数据驱动的核心基石:概率分布全家桶的技术实践与方法论思考
前言
在“数据驱动”成为各行各业核心方法论的今天,我们对世界的认知、对业务的决策,越来越依赖于数据背后隐藏的数学规律。而概率分布,作为描述随机变量取值规律的数学工具,正是我们从海量数据中挖掘价值、建立驱动模型的“核心基石”。从用户行为的预测到工业设备的故障预警,从金融市场的波动分析到生物医学的统计检验,不同的概率分布如同不同的“模具”,能精准匹配各类数据的内在特征。今天,我们就围绕“概率分布全家桶”,深入聊聊它们在数据驱动中的技术运用与方法论心得。
一、正态分布(Normal Distribution):数据世界的“黄金标杆”
(一)公式与核心特征
正态分布的概率密度函数为:
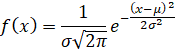
其中,![]() 是均值(反映数据的集中趋势),
是均值(反映数据的集中趋势),![]() 是标准差(反映数据的离散程度)。当
是标准差(反映数据的离散程度)。当![]() 且
且![]() 时,称为标准正态分布:
时,称为标准正态分布:
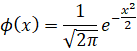
(二)技术运用:数据驱动的“基准线”
正态分布在数据驱动领域的应用,几乎贯穿了“数据采集-建模-验证-决策”全流程,核心在于它对“中心极限定理”的支撑——大量独立随机变量的和(或均值)会趋近于正态分布。
1. 误差分析与参数估计
在实验科学或工程测量中,测量误差往往服从正态分布。比如用传感器采集温度数据,多次测量的误差(真实值与测量值的偏差)可通过正态分布建模,进而计算“真实值落在某区间的概率”。此时,我们会用极大似然估计(MLE)来确定μ![]() 和σ
和σ![]() :
:
- 对于样本![]() ,均值的极大似然估计为
,均值的极大似然估计为![]() ;
;
- 方差的极大似然估计为![]() 。
。
借助正态分布的“3σ原则”(约99.7%的数据落在![]() 内),还能快速识别异常值:超出该区间的测量值,有极大可能是错误数据,需清洗或重测。
内),还能快速识别异常值:超出该区间的测量值,有极大可能是错误数据,需清洗或重测。
2. 假设检验与统计推断
数据驱动的决策往往需要“量化不确定性”,正态分布是t检验、方差分析(ANOVA)等假设检验的基础。比如比较两组用户的活跃度(假设为正态分布),通过t检验判断“活跃度差异是随机波动还是真实存在”,从而指导产品策略(如是否针对某组用户优化功能)。
3. 机器学习中的隐式应用
许多机器学习模型默认数据服从正态分布。例如线性回归,假设残差(预测值与真实值的差)服从正态分布;高斯朴素贝叶斯分类器,直接以正态分布为“先验”建模特征概率。若数据偏离正态,需先做变换(如对数变换、Box-Cox变换),这是数据预处理的关键步骤。
(三)方法论心得:“正态思维”的利与弊
1. 别迷信“正态”,先做分布检验
数据驱动的第一步是“认识数据”,而非直接套用正态分布。可通过QQ图(分位数-分位数图)或Kolmogorov-Smirnov检验(K-S检验)判断数据是否服从正态:
- QQ图中,若样本点近似落在“45度直线”上,说明与正态分布拟合度高;
- K-S检验中,若p值大于显著性水平(如0.05),则不能拒绝“数据服从正态分布”的原假设。
曾在一个电商用户购买间隔的项目中,最初假设数据正态,但QQ图明显弯曲,后续改用指数分布才得到合理结果——“先验假设要被数据验证,而非被经验绑架”。
2. 正态分布的“鲁棒性”:趋势的力量
即使数据不完全正态,只要样本量足够大,基于中心极限定理,“均值的分布”仍近似正态。这也是为什么A/B测试中,即使单个用户的行为(如点击、购买)是二值的(不服从正态),但“点击率(成功次数/总次数)”的分布会随着样本量增加而趋近正态,从而能用量化方法比较两组差异。
二、指数分布(Exponential Distribution):“无记忆性”的时间密码
(一)公式与核心特征
指数分布的概率密度函数为: