[数据结构——lesson12.希尔排序]
目录
前言
学习目标:
希尔排序:
🌟排序过程详解
动画展示
代码分析
两种排序算法的时间复杂度深度分析
结束语
前言
上节内容我们学习了第一种排序算法——直接插入排序[数据结构lesson12——直接插入排序],这一节我们将学习插入排序的一种延伸排序——希尔排序
学习目标:
- 什么是希尔排序
- 代码分析
- 直接插入排序与希尔排序时间复杂度深度分析
1.希尔排序:
希尔排序(Shell Sort)是插入排序的一种延伸,也称为缩小增量排序。它是 1959 年由 Donald Shell 发明的,是第一个突破 O (n²) 的排序算法
- 基本思想:先将整个待排元素序列分割成若干个子序列(由相隔某个 “增量”(gap值)的元素组成),分别对这些子序列进行直接插入排序,然后依次缩减增量再进行排序。待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。
- 排序过程:将记录按下标的一定增量分组,针对各组使用直接插入排序算法进行排序。随着增量逐渐减少,每组包含的关键词越来越多。当增量减至 1 时,整个文件则分成一组,算法随即终止。
- 核心特点:与插入排序每次都和之前的一个元素进行比较不同,希尔排序尝试每次和之前第 h 个元素进行比较,通过将 h 从一个很大的值逐渐缩小到 1,把完全无序的数组变成近乎有序,最后变成有序数组。
- 增量序列:希尔排序的核心在于间隔序列(增量序列)的设定1。既可以提前设定好,也可以动态定义。常见的增量序列有希尔增量序列 {1,2,4,8,...},即 2^k(k=1,2,3,...)。还有《算法(第 4 版)》中 Robert Sedgewick 提出的动态定义方法。另外,也可以使用如 step (n)=⌊1/2 (3^n - 1)⌋(n≥1)这样的公式来计算增量。
1.2🌟排序过程详解
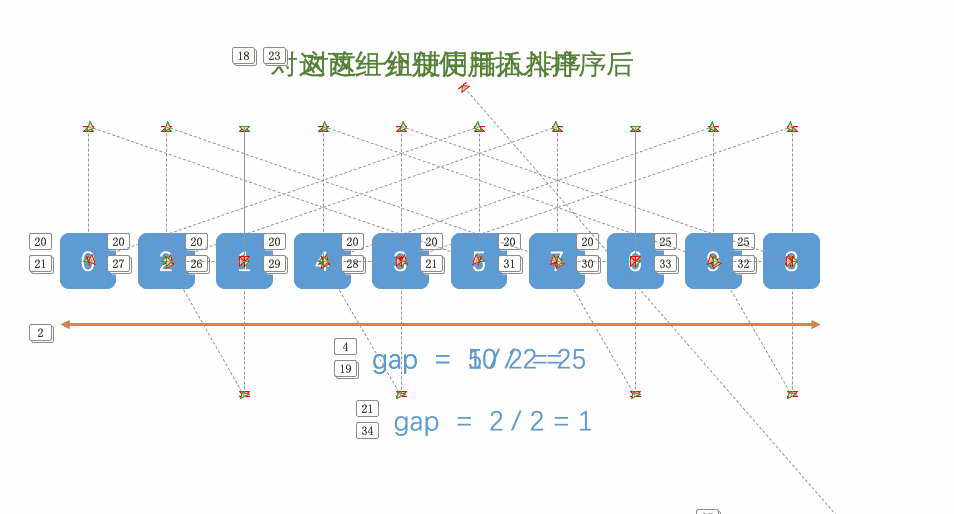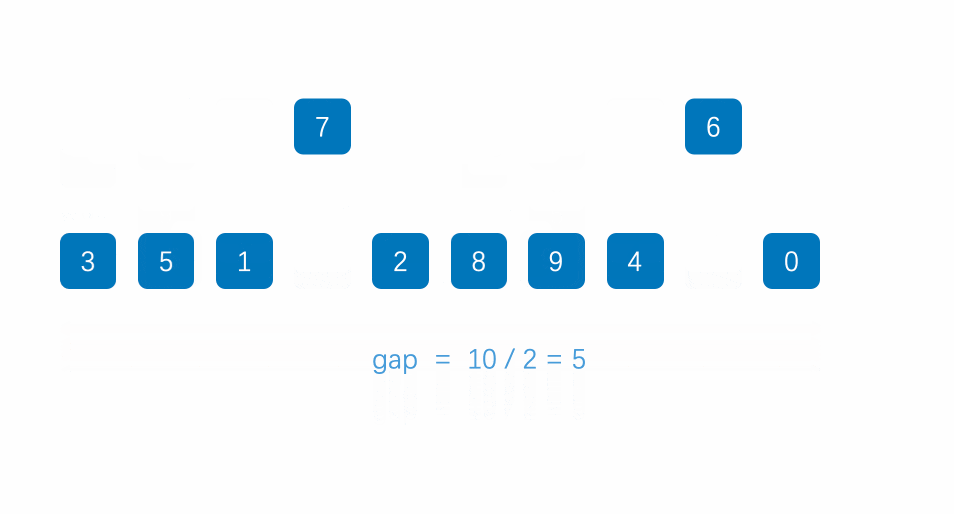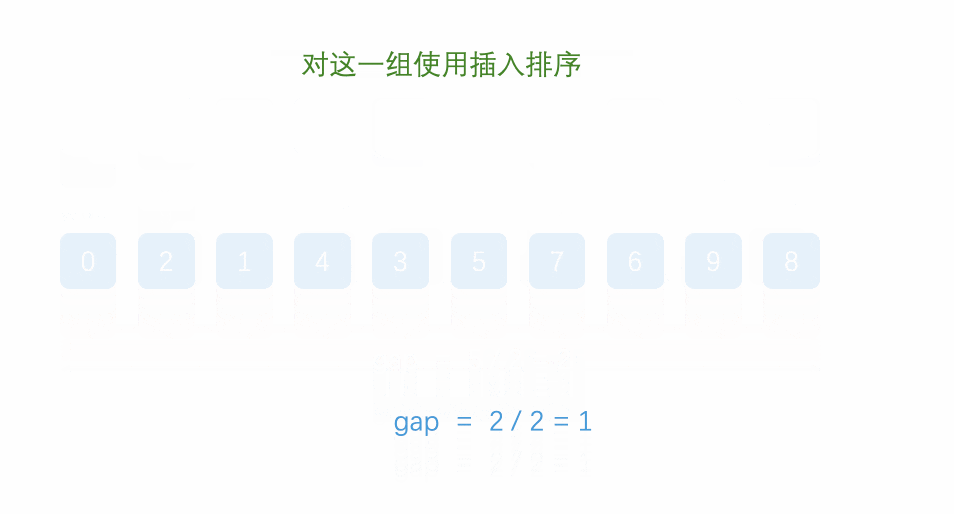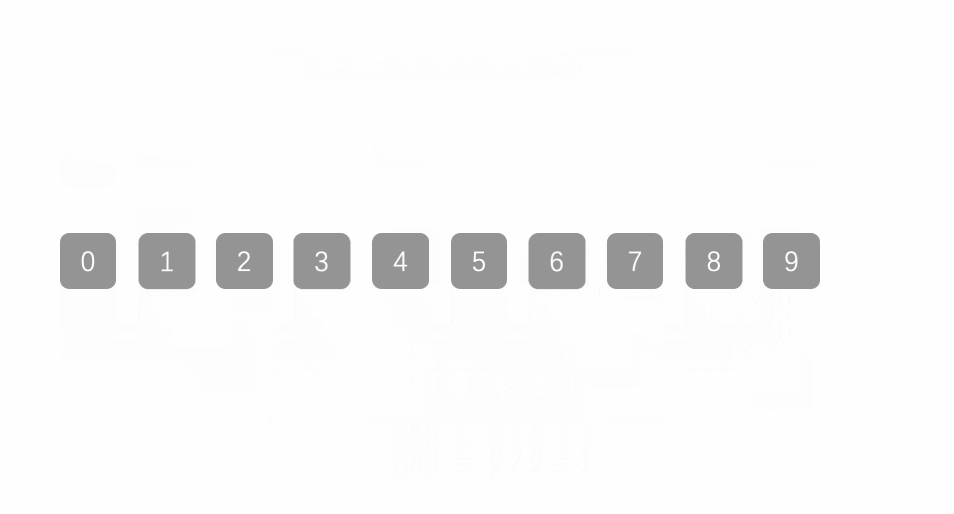
- 首先说明,这个gap增量每次是以2的倍数递减
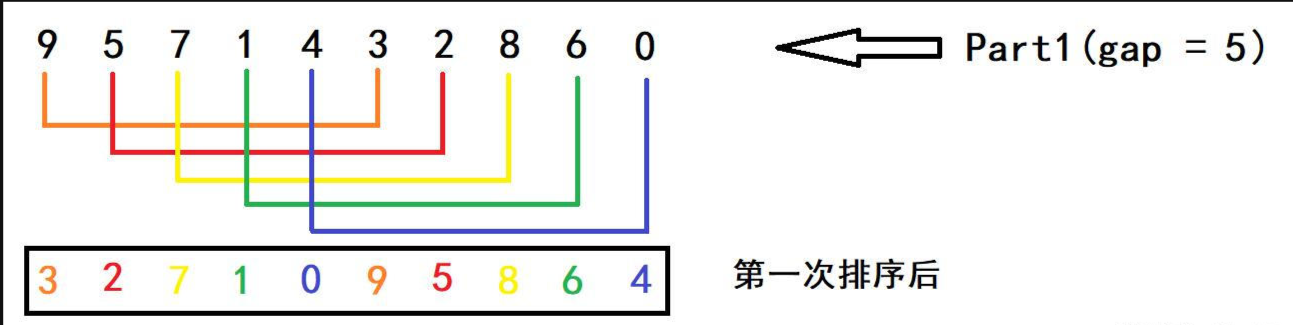
- 我们看到这里有10个数,因此gap = 10 / 2 = 5,也就是每个数字之间间隔为5,然后以将它们分为很多组,若是后者比前者大,则进行一个交换
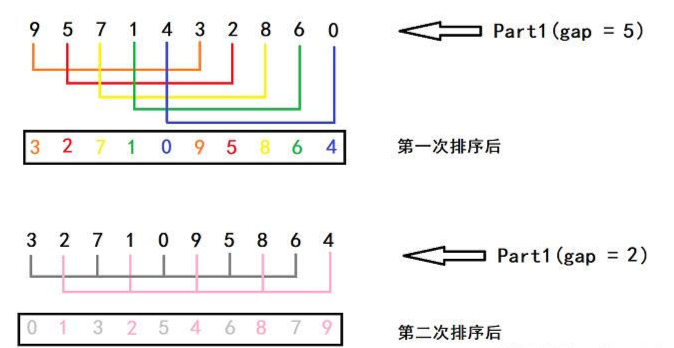
- 上面是第二次排序后地结果,此时得gap = 5 / 2 = 2,所以增量为2的是一组
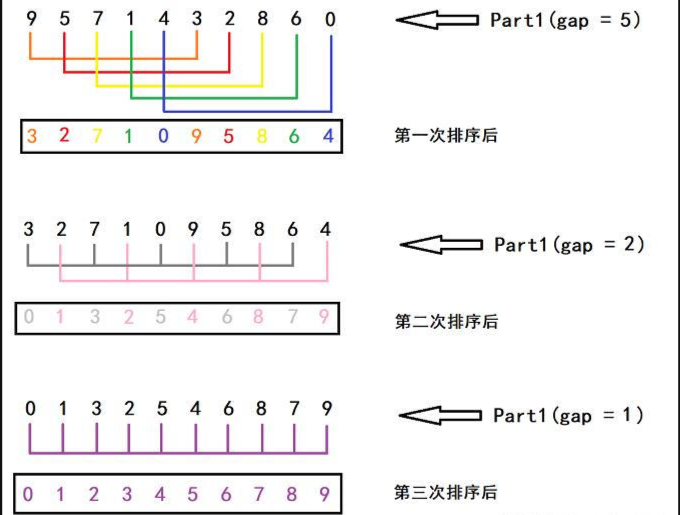
- 以上,便是第三次排序后的结果,可以看到,第三次得gap = 2 / 2 = 1,因为间隔为1,也就是全体数据为一组,那就是最后进行一次直接插入排序即可
1.3动画展示
1.4代码分析
还是一样,我们由简至易,做单步分析
①确定单趟排序的过程
- 对于希尔排序,上面说到过,它是隶属于插入排序,所以对于单趟的逻辑只需要在直接插入排序的基础上做一个修改即可,但是对于移动的间距我们肯定需要去做一个控制,因为希尔排序的数是被分成了一组一组的,而且每一组的数之间的间隔取决于gap的大小,因此 对于tmp = a[end + gap];保存的就是当前待比较元素的后移gap位元素
- 在实现后移的过程中也是移动gap步,对于end也是同理
- 那在跳出循环之后的tmp也是要放在a[end + gap]的地方
int gap = 3;
int end;
int tmp = a[end + gap];
while (end >= 0)
{if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}
}
a[end + gap] = tmp;
②循环控制每一趟插入排序
- 对于这个有两种解法,都给大家点到
方法1:
for (int i = 0; i < n - gap; i += gap) //一组一组走
方法2:
for (int i = 0; i < n - gap; i++) //一位一位走
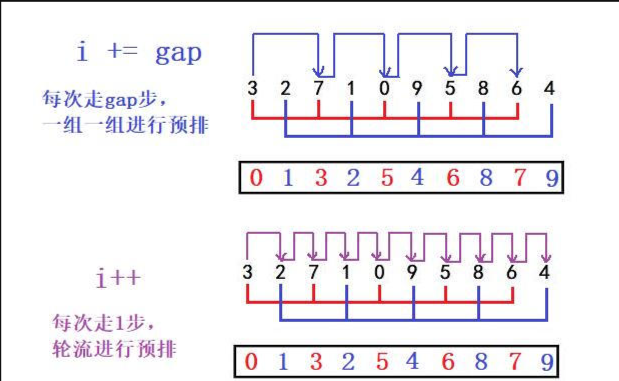
我们来看看上面两种情况的不同之处
- 对于i += gap来说,在排序的过程中是先把每一组先排好,再排下一组
- 对于i++来说,在排序的过程中第一组排好了一个数据后,i++又进行下一组的排序,每次只插入一个,然后到后面又回到这一组来,像是一个轮回的过程。
③单趟gap的排序控制好后,我们就需要去控制这个增量gap了,网上很多写法都是gap /= 2,这种比较经典一些,也是我上面所展示的一种
int gap = n / 2;for (int j = 0; j < gap; ++j)
{gap /= 2;for (int i = j; i < n - gap; i += gap){ //一组一组走//单趟插入过程...}
}
但是在这里,我会优先采用下面这种写法,因为当gap越大的时候,数字跳动得越快;当gap越小的时候,数字跳动的间距越小,此时会更进一步得接近有序,所以我们要将gap尽快地进行缩小,但是在gap / 3之后可能在最后无法使【gap = 1】,那此时的话就需要在最后加上一个1使得最后一次缩小gap增量的时候可以使其到达1
int gap = n;
while (gap > 1)
{/** gap > 1 —— 预排序* gap == 1 —— 直接插入排序*///gap /= 2;gap = gap / 3 + 1; //保证最后的gap值为1,为直接插入排序for (int i = 0; i < n - gap; i++){ //单趟插入过程...}
}
整体代码展示
/*希尔排序*/
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1) {/** gap > 1 —— 预排序* gap == 1 —— 直接插入排序*///gap /= 2;gap = gap / 3 + 1; //保证最后的gap值为1,为直接插入排序for (int i = 0; i < n - gap; i++){ //一位一位走int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
了解了希尔排序地内部排序过程,现在我们就知道了为什么希尔排序是直接插入排序的优化了👀
- 首先我们来看中间的一段代码,这其实就是直接插入排序的改良版,只是将【end + 1】改换成了【end + gap】而已,但这里可要注意,虽然只是改换了这么一小个地方,变化的程度可是相当地大
- 你将具体的值带入一演算一遍就可以知道,我们以gap = 5为例
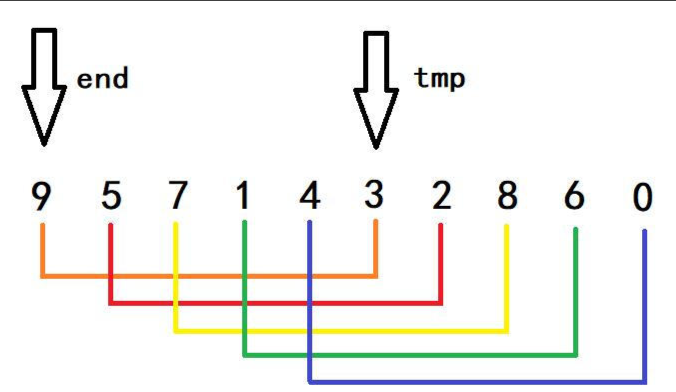
首先看到end所指向得是这组数据得首元素,然后tmp所保存的是end + gap后的位置,因为tmp < arr[end],因此9会移动到3的位置,此时end会向前移动gap个位置,这样数组就向前越界了,是的end < 0,然后便执行arr[end + gap] = tmp;这句话,这时才将9的位置放入3
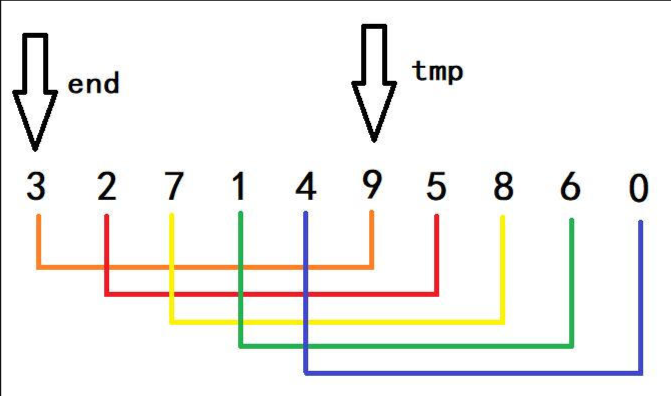
- 接下来一步很重要,从上一步可以得知,此时的end又回到了最初的位置,然后又进入for循环i++,这个end就移到了5的位置,而tmp记录的则是2的位置
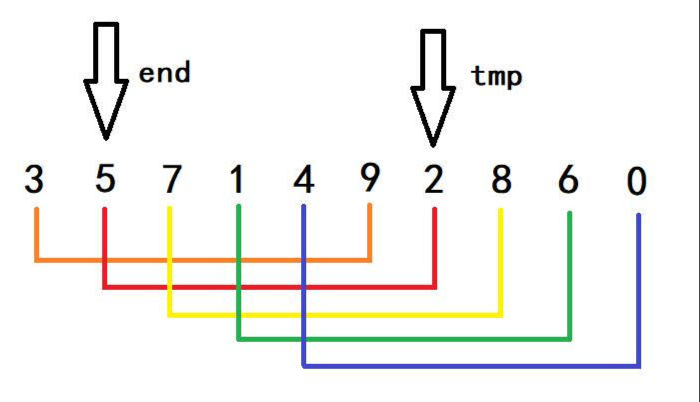
- 同理可得,推出下面这个样子,此时的end又回到了原来得位置
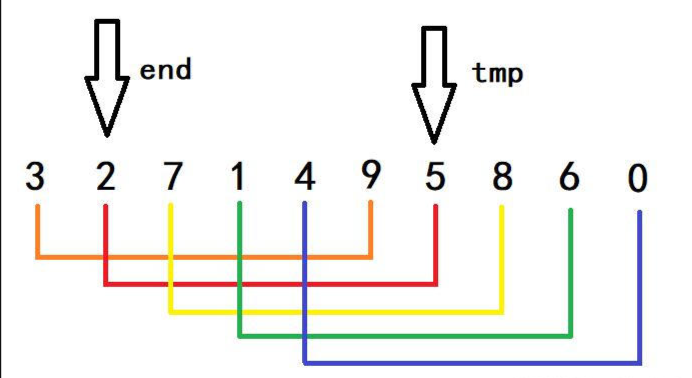
- 接下来end继续经过i++向后移,end此时指向7,tmp指向8,可以知晓,这不会进入第一个if分支,而会进入第二个else分支,此时break,强制跳出while循环,也可以进行一个换位
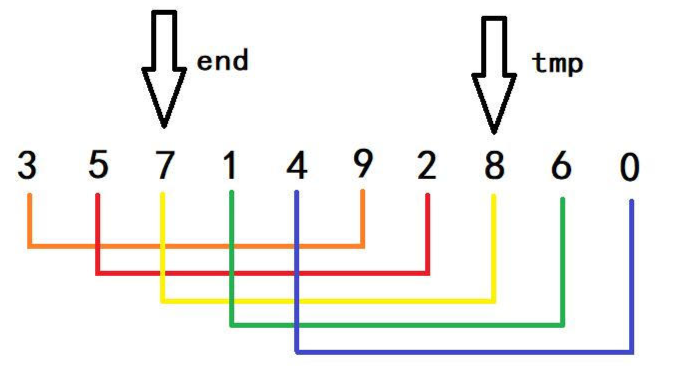
所以我们可以得出结论
- 核心原理:希尔排序先将数据按间隔分组,先进行组内排序,再逐步缩小间隔直至为 1。这如同管理员先整理各层书架的大类(间隔较大),再调整每层内部的顺序(间隔较小)。
- 排序过程:首先选择一个初始增量,将数组元素按照增量分组,对每组分别进行插入排序。然后随着增量的逐步减小,每组包含的元素逐渐增多,当增量减至 1 时,整个数组被分成一组,排序完成。
- 效率提升原因:在初始阶段,增量较大,每组元素较少,排序速度较快,能快速减少无序程度。当增量逐渐变小,数组变得基本有序,此时再进行插入排序,由于数据已接近有序,插入排序的效率就会很高,接近线性复杂度,从而整体上增强了排序效率。
2.两种排序算法的时间复杂度深度分析
对于直接插入排序的时间复杂度,我们已经分析过了,我们来看看希尔排序的时间复杂度是怎样的
- 外部循环时间复杂度分析:增量
gap一直处于折半缩小的过程,从初始值逐渐缩小到 1。设初始增量为 N(待排序序列长度),经过 x 次折半后gap变为 1,可得到表达式1=N/2x,变形后为2x=N,根据对数的定义可得x=log2N。这意味着控制gap的循环次数与log2N成正比,根据【大 O 渐进法】,外部循环的时间复杂度为 O (logN)(这里一般省略底数 2,写成 O (logN))。 - 内部操作时间复杂度分析:当
gap比较大时,每组数据中各个数字之间差距较远,每次交换操作的次数相对较少,但由于要处理 n 个元素,整体操作次数与 n 成正比,时间复杂度趋近于 O (n)。当gap减小到 1 时,相当于进行一次直接插入排序,直接插入排序的时间复杂度为 O (n)。所以,无论gap大小如何,内部进行元素交换等操作的时间复杂度都可视为 O (n)。 - 整体时间复杂度分析:根据上述分析,外部控制
gap的循环时间复杂度为 O (logN),内部交换操作时间复杂度为 O (n)。由于内外是嵌套关系,根据时间复杂度的计算规则,嵌套循环的时间复杂度是各层循环时间复杂度的乘积,所以整个算法的时间复杂度为 O (NlogN)。
接下来我们直接提供一个非常大的数据(假设N是10W),将二个排序算法的性能测试一下。
代码测试:
void TestOP()
{srand(time(0));const int N = 100000;int* a1 = (int*)malloc(sizeof(int)*N);int* a2 = (int*)malloc(sizeof(int)*N);int* a3 = (int*)malloc(sizeof(int)*N);int* a4 = (int*)malloc(sizeof(int)*N);int* a5 = (int*)malloc(sizeof(int)*N);int* a6 = (int*)malloc(sizeof(int)*N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N-1);int end5 = clock();int begin6 = clock();MergeSort(a6, N);int end6 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);printf("HeapSort:%d\n", end4 - begin4);printf("QuickSort:%d\n", end5 - begin5);printf("MergeSort:%d\n", end6 - begin6);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);
}
测试结果
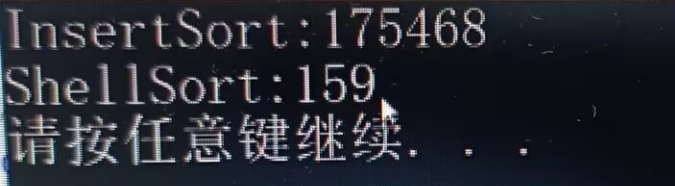
由此可见希尔排序的效率还是很可观的
结束语
本节我们学习了希尔排序,这是属于插入排序的一种,对于直接插入排序,其时间复杂度是O(n2),对于希尔排序,时间复杂度是O(nlog2N),我们能从原理到图示再到代码实现,去分析了这两个排序算法
感谢您的三连支持!!!
