MySQL——库的操作
1、创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name这里的CHARACTER SET表示指定数据库采用的字符集
COLLATE 表示指定数据库字符集的校验规则
2、字符集和字符集校验规则
字符集
字符集是一套符号和编码的集合。它定义了数据库可以存储哪些字符,以及如何将这些字符转换为二进制数据存储到计算机中。
通俗解释:
你可以把字符集想象成一本“密码本”。这本密码本规定了:
有哪些字符:比如字母
A、a,中文中,表情符号😊等。每个字符对应的编号(编码)是什么:比如在
ASCII字符集中,字母A的编号是65(二进制是01000001)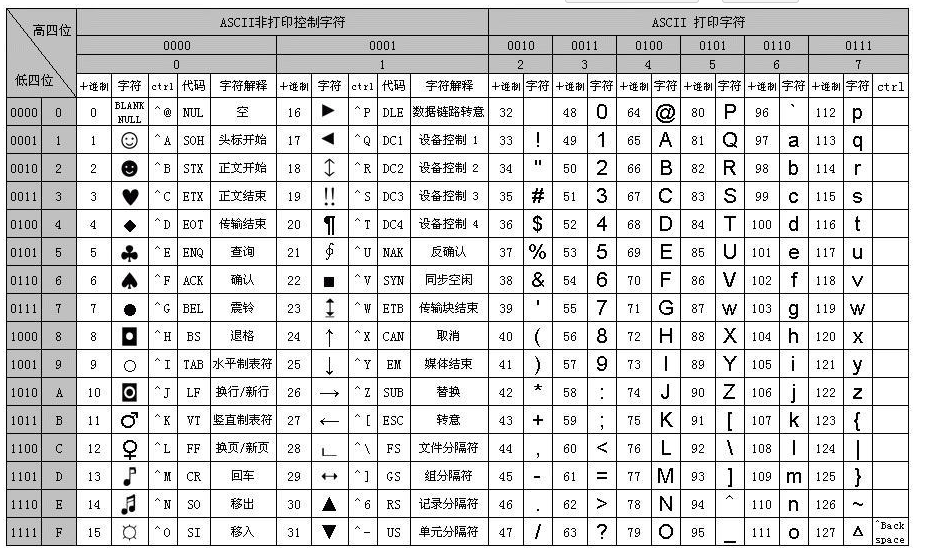
常见字符集:
ASCII:最早的英文字符集,包含英文字母、数字和一些控制字符,共128个字符。
ISO-8859-1 (Latin-1):扩展了 ASCII,加入了西欧语言字符,如
ñ,ç,ö等。GB2312 / GBK / GB18030:中国国家标准,用于存储简体中文字符。GBK 是 GB2312 的扩展,GB18030 是更全面的扩展。
BIG5:繁体中文标准,主要用于台湾、香港等地。
UTF-8:当今最重要的字符集。它是 Unicode 标准的一种可变长度实现,可以表示世界上几乎所有语言的字符,包括大量表情符号和特殊符号。它是国际化的首选。
为什么重要?
如果字符集设置不正确,就会出现“乱码”。例如,如果你用 GBK 编码去解码一段用 UTF-8 存储的中文文本,显示出来的就是一堆无法识别的字符。
字符集校验规则
至于校验规则是在字符集内,用于比较和排序字符的一套规则。它定义了字符如何被比较、排序以及是否区分大小写和重音。
通俗解释:
字符集定义了“有什么字”,而校验规则定义了“这些字怎么排顺序、怎么算相等”。
比如,有一组单词:apple, Apple, Banana。
如果使用区分大小写的校验规则,排序可能是:
Apple,Banana,apple(根据 ASCII 码,大写字母在前)。如果使用不区分大小写的校验规则,排序可能是:
apple,Apple,Banana(a和A被视为相同,按下一个字母排序)。
校验规则通常包含以下信息:
是否区分大小写(Case Sensitivity):
A和a是否相同?_cs(case sensitive):区分_ci(case insensitive):不区分
是否区分重音(Accent Sensitivity):
a和á是否相同?_as(accent sensitive):区分_ai(accent insensitive):不区分
其他规则,如是否区分空格等。
常见校验规则(以 MySQL 的 utf8mb4 字符集为例):
utf8mb4_general_ci:一种较老的校验规则,排序精度不高但速度快。不区分大小写。utf8mb4_unicode_ci:基于 Unicode 标准进行排序和比较,能更准确地处理各种语言的排序(如德语中的ß),速度稍慢。不区分大小写。推荐使用。utf8mb4_0900_ai_ci:MySQL 8.0 引入的,基于更现代的 Unicode 9.0 标准,比unicode_ci更精确和高效。不区分重音,不区分大小写。utf8mb4_bin:将每个字符直接根据其二进制编码进行比较。这意味着它区分大小写和重音。A(0x41) 和a(0x61) 是不同的。
具体使用
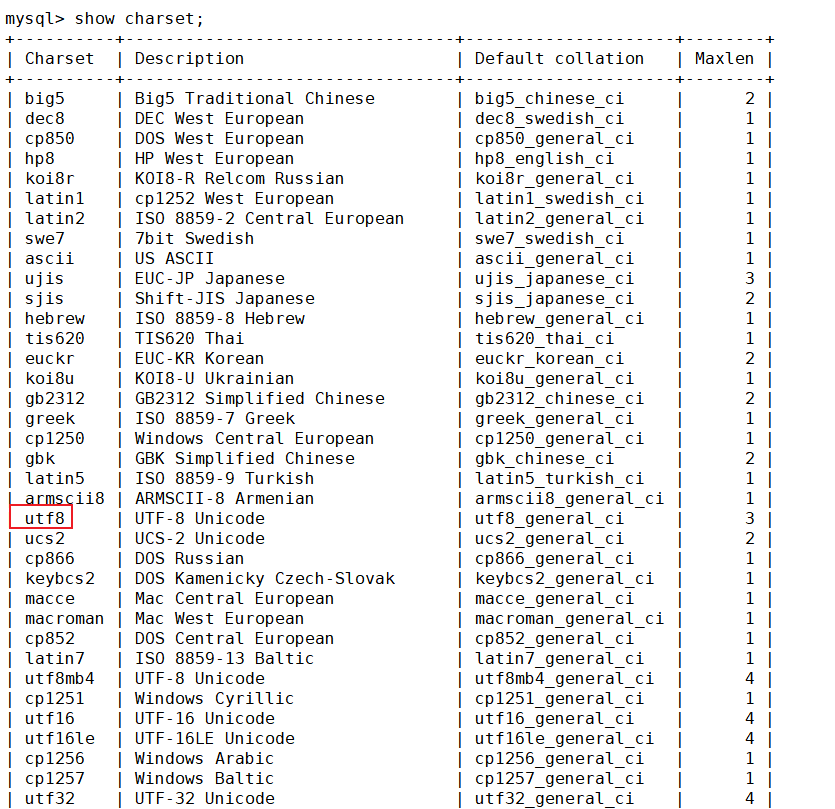
先来看看MySQL数据库都支持哪些字符集和校验规则
查看数据库支持的字符集
show charset;这是表格一部分,可以在其中找到utf8字符集
查看数据库支持的字符集校验规则
show collation;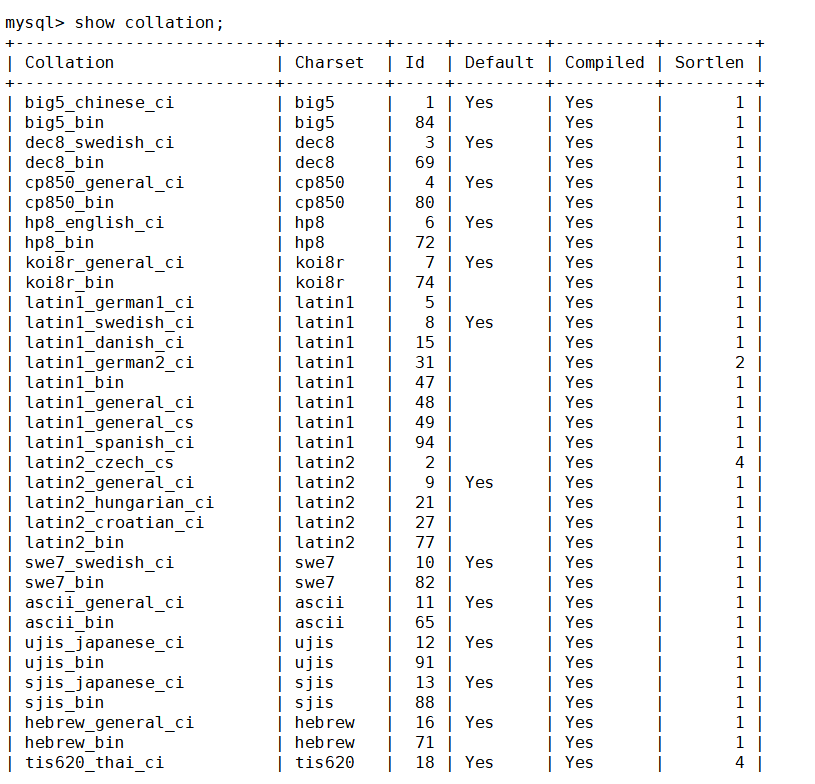
首先创建一个数据库
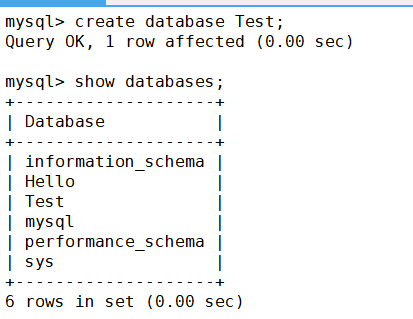
注:这里创建数据库时没有指名字符集和字符集校验规则时,默认字符集就是utf8,校验规则就是
utf8_ general_ ci(utf8_general_ci不会区分大小写)
然后在库里创建一个表,并插入若干个数据,最后查询一下
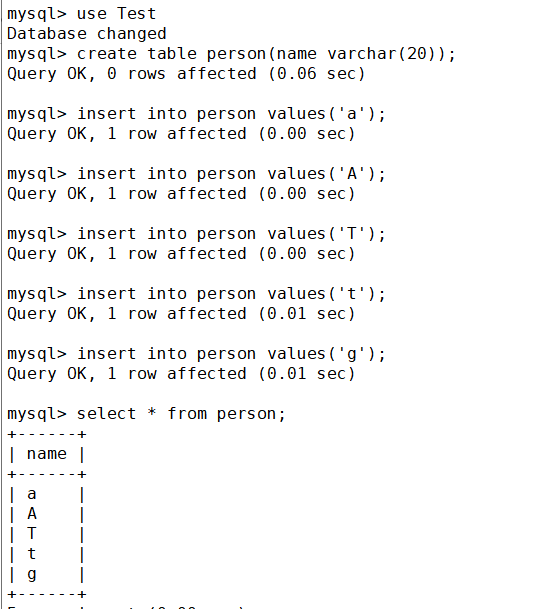
这是表里现有的数据,那么如果查一下字符’a‘呢?

可以发现并没有区分大小写
那如果是进行排序呢?

结果显而易见。
然后再来创建一个数据库test_db1,这时选用utf8_bin(区分大小写)校验规则

然后来查询一下字符‘a'以及进行排序
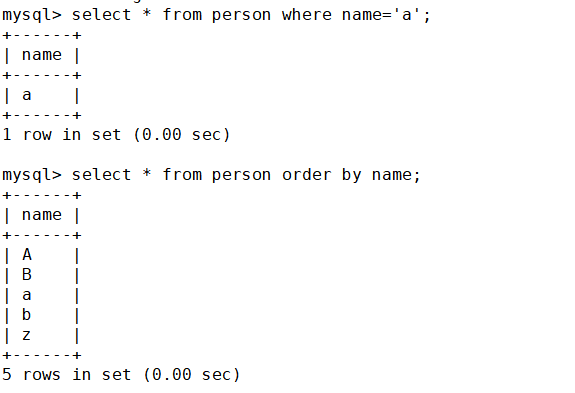
上面还用到了两个没见过的子句
where 和 order by
where子句
功能:用来过滤行,决定哪些数据行能进入结果集。
用法:
select 列名
from 表名
where 条件表达式;特点:
在数据返回之前就执行过滤。
支持比较运算符(
=, >, <, >=, <=, <>)、逻辑运算符(AND, OR, NOT)、范围(BETWEEN)、集合(IN)、模式匹配(LIKE)、空值判断(IS NULL)等。
order by 子句
功能:用来对结果集排序,不影响数据存储顺序,只是展示时排序。
用法:
select 列名
from 表名
order by 列名 [asc|desc];asc升序(默认)。desc降序。
特点:
只能排在整个 SQL 的最后(
limit之前也可以)。可以按多个字段排序。
排序规则受 collation(排序规则) 影响,比如
utf8_general_ci大小写不敏感,utf8_bin大小写敏感。
操纵数据库
显示创建语句
show create database 数据库名;
说明:
- MySQL 建议我们关键字使用大写,但是不是必须的。
- 数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
- /*!40100 default.... */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话
修改数据库
语法:
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name对数据库的修改主要指的是修改数据库的字符集,校验规则
这里修改一下test_db1数据库的字符集
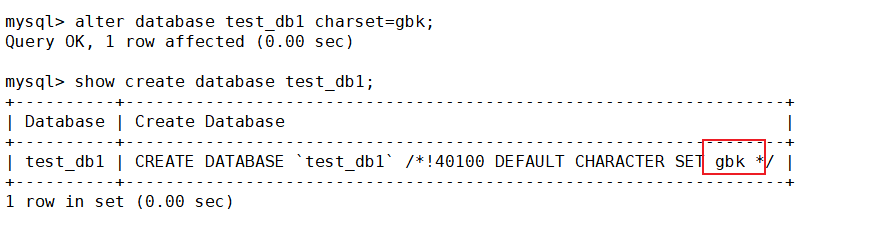
可以看到,默认执行的语句变了
数据库删除
语法:
DROP DATABASE [IF EXISTS] db_ name;执行删除之后的结果:
- 数据库内部看不到对应的数据库
- 对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
注意:不要随意删除数据库
数据库备份
mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径将test_db1备份到root目录下的MySQL目录里
注:这是在shell里面输入,而不是在mysql里
这下可以在相关目录里看见备份的文件了

如果再查看一下备份文件的内容呢?
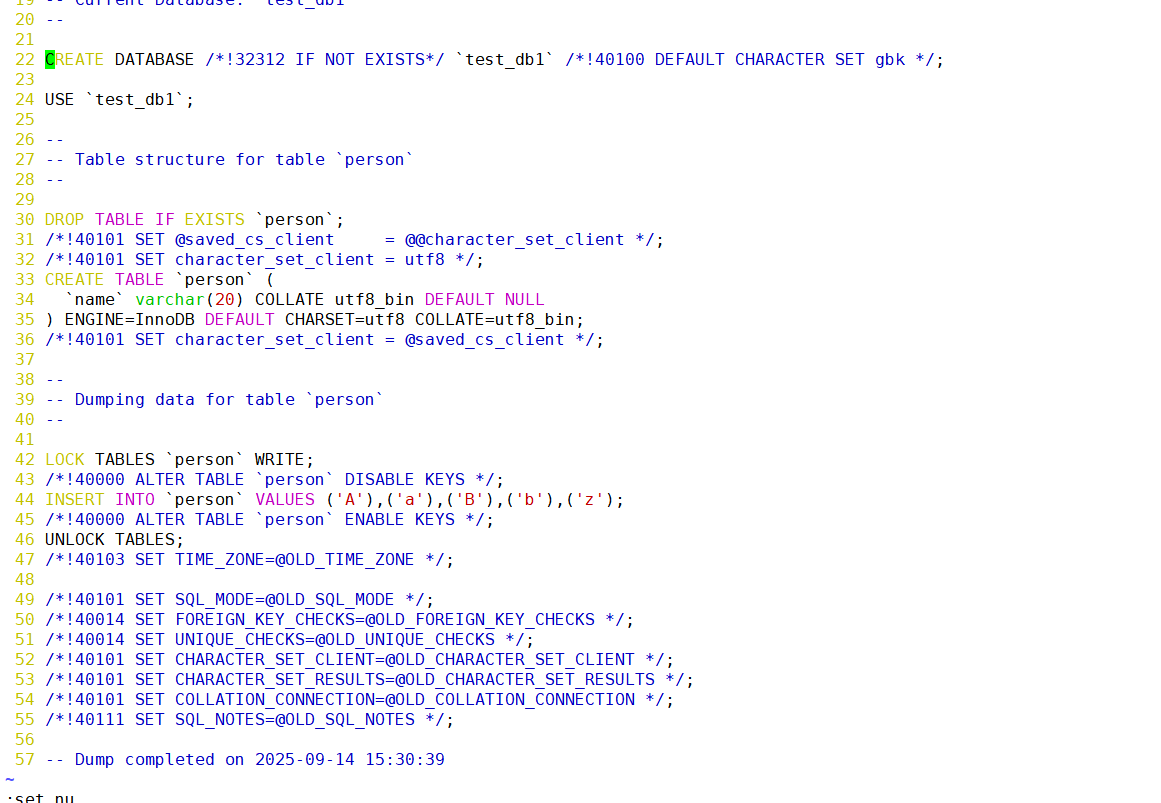
会发现原来是一串之前输入过的mysql语句
那么既然已经备份了就可以删除mysql里面的库文件了
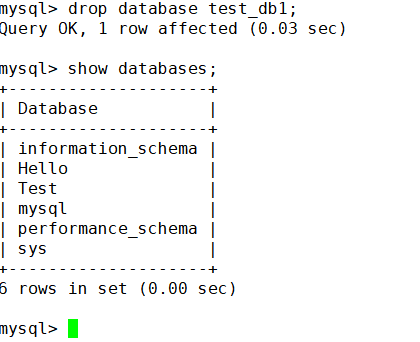
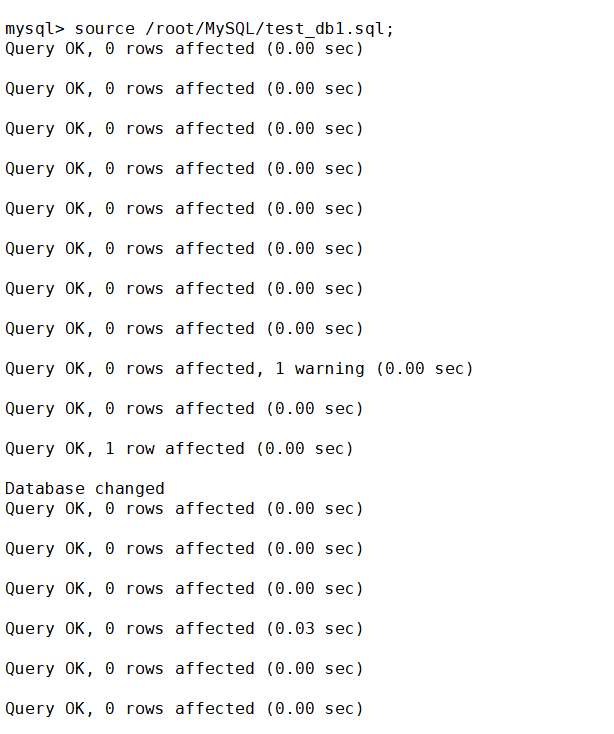
现在还原一下删除的库
这次是在mysql客户端里输入
source 相关路径/mytest.sql;可以看到有很多语句被执行的提示
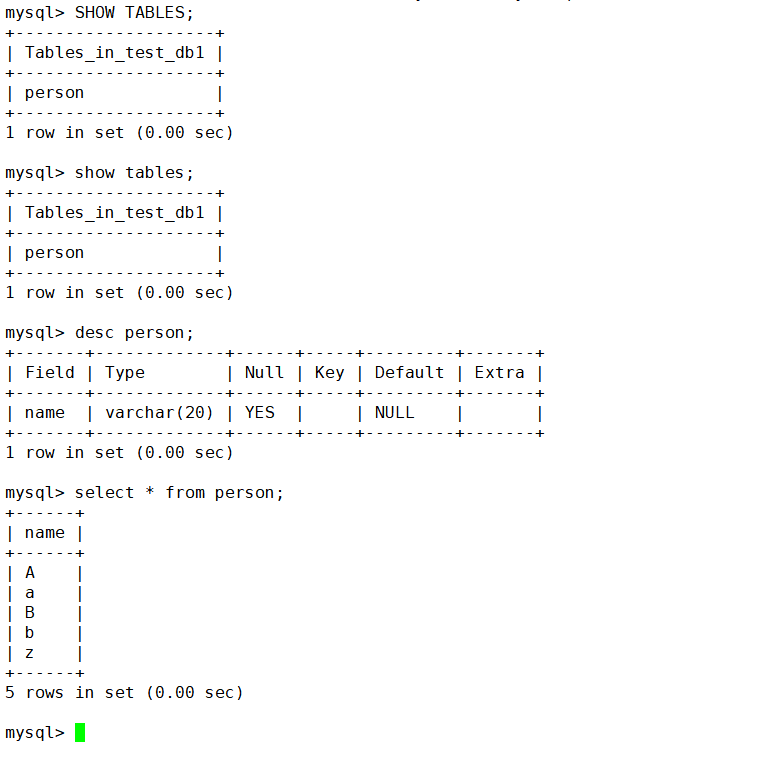
查看库里都存在的表
show tables;查看表的结构
desc 表名;这样删除的库就被还原了
如果备份的不是整个数据库,而是其中的一张表,怎么做?
# mysqldump -u root -p 数据库名 表名1 表名2 > 路径
同时备份多个数据库
# mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用source来还原
查看连接情况
show processlist可以看到目前只有我一个root用户在连接数据库
