《C++ 容器适配器:stack、queue 与 priority_queue 的设计》
stack栈
正常情况下,应该这样实现栈
template <class T>
class stack
{
private:T* _arr;size_t _top;size_t _capacity;
};主要就是在栈顶插入,在栈顶删除,那我们的栈就可以不用原生的实现,直接用现有的容器,如vector,list去封装一下,只要能在一段进行插入删除即可
比如这样,
template <class T>
class stack
{
private:vector<T> _arr;//or list<T> _arr
};但这样就写死了,只能是数组栈/链式栈,模板参数不一定是数据类型,还可以是容器类型
因此定义一个容器Container,传入相应的容器模板,用Container适配转换出stack
template <class T,class Container>
class stack
{
private:Container _con;//vector,list等的底层容器
};这样传不同的容器就可以是数组栈,也可以是链式栈
sxm::stack<int, vector<int>> st;sxm::stack<int, list<int>> st2;适配器
什么是适配器?是基于现有的容器,对其进行底层的封装,通过封装这个容器来实现需要的功能,提供了特定的接口,隐去了原本现有容器的部分功能。只暴露符合该数据结构特性的方法。
不用写构造函数了,因为_con是一个自定义类型(vector<T>/list<T>等),即使没有显示写初始化列表,也会走初始化列表,然后调用它的默认构造
模板参数传类型,函数参数传对象
namespace sxm
{ template <class T,class Container=vector<T>>//模板参数传类型,给个缺省值//template <class T, class Container = deque<T>>class stack{public:void push(const T& x){//尾部当栈顶_con.push_back(x);}void pop(){return _con.pop_back();}const T& top()const{return _con.back();//不要使用[],因为容易不一定是vector,也有可能是list,而list没有[]重载}size_t size()const{return _con.size();}bool empty()const{return _con.empty();}private:Container _con;//底层容器};
}queuq队列
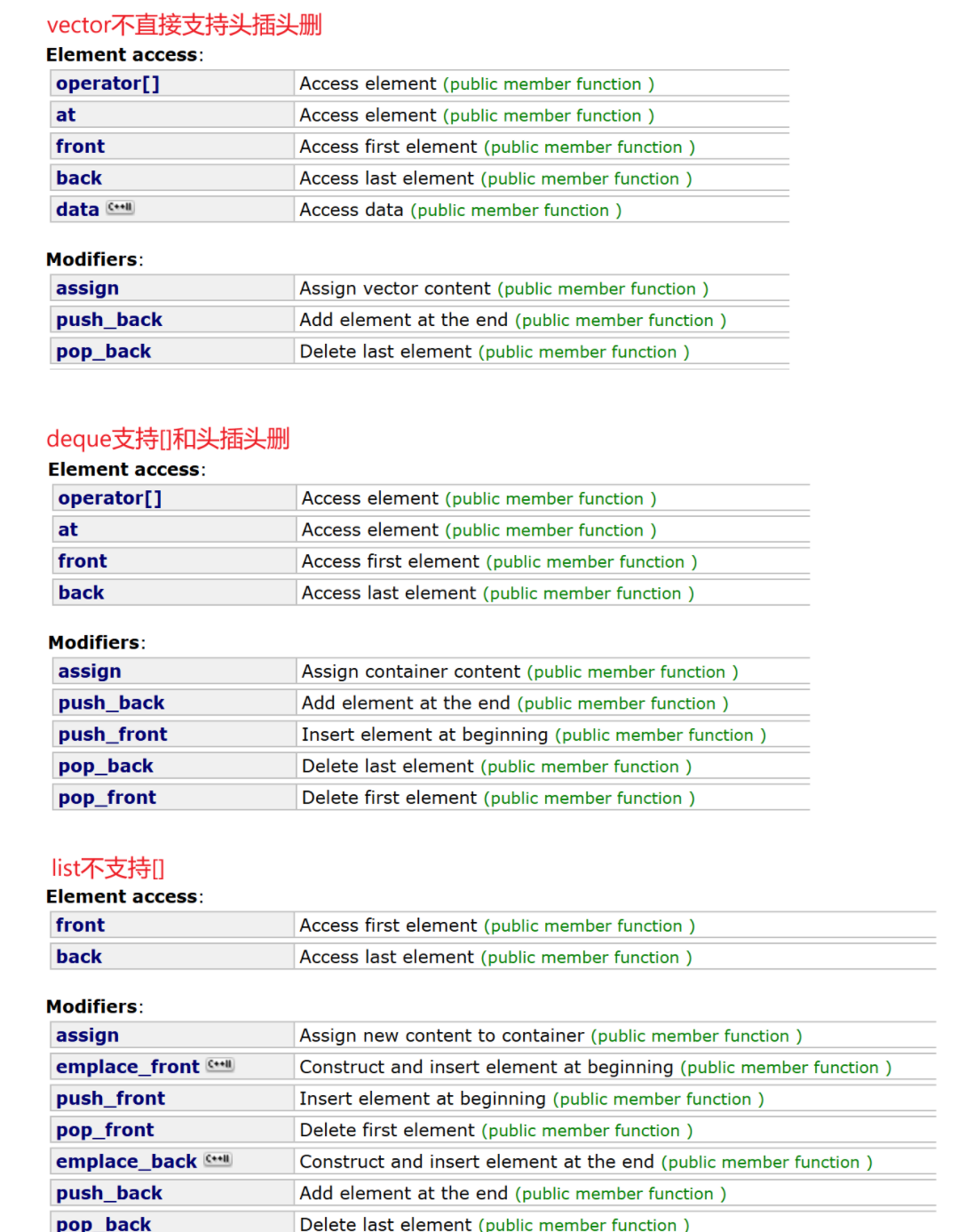
queue也是同理,但是队列是在一端进,另一端出,如果用vector容器来适配就不合适,因为vector不支持头删pop_front(),效率极低,但可以用erase+begin,只是太麻烦,可以用list容器
namespace sxm
{template <class T, class Container = list<T>>//template <class T, class Container = deque<T>>class queue//队列先进先出{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& front()const//队头出{return _con.front();}const T& back()const//队尾入{return _con.back();}size_t size()const{return _con.size();}bool empty()const{return _con.empty();}private:Container _con;//底层容器};
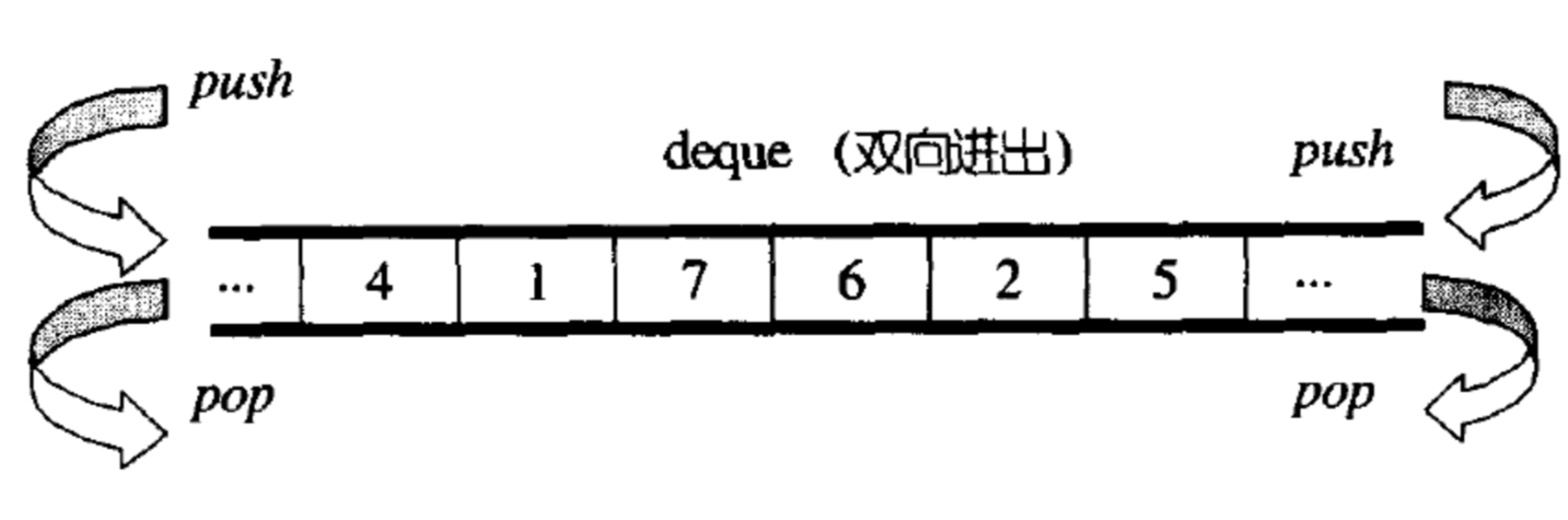
}deque
但是C++标准库里的默认容器是deque
deque是缝合怪
vector和list的缝合,支持vector的下标随机访问[],和list的头尾的插入删除,因此搞出了deque
deque本质上是双端队列,允许在队列的两端进行插入删除,时间复杂度为O(1)
vector
优点:
1.尾插尾删效率不错,支持高效的下标随机访问
2.物理空间连续,缓存利用率高
缺点:
1.空间不够需要扩容,扩容有代价
2.头部和中间插入的效率低
list
优点:
1.按需申请空间,不需要扩容
2.支持任意位置的插入删除
缺点:
1.不支持下标的随机访问(空间碎)
deque:
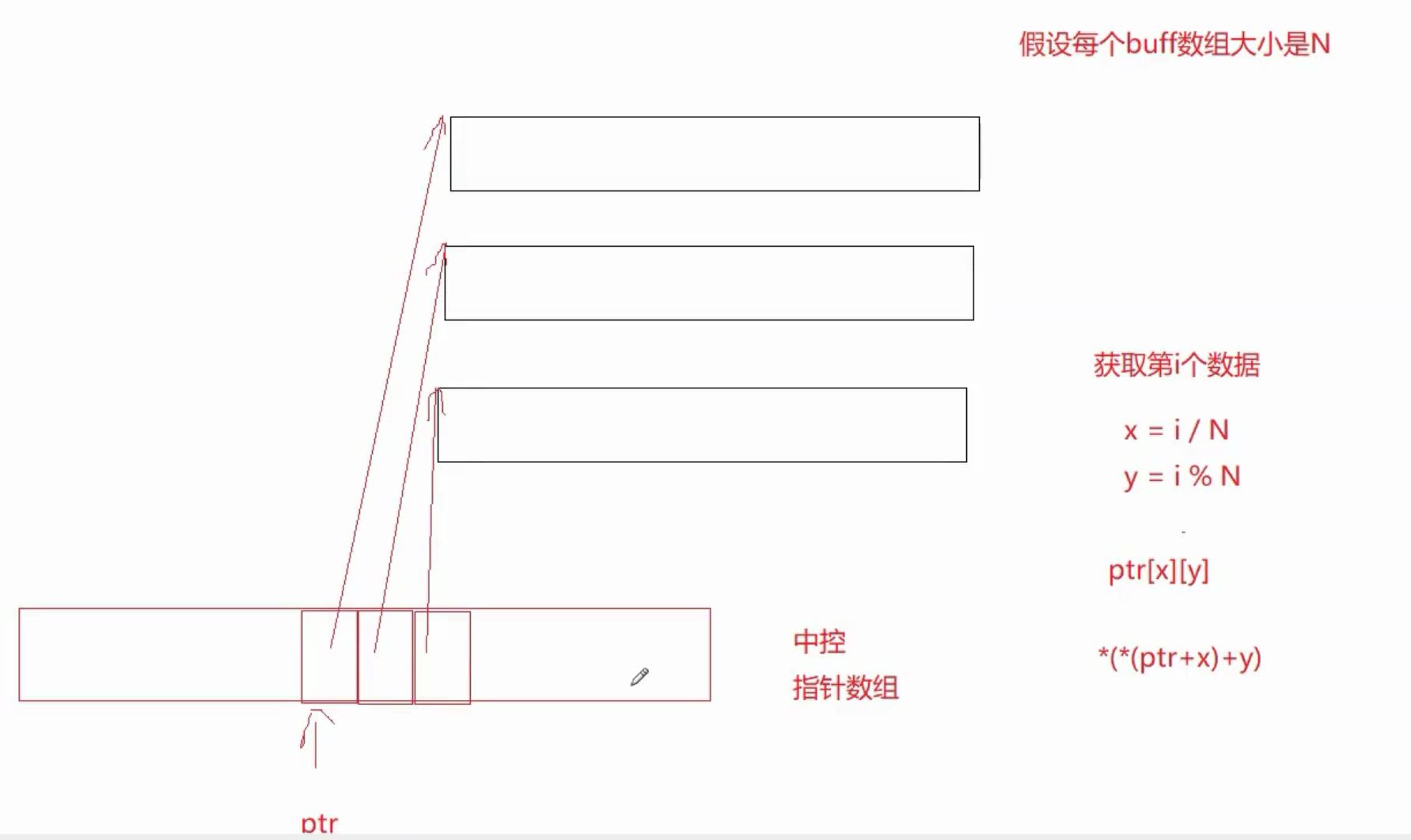
与vector的连续内存不同,deque采用分段连续内存,有一个中控数组,用来存储每个内存块的指针,第一个内存块的数组指针处于中控数组的中间部位,当进行头插时,在左侧新增内存块,避免了vector进行头插需要移动整个数组的操作。
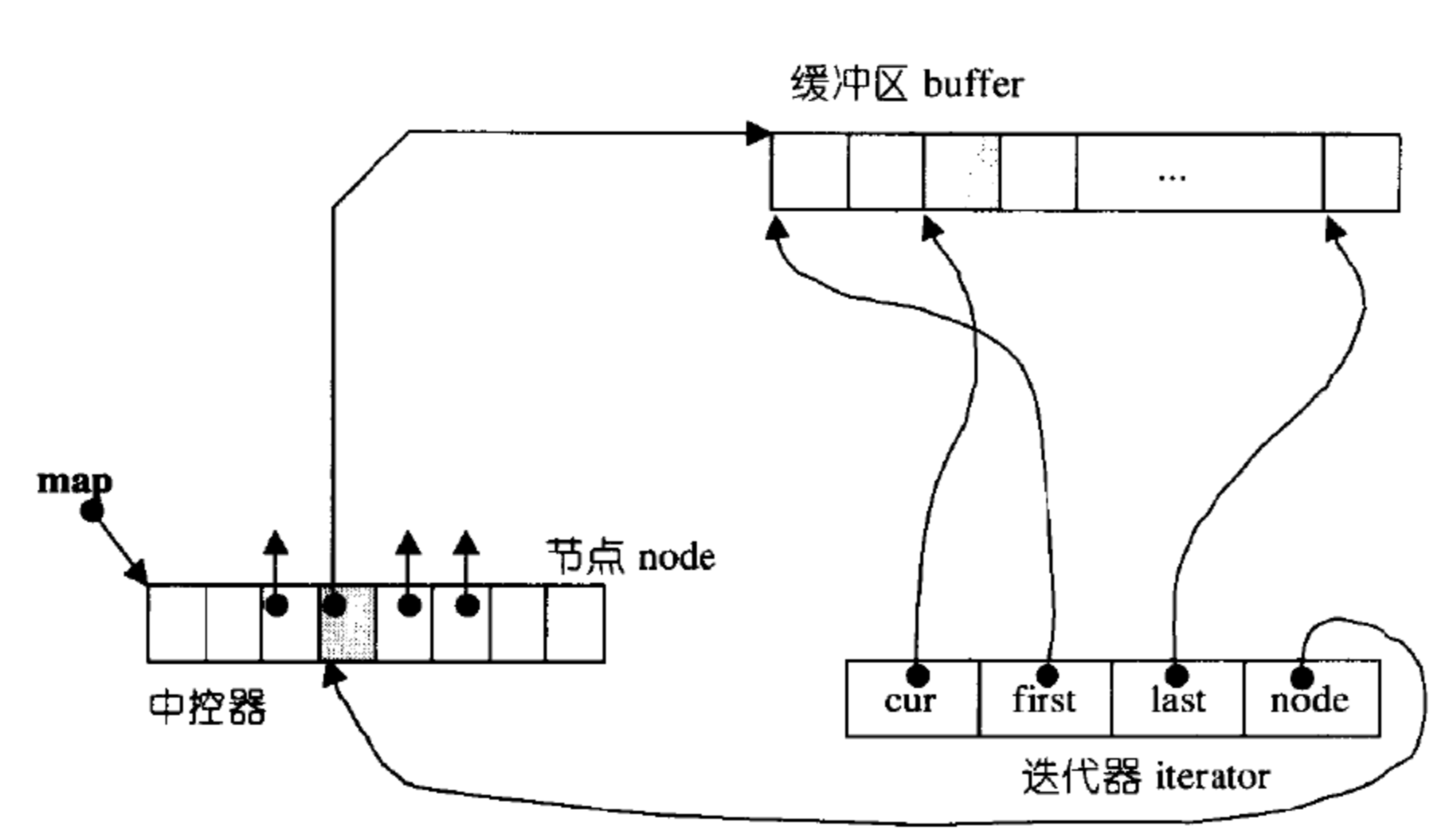
deque迭代器的实现
迭代器有四个指针:
first指向当前buff的起始位置
last指向当前buff的末尾(最后一个元素的下一个位置)
cur代表访问这个buff的当前数据
node是指向中控器中某个元素(当前内存块buff)的指针,是一个二级指针
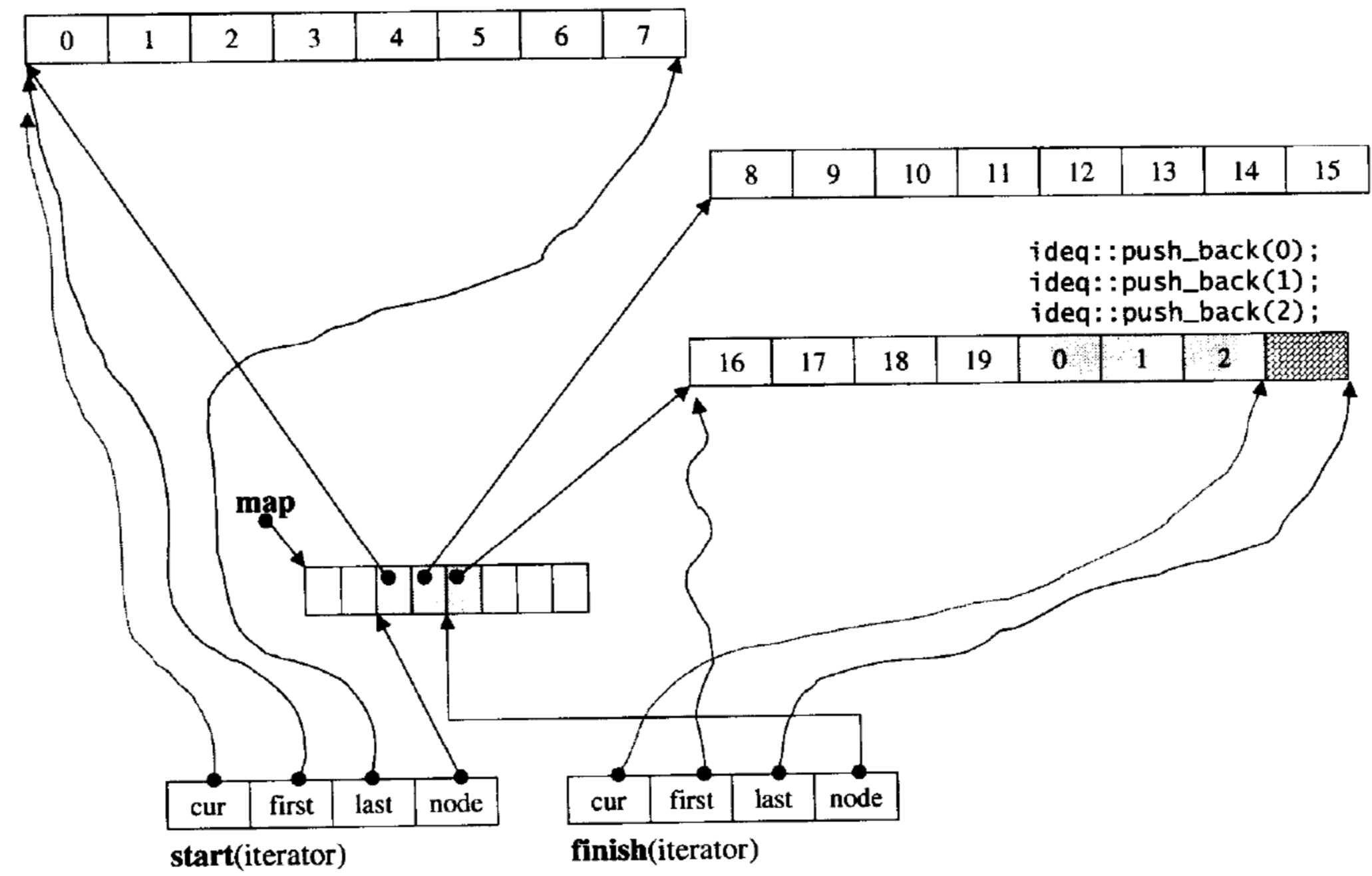
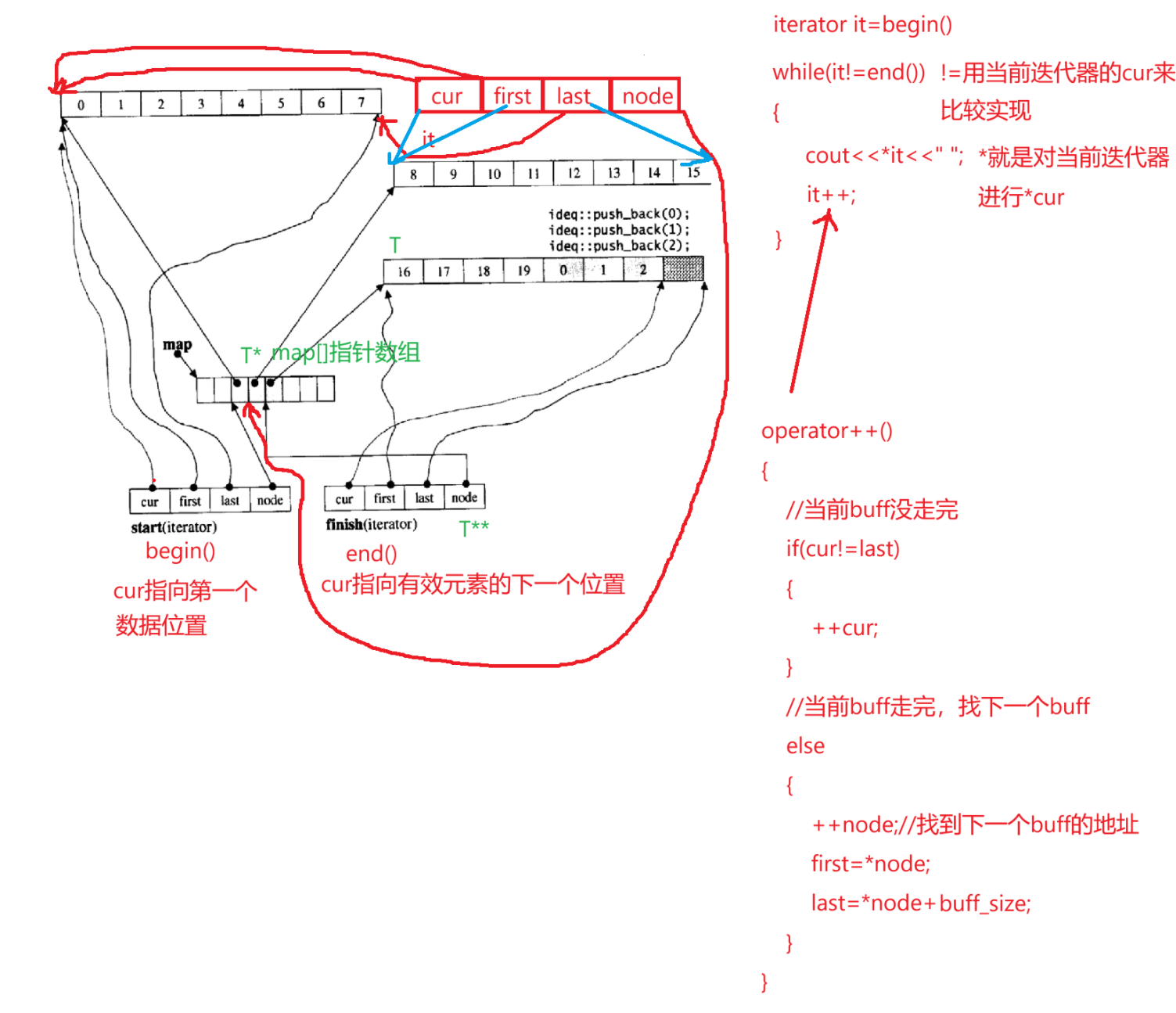
deque插入的实现
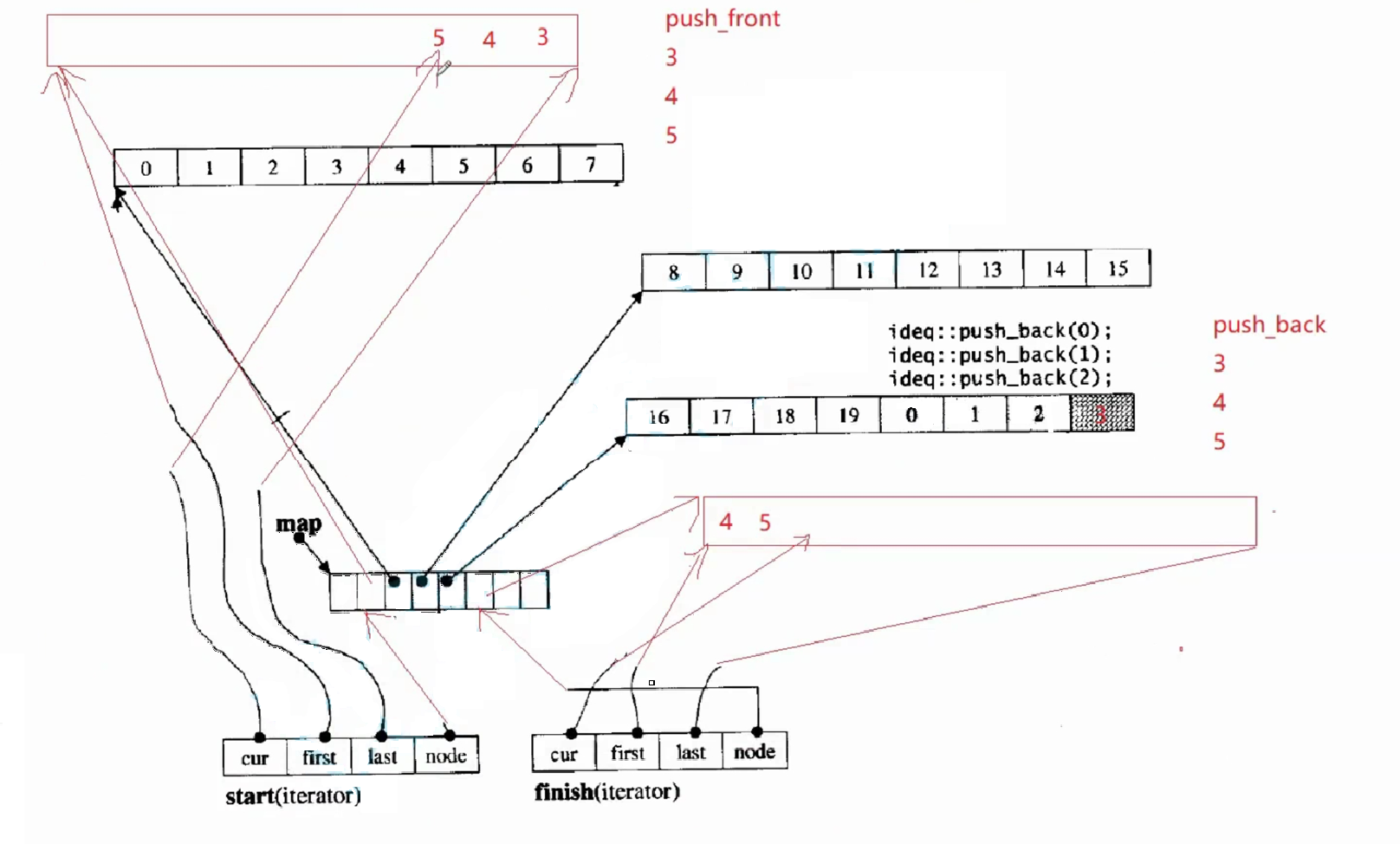
尾插找到finish,如果finish迭代器里的cur!=last,表示没有满,直接在cur的位置插入即可,如果已经满了,说明最后一个buff已经满了,接下来增加新的buff,这时在node的下一个位置给给这个新的buff的地址,更新迭代器中的指针,再进行插入,cur指向当前有效元素的下一个位置。
如果是头插,找到当前node的前一个位置,开一段新的buff,更新迭代器中的四个指针,这个cur指向元素本身,不是元素的下一个位置,因为start相当于begin。指向第一个数据,只要cur!=first,那cur就一直往前走,直到这个buff满了
那如果是中间插入呢,insert与erase,效率贼低,需要移动buff中的数据,两种选择,当前buff挪动还是所有buff挪动。如果是所有buff挪动,那下一个buff的数据会进入到这个buff里,类似于vectorO(n);而如果只控制当前buff,可对当前buff扩容,但是会导致每个buff的大小不一样。导致[]的效率进一步下降,不能直接通过/ 来判断是在第几个buff,而需要减去之前所有buff中的元素个数。库里面选择牺牲insert/erase,这里使用 / ,保证每个buff的大小不变
deque下标随机访问[]的实现
[]是如何实现的,先看是不是在第一个buff内,如果不是先把第一个buff减掉,再进行/和%
看看库里面是如何实现的--通过cur-first+n,要访问当前buff的第几个数据,相当于把当前的buff补满。相当于把起始位置挪到了开始。

如果不在当前的buff,就找到对应的buff,通过/buff_size,找到是第几个buff;然后算在这个buff的第几个位置,减去前面每个buff的数据个数,类似于%,只不过第一个buff的数据个数不确定。

总结:
1.deque头插尾插效率很高,优于list与vector(缓存利用率高)
2.下标随机访问效率也不错,但比不上vector(deque里面有好多运算)
3.中间插入效率很低(挪动插入之后的所有数据)
如果不考虑第3点,deque还是很合适的
栈和队列一个在一端进行插入删除,一个在两端进行插入或删除,不涉及中间的插入和删除,deque可以做底层的适配器。现在栈和队列可以用同一个结构来实现了。
stack
#include<deque>
namespace sxm
{ template <class T, class Container = deque<T>>//缺省容器类型class stack{public:void push(const T& x){_con.push_back(x);}void pop(){return _con.pop_back();}const T& top()const{return _con.back();}size_t size()const{return _con.size();}bool empty()const{return _con.empty();}private:Container _con;//底层容器};
}
queue
#include<deque>
namespace sxm
{template <class T, class Container = deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& front()const{return _con.front();}const T& back()const{return _con.back();}size_t size()const{return _con.size();}bool empty()const{return _con.empty();}private:Container _con;//底层容器};
}priority_queue优先级队列
要取优先级高的,默认是大的值优先级高,底层是堆,堆的底层是数组,默认适配容器是vector
默认是大堆
namespace sxm
{template<class T,class Container=vector<T>>class priority_queue{public://插入void AdjustUp(int child){int parent = (child - 1) / 2;while(child>0){if (_con[child] > _con[parent])//大堆{swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void push(const T& x){//在尾部插入,向上调整(是堆),//插入之前就已经是一个堆 _con.push_back(x);//第一个数插入是堆,第二个插入向上调整也是堆,类推AdjustUp(_con.size() - 1);}//删除,先进行向下调整,要求左右子树为大堆void AdjustDown(int parent){size_t child = 2 * parent + 1;while (child<_con.size()){if (child+1<_con.size()&&_con[child] < _con[child + 1]){++child;//左右孩子中大的那个}if (_con[parent] < _con[child]){swap(_con[parent], _con[child]);parent = child;child = 2 * parent + 1;}else{break;}}}//第一个和最后一个交换,删除最后一个元素,再进行向下调整(左右子树是堆)void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();AdjustDown(0);//进行向下调整}//取堆顶元素const T& top(){return _con[0];}//堆的大小size_t size(){return _con.size();}//判空bool empty(){return _con.size() == 0;}private:Container _con;//vector类型的对象,支持下标访问};
}优先级队列这里是写死的,这里现在是大堆,如果现在想改成小堆,难道要直接改代码或再实现一个小堆吗?
仿函数
这里引入仿函数,仿函数是一个类,重载了operator(),用于进行两个数据间的比较大小,仿函数没有成员变量,是一个空类,大小是1,它的对象可以像函数一样使用
看下面一段代码,Less<T>和Greater<T>就是两个仿函数类型,
template <class T>
class Less
{
public:bool operator()(const T& x,const T& y){return x < y;}
};template <class T>
class Greater
{
public:bool operator()(const T& x, const T& y){return x > y;}
};int main()
{Less<int> LessFunc;cout << LessFunc(1, 2);//我会认为LessFunc是一个函数名,但现在它只是一个对象return 0;
}LessFunc(1,2),本质上是调用LessFunc()(1,2),仿函数的对象可以向函数一样调用,对象名(参数)
再比如我们看冒泡排序,
void BubbleSort(int* a, int n)
{for (int j = 0; j < n; j++){int flag = 0;for (int i = 1; i < n - j; i++){if(a[i-1] > a[i])//升序{swap(a[i - 1], a[i]);flag = 1;}}if (flag == 0){break;}}
}这里采用的是>升序,如果要实现降序,需要调整内部代码,将">"改成"<" 。但也可以不这么做,
因为仿函数是一个类型,这时我们再加一个模板Compare,模板类型是一个仿函数类
template<class Compare>
void BubbleSort(int* a, int n,Compare com)
{for (int j = 0; j < n; j++){int flag = 0;for (int i = 1; i < n - j; i++){if (com(a[i - 1] , a[i]))//升序{swap(a[i - 1], a[i]);flag = 1;}}if (flag == 0){break;}}
}
int main()
{Less<int> LessFunc;Greater<int> GreaterFunc;int a[] = { 3,6,3,2,8 };BubbleSort(a, 5, LessFunc);
//也可以传匿名的仿函数类型的对象 如:
//BubbleSort(a,5,Less<int>());BubbleSort(a, 5, GreaterFunc);return 0;
}com是一个仿函数类类型的对象,它的类型可以是Less<T>仿函数类型,也可以是Greater<T>仿函数类型,这个对象通过类似于函数调用的方式com(a[i-1],a[i]),来返回真或假,进而来判断是升序还是降序。
在主函数里面,可以定义不同类型的仿函数对象,LessFunc,GreaterFunc,通把这个仿函数对象传给冒泡排序当作参数,编译器自动推导这个仿函数对象对应的类型是Less<T>,或是GreaterFunc<T>,然后通过不同的仿函数类型的对象调用其对应的仿函数模板下的()重载,来实现想要的功能
因此,无需修改 BubbleSort 内部代码,仅通过更换传入的仿函数对象,即可切换排序方式。
//我们传一个缺省值,默认时是大堆,但如果想实现小堆,可以传一个Greater
#pragma oncetemplate <class T>
class Less
{
public:bool operator()(const T& x, const T& y){return x < y;}
};template <class T>
class Greater
{
public:bool operator()(const T& x, const T& y){return x > y;}
};namespace sxm
{template<class T,class Container=vector<T>,class Compare = Less<T>>//Compare为仿函数类型,类模板class priority_queue{public://插入void AdjustUp(int child){Compare com;//仿函数类型的对象,默认是Less仿函数类型的对象,Less对象调用类内重载的(),来比较大小int parent = (child - 1) / 2;while(child>0){if (com(_con[parent], _con[child]))//大堆,这里不写死是< 还是>,而是调用仿函数对象(默认为Less<T>类型)com,如果_con[parent]<_con[child],则交换{swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void push(const T& x){//在尾部插入,向上调整(是堆),//插入之前就已经是一个堆 _con.push_back(x);//第一个数插入是堆,第二个插入向上调整也是堆,类推AdjustUp(_con.size() - 1);}//删除,先进行向下调整,要求左右子树为大堆void AdjustDown(int parent){Compare com;size_t child = 2 * parent + 1;while (child<_con.size()){if (child + 1 < _con.size() && com(_con[child] , _con[child + 1]))//右节点大于左节点{++child;//更新为右节点}if (com(_con[parent],_con[child]))//_con[parent]<_con[child],则交换{swap(_con[parent], _con[child]);parent = child;child = 2 * parent + 1;}else{break;}}}//第一个和最后一个交换,删除最后一个元素,再进行向下调整(左右子树是堆)void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();AdjustDown(0);//进行向下调整}//取堆顶元素const T& top(){return _con[0];}//堆的大小size_t size(){return _con.size();}//判空bool empty(){return _con.size() == 0;}private:Container _con;//vector类型的对象,支持下标访问};
}缺省值还是很有用的,当不显示写Less时是默认调整为大堆;如果想改为小堆,则显示写一个Greater。