高中数学竞赛,被认为是通往国际数学奥林匹克(IMO)的重要途径。它的题目以其高难度、需要精确计算和深刻的数学洞察力而闻名,涵盖代数、几何、数论和组合学等多个领域。
2025 AIME Benchmark:挑战与规则
这个基准测试由 Artificial Analysis 机构独立进行,其核心任务是让 AI 模型解决来自 2025 年 AIME 竞赛的全部 30 道题目。这些题目的答案都是 000-999 之间的三位整数。
与传统基准测试不同的是,这个测试的重点在于评估 AI 在处理奥数级别问题时的 推理能力。它不仅仅是考察计算或记忆,更是检验模型能否像人类一样,通过逻辑推理、问题分解和数学知识的灵活运用,找到正确的解题路径。
成绩单:谁是奥数之王?
基准测试的结果令人印象深刻,但同时也揭示了不同模型之间的巨大差距。根据排行榜,一些模型的表现遥遥领先:
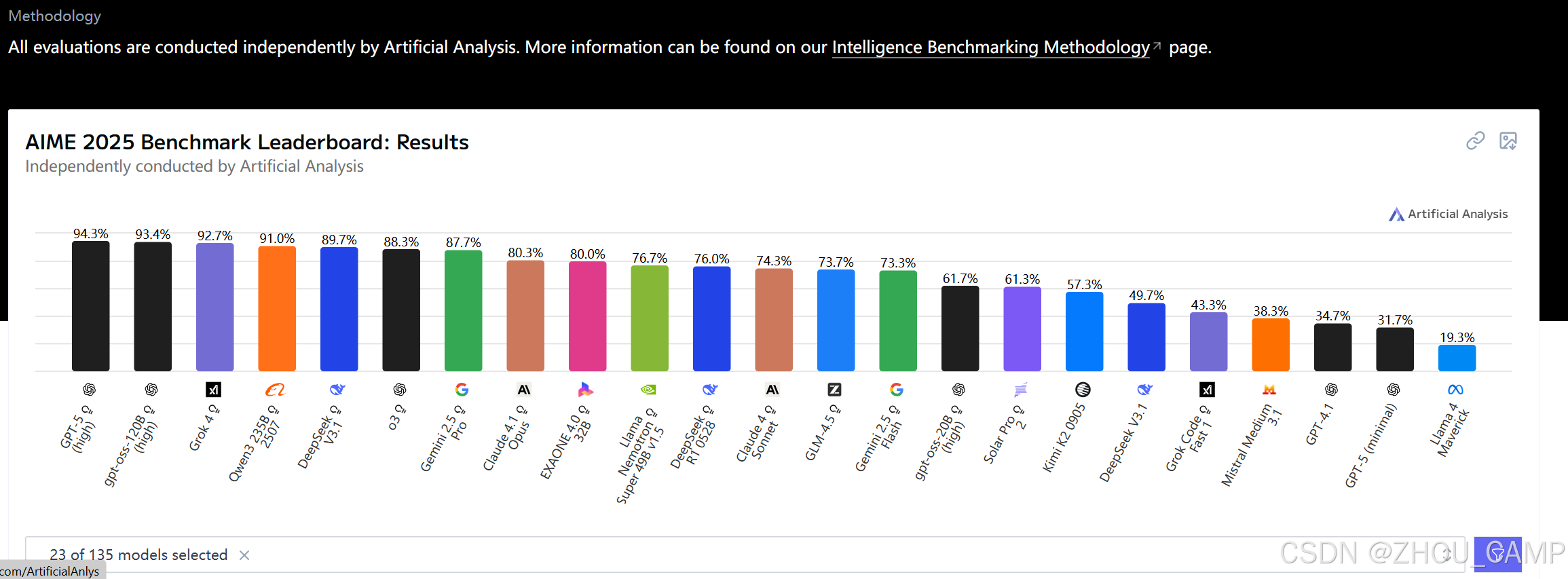
领先模型: GPT-5 (high) 以 94.3% 的得分位居榜首,显示出在此次评测任务中具有卓越的性能。gpt-oss-120B (high) 以 93.4% 紧随其后,Grok 4.0 以 92.7% 的成绩位列第三。
其他模型: 众多模型得分分布在不同区间,体现出各模型在性能上存在差异。比如 Llama 4 的 Mavwenix 版本得分仅为 19.3%,在展示的模型中排名靠后 。
值得注意的是,即使是排名前列的模型,也无法做到 100% 正确。这表明,即使是最先进的 AI,在面对奥数这样需要深层推理和创造性思维的问题时,依然存在挑战。同时,榜单上也显示,一些模型在这个领域的表现相对较弱,正确率甚至低于 20%,这进一步说明了在奥数推理方面,模型的性能差异巨大。
结论与展望
2025 AIME Benchmark 不仅是一场关于 AI 性能的竞赛,它更是衡量我们当前 AI 模型 “思考”和“解决问题” 能力的一个重要里程碑。
尽管顶尖模型取得了令人振奋的成绩,但要完全掌握奥数级别的复杂推理,人工智能还有很长的路要走。我们期待未来,随着算法和模型的不断优化,AI 能够在更多需要高阶认知能力的领域展现出更强大的潜力。