框架-SpringCloud-1
目录
1. 说说你对微服务的理解
② 微服务架构的演进
③ 微服务解决方案有哪些?
④ 微服务架构的典型组件
⑤ 微服务架构的实践选型
2.注册中心
3. Nacos的实现原理
3. 配置中心
3. Nacos配置中心原理
4. Nacos配置中心长轮询机制?
4. 远程调用
1.微服务通信方式:
2. Feign和Dubbo的区别
3. 服务端负载均衡器和客户端负载均衡器的区别
4. 介绍下OpenFeign
5. 为什么Feign第一次调用耗时很长?
6.Feign怎么实现认证传递?
7. Fegin怎么做负载均衡?Ribbon?
8. 说说有哪些负载均衡算法?
9 介绍下Dubbo
一、Dubbo简介
二、Dubbo示例
三、Dubbo支持的负载均衡
5. 服务网关
1. 什么是API网关?
2.SpringCloud可以选择哪些API网关?
3.Spring Cloud Gateway核心概念?
4. Gateway使用示例
附录:网关中的限流策略
6. 服务容灾
1.什么是服务雪崩?
2. 什么是服务熔断和服务降级?
3. 有哪些熔断降级方案实现?
4. Hystrix怎么实现服务容错?
使用示例
5. 介绍下Resilience4j
使用示例
6. Sentinel
① 初始sentinel
- 雪崩问题及解决方案
- 安装Sentinel
- 微服务整合Sentinel
② 限流规则
- 快速入门
- 流控模式之关联模式
- 流控模式之链路模式
- 流控效果
- 热点参数限流
③ 隔离和降级
- Feign整合Sentinel
- 线程隔离(信号量隔离)
- 熔断降级原理
- 熔断策略
④ 授权规则
- 实现网关授权
- 自定义异常结果
⑤ 规则持久化
- 规则管理三种模式
- 实现push模式持久化
7. 链路追踪
8. 分布式事务
9. 服务监控
10. OAuth2授权模式
1. 说说你对微服务的理解
① 概念
微服务(Microservices)是一种软件架构设计模式,它将应用程序分解为小型、自治的服务单元,这些服务单元可以独立部署、扩展和维护,其中每一个服务单元也都是一个微服务。
基于微服务形成的软件架构风格称为微服务架构(Microservices Architecture),它涵盖了使用微服务构建应用程序的全套原则、模式和最佳实践,关注如何将应用程序分解为多个微服务,以及这些服务如何交互、如何维护服务之间的独立性、如何实现服务的持续交付和部署等。在日常使用中,微服务又常被称为微服务架构,两者不区分使用。
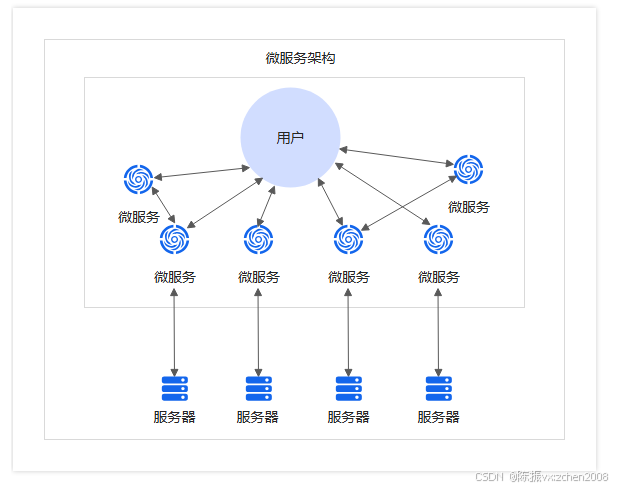
② 微服务架构的演进
关键词: 单体架构->面向服务架构(SOA)->微服务架构 & 云原生架构
-
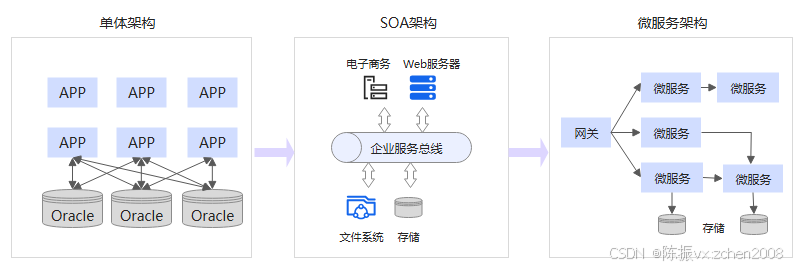
单体架构:从最初传统的单体架构,它将应用程序作为一个整体部署和运行,可扩展性、容错性、可靠性等都有很大限制,而且单体架构的应用通常具有大量的代码和复杂的代码结构,导致维护成本极高。
-
缺点:可扩展性受限、难以维护和更新、高风险、技术栈限制、谈对协作复杂
-
-
面向服务架构(SOA):随着业务架构的不断演进,后续有人提出拆分单体架构,解耦代码,形成一个个独立的功能单元,每个功能单元可以远程服务的方式提供(比如 Web 服务,通过80端口向用户提供网页访问服务),即面向服务架构(Service-oriented Architecture,简称 SOA)。虽然SOA能够解决单体架构的一些问题,但是也存在一些缺陷,比如服务相互依赖,性能差和部署运维复杂等问题。
-
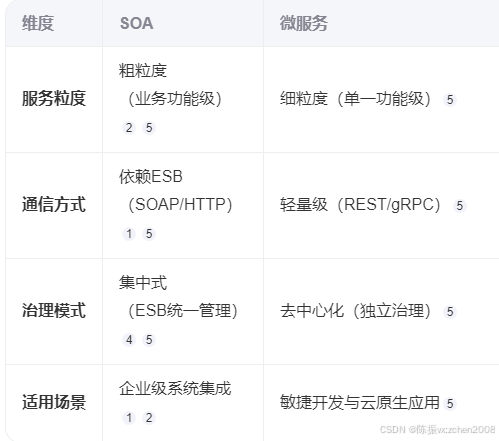
SOA(Service-Oriented Architecture,面向服务架构)是一种以服务为核心的软件架构模型,旨在通过标准化接口实现分布式系统的高效集成与复用
-
SOA将应用功能拆分为独立、可复用的服务单元,每个服务通过明确定义的接口(如SOAP/REST)进行通信,支持跨平台、跨语言的互操作。
- 核心特征:松耦合、粗粒度、基于开放标准。
- 典型组件:服务提供者、消费者、注册中心、企业服务总线(ESB)
- 与微服务的区别:
-
-
后来越来越多的应用部署在云端,软件应用需要满足快速迭代、高并发访问、业务逻辑更加复杂等业务需求,微服务架构应运而生。
微服务架构按照业务功能划分服务,服务之间调用采用轻量级的通信框架,具备以下优势:
-
降低应用复杂度:当一个系统变得庞大且复杂时,微服务架构可以将系统拆分成多个小服务,每个服务专注于一个特定的业务领域,简化了应用的复杂性,提高了开发和维护的效率。比如应用在电子商务平台。
-
高并发处理:在需要处理大量并发请求的场景下,通过微服务架构,将系统拆分成多个独立的服务,每个服务独立扩展和部署,从而实现更好的并发处理能力。比如应用在社交媒体应用。
-
快速迭代和持续交付(独立部署和维护):微服务架构可以将系统拆分成多个小的服务,每个服务可以独立地进行开发、测试和部署。因此可以实现快速迭代和持续交付,不同的团队可以并行开发和部署各自的服务,允许每个服务使用适合自身需求的最佳技术栈,加快了软件发布的速度,提高了系统的灵活性和可扩展性。
-
可伸缩性和弹性:微服务架构具有良好的可伸缩性,可以根据负载的变化,对系统中某些服务做水平扩展或收缩,更好地适应流量峰值并节省资源。比如应用在流媒体服务。
-
故障隔离和容错性: 单个微服务的故障通常不会影响其他服务,提高了应用程序的容错性,同时更容易识别和解决故障。
挑战:
- 成本挑战:
- 基础设施成本增加: 微服务应用通常需要更多的基础设施资源,例如服务器、容器管理、负载均衡器等,这可能导致运营成本增加。
- 开发和维护成本: 管理多个微服务的开发、测试、部署和维护需要更多的工程师资源,这可能导致开发和维护成本上升。
- 复杂性挑战:
- 分布式系统复杂性: 微服务应用是分布式系统,涉及多个独立运行的服务,这增加了系统的复杂性,包括网络通信、故障处理和事务管理等方面。
- 服务发现和治理: 管理多个微服务的发现、注册、版本控制和路由需要额外的复杂性,例如使用服务网格或API网关。
- 部署挑战:
- 自动化部署需求: 为了有效地部署多个微服务,需要建立自动化的部署流程,这可能需要额外的工作和资源
- 版本控制和回滚: 管理不同版本的微服务以及版本之间的兼容性可能会变得复杂,特别是在需要回滚时。
- 一致性挑战:
- 数据一致性: 不同微服务可能拥有各自的数据存储,确保数据一致性和同步可能需要复杂的解决方案,如分布式事务或事件驱动的一致性。
- 事务管理: 管理跨多个微服务的事务变得复杂,确保事务的一致性和隔离性需要额外的努力和技术。
- 监控和故障排除挑战:
- 性能监控: 在微服务环境中,跟踪性能问题和故障排除可能更加困难,因为问题可能涉及多个服务,需要强大的监控和诊断工具。
- 故障排除: 需要有效的方法来跟踪和诊断跨多个服务的故障,以便快速恢复。
微服务不是万金油,是用来处理海量用户、业务复杂和需求频繁变更场景下的一种架构风格。引用一句话“好的架构是演化出来的,而不是设计出来的”。任何一种架构的引入,都会带来利弊两个方面的影响,如何平衡才最重要。
微服务架构与云原生架构
微服务架构和云原生架构是现代软件开发中两个紧密相关且经常一起使用的概念,但它们关注的侧重点和应用的范围等有所不同。
-
云原生架构是一种基于云环境设计和构建应用程序的方法,它天然利用了云计算的优势,如弹性、可扩展性、自动化和敏捷性。Matt Stine 于2013年首次提出云原生(CloudNative)的概念,随着技术的不断演进,其定义也在不断地迭代和更新,云原生可以概括为四个要素:微服务、容器、DevOps 和持续交付。
云原生架构的主要目的是如何最大化地利用云平台的特性来实现高效的资源利用、快速迭代和自动化运维。
-
微服务架构的目的则是为了提高应用程序的模块化,使得开发,部署和扩展可以更加独立和灵活
总结来看,微服务架构和云原生架构是相辅相成的。微服务架构可以被视为云原生架构的基石,为云原生应用提供了架构设计、分布式部署、敏捷开发等方案,以适应云计算平台的动态特性,为更高层次的云原生架构打下坚实的基础,而云原生技术则提供了实施微服务架构的最佳实践和平台支持。
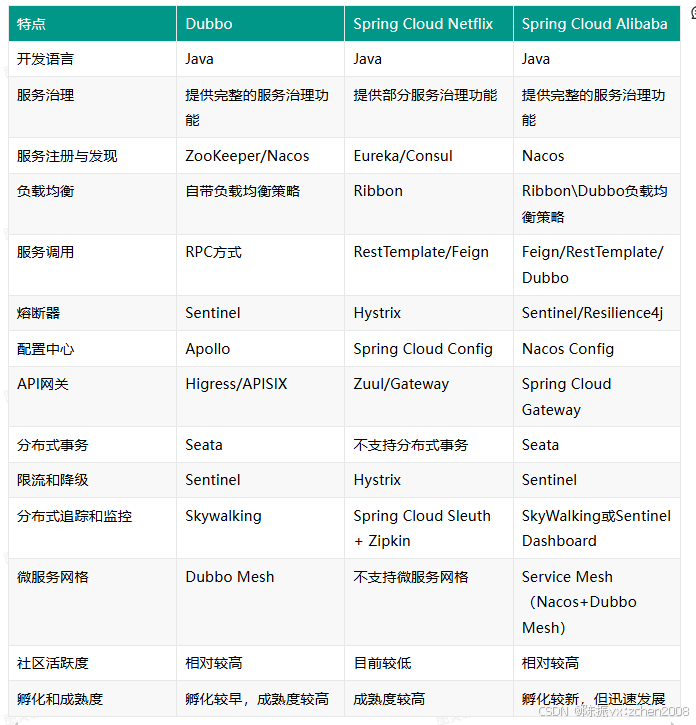
③ 微服务解决方案有哪些?
④ 微服务架构的典型组件
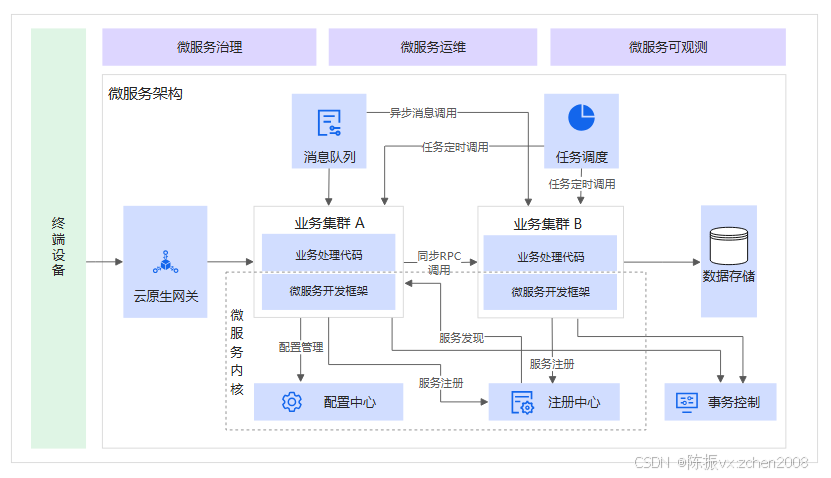
微服务架构的典型组件概览如下图。
-
业务入口。从终端设备(例如IoT(物联网)、PC、Moblie等)通过网关入口访问后端微服务,网关对南北向流量提供服务路由到对应的后端服务中。
-
微服务的业务处理链路。后端微服务通常会根据业务领域或功能进行划分,每个微服务负责一部分独立的业务逻辑。为了完成更复杂的业务流程,微服务之间可能会存在依赖关系。从服务间通信的交互方式可以分为同步阻塞式和异步非阻塞式调用,主要的实现方式包括:同步RPC调用和异步消息调用。所有的交互调用本质上都是数据的交换,数据最终会存储到各类存储介质中。在服务交互过程中需要特定的组件来保证数据一致性,对流量精细化管理以及提供强大的运维和可观测能力。
-
微服务的OPS链路。利用微服务运维过程中的一系列操作和工具链,开发运维团队可以构建出高效、稳定和可维护的微服务系统。通过自动化、监控和智能化的运维治理实践,可以大幅降低系统复杂性带来的挑战。
在实际应用时,您需要根据具体业务选择合适的组件构建应用架构。
⑤ 微服务架构的实践选型
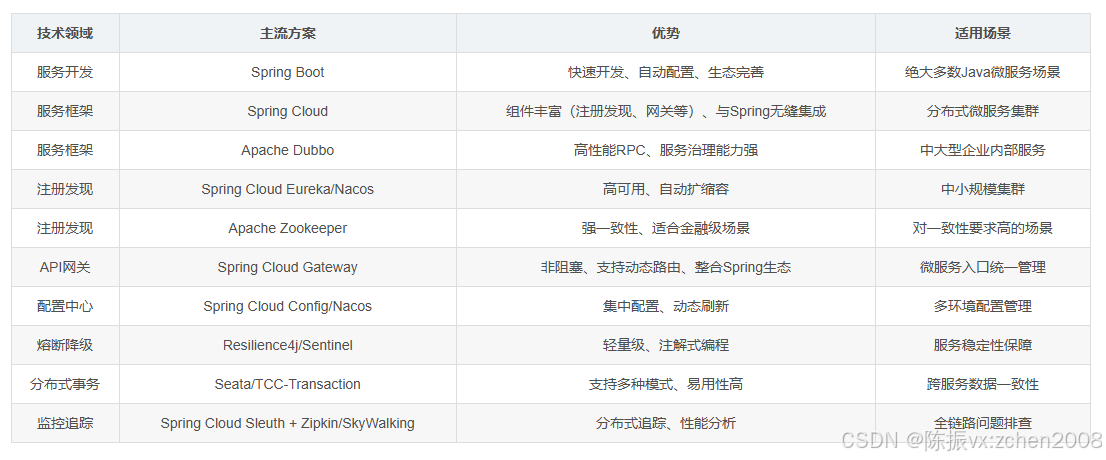
选型建议:中小团队优先选择Spring Cloud + Spring Boot生态,组件开箱即用;有性能要求的中大型团队可考虑Dubbo + Nacos组合;金融级场景需强化一致性和稳定性,可选用Zookeeper + Seata。
1.服务开发:SpringBoot
2.服务框架: SpringCloud /Apache Dubbo
3.注册中心:用于服务的注册与发现,管理微服务的地址信息。常见的实现包括:
Spring Cloud Netflix:Eureka、Consul
Spring Cloud Alibaba:Nacos
4.配置中心:用于集中管理微服务的配置信息,可以动态修改配置而不需要重启服务。常见的实现包括:
Spring Cloud Netflix:Spring Cloud Config
Spring Cloud Alibaba:Nacos Config
5.远程调用:用于在不同的微服务之间进行通信和协作。常见的实现保包括:
RESTful API:如RestTemplate、Feign、OpenFeign
RPC(远程过程调用):如Dubbo、gRPC
6.API网关:作为微服务架构的入口,统一暴露服务,并提供路由、负载均衡、安全认证等功能。常见的实现包括:
Spring Cloud Netflix:Zuul、Gateway
Spring Cloud Alibaba:Gateway、Apisix等
7.分布式事务:保证跨多个微服务的一致性和原子性操作。常见的实现包括:
Spring Cloud Alibaba:Seata
8.熔断器:用于防止微服务之间的故障扩散,提高系统的容错能力。常见的实现包括:
Spring Cloud Netflix:Hystrix
Spring Cloud Alibaba:Sentinel、Resilience4j
9.限流和降级:用于防止微服务过载,对请求进行限制和降级处理。常见的实现包括:
Spring Cloud Netflix:Hystrix
Spring Cloud Alibaba:Sentinel
10.分布式追踪和监控:用于跟踪和监控微服务的请求流程和性能指标。常见的实现包括:
Spring Cloud Netflix:Spring Cloud Sleuth (链路追踪)+ Zipkin(支持网络设备、服务器、虚拟机、应用程序等监控,具备数据采集、告警、可视化、自动化等功)
Spring Cloud Alibaba:SkyWalking(服务拓扑图 + 链路追踪)、Sentinel Dashboard
Prometheus:JVM 内存/CPU 实时曲线
⑥ 微软设计中的9种设计模式(了解)
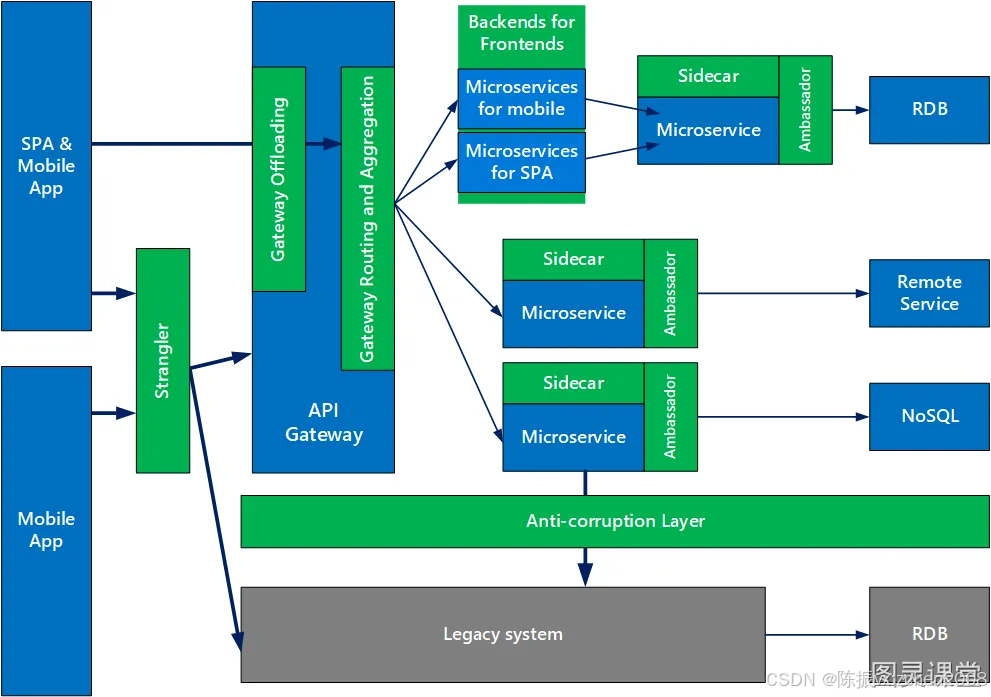
下图是微软团队建议如何在微服务架构中使用这些模式:
文中提到的 9 个模式包括:外交官模式(Ambassador),防腐层(Anti-corruption layer),后端服务前端(Backends for Frontends),舱壁模式(Bulkhead),网关聚合(Gateway Aggregation),网关卸载(Gateway Offloading),网关路由(Gateway Routing),挎斗模式(Sidecar)和绞杀者模式(Strangler)。这些模式绝大多数也是目前业界比较常用的模式,如:
●外交官模式(Ambassador):可以用与语言无关的方式处理常见的客户端连接任务,如监视,日志记录,路由和安全性(如 TLS)。
●防腐层(Anti-corruption layer):介于新应用和遗留应用之间,用于确保新应用的设计不受遗留应用的限制。
●后端服务前端(Backends for Frontends):为不同类型的客户端(如桌面和移动设备)创建单独的后端服务。这样,单个后端服务就不需要处理各种客户端类型的冲突请求。这种模式可以通过分离客户端特定的关注来帮助保持每个微服务的简单性。
●舱壁模式(Bulkhead):隔离了每个工作负载或服务的关键资源,如连接池、内存和 CPU。使用舱壁避免了单个工作负载(或服务)消耗掉所有资源,从而导致其他服务出现故障的场景。这种模式主要是通过防止由一个服务引起的级联故障来增加系统的弹性。
●网关聚合(Gateway Aggregation):将对多个单独微服务的请求聚合成单个请求,从而减少消费者和服务之间过多的请求。
●挎斗模式(Sidecar):将应用程序的辅助组件部署为单独的容器或进程以提供隔离和封装。
设计模式是对针对某一问题域的解决方案,它的出现也代表了工程化的可能。随着微服务在业界的广泛实践,相信这个领域将会走向成熟和稳定,笔者期望会有更多的模式和实践出现,帮助促进这一技术的进一步发展。感兴趣的读者可以参考微软的微服务设计模式一文以及Azure 架构中心的资料为自己的微服务选择合适的模式或者提出新的模式。
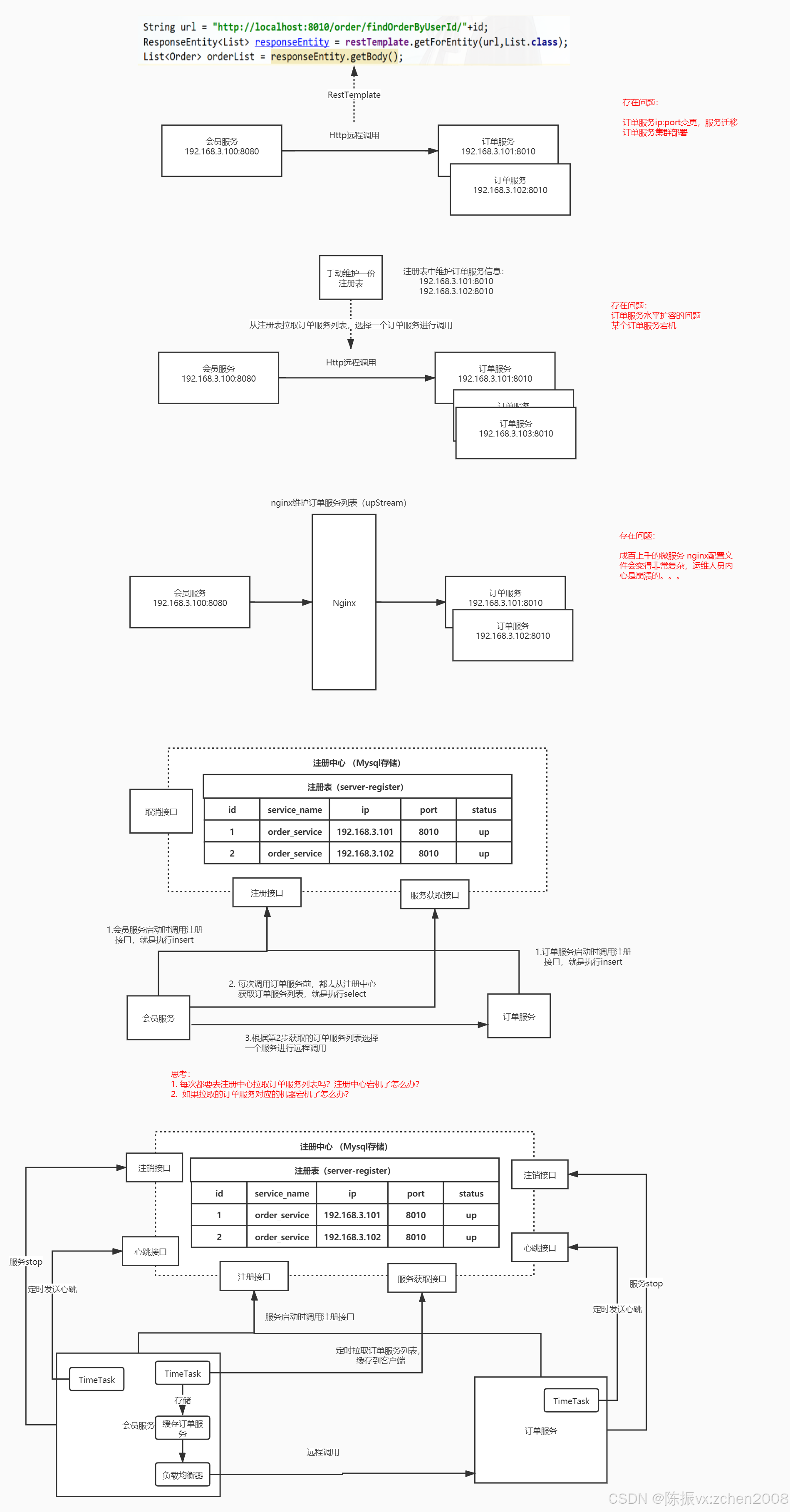
2.注册中心
1. 概述&作用
注册中心是用来管理和维护分布式系统中各个服务的地址和元数据的组件。它主要用于实现服务发现和服务注册功能。
注册中心的作用:
① 服务注册:
各个服务在启动时向注册中心注册自己的网络地址、服务实例信息和其他相关元数据。这样,其他服务就可以通过注册中心获取到当前可用的服务列表。
② 服务发现:
客户端通过向注册中心查询特定服务的注册信息,获得可用的服务实例列表。这样客户端就可以根据需要选择合适的服务进行调用,实现了服务间的解耦。
③ 负载均衡:
注册中心可以对同一服务的多个实例进行负载均衡,将请求分发到不同的实例上,提高整体的系统性能和可用性。
④ 故障恢复:
注册中心能够监测和检测服务的状态,当服务实例发生故障或下线时,可以及时更新注册信息,从而保证服务能够正常工作。
⑤ 服务治理:
通过注册中心可以进行服务的配置管理、动态扩缩容、服务路由、灰度发布等操作,实现对服务的动态管理和控制。
2. 注册中心有哪些?
SpringCloud可以与多种注册中心进行集成,常见的注册中心包括:
① Nacos:
Nacos 是阿里巴巴开源的一个动态服务发现、配置管理和服务管理平台。它提供了服务注册和发现、配置管理、动态 DNS 服务等功能。 ap
② Eureka:
Eureka 是 Netflix 开源的服务发现框架,具有高可用、弹性、可扩展等特点,并与 Spring Cloud 集成良好,已闭源。ap
③ Consul:
Consul 是一种分布式服务发现和配置管理系统,由 HashiCorp 开发。它提供了服务注册、服务发现、健康检查、键值存储等功能,并支持多数据中心部署。c/ap
④ ZooKeeper:
ZooKeeper 是 Apache 基金会开源的分布式协调服务,可以用作服务注册中心。它具有高可用、一致性、可靠性等特点。 cp
⑤ etcd:
etcd 是 CoreOS 开源的一种分布式键值存储系统,可以被用作服务注册中心。它具有高可用、强一致性、分布式复制等特性。 cp
CAP理论:
一致性(C)
所有节点在同一时刻访问的数据必须相同,强调整体数据状态的一致性。
示例:分布式数据库更新后,所有节点必须同步最新数据。可用性(A)
系统在部分节点故障时仍能响应请求,保证服务持续可用。
示例:电商系统在部分服务器宕机时仍可处理订单。分区容错性(P)
系统在网络分区(节点间通信中断)时仍能继续运行。
示例:跨机房部署的微服务在光缆断裂时仍能局部运行。
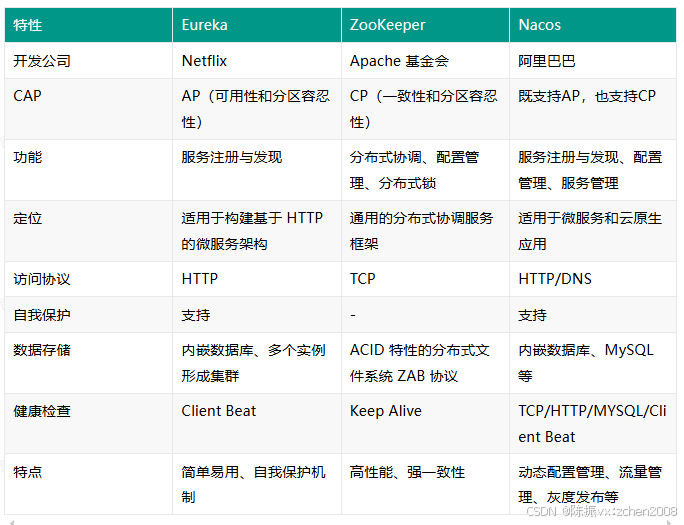
说下Eureka、ZooKeeper、Nacos的区别?
可以看到Eureka和ZooKeeper的最大区别是一个支持AP,一个支持CP,Nacos既支持既支持AP,也支持CP。
3. Nacos的实现原理
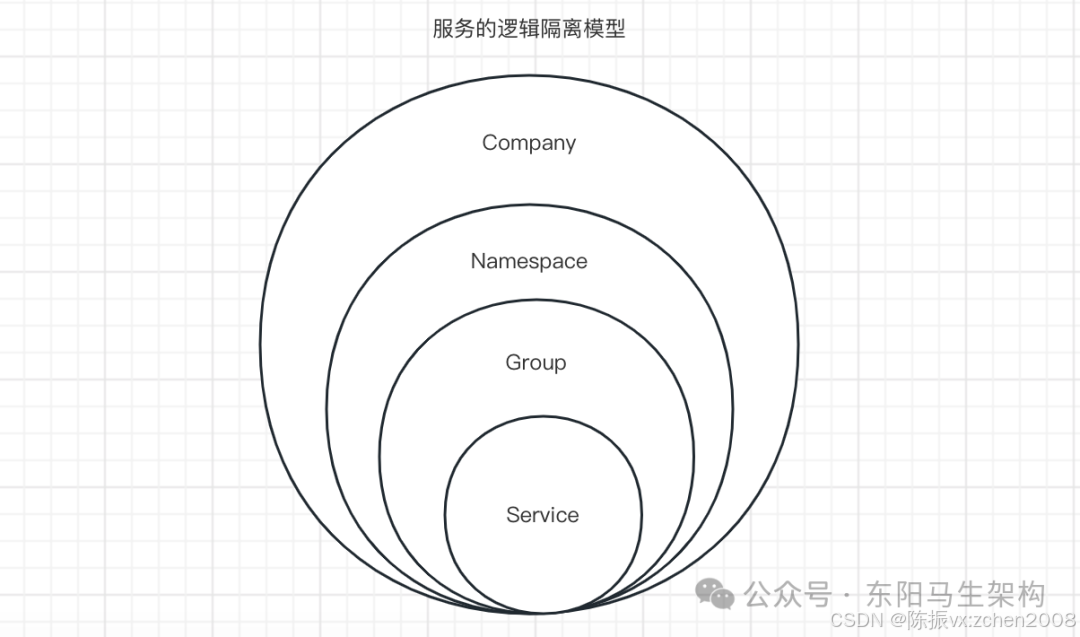
① Nacos注册概括来说有6个步骤:
0、服务容器负责启动,加载,运行服务提供者。
1、服务提供者在启动时,向注册中心注册自己提供的服务。
2、服务消费者在启动时,向注册中心订阅自己所需的服务。
3、注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4、服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5、服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
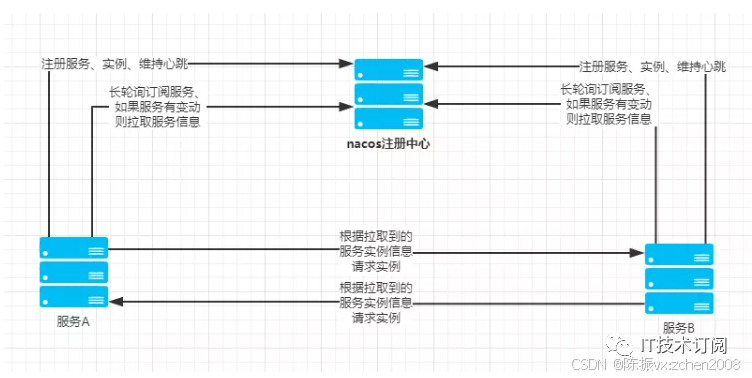
Nacos 服务注册与订阅的完整流程
Nacos 客户端进行服务注册有两个部分组成,一个是将服务信息注册到服务端,另一个是像服务端发送心跳包,这两个操作都是通过 NamingProxy 和服务端进行数据交互的。
Nacos 客户端进行服务订阅时也有两部分组成,一个是不断从服务端查询可用服务实例的定时任务,另一个是不断从已变服务队列中取出服务并通知 EventListener 持有者的定时任务。
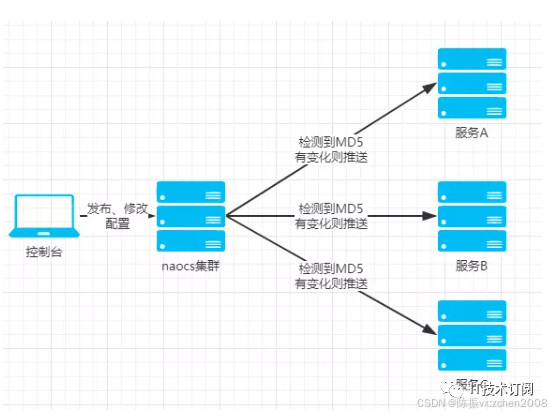
② Nacos配置:
3. 配置中心
1 概述&作用
微服务架构中的每个服务通常都需要一些配置信息,例如数据库连接地址、服务端口、日志级别等。这些配置可能因为不同环境、不同部署实例或者动态运行时需要进行调整和管理。
微服务的实例一般非常多,如果每个实例都需要一个个地去做这些配置,那么运维成本将会非常大,这时候就需要一个集中化的配置中心,去管理这些配置。
2. 配置中心有哪些?
和注册中心一样,SpringCloud也支持对多种配置中心的集成。常见的配置中心选型包括:
① Nacos:
阿里巴巴开源的服务发现、配置管理和服务管理平台,也可以作为配置中心使用。支持服务注册与发现、动态配置管理、服务健康监测和动态DNS服务等功能。
② Spring Cloud Config:
官方推荐的配置中心,支持将配置文件存储在Git、SVN等版本控制系统中,并提供RESTful API进行访问和管理。
③ ZooKeeper:
一个开源的分布式协调服务,可以用作配置中心。它具有高可用性、一致性和通知机制等特性。
④ Consul:
另一个开源的分布式服务发现和配置管理工具,也可用作配置中心。支持多种配置文件格式,提供健康检查、故障转移和动态变更等功能。
⑤ Etcd:
一个分布式键值存储系统,可用作配置中心。它使用基于Raft算法的一致性机制,提供分布式数据一致性保证。
⑥ Apollo:
携程开源的配置中心,支持多种语言和框架。提供细粒度的配置权限管理、配置变更通知和灰度发布等高级特性,还有可视化的配置管理界面。
3. Nacos配置中心原理
配置中心,说白了就是一句话:配置信息的CRUD。
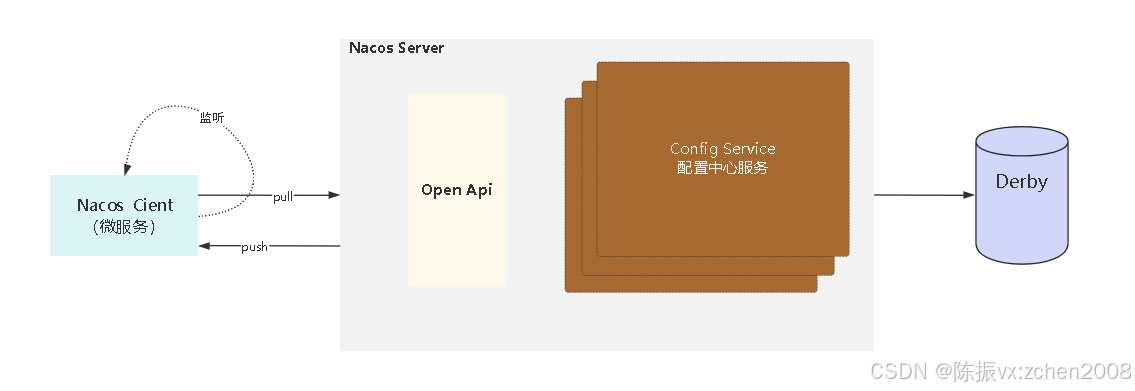
具体的实现大概可以分成这么几个部分:
① 配置信息存储:
Nacos默认使用内嵌数据库Derby来存储配置信息,还可以采用MySQL等关系型数据库。
② 注册配置信息:
服务启动时,Nacos Client会向Nacos Server注册自己的配置信息,这个注册过程就是把配置信息写入存储,并生成版本号。
③ 获取配置信息:
服务运行期间,Nacos Client通过API从Nacos Server获取配置信息。Server根据键查找对应的配置信息,并返回给Client。
④ 监听配置变化:
Nacos Client可以通过注册监听器的方式,实现对配置信息的监听。当配置信息发生变化时,Nacos Server会通知已注册的监听器,并触发相应的回调方法。
4. Nacos配置中心长轮询机制?
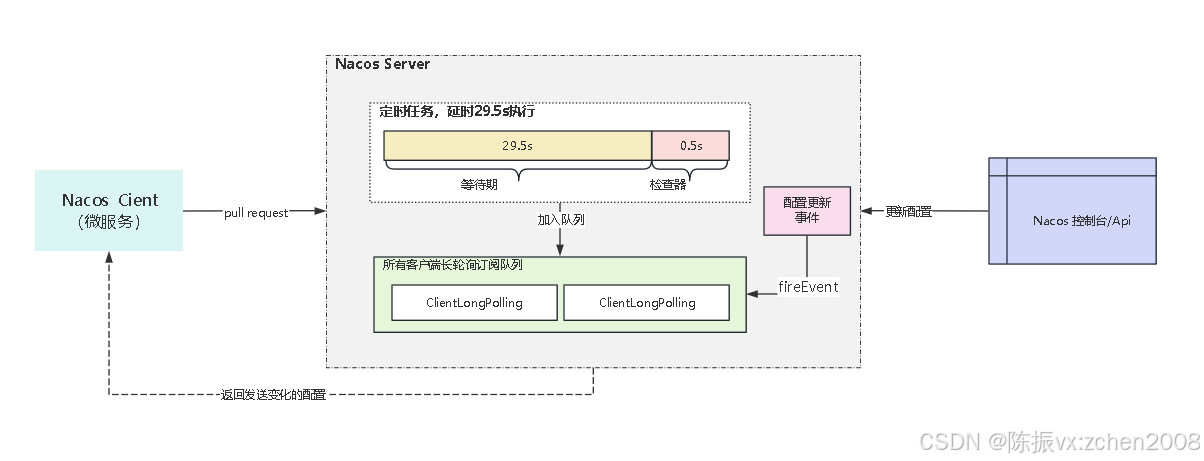
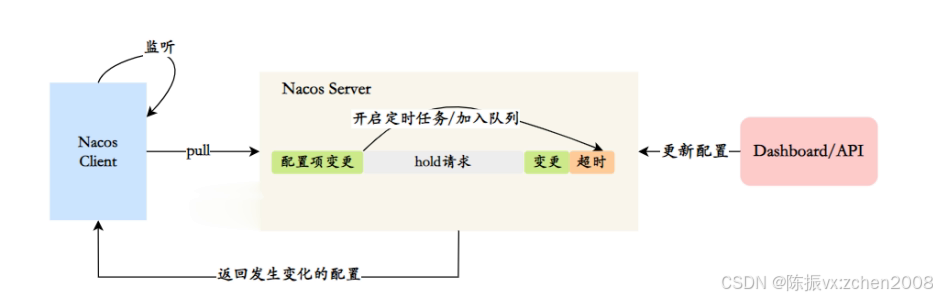
一般来说客户端和服务端的交互分为两种:推(Push)和拉(Pull),Nacos在Pull的基础上,采用了长轮询来进行配置的动态刷新。
在长轮询模式下,客户端定时向服务端发起请求,检查配置信息是否发生变更。如果没有变更,服务端会"hold"住这个请求,即暂时不返回结果,直到配置发生变化或达到一定的超时时间。
具体的实现过程如下:
① 如果客户端发起 Pull 请求,服务端收到请求之后,先检查配置是否发生了变更:
② 变更:返回变更配置;
③ 无变更:设置一个定时任务,延期 29.5s 执行,把当前的客户端长轮询连接加入 allSubs 队列;
在这 29.5s 内的配置变化:
④ 配置无变化:等待 29.5s 后触发自动检查机制,返回配置;
⑤ 配置变化:在 29.5s 内任意一个时刻配置变化,会触发一个事件机制,监听到该事件的任务会遍历 allSubs 队列,找到发生变更的配置项对应的 ClientLongPolling 任务,将变更的数据通过该任务中的连接进行返回。相当于完成了一次 PUSH 操作;
⑥ 长轮询机制结合了 Pull 机制和 Push 机制的优点;
通过长轮询的方式,Nacos客户端能够实时感知配置的变化,并及时获取最新的配置信息。同时,这种方式也降低了服务端的压力,避免了大量的长连接占用内存资源。
4. 远程调用
用于在不同的微服务自建进行通信和协作。
1.微服务通信方式:
① REST FUL API
- RESTful API 使用文本格式来传输数据,通常使用 JSON 或 XML 进行序列化。
- 主流实现方式:
- RestTemplate:Spring 内置的用于执行 HTTP 请求的类。
- Spring Cloud OpenFegin:OpenFeign 是 Spring Cloud 对 Feign 库的封装,提供声明式的 HTTP 客户端,简化了服务调用的编码工作。(替代Rest Template)
② RPC(远程过程调用)
- RPC 通常使用二进制格式来传输数据,例如 Protocol Buffers(ProtoBuf)或 Apache Thrift。
- 主流实现方式:
- Dubbo:阿里巴巴公司开源的一个 Java 高性能优秀的服务框架,它基于 TCP 或 HTTP 的 RPC 远程过程调用,支持负载均衡和容错,自动服务注册和发现。
- gRPC:Google 开发的高性能、通用的开源 RPC 框架,它主要面向移动应用开发并基于 HTTP/2 协议标准设计。gRPC 使用 ProtoBuf(Protocol Buffers)作为序列化工具和接口定义语言,要求在调用前需要先定义好接口契约,并使用工具生成代码,然后在代码中调用这些生成的类进行服务调用
③ 消息队列通讯
④ 事件驱动通讯
⑤ WebSocket(长连接通信)
2. Feign和Dubbo的区别
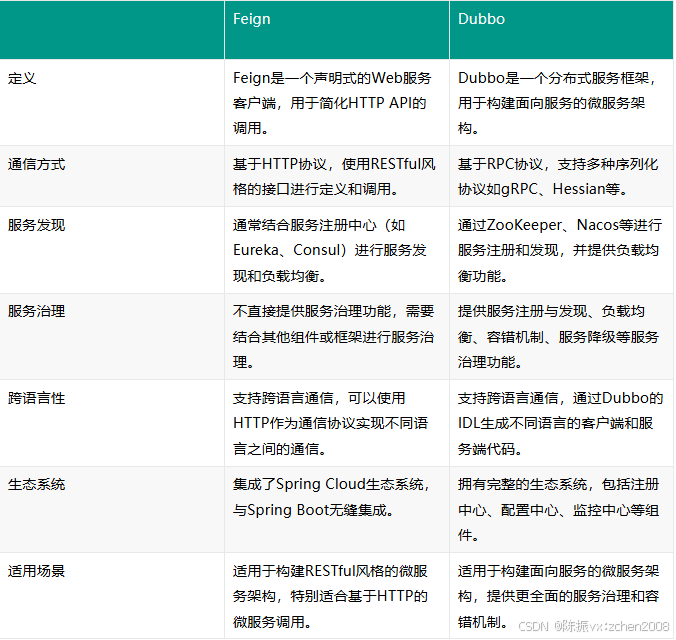
需要注意的是,Feign和Dubbo并不是互斥的关系。实际上,Dubbo可以使用HTTP协议作为通信方式,而Feign也可以集成RPC协议进行远程调用。选择使用哪种远程调用方式取决于具体的业务需求和技术栈的选择。
3. 服务端负载均衡器和客户端负载均衡器的区别
在分布式系统中,负载均衡是确保系统高可用性、提高系统吞吐量和响应时间的一种关键技术手段。负载均衡可以分为 客户端负载均衡 和 服务端负载均衡,它们各自有不同的实现方式,适用于不同的应用场景。
①. 客户端负载均衡(Client-Side Load Balancing)
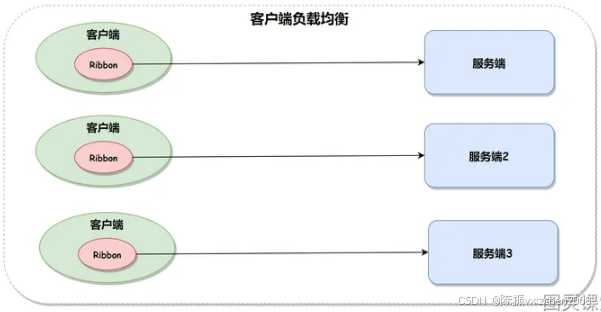
客户端负载均衡是指负载均衡的决策由客户端来进行,客户端会根据可用的服务器节点列表、负载策略和路由算法等信息,直接向某个服务器发送请求。
实现方式:
客户端负载均衡通常通过以下几种方式实现:
(1)静态配置:客户端硬编码多个服务端节点地址,客户端通过自己的负载均衡算法来选择一个服务节点。
(2)服务发现:客户端从服务注册中心(如 Eureka、Consul、Zookeeper、Nacos 等)获取服务实例列表,再根据负载均衡算法进行选择。
(3)负载均衡算法:常见的客户端负载均衡算法有:
- 轮询(Round-Robin):客户端依次选择服务节点,适用于负载相对均衡的场景。
- 加权轮询(Weighted Round-Robin):根据服务器的权重值来分配请求,权重较大的服务器接收更多请求。
- 随机(Random):客户端随机选择一个服务节点,适用于节点负载相对均匀的场景。
- 最少连接(Least Connections):客户端选择当前连接数最少的服务器,适用于连接数差异较大的场景。
- 哈希(Hash):通过某个特定的请求参数(如用户 ID、IP 等)计算哈希值来选择服务器,保证同一请求总是访问同一服务节点。
客户端负载均衡的优势:
- 高可用性:客户端可以在发现某个服务节点不可用时,自动切换到其他节点。
- 灵活性:客户端可以根据不同的负载均衡算法选择合适的策略。
客户端负载均衡的劣势:
- 客户端负担较重:每个客户端都需要实现负载均衡算法和服务发现机制,增加了客户端的复杂性。
- 服务发现的复杂性:客户端需要从注册中心实时获取最新的服务实例列表,增加了与注册中心的通信负担。
常见框架:
- Spring Cloud Ribbon:Spring Cloud 提供的客户端负载均衡工具,通常与 Eureka、Consul 等服务发现工具一起使用。
- Netflix Ribbon:一个强大的客户端负载均衡库,已经被 Spring Cloud 默认集成。
- Consul、Eureka:提供服务发现功能,客户端可以从这些工具获取服务实例列表。
②. 服务端负载均衡(Server-Side Load Balancing)
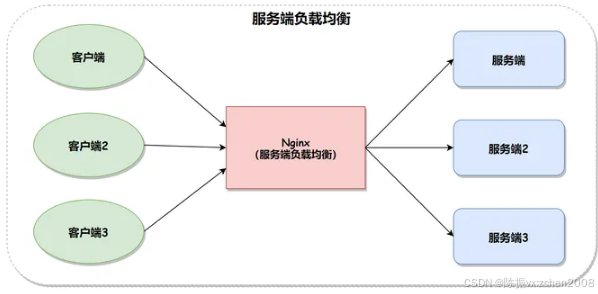
服务端负载均衡是指负载均衡的决策由服务端进行,客户端将请求发送到负载均衡器,由负载均衡器选择合适的服务节点处理请求。
实现方式:
服务端负载均衡的核心是在服务器层面使用负载均衡器来处理请求,常见的实现方式有:
(1)硬件负载均衡:使用硬件设备(如 F5、Cisco)来分发流量。硬件负载均衡器通常会根据流量情况、服务健康状态等因素来动态选择服务器。
(2)软件负载均衡:使用软件负载均衡工具或代理(如 Nginx、HAProxy、Traefik 等)来实现请求的分发和负载均衡。这些工具通常部署在服务前端,所有客户端请求都必须通过它们进行路由。
(3)反向代理:在负载均衡器和客户端之间,反向代理服务器会根据设定的负载均衡策略将请求转发到后端的服务节点。
(4)请求转发:服务端负载均衡通过代理服务器或网关(如 API Gateway)实现请求转发,代理会根据负载均衡算法选择一个合适的后端服务实例来处理请求。
服务端负载均衡的优势:
- 透明性:客户端只需要与负载均衡器进行交互,客户端无需了解服务节点的具体信息。
- 集中管理:负载均衡的策略、规则可以集中配置和管理,简化了客户端的设计和实现。
- 高效性:负载均衡器通常具有较高的性能和可扩展性,能够处理大量并发请求。
服务端负载均衡的劣势:
- 单点故障:如果负载均衡器出现故障,可能会导致整个系统不可用,除非部署了高可用的负载均衡器。
- 延迟增加:请求需要先通过负载均衡器,再转发到服务节点,可能会增加一定的网络延迟。
- 配置复杂性:需要为负载均衡器配置策略和服务节点的健康检查等,增加了运维复杂度。
常见工具与框架:
- Nginx:支持 HTTP、TCP、UDP 协议的负载均衡,广泛用于 Web 服务和 API 网关。
- HAProxy:一个高性能的负载均衡器,广泛用于 HTTP/HTTPS 和 TCP 负载均衡。
- Traefik:支持自动发现服务、负载均衡、API 网关等功能,适用于微服务架构。
- Kubernetes:Kubernetes 提供了 Service 和 Ingress Controller 来实现服务的负载均衡和路由。
3. 客户端负载均衡与服务端负载均衡的比较
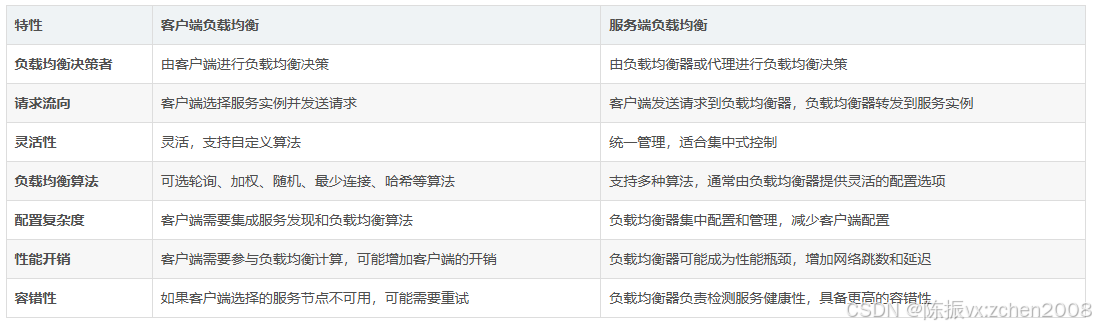
总结:
- 客户端负载均衡 适合于分布式、去中心化的场景,能够使得客户端更加灵活地选择服务节点,减少服务端负担,但客户端需要实现更多的负载均衡逻辑和服务发现功能,可能增加客户端的复杂性。
- 服务端负载均衡 适用于集中化管理和统一负载均衡控制的场景,负载均衡器负责做所有的负载均衡决策,客户端和服务端的通信更加简化,但如果负载均衡器出现故障或性能瓶颈,可能影响整个系统的可用性。
在微服务架构中,可以根据实际需求选择合适的负载均衡策略,或者结合使用客户端和服务端负载均衡来满足不同的应用场景。
4. 介绍下OpenFeign
一、概述
1.1.OpenFeign是什么?
Feign是一个声明式的Web服务客户端(Web服务客户端就是Http客户端),让编写Web服务客户端变得非常容易,只需创建一个接口并在接口上添加注解即可。
cloud官网介绍Feign: https://docs.spring.io/spring-cloud-openfeign/docs/current/reference/html/
OpenFeign源码: https://github.com/OpenFeign/feign
1.2.OpenFeign能干什么
Java当中常见的Http客户端有很多,除了Feign,类似的还有Apache 的 HttpClient 以及OKHttp3,还有SpringBoot自带的RestTemplate这些都是Java当中常用的HTTP 请求工具。
什么是Http客户端?
当我们自己的后端项目中 需要 调用别的项目的接口的时候,就需要通过Http客户端来调用。在实际开发当中经常会遇到这种场景,比如微服务之间调用,除了微服务之外,可能有时候会涉及到对接一些第三方接口也需要使用到 Http客户端 来调用 第三方接口。
所有的客户端相比较,Feign更加简单一点,在Feign的实现下,我们只需创建一个接口并使用注解的方式来配置它(以前是Dao接口上面标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完成对服务提供方的接口绑定。
1.3.OpenFeign和Feign的区别
Feign:
Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务客户端,Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务。
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-feign</artifactId>
</dependency>OpenFeign:
OpenFeign是Spring Cloud 在Feign的基础上支持了SpringMVC的注解,如@RequesMapping等等。OpenFeign的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>Feign是在2019就已经不再更新了,通过maven网站就可以看出来,随之取代的是OpenFeign,从名字上就可以知道,它是Feign的升级版。
1.4.@FeignClient
使用OpenFeign就一定会用到这个注解,@FeignClient属性如下:
- name:指定该类的容器名称,类似于@Service(容器名称)。
- url: url一般用于调试,可以手动指定@FeignClient调用的地址。
- *decode404:*当发生http 404错误时,如果该字段位true,会调用decoder进行解码,否则抛出FeignException。
- configuration: Feign配置类,可以自定义Feign的Encoder、Decoder、LogLevel、Contract。
- fallback: 定义容错的处理类,当调用远程接口失败或超时时,会调用对应接口的容错逻辑,fallback指定的类必须实现@FeignClient标记的接口。
- fallbackFactory: 工厂类,用于生成fallback类示例,通过这个属性我们可以实现每个接口通用的容错逻辑,减少重复的代码。
- path: 定义当前FeignClient的统一前缀,当我们项目中配置了server.context-path,server.servlet-path时使用。
下面这两种本质上没有什么区别:
他们都是一个作用就是将FeignClient注入到spring容器当中
@FeignClient(name = "feignTestService", url = "http://localhost/8001")
public interface FeignTestService {}@Component
@FeignClient(url = "http://localhost/8001")
public interface PaymentFeignService{}远程调用接口当中,一般我们称提供接口的服务为提供者,而调用接口的服务为消费者。而OpenFeign一定是用在消费者上。
二、OpenFeign使用
2.1.OpenFeign 常规远程调用
所谓常规远程调用,指的是对接第三方接口,和第三方并不是微服务模块关系,所以肯定不可能通过注册中心来调用服务。
第一步:导入OpenFeign的依赖。
第二步:启动类需要添加@EnableFeignClients。
第三步:提供者的接口。
@RestController
@RequestMapping("/test")
public class FeignTestController {@GetMapping("/selectPaymentList")public CommonResult<Payment> selectPaymentList(@RequestParam int pageIndex, @RequestParam int pageSize) {System.out.println(pageIndex);System.out.println(pageSize);Payment payment = new Payment();payment.setSerial("222222222");return new CommonResult(200, "查询成功, 服务端口:" + payment);}@GetMapping(value = "/selectPaymentListByQuery")public CommonResult<Payment> selectPaymentListByQuery(Payment payment) {System.out.println(payment);return new CommonResult(200, "查询成功, 服务端口:" + null);}@PostMapping(value = "/create", consumes = "application/json")public CommonResult<Payment> create(@RequestBody Payment payment) {System.out.println(payment);return new CommonResult(200, "查询成功, 服务端口:" + null);}@GetMapping("/getPaymentById/{id}")public CommonResult<Payment> getPaymentById(@PathVariable("id") String id) {System.out.println(id);return new CommonResult(200, "查询成功, 服务端口:" + null);}
}第四步:消费者调用提供者接口。
@FeignClient(name = "feignTestService", url = "http://localhost/8001")
public interface FeignTestService {@GetMapping(value = "/payment/selectPaymentList")CommonResult<Payment> selectPaymentList(@RequestParam int pageIndex, @RequestParam int pageSize);@GetMapping(value = "/payment/selectPaymentListByQuery")CommonResult<Payment> selectPaymentListByQuery(@SpringQueryMap Payment payment);@PostMapping(value = "/payment/create", consumes = "application/json")CommonResult<Payment> create(@RequestBody Payment payment);@GetMapping("/payment/getPaymentById/{id}")CommonResult<Payment> getPaymentById(@PathVariable("id") String id);
}@SpringQueryMap注解
spring cloud项目使用feign的时候都会发现一个问题,就是get方式无法解析对象参数。其实feign是支持对象传递的,但是得是Map形式,而且不能为空,与spring在机制上不兼容,因此无法使用。spring cloud在2.1.x版本中提供了@SpringQueryMap注解,可以传递对象参数,框架自动解析。
2.2.OpenFeign 微服务使用步骤
微服务之间使用OpenFeign,肯定是要通过注册中心来访问服务的。提供者将自己的ip+端口号注册到注册中心,然后对外提供一个服务名称,消费者根据服务名称去注册中心当中寻找ip和端口。
第一步:导入OpenFeign的依赖。
第二步:启动类需要添加@EnableFeignClients。
第三步:作为消费者,想要调用提供者需要掌握以下。
CLOUD-PAYMENT-SERVICE是提供者的服务名称。消费者要想通过服务名称来调用提供者,那么就一定需要配置注册中心当中的服务发现功能。假如提供者使用的是Eureka,那么消费者就需要配置Eureka的服务发现,假如是consul就需要配置consul的服务发现。
@Component
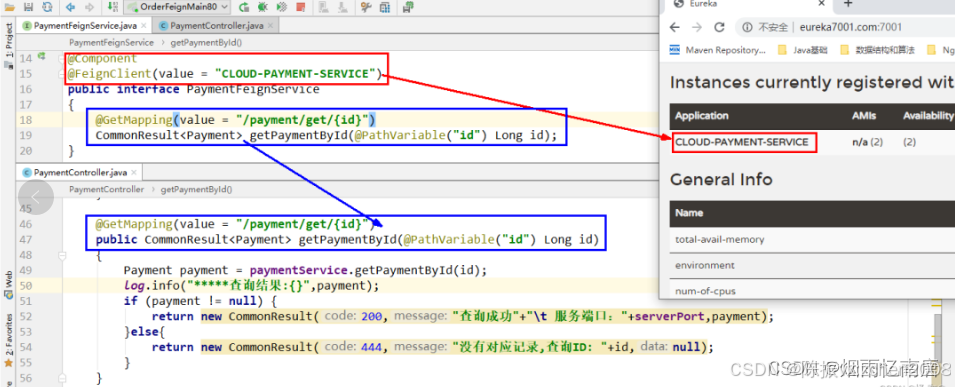
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")
public interface PaymentFeignService {@GetMapping(value = "/payment/get/{id}")CommonResult<Payment> getPaymentById(@PathVariable("id") Long id);}第四步:提供者的接口,提供者可以是集群。
@Slf4j
@RestController
public class PaymentController {@Autowiredprivate PaymentMapper paymentMapper;@Value("${server.port}")private String serverPort;@GetMapping(value = "/payment/get/{id}")public CommonResult<Payment> getPaymentById(@PathVariable("id") Long id) {Payment payment = paymentMapper.selectById(id);log.info("*****查询结果:{}", payment);if (payment != null) {return new CommonResult(200, "查询成功, 服务端口:" + serverPort, payment);} else {return new CommonResult(444, "没有对应记录,查询ID: " + id + ",服务端口:" + serverPort, null);}}}第五步:然后我们启动注册中心以及两个提供者服务,启动后浏览器我们进行访问。
他不仅限于和Eureka注册中心使用,我这里是基于Eureka来进行使用的,需要了解Eureka注册中心的搭建可以看这篇文章:https://blog.csdn.net/weixin_43888891/article/details/125325794
使用OpenFeign,假如是根据服务名称调用,OpenFeign他本身就集成了ribbon自带负载均衡。
2.3.OpenFeign 超时控制
第一步:提供方接口,制造超时场景。
@GetMapping(value = "/payment/feign/timeout")
public String paymentFeignTimeOut() {System.out.println("*****paymentFeignTimeOut from port: " + serverPort);//暂停几秒钟线程try {TimeUnit.SECONDS.sleep(3);} catch (InterruptedException e) {e.printStackTrace();}return serverPort;
}第二步:消费方接口调用。
@Component
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")
public interface PaymentFeignService{@GetMapping(value = "/payment/feign/timeout")String paymentFeignTimeOut();}当消费方调用提供方时候,OpenFeign默认等待1秒钟,超过后报错。
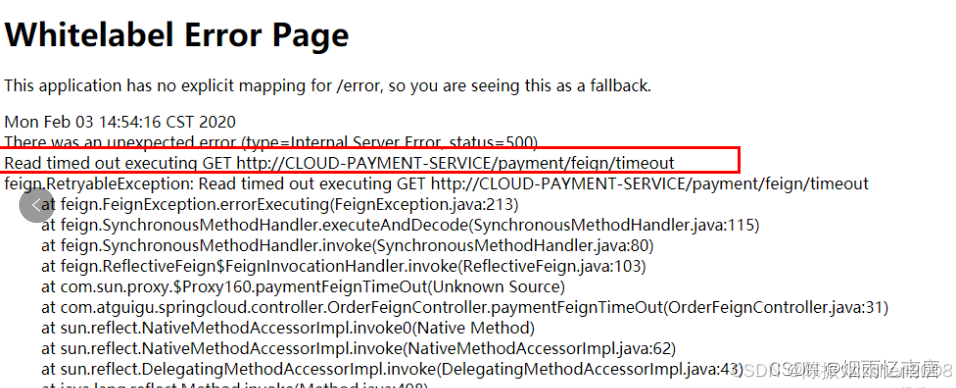
第三步:在消费者添加如下配置。
#设置feign客户端超时时间(OpenFeign默认支持ribbon)
ribbon:#指的是建立连接所用的时间,适用于网络状况正常的情况下,两端连接所用的时间ReadTimeout: 5000#指的是建立连接后从服务器读取到可用资源所用的时间ConnectTimeout: 5000在openFeign高版本当中,我们可以在默认客户端和命名客户端上配置超时。OpenFeign 使用两个超时参数:
- connectTimeout:防止由于服务器处理时间长而阻塞调用者。
- readTimeout:从连接建立时开始应用,在返回响应时间过长时触发。
2.4.OpenFeign 日志打印
Feign 提供了日志打印功能,我们可以通过配置来调整日志级别,从而了解 Feign 中 Http 请求的细节。
说白了就是对Feign接口的调用情况进行监控和输出。
日志级别:
- NONE:默认的,不显示任何日志;
- BASIC:仅记录请求方法、URL、响应状态码及执行时间;
- HEADERS:除了 BASIC 中定义的信息之外,还有请求和响应的头信息;
- FULL:除了 HEADERS 中定义的信息之外,还有请求和响应的正文及元数据。
配置日志Bean:
import feign.Logger;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class FeignConfig {@BeanLogger.Level feignLoggerLevel() {return Logger.Level.FULL;}}YML文件里需要开启日志的Feign客户端
logging:level:# feign日志以什么级别监控哪个接口com.gzl.cn.service.PaymentFeignService: debug后台日志查看:
2.5.OpenFeign 添加Header
以下提供了四种方式:
1、在@RequestMapping中添加,如下:
@FeignClient(name="custorm", fallback=Hysitx.class)
public interface IRemoteCallService {@RequestMapping(value="/custorm/getTest", method = RequestMethod.POST, headers = {"Content-Type=application/json;charset=UTF-8"})List<String> test(@RequestParam("names") String[] names);}2、在方法参数前面添加@RequestHeader注解,如下:
@FeignClient(name="custorm", fallback=Hysitx.class)
public interface IRemoteCallService {@RequestMapping(value="/custorm/getTest", method = RequestMethod.POST, headers = {"Content-Type=application/json;charset=UTF-8"})List<String> test(@RequestParam("names") @RequestHeader("Authorization") String[] names);}设置多个属性时,可以使用Map,如下:
@FeignClient(name="custorm", fallback=Hysitx.class)
public interface IRemoteCallService {@RequestMapping(value="/custorm/getTest", method = RequestMethod.POST, headers = {"Content-Type=application/json;charset=UTF-8"})List<String> test(@RequestParam("names") String[] names, @RequestHeader MultiValueMap<String, String> headers);}3、使用@Header注解,如下:
@FeignClient(name="custorm", fallback=Hysitx.class)
public interface IRemoteCallService {@RequestMapping(value="/custorm/getTest", method = RequestMethod.POST)@Headers({"Content-Type: application/json;charset=UTF-8"})List<String> test(@RequestParam("names") String[] names);}4、实现RequestInterceptor接口(拦截器),如下:
只要通过FeignClient访问的接口都会走这个地方,所以使用的时候要注意一下。
@Configuration
public class FeignRequestInterceptor implements RequestInterceptor {@Overridepublic void apply(RequestTemplate temp) {temp.header(HttpHeaders.AUTHORIZATION, "XXXXX");}}2.6.手动创建 Feign 客户端
@FeignClient无法支持同一service具有多种不同配置的FeignClient,因此,在必要时需要手动build FeignClient。
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")以这个为例,假如出现两个服务名称为CLOUD-PAYMENT-SERVICE的FeignClient,项目直接会启动报错,但是有时候我们服务之间调用的地方较多,不可能将所有调用都放到一个FeignClient下,这时候就需要自定义来解决这个问题!
官网当中也明确提供了自定义FeignClient,以下是在官网基础上对自定义FeignClient的一个简单封装,供参考!
首先创建FeignClientConfigurer类,这个类相当于build FeignClient的工具类。
import feign.*;
import feign.codec.Decoder;
import feign.codec.Encoder;
import feign.slf4j.Slf4jLogger;
import org.springframework.cloud.openfeign.FeignClientsConfiguration;
import org.springframework.context.annotation.Import;@Import(FeignClientsConfiguration.class)
public class FeignClientConfigurer {private Decoder decoder;private Encoder encoder;private Client client;private Contract contract;public FeignClientConfigurer(Decoder decoder, Encoder encoder, Client client, Contract contract) {this.decoder = decoder;this.encoder = encoder;this.client = client;this.contract = contract;}public RequestInterceptor getUserFeignClientInterceptor() {return new RequestInterceptor() {@Overridepublic void apply(RequestTemplate requestTemplate) {// 添加header}};}public <T> T buildAuthorizedUserFeignClient(Class<T> clazz, String serviceName) {return getBasicBuilder().requestInterceptor(getUserFeignClientInterceptor())//默认是Logger.NoOpLogger.logger(new Slf4jLogger(clazz))//默认是Logger.Level.NONE(一旦手动创建FeignClient,全局配置的logger就不管用了,需要在这指定).logLevel(Logger.Level.FULL).target(clazz, buildServiceUrl(serviceName));}private String buildServiceUrl(String serviceName) {return "http://" + serviceName;}protected Feign.Builder getBasicBuilder() {return Feign.builder().client(client).encoder(encoder).decoder(decoder).contract(contract);}
}使用工具类的方法创建多个FeignClient配置
import com.gzl.cn.service.FeignTest1Service;
import feign.Client;
import feign.Contract;
import feign.codec.Decoder;
import feign.codec.Encoder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class FeignClientConfiguration extends FeignClientConfigurer {public FeignClientConfiguration(Decoder decoder, Encoder encoder, Client client, Contract contract) {super(decoder, encoder, client, contract);}@Beanpublic FeignTest1Service feignTest1Service() {return super.buildAuthorizedUserFeignClient(FeignTest1Service.class, "CLOUD-PAYMENT-SERVICE");}// 假如多个FeignClient在这里定义即可
}其中,super.buildAuthorizedUserFeignClient()方法中,第一个参数为调用别的服务的接口类,第二个参数为被调用服务在注册中心的service-id。
public interface FeignTest1Service {@GetMapping(value = "/payment/get/{id}")CommonResult<Payment> getPaymentById(@PathVariable("id") Long id);}使用的时候正常注入使用即可
@Resource
private FeignTest1Service feignTest1Service;2.7.Feign 继承支持
Feign 通过单继承接口支持样板 API。这允许将常用操作分组到方便的基本接口中。
UserService.java
public interface UserService {@RequestMapping(method = RequestMethod.GET, value ="/users/{id}")User getUser(@PathVariable("id") long id);}
UserResource.java
@RestController
public class UserResource implements UserService {}UserClient.java
package project.user;@FeignClient("users")
public interface UserClient extends UserService {}2.8.Feign 和Cache集成
如果@EnableCaching使用注解,CachingCapability则创建并注册一个 bean,以便您的 Feign 客户端识别@Cache*其接口上的注解:
public interface DemoClient {@GetMapping("/demo/{filterParam}")@Cacheable(cacheNames = "demo-cache", key = "#keyParam")String demoEndpoint(String keyParam, @PathVariable String filterParam);}您还可以通过 property 禁用该功能feign.cache.enabled=false
注意feign.cache.enabled=false只有在高版本才有
2.9.OAuth2 支持
可以通过设置以下标志来启用 OAuth2 支持:
feign.oauth2.enabled=true当标志设置为 true 并且存在 oauth2 客户端上下文资源详细信息时,将OAuth2FeignRequestInterceptor创建一个类 bean。在每个请求之前,拦截器解析所需的访问令牌并将其作为标头包含在内。有时,当为 Feign 客户端启用负载平衡时,您可能也希望使用负载平衡来获取访问令牌。
为此,您应该确保负载均衡器位于类路径 (spring-cloud-starter-loadbalancer) 上,并通过设置以下标志显式启用 OAuth2FeignRequestInterceptor 的负载均衡:
feign.oauth2.load-balanced=true注意feign.cache.enabled=false只有在高版本才有
5. 为什么Feign第一次调用耗时很长?
主要原因是由于Ribbon的懒加载机制,当第一次调用发生时,Feign会触发Ribbon的加载过程,包括从服务注册中心获取服务列表、建立连接池等操作,这个加载过程会增加首次调用的耗时。
ribbon:eager-load:enabled: trueclients: service-1那怎么解决这个问题呢?
可以在应用启动时预热Feign客户端,自动触发一次无关紧要的调用,来提前加载Ribbon和其他相关组件。这样,就相当于提前进行了第一次调用。
6.Feign怎么实现认证传递?
比较常见的一个做法是,使用拦截器传递认证信息。可以通过实现RequestInterceptor接口来定义拦截器,在拦截器里,把认证信息添加到请求头中,然后将其注册到Feign的配置中。
@Configuration
public class FeignClientConfig {@Beanpublic RequestInterceptor requestInterceptor() {return new RequestInterceptor() {@Overridepublic void apply(RequestTemplate template) {// 添加认证信息到请求头中template.header("Authorization", "Bearer " + getToken());}};}private String getToken() {// 获取认证信息的逻辑,可以从SecurityContext或其他地方获取// 返回认证信息的字符串形式return "your_token";}
}7. Fegin怎么做负载均衡?Ribbon?
在Feign中,负载均衡是通过集成Ribbon来实现的。
Ribbon是Netflix开源的一个客户端负载均衡器,可以与Feign无缝集成,为Feign提供负载均衡的能力。
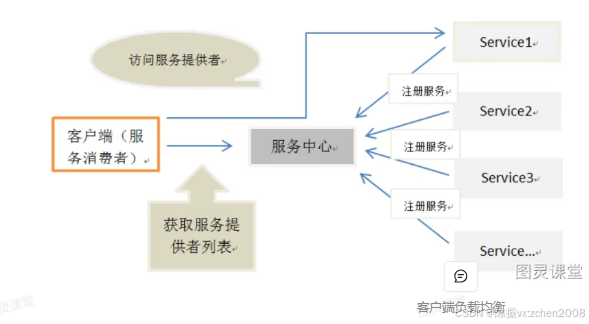
Ribbon在发起请求前,会从“服务中心”获取服务列表(清单),然后按照一定的负载均衡策略去发起请求,从而实现客户端的负载均衡。Ribbon本身也维护着“服务提供者”清单的有效性。如果它发现“服务提供者”不可用,则会重新从“服务中心”获取有效的“服务提供者”清单来及时更新。
8. 说说有哪些负载均衡算法?
常见的负载均衡算法包含以下几种:

① 轮询算法(Round Robin):轮询算法是最简单的负载均衡算法之一。它按照顺序将请求依次分配给每个后端服务器,循环往复。当请求到达时,负载均衡器按照事先定义的顺序选择下一个服务器。轮询算法适用于后端服务器具有相同的处理能力和性能的场景。
② 加权轮询算法(Weighted Round Robin):加权轮询算法在轮询算法的基础上增加了权重的概念。每个后端服务器都被赋予一个权重值,权重值越高,被选中的概率就越大。这样可以根据服务器的处理能力和性能调整请求的分配比例,使得性能较高的服务器能够处理更多的请求。
③ 随机算法(Random):随机算法将请求随机分配给后端服务器。每个后端服务器有相等的被选中概率,没有考虑服务器的实际负载情况。这种算法简单快速,适用于后端服务器性能相近且无需考虑请求处理能力的场景。
④ 加权随机算法(Weighted Random):加权随机算法在随机算法的基础上引入了权重的概念。每个后端服务器被赋予一个权重值,权重值越高,被选中的概率就越大。这样可以根据服务器的处理能力和性能调整请求的分配比例。
⑤ 最少连接算法(Least Connection):最少连接算法会根据后端服务器当前的连接数来决定请求的分配。负载均衡器会选择当前连接数最少的服务器进行请求分配,以保证后端服务器的负载均衡。这种算法适用于后端服务器的处理能力不同或者请求的处理时间不同的场景。
⑥ 哈希算法(Hash):哈希算法会根据请求的某个特定属性(如客户端IP地址、请求URL等)计算哈希值,然后根据哈希值选择相应的后端服务器。
常见的负载均衡器,比如Ribbion、Gateway等等,基本都支持这些负载均衡算法。
9 介绍下Dubbo
一、Dubbo简介
1、什么是Dubbo
Dubbo是一款高性能、高可用的、基于Java开源的RPC框架;由阿里巴巴开发并开源,
现为 Apache 顶级项目;它提供了三大核心功能,即:
(1)面向接口的远程方法调用
(2)智能容错和负载均衡
(3)服务自动注册和发现
所以 Dubbo框架不仅仅是具备RPC访问功能,还包含服务治理功能;
2、Dubbo核心架构
2.1、Dubbo架构图
Dubbo 架构图如下所示:
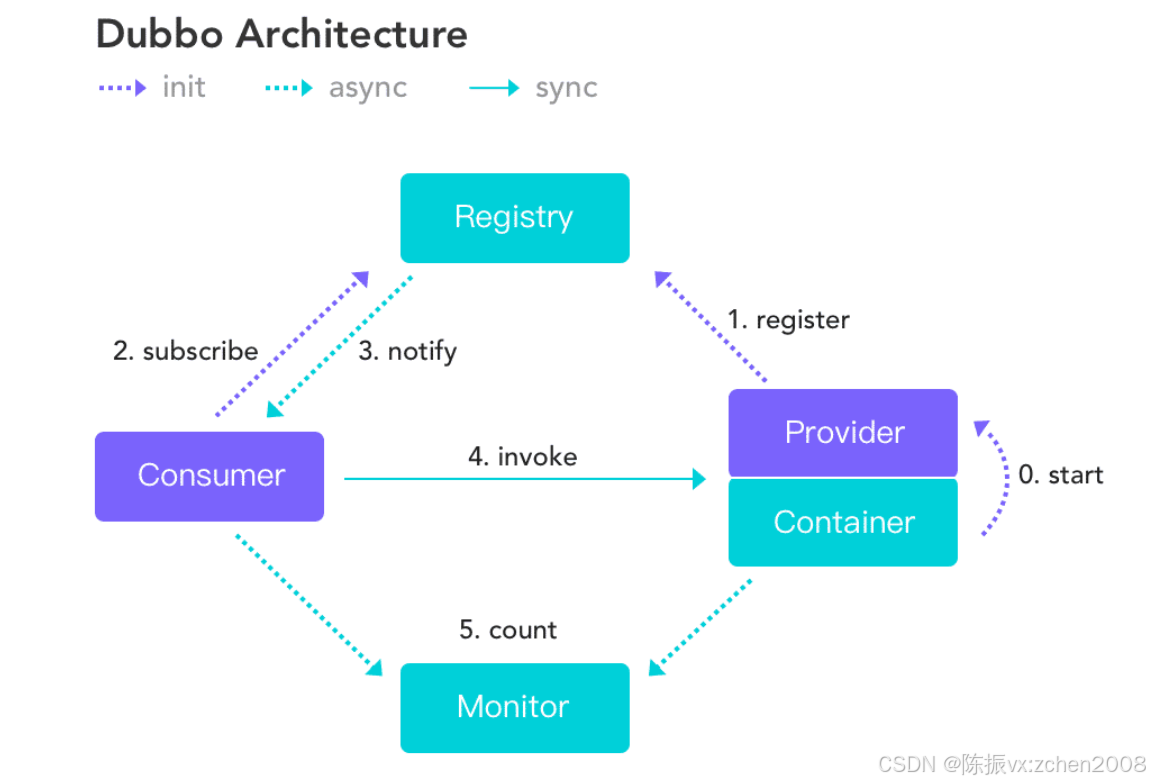
注:上图中虚线表示异步,实线表示同步;异步不阻塞线程性能高,同步阻塞线程必须
等待响应结果才能继续执行,相对性能低
2.2、Dubbo 架构中的角色
由上图中可以发现,在Dubbo 中主要包含 Provicer、Consumer、Registry、Container、
Monitor 等角色,下边分别对这些角色及功能进行介绍。
2.2.1、Provicer
Provicer 是服务提供者,暴露服务供消费者调用,处理消费者请求;在项目启动时,
Provicer 主动向注册中心注册自己提供的服务;另外 Provicer 主要实现具体的业务逻辑,
并定期向监控中心发送调用统计数据;
注意:
Provicer 暴露的对外提供服务的接口并不是在 Provicer 项目中定义的,该服务接口
是单独定义在一个项目中,Provicer 中对外的服务需要实现该接口,然后由Consumer
客户端调用。该服务接口在 Consumer远程调用 Provicer 过程中起到“桥梁”的作用;
2.2.2、Consumer
Consumer 是服务消费者,用于远程调用其他服务;启动时,向注册中心订阅所需的服
务,获取服务提供者的列表并缓存,通过负载均衡策略选择提供者;Consumer也会定期
向监控中心发送调用统计数据
2.2.3、Registry
Registry 是服务注册中心(提供服务注册与发现),放置所有Provider对外提供的信息。
包含Provider的IP,访问端口,访问遵守的协议,对外提供的接口,接口中有哪些方法
等相关信息;
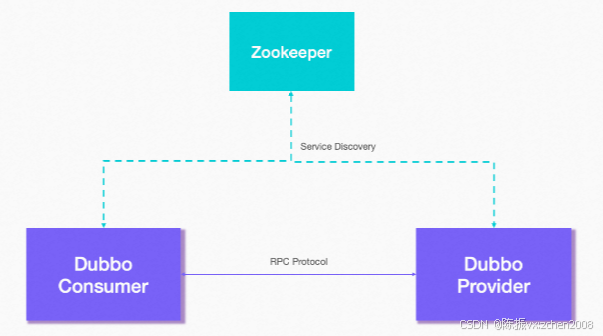
Dubbo常用的注册中心有:Zookeeper、Nacos、Redis、Multicast、Simple
另外,客户端 Consumer 要想订阅到目标Provicer服务,则也需要注册到注册中心中,
如下图所示:
注:以zookeeper作为注册中心为例
2.2.4、Container
Container 是服务运行的容器,一般指spring容器,因为Dubbo是完全基于spring实现的;
负责启动、加载和运行服务提供者、管理服务生命周期和提供必要的运行环境支持
2.2.5、Monitor
Monitor 是监控中心,监控Provider的压力情况等。每隔2分钟Consumer和Provider会把
调用次数发送给Monitor,由Monitor进行统计
2.3、Dubbo的执行流程
以上边Dubbo架构图中的步骤顺序来看下Dubbo的执行流程。
Step 0 start :
启动容器(即spring 容器)时,会把Provicer启动,并将服务接口实现类封装为
Invoker,接着将 Invoker 转换为 Exporter;最后通过具体的 Protocol 协议将服务
暴露到网络中供Consumer调用
Step 1 register :
把Provider服务注册到Registry里,注册内容包括服务提供者地址、接口、方法等信息
Step 2 subscribe :
Consumer消费者启动时,从注册中心订阅所需服务,
Step 3 notify :
注册中心返回提供者地址列表给Consumer,Consumer缓存服务提供者Provider列表
Step 4 invoke :
Consumer消费者根据注册中心Registry提供的服务提供者信息,并通过 ProxyFactory
创建服务接口的代理对象,代理对象内部封装了远程调用逻辑,可以远程调用服务提
供者
Step 5 count:
Consumer和Provider把调用次数信息异步发送给Monitor进行统计
3、Dubbo 支持的协议介绍
3.1、Dubbo支持的协议
一般Provider需要配置Dubbo的协议,Consumer不需要配置
3.1.1、Dubbo协议(官方推荐)
优点:采用NIO复用单一长连接,并使用线程池并发处理请求,减少握手和加大并发效率,
性能较好(推荐使用)
缺点:大文件上传时,可能出现问题(不使用Dubbo文件上传)
3.1.2、RMI(Remote Method Invocation)协议
优点:JDK自带的功能,不用引入其他依赖,兼容性好,
缺点:偶尔连接失败
3.1.3、Hessian协议
优点:可与原生Hessian互操作,基于HTTP协议
缺点:需hessian.jar支持,http短连接的开销大
二、Dubbo示例
1、创建父工程dubbo-demo,dubbo-demo包含3个子模块,分别是api(定义服务接口)、
provider(服务提供者)和consumer(消费者);因为 provider和consumer都要引入
api 模块,所以我们把公用的dubbo依赖放在api模块中,
导入dubbo依赖如下:
<dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo-spring-boot-starter</artifactId></dependency><!-- curator-recipes --><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId></dependency><!-- curator-framework --><dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId></dependency>2、api 模块
api 中只用来定义Provider 的对外服务接口,其他什么也不干,也不需要启动;
Provider 的对外提供的服务需要实现api 中相关的接口;consumer中需要api的接口来实现远
程调用;所以 provider和consumer都要引入api模块。
示例代码如下所示:
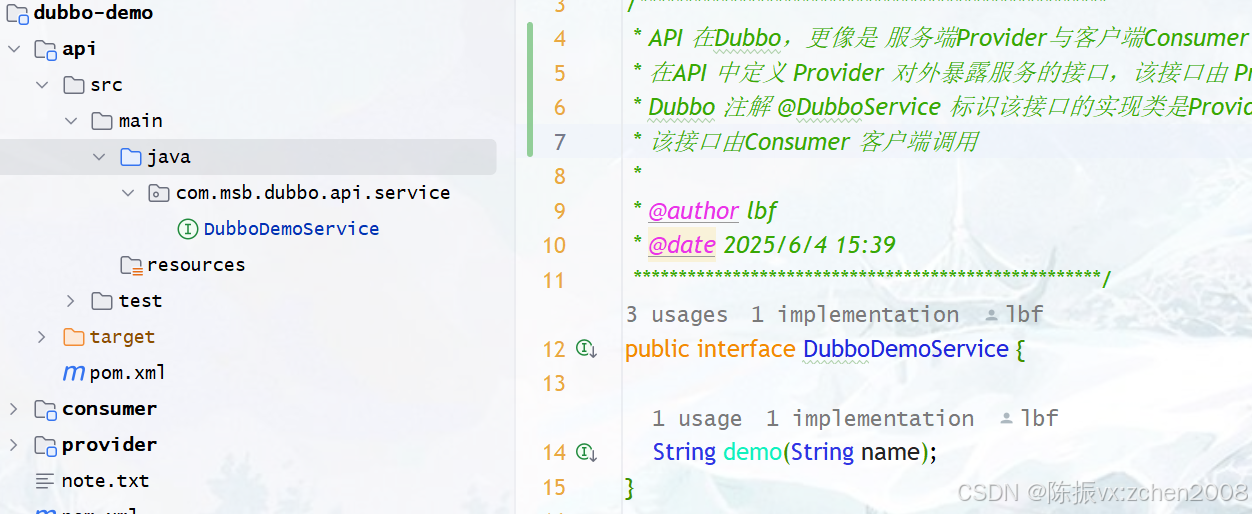
/***************************************************** API 在Dubbo,更像是 服务端Provider与客户端Consumer 中间的桥梁,* 在API 中定义 Provider 对外暴露服务的接口,该接口由 Provider 实现,并使用* Dubbo 注解 @DubboService 标识该接口的实现类是Provider暴露的服务;* 该接口由Consumer 客户端调用** @author * @date 2025/6/4 15:39****************************************************/
public interface DubboDemoService {String demo(String name);
}3、provider 模块
1)定义对外提供的服务,该服务需要实现api中定义的服务接口并使用Dubbo中的注解
@DubboService 标识该类是一个Dubbo服务,示例代码如下:
import com.msb.dubbo.api.service.DubboDemoService;
import org.apache.dubbo.config.annotation.DubboService;/***************************************************** todo: 注意:* 1)该类需要加上 注解@DubboService(或apache dubbo 包下的@Service) ,标识该类是一个Dubbo服务,* 才能被注册,* 2)该类需要实现API 端定义的接口** @author * @date 2025/6/4 15:50****************************************************/
@DubboService
public class DubboDemoServiceImpl implements DubboDemoService {@Overridepublic String demo(String name) {return name+" hello Dubbo test!";}
}2)在启动类上添加注解 @EnableDubbo 开启dubbo应用,示例代码如下:
import org.apache.dubbo.config.spring.context.annotation.EnableDubbo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;/***************************************************** dubbo 使用步骤:* 1、定义api接口模块,如: api;在客户端模块定义对外接口* 2、定义服务端Provider,如:provider,服务端需要引入客户端依赖,* 3、在服务端定义Dubbo服务,并实现客户端定义的对外接口* 4、在服务端开启Dubbo,如在启动类上加上注解 @EnableDubbo* 5、Consumer 客户端通过 api中的接口实现远程调用** @author * @date 2025/6/4 15:44****************************************************/
@EnableDubbo //启用dubbo
@SpringBootApplication
public class DubboProviderApplication {public static void main(String[] args) {SpringApplication.run(DubboProviderApplication.class);}
}3)配置Dubbo 信息
provider 需要配置protocol 协议信息,而consumer客户端不需要该项配置
配置信息如下:
dubbo:application:#dubbo注册到服务中心的服务名称name: dubbo-providerregistry:#dubbo注册中心地址,zookeeper表示这里以zookeeper作为注册中心address: zookeeper://47.117.80.49:2181#配置dubbo连接zookeeper的超时时间timeout: 10000#配置dubbo 协议端口号protocol:port: 20884#注意:此属性有默认值,但还需要手动指定,否则有可能报错name: dubbo4、consumer 模块
consumer 是远程服务的调用者,在 consumer 中通过api中定义的服务接口来执行远程调用
,有一点需要注意,注入 api 提供的服务接口时需要使用注解 @DubboReference。
步骤如下:
1)定义正常的service服务,该服务正常使用spring提供的@Service 注解,或spring提供的
其他注解,但 注入 api 提供的服务接口时需要使用Dubbo提供的解 @DubboReference
示例代码如下:
/****************************************************** @author * @date 2025/6/4 16:24****************************************************/
public interface DubboDemoService {public String demo();
}/****************************************************** @author * @date 2025/6/4 16:26****************************************************/
@Service
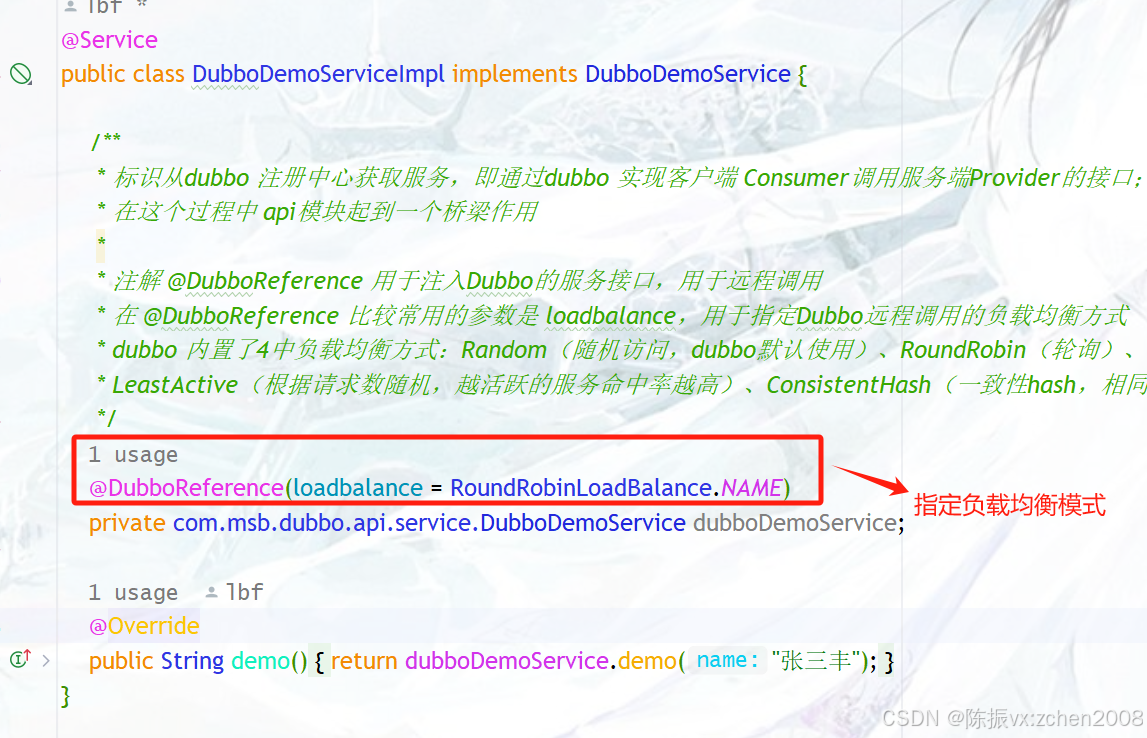
public class DubboDemoServiceImpl implements DubboDemoService {/*** 标识从dubbo 注册中心获取服务,即通过dubbo 实现客户端 Consumer调用服务端Provider的接口;* 在这个过程中 api模块起到一个桥梁作用*/@DubboReferenceprivate com.msb.dubbo.api.service.DubboDemoService dubboDemoService;@Overridepublic String demo() {return dubboDemoService.demo("张三丰");}/****************************************************** @author * @date 2025/6/4 16:29****************************************************/
@RestController
public class DubboDemoController {@Autowiredprivate DubboDemoService dubboDemoService;@RequestMapping("/test")public String test(){return dubboDemoService.demo();}
}2)在启动类上添加注解 @EnableDubbo 开启dubbo应用,示例代码如下:
/****************************************************** @author * @date 2025/6/4 16:23****************************************************/
@EnableDubbo
@SpringBootApplication
public class ConsumerApplication {public static void main(String[] args) {SpringApplication.run(ConsumerApplication.class);}
}3)配置Dubbo 信息
server:port: 8003#配置dubbo
dubbo:application:#配置服务名称,在dubbo中的服务名称name: dubbo-consumerregistry:#配置注册中心地址,这里用zookeeper作为dubbo注册中心address: zookeeper://47.117.80.49:2181timeout: 10000三、Dubbo支持的负载均衡
Dubbo 内部提供了4中负载均衡策略,分别是 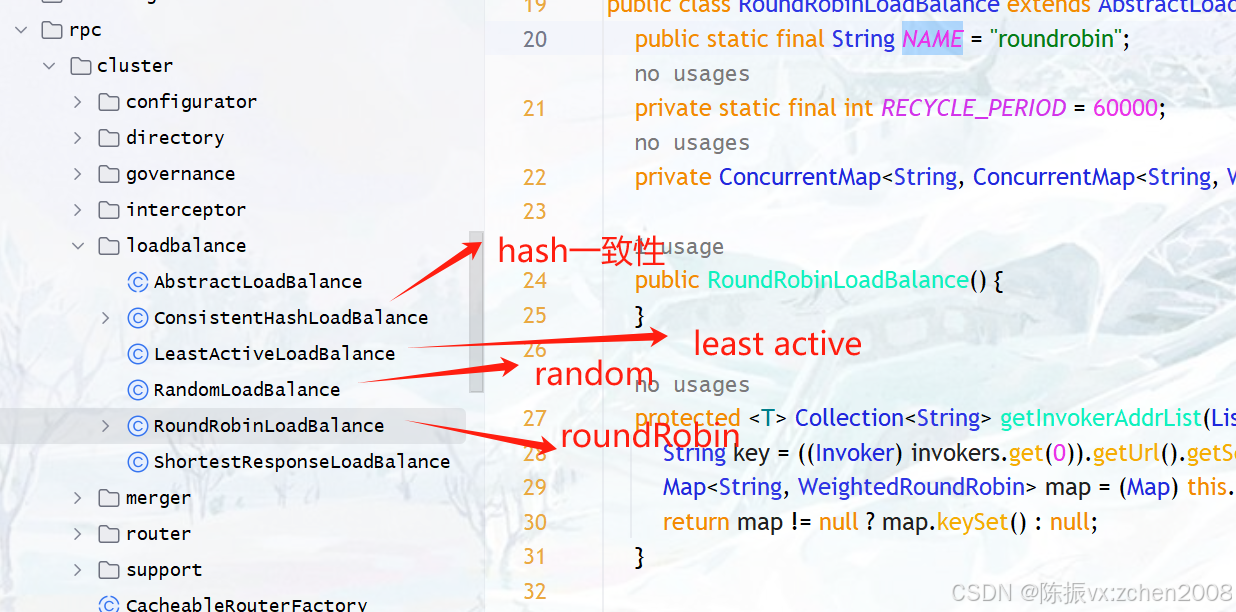
1)Random LoadBalance(随机负载均衡)
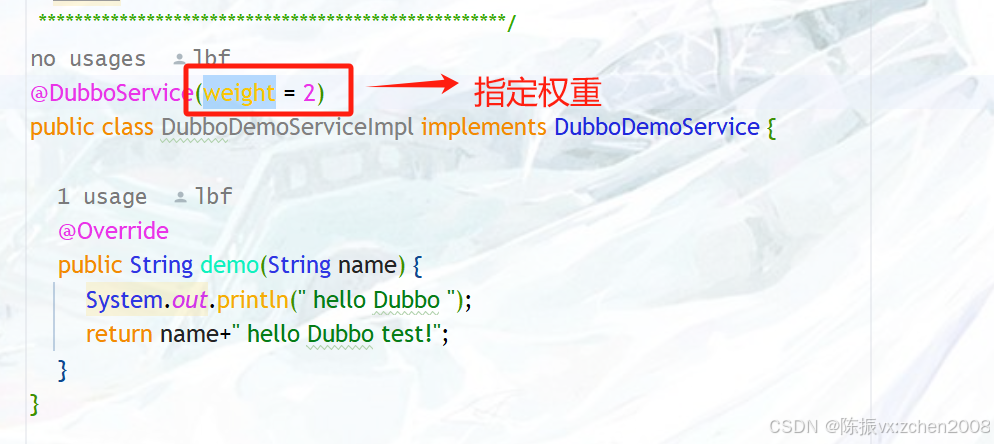
随机选择一个服务提供者进行调用,访问概率与权重有关。
在Dubbo服务上的注解@DubboService 的属性 weight 来指定服务的权重,如下图:
适用于服务提供者数量不多的情况,或者对服务调用的顺序没有严格要求时。
2)RoundRobin LoadBalance(轮询负载均衡)
按顺序轮流选择服务提供者进行调用,访问频率与权重有关。
适用于请求均匀分配到每个服务提供者,保证每个服务提供者都能被平均调用。
3)LeastActive LoadBalance(最少活跃调用数负载均衡)
根据服务提供者的当前活跃调用数选择一个服务提供者进行调用,活跃调用数越
少,被选中的概率越大。
适用于处理请求速度差异较大的服务提供者,能够优先选择较空闲的服务提供者。
4)ConsistentHash LoadBalance(一致性Hash负载均衡)
根据请求的参数(如URL的某个部分或特定的参数)进行hash,然后根据hash结果
选择一个服务提供者。
适用于需要保证相同参数的请求总是路由到同一服务提供者的场景,比如缓存数据
的一致性需求。
Dubbo 负载均衡使用很简单,只需要在客户Consumer在调用Dubbo 服务时,在Dubbo 注解
@DubboReference 中使用属性 loadbalance 来指定负载均衡模式,如下图所示:
5. 服务网关
1. 什么是API网关?
API网关(API Gateway)是一种中间层服务器,用于集中管理、保护和路由对后端服务的访问。它充当了客户端与后端服务之间的入口点,提供了一组统一的接口来管理和控制API的访问。
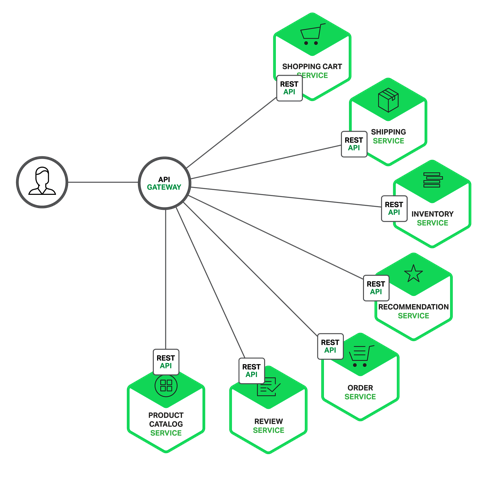
API网关的主要功能包括:
① 路由转发:API网关根据请求的URL路径或其他标识,将请求路由到相应的后端服务。通过配置路由规则,可以灵活地将请求分发给不同的后端服务。
② 负载均衡:API网关可以在后端服务之间实现负载均衡,将请求平均分发到多个实例上,提高系统的吞吐量和可扩展性。
③ 安全认证与授权:API网关可以集中处理身份验证和授权,确保只有经过身份验证的客户端才能访问后端服务。它可以与身份提供者(如OAuth、OpenID Connect)集成,进行用户认证和授权操作。
④ 缓存:API网关可以缓存后端服务的响应,减少对后端服务的请求次数,提高系统性能和响应速度。
⑤ 监控与日志:API网关可以收集和记录请求的指标和日志,提供实时监控和分析,帮助开发人员和运维人员进行故障排查和性能优化。
⑥ 数据转换与协议转换:API网关可以在客户端和后端服务之间进行数据格式转换和协议转换,如将请求从HTTP转换为WebSocket,或将请求的参数进行格式转换,以满足后端服务的需求。
⑦ API版本管理:API网关可以管理不同版本的API,允许同时存在多个API版本,并通过路由规则将请求正确地路由到相应的API版本上。
……
通过使用API网关,可以简化前端与后端服务的交互,提供统一的接口和安全性保障,同时也方便了服务治理和监控。它是构建微服务架构和实现API管理的重要组件之一。
2.SpringCloud可以选择哪些API网关?
使用SpringCloud开发,可以采用以下的API网关选型:
① Netflix Zuul(已停止更新):Netflix Zuul是Spring Cloud早期版本中提供的默认API网关。它基于Servlet技术栈,可以进行路由、过滤、负载均衡等功能。然而,自2020年12月起,Netflix宣布停止对Zuul 1的维护,转而支持新的API网关项目。
② Spring Cloud Gateway(推荐):Spring Cloud Gateway是Spring Cloud官方推荐的API网关,取代了Netflix Zuul。它基于非阻塞的WebFlux框架,充分利用了响应式编程的优势,并提供了路由、过滤、断路器、限流等特性。Spring Cloud Gateway还支持与Spring Cloud的其他组件集成,如服务发现、负载均衡等。
采用限流策略为:令牌桶算法
③ Kong:Kong是一个独立的、云原生的API网关和服务管理平台,可以与Spring Cloud集成。Kong基于Nginx,提供了强大的路由、认证、授权、监控和扩展能力。它支持多种插件和扩展,可满足不同的API管理需求。
④ APISIX:APISIX基于Nginx和Lua开发,它具有强大的路由、流量控制、插件扩展等功能。APISIX支持灵活的配置方式,可以根据需求进行动态路由、负载均衡和限流等操作。
……
3.Spring Cloud Gateway核心概念?
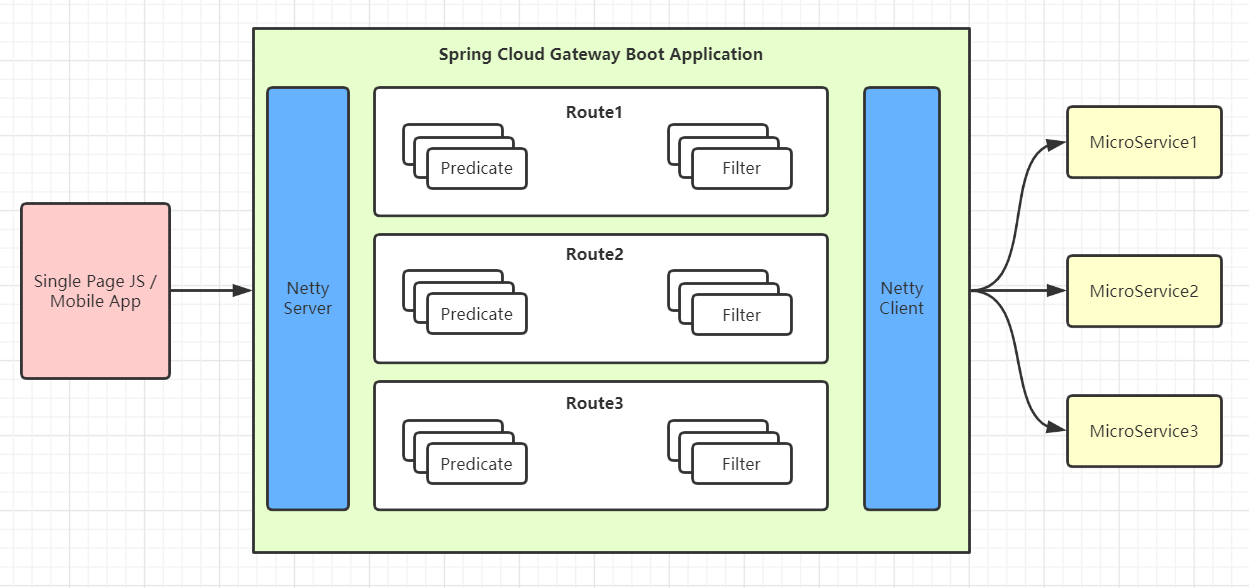
在Spring Cloud Gateway里,有三个关键组件:
●Route(路由):路由是Spring Cloud Gateway的基本构建块,它定义了请求的匹配规则和转发目标。通过配置路由,可以将请求映射到后端的服务实例或URL上。路由规则可以根据请求的路径、方法、请求头等条件进行匹配,并指定转发的目标URI。
●Predicate(断言):断言用于匹配请求的条件,如果请求满足断言的条件,则会应用所配置的过滤器。Spring Cloud Gateway提供了多种内置的断言,如Path(路径匹配)、Method(请求方法匹配)、Header(请求头匹配)等,同时也支持自定义断言。
●Filter(过滤器):过滤器用于对请求进行处理和转换,可以修改请求、响应以及执行其他自定义逻辑。Spring Cloud Gateway提供了多个内置的过滤器,如请求转发、请求重试、请求限流等。同时也支持自定义过滤器,可以根据需求编写自己的过滤器逻辑。
我们再来看下Spring Cloud Gateway的具体工作流程:
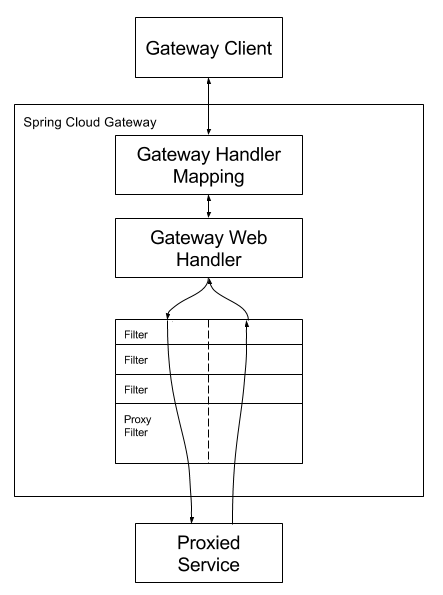
又有两个比较重要的概念:
●Gateway Handler(网关处理器):网关处理器是Spring Cloud Gateway的核心组件,负责将请求转发到匹配的路由上。它根据路由配置和断言条件进行路由匹配,选择合适的路由进行请求转发。网关处理器还会依次应用配置的过滤器链,对请求进行处理和转换。
●Gateway Filter Chain(网关过滤器链):网关过滤器链由一系列过滤器组成,按照配置的顺序依次执行。每个过滤器可以在请求前、请求后或请求发生错误时进行处理。过滤器链的执行过程可以修改请求、响应以及执行其他自定义逻辑。
4. Gateway使用示例
① 基础路由配置示例
通过YAML文件定义路由规则,实现请求转发至目标URI:
server:port: 8080
spring:cloud:gateway:routes:- id: url-proxyuri: https://blog.csdn.netpredicates:- Path=/csdn/**
此配置将/csdn/**路径的请求转发至CSDN博客地址,id需保持唯一性8。
② 动态路由与服务发现
集成Nacos注册中心实现负载均衡路由:
spring:cloud:gateway:discovery:locator:enabled: true # 启用服务发现routes:- id: payment-serviceuri: lb://payment-service # lb表示负载均衡predicates:- Path=/payment/**
该配置通过lb://前缀自动从注册中心获取服务实例列表911。
③ 自定义全局过滤器
实现GlobalFilter接口进行权限校验:
@Component
@Order(-1) // 值越小优先级越高
public class AuthFilter implements GlobalFilter {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {String token = exchange.getRequest().getHeaders().getFirst("token");if (!"valid_token".equals(token)) {exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);return exchange.getResponse().setComplete();}return chain.filter(exchange);}
}
此过滤器会拦截所有请求并验证Token有效性27。
④ 跨域解决方案
通过配置解决前端跨域访问问题:
spring:cloud:gateway:globalcors:cors-configurations:'[/**]':allowedOrigins: "*"allowedMethods:- GET- POST
允许所有来源的GET/POST请求访问网关接口35。
⑤ 限流配置
使用Redis实现请求限流:
spring:redis:host: localhostcloud:gateway:routes:- id: rate-limit-routeuri: http://example.compredicates:- Path=/api/**filters:- name: RequestRateLimiterargs:redis-rate-limiter.replenishRate: 10 # 每秒允许10个请求redis-rate-limiter.burstCapacity: 20 # 最大突发流量20
需配合spring-boot-starter-data-redis-reactive依赖使用14。
完整项目需包含以下Maven依赖:
<dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency>
</dependencies>
建议使用Spring Boot 2.6.x及以上版本
附录:常见的限流策略
参考:限流策略
6. 服务容灾
1.什么是服务雪崩?
在微服务中,假如一个或者多个服务出现故障,如果这时候,依赖的服务还在不断发起请求,或者重试,那么这些请求的压力会不断在下游堆积,导致下游服务的负载急剧增加。不断累计之下,可能会导致故障的进一步加剧,可能会导致级联式的失败,甚至导致整个系统崩溃,这就叫服务雪崩。
微服务之间互相调用,因为调用链中的一个服务故障,引起整个链路都无法访问的情况。
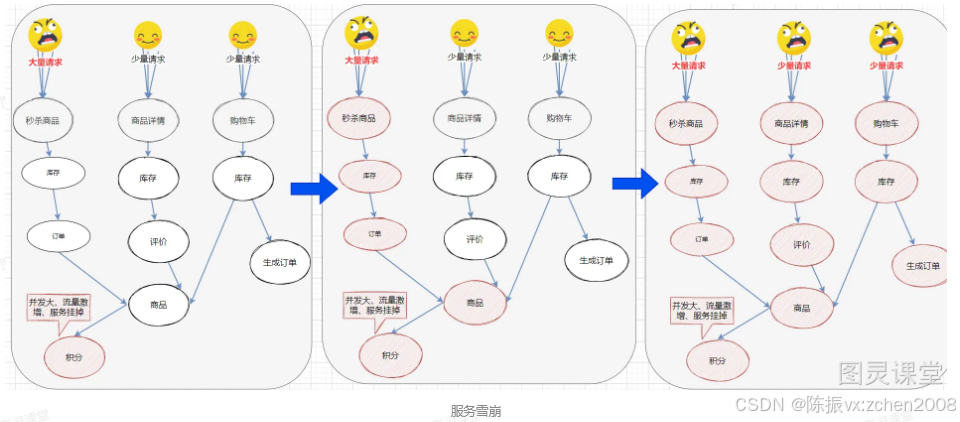
一般,为了防止服务雪崩,可以采用这些措施:
① 超时处理: 设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待。(缓解服务雪崩问题)
② 舱壁模式:限定每个业务能使用的线程,避免耗尽整个tomcat的资源,因此也叫作线程隔离。(少量资源浪费)
③ 熔断降级:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。(比较好的方式)
④ 流量控制: 限制业务访问的QPS, 避免服务因流量的突增而故障。(预防雪崩)
① 服务高可用部署:确保各个服务都具备高可用性,通过冗余部署、故障转移等方式来减少单点故障的影响。
② 缓存和降级:合理使用缓存来减轻后端服务的负载压力,并在必要时进行服务降级,保证核心功能的可用性。
2. 什么是服务熔断和服务降级?
① 什么是服务熔断?
服务熔断是微服务架构中的容错机制,用于保护系统免受服务故障或异常的影响。当某个服务出现故障或异常时,服务熔断可以快速隔离该服务,确保系统稳定可用。
它通过监控服务的调用情况,当错误率或响应时间超过阈值时,触发熔断机制,后续请求将返回默认值或错误信息,避免资源浪费和系统崩溃。
服务熔断还支持自动恢复,重新尝试对故障服务的请求,确保服务恢复正常后继续使用。
② 什么是服务降级?
服务降级是也是一种微服务架构中的容错机制,用于在系统资源紧张或服务故障时保证核心功能的可用性。
当系统出现异常情况时,服务降级会主动屏蔽一些非核心或可选的功能,而只提供最基本的功能,以确保系统的稳定运行。通过减少对资源的依赖,服务降级可以保证系统的可用性和性能。
它可以根据业务需求和系统状况来制定策略,例如替换耗时操作、返回默认响应、返回静态错误页面等。
3. 有哪些熔断降级方案实现?
目前常见的服务熔断降级实现方案有这么几种:

4. Hystrix怎么实现服务容错?
尽管已经不再更新,但是Hystrix是非常经典的服务容错开源库,它提供了多种机制来保护系统:
Hystrix服务容错六大机制
① 服务熔断(Circuit Breaker):Hystrix通过设置阈值来监控服务的错误率或响应时间。当错误率或响应时间超过预设的阈值时,熔断器将会打开,后续的请求将不再发送到实际的服务提供方,而是返回预设的默认值或错误信息。这样可以快速隔离故障服务,防止故障扩散,提高系统的稳定性和可用性。
② 服务降级(Fallback):当服务熔断打开时,Hystrix可以提供一个备用的降级方法或返回默认值,以保证系统继续正常运行。开发者可以定义降级逻辑,例如返回缓存数据、执行简化的逻辑或调用其他可靠的服务,以提供有限但可用的功能。
③ 请求缓存(Request Caching):Hystrix可以缓存对同一请求的响应结果,当下次请求相同的数据时,直接从缓存中获取,避免重复的网络请求,提高系统的性能和响应速度。
④ 请求合并(Request Collapsing):Hystrix可 以将多个并发的请求合并为一个批量请求,减少网络开销和资源占用。这对于一些高并发的场景可以有效地减少请求次数,提高系统的性能。
⑤ 实时监控和度量(Real-time Monitoring and Metrics):Hystrix提供了实时监控和度量功能,可以对服务的执行情况进行监控和统计,包括错误率、响应时间、并发量等指标。通过监控数据,可以及时发现和解决服务故障或性能问题。
⑥ 线程池隔离(Thread Pool Isolation):Hystrix将每个依赖服务的请求都放在独立的线程池中执行,避免因某个服务的故障导致整个系统的线程资源耗尽。通过线程池隔离,可以提高系统的稳定性和可用性。
使用示例
一、基础环境搭建
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId><version>2.2.10.RELEASE</version> </dependency>启用Hystrix支持:
@SpringBootApplication @EnableCircuitBreaker // 关键注解 public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);} }二、熔断降级示例
@Service public class OrderService {@HystrixCommand(fallbackMethod = "getOrderFallback",commandProperties = {@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"), //触发统计的最小请求量@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"), // 触发熔断的错误率阈值@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "5000") //OPEN→HALF_OPEN等待时间})public String getOrder(String orderId) {if("999".equals(orderId)) throw new RuntimeException("模拟服务异常");return "订单" + orderId + "详情";}private String getOrderFallback(String orderId, Throwable e) {return "[降级]订单服务暂不可用,订单ID:" + orderId;} }配置说明:
- 当10秒内请求量≥10次且失败率≥50%时触发熔断
- 熔断5秒后进入半开状态
三、线程池隔离配置
@HystrixCommand(threadPoolKey = "paymentThreadPool",threadPoolProperties = {@HystrixProperty(name = "coreSize", value = "5"),@HystrixProperty(name = "maxQueueSize", value = "10")},commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000")} ) public String processPayment(PaymentRequest request) {// 支付处理逻辑 }特点:
- 独立线程池(5核心线程+10队列)
- 2秒超时自动中断
四、Feign集成示例
@FeignClient(name = "inventory-service",fallback = InventoryFallback.class ) public interface InventoryClient {@GetMapping("/stock/{productId}")String checkStock(@PathVariable String productId); }@Component public class InventoryFallback implements InventoryClient {@Overridepublic String checkStock(String productId) {return "[降级]库存服务不可用";} }需配合配置开启Feign熔断:
feign:hystrix:enabled: true五、请求合并示例
@HystrixCollapser(batchMethod = "batchGetUsers",collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds", value = "100"),@HystrixProperty(name = "maxRequestsInBatch", value = "20")} ) public Future<User> getUserById(String id) {return null; // 实际由batchMethod处理 }@HystrixCommand public List<User> batchGetUsers(List<String> ids) {// 批量查询逻辑 }特点:
- 100ms时间窗口合并请求
- 每批最多处理20个请求
六、监控配置
- 添加依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId> </dependency>- 启用监控端点:
management:endpoints:web:exposure:include: hystrix.stream访问
/actuator/hystrix.stream获取实时数据
5. 介绍下Resilience4j
Resilience4j是专为Java 8设计的轻量级容错库,提供断路器、限流、重试等模块化功能组件。其核心特点包括:
- 模块化设计:仅需引入所需功能依赖(如
resilience4j-circuitbreaker) - 函数式编程支持:通过装饰器模式(如
CircuitBreaker.decorateSupplier())实现链式调用 - 低开销:相比Hystrix无额外线程池开销,基于Vavr库实现,无重型依赖
- 丰富监控:内置Micrometer指标集成和事件监听机制
与Hystrix关键对比
| 特性 | Resilience4j | Hystrix |
|---|---|---|
| 隔离机制 | 信号量(默认)或自定义线程池 | 强制线程池隔离 |
| 熔断策略 | 支持慢调用比例+异常比例双阈值 | 仅异常比例阈值 |
| 配置方式 | 代码配置+配置文件双支持 | 主要依赖Archaius配置 |
| 资源消耗 | 无额外线程开销,内存占用更低 | 每个命令独立线程池 |
| 维护状态 | 持续更新(2025年活跃) | 已停止维护 |
使用示例
与Spring Boot集成示例
1. 基础配置
pom.xml
<dependency><groupId>io.github.resilience4j</groupId><artifactId>resilience4j-spring-boot2</artifactId><version>1.7.1</version>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId>
</dependency>
YAML配置示例:
resilience4j:circuitbreaker:instances:orderService:failureRateThreshold: 50minimumNumberOfCalls: 10waitDurationInOpenState: 5sslidingWindowType: TIME_BASEDslidingWindowSize: 10s
2. 断路器实战
@Service
public class OrderService {@CircuitBreaker(name = "orderService", fallbackMethod = "fallback")public String getOrder(String id) {if(id.equals("999")) throw new RuntimeException("模拟故障");return "订单"+id+"详情";}private String fallback(String id, Exception e) {return "[降级]订单服务暂不可用,ID:" + id;}
}
- 失败率≥50%时触发熔断
- 10秒时间窗口统计指标
- 5秒后自动转为半开状态
3. 限流器+重试组合
@RateLimiter(name = "paymentApi")
@Retry(name = "paymentRetry", fallbackMethod = "paymentFallback")
public String processPayment(PaymentRequest req) {return paymentClient.submit(req); // HTTP调用
}public String paymentFallback(PaymentRequest req, Exception e) {return "支付请求繁忙,请10秒后重试";
}
配置示例:
resilience4j:ratelimiter: //限流控制(RateLimiter)instances:paymentApi:limitForPeriod: 10 //通过@RateLimiter注解限制接口每秒最多处理10次请求(令牌桶算法)limitRefreshPeriod: 1sretry: //自动重试机制(Retry)instances:paymentRetry:maxAttempts: 3 //失败时自动重试最多3次,每次间隔500毫秒waitDuration: 500ms
resilience4j.circuitbreaker:
instances:
backendService:
failureRateThreshold: 50 # 触发熔断的失败率阈值(%)
waitDurationInOpenState: 10s # OPEN状态持续时间
permittedNumberOfCallsInHalfOpenState: 3 # 半开状态允许的试探请求数
slidingWindowType: TIME_BASED # 滑动窗口类型(TIME_BASED/COUNT_BASED)
slidingWindowSize: 60s # 统计时间窗口长度
minimumNumberOfCalls: 10 # 触发熔断的最小请求数
4. 隔离舱(Bulkhead)
@Bulkhead(name = "inventoryService", type = Bulkhead.Type.SEMAPHORE)
public Inventory checkStock(String productId) {// 库存查询逻辑
}
配置参数:
- maxConcurrentCalls:最大并发数(默认25)
- maxWaitDuration:等待超时时间(默认0)
高级功能示例
1. 自定义事件监听
circuitBreaker.getEventPublisher().onSuccess(event -> log.info("调用成功: {}", event)).onError(event -> log.error("失败事件: {}", event));
2. 动态配置更新
CircuitBreakerRegistry registry = CircuitBreakerRegistry.ofDefaults();
registry.circuitBreaker("dynamicService").changeConfig(c -> c.waitDurationInOpenState(Duration.ofSeconds(10)));
3. Feign集成
@FeignClient(name = "user-service", configuration = FeignConfig.class)
public interface UserClient {@GetMapping("/users/{id}")@CircuitBreaker(name = "userService")User getUser(@PathVariable Long id);
}
监控与指标
- Actuator端点:通过
/actuator/circuitbreakers查看状态6 - Prometheus集成:
6. Sentinel
① 初始sentinel
- 雪崩问题及解决方案
- 安装Sentinel
- 微服务整合Sentinel
② 限流规则
- 快速入门
- 流控模式之关联模式
- 流控模式之链路模式
- 流控效果
- 热点参数限流
③ 隔离和降级
- Feign整合Sentinel
- 线程隔离(信号量隔离)
- 断路器的三个状态
- 熔断策略
④ 授权规则
- 实现网关授权
- 自定义异常结果
⑤ 规则持久化
- 规则管理三种模式
- 实现push模式持久化
① 初始sentinel
- 雪崩问题及解决方案
雪崩问题
微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
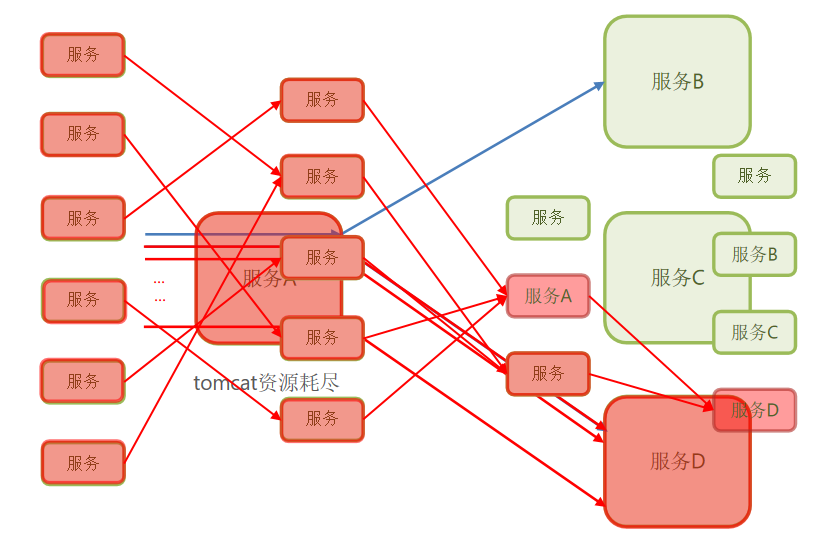
雪崩问题解决方案
解决雪崩问题的常见方式有四种:
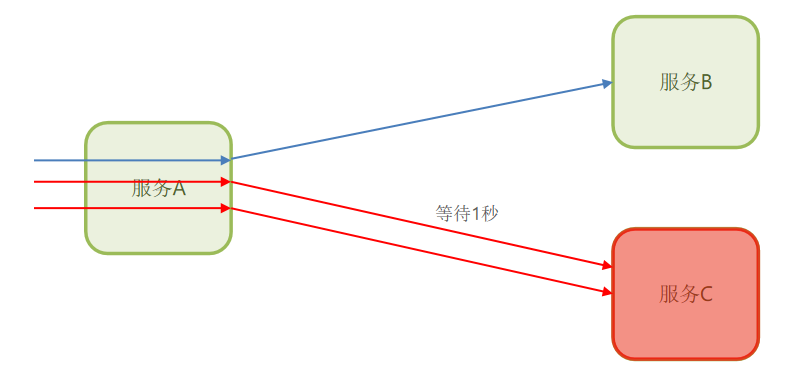
a.超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待。(环缓解服务雪崩问题)
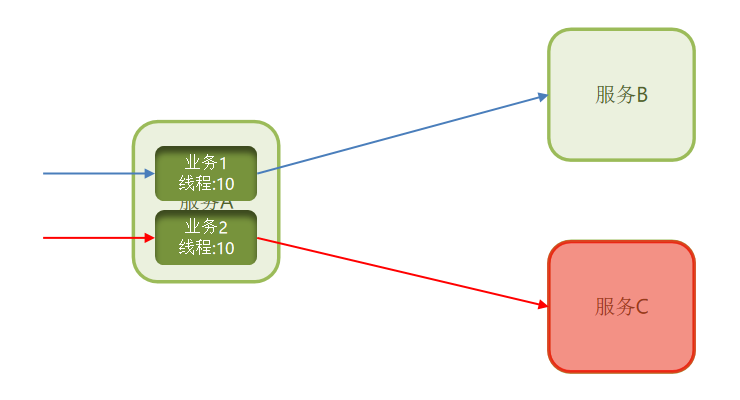
b.线程隔离:限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,会有一定的资源浪费。
c.熔断降级:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
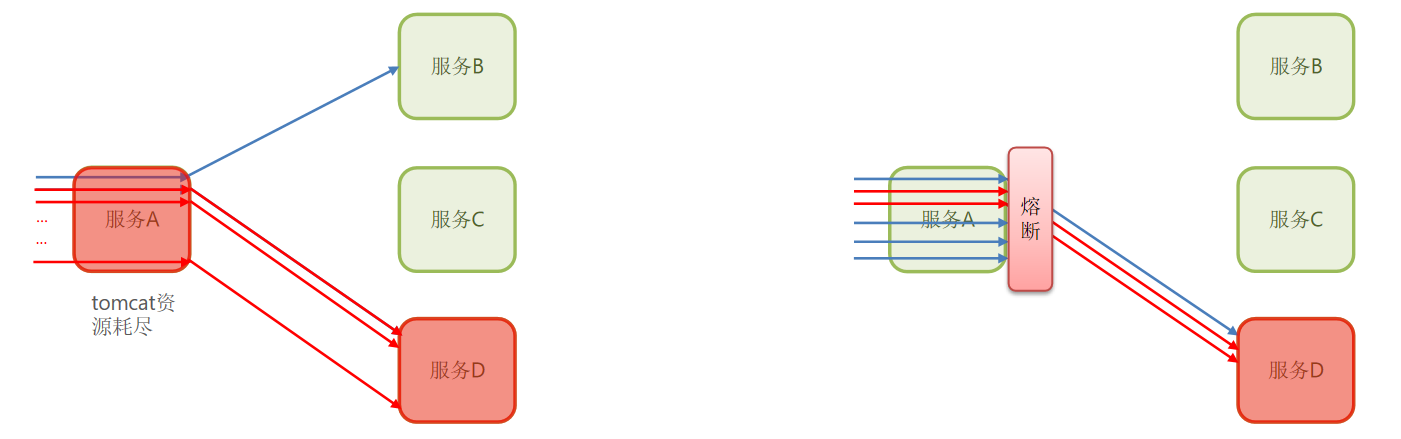
d.流量控制:限制业务访问的QPS,避免服务因流量的突增而故障。

总结
什么是雪崩问题?
微服务之间相互调用,因为调用链中的一个服务故障,引起整个链路都无法访问的情况。
如何避免因瞬间高并发流量而导致服务故障?
流量控制
如何避免因服务故障引起的雪崩问题?
超时处理
线程隔离
降级熔断
采用的限流算法:
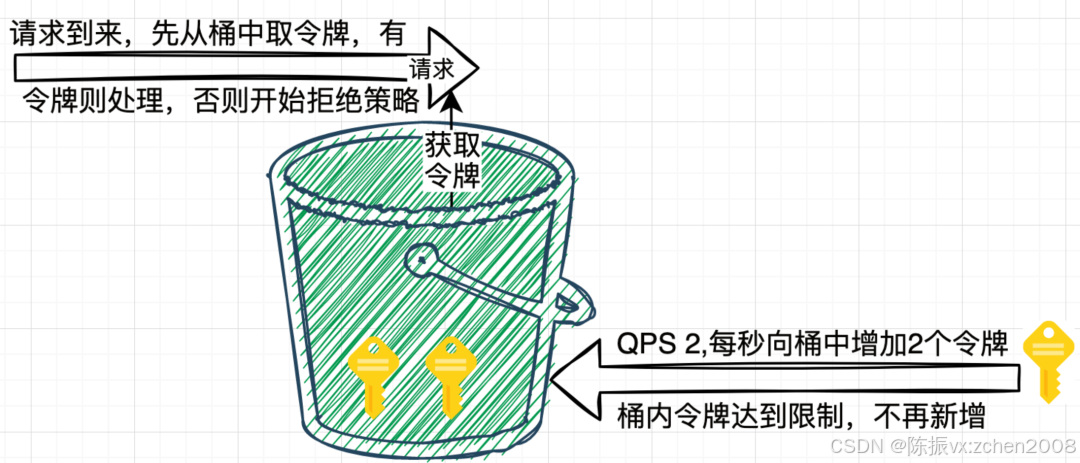
-
令牌桶算法原理
令牌桶算法通过以固定速率向桶中添加令牌,请求需要获取令牌才能被处理。如果桶中没有足够的令牌,请求会被限流。这种算法可以平滑突发流量,同时保证系统的稳定性。 -
Sentinel中的实现
Sentinel在FlowSlot中实现了令牌桶算法,用于流量控制。开发者可以通过配置规则来定义限流阈值和触发条件。
- 安装Sentinel
sentinel官方提供了UI控制台,方便我们对系统做限流设置。大家可以在GitHub下载:sentinel-dashboard-1.8.1.jar。
Sentinel wiki文档
启动Sentinel控制台
$ java -jar sentinel-dashboard-1.8.1.jar
访问Sentinel控制台
localhost:8080
即可看到控制台页面,默认的账户和密码都是sentinel
如果要修改Sentinel的默认端口、账户、密码,可以通过下列配置:
配置项 默认值 说明 server.port 8080 服务端口 sentinel.dashboard.auth.username sentinel 默认用户名 sentinel.dashboard.auth.password sentinel 默认密码
eg:java -jar sentinel-dashboard-1.8.1.jar -Dserver.port=8090
- 微服务整合Sentinel
我们在order-service中整合Sentinel,并且连接Sentinel的控制台,步骤如下:
1.引入sentinel依赖:
<!--引入sentinel依赖-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>2.配置控制台地址:
spring:cloud:sentinel:transport:dashboard: localhost:8080 # sentinel控制台地址3.访问微服务的任意端点,触发sentinel监控
② 限流规则
- 快速入门
簇点链路
簇点链路:就是项目内的调用链路,链路中被监控的每个接口就是一个资源。默认情况下sentinel会监控SpringMVC的每一个端点(Endpoint),因此SpringMVC的每一个端点(Endpoint)就是调用链路中的一个资源。
流控、熔断等都是针对簇点链路中的资源来设置的,因此我们可以点击对应资源后面的按钮来设置规则:
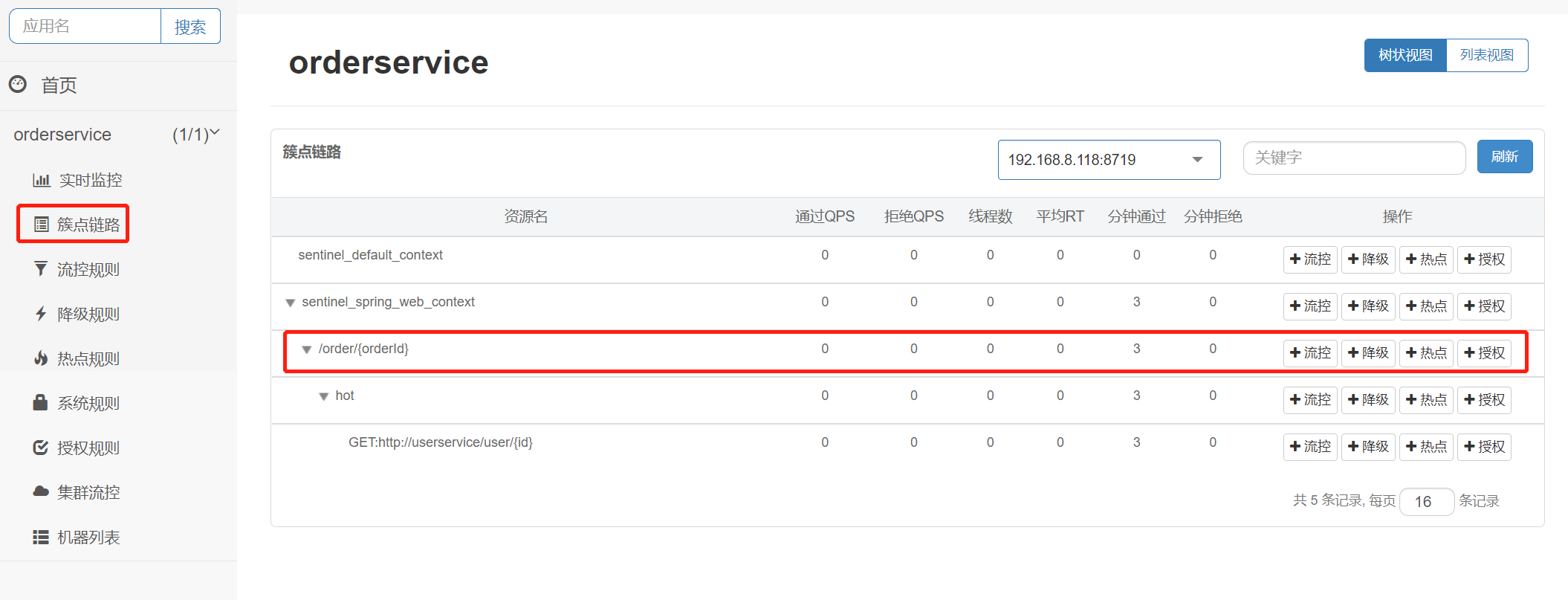
点击资源/order/{orderId}后面的[流控按钮],就可以弹出表单。表单中可以添加流控规则,如下图所示:
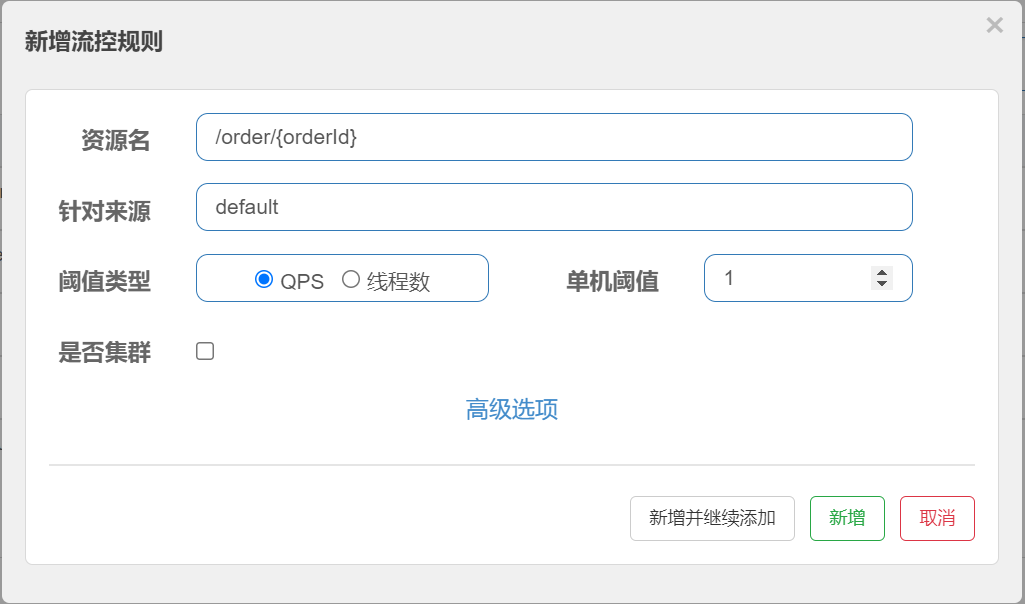
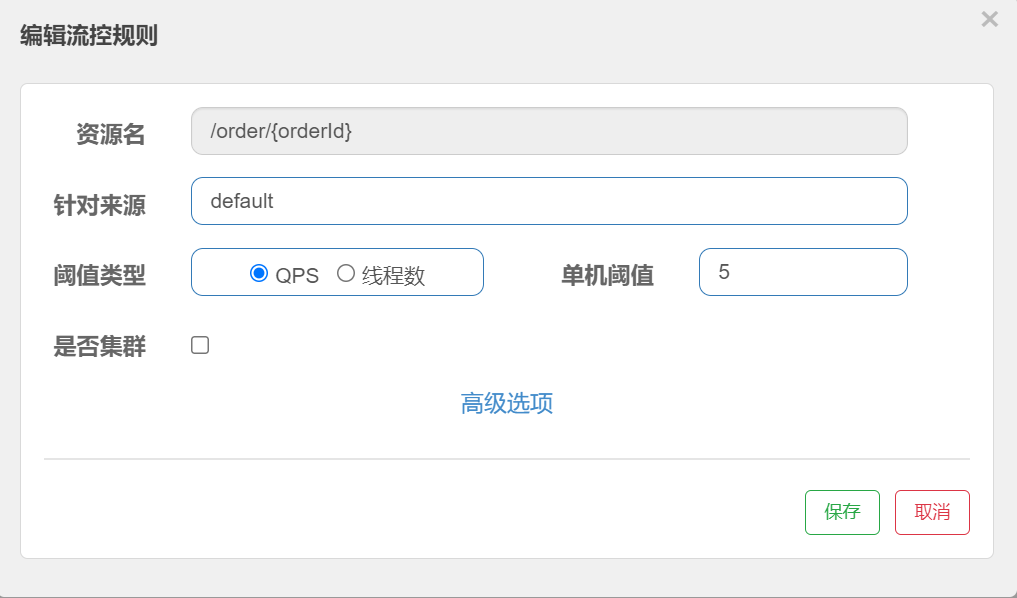
其含义是限制 /order/{orderId}这个资源的单机QPS为1,即每秒只允许1次请求,超出的请求会被拦截并报错。
案例-流控规则入门案例
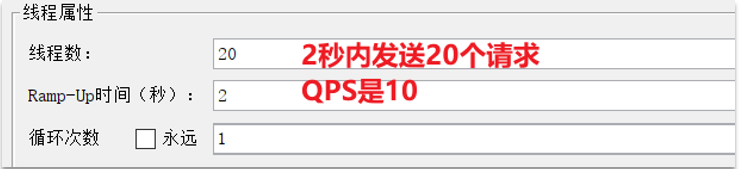
需求:给 /order/{orderId}这个资源设置流控规则,QPS不能超过 5。然后利用jemeter测试。
1.设置流控规则:

2.jemeter测试:
- 流控模式之关联模式
在添加限流规则时,点击高级选项,可以选择三种流控模式:
1.直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
2.关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
3.链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
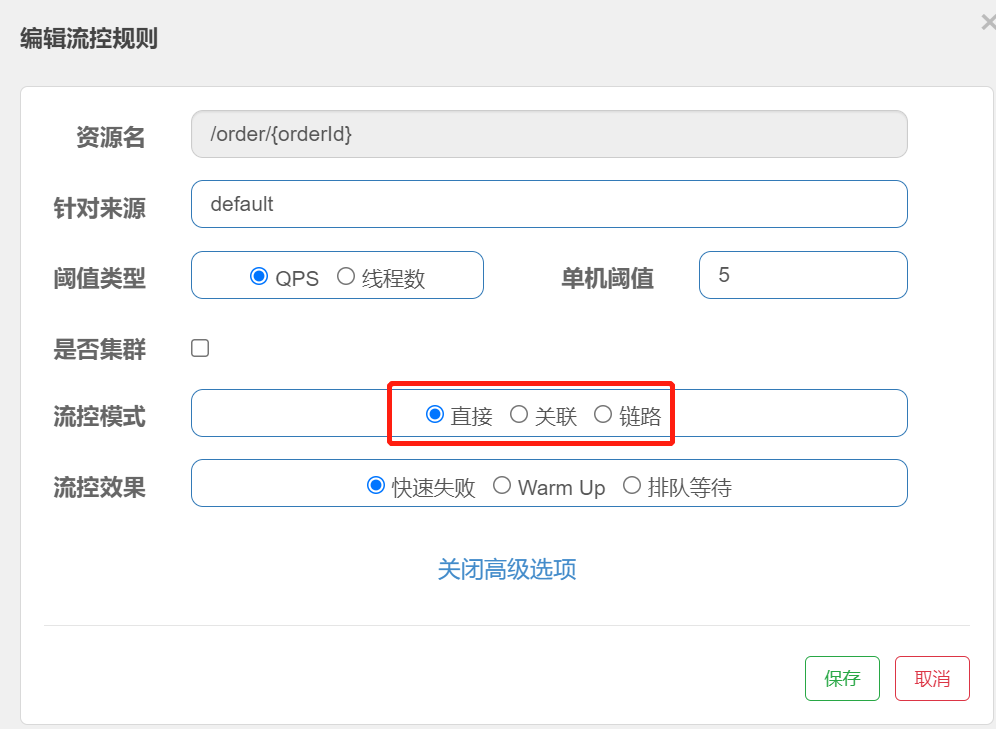
流控模式-关联
关联模式:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
使用场景:比如用户支付时需要修改订单状态,同时用户要查询订单。查询和修改操作会争抢数据库锁,产生竞争。业务需求是有限支付和更新订单的业务,因此当修改订单业务触发阈值时,需要对查询订单业务限流。
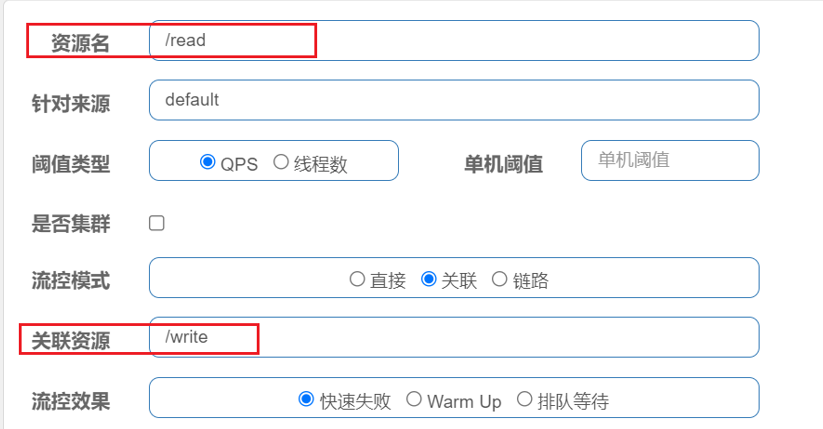
/read和/write产生关联,将来会统计关联资源/write,当/write QPS达到触发阈值时,对/read进行限流。
当/write资源访问量触发阈值时,就会对/read资源限流,避免影响/write资源。
案例:流控模式-关联
需求:在OrderController新建两个端点:/order/query和/order/update,无需实现业务;
配置流控规则,当/order/update资源被访问的QPS超过5时,对/order/query请求限流;
限流生效时,/order/update 正常访问,/order/query 触发限流提示。
注意:给谁限流,就给谁添加流控规则
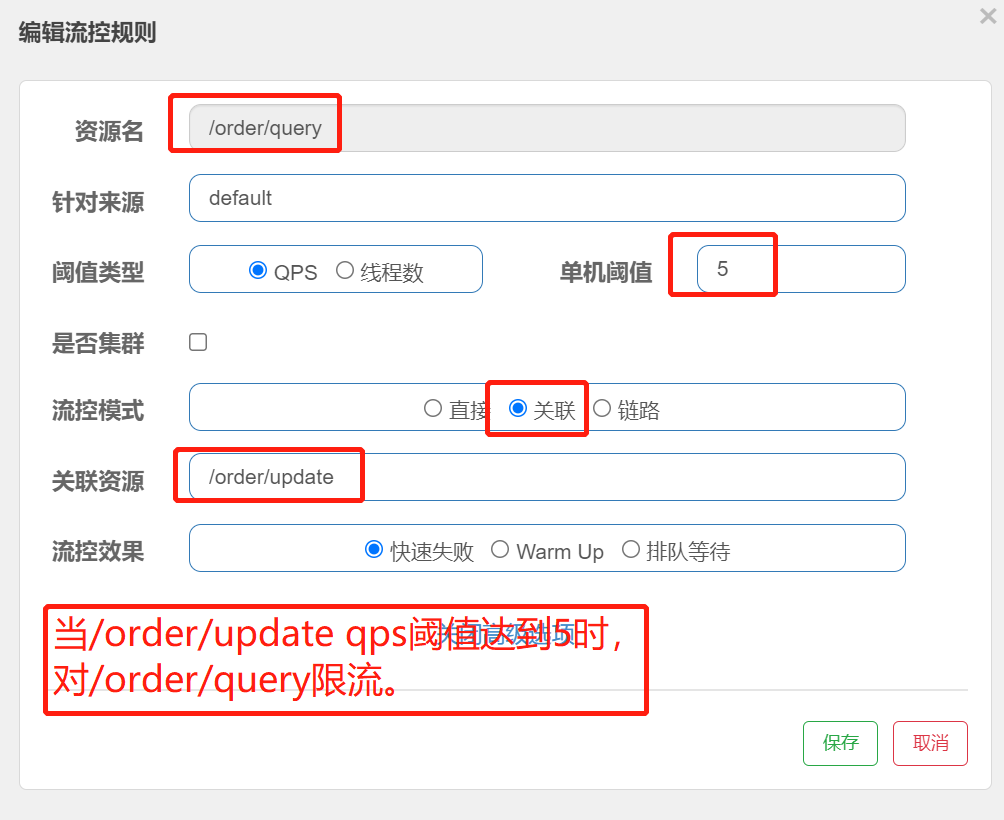
访问/order/query、/order/update资源 http://localhost:8088/order/query ##触发关联限流 http://localhost:8088/order/update ##不会触发关联限流
总结
满足下面条件可以使用关联模式:
1.两个有竞争关系的资源
2.一个优先级较高,一个优先级较低
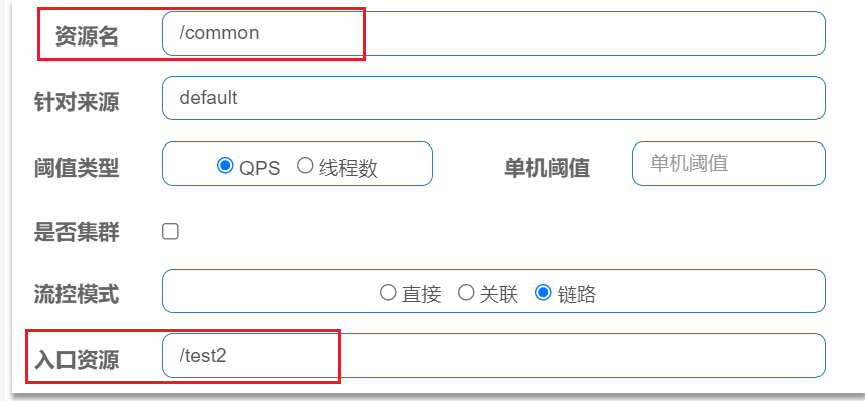
- 流控模式之链路模式
链路模式:只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值。
例如有两条请求链路:
/test1 /common /test2 /common
如果只希望统计从/test2进入到/common的请求,对/test2 进行限流,则可以这样配置:
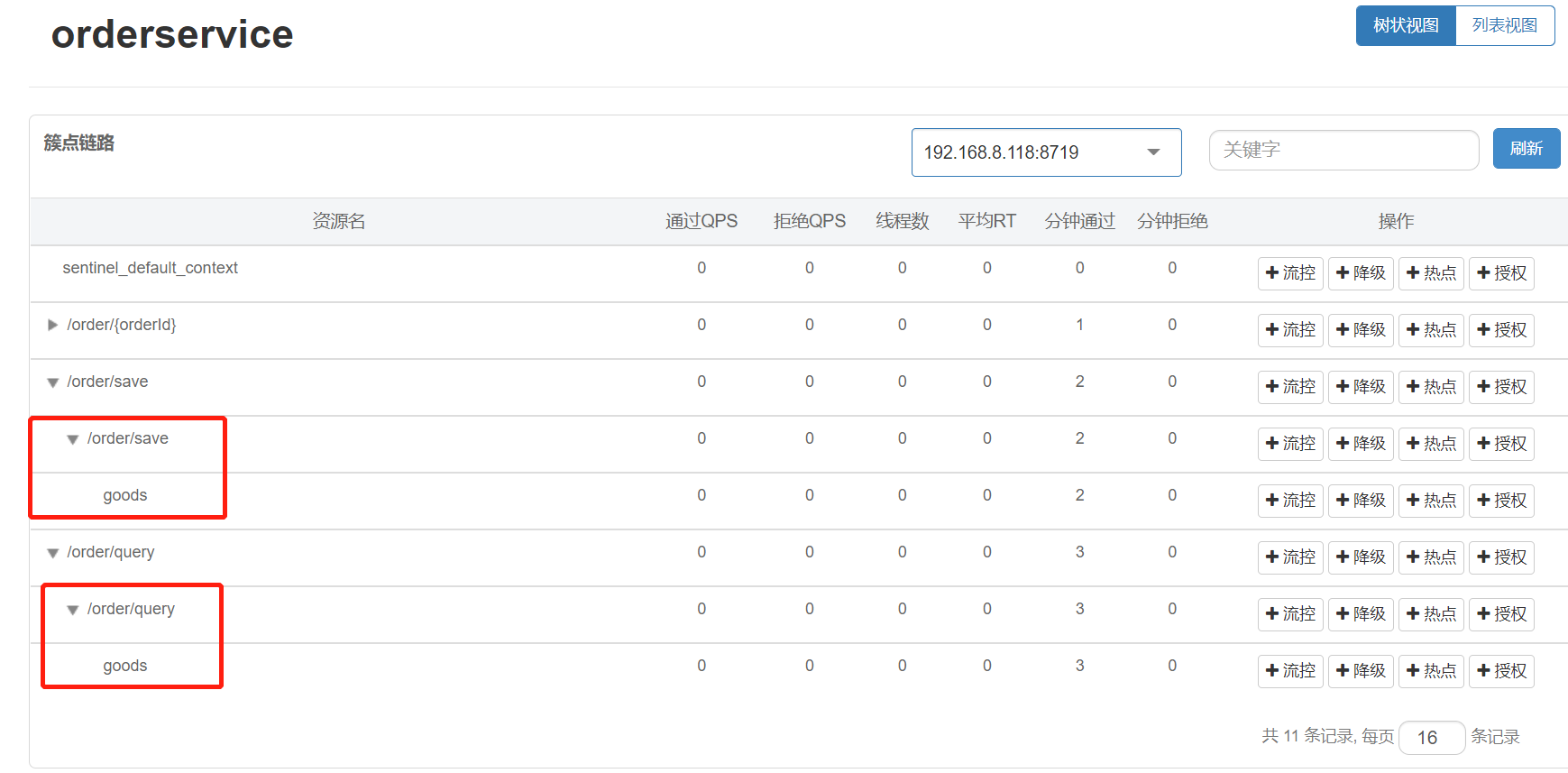
案例:流控模式-链路
需求:有查询订单和创建订单业务,两者都需要查询商品。针对从查询订单进入到查询商品的请求统计,并设置限流。
步骤:
1.在OrderService中添加一个queryGoods方法,不用实现业务
2.在OrderController中,改造/order/query端点,调用OrderService中的queryGoods方法(/order/query -> queryGoods)
3.在OrderController中添加一个/order/save的端点,调用OrderService的queryGoods方法(/order/save -> queryGoods)
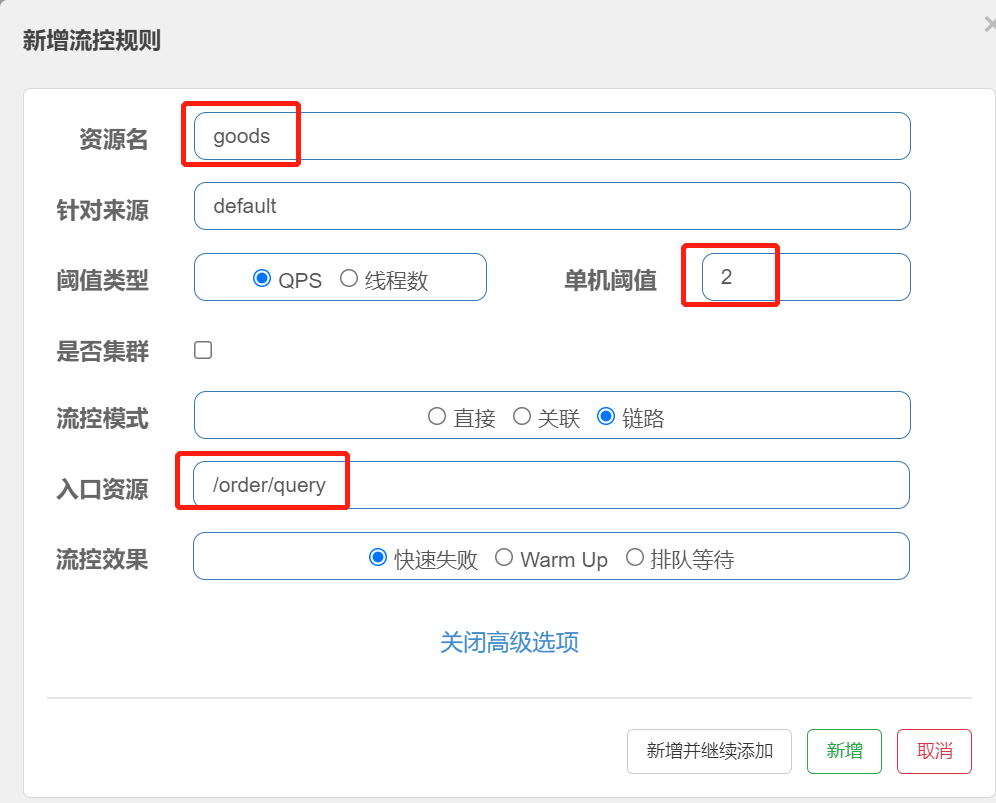
4.给queryGoods设置限流规则,从/order/query进入queryGoods的方法限制QPS必须小于2(设置/order/query qqs<2)
Sentinel默认只标记Controller中的方法为资源,如果要标记其它方法,需要利用@SentinelResource注解,示例:
@SentinelResource("goods")
public void queryGoods(){System.err.println("查询商品");
}Sentinel默认会将Controller方法做context整合,导致链路模式的流控失效,需要修改application.yml,添加配置:
spring:cloud:sentinel:transport:dashboard: localhost:8080 # sentinel控制台地址web-context-unify: false # 关闭context整合访问/order/query、/order/save资源
http://localhost:8088/order/query ##触发链路限流
http://localhost:8088/order/save ##不会触发链路限流
设置限流规则
流控模式有哪些?
1.直接:对当前资源限流
2.关联:高优先级资源触发阈值,对低优先级资源限流。
3.链路:阈值统计时,只统计从指定资源进入当前资源的请求,是对请求来源的限流
- 流控效果
流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
1.快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常。是默认的处理方式。
2.warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常。但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值。
3.排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长
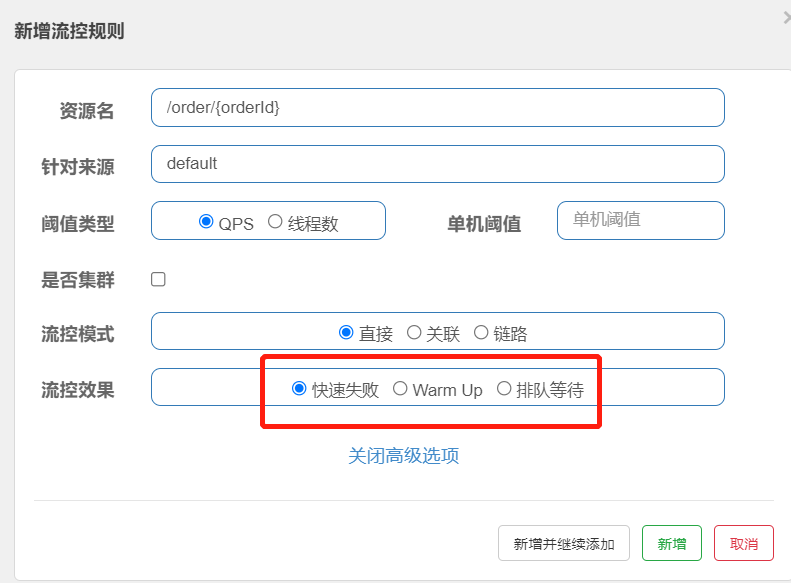
流控效果-warm up(预热模式)
warm up也叫预热模式,是应对服务冷启动的一种方案。请求阈值初始值是 threshold / coldFactor,
持续指定时长后,逐渐提高到threshold值。而coldFactor的默认值是3.
例如,我设置QPS的threshold为10,预热时间为5秒,那么初始阈值就是 10 / 3 ,也就是3,然后在5秒后逐渐增长到10.
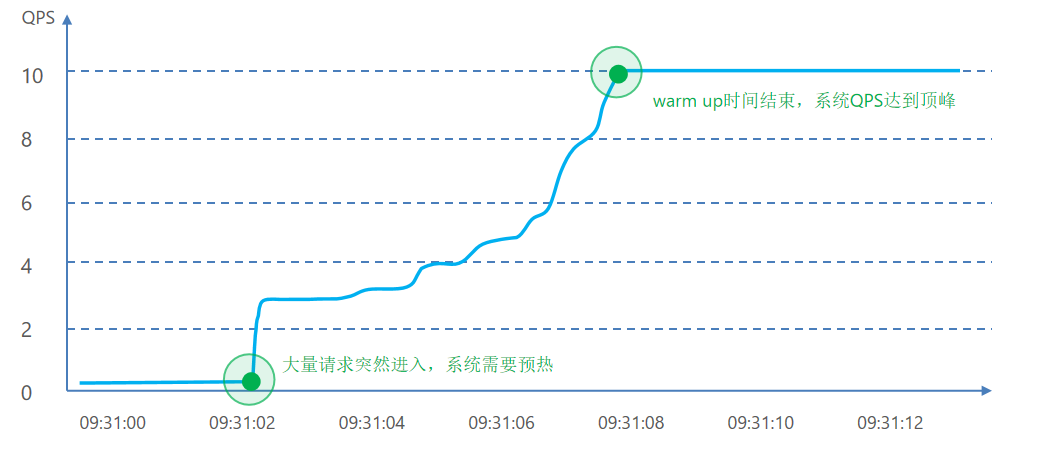
需求:给/order/{orderId}这个资源设置限流,最大QPS为10,利用warm up效果,预热时长为5秒
流控效果-排队等待
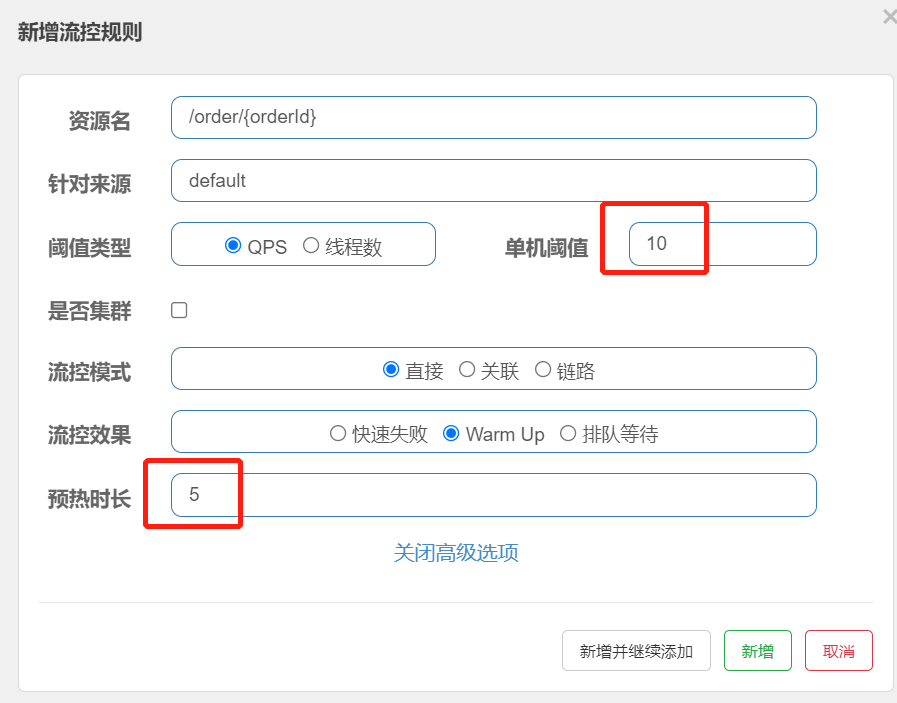
当请求超过QPS阈值时,快速失败和warm up 会拒绝新的请求并抛出异常。
而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。
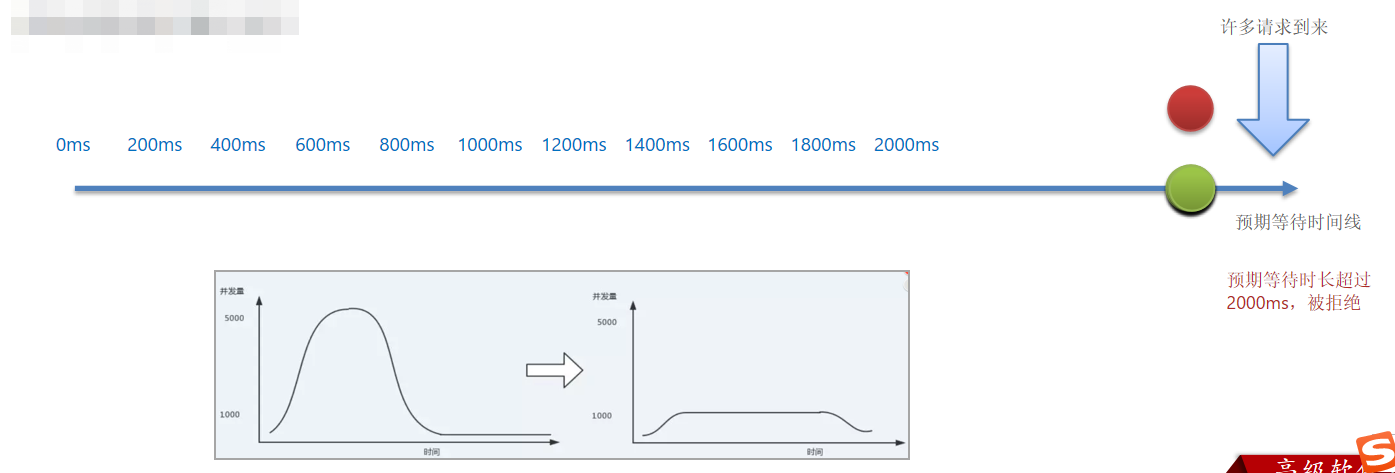
例如:QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待超过2000ms的请求会被拒绝并抛出异常
需求:给/order/{orderId}这个资源设置限流,最大QPS为10,利用排队的流控效果,超时时长设置为5s
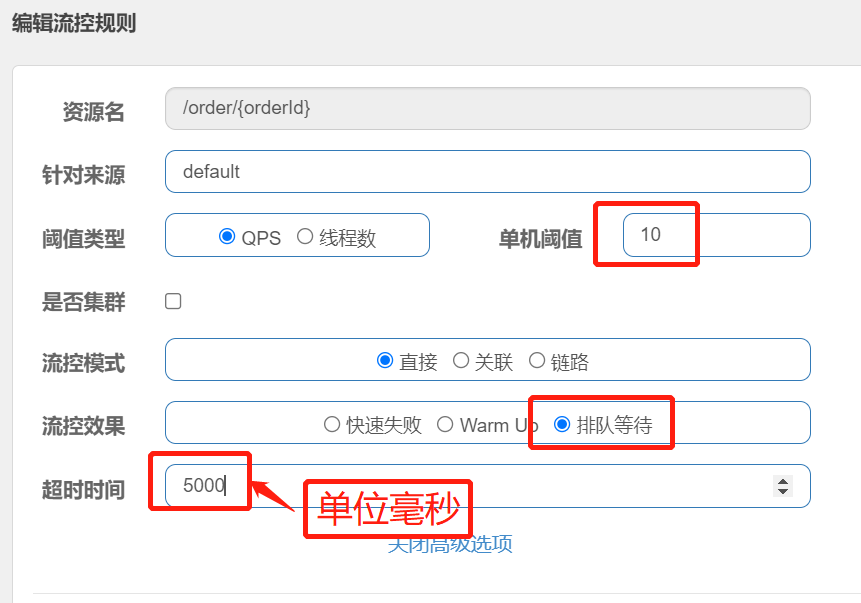
流控效果有哪些?
1.快速失败:QPS超过阈值时,拒绝新的请求
2.warm up: QPS超过阈值时,拒绝新的请求;QPS阈值是逐渐提升的,可以避免冷启动时高并发导致服务宕机。
3.排队等待:请求会进入队列,按照阈值允许的时间间隔依次执行请求;如果请求预期等待时长大于超时时间,直接拒绝
- 热点参数限流
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求(或统计参数值相同的资源),判断是否超过QPS阈值。
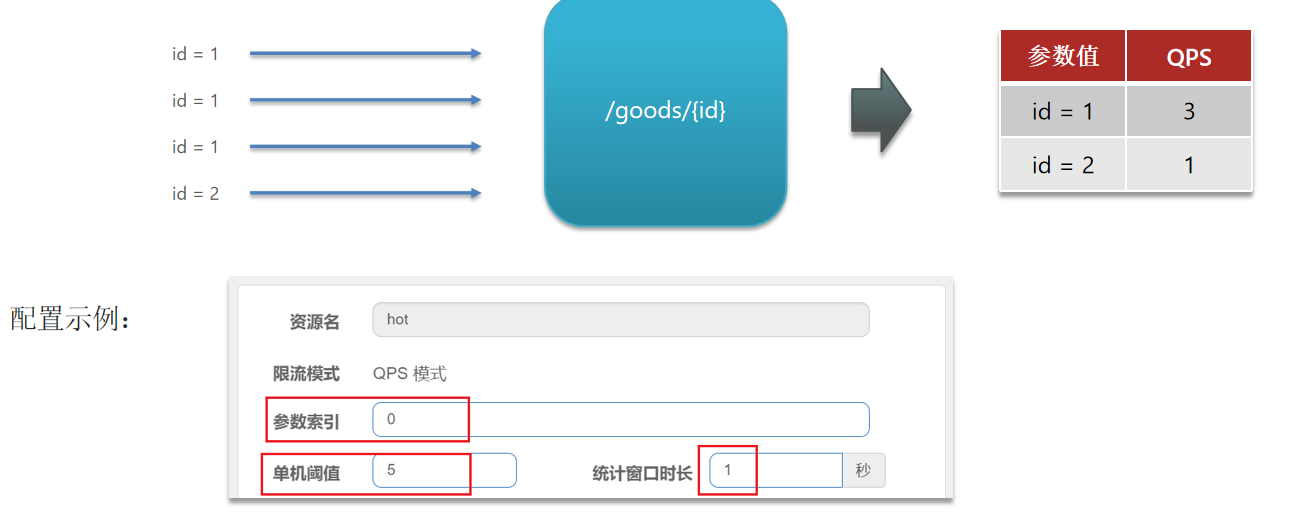
代表的含义是:对hot这个资源的0号参数(第一个参数)做统计,每1秒相同参数值的请求数不能超过5
在热点参数限流的高级选项中,可以对部分参数设置例外配置:
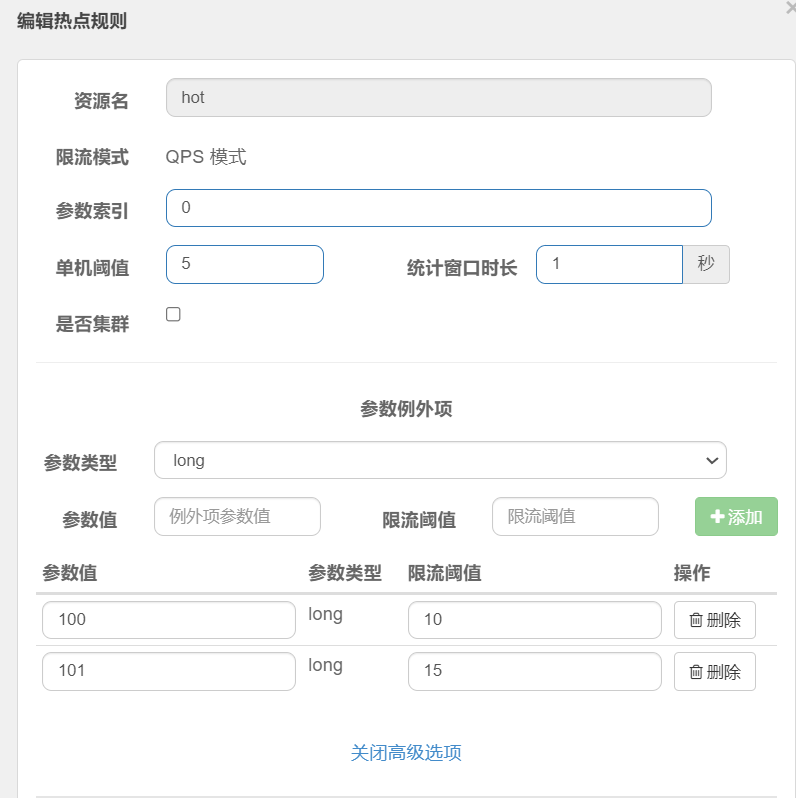
结合上一个配置,这里的含义是对0号的long类型参数限流,每1秒相同参数的QPS不能超过5,有两个例外:
如果参数值是100,则每1秒允许的QPS为10
如果参数值是101,则每1秒允许的QPS为15
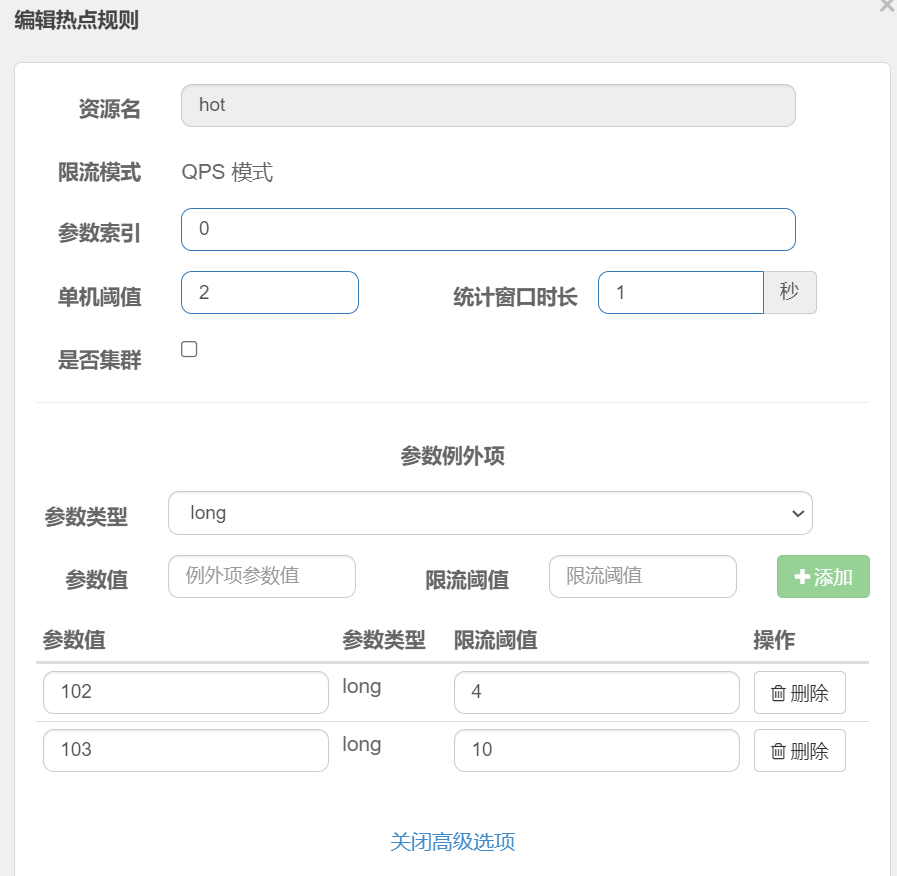
案例:给/order/{orderId}这个资源添加热点参数限流,规则如下:
1.默认的热点参数规则是每1秒请求量不超过2
2.给102这个参数设置例外:每1秒请求量不超过4
3.给103这个参数设置例外:每1秒请求量不超过10
注意:热点参数限流对默认的SpringMVC资源无效,修改代码如下:
@SentinelResource("hot")
@GetMapping("{orderId}")
public Order queryOrderByUserId(@PathVariable("orderId") Long orderId) {// 根据id查询订单并返回return orderService.queryOrderById(orderId);
}
③ 隔离和降级
- Feign整合Sentinel
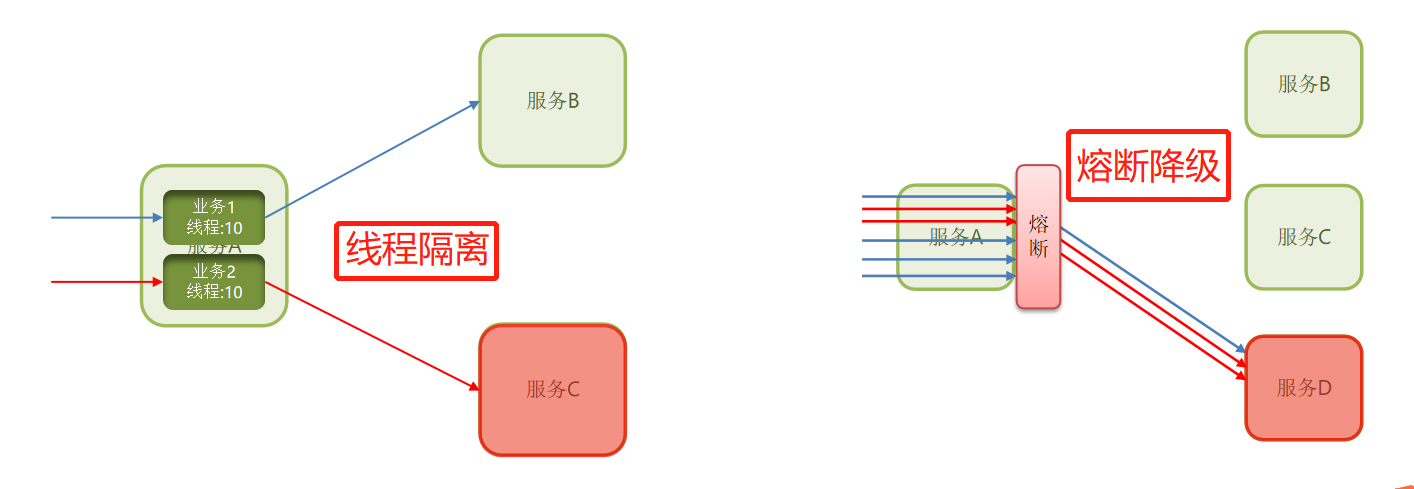
虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。
不管是线程隔离还是熔断降级,都是对客户端(调用方)的保护。
Feign整合Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合Feign和Sentinel。
1.修改OrderService的application.yml文件,开启Feign的Sentinel功能
# 开启feign对sentinel的支持
feign:sentinel:enabled: true
2.给FeignClient编写失败后的降级逻辑
方式一:FallbackClass,无法对远程调用的异常做处理
方式二:FallbackFactory,可以对远程调用的异常做处理,我们选择这种
步骤一:在feing-api项目中定义类,实现FallbackFactory:
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory<UserClient> {@Overridepublic UserClient create(Throwable throwable) {// 创建UserClient接口实现类,实现其中的方法,编写失败降级的处理逻辑return new UserClient() {@Overridepublic User findById(Long id) {// 记录异常信息log.error("查询用户异常", throwable);// 根据业务需求返回默认的数据,这里是空用户return new User();}};}
}步骤二:在feing-api项目中的DefaultFeignConfiguration类中将UserClientFallbackFactory注册为一个Bean:
public class DefaultFeignConfiguration {@Beanpublic UserClientFallbackFactory userClientFallbackFactory(){return new UserClientFallbackFactory();}
}步骤三:在feing-api项目中的UserClient接口中使用UserClientFallbackFactory:
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {@GetMapping("/user/{id}")User findById(@PathVariable("id") Long id);
}总结
Sentinel支持的雪崩解决方案:
线程隔离(仓壁模式)
降级熔断
- 线程隔离(信号量隔离)
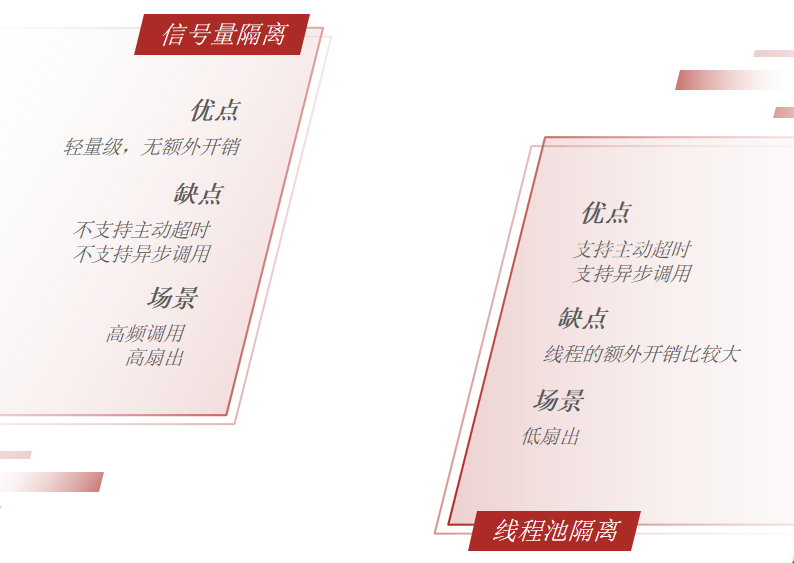
线程隔离有两种方式实现:
1.线程池隔离
2.信号量隔离(Sentinel默认采用)
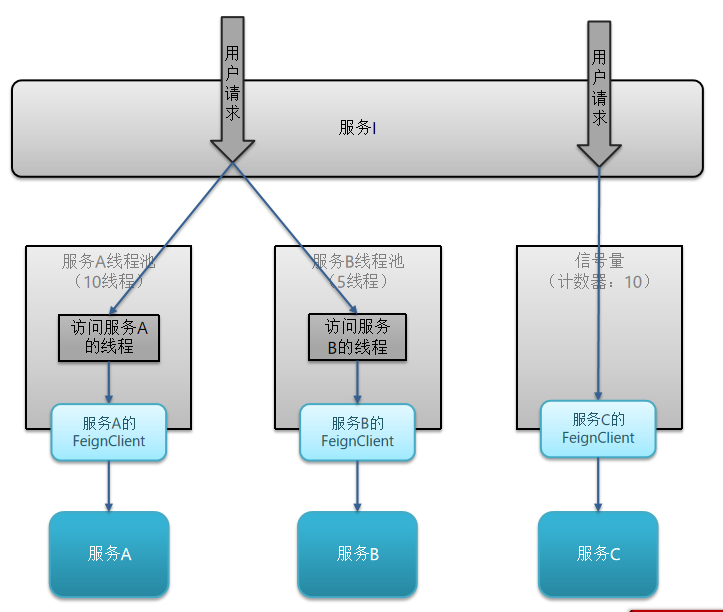
线程池隔离和信号量隔离优缺点
在添加限流规则时,可以选择两种阈值类型:
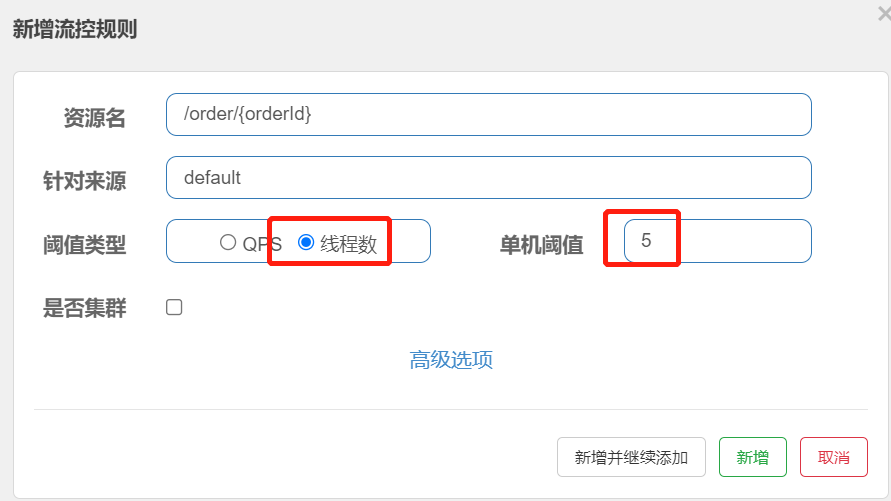
QPS:就是每秒的请求数,在快速入门中已经演示过
线程数:是该资源能使用的tomcat线程数的最大值。也就是通过限制线程数量,实现舱壁模式。
总结
线程隔离的两种手段是?
信号量隔离
线程池隔离
信号量隔离的特点是?
基于计数器模式,简单,开销小
线程池隔离的特点是?
基于线程池模式,有额外开销,但隔离控制更强
- 熔断降级原理
断路器的三个状态
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例、异常数,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
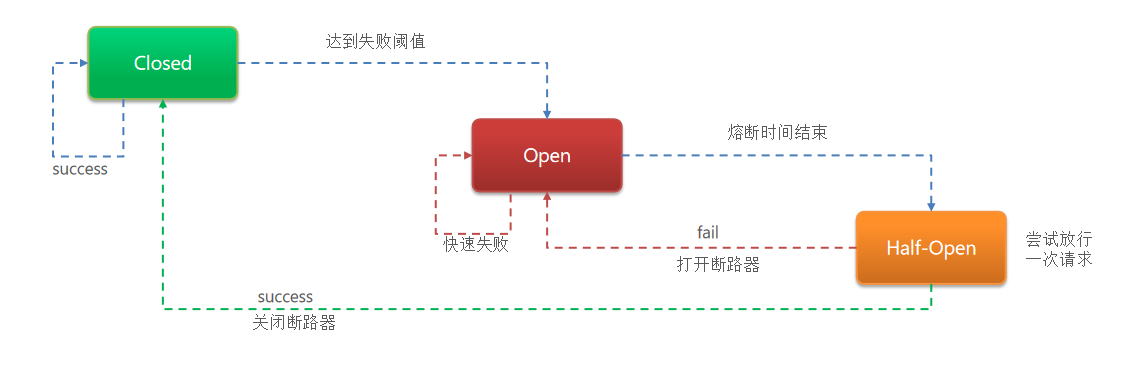
断路器很好理解,当Hystrix Command请求后端服务失败数量超过一定比例(默认50%),断路器会切换到开路状态(Open)。这时所有请求会直接失败而不会发送到后端服务。 断路器保持在开路状态一段时间后(默认5秒),自动切换到半开路状态(HALF-OPEN)。这时会判断下一次请求的返回情况, 如果请求成功,断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN)。
Hystrix的断路器就像我们家庭电路中的保险丝,一旦后端服务不可用,断路器会直接切断请求链,避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力。
- 熔断策略
断路器熔断策略有三种:慢调用、异常比例、异常数
1.慢调用
业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。例如:
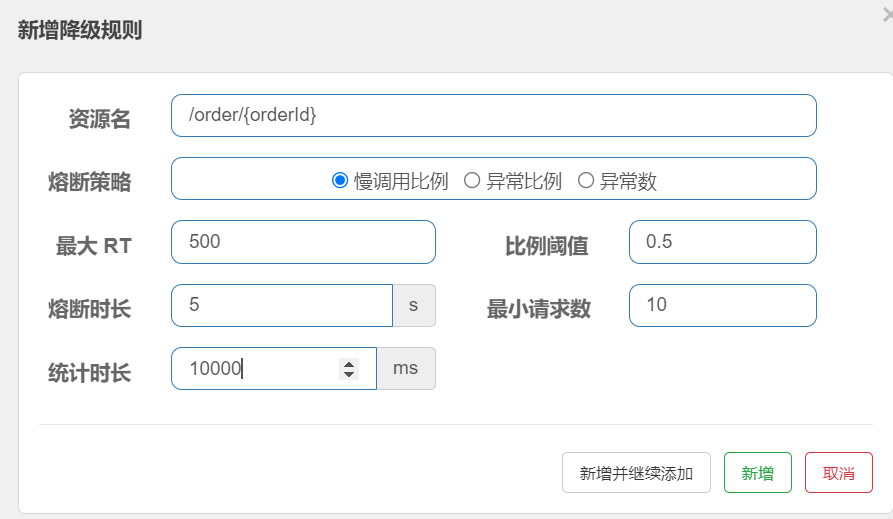
解读:RT超过500ms的调用是慢调用,统计最近10000ms内的请求,如果请求量超过10次,并且慢调用比例>=0.5,则触发熔断,熔断时长为5秒。然后进入half-open状态(半开路状态),放行一次请求做测试。
需求:给 UserClient的查询用户接口设置降级规则,慢调用的RT阈值为50ms,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5
提示:为了触发慢调用规则,我们需要修改UserService中的业务,增加业务耗时:
/*** 路径: /user/110** @param id 用户id* @return 用户*/@GetMapping("/{id}")public User queryById(@PathVariable("id") Long id,@RequestHeader(value = "Truth", required = false) String truth) throws InterruptedException {log.info(String.format("userId=%s", id));if (id == 1) {// 休眠,触发熔断Thread.sleep(60);} else if (id == 2) {throw new RuntimeException("故意出错,触发熔断");}return userService.queryById(id);}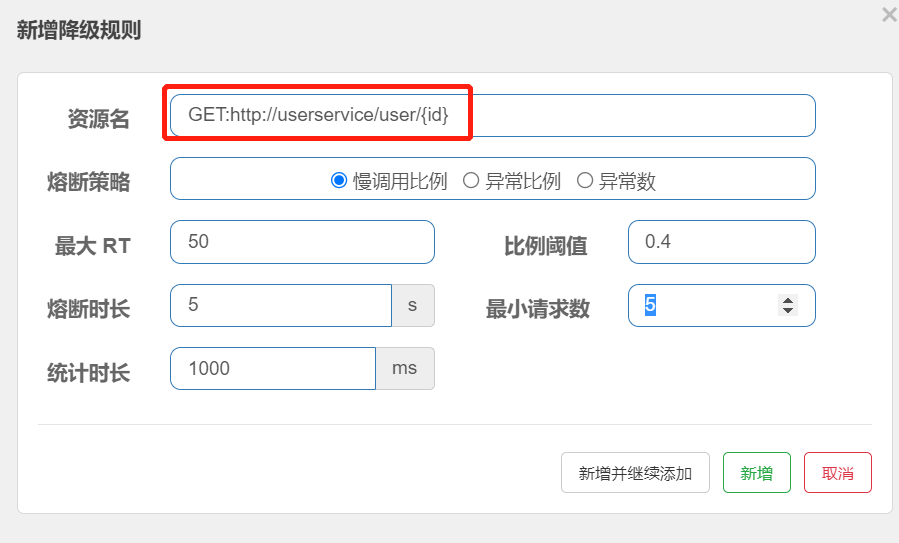
2.熔断策略-异常比例、异常数
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。例如:
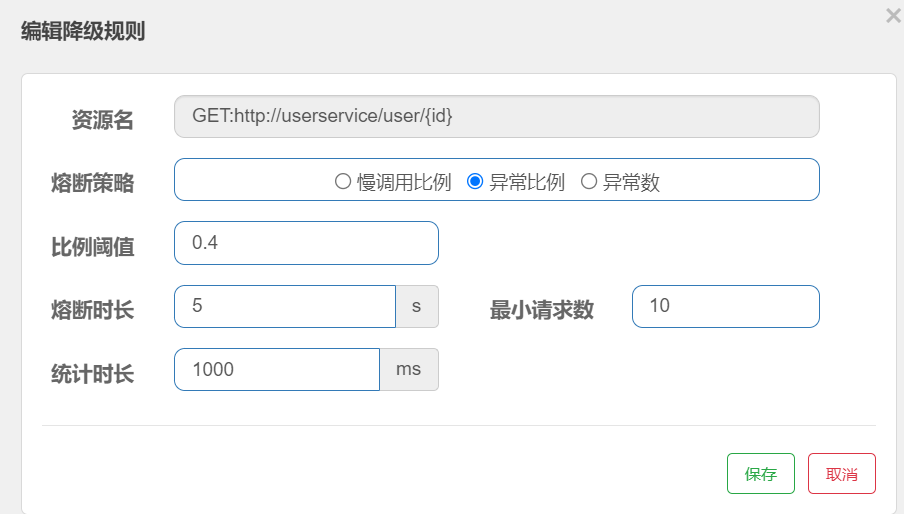
解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于0.4,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
总结
Sentinel熔断降级的策略有哪些?
1.慢调用比例:超过指定时长的调用为慢调用,统计单位时长内慢调用的比例,超过阈值则熔断
2.异常比例:统计单位时长内异常调用的比例,超过阈值则熔断
3.异常数:统计单位时长内异常调用的次数,超过阈值则熔断
④ 授权规则
- 实现网关授权
授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式。
1.白名单:来源(origin)在白名单内的调用者允许访问
2.黑名单:来源(origin)在黑名单内的调用者不允许访问
例如,我们限定只允许从网关来的请求访问order-service,那么流控应用中就填写网关的名称
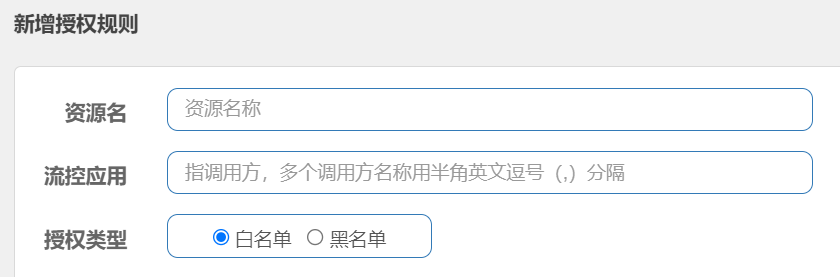
Sentinel是通过RequestOriginParser这个接口的parseOrigin来获取请求的来源的。
public interface RequestOriginParser {/** * 从请求request对象中获取origin,获取方式自定义*/String parseOrigin(HttpServletRequest request);
}
例如,在order-service服务中我们尝试从request中获取一个名为origin的请求头,作为origin的值:
@Component
public class HeaderOriginParser implements RequestOriginParser {@Overridepublic String parseOrigin(HttpServletRequest request) {// 1.获取请求头String origin = request.getHeader("origin");// 2.非空判断if (StringUtils.isEmpty(origin)) {origin = "blank";}return origin;}
}我们还需要在gateway服务中,利用网关的过滤器添加名为gateway的origin头:
spring:application:name: gatewaycloud:gateway:default-filters:- AddRequestHeader=Truth,Itcast is freaking awesome!- AddRequestHeader=origin,gateway给/order/{orderId} 配置授权规则:
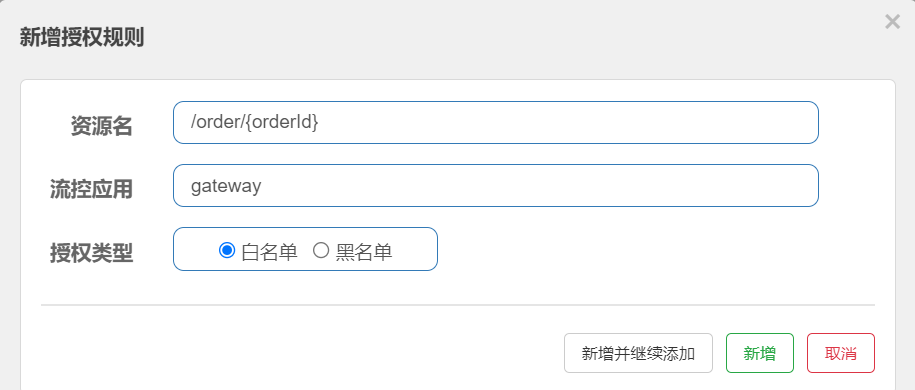
效果实例
http://localhost:8088/order/103 ##服务直接访问拒绝
{"msg": 没有权限访问, "status": 401}http://localhost:10010/order/103 ##网关访问直接通过
{"id":103,"price":43900,"name":"骆驼(CAMEL)休闲运动鞋女","num":1,"userId":3,"user":{"id":null,"username":null,"address":null}}- 自定义异常结果
默认情况下,发生限流、降级、授权拦截时,都会抛出异常到调用方。如果要自定义异常时的返回结果,需要实现BlockExceptionHandler接口:
public class SentinelExceptionHandler implements BlockExceptionHandler {/** * 处理请求被限流、降级、授权拦截时抛出的异常:BlockException*/public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception;
}而BlockException包含很多个子类,分别对应不同的场景:
异常 说明
FlowException 限流异常
ParamFlowException 热点参数限流的异常
DegradeException 降级异常
AuthorityException 授权规则异常
SystemBlockException 系统规则异常自定义异常结果
我们在order-service中定义类,实现BlockExceptionHandler接口:
@Component
public class SentinelExceptionHandler implements BlockExceptionHandler {@Overridepublic void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {String msg = "未知异常";int status = 429;if (e instanceof FlowException) {msg = "请求被限流了";} else if (e instanceof ParamFlowException) {msg = "请求被热点参数限流";} else if (e instanceof DegradeException) {msg = "请求被降级了";} else if (e instanceof AuthorityException) {msg = "没有权限访问";status = 401;}response.setContentType("application/json;charset=utf-8");response.setStatus(status);response.getWriter().println("{\"msg\": " + msg + ", \"status\": " + status + "}");}
}总结
获取请求来源的接口是什么?
RequestOriginParser
处理BlockException的接口是什么?
BlockExceptionHandler
⑤ 规则持久化
- 规则管理三种模式
Sentinel的控制台规则管理有三种模式:

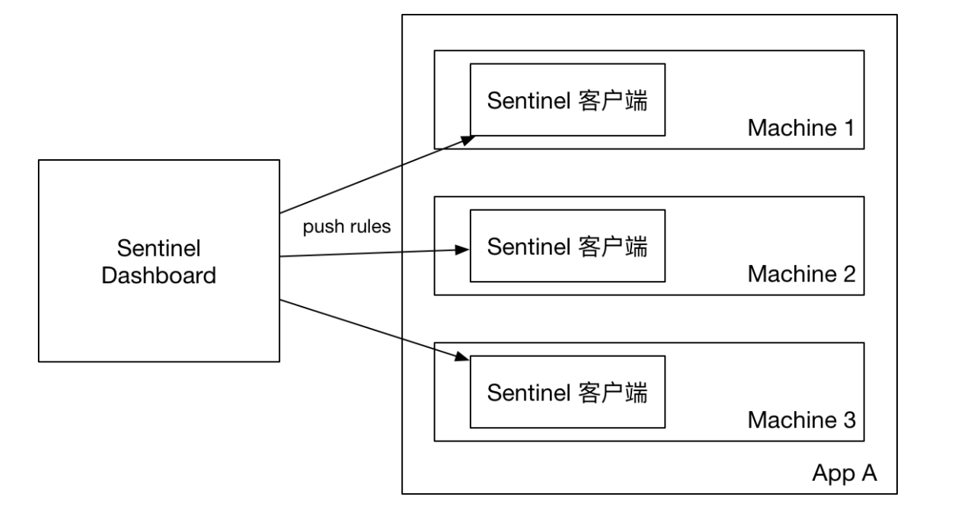
原始模式
控制台配置的规则直接推送到Sentinel客户端,也就是我们的应用。然后保存在内存中,服务重启则丢失
pull模式
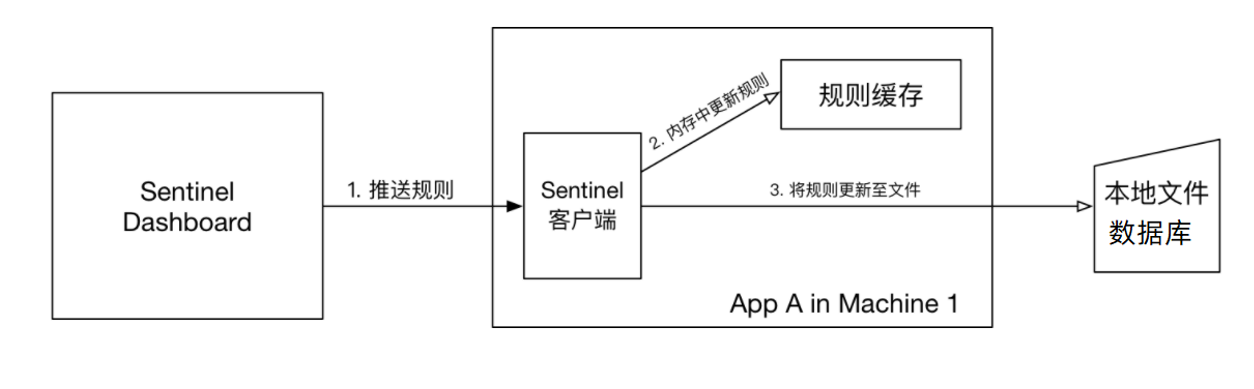
控制台将配置的规则推送到Sentinel客户端,而客户端会将配置规则保存在本地文件或数据库中。以后会定时去本地文件或数据库中查询,更新本地规则。
push模式(推荐)
控制台将配置规则推送到远程配置中心,例如Nacos。Sentinel客户端监听Nacos,获取配置变更的推送消息,完成本地配置更新。
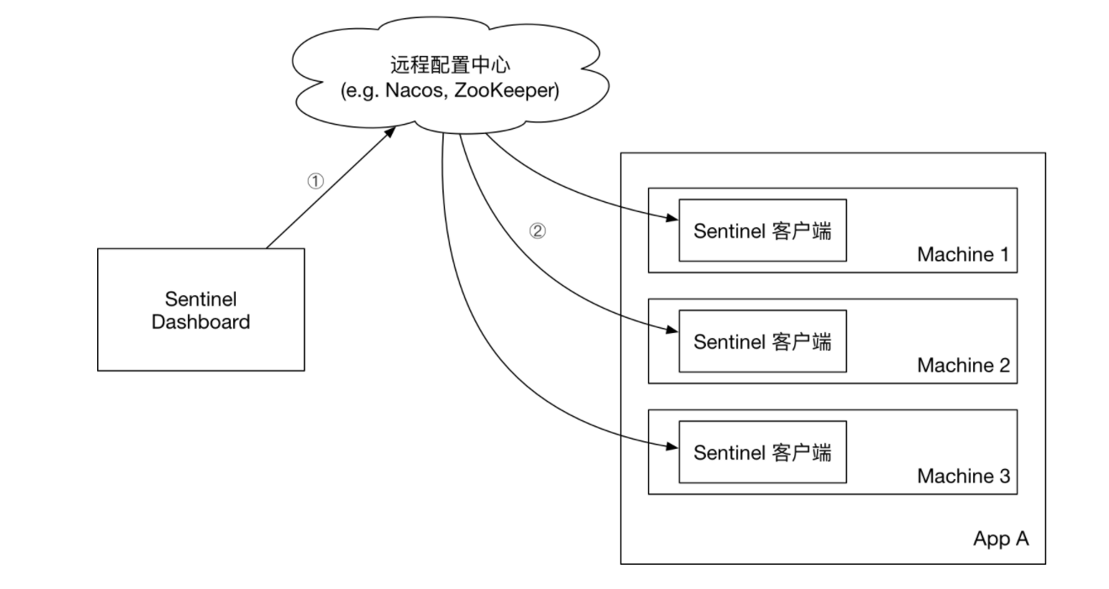
Sentinel的三种配置管理模式是什么?
1.原始模式:保存在内存
2.pull模式:保存在本地文件或数据库,定时去读取
3.push模式:保存在nacos,监听变更实时更新(推荐)
- 实现push模式持久化
TODO 比较复杂
7. 分布式事务
参考:分布式事务
8. 链路追踪 / 9. 服务监控
参考:系统监控技术-硬件指标/链路追踪
10. OAuth2授权模式
https://blog.csdn.net/jokemqc/article/details/136702710
nacos 1.8.6 持久化版没有
https://www.zhihu.com/question/500080763/answer/95269796659
https://www.cnblogs.com/linjiqin/category/368566.html
线程隔离(网关)-信号量隔离/线程池隔离 RAG MCP
TODO1-nacos待完善-https://www.cnblogs.com/linjiqin/category/1967066.html?page=3
TODO2-gateway待完善-https://www.cnblogs.com/linjiqin/category/1967066.html?page=2
https://www.cnblogs.com/linjiqin/p/archive/2021/10
https://www.cnblogs.com/bandaoyu/p/16752378.html