JVM 垃圾收集算法详解!

目录
- 一、 内存管理的挑战与垃圾收集的必要性
- 二、 基础垃圾收集算法
- 1. 标记-清除(Mark-Sweep)算法
- 2. 复制(Copying)算法
- 3. 标记-整理(Mark-Compact)算法
- 三、 HotSpot JVM的基石:分代收集(Generational Collection)算法
- 1. 新生代(Young Generation)
- 2. 老年代(Old Generation)
- 分代收集的工作流程(简化版):
- 四、 总结与展望
摘要:在Java的GC机制中,垃圾收集算法是其核心基石。理解这些算法,是Javacode开发者掌握JVM内存管理、排查内存泄漏和JVM性能调优不可或缺的一步。本文将详细剖析JVM中最常用的几种基本垃圾收集算法的原理、优缺点及其在HotSpot JVM中的实际应用,揭示它们如何共同协作,构建起一套高效的自动化内存管理系统。
一、 内存管理的挑战与垃圾收集的必要性
在Java世界里,我们程序员无需手动为新创建的对象分配和释放内存,JVM的垃圾收集器(Garbage Collector, GC)会自动接管这项繁重而易错的工作。这种“自动挡”的内存管理机制,极大地提高了开发效率,减少了内存泄漏和野指针等问题。
然而,GC并非神秘魔法,它的背后是一系列精妙的算法在支撑。理解这些算法,是理解GC行为与进行JVM性能调优的起点。
在深入算法之前,我们首先要知道GC是如何判断一个对象是否是“垃圾”的。现代JVM普遍采用可达性分析(Reachability Analysis) 算法:从被称为“GC Roots”的根对象出发,遍历所有的引用链。如果一个对象无法通过任何引用链从GC Roots到达,那么它就被判定为“不可达”,即为可回收的垃圾。
二、 基础垃圾收集算法
接下来,我们逐一介绍三种最基础也是最重要的垃圾收集算法。
1. 标记-清除(Mark-Sweep)算法
这是最古老、最基础的垃圾收集算法,也是许多其他更复杂算法的基础。它分为两个主要阶段:
- 标记(Mark)阶段:垃圾收集器从GC Roots开始遍历,标记所有可达(即存活)的对象。
- 清除(Sweep)阶段:标记完成后,垃圾收集器会遍历整个堆内存,回收所有未被标记的对象,即所谓的“垃圾”,并释放它们所占用的内存空间。
工作原理图示:
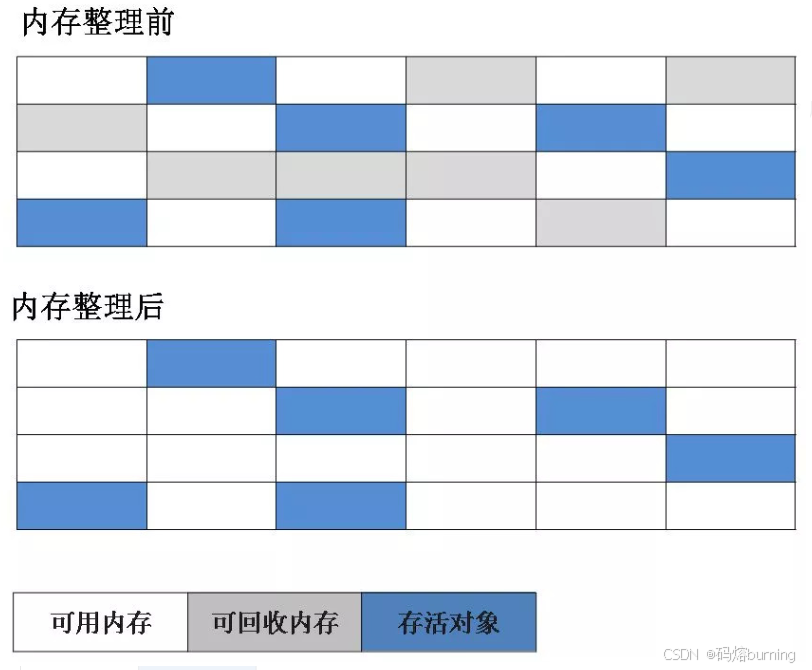
优点:
- 实现相对简单。
缺点:
- 效率低下:标记和清除两个过程都需要遍历整个堆,耗时较长。
- 内存碎片化(Fragmentation):清除过程不会移动存活对象,导致释放后的内存空间是不连续的。如果堆内存中产生大量不连续的碎片,当需要分配大对象时,即使总的空闲内存足够,也可能找不到一块连续的内存空间来分配,从而触发另一次GC(提前Full GC),影响性能。
2. 复制(Copying)算法
为了解决标记-清除算法的效率和内存碎片问题,复制算法应运而生。它将可用内存按容量划分为大小相等的两块,每次只使用其中一块。
工作原理:
当一块内存用完时,垃圾收集器就将这块内存中所有存活的对象,复制到另一块空闲的内存上,然后一次性清空已使用过的内存。
工作原理图示:
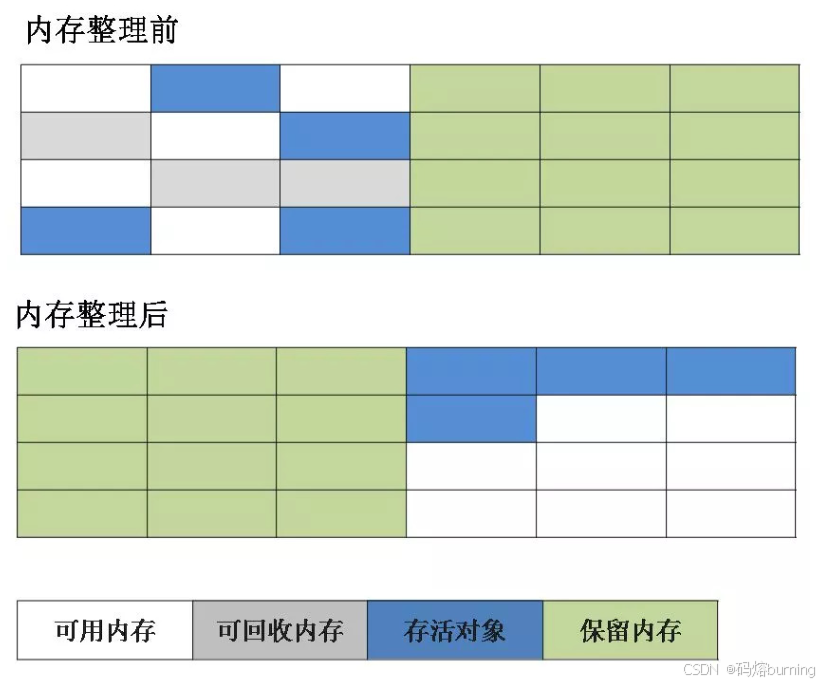
优点:
- 运行高效:不需要遍历整个堆,只需遍历存活对象并进行复制,然后直接清空已使用区域,避免了标记和清除阶段的复杂性。
- 没有内存碎片:存活对象被复制到新区域时是紧凑排列的,保证了内存的连续性。
缺点:
- 内存利用率低:每次只有一半的内存空间被利用,空间浪费严重。
鉴于其“高效率”和“无碎片”的优点,复制算法在年轻代(Young Generation) 中得到了广泛的应用。通常,年轻代由一个Eden区和两个大小相等的Survivor区(S0和S1)组成。HotSpot JVM的默认分配比例为Eden:S0:S1 = 8:1:1,总共只浪费10%的内存(S0或S1中某一个始终为空闲)。
3. 标记-整理(Mark-Compact)算法
标记-整理算法是标记-清除算法的改进版,它在标记存活对象后,不是直接清除,而是将所有存活对象向一端移动,然后清理掉边界以外的内存。
工作原理:
- 标记(Mark)阶段:同标记-清除算法,标记所有存活对象。
- 整理(Compact)阶段:将所有被标记为存活的对象,都移动到内存空间的某一端。
- 清除(Clear)阶段:直接清理掉被移动对象边界以外的所有内存,从而得到一段完整而连续的空闲空间。
工作原理图示:
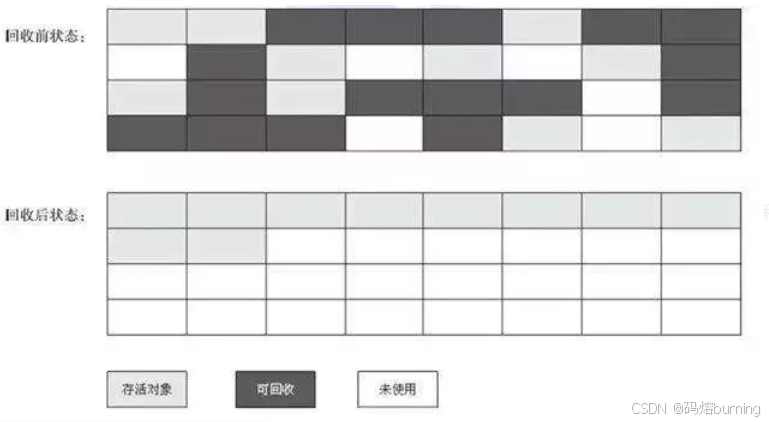
优点:
- 没有内存碎片:解决了标记-清除算法的内存碎片问题。
- 内存利用率高:没有像复制算法那样牺牲一半内存。
缺点:
- 效率低下:除了标记阶段,整理阶段也需要移动所有存活对象。这个移动操作,尤其是在老年代对象多且大时,是一个耗时且会造成较长停顿(Stop-The-World, STW)的操作。
标记-整理算法在老年代(Old Generation) 中被广泛使用,因为老年代的对象存活率通常较高,如果使用复制算法,复制成本会很高。
三、 HotSpot JVM的基石:分代收集(Generational Collection)算法
我们前面提到了三种基本算法,但它们都有各自的优缺点。HotSpot JVM通过分代收集策略,将这些算法巧妙地结合起来,以期达到整体最优的效果。
分代收集是基于一个重要的经验法则——分代假说(Generational Hypothesis):
- 弱分代假说(Weak Generational Hypothesis):绝大部分对象都是朝生夕灭的(如局部变量、方法参数等)。
- 强分代假说(Strong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以消亡,其生命周期会越长。
基于这两个假说,JVM将堆内存划分为两个主要区域:
1. 新生代(Young Generation)
- 特点:这里存放着新创建的对象。根据弱分代假说,大部分对象在这里很快就会死亡。
- 构成:通常由一个 Eden 区 和两个 Survivor 区(S0和S1) 组成。
- 垃圾收集算法:主要采用复制算法。因为存活对象少,复制开销小,且能有效避免内存碎片。
- GC类型:发生在新生代的GC被称为 Minor GC(或 Young GC)。它的特点是发生频繁、回收速度快、停顿时间短。
- 对象去向:新创建的对象首先在Eden区分配。当Eden区满时,触发Minor GC。Eden区和其中一个Survivor区(From Space)的存活对象会被复制到另一个空的Survivor区(To Space),同时年龄加1。当对象的年龄达到一定阈值或Survivor区空间不足时,它们会被晋升到老年代。
2. 老年代(Old Generation)
- 特点:存放经过多次Minor GC仍然存活的对象(即生命周期长的对象),以及一些直接在老年代分配的大对象。老年代的对象存活率高。
- 垃圾收集算法:通常采用标记-清除或标记-整理算法(或两者的混合)。因为存活对象多,如果使用复制算法开销太大;使用标记-整理可以避免内存碎片。
- GC类型:发生在老年代的GC被称为 Major GC(或 Old GC)。对整个堆(包括新生代和老年代)进行的GC被称为 Full GC。Major GC和Full GC的特点是发生频率低、耗时较长、停顿时间明显。
- 对象去向:老年代的对象生命周期长,直到它们变得不可达时才会被回收。
分代收集的工作流程(简化版):
- 新对象在 Eden区 分配。
- 当 Eden 区满时,触发 Minor GC。
- Eden 区和 From Survivor 区 的存活对象被复制到 To Survivor 区,年龄计数器加1。所有被复制的对象紧密排列。Eden 区和 From Survivor 区被清空。
- From 和 To Survivor 区互换角色。
- 对象在 Survivor 区中经历多次 Minor GC,年龄逐渐增长。
- 当对象年龄达到晋升阈值 (
-XX:MaxTenuringThreshold),或 Survivor 区空间不足以容纳时,对象被晋升到 老年代。 - 当老年代空间不足时,触发 Major GC 或 Full GC。
四、 总结与展望
垃圾收集算法是JVM内存管理的核心。从基础的标记-清除、复制、标记-整理,到综合应用这些算法的分代收集,JVM的演进始终围绕着如何更高效、更低停顿地回收内存。
理解这些算法,能帮助我们更好地:
- 解读GC日志:明白“Young GC”、“Full GC”背后的内存区域和回收机制。
- 进行JVM参数调优:例如,调整新生代和老年代的比例 (
-XX:NewRatio),调整Survivor区比例 (-XX:SurvivorRatio),都是为了让分代收集算法发挥最大效率。 - 排查性能问题:当发现应用卡顿或内存持续增长时,能够根据GC表现(如Full GC频繁)迅速定位问题可能出在哪个代,从而制定有效的优化策略。
随着硬件技术的发展和应用场景的多样化,现代JVM的垃圾收集器(如G1、ZGC、Shenandoah等)在基本算法的基础上进行了大量的创新与优化,例如区域化分代、并发处理、超低停顿等。它们是分代收集思想的进一步扩展和增强,但其根本依然离不开我们今天讲解的这些基础算法原理。深入学习这些基础,是掌握更高级GC技术不可逾越的桥梁。