C++编程语言:标准库:第38章——输入输出流(Bjarne Stroustrup)
第 38章 输入输出流(I/O Streams)
目录
38.1 引言
38.2 I/O流之层级结构
38.2.1 文件流
38.2.2 字符串流
38.3 错误处理
38.4 I/O 操作
38.4.1 输入操作
38.4.1.1 格式化输入
38.4.1.2 非格式化输入
38.4.2 输出操作
38.4.2.1 虚输出函数
38.4.3 操作符(Manipulators)
38.4.4 流状态(Manipulators)
38.4.5 格式化(Formatting)
38.4.5.1 格式化状态
38.4.5.2 标准操作符(Standard Manipulators)
38.4.5.3 用户定义操作符(User-Defined Manipulators)
38.5 流迭代器(Stream Iterators)
38.6 缓冲区(Buffering)
38.6.1 输出流和缓冲区(Output Streams and Buffers)
38.6.2 输入流和缓冲区(Input Streams and Buffers)
38.6.3缓冲区迭代器(Buffer Iterators)
38.6.3.1 istreambuf_iterator
38.6.3.2 ostreambuf_iterator
38.7 建议(Advice)
38.1 引言
I/O 流库提供格式化和非格式化的缓冲文本和数值 I/O。I/O 流工具的定义可以在 <istream>,<ostream> 等中找到;参见 §30.2。
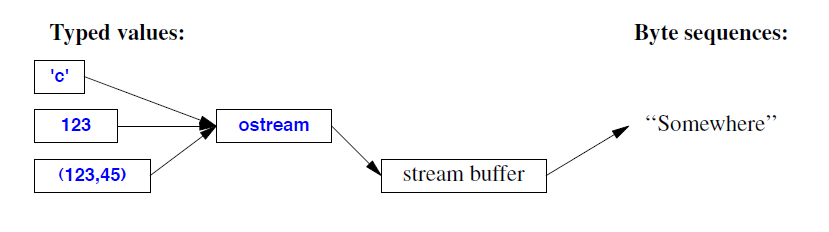
ostream 将类型化对象转换为字符流(字节):
istream 将字符流(字节)转换为类型对象:
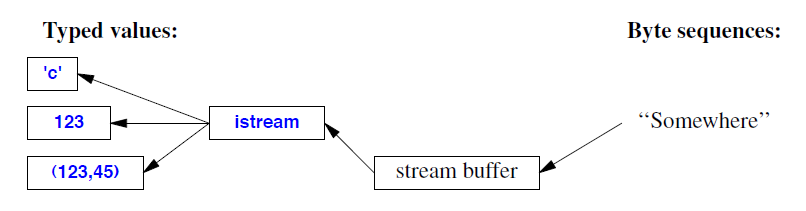
iostream 是一种既可以充当 istream 又可以充当 ostream 的流。图中的缓冲区是流缓冲区(streambufs;§38.6)。你需要它们来定义从 iostream 到新类型设备、文件或内存的映射。istream 和 ostream 的操作在 §38.4.1 和 §38.4.2 中描述。
使用该库不需要了解实现流库的技术。因此,我仅介绍理解和使用 iostream 所需的一般概念。如果你需要实现标准流、提供一种新的流或提供新的本地化(locale),除了此处提供的内容外,你还需要一份标准副本、一本完善的系统手册以及一些可运行的代码示例。
流 I/O 系统的关键组件可以用图形方式表示如下:
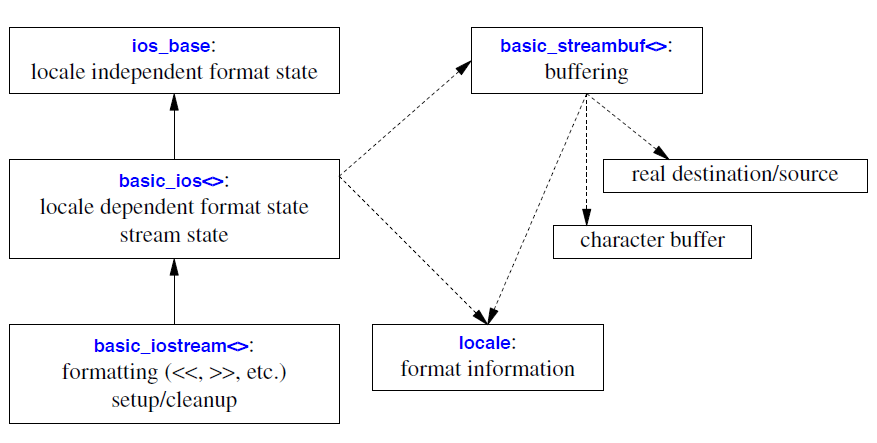
实线箭头表示“派生自……”。虚线箭头表示“指向……”。标有 <> 的类是通过字符类型参数化并包含locale的模板。
I/O 流操作:
• 类型安全且类型敏感
• 可扩展(设计新类型时,无需修改现有代码即可添加匹配的 I/O 流操作符)
• 本地化敏感(第 39 章)
• 高效(尽管其潜力并非总能充分发挥)
• 可与 C 风格的 stdio 互操作(§43.3)
• 包含格式化、非格式化和字符级操作
basic_iostream基于 basic_istream (§38.6.2) 和 basic_ostream (§38.6.1) 定义:
template<typename C, typename Tr = char_traits<C>>
class basic_iostream :
public basic_istream<C,Tr>, public basic_ostream<C,Tr> {
public:
using char_type = C;
using int_type = typename Tr::int_type;
using pos_type = typename Tr::pos_type;
using off_type = typename Tr::off_type;
using traits_type = Tr;
explicit basic_iostream(basic_streambuf<C,Tr>∗ sb);
virtual ˜basic_iostream();
protected:
basic_iostream(const basic_iostream& rhs) = delete;
basic_iostream(basic_iostream&& rhs);
basic_iostream& operator=(const basic_iostream& rhs) = delete;
basic_iostream& operator=(basic_iostream&& rhs);
void swap(basic_iostream& rhs);
};
模板参数分别指定字符类型和用于操作字符的特征(§36.2.2)。
请注意,不提供复制操作:共享或克隆相当复杂的流状态将难以实现且使用成本高昂。移动操作旨在供派生类使用,因此受到保护。移动 iostream 而不移动其定义派生类(例如 fstream)的状态会导致错误。
标准库有三个标准流:
| 标准 I/O 流 | |
| cout | 标准字符输出流(通常默认输出到屏幕) |
| cin | 标准字符输入流(通常默认为键盘输入) |
| cerr | 标准字符错误输出(无缓冲区) |
| clog | 标准字符错误输出(有缓冲区) |
| wcin | cin的wistream版本 |
| wcout | cout的wostream版本 |
| wcerr | cerr的wostream版本 |
| wclog | clog的wostream版本 |
<iosfwd> 中提供了流类型和流对象的前向声明。
38.2 I/O流之层级结构
istream 可以连接到输入设备(例如键盘)、文件或string。同样,ostream 可以连接到输出设备(例如文本窗口或 HTML 引擎)、文件或string。I/O 流工具按类层级结构进行组织:
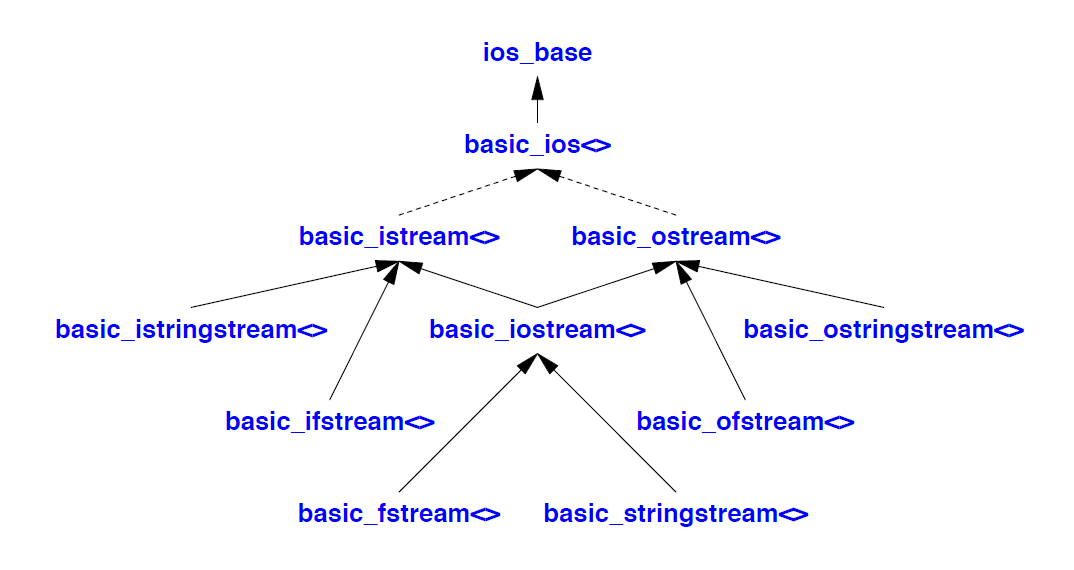
以 <> 为后缀的类是基于字符类型参数化的模板。虚线表示虚基类(§21.3.5)。
关键类是 basic_ios,其中定义了大部分实现和许多操作。然而,大多数普通用户(以及一些非普通用户)从未见过它:它主要是流的实现细节。它在§38.4.4中进行了描述。它的大部分功能都是在其功能的语境中描述的(例如,格式化;§38.4.5)。
38.2.1 文件流
在 <fstream> 中,标准库提供了往返于文件的流:
• ifstreams 用于读取文件
• ofstreams 用于写入文件
• fstreams 用于读取和写入文件
文件流遵循一个共同的模式,因此我仅描述 fstream:
template<typename C, typename Tr=char_traits<C>>
class basic_fstream
: public basic_iostream<C,Tr> {
public:
using char_type = C;
using int_type = typename Tr::int_type;
using pos_type = typename Tr::pos_type; // for positions in file
using off_type = typename Tr::off_type; // for offsets in file
using traits_type = Tr;
// ...
};
fstream 操作集相当简单:
| basic_fstream<C,Tr> (§iso.27.9) | |
| fstream fs {}; | fs 是未附加到文件的文件流 |
| fstream fs {s,m}; | fs 是为名为 s 的文件打开的文件流,文件流模式为 m;s 可以是string或 C 风格的字符串 |
| fstream fs {fs2}; | 移动构造函数:fs2 移动到 fs;fs2 变为未附加 |
| fs=move(fs2) | 移动赋值函数:fs2 移动到 fs;fs2 变为未附加 |
| fs.swap(fs2) | 交换fs 移动到 fs2的状态 |
| p=fs.rdbuf() | p 是指向 fs 的文件流缓冲区 (basic_filebuf<C,Tr>) 的指针 |
| fs.is_open() | fs是打开的吗? |
| fs.open(s,m) | 使用模式 m 打开名为 s 的文件并让 fs 引用它;如果无法打开文件,则设置 fs 的失败位;s 可以是string或 C 风格字符串 |
| fs.close() | 关闭与 fs 关联的文件(如果有) |
此外,字符串流重写了 basic_ios 保护的虚函数 underflow()、pbackfail()、overflow()、setbuf()、seekoff() 和 seekpos()(§38.6)。
文件流没有复制操作。如果希望两个名称引用同一个文件流,请使用引用或指针,或者谨慎操作文件流缓冲区(§38.6)。
如果 fstream 打开失败,则该流处于 bad() 状态(§38.3)。
<fstream> 中定义了六个文件流别名:
using ifstream = basic_ifstream<char>;
using wifstream = basic_ifstream<wchar_t>;
using ofstream = basic_ofstream<char>;
using wofstream = basic_ofstream<wchar_t>;
using fstream = basic_fstream<char>;
using wfstream = basic_fstream<wchar_t>;
你可以使用 ios_base (§38.4.4) 中指定的几种模式之一打开文件:
| 流模式(§iso.27.5.3.1.4) | |
| ios_base::app | 追加(append)(即,加到文件末尾) |
| ios_base::ate | “at end”(打开文件并定位到文件尾) |
| os_base::binary | 二进制模式;注意系统特定的行为 |
| os_base::in | 针对读 |
| os_base::out | 针对写 |
| os_base::trunc | 清除文件内容,使其长度变为0 |
在每一种情况下,打开文件的具体效果可能取决于操作系统。如果操作系统无法以某种方式执行打开文件的请求,则会导致流处于 bad() 状态(§38.3)。例如:
ofstream ofs("target"); // ‘‘o’’ for ‘‘output’’ implying ios::out
if (!ofs)
error("couldn't open 'target' for writing");
fstream ifs; // ‘‘i’’ for ‘‘input’’ implying ios::in
ifs.open("source",ios_base::in);
if (!ifs)
error("couldn't open 'source' for reading");
有关文件中的定位,请参阅§38.6.1。
38.2.2 字符串流
在 <sstream> 中,标准库提供了往返于字符串的流:
• istringstreams 用于读取字符串
• ostringstreams 用于写入字符串
• stringstreams 用于读取和写入字符串
字符串流遵循一个共同的模式,因此我仅描述 stringstream:
template<typename C, typename Tr = char_traits<C>, typename A = allocator<C>>
class basic_stringstream
: public basic_iostream<C,Tr> {
public:
using char_type = C;
using int_type = typename Tr::int_type;
using pos_type = typename Tr::pos_type; // for positions in string
using off_type = typename Tr::off_type; // for offsets in string
using traits_type = Tr;
using allocator_type = A;
// ...
stringstream 的操作有:
| basic_stringstream<C,Tr,A> (§iso.27.8) | |
| stringstream ss {m}; | ss 是模式为 m 的空字符串流 |
| stringstream ss {}; | 默认构造函数:stringstream ss {ios_base::out|ios_base::in}; |
| stringstream ss {s,m}; | ss 是一个字符串流,其缓冲区由字符串 s 初始化,模式为 m |
| stringstream ss {s}; | stringstream ss {s,ios_base::out|ios_base::in}; |
| stringstream ss {ss2}; | 移动构造函数:ss2 移动到 ss;ss2 变为空 |
| ss=move(ss2) | 移动赋值函数:ss2 移动到 ss;ss2 变为空 |
| p=ss.rdbuf() | p指向 ss的字条串缓冲区(一个 basic_string buf<C,Tr,A>) |
| s=ss.str() | s 是 ss 中字符的字符串副本:s=ss.rdbuf()−>str() |
| ss.str(s) | ss 的缓冲区由字符串 s 初始化:ss.rdbuf()->str(s); 如果 ss 的模式为 ios::ate (''at end''),则写入 s 的值会添加到 s 的字符之后; 否则,写入的值会覆盖 s 的字符 |
| ss.swap(ss2) | 交换 ss 和 ss2 的状态 |
打开模式在§38.4.4中描述。对于istringstream,默认模式为ios_base::in。对于ostringstream,默认模式为ios_base::out 。
此外,字符串流重写了 basic_ios 保护的虚函数 underflow()、pbackfail()、overflow()、setbuf()、seekoff() 和 seekpos()(§38.6)。
字符串流没有复制操作。如果希望两个名称引用同一个字符串流,请使用引用或指针。
<sstream> 中定义了六个字符串流别名:
using istringstream = basic_istringstream<char>;
using wistringstream = basic_istringstream<wchar_t>;
using ostringstream = basic_ostringstream<char>;
using wostringstream = basic_ostringstream<wchar_t>;
using stringstream = basic_stringstream<char>;
using wstringstream = basic_stringstream<wchar_t>;
例如:
void test()
{
ostringstream oss {"Label: ",ios::ate}; // write at end
cout << oss.str() << '\n'; // writes "Label: "
oss<<"val";
cout << oss.str() << '\n'; // writes "Label: val" ("val" appended after "Label: ")
ostringstream oss2 {"Label: "}; // write at beginning
cout << oss2.str() << '\n'; // writes "Label: "
oss2<<"val";
cout << oss2.str() << '\n'; // writes "valel: " (val overwr ites "Label: ")
}
我倾向于仅使用 str() 来读取 istringstream 的结果。
无法直接输出字符串流;必须使用 str():
void test2()
{
istringstream iss;
iss.str("Foobar"); // Fill iss
cout << iss << '\n'; // writes 1
cout << iss.str() << '\n'; // OK: writes "Foobar"
}
可能令人惊讶的 1 的原因是, iostream 转换为其状态以进行测试:
if (iss) { // the last operation of iss succeeded; iss’s state is good() or eof()
// ...
}
else {
// handle problem
}
38.3 错误处理
iostream 可以处于四种状态之一,在 <ios> (§38.4.4) 的 basic_ios 中定义:
| 流状态(§iso.27.5.5.4) | |
| good() | 前面的iostream操作成功 |
| eof() | 我们到达了输入结束(“文件结束”) |
| fail() | 发生了一些意外的事情(例如,我们寻找一个数字并找到了“x”) |
| bad() | 发生了一些意外的严重事件(例如磁盘读取错误) |
对未处于 good() 状态的流执行任何操作均无效;视为无操作。iostream 可以用作条件。在这种情况下,如果 iostream 的状态为 good(),则条件为真(成功)。这就是读取值流的惯用法的基础:
for (X x; cin>>x;) { // 读入类型 X 的输入缓冲区
// ... 用 x 做某事 ...
}
// 当 >> 无法从 cin 读取另一个 X 时,我们到达这里
读取失败后,我们可能能够清除流并继续:
int i;
if (cin>>i) {
// ... use i ...
} else if (cin.fail()){ //可能是格式化错误
cin.clear();
string s;
if (cin>>s) { // 我们也许可以使用字符串来恢复
// ... 使用s ...
}
}
或者,可以使用异常来处理错误:
| 异常控制:basic_ios<C,Tr> (§38.4.4, §iso.27.5.5) | |
| st=ios.exceptions() | st 是 ios 的 iostate |
| ios.exceptions(st) | 将ios的iostate设置为st |
例如,当 cin 的状态设置为 bad() 时(例如,通过 cin.setstate(ios_base::badbit)),我们可以让 cin 抛出 basic_ios::failure:
cin.exceptions(cin.exceptions()|ios_base::badbit);
例如:
struct Io_guard { // RAII class for iostream exceptions
iostream& s;
auto old_e = s.exceptions();
Io_guard(iostream& ss, ios_base::iostate e) :s{ss} { s.exceptions(s.exceptions()|e); }
˜Io_guard() { s.exceptions(old_e); }
};
void use(istream& is)
{
Io_guard guard(is.ios_base::badbit);
// ... use is ...
}
catch (ios_base::badbit) {
// ... bail out! ...
}
我倾向于使用异常来处理那些我认为无法恢复的 iostream 错误。这通常意味着所有 bad() 异常。
38.4 I/O 操作
I/O 操作的复杂性反映了传统、对 I/O 性能的需求以及人类期望的多样性。此处的描述基于传统的英语小字符集 (ASCII)。不同字符集和不同自然语言的处理方式将在第 39 章中描述。
38.4.1 输入操作
输入操作由 istream (§38.6.2) 提供,这些操作位于 <istream> 中,除了读入字符串的操作外;这些操作位于 <string> 中。basic_istream 主要用作更具体的输入类(例如 istream 和 istringstream)的基类:
template<typename C, typename Tr = char_traits<C>>
class basic_istream : virtual public basic_ios<C,Tr> {
public:
using char_type = C;
using int_type = typename Tr::int_type;
using pos_type = typename Tr::pos_type;
using off_type = typename Tr::off_type;
using traits_type = Tr;
explicit basic_istream(basic_streambuf<C,Tr>∗ sb);
virtual ˜basic_istream(); // release all resources
class sentry;
// ...
protected:
// move but no copy:
basic_istream(const basic_istream& rhs) = delete;
basic_istream(basic_istream&& rhs);
basic_istream& operator=(const basic_istream& rhs) = delete;
basic_istream& operator=(basic_istream&& rhs);
// ...
};
对于 istream 的用户来说,sentry 类是一个实现细节。它提供了标准库和用户自定义输入操作的通用代码。需要首先执行的代码(“前缀代码”)——例如刷新绑定流——由 sentry 的构造函数提供。例如:
template<typename C, typename Tr = char_traits<C>>
basic_ostream<C,Tr>& basic_ostream<C,Tr>::operator<<(int i)
{
sentry s {∗this};
if (!s) { // check whether all is well for output to start
setstate(failbit);
return ∗this;
}
// ... output the int ...
return ∗this;
}
sentry是由输入操作的实施者而不是其用户使用的。
38.4.1.1 格式化输入
格式化的输入主要由 >>(“输入”、“获取”或“提取”)运算符提供:
| 格式化输入(§27.7.2.2, §iso.21.4.8.9) | |
| in>>x | 根据 x 的类型,从 in 读取到 x 中;x 可以是算术类型、指针、basic_string、valarray、basic_streambuf,或用户提供了合适的operation>>() 的任何类型 |
| getline(in,s) | 从 in 中读一行到string s 中 |
内置类型对于 istream( 和 ostream )来说是“已知的”,因此如果 x 是内置类型,cin>>x 表示 cin.operator>>(x)。如果 x 是用户定义类型,cin>>x 表示 operand>>(cin,x) (§18.2.5)。也就是说,iostream 输入是类型敏感的、固有类型安全的且可扩展。新类型的设计者无需直接访问 iostream 的实现即可提供 I/O 操作。
如果指向函数的指针是 >> 的目标,则该函数将被调用,并以 istream 作为其参数。例如,cin>>pf 的结果为 pf(cin)。这是输入操作符(例如 skipws (§38.4.5.2))的基础。输出流操作符比输入流操作符更常见,因此该技术将在 §38.4.3 中进一步解释。
除非另有说明,istream 操作都会返回其 istream 的引用,以便我们可以进行“链式”操作。例如:
template<typename T1, typename T2>
void read_pair(T1& x, T2& y)
{
cin >> c1 >> x >> c2 >> y >> c3;
if (c1!='{' || c2!=',' || c3!='}') { // 无法恢复的输入格式错误
cin.setstate(ios_base::badbit); // set badbit
throw runtime_error("bad read of pair");
}
}
默认情况下 >> 会跳过空格。例如:
for (int i; cin>>i && 0<i;)
cout << i << '\n';
这将采用空格分隔的正整数序列并将它们打印到一列。
可以使用 noskipws (§38.4.5.2) 来抑制跳过空格。
输入操作并非virtual函数。也就是说,用户无法执行 in>>base 操作(其中 base 是一个类层次结构),并自动将 >> 解析为针对相应派生类的操作。然而,一种简单的技术可以实现这种行为;参见 §38.4.2.1。此外,可以扩展此类方案,使其能够从输入流中读取任意类型的对象;参见 §22.2.4。
38.4.1.2 非格式化输入
非格式化输入可用于更精细地控制读取,并可能提升性能。非格式化输入的一种用途是实现格式化输入:
| 非格式化输入(§27.7.2.3) | |
| x=in.get() | 从 in 读取一个字符并返回其整数值;返回 EOF 表示文件结束 |
| n.get(c) | 将一个字符从 in 读入 c |
| in.get(p,n,t) | 从 in 中读取最多 n 个字符到 [p:...); 将 t 视为终止符 |
| in.get(p,n) | in.get(p,n,'\n') |
| in.getline(p,n,t) | 从 in 中读取最多 n 个字符到 [p:...); 将 t 视为终止符;从 in 中删除终止符 |
| in.getline(p,n) | in.g etline(p,n,'\n') |
| in.read(p,n) | 从 in 中读取最多 n 个字符到 [p:...) |
| x=in.gcount() | x 是最近一次非格式化输入操作读取的字符数 |
| in.putback(c) | 将 c 放回 in 的流缓冲区 |
| in.unget() | 将流缓冲区后退一个,以便读取的下一个字符与前一个字符相同 |
| in.ignore(n,d) | 从 in 中提取字符并丢弃,直到 n 个字符被丢弃,或者找到 d(并丢弃) |
| in.ignore(n) | in.ignore(n,traits::eof()) |
| in.ignore() | in.ignore(1,traits::eof()) |
| in.swap(in2) | 交换 in 和 in2 的值 |
如果可以选择,请使用格式化输入(§38.4.1.1)代替这些底层输入函数。
当你需要用字符组成值时,简单的 get(c) 非常有用。另一个 get() 函数和 getline() 函数会将字符序列读入固定大小的区域 [p:...]。它们会一直读取,直到达到最大字符数或找到终止符(默认为 '\n')。它们会在写入的字符(如果有)末尾放置一个 0;getline() 会从输入中删除其终止符(如果找到),而 get() 则不会。例如:
void f() // low-level, old-style line read
{
char word[MAX_WORD][MAX_LINE]; // MAX_WORD arrays of MAX_LINE char each
int i = 0;
while(cin.getline(word[i++],MAX_LINE,'\n') && i<MAX_WORD)
/* do nothing */ ;
// ...
}
对于这些函数,终止读取的原因并不明显:
• 我们找到了终止符。
• 我们读取了最大数量的字符。
• 我们到达了文件末尾。
• 存在非格式输入错误
后两种情况通过查看文件状态(§38.3)来处理。通常情况下,针对这些情况,相应的处理措施会有所不同。
read(p,n) 不会在读取字符后将 0 写入数组。显然,格式化的输入运算符比未格式化的运算符更易于使用且更不容易出错。
以下函数取决于流缓冲区(§38.6)与实际数据源之间的详细交互,应仅在必要时使用,并务必谨慎:
| 非格式化输入(§27.7.2.3) | |
| x=in.peek() | x 是当前输入字符;x 不会从 in 的流缓冲区中提取,而是作为下一个读取的字符 |
| n=in.readsome(p,n) | 如果 rdbuf()−>in_avail()==−1,则调用 setstate(eofbit);否则,读取 min(n,mostrdbuf()−>in_avail()) 个字符到 [p:...); n 为读取的字符数 |
| x=in.sync() | 同步缓冲区:in.rdbuf()->pubsync() |
| pos=in.tellg() | pos 是 in 的 get 指针的位置 |
| in.seekg(pos) | 将获取in指针放置在位置 pos |
| in.seekg(off,dir) | 将获取in指针放置在方向 dir 的偏移off处 |
38.4.2 输出操作
输出操作由 ostream (§38.6.1) 提供,可以在 <ostream> 中找到,但写出string的操作除外;这些操作可以在 <string> 中找到:
template<typename C, typename Tr = char_traits<C>>
class basic_ostream : virtual public basic_ios<C,Tr> {
public:
using char_type = C;
using int_type = typename Tr::int_type;
using pos_type = typename Tr::pos_type;
using off_type = typename Tr::off_type;
using traits_type = Tr;
explicit basic_ostream(basic_streambuf<char_type ,Tr>∗ sb);
virtual ˜basic_ostream(); // release all resources
class sentry; // see §38.4.1
// ...
protected:
// move but no copy:
basic_ostream(const basic_ostream& rhs) = delete;
basic_ostream(basic_ostream&& rhs);
basic_ostream& operator=(basic_ostream& rhs) = delete;
basic_ostream& operator=(const basic_ostream&& rhs);
// ...
};
ostream 提供格式化输出、非格式化输出(字符输出)以及对其 streambuf 的简单操作(§38.6):
| 输出操作(§iso.27.7.3.6, §iso.27.7.3.7, §iso.21.4.8.9) | |
| out<<x | 根据 x 的类型将 x 写入 out;x 可以是算术类型、指针、basic_string、bitset、complex、valarray,或任何用户已定义合适operation<<() 的类型 |
| out.put(c) | 将字符 c 写入 out |
| out.write(p,n) | 将字符 [p:p+n) 写入 out |
| out.flush() | 清空字符缓冲区至目标 |
| pos=out.tellp() | pos 是 out 的 put 指针的位置 |
| out.seekp(pos) | 将 out 的放置指针放在位置 pos |
| out.seekp(off,dir) | 将 out 的放置指针放置在方向dir的偏移量off处 |
除非另有说明,否则 ostream 操作都会返回指向其 ostream 的引用,以便我们可以进行“链式”操作。例如:
cout << "The value of x is " << x << '\n';
请注意,char 值输出为字符,而不是小整数。例如:
void print_val(char ch)
{
cout << "the value of '" << ch << "' is " << int{ch} << '\n';
}
void test()
{
print_val('a');
print_val('A');
}
这将打印:
the value of 'a' is 97
the value of 'A' is 65
对于用户定义类型,运算符 << 的版本通常很容易编写:
template<typename T>
struct Named_val {
string name;
T value;
};
ostream& operator<<(ostream& os, const Named_val& nv)
{
return os << '{' << nv.name << ':' << nv.value << '}';
}
这对于每个 Named_val<X> 都有效,其中 X 定义了 <<。为了完全通用,必须为 basic_string<C,Tr> 定义 << 。
38.4.2.1 虚输出函数
ostream 的成员不是虚函数。程序员可以添加的输出操作不是成员,因此它们也不能是虚函数。这样做的原因之一是为了让一些简单操作(例如将字符放入缓冲区)达到接近最佳的性能。这类操作的运行时效率通常至关重要,因此必须使用内联。虚函数仅用于为处理缓冲区溢出和下溢的操作提供灵活性(§38.6)。
然而,程序员有时想要输出一个只知道基类的对象。由于不知道确切的类型,因此无法简单地通过为每个新类型定义一个 << 来实现正确的输出。相反,可以在抽象基类中提供一个虚输出函数:
class My_base {
public:
// ...
virtual ostream& put(ostream& s) const = 0; // write *this to s
};
ostream& operator<<(ostream& s, const My_base& r)
{
return r.put(s); // use the right put()
}
也就是说,put() 是一个虚函数,它确保在 << 中使用正确的输出操作。
鉴于此,我们可以写出:
class Sometype : public My_base {
public:
// ...
ostream& put(ostream& s) const override; // 实输出函数
};
void f(const My_base& r, Sometype& s) // 使用 << 调用正确的 put()
{
cout << r << s;
}
这将虚 put() 函数集成到 ostream 和 << 提供的框架中。该技术通常用于提供类似函数的操作,但运行时选择基于其第二个参数。这类似于通常用于根据两种动态类型选择操作的名为“双重派发(double dispatch)”的技术(§22.3.1)。类似的技术也可用于将输入操作virtual(§22.2.4)。
38.4.3 操作符(Manipulators)
如果将指向函数的指针作为 << 的第二个参数,则调用指向的函数。例如,cout<<pf 表示 pf(cout)。这样的函数称为操作符。接受参数的操作符可能很有用。例如:
cout << setprecision(4) << angle;
这将打印四位浮点变量angle的值。
为此,setprecision 返回一个由 4 初始化的对象,并在调用时调用cout.precision(4)。这样的操作符是一个函数对象,它通过 << 而不是 () 调用。该函数对象的确切类型由实现定义,但可以像这样定义:
struct smanip {
ios_base& (∗f)(ios_base&,int); // 被调函数
int i; // value to be used
smanip(ios_base&(∗ff)(ios_base&,int), int ii) :f{ff}, i{ii} { }
};
template<typename C, typename Tr>
basic_ostream<C,Tr>& operator<<(basic_ostream<C,Tr>& os, const smanip& m)
{
m.f(os,m.i); //使用 m 的存储值调用 m 的 f
return os;
}
现在我们像这样定义 setprecision():
inline smanip setprecision(int n)
{
auto h = [](ios_base& s, int x) −> ios_base& { s.precision(x); return s; };
return smanip(h,n); // 使函数对象化
}
要返回引用,需要明确指定 lambda 的返回类型。ios_base 不能被用户复制。
现在我们可以写出:
cout << setprecision(4) << angle;
程序员可以根据需要以 smanip 的风格定义新的操作符。这样做不需要修改标准库模板和类的定义。
标准库操作符在§38.4.5.2 中描述。
38.4.4 流状态(Manipulators)
在 <ios> 中,标准库定义了基类 ios_base,在其中定义了流类的大部分接口:
template<typename C, typename Tr = char_traits<C>>
class basic_ios : public ios_base {
public:
using char_type = C;
using int_type = typename Tr::int_type;
using pos_type = typename Tr::pos_type;
using off_type = Tr::off_type;
using traits_type = Tr;
// ...
};
basic_ios 类管理流的状态:
• 流与其缓冲区之间的映射(§38.6)
• 格式化选项(§38.4.5.1)
• 本地化设置的使用(第 39 章)
• 错误处理(§38.3)
• 与其他流和 stdio 的联系(§38.4.4)
它可能是标准库中最复杂的类。
ios_base 保存不依赖于模板参数的信息:
class ios_base {
public:
using fmtflags = /* implementation-defined type */;
using iostate = /* implementation-defined type */;
using openmode = /* implementation-defined type */;
using seekdir = /* implementation-defined type */;
class failure; // exception class
class Init; // initialize standard iostreams
};
所有实现定义的类型均为位掩码类型;也就是说,它们支持按位逻辑运算,例如 & 和 |。例如 int(§11.1.2)和 bitset(§34.2.2)。
ios_base 控制 iostream 与 stdio 的联系(或断开联系)(§43.3):
| 基本ios_base操作(§27.7.2.2, §iso.27.5.3.4) | |
| ios_base b {}; | 默认构造函数;protected |
| ios.˜ios_base() | 析构函数;virtual |
| b2=sync_with_stdio(b) | 如果 b==true,则将 ios 与 stdio 同步; 否则共享缓冲区可能已损坏; b 是之前的同步状态;static |
| b=sync_with_stdio() | b=sync_with_stdio(true) |
在程序执行过程中,在第一个 iostream 操作之前调用 sync_with_stdio(true)可确保 iostream 和 stdio (§43.3) I/O 操作共享缓冲区。在第一个流 I/O 操作之前调用 sync_with_stdio(false) 可防止缓冲区共享,并可在某些实现中显著提高 I/O 性能。
请注意,ios_base 没有复制或移动操作。
| ios_base流状态iostate成员常量(§iso.27.5.3.1.3) | |
| badbit | 发生了一些意外的严重事件(例如,磁盘读取错误) |
| failbit | 发生了一些意外的事情(例如,我们寻找一个数字并找到了“x”) |
| eofbit | 我们到达输入结束(例如,文件结束) |
| goodbit | 一切都很好 |
basic_ios 提供了用于读取流中的这些位( good()、fail() 等)的函数。
| ios_base模式openmode成员常量(§iso.27.5.3.1.4) | |
| app | 追加(在流末尾插入输出) |
| ate | 末尾(流末尾的位置) |
| binary | 不要对字符应用格式 |
| in | 输入流 |
| out | 输出流 |
| trunc | 使用前截断流(将流的大小设置为零) |
ios_base::binary 的具体含义取决于具体实现。不过,通常的含义是将一个字符映射到一个字节。例如:
template<typename T>
char∗ as_bytes(T& i)
{
return static_cast<char∗>(&i); // treat that memory as bytes
}
void test()
{
ifstream ifs("source",ios_base::binar y); // stream mode is binary
ofstream ofs("target",ios_base::binar y); // stream mode is binary
vector<int> v;
for (int i; ifs.read(as_bytes(i),siz eof(i));) // read bytes from binary file
v.push_back(i);
// ... do something with v ...
for (auto i : v) // write bytes to binary file:
ofs.write(as_bytes(i),siz eof(i));
}
当处理“仅仅是一些位(bits)时”且没有明显且合理的字符串表示的对象时,请使用二进制 I/O。图像和音频/视频流就是例子。
seekg() (§38.6.2) 和 seekp() (§38.6.2) 操作需要一个方向:
| ios_base方向seekdir成员常量(§iso.27.5.3.1.5) | |
| beg | 从当前文件开头查找 |
| cur | 从当前位置开始搜索 |
| end | 从当前文件末尾向后搜索 |
从 basic_ios 派生的类会根据存储在其 basic_io 中的信息来格式化输出并提取对象。
ios_base 的操作可以概括为:
| basic_ios<C,Tr>(§iso.27.5.5) | |
| basic_ios ios {p}; | 根据 p 指向的流缓冲区构造 ios |
| ios.˜basic_ios() | 销毁ios:释放ios的所有资源 |
| bool b {ios}; | 转换为 bool:b 初始化为 !ios.fail(); explicit |
| b=!ios | b=ios.fail() |
| st=ios.rdstate() | st 是 ios 的 iostate |
| ios.clear(st) | 将ios的iostate设置为st |
| ios.clear() | 将ios的iostate设置为good |
| ios.setstate(st) | 将 st 添加到 ios 的 iostate 中 |
| ios.good() | ios 的状态是否良好(是否设置了 goodbit)? |
| ios.eof() | ios的状态是文件结束吗? |
| ios.fail() | ios状态是否失败? |
| ios.bad() | ios的状态不好吗? |
| st=ios.exceptions() | st 是 ios iostate 的异常位 |
| ios.exceptions(st) | 将 ios 的 iostate 的异常位设置为 st |
| p=ios.tie() | p 是指向绑定流或 nullptr 的指针 |
| p=ios.tie(os) | 将输出流 os 绑定到 ios; p 是指向先前绑定的流的指针或 nullptr |
| p=ios.rdbuf() | pi 是指向 ios 流缓冲区的指针 |
| p=ios.rdbuf(p2) | 将 ios 的流缓冲区设置为 p2 指向的缓冲区; p 是指向前一个流缓冲区的指针 |
| ios3=ios.copyfmt(ios2) | 将 io2 状态中与格式化相关的部分复制到 ios;调用任何类型为 copyfmt_event 的 ios2 回调;复制 ios2.pword 和 ios2.iword 指向的值;ios3 是之前的格式化状态 |
| c=ios.fill() | c是ios的填充字符 |
| c2=ios.fill(c) | 设置c为ios的填充字符;c2为前一个填充字符 |
| loc2=ios.imbue(loc) | 将 ios 的语言环境设置为 loc;loc2 是之前的语言环境 |
| c2=narrow(c,d) | c2 是将 c 转换为 char_type 后得到的 char 值,d 是默认值: use_facet<ctype<char_type>>(getloc()).narrow(c,d)) |
| c2=widen(c) | c2 是将 c 转换为 char 类型后得到的 char_type 值: use_facet<ctype<char_type>>(getloc()).widen(c)) |
| ios.init(p) | 将ios设置为默认状态,并使用p指向的流缓冲区;protected |
| ios.set_rdbuf(p) | 让ios使用p指向的流缓冲区;受保护 |
| ios.move(ios2) | 复制和移动操作;protected |
| ios.swap(ios2) | 交换ios和ios2的状态;protected;noexcept |
将 ios(包括 istream 和 ostream)转换为 bool 类型对于读取多个值的常用习惯用法至关重要:
for (X x; cin>>x;) {
// ...
}
这里,cin>>x 的返回值是对 cin 的 ios 的引用。这个 ios 被隐式转换为表示 cin 状态的bool值。因此,我们可以等效地写成:
for (X x; !(cin>>x).fail();) {
// ...
}
tie() 用于确保绑定流的输出出现在与其绑定的流的输入之前。例如,cout 绑定到 cin:
cout << "Please enter a number: ";
int num;
cin >> num;
此代码没有明确调用 cout.flush(),因此如果 cout 没有与 cin 绑定,用户就会看到输入请求。
| ios_base操作(§iso.27.5.3.5, §iso.27.5.3.6) | |
| i=xalloc() | i 是新 (word,word) 对的索引;static |
| r=iob.iword(i) | r 是对第 i 个 long 的引用 |
| r=iob.pword(i) | r 是对第 i 个 void∗ 的引用 |
| iob.register_callback(fn,i) | 将回调 fn 注册到 iword(i) |
有时,人们希望添加流的状态。例如,人们可能希望一个流“知晓”一个complex应该以极坐标还是笛卡尔坐标输出。ios_base 类提供了一个函数 xalloc() 来为这种简单的状态信息分配空间。xalloc() 返回的值标识了一对可以通过 iword() 和 pword() 访问的位置。
有时,实现者或用户需要收到流状态变化的通知。register_callback() 函数会“注册”一个函数,当其对应的“事件”发生时,该函数会被调用。因此,调用 imbue()、copyfmt() 或 ˜ios_base() 函数将分别调用已注册的 imbue_event、copyfmt_event 或 erasing_event 函数。当状态发生变化时,已注册的函数会被调用,参数为 register_callback() 提供的 i 。
event 和 event_callback 类型在 ios_base 中定义:
enum event {
erase_event,
imbue_event,
copyfmt_event
};
using event_callback = void (∗)(event, ios_base&, int index);
38.4.5 格式化(Formatting)
流 I/O 的格式由对象类型、流状态(§38.4.4)、格式状态(§38.4.5.1)、区域设置信息(第 39 章)和显式操作(例如,操纵器;§38.4.5.2)的组合控制。
38.4.5.1 格式化状态
在 <ios> 中,标准库定义了一组实现定义的位掩码类型 fmtflags 的格式化常量,作为 ios_base 类的成员:
| ios_base格式化fmtflags常量(§iso.27.5.3.1.2) | |
| boolalpha | 使用true与false的符号表示 |
| dec | 整数基是10 |
| hex | 整数基是10进制 |
| oct | 整数基是8 |
| fixed | 浮点格式 dddd.dd |
| scientific | 科学格式 d.ddddEdd |
| internal | 在前缀(例如+)和数字之间填充 |
| left | 在值后填充 |
| right | 在值前填充 |
| showbase | 输出时,八进制数前面加 0,十六进制数前面加 0x |
| showpoint | 始终显示小数点(例如 123)。 |
| showpos | 正数显示 +(例如 +123) |
| skipws | 跳过输入中的空格 |
| unitbuf | 每次输出操作后刷新 |
| uppercase | 在数字输出中使用大写字母,例如 1.2E10 和 0X1A2 |
| adjustfield | 设置值在其字段中的位置:left, right或internal |
| basefield | 设置整数的基数:dec,oct或hex |
| floatfield | 设置浮点格式:scientific或fixed |
奇怪的是,没有 defaultfloat 或 hexfloat 标志。要获得等效值,请使用操作符 defaultfloat 和 hexfloat (§38.4.5.2),或者直接操作 ios_base:
ios.unsetf(ios_base::floatfield); //use the default floating-point for mat
ios.setf(ios_base::fixed | ios_base::scientific, ios_base::floatfield); // use hexadecimal floats
iostream 的格式状态可以通过其 ios_base 中提供的操作读取和写入(设置):
| ios_base格式化fmtflags操作(§iso.27.5.3.2) | |
| f=ios.flags() | f 是 ios 的格式化标志 |
| f2=ios.flags(f) | 将 ios 的格式化标志设置为 f;f2 是标志的旧值 |
| f2=ios.setf(f) | 将 ios 的格式化标志设置为 f;f2 是标志的旧值 |
| f2=ios.setf(f,m) | f2=ios.setf(f&m) |
| ios.unsetf(f) | 清除 ios 中的标志 f |
| n=ios.precision() | n 是 ios 的精度 |
| n2=ios.precision(n) | 将 ios 的精度设置为 n;n2 是旧精度 |
| n=ios.width() | n 是 ios 的宽度 |
| n2=ios.width(n) | 将 ios 的宽度设置为 n;n2 是旧宽度 |
精度是一个整数,它决定了显示浮点数的位数:
• 通用格式 (defaultfloat) 允许实现选择一种格式,以在可用空间内最佳地保留值的样式呈现值。精度指定了最大位数。
• 科学格式 (scientific) 呈现小数点前一位数字和指数的数值。精度指定了小数点后的最大位数。
• 固定格式 (fixed) 呈现整数部分后跟小数点和小数部分的数值。精度指定了小数点后的最大位数。例如,参见 §38.4.5.2。
浮点值会被四舍五入,而不是截断,precision() 不会影响整数输出。例如:
cout.precision(8);
cout << 1234.56789 << ' ' << 1234.56789 << ' ' << 123456 << '\n';
cout.precision(4);
cout << 1234.56789 << ' ' << 1234.56789 << ' ' << 123456 << '\n';
输出:
1234.5679 1234.5679 123456
1235 1235 123456
width() 函数指定下一个标准库输出操作(数值、bool、C 风格字符串、字符、指针、string和bitset)所需的最小字符数(§34.2.2)。例如:
cout.width(4);
cout << 12; // print 12 preceded by two spaces
可以通过 fill() 函数指定“填充”或“填充符”。例如:
cout.width(4);
cout.fill('#');
cout << "ab"; // print ##ab
默认填充字符为空格,默认字段大小为 0,表示“根据需要填充任意数量的字符”。字段大小可以重置为默认值,如下所示:
cout.width(0); // ‘‘尽可能多的字符’’
调用 width(n) 将最小字符数设置为 n 。如果提供的字符数超过 n,则所有字符都会被打印出来。例如:
cout.width(4);
cout << "abcdef"; // print abcdef
它不会将输出截断为 abcd。通常情况下,让正确的输出看起来丑陋总比让错误的输出看起来正常要好。
width(n) 调用仅影响紧随其后的 << 输出操作。例如:
cout.width(4);
cout.fill('#');
cout << 12 << ':' << 13; // print ##12:13
这将生成 ##12:13,而不是 ##12###:##13 。
如果通过许多单独的操作明确控制格式选项变得繁琐,我们可以使用用户定义的操作器(§38.4.5.3)将它们组合起来。
ios_base 还允许程序员设置 iostream 的区域设置(第 39 章):
| ios_base locale操作(§iso.27.5.3.5, §iso.27.5.3.3) | |
| loc2=ios.imbue(loc) | 将 ios 的语言环境设置为 loc;loc2 是语言环境的旧值 |
| loc=ios.getloc() | loc 是 ios 的语言环境 |
38.4.5.2 标准操作符(Standard Manipulators)
标准库提供了与各种格式状态和状态变化相对应的操作符。标准操作符定义在 <ios>、<istream>、<ostream> 和 <iomanip>(用于接受参数的操作符)中:
| 基于<ios>的I/O操作符(§iso.27.5.6, §iso.27.7.4) | |
| s<<boolalpha | 使用true和false的符号表示(输入和输出) |
| s<<noboolalpha | s.unsetf(ios_base::boolalpha) |
| s<<showbase | 输出时,八进制数以 0 为前缀,十六进制数以 0x 为前缀 |
| s<<noshowbase | s.unsetf(ios_base::showbase) |
| s<<showpoint | 始终显示小数点 |
| s<<noshowpoint | s.unsetf(ios_base::showpoint) |
| s<<showpos | 对于正数显示 + |
| s<<noshowpos | s.unsetf(ios_base::showpos) |
| s<<uppercase | 在数字输出中使用大写字母,例如 1.2E10 和 0X1A2 |
| s<<nouppercase | 在数字输出中使用小写,例如 1.2e10 和 0x1a2 |
| s<<unitbuf | 每次输出操作后刷新 |
| s<<nounitbuf | 每次输出操作后不要刷新 |
| s<<internal | 在格式化模式标记的位置进行填充 |
| s<<left | 值后填充 |
| s<<right | 在值之前填充 |
| s<<dec | 整数基数为 10 |
| s<<hex | 整数基数为 16 |
| s<<oct | 整数基数为 8 |
| s<<fixed | 浮点格式 dddd.dd |
| s<<scientific | 科学格式 d.ddddEdd |
| s<<hexfloat | 尾数和指数均以 16 为基数,指数以 p 开头,例如 A.1BEp−C 和 a.bcdef |
| s<<defaultfloat | 使用默认浮点格式 |
| s>>skipws | 跳过空格 |
| s>>noskipws | s.unsetf(ios_base::skipws) |
以下每个操作都返回对其第一个(流)操作数 s 的引用。例如:
cout << 1234 << ',' << hex << 1234 << ',' << oct << 1234 << '\n'; // print 1234,4d2,2322
我们可以明确设置浮点数的输出格式:
constexpr double d = 123.456;
cout << d << "; "
<< scientific << d << "; "
<< hexfloat << d << "; "
<< fixed << d << "; "
<< defaultfloat << d << '\n';
输出:
123.456; 1.234560e+002; 0x1.edd2f2p+6; 123.456000; 123.456
浮点格式是“粘性的(sticky)”;也就是说,它会在后续的浮点运算中持续存在。
| 基于<ostream>的I/O操作符(§iso.27.5.6, §iso.27.7.4) | |
| os<<endl | 输入 '\n' 并刷新 |
| os<<ends | 输入 '\0' |
| os<<flush | 刷新 |
当 ostream 被销毁、tie() 绑定的 istream 需要输入(§38.4.4)以及实现认为有利时,都会刷新 ostream。显式刷新流的情况很少见。同样,<<endl 可以被认为等同于 <<'\n',但后者可能更快一些。我发现
cout << "Hello, World!\n";
比
cout << "Hello, World!" << endl;
更容易阅读和编写。
如果你确实需要频繁刷新,请考虑使用 cerr 和 unitbuf。
| 基于<iomanip>的I/O操作符(§iso.27.5.6, §iso.27.7.4) | |
| s<<resetiosflags(f) | 清除标记f |
| s<<setiosflags(f) | 设置标记f |
| s<<setbase(b) | 输出以 b 为基数的整数 |
| s<<setfill(int c) | 将 c 设为填充字符 |
| s<<setprecision(n) | 精度为 n 位数字 |
| s<<setw(n) | 下一个字段宽度为 n 个字符 |
| is>>get_money(m,intl) | 使用 is 的 money_g 和 facet 读取 is; m 为长整型双精度数或 basic_string; 如果 intl==true,则使用标准的三字母货币名称 |
| is>>get_money(m) | s>>get_money(m,false) |
| os<<put_money(m,intl) | 使用 os 的 money_put 接口将 m 写入 os; money_put 接口决定 m 可接受的类型; 如果 intl==true,则使用标准的三字母货币名称 |
| os<<put_money(m) | s<<put_money(m,false) |
| is>>get_time(tmp,fmt) | 根据 fmt 格式读入 ∗tm,使用 is 的 time_get facet |
| os<<put_time(tmp,fmt) | 根据 fmt 格式将 ∗tm 写入 os,使用 os 的 time_put facet |
时间facet见§39.4.4,时间格式见§43.6。
例如:
cout << '(' << setw(4) << setfill('#') << 12 << ") (" << 12 << ")\n"; // print (##12) (12)
| istream操作符(§iso.27.5.6, §iso.27.7.4) | |
| s>>skipws | 跳过空格(在 <ios> 中) |
| s>>noskipws | s.unsetf(ios_base::skipws) (在 <ios> 中) |
| is>>ws | 去掉空白(在 <istream> 中) |
默认情况下,>> 会跳过空格 (§38.4.1)。此默认值可以通过 >>skipws 和 >>noskipws 修改。例如:
string input {"0 1 2 3 4"};
istringstream iss {input};
string s;
for (char ch; iss>>ch;)
s += ch;
cout << s; // print "01234"
istringstream iss2 {input};
iss>>noskipws;
for (char ch; iss2>>ch;)
s += ch;
cout << s; // print "0 1 2 3 4"
}
如果你想明确处理空格(例如,使换行符有意义)并且仍然使用 >> ,那么 noskipws 和 >>ws 会很方便。
38.4.5.3 用户定义操作符(User-Defined Manipulators)
程序员可以添加标准风格的操作符。这里,我介绍一种我发现对格式化浮点数很有用的附加风格。
格式化由大量令人困惑的独立函数控制(§38.4.5.1)。例如,precision() 函数会保留所有输出操作,而 width() 函数仅应用于下一个数字输出操作。我想要的是能够轻松地以预定义的格式输出浮点数,而不会影响流上后续的输出操作。基本思路是定义一个类来表示格式,另一个类表示格式和待格式化的值,然后定义一个运算符 << 来根据格式将值输出到 ostream 。例如:
Form gen4 {4}; // general for mat, precision 4
void f(double d)
{
Form sci8;
sci8.scientific().precision(8); // scientific for mat, precision 8
cout << d << ' ' << gen4(d) << ' ' << sci8(d) << ' ' << d << '\n';
Form sci {10,ios_base::scientific}; // scientific for mat, precision 10
cout << d << ' ' << gen4(d) << ' ' << sci(d) << ' ' << d << '\n';
}
调用 f(1234.56789) 会输出:
1234.57 1235 1.23456789e+003 1234.57
1234.57 1235 1.2345678900e+003 1234.57
请注意,使用Form不会影响流的状态,因此 d 的最后一个输出具有与第一个相同的默认格式。
这是一个简化的实现:
class Form; // our for matting type
struct Bound_form { // Form plus value
const Form& f;
double val;
};
class Form {
friend ostream& operator<<(ostream&, const Bound_form&);
int prc; // precision
int wdt; // width 0 means ‘‘as wide as necessary’’
int fmt; // general, scientific, or fixed (§38.4.5.1)
// ...
public:
explicit Form(int p =6, ios_base::fmtflags f =0, int w =0) : prc{p}, fmt{f}, wdt{w} {}
Bound_form Form::operator()(double d) const // make a Bound_for m for *this and d
{
return Bound_form{∗this,d};
}
Form& scientific() { fmt = ios_base::scientific; return ∗this; }
Form& fixed() { fmt = ios_base::fixed; return ∗this; }
Form& general() { fmt = 0; return ∗this; }
Form& uppercase();
Form& lowercase();
Form& precision(int p) { prc = p; return ∗this; }
Form& width(int w) { wdt = w; return ∗this; } // applies to all types
Form& fill(char);
Form& plus(bool b = true); // explicit plus
Form& trailing_zeros(bool b = true); // print trailing zeros
// ...
};
其理念是,一个 Form 包含格式化一个数据项所需的所有信息。默认值的选择对于许多用途来说都是合理的,并且可以使用各种成员函数来重置格式化的各个方面。() 运算符用于将值与要用于输出的格式绑定。然后,可以通过合适的 << 函数将 Bound_form(即 Form 加上一个值)输出到给定的流:
ostream& operator<<(ostream& os, const Bound_form& bf)
{
ostringstream s; // §38.2.2
s.precision(bf.f.prc);
s.setf(bf.f.fmt,ios_base::floatfield);
s << bf.val; //compose string in s
return os << s.str(); // output s to os
}
编写一个不太简单的 << 实现留作练习。
请注意,这些声明将 << 和 () 的组合变成了一个三元运算符;cout<<sci4{d} 在进行任何实际计算之前,将 ostream、格式和值收集到一个函数中。
38.5 流迭代器(Stream Iterators)
在 <iterator> 中,标准库提供了迭代器,允许将输入和输出流视为序列[输入开始:输入结束)和[输出开始:输出结束):
template<typename T,
typename C = char,
typename Tr = char_traits<C>,
typename Distance = ptrdiff_t>
class istream_iterator
:public iterator<input_iterator_tag, T, Distance , const T∗, const T&> {
using char_type = C;
using traits_type = Tr;
using istream_type = basic_istream<C,Tr>;
// ...
};
template<typename T, typename C = char, typename Tr = char_traits<C>>
class ostream_iterator: public iterator<output_iterator_tag, void, void, void, void> {
using char_type = C;
using traits_type = Tr;
using ostream_type = basic_ostream<C,Tr>;
// ...
};
例如:
copy(istream_iterator<double>{cin}, istream_iterator<double ,char>{},
ostream_iterator<double>{cout,";\n"});
当 ostream_iterator 使用第二个(string)参数构造时,该字符串将作为每个元素值后的终止符输出。因此,如果你在 copy() 调用中输入 1 2 3,则输出为:
1;
2;
3;
为 stream_iterator 提供的操作符与其他迭代器适配器相同(§33.2.2):
| 流迭代器操作(§iso.24.6) | |
| istream_iterator p {st}; | 输入流st 的迭代器 |
| istream_iterator p {p2}; | 复制构造函数:p 是 istream_iterator p2 的副本 |
| ostream_iterator p {st}; | 输出流st 的迭代器 |
| ostream_iterator p {p2}; | 复制构造函数:p 是 ostream_iterator p2 的副本 |
| ostream_iterator p {st,s}; | 输出流 st 的迭代器;使用 C 风格字符串 s 作为输出元素之间的分隔符 |
| p=p2 | p 是 p2 的副本 |
| p2=++p | p 和 p2 指向下一个元素 |
| p2=p++ | p2=p,++p |
| ∗p=x | 在 p 之前插入 x |
| ∗p++=x | 在 p 之前插入 x,然后增加 p |
除了构造函数之外,这些操作通常由通用算法使用,例如 copy(),而不是由用户直接使用。
38.6 缓冲区(Buffering)
从概念上讲,输出流将字符放入缓冲区。一段时间后,这些字符会被写入(“刷新到”)它们应该去的地方。这样的缓冲区称为流缓冲区 (streambuf)。其定义见 <streambuf>。不同类型的流缓冲区实现不同的缓冲策略。通常,流缓冲区将字符存储在数组中,直到发生溢出迫使其将字符写入其实际目标位置。因此,输出流 (ostream) 可以用图形方式表示如下:
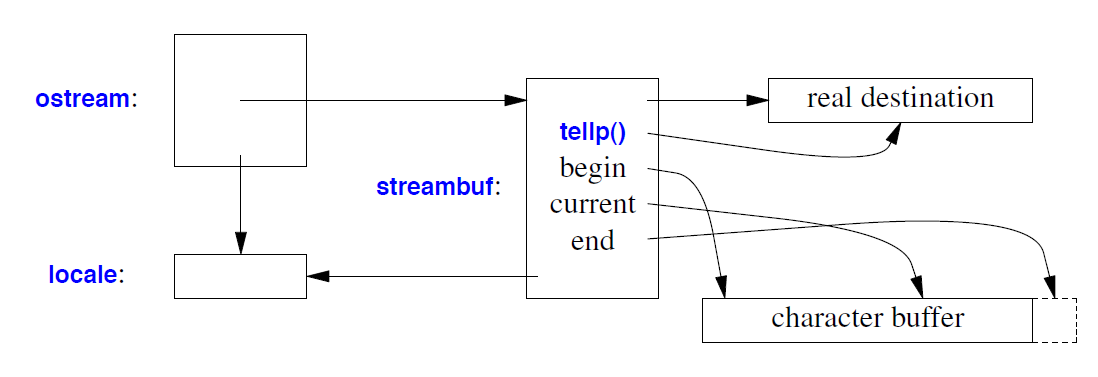
ostream 及其 streambuf 的模板参数集必须相同,并且它们决定字符缓冲区中使用的字符类型。
istream 与之类似,只是字符以相反的方向流动。
无缓冲 I/O 简单来说就是 streambuf 立即传输每一个字符,而不是保留字符直到收集到足够的字符以实现高效传输。
缓冲机制中的关键类是basic_streambuf:
template<typename C, typename Tr = char_traits<C>>
class basic_streambuf {
public:
using char_type = C; // the type of a character
using int_type = typename Tr::int_type; // the integer type to which
// a character can be converted
using pos_type = typename Tr::pos_type; // type of position in buffer
using off_type = typename Tr::off_type; // type of offset from position in buffer
using traits_type = Tr;
// ...
virtual ˜basic_streambuf();
};
与往常一样,针对(据称)最常见的情况提供了几个别名:
using streambuf = basic_streambuf<char>;
using wstreambuf = basic_streambuf<wchar_t>;
basic_streambuf 包含大量操作。许多public操作只是调用一个protected虚函数,该函数确保派生类中的函数针对特定类型的缓冲区正确实现相应操作:
| public basic_streambuf<C,Tr> 操作(§iso.27.6.3) | |
| sb.˜basic_streambuf() | 析构函数:释放所有资源;虚函数 |
| loc=sb.getloc() | loc 是sb的本地化 |
| loc2=sb.pubimbue(loc) | sb.imbue(loc); loc2 是指向前一个本地化的指针 |
| psb=sb.pubsetbuf(s,n) | psb=sb.setbuf(s,n) |
| pos=sb.pubseekoff(n,w,m) | pos=sb.seekoff(n,w,m) |
| pos=sb.pubseekoff(n,w) | pos=sb.seekoff(n,w) |
| pos=sb.pubseekpos(n,m) | pos=sb.seekpos(n,m) |
| pos=sb.pubseekpos(n) | pos=sb.seekpos(n,ios_base::in|ios_base::out) |
| sb.pubsync() | sb.sync() |
所有构造函数都受到保护,因为 basic_streambuf 被设计为基类。
| protected basic_streambuf<C,Tr> 操作(§iso.27.6.3) | |
| basic_streambuf sb {}; | 构建没有字符缓冲区和全局本地化的 sb |
| basic_streambuf sb{sb2}; | sb 是 sb2 的副本(它们共享一个字符缓冲区) |
| sb=sb2 | sb 是 sb2 的副本(它们共享一个字符缓冲区); sb 的旧资源被释放 |
| sb.swap(sb2) | 交换 sb 和 sb2 的状态 |
| sb.imbue(loc) | loc 成为sb的本地化;virtual |
| psb=sb.setbuf(s,n) | 设置 sb 的缓冲区;psb=&sb; s 为 const char∗ 类型,n 为 streamsize 类型;virtual |
| pos=sb.seekoff(n,w,m) | 使用偏移量 n、方向 w 和模式 m 进行搜索;pos 是结果位置或 pos_type(off_type(-1)),表示错误;virtual |
| pos=sb.seekoff(n,w) | pos=sb.seekoff(n,way,ios_base::in|ios_base::out) |
| pos=sb.seekpos(n,m) | 定位到位置 n 和模式 m; pos 是最终位置,或 pos_type(off_type(-1)),表示错误;virtual |
| n=sb.sync() | 将字符缓冲区与真实目标或源同步;virtual |
虚函数的具体含义由派生类决定。
streambuf 包含一个用于 << 和其他输出操作写入的 “输出区域(put area)”(§38.4.2),以及一个用于 >> 和其他输入操作读取的 “获取区域(get area)”(§38.4.1)。每一个区域都由一个起始指针、一个当前指针和一个尾后指针描述:
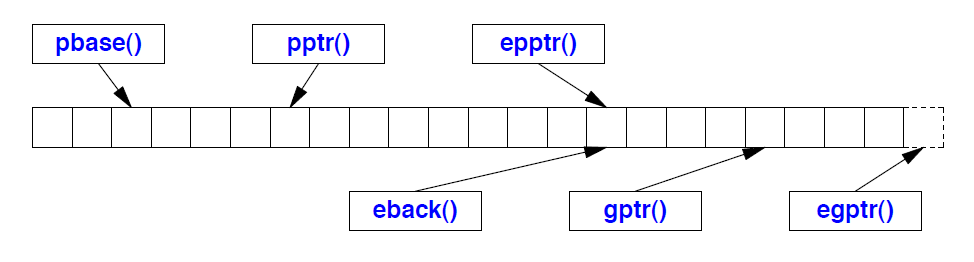
溢出由虚函数 overflow()、underflow() 和 uflow() 处理。
对于定位的使用,请参阅§38.6.1。
放入和获取接口分为公共接口和受保护接口:
| public 放置和获取basic_streambuf<C,Tr> 操作 (§iso.27.6.3) | |
| n=sb.in_avail() | 如果有可用的读取位置,则n=sb.egptr()−sb.gptr();否则返回 sb.showmanyc() |
| c=sb.snextc() | 增加sb的get指针,则c=∗sb.gptr() |
| n=sb.sbumpc() | 增加sb的获取指针 |
| c=sb.sgetc() | 如果没有剩余字符可获取,则 c=sb.underflow();否则 c=∗sb.gptr() |
| n=sb.sgetn(p,n) | n=sb.xsgetn(p,n); p 是一个 char* |
| n=sb.sputbackc(c) | 将 c 放回获取区域并减少 gptr; 如果放回成功,则n=Tr::to_int_type(∗sb.gptr()); 否则 n=sb.pbackfail(Tr::to_int_type(c)) |
| n=sb.sungetc() | 减少获取指针; 如果获取成功,n=Tr::to_int_type(∗sb.gptr()); 否则,n=sb.pbackfail(Tr::to_int_type()) |
| n=sb.sputc(c) | 如果没有剩余字符可填入,n=sb.overflow(Tr::to_int_type(c)); 否则 ∗sb.sptr()=c; n=Tr::to_int_type(c) |
| n=sb.sputn(s,n) | n=sb.xsputn(s,n); s 是一个 const char∗ |
受保护的接口提供了简单、高效且通常为内联的函数来操作放置和获取指针。此外,还有一些虚函数可供派生类重写。
| protected放置和获取basic_streambuf<C,Tr> 操作 (§iso.27.6.3) | |
| sb.setg(b,n,end) | 获取区域为[b,e);当前获取指针为n |
| pc=sb.eback() | [pc:sb.egptr())是获取区域 |
| pc=sb.gptr() | pc 是获取指针 |
| pc=sb.egptr() | [sb.eback():pc)是获取区域 |
| sb.gbump(n) | 增加sb的获取指针 |
| n=sb.showmanyc() | “显示字符数”;n 表示无需调用 sb.underflow() 即可读取的字符数或 n=-1 表示没有字符可供读取;virtual |
| n=sb.underflow() | 获取区域中没有其他字符;补充获取区域; n=Tr::to_int_type(c),其中 c 是新的当前获取字符;virtual |
| n=sb.uflow() | 类似于 sb.underflow(),但在读取新的当前获取字符后推进获取指针;virtual |
| n=sb.pbackfail(c) | 放回操作失败;如果覆盖的 pbackfail() 无法放回,则 n=Tr::eof();virtual |
| n=sb.pbackfail() | n=sb.pbackfail(Tr::eof()) |
| sb.setp(b,e) | put 区域为 [b,e) 当前 put 指针为 b |
| pc=sb.pbase() | [pc:sb.epptr())是放置区域 |
| pc=sb.pptr() | pc是放置指针 |
| pc=sb.epptr() | [sb.pbase(),pc) 是放置区域 |
| sb.pbump(n) | 放置指针加一 |
| n2=sb.xsgetn(s,n) | s 是 const char∗;对 [s:s+n) 中的每一个 p 执行 sb.sgetc(∗p); n2 是读取的字符数;virtual |
| n2=sb.xsputn(s,n) | s 是一个 [const char∗; sb.sputc(∗p),用于 [s:s+n] 中的每个 p; n2 是写入的字符数;virtual |
| n=sb.overflow(c) | 补充put区域,则n=sb.sputc(c);virtual |
| n=sb.overflow() | n=sb.overflow(Tr::eof()) |
showmanyc()(“显示字符数”)函数是一个奇怪的函数,旨在让用户了解机器输入系统的状态。它返回一个预估值,即“很快”可以读取多少个字符,例如,通过清空操作系统的缓冲区而不是等待磁盘读取。如果无法保证在不遇到文件末尾的情况下读取任何字符,则调用 showmanyc() 会返回 -1 。这(必然)是相当底层的,并且高度依赖于实现。在使用 showmanyc() 之前,请务必仔细阅读系统文档并进行一些实验。
38.6.1 输出流和缓冲区(Output Streams and Buffers)
ostream 提供根据约定(§38.4.2)和显式格式指令(§38.4.5)将各种类型的值转换为字符序列的操作。此外,ostream 还提供直接处理其 streambuf 的操作:
template<typename C, typename Tr = char_traits<C>>
class basic_ostream : virtual public basic_ios<C,Tr> {
public:
// ...
explicit basic_ostream(basic_streambuf<C,Tr>∗ b);
pos_type tellp(); // get current position
basic_ostream& seekp(pos_type); // set current position
basic_ostream& seekp(off_type, ios_base::seekdir); // set current position
basic_ostream& flush(); // empty buffer (to real destination)
basic_ostream& operator<<(basic_streambuf<C,Tr>∗ b); // write from b
};
basic_ostream 函数覆盖了 basic_ios 基础中的等效函数。
ostream 的构造需要一个 streambuf 参数,该参数决定了写入的字符的处理方式以及最终的目的地。例如,ostringstream (§38.2.2) 或 ofstream (§38.2.1) 是通过用合适的 streambuf (§38.6) 初始化 ostream 来创建的。
seekp() 函数用于定位 ostream 以进行写入。p 后缀表示它是将字符放入流中的位置。除非流附加到具有定位意义的对象(例如文件),否则这些函数无效。pos_type 表示字符在文件中的位置,off_type 表示相对于 ios_base::seekdir 所指示点的偏移量。
流的位置从 0 开始,因此我们可以将文件视为一个包含 n 个字符的数组。例如:
int f(ofstream& fout) // fout refers to some file
{
fout << "0123456789";
fout.seekp(8); //8 from beginning
fout << '#'; // add '#' and move position (+1)
fout.seekp(−4,ios_base::cur); // 4 backward
fout << '∗'; //add '*' and move position (+1)
}
如果文件最初是空的,我们会得到:
01234∗67#9
在普通的 istream 或 ostream 中,没有类似的方法可以对元素进行随机访问。尝试在文件开头或结尾之外进行定位通常会导致流进入 bad() 状态(§38.4.4)。但是,某些操作系统的操作模式会有所不同(例如,定位可能会调整文件大小)。
flush() 操作允许用户清空缓冲区,而无需等待溢出。
可以使用 << 将 streambuf 直接写入 ostream。这对于 I/O 机制的实现者来说非常方便。
38.6.2 输入流和缓冲区(Input Streams and Buffers)
istream 提供读取字符并将其转换为各种类型值的操作(§38.4.1)。此外,istream 还提供直接处理其 streambuf 的操作:
template<typename C, typename Tr = char_traits<C>>
class basic_istream : virtual public basic_ios<C,Tr> {
public:
// ...
explicit basic_istream(basic_streambuf<C,Tr>∗ b);
pos_type tellg(); // get current position
basic_istream& seekg(pos_type); // set current position
basic_istream& seekg(off_type, ios_base::seekdir); // set current position
basic_istream& putback(C c); // put c back into the buffer
basic_istream& unget(); // put back most recent char read
int_type peek(); // look at next character to be read
int sync(); // clear buffer (flush)
basic_istream& operator>>(basic_streambuf<C,Tr>∗ b); // read into b
basic_istream& get(basic_streambuf<C,Tr>& b, C t = Tr::newline());
streamsize readsome(C∗ p, streamsize n); // read at most n char
};
basic_istream 函数覆盖了 basic_ios 基础中的等效函数。
定位函数的工作原理与 ostream 中的对应函数(§38.6.1)类似。g 后缀表示它是用于从流中获取字符的位置。p 和 g 后缀是必需的,因为我们可以创建一个从 istream 和 ostream 派生的 iostream,而这样的流需要同时跟踪获取位置和放置位置。
putback() 函数允许程序将一个字符“放回”istream中,作为下一个读取的字符。unget() 函数将最近读取的字符放回。遗憾的是,回退输入流并不总是可行的。例如,尝试回退到第一个读取字符之后会设置 ios_base::failbit。可以保证的是,在成功读取后可以回退一个字符。peek() 函数读取下一个字符,并将该字符保留在 streambuf 中,以便再次读取。因此,c=peek() 在逻辑上等同于 (c=get(),unget(),c)。设置 failbit 可能会触发异常(§38.3)。
使用 sync() 刷新 istream。这并非总是正确完成。对于某些类型的流,我们必须从实际源重新读取字符——但这并不总是可行或可取的(例如,对于连接到网络的流)。因此,如果 sync() 成功,则返回 0。如果失败,它会设置 ios_base::badbit (§38.4.4) 并返回 -1。设置 badbit 可能会触发异常(§38.3)。对连接到 ostream 的缓冲区执行 sync() 会将缓冲区刷新到输出。
直接从 streambuf 读取的 >> 和 get() 操作主要对 I/O 设施的实现者有用。
readsome() 函数是一个底层操作,允许用户查看流中是否有任何可读取的字符。当不需要等待输入(例如键盘输入)时,此功能非常有用。另请参阅 in_avail() (§38.6)。
38.6.3缓冲区迭代器(Buffer Iterators)
在 <iterator> 中,标准库提供了 istreambuf_iterator 和 ostreambuf_iterator 函数,允许用户(主要是新型 iostream 的实现者)迭代流缓冲区的内容。这些迭代器尤其被本地化facet (第 39 章)广泛使用。
38.6.3.1 istreambuf_iterator
istreambuf_iterator 从 istream_buffer 读取字符流:
template<typename C, typename Tr = char_traits<C>> // §iso.24.6.3
class istreambuf_iterator
:public iterator<input_iterator_tag, C, typename Tr::off_type , /*unspecified*/, C> {
public:
using char_type = C;
using traits_type = Tr;
using int_type = typename Tr::int_type;
using streambuf_type = basic_streambuf<C,Tr>;
using istream_type = basic_istream<C,Tr>;
// ...
};
Iterator 基类的reference成员未被使用,因此未指定。
如果使用 istreambuf_iterator 作为输入迭代器,其效果与其他输入迭代器类似:可以使用 c=∗p++ 从输入中读取字符流:
| istreambuf_iterator<C,Tr> (§iso.24.6.3) | |
| istreambuf_iterator p {}; | p 是流末尾迭代器;noexcept;constexpr |
| istreambuf_iterator p {p2}; | 复制构造函数;noexcept |
| istreambuf_iterator p {is}; | p 是 is.rdbuf() 的迭代器;noexcept |
| istreambuf_iterator p{psb}; | p 是 istreambuf ∗psb 的迭代器;noexcept |
| istreambuf_iterator p {nullptr}; | p 是流末尾迭代器 |
| istreambuf_iterator p {prox}; | p 指向 prox 指定的 istreambuf;noexcept |
| p.˜istreambuf_iterator() | 析构函数 |
| c=∗p | c 是 streambuf 的 sgetc() 返回的字符 |
| p−>m | ∗p 的成员 m,如果它是一个类对象 |
| p=++p | streambuf 的 sbumpc() |
| prox=p++ | 让 prox 指定与 p 相同的位置;然后 ++p |
| p.equal(p2) | p 和 p2 是否都位于流末尾,或者都不位于流末尾 |
| p==p2 | p.equal(p2) |
| p!=p2 | !p.equal(p2) |
请注意,在比较 istreambuf_iterators 时,任何耍小聪明的尝试都将失败:在输入过程中,你不能依赖两个迭代器引用同一个字符。
38.6.3.2 ostreambuf_iterator
ostreambuf_iterator 将字符流写入 ostream_buffer:
template<typename C, typename Tr = char_traits<C>> // §iso.24.6.4
class ostreambuf_iterator
:public iterator<output_iterator_tag, void, void, void, void> {
public:
using char_type = C;
using traits_type = Tr;
using streambuf_type = basic_streambuf<C,Tr>;
using ostream_type = basic_ostream<C,Tr>;
// ...
};
从大多数标准来看,ostreambuf_iterator 的操作都很奇怪,但实际效果是,如果你将它用作输出迭代器,它的效果与其他输出迭代器类似:可以使用 ∗p++=c 将字符流写入输出:
| ostreambuf_iterator<C,Tr> (§iso.24.6.4) | |
| ostreambuf_iterator p {os}; | p 是 os.rdbuf() 的迭代器;noexcept |
| ostreambuf_iterator p {psb}; | p 是 istreambuf ∗psb 的迭代器;noexcept |
| p=c | 如果 !p.failed() 调用 streambuf 的 sputc(c) |
| ∗p | 无操作 |
| ++p | 无操作 |
| p++ | 无操作 |
| p.failed() | p 的 streambuf 上的 sputc() 是否已到达eof?noexcept |
38.7 建议(Advice)
[1] 对于具有有意义的文本表示的用户定义类型,请定义 << 和 >>;§38.1,§38.4.1,§38.4.2。
[2] 使用 cout 进行正常输出,使用 cerr 进行错误输出;§38.1。
[3] 有用于普通字符和宽字符的 iostream,你可以为任何类型的字符定义一个 iostream;§38.1。
[4] 标准 I/O 流、文件和字符串都有标准 iostream;§38.2。
[5] 不要尝试复制文件流;§38.2.1。
[6] 二进制 I/O 是系统特定的;§38.2.1。
[7] 在使用文件流之前,请务必检查它是否已附加到文件;§38.2.1。
[8] 优先使用 ifstreams 和 ofstreams,而不是通用的 fstream; §38.2.1.
[9] 使用字符串流进行内存格式化;§38.2.2.
[10] 使用异常捕获罕见的 bad() I/O 错误;§38.3.
[11] 使用流状态 fail 来处理可能可恢复的 I/O 错误;§38.3.
[12] 无需修改 istream 或 ostream 即可添加新的 << 和 >> 运算符;§38.4.1.
[13] 实现 iostream 原语操作时,请使用 sentry;§38.4.1.
[14] 优先使用格式化输入,而不是未格式化的底层输入;§38.4.1.
[15] 字符串输入不会溢出;§38.4.1.
[16] 使用 get(),getline() 和 read() 时,请谨慎使用终止条件;§38.4.1.
[17] 默认情况下,>> 会跳过空格;§38.4.1。
[18] 你可以定义 << (或 >>),使其基于其第二个操作数表现为虚函数;§38.4.2.1。
[19] 控制 I/O 时,优先使用操作符而不是状态标志;§38.4.3。
[20] 如果要混合使用 C 风格和 iostream I/O,请使用 sync_with_stdio(true);§38.4.4。
[21] 使用 sync_with_stdio(false) 来优化 iostream;§38.4.4。
[22] 绑定用于交互式 I/O 的流;§38.4.4。
[23] 使用 imbue() 使 iostream 反映本地化的“文化差异”;§38.4.4。
[24] width() 规范仅适用于紧随其后的 I/O 操作;§38.4.5.1。
[25] precision() 规范适用于所有后续的浮点输出操作;§38.4.5.1。
[26] 浮点格式规范(例如,科学计数法)适用于所有后续的浮点输出操作;§38.4.5.2。
[27] 使用带有参数的标准操作符时,#include <iomanip>;§38.4.5.2。
[28] 几乎不需要使用 flush();§38.4.5.2。
内容来源:
<<The C++ Programming Language >> 第4版,作者 Bjarne Stroustrup