《大数据之路1》笔记3:数据管理
一 元数据
1.1 元数据概述
定义: 元数据是关于数据的数据,元数据打通了源数据、数据仓库、数据应用,记录了数据从生产到消费的全部过程。元数据主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态和ETL的任务运行状态。
分为:技术元数据、业务元数据
-
技术元数据: 存储关于数据仓库系统技术细节的数据,是用于开发和管理数据仓库使用的数据。比如:分布式计算系统存储元数据;分布式计算系统运行元数据;数据开发平台中数据同步、计算任务、任务调度等信息;数据质量和运维相关元数据
-
业务元数据: 从业务角度描述了数据仓库中的数据,提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员能够读懂数据据仓库中的数据
价值: 数据管理、数据内容、数据应用的基础。在数据管理方面为集团数据提供在计算、存储、成本、质量、安全、模型等治理领域上的数据支持
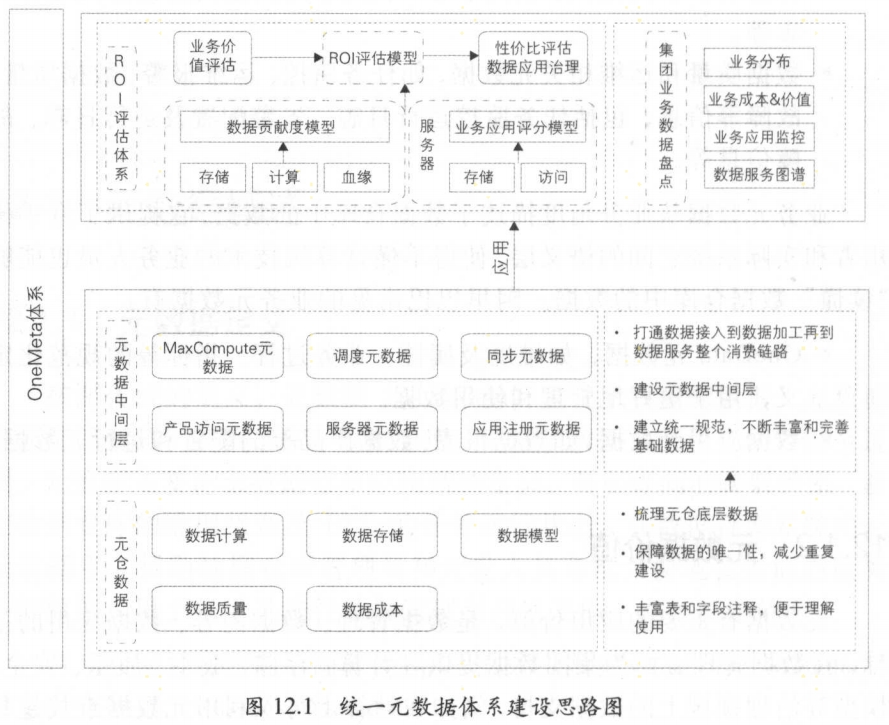
1.2 统一元数据体系建设
- 首先梳理清楚元仓底层数据,对元数据做分类,如计算元数据、存储元数据、质量元数据等,减少数据重复建设,保障数据的唯一性
- 要丰富表和字段使用说明,方便使用和理解。根据元仓底层数据构建元仓中间层,依据 OneData 规范,建设元数据基础宽表,也就是元数据中间层,打通从数据产生到消费整个链路 ,不断丰富中间层数据
- 基于元数据中间层,对外提供标准统一的元数据服务出口,保障元数据产出的质量。
1.3 元数据应用
数据的真正价值在于数据驱动决策,通过数据指导运营
对于元数据,可以用于指导数据相关人员进行日常工作,实现数据化“运营”。 对ETL 工程师,可以通过元数据指导其进行模型设计、任务优化和任务下线等各种日常 ETL 工作; 对于运维工程师,可以通过元数据指导其进行整个集群的存储、计算和系统优化等运维工作。
Data Profile
-
元数据门户: 数据地图围绕数据搜索,服务于数据分析、数据开发、数据挖掘、算法工程师、数据运营等数据表的使用者和拥有者,提供方便快捷的数据搜索服务,拥有功能强大的血缘信息及影响分析,利用表使用说明、评价反馈 、表收藏及精品表机制,为用户浮现高质量、高保障的目标数据
-
应用链路分析: 通过元数据血缘来分析产品及应用的链路,通过血缘链路可以清楚地统计到某个产品所用到的数据在计算、存储、质量上存在哪些问题,通过治理优化保障产品数据的稳定。 通过应用链路分析,产出表级血缘、字段血缘、表的应用血缘
-
数据建模: 有别于传统的经验建模方式,通过下游所使用的元数据指导数据参考建模。可以在一定程度上解决此问题,提高数据仓库建模的数据化指导,提升建模效率
所使用的元数据: 表的基础元数据;表的关联关系元数据;表的字段的基础元数据,举例:
-
驱动ETL开发
二 计算管理
如何降低计算资源的消耗,提高任务执行的性能,提升任务产出 的时间,是计算平台和 ETL 开发工程师孜孜追求的目标。本章分别从系统优化和任务优化 面介绍计算优化。
[[SQL性能优化]]
2.1 系统优化
HB(Oistory-Based Optimizer,基于历史的优化器): HBO 是根据任务历史执行情况为任务分配更合理的资源,包括内存、 CPU 以及 Instance 个数。
HBO 是对集群资源分配的 种优化,概括起来就是:任务执行历史+集群状态信息+优化规则→更优的执行配置。 HBO的提出 通过数据分析,发现在系统中存在大量的周期性调度的脚本(物理计划稳定),且这些脚本的输入 般比较稳定,如果能对这部分脚本进行优化,那么对整个集群的计算资源的使用率将会得到显著提升。由此,我们想到了 HBO ,根据任务的执行历史为其分配更合理的计算资源。HBO 般通过自造应调整系统参数来达到控制计算资源的目的。
CBO: 优化器( Optimizer )引人了 Volcano 模型(请参考论文 The Volcano Optimizer Gener tor: Extensibility and fficient Search ,该模型是基于代价的优化器( CBO ),并且引人了重新排序 Join (Join Reorder )和MapJoin (Auto MapJoin )优化规则等,同时基于 Volcano 模型的优化器会尽最大的搜索宽度来获取最优计划。
2.2 任务优化
[[数据倾斜]]
主要介绍数据倾斜方面
-
Map倾斜
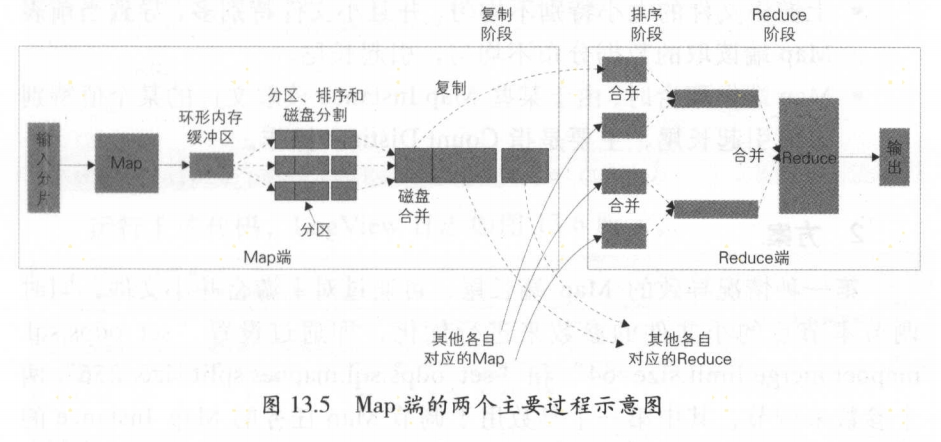 背景: 在Map 端读数据时,由于读入数据的文件大小分布不均匀,因此会导致有些 Map Instance 读取并且处理的数据特别多,而有些 Map Instance 处理的数据特别少,造成 Map 端长尾: - 上游表文件的大小特别不均匀,并且小文件特别多,导致当前表Map 端读取的数据分布不均匀,引起长尾。 - Map 端做聚合时,由于某些 Map Instance 读取文件的某个值特别多而引起长尾,主要是指 Count Distinct 操作
背景: 在Map 端读数据时,由于读入数据的文件大小分布不均匀,因此会导致有些 Map Instance 读取并且处理的数据特别多,而有些 Map Instance 处理的数据特别少,造成 Map 端长尾: - 上游表文件的大小特别不均匀,并且小文件特别多,导致当前表Map 端读取的数据分布不均匀,引起长尾。 - Map 端做聚合时,由于某些 Map Instance 读取文件的某个值特别多而引起长尾,主要是指 Count Distinct 操作方案:
- 第一种情况导致的 Map 端长尾,可通过对上游合并小文件,同时调节本节点的小文件的参数来进行优化,即通过设置“ set odps.sql.mapper.merge.limit.size 64 ”和“ set odps .sql.mapper.s plit.size=256“两个参数来调节,其中第一个参数用于调节 Map 任务的 Map Instance个数;第二个参数用于调节单个 Map Instance 读取的小文件个数,防止由于小文件过多导致 Map Instance 读取的数据量很不均匀;两个参数配合调整。
- 通过“distribute by rand ()”会将 Map 端分发后的数据重新按照随机值再进行一次分发。原先不加随机分发函数时,Map 阶段需要与使用MapJoin 的小表进行笛卡儿积操作, Map 端完成了大小表的分发和笛卡儿积操作。使用随机分布函数后,Map 端只负责数据的分发,不再有复杂的聚合或者笛卡儿积操作,因此不会导致 Map 端长尾。
-
Join倾斜
- Join的某路输入比较小,可以采用MapJoin,避免分发引起长尾。
- Join 的每路输入都较大,且长尾是空值导致的,可以将空值处理成随机值,避免聚集。
- Join 的每路输入都较大,且长尾是热点值导致的,可以对热点值和非热点值分别进行处理,再合并数据
解决方案: - mapjoin方案:MapJoin 的原理是将Join操作提前到Map 端执行,将小表读入内存,顺序扫描大表完成Join。这样可以避免因为分发key不均匀导致数据倾斜。但是 MapJoin的使用有限制,必须是Join中的从表比较小才可用。所谓从表,即左外连接中的右表,或者右外连接中的左表 。。。
-
Reduce倾斜
三 存储和成本管理
3.1 数据压缩
[[数据压缩]]
在分布式文件系统中,为了提高数据的可用性与性能,通常会将数据存储3份,这就意味着存储ITB的逻辑数据,实际上会占用3TB的物理空间。目前 MaxCompute中提供了 archive 压缩方法,它采用了具有更高压缩比的压缩算法,可以将数据保存为RAID file 的形式,数据不再简单地保存为3份,而是使用盘古RAIDfile的默认值(6,3)格式的文件,即 6份数据+3 份校验块的方式,这样能够有效地将存储比约为1:3提高到1:1.5,大约能够省下一半的物理空间。
3.2 数据重分布
在MaxCompute中主要采用基于列存储的方式,由于每个表的数据分布不同,插入的数据的顺序不一样,会导致压缩效果有很大差异,因此通过修改表的数据重分布,避免列热点,将会节省一定的存储空间,主要通过修改distrubute by 和sort by字段的方法实现数据重分布

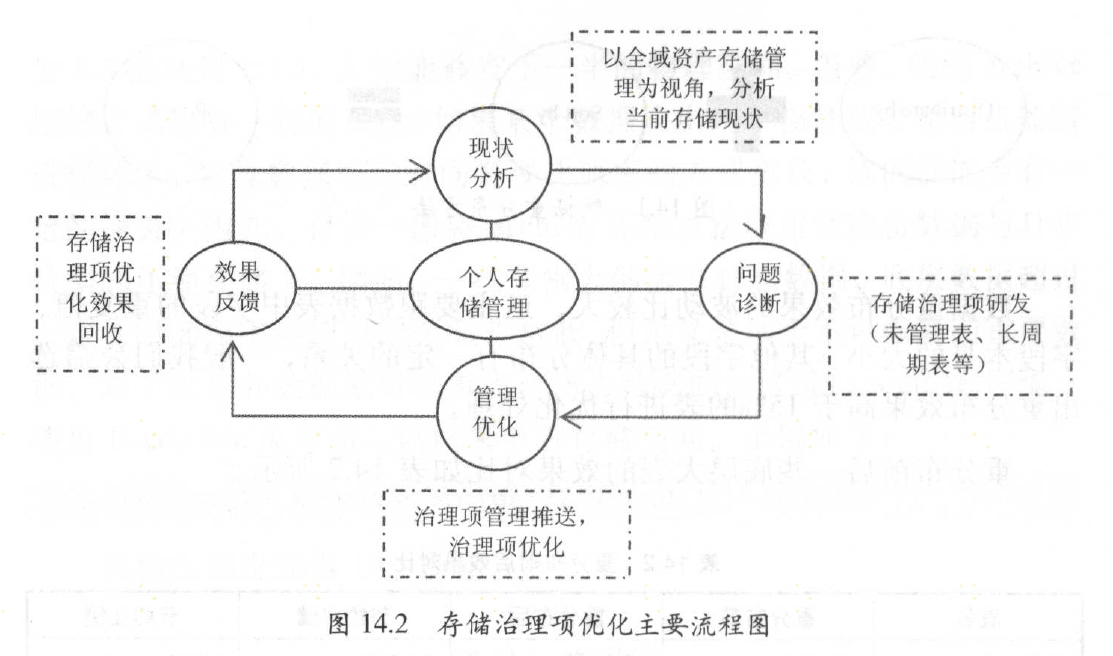
3.3 存储治理项优化
阿里巴巴数据仓库在资源管理的过程中,经过不断地实践,慢慢摸索出一套适合大数据的存储优化方法,在元数据的基础上,诊断、加工成多个存储治理优化项。目前已有的存储治理优化项有未管理表、空表、最近62 天未访问表、数据无更新无任务表、数据无更新有任务表、开发库数据大于lOOGB 且无访问表、长周期表等。通过对该优化项的数据诊断, 形成治理项,治理项通过流程的方式进行运转、管理,最终推动各个E TL 开发人员进行操作,优化存储管理,并及时回收优化的存储效果。在这个体系下,形成现状分析、问题诊断、管理优化、效果反馈的存储治理项优化的闭环。通过这个闭环,可以有效地推进数据存储的优化,降低存储管理的成本
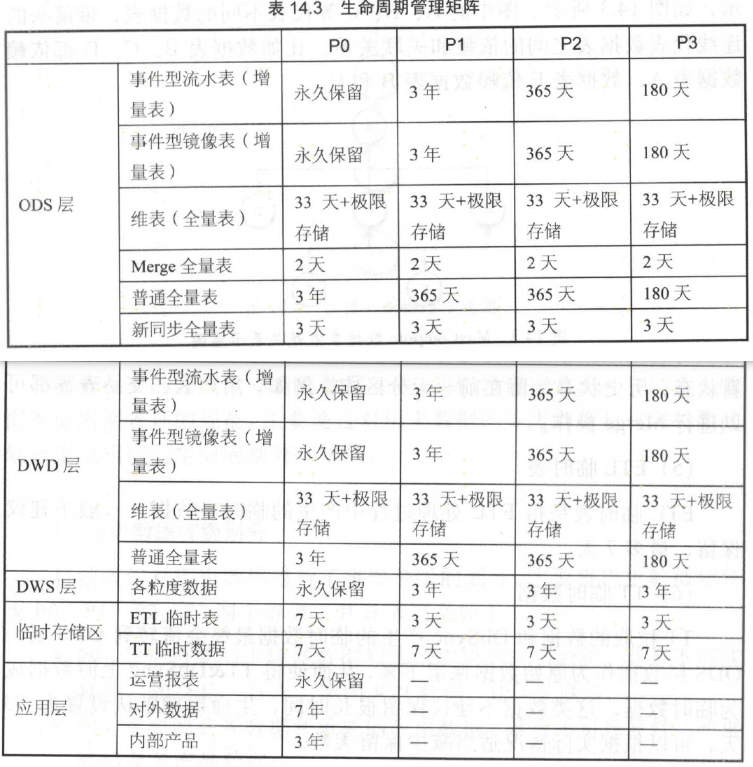
3.4 生命周期管理
生命周期管理策略:
- 周期性删除策略
- 彻底删除策略
- 永久保留策略
- 极限存储策略
- 冷存储管理策略
- 增量表merge全量表策略
通用的生命周期管理矩阵:
- 历史数据等级划分,P1\P2\P3\P4
- 表类型划分
3.5 数据成本计算
分为:存储成本、计算成本、扫描成本。 通过在数据成本计量中引入扫描成本的概念,可以避免仅仅将表自身硬件资源的消耗作为数据表的成本,以及对数据表成本进行分析时,孤立地分析单独的一个数据表,能够很好地体现出数据在加工链路中的上下游依赖关系,使得成本的评估尽量准确、公平、合理。
3.6 数据使用计费
四 数据质量
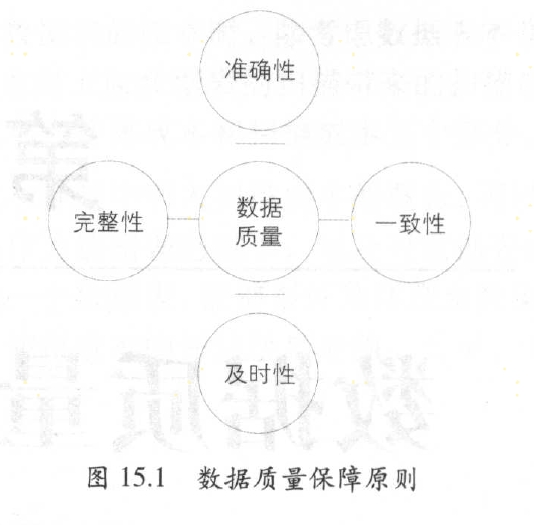
4.1 数据质量保障原则
4.2 数据质量方法概述
- 消费场景知晓

- 数据加工过程卡点校验
- 风险点监控
- 质量平衡
[[《大数据之路1》笔记1:总述和数据技术篇]]
[[《大数据之路1》笔记2:数据模型]]