机器学习面试题:请介绍一下你理解的集成学习算法

集成学习(Ensemble Learning)的核心思想是“集思广益”,它通过构建并结合多个基学习器(Base Learner)来完成学习任务,从而获得比单一学习器更显著优越的泛化性能。俗话说,“三个臭皮匠,顶个诸葛亮”。
根据基学习器的生成方式,集成学习主要可以分为三大流派:Bagging、Boosting 和 Stacking。
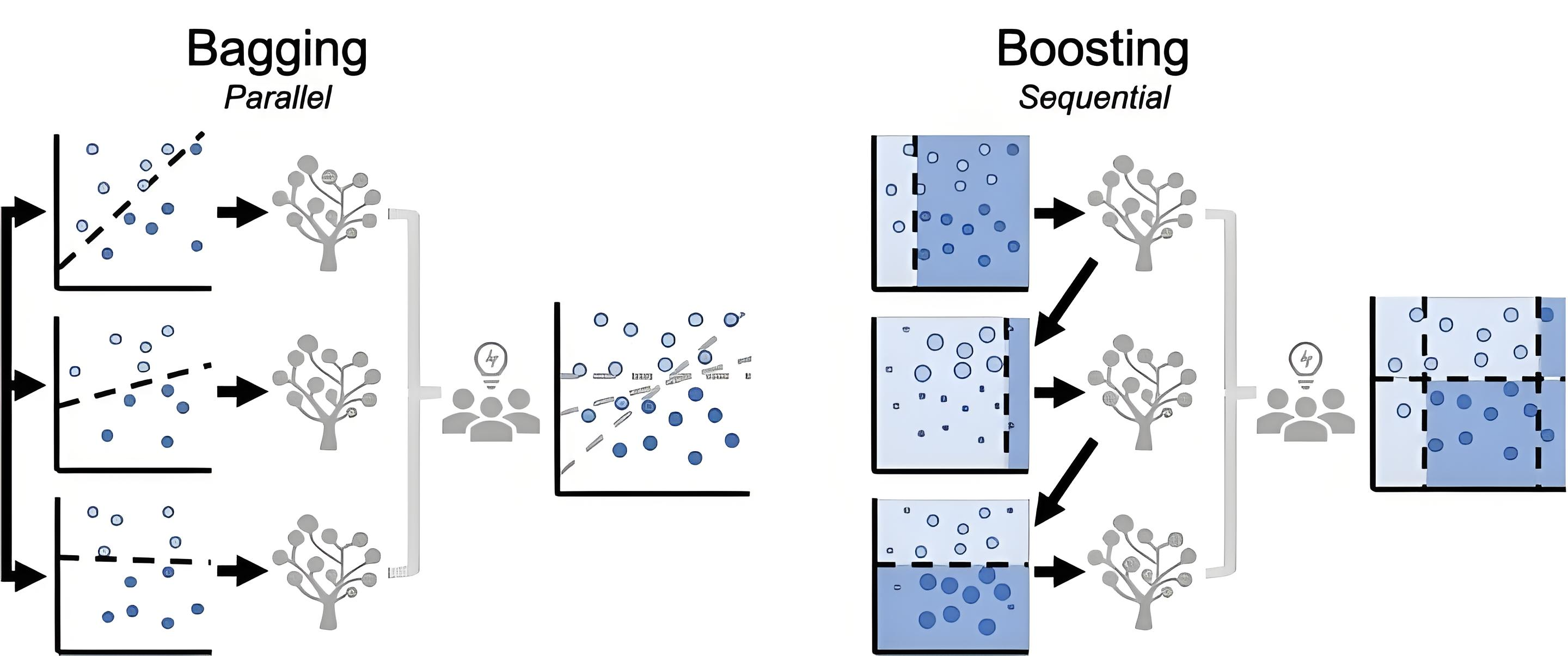
1. Bagging - 并行之道
核心思想: Bootstrap Aggregating 的缩写。
Bootstrap: 通过有放回的随机抽样(自助采样法)从训练集中生成多个不同的子训练集。
Aggregating: 每个子训练集独立地训练一个基学习器(通常是决策树这样的不稳定学习器),最后通过投票(分类)或平均(回归)的方式聚合所有基学习器的预测结果。
核心假设: 通过降低模型的方差(Variance)来提高整体泛化能力。通过平均多个模型,可以平滑掉单个模型因训练数据噪声而带来的过拟合风险。
最著名的算法:随机森林(Random Forest)
随机森林是Bagging的一个扩展变体,它在Bagging的“数据随机性”基础上,增加了“特征随机性”。
工作流程:
从原始数据集中使用Bootstrap采样抽取N个样本子集。
对于每棵决策树的每个节点进行分裂时,不是从所有特征中而是从一个随机选择的特征子集(例如√p个特征,p是总特征数) 中选择最优分裂特征。
优点:
强大的抗过拟合能力: 双重随机性(数据+特征)的引入,使得每棵树都变得不同,降低了模型复杂度。
训练高效,可并行化: 因为每棵树的训练是独立的,可以轻松进行分布式训练。
能处理高维数据: 特征随机子集的选择使其能处理特征数量很大的数据集。
内置特征重要性评估: 通过观察每个特征被用于分裂时带来的不纯度下降的平均值,可以评估特征的重要性。
适用场景: 当您的基模型容易过拟合(高方差)时,Bagging非常有效。随机森林是许多任务的“首选基准模型”,因为它开箱即用,效果通常很好。
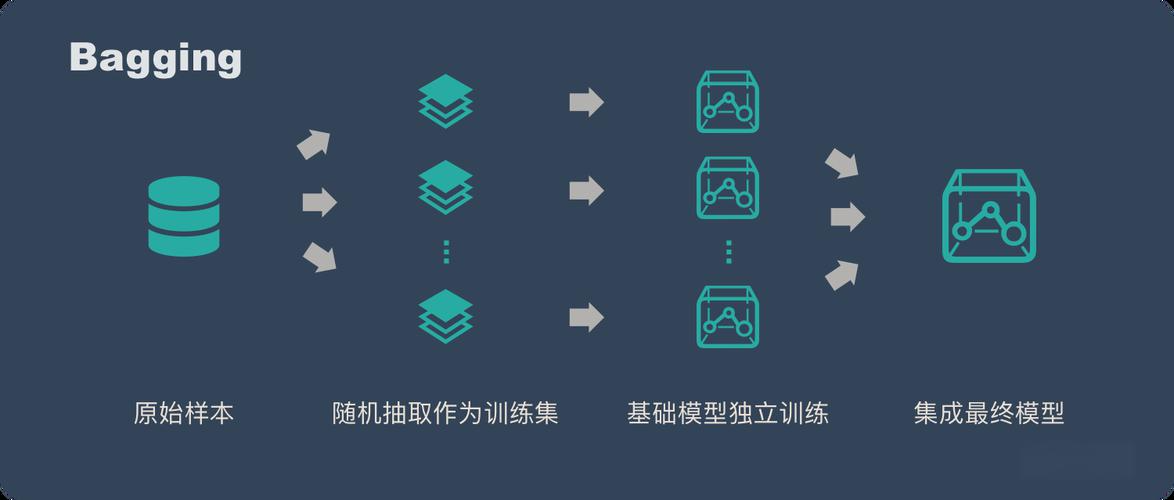
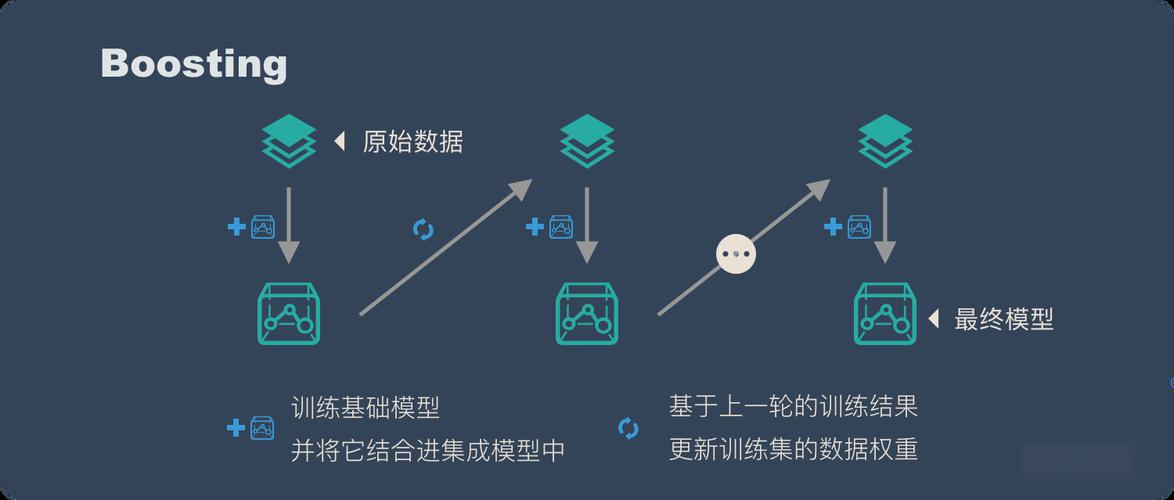
2. Boosting - 串行之道
核心思想: 与Bagging的并行独立训练不同,Boosting的基学习器是顺序生成的。
每一个后续的模型都会更加关注前一个模型预测错误的样本。
通过不断地迭代和修正错误,提升整体模型的性能。它是一个“知错就改”的过程。
核心假设: 通过持续降低模型的偏差(Bias)来提升性能,将多个弱学习器(如浅层决策树)组合成一个强学习器。
著名算法:
AdaBoost (Adaptive Boosting)
工作流程:
第一棵树正常训练。
训练完成后,增加那些被错误预测样本的权重,降低正确预测样本的权重。
用更新权重后的数据训练下一棵树。
重复此过程,最后将所有树的预测结果进行加权投票(准确率越高的树,权重越大)。
直观理解: 让后面的学习器“重点关照”之前犯过的错误。
梯度提升决策树 (Gradient Boosting Decision Tree, GBDT)
工作流程: 这是Boosting思想的一种更通用的实现。它不是通过调整样本权重,而是通过拟合损失函数的负梯度(即残差的近似) 来迭代训练。
第一棵树直接预测目标值。
计算当前所有样本的预测值与真实值之间的残差(对于平方损失函数来说,负梯度就是残差)。
训练下一棵树来拟合这个残差。
将新树的预测结果加到之前的预测上,逐步减小残差。
直观理解: 每一步都在弥补当前模型与真实值之间的差距。
XGBoost, LightGBM, CatBoost
这些都是GBDT的高效、现代化实现,在算法和工程上做了大量优化(正如我们之前讨论的XGBoost)。
它们是目前在Kaggle等数据科学竞赛和工业界中最主流、最强大的集成算法。
适用场景: 当您的基模型表现较弱(高偏差)时,Boosting能显著提升模型精度。它在结构化/表格数据上几乎是无敌的存在。
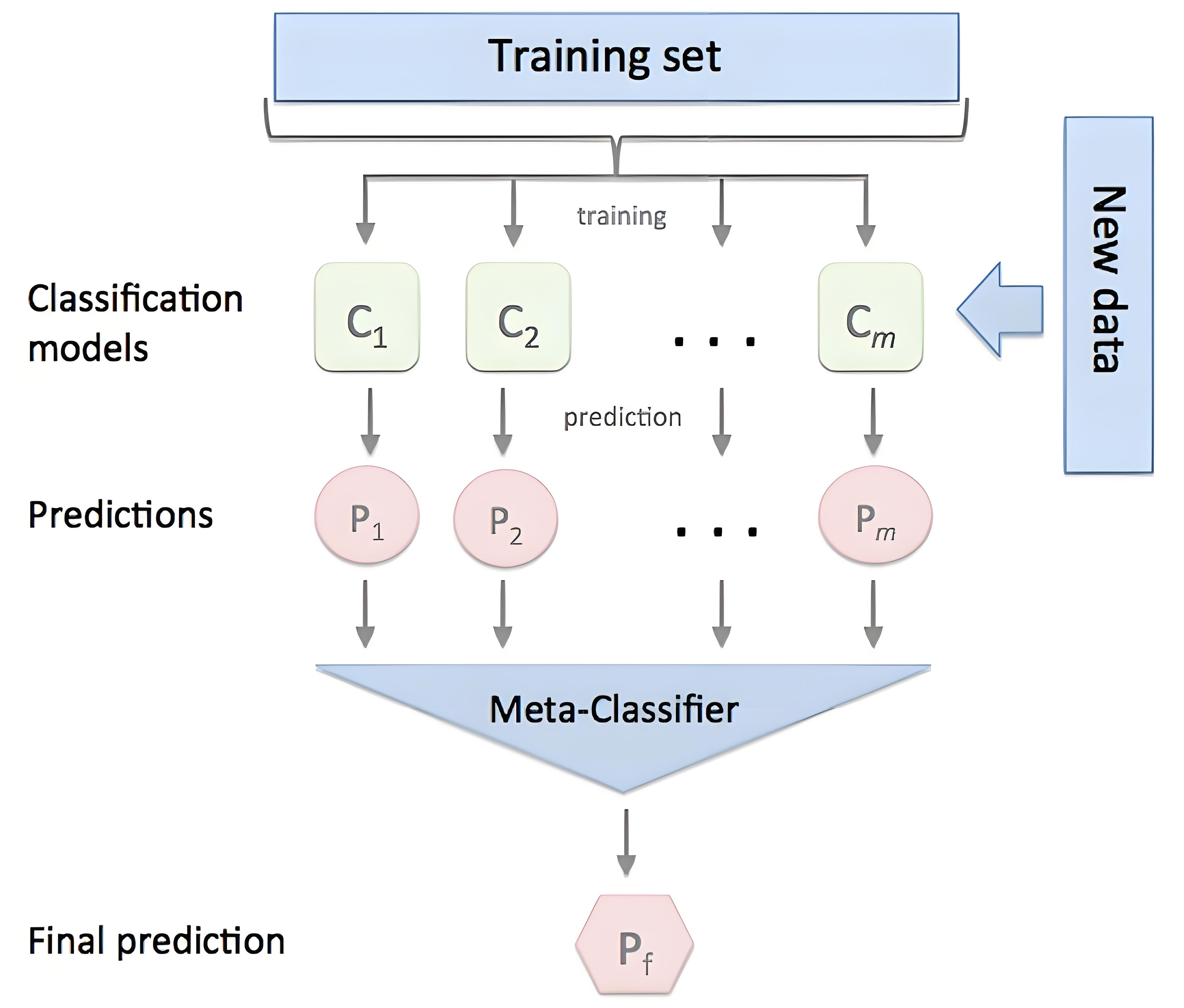
3. Stacking - 模型聚合之道
核心思想: 训练一个元学习器(Meta-Learner),来学习如何最佳地组合多个基学习器(Base-Learner) 的预测结果。
第一层: 用原始训练数据训练多个不同的基模型(例如,一个随机森林、一个XGBoost、一个SVM)。
第二层: 将第一层所有模型的预测输出作为新的特征,并以其真实标签为目标,训练一个新的元模型(通常是线性回归、逻辑回归等简单模型)。
关键要点: 为了防止信息泄露和过拟合,通常使用交叉验证的方式生成第一层模型的预测。例如,使用5折交叉验证,每次用4折训练基模型,预测剩下的1折,这样就能得到整个训练集完整且无偏的OOF(Out-of-Fold)预测,用于训练元模型。
适用场景: 当您想榨干最后一滴性能,不介意复杂的训练流程时。常用于顶级机器学习竞赛中,但在工业界中由于复杂度高,部署维护成本也高,应用相对较少。
总结与对比
| 方法 | 核心思想 | 训练方式 | 核心目标 | 代表算法 |
|---|---|---|---|---|
| Bagging | 自主采样,平等聚合 | 并行 | 降低方差 | 随机森林 |
| Boosting | 关注错误,迭代修正 | 串行 | 降低偏差 | AdaBoost, GBDT, XGBoost |
| Stacking | 模型预测作为新特征,元模型学习组合 | 分层训练 | 提升预测精度 | 各种模型的组合 |
如何选择?
追求简单、高效、稳定: 从随机森林开始。
追求极致的预测精度: 首选梯度提升框架(XGBoost, LightGBM)。
参加竞赛或研究: 可以尝试复杂的Stacking或Blending。
总而言之,集成学习通过巧妙地组合多个模型,有效地突破了单一模型的性能瓶颈,是现代机器学习中不可或缺的强大工具。