时序数据库选型指南:Apache IoTDB企业级解决方案深度解析
本文目录:
- 时序数据库技术挑战与选型要素
- 大数据环境下的性能挑战
- IoTDB快速入门:连接与数据写入
- 主流时序数据库技术对比分析
- 国外产品现状与局限性
- IoTDB的技术架构优势
- 高级查询与数据分析功能
- 复杂时序查询实现
- Python客户端实现数据分析
- 工业级应用场景与最佳实践
- 智能制造解决方案
- 新能源监控系统
- 技术发展趋势与产业展望
- 云原生与边缘计算融合
- 企业级服务与生态建设
- 资源链接
随着物联网、工业4.0、智能监控等技术的快速发展,时序数据的规模呈现爆发式增长。从传感器数据、监控指标到金融交易记录,时序数据已成为现代数字化企业的核心资产。如何选择一个合适的时序数据库来存储、管理和分析这些海量数据,成为了技术决策者面临的重要挑战。
时序数据库技术挑战与选型要素
大数据环境下的性能挑战
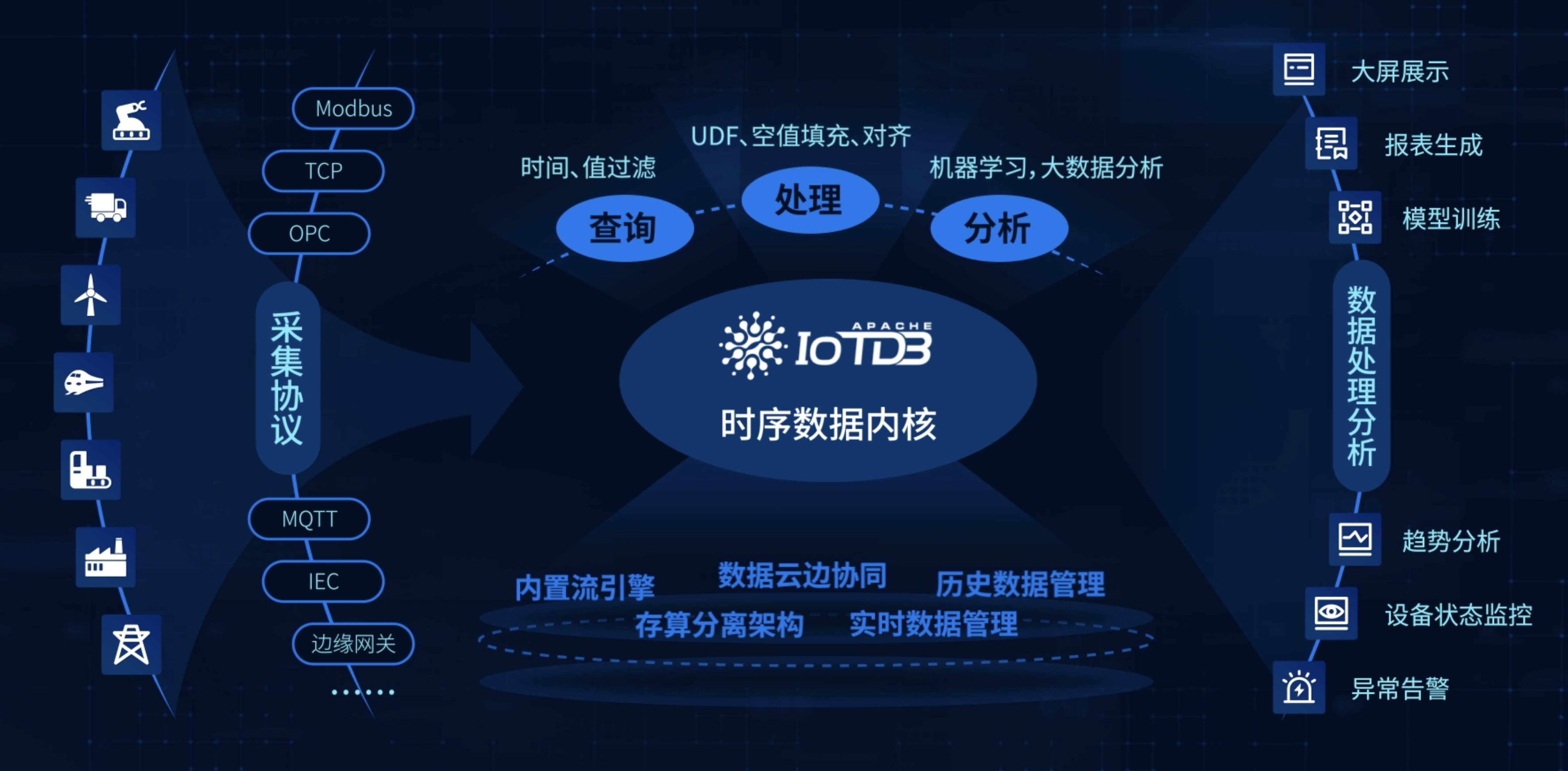
在评估时序数据库时,性能表现是最重要的考量因素。时序数据具有数据量大、写入频繁的特点,一个典型的工业物联网系统可能需要每秒处理数百万级别的数据点写入。数据库必须能够处理如此高频的写入操作,同时保证数据的完整性和一致性。除了写入性能,查询响应速度同样关键,因为时序数据的价值在于实时分析和历史趋势挖掘。
存储效率是另一个不可忽视的因素。时序数据的累积速度惊人,一个中等规模的监控系统一年产生的数据量可能达到TB甚至PB级别。高效的数据压缩算法不仅能节省存储成本,还能提升查询性能,因为减少了磁盘I/O操作。同时,数据库需要支持多级存储架构,能够自动将冷数据迁移到成本更低的存储介质中。
IoTDB快速入门:连接与数据写入
Apache IoTDB提供了简洁的API接口,让开发者能够快速上手。以下是基本的连接和数据写入操作:
// Java客户端连接示例
import org.apache.iotdb.session.Session;public class IoTDBQuickStart {public static void main(String[] args) throws Exception {// 创建Session连接Session session = new Session.Builder().host("localhost").port(6667).username("root").password("root").build();session.open();// 创建时间序列session.createTimeseries("root.factory.workshop01.device001.temperature", TSDataType.FLOAT, TSEncoding.RLE, CompressionType.SNAPPY);// 批量插入数据List<String> deviceIds = Arrays.asList("root.factory.workshop01.device001");List<Long> times = Arrays.asList(1L, 2L, 3L, 4L, 5L);List<List<String>> measurementsList = Arrays.asList(Arrays.asList("temperature", "humidity", "pressure"));List<List<TSDataType>> typesList = Arrays.asList(Arrays.asList(TSDataType.FLOAT, TSDataType.FLOAT, TSDataType.FLOAT));List<List<Object>> valuesList = Arrays.asList(Arrays.asList(25.6f, 60.3f, 1013.2f),Arrays.asList(26.1f, 61.5f, 1012.8f),Arrays.asList(24.9f, 59.8f, 1014.1f));session.insertRecordsOfOneDevice(deviceIds.get(0), times, measurementsList.get(0), typesList.get(0), valuesList);session.close();}
}
这段代码展示了IoTDB的核心特性:首先建立到数据库的连接,然后创建时间序列定义数据结构,最后进行批量数据插入。IoTDB的设备-传感器层次化模型在这里体现得很清楚,root.factory.workshop01.device001.temperature这样的路径结构直观地表达了数据的组织方式。批量插入功能能够显著提升写入性能,在实际生产环境中,这种方式比单条插入效率高出数十倍。
主流时序数据库技术对比分析
国外产品现状与局限性
目前市场上的时序数据库产品各有特色。InfluxDB作为时序数据库领域的知名产品,在中小规模应用中表现良好,其类SQL的查询语言和丰富的生态工具受到开发者欢迎。然而,InfluxDB在大规模集群环境下存在明显局限性,开源版本的集群功能受限,企业级特性需要商业授权,这在一定程度上限制了其在大型企业中的应用。
TimescaleDB基于PostgreSQL扩展实现,继承了关系型数据库的SQL兼容性优势,对于已经熟悉PostgreSQL的团队来说学习成本较低。但是,TimescaleDB的性能优化主要依赖于PostgreSQL本身,在纯时序数据处理场景下,其专业性和性能表现相比原生时序数据库有一定差距。
Prometheus在DevOps监控领域表现出色,其拉取模式的数据采集和强大的告警机制深受运维人员喜爱。不过,Prometheus主要面向短期监控数据存储,默认数据保留期较短,不适合需要长期数据存储和历史分析的业务场景。
IoTDB的技术架构优势
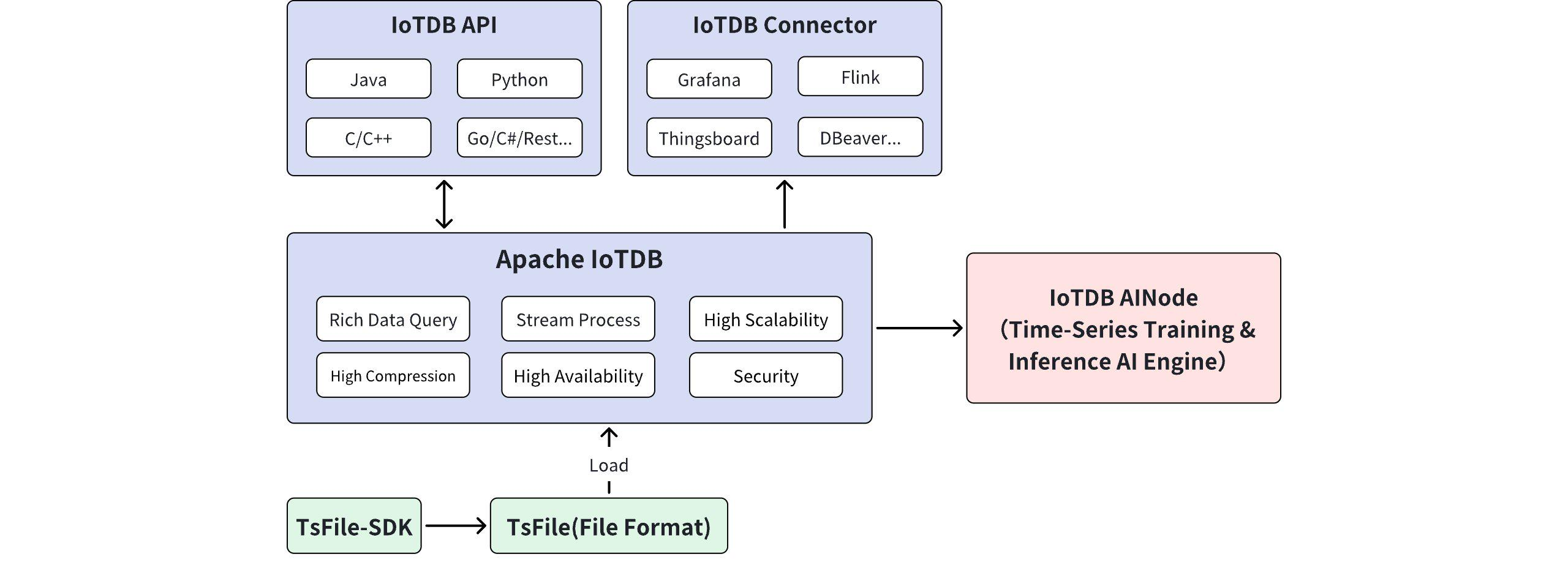
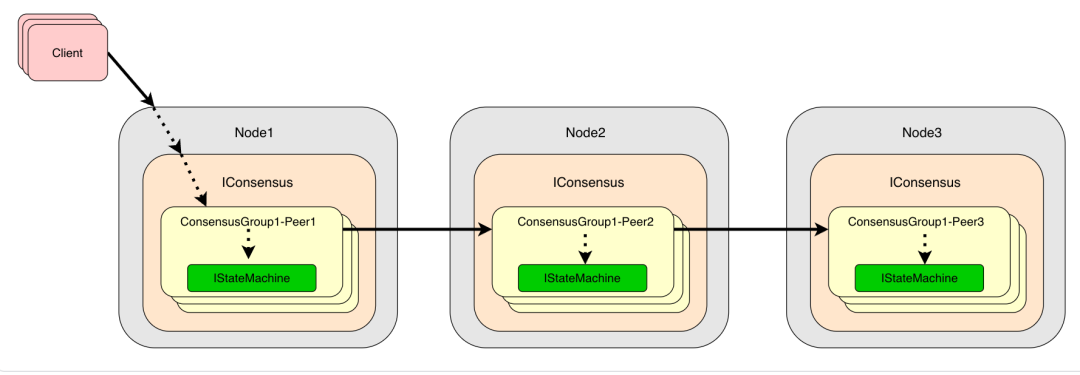
Apache IoTDB是由清华大学主导开发的开源时序数据库,经过多年的技术积累和产业实践,已经成为时序数据库领域的重要力量。与其他产品相比,IoTDB在技术架构上有着根本性的优势。
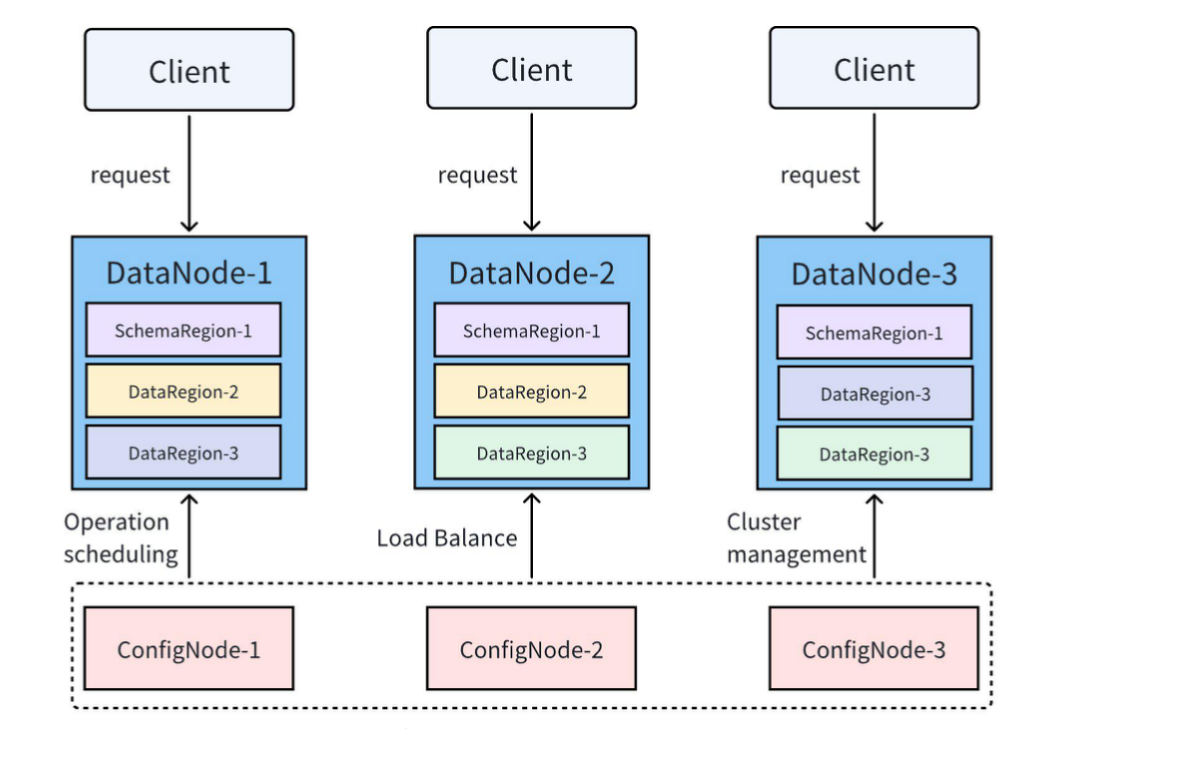
IoTDB采用了专门针对时序数据特点设计的存储引擎。传统关系型数据库的B+树索引在处理时序数据时效率低下,而IoTDB使用的LSM树结构能够充分利用时序数据的时间局部性特点,实现高效的数据写入和压缩。其独特的TsFile存储格式针对时序数据进行了深度优化,不仅支持多种数据类型和编码方式,还能够根据数据特征自动选择最佳压缩算法,压缩比通常可达10:1以上。
高级查询与数据分析功能
复杂时序查询实现
IoTDB的查询功能非常强大,支持各种复杂的时序分析操作。以下是一些典型的查询示例:
-- 基础时间范围查询
SELECT temperature, humidity
FROM root.factory.workshop01.device001
WHERE time >= '2023-01-01T00:00:00' AND time <= '2023-12-31T23:59:59';-- 聚合函数查询
SELECT avg(temperature) as avg_temp,max(temperature) as max_temp,min(temperature) as min_temp,count(temperature) as data_points
FROM root.factory.workshop01.device001
WHERE time >= now() - 1d
GROUP BY(1h);-- 多设备关联查询
SELECT d1.temperature, d2.temperature, d3.temperature
FROM root.factory.workshop01.device001 d1, root.factory.workshop01.device002 d2,root.factory.workshop01.device003 d3
WHERE time >= '2023-01-01' AND time <= '2023-01-02'
ALIGN BY TIME;-- 窗口函数和数据填充
SELECT temperature, FILL(temperature, linear, 5m) as filled_temp,DERIVATIVE(temperature) as temp_change_rate
FROM root.factory.workshop01.device001
WHERE time >= now() - 2h;
这些查询语句展示了IoTDB在时序数据分析方面的强大能力。基础的时间范围查询是时序数据库的核心功能,IoTDB通过时间分区索引能够在秒级时间内完成对TB级数据的查询。聚合函数查询支持按时间窗口进行数据统计,这对于监控报表和趋势分析非常有用。多设备关联查询允许同时分析多个设备的数据,通过ALIGN BY TIME确保不同设备的数据按时间对齐。窗口函数和数据填充功能则解决了实际应用中常见的数据缺失和异常处理需求。
Python客户端实现数据分析
对于数据分析师和算法工程师,IoTDB提供了便捷的Python客户端:
from iotdb.Session import Session
import pandas as pd
import numpy as np# 连接IoTDB
session = Session('localhost', 6667, 'root', 'root')
session.open()# 执行查询并转换为DataFrame
query_sql = """
SELECT temperature, humidity, pressure
FROM root.factory.workshop01.device001
WHERE time >= '2023-01-01' AND time <= '2023-01-31'
"""session_data_set = session.execute_query_statement(query_sql)
df = session_data_set.todf()# 数据预处理和分析
df['timestamp'] = pd.to_datetime(df['Time'])
df.set_index('timestamp', inplace=True)# 计算移动平均
df['temp_ma_5'] = df['temperature'].rolling(window=5).mean()
df['humid_ma_5'] = df['humidity'].rolling(window=5).mean()# 异常检测
temp_mean = df['temperature'].mean()
temp_std = df['temperature'].std()
df['temp_anomaly'] = np.abs(df['temperature'] - temp_mean) > 3 * temp_std# 相关性分析
correlation_matrix = df[['temperature', 'humidity', 'pressure']].corr()
print(correlation_matrix)session.close()
这段Python代码演示了如何使用IoTDB进行数据科学分析。通过将查询结果转换为pandas DataFrame,数据分析师可以使用熟悉的Python数据科学工具栈进行深度分析。移动平均计算有助于平滑数据波动,异常检测算法可以识别设备异常状态,相关性分析则能够发现不同传感器之间的关联关系。这种seamless的集成能力让IoTDB不仅仅是一个存储系统,更是完整数据分析解决方案的基础。
工业级应用场景与最佳实践
智能制造解决方案
在智能制造领域,某大型钢铁企业使用IoTDB构建了全厂设备监控系统,接入了超过10万个传感器,实时采集温度、压力、流量等关键参数。通过IoTDB的高性能写入能力和实时查询功能,企业能够及时发现设备异常,预防生产事故,每年节省维护成本数千万元。
// 设备异常检测算法实现
public class DeviceAnomalyDetector {private Session session;public void detectAnomalies(String devicePath, long startTime, long endTime) {String query = String.format("SELECT temperature, pressure, vibration " +"FROM %s " + "WHERE time >= %d AND time <= %d",devicePath, startTime, endTime);SessionDataSet dataSet = session.executeQueryStatement(query);List<RowRecord> records = dataSet.toRowRecords();// 基于3σ准则的异常检测double tempMean = records.stream().mapToDouble(r -> r.getFields().get(0).getDoubleV()).average().orElse(0);double tempStd = calculateStandardDeviation(records, 0);records.forEach(record -> {double temp = record.getFields().get(0).getDoubleV();if (Math.abs(temp - tempMean) > 3 * tempStd) {triggerAlert(devicePath, record.getTimestamp(), "Temperature anomaly detected: " + temp);}});}private void triggerAlert(String device, long timestamp, String message) {// 发送实时告警System.out.println("[ALERT] " + new Date(timestamp) + " - " + device + ": " + message);}
}
这个异常检测算法展示了IoTDB在工业场景中的应用价值。通过实时查询历史数据并应用统计学方法,系统能够自动识别设备运行异常,为预测性维护提供数据支撑。
新能源监控系统
在新能源行业,某风电场运营商采用IoTDB存储风机运行数据,包括风速、发电功率、轴承温度等数百个指标。基于IoTDB的历史数据分析能力,运营商建立了精确的发电量预测模型,优化了电力交易策略,显著提升了经济效益。
# 风机发电量预测模型
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from iotdb.Session import Sessionclass WindPowerPredictor:def __init__(self):self.session = Session('localhost', 6667, 'root', 'root')self.session.open()self.model = RandomForestRegressor(n_estimators=100, random_state=42)def prepare_training_data(self, start_time, end_time):query = f"""SELECT wind_speed, wind_direction, temperature, humidity, atmospheric_pressure, power_outputFROM root.windfarm.turbine001WHERE time >= '{start_time}' AND time <= '{end_time}'"""dataset = self.session.execute_query_statement(query)df = dataset.todf()# 特征工程df['wind_speed_squared'] = df['wind_speed'] ** 2df['wind_speed_cubed'] = df['wind_speed'] ** 3df['temp_pressure_interaction'] = df['temperature'] * df['atmospheric_pressure']features = ['wind_speed', 'wind_speed_squared', 'wind_speed_cubed', 'wind_direction', 'temperature', 'humidity', 'atmospheric_pressure', 'temp_pressure_interaction']X = df[features].valuesy = df['power_output'].valuesreturn X, ydef train_model(self, start_time, end_time):X, y = self.prepare_training_data(start_time, end_time)self.model.fit(X, y)def predict_power(self, weather_data):# weather_data: [wind_speed, wind_direction, temperature, humidity, pressure]wind_speed = weather_data[0]features = [wind_speed,wind_speed ** 2,wind_speed ** 3,weather_data[1], # wind_directionweather_data[2], # temperatureweather_data[3], # humidityweather_data[4], # atmospheric_pressureweather_data[2] * weather_data[4] # temp_pressure_interaction]prediction = self.model.predict([features])[0]return max(0, prediction) # 确保预测值非负
这个预测模型代码展示了IoTDB在新能源领域的应用。通过整合多维度的环境数据和设备运行数据,运营商能够建立准确的发电量预测模型,为电网调度和电力交易提供科学依据。
技术发展趋势与产业展望

云原生与边缘计算融合
随着5G、边缘计算、人工智能等技术的快速发展,时序数据的生成速度和应用场景都在快速扩展。未来的时序数据库不仅要处理更大规模的数据,还需要具备更强的实时分析能力和智能化特性。IoTDB正在这个方向上持续演进,其最新版本已经集成了机器学习算法,支持异常检测、预测分析等高级功能。
在云原生时代,IoTDB也在积极拥抱容器化和微服务架构。通过Kubernetes部署,IoTDB可以实现自动扩缩容、故障自愈等云原生特性,进一步降低运维复杂度。同时,IoTDB正在开发Serverless版本,让用户能够按需使用数据库服务,无需关心底层基础设施管理。
企业级服务与生态建设
选择时序数据库是一个关乎企业数字化转型成败的重要决策。Apache IoTDB凭借其先进的技术架构、优异的性能表现和完善的生态支持,已经成为时序数据库领域的佼佼者。对于追求高性能、高可靠性的企业用户来说,IoTDB无疑是一个值得信赖的选择。
IoTDB的生态系统正在不断完善,从数据采集、存储、分析到可视化,形成了完整的解决方案链条。企业版IoTDB还提供了专业的技术支持和咨询服务,帮助用户快速实现业务目标。随着国产化替代趋势的加强,IoTDB在数据安全、本土化服务等方面的优势将更加突出。
资源链接
🔗 Apache IoTDB 下载地址:
https://iotdb.apache.org/zh/Download/
🏢 企业版官网:
https://timecho.com
通过官方渠道获取最新版本,享受完整的技术支持和企业级服务。