V100 部署qwen2.5-vl
使用镜像部署llama.cpp
Docker images: ghcr.io/ggml-org/llama.cpp:server-cuda
https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
下载模型文件:
40地址:/home/migu/cdm/project/deepseek-r1/llm
地址:https://huggingface.co/samgreen/Qwen2.5-VL-32B-Instruct-GGUF/tree/main
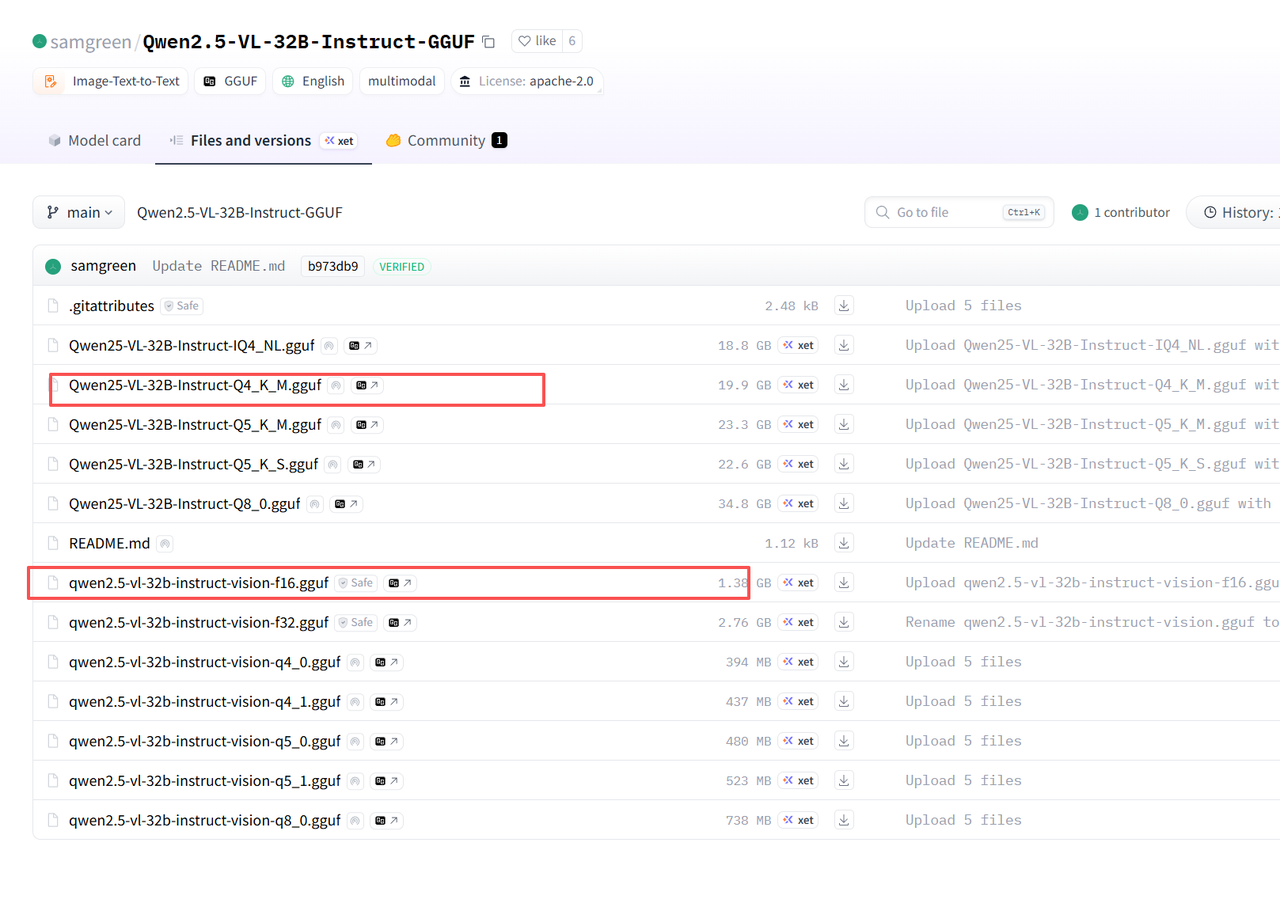
然后进行docker compose 配置:
40地址:/home/migu/cdm/project/deepseek-r1/docker-compose.yml
services:xinference:# 使用指定版本的 GPU 镜像image: ghcr.io/ggml-org/llama.cpp:server-cuda# 容器名称(方便管理)container_name: llama# 重启策略:除非手动停止,否则总是重启restart: unless-stopped# GPU 配置(关键:允许容器访问 NVIDIA 显卡)deploy:resources:reservations:devices:- driver: nvidiacount: all # 使用所有可用 GPU(也可指定数量,如 count: 1)capabilities: [gpu]# 端口映射:本地端口:容器端口(保持与之前一致)ports:- "8002:8000"# 数据卷挂载:持久化存储模型和配置volumes:- ./llm:/llm# 环境变量配置environment:- LOG_LEVEL=INFO # 日志级别# 容器启动命令(与直接运行 Docker 时一致)command: -m /llm/Qwen25-VL-32B-Instruct-Q4_K_M.gguf --alias Qwen2.5-VL-32B-Instruct-awq --mmproj /llm/qwen2.5-vl-32b-instruct-vision-f16.gguf --port 8000 --host 0.0.0.0 -n 5120# docker run -v ./llm:/llm -p 8000:8000 ghcr.io/ggml-org/llama.cpp:server-cuda -m /llm/Qwen25-VL-32B-Instruct-Q4_K_M.gguf --mmproj /llm/qwen2.5-vl-32b-instruct-vision-f16.gguf --port 8000 --host 0.0.0.0 -n 512
启动
| Docker compose up