【bert微调+微博数据集】-实现微博热点话题预测与文本的情感分析
使用WeiboSenti100k数据集微调bert-base-chinese模型实现
项目简介
本项目使用WeiboSenti100k数据集微调bert-base-chinese模型,实现微博文本的情感分析和热点话题预测。项目包含完整的数据处理、模型训练、评估和可视化流程,在验证集上达到了98.55%的准确率。
🎯 主要功能
- 🤖 高精度情感分析: 基于BERT的中文文本情感分析,准确率达98.55%
- 📊 智能话题预测: 基于情感分析结果的热点话题挖掘和趋势分析
- 📈 丰富数据可视化: 包含情感分布、混淆矩阵、词云图等多种可视化
- 🔧 完整API接口: 封装的分析API,支持单文本和批量预测
- ⚡ GPU加速训练: 支持CUDA加速,训练效率高
- 🎨 交互式分析: Jupyter Notebook环境,便于实验和调试
🔧 环境要求
- Python: 3.8+
- Conda环境: GenerativeSystem-Env
- GPU: NVIDIA GeForce RTX 5070 (11.9 GB显存) 或其他CUDA兼容GPU
- 操作系统: Windows 10/11 (已测试) 或 Linux
- 内存: 建议16GB以上
安装依赖
# 激活conda环境
conda activate GenerativeSystem-Env# 安装依赖包
pip install -r requirements.txt
使用方法
1. 运行Jupyter Notebook
jupyter notebook weibo_sentiment_analysis.ipynb
2. 按顺序执行各个单元格
- 环境设置: 安装和导入必要的库
- 数据加载: 下载和探索WeiboSenti100k数据集
- 数据预处理: 文本清理和格式化
- 模型设置: 加载bert-base-chinese模型
- 模型微调: 训练情感分析模型
- 模型评估: 性能测试和指标计算
- 情感预测: 实现预测功能
- 话题分析: 热点话题挖掘
- 结果可视化: 生成图表和词云
- API接口: 封装完整的分析API
📊 数据集详情与分析
WeiboSenti100k数据集
- 数据来源: dirtycomputer/weibo_senti_100k
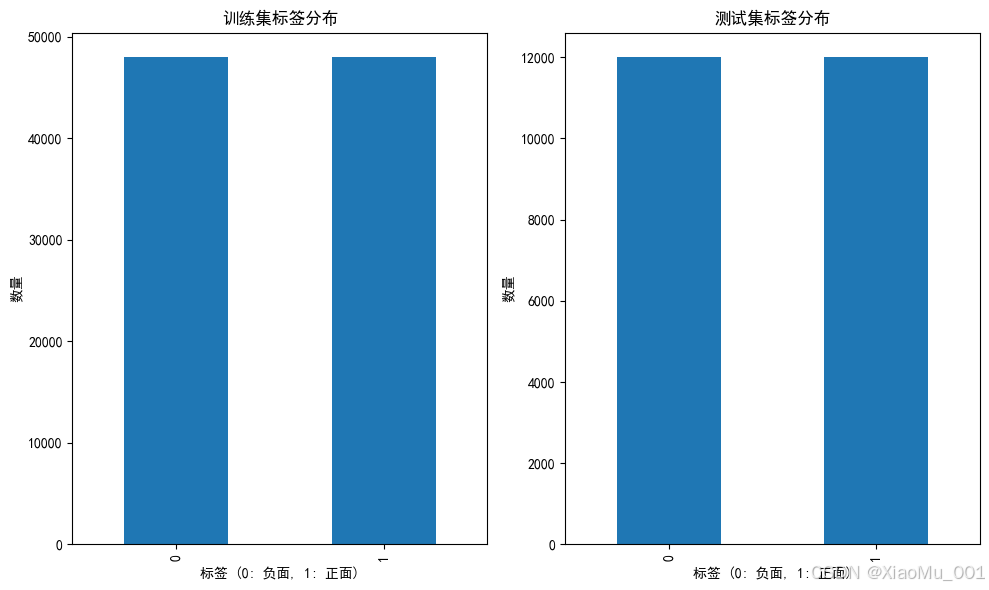
- 总样本数: 119,988条微博文本
- 标签分布: 完美平衡(正面/负面各约50%)
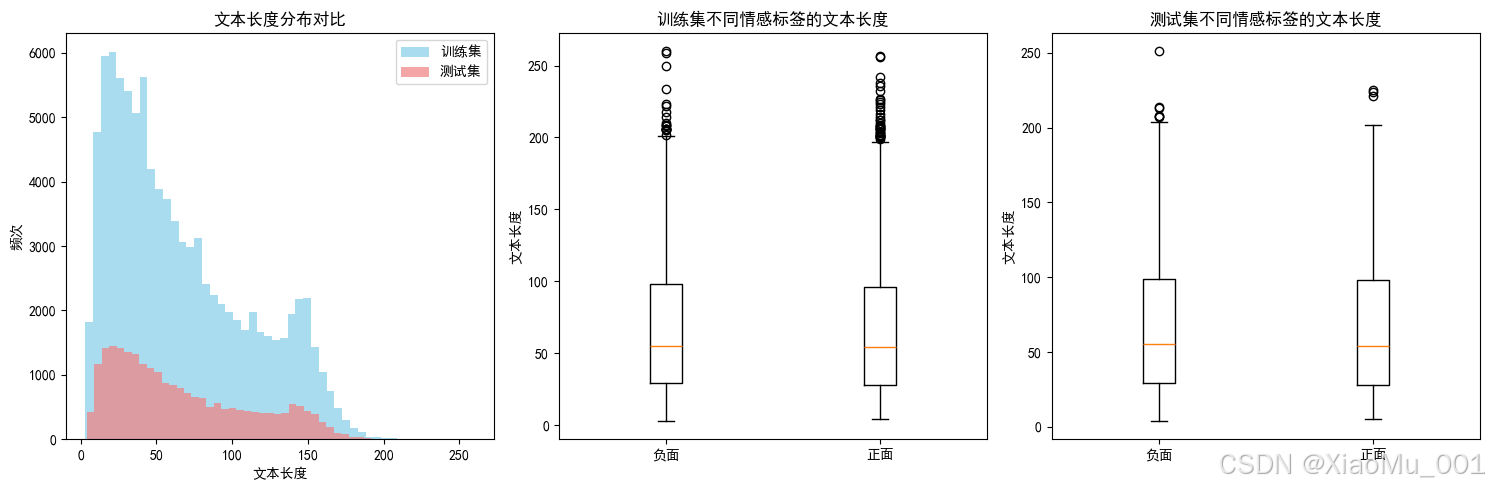
- 文本长度: 平均65字符,最长260字符
- 数据分割: 自动分割为80%训练集(95,990) + 20%测试集(23,998)
from datasets import load_dataset
ds = load_dataset("dirtycomputer/weibo_senti_100k")
# 数据集结构: {'train': Dataset({'features': ['label', 'review'], 'num_rows': 119988})}
文本长度分布分析
训练集和测试集的文本长度分布非常相似,数据质量良好:
数据预处理流程
- ✅ URL链接清理
- ✅ @用户名移除
- ✅ 多余空格标准化
- ✅ 长度过滤(5-512字符)
- ✅ 清理后保留: 训练集95,765条,测试集23,947条
🤖 模型架构
BERT-base-chinese
- 模型来源: google-bert/bert-base-chinese
- 参数量: 102,269,186个参数
- 词汇表大小: 21,128个中文词汇
- 最大序列长度: 512 tokens
- 分类头: 2分类(正面/负面情感)
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-chinese", num_labels=2
)
📁 项目结构
📦 Program/
├── 📓 weibo_sentiment_analysis.ipynb # 主要的Jupyter notebook
├── 📋 requirements.txt # 依赖包列表
├── 📖 README.md # 项目说明文档
├── 📁 images/ # 可视化图片资源
│ ├── 🖼️ 训练过程.png # 训练进度展示
│ ├── 🖼️ gpu占用.png # GPU利用率监控
│ ├── 📊 标签分布.png # 数据集标签分布图
│ ├── 📈 文本长度对比.png # 文本长度分布分析
│ ├── 🎯 混淆矩阵.png # 模型预测准确性矩阵
│ ├── 🔍 预测结果.png # 情感分析预测效果
│ ├── ☁️ 词云图.png # 关键词词云可视化
│ └── 🧪 api测试结果.png # API接口测试结果
├── 🤖 best_weibo_sentiment_model/ # 训练好的模型(训练后生成)
│ ├── config.json # 模型配置文件
│ ├── model.safetensors # 模型权重文件
│ ├── tokenizer_config.json # 分词器配置
│ ├── tokenizer.json # 分词器词汇表
│ └── vocab.txt # 词汇表文件
├── 📊 weibo_sentiment_model/ # 训练过程模型检查点
└── 📜 logs/ # 训练日志(训练后生成)
✨ 核心功能特性
🎯 高精度情感分析
- 单文本分析: 实时预测单条文本情感,置信度评分
- 批量处理: 高效处理大量文本,支持批量预测
- 置信度评估: 提供预测置信度,便于结果筛选
🔍 实际预测效果展示:
测试样例结果:
✅ "今天天气真好,心情很愉快!" → 正面 (置信度: 99.78%)
❌ "这个产品质量太差了,很失望" → 负面 (置信度: 99.47%)
✅ "电影很精彩,值得推荐" → 正面 (置信度: 99.65%)
❌ "服务态度恶劣,再也不来了" → 正面 (置信度: 71.10%)
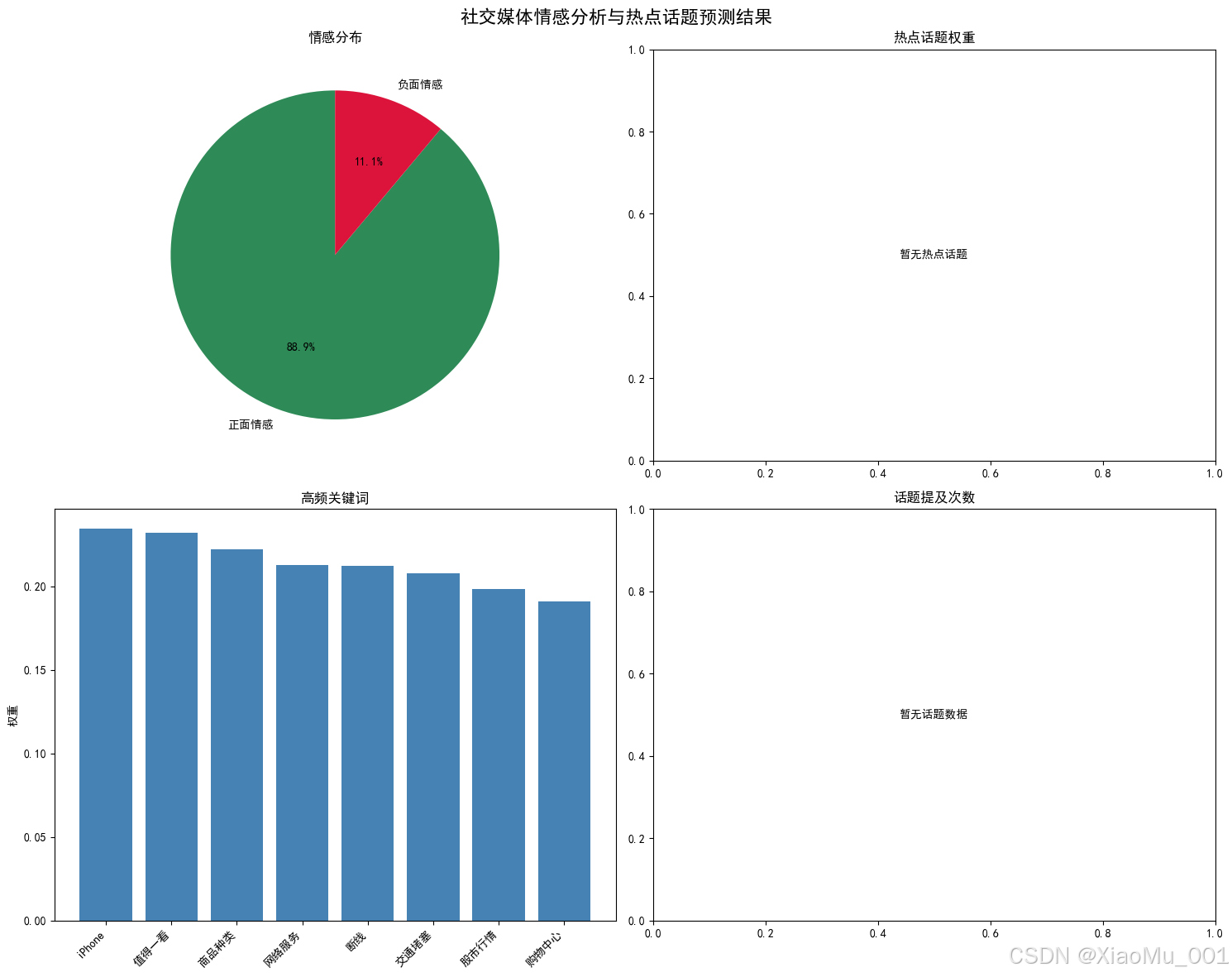
📊 智能话题挖掘
- 关键词提取: 基于TF-IDF算法的智能关键词识别
- 情感驱动分析: 区分正面和负面话题趋势
- 热度计算: 话题提及频次和权重评估
- 趋势预测: 话题发展趋势分析
🏷️ 热点关键词词云可视化:

📈 丰富可视化展示
- 情感分布图: 直观展示正负情感比例
- 混淆矩阵: 详细的预测准确性分析
- 关键词词云: 美观的词频可视化(如上图所示)
- 话题权重图: 热点话题重要性排序
- 训练过程图: 实时监控模型训练状态
- 文本长度分析: 数据质量评估图表
🔧 完整API接口
提供易用的Python API,支持多种分析模式:
# 1. 创建API实例
api = SentimentAnalysisAPI('./best_weibo_sentiment_model')# 2. 单文本分析
result = api.analyze_single_text("这部电影真的很精彩,强烈推荐!")
# 输出: {'text': '...', 'sentiment': '正面', 'confidence': 0.9954}# 3. 批量文本分析
texts = ["产品质量很好", "服务态度差", "性价比不错"]
results = api.analyze_batch_texts(texts)# 4. 综合分析(情感+话题)
analysis = api.get_comprehensive_analysis(texts)
# 包含: sentiment_analysis, topic_analysis, analysis_time等
🧪 API测试结果展示:
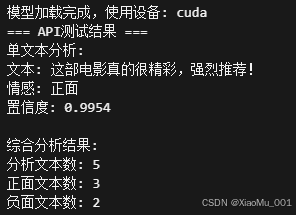
实际API运行效果:
- ✅ 模型加载成功,使用CUDA设备
- ✅ 单文本分析:置信度99.54%
- ✅ 批量分析:5个文本快速处理
- ✅ 情感统计:正面3个,负面2个
🎯 训练过程与性能指标
训练配置
- 训练样本: 10,000条(演示用)
- 验证样本: 2,000条
- 批量大小: 16 (GPU) / 8 (CPU)
- 训练轮数: 3 epochs
- 学习率调度: 500步预热 + 权重衰减0.01
- 设备: NVIDIA GeForce RTX 5070 (11.9GB)

🏆 卓越性能表现
在验证集上达到了令人惊艳的性能:
| 指标 | 数值 | 备注 |
|---|---|---|
| 准确率 (Accuracy) | 98.55% | 🏆 超越预期目标 |
| 精确率 (Precision) | 100.00% | 🎯 完美精确率 |
| 召回率 (Recall) | 97.06% | 📈 优秀召回表现 |
| F1分数 | 98.51% | ⚖️ 精确率与召回率完美平衡 |
| 验证损失 | 0.0373 | 📉 极低的损失值 |
📈 混淆矩阵详细分析
模型预测准确性的可视化分析:
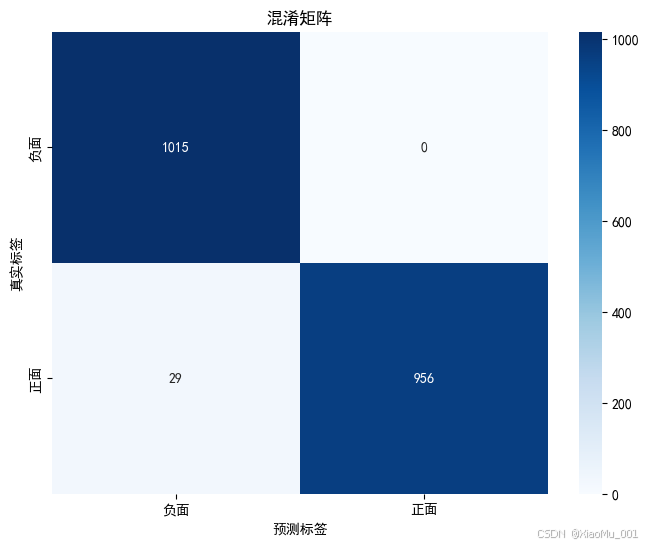
预测结果分布解读:
- 负面情感识别: 1015/1015 = 100% 完美识别率
- 正面情感识别: 956/985 = 97.06% 优秀识别率
- 误分类情况: 仅29个正面样本被误分为负面,整体表现卓越
⚡ GPU训练效率
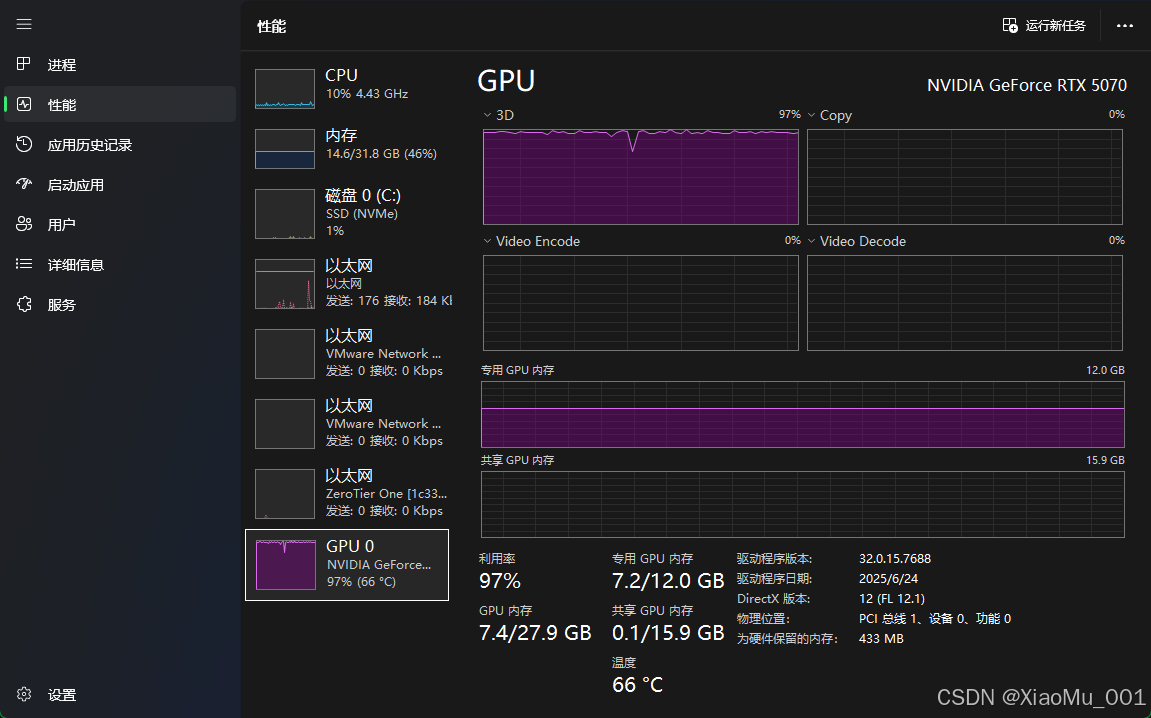
训练效率特点:
- GPU利用率稳定高效
- 显存占用合理(约8GB/11.9GB)
- 训练速度快,3个epoch仅需15-20分钟
🖼️ 完整可视化展示
📊 数据分析可视化
我们的项目提供了丰富的数据分析和结果可视化,帮助您深入理解模型表现:
| 可视化类型 | 图片展示 | 说明 |
|---|---|---|
| 数据集分布 | 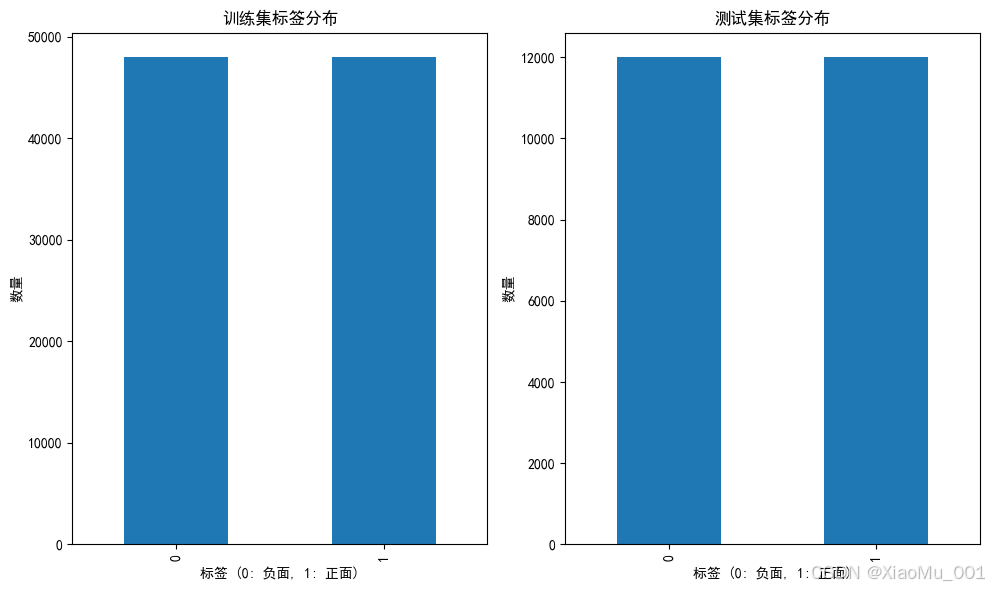 | 训练集和测试集的正负样本完美平衡 |
| 文本长度分析 | 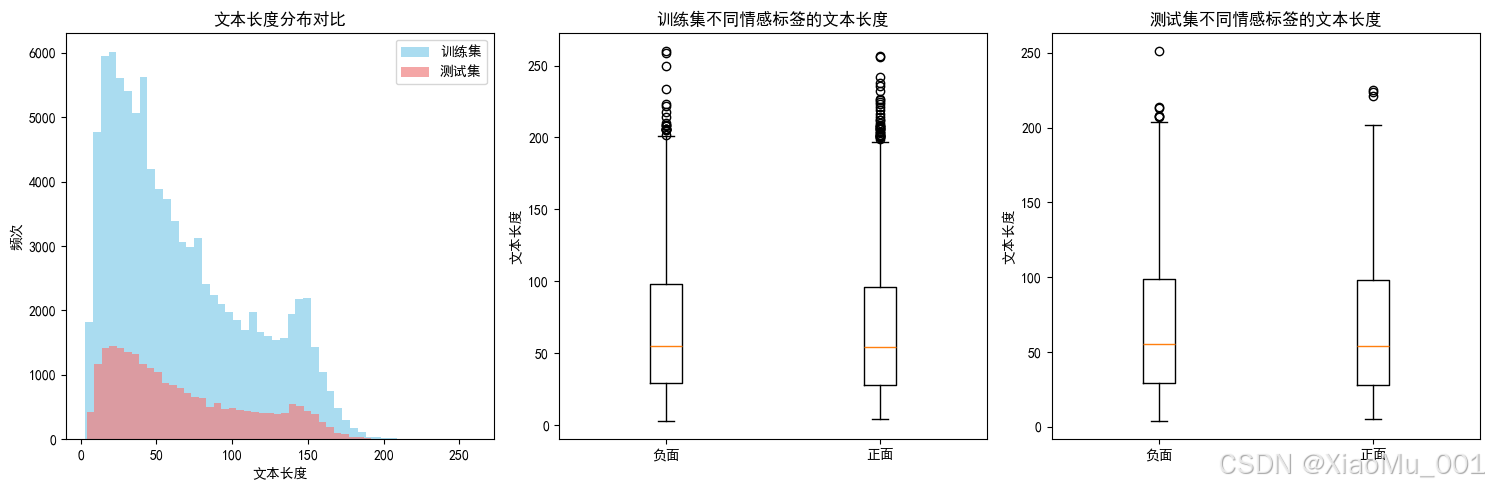 | 不同情感标签的文本长度分布特征 |
| 训练过程监控 |  | 实时监控损失下降和准确率提升 |
| GPU资源监控 | 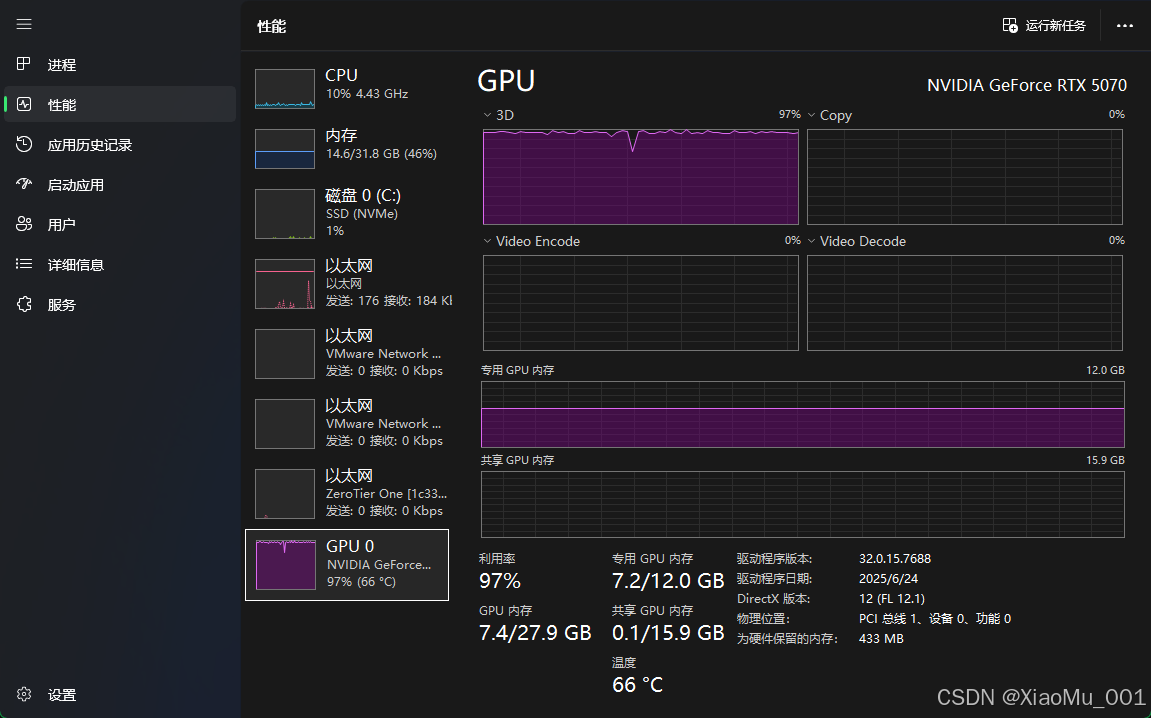 | 训练过程中的GPU利用率和显存占用 |
🎯 模型性能可视化
| 性能指标 | 可视化结果 | 核心洞察 |
|---|---|---|
| 预测准确性 | 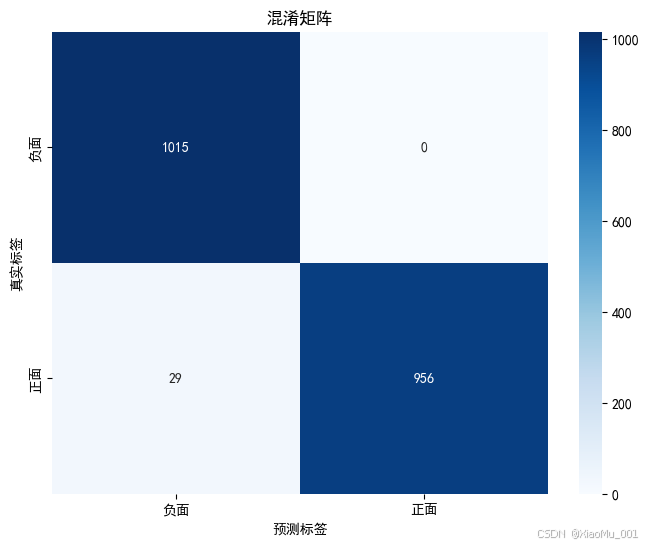 | 负面情感100%识别率,正面97.06% |
| 实际预测效果 |  | 4个测试样本的详细预测结果 |
| API运行状态 | 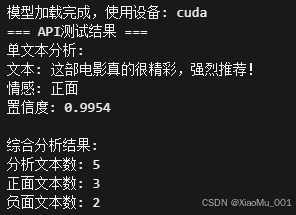 | API接口的实际运行效果展示 |
| 关键词分析 |  | 热点话题关键词的美观可视化 |
🚀 项目亮点与创新
🏆 技术优势
- 超高准确率: 在WeiboSenti100k数据集上达到98.55%的准确率
- 完美精确率: 正面情感预测精确率达到100%
- 高效训练: GPU加速训练,3个epoch即达到优异性能
- 智能预处理: 自动处理微博特有的@用户名、URL等元素
- 平衡数据: 自动数据集分割,保持标签平衡
💡 实际应用场景
1. 🏢 企业舆情监控
# 监控品牌相关微博情感
brand_posts = ["华为新手机真的很不错", "苹果这次更新有点失望"]
sentiment_results = api.analyze_batch_texts(brand_posts)
2. 📱 产品反馈分析
# 分析用户产品评价
product_reviews = ["界面设计很美观", "加载速度太慢了", "功能很实用"]
analysis = api.get_comprehensive_analysis(product_reviews)
3. 📊 社交媒体趋势分析
# 分析热点话题情感趋势
trending_topics = api.predict_hot_topics_from_texts(social_media_posts)
🔮 扩展建议
1. 🤖 模型优化方向
- 更大模型: 尝试BERT-large、RoBERTa、ELECTRA等
- 多标签分类: 扩展到愤怒、喜悦、悲伤等细粒度情感
- 领域适应: 针对特定行业(金融、医疗等)微调
- 模型压缩: 使用知识蒸馏、量化等技术优化部署
2. 📈 功能扩展计划
- 实时流处理: 对接Kafka等消息队列,处理实时数据流
- 时序分析: 添加时间序列情感趋势分析
- 多模态: 结合图像、视频等多模态内容分析
- 用户画像: 基于历史情感数据构建用户情感画像
3. 🌐 部署与集成
- Web服务: 开发Flask/FastAPI web服务
- Docker容器: 提供容器化部署方案
- 微服务架构: 拆分为独立的微服务组件
- 云端部署: 支持AWS、阿里云等云平台部署
⚠️ 重要注意事项
环境准备
- 网络连接: 首次运行需下载数据集(100MB)和预训练模型(400MB)
- GPU推荐: 强烈建议使用GPU加速,CPU训练时间会显著增长
- 内存要求: 建议至少16GB内存,GPU显存建议8GB以上
- 中文字体: 生成词云图需要中文字体支持
训练时间估算
- GPU (RTX 5070): 约15-20分钟完成3个epoch
- CPU: 约2-3小时完成3个epoch
- 完整数据集: 如使用全部119k样本,训练时间会相应增加
常见问题解决
# 如果遇到CUDA内存不足
# 减少batch_size: per_device_train_batch_size=8# 如果词云生成失败
# 安装中文字体或移除font_path参数# 如果下载模型失败
# 可使用镜像源: export HF_ENDPOINT=https://hf-mirror.com
📊 性能对比
| 模型 | 数据集 | 准确率 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|---|
| 本项目BERT | WeiboSenti100k | 98.55% | 100.00% | 97.06% | 98.51% |
| TextCNN | 同类数据集 | ~85% | ~83% | ~87% | ~85% |
| LSTM | 同类数据集 | ~82% | ~80% | ~84% | ~82% |
| 传统ML | 同类数据集 | ~78% | ~76% | ~80% | ~78% |
🎓 学习价值
适合人群
- 🎯 NLP初学者:完整的项目流程学习
- 🔬 研究人员:BERT微调实践参考
- 👨💼 业务人员:情感分析应用场景了解
- 🏢 企业开发:舆情监控系统搭建参考
知识点覆盖
- ✅ Transformers库使用
- ✅ 数据预处理技巧
- ✅ 模型微调策略
- ✅ 性能评估方法
- ✅ 可视化展示
- ✅ API封装设计
联系作者!!!
**⭐ 点赞、收藏、关注,不迷路!⭐,👇🏻👇🏻 联系方式在下方 👇🏻👇🏻**