Mysql杂志(十六)——缓存池
缓存池
我们之前十四篇的时候有说过这个mysql的逻辑结构是什么样子的,其中就有缓存池的部分,今天就来说说这个缓存池都有哪些部件,他在Mysql中又有着什么作用,下面这个图是InnoDB的缓存池组件图了,里面的六大组件我们一个一个来说
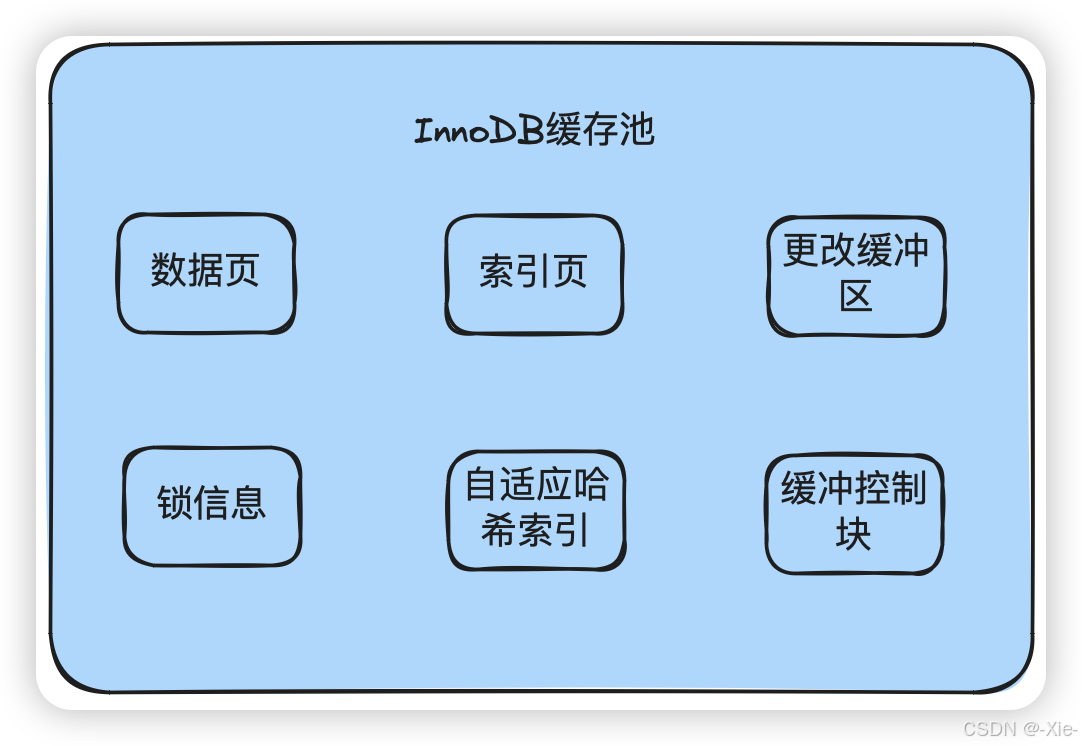
数据页 (Data Pages)
核心功能就是缓存表数据的行记录(Row Data)。这是缓存池最主要、占比最大的部分,所有用户表的行数据都存储在这里。当执行SELECT * FROM table或通过索引访问到具体行时,InnoDB会将整个数据页(通常16KB)从磁盘的.ibd文件加载到缓存池的数据页区域。后续对该页中任何行的读写操作都在内存中进行,速度极快。直接减少了查询所需的数据磁盘I/O,是提升性能最根本的机制。如果缓存池能容纳整个热数据集,性能将得到极大提升。就好像图书馆的书架。书架上放着书籍的实际内容。
索引页 (Index Pages)
核心功能就是缓存索引数据,即B+Tree结构的节点(包括非叶子节点和叶子节点)。当执行带WHERE条件过滤、ORDER BY排序或JOIN操作的查询时,InnoDB会遍历索引树。索引页被缓存后,这些遍历操作完全在内存中进行,无需读盘。加速了数据定位和访问路径。数据库的性能很大程度上取决于索引的效率,而将索引缓存到内存是保证其效率的关键。图书馆的索引卡片柜。卡片柜本身不存储书的内容,但能告诉你书在哪里。
更改缓冲区 (Change Buffer)
缓存对“非唯一”二级索引的插入、更新、删除操作。当要修改一个非唯一索引时(如INSERT一条新记录),如果对应的索引页不在缓存池中,InnoDB不会立即去磁盘加载它。而是将这次修改操作(如“在索引k中插入值v”)缓存到Change Buffer中。未来,当这个索引页因查询等原因被加载到缓存池时,再将Change Buffer中的修改合并(Merge) 到该索引页上。将随机磁盘I/O转换为顺序I/O,极大地提升了涉及二级索引的写操作性能(特别是大批量插入和更新),是InnoDB的一大性能利器。如图书馆的借阅登记处。读者还书时,管理员不会立刻跑回书架归位,而是先放在登记处,等下次去书架区时再一并处理。
自适应哈希索引 (Adaptive Hash Index - AHI)
自动为频繁访问的索引页创建内存中的哈希索引,将B+Tree的O(log n)查找复杂度提升到近乎O(1)。InnoDB监控查询模式,如果发现某个索引页被以相同模式的等值查询(=, IN)频繁访问,则会自动为其在内存中构建一个哈希索引。后续查询直接通过哈希计算定位,无需再走B+Tree的根节点到叶节点的路径。进一步加速了热点数据的等值查询速度。这是一个完全自动、内部优化的功能,用户无法干预。如图书馆员为最热门、最常被询问的书籍制作了一份私人快速查找表,别人问时她不用去查卡片柜,直接就能报出位置。
锁系统 (Lock System)
实现行级锁,管理并发事务间的数据访问冲突,保证事务的隔离性(Isolation)。当一个事务要修改某一行时,会在锁系统中为这一行申请一个锁(如排他锁,X-Lock)。如果其他事务也要修改同一行,则必须等待这个锁被释放。锁信息存储在缓存池相关的内存结构中。是数据库支持高并发、保证数据一致性的基石。没有锁,多个事务同时修改同一数据会导致数据损坏。就好像图书馆研究小间的门锁。一个人在里面看书做笔记(修改数据)时,会把门锁上,其他人只能等待,从而避免干扰。
缓冲控制块 (Control Blocks)
缓存池的“元数据管理系统”或“大脑”。它为缓存池中的每一个数据页/索引页维护一个描述信息(元数据)。控制块并不存储实际数据,而是存储关于页的管理信息,例如:该页属于哪个表空间、哪个页号。该页是“脏页”还是“干净页”。该页的访问历史(用于LRU算法淘汰)。该页是否被加锁。通过Free List、LRU List、Flush List这三种链表,控制块高效地组织和管理着所有缓存页。没有控制块,缓存池就是一盘散沙。它负责调度、淘汰、刷脏,确保有限的内存空间被最高效地利用。就好像图书馆的中央管理系统。系统本身不存放书籍,但它记录着每本书的状态(在架、借出、在哪个书架)、热度(借阅次数),并据此决定采购新书和下架旧书的策略。
列表 | 角色 | 管理的内容 | 生命周期 |
|---|---|---|---|
Free List | 资源分配者 | 所有空闲的页 | 页被使用时离开此列表 |
LRU List | 绩效管理者 | 所有已被使用的页(干净页+脏页) | 页从被加载到被淘汰,一直在此列表 |
Flush List | 质量监督员 | 所有已被使用的脏页 | 页从被修改到被刷盘,在此列表 |
既然说到这三个了那我们就来讲讲呗
Free List(空闲列表)
管理所有未被使用的、空闲的缓存页帧(Frame)。当需要从磁盘加载新数据页到缓存池时会使用到他。工作流程就是首先检查Free List,如果有空闲页,直接从这里分配一个。如果Free List为空,则触发LRU List进行页面淘汰,腾出空闲页。
LRU List(最近最少使用列表)
管理所有已被使用的缓存页(包括干净页和脏页)的访问顺序,并根据访问频率决定淘汰谁。当Free List为空,需要淘汰旧页来加载新页时。会采用改进的Midpoint LRU算法,列表分为:
New Sublist(新生代,5/8):存放最近被访问过的热点数据。
Old Sublist(老生代,3/8):存放新加载的或访问较少的数据。淘汰主要发生在这里的尾部。
工作流程:
1.数据页第一次从磁盘读入时,被插入到Old Sublist的头部。
2.如果这个页在Old Sublist中再次被访问,它才会被提升到New Sublist的头部。
3.随着新页的加入,LRU列表尾部的页(最久未使用)会被淘汰。
4.如果淘汰的页是脏页(被修改过),则会由后台线程刷回磁盘后淘汰。
这种设计的好处:有效预防一次性的全表扫描操作污染整个缓存池。一次性的扫描数据只会停留在Old区并很快被淘汰,而不会冲掉New区的真正热点数据。
这个和JVM的顺序是反过来的,JVM是新生代GC的多,mysql确实老年代回收的多。
Flush List(刷新列表)
专门跟踪和管理所有已被修改但未写入磁盘的缓存页,即脏页(Dirty Page)。当一个页面第一次被修改时,它会被加入Flush List。由后台的Page Cleaner线程定期扫描此列表,将脏页异步刷回磁盘,确保数据持久性。刷盘成功后,该页并不会从缓存池移除,但会从Flush List中移除。
操作过程
下面这个就是主包画的操作图了,很清晰的可以看到Mysql的操作过程,都是先查缓存池的,没有再读磁盘然后写到缓存池,再放回给客户端,增删改也是先改缓存池的,然后要修改的数据缓存池没有,也会先从磁盘读到缓存池再修改,定期或者没有空白列表了才会更新到磁盘。
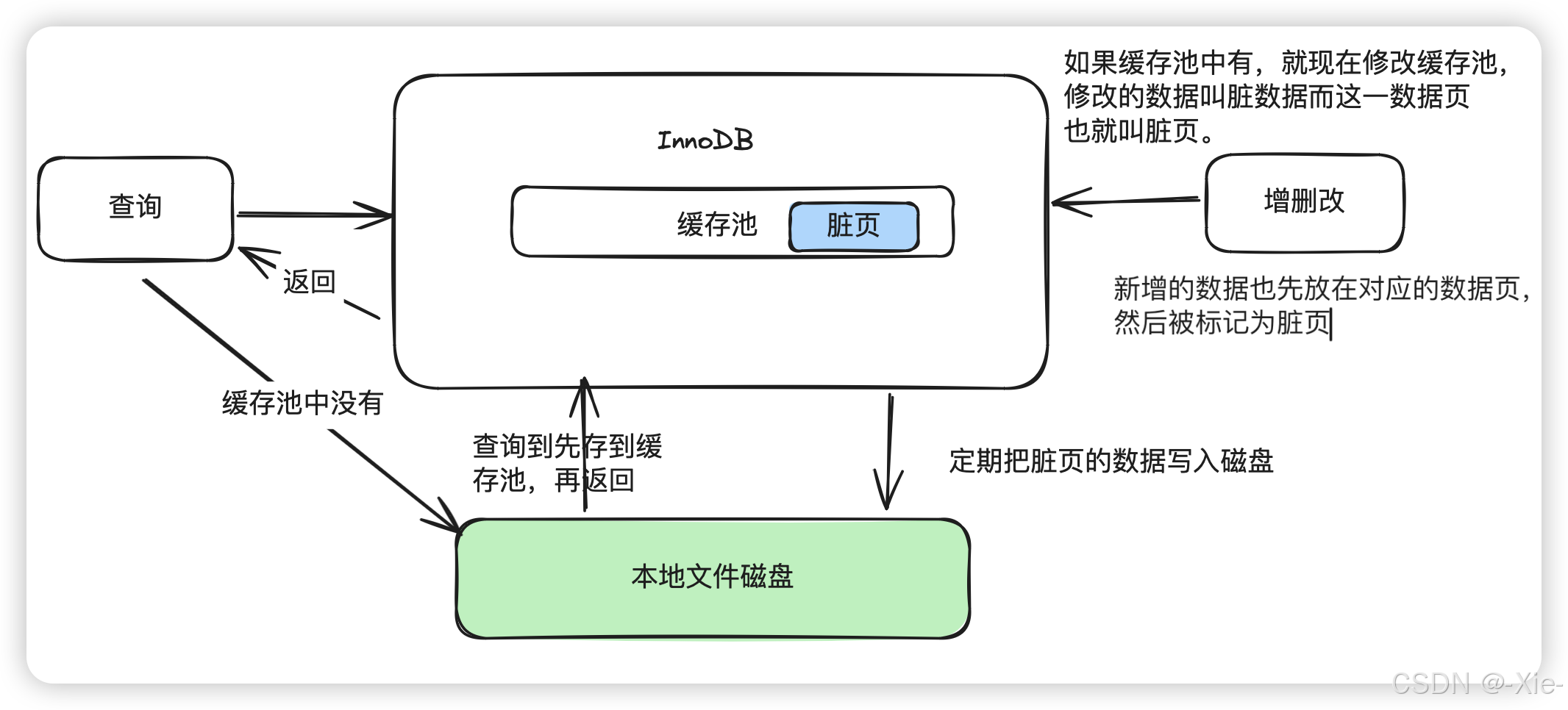
脏页(Dirty Page)的标记方式
当数据被修改(UPDATE、INSERT、DELETE)时:修改的是缓存池中的“数据页”(Data Page),而不是单独修改某一行。整个数据页会被标记为“脏页”,而不仅仅是修改的那一行。
脏页会被加入 Flush List(刷新列表),等待后台线程(Page Cleaner)将其刷回磁盘。
为什么是整个页?因为InnoDB 的存储单位是 页(Page,默认16KB),而不是行(Row)。而且磁盘 I/O 是按页进行的,所以即使只修改了一行,InnoDB 也会把整个页标记为脏页,并在合适的时机刷回磁盘。
INSERT(新增数据)
- 新数据会被写入缓存池的某个数据页(Data Page)。
- 如果该页原本不在缓存池中,InnoDB 会先将其从磁盘加载到缓存池,然后插入新数据。
- 该页会被标记为脏页,并加入
Flush List,等待刷盘。
DELETE(删除数据)
InnoDB 并不会立即从磁盘物理删除数据,而是:
- 在缓存池的数据页中标记该行为“已删除”(逻辑删除)。
- 该页会被标记为脏页,并加入
Flush List。 - 后台线程(
Purge)会在合适的时机清理这些已删除的行(物理删除)。
总结
本篇主要讲了mysql中缓存池的作用,相对来说还是十分有用的,不然我们查数据也不会这么快,因为从磁盘读是非常慢的。