重定向、命令行判断、管道、正则三剑客
文章目录
- 特殊符号
- 数据流重定向
- 输出重定向
- 输入重定向
- 命令执行的判断根据:;、&&、||
- 管道命令(pipe)
- 选取命令:cut、grep
- 排序命令:sort、wc、uniq
- 双向重定向:tee
- 字符转换命令:tr、col、join、paste、expand
- 划分命令:split
- 参数代码:xargs
- 关于减号【-】的用途
- 正则表达式是什么
- grep(擅长查找功能)
- grep配合基本正则表达式案例
- grep配合扩展正则表达式案例
- sed(擅长取行和替换)
- awk(擅长取列)
- awk常见用法
- awk自定义变量
- awk的逻辑运算字符
- printf格式化输出
- echo 和printf区别
特殊符号
| 引号类型 | 解析变量($var) | 解析命令($(cmd)) | 解析通配符(*) | 典型用途 |
|---|---|---|---|---|
| 反引号 ` (优先执行) | 无(自身是命令替换) | 优先执行并替换结果 | 不解析 | 命令结果嵌入和 $(...)相同 |
单引号 ' | 不解析 | 不解析 | 不解析 | 原样输出特殊字符 |
双引号 " | 解析 | 解析 | 不解析 | 保留格式并解析变量 |
| 不加引号 | 解析 | 解析 | 解析 | 自动分词或扩展通配符 |
[root@ubt2404csq ~]# echo "123 `whoami` $(pwd) csq{01..5}"
123 root /root csq{01..5}
[root@ubt2404csq ~]# echo '123 `whoami` $(pwd) csq{01..5}'
123 `whoami` $(pwd) csq{01..5}
[root@ubt2404csq ~]# echo 123 `whoami` $(pwd) csq{01..5}
123 root /root csq01 csq02 csq03 csq04 csq05
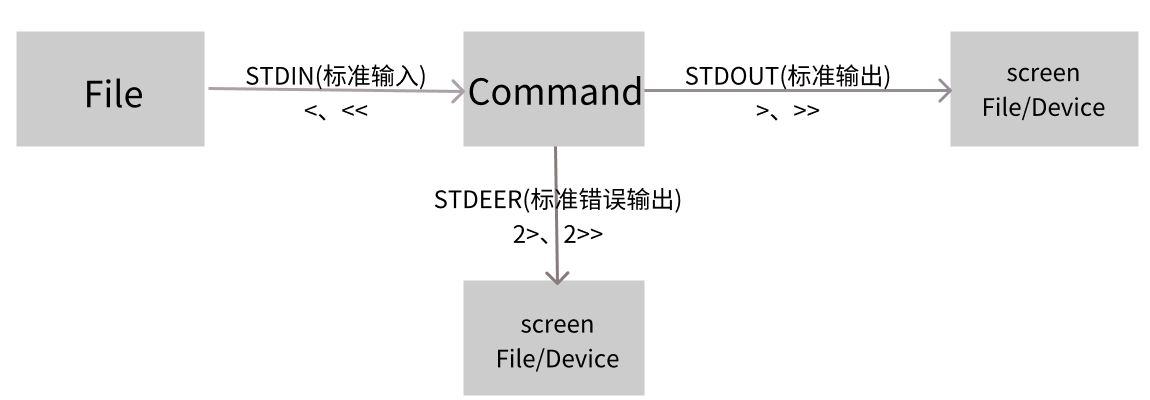
数据流重定向
数据流重定向是指将命令执行后本应输出到屏幕的数据,定向传输到文件、设备或其他位置
什么是数据流重定向
什么是数据流重定向呢?这得由命令的执行说起,一般来说,如果你要执行一个命令,通常它会是这样的:
| 数据流名称 | 文件描述符(FD) | 默认方向 | 作用说明 |
|---|---|---|---|
| 标准输入 | 0 | 键盘 | 命令从这里读取输入数据 |
| 标准输出 | 1 | 终端(屏幕) | 命令的正常执行结果输出到这里 |
| 标准错误输出 | 2 | 终端(屏幕) | 命令的错误信息(如报错)输出到这里 |
我们执行一个命令的时候,这个命令可能会由文件读入数据,经过处理之后,再将数据输出到屏幕上。
输出重定向
基本输输出重定向:>与>>
针对 标准输出,默认可省略文件描述符 1。
| 符号 | 语法格式 | 作用说明 |
|---|---|---|
> | command > file | 将命令的 stdout 重定向到 file,覆盖文件原有内容(若文件不存在则创建) |
>> | command >> file | 将命令的 stdout 重定向到 file,追加到文件末尾(若文件不存在则创建) |
- 覆盖写入文件
# 将 "Hello Linux" 覆盖写入 test.txt(原内容会丢失)
echo "Hello Linux" > test.txt# 查看结果
cat test.txt # 输出:Hello Linux
- 追加写入文件
# 将 "I love Redirection" 追加到 test.txt 末尾
echo "I love Redirection" >> test.txt# 查看结果
cat test.txt
# 输出:
# Hello Linux
# I love Redirection
错误输出重定向:2>与2>>
针对 标准错误输出,必须显式指定文件描述符 2
| 符号 | 语法格式 | 作用说明 |
|---|---|---|
2> | command 2> error.log | 将命令的 stderr 重定向到 error.log,覆盖原有内容 |
2>> | command 2>> error.log | 将命令的 stderr 重定向到 error.log,追加到末尾 |
- 捕获错误信息
# 尝试读取不存在的文件,错误信息会输出到屏幕
cat no_such_file.txt # 输出:cat: no_such_file.txt: No such file or directory# 将错误信息捕获到 error.log
cat no_such_file.txt 2> error.log# 查看错误日志
cat error.log # 输出:cat: no_such_file.txt: No such file or directory
合并输出:stdout + stderr 重定向到同一文件
「正常结果」和「错误信息」保存到同一个文件
| 符号组合 | 语法格式 | 作用说明 |
|---|---|---|
2>&1 | command > combined.log 2>&1 | 先将 stdout 重定向到文件,再将 stderr 「复制」stdout 的方向(覆盖) |
| &> | command &> combined.log | 将 stdout(1)和 stderr(2)同时重定向到 combined.log(覆盖) |
- 将错误和正确的消息都输出到垃圾桶
# 安装软件时屏蔽所有输出(不看进度和提示)
apt update > /dev/null 2>&1
输入重定向
输入重定向用于改变命令的「输入来源」,从默认的「键盘」改为「文件」或「字符串」
基本输入重定向:<
针对 标准输入,默认可省略文件描述符 0
- 利用cat命令来建立一个文件的简单流程
[csq@localhost ~]$ cat > catfile
I like Linux
but I don't like English
<== 这里按下ctrl + d 来退出
[csq@localhost ~]$ cat catfile
I like Linux
but I don't like Englisht
- 用stdin替换键盘的输入以建立新文件的简单流程
[csq@localhost ~]$ cat > catfile < ~/.bashrc
[csq@localhost ~]$ ll catfile ~/.bashrc
-rw-rw-r--. 1 csq csq 231 Apr 25 15:13 catfile
-rw-r--r--. 1 csq csq 231 Apr 1 2020 /home/csq/.bashrc
# 可以看到两个文件大小一模一样,可以自行查看一下内容也是一模一样的
基本输入追加重定向:<<
<< 允许你在命令行中直接输入多行文本作为命令的 stdin,无需单独创建文件,语法为
命令 << 分隔符
多行文本内容
EOF
# 注意:若分隔符单引号(如 << 'EOF'),则多行文本中的变量、命令不会被解析
# 不加引号则会解析
- 生成多行文件
cat > poem.txt << EOF
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
EOF
- 解析变量
#1.单引号不能解析变量(常用于写入yum.repo文件)
[root@kylin-v10-sp3-csq ~]# home=/root
[root@kylin-v10-sp3-csq ~]# cat << 'EOF'
> echo $home
> EOF
echo $home
#2.去除单引号即可解析变量(常用于编写脚本,可以避免使用大量echo)
[root@kylin-v10-sp3-csq ~]# cat << EOF
echo $home
EOF
echo /root
命令执行的判断根据:;、&&、||
在某些情况下,我想要一次执行很多命令,而不想分次执行时,该怎么办?基本上你有两种选择,一个是通过shell脚本去执行,一种则是通过下面的介绍来输入多个命令。
cmd ; cmd(不考虑命令相关性的连续命令执行)
在某些时候,我们希望可以一次执行多个命令,例如关机的时候我希望可以执行两次 sync同步写入磁盘后才shutdown计算机,那么可以怎么做呢?
[root@localhost ~]# sync ; sync ; shutdown -h now
在命令与命令中间利用分号【;】开隔开,这样一来,分号前的命令执行完后就立刻接着执行后面的命令。
那么我如果想在某个目录下面建一个文件,也就是说,如果该目录存在的话,那我才建立文件,如果不存在,那就不创建文件。也就是说这两个命令彼此之间是由相关性的,前一个命令是否成功执行与后一个命令要是否执行有关,那就要用&&或||
$?(命令返回值)与&&或||
如同上面谈到的,两个命令之间有依赖性,而这个依赖性主要判断的地方就在于前面一个命令的执行结果是否正确。判断原理就是【若前面一个命令执行结果正确,在Linux下面就会返回一个$?=0的值】
| 命令执行情况 | 说明 |
|---|---|
| cmd1 && cmd2 | 1. 若cmd1 执行完毕且正确执行($?=0),则开始执行cmd2 2. 若cmd1 执行完毕且为错误($?≠0),则cmd2不执行 |
| cmd1 || cmd2 | 1. 若cmd1 执行完毕且正确执行($?=0),则cmd2 不执行 2. 若cmd1 执行完毕且为错误($?≠0),则开始执行cmd2 |
上述cmd1 及 cmd2 都是命令。
# 示例1 使用ls 查看目录/tmp/abc是否存在,若存在则用touch 建立/tmp/abc/heh
[root@localhost ~]# ls /tmp/abc/ && touch /tmp/abc/hehe
ls: cannot access /tmp/abc/: No such file or directory
# ls说无法访问/tmp/abc/: 没有那个文件或目录,并没有touch的错误,表示touch并没有执行。
[root@localhost ~]# mkdir /tmp/abc
[root@localhost ~]# ls /tmp/abc/ && touch /tmp/abc/hehe
[root@localhost ~]# ll /tmp/abc/hehe
-rw-r--r--. 1 root root 0 Apr 25 16:20 /tmp/abc/hehe# 示例2 看到了吧,/tmp/abc不存在,touch就不会执行,若/tmp/abc存在的话,
# 那么touch就会开始执行。不过这样非常麻烦!能不能自动判断,如果没有该目录就自己建立一个
[root@localhost ~]# rm -rf /tmp/abc/ # 先删除此目录方便测试
[root@localhost ~]# ls /tmp/abc || mkdir /tmp/abc
ls: cannot access /tmp/abc: No such file or directory # ls报错没有/tmp/abc
[root@localhost ~]# ll -d /tmp/abc
drwxr-xr-x. 2 root root 6 Apr 25 16:23 /tmp/abc # mkdir创建了# 示例3 如果你再重复执行【ls /tmp/abc || mkdir /tmp/abc】也不会出现重复mkdir的错误,
# 这是因为/tmp/abc已经存在了,后续的mkdir 就不会执行。
# 如果我想要建立/tmp/abc/hehe这个文件,但我不知道/tmp/abc是否存在,那该如何是好?
[root@localhost ~]# ls /tmp/abc || mkdir /tmp/abc && touch /tmp/abc/hehe
上述案例种尝试建立/tmp/abc/hehe,不管/tmp/abc 是否存在。那么案例三应该如何解释?由于Linux下面的命令都是由左向右执行,所以说上述案例有几种情况来分析一下:
-
(1) 若/tmp/abc 不存在故返回 $?≠0,则 (2) 因为 || 遇到非为 0 的$?故开始 mkdir /tmp/abc ,由于mkdir /tmp/abc 会成功执行,所以返回 $?=0 (3) 遇到$?=0 故会执行 touch /tmp/abc/hehe 最终hehe被建立
-
(2) 若/tmp/abc存在故返回 $?=0 则(2) 因为|| 遇到0的$?不会执行,此时 $?=0继续向后传,故(3)因为遇到$?=0 开始建立 /tmp/abc/hehe 了,最终 /tmp/abc/hehe 被建立
整个流程图如下:

上面这张图的两股数据种,上方的线程为不存在 /tmp/abc 时所进行的命令操作,下方的线段则是存在 /tmp/abc 的命令操作。
# 以ls 测试/tmp/csq 是否存在,若存在则显示 "yes" 不存在则显示 "no"
[root@chenshiren ~]# ls /tmp/csq >/dev/null 2>&1 && echo "yes" || echo "no"
no
练习到这里你应该知道了,命令是一个接着一个去执行的,因此,如果真的使用判断,那么整个 && 与 || 的顺序不能搞错。一般来说,假设判断式有三个,也就是:
command1 && command2 || command3
一般来说 command2 和command3 会使用肯定可以执行的成功的命令。
管道命令(pipe)
有时候我在bash命令执行输出数据的时候,有时候数据必须要经过好几个命令处理后才能得到我们想要的结果。这时候我们就可以时候管道命令,管道命令使用的是【|】这个符号shift + \即可输出。我们来利用管道命令简单的举个例子
假设我们想要知道/etc/下面有多少文件,那么可以利用【 ls /etc】 来查看,不过,因为/etc 下面文件太多了,导致输出以后屏幕很多内容,此时我们可以通过 less命令的协助
[root@localhost ~]# ls /etc/ | less
如此一来,使用ls命令输出后的内容,就能够被less读取,并且利用less功能,我们就可以前后翻动或者/file 查找文件,非常方便。其实这个管道命令【|】仅能处理前一个命令传来的正确信息,也就是标准输出信息,对于标准错误信息并没有直接处理能力。
管道命令处理流程图如下所示

如上图所示,每个管道后面接的第一个数据必定是【命令】,而且这个命令必须能够接受标准输入的数据才行,这样的命令才可为管道命令,如less、more、head、tail 等都是可以接受标准输入的管道命令至于例如 ls、cp、mv等就不是管道命令。因为ls、cp、mv并不会接受来自stdin的数据,也就是说,管道命令主要有两个比较特殊的地方:
管道命令仅会处理标准输出,对于标准错误输出会给予忽略管道命令必须要能够接受来自前一个命令的数据成为标准输入继续处理才行。
如果你硬是要让标准错误可以被管道命令所使用的话,可以这么做。可以使用数据流重定向,让2>&1加入命令中,就可以让2> 变成1>。
选取命令:cut、grep
什么是选取命令?就是将一段数据经过分析后,取出我们所想要的,或是经由分析关键词,取得我们所想要的那一行。不过,要注意的是,一般来说,选取信息通常是针对【一行一行】来分析的,并不是整篇信息分析,下面介绍两个很常用的信息选取命令
cut
cut翻译成英格利希的意思就是【切】,这个命令可以将一段信息的某一段给他【切】出来,处理的信息就是以【行】为单位
cut -d '分隔字符' -f 字段
cut -c 字符区间
选项:
-d:后面接分隔字符,与-f一起使用
-f:根据-d分隔字符将一段信息划分成为数段,用-f取出第几段的意思
-c:以字符的单位取出固定字符的区间# 示例1 将PATH变量取出,我要找出第五个路径
[root@localhost ~]# echo ${PATH}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin1 2 3 4 5
[root@localhost ~]# echo ${PATH} | cut -d ':' -f 5
/root/bin
# 如同上面数字显示,我们是以【:】作为分隔,因此会出现/root/bin# 示例2 如果想要列出第3和第5,可以这样
[root@localhost ~]# echo ${PATH} | cut -d ':' -f 3,5
/usr/sbin:/root/bin# 示例3 将export输出的信息,取得第12字符以后的所有字符
[root@localhost ~]# export
declare -x HISTCONTROL="ignoredups"
declare -x HISTSIZE="1000"
declare -x HOME="/root"
declare -x HOSTNAME="localhost.localdomain"
declare -x LANG="zh_CN.UTF-8"
declare -x LESSOPEN="||/usr/bin/lesspipe.sh %s"
declare -x LOGNAME="root"
.....
.......
...
# 注意看,每个数据都是整齐的输出,如果我们不想要【declare -x 】时,就得这样做
[root@localhost ~]# export | cut -c 12-
HISTCONTROL="ignoredups"
HISTSIZE="1000"
HOME="/root"
HOSTNAME="localhost.localdomain"
LANG="zh_CN.UTF-8"
LESSOPEN="||/usr/bin/lesspipe.sh %s"
LOGNAME="root"
...........
......
...# 示例4 用last将显示的登录者的信息中,仅留下使用者的大名
[root@localhost ~]# last
root pts/1 192.168.100.1 Wed Apr 26 08:42 still logged in
root pts/0 192.168.100.1 Wed Apr 26 08:42 still logged in
root pts/1 192.168.100.1 Tue Apr 25 15:54 - 18:56 (03:01)
root pts/0 192.168.100.1 Tue Apr 25 15:54 - 18:56 (03:01)
reboot system boot 3.10.0-1160.el7. Tue Apr 25 15:51 - 09:37 (17:45)
.....
.......
...
# last 可以输出【账号/终端/来源/日期时间】的数据,并且是排列整齐的。
[root@localhost ~]# last | cut -d ' ' -f 1
root
root
root
root
reboot
root
root
.....
.......
...
# 由输出的结果我们可以发现第一个空白分隔的栏位代表账号,所以使用如上命令
# 但是因为root pts/1 之间空格有好几个,并非仅有一个,所以,如果要找出
# pts1/1 其实不能以 cut -d ' ' -f 1,2 输出结果会不是我们想要的
grep
grep命令将会在下面的内容中介绍
排序命令:sort、wc、uniq
很多时候,我们都会区计算一次数据里面的相同形式的数据总数,举例来说,使用last可以查得系统上面有登录主机者的身份。那么我可以针对每个用户查出它们的总登录次数吗?此时就要排序与计算之类的命令来辅助,下面介绍一下几个好用的排序与统计的命令。
sort
sort它可以帮我们进行排序,而且可以根据不同的数据形式来排序,例如数字与文字的排序就不一样。
sort [-fbMnrtuk] [file 或 stdin]
选项:
-f:忽略大小写的差异,例如A与a视为编码相同
-b:忽略最前面的空格字符部分
-M:以月份的名字来排序,例如JAN、DEC等排序方法
-n:使用【纯数字】进行排序(默认是以文字形式来排序的)
-r:反向排序
-u:就是uniq,相同的数据中,仅出现一行代表。
-t:分隔符号,默认是使用[TAB]键来分隔
-k:以哪个区间来进行排序的意思。
-h:以人类可读的方式排序# 示例1 个人账号都记录在/etc/passwd下,请将账号进行排序
[root@localhost ~]# cat /etc/passwd | sort
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
csq:x:1000:1000::/home/csq:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....
...
# 直接输入sort 默认是以【文字】形式来排序的,所以由a开始排序到最后# 示例2 /etc/passwd内容是以【:】分隔的,我想以第三栏来排序,该如何?
[root@localhost ~]# cat /etc/passwd | sort -t ':' -k 3
root:x:0:0:root:/root:/bin/bash
csq:x:1000:1000::/home/csq:/bin/bash
zhw:x:1001:1001::/home/zhw:/bin/bash
zzh:x:1002:1002::/home/zzh:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
....
......
..
# 发现了吗sort默认是以文字形式来排序的,如果想要数字排序
# cat /etc/passwd | sort -t ':' -k 3 -n 这样才行 加上-n来告知sort是以数字来排序# 示例3 利用last,将输出的数据仅显示账号,并加以排序
[root@localhost ~]# last | cut -d ' ' -f 1 | sort
# 示例4 查找系统中最大的文件
du -sh /* 2>/dev/null | sort -rnk1
#然后一级一级查找直到查到最大的文件
uniq
如果我完成了排序,我想要将重复的数据仅列出一个显示,可以怎么做呢?
uniq [-ic]
选项:
-i:忽略大小写字符的不同
-c:进行计数# 示例1 使用last将账号列出,仅取出账号栏,进行排序后,仅取出一位
[root@localhost ~]# last | cut -d ' ' -f 1 | sort | uniq reboot
root
wtmp# 示例2 如果我还想要知道每个人登录的总次数呢?
[root@localhost ~]# last | cut -d ' ' -f 1 | sort | uniq -c1 7 reboot34 root1 wtmp
# 1.先将所有的数据列出来 2.再将人名独立出来 3.经过排序 4.只显示一个
# 从上述案例得知可以发现reboot出现了7次,root登录则有34次,大部分都是root在登录
# wtmp与第一行的空白都是last的默认字符,两个可以忽略
这个命令用来将重复的行删除掉只显示一个,举例来说,你要知道这个月登录你主机的用户有谁,而不在乎它的登录次数,那么就可以使用上面的案例。
wc
如果我想知道/etc/man_db.conf 这个文件里面有多少文字?多少行?多少字符?,可以利用wc这个命令来完成,它可以帮我们计算出信息的整体数据
wc [-lwm]
选项:
-l:仅列出行
-w:仅列出多少字
-m:多少字符# 示例1 man_db.conf里面到底有多少行、字数、字符数呢?
[root@localhost ~]# cat /etc/man_db.conf | wc131 723 5171
# 输出的三个数字中,分别代表:【行、字数、字符数】# 示例2 使用last可以输出登录者,但是last最后两行并非账号内容,
# 那么请问,我该如何以一行命令串取得登录系统的总人次呢?
[root@localhost ~]# last |grep [a-zA-z] |grep -v 'wtmp' | grep -v 'reboot' | wc -l
34# 由于last会输出空白行,wtmp、reboot等无关账号登录的信息
# 因此,利用grep 取出非空白行,以及取出上述关键字的那几行,在计算行数,就好了
双向重定向:tee
前面我们了解过数据流重定向知道【>】会将数据流整个传送给文件或设备,因此我们除非去读取该文件或设备,否则就无法继续利用整个数据流。那如果我想要将整个数据流处理过程中将某段信息存下来,应该怎么做呢?利用tee就行

tee会同时将数据流分送到文件与屏幕,而输出到屏幕,其实是stdout,那就可以让下个命令继续处理
tee [-a] file
选项:
-a:以累加的方式,将数据加入file当中# 示例1 将last输出存一份到last.list文件中
[root@localhost ~]# last | tee last.list | cut -d " " -f 1
root
root
root
root
......
...# 示例2 将ls -l /home 的数据存一份到~/homefile,同时屏幕也有输出信息
[root@localhost ~]# ls -l /home | tee ~/homefile
total 0
drwx------. 2 csq csq 162 Apr 25 14:48 csq
drwx------. 2 zhw zhw 62 Apr 25 09:52 zhw
drwx------. 2 zzh zzh 62 Apr 25 09:52 zzh
# 如果信息很多的话在后面可以加一个【 | less】# 示例3 再ls -l /etc的数据累加到~/homefile中,同时屏幕也要输出信息
[root@localhost ~]# ls -l /etc/ | tee -a ~/homefile | less
# 是否累加成功可以自行查看
字符转换命令:tr、col、join、paste、expand
tr
可以用来删除一段信息当中的文件,或是进行文字信息的替换
tr [-ds] SET1 ....
选项:
-d:删除信息当中的SET1字符
-s:替换掉重复的字符# 示例1 将last输出的信息中,所有的小写变成大写字符
[root@localhost ~]# last | tr '[a-z]' '[A-Z]'
ROOT PTS/1 192.168.100.1 WED APR 26 09:42 STILL LOGGED IN
ROOT PTS/0 192.168.100.1 WED APR 26 09:42 STILL LOGGED IN
.....
...# 示例2 将/etc/passwd 输出信息中,将冒号【:】删除
[root@localhost ~]# cat /etc/passwd | tr -d ':'
rootx00root/root/bin/bash
binx11bin/bin/sbin/nologin
daemonx22daemon/sbin/sbin/nologin
admx34adm/var/adm/sbin/nologin
.....
...# 示例3 将/etc/passwd转成dos换行到/root/passwd中,再将^M符号删除
[root@localhost ~]# cp -rf /etc/passwd ~/passwd && unix2dos ~/passwd
unix2dos: converting file /root/passwd to DOS format ...
[root@localhost ~]# file ~/passwd
/root/passwd: ASCII text, with CRLF line terminators # 这就是DOS换行
[root@localhost ~]# cat ~/passwd | tr -d '\r' > ~/passwd.Linux
[root@localhost ~]# ll /etc/passwd ~/passwd*
-rw-r--r--. 1 root root 957 Apr 25 09:52 /etc/passwd
-rw-r--r--. 1 root root 979 Apr 26 15:12 /root/passwd
-rw-r--r--. 1 root root 957 Apr 26 15:12 /root/passwd.Linux
# 处理过后,发现文件大小与原本的/etc/passwd就一致了
上述案例,为什么可以使用\r替换?
回车符(Carriage Return)或者 \r 是一个控制字符,它在DOS/Windows系统中作为换行符的一部分存在,表示将光标移动到行首。在Linux和Unix系统中,换行符只有一个,是一个叫做 Line Feed 的字符,也就是 \n。
因此,当我们在Linux系统中使用cat命令查看一个DOS/Windows系统中的文本文件时,会看到很多 ^M 字符,这是因为 ^M 是 \r 的可见表示。而在Linux系统中,这个字符并不是换行符的一部分,因此需要将它替换掉。
tr命令可以用来替换文本中的字符,其中 -d 选项表示删除指定的字符,因此 tr -d ‘\r’ 表示删除文本中的 \r 字符。所以,使用 tr -d ‘\r’ 命令可以将 DOS/Windows 格式的文本文件转换为 Linux 格式。
col
col [-xb]
选项:
-x:将tab键转换成对的空格键# 示例1 利用cat -A 显示出所有的特殊按键,最后以col 将[TAB]转成空白
[root@localhost ~]# cat -A /etc/man_db.conf
# 执行完这个命令你就看到很多^I的符号,那就是tab
[root@localhost ~]# cat /etc/man_db.conf | col -x | cat -A |less
# 执行完命令就可以看到所有的[TAB]按键会被替换成为空格键
col的用途就是简单的处理[tab]按键替换成空格键。
join
join翻译成英格利希的意思就是(参加/加入),它是在处理两个文件之前的数据,而且,主要是在处理【两个文件当中,有相同数据的那一行,才将它加在一起的意思。
join [-ti12] file1 file2
选项:
-t:join默认以空格字符分隔数据,并且比对【第一个栏位】的数据如果两个文件相同,则将两条数据连成一行,且第一个栏位放在第一个
-i:忽略大小写的差异
-1:这个是数字的1,代表【第一个文件要用哪个栏位来分析】的意思
-2:代表【第二个文件要用哪个栏位来分析】的意思# 示例1 用root身份,将/etc/passwd与/etc/shadow相关数据整合成一栏
[root@localhost ~]# head -n 3 /etc/passwd /etc/shadow
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin==> /etc/shadow <==
root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:*:18353:0:99999:7:::
daemon:*:18353:0:99999:7:::
# 由于输出的数据可以发现在两个文件的最左边栏都是相同账号,且以:分隔
[root@localhost ~]# join -t ':' /etc/passwd /etc/shadow | head -n 3
root:x:0:0:root:/root:/bin/bash:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin:*:18353:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin:*:18353:0:99999:7:::
# 通过上面的操作,我们可以将两个文件第一栏位相同者整合成一行
# 第二个文件的相同栏位并不会显示(因为已经在最左边的栏位出现了)# 示例2 我们知道/etc/passwd 第四个栏位是GID
# 这个GID记录在/etc/group 当中的第三个栏位,请问如何将两个文件整合?
[root@localhost ~]# head -n 3 /etc/passwd /etc/group
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin==> /etc/group <==
root:x:0:
bin:x:1:
daemon:x:2:
# 从上面可以看出确实有相同的部分
[root@localhost ~]# join -t ':' -1 4 /etc/passwd -2 3 /etc/group | head -n 3
0:root:x:0:root:/root:/bin/bash:root:x:
1:bin:x:1:bin:/bin:/sbin/nologin:bin:x:
2:daemon:x:2:daemon:/sbin:/sbin/nologin:daemon:x:# 同样的,相同的栏位部分移动到了最前面,所以第二个文件的内容就每显示
paste
这个paste就要比join简单多了。相对于join必须要比对两个文件的数据相关性,paste就直接将两行贴在一起,且中间以【TAB】键隔开
paste [-d] file1 file2
选项:
-d:后面可以接分隔字符,默认是以【TAB】来分隔
- :如果file部分写错了 -,表示来自标准输入的数据的意思# 示例1 用root的身份,将/etc/passwd与/etc/shadow同行贴在一起,且仅取出前3行
[root@localhost ~]# paste /etc/passwd /etc/shadow |head -n 3
root:x:0:0:root:/root:/bin/bash root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:18353:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:18353:0:99999:7:::
# 注意同一行间是以【TAB】按键隔开的可以仔细看一下# 示例2 先将/etc/group读出(用cat),然后与上述案例的那两个文件忒在一起,且仅取出前3行
[root@localhost ~]# cat /etc/group | paste /etc/passwd /etc/shadow - | head -n 3
root:x:0:0:root:/root:/bin/bash root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7::: root:x:0:
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:18353:0:99999:7::: bin:x:1:
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:18353:0:99999:7::: daemon:x:2:
expand
这个命令就是在将【TAB】按键转成空格键
expand [-t] file
选项:
-t:后面可接数字,一般来说一个TAB按键可以用8个空格键来替换我们也可以自定义一个【TAB】按键代表多少个字符
# 示例1 将/etc/man_db.conf 内行首的MANPATH的字样就取出,仅取前三行
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3
MANPATH_MAP /bin /usr/share/man
MANPATH_MAP /usr/bin /usr/share/man
MANPATH_MAP /sbin /usr/share/man
# 行首的 ^ 的意思是找出以MANPATH的行# 示例2 上述案例,如果我想要将所有的符号都列出来来?
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3 | cat -A
MANPATH_MAP^I/bin^I^I^I/usr/share/man$
MANPATH_MAP^I/usr/bin^I^I/usr/share/man$
MANPATH_MAP^I/sbin^I^I^I/usr/share/man$
# cat -A 可以将【TAB】键显示为【^I】
承接上述案例,我将【TAB】按键设置成6个字符的话?

如果你字符长度设置为 9 或 10就又不同了,还有个命令unexpand是将空格转成【TAB】命令
我们把上述的案例改一下 在让他转成【TAB】命令
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3 | expand -t 8 -| unexpand -t 8 - | cat -A
MANPATH_MAP^I/bin^I^I^I/usr/share/man$
MANPATH_MAP^I/usr/bin^I^I/usr/share/man$
MANPATH_MAP^I/sbin^I^I^I/usr/share/man$
# 就像这样 好像转空格了 又好像没转,左右摇摆
划分命令:split
split命令它可以帮你将一个大文件,依据文件大小或行数来划分,就可以将大文件划分为小文件了
split [-bl] file PREFIX
选项:
-b:后面可接欲划分成的文件大小,可加单位,例如b、k、m等
-l:以行数来进行划分
PREFIX:代表前缀字符的意思,可作为划分文件的前缀文字# 示例1 我的/etc/services 有600多K,若想要分成300K一个文件时
[root@localhost ~]# cd /tmp/;split -b 300K /etc/services services
[root@localhost tmp]# ll -k services*
-rw-r--r--. 1 root root 307200 Apr 26 16:10 servicesaa
-rw-r--r--. 1 root root 307200 Apr 26 16:10 servicesab
-rw-r--r--. 1 root root 55893 Apr 26 16:10 servicesac
# 这个文件名可随意取,我们只要写上前缀文字,小文件就会以xxxaaa,xxxab,xxxac等方式来建立小文件# 示例2 如何将上面的三个小文件合成一个文件,文件名servicesback
[root@localhost tmp]# cat services* >> servicesback
[root@localhost tmp]# ls -l servicesback /etc/services
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
-rw-r--r--. 1 root root 670293 Apr 26 16:13 servicesback# 示例3 使用ls -al /输出的信息中,每十行记录一个文件
[root@localhost tmp]# ls -al /etc/ | split -l 10 - lsroot
[root@localhost tmp]# wc -l lsroot*0 lsroot10 lsrootaa10 lsrootab10 lsrootac10 lsrootad........
# 重点在这个-号,一般来说如果需要stdout或是stdin时,但偏偏又没有文件
# 有的只是 - 时,那么这个 - 就会被当成 stdin或stdout
参数代码:xargs
xargs是在做什么?以字面的意义来看,x是加减乘除的乘号,args则是参数的意思,所以说这个命令就是在产生某个目录的参数的意思。xargs可以读入stdin的数据,并且以空格符或换行符作为识别符,将stdin的数据分隔为参数。因为是以空格符作为分隔,所以,如果有一些文件名或是其他意义的名词内含有空格符的时候,xargs可能就会误判,用法如下
xargs [-0epn] command
选项:
-0:如果输入stdin含有特殊字符,例如:`、\、空格等特殊字符时,这个-0参数可以将它还原成一般的字符,这个参数可以用于特殊状态
-e:这个是EOF的意思,后面可以接一个字符,当xargs分析到这个1字符时,就会停止工作
-p:在执行每个命令时,都会询问使用者的意思
-n:后面接次数,每次command命令执行时,要使用几个参数的意思
当xargs后面没有接任何命令的时候,默认是以echo 来进行输出# 示例1 将/etc/passwd内的第一栏取出,仅取三行,使用id这个命令将每个账号内容显示出来
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -n 1 id
uid=0(root) gid=0(root) groups=0(root)
uid=1(bin) gid=1(bin) groups=1(bin)
uid=2(daemon) gid=2(daemon) groups=2(daemon)
# 通过-n处理,一次给予一个参数# 示例2 同上,但是执行id时,都要询问使用者是否操作?
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -p -n 1 id
id root ?...y
uid=0(root) gid=0(root) groups=0(root)
id bin ?...y
uid=1(bin) gid=1(bin) groups=1(bin)
id daemon ?...y
uid=2(daemon) gid=2(daemon) groups=2(daemon)# 示例3 将所有的/etc/passwd内的账号都以id查看,但查到sync就结束命令串
[root@localhost ~]# cat /etc/passwd | head -n 7
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | xargs -e'sync' -n 1 id
uid=0(root) gid=0(root) groups=0(root)
uid=1(bin) gid=1(bin) groups=1(bin)
uid=2(daemon) gid=2(daemon) groups=2(daemon)
uid=3(adm) gid=4(adm) groups=4(adm)
uid=4(lp) gid=7(lp) groups=7(lp)
# 注意上述案例中那个-e'sync'是连在一起的,中间没有空格
# 可以看到我们查看 /etc/passwd sync在第6行,当分析到第6行内容时就自动停止了
关于减号【-】的用途
管道命令在bash的连续的处理程序中是相当重要的。另外,在日志文件的分析中也是相当的重要。在管道命令中,常常会使用到一个命令的标准输出(stdout)作为这次的标准输入(stdin),某些命令需要用到文件名(例如 tar)来进行处理时,该stdin与stdout可以利用减号【-】来替代,举例来说
[root@localhost ~]# tar -cvf - /home | tar -xvf - -C /tmp/homeback/
上面的例子是说:【我将/home里面的文件给他打包,但打包的数据不是记录到文件,而是传送到stdout,经过管道后,将tar -cvf - /home 串送给后面的 tar -xvf -】后面的这个【-】则是使用前一个命令的stdout,因此,我们就不需要文件名了。
正则表达式是什么
简单来说就是通过一些特殊的符号,可以让用户完成查找 删除 替换。
正则表达式分两类:
- 基本正则表达式(BRE),对应元字符有【 ^ $ . [ ] *】。
- 扩展正则表达式(ERE) 在BRE基础上增加了 【( ) { } ? + | 】等字符
基本正则表达式集合
| 符号 | 作用 |
|---|---|
| ^ | 尖角号,用于模式的最左侧,如" ^csq " 就是匹配以csq开头的行 |
| $ | 美元符,用于模式的最右侧,如“csq$”,表示以csq结尾的行 |
| ^$ | 组合符,表示空行 |
| . | 匹配任意一个且只有一个字符,不能匹配空行 |
| \ | 转义字符,让特殊含义的符号现出原形,如\ . 代表小数点. |
| * | 匹配前一个字符(连续出现) 0次或1次以上,重复0次代表空,即匹配所有内容 |
| .* | 组合符,匹配所有内容 |
| ^.* | 组合符,匹配任意多个字符开头的内容 |
| .*$ | 组合符,匹配以任意多个字符结尾的内容 |
| [abc] | 匹配[ ]集合内的任意一个字符,a或b或c,可以写成[a-c] |
| [^abc] | 匹配除了^后面的任意字符,a或b或c,^表示对[abc]的取反 |
扩展正则表达式集合
扩展正则必须用 grep -E 才能生效
| 字符 | 作用 |
|---|---|
| + | 匹配前一个字符1次或多次 |
| [ : / ] + | 匹配括号内的":"或者“/”字符1次或多次 |
| ? | 匹配前一个字符0次或1次 |
| | | 表示或者,同时过滤多个字符 |
| () | 分组过滤,被括起来的内容表示一个整体 |
| a{n,m} | 匹配前一个字符最少n次,最多M次 |
| a{n,} | 匹配前一个字符最少n次 |
| a{n} | 匹配前一个字符正好n次 |
| a{,m} | 匹配前一个字符最多m次 |
grep(擅长查找功能)
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行
用法: grep [参数选项]... PATTERN [FILE]...
在每个 FILE 或是标准输入中查找 PATTERN。
默认的 PATTERN 是一个基本正则表达式(缩写为 BRE)。
例如: grep -i 'hello world' menu.h main.c
| 参数选项 | 解释说明 |
|---|---|
| -v | 排除匹配结果 |
| -n | 显示匹配行与行号 |
| -i | 不区分大小写 |
| -c | 只统计匹配的行数 |
| -E | 使用扩展正则表达式命令 |
| –color=auto | 为grep过滤结果添加颜色 |
| -w | 只匹配过滤的单词 |
| -o | 只输出匹配的内容 |
grep配合基本正则表达式案例
测试文件
cat > re.txt <<EOF
I am a student!
I study Linux.I like play computer game
my blog is https://www.chenshiren.xyz
our site is https://www.chenshiren.xyzmy qq is 222333300
not 222333000.good bey see you.
EOF
(1)^以xxxx开头的行

(2)$以xxxx结尾的行

(3)^$空行
一般排除空行或者包含井号开头的行
排除空行
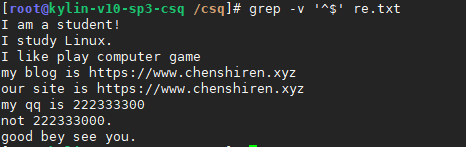
排除空行和井号开头的行

(4). 任意一个字符
过滤出以.结尾的行

(5)* 前一个字符出现0次或1次以上
出现/重复/连续出现
过滤出所有包含o的行
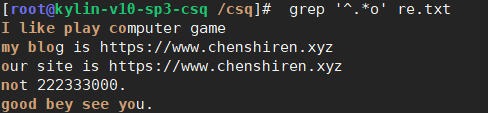
正则表达式匹配所有或连续出现的时候:贪婪性
过滤以I开头任意内容以game号结尾的行

(6)[][abc]一个整体包含3个情况,匹配a或b或c
过滤a或b或c
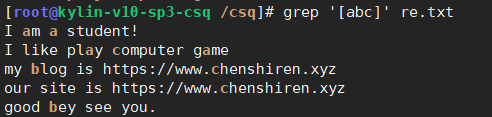
过滤大小写字母和数字
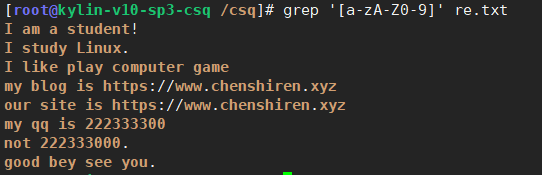
过滤出文件中以I或n或g开头的行

过滤出文件中以I或m或n开头的然后结束是数字或字母的

(7)[^][^abc]不匹配a或b或c
不匹配a或b或c
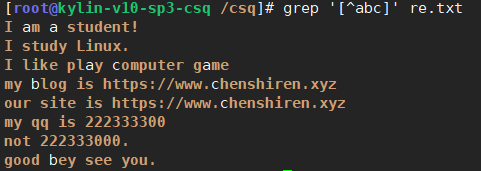
不匹配小写字母
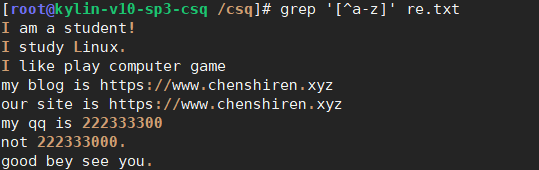
(8)过滤出以.结尾的行
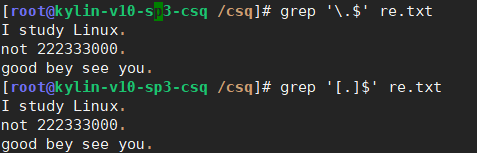
匹配.结尾的行,[]也可以让.变为普通字符
grep配合扩展正则表达式案例
(1)| 或者
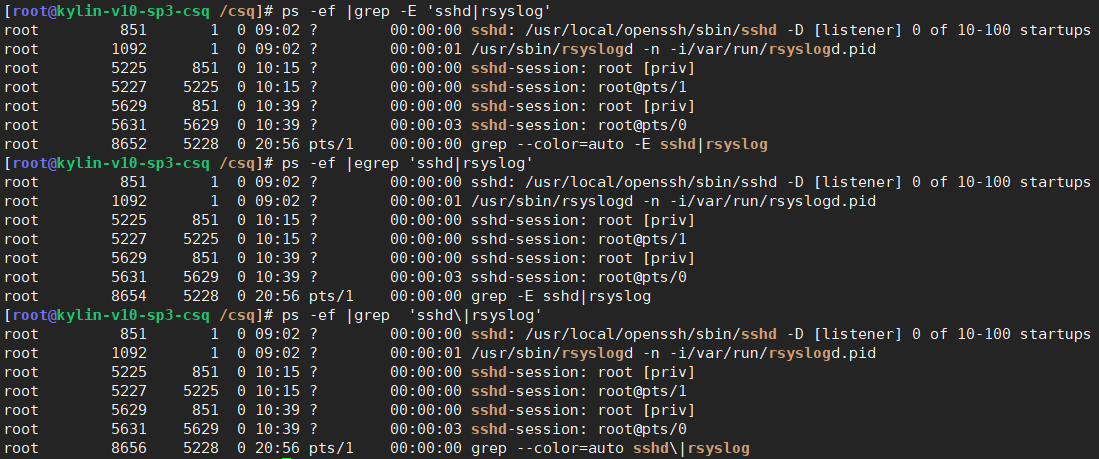
找出进程关于sshd和rsyslog的进程,常见的三种写法
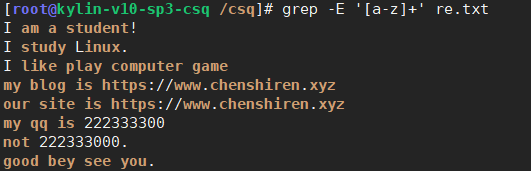
(2)+前一个字符出现1次或1次以上
出现/重复/连续出现
经常与[]搭配实现
匹配出re.txt文件中连续出现的单词
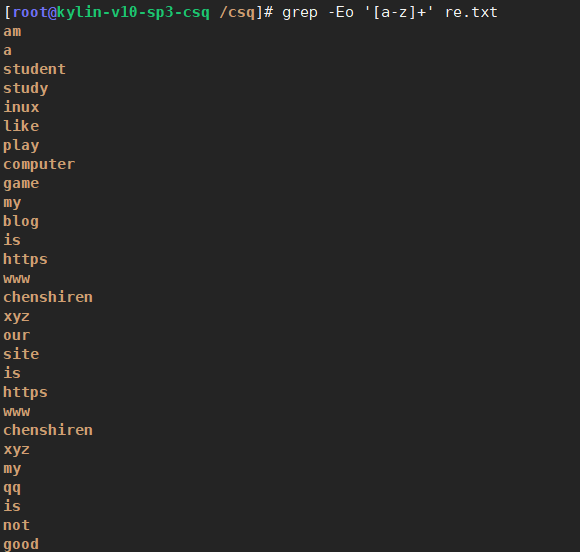
只输出re.txt文件中连续出现的单词
取出re.txt文件中连续出现的单词统计次数,取出前5

取出re.txt文件中出现的字母统计次数,取出前5

(3){}o{n,m}前一个字符o,出现至少n次,最多m次
表示范围的匹配,出现1位数字到3位数字
匹配re.txt文件中数字出现的次数最少1次最多3次

匹配ret.txt文件中数字出现的次数等于3次

使用正则匹配ifconfig的地址

(4)()一个整体(sed命令中表示反向引用)
找出lscpu命令中CPU缓冲存储器信息,4种写法



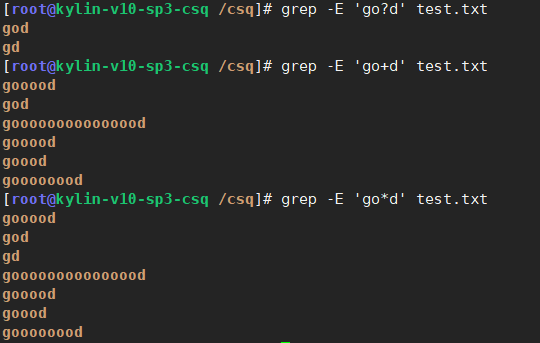
(5)? 前一个字符出现0次或1次
对比+和*
sed(擅长取行和替换)
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换文本内容的强大工具
其中最常用的功能就是过滤和取行(指定行)
用法: sed [选项]... {sed内置命令符} [输入文件]...
| 选项参数 | 解释 |
|---|---|
| -e | 进行多项(多次)编辑 |
| -n | 取消默认输出,只有经过sed特殊处理的那一行才会被列出来 |
| -r | 使用扩展正则表达式 |
| -i | 原地编辑(修改文件) |
| -f | 指定sed脚本的文件名 |
常用的处理动作
所有动作都要在单引号里
| 动作 | 解释 |
|---|---|
| p | 打印 |
| i | 在指定行之前插入内容 |
| a | 在指定行之后插入内容 |
| c | 替换指定行的所有内容 |
| d | 删除指定行 |
| s | 查找并替换 |
# 测试内容
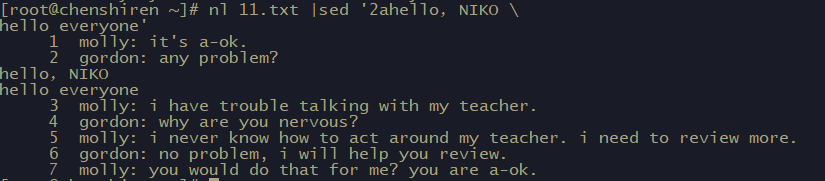
[root@csq ~]# cat 11.txt
molly: it's a-ok.
gordon: any problem?
molly: i have trouble talking with my teacher.
gordon: why are you nervous?
molly: i never know how to act around my teacher. i need to review more.
gordon: no problem, i will help you review.
molly: you would do that for me? you are a-ok.
以行为单位新增功能
删除文件1~2行

在第2行和第3行中间加上【hello,NIKO】字样

添加多行?
以行为单位替换与显示功能
将1~2行的内容替换为【No 1~2 number】

仅列出文件的1~2行

部分数据的查找与替换
# 示例1
# 1.先观察原始信息,利用ifconfig查询IP是什么
[root@chenshiren ~]# ifconfig
ens160: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 192.168.200.20 netmask 255.255.255.0 broadcast 192.168.200.255
...
...
# 2.利用grep选取出关键一行的数据
[root@chenshiren ~]# ifconfig ens160 |grep 'inet 'inet 192.168.200.20 netmask 255.255.255.0 broadcast 192.168.200.255
# 3.将IP前后的部分删除
[root@chenshiren ~]# ifconfig ens160 |grep -w 'inet'|sed 's/^.*inet //g' | sed 's/netmask.*$//g'
#直接使用sed只在屏幕输出替换结果,不修改原文件
192.168.200.20 # 示例2
# 1.使用关键字MAN所在行取出来
[root@chenshiren ~]# cat /etc/man_db.conf |grep -n 'MAN'
12:# MANDATORY_MANPATH manpath_element
13:# MANPATH_MAP path_element manpath_element
14:# MANDB_MAP global_manpath [relative_catpath]
16:# every automatically generated MANPATH includes these fields
18:#MANDATORY_MANPATH /usr/src/pvm3/man
20:MANDATORY_MANPATH /usr/man
....
# 2.删除掉注释行和空行
[root@chenshiren ~]# cat /etc/man_db.conf |grep 'MAN' |sed 's/#.*$//g' | sed '/^$/d'
MANDATORY_MANPATH /usr/man
MANDATORY_MANPATH /usr/share/man
MANDATORY_MANPATH /usr/local/share/man
MANPATH_MAP /bin /usr/share/man
MANPATH_MAP /usr/bin /usr/share/man
MANPATH_MAP /sbin /usr/share/man
MANPATH_MAP /usr/sbin /usr/share/man
MANPATH_MAP /usr/local/bin /usr/local/man
MANPATH_MAP /usr/local/bin /usr/local/share/man
...
...
直接修改文件内容
# 示例1 将11.test文件中的所有的you换成my
[root@chenshiren ~]# sed -i 's/you/my/g' 11.txt# 示例2 在文件最后一行加入 【# This is a test】
[root@chenshiren ~]# sed -i '$a # This is a test\!' 11.txt
[root@chenshiren ~]# tail -n 1 11.txt
# This is a test!# 示例3 在每一行添加----分隔
[root@chenshiren ~]# sed -i 'a -------------' 11.txt
[root@chenshiren ~]# head -n 4 11.txt
molly: it's a-ok.
-------------
gordon: any problem?
-------------
# 示例4 删除-------分隔
[root@chenshiren ~]# sed -i '/^-.*/d' csq.txt
awk(擅长取列)
awk是一个强大的Linux命令,有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表样式
awk早期在Unix上实现,我们用的awk是gawk,是GUN awk的意思

awk也是一门编程语言,支持条件判断、数组、循环功能等
awk options 'pattern[action]'... filename
# options:awk可选参数
# pattern :条件类型
# action:操作
awk主要是处理每一行的字段内的数据,而默认的字段的分隔符为【空格键】或【Tab】键
# 示例1 使用last将登录者的数据取出来
[root@chenshiren ~]# last |grep -n 'csq'
16:csq pts/1 192.168.200.1 Tue Mar 12 00:57 - 01:01 (00:03)
17:csq pts/1 192.168.200.1 Tue Mar 12 00:56 - 00:57 (00:01)
20:csq pts/2 192.168.200.1 Tue Mar 12 00:06 - 00:07 (00:00)
28:csq pts/1 192.168.200.1 Sun Mar 10 20:04 - 20:10 (00:06)
29:csq pts/1 192.168.200.1 Sun Mar 10 20:02 - 20:04 (00:01)
97:csq pts/1 192.168.200.1 Thu Feb 29 18:40 - crash (03:46)
101:csq pts/1 192.168.200.1 Wed Feb 28 18:35 - 19:24 (00:49)
104:csq pts/2 192.168.200.1 Tue Feb 27 23:29 - crash (17:57)
# 承上,若我想取出账号与登录者的IP,且账号与IP之间以[TAB]隔开
[root@chenshiren ~]# last | grep -n 'csq' | awk '{print $1 "\t\t" $3}'
16:csq 192.168.200.1
17:csq 192.168.200.1
20:csq 192.168.200.1
28:csq 192.168.200.1
29:csq 192.168.200.1
97:csq 192.168.200.1
101:csq 192.168.200.1
104:csq 192.168.200.1
# 每一行的字段都是有变量名称,那就是$1,$2等变量名称
# csq是$1因为是第一栏,IP是第三栏所以就是$3
# $0 代表整个当前行的文本内容,包括该行中所有的字段和分隔符
整个awk的处理流程
- 读入第1行,并将第1行的数据写入$0,$1,$2等变量中
- 根据”条件类型“的限制,判断是否需要进行后面的操作
- 完成所有操作与条件类型
- 若还有后续的【行】的数据,则重复上面1~3行步骤,直到所有的数据读完为止
参数
| 选项 | 说明 |
|---|---|
| -F | 指定分隔字段符 |
| -v | 定义或修改一个awk内部变量 |
| -f | 从脚本文件中读取awk命令 |
内置变量
| 变量名称 | 代表意义 |
|---|---|
| ORS | 输出当前记录分隔符 |
| FS | 输入字符风隔符,默认为空白字符 |
| OFS | 输出字段分隔符,默认为空白 字符 |
| RS | 输入记录分隔符(输入换行符),指定输入时的额换行符 |
| NF | number of Field,当前行的字段的个数,字段数量 |
| NR | 行号,当前处理的文本行的行号 |
| FNR | 各文件分别计数的行号 |
| FILENAME | 当前文件名 |
| ARGC | 命令行参数的个数 |
| ARGV | 数组,保存的是命令行所给定的各参数 |

awk常见用法
# 示例1: 列出每一行的账号($1)以及目前处理的行数(awk内的NR变量),并说明该行有多少字段
[root@chenshiren ~]# last |grep 'csq' |awk '{print $1 "\t lines: " NR "\t columes: "NF}'
csq lines: 1 columes: 10
csq lines: 2 columes: 10
csq lines: 3 columes: 10
csq lines: 4 columes: 10
csq lines: 5 columes: 10
csq lines: 6 columes: 10
csq lines: 7 columes: 10
csq lines: 8 columes: 10# 示例2 awk取本机IP方法
[root@chenshiren ~]# ifconfig ens160 |awk 'NR==2{print $2}'
192.168.200.20# 示例3 输出passwd中所有用户名和所对应的shell
[root@chenshiren ~]# awk -F ':' '{print $1 "\t" $7}' /etc/passwd
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
....# 示例4 利用OFS输出分隔符分隔开,第一列,第二列,第三列
[root@chenshiren ~]# awk -F ':' -v OFS='---' '{print $1,$3,$7}' /etc/passwd
root---0---/bin/bash
bin---1---/sbin/nologin
daemon---2---/sbin/nologin
adm---3---/sbin/nologin
lp---4---/sbin/nologin
sync---5---/bin/sync
....
....# 示例5 我们也可以自定义 空格 作为 行分隔符 每遇到一个空格就换行处理
[root@chenshiren ~]# echo {A..Z} > number.txt
[root@chenshiren ~]# awk -v RS=' ' '{print NR,$0}' number.txt
1 A
2 B
3 C
4 D
5 E
6 F
7 G
8 H
9 I
10 J
11 K
12 L
13 M
14 N
15 O
16 P
17 Q
18 R
19 S
20 T
21 U
22 V
23 W
24 X
25 Y
26 Z# 示例6 ORS是输出分隔符的意思,awk默认认为,每一行结束了,就得添加 回车换行符
[root@chenshiren ~]# awk -v ORS='\t结束' '{print $0}' number.txt
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 结束# 示例7 显示awk正在处理文件的名字
[root@chenshiren ~]# awk -F ":" '{print FILENAME,NR,$1}' /etc/passwd
/etc/passwd 1 root
/etc/passwd 2 bin
/etc/passwd 3 daemon
/etc/passwd 4 adm
/etc/passwd 5 lp
/etc/passwd 6 sync
/etc/passwd 7 shutdown
/etc/passwd 8 halt
/etc/passwd 9 mail
/etc/passwd 10 operator
/etc/passwd 11 games
/etc/passwd 12 ftp
/etc/passwd 13 nobody
变量ARGC,ARGV
ARGV表示的是一个数组,数组中保存的命令行所给的 参数
数组是一种数据类型,如同一个盒子
盒子有它的名字,且内部有N个小格子,标号从0开始
BEGIN表示你在打印动作的时候先做的事
[root@csq ~]# awk 'BEGIN{print "csqcsq"} {print $2}' 22.txt
csqcsq
csq1
csq6
csq11
csq15
argv[0] 指向程序运行的全路径名
[root@csq ~]# awk 'BEGIN{print "csqcsq"} {print ARGV[0]}' 22.txt
csqcsq
awk
awk
awk
awk
argv[1] 指向在DOS命令行中执行程序名后的第一个字符串
[root@csq ~]# awk 'BEGIN{print "csqcsq"} {print ARGV[1]}' 22.txt
csqcsq
22.txt
22.txt
22.txt
22.txt
argv[2] 指向执行程序名后的第二个字符串
[root@csq ~]# awk 'BEGIN{print "csqcsq"} {print ARGV[0], ARGV[1],ARGV[2]}' 22.txt 33.txt
csqcsq
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk自定义变量
顾名思义,就是我们自己定义变量
- 方法①:-v varName=value
- 方法②:在程序中直接定义
方法①:
[root@chenshiren ~]# awk -F ":" -v filename="/etc/passwd" 'BEGIN{print "文件名:",filename} {print $1"\t"$3"\t"$7}' /etc/passwd
文件名: /etc/passwd
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
nobody 65534 /sbin/nologin
...
...
方法②:
[root@csq ~]# [root@chenshiren ~]# awk 'BEGIN{csq1="11111111";csq2="222222222";print csq1,csq2,csq1,csq2}'
11111111 222222222 11111111 222222222# 定义了2个变量,最后打印变量
方法③:间接引用shell变量
[root@csq ~]# Linuxbianliang="这个是Linux定义的变量"
[root@chenshiren ~]# awk -v awkbl=$Linuxbianliang 'BEGIN{print awkbl }'
这个是Linux定义的变量
awk的逻辑运算字符
| 运算单元 | 代表意义 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于或等于 |
| <= | 小于或等于 |
| == | 等于 |
| != | 不等于 |
# 示例1 在/etc/passwd当中是以":"来作为字段分隔,该文件中第一字段为账号,第三字段是UID
# 那么第三栏小于10以下的数据,并且仅列出账号与第三列
[root@chenshiren ~]# cat /etc/passwd |awk 'BEGIN{FS=":"} $3 < 10 {print $1,$3}'
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8# 示例2 假设有一份薪资数据表文件名为pay.txt 内容如下
Name 1st 2nd 3th
csq 2300 2400 2500
zhw 2100 2000 1000
ccc 1000 2000 3000
# 计算总额
[root@chenshiren ~]# awk 'NR>1 {sum=0; for(i=2; i<=NF; i++) sum+=$i; print $1, "Total:", sum}' pay.txt
csq Total: 7200
zhw Total: 5100
ccc Total: 6000
- awk的命令间隔:所有awk操作,就是在{}内的操作,如果有需要多个命令辅助时,可利用分号【;】间隔或直接以【Enter】按键来隔开每个命令
- 逻辑运算当中,如果是【等于】的情况,则务必使用两个等号【==】
printf格式化输出
之前大部分内容都是写的{print}的功能,之呢个对文本简单的输出,并不能美化或者修改格式
printf命令的作用是按照我们指定的格式输出文本
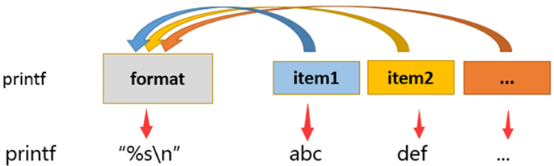
printf命令的语法如下
printf "指定的格式" "文本1" "文本2" "文本3" ......
选项:
关于格式方面的几个特殊样式:\a 警告声音输出\b 退格键\f 清除屏幕\n 输出新的一行\r 就是回车按键\t 水平的[tab]按键\v 垂直的[tab]按键\xNN NN为两位数的数字,可以转换数字成为字符
关于C语言常见的变量格式:%ns n是数字,代表string,就是多少个字符%ni n是数字,代表irteger,就是多少个整数位数%N.nf n与N都是数字,f代表floating(浮点),如果有小鼠位数假设共要十位数,小数点两位即为 %10.2f
printf修饰符:
-:左对齐(默认是右对齐)
+:显示数值符号:printf "%+d"
echo 和printf区别
输出文本,echo命令也可以进行输出,它们的无别
[root@csq ~]# echo "mynamecsq"
mynamecsq
[root@csq ~]# printf "mynamecsq"
mynamecsq[root@csq ~]#
# 在输出文本时,echo会对输出的文本进行换行
# 而printf命令则不会对输出的文本进行换行,我们使用转义符\n就可以换行
[root@csq ~]# printf "mynamecsq\n"
mynamecsq
printf和print的区别
- printf:
printf是一个用于格式化输出的函数,可以按照指定的格式输出文本。- 它允许使用格式控制符(如
%s、%d等)指定输出的格式和数据类型。 - 可以通过
printf来控制输出的对齐和宽度等格式化要求。 printf不会自动换行,需要显式指定换行符\n才会换行。- 例子:
printf "Hello, %s!\n" "World"会输出Hello, World!到标准输出并换行。
- print:
print是一个用于输出文本的函数,通常用于打印一行文本到标准输出。print会自动添加换行符\n到输出的文本末尾。print不支持像printf那样的格式化控制符。print在输出末尾自动换行,不需要显示指定换行符。- 例子:
print "Hello, World"会输出Hello, World到标准输出并换行。
printf添加格式
格式化字符串%s代表字符串的意思
[root@csq ~]# awk '{printf "%s\n",$1}' 22.txt
csq
csq5
csq10
csq14
对多个变量进行格式化
当我们使用linux命令printf时,是这样的,一个%s格式替换符,可以对多个参数进行重复格式化
[root@csq ~]# printf "%s\n" a a a a a
a
a
a
a
a
然而awk的格式替换符想要修改多个变量,必须传入多个
[root@chenshiren ~]# awk 'BEGIN{printf "%d\n%d\n%d\n",1+1,2+2,3+3}'
2
4
6
printf案例
准备测试文件
[root@csq ~]# cat 22.txt
csq csq1 csq2 csq3 csq4
csq5 csq6 csq7 csq8 csq9
csq10 csq11 csq12 csq13
csq14 csq15 csq16 csq17
[root@csq ~]# awk '{printf "第一列:%s 第二列:%s 第三列:%s\n",$1,$2,$3}' 22.txt
第一列:csq 第二列:csq1 第三列:csq2
第一列:csq5 第二列:csq6 第三列:csq7
第一列:csq10 第二列:csq11 第三列:csq12
第一列:csq14 第二列:csq15 第三列:csq16- awk通过空格切割文档
- printf动作对数据格式化
# 示例1 对/etc/passwd文件格式化
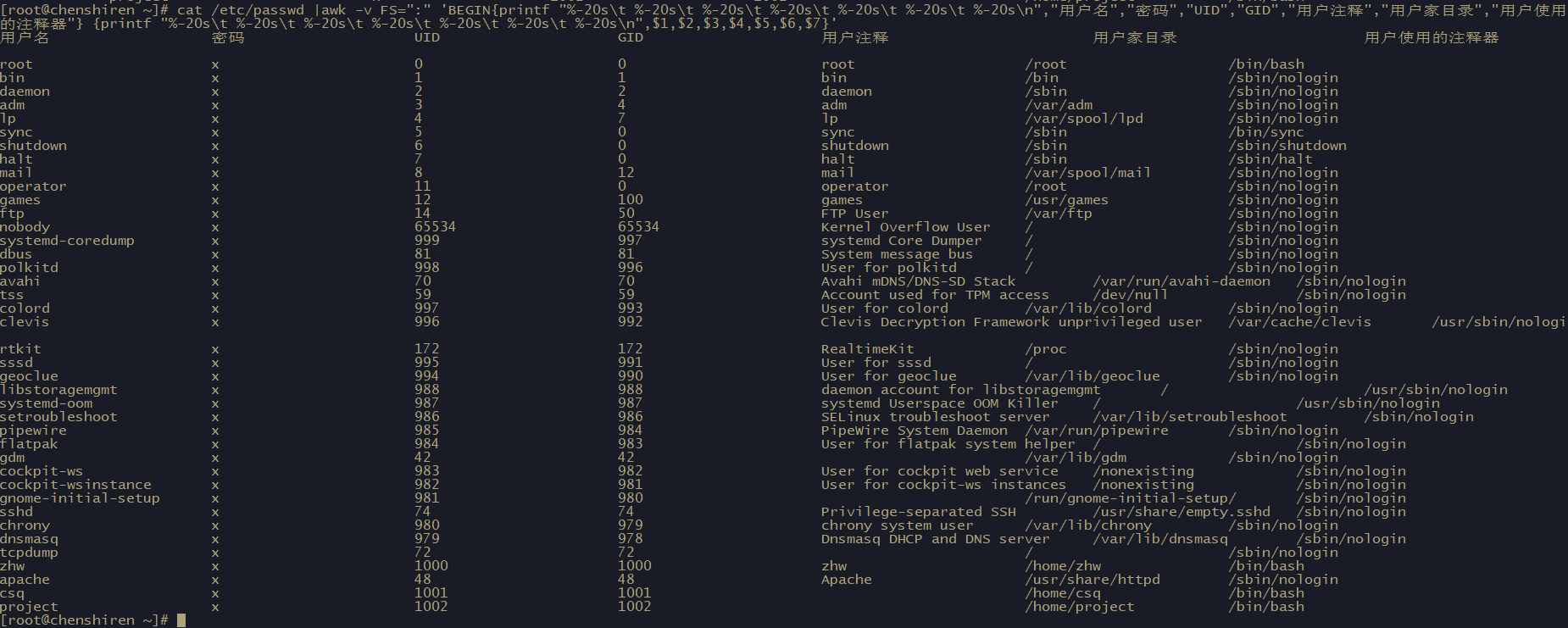
[root@chenshiren ~]# cat /etc/passwd |awk -v FS=":" 'BEGIN{printf "%-20s\t %-20s\t %-20s\t %-20s\t %-20s\t %-20s\t %-20s\n","用户名","密码","UID","GID","用户注释","用户家目录","用户使用的注释器"} {printf "%-20s\t %-20s\t %-20s\t %-20s\t %-20s\t %-20s\t %-20s\n",$1,$2,$3,$4,$5,$6,$7}'
# 示例2 假设有一份薪资数据表文件名为pay.txt 内容如下
Name 1st 2nd 3th
csq 2300 2400 2500
zhw 2100 2000 1000
ccc 1000 2000 3000
# 计算总额
[root@chenshiren ~]# cat pay.txt| awk 'NR==1{printf "%-20s\t %-20s\t %-20s\t %-20s\t %-20s\t\n", $1,$2,$3,$4,"Total"};
NR>=2{total = $2 + $3 + $4 ; printf "%-20s\t %-20d\t %-20d\t %-20d\t %-20.2f\t\n",$1,$2,$3,$4,total}'
