Ubuntu下搭建vllm+modelscope+deepseek qwen3
一 保证运行环境正常
主要是显卡的运行环境。
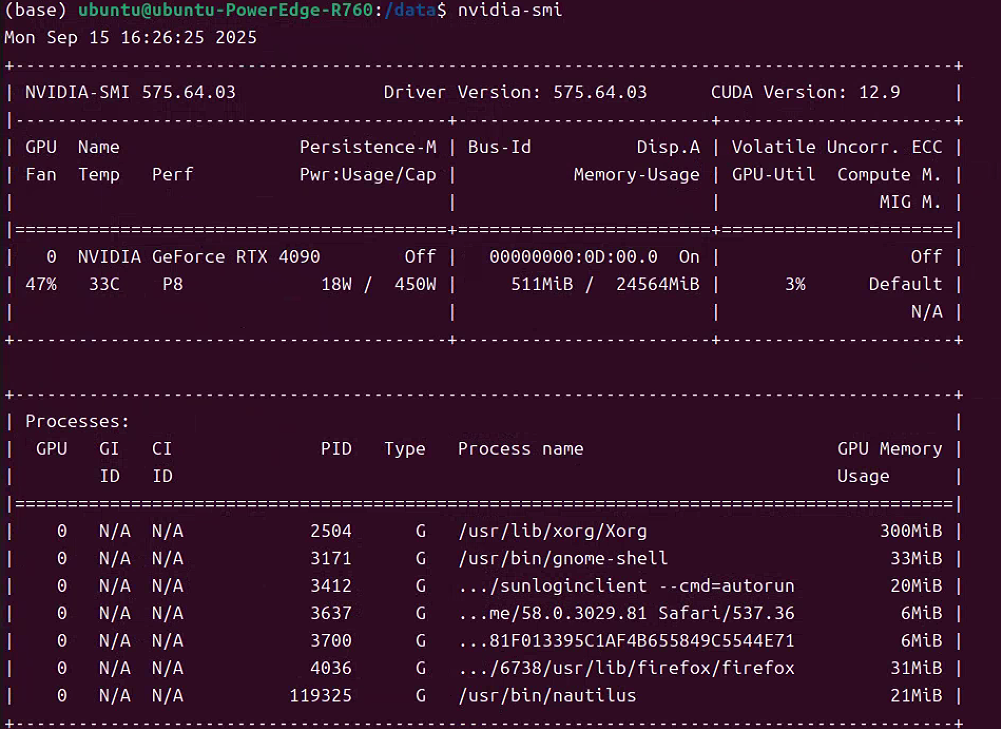
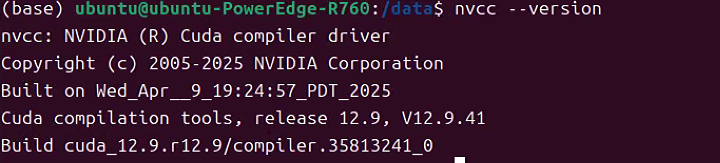
如果不会装驱动, 看这篇文章, 以前写过,很全面:
新服务器从0开始搭配Ubuntu+Conda+Docker+Dify
二 安装vllm python环境
最好用全新的conda环境,独立干净
pip install vllm -i https://mirrors.huaweicloud.com/repository/pypi/simple #用华为源
三 安装 modelscope
参考:https://modelscope.cn/docs/intro/quickstart
pip install modelscope
四 模型下载
模型下载的方式很多:
- 1 高速下载,可以断点续传
modelscope download --model="Qwen/Qwen2.5-0.5B-Instruct" --local_dir ./model-dir
- 2 Python 下载
建个py文件下载:
from modelscope import snapshot_download
model_dir = snapshot_download("Qwen/Qwen2.5-0.5B-Instruct")
或
#创建下载文件
vi down_model.py
#下载代码
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B', cache_dir='/root/deepseekr1_1.5b', revision='master')
#执行下载
python down_model.py
- 3 Git LFS 下载
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
我用了第一种方法:
modelscope download --model="Qwen/Qwen2.5-0.5B-Instruct" --local_dir /data/model/Qwen/Qwen2.5-0.5B-Instructmodelscope download --model="deepseek-ai/DeepSeek-V3.1" --local_dir /data/model/deepseek-ai/DeepSeek-V3.1
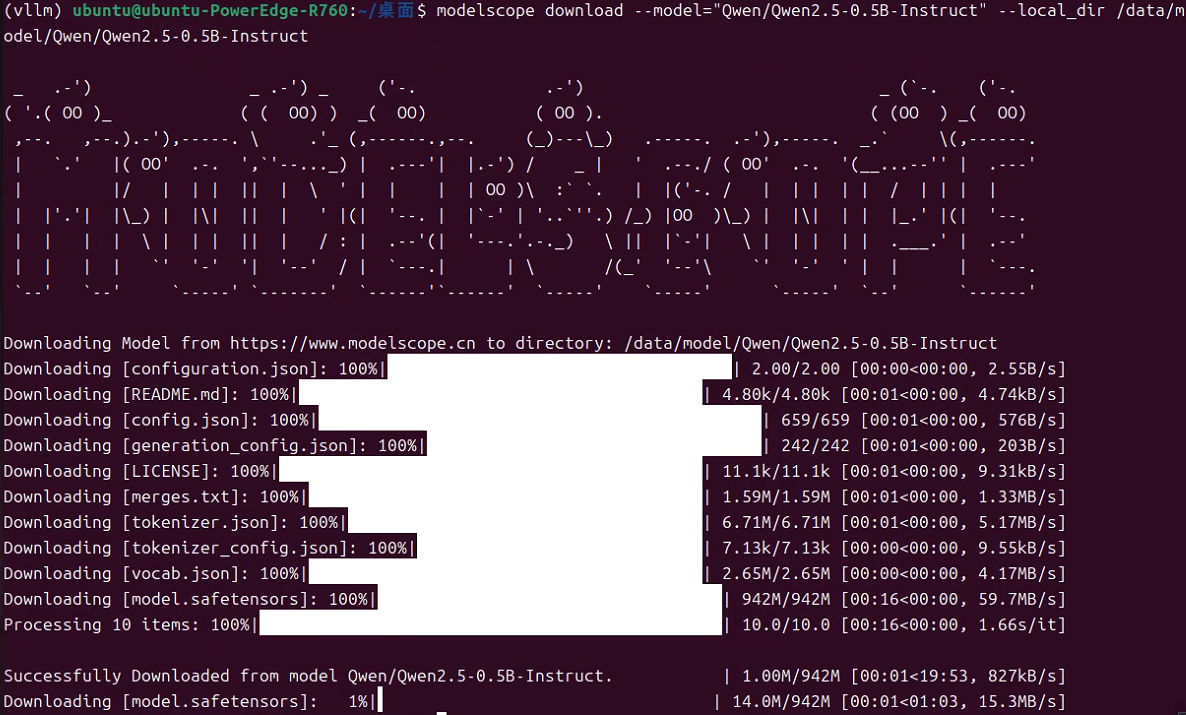
四 运行 vllm
#简版
vllm serve \
/data/model/Qwen/Qwen2.5-0.5B-Instruct \
--dtype=half#复杂版
vllm serve \
--model=/data/model/Qwen/Qwen2.5-0.5B-Instruct \
--tensor-parallel-size 1 \
--trust-remote-code \
--dtype=half \
--served-model-name "Qwen2.5-0.5B-Instruct" \
--host 0.0.0.0 \
--port 8765vllm serve \
--model=/data/model/deepseek-ai/DeepSeek-V3.1 \
--tensor-parallel-size 1 \
--trust-remote-code \
--dtype=half \
--served-model-name "DeepSeek-V3.1" \
--host 0.0.0.0 \
--port 8765简单参数:
| 参数 | 说明 |
|---|---|
| model | 模型路径,以文件夹结尾 |
| tensor-parallel-size | 张量并行副本数,即GPU的数量,咱这儿只有2张卡 |
| trust-remote-code | 信任远程代码,主要是为了防止模型初始化时不能执行仓库中的源码,默认值是False |
| device | 用于执行 vLLM 的设备。可选auto、cuda、neuron、cpu |
| gpu-memory-utilization | 用于模型推理过程的显存占用比例,范围为0到1。例如0.5表示显存利用率为 50%。如果未指定,则将使用默认值 0.9。 |
| dtype | “auto”将对 FP16 和 FP32 型使用 FP16 精度,对 BF16 型使用 BF16 精度。 “half”指FP16 的“一半”。推荐用于 AWQ 量化模型。 “float16”与“half”相同。 “bfloat16”用于在精度和范围之间取得平衡。 “float”是 FP32 精度的简写。 “float32”表示 FP32 精度。 |
| kv-cache-dtype | kv 缓存存储的数据类型。如果为“auto”,则将使用模型默认的数据类型。CUDA 11.8及以上版本 支持 |
| served-model-name | 对外提供的API中的模型名称 |
| host | 监听的网络地址,0.0.0.0表示所有网卡的所有IP,127.0.0.1表示仅限本机 |
| port | API服务的端口 |
更详细的参数:
1、网络参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –host | string | localhost | API服务监听地址,生产环境建议设为0.0.0.0以允许外部访问 |
| –port | int | 8000 | API服务监听端口号 |
| –uvicorn-log-level | enum | info | 控制Uvicorn框架日志粒度,可选:debug,trace,info,warning,error,critical |
| –allowed-origins | list | 空 | 允许跨域请求的来源列表(例:http://example.com) |
| –allow-credentials | flag | False | 允许发送Cookies等凭证信息 |
| –ssl-keyfile/–ssl-certfile | path | 无 | HTTPS所需的私钥和证书文件路径 |
2、硬件资源管理
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –tensor-parallel-size | int | 1 | 张量并行度(必须等于物理GPU数量) |
| –gpu-memory-utilization | float | 0.9 | GPU显存利用率阈值(0.9=90%显存上限) |
| –block-size | enum | 16 | 连续Token块大小,取值8/16/32/64/128 |
| –device | enum | auto | 执行设备类型(cuda/tpu/hpu/xpu/cpu等) |
3、异构存储配置
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –swap-space | int | 4 | 每个GPU的CPU换页空间大小(GiB) |
| –cpu-offload-gb | int | 0 | 每GPU使用CPU内存扩展显存的GiB数(需高速CPU-GPU互联) |
| –max-cpu-loras | int | max_loras | CPU内存缓存的最大LoRA适配器数量 |
4、模型基础参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –model | string | 必填 | 模型名称(如gpt-3.5-turbo)或本地路径 |
| –dtype | enum | auto | 计算精度控制,常用float16/bfloat16 |
| –max-model-len | int | 自动获取 | 模型最大支持的上下文长度 |
| –tokenizer-mode | enum | auto | Tokenizer模式(auto自动选择快速实现) |
5、高级加载控制
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –load-format | enum | auto | 权重加载协议,优先safetensors更安全 |
| –config-format | enum | auto | 配置格式hf/mistral或自动检测 |
| –trust-remote-code | flag | False | 加载HuggingFace自定义代码时必须启用,有安全风险 |
| –hf-overrides | JSON | 无 | 动态覆盖HuggingFace模型配置(如调整隐藏层维度) |
6、推理参数限制
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –max-num-seqs | int | 256 | 单批次允许多少序列并行处理 |
| –max-num-batched-tokens | int | 动态调整 | 每个推理阶段处理的Token总数上限 |
| –max-logprobs | int | 5 | 返回每个位置的概率最高前N个token |
| –speculative-disable-by-batch-size | int | 无 | 排队请求超过该阈值时关闭推测解码 |
7、安全与许可控制
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –api-key | string | 无 | API访问密钥,设置后所有请求需包含Authorization头 |
| –allowed-local-media-path | path | 无 | 允许服务端访问的本地媒体路径(仅可信环境启用) |
| –cert-reqs | enum | 无 | SSL证书验证级别(参考Python ssl模块) |
8、量化配置
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –quantization | enum | 无 | 权重量化方法,如awq/gptq/marlin等 |
| –kv-cache-dtype | enum | auto | KV缓存量化类型(fp8/fp8_e5m2等) |
| –lora-dtype | enum | auto | LoRA适配器的量化精度设置 |
| –calculate-kv-scales | flag | False | 动态计算FP8量化比例 |
测试vllm服务通不通:
curl http://localhost:8765/v1/completions -H "Content-Type: application/json" -d '{"model": "/data/model/Qwen/Qwen2.5-0.5B-Instruct","prompt": ["<|begin▁of▁sentence|>你好,DeepSeek!<|end▁of▁sentence|>"],"max_tokens": 100,"temperature": 0.6 }'
有问题可以link q:316853809