深度学习-计算机视觉-目标检测三大算法-R-CNN、SSD、YOLO
我们大概确定了目标检测问题需要两步走:
侯选框选取;
将侯选框中的物体分类;(后面需要剔除得分低的框)
这样就得到了【两步走(Two-Stage)】的算法原型,代表是【RCNN】,之后的【Fast-RCNN】、【Faster-RCNN】都是基于它迭代的。
那能不能在侯选框选取的同时预测分类呢?也是可以的,这样就有了【SSD】和【YOLO】(One-Stage)。
1. 区域卷积神经网络 R-CNN
所谓RCNN就是【Region】+【CNN】。完美地对应到了上述说的选框+分类。
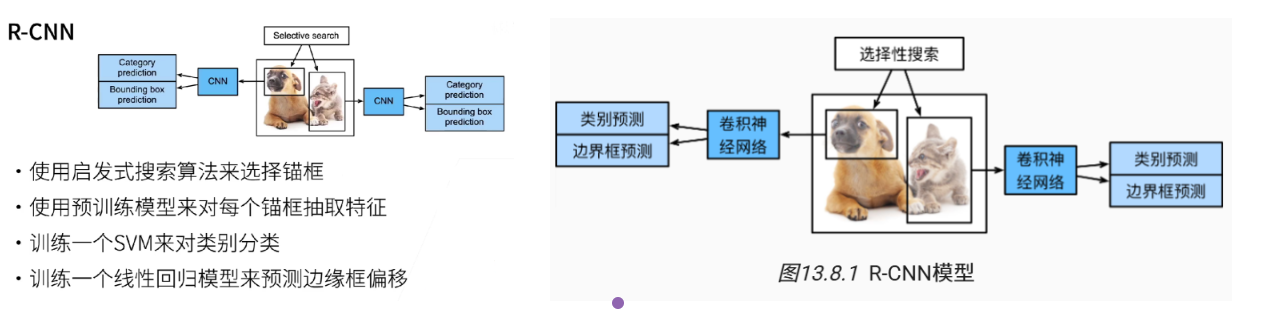
1.1 RCNN
R-CNN系列开创了基于深度学习的现代目标检测方法,其核心思想是“先找区域,再分类”(Two-Stage)。即先提取可能包含目标的候选区域(Region Proposals),再对每个区域进行深度特征提取和分类。
具体来说,R-CNN包括以下四个步骤:
对输入图像使用选择性搜索来选取多个高质量的提议区域。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框;
选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸(ROI pooling),并通过前向传播输出抽取的提议区域特征;
将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别;
将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。

核心思想:
区域提议:使用选择性搜索(Selective Search)等传统算法从输入图像中提取约2000个可能存在目标的候选区域。
放缩区域:将每个候选区域缩放到固定大小(例如 227x227)。
特征提取:将每个缩放后的区域输入一个预训练好的CNN(如AlexNet)中,提取固定长度的特征向量。
分类与回归:对每个特征向量,使用一系列类别特定的线性SVM进行分类(判断是什么物体),同时使用一个边界框回归器来微调候选框的位置,使其更精确。
优点:
首次将CNN成功应用于目标检测,在PASCAL VOC数据集上大幅提升了检测精度。
缺点:
速度极慢:需要对每个候选区域单独进行CNN前向传播,计算冗余极大(2000个区域 * 1个CNN)。
训练复杂:需要分多步训练(微调CNN、训练SVM、训练回归器)。
内存占用大:所有区域的特征需要写入磁盘,占用大量空间。
【补充目标检测中的选择性搜索的例子】:
假设我们要在一张街景图片中检测出所有汽车。
初始分割:
首先,算法会将输入的街景图片分割成若干个小的区域。例如,根据像素的颜色、纹理等特征相似性,把图片分割成类似于树叶大小的初始小区域。这些初始区域就像是一个个基本的 “拼图块”,为后续的合并操作做准备。区域合并与候选区域生成:
然后,算法会按照一定的相似性准则(如颜色相似度、纹理相似度等)将这些小区域逐步合并。比如,两个相邻的小区域如果颜色比较接近,就会被合并成一个较大的区域。随着合并的进行,会生成不同大小和形状的候选区域。
这些候选区域可能包括汽车的整体轮廓、汽车的一部分(如车头、车尾等),也可能包含一些非汽车的区域,如路边的树木、建筑物的一部分等。
特征提取与分类:
对于每一个候选区域,会提取其特征,如边缘特征、形状特征、颜色直方图等。然后将这些特征输入到预先训练好的分类器(如支持向量机SVM)中。分类器的作用是判断该候选区域是否是汽车。
例如,一个候选区域经过特征提取后,其形状特征比较符合汽车的典型轮廓特征,颜色特征也和常见的汽车颜色相符,经过分类器判定后,它就有可能被识别为汽车。
结果输出与后处理:
最后,将所有被分类器判定为汽车的候选区域保留下来,并在原图上绘制边框以标记汽车的位置。同时,可能会对这些标记的汽车区域进行一些后处理操作,如非极大值抑制NMS,以去除一些重复的、不必要的标记框,得到最终准确的汽车检测结果。
1.2 Fast RCNN
R-CNN的主要性能瓶颈在于,对每个提议区域,卷积神经网络的前向传播是独立的,而没有共享计算。 由于这些区域通常有重叠,独立的特征抽取会导致重复的计算。
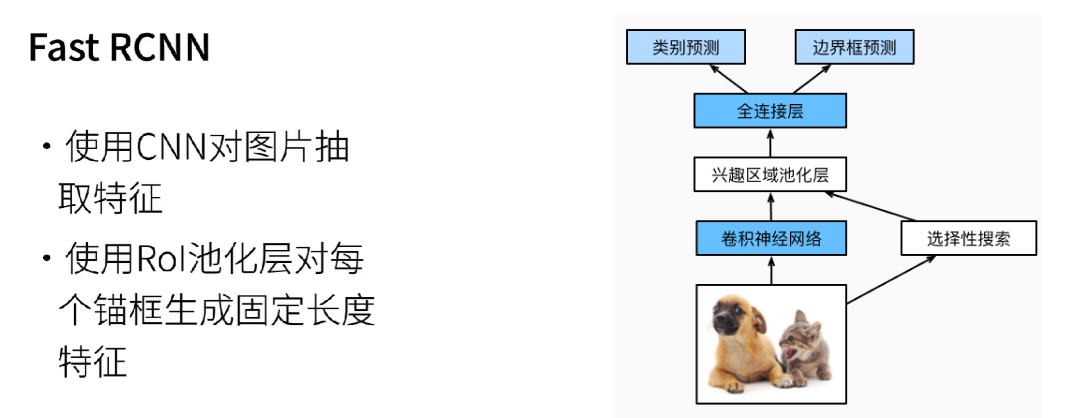

核心改进:
共享计算:不再对每个候选区域单独跑CNN。而是将整张图像输入一个CNN,生成一个共享的特征图(Feature Map)。这极大地减少了计算量。
ROI Pooling:对于每个候选区域,在共享的特征图上找到其对应的区域,并通过一个称为RoI Pooling(Region of Interest Pooling) 的层,将其转换为固定大小的特征块。这解决了区域大小不一的问题。
端到端训练:将分类(改用Softmax)和边界框回归任务合并到一个网络中,使用多任务损失函数进行端到端的训练,简化了流程。
优点:
速度显著提升(比R-CNN快数百倍)。
精度更高。
训练过程得到简化。
剩余缺点:
区域提议(Region Proposal)步骤(如选择性搜索)仍然在CPU上完成,速度慢,成为整个检测流程的瓶颈。
1.3 Faster RCNN
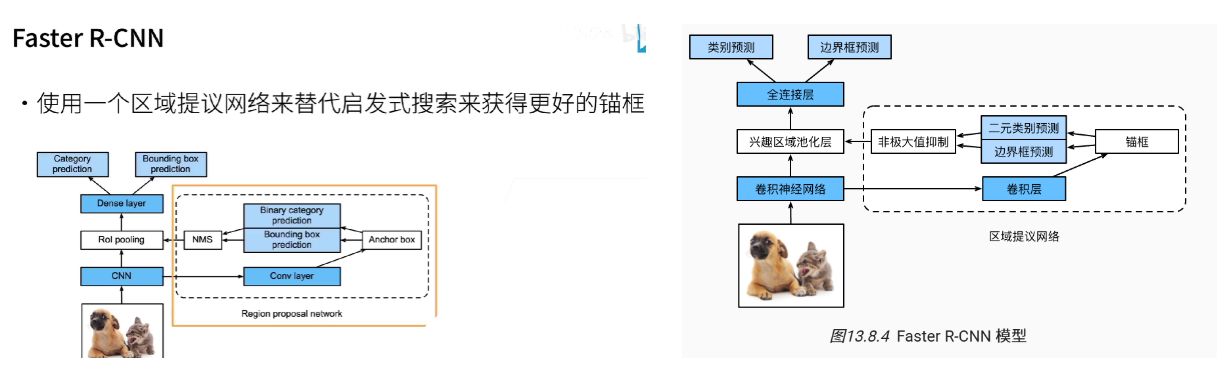
加入ROI池化:

核心创新:
引入了 RPN(Region Proposal Network,区域提议网络),用神经网络直接学习生成候选区域,取代了耗时的选择性搜索。
工作流程:
输入图像通过一个基础CNN(如VGG/ResNet)得到共享特征图。
在共享特征图上滑动一个小网络(RPN),该网络在每个位置同时预测:
边界框(
k个预定义形状和大小的锚点框,即anchors的偏移量)。目标得分(判断锚点框是前景还是背景)。
RPN提出的优质候选区域(RoIs)被送入与Fast R-CNN中相同的RoI Pooling层和后续的分类/回归头。
优点:
真正意义上的端到端目标检测系统,所有计算都在GPU上完成。
区域提议几乎不花时间,速度比Fast R-CNN快得多,同时保持了极高的精度。
成为两阶段检测器的标杆,至今仍是许多精度要求高的应用场景的首选。
缺点:
整体流程相比单阶段方法仍显复杂,速度达不到实时(但接近实时)。
总结:
需要两阶段的处理,即候选区域生成和特征提取,因此速度相对较慢,不适合需要实时性的应用场景。
R-CNN对图像选取若干提议区域,使用卷积神经网络对每个提议区域执行前向传播以抽取其特征,然后再用这些特征来预测提议区域的类别和边界框。
Fast R-CNN对R-CNN的一个主要改进:只对整个图像做卷积神经网络的前向传播。它还引入了兴趣区域汇聚层,从而为具有不同形状的兴趣区域抽取相同形状的特征。
Faster R-CNN将Fast R-CNN中使用的选择性搜索替换为参与训练的区域提议网络,这样后者可以在减少提议区域数量的情况下仍保证目标检测的精度。
2. 单发多框检测 SSD
该模型简单、快速且被广泛使用。
尽管这只是其中一种目标检测模型,但本节中的一些设计原则和实现细节也适用于其他模型。
SSD原理:
多尺度特征图检测
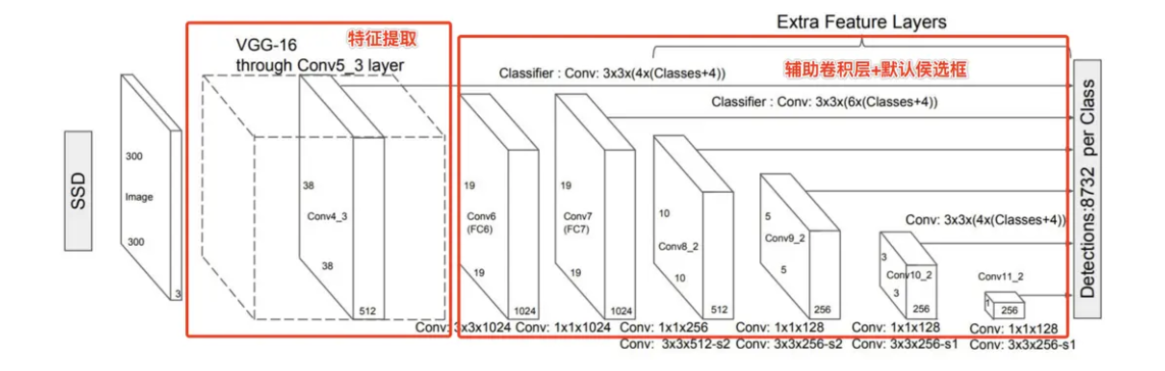
SSD使用不同尺度的特征图来检测不同大小的目标。较小的目标一般在较浅层的特征图上检测,较大的目标在较深层的特征图上检测。
例如,VGG16作为基础网络,会在conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11_2等多个不同尺度的特征图上进行检测。
锚框生成
在每个特征图的每个位置,生成多个锚框(Anchor Boxes)。这些锚框有固定的大小和宽高比。对于不同尺度的特征图,会设置相应大小的锚框。
例如,在较小的特征图上,锚框的大小相对较大,用于检测大目标。
类别预测与位置回归
对于每个锚框,同时进行类别预测和位置回归。类别预测是判断锚框内包含的目标类别,位置回归是对锚框的位置和大小进行调整,使其更准确地包围目标。
类别预测一般使用softmax函数,位置回归使用平滑L1损失函数。
非极大值抑制(NMS)
在完成类别预测和位置回归后,使用非极大值抑制(NMS)去除冗余的、重叠度高的边界框,保留最优的检测框。
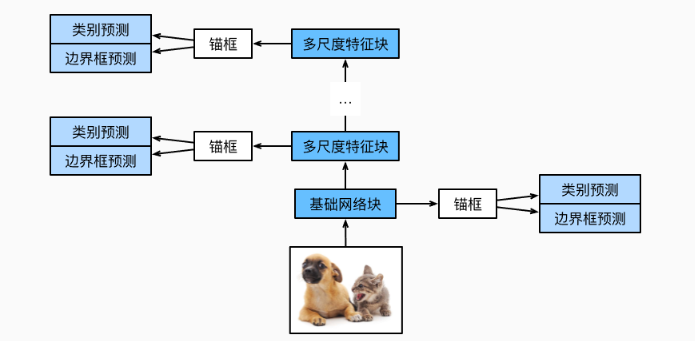
省去了区域候选框生成的步骤,能够以极高的效率完成检测任务,适用于实时性要求较高的场景。
单发多框检测是一种多尺度目标检测模型。基于基础网络块和各个多尺度特征块,单发多框检测生成不同数量和不同大小的锚框,并通过预测这些锚框的类别和偏移量检测不同大小的目标。
在训练单发多框检测模型时,损失函数是根据锚框的类别和偏移量的预测及标注值计算得出的。
核心思想:“单次射击”(One-Stage)。摒弃了“区域提议”的步骤,只使用一个网络直接预测目标的类别和边界框。
关键创新:
多尺度特征图:在不同深度的特征图(越靠后的特征图尺寸越小,感受野越大)上进行预测。浅层特征图负责检测小目标,深层特征图负责检测大目标。
默认框(Default Boxes):在每个特征图的每个单元格上,预定义一系列不同大小和长宽比的默认框(类似于Faster R-CNN中的锚点框)。网络直接预测:
每个默认框的类别得分。
每个默认框相对于真实目标的偏移量。
优点:
速度极快:单次网络前向传播即可得到所有检测结果,远超Faster R-CNN,达到实时要求。
对小目标检测效果较好(得益于多尺度预测)。
缺点:
精度,尤其是对中小目标的精度,通常仍略低于Faster R-CNN。
需要手动设置默认框的尺寸和比例等超参数。
一个例子:
输入图像: 走进教室。
基础网络提取特征: 快速获取教室的整体布局信息(座位排列)。
多尺度特征图: 关注前排(细节)、中排、后排(整体)。
预设默认框: 心里装着教室的座位表(每个座位位置就是一个默认框)。
单次预测: 扫视一次全班,对每一个座位框,同时预测:
坐在这个框里的是谁?(分类概率:张三、李四、空座位)
这个同学坐得正不正?框要不要微调?(位置偏移量)
匹配与训练: 老师通过经验(训练数据)知道:
哪个座位大概率坐谁(比如班长坐第一排)。
高个子坐后排框需要往上调(学习位置偏移)。
NMS 后处理: 删除对同一个学生(物体)的低置信度、重复的检测框。
输出结果: 最终名单(检测到的物体类别 + 精确位置)。
3. YOLO

YOLO是单阶段检测器的另一开创性工作,其哲学比SSD更彻底:将目标检测视为一个单一的回归问题。
核心思想:
网格划分:将输入图像划分为
S x S的网格。负责机制:每个网格单元负责预测那些中心点落在该网格内的目标。
统一预测:每个网格单元预测
B个边界框以及这些框的置信度(Confidence Score) 和 C` 个类别概率。置信度反映了框包含目标的可能性以及预测框的准确度。
工作流程:图像只需通过CNN“看一次”,网络直接输出一个
S x S x (B*5 + C)的张量,包含了所有检测结果。演变:
YOLOv1:开创了理念,但精度一般,尤其对密集小目标检测差。
YOLOv2 (YOLO9000):引入批量归一化(Batch Normalization)、锚点框(Anchor Boxes)、多尺度训练等,大幅提升速度和精度。
YOLOv3:引入更优的主干网络Darknet-53、多尺度预测(类似SSD)、更好的分类器,成为非常流行和实用的版本。
YOLOv4/v5/v7/v8...:此后进入“群雄逐鹿”阶段,融合了大量工程技巧和优化(如Mosaic数据增强、自适应锚框计算、新的网络结构如CSPNet),在速度和精度上不断刷新纪录,形成了庞大的YOLO家族,成为工业界应用最广泛的实时检测算法。
优点:
速度极快:真正的实时检测,可轻松达到每秒上百帧。
背景误检少:其网格设计使其对背景区域的误判率较低。
缺点(早期):
定位精度,尤其是对罕见长宽比或密集小目标的检测,一度落后于两阶段方法(但在后续版本中得到极大改善)。
4. 算法的比较
RCNN:
RCNN 是一种两阶段(two-stage)目标检测算法,首先在图像中提取可能包含目标的区域建议,然后对这些区域进行分类和边界框回归。
RCNN 的缺点是速度较慢,因为它需要对每个候选区域进行独立的分类,计算量较大。
Faster R-CNN:
Faster R-CNN 是 RCNN 的改进版本,引入了区域提议网络(Region Proposal Network, RPN),用于生成候选区域。这样一来,Faster R-CNN 可以端到端地训练,速度比原始的 RCNN 更快。
SSD (Single Shot MultiBox Detector):
SSD 是一种单阶段(single-stage)目标检测算法,类似于 YOLO,但它采用了不同的策略来预测多个尺度的边界框。SSD 在不同尺度上预测边界框,并通过一系列固定大小的卷积核来实现。
YOLO:
YOLO 也是一种单阶段(single-stage)目标检测算法,其核心思想是将目标检测问题转化为一个回归问题。它将整个图像划分为固定大小的网格,并为每个网格预测边界框和类别概率。
YOLO 的主要优势是速度快,因为它一次性完成了整个检测过程,不需要复杂的区域建议(region proposals)步骤。
5. 算法示例
假设我们有一个输入图像,大小为 300×300 像素,图像中包含一辆汽车和一个人。我们需要使用不同的目标检测算法来检测这两个目标。
RCNN(Region-based CNN)
处理过程 :
区域提议 :使用选择性搜索(Selective Search)在图像上生成约 2000 个区域提议。这些区域提议是可能包含目标的候选区域。
特征提取 :将每个区域提议裁剪并缩放到固定大小(如 224×224),然后通过 CNN(如 VGG16)提取特征。每个区域提议生成一个特征向量。
分类和回归 :将提取的特征向量输入到分类器(如 SVM)和边界框回归器中,分别预测目标类别和调整边界框位置。
结果 :检测到汽车和人的位置,但速度较慢,因为需要处理约 2000个区域提议。
Fast RCNN
处理过程 :
区域提议 :同样使用选择性搜索生成约 2000个区域提议。
特征提取 :将整个图像输入 CNN,提取全图特征,然后将区域提议映射到全图特征图上,使用 ROI(Region of Interest)池化层将每个区域提议裁剪并缩放到固定大小的特征图。
分类和回归 :将 ROI 池化后的特征输入到全连接层,进行分类和边界框回归。
结果 :检测到汽车和人的位置,速度比 RCNN 快,因为只对整个图像进行一次特征提取,但区域提议生成仍然较慢。
Faster RCNN
处理过程 :
区域提议网络(RPN) :用 RPN 代替选择性搜索,RPN 在特征图上直接生成约 300 个区域提议,减少数量。
特征提取 :将整个图像输入 CNN,提取全图特征,将 RPN 生成的区域提议映射到特征图上,使用 ROI 池化层裁剪并缩放。
分类和回归 :将 ROI 池化后的特征输入到全连接层,进行分类和边界框回归。
结果 :检测到汽车和人的位置,速度比 Fast RCNN 更快,因为 RPN 更高效。
SSD(Single Shot MultiBox Detector)
处理过程 :
多尺度特征图 :使用不同尺度的特征图(如 19×19、10×10、5×5、3×3、1×1)检测不同大小的目标。
锚框生成 :在每个特征图位置生成多个锚框(如 4 个锚框)。
分类和回归 :对每个锚框直接进行分类和边界框回归,省略区域提议步骤。
结果 :检测到汽车和人的位置,速度较快,因为直接在特征图上进行检测,没有区域提议步骤。
YOLO(You Only Look Once)
处理过程 :
网格划分 :将图像划分为 S×S 个网格(如 7×7)。
边界框和类别预测 :每个网格预测多个边界框(如 2 个)及其置信度和类别概率。
非极大值抑制 :使用非极大值抑制去除冗余边界框。
结果 :
检测到汽车和人的位置,速度极快,因为直接将目标检测转化为回归问题,一次性完成检测。
总体来说,YOLO 和 SSD 是单阶段目标检测算法,速度快但精度可能稍低;而 RCNN 和 Faster R-CNN 是两阶段目标检测算法,精度较高但速度较慢。Faster R-CNN 在 RCNN 的基础上加入了 RPN,速度较 RCNN 有所提升。选择哪种算法取决于具体的应用场景和对速度和精度的要求。