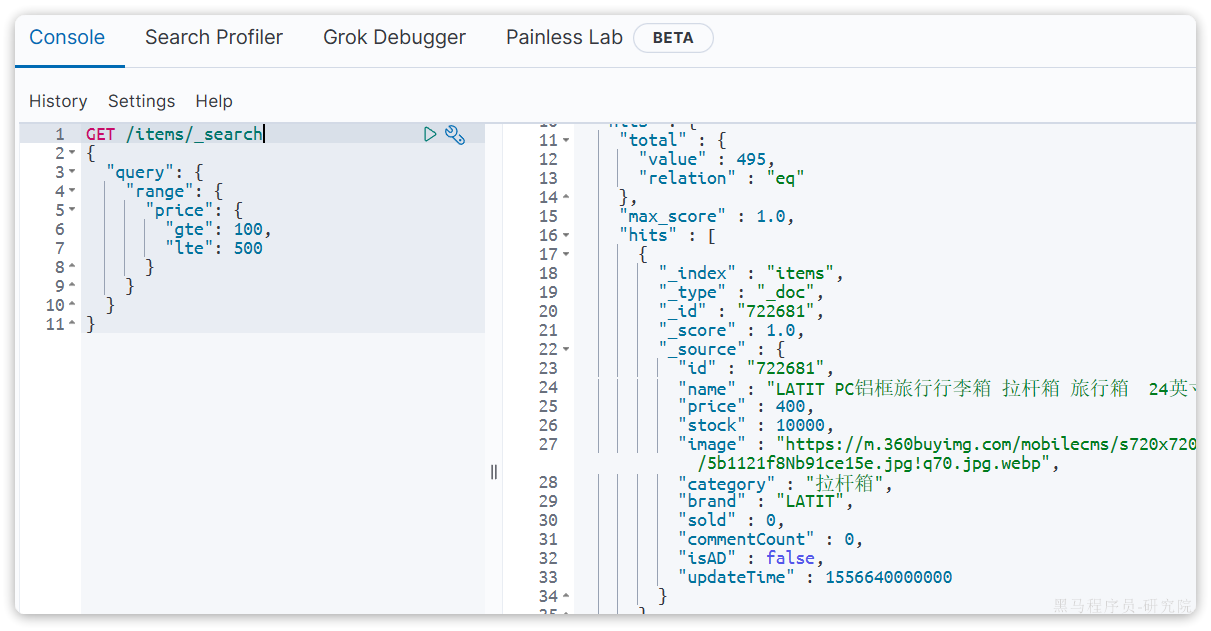
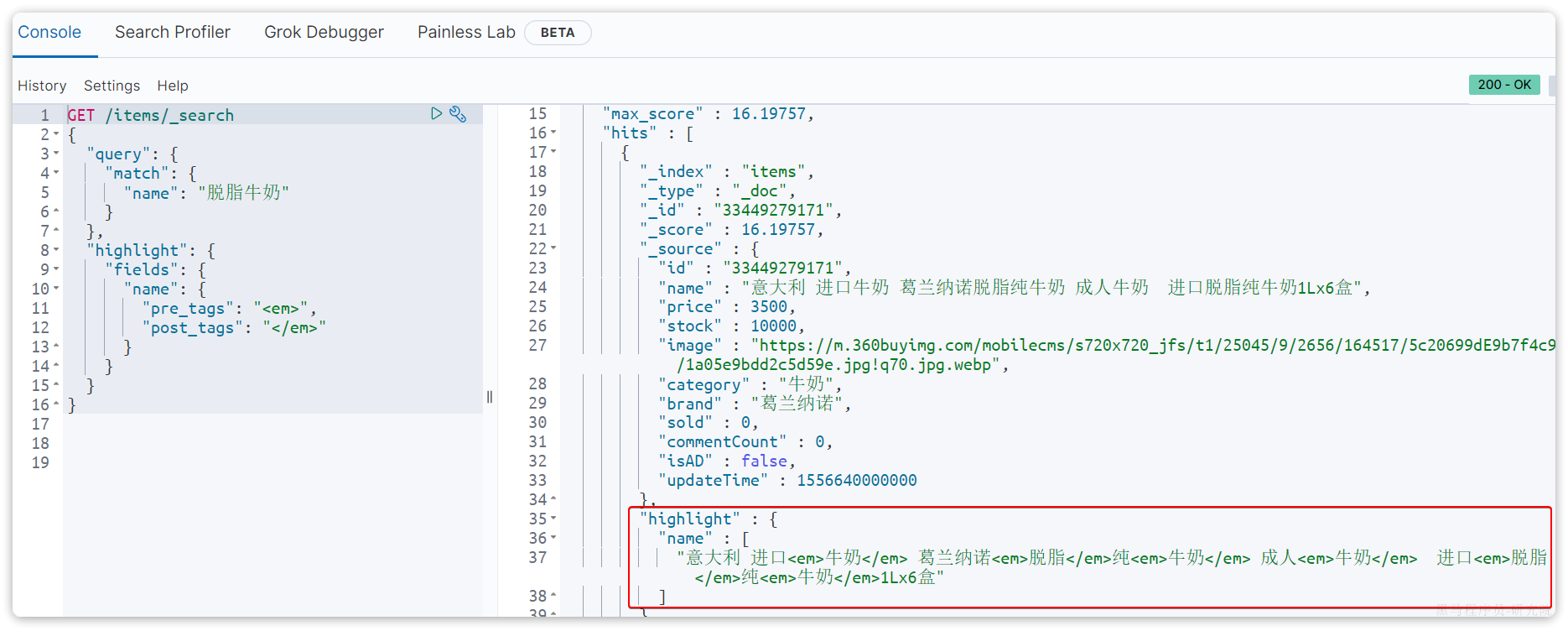
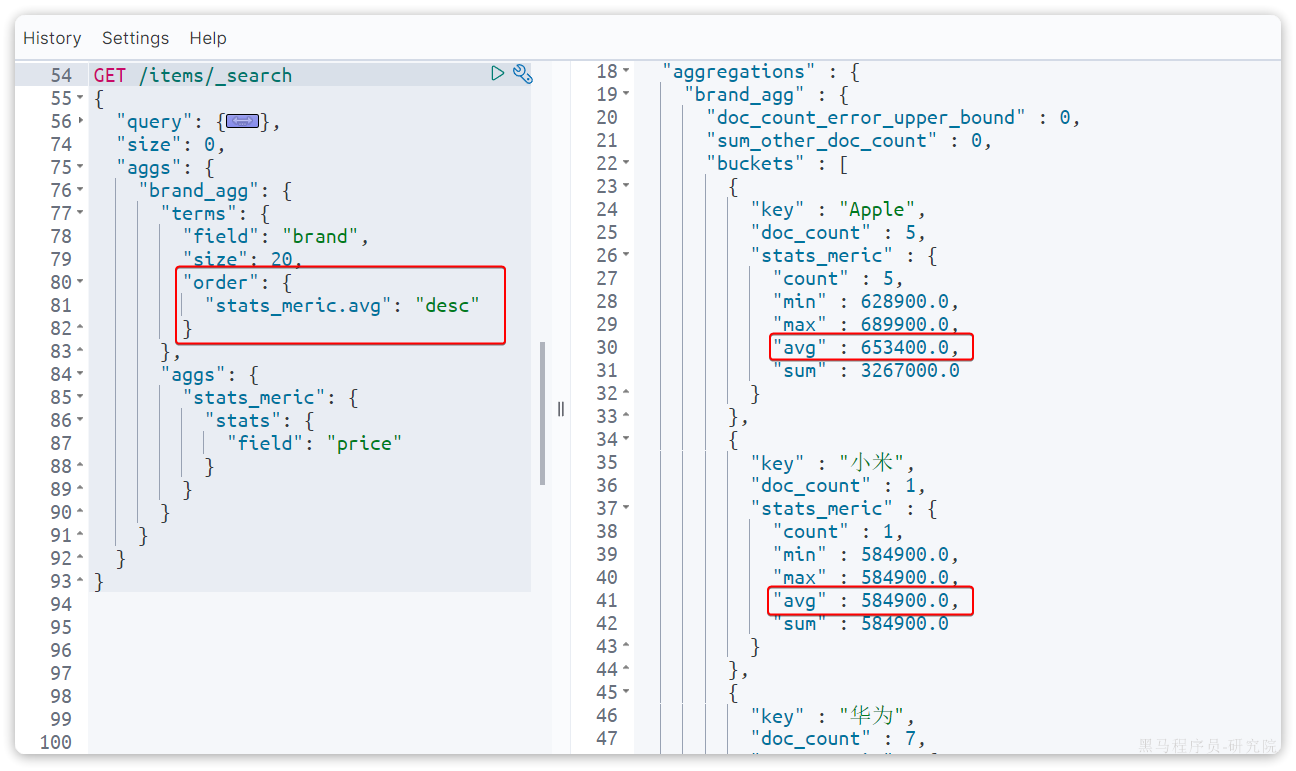
微服务学习笔记25版
认识微服务
微服务
微服务架构,首先是服务化,就是将单体架构中的功能模块从单体应用中拆分出来,独立部署为多个服务。同时要满足下面的一些特点:
- 单一职责:一个微服务负责一部分业务功能,并且其核心数据不依赖于其它模块。
- 团队自治:每个微服务都有自己独立的开发、测试、发布、运维人员,团队人员规模不超过10人(2张披萨能喂饱)
- 服务自治:每个微服务都独立打包部署,访问自己独立的数据库。并且要做好服务隔离,避免对其它服务产生影响
单体架构存在的问题有没有解决呢?
- 团队协作成本高?
- 由于服务拆分,每个服务代码量大大减少,参与开发的后台人员在1~3名,协作成本大大降低
- 系统发布效率低?
- 每个服务都是独立部署,当有某个服务有代码变更时,只需要打包部署该服务即可
- 系统可用性差?
- 每个服务独立部署,并且做好服务隔离,使用自己的服务器资源,不会影响到其它服务。
综上所述,微服务架构解决了单体架构存在的问题,特别适合大型互联网项目的开发,因此被各大互联网公司普遍采用。大家以前可能听说过分布式架构,分布式就是服务拆分的过程,其实微服务架构正式分布式架构的一种最佳实践的方案。
微服务拆分
什么时候拆
一般情况下,对于一个初创的项目,首先要做的是验证项目的可行性。因此这一阶段的首要任务是敏捷开发,快速产出生产可用的产品,投入市场做验证。为了达成这一目的,该阶段项目架构往往会比较简单,很多情况下会直接采用单体架构,这样开发成本比较低,可以快速产出结果,一旦发现项目不符合市场,损失较小。
如果这一阶段采用复杂的微服务架构,投入大量的人力和时间成本用于架构设计,最终发现产品不符合市场需求,等于全部做了无用功。
所以,对于大多数小型项目来说,一般是先采用单体架构,随着用户规模扩大、业务复杂后再逐渐拆分为微服务架构。这样初期成本会比较低,可以快速试错。但是,这么做的问题就在于后期做服务拆分时,可能会遇到很多代码耦合带来的问题,拆分比较困难(前易后难)。
而对于一些大型项目,在立项之初目的就很明确,为了长远考虑,在架构设计时就直接选择微服务架构。虽然前期投入较多,但后期就少了拆分服务的烦恼(前难后易)。
怎么拆
之前我们说过,微服务拆分时粒度要小,这其实是拆分的目标。具体可以从两个角度来分析:
- 高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。
- 低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖,或者依赖接口的稳定性要强。
高内聚首先是**单一职责,**但不能说一个微服务就一个接口,而是要保证微服务内部业务的完整性为前提。目标是当我们要修改某个业务时,最好就只修改当前微服务,这样变更的成本更低。
一旦微服务做到了高内聚,那么服务之间的耦合度自然就降低了。
当然,微服务之间不可避免的会有或多或少的业务交互,比如下单时需要查询商品数据。这个时候我们不能在订单服务直接查询商品数据库,否则就导致了数据耦合。而应该由商品服务对应暴露接口,并且一定要保证微服务对外接口的稳定性(即:尽量保证接口外观不变)。虽然出现了服务间调用,但此时无论你如何在商品服务做内部修改,都不会影响到订单微服务,服务间的耦合度就降低了。
明确了拆分目标,接下来就是拆分方式了。我们在做服务拆分时一般有两种方式:
- 纵向拆分
- 横向拆分
所谓纵向拆分,就是按照项目的功能模块来拆分。例如黑马商城中,就有用户管理功能、订单管理功能、购物车功能、商品管理功能、支付功能等。那么按照功能模块将他们拆分为一个个服务,就属于纵向拆分。这种拆分模式可以尽可能提高服务的内聚性。
而横向拆分,是看各个功能模块之间有没有公共的业务部分,如果有将其抽取出来作为通用服务。例如用户登录是需要发送消息通知,记录风控数据,下单时也要发送短信,记录风控数据。因此消息发送、风控数据记录就是通用的业务功能,因此可以将他们分别抽取为公共服务:消息中心服务、风控管理服务。这样可以提高业务的复用性,避免重复开发。同时通用业务一般接口稳定性较强,也不会使服务之间过分耦合。
服务调用
在拆分的时候,我们发现一个问题:就是购物车业务中需要查询商品信息,但商品信息查询的逻辑全部迁移到了item-service服务,导致我们无法查询。
最终结果就是查询到的购物车数据不完整,因此要想解决这个问题,我们就必须改造其中的代码,把原本本地方法调用,改造成跨微服务的远程调用(RPC,即Remote Produce Call)。
而这种查询就是通过http请求的方式来完成的,不仅仅可以实现远程查询,还可以实现新增、删除等各种远程请求。
Spring给我们提供了一个RestTemplate的API,可以方便的实现Http请求的发送。其中提供了大量的方法,方便我们发送Http请求,例如:
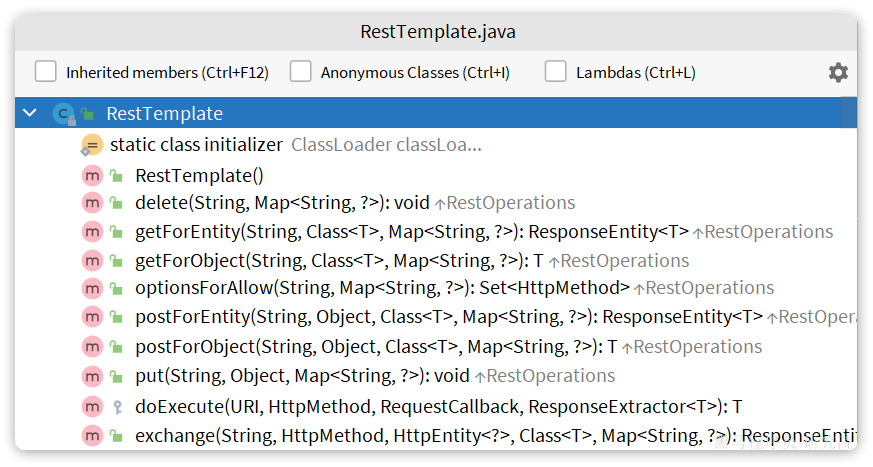
可以看到常见的Get、Post、Put、Delete请求都支持,如果请求参数比较复杂,还可以使用exchange方法来构造请求。
Nacos注册中心
服务注册和发现
在上一章我们实现了微服务拆分,并且通过Http请求实现了跨微服务的远程调用。不过这种手动发送Http请求的方式存在一些问题。
试想一下,假如商品微服务被调用较多,为了应对更高的并发,我们进行了多实例部署,如图:
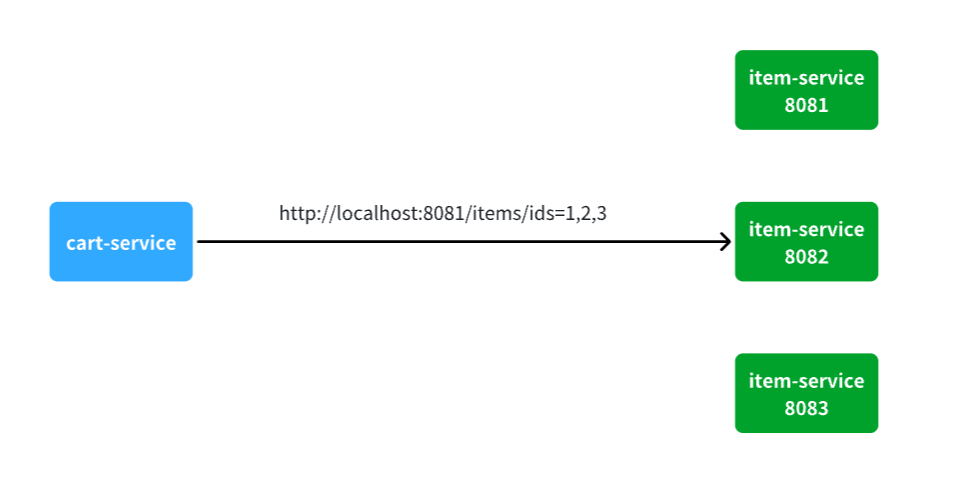
此时,每个item-service的实例其IP或端口不同,问题来了:
- item-service这么多实例,cart-service如何知道每一个实例的地址?
- http请求要写url地址,
cart-service服务到底该调用哪个实例呢? - 如果在运行过程中,某一个
item-service实例宕机,cart-service依然在调用该怎么办? - 如果并发太高,
item-service临时多部署了N台实例,cart-service如何知道新实例的地址?
为了解决上述问题,就必须引入注册中心的概念了,接下来我们就一起来分析下注册中心的原理。
在微服务远程调用的过程中,包括两个角色:
- 服务提供者:提供接口供其它微服务访问,比如
item-service - 服务消费者:调用其它微服务提供的接口,比如
cart-service
在大型微服务项目中,服务提供者的数量会非常多,为了管理这些服务就引入了注册中心的概念。注册中心、服务提供者、服务消费者三者间关系如下:
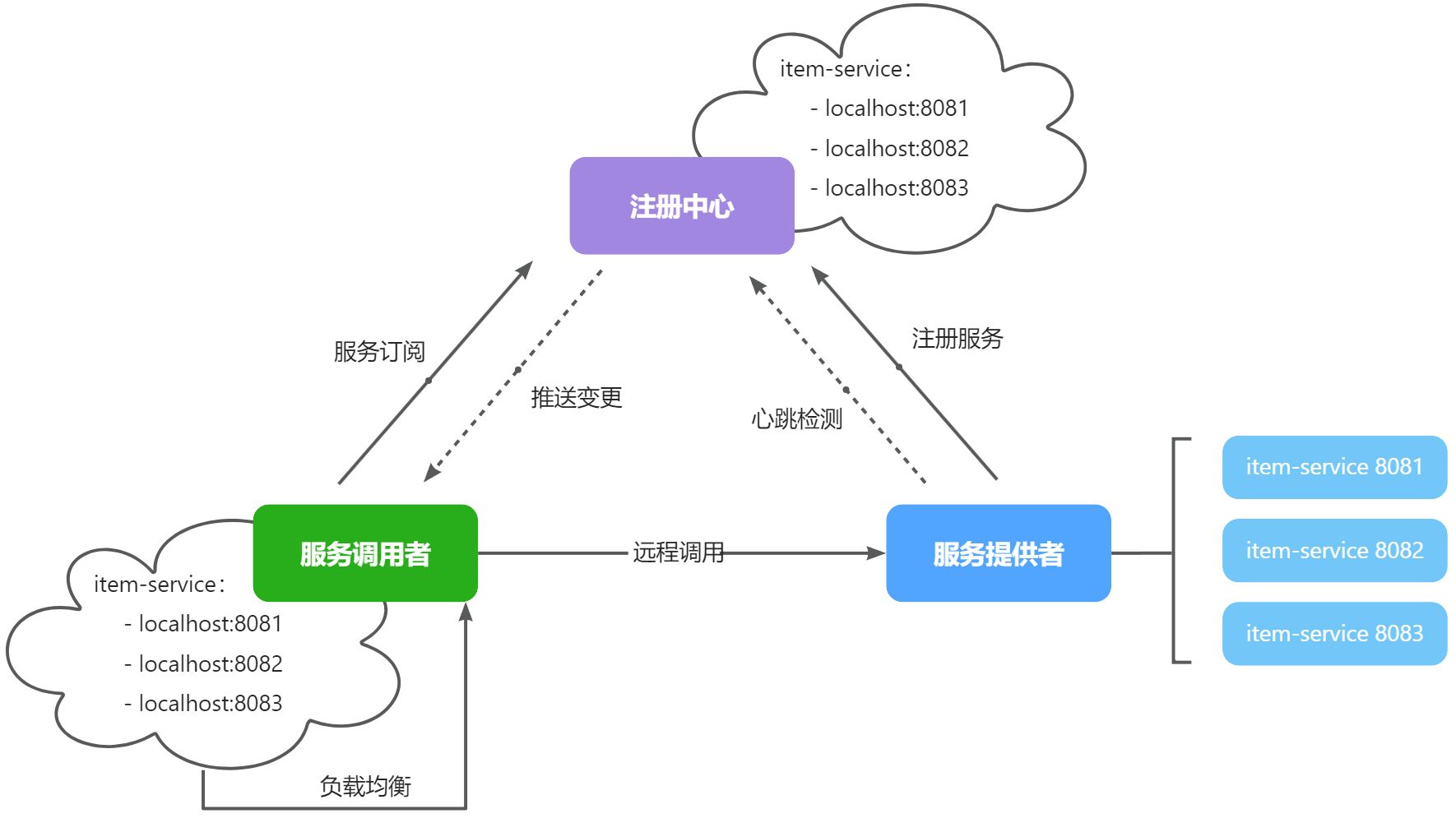
流程如下:
- 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心
- 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署)
- 调用者自己对实例列表负载均衡,挑选一个实例
- 调用者向该实例发起远程调用
当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢?
- 服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求)
- 当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除
- 当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表
- 当注册中心服务列表变更时,会主动通知微服务,更新本地服务列表
Nacos服务注册
准备Nacos
我们基于Docker来部署Nacos的注册中心,首先我们要准备MySQL数据库表,用来存储Nacos的数据。由于是Docker部署,所以大家需要将资料中的SQL文件导入到你Docker中的MySQL容器中:
最终表结构如下:
然后,找到课前资料下的nacos文件夹:
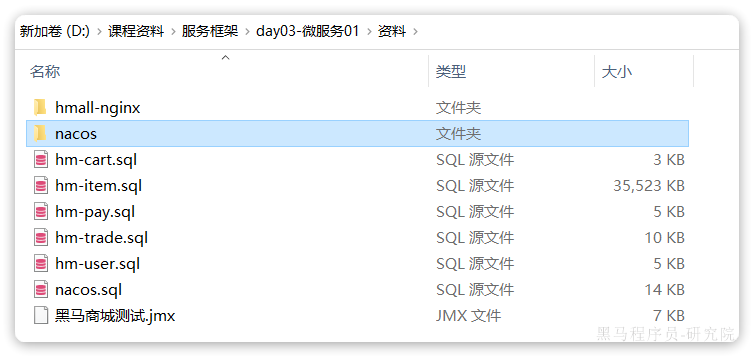
其中的nacos/custom.env文件中,有一个MYSQL_SERVICE_HOST也就是mysql地址,需要修改为你自己的虚拟机IP地址:
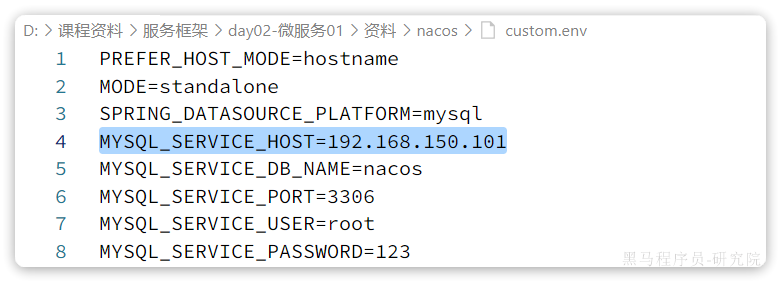
然后,将课前资料中的nacos目录上传至虚拟机的/root目录。
进入root目录,然后执行下面的docker命令:
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim
启动完成后,访问下面地址:http://192.168.150.101:8848/nacos/,注意将192.168.150.101替换为你自己的虚拟机IP地址。
首次访问会跳转到登录页,账号密码都是nacos
服务添加依赖
在item-service的pom.xml中添加依赖:
<!--nacos 服务注册发现-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
服务配置Nacos
在item-service的application.yml中添加nacos地址配置:
spring:application:name: item-service # 服务名称cloud:nacos:server-addr: 192.168.150.101:8848 # nacos地址
启动服务实例
为了测试一个服务多个实例的情况,我们再配置一个item-service的部署实例:
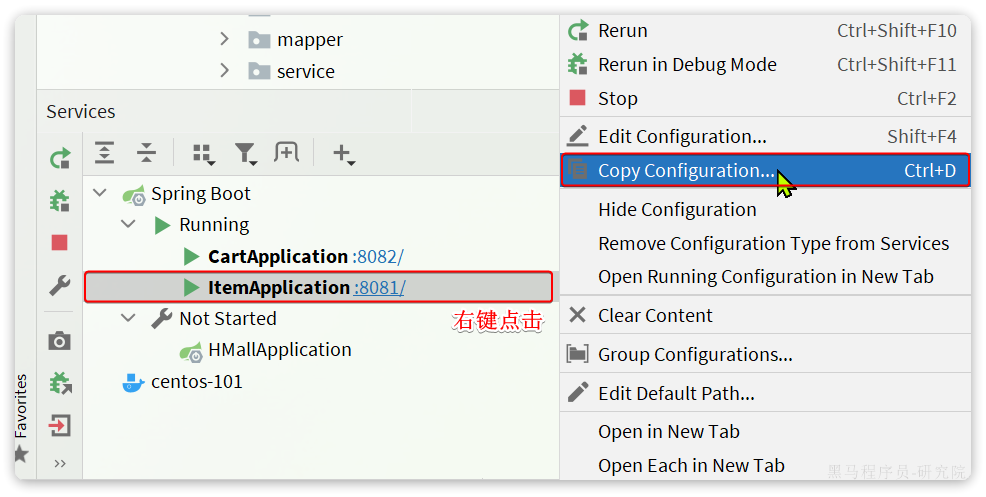
然后配置启动项,注意重命名并且配置新的端口,避免冲突:
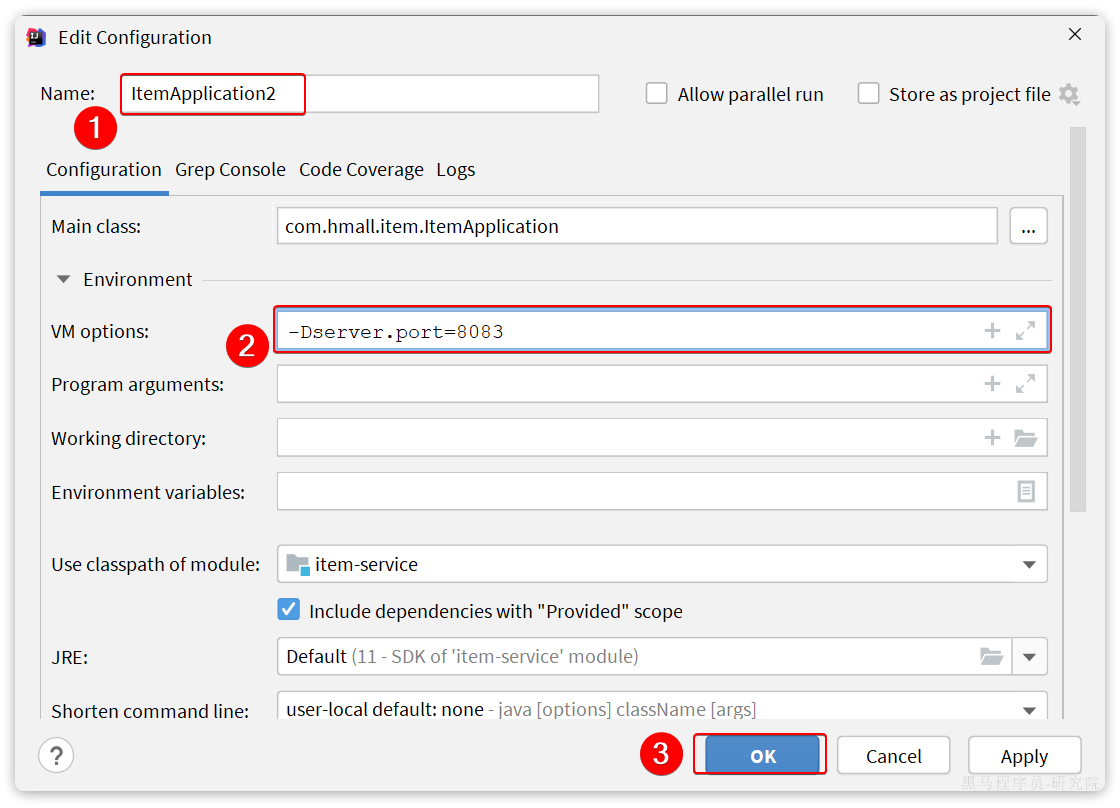
重启item-service的两个实例:
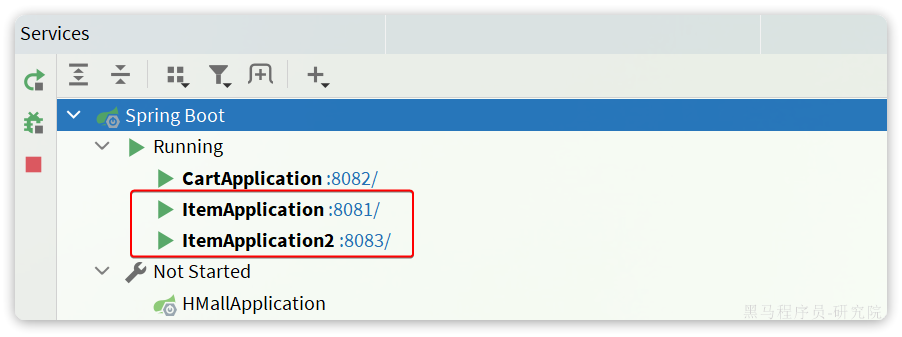
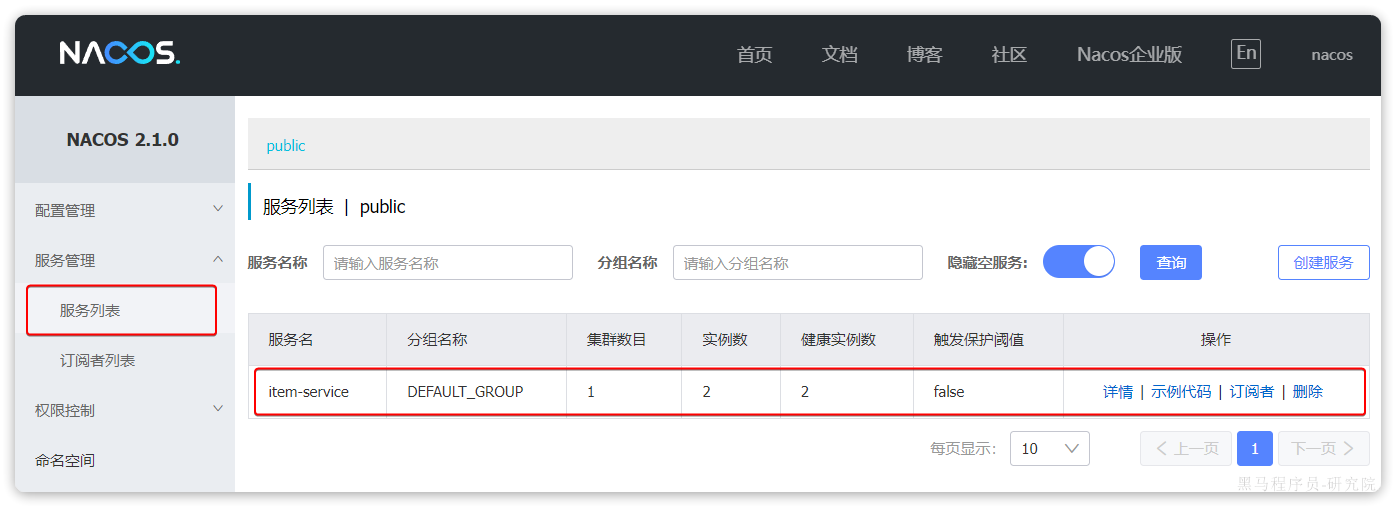
访问nacos控制台,可以发现服务注册成功:
Nacos服务发现
服务的消费者要去nacos订阅服务,这个过程就是服务发现,步骤如下:
- 引入依赖
- 配置Nacos地址
- 发现并调用服务
引入依赖
服务发现除了要引入nacos依赖以外,由于还需要负载均衡,因此要引入SpringCloud提供的LoadBalancer依赖。
我们在cart-service中的pom.xml中添加下面的依赖:
<!--nacos 服务注册发现-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
可以发现,这里Nacos的依赖于服务注册时一致,这个依赖中同时包含了服务注册和发现的功能。因为任何一个微服务都可以调用别人,也可以被别人调用,即可以是调用者,也可以是提供者。
因此,等一会儿cart-service启动,同样会注册到Nacos
配置Nacos地址
在cart-service的application.yml中添加nacos地址配置:
spring:cloud:nacos:server-addr: 192.168.150.101:8848
发现并调用服务
接下来,服务调用者cart-service就可以去订阅item-service服务了。不过item-service有多个实例,而真正发起调用时只需要知道一个实例的地址。
因此,服务调用者必须利用负载均衡的算法,从多个实例中挑选一个去访问。常见的负载均衡算法有:
- 随机
- 轮询
- IP的hash
- 最近最少访问
- …
这里我们可以选择最简单的随机负载均衡。
另外,服务发现需要用到一个工具,DiscoveryClient,SpringCloud已经帮我们自动装配,我们可以直接注入使用:
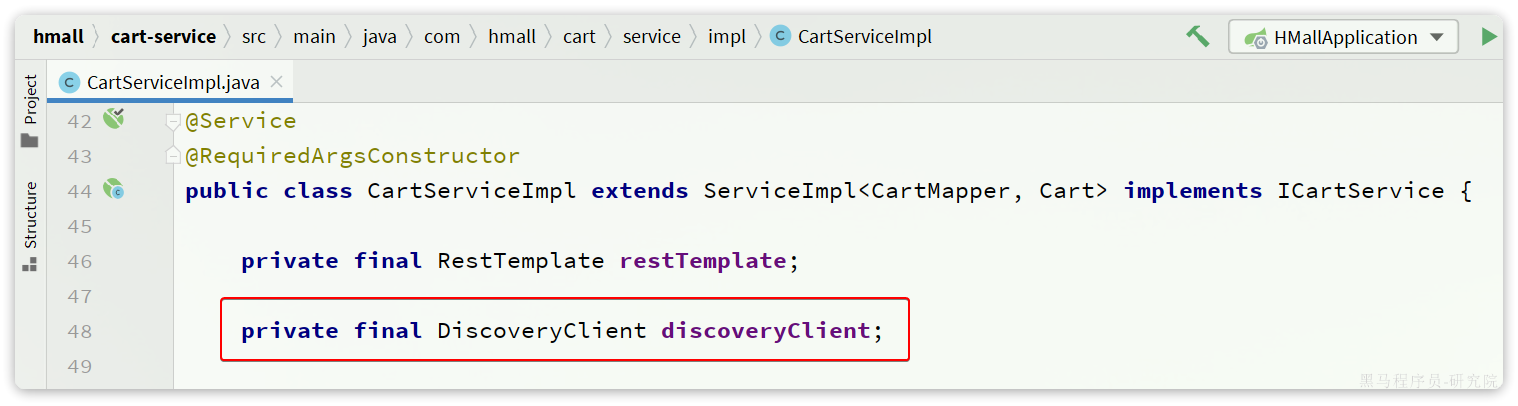
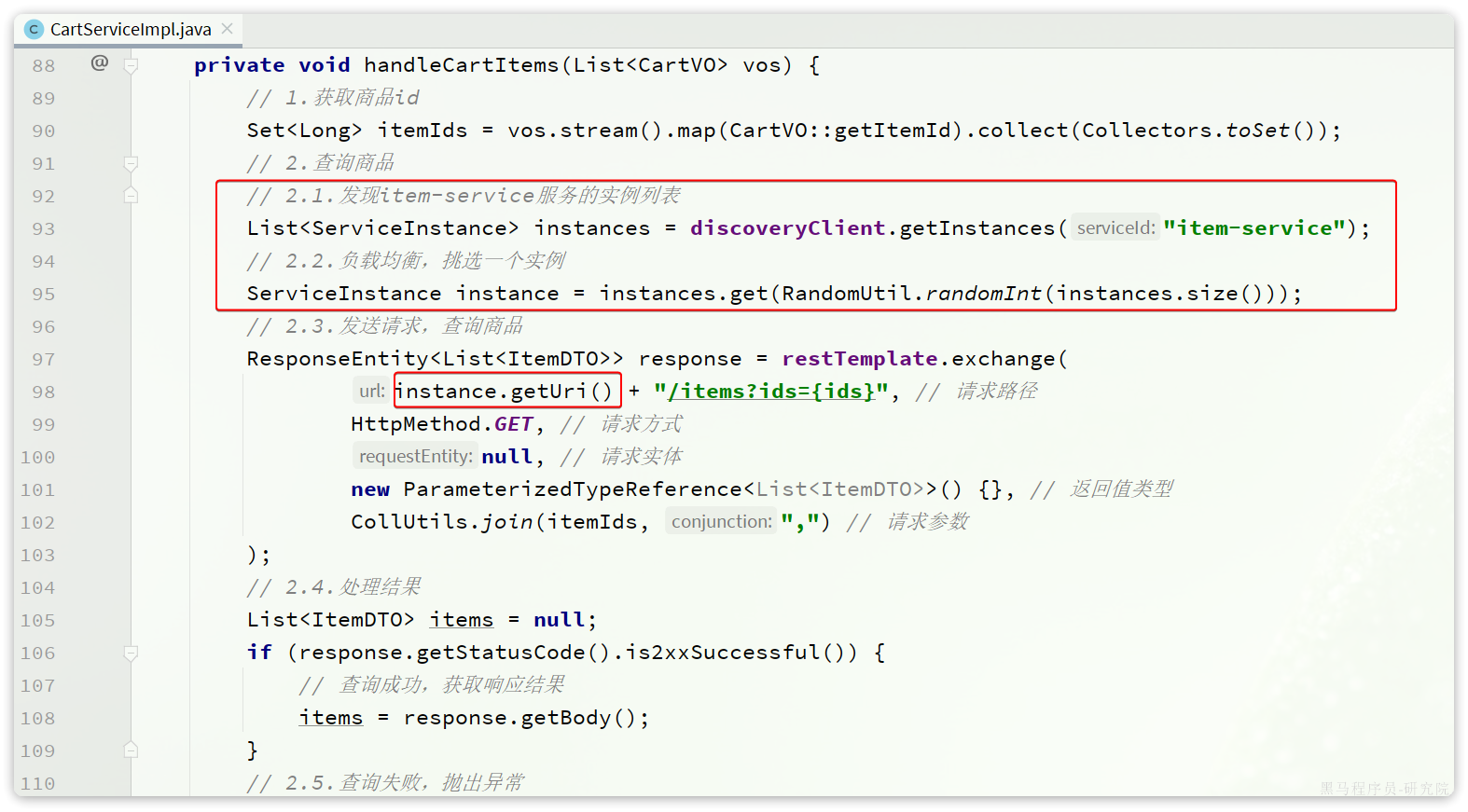
接下来,我们就可以对原来的远程调用做修改了,之前调用时我们需要写死服务提供者的IP和端口:
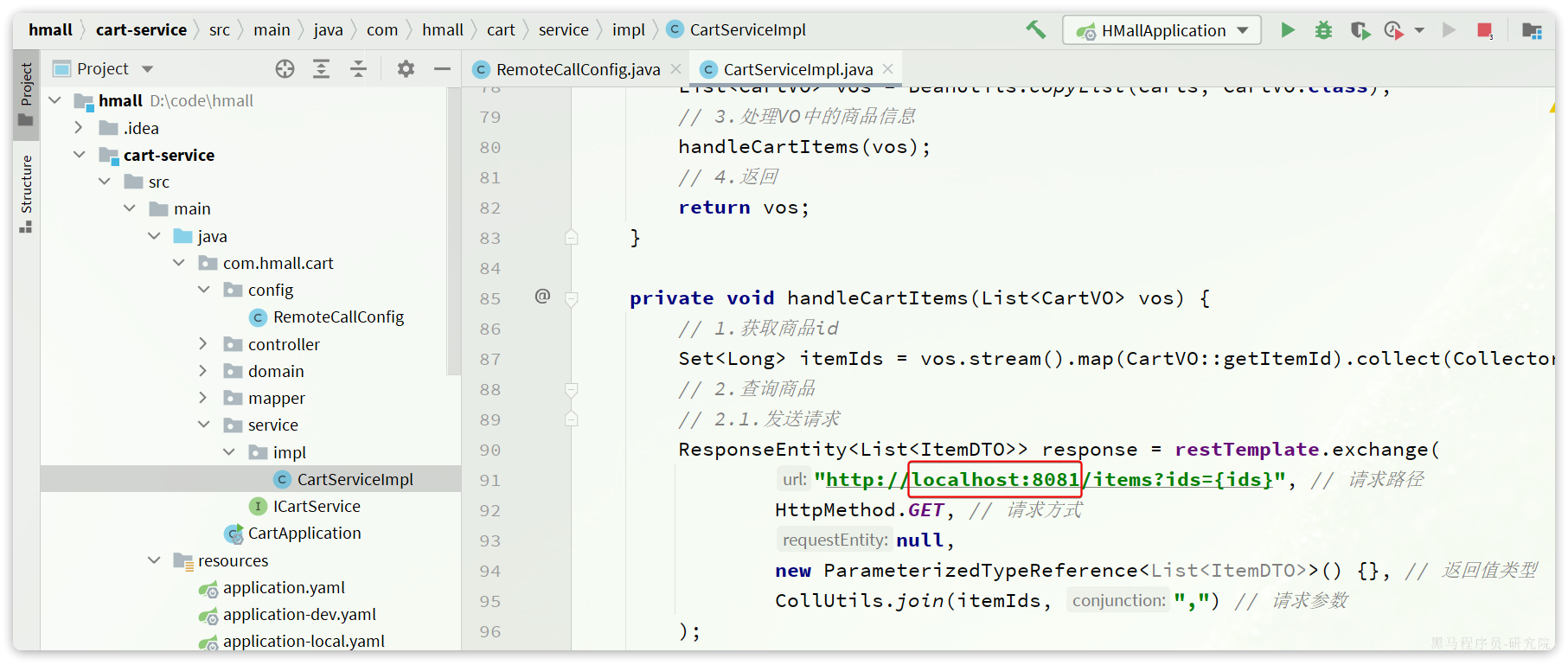
但现在不需要了,我们通过DiscoveryClient发现服务实例列表,然后通过负载均衡算法,选择一个实例去调用:
环境隔离
企业实际开发中,往往会搭建多个运行环境,例如:
- 开发环境
- 测试环境
- 预发布环境
- 生产环境
这些不同环境之间的服务和数据之间需要隔离。
还有的企业中,会开发多个项目,共享nacos集群。此时,这些项目之间也需要把服务和数据隔离。
因此,Nacos提供了基于namespace的环境隔离功能。具体的隔离层次如图所示:
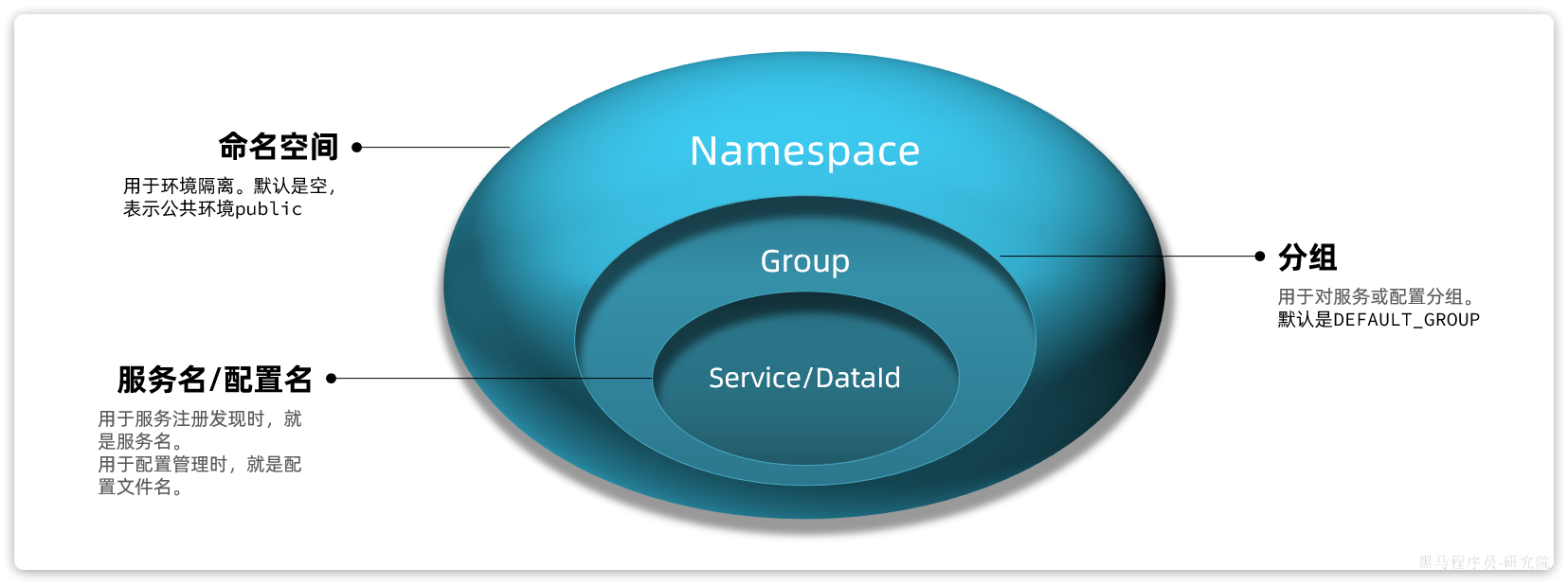
说明:
- Nacos中可以配置多个
namespace,相互之间完全隔离。默认的namespace名为public namespace下还可以继续分组,也就是group ,相互隔离。 默认的group是DEFAULT_GROUPgroup之下就是服务和配置了
可以在Nacos当中创建命名空间,微服务只需要在bootstrap.yml当中配置spring.cloud.nacos.discovery.namespace设置对应的id就可以了
或者在spring.cloud.nacos.config.namespace当中设置
分级模型
在一些大型应用中,同一个服务可以部署很多实例。而这些实例可能分布在全国各地的不同机房。由于存在地域差异,网络传输的速度会有很大不同,因此在做服务治理时需要区分不同机房的实例。
Nacos中提供了集群(cluster)的概念,来对应不同机房。也就是说,一个服务(service)下可以有很多集群(cluster),而一个集群(cluster)中下又可以包含很多实例(instance)。
如图:
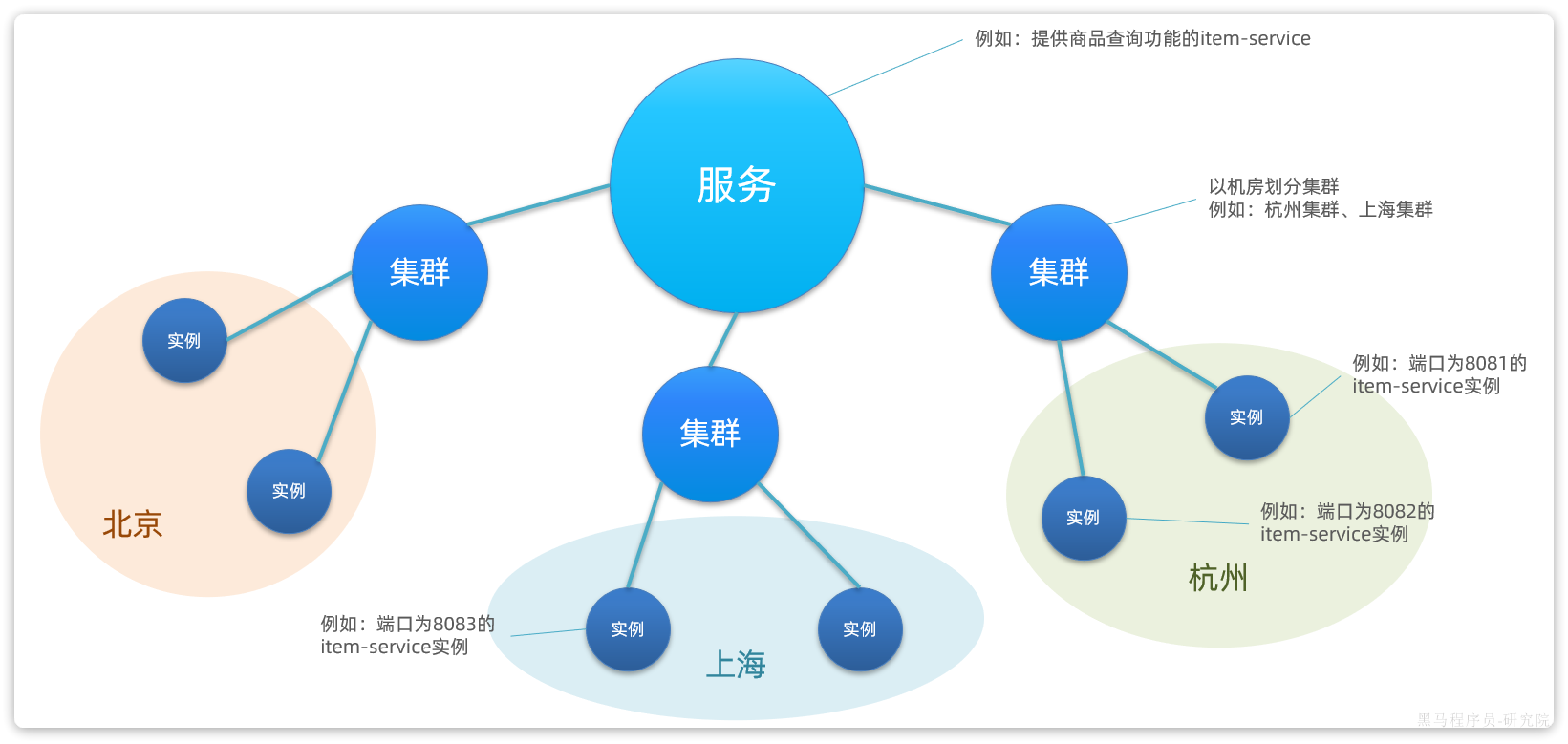
因此,结合我们上一节学习的namespace命名空间的知识,任何一个微服务的实例在注册到Nacos时,都会生成以下几个信息,用来确认当前实例的身份,从外到内依次是:
- namespace:命名空间
- group:分组
- service:服务名
- cluster:集群
- instance:实例,包含ip和端口
这就是nacos中的服务分级模型。
在Nacos内部会有一个服务实例的注册表,是基于Map实现的,其结构与分级模型的对应关系如下:
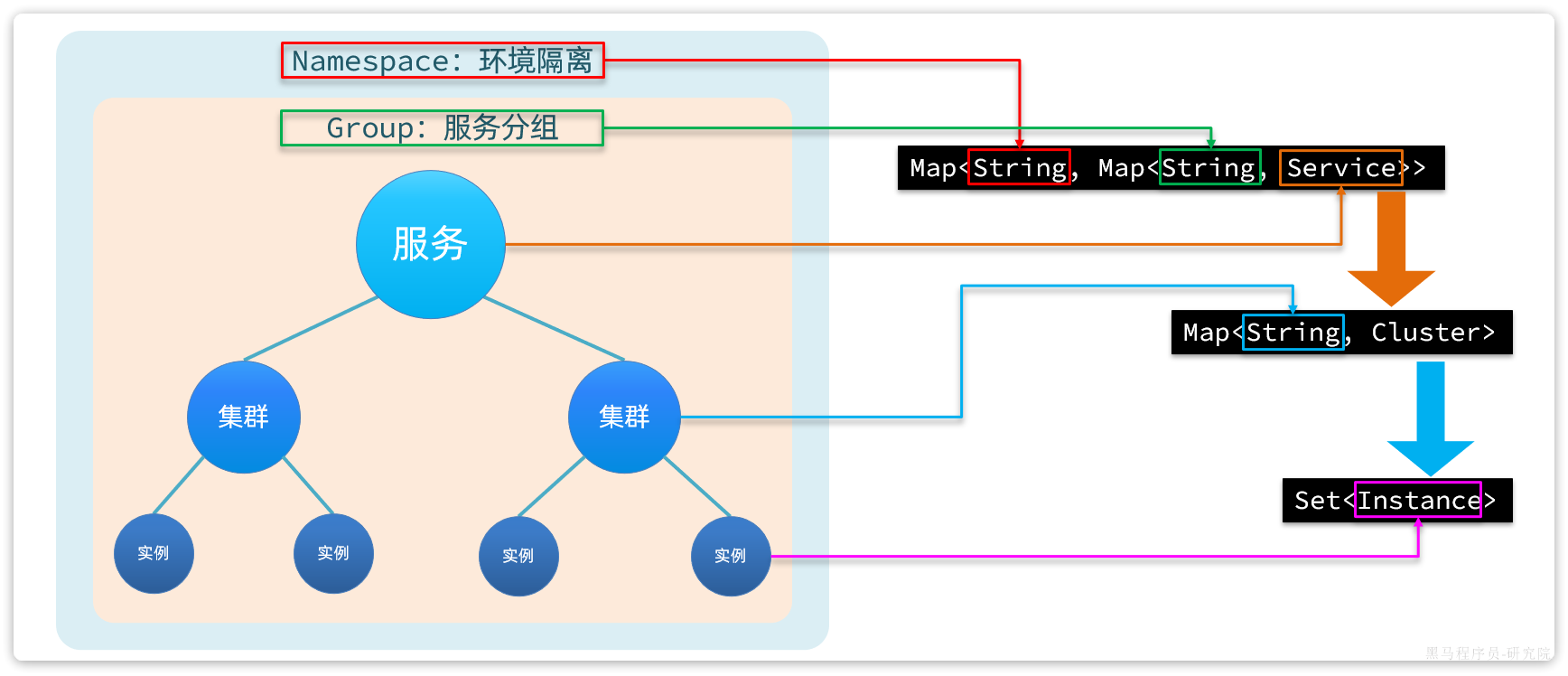
微服务只需要在bootstrap.yml当中配置spring.cloud.nacos.discovery.cluster-name设置对应的名称就可以了
当中的Group分组,可以实现业务隔离,默认情况下不能直接相互调用,但通过正确的配置和代码实现,完全可以实现相互调用
// 本项目Group(USER_GROUP)下的Feign Client
@FeignClient(name = "user-service", path = "/api/user") // 默认会使用应用自身的group
public interface LocalUserServiceFeignClient {@GetMapping("/{id}")User getUserById(@PathVariable Long id);
}// 调用另一个Group(ORDER_GROUP)下的服务的Feign Client
// contextId 避免bean名冲突, name 指定为 「GROUP_NAME@@SERVICE_NAME」
@FeignClient(contextId = "remoteOrderService", name = "ORDER_GROUP@@order-service", path = "/api/order")
public interface RemoteOrderServiceFeignClient {@PostMappingOrder createOrder(@RequestBody Order order);
}
与Eureka注册中心的对比
Eureka是Netflix公司开源的一个服务注册中心组件,早期版本的SpringCloud都是使用Eureka作为注册中心。由于Eureka和Nacos的starter中提供的功能都是基于SpringCloudCommon规范,因此两者使用起来差别不大。
Eureka和Nacos都能起到注册中心的作用,用法基本类似。但还是有一些区别的,例如:
- Nacos支持配置管理,而Eureka则不支持。
服务注册发现上也有区别,Eureka是尽量不剔除服务,避免“误杀”,宁可放过一千,也不错杀一个。这就导致当服务真的出现故障时,迟迟不会被剔除,给服务的调用者带来困扰。当Eureka发现服务宕机并从服务列表中剔除以后,并不会将服务列表的变更消息推送给所有微服务。而是等待微服务自己来拉取时发现服务列表的变化。
综上,Eureka和Nacos的相似点有:
- 都支持服务注册发现功能
- 都有基于心跳的健康监测功能
- 都支持集群,集群间数据同步默认是AP模式,即最全高可用性
Eureka和Nacos的区别有:
- Eureka的心跳是30秒一次,Nacos则是5秒一次
- Eureka如果90秒未收到心跳,则认为服务疑似故障,可能被剔除。Nacos中则是15秒超时,30秒剔除。
- Eureka每隔60秒执行一次服务检测和清理任务;Nacos是每隔5秒执行一次。
- Eureka只能等微服务自己每隔30秒更新一次服务列表;Nacos即有定时更新,也有在服务变更时的广播推送
- Eureka仅有注册中心功能,而Nacos同时支持注册中心、配置管理
总结
核心依赖
在项目的 pom.xml 中引入 Nacos 服务发现 依赖,这是实现服务注册与发现的基础。
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
基础配置
要让一个服务作为客户端连接到 Nacos 服务器并获取服务列表,只需进行最基础的地址配置。
配置示例 (application.yaml):
spring:cloud:nacos:discovery:server-addr: 192.168.150.101:8848 # Nacos服务器地址
服务注册配置
若想将当前服务也注册到 Nacos 注册中心,成为其他服务可发现的一个实例,需要额外配置服务的名称。
配置示例 (application.yaml):
spring:application:name: item-service # 服务名称,这是注册到Nacos的唯一标识cloud:nacos:discovery:server-addr: 192.168.150.101:8848 # Nacos服务器地址
服务发现与调用
服务注册到 Nacos 后,即可通过 Spring Cloud 的标准接口 DiscoveryClient 来查询和调用其他服务。
1. 自动装配 DiscoveryClient
@Autowired
private DiscoveryClient discoveryClient; // Spring Cloud 标准接口
2. 手动实现服务发现与调用(示例)
此示例展示了最底层的原理:先获取实例列表,再通过负载均衡策略选择一个实例,最后发送请求。
// 1. 发现指定服务的所有健康实例列表
List<ServiceInstance> instances = discoveryClient.getInstances("item-service");// 2. 实现负载均衡(这里用了随机,实际常用轮询或权重)
ServiceInstance instance = instances.get(RandomUtil.randomInt(instances.size()));// 3. 使用 RestTemplate 向选中的实例发送请求
ResponseEntity<List<ItemDTO>> response = restTemplate.exchange(instance.getUri() + "/items?ids={ids}", // 拼接请求URLHttpMethod.GET, // 请求方法null, // 请求体new ParameterizedTypeReference<List<ItemDTO>>() {}, // 复杂返回值类型CollUtils.join(itemIds, ",") // URL参数
);
最佳实践:在实际开发中,通常使用
@LoadBalanced注解修饰的RestTemplate或OpenFeign客户端,它们会自动完成服务发现和负载均衡,无需手动编写上述代码。
Nacos 集群模型与隔离
Nacos 提供了多层模型来实现服务的逻辑隔离。
-
四级模型:
Namespace (命名空间) -> Group (分组) -> Service (服务) -> Cluster (集群) -> Instance (实例) -
Namespace (命名空间):
- 用途:实现环境隔离(如:开发
dev、测试test、生产prod环境)。不同命名空间下的服务完全网络隔离,默认不能相互发现和调用。 - 配置:
spring.cloud.nacos.discovery.namespace: <namespace-id>
- 用途:实现环境隔离(如:开发
-
Group (分组):
-
用途:实现业务逻辑隔离(如:
mall-project组、erp-project组)。默认分组为DEFAULT_GROUP。 -
特性:同 Namespace 下的不同 Group 的服务,默认不可以相互调用,也不建议相互调用,因为一个Group一般用于存放一个完整的微服务项目,可以调用其他微服务以及发布的产品实现相同的功能。但是你一定要实现跨 Group 调用,你必须通过配置负载均衡器显式地告诉 Nacos 你要调用的服务在哪个 Group。
-
spring:cloud:loadbalancer:nacos:enabled: trueversion:item-service: ANOTHER_GROUP # 显式指定:调用item-service时,请去ANOTHER_GROUP里找 -
配置:
spring.cloud.nacos.discovery.group: <group-name>
-
Nacos 与 Eureka 健康检查对比
| 特性 | Nacos | Eureka |
|---|---|---|
| 健康检查机制 | 主动发送心跳 + 客户端健康检查(如检查MySQL连接) | 主要依赖客户端心跳 |
| 实例异常感知 | 快速(约15秒即可标记非健康实例,30秒将其剔除) | 缓慢(默认约90秒) |
| 服务列表推送 | 主动推送(变更后立即推送给所有订阅服务,更新非常及时) | 定时拉取(客户端默认每30秒拉取一次,存在延迟) |
| 模式 | AP(高可用与分区容错) + CP(数据一致性)模式切换 | AP(高可用与分区容错) |
OpenFeign服务调用
直接使用Discovery+RestTemplate的方式进行远程调用实在是太复杂了。
而且这种调用方式,与原本的本地方法调用差异太大,编程时的体验也不统一,一会儿远程调用,一会儿本地调用。
因此,我们必须想办法改变远程调用的开发模式,让远程调用像本地方法调用一样简单。而这就要用到OpenFeign组件了。
其实远程调用的关键点就在于四个:
- 请求方式
- 请求路径
- 请求参数
- 返回值类型
所以,OpenFeign就利用SpringMVC的相关注解来声明上述4个参数,然后基于动态代理帮我们生成远程调用的代码,而无需我们手动再编写,非常方便。
快速入门
我们还是以cart-service中的查询我的购物车为例。因此下面的操作都是在cart-service中进行。
引入依赖
在cart-service服务的pom.xml中引入OpenFeign的依赖和loadBalancer依赖:
<!--openFeign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--负载均衡器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency>
启用OpenFeign
接下来,我们在cart-service的CartApplication启动类上添加注解,启动OpenFeign功能:
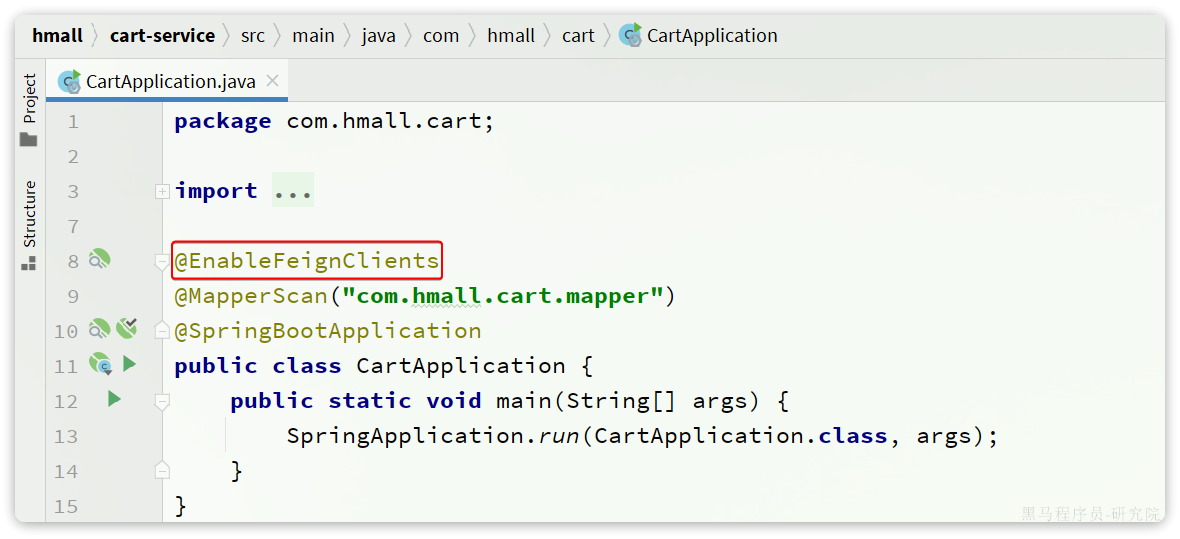
编写OpenFeign客户端
在cart-service中,定义一个新的接口,编写Feign客户端:
其中代码如下:
@FeignClient("item-service")
public interface ItemClient {@GetMapping("/items")List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}
这里只需要声明接口,无需实现方法。接口中的几个关键信息:
@FeignClient("item-service"):声明服务名称@GetMapping:声明请求方式@GetMapping("/items"):声明请求路径@RequestParam("ids") Collection<Long> ids:声明请求参数List<ItemDTO>:返回值类型
有了上述信息,OpenFeign就可以利用动态代理帮我们实现这个方法,并且向http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List<ItemDTO>。
我们只需要直接调用这个方法,即可实现远程调用了。
使用FeignClient
最后,我们在cart-service的com.hmall.cart.service.impl.CartServiceImpl中改造代码,直接调用ItemClient的方法:
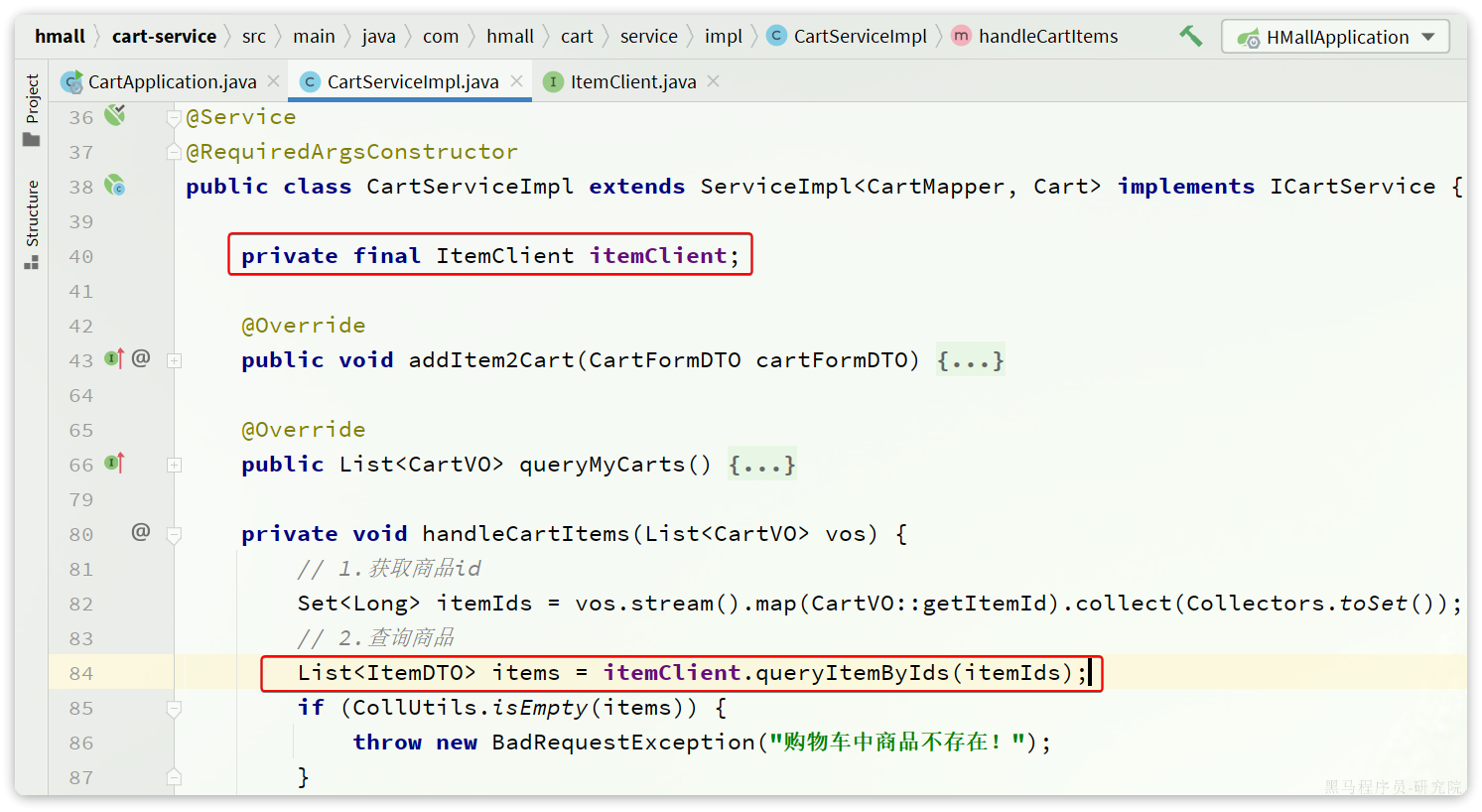
feign替我们完成了服务拉取、负载均衡、发送http请求的所有工作,是不是看起来优雅多了。
而且,这里我们不再需要RestTemplate了,还省去了RestTemplate的注册。
连接池
Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括:
- HttpURLConnection:默认实现,不支持连接池
- Apache HttpClient :支持连接池
- OKHttp:支持连接池
因此我们通常会使用带有连接池的客户端来代替默认的HttpURLConnection。比如,我们使用OK Http.
引入依赖
在cart-service的pom.xml中引入依赖:
<!--OK http 的依赖 -->
<dependency><groupId>io.github.openfeign</groupId><artifactId>feign-okhttp</artifactId>
</dependency>
开启连接池
在cart-service的application.yml配置文件中开启Feign的连接池功能:
feign:okhttp:enabled: true # 开启OKHttp功能
重启服务,连接池就生效了。
验证
我们可以打断点验证连接池是否生效,在org.springframework.cloud.openfeign.loadbalancer.FeignBlockingLoadBalancerClient中的execute方法中打断点:
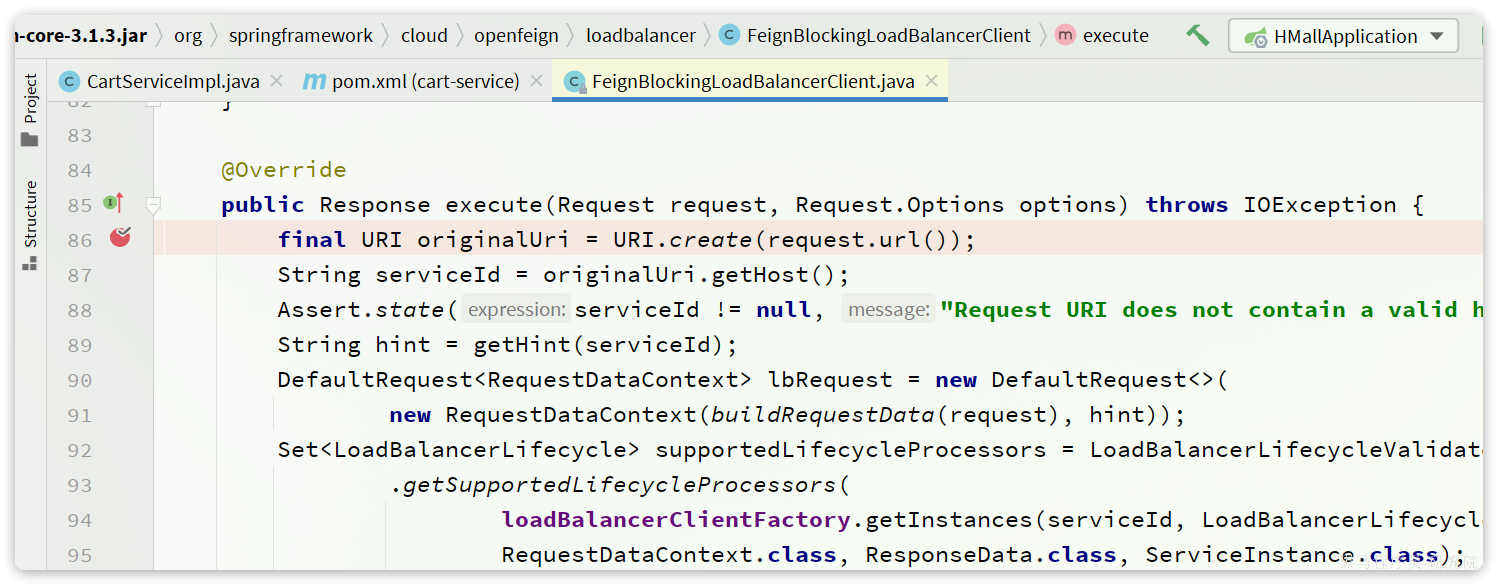
最佳实践
为了避免一个项目当中重复编码Feign相关的内容可以采用抽取。不过这里有两种抽取思路:
- 思路1:抽取到微服务之外的公共module
- 思路2:每个微服务自己抽取一个module
如图:
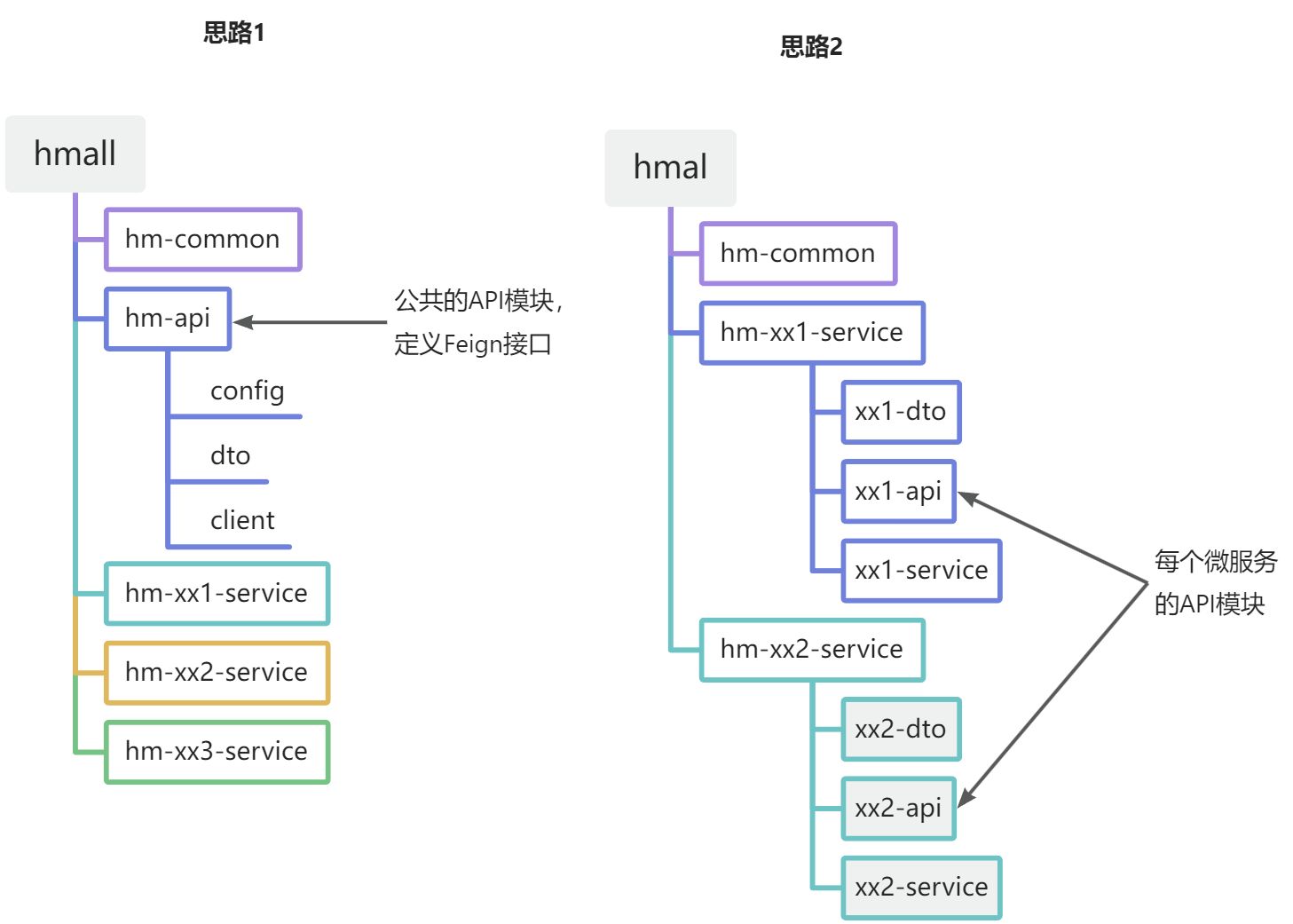
方案1抽取更加简单,工程结构也比较清晰,但缺点是整个项目耦合度偏高。
方案2抽取相对麻烦,工程结构相对更复杂,但服务之间耦合度降低。
抽取Feign客户端
在hmall下定义一个新的module,命名为hm-api
其依赖如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>hmall</artifactId><groupId>com.heima</groupId><version>1.0.0</version></parent><modelVersion>4.0.0</modelVersion><artifactId>hm-api</artifactId><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target></properties><dependencies><!--open feign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!-- load balancer--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency><!-- swagger 注解依赖 --><dependency><groupId>io.swagger</groupId><artifactId>swagger-annotations</artifactId><version>1.6.6</version><scope>compile</scope></dependency></dependencies>
</project>
然后把ItemDTO和ItemClient都拷贝过来,最终结构如下:
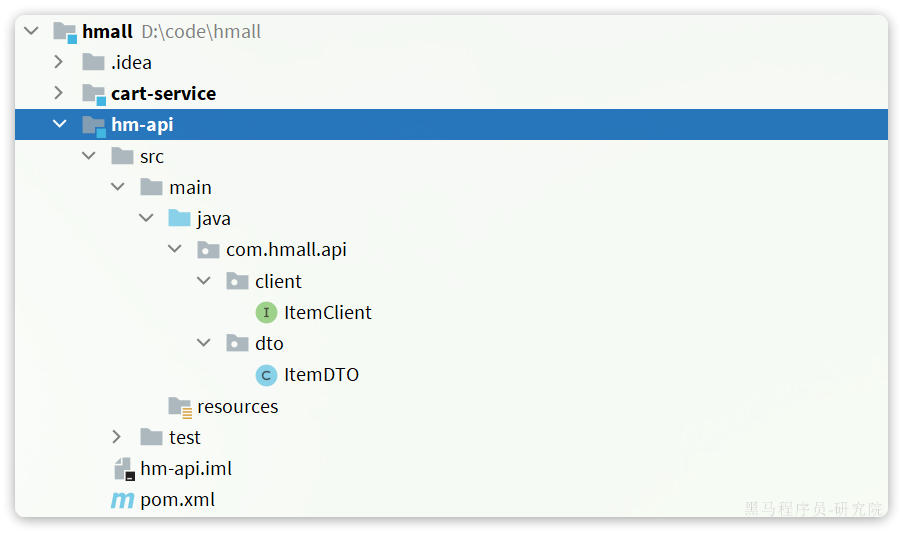
现在,任何微服务要调用item-service中的接口,只需要引入hm-api模块依赖即可,无需自己编写Feign客户
扫描包
接下来,我们在cart-service的pom.xml中引入hm-api模块:
<!--feign模块--><dependency><groupId>com.heima</groupId><artifactId>hm-api</artifactId><version>1.0.0</version></dependency>
删除cart-service中原来的ItemDTO和ItemClient,重启项目,发现报错了:
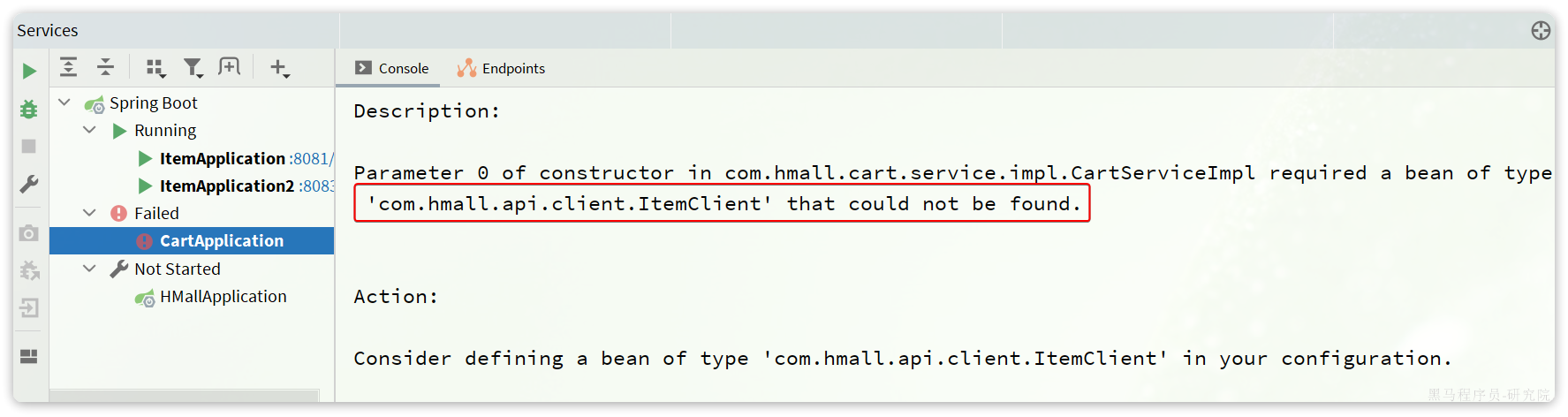
这里因为ItemClient现在定义到了com.hmall.api.client包下,而cart-service的启动类定义在com.hmall.cart包下,扫描不到ItemClient,所以报错了。
解决办法很简单,在cart-service的启动类上添加声明即可,两种方式:
- 方式1:声明扫描包:
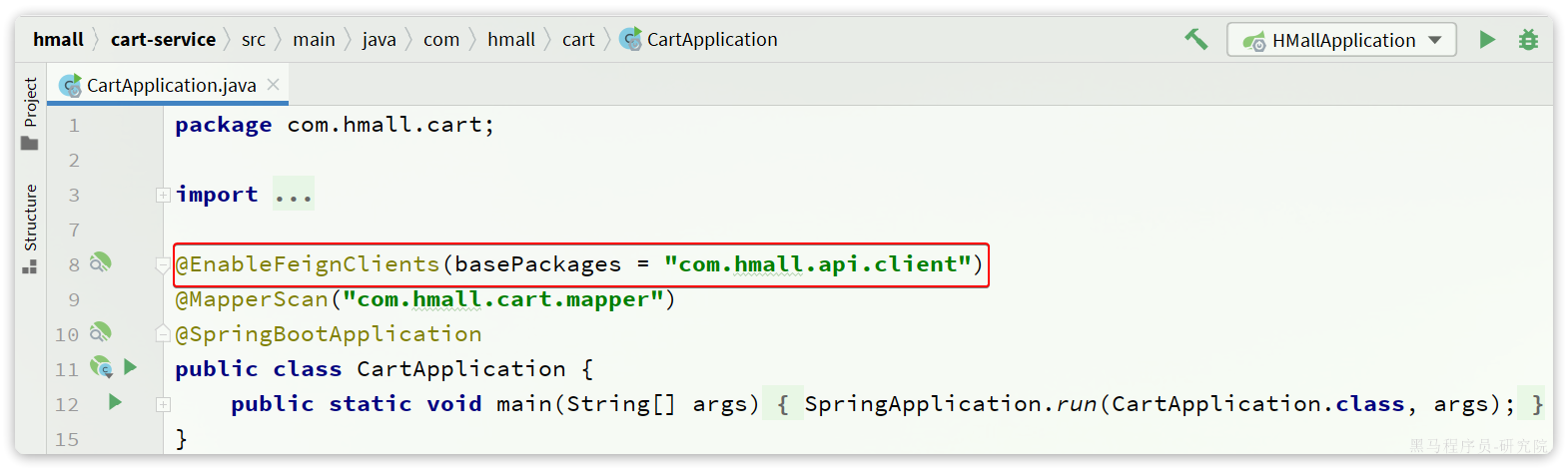
- 方式2:声明要用的FeignClient
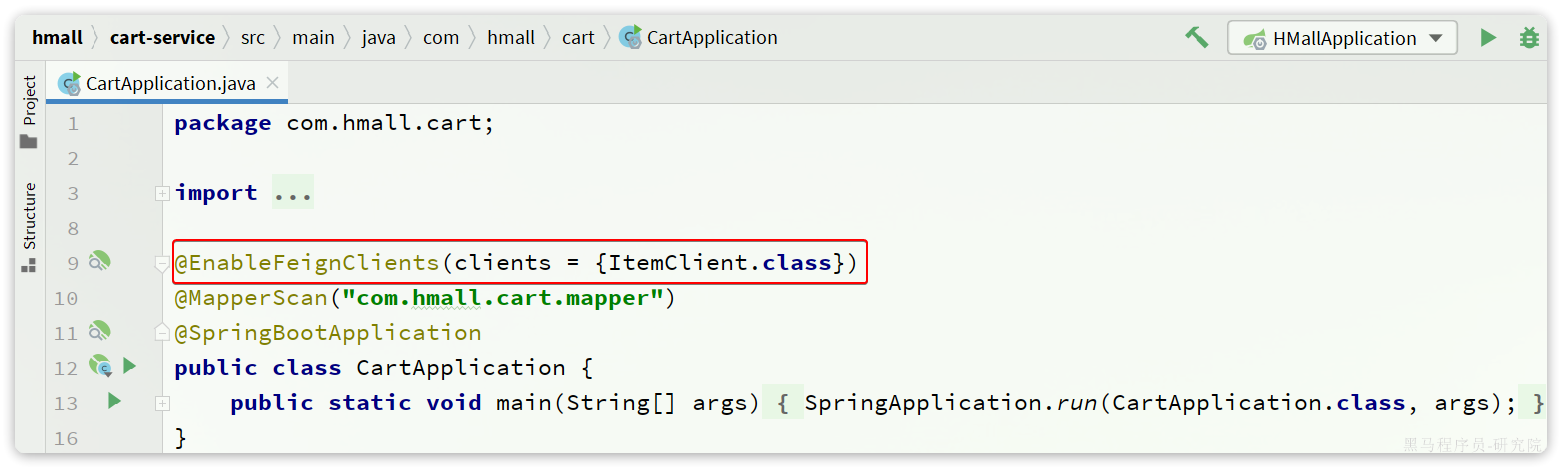
日志配置
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。
定义日志级别
在hm-api模块下新建一个配置类,定义Feign的日志级别:
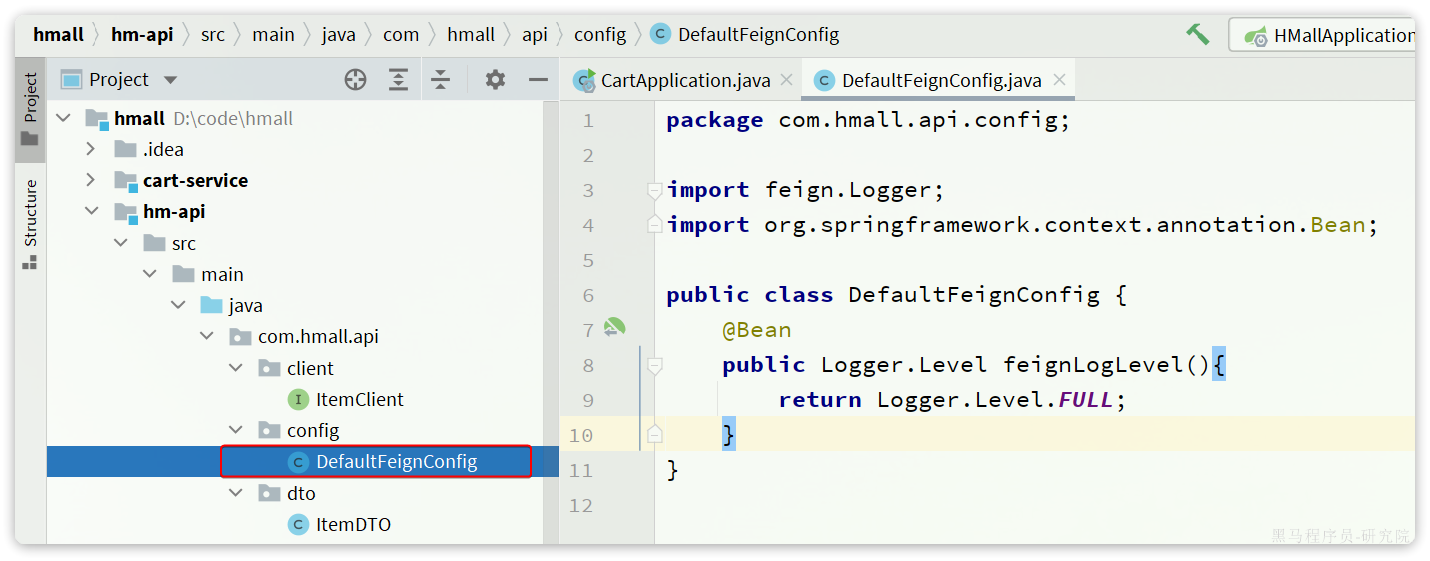
代码如下:
package com.hmall.api.config;import feign.Logger;
import org.springframework.context.annotation.Bean;public class DefaultFeignConfig {@Beanpublic Logger.Level feignLogLevel(){return Logger.Level.FULL;}
}
配置
接下来,要让日志级别生效,还需要配置这个类。有两种方式:
- 局部生效:在某个
FeignClient中配置,只对当前FeignClient生效
@FeignClient(value = "item-service", configuration = DefaultFeignConfig.class)
- 全局生效:在
@EnableFeignClients中配置,针对所有FeignClient生效。
@EnableFeignClients(defaultConfiguration = DefaultFeignConfig.class)
负载均衡
我们知道微服务间远程调用都是有OpenFeign帮我们完成的,甚至帮我们实现了服务列表之间的负载均衡。但具体负载均衡的规则是什么呢?何时做的负载均衡呢?
负载均衡原理
在SpringCloud的早期版本中,负载均衡都是有Netflix公司开源的Ribbon组件来实现的,甚至Ribbon被直接集成到了Eureka-client和Nacos-Discovery中。
但是自SpringCloud2020版本开始,已经弃用Ribbon,改用Spring自己开源的Spring Cloud LoadBalancer了,我们使用的OpenFeign的也已经与其整合。
接下来我们就通过源码分析,来看看OpenFeign底层是如何实现负载均衡功能的。
源码跟踪
要弄清楚OpenFeign的负载均衡原理,最佳的办法肯定是从FeignClient的请求流程入手。
首先,我们在com.hmall.cart.service.impl.CartServiceImpl中的queryMyCarts方法中打一个断点。然后在swagger页面请求购物车列表接口。
进入断点后,观察ItemClient这个接口:
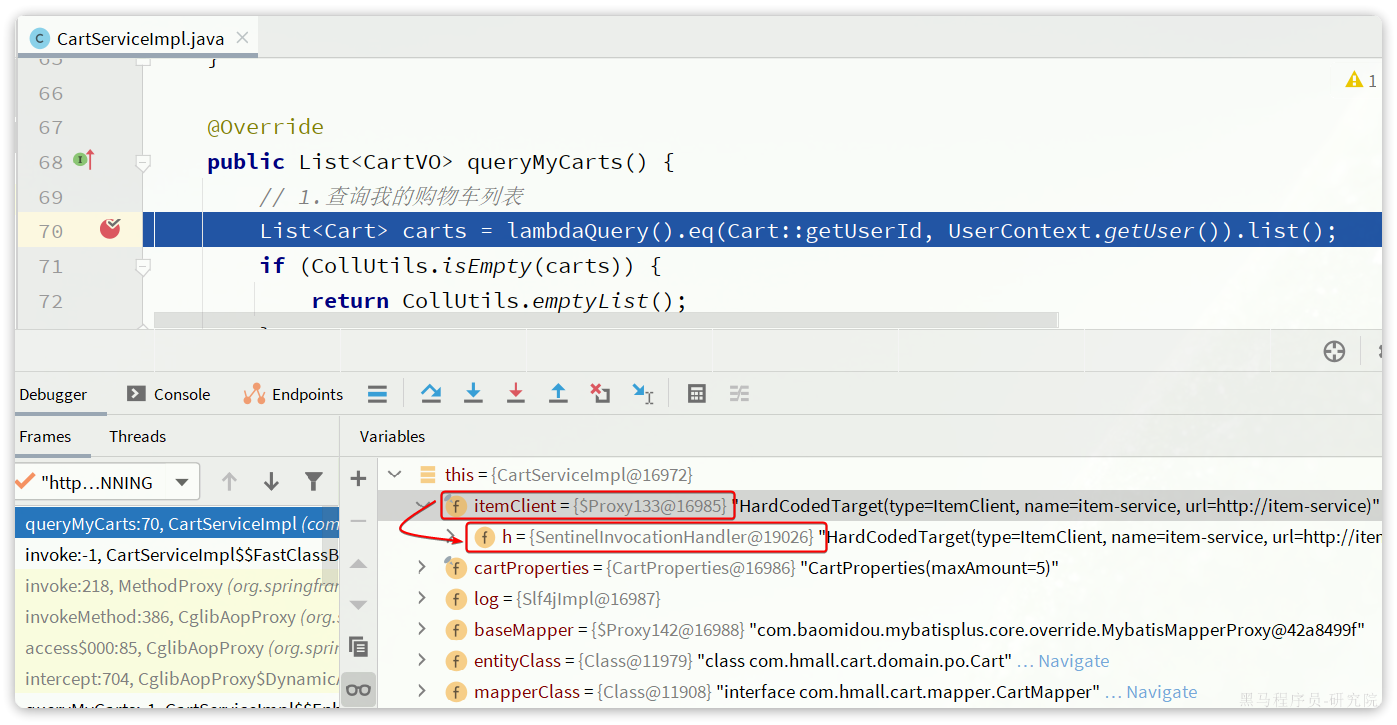
你会发现ItemClient是一个代理对象,而代理的处理器则是SentinelInvocationHandler。这是因为我们项目中引入了Sentinel导致。
我们进入SentinelInvocationHandler类中的invoke方法看看:
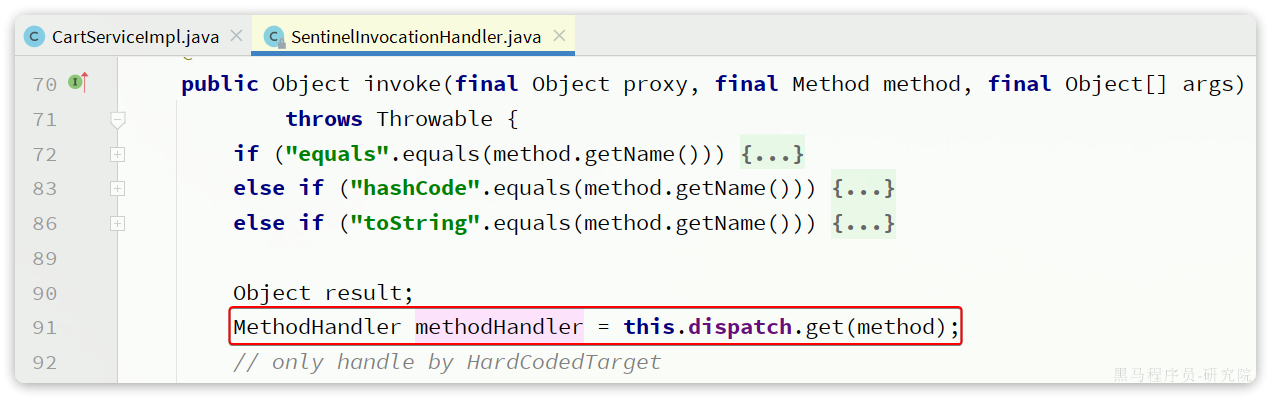
可以看到这里是先获取被代理的方法的处理器MethodHandler,接着,Sentinel就会开启对簇点资源的监控:

开启Sentinel的簇点资源监控后,就可以调用处理器了,我们尝试跟入,会发现有两种实现:
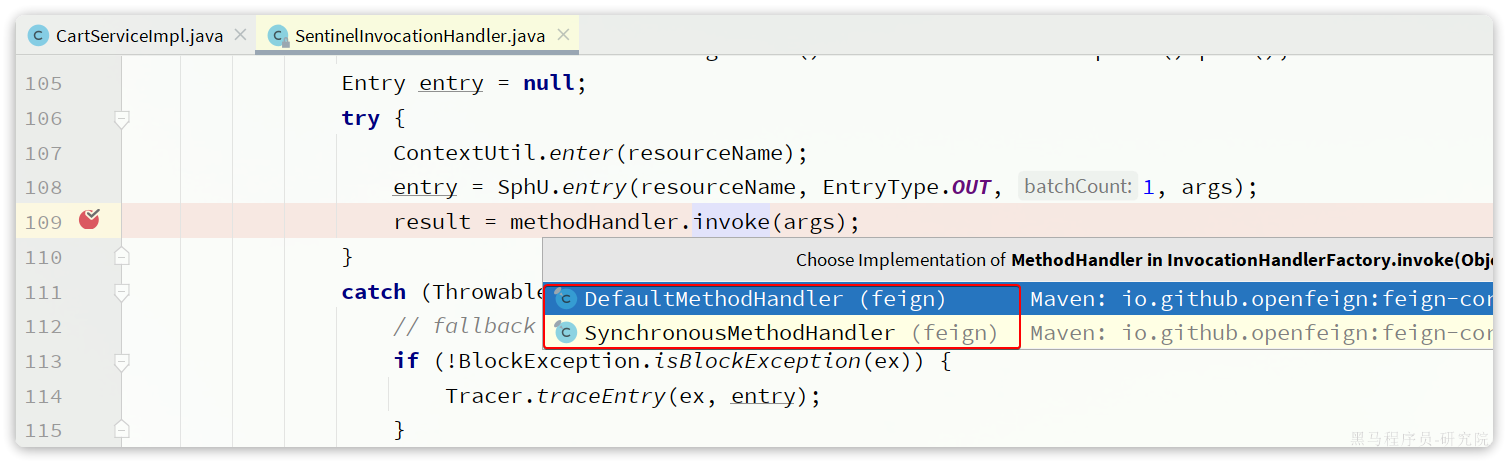
这其实就是OpenFeign远程调用的处理器了。继续跟入会进入SynchronousMethodHandler这个实现类:
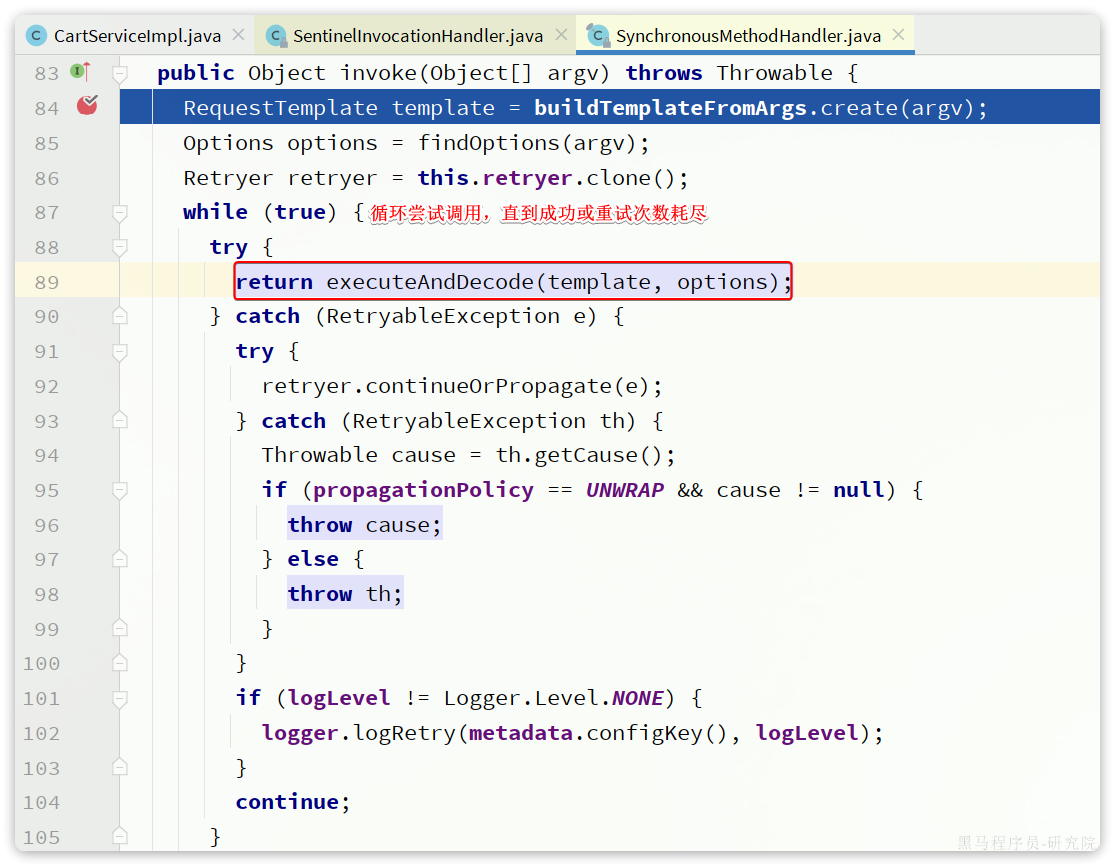
在上述方法中,会循环尝试调用executeAndDecode()方法,直到成功或者是重试次数达到Retryer中配置的上限。
我们继续跟入executeAndDecode()方法:
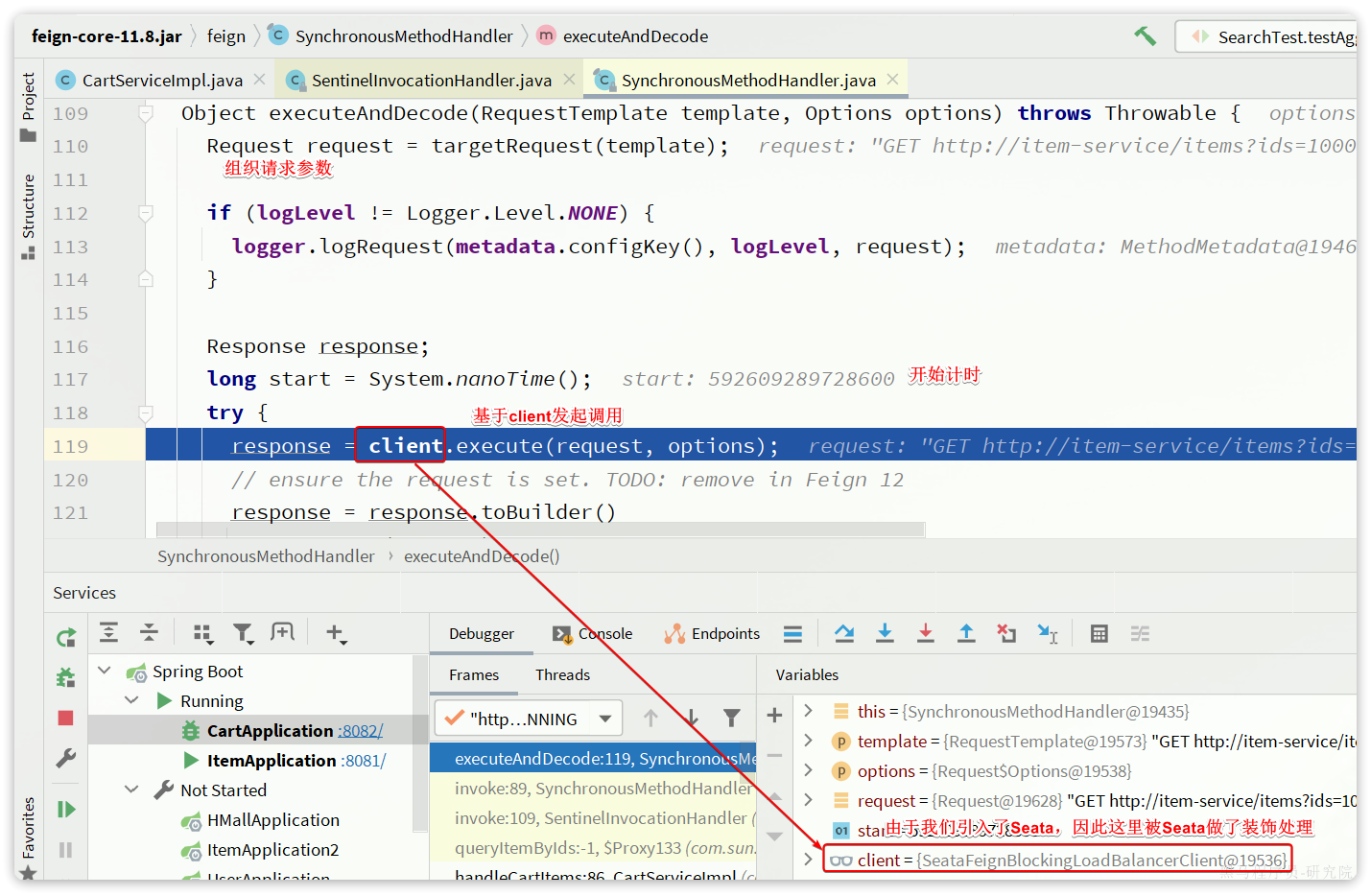
executeAndDecode()方法最终会利用client去调用execute()方法,发起远程调用。
这里的client的类型是feign.Client接口,其下有很多实现类:
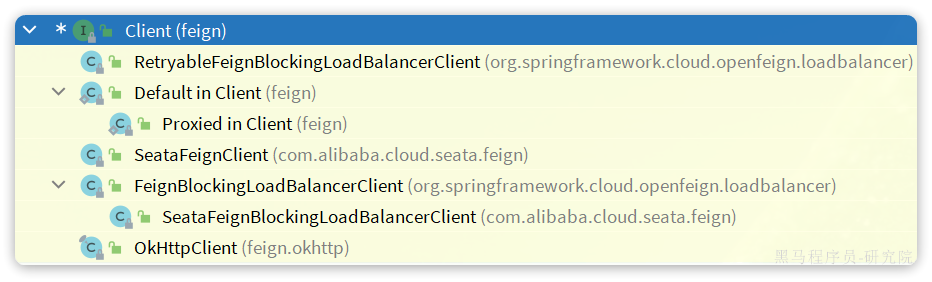
由于我们项目中整合了seata,所以这里client对象的类型是SeataFeignBlockingLoadBalancerClient,内部实现如下:
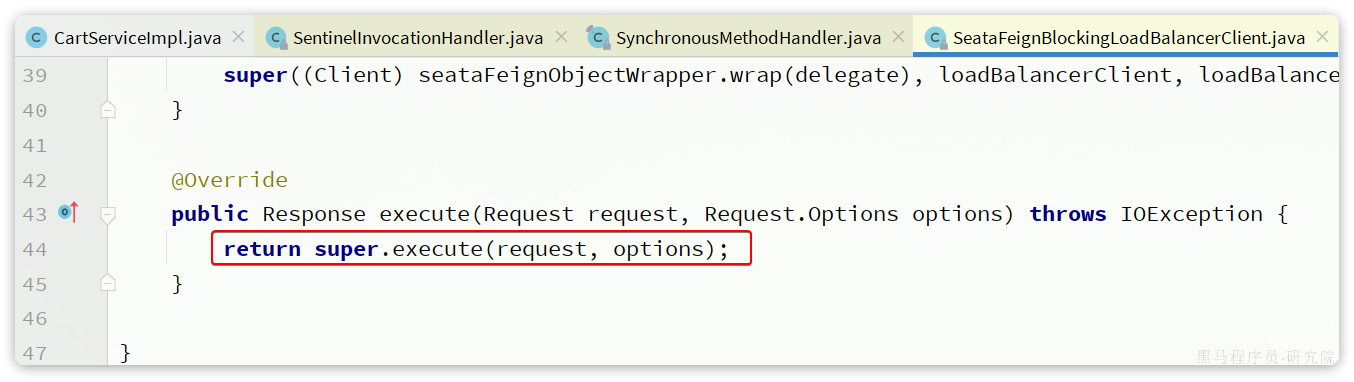
这里直接调用了其父类,也就是FeignBlockingLoadBalancerClient的execute方法,来看一下:
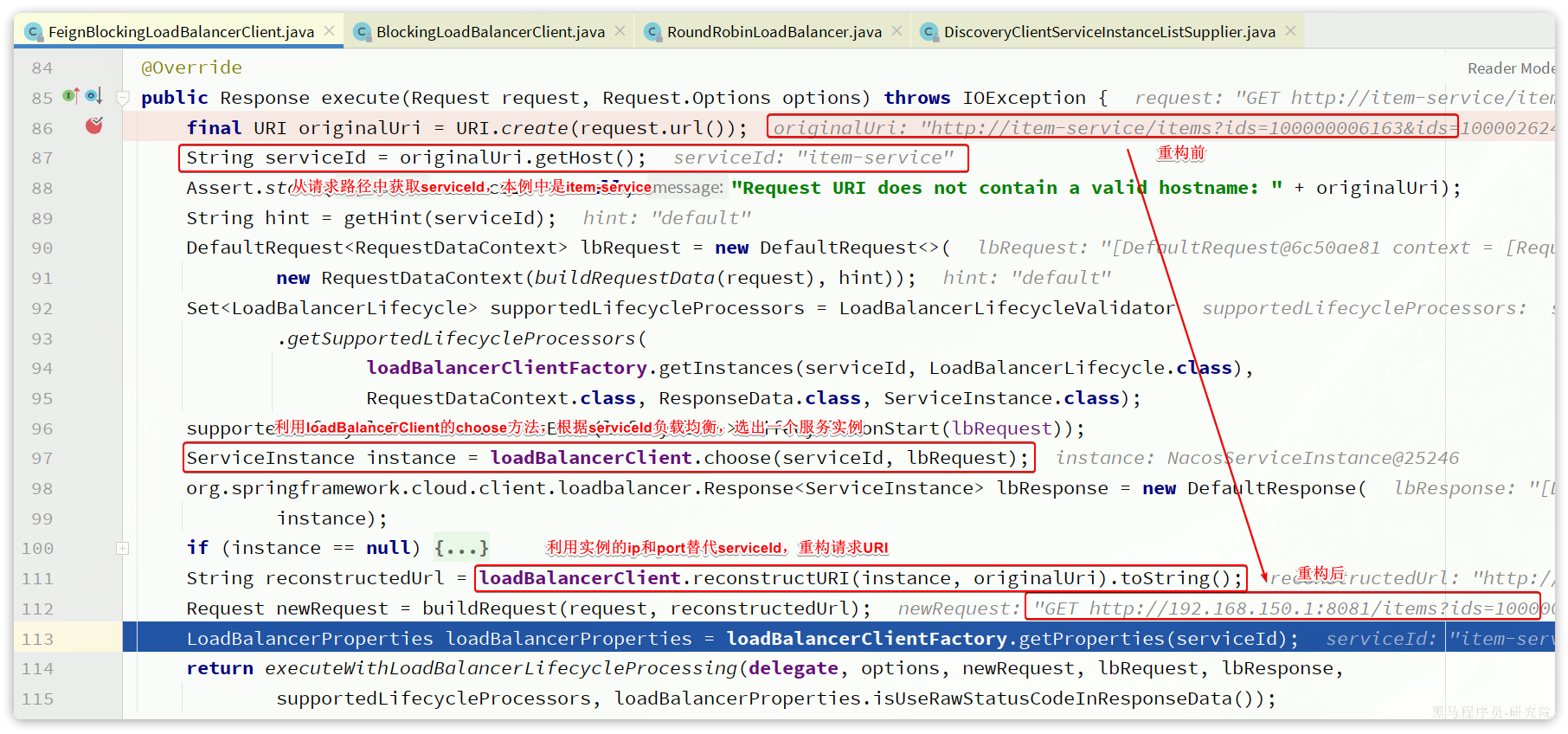
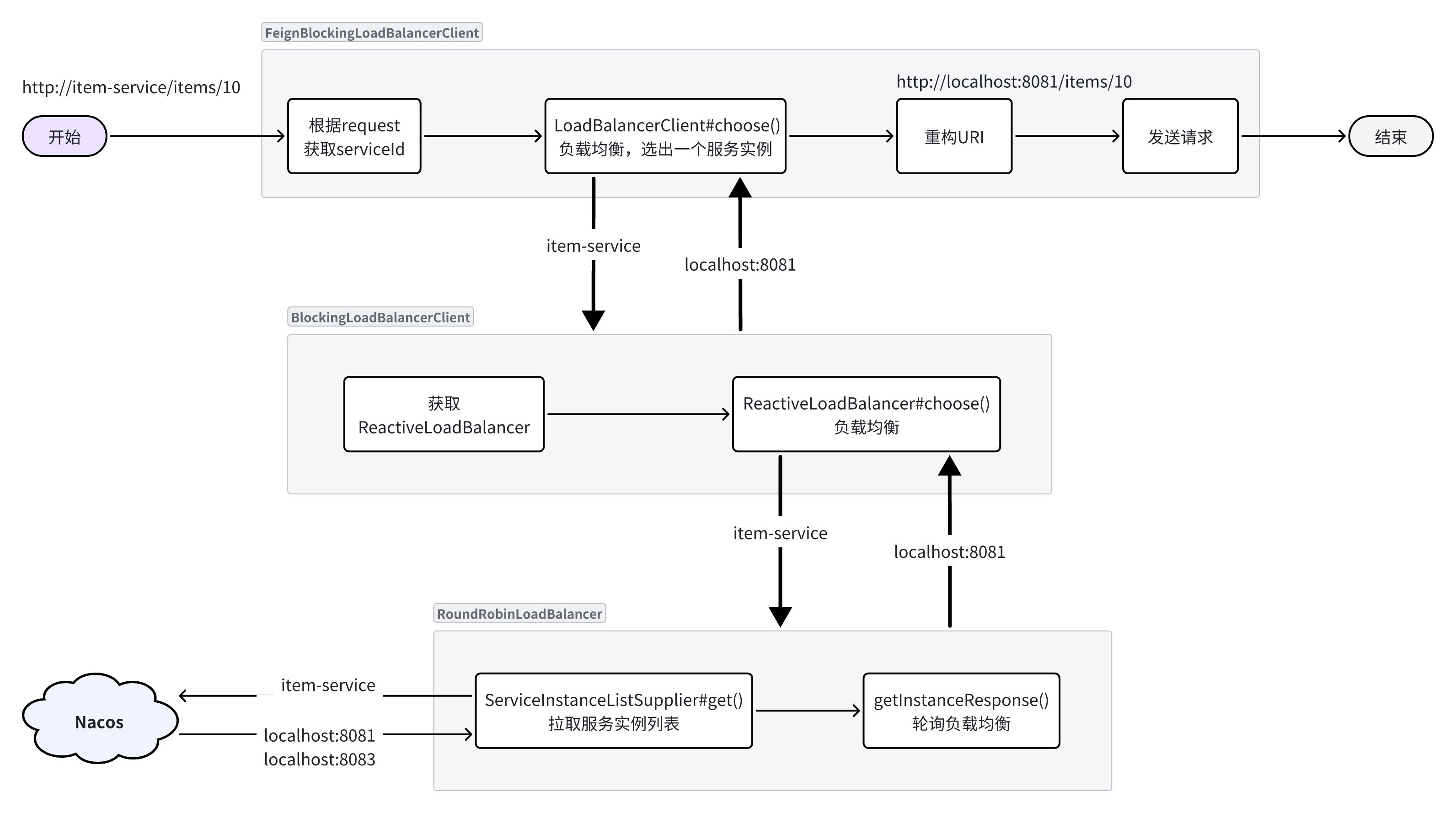
整段代码中核心的有4步:
- 从请求的
URI中找出serviceId - 利用
loadBalancerClient,根据serviceId做负载均衡,选出一个实例ServiceInstance - 用选中的
ServiceInstance的ip和port替代serviceId,重构URI - 向真正的URI发送请求
所以负载均衡的关键就是这里的loadBalancerClient,类型是org.springframework.cloud.client.loadbalancer.LoadBalancerClient,这是Spring-Cloud-Common模块中定义的接口,只有一个实现类:

而这里的org.springframework.cloud.client.loadbalancer.BlockingLoadBalancerClient正是Spring-Cloud-LoadBalancer模块下的一个类:
我们继续跟入其BlockingLoadBalancerClient#choose()方法:
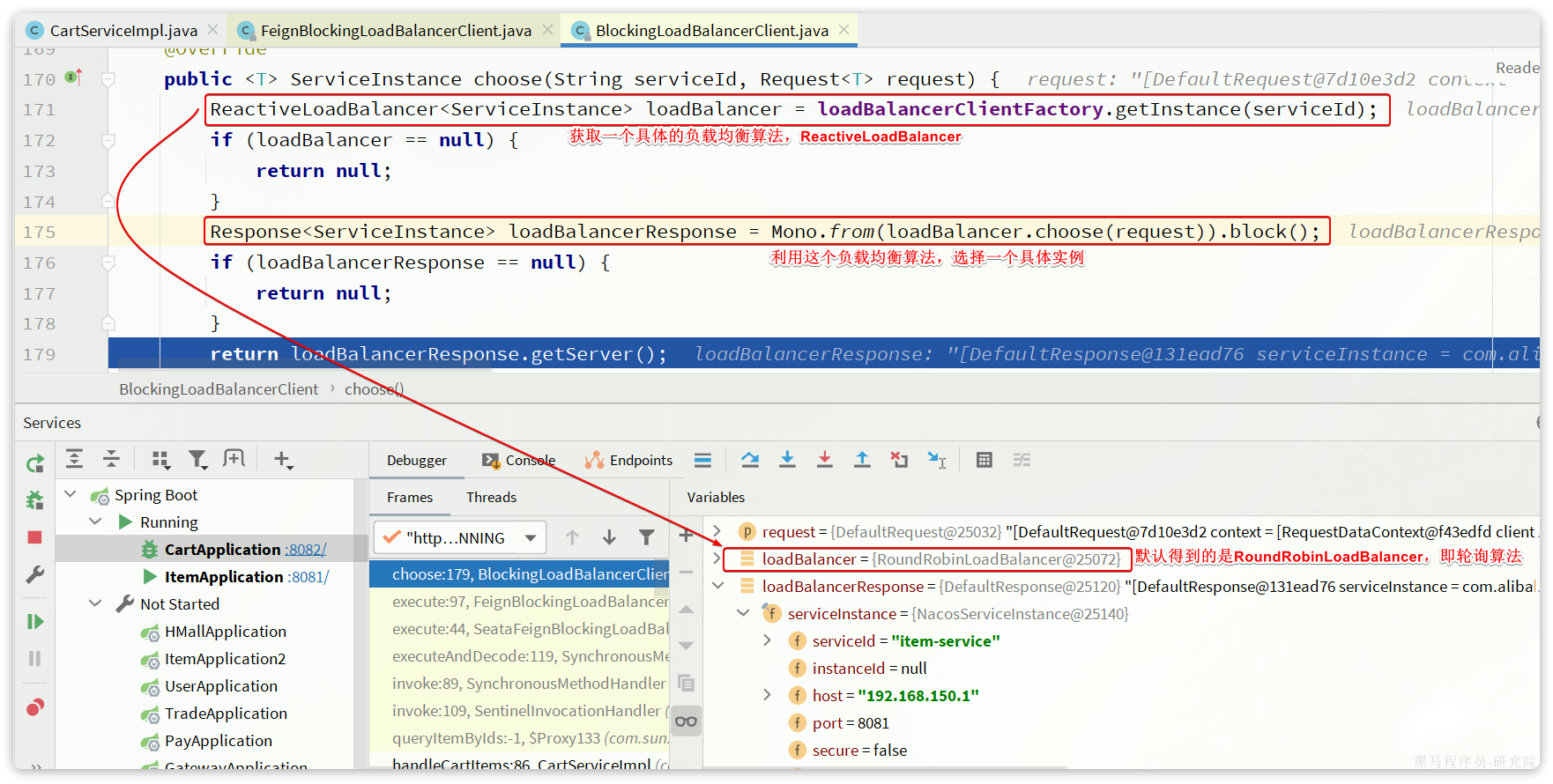
图中代码的核心逻辑如下:
- 根据serviceId找到这个服务采用的负载均衡器(
ReactiveLoadBalancer),也就是说我们可以给每个服务配不同的负载均衡算法。 - 利用负载均衡器(
ReactiveLoadBalancer)中的负载均衡算法,选出一个服务实例
ReactiveLoadBalancer是Spring-Cloud-Common组件中定义的负载均衡器接口规范,而Spring-Cloud-Loadbalancer组件给出了两个实现:
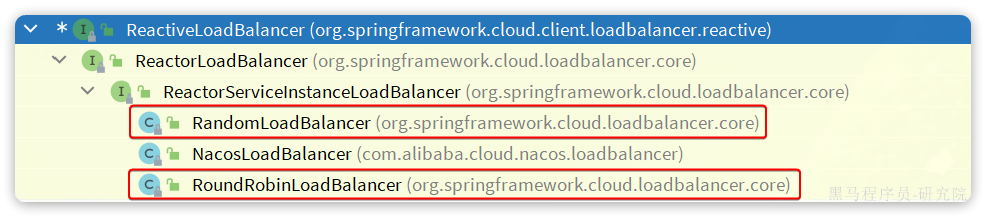
默认的实现是RoundRobinLoadBalancer,即轮询负载均衡器。负载均衡器的核心逻辑如下:
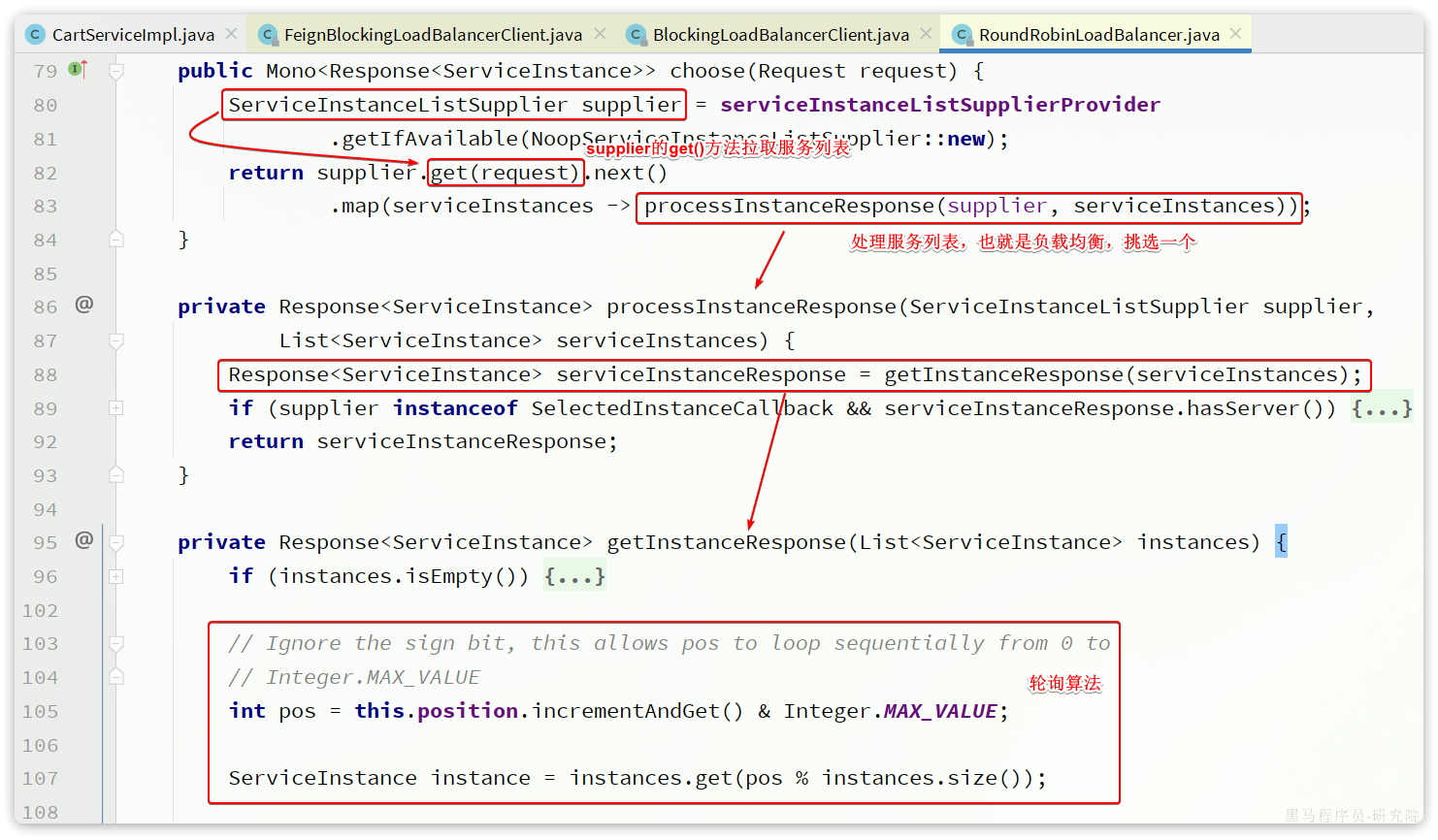
核心流程就是两步:
- 利用
ServiceInstanceListSupplier#get()方法拉取服务的实例列表,这一步是采用响应式编程 - 利用本类,也就是
RoundRobinLoadBalancer的getInstanceResponse()方法挑选一个实例,这里采用了轮询算法来挑选。
这里的ServiceInstanceListSupplier有很多实现:
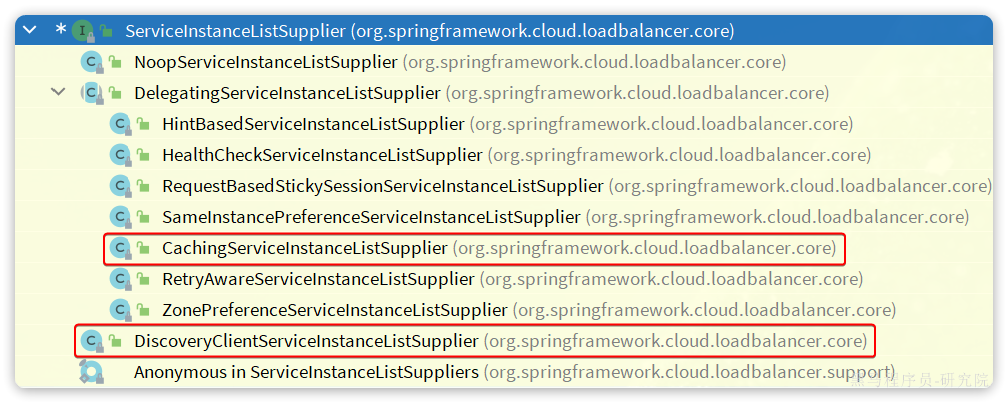
其中CachingServiceInstanceListSupplier采用了装饰模式,加了服务实例列表缓存,避免每次都要去注册中心拉取服务实例列表。而其内部是基于DiscoveryClientServiceInstanceListSupplier来实现的。
在这个类的构造函数中,就会异步的基于DiscoveryClient去拉取服务的实例列表:
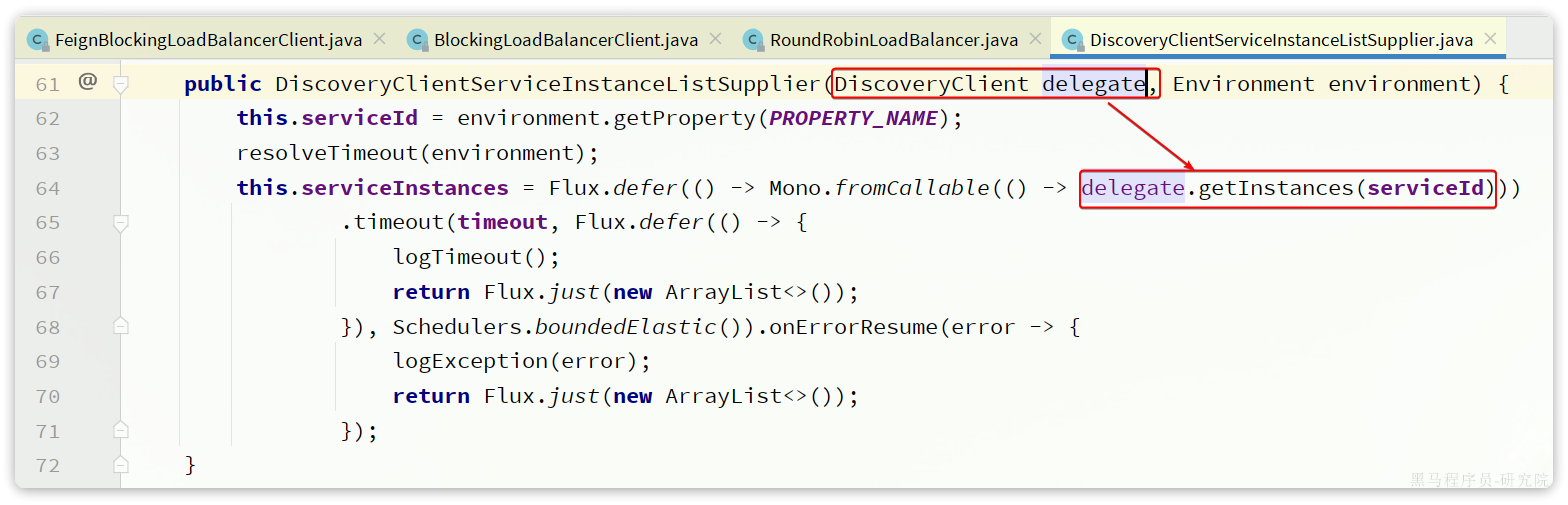
流程梳理
根据之前的分析,我们会发现Spring在整合OpenFeign的时候,实现了org.springframework.cloud.openfeign.loadbalancer.FeignBlockingLoadBalancerClient类,其中定义了OpenFeign发起远程调用的核心流程。也就是四步:
- 获取请求中的
serviceId - 根据
serviceId负载均衡,找出一个可用的服务实例 - 利用服务实例的
ip和port信息重构url - 向真正的url发起请求
而具体的负载均衡则是不是由OpenFeign组件负责。而是分成了负载均衡的接口规范,以及负载均衡的具体实现两部分。
负载均衡的接口规范是定义在Spring-Cloud-Common模块中,包含下面的接口:
LoadBalancerClient:负载均衡客户端,职责是根据serviceId最终负载均衡,选出一个服务实例ReactiveLoadBalancer:负载均衡器,负责具体的负载均衡算法
OpenFeign的负载均衡是基于Spring-Cloud-Common模块中的负载均衡规则接口,并没有写死具体实现。这就意味着以后还可以拓展其它各种负载均衡的实现。
不过目前SpringCloud中只有Spring-Cloud-Loadbalancer这一种实现。
Spring-Cloud-Loadbalancer模块中,实现了Spring-Cloud-Common模块的相关接口,具体如下:
BlockingLoadBalancerClient:实现了LoadBalancerClient,会根据serviceId选出负载均衡器并调用其算法实现负载均衡。RoundRobinLoadBalancer:基于轮询算法实现了ReactiveLoadBalancerRandomLoadBalancer:基于随机算法实现了ReactiveLoadBalancer,
这样一来,整体思路就非常清楚了,流程图如下:
NacosRule
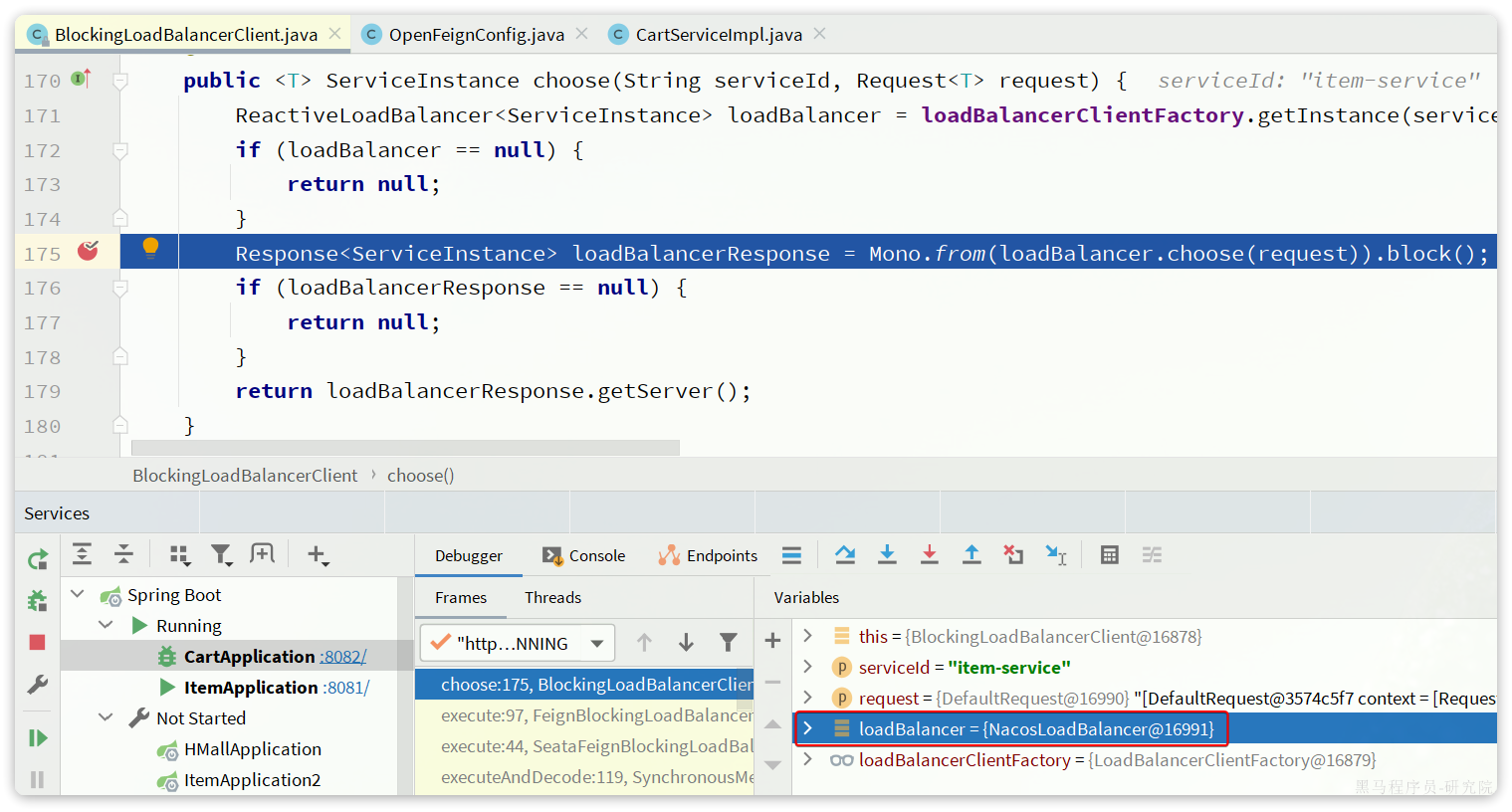
之前分析源码的时候我们发现负载均衡的算法是有ReactiveLoadBalancer来定义的,我们发现它的实现类有三个:
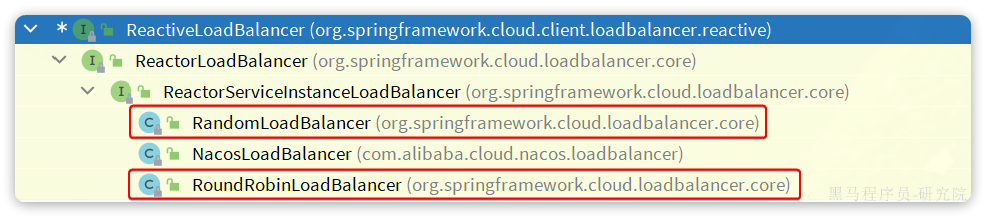
其中RoundRobinLoadBalancer和RandomLoadBalancer是由Spring-Cloud-Loadbalancer模块提供的,而NacosLoadBalancer则是由Nacos-Discorvery模块提供的。
默认采用的负载均衡策略是RoundRobinLoadBalancer,那如果我们要切换负载均衡策略该怎么办?
修改负载均衡策略
查看源码会发现,Spring-Cloud-Loadbalancer模块中有一个自动配置类:
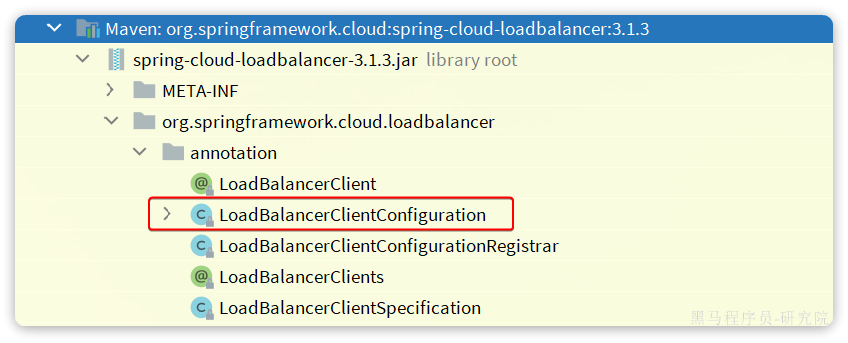
其中定义了默认的负载均衡器:
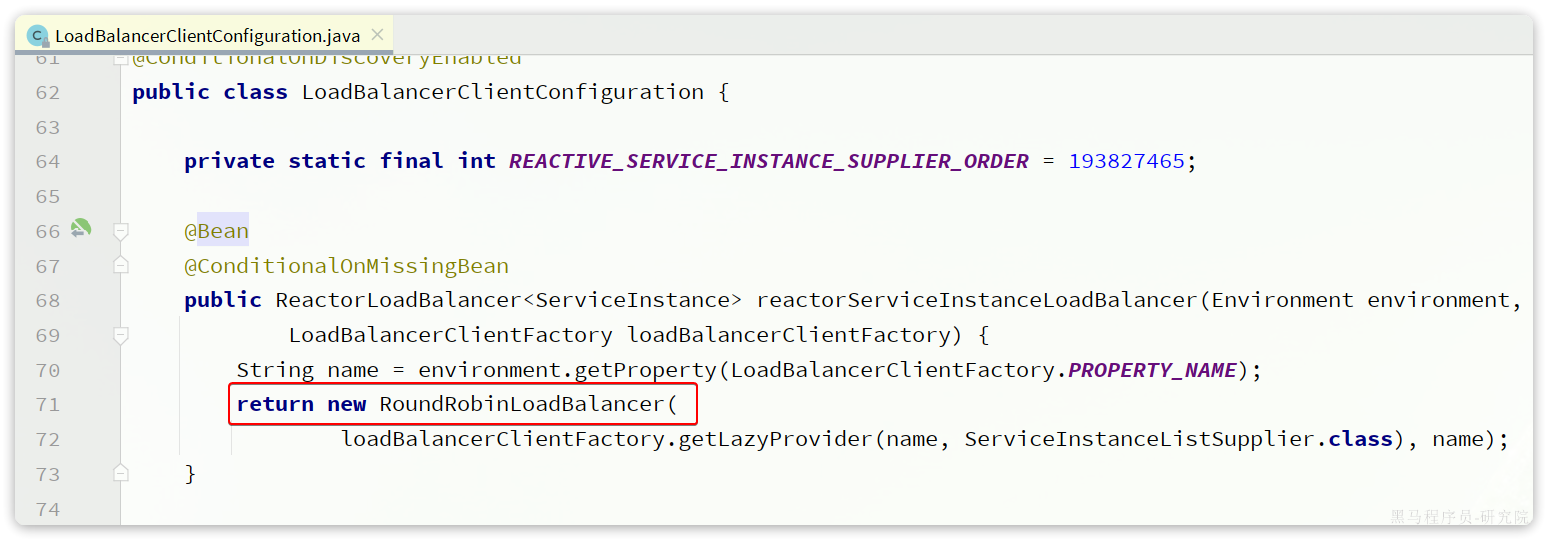
这个Bean上添加了@ConditionalOnMissingBean注解,也就是说如果我们自定义了这个类型的bean,则负载均衡的策略就会被改变。
我们在hm-cart模块中的添加一个配置类:
代码如下:
package com.hmall.cart.config;import com.alibaba.cloud.nacos.NacosDiscoveryProperties;
import com.alibaba.cloud.nacos.loadbalancer.NacosLoadBalancer;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.loadbalancer.core.ReactorLoadBalancer;
import org.springframework.cloud.loadbalancer.core.ServiceInstanceListSupplier;
import org.springframework.cloud.loadbalancer.support.LoadBalancerClientFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.core.env.Environment;public class OpenFeignConfig {@Beanpublic ReactorLoadBalancer<ServiceInstance> reactorServiceInstanceLoadBalancer(Environment environment, NacosDiscoveryProperties properties,LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);return new NacosLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name, properties);}}
注意:
这个配置类千万不要加@Configuration注解,也不要被SpringBootApplication扫描到。
由于这个OpenFeignConfig没有加@Configuration注解,也就没有被Spring加载,因此是不会生效的。接下来,我们要在启动类上通过注解来声明这个配置。
有两种做法:
- 全局配置:对所有服务生效
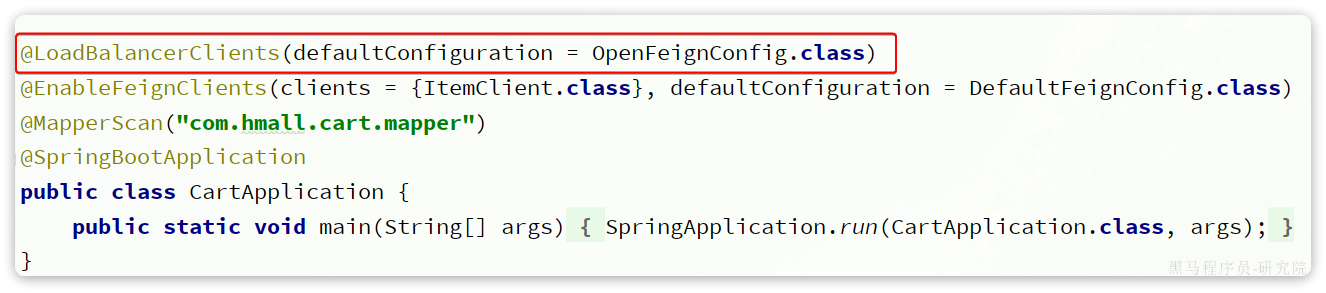
@LoadBalancerClients(defaultConfiguration = OpenFeignConfig.class)
- 局部配置:只对某个服务生效
@LoadBalancerClients({@LoadBalancerClient(value = "item-service", configuration = OpenFeignConfig.class)
})
我们选择全局配置:
DEBUG重启后测试,会发现负载均衡器的类型确实切换成功:
集群优先
RoundRobinLoadBalancer是轮询算法,RandomLoadBalancer是随机算法,那么NacosLoadBalancer是什么负载均衡算法呢?
我们通过源码来分析一下,先看第一部分:
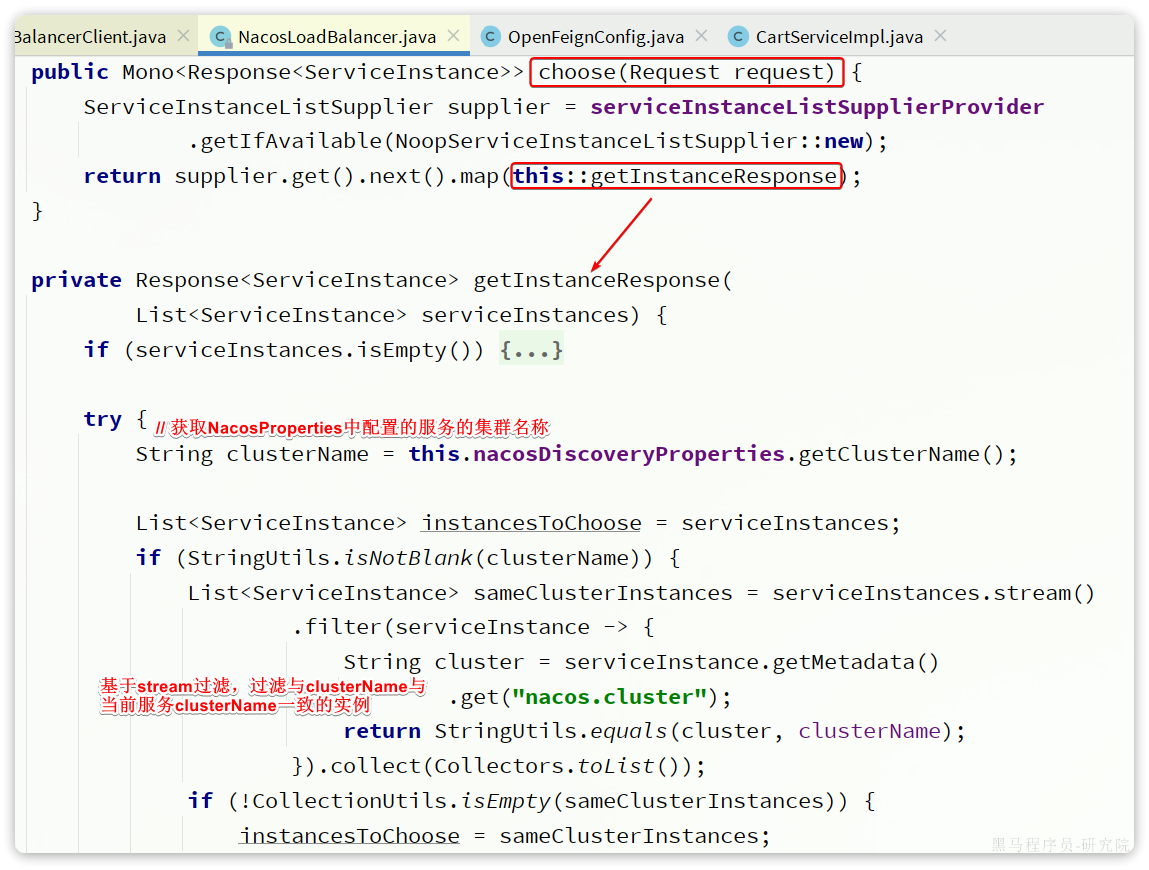
这部分代码的大概流程如下:
- 通过
ServiceInstanceListSupplier获取服务实例列表 - 获取
NacosDiscoveryProperties中的clusterName,也就是yml文件中的配置,代表当前服务实例所在集群信息(参考2.2小节,分级模型) - 然后利用stream的filter过滤找到被调用的服务实例中与当前服务实例
clusterName一致的。简单来说就是服务调用者与服务提供者要在一个集群
为什么?
假如我现在有两个机房,都部署有item-service和cart-service服务:

假如这些服务实例全部都注册到了同一个Nacos。现在,杭州机房的cart-service要调用item-service,会拉取到所有机房的item-service的实例。调用时会出现两种情况:
- 直接调用当前机房的
item-service - 调用其它机房的
item-service
本机房调用几乎没有网络延迟,速度比较快。而跨机房调用,如果两个机房相距很远,会存在较大的网络延迟。因此,我们应该尽可能避免跨机房调用,优先本地集群调用:
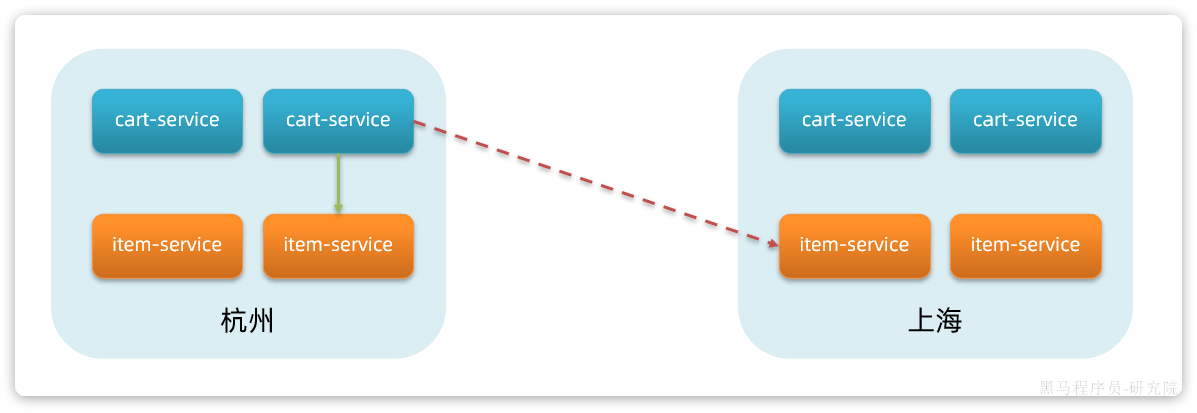
现在的情况是这样的:
cart-service所在集群是defaultitem-service的8081、8083所在集群的defaultitem-service的8084所在集群是BJ
cart-service访问item-service时,应该优先访问8081和8082,我们重启cart-service,测试一下:
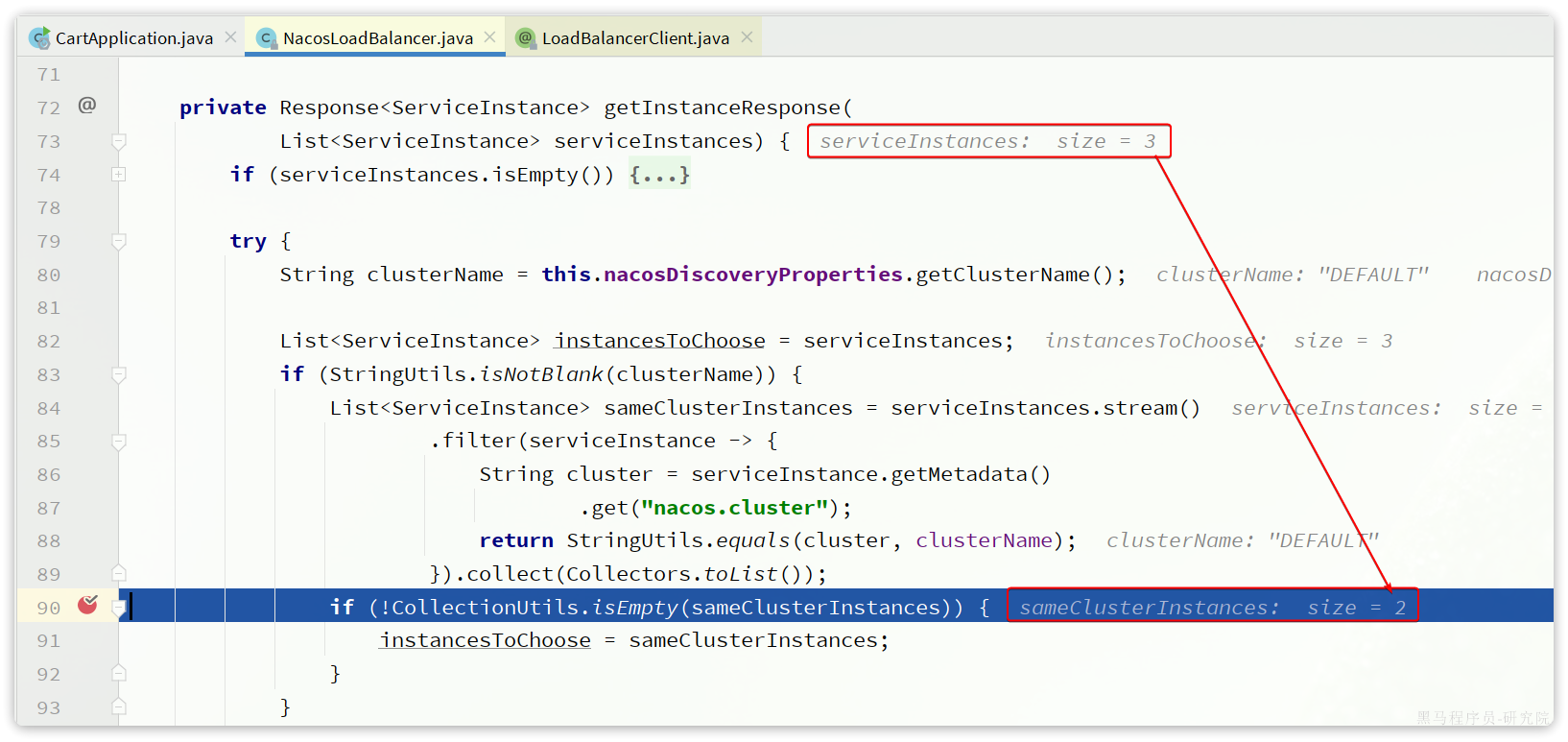
可以看到原本是3个实例,经过筛选后还剩下2个实例。
查看Debug控制台:

同集群的实例还剩下两个,接下来就需要做负载均衡了,具体用的是什么算法呢?
权重配置
我们继续跟踪NacosLoadBalancer源码:
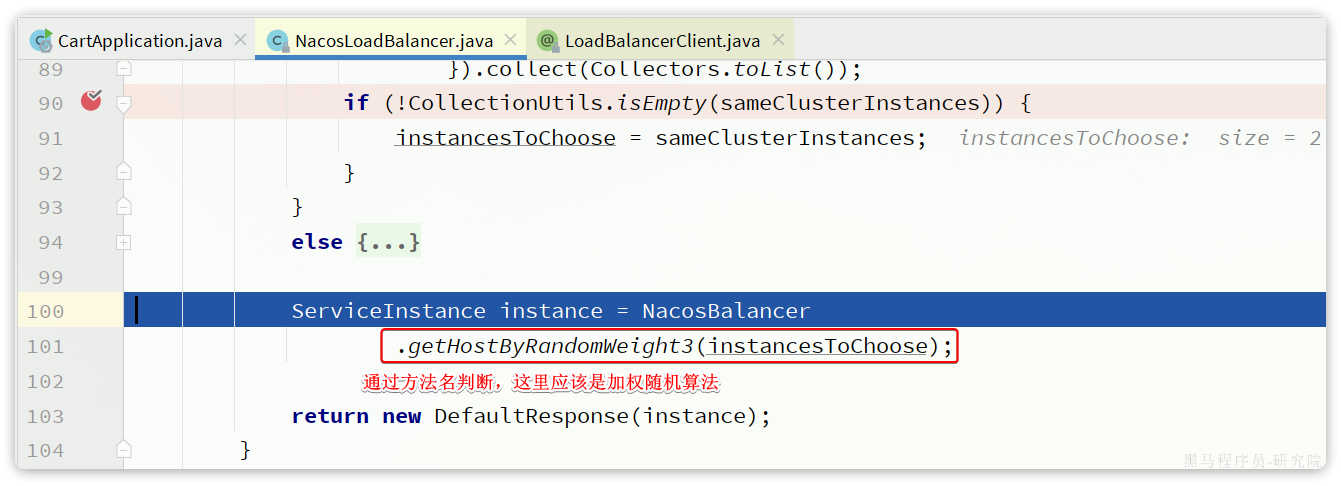
那么问题来了, 这个权重是怎么配的呢?
我们打开nacos控制台,进入item-service的服务详情页,可以看到每个实例后面都有一个编辑按钮:
点击,可以看到一个编辑表单:
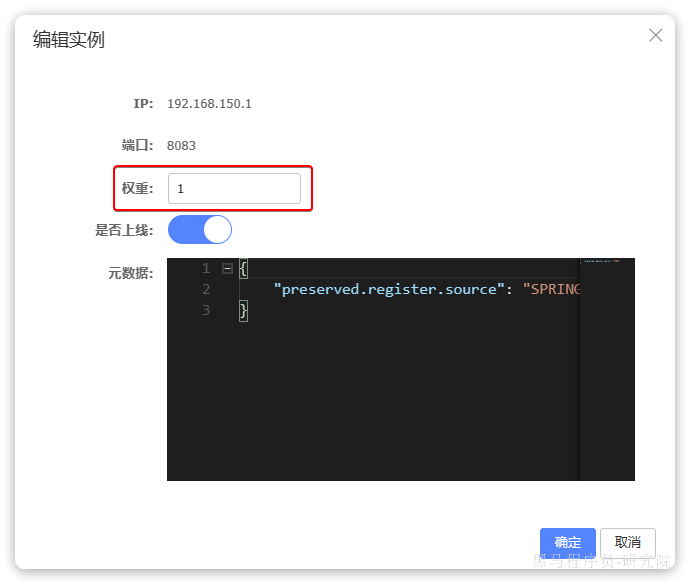
我们将这里的权重修改为5:
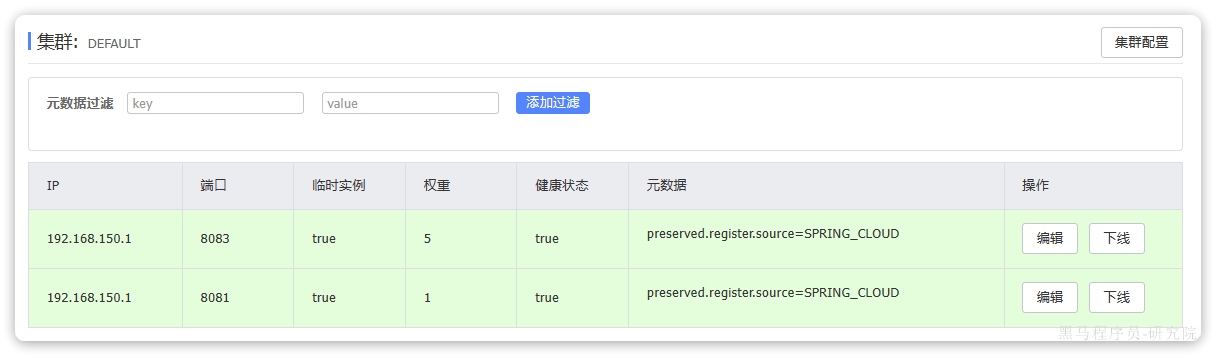
访问10次购物车接口,可以发现大多数请求都访问到了8083这个实例。
总结
OpenFeign 的优势与使用
- 目的:替代繁琐的
RestTemplate+DiscoveryClient手动服务调用方式,实现声明式、模板化的远程调用,让远程调用像本地方法调用一样简单。 - 核心步骤:
- 引入依赖:
spring-cloud-starter-openfeign - 启用功能:在主启动类上添加
@EnableFeignClients注解。 - 定义客户端:编写一个接口,使用
@FeignClient("service-name")注解声明要调用的服务,接口中的方法使用 SpringMVC 注解(如@GetMapping)来定义请求。 - 注入使用:像使用普通 Spring Bean 一样注入该接口并调用方法。
- 引入依赖:
- 性能优化:
- 连接池:默认使用 JDK 的
HttpURLConnection,性能差。可通过引入feign-okhttp依赖并在配置中feign.okhttp.enabled=true来切换为高性能的 OKHttp 连接池。 - 日志:默认日志级别为
NONE。可通过配置全局或客户端的日志级别(BASIC,HEADERS,FULL)来输出请求和响应的详细信息,便于调试。
- 连接池:默认使用 JDK 的
OpenFeign 的工作流程(宏观)
OpenFeign 在发起调用时,背后完成了以下几步:
- 解析请求:根据接口上的注解,确定请求方式、路径、参数。
- 服务发现:根据
@FeignClient中的服务名(如item-service),向注册中心(Nacos)获取该服务的所有可用实例列表。 - 负载均衡:从实例列表中,根据配置的规则选择一个实例。
- 重构URL:将原始URL中的服务名(
item-service)替换为选中实例的 IP:Port。 - 发送请求:通过底层客户端(如OKHttp)向重构后的真实URL发送HTTP请求。
负载均衡的架构与实现(微观)
- 设计理念:Spring Cloud 采用了关注点分离的设计。OpenFeign 只负责定义和发起请求,而负载均衡的具体实现被抽象出来,由专门的模块
spring-cloud-loadbalancer完成。 - 核心接口与实现:
LoadBalancerClient(接口): 定义了负载均衡客户端的核心行为(如选择实例)。BlockingLoadBalancerClient(实现类): 是LoadBalancerClient的具体实现,负责协调整个负载均衡流程。ReactiveLoadBalancer(接口): 定义了负载均衡算法的规范。RoundRobinLoadBalancer(实现类): 基于轮询算法实现了ReactiveLoadBalancer。RandomLoadBalancer(实现类): 基于随机算法实现了ReactiveLoadBalancer。NacosLoadBalancer(实现类): Nacos 提供的实现,具备集群优先和权重(可以在控制台配置)感知能力。
自定义与切换负载均衡策略
- 默认策略:Spring Cloud LoadBalancer 默认采用
RoundRobinLoadBalancer(轮询)。 - 切换策略:可以通过自定义配置类来覆盖默认的负载均衡器。
- 编写配置类:创建一个配置类,返回
ReactorLoadBalancer<ServiceInstance>类型的 Bean。切记不要加@Configuration,以免被全局扫描。 - 声明配置:
- 全局生效:在主启动类上使用
@LoadBalancerClients(defaultConfiguration = MyConfig.class)。 - 局部生效:使用
@LoadBalancerClients(value = @LoadBalancerClient(name = "service-name", configuration = MyConfig.class)),只为指定服务配置。
- 全局生效:在主启动类上使用
- 编写配置类:创建一个配置类,返回
Gateway服务网关
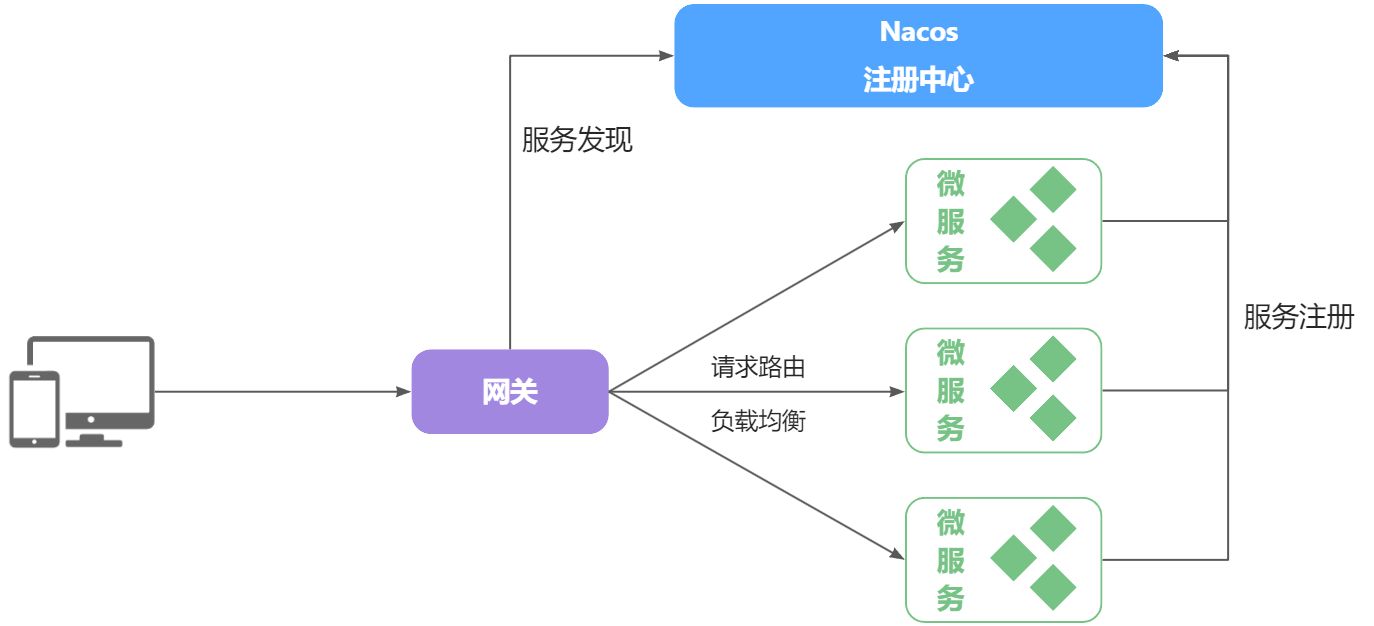
网关就是网络的关口。数据在网络间传输,从一个网络传输到另一网络时就需要经过网关来做数据的路由和转发以及数据安全的校验。
现在,微服务网关就起到同样的作用。前端请求不能直接访问微服务,而是要请求网关:
- 网关可以做安全控制,也就是登录身份校验,校验通过才放行
- 通过认证后,网关再根据请求判断应该访问哪个微服务,将请求转发过去
SpringCloudGateway快速入门
接下来,我们先看下如何利用网关实现请求路由。由于网关本身也是一个独立的微服务,因此也需要创建一个模块开发功能。大概步骤如下:
- 创建网关微服务
- 引入SpringCloudGateway、NacosDiscovery依赖
- 编写启动类
- 配置网关路由
创建项目
首先,我们要在hmall下创建一个新的module,命名为hm-gateway,作为网关微服务:
引入依赖
在hm-gateway模块的pom.xml文件中引入依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>hmall</artifactId><groupId>com.heima</groupId><version>1.0.0</version></parent><modelVersion>4.0.0</modelVersion><artifactId>hm-gateway</artifactId><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target></properties><dependencies><!--common--><dependency><groupId>com.heima</groupId><artifactId>hm-common</artifactId><version>1.0.0</version></dependency><!--网关--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><!--nacos discovery--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--负载均衡--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
</project>
启动类
在hm-gateway模块的com.hmall.gateway包下新建一个启动类:

代码如下:
package com.hmall.gateway;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class GatewayApplication {public static void main(String[] args) {SpringApplication.run(GatewayApplication.class, args);}
}
配置路由
接下来,在hm-gateway模块的resources目录新建一个application.yaml文件,内容如下:
server:port: 8080
spring:application:name: gatewaycloud:nacos:server-addr: 192.168.150.101:8848gateway:routes:- id: item # 路由规则id,自定义,唯一uri: lb://item-service # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务- Path=/items/**,/search/** # 这里是以请求路径作为判断规则- id: carturi: lb://cart-servicepredicates:- Path=/carts/**- id: useruri: lb://user-servicepredicates:- Path=/users/**,/addresses/**- id: tradeuri: lb://trade-servicepredicates:- Path=/orders/**- id: payuri: lb://pay-servicepredicates:- Path=/pay-orders/**
三大核心组件
路由
路由是Spring Cloud Gateway的基本模块,它定义了请求如何被转发到目标服务。每个路由由一个ID、目标URI、一系列的断言和过滤器组成。如果断言为真,则匹配该路由并进行转发。
路由规则的定义语法如下:
spring:cloud:gateway:routes:- id: itemuri: lb://item-servicepredicates:- Path=/items/**,/search/**
其中routes对应的类型如下:
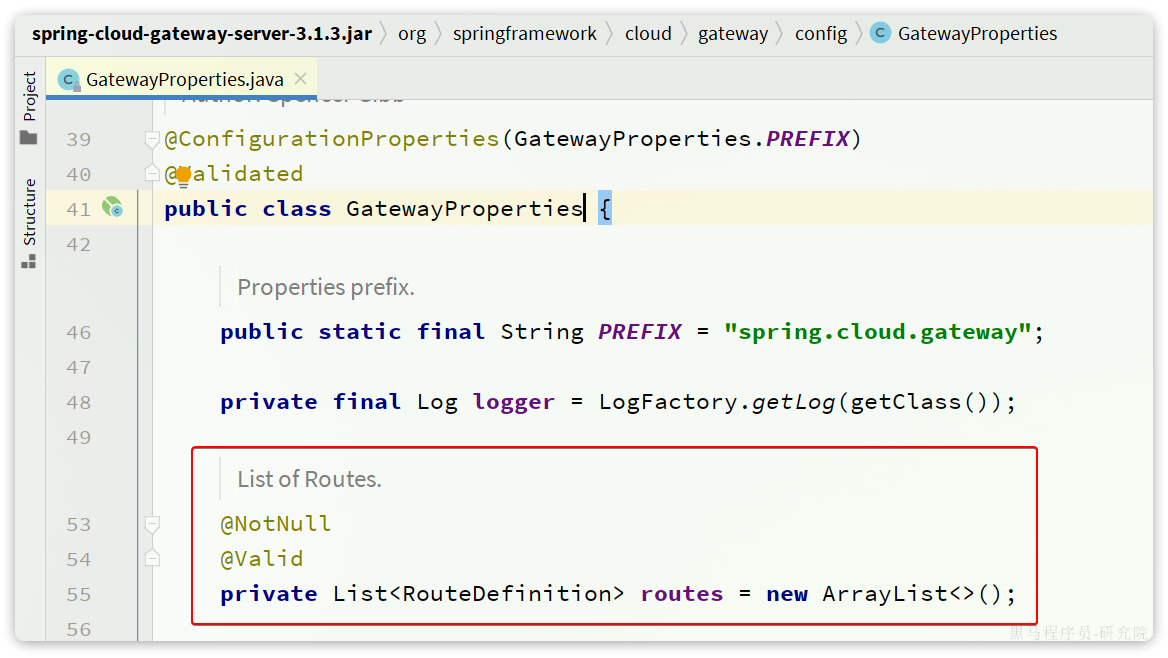
是一个集合,也就是说可以定义很多路由规则。集合中的RouteDefinition就是具体的路由规则定义,其中常见的属性如下:
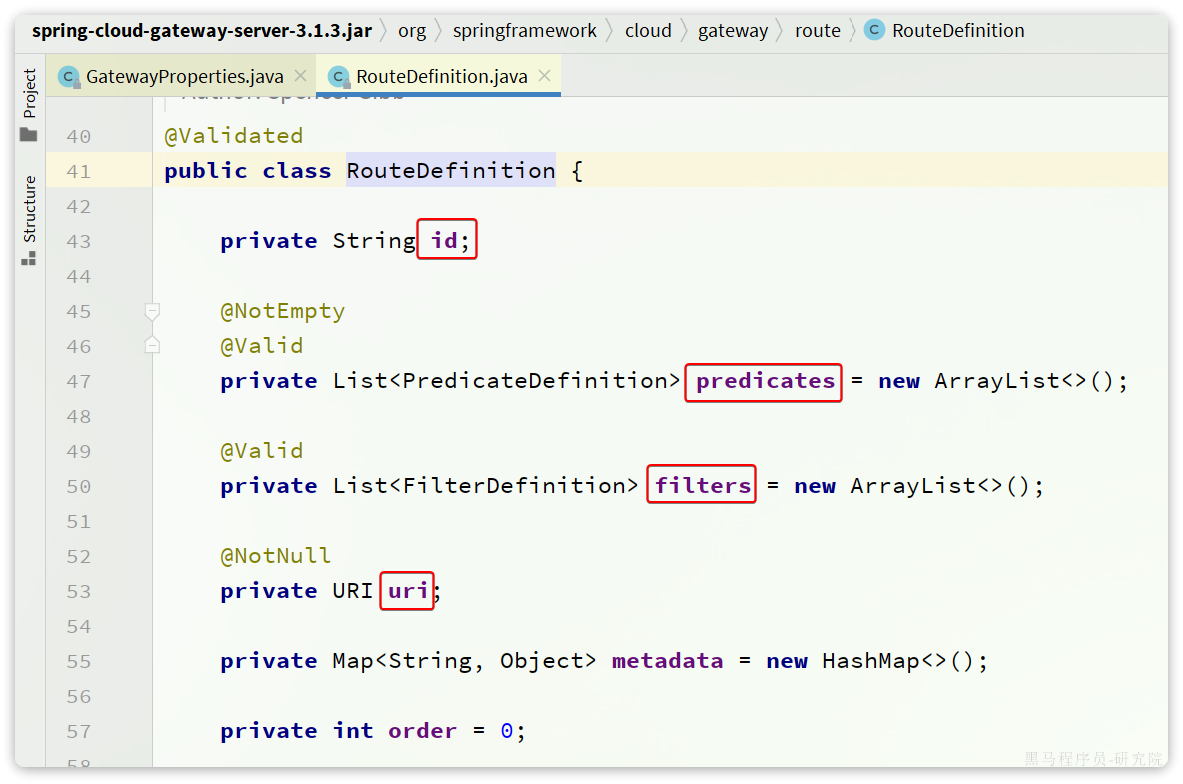
四个属性含义如下:
- id:作为路由的唯一标识符,可以用于配置和管理路由。
- uri:指定请求要转发的目标服务的地址。可以是一个完整的 URL,也可以是一个注册在服务注册中心的服务名。
- predicates:用于匹配请求的一系列条件,如果请求满足所有的匹配条件,它将会被路由到该路由所指定的目标 URI。
- filters:用于在请求被路由之前或之后对请求进行处理和修改的组件。过滤器可以对请求进行增强、校验、修改和校验等操作。
- order:用于多个 Route 之间的排序,数值越小排序越靠前,匹配优先级越高。
断言predicates
这里我们重点关注predicates,也就是路由断言。
路由断言(Predicate)是用于判断当前请求是否符合特定路由规则的条件。只有当请求满足路由断言中定义的所有条件时,该请求才会被路由到对应的目标微服务。
SpringCloudGateway中支持的断言类型有很多:
常见的断言类型包括路径(Path)、请求方法(Method)、请求头(Header)、Cookie等。
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| weight | 权重处理 |
过滤器
过滤器用于在请求被路由前或路由后对请求进行修改。过滤器可以用于实现各种功能,如鉴权、日志记录、限流等。例如:
| 名称 | 说明 | 示例 |
|---|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 | AddrequestHeader=headerName ,headerValue |
| RemoveRequestHeader | 移除请求中的一个请求头 | RemoveRequestHeader=headerName |
| AddResponseHeader | 给响应结果中添加一个响应头 | AddResponseHeader=headerName , headerValue |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 | RemoveResponseHeader=headerName |
| RewritePath | 请求路径重写 | RewritePath=/red/?(?<segment>.*), /${segment} |
| StripPrefix | 去除请求路径中的N段前缀 | StripPrefix=1, 则路径/a/b转发时只保留/b |
网关登录校验
单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,不再共享数据。也就意味着每个微服务都需要做登录校验,这显然不可取。
鉴权思路分析
我们的登录是基于JWT来实现的,校验JWT的算法复杂,而且需要用到秘钥。如果每个微服务都去做登录校验,这就存在着两大问题:
- 每个微服务都需要知道JWT的秘钥,不安全
- 每个微服务重复编写登录校验代码、权限校验代码,麻烦
既然网关是所有微服务的入口,一切请求都需要先经过网关。我们完全可以把登录校验的工作放到网关去做,这样之前说的问题就解决了:
- 只需要在网关和用户服务保存秘钥
- 只需要在网关开发登录校验功能
此时,登录校验的流程如图:
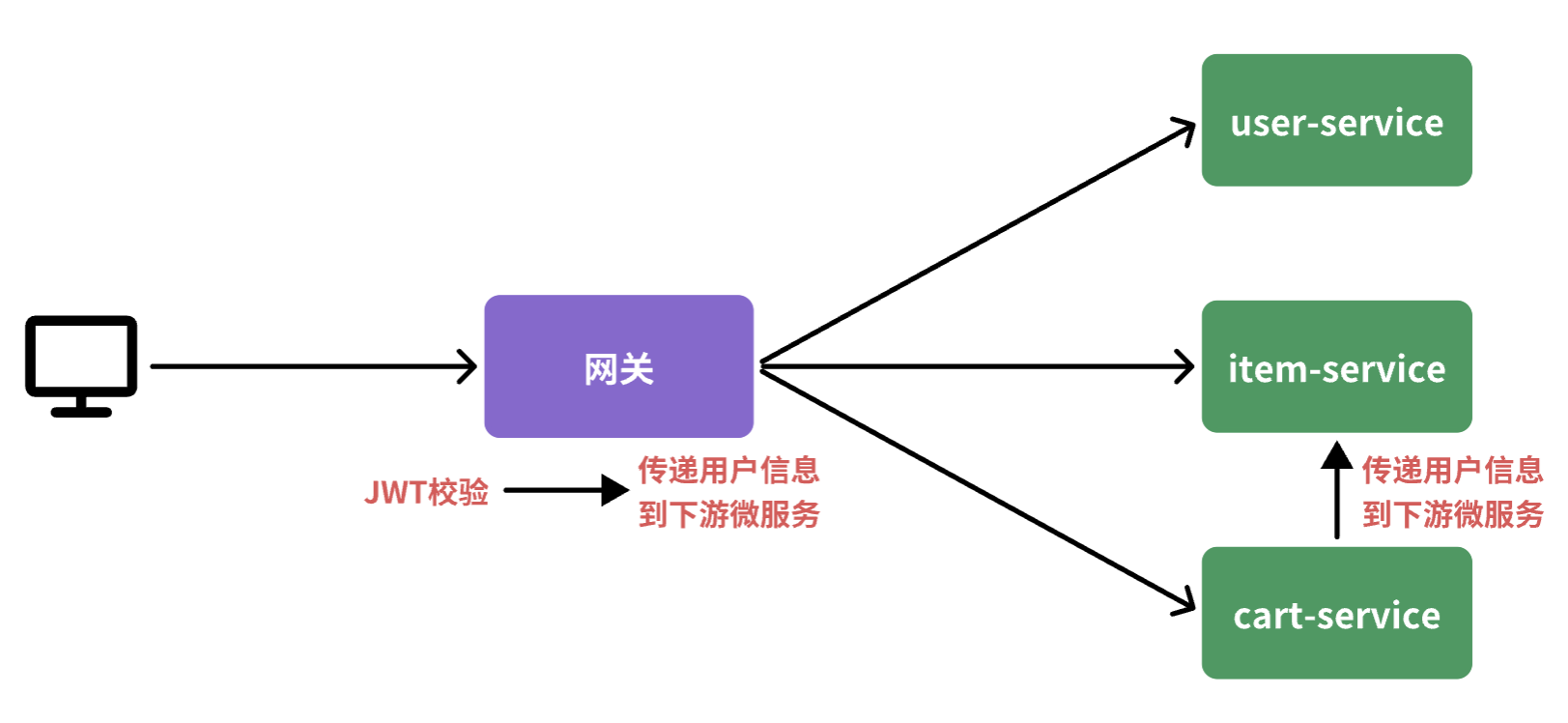
不过,这里存在几个问题:
- 网关路由是配置的,请求转发是Gateway内部代码,我们如何在转发之前做登录校验?:使用网关全局过滤器
- 网关校验JWT之后,如何将用户信息传递给微服务?:将用户信息存入请求Head,并在Common模块当中用LocalThread存储
- 微服务之间也会相互调用,这种调用不经过网关,又该如何传递用户信息?
网关过滤器
登录校验必须在请求转发到微服务之前做,否则就失去了意义。而网关的请求转发是Gateway内部代码实现的,要想在请求转发之前做登录校验,就必须了解Gateway内部工作的基本原理。
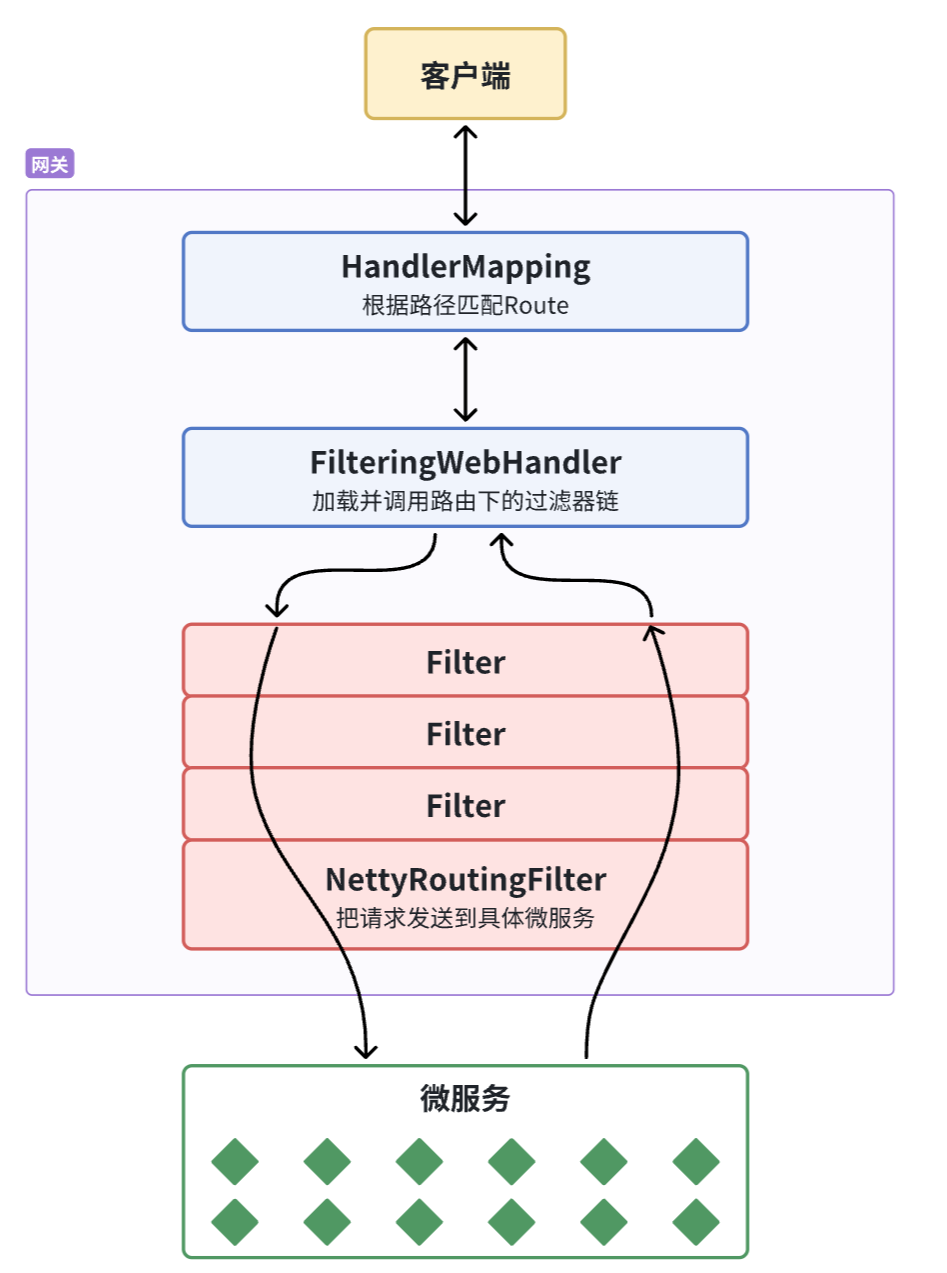
如图所示:
- 客户端请求进入网关后由
HandlerMapping对请求做判断,找到与当前请求匹配的路由规则(Route),然后将请求交给WebHandler去处理。 WebHandler则会加载当前路由下需要执行的过滤器链(Filter chain),然后按照顺序逐一执行过滤器(后面称为**Filter**)。- 图中
Filter被虚线分为左右两部分,是因为Filter内部的逻辑分为pre和post两部分,分别会在请求路由到微服务之前和之后被执行。 - 只有所有
Filter的pre逻辑都依次顺序执行通过后,请求才会被路由到微服务。 - 微服务返回结果后,再倒序执行
Filter的post逻辑。 - 最终把响应结果返回。
如图中所示,最终请求转发是有一个名为**NettyRoutingFilter**的过滤器来执行的,而且这个过滤器是整个过滤器链中顺序最靠后的一个。如果我们能够定义一个过滤器,在其中实现登录校验逻辑,并且将过滤器执行顺序定义到NettyRoutingFilter之前,这就符合我们的需求了!
过滤器类别
网关过滤器链中的过滤器有两种:
GatewayFilter:路由过滤器,作用范围比较灵活,可以是任意指定的路由Route. ;需要配置到路由蔡生效GlobalFilter:全局过滤器,作用范围是所有路由,不可配置。;声明后自动生效
其实
GatewayFilter和GlobalFilter这两种过滤器的方法签名完全一致;
FilteringWebHandler在处理请求时,会将GlobalFilter装饰为GatewayFilter,然后放到同一个过滤器链中,排序以后依次执行。
Gateway内置的GatewayFilter过滤器使用起来非常简单,无需编码,只要在yaml文件中简单配置即可。而且其作用范围也很灵活,配置在哪个Route下,就作用于哪个Route.例如,有一个过滤器叫做
AddRequestHeaderGatewayFilterFacotry,顾明思议,就是添加请求头的过滤器,可以给请求添加一个请求头并传递到下游微服务。使用的使用只需要在application.yaml中这样配置:
spring:cloud:gateway:routes:- id: test_routeuri: lb://test-servicepredicates:-Path=/test/**filters:- AddRequestHeader=key, value # 逗号之前是请求头的key,逗号之后是value
如果想要让过滤器作用于所有的路由,则可以这样配置:
spring:cloud:gateway:default-filters: # default-filters下的过滤器可以作用于所有路由- AddRequestHeader=key, valueroutes:- id: test_routeuri: lb://test-servicepredicates:-Path=/test/**
自定义过滤器
无论是GatewayFilter还是GlobalFilter都支持自定义,只不过编码方式、使用方式略有差别。
自定义GatewayFilter
自定义GatewayFilter不是直接实现GatewayFilter,而是实现AbstractGatewayFilterFactory。最简单的方式是这样的:
@Component
public class PrintAnyGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {@Overridepublic GatewayFilter apply(Object config) {return new GatewayFilter() {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 获取请求ServerHttpRequest request = exchange.getRequest();// 编写过滤器逻辑System.out.println("过滤器执行了");// 放行return chain.filter(exchange);}};}
}
注意:该类的名称一定要以GatewayFilterFactory为后缀!
如果需要控制过滤器的执行顺序,可以return new orderedGatewayFilter(GatewayFilter g, int Order);其中Order的大小越小,则优先级越高
然后在yaml配置中这样使用:
spring:cloud:gateway:default-filters:- PrintAny # 此处直接以自定义的GatewayFilterFactory类名称前缀类声明过滤器
另外,这种过滤器还可以支持动态配置参数,不过实现起来比较复杂,示例:
@Component
public class PrintAnyGatewayFilterFactory // 父类泛型是内部类的Config类型extends AbstractGatewayFilterFactory<PrintAnyGatewayFilterFactory.Config> {@Overridepublic GatewayFilter apply(Config config) {// OrderedGatewayFilter是GatewayFilter的子类,包含两个参数:// - GatewayFilter:过滤器// - int order值:值越小,过滤器执行优先级越高return new OrderedGatewayFilter(new GatewayFilter() {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 获取config值String a = config.getA();String b = config.getB();String c = config.getC();// 编写过滤器逻辑System.out.println("a = " + a);System.out.println("b = " + b);System.out.println("c = " + c);// 放行return chain.filter(exchange);}}, 100);}// 自定义配置属性,成员变量名称很重要,下面会用到@Datastatic class Config{private String a;private String b;private String c;}// 将变量名称依次返回,顺序很重要,将来读取参数时需要按顺序获取@Overridepublic List<String> shortcutFieldOrder() {return List.of("a", "b", "c");}// 返回当前配置类的类型,也就是内部的Config@Overridepublic Class<Config> getConfigClass() {return Config.class;}}
然后在yaml文件中使用:
spring:cloud:gateway:default-filters:- PrintAny=1,2,3 # 注意,这里多个参数以","隔开,将来会按照shortcutFieldOrder()方法返回的参数顺序依次复制
上面这种配置方式参数必须严格按照shortcutFieldOrder()方法的返回参数名顺序来赋值。
还有一种用法,无需按照这个顺序,就是手动指定参数名:
spring:cloud:gateway:default-filters:- name: PrintAnyargs: # 手动指定参数名,无需按照参数顺序a: 1b: 2c: 3
自定义GlobalFilter
自定义GlobalFilter则简单很多,直接实现GlobalFilter即可,而且也无法设置动态参数:
@Component
public class PrintAnyGlobalFilter implements GlobalFilter, Ordered {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 编写过滤器逻辑System.out.println("未登录,无法访问");// 放行// return chain.filter(exchange);// 拦截ServerHttpResponse response = exchange.getResponse();response.setRawStatusCode(401);return response.setComplete();}@Overridepublic int getOrder() {// 过滤器执行顺序,值越小,优先级越高return 0;}
}
登录校验
接下来,我们就利用自定义GlobalFilter来完成登录校验。
JWT工具
登录校验需要用到JWT,而且JWT的加密需要秘钥和加密工具。这些在hm-service中已经有了,我们直接拷贝过来:
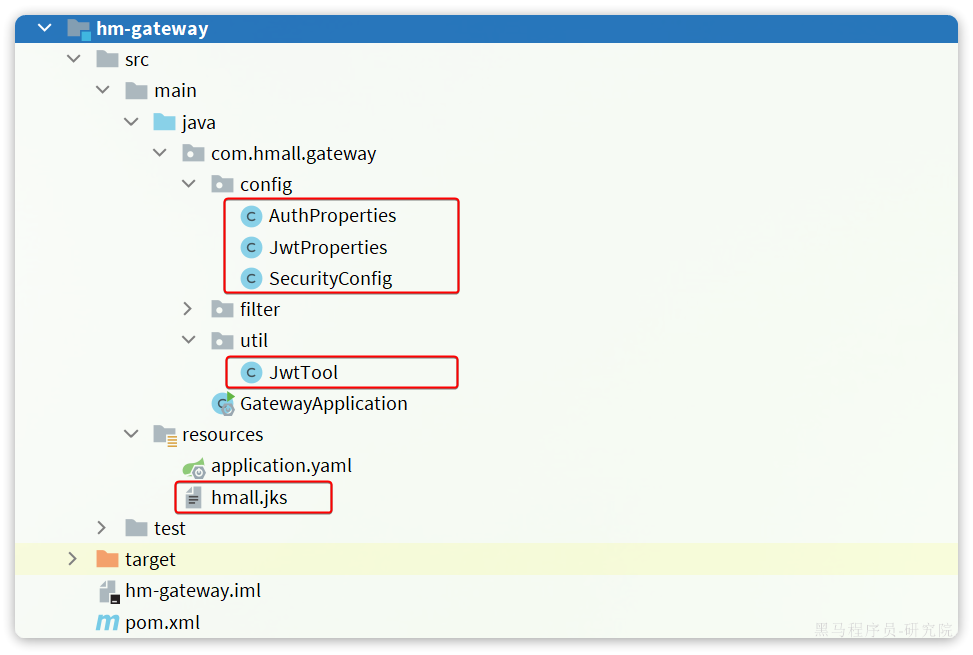
具体作用如下:
AuthProperties:配置登录校验需要拦截的路径,因为不是所有的路径都需要登录才能访问JwtProperties:定义与JWT工具有关的属性,比如秘钥文件位置SecurityConfig:工具的自动装配JwtTool:JWT工具,其中包含了校验和解析token的功能hmall.jks:秘钥文件
其中AuthProperties和JwtProperties所需的属性要在application.yaml中配置:
hm:jwt:location: classpath:hmall.jks # 秘钥地址alias: hmall # 秘钥别名password: hmall123 # 秘钥文件密码tokenTTL: 30m # 登录有效期auth:excludePaths: # 无需登录校验的路径- /search/**- /users/login- /items/**
登录校验过滤器
接下来,我们定义一个登录校验的过滤器:
代码如下:
package com.hmall.gateway.filter;@Component
@RequiredArgsConstructor
@EnableConfigurationProperties(AuthProperties.class)
public class AuthGlobalFilter implements GlobalFilter, Ordered {private final JwtTool jwtTool;private final AuthProperties authProperties;private final AntPathMatcher antPathMatcher = new AntPathMatcher();@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 1.获取RequestServerHttpRequest request = exchange.getRequest();// 2.判断是否不需要拦截if(isExclude(request.getPath().toString())){// 无需拦截,直接放行return chain.filter(exchange);}// 3.获取请求头中的tokenString token = null;List<String> headers = request.getHeaders().get("authorization");if (!CollUtils.isEmpty(headers)) {token = headers.get(0);}// 4.校验并解析tokenLong userId = null;try {userId = jwtTool.parseToken(token);} catch (UnauthorizedException e) {// 如果无效,拦截ServerHttpResponse response = exchange.getResponse();response.setRawStatusCode(401);return response.setComplete();}// TODO 5.如果有效,传递用户信息String userInfo userId.tostring();ServerWebExchange ex = exchange.mutate().request(b -b.header("user-info",userInfo)).build();// 6.放行return chain.filter(ex);}private boolean isExclude(String antPath) {for (String pathPattern : authProperties.getExcludePaths()) {if(antPathMatcher.match(pathPattern, antPath)){return true;}}return false;}@Overridepublic int getOrder() {return 0;}
}
微服务获取用户
现在,网关已经可以完成登录校验并获取登录用户身份信息。但是当网关将请求转发到微服务时,微服务又该如何获取用户身份呢?
由于网关发送请求到微服务依然采用的是Http请求,因此我们可以将用户信息以请求头的方式传递到下游微服务。然后微服务可以从请求头中获取登录用户信息。考虑到微服务内部可能很多地方都需要用到登录用户信息,因此我们可以利用SpringMVC的拦截器来实现登录用户信息获取,并存入ThreadLocal,方便后续使用。
据图流程图如下:
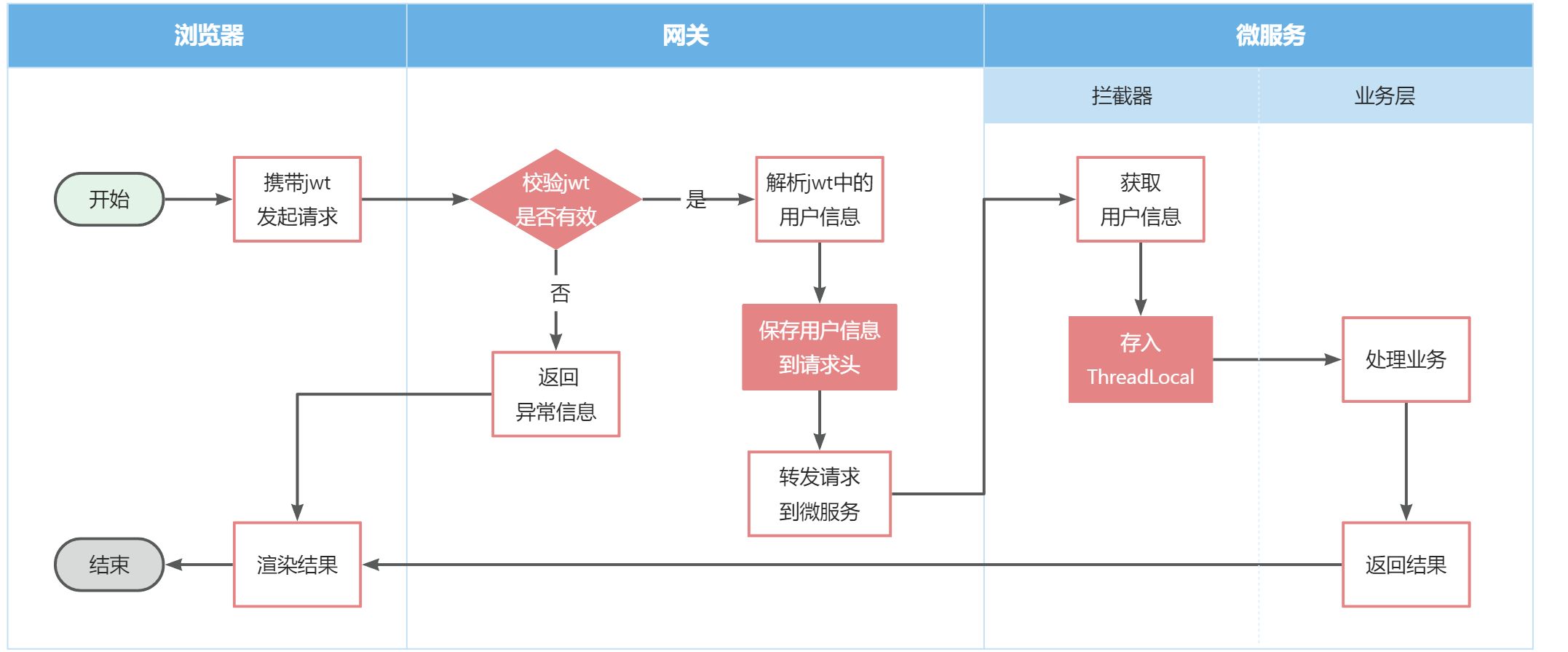
因此,接下来我们要做的事情有:
- 改造网关过滤器,在获取用户信息后保存到请求头,转发到下游微服务
- 编写微服务拦截器,拦截请求获取用户信息,保存到ThreadLocal后放行
保存用户到请求头
首先,我们修改登录校验拦截器的处理逻辑,保存用户信息到请求头中:
拦截器获取用户
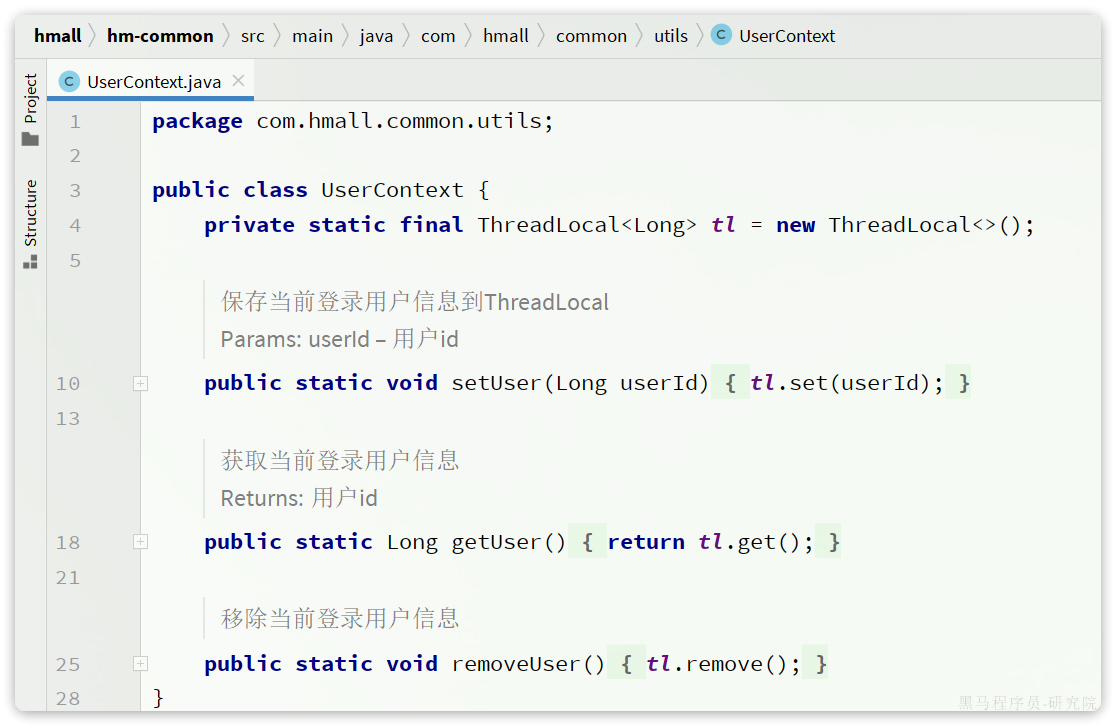
在hm-common中已经有一个用于保存登录用户的ThreadLocal工具:
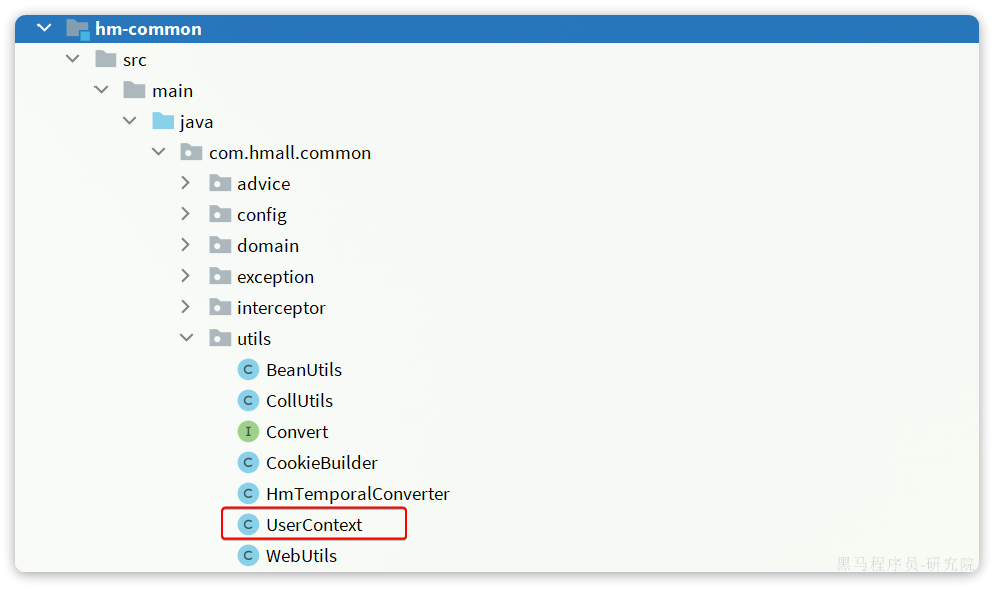
其中已经提供了保存和获取用户的方法:
接下来,我们只需要编写拦截器,获取用户信息并保存到UserContext,然后放行即可。
由于每个微服务都有获取登录用户的需求,因此拦截器我们直接写在hm-common中,并写好自动装配。这样微服务只需要引入hm-common就可以直接具备拦截器功能,无需重复编写。
我们在hm-common模块下定义一个拦截器:
具体代码如下:
package com.hmall.common.interceptor;public class UserInfoInterceptor implements HandlerInterceptor {@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {// 1.获取请求头中的用户信息String userInfo = request.getHeader("user-info");// 2.判断是否为空if (StrUtil.isNotBlank(userInfo)) {// 不为空,保存到ThreadLocalUserContext.setUser(Long.valueOf(userInfo));}// 3.放行return true;}@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {// 移除用户UserContext.removeUser();}
}
接着在hm-common模块下编写SpringMVC的配置类,配置登录拦截器:
具体代码如下:
package com.hmall.common.config;import com.hmall.common.interceptors.UserInfoInterceptor;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.DispatcherServlet;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;@Configuration
@ConditionalOnClass(DispatcherServlet.class)
public class MvcConfig implements WebMvcConfigurer {@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new UserInfoInterceptor());}
}
不过,需要注意的是,这个配置类默认是不会生效的,因为它所在的包是com.hmall.common.config,与其它微服务的扫描包不一致,无法被扫描到,因此无法生效。
基于SpringBoot的自动装配原理,我们要将其添加到resources目录下的META-INF/spring.factories文件中:
内容如下:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\com.hmall.common.config.MyBatisConfig,\com.hmall.common.config.MvcConfig
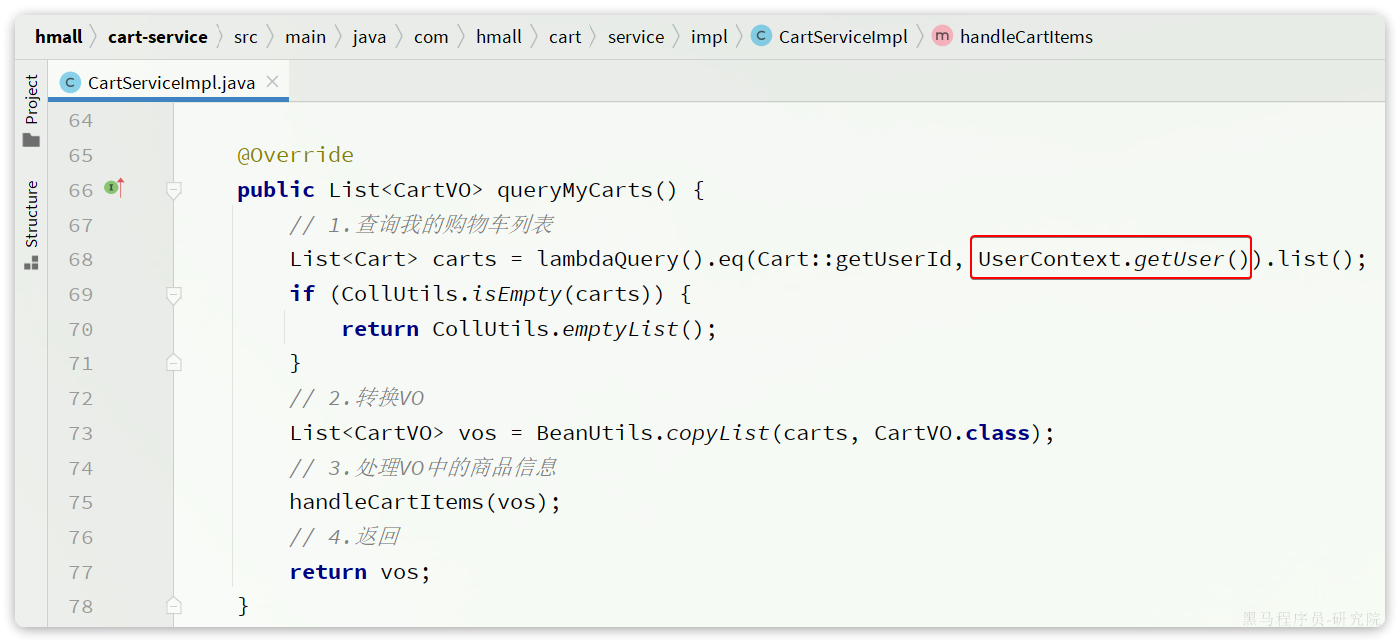
恢复购物车代码
之前我们无法获取登录用户,所以把购物车服务的登录用户写死了,现在需要恢复到原来的样子。
找到cart-service模块的com.hmall.cart.service.impl.CartServiceImpl:
修改其中的queryMyCarts方法:
OpenFeign传递用户
前端发起的请求都会经过网关再到微服务,由于我们之前编写的过滤器和拦截器功能,微服务可以轻松获取登录用户信息。
但有些业务是比较复杂的,请求到达微服务后还需要调用其它多个微服务。比如下单业务,流程如下:
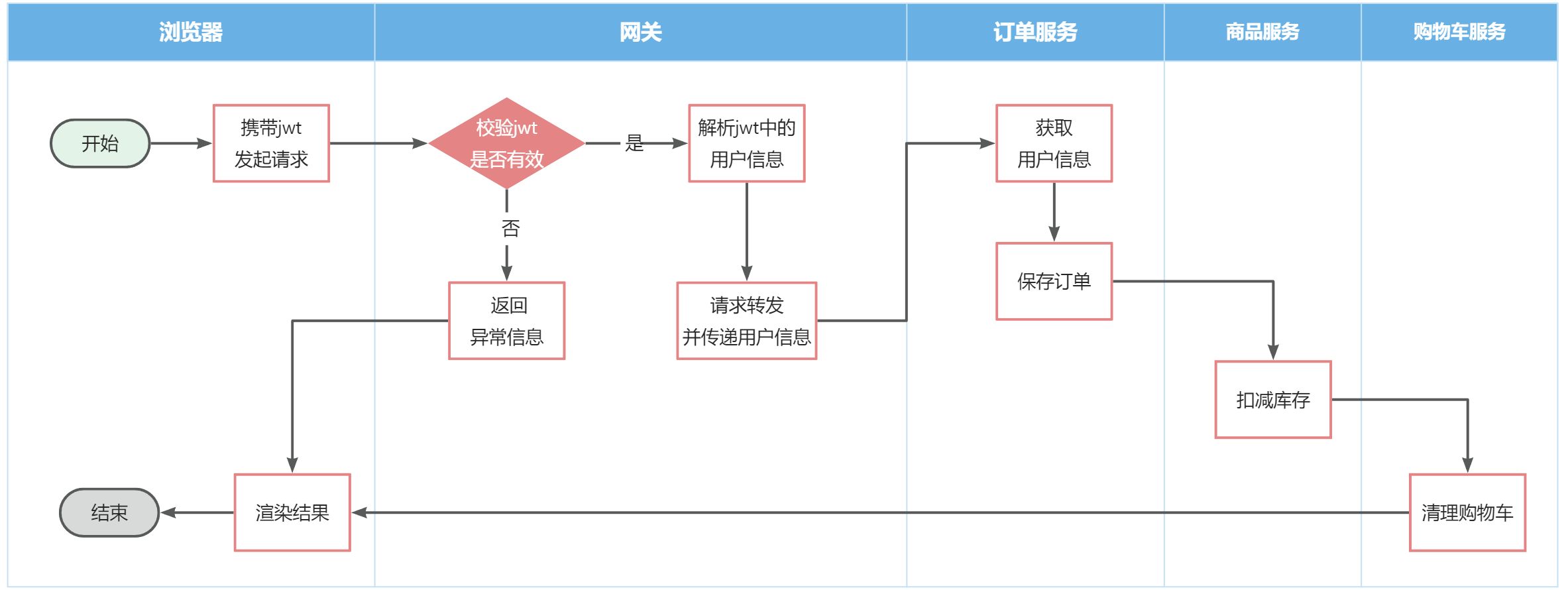
下单的过程中,需要调用商品服务扣减库存,调用购物车服务清理用户购物车。而清理购物车时必须知道当前登录的用户身份。但是,订单服务调用购物车时并没有传递用户信息,购物车服务无法知道当前用户是谁!
由于微服务获取用户信息是通过拦截器在请求头中读取,因此要想实现微服务之间的用户信息传递,就必须在微服务发起调用时把用户信息存入请求头。
微服务之间调用是基于OpenFeign来实现的,并不是我们自己发送的请求。我们如何才能让每一个由OpenFeign发起的请求自动携带登录用户信息呢?
这里要借助Feign中提供的一个拦截器接口:feign.RequestInterceptor
public interface RequestInterceptor {/*** Called for every request. * Add data using methods on the supplied {@link RequestTemplate}.*/void apply(RequestTemplate template);
}
我们只需要实现这个接口,然后实现apply方法,利用RequestTemplate类来添加请求头,将用户信息保存到请求头中。这样以来,每次OpenFeign发起请求的时候都会调用该方法,传递用户信息。
由于FeignClient全部都是在hm-api模块,因此我们在hm-api模块的com.hmall.api.config.DefaultFeignConfig中编写这个拦截器:
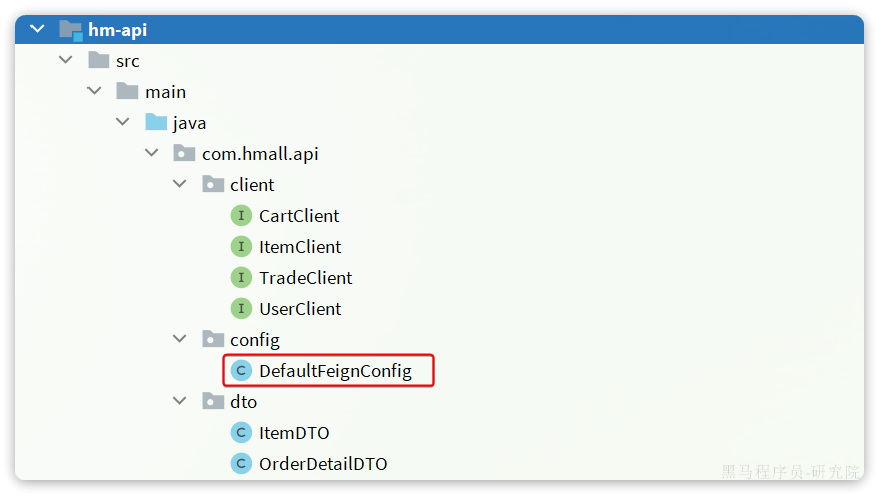
在com.hmall.api.config.DefaultFeignConfig中添加一个Bean:
@Bean
public RequestInterceptor userInfoRequestInterceptor(){return new RequestInterceptor() {@Overridepublic void apply(RequestTemplate template) {// 获取登录用户Long userId = UserContext.getUser();if(userId == null) {// 如果为空则直接跳过return;}// 如果不为空则放入请求头中,传递给下游微服务template.header("user-info", userId.toString());}};
}
好了,现在微服务之间通过OpenFeign调用时也会传递登录用户信息了。
总结
为什么需要 API 网关
- 统一入口,简化客户端调用:微服务架构下服务实例众多,客户端难以直接维护所有服务的地址。网关作为唯一的入口(
api.example.com),客户端只需与网关交互,由网关负责将请求路由到正确的后端服务。 - 集中治理,解耦业务与非业务功能:将各个微服务中都需要实现的通用功能提取到网关层,例如:
- 身份认证与鉴权 (Authentication & Authorization)
- 流量监控与限流 (Rate Limiting)
- 请求过滤与修改 (Request/Response Modification)
- 负载均衡
- 日志收集
- 这避免了在每个微服务中重复开发,实现了关注点分离。
Spring Cloud Gateway 的三大核心概念
| 核心组件 | 职责 | 示例 |
|---|---|---|
| 路由 (Route) | 定义请求的转发规则,是网关最基础的部分。一个路由包含 ID、目标 URI、断言和过滤器。 | uri: lb://user-service 表示转发到名为 user-service 的服务,并进行负载均衡。 |
| 断言 (Predicate) | 定义匹配条件(基于请求头、路径、方法、时间等)。只有满足所有断言条件的请求,才会被该路由处理。 | - Path=/user/** 表示路径以 /user/ 开头的请求会被该路由捕获。 |
| 过滤器 (Filter) | 在处理请求前后执行操作,用于修改请求和响应。除了多种自带的过滤器;自定义的过滤器分为两种:GatewayFilter(作用于特定路由)和 GlobalFilter(全局生效)。 | - AddRequestHeader=Truth, Itcast-is-awesome 会在转发前给请求添加一个请求头。 |
配置示例解读:
spring:cloud:gateway:routes:- id: test_route # 路由唯一标识uri: lb://test-service # 目标服务地址 (lb代表负载均衡)predicates: # 断言:匹配条件- Path=/test/** # 路径匹配filters: # 过滤器:处理逻辑- AddRequestHeader=key, value # 添加请求头
典型案例:网关统一登录校验(JWT)流程
其核心思想是 “网关认证,微服务授权”:
- 网关统一认证 (Authentication):网关作为唯一入口,通过自定义的
GlobalFilter对所有进入的请求进行 JWT Token 的校验(签名、有效期等)。这保证了非法请求在进入内部网络前就被拦截。 - 数据透传:Token 校验通过后,网关将从 Token 中解析出的用户信息(如 userId)存入请求头(如
user-info: 123),然后再转发给下游微服务。 - 微服务直接使用 (Authorization):各个微服务无需再重复校验 JWT,只需直接从请求头中获取用户信息即可进行业务逻辑处理和权限判断。
- 服务间调用透传:当一个微服务需要通过 OpenFeign 调用另一个微服务时,为了保证用户信息不丢失,需要配置一个 OpenFeign 的
RequestInterceptor。该拦截器会自动从当前请求中获取用户信息,并将其添加到新的 Feign 请求头中,从而实现用户身份在完整调用链中的无缝传递。
Nacos配置中心
Nacos不仅仅具备注册中心功能,也具备配置管理的功能:
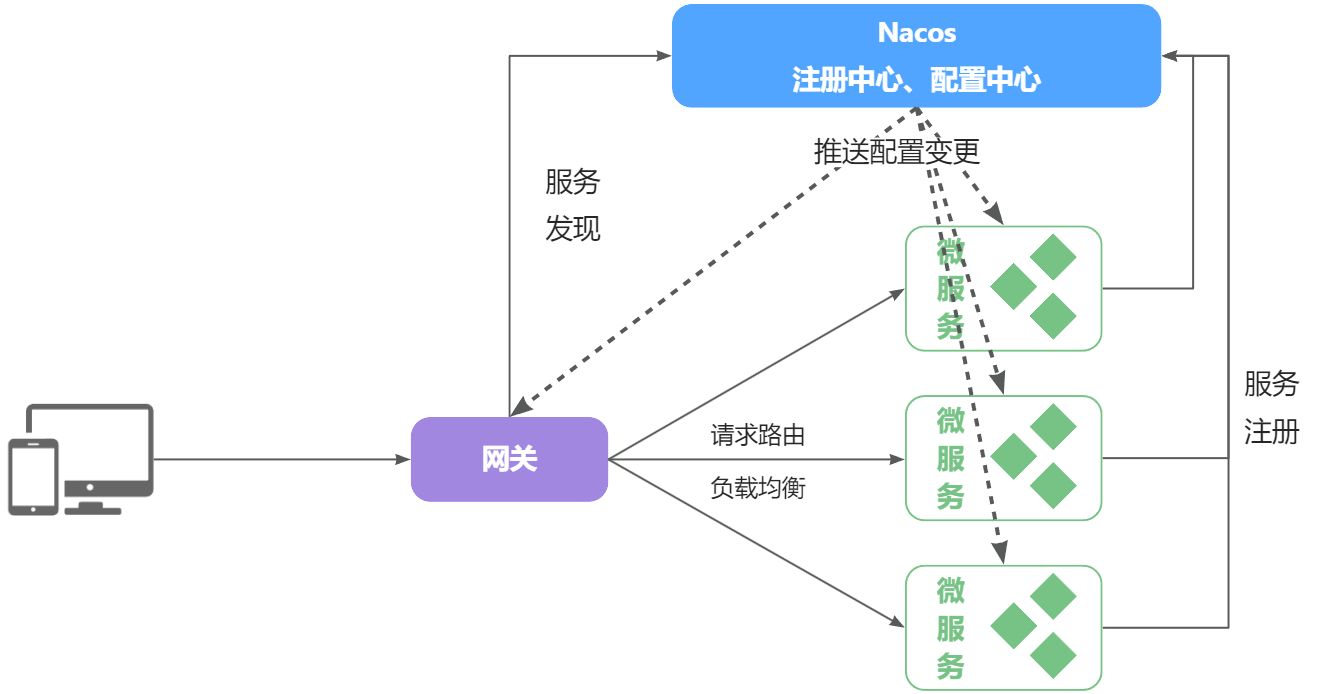
微服务共享的配置可以统一交给Nacos保存和管理,在Nacos控制台修改配置后,Nacos会将配置变更推送给相关的微服务,并且无需重启即可生效,实现配置热更新。
网关的路由同样是配置,因此同样可以基于这个功能实现动态路由功能,无需重启网关即可修改路由配置。
配置共享
我们可以把微服务共享的配置抽取到Nacos中统一管理,这样就不需要每个微服务都重复配置了。分为两步:
- 在Nacos中添加共享配置
- 微服务拉取配置
在配置管理->配置列表中点击+新建一个配置:
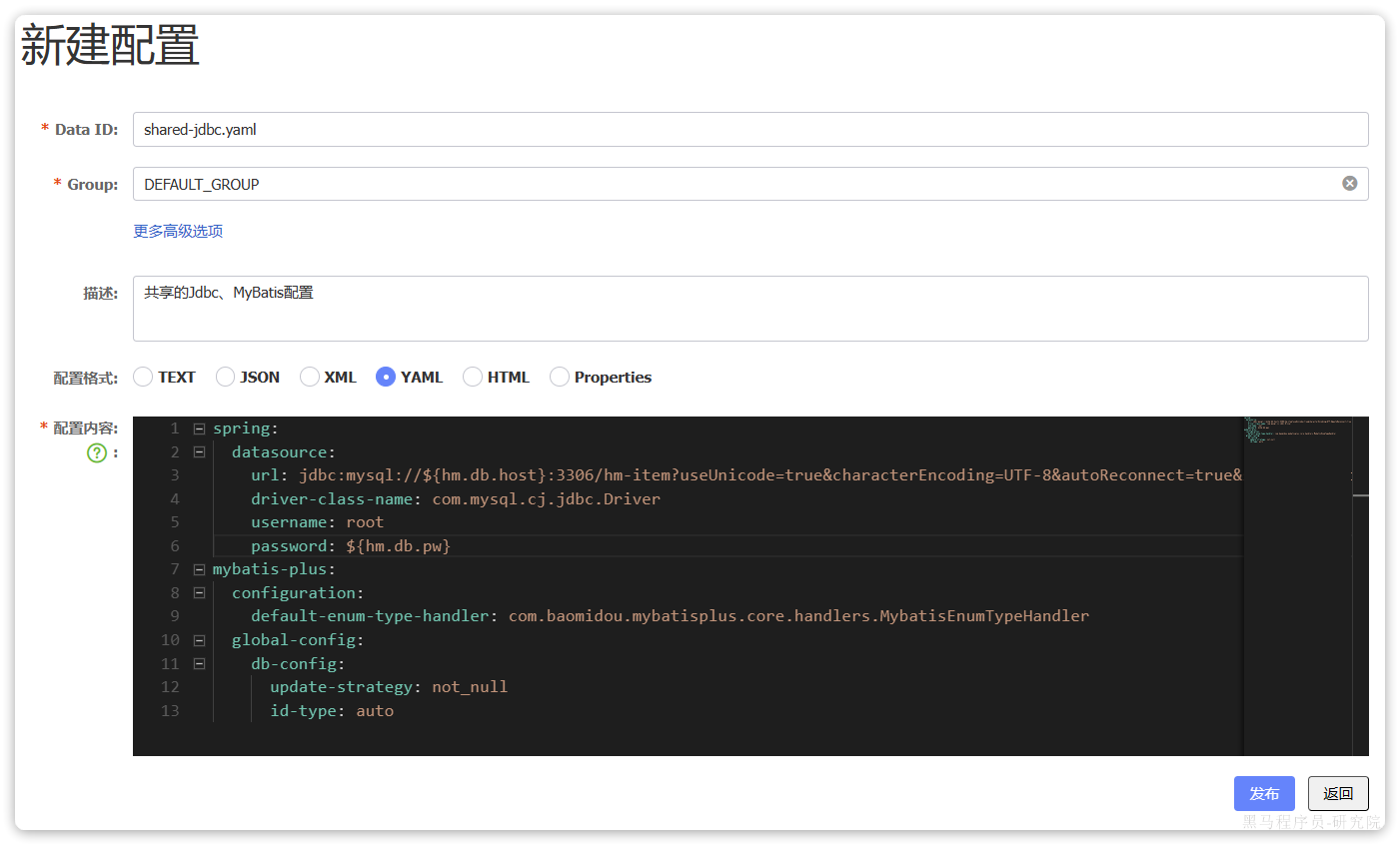
在弹出的表单中填写信息:
接下来,我们要在微服务拉取共享配置。将拉取到的共享配置与本地的application.yaml配置合并,完成项目上下文的初始化。
不过,需要注意的是,读取Nacos配置是SpringCloud上下文(ApplicationContext)初始化时处理的,发生在项目的引导阶段。然后才会初始化SpringBoot上下文,去读取application.yaml。
也就是说引导阶段,application.yaml文件尚未读取,根本不知道nacos 地址,该如何去加载nacos中的配置文件呢?
SpringCloud在初始化上下文的时候会先读取一个名为bootstrap.yaml(或者bootstrap.properties)的文件,如果我们将nacos地址配置到bootstrap.yaml中,那么在项目引导阶段就可以读取nacos中的配置了。
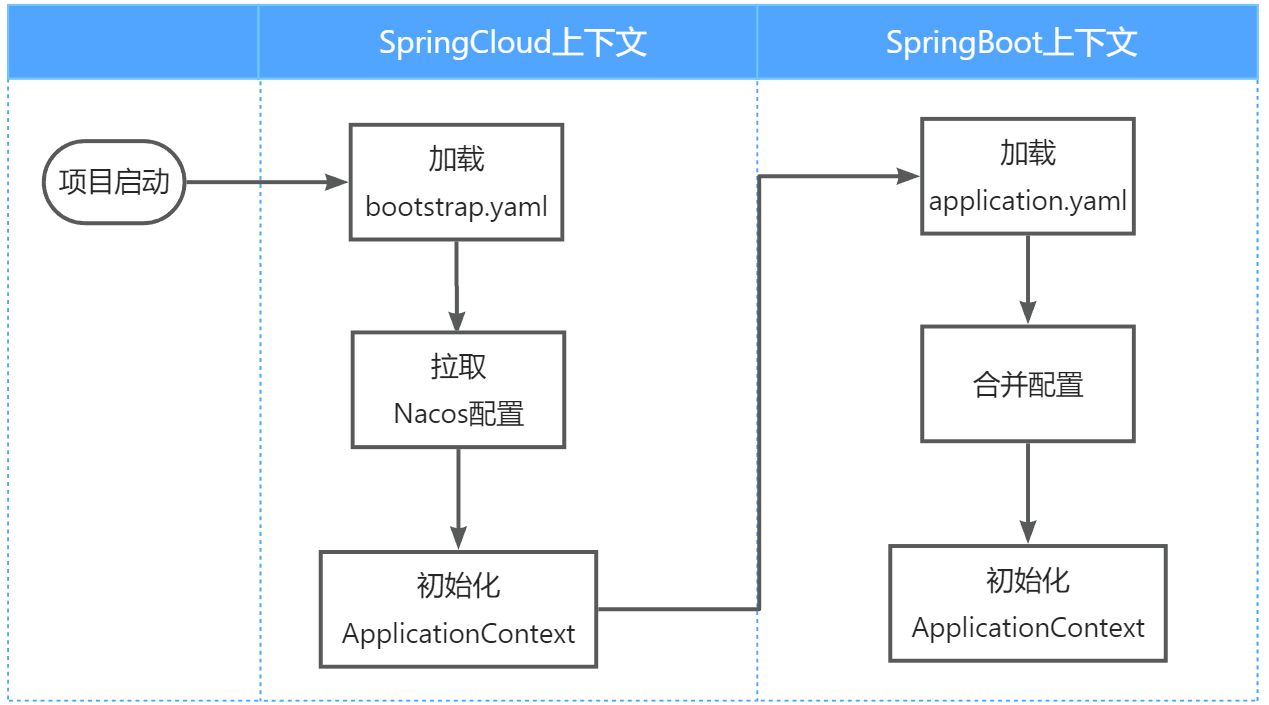
整合步骤
1)引入依赖:
在cart-service模块引入依赖:
<!--nacos配置管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--读取bootstrap文件--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency>
2)新建bootstrap.yaml
在cart-service中的resources目录新建一个bootstrap.yaml文件:
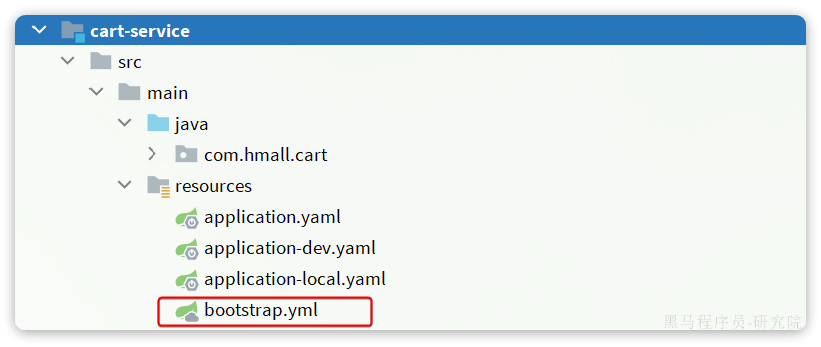
内容如下:
spring:application:name: cart-service # 服务名称profiles:active: devcloud:nacos:server-addr: 192.168.150.101 # nacos地址config:file-extension: yaml # 文件后缀名shared-configs: # 共享配置,撰写已经在nacos中建立的配置名- dataId: shared-jdbc.yaml # 共享mybatis配置- dataId: shared-log.yaml # 共享日志配置- dataId: shared-swagger.yaml # 共享日志配置
3)修改application.yaml
由于一些配置挪到了bootstrap.yaml,因此application.yaml需要修改为:
server:port: 8082
feign:okhttp:enabled: true # 开启OKHttp连接池支持
hm:swagger:title: 购物车服务接口文档package: com.hmall.cart.controllerdb:database: hm-cart
Nacos分组
作为配置中心,Nacos 的配置可见性主要由三个层级决定,其隔离强度从强到弱依次为:Namespace (命名空间) > Group (分组) > Data ID (配置集)。
namespace是完全不可见的
Group (分组) - 默认不可见,但可通过配置“有条件可见”;
在同一个 Namespace 内,客户端默认只会去加载与自己所属 group 相同的配置。Spring Cloud Alibaba 提供了强大的扩展配置能力,允许一个应用额外加载其他 Group 的配置。这是通过 spring.cloud.nacos.config.ext-config 或 spring.cloud.nacos.config.shared-configs 参数来实现的。
spring:cloud:nacos:config:server-addr: localhost:8848namespace: dev-idgroup: USER_GROUP # 默认加载的Group# 使用 ext-config 或 shared-configs 加载其他Group的配置ext-config:- data-id: redis-config.ymlgroup: COMMON_GROUP # 指定另一个Grouprefresh: true # 是否自动刷新- data-id: datasource-config.ymlgroup: COMMON_GROUPrefresh: trueshared-configs:- data-id: global-config.ymlgroup: DEFAULT_GROUP # 甚至可以加载默认分组下的配置refresh: false
在同一个 Namespace 和同一个 Group 下,所有的 Data ID 对客户端都是“可见”的(即可以通过接口读取)。
但是,客户端并不会自动加载所有 Data ID。客户端加载哪些配置取决于其自身的配置规则。一个应用默认会加载与 spring.application.name 匹配的 Data ID
通过 spring.profiles.active 参数,可以实现更细粒度的配置隔离。例如,应用会同时加载 user-service.yml 和 user-service-dev.yml,并且后者的属性会覆盖前者,从而实现环境差异化配置。
当多个配置集包含相同的属性时,后加载的配置会覆盖先加载的配置。加载顺序通常为:
共享配置 (shared-configs) -> 扩展配置 (ext-config) -> 默认应用配置 (基于application.name) -> 应用Profile配置 (基于profile)。
扩展配置的最大作用就是对于特定的范围内的应用需要覆盖共享配置的部分内容,使用扩展配置覆盖;
配置热更新
前提条件
1、nacos中要有一个与微服务名有关的配置文件。
- [spring.application.name]-[spring.profiles.active].[file-extension]
- 这样项目启动之后就会自动取寻找[spring.cloud.nacos.server-addr]地址下nacos管理的[spring.application.name]-[spring.profiles.active].[spring.cloud.nacos.config.file-extension]文件,并拉取其中的配置。
- 也就是192.168.150.101地址下的cart-service-dev.yaml文件以及cart-service.yaml文件
2、微服务中要以特定方式读取需要热更新的配置属性

扩展配置和共享配置的热更新条件
扩展配置和共享配置和默认应用配置以及Profile 配置不一样,需要手动指定refresh: true,才可以开启;否则默认是不开启的;
在Nacos中添加配置
首先,我们在nacos中添加一个配置文件,将购物车的上限数量添加到配置中:
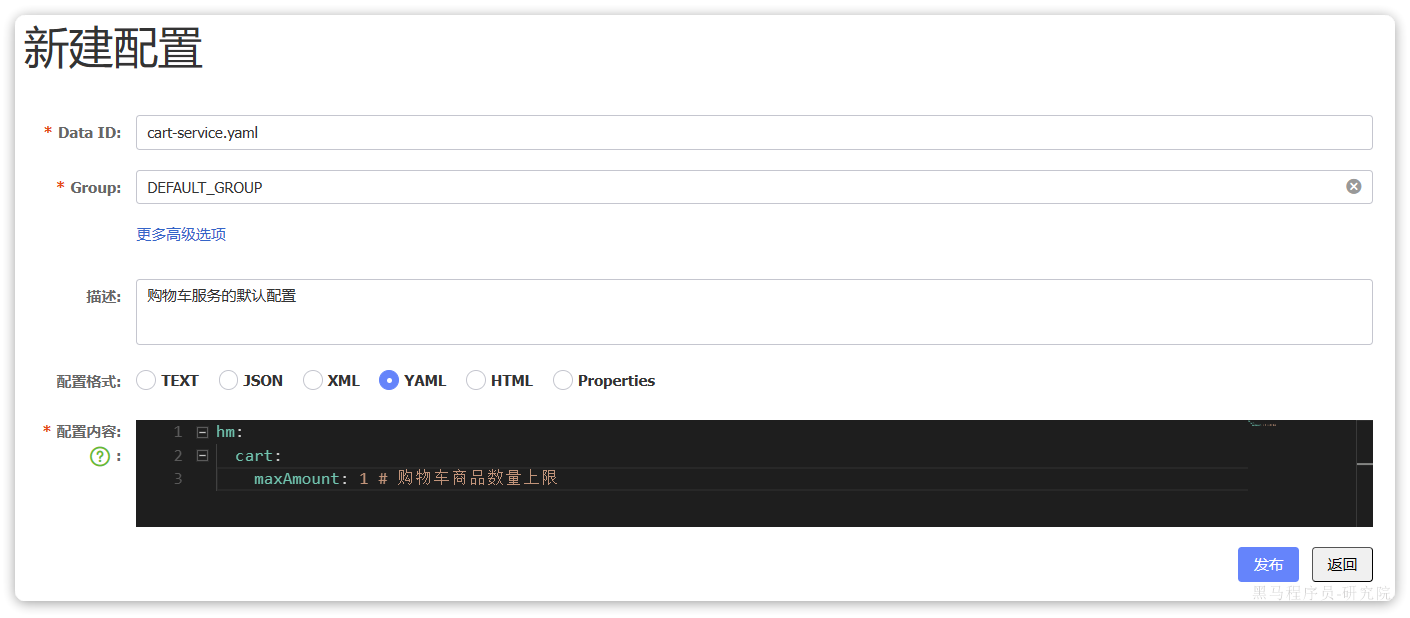
注意文件的dataId格式:
[服务名]-[spring.active.profile].[后缀名]
文件名称由三部分组成:
服务名:我们是购物车服务,所以是cart-servicespring.active.profile:就是spring boot中的spring.active.profile,可以省略,则所有profile共享该配置后缀名:例如yaml
这里我们直接使用cart-service.yaml这个名称,则不管是dev还是local环境都可以共享该配置。
配置内容如下:
hm:cart:maxAmount: 1 # 购物车商品数量上限
提交配置,在控制台能看到新添加的配置:
在微服务读取配置
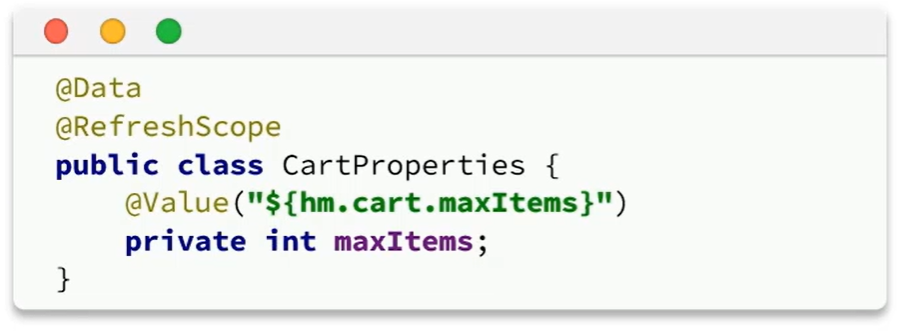
接着,我们在微服务中读取配置,实现配置热更新。
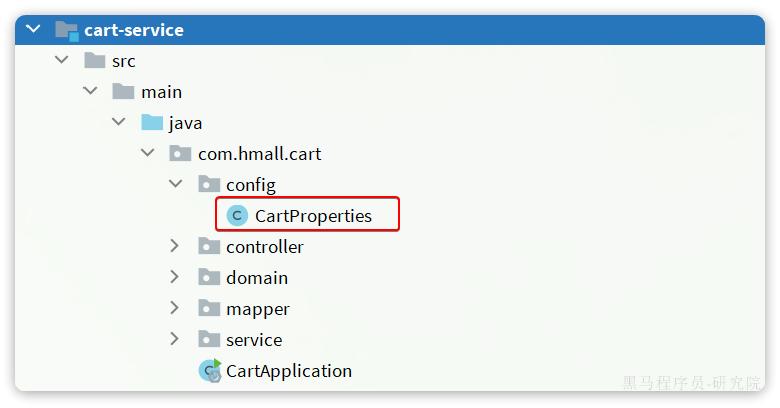
在cart-service中新建一个属性读取类:
代码如下:
package com.hmall.cart.config;import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;@Data
@Component
@ConfigurationProperties(prefix = "hm.cart")
public class CartProperties {private Integer maxAmount;
}
接着,在业务中使用该属性加载类:
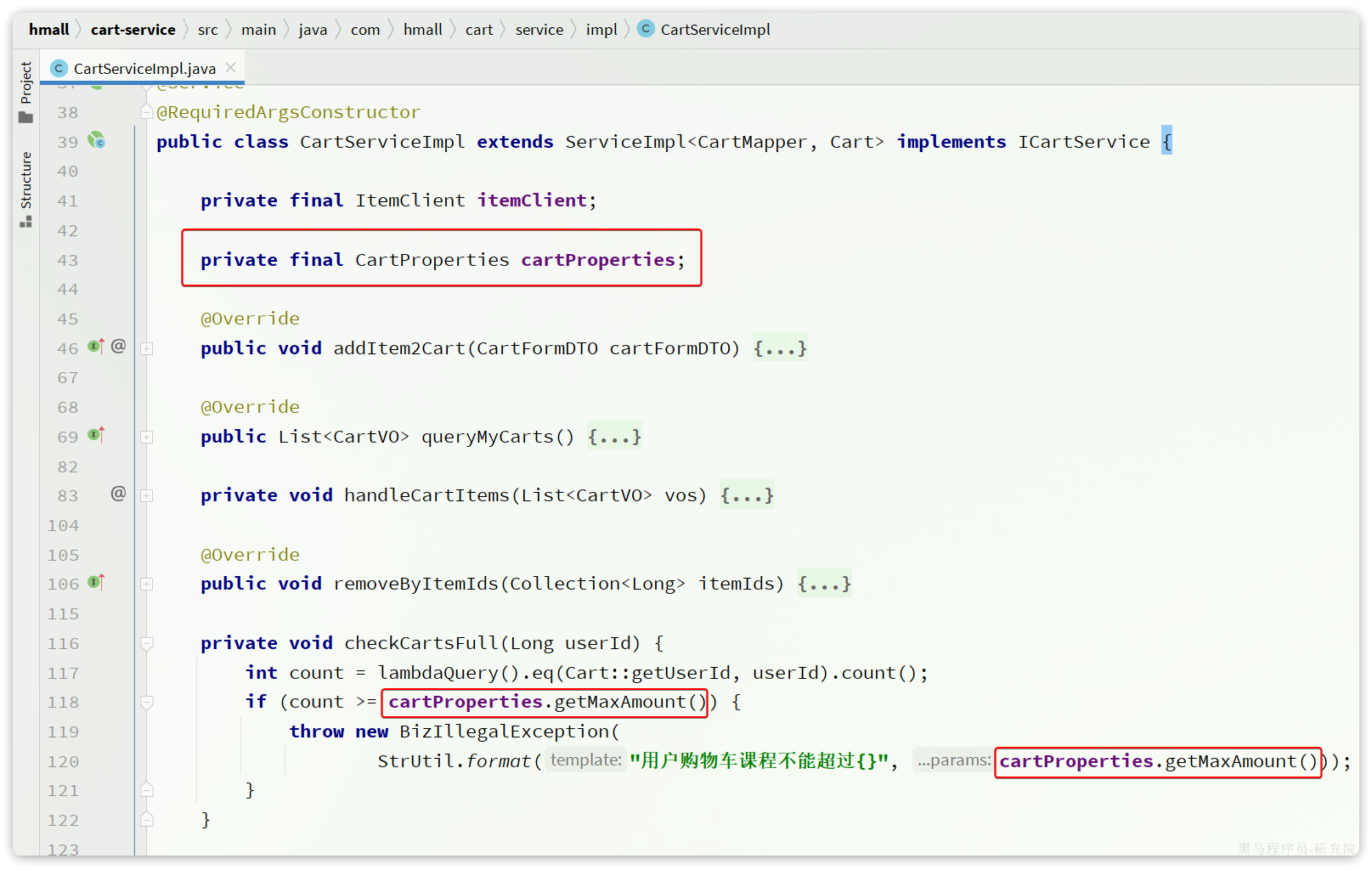
无需重启服务,配置热更新就生效了!
动态路由
网关的路由配置全部是在项目启动时由org.springframework.cloud.gateway.route.CompositeRouteDefinitionLocator在项目启动的时候加载,并且一经加载就会缓存到内存中的路由表内(一个Map),不会改变。也不会监听路由变更,所以,我们无法利用配置热更新来实现路由更新。
监听Nacos配置变更
如果希望 Nacos 推送配置变更,可以使用 Nacos 动态监听配置接口来实现。
public void addListener(String dataId, String group, Listener listener)
请求参数说明:
| 参数名 | 参数类型 | 描述 |
|---|---|---|
| dataId | string | 配置 ID,保证全局唯一性,只允许英文字符和 4 种特殊字符(“.”、“:”、“-”、“_”)。不超过 256 字节。 |
| group | string | 配置分组,一般是默认的DEFAULT_GROUP。 |
| listener | Listener | 监听器,配置变更进入监听器的回调函数。 |
示例代码:
String serverAddr = "{serverAddr}";
String dataId = "{dataId}";
String group = "{group}";
// 1.创建ConfigService,连接Nacos
Properties properties = new Properties();
properties.put("serverAddr", serverAddr);
ConfigService configService = NacosFactory.createConfigService(properties);
// 2.读取配置
String content = configService.getConfig(dataId, group, 5000);
// 3.添加配置监听器
configService.addListener(dataId, group, new Listener() {@Overridepublic void receiveConfigInfo(String configInfo) {// 配置变更的通知处理System.out.println("recieve1:" + configInfo);}@Overridepublic Executor getExecutor() {return null;}
});
这里核心的步骤有2步:
- 创建ConfigService,目的是连接到Nacos
- 添加配置监听器,编写配置变更的通知处理逻辑
由于我们采用了spring-cloud-starter-alibaba-nacos-config自动装配,因此ConfigService已经在com.alibaba.cloud.nacos.NacosConfigAutoConfiguration中自动创建好了:
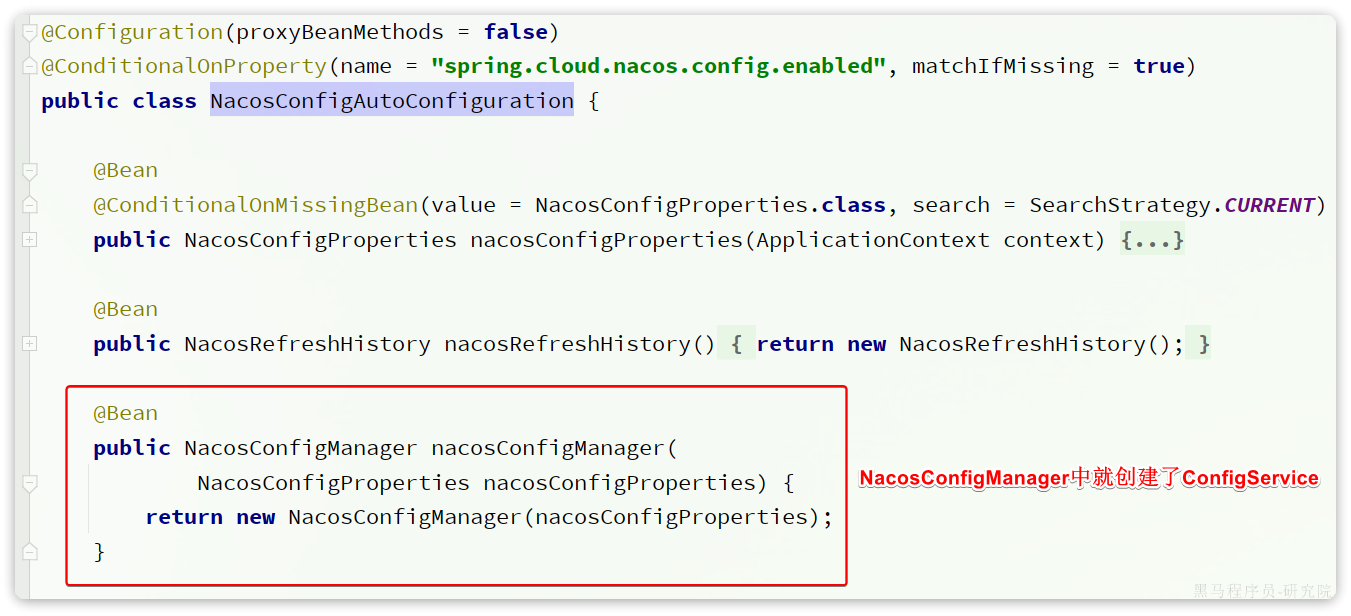
NacosConfigManager中是负责管理Nacos的ConfigService的,具体代码如下:
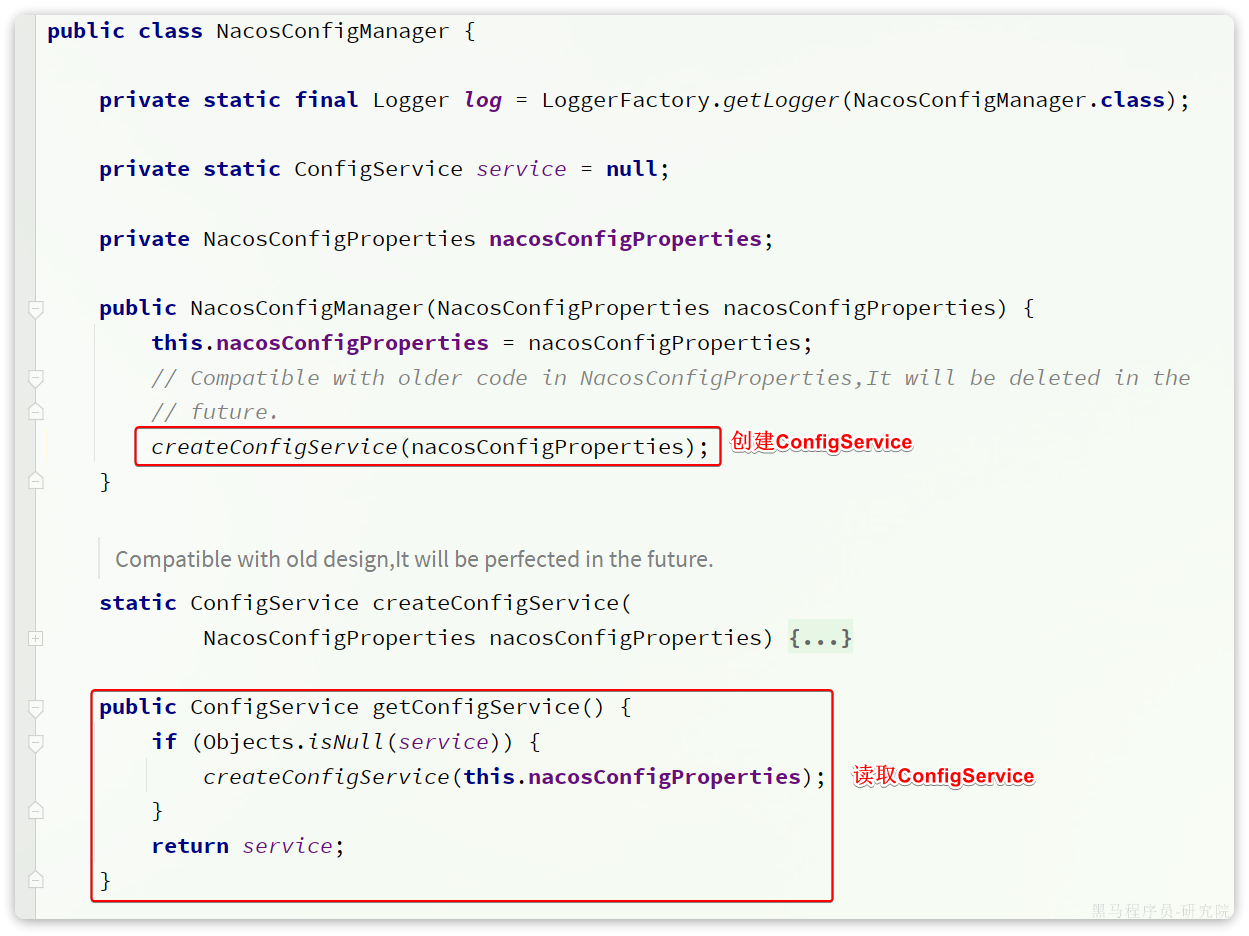
因此,只要我们拿到NacosConfigManager就等于拿到了ConfigService,第一步就实现了。
第二步,编写监听器。虽然官方提供的SDK是ConfigService中的addListener,不过项目第一次启动时不仅仅需要添加监听器,也需要读取配置,因此建议使用的API是这个:
String getConfigAndSignListener(String dataId, // 配置文件idString group, // 配置组,走默认long timeoutMs, // 读取配置的超时时间Listener listener // 监听器
) throws NacosException;
既可以配置监听器,并且会根据dataId和group读取配置并返回。我们就可以在项目启动时先更新一次路由,后续随着配置变更通知到监听器,完成路由更新。
更新路由
更新路由要用到org.springframework.cloud.gateway.route.RouteDefinitionWriter这个接口:
package org.springframework.cloud.gateway.route;import reactor.core.publisher.Mono;/*** @author Spencer Gibb*/
public interface RouteDefinitionWriter {/*** 更新路由到路由表,如果路由id重复,则会覆盖旧的路由*/Mono<Void> save(Mono<RouteDefinition> route);/*** 根据路由id删除某个路由*/Mono<Void> delete(Mono<String> routeId);}
这里更新的路由,也就是RouteDefinition,之前我们见过,包含下列常见字段:
- id:路由id
- predicates:路由匹配规则
- filters:路由过滤器
- uri:路由目的地
将来我们保存到Nacos的配置也要符合这个对象结构,将来我们以JSON来保存,格式如下:
{"id": "item","predicates": [{"name": "Path","args": {"_genkey_0":"/items/**", "_genkey_1":"/search/**"}}],"filters": [],"uri": "lb://item-service"
}
以上JSON配置就等同于:
spring:cloud:gateway:routes:- id: itemuri: lb://item-servicepredicates:- Path=/items/**,/search/**
实现动态路由
首先, 我们在网关gateway引入依赖:
<!--统一配置管理-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--加载bootstrap-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
然后在网关gateway的resources目录创建bootstrap.yaml文件,内容如下:
spring:application:name: gatewaycloud:nacos:server-addr: 192.168.150.101config:file-extension: yamlshared-configs:- dataId: shared-log.yaml # 共享日志配置
接着,修改gateway的resources目录下的application.yml,把之前的路由移除,最终内容如下:
server:port: 8080 # 端口
hm:jwt:location: classpath:hmall.jks # 秘钥地址alias: hmall # 秘钥别名password: hmall123 # 秘钥文件密码tokenTTL: 30m # 登录有效期auth:excludePaths: # 无需登录校验的路径- /search/**- /users/login- /items/**
然后,在gateway中定义配置监听器:
其代码如下:
package com.hmall.gateway.route;@Slf4j
@Component
@RequiredArgsConstructor
public class DynamicRouteLoader {private final RouteDefinitionWriter writer;private final NacosConfigManager nacosConfigManager;// 路由配置文件的id和分组private final String dataId = "gateway-routes.json";private final String group = "DEFAULT_GROUP";// 保存更新过的路由idprivate final Set<String> routeIds = new HashSet<>();@PostConstructpublic void initRouteConfigListener() throws NacosException {// 1.注册监听器并首次拉取配置String configInfo = nacosConfigManager.getConfigService().getConfigAndSignListener(dataId, group, 5000, new Listener() {@Overridepublic Executor getExecutor() {return null;}@Overridepublic void receiveConfigInfo(String configInfo) {updateConfigInfo(configInfo);}});// 2.首次启动时,更新一次配置updateConfigInfo(configInfo);}private void updateConfigInfo(String configInfo) {log.debug("监听到路由配置变更,{}", configInfo);// 1.反序列化List<RouteDefinition> routeDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class);// 2.更新前先清空旧路由// 2.1.清除旧路由for (String routeId : routeIds) {writer.delete(Mono.just(routeId)).subscribe();}routeIds.clear();// 2.2.判断是否有新的路由要更新if (CollUtils.isEmpty(routeDefinitions)) {// 无新路由配置,直接结束return;}// 3.更新路由routeDefinitions.forEach(routeDefinition -> {// 3.1.更新路由writer.save(Mono.just(routeDefinition)).subscribe();// 3.2.记录路由id,方便将来删除routeIds.add(routeDefinition.getId());});}
}
接下来,我们直接在Nacos控制台添加路由,路由文件名为gateway-routes.json,类型为json:
配置内容如下:
[{"id": "item","predicates": [{"name": "Path","args": {"_genkey_0":"/items/**", "_genkey_1":"/search/**"}}],"filters": [],"uri": "lb://item-service"},{"id": "cart","predicates": [{"name": "Path","args": {"_genkey_0":"/carts/**"}}],"filters": [],"uri": "lb://cart-service"},{"id": "user","predicates": [{"name": "Path","args": {"_genkey_0":"/users/**", "_genkey_1":"/addresses/**"}}],"filters": [],"uri": "lb://user-service"},{"id": "trade","predicates": [{"name": "Path","args": {"_genkey_0":"/orders/**"}}],"filters": [],"uri": "lb://trade-service"},{"id": "pay","predicates": [{"name": "Path","args": {"_genkey_0":"/pay-orders/**"}}],"filters": [],"uri": "lb://pay-service"}
]
总结
Spring Cloud Alibaba Nacos 配置中心整合与最佳实践
核心依赖
在项目的 pom.xml 中引入 Nacos Config 依赖,这是使用 Nacos 作为配置中心的基础。
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
配置文件:bootstrap.yaml
为什么是 bootstrap.yaml?
- 加载时机:
bootstrap.yaml由父级的Bootstrap Context加载,优先于application.yaml。 - 必要性:应用启动的第一时间就需要知道 Nacos 服务器的地址去拉取配置。如果将 Nacos 地址配置在
application.yaml中,此时应用上下文还未初始化,会导致无法连接 Nacos 从而启动失败。
配置内容示例:
spring:application:name: cart-service # 服务名称,用于拼接Data IDprofiles:active: dev # 环境标识,用于拼接Data IDcloud:nacos:server-addr: 192.168.150.101:8848 # Nacos服务器地址config:file-extension: yaml # 配置文件的扩展名# 扩展配置 (属于当前服务的特定扩展配置,优先级高于共享配置)ext-config:- data-id: redis-config.yml # 配置集IDgroup: COMMON_GROUP # 配置集分组,默认为DEFAULT_GROUPrefresh: true # 是否支持自动刷新(热更新)- data-id: datasource-config.yml # 不指定group则使用默认DEFAULT_GROUP# 共享配置 (被多个服务共同使用的配置)shared-configs:- dataId: shared-jdbc.yaml # 共享数据源配置- dataId: shared-log.yaml # 共享日志配置group: DEFAULT_GROUP # 指定分组refresh: false # 通常基础共享配置无需热更新- dataId: shared-swagger.yaml # 共享API文档配置
配置的加载顺序与覆盖关系
应用启动后,会根据 bootstrap.yaml 的配置从 Nacos 加载多份配置,共同组成项目的环境。
-
加载的配置列表:
- Profile-specific配置:
cart-service-dev.yaml(由name,active,file-extension拼接) - 默认应用配置:
cart-service.yaml - 扩展配置 (ext-config):
redis-config.yml,datasource-config.yml - 共享配置 (shared-configs):
shared-jdbc.yaml,shared-log.yaml,shared-swagger.yaml
- Profile-specific配置:
-
加载优先级 (从低到高):
共享配置 (shared-configs) → 扩展配置 (ext-config) → 默认应用配置 (基于application.name) → 应用Profile配置 (基于profile)后加载的配置会覆盖先加载的配置中相同的属性。因此,
cart-service-dev.yaml的优先级最高。
热更新 (Refresh)
热更新是指在不重启应用的情况下,应用自动感知 Nacos 中配置的变更并生效。
- 实现方式:在 Java Bean 上使用
@RefreshScope注解,或使用@ConfigurationProperties注解自动绑定配置。 - 触发条件:扩展配置和共享配置只有在 Nacos 中配置了
refresh: true的配置集发生变更时,与之对应的 Bean 才会刷新。- 例如:上例中的
redis-config.yml配置了refresh: true,那么当其内容变化时,使用相关配置的 Bean(如 RedisTemplate)会自动更新。而shared-log.yaml的refresh为false,变更后不会热更新。 - 而
cart-service-dev.yaml和cart-service.yaml默认就是会触发热更新的
- 例如:上例中的
特殊场景:动态路由更新(以Gateway为例)
网关的路由配置通常在启动时加载一次,配置在 Nacos 中的变更不会自动触发热更新到网关的路由定义中。需要编写代码手动监听配置变化。
实现方案:
- 监听配置:利用
NacosConfigManager监听指定的路由配置文件(如gateway-routes.json)。 - 自定义更新:当监听到配置变更时,手动反序列化路由定义,并更新到 Gateway 的
RouteDefinitionWriter中。
核心代码示例:
@Component
@Slf4j
@RequiredArgsConstructor
public class DynamicRouteLoader {private final RouteDefinitionWriter writer;private final NacosConfigManager nacosConfigManager;private final String dataId = "gateway-routes.json";private final String group = "DEFAULT_GROUP";// 记录已加载的路由ID,用于更新前清理private final Set<String> routeIds = new HashSet<>();@PostConstructpublic void initRouteConfigListener() throws NacosException {// 1. 添加监听器并首次获取配置String initialConfig = nacosConfigManager.getConfigService().getConfigAndSignListener(dataId, group, 5000, new Listener() {@Overridepublic void receiveConfigInfo(String configInfo) {// 当配置变化时,调用更新方法updateRoutes(configInfo);}@Overridepublic Executor getExecutor() {return null;}});// 2. 项目启动时,立即更新一次路由updateRoutes(initialConfig);}private void updateRoutes(String configInfo) {log.info("监听到路由配置变更: {}", configInfo);// 1. 解析JSON配置为RouteDefinition列表List<RouteDefinition> newDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class);// 2. 清理旧路由for (String id : routeIds) {writer.delete(Mono.just(id)).subscribe();}routeIds.clear();if (CollUtil.isEmpty(newDefinitions)) {return;}// 3. 添加新路由newDefinitions.forEach(definition -> {writer.save(Mono.just(definition)).subscribe();routeIds.add(definition.getId());});log.info("路由更新完成");}
}
总结要点
- 依赖:记得引入
spring-cloud-starter-alibaba-nacos-config。 - 入口:Nacos 连接信息必须配置在
bootstrap.yaml中。 - 配置源:一个应用会加载多份配置(共享、扩展、应用本身)。
- 优先级:
profile配置 > 默认应用配置 > 扩展配置(ext-config) > 共享配置(shared-configs)。 - 热更新:依赖
@RefreshScope或@ConfigurationProperties,并且必须在 Nacos 中配置refresh: true才会生效。 - 动态路由:网关等特殊组件需要手动编码实现配置监听和更新逻辑。
Sentinel服务保护
在微服务远程调用的过程中,还存在几个问题需要解决。
首先是业务健壮性问题:
例如在之前的查询购物车列表业务中,购物车服务需要查询最新的商品信息,与购物车数据做对比,提醒用户。大家设想一下,如果商品服务查询时发生故障,查询购物车列表在调用商品服 务时,是不是也会异常?从而导致购物车查询失败。但从业务角度来说,为了提升用户体验,即便是商品查询失败,购物车列表也应该正确展示出来,哪怕是不包含最新的商品信息。
还有级联失败问题:
还是查询购物车的业务,假如商品服务业务并发较高,占用过多Tomcat连接。可能会导致商品服务的所有接口响应时间增加,延迟变高,甚至是长时间阻塞直至查询失败。
此时查询购物车业务需要查询并等待商品查询结果,从而导致查询购物车列表业务的响应时间也变长,甚至也阻塞直至无法访问。而此时如果查询购物车的请求较多,可能导致购物车服务的Tomcat连接占用较多,所有接口的响应时间都会增加,整个服务性能很差, 甚至不可用。
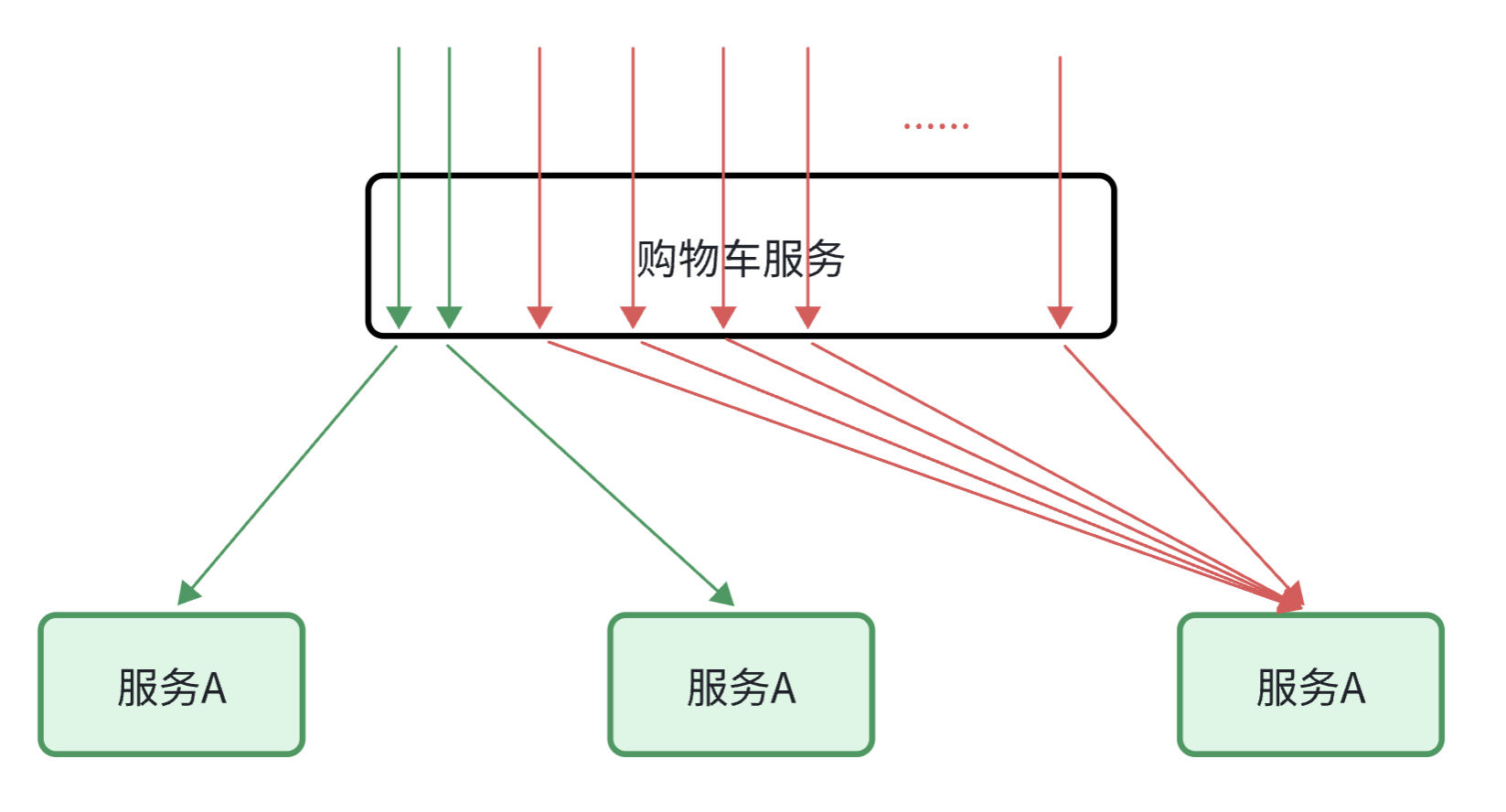
依次类推,整个微服务群中与购物车服务、商品服务等有调用关系的服务可能都会出现问题,最终导致整个集群不可用。
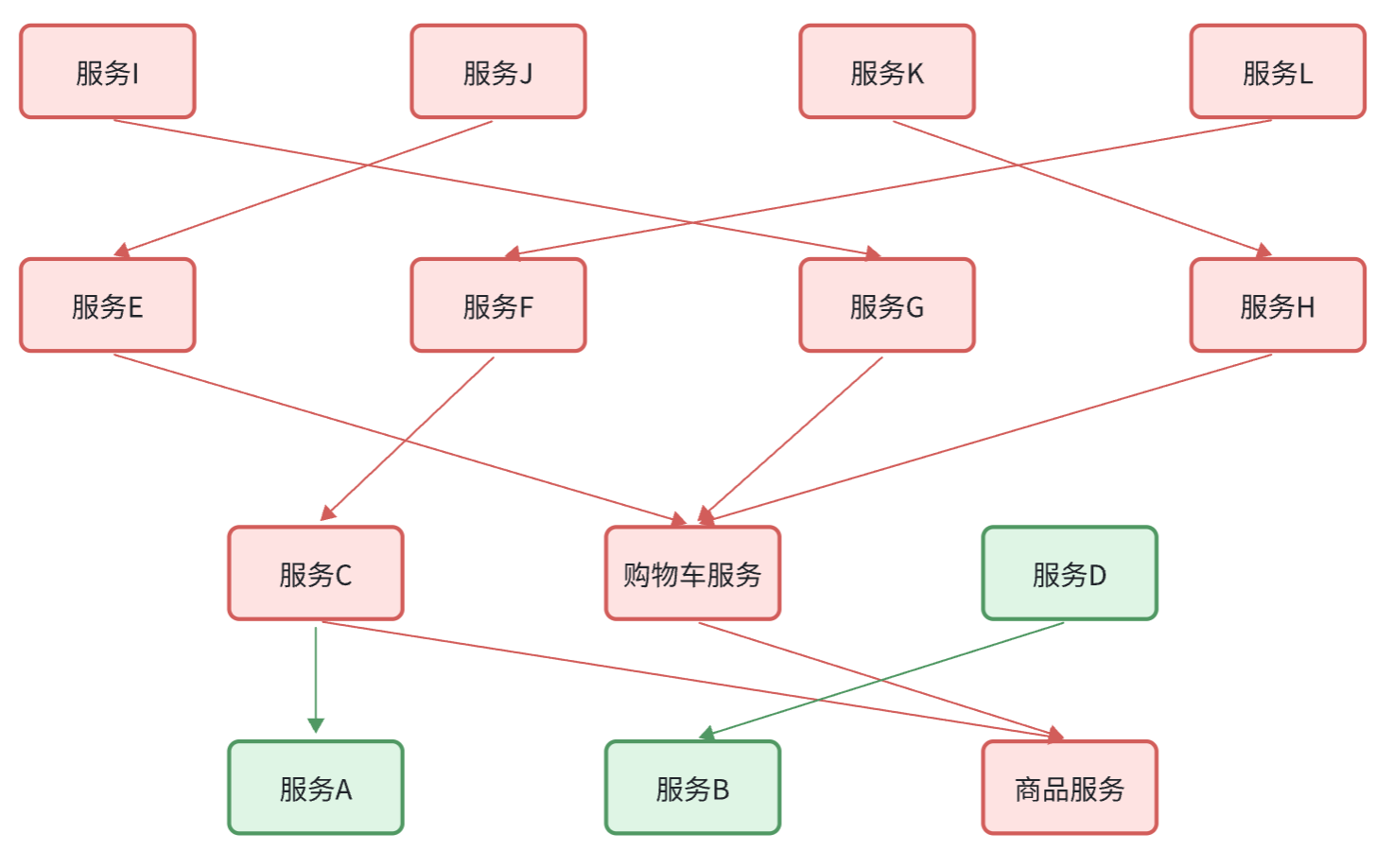
这就是级联失败问题,或者叫雪崩问题。
保证服务运行的健壮性,避免级联失败导致的雪崩问题,就属于微服务保护。
服务保护方案
微服务保护的方案有很多,比如:
- 请求限流
- 线程隔离
- 服务熔断
共同特点:
这些方案或多或少都会导致服务的体验上略有下降,比如请求限流,降低了并发上限;线程隔离,降低了可用资源数量;服务熔断,降低了服务的完整度,部分服务变的不可用或弱可用。因此这些方案都属于服务降级的方案。但通过这些方案,服务的健壮性得到了提升,
请求限流(保护服务提供者)
服务故障最重要原因,就是并发太高!解决了这个问题,就能避免大部分故障。当然,接口的并发不是一直很高,而是突发的。因此请求限流,就是限制或控制接口访问的并发流量,避免服务因流量激增而出现故障。
请求限流往往会有一个限流器,数量高低起伏的并发请求曲线,经过限流器就变的非常平稳。这就像是水电站的大坝,起到蓄水的作用,可以通过开关控制水流出的大小,让下游水流始终维持在一个平稳的量。
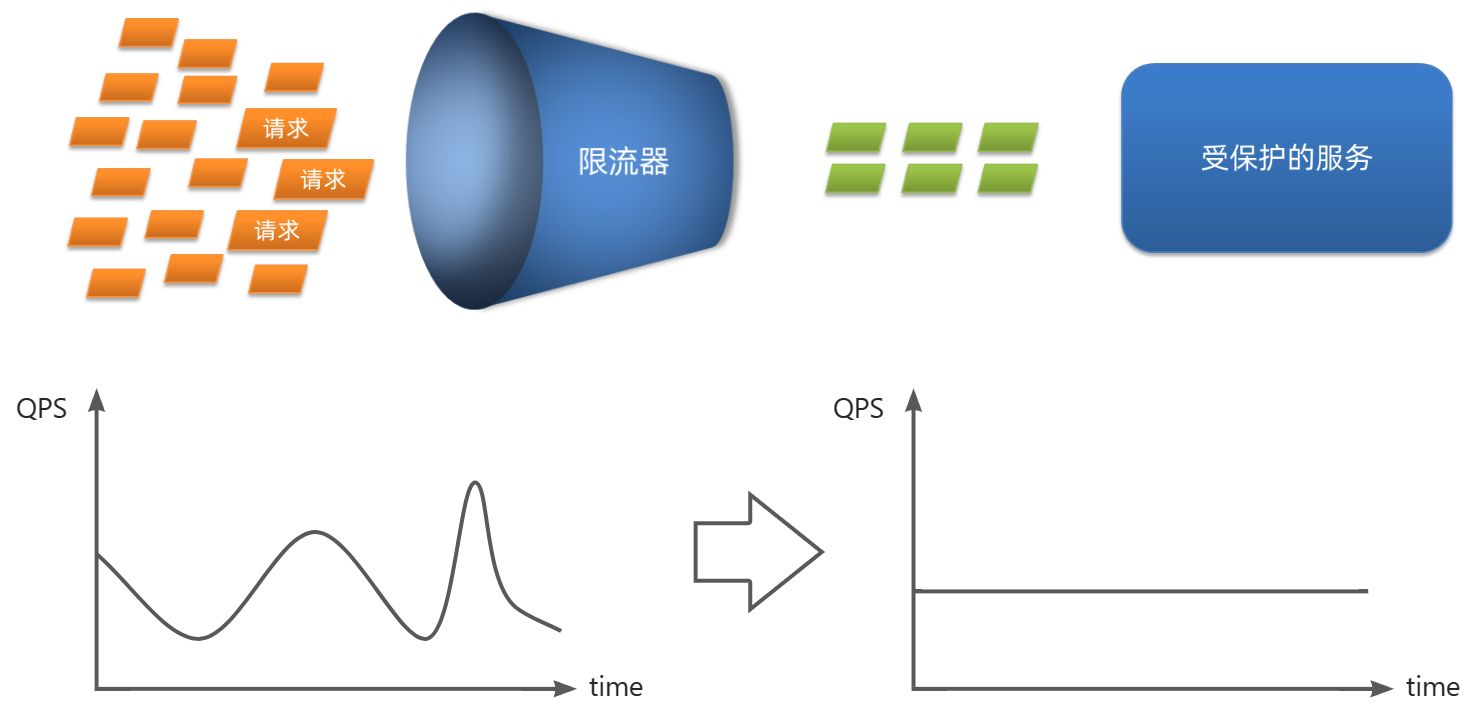
线程隔离(保护服务调用者)
当一个业务接口响应时间长,而且并发高时,就可能耗尽服务器的线程资源,导致服务内的其它接口受到影响。所以我们必须把这种影响降低,或者缩减影响的范围。线程隔离正是解决这个问题的好办法。
为了避免某个接口故障或压力过大导致整个服务不可用,我们可以限定每个接口可以使用的资源范围,也就是将其“隔离”起来。
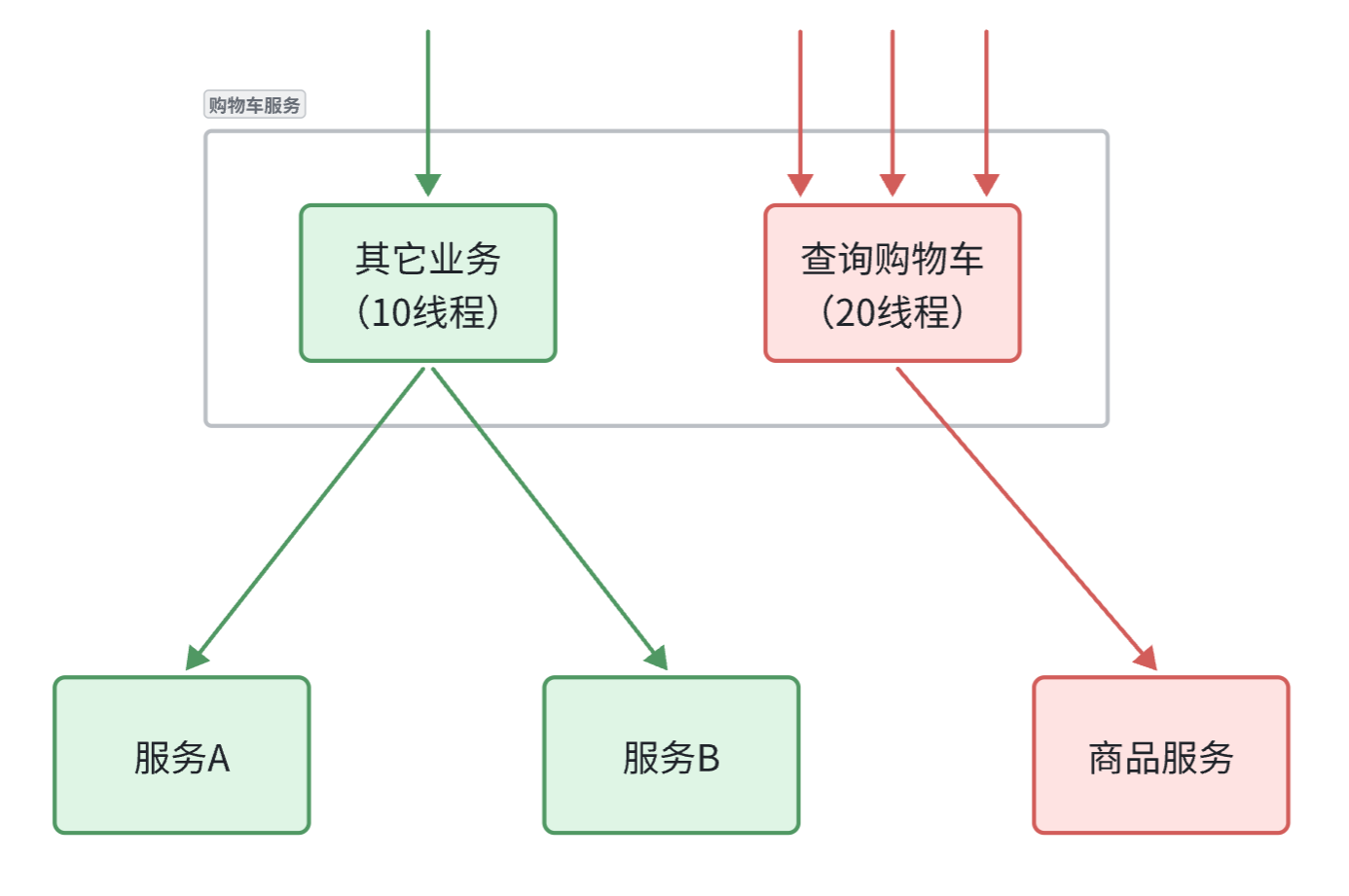
如图所示,我们给查询购物车业务限定可用线程数量上限为20,这样即便查询购物车的请求因为查询商品服务而出现故障,也不会导致服务器的线程资源被耗尽,不会影响到其它接口。
服务熔断(保护服务调用者)
线程隔离虽然避免了雪崩问题,但故障服务(商品服务)依然会拖慢购物车服务(服务调用方)的接口响应速度。而且商品查询的故障依然会导致查询购物车功能出现故障,购物车业务也变的不可用了。
所以,我们要做两件事情:
- 编写服务降级逻辑:就是服务调用失败后的处理逻辑,根据业务场景,可以抛出异常,也可以返回友好提示或默认数据。
- 异常统计和熔断:统计服务提供方的异常比例,当比例过高表明该接口会影响到其它服务,应该拒绝调用该接口,而是直接走降级逻辑。
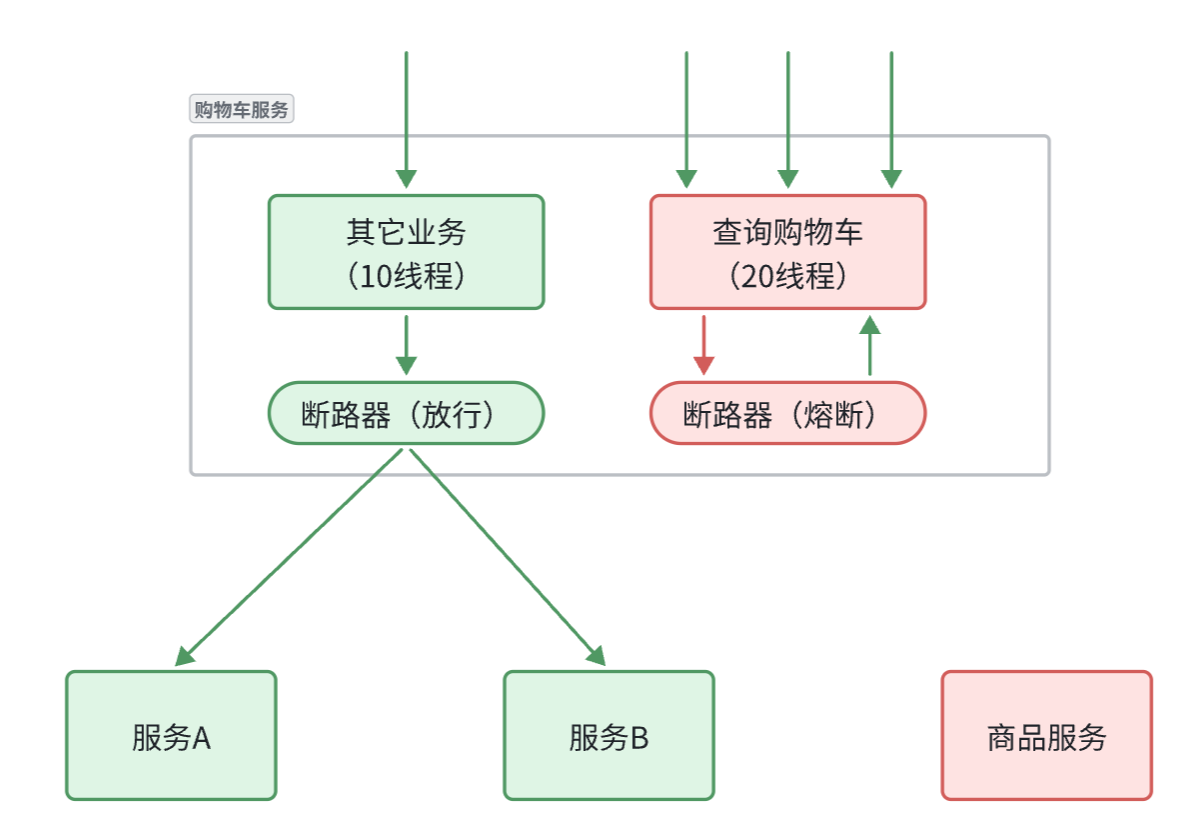
Sentinel
Sentinel是阿里巴巴开源的一款服务保护框架,目前已经加入SpringCloudAlibaba中。官方网站:
https://sentinelguard.io/zh-cn/
Sentinel 的使用可以分为两个部分:
- 核心库(Jar包):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。在项目中引入依赖即可实现服务限流、隔离、熔断等功能。
- 控制台(Dashboard):Dashboard 主要负责管理推送规则、监控、管理机器信息等。
安装
下载Jar包后
直接使用命令启动
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
其它启动时可配置参数可参考官方文档:
https://github.com/alibaba/Sentinel/wiki/%E5%90%AF%E5%8A%A8%E9%85%8D%E7%BD%AE%E9%A1%B9
访问http://localhost:8090页面,就可以看到sentinel的控制台了:

需要输入账号和密码,默认都是:sentinel
登录后,即可看到控制台,默认会监控sentinel-dashboard服务本身:
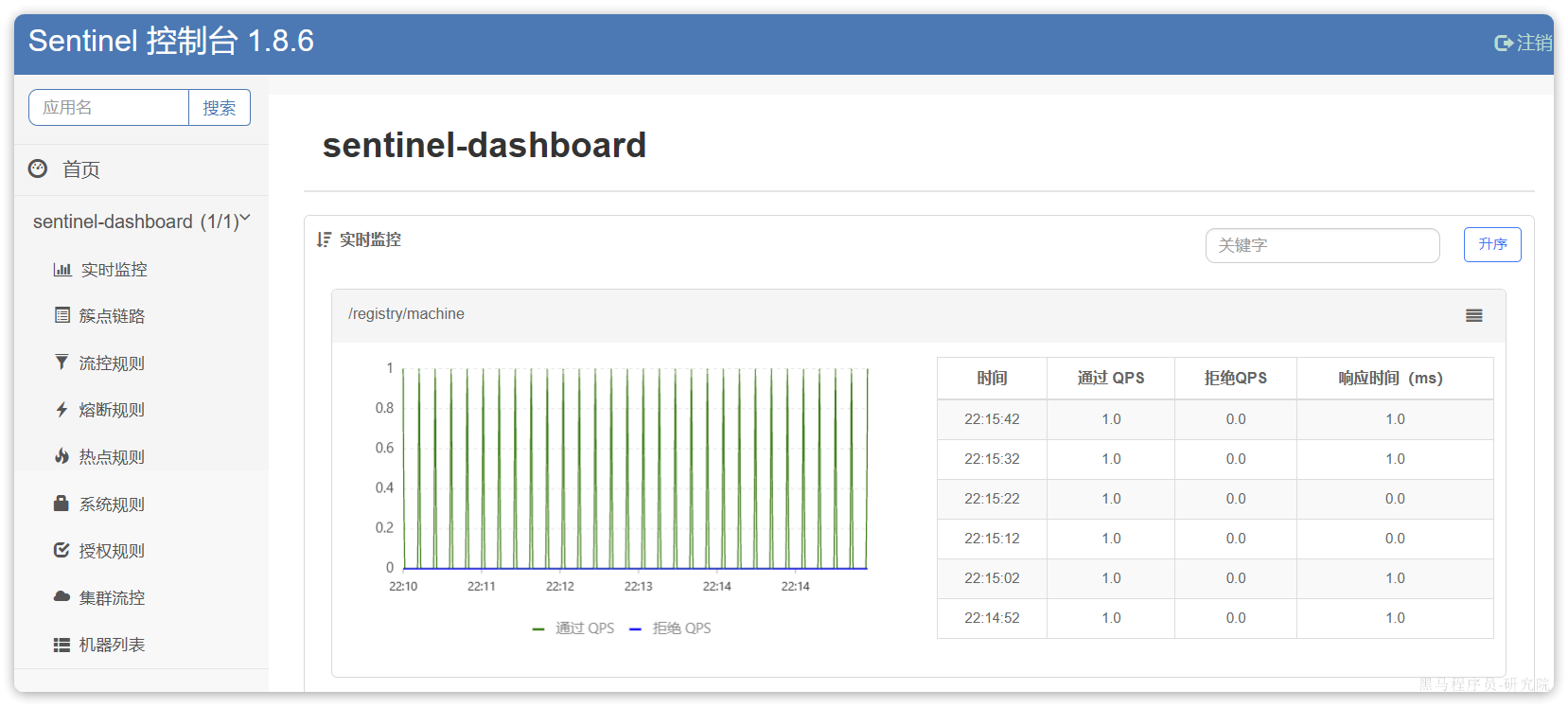
微服务整合
我们在cart-service模块中整合sentinel,连接sentinel-dashboard控制台,步骤如下: 1)引入sentinel依赖
<!--sentinel-->
<dependency><groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2)配置控制台
修改application.yaml文件,添加下面内容:
spring:cloud: sentinel:transport:dashboard: localhost:8090
3)访问cart-service的任意端点
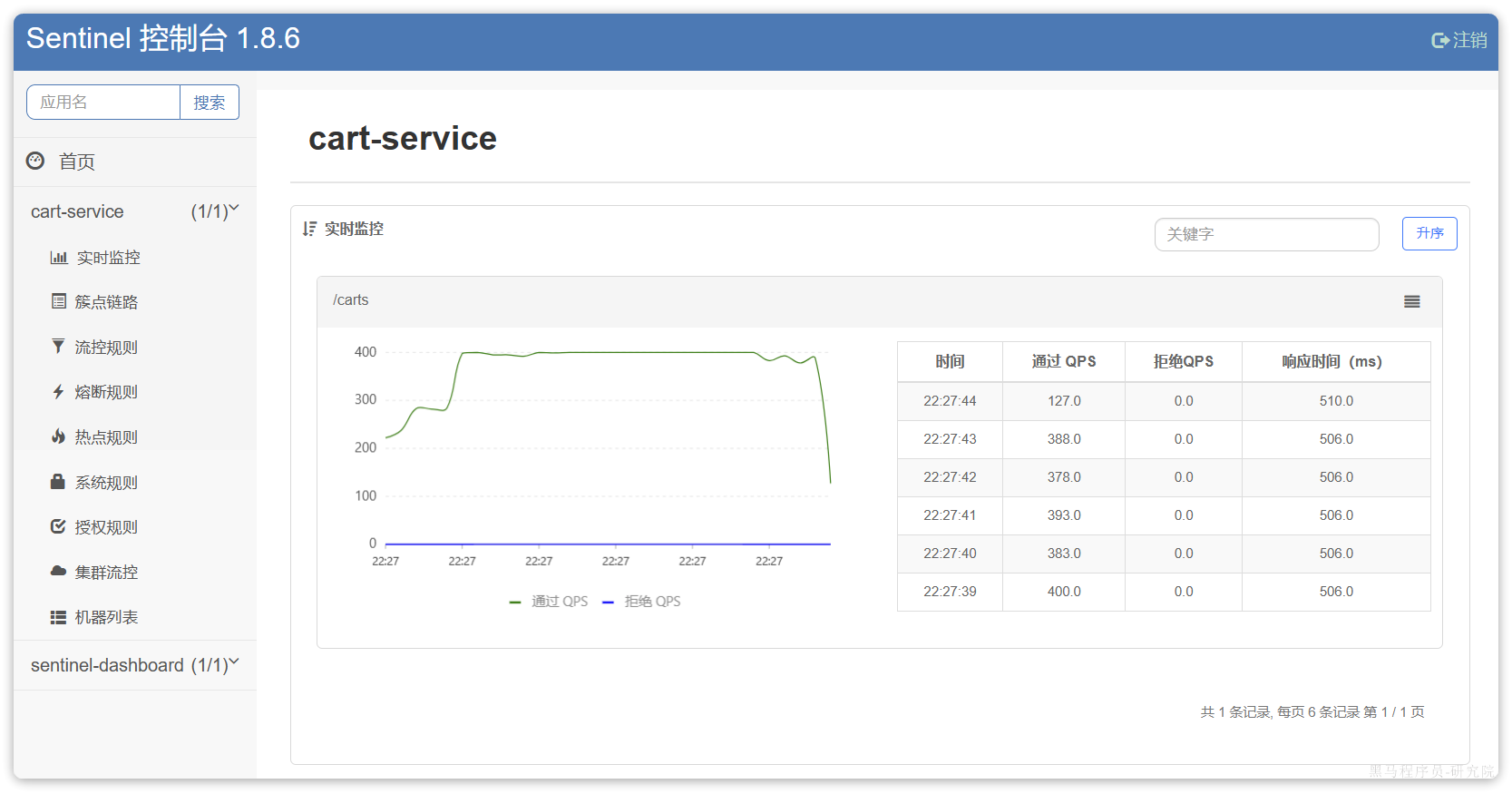
重启cart-service,然后访问查询购物车接口,sentinel的客户端就会将服务访问的信息提交到sentinel-dashboard控制台。并展示出统计信息:
点击簇点链路菜单,会看到下面的页面:
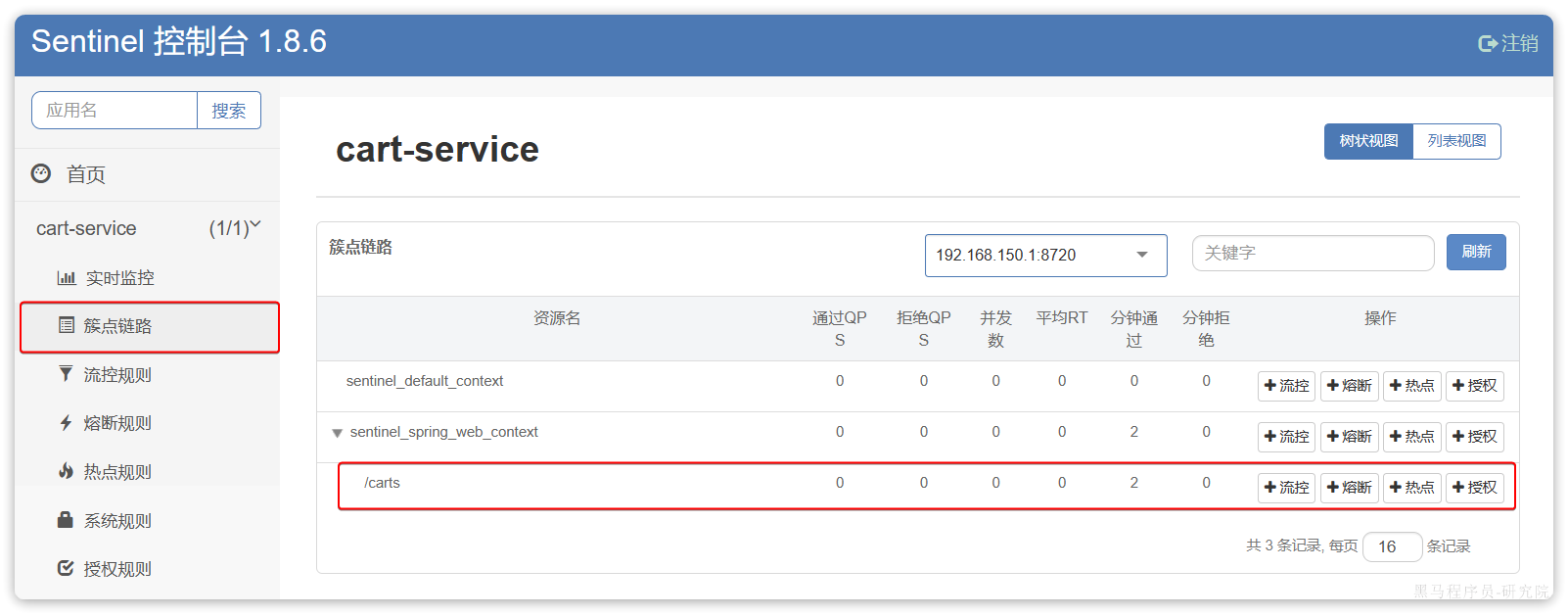
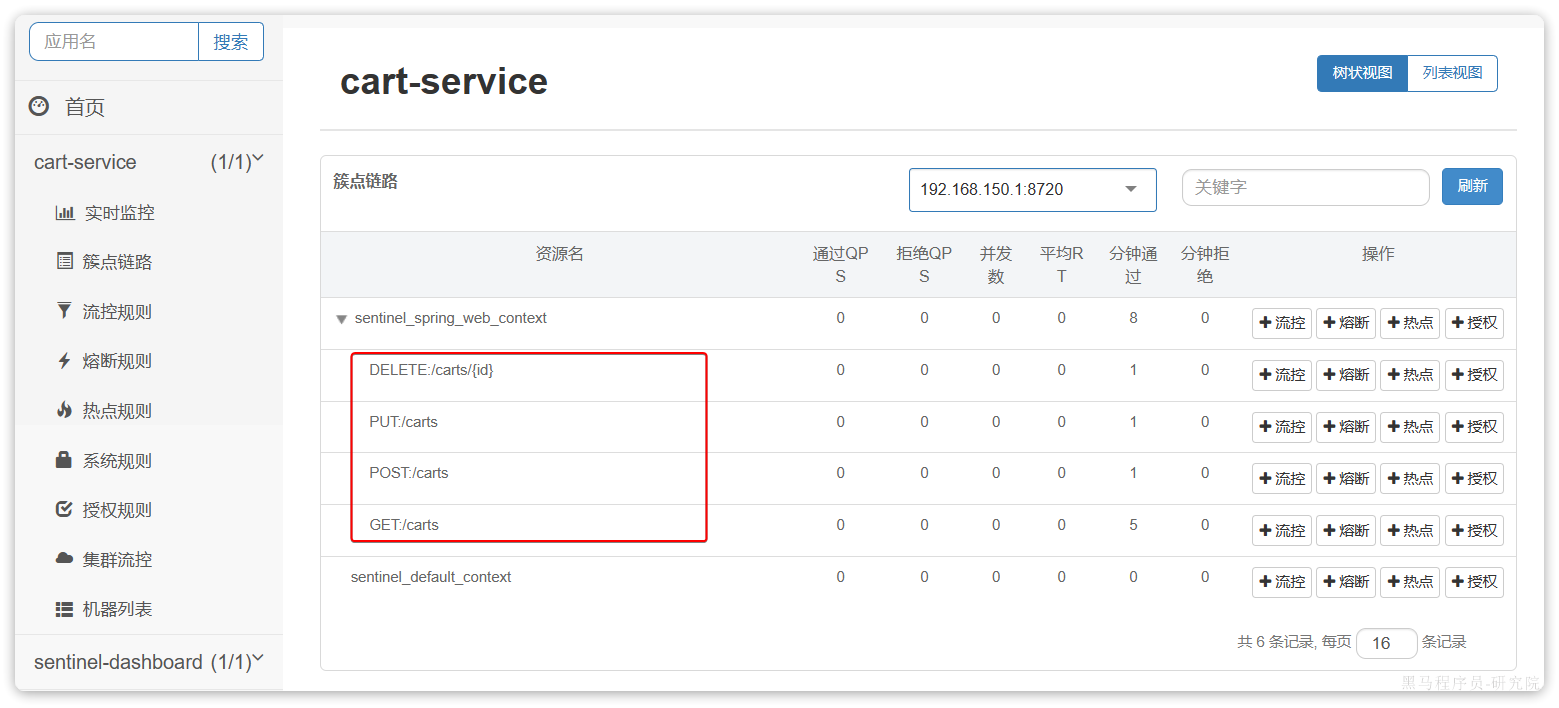
所谓簇点链路,就是单机调用链路,是一次请求进入服务后经过的每一个被Sentinel监控的资源。默认情况下,Sentinel会监控SpringMVC的每一个Endpoint(接口)。
因此,我们看到/carts这个接口路径就是其中一个簇点,我们可以对其进行限流、熔断、隔离等保护措施。
不过,需要注意的是,我们的SpringMVC接口是按照Restful风格设计,因此购物车的查询、删除、修改等接口全部都是/carts路径:
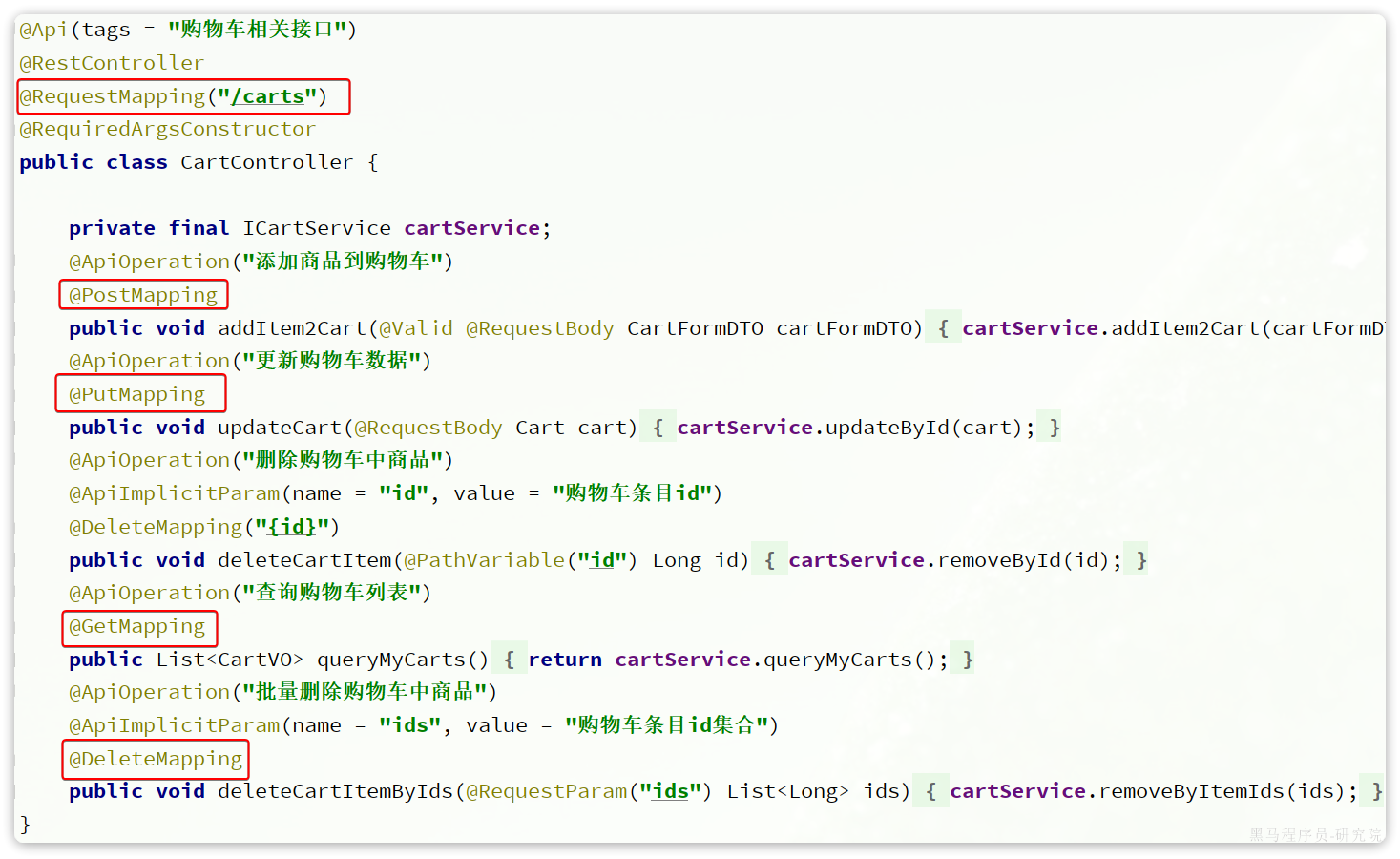
默认情况下Sentinel会把路径作为簇点资源的名称,无法区分路径相同但请求方式不同的接口,查询、删除、修改等都被识别为一个簇点资源,这显然是不合适的。
所以我们可以选择打开Sentinel的请求方式前缀,把请求方式 + 请求路径作为簇点资源名:
首先,在cart-service的application.yml中添加下面的配置:
spring:cloud:sentinel:transport:dashboard: localhost:8090http-method-specify: true # 开启请求方式前缀
然后,重启服务,通过页面访问购物车的相关接口,可以看到sentinel控制台的簇点链路发生了变化:
请求限流
在簇点链路后面点击流控按钮,即可对其做限流配置:
在弹出的菜单中这样填写:
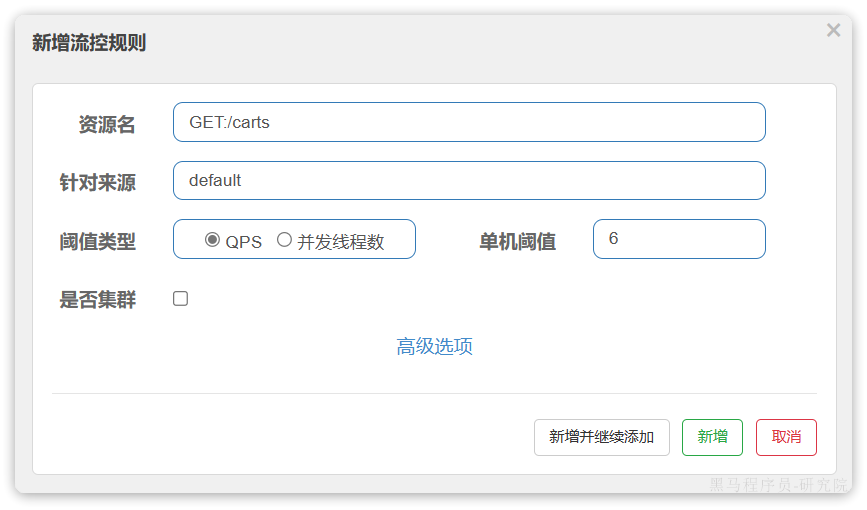
这样就把查询购物车列表这个簇点资源的流量限制在了每秒6个,也就是最大QPS为6.
我们利用Jemeter做限流测试,我们每秒发出10个请求:
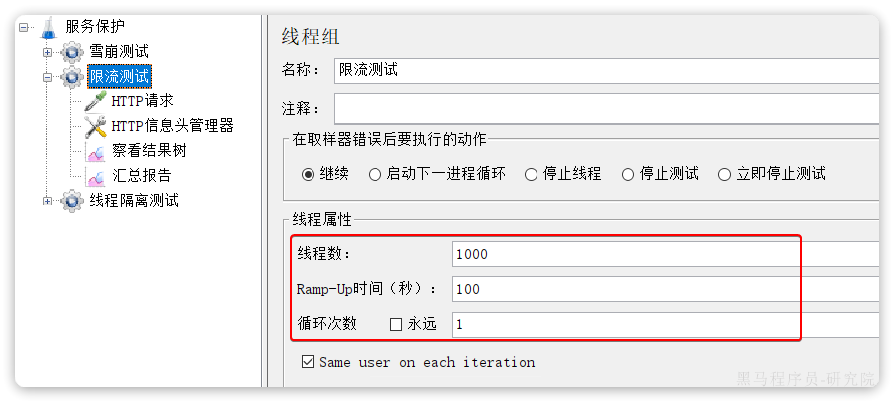
最终监控结果如下:
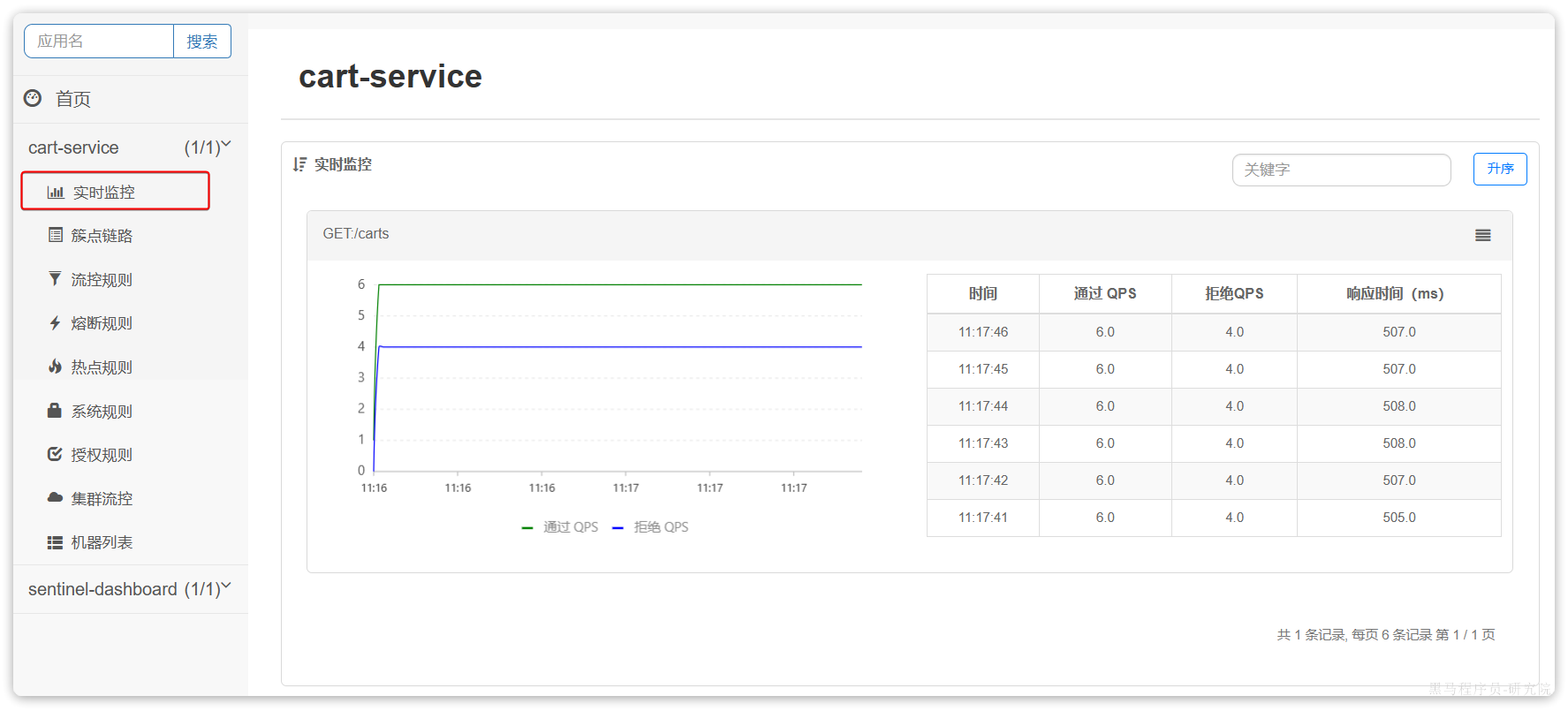
可以看出GET:/carts这个接口的通过QPS稳定在6附近,而拒绝的QPS在4附近,符合我们的预期。
线程隔离
限流可以降低服务器压力,尽量减少因并发流量引起的服务故障的概率,但并不能完全避免服务故障。一旦某个服务出现故障,我们必须隔离对这个服务的调用,避免发生雪崩。
比如,查询购物车的时候需要查询商品,为了避免因商品服务出现故障导致购物车服务级联失败,我们可以把购物车业务中查询商品的部分隔离起来,限制可用的线程资源:
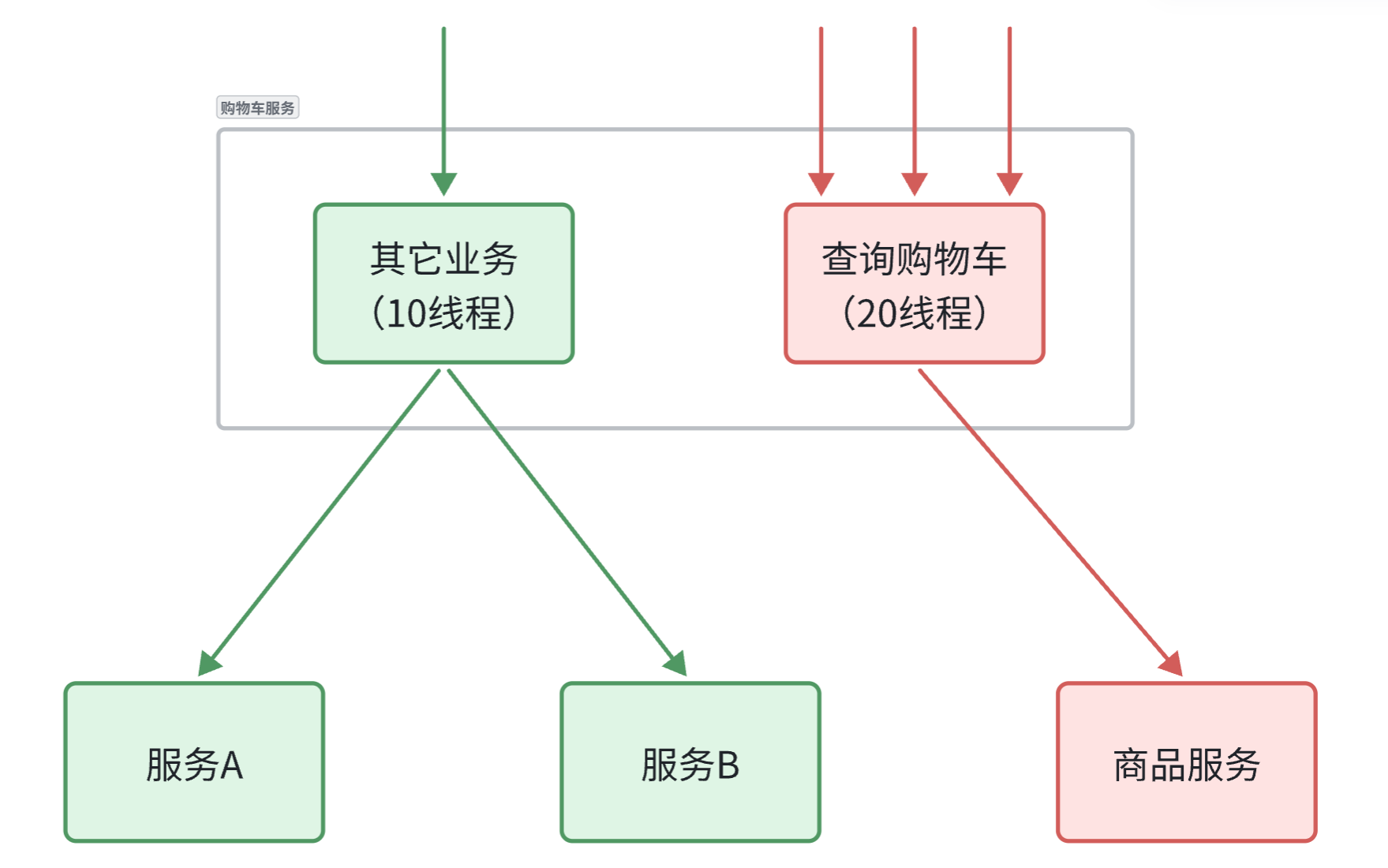
这样,即便商品服务出现故障,最多导致查询购物车业务故障,并且可用的线程资源也被限定在一定范围,不会导致整个购物车服务崩溃。
所以,我们要对查询商品的FeignClient接口做线程隔离。
OpenFeign整合Sentinel
修改cart-service模块的application.yml文件,开启Feign的sentinel功能:
feign:sentinel:enabled: true # 开启feign对sentinel的支持
需要注意的是,默认情况下SpringBoot项目的tomcat最大线程数是200,允许的最大连接是8492,单机测试很难打满。
所以我们需要配置一下cart-service模块的application.yml文件,修改tomcat连接:
server:port: 8082tomcat:threads:max: 50 # 允许的最大线程数accept-count: 50 # 最大排队等待数量max-connections: 100 # 允许的最大连接
然后重启cart-service服务,可以看到查询商品的FeignClient自动变成了一个簇点资源:
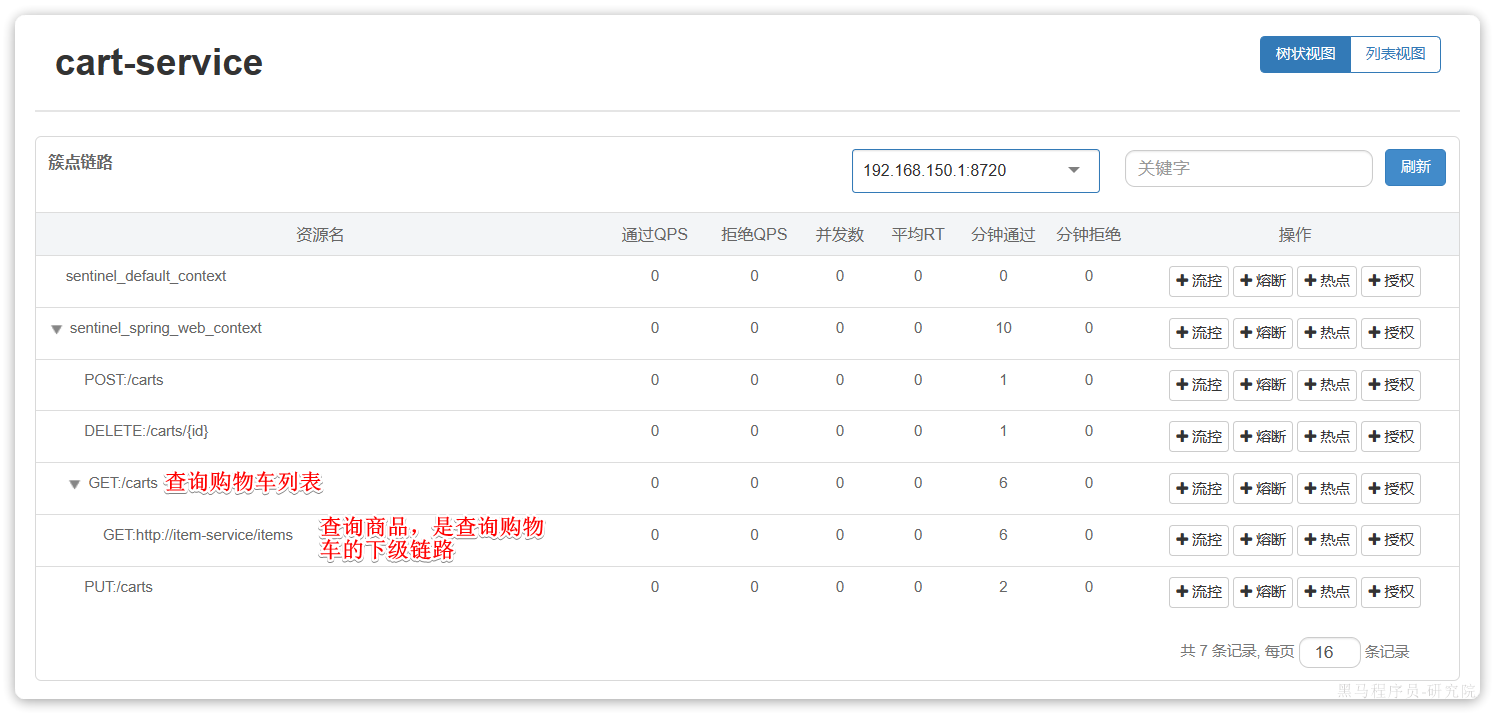
配置线程隔离
接下来,点击查询商品的FeignClient对应的簇点资源后面的流控按钮:
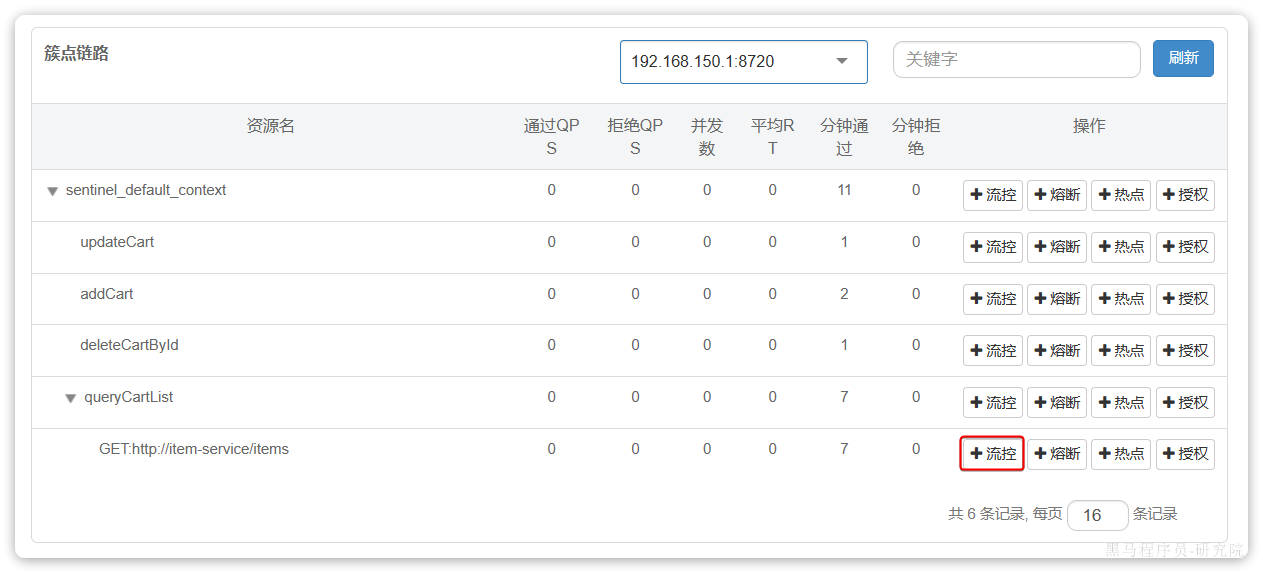
在弹出的表单中填写下面内容:
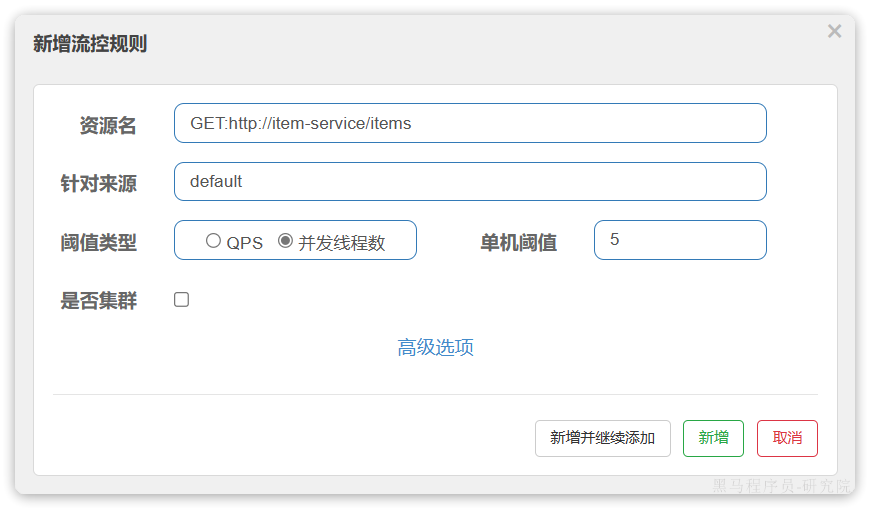
注意,这里勾选的是并发线程数限制,也就是说这个查询功能最多使用5个线程,而不是5QPS。如果查询商品的接口每秒处理2个请求,则5个线程的实际QPS在10左右,而超出的请求自然会被拒绝。
服务熔断
在上节课,我们利用线程隔离对查询购物车业务进行隔离,保护了购物车服务的其它接口。由于查询商品的功能耗时较高(我们模拟了500毫秒延时),再加上线程隔离限定了线程数为5,导致接口吞吐能力有限,最终QPS只有10左右。这就导致了几个问题:
第一,超出的QPS上限的请求就只能抛出异常,从而导致购物车的查询失败。但从业务角度来说,即便没有查询到最新的商品信息,购物车也应该展示给用户,用户体验更好。也就是给查询失败设置一个降级处理逻辑。
第二,由于查询商品的延迟较高(模拟的500ms),从而导致查询购物车的响应时间也变的很长。这样不仅拖慢了购物车服务,消耗了购物车服务的更多资源,而且用户体验也很差。对于商品服务这种不太健康的接口,我们应该直接停止调用,直接走降级逻辑,避免影响到当前服务。也就是将商品查询接口熔断。
编写降级逻辑
触发限流或熔断后的请求不一定要直接报错,也可以返回一些默认数据或者友好提示,用户体验会更好。
给FeignClient编写失败后的降级逻辑有两种方式:
- 方式一:FallbackClass,无法对远程调用的异常做处理
- 方式二:FallbackFactory,可以对远程调用的异常做处理,我们一般选择这种方式。
这里我们演示方式二的失败降级处理。
步骤一:在hm-api模块中给ItemClient定义降级处理类,实现FallbackFactory:
代码如下:
package com.hmall.api.client.fallback;import com.hmall.api.client.ItemClient;
import com.hmall.api.dto.ItemDTO;
import com.hmall.api.dto.OrderDetailDTO;
import com.hmall.common.exception.BizIllegalException;
import com.hmall.common.utils.CollUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.openfeign.FallbackFactory;import java.util.Collection;
import java.util.List;@Slf4j
public class ItemClientFallback implements FallbackFactory<ItemClient> {@Overridepublic ItemClient create(Throwable cause) {return new ItemClient() {@Overridepublic List<ItemDTO> queryItemByIds(Collection<Long> ids) {log.error("远程调用ItemClient#queryItemByIds方法出现异常,参数:{}", ids, cause);// 查询购物车允许失败,查询失败,返回空集合return CollUtils.emptyList();}@Overridepublic void deductStock(List<OrderDetailDTO> items) {// 库存扣减业务需要触发事务回滚,查询失败,抛出异常throw new BizIllegalException(cause);}};}
}
步骤二:在hm-api模块中的com.hmall.api.config.DefaultFeignConfig类中将ItemClientFallback注册为一个Bean:
步骤三:在hm-api模块中的ItemClient接口中使用ItemClientFallbackFactory:
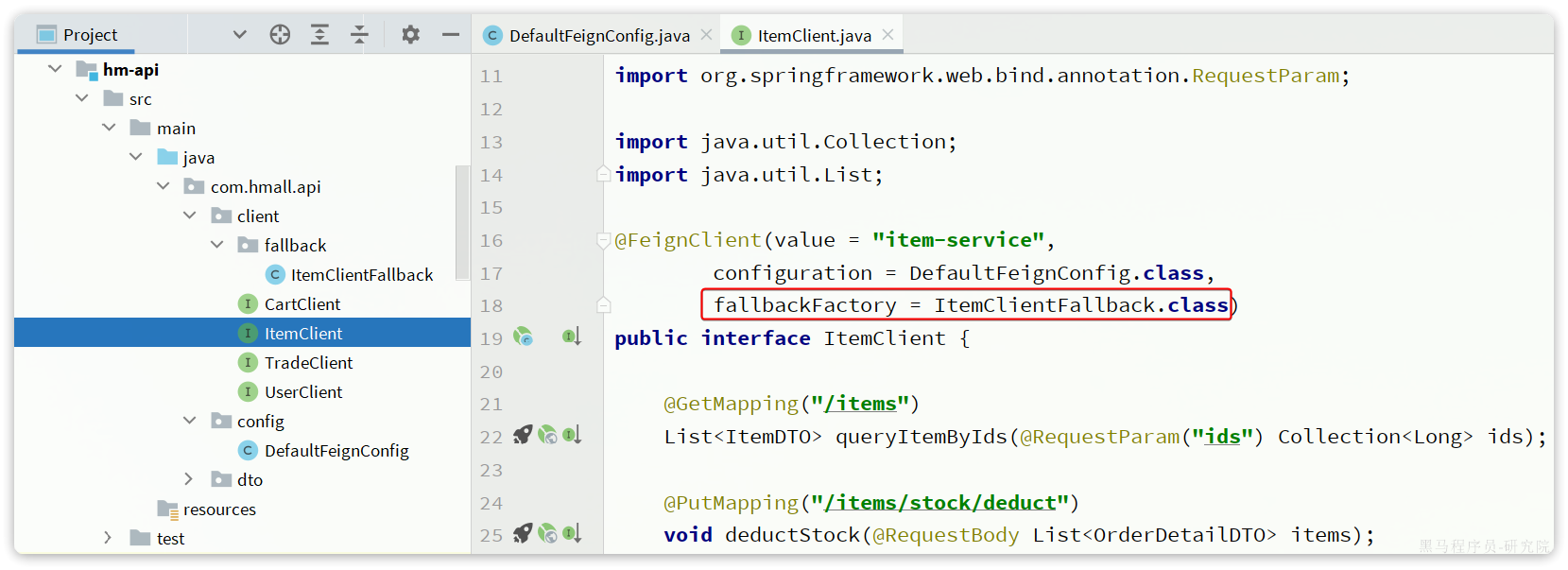
服务熔断
查询商品的RT较高(模拟的500ms),从而导致查询购物车的RT也变的很长。这样不仅拖慢了购物车服务,消耗了购物车服务的更多资源,而且用户体验也很差。
对于商品服务这种不太健康的接口,我们应该停止调用,直接走降级逻辑,避免影响到当前服务。也就是将商品查询接口熔断。当商品服务接口恢复正常后,再允许调用。这其实就是断路器的工作模式了。
Sentinel中的断路器不仅可以统计某个接口的慢请求比例,还可以统计异常请求比例。当这些比例超出阈值时,就会熔断该接口,即拦截访问该接口的一切请求,降级处理;当该接口恢复正常时,再放行对于该接口的请求。
断路器的工作状态切换有一个状态机来控制:
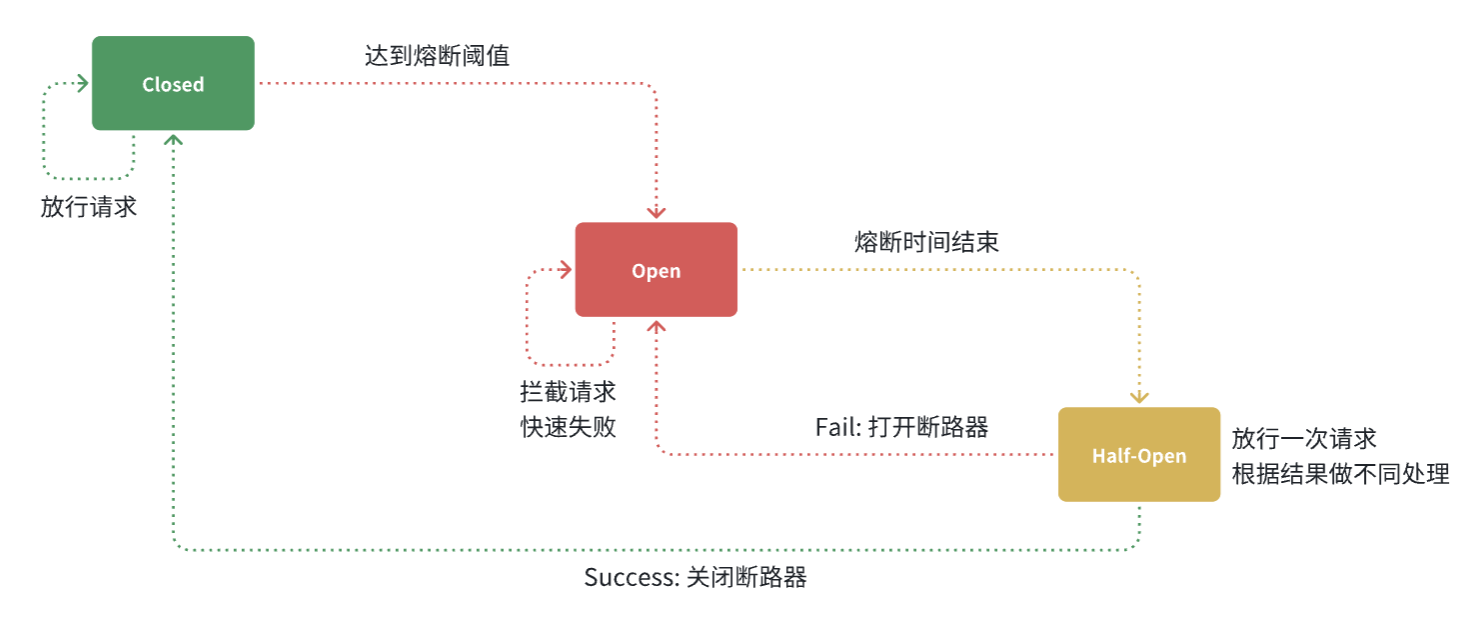
状态机包括三个状态:
- closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
- open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态持续一段时间后会进入half-open状态
- half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
- 请求成功:则切换到closed状态
- 请求失败:则切换到open状态
我们可以在控制台通过点击簇点后的**熔断**按钮来配置熔断策略:
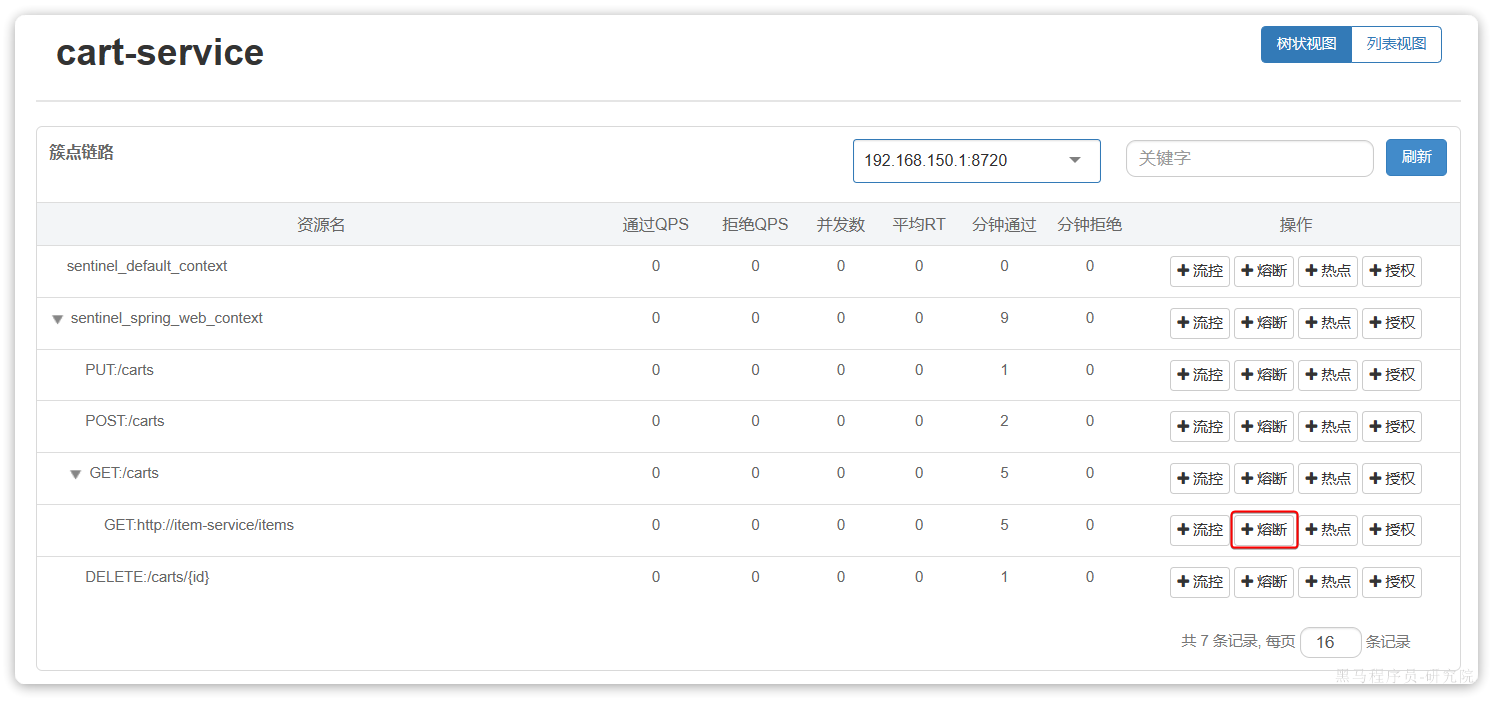
我们可以在控制台通过点击簇点后的**熔断**按钮来配置熔断策略:
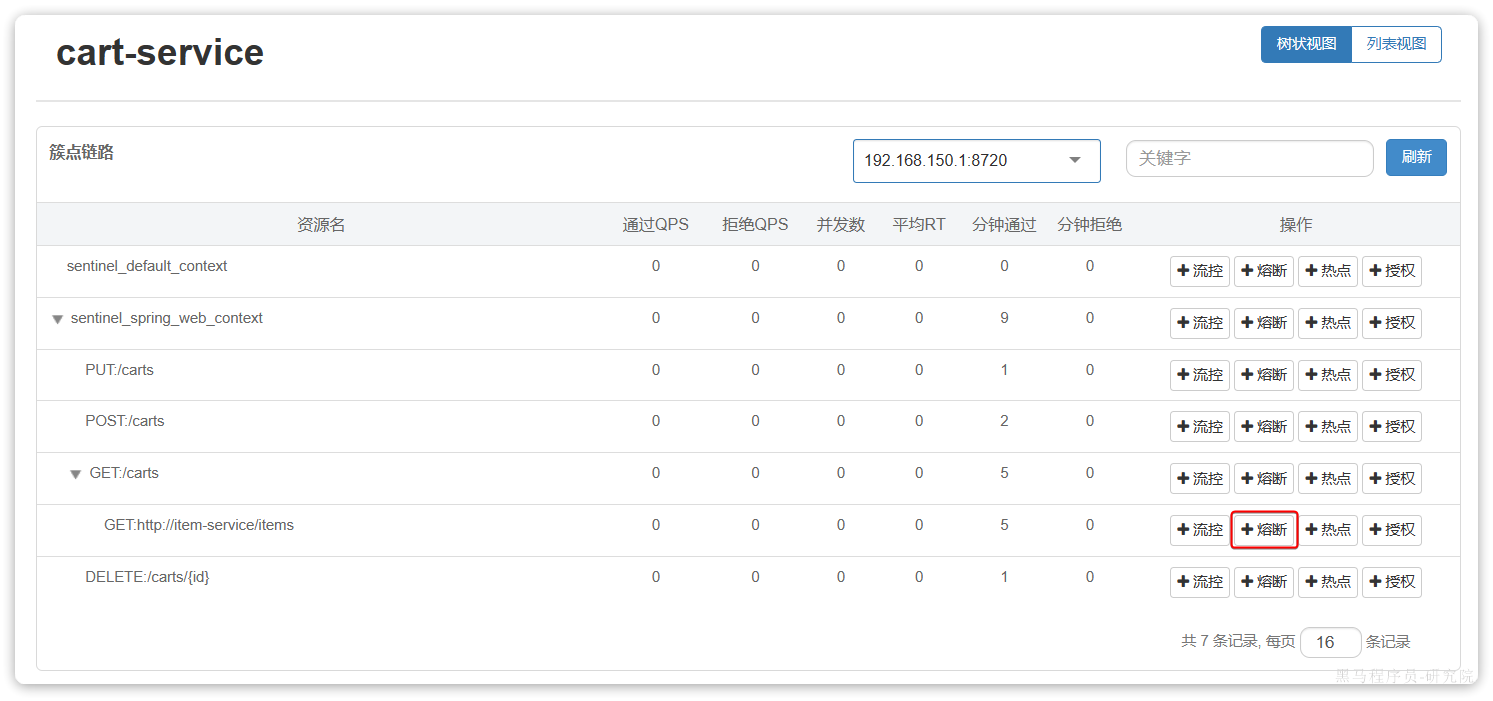
在弹出的表格中这样填写:
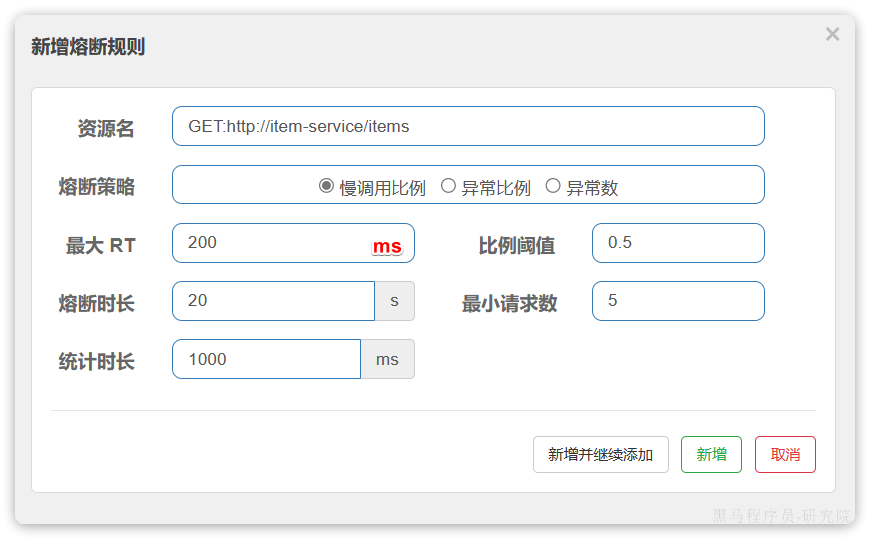
这种是按照慢调用比例来做熔断,上述配置的含义是:
- RT超过200毫秒的请求调用就是慢调用
- 统计最近1000ms内的最少5次请求,如果慢调用比例不低于0.5,则触发熔断
- 熔断持续时长20s
Sentinel组件基本实现原理
线程隔离
线程隔离有两种方式实现:
- 线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果
- 信号量隔离:不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求
如图:
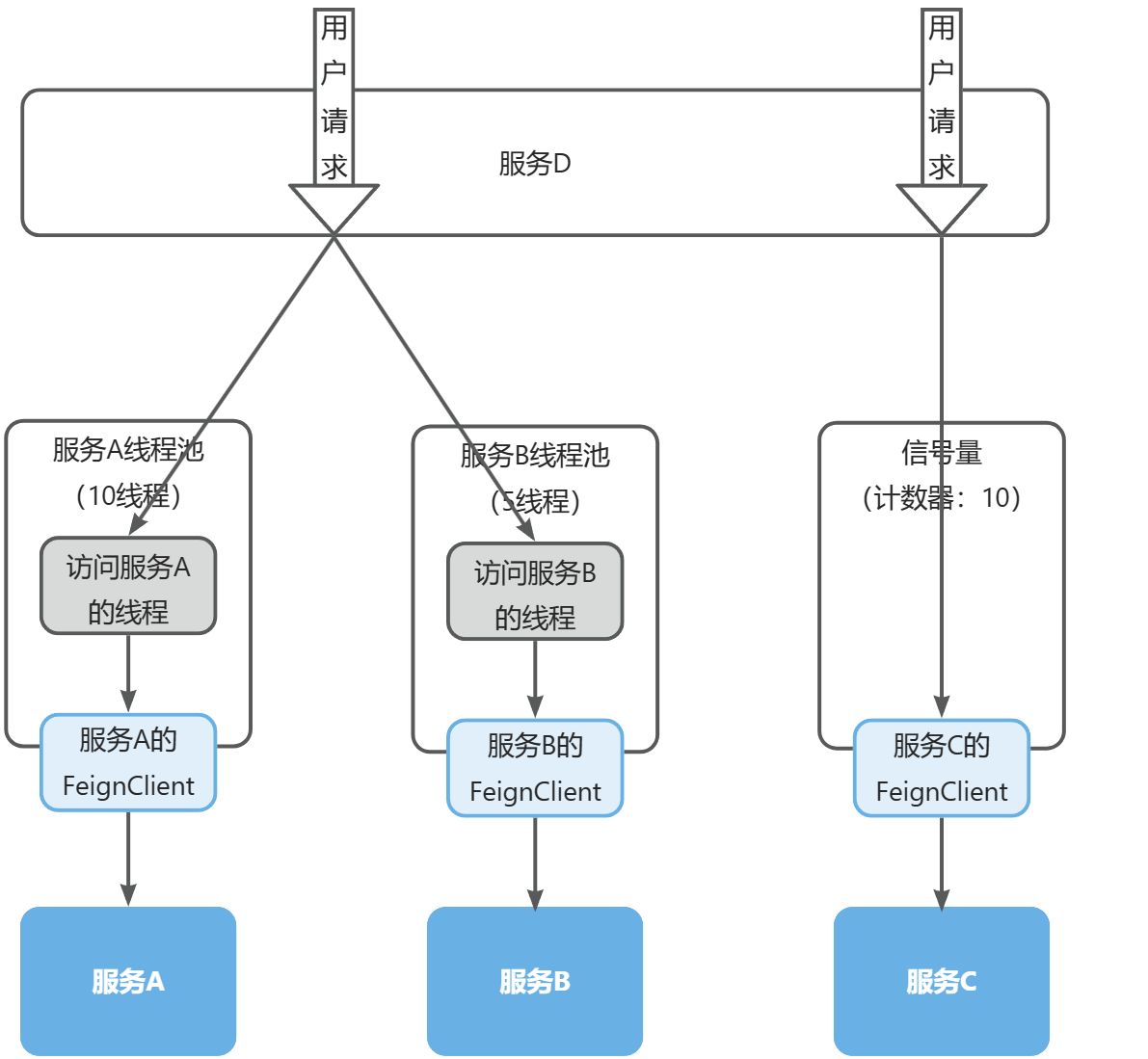
两者的优缺点如下:

Sentinel的线程隔离就是基于信号量隔离实现的,而Hystix两种都支持,但默认是基于线程池隔离。
限流算法
在熔断功能中,需要统计异常请求或慢请求比例,也就是计数。在限流的时候,要统计每秒钟的QPS,同样是计数。可见计数算法在熔断限流中的应用非常多。sentinel中采用的计数器算法就是滑动窗口计数算法。
固定窗口计数
要了解滑动窗口计数算法,我们必须先知道固定窗口计数算法,其基本原理如图:
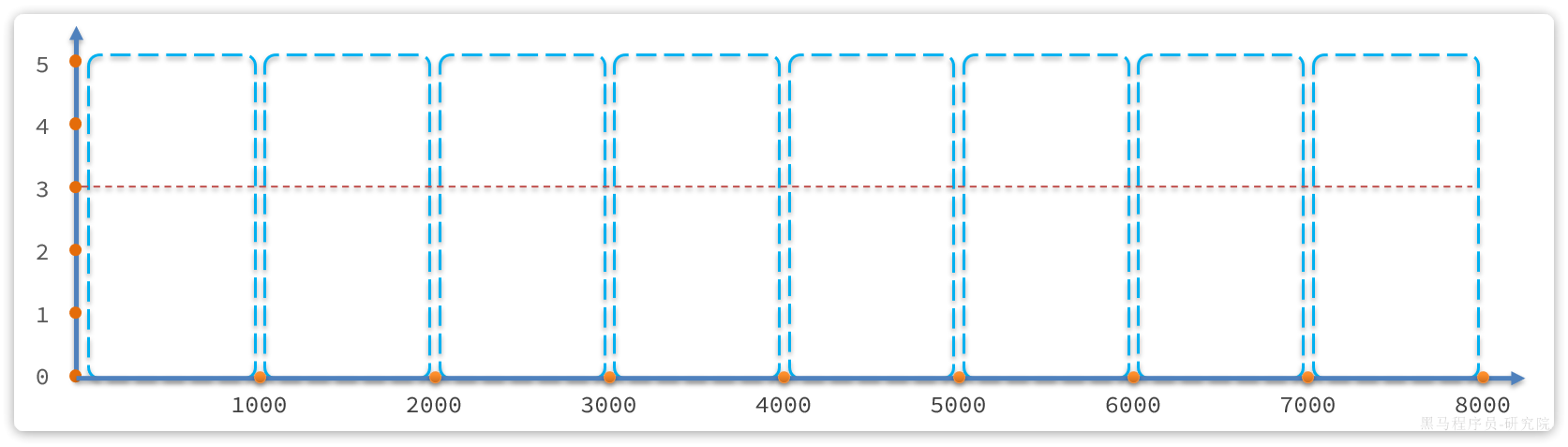
说明:
- 将时间划分为多个窗口,窗口时间跨度称为
Interval,本例中为1000ms; - 每个窗口维护1个计数器,每有1次请求就将计数器
+1。限流就是设置计数器阈值,本例为3,图中红线标记 - 如果计数器超过了限流阈值,则超出阈值的请求都被丢弃。
示例:
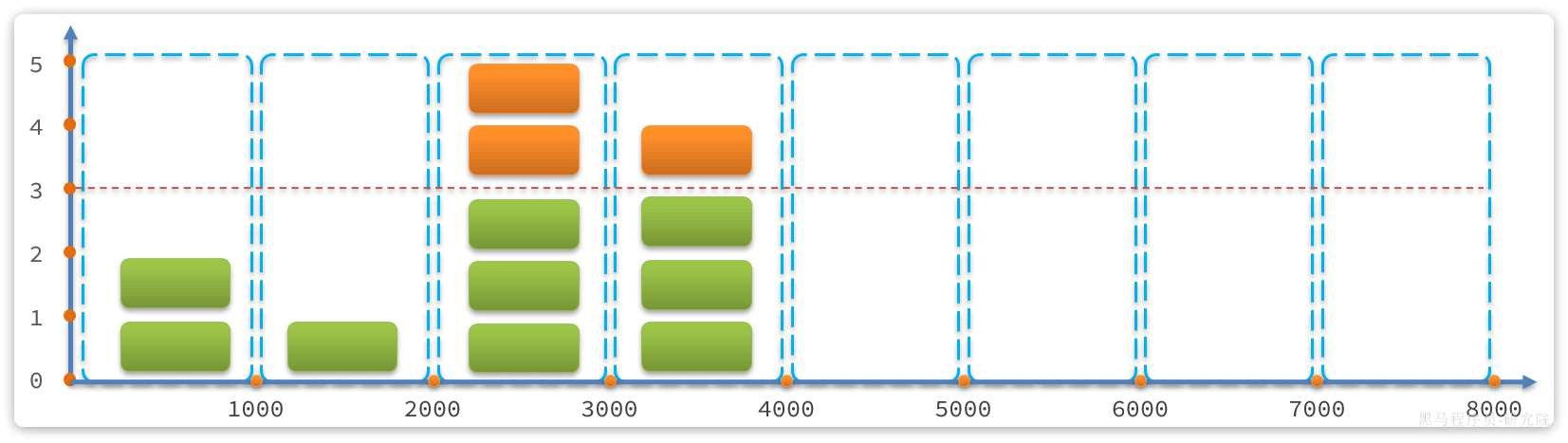
说明:
- 第1、2秒,请求数量都小于3,没问题
- 第3秒,请求数量为5,超过阈值,超出的请求被拒绝
但是我们考虑一种特殊场景,如图:
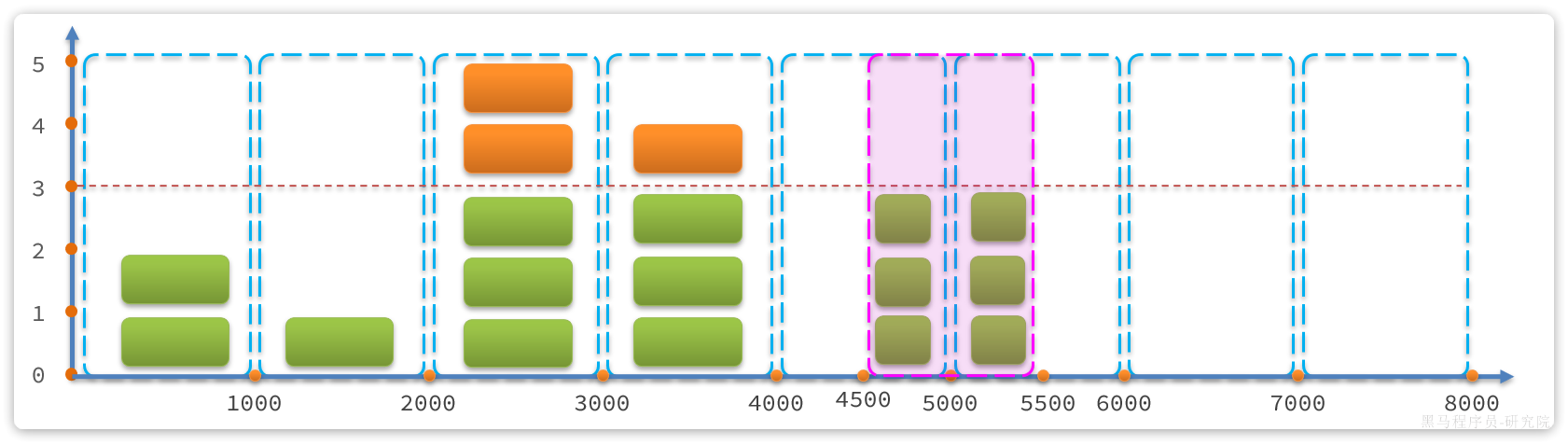
说明:
- 假如在第5、6秒,请求数量都为3,没有超过阈值,全部放行
- 但是,如果第5秒的三次请求都是在4.55秒之间进来;第6秒的请求是在55.5之间进来。那么从第4.5~5.之间就有6次请求!也就是说每秒的QPS达到了6,远超阈值。
这就是固定窗口计数算法的问题,它只能统计当前某1个时间窗的请求数量是否到达阈值,无法结合前后的时间窗的数据做综合统计。
因此,我们就需要滑动时间窗口算法来解决。
滑动窗口算法
固定时间窗口算法中窗口有很多,其跨度和位置是与时间区间绑定,因此是很多固定不动的窗口。而滑动时间窗口算法中只包含1个固定跨度的窗口,但窗口是可移动动的,与时间区间无关。
具体规则如下:
- 窗口时间跨度
Interval大小固定,例如1秒 - 时间区间跨度为
Interval / n,例如n=2,则时间区间跨度为500ms - 窗口会随着当前请求所在时间
currentTime移动,窗口范围从currentTime-Interval时刻之后的第一个时区开始,到currentTime所在时区结束。
如图所示:
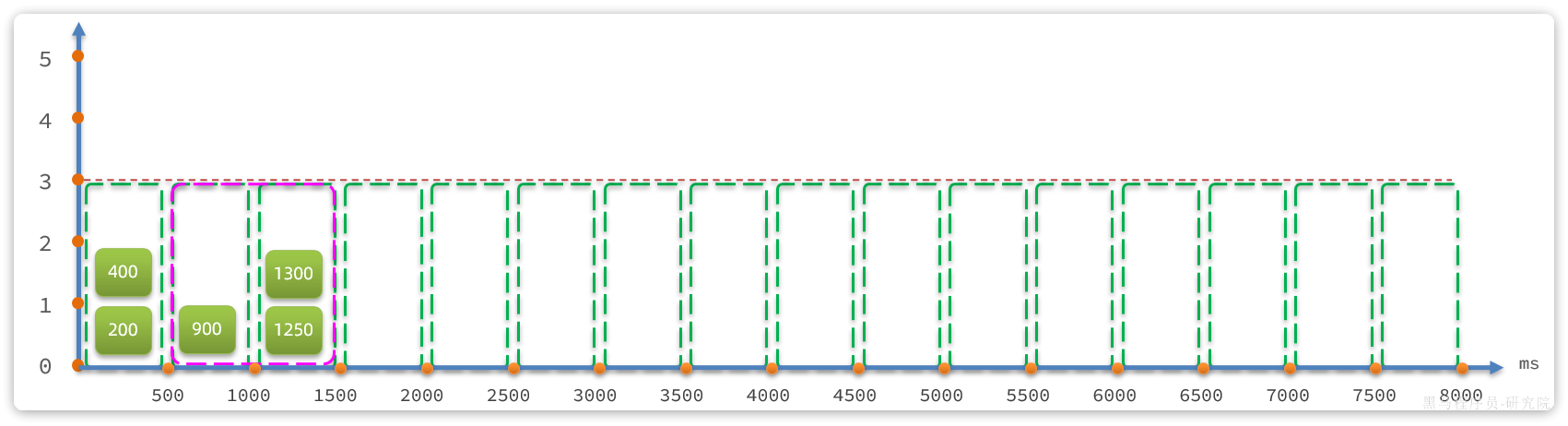
限流阈值依然为3,绿色小块就是请求,上面的数字是其currentTime值。
- 在第1300ms时接收到一个请求,其所在时区就是1000~1500
- 按照规则,currentTime-Interval值为300ms,300ms之后的第一个时区是5001000,因此窗口范围包含两个时区:5001000、1000~1500,也就是粉红色方框部分
- 统计窗口内的请求总数,发现是3,未达到上限。
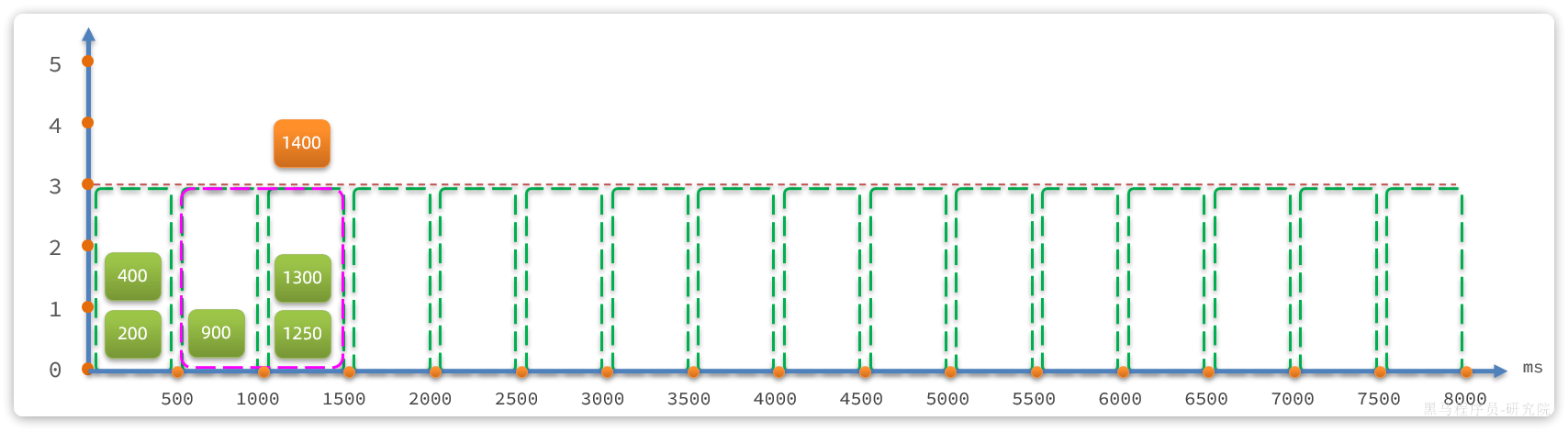
若第1400ms又来一个请求,会落在1000~1500时区,虽然该时区请求总数是3,但滑动窗口内总数已经达到4,因此该请求会被拒绝:
假如第1600ms又来的一个请求,处于15002000时区,根据算法,滑动窗口位置应该是10001500和1500~2000这两个时区,也就是向后移动:
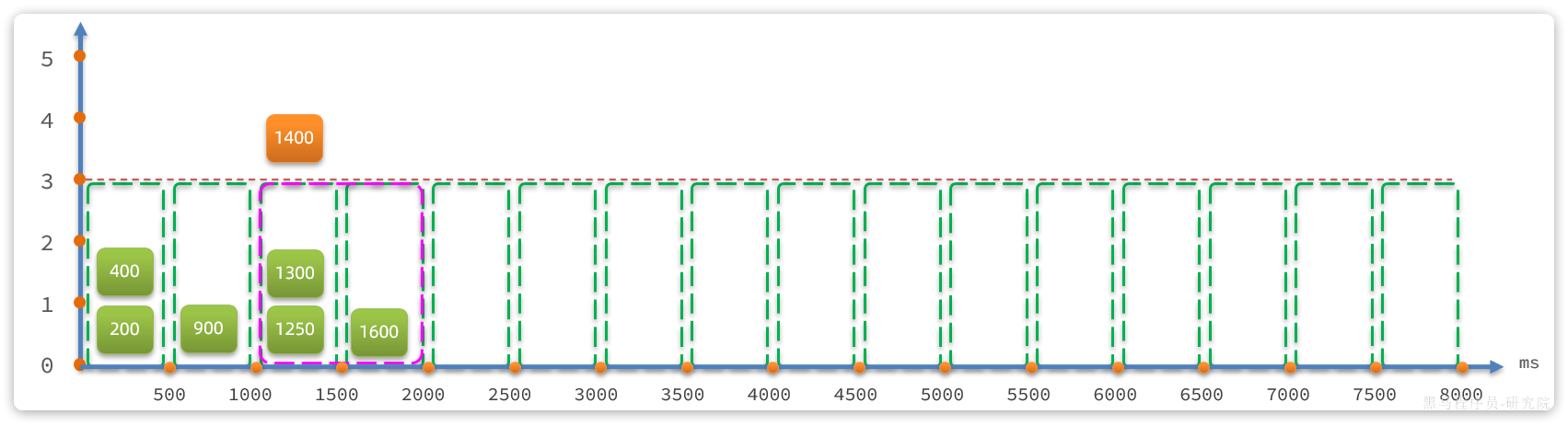
这就是滑动窗口计数的原理,解决了我们之前所说的问题。而且滑动窗口内划分的时区越多,这种统计就越准确。
令牌桶算法
限流的另一种常见算法是令牌桶算法。Sentinel中的热点参数限流正是基于令牌桶算法实现的。其基本思路如图:
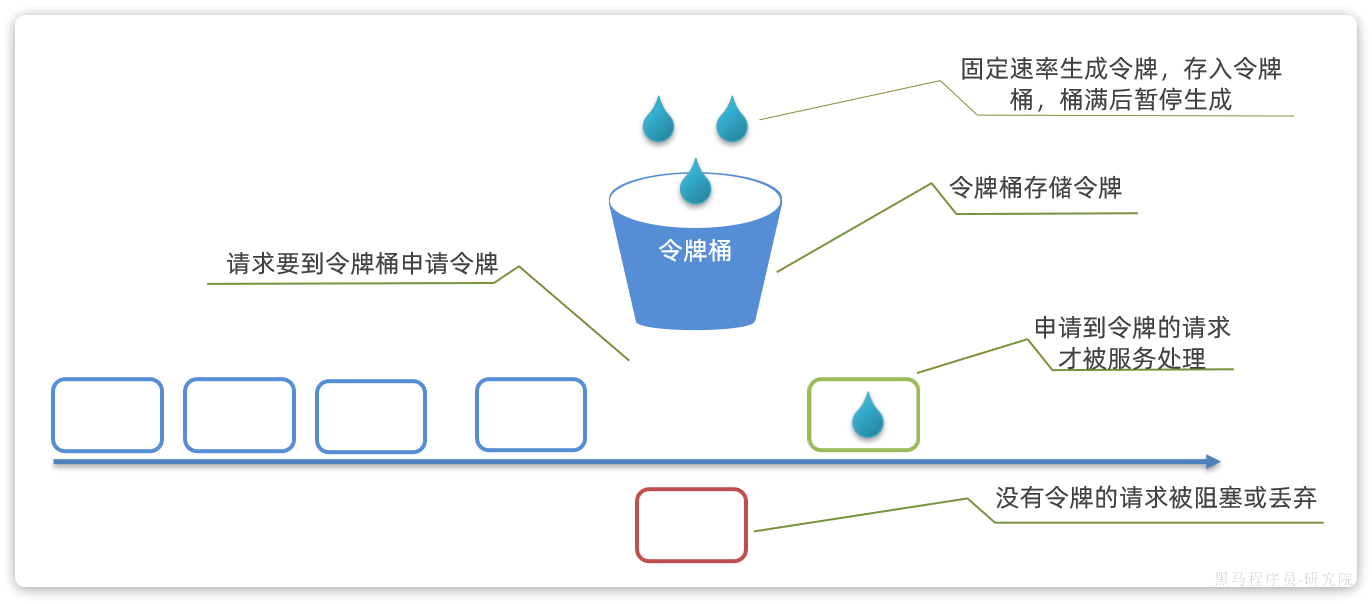
说明:
- 以固定的速率生成令牌,存入令牌桶中,如果令牌桶满了以后,多余令牌丢弃
- 请求进入后,必须先尝试从桶中获取令牌,获取到令牌后才可以被处理
- 如果令牌桶中没有令牌,则请求等待或丢弃
基于令牌桶算法,每秒产生的令牌数量基本就是QPS上限。
当然也有例外情况,例如:
- 某一秒令牌桶中产生了很多令牌,达到令牌桶上限N,缓存在令牌桶中,但是这一秒没有请求进入。
- 下一秒的前半秒涌入了超过2N个请求,之前缓存的令牌桶的令牌耗尽,同时这一秒又生成了N个令牌,于是总共放行了2N个请求。超出了我们设定的QPS阈值。
因此,在使用令牌桶算法时,尽量不要将令牌上限设定到服务能承受的QPS上限。而是预留一定的波动空间,这样我们才能应对突发流量。
漏桶算法
漏桶算法与令牌桶相似,但在设计上更适合应对并发波动较大的场景,以解决令牌桶中的问题。
简单来说就是请求到达后不是直接处理,而是先放入一个队列。而后以固定的速率从队列中取出并处理请求。之所以叫漏桶算法,就是把请求看做水,队列看做是一个漏了的桶。
如图:
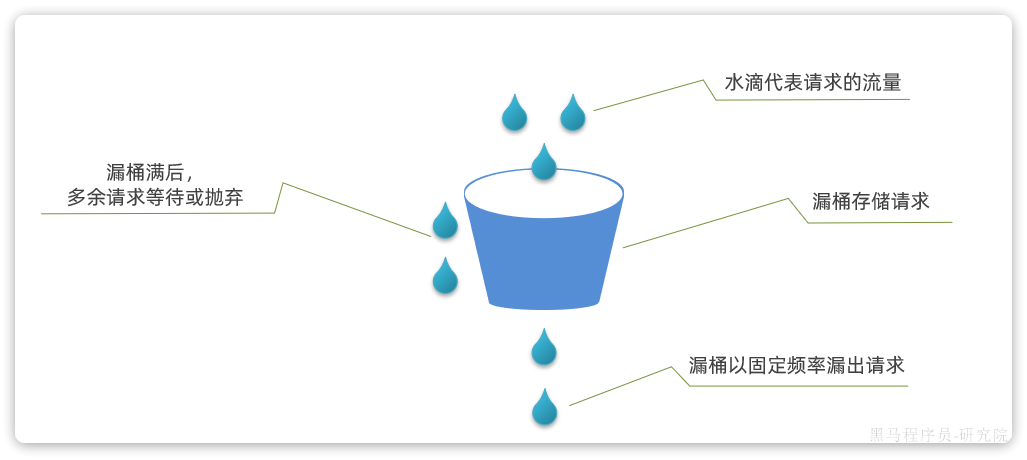
说明:
- 将每个请求视作"水滴"放入"漏桶"进行存储;
- "漏桶"以固定速率向外"漏"出请求来执行,如果"漏桶"空了则停止"漏水”;
- 如果"漏桶"满了则多余的"水滴"会被直接丢弃。
漏桶的优势就是流量整型,桶就像是一个大坝,请求就是水。并发量不断波动,就如图水流时大时小,但都会被大坝拦住。而后大坝按照固定的速度放水,避免下游被洪水淹没。
因此,不管并发量如何波动,经过漏桶处理后的请求一定是相对平滑的曲线:
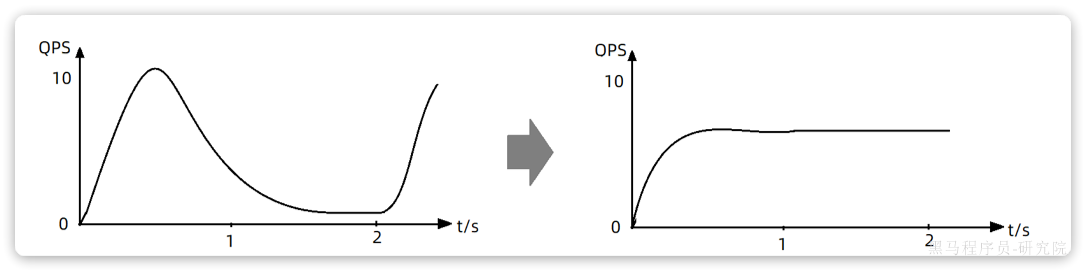
sentinel中的限流中的排队等待功能正是基于漏桶算法实现的。
总结
核心目标与理念
- 目标:增强分布式系统的健壮性 (Robustness),防范因单一服务故障引发的级联失败 (Cascading Failure) 和 雪崩效应 (Avalanche Effect)。
- 核心理念:服务降级 (Degradation)。通过有策略地暂时牺牲非核心服务的性能或功能完整性(如返回兜底数据),来保障整个系统核心链路的可用性 (Availability)。
三大保护策略
这三种策略构筑了系统稳定性的三道防线,通常协同工作。
| 策略 | 保护对象 | 核心思想 | Sentinel 实现方式 |
|---|---|---|---|
| 1. 请求限流 (Rate Limiting) | 服务提供者 | 控制流入系统的请求速率,将突发流量整形为平稳流量,防止系统被冲垮。 | 流控规则 - 设置 QPS (每秒请求数) 阈值。 |
| 2. 线程隔离 (Isolation) | 服务调用者 | 将资源隔离开,避免故障服务耗尽所有资源,影响其他健康服务。 | 流控规则 - 设置 并发线程数 阈值。 |
| 3. 服务熔断 (Circuit Breaking) | 服务调用者 | 对故障服务进行快速失败,防止大量请求阻塞。具备自动检测与恢复机制。 | 熔断规则 - 基于慢调用比例、异常比例或异常数触发。 |
补充:线程隔离的两种模式
- 线程池隔离:为不同服务分配独立线程池。隔离性最强,但开销大,性能较差。(Hystrix 默认)
- 信号量隔离:通过计数器限制并发数。隔离性稍弱(在调用线程上执行),但性能更好。(Sentinel 默认)
底层基石:常见限流算法
这些算法是实现“计数”和“限流”的理论基础。
| 算法 | 核心思想 | 特点与应用场景 |
|---|---|---|
| 滑动窗口 (Sliding Window) | 将时间划分为细粒度单元,动态统计一个时间窗口内的请求数。 | 解决了固定窗口的临界问题,是 Sentinel 核心采用的计数算法(用于限流和熔断计数)。 |
| 漏桶 (Leaky Bucket) | 请求以任意速率流入“漏桶”,但桶底以恒定速率漏出请求进行处理。 | 流量整形,平滑突发流量,输出速率恒定,无法应对突发流量。Sentinel 的“排队等待”模式基于此。 |
| 令牌桶 (Token Bucket) | 系统以固定速率生成“令牌”,请求必须获取到令牌才能被处理。 | 允许一定程度的突发流量(消耗积攒的令牌),是最常用的限流算法模型。 |
⚠️ 重要提示:
- 令牌桶的突发性:设定 QPS 阈值时应预留缓冲空间,因为突发流量可能消耗积攒的令牌,导致瞬时 QPS 远超设定值。
- Sentinel 的算法组合:
- 默认限流和熔断计数基于滑动时间窗口。
- 排队等待的限流效果基于漏桶算法。
- 热点参数限流基于令牌桶算法。
熔断器状态机
熔断器通过状态机实现自动切换和恢复:
- Closed (关闭状态):请求正常通行,同时持续统计调用指标(如异常率)。
- Open (打开状态):当统计指标超过阈值,熔断器打开,所有请求被快速失败,直接拒绝。
- Half-Open (半开状态):熔断器打开一段时间后,会自动进入半开状态,试探性地放行一个请求。
- 若成功 -> 熔断器关闭,服务恢复。
- 若失败 -> 熔断器再次打开,继续等待。
技术实践:Sentinel 实战指南
1. 核心概念:簇点链路
- 代表微服务内部的调用链路节点(如 API 接口)。
- 默认监控所有
@RequestMapping端点。 - 需额外配置才能将 RESTful 不同方法(GET/POST)和 OpenFeign 客户端显示为独立链路。
2. 操作流程
- 集成:引入
spring-cloud-starter-alibaba-sentinel依赖并配置控制台地址。 - 访问:访问服务接口,才能在 Sentinel 控制台的“簇点链路”页面看到监控项。
- 配置规则:在对应簇点上设置流控规则(限流、隔离)和熔断规则。
- 设置降级:配置
FallbackFactory实现请求被阻断时的友好返回。
3. 兜底方案:降级逻辑 (Fallback)
当请求被限流、熔断或服务异常时,应返回兜底数据而非错误。
- 实现方式:为 OpenFeign 客户端编写
FallbackFactory。
// 1. 实现 FallbackFactory
@Component
public class ItemClientFallback implements FallbackFactory<ItemClient> {@Overridepublic ItemClient create(Throwable cause) {// 2. 在匿名实现中为每个方法编写降级逻辑return new ItemClient() {@Overridepublic List<ItemDTO> queryItemByIds(Collection<Long> ids) {log.error("查询商品失败,触发降级", cause);// 返回空集合、缓存数据或默认值return Collections.emptyList();}};}
}// 3. 在 Feign 客户端指定降级工厂
@FeignClient(value = "item-service", fallbackFactory = ItemClientFallback.class)
public interface ItemClient {@GetMapping("/items")List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}
Seata分布式事务
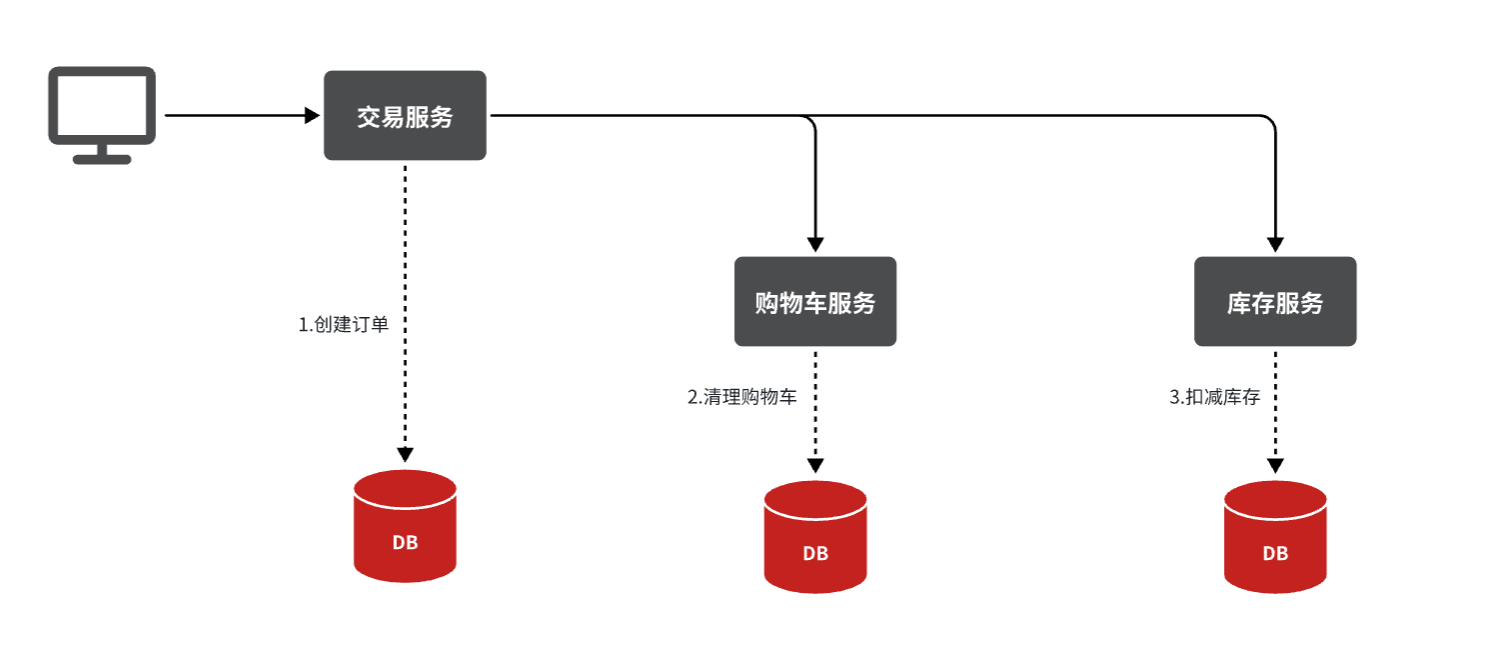
由于订单、购物车、商品分别在三个不同的微服务,而每个微服务都有自己独立的数据库,因此下单过程中就会跨多个数据库完成业务。而每个微服务都会执行自己的本地事务:
- 交易服务:下单事务
- 购物车服务:清理购物车事务
- 库存服务:扣减库存事务
整个业务中,各个本地事务是有关联的。因此每个微服务的本地事务,也可以称为分支事务。多个有关联的分支事务一起就组成了全局事务。我们必须保证整个全局事务同时成功或失败。
但是传统的方案只能保证分支事务的事务特性,不能保证全局事务。
认识Seata
解决分布式事务的方案有很多,但实现起来都比较复杂,因此我们一般会使用开源的框架来解决分布式事务问题。在众多的开源分布式事务框架中,功能最完善、使用最多的就是阿里巴巴在2019年开源的Seata了。
https://seata.io/zh-cn/docs/overview/what-is-seata.html
其实分布式事务产生的一个重要原因,就是参与事务的多个分支事务互相无感知,不知道彼此的执行状态。因此解决分布式事务的思想非常简单:
就是找一个统一的事务协调者,与多个分支事务通信,检测每个分支事务的执行状态,保证全局事务下的每一个分支事务同时成功或失败即可。大多数的分布式事务框架都是基于这个理论来实现的。
Seata也不例外,在Seata的事务管理中有三个重要的角色:
- TC (Transaction Coordinator) - **事务协调者:**维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - **事务管理器:**定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - **资源管理器:**管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata的工作架构如图所示:
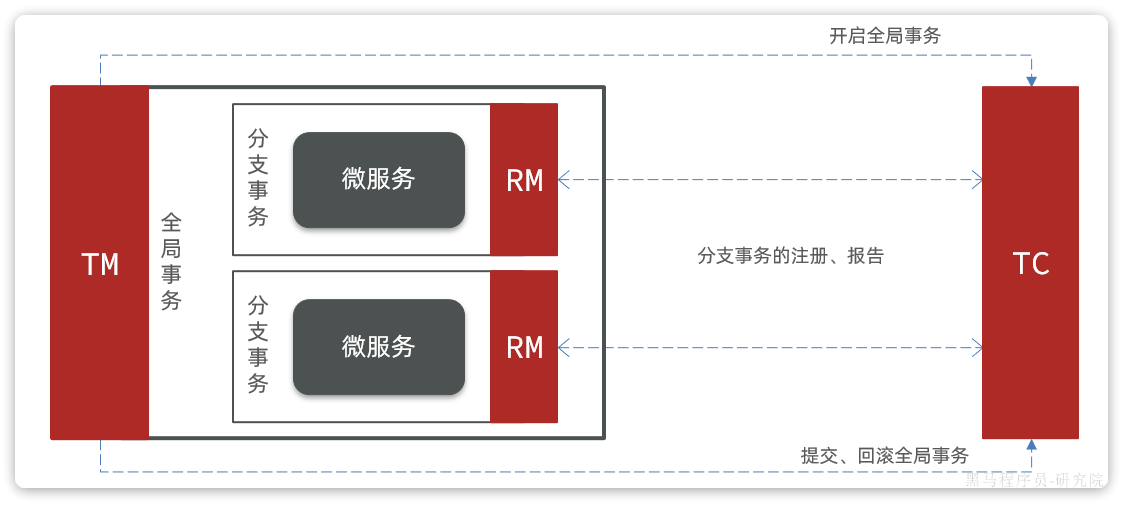
其中,TM和RM可以理解为Seata的客户端部分,引入到参与事务的微服务依赖中即可。将来TM和RM就会协助微服务,实现本地分支事务与TC之间交互,实现事务的提交或回滚。
而TC服务则是事务协调中心,是一个独立的微服务,需要单独部署。
部署TC服务
准备数据库表
Seata支持多种存储模式,但考虑到持久化的需要,我们一般选择基于数据库存储。执行课前资料提供的《seata-tc.sql》,导入数据库表:
准备配置文件
课前资料准备了一个seata目录,其中包含了seata运行时所需要的配置文件:
其中包含中文注释,大家可以自行阅读。
我们将整个seata文件夹拷贝到虚拟机的/root目录:
Docker部署
需要注意,要确保nacos、mysql都在hm-net网络中。如果某个容器不再hm-net网络,可以参考下面的命令将某容器加入指定网络:
docker network connect [网络名] [容器名]
在虚拟机的/root目录执行下面的命令:
docker run --name seata \
-p 8099:8099 \
-p 7099:7099 \
-e SEATA_IP=192.168.150.101 \
-v ./seata:/seata-server/resources \
--privileged=true \
--network hm-net \
-d \
seataio/seata-server:1.5.2
微服务集成Seata
参与分布式事务的每一个微服务都需要集成Seata,我们以trade-service为例。
引入依赖
为了方便各个微服务集成seata,我们需要把seata配置共享到nacos,因此trade-service模块不仅仅要引入seata依赖,还要引入nacos依赖:
<!--统一配置管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--读取bootstrap文件--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency><!--seata--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>
改造配置
首先在nacos上添加一个共享的seata配置,命名为shared-seata.yaml:
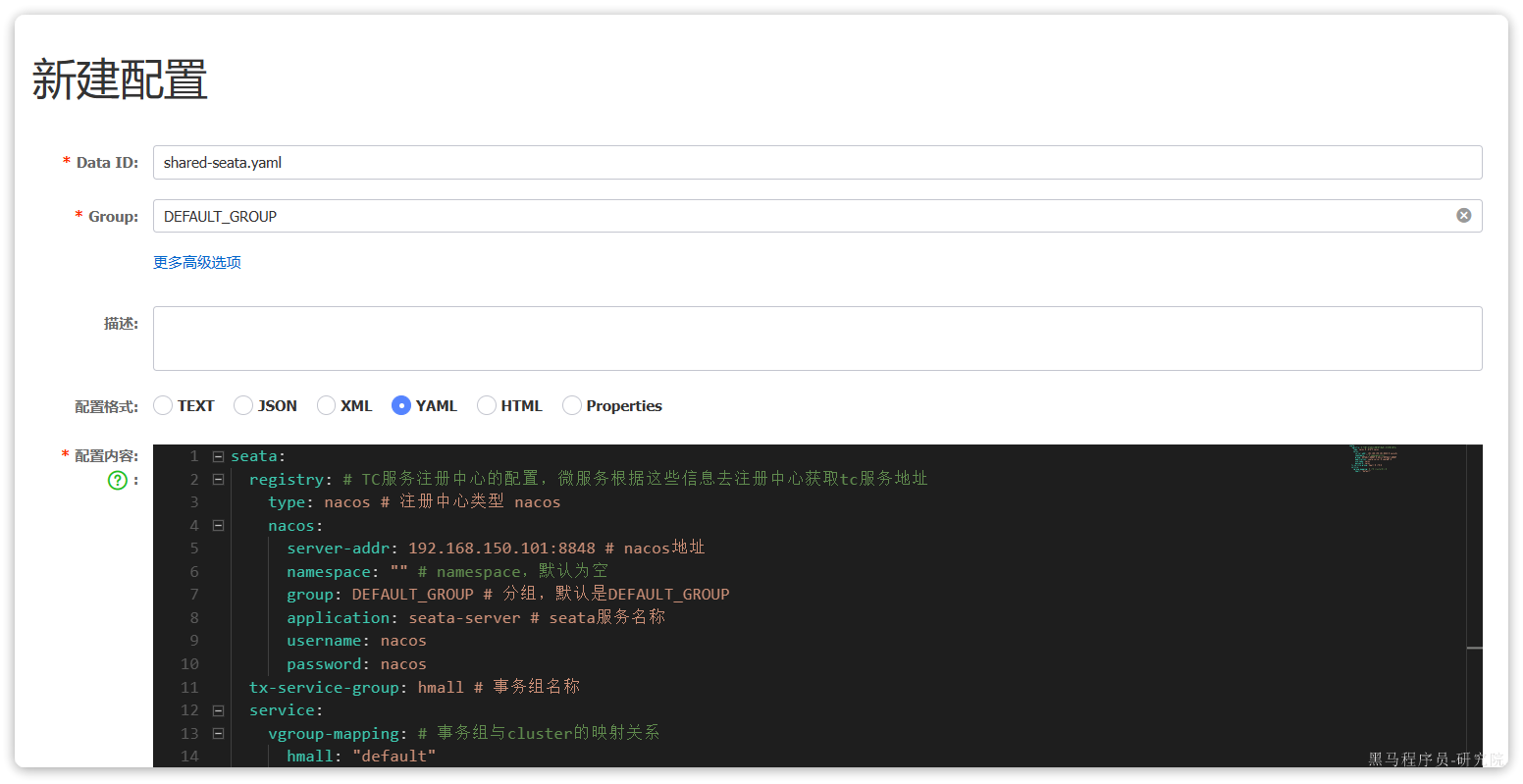
内容如下:
seata:registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址type: nacos # 注册中心类型 nacosnacos:server-addr: 192.168.150.101:8848 # nacos地址namespace: "" # namespace,默认为空group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUPapplication: seata-server # seata服务名称username: nacospassword: nacostx-service-group: hmall # 事务组名称service:vgroup-mapping: # 事务组与tc集群的映射关系hmall: "default"
然后,改造trade-service模块,添加bootstrap.yaml:
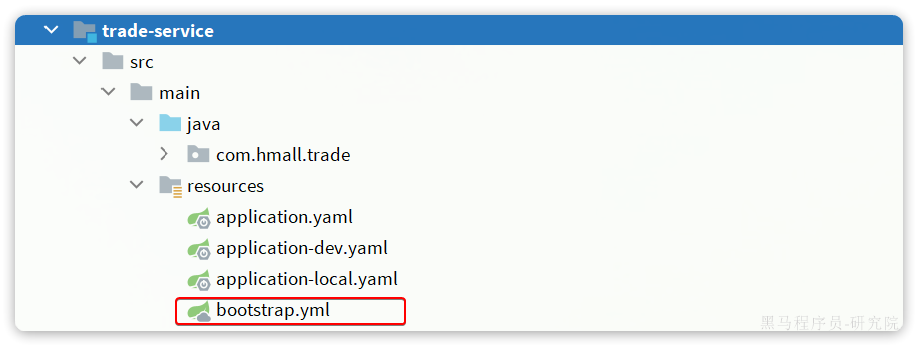
内容如下:
spring:application:name: trade-service # 服务名称profiles:active: devcloud:nacos:server-addr: 192.168.150.101 # nacos地址config:file-extension: yaml # 文件后缀名shared-configs: # 共享配置- dataId: shared-jdbc.yaml # 共享mybatis配置- dataId: shared-log.yaml # 共享日志配置- dataId: shared-swagger.yaml # 共享日志配置- dataId: shared-seata.yaml # 共享seata配置
可以看到这里加载了共享的seata配置。
然后改造application.yaml文件,内容如下:
server:port: 8085
feign:okhttp:enabled: true # 开启OKHttp连接池支持sentinel:enabled: true # 开启Feign对Sentinel的整合
hm:swagger:title: 交易服务接口文档package: com.hmall.trade.controllerdb:database: hm-trade
参考上述办法分别改造hm-cart和hm-item两个微服务模块。
添加数据库表
seata的客户端在解决分布式事务的时候需要记录一些中间数据,保存在数据库中。因此我们要先准备一个这样的表。
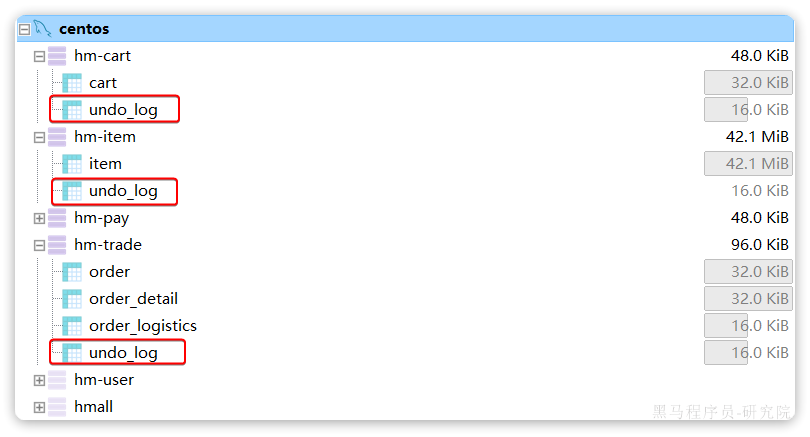
将课前资料的seata-at.sql分别文件导入hm-trade、hm-cart、hm-item三个数据库中:
结果:
测试
接下来就是测试的分布式事务的时候了。
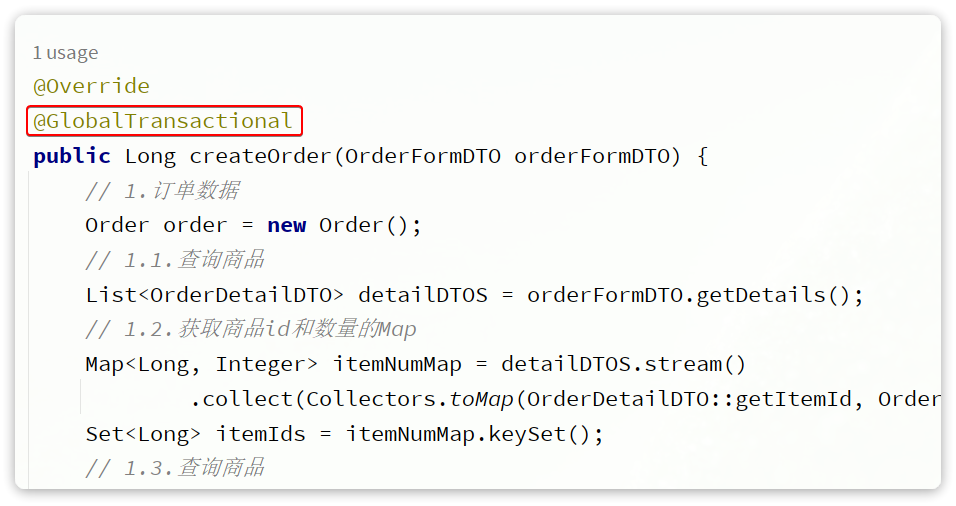
我们找到trade-service模块下的com.hmall.trade.service.impl.OrderServiceImpl类中的createOrder方法,也就是下单业务方法。
将其上的@Transactional注解改为Seata提供的@GlobalTransactional:
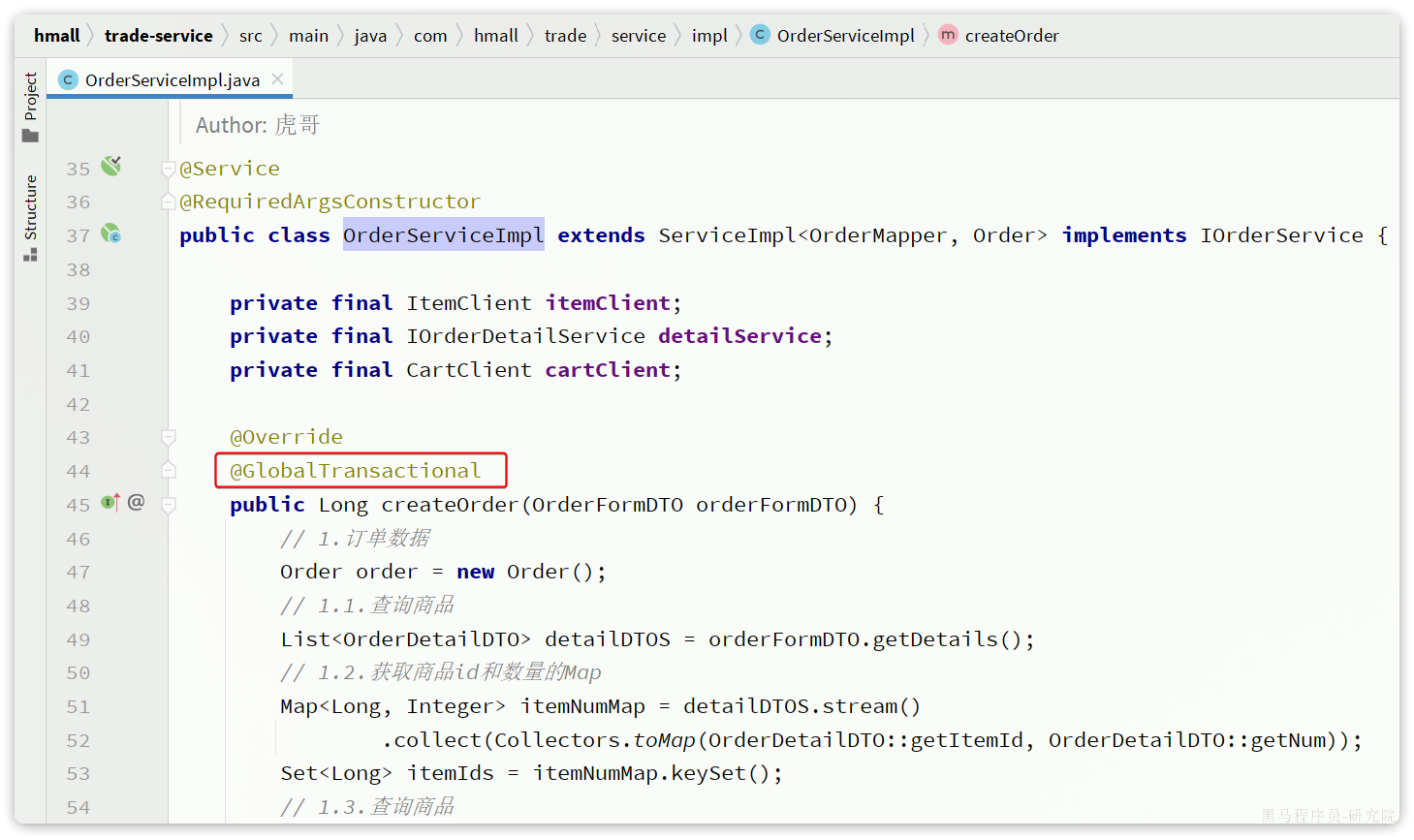
@GlobalTransactional注解就是在标记事务的起点,将来TM就会基于这个方法判断全局事务范围,初始化全局事务。
XA模式
Seata支持四种不同的分布式事务解决方案:
- XA
- TCC
- AT
- SAGA
这里我们以XA模式和AT模式来给大家讲解其实现原理。
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。
两阶段提交
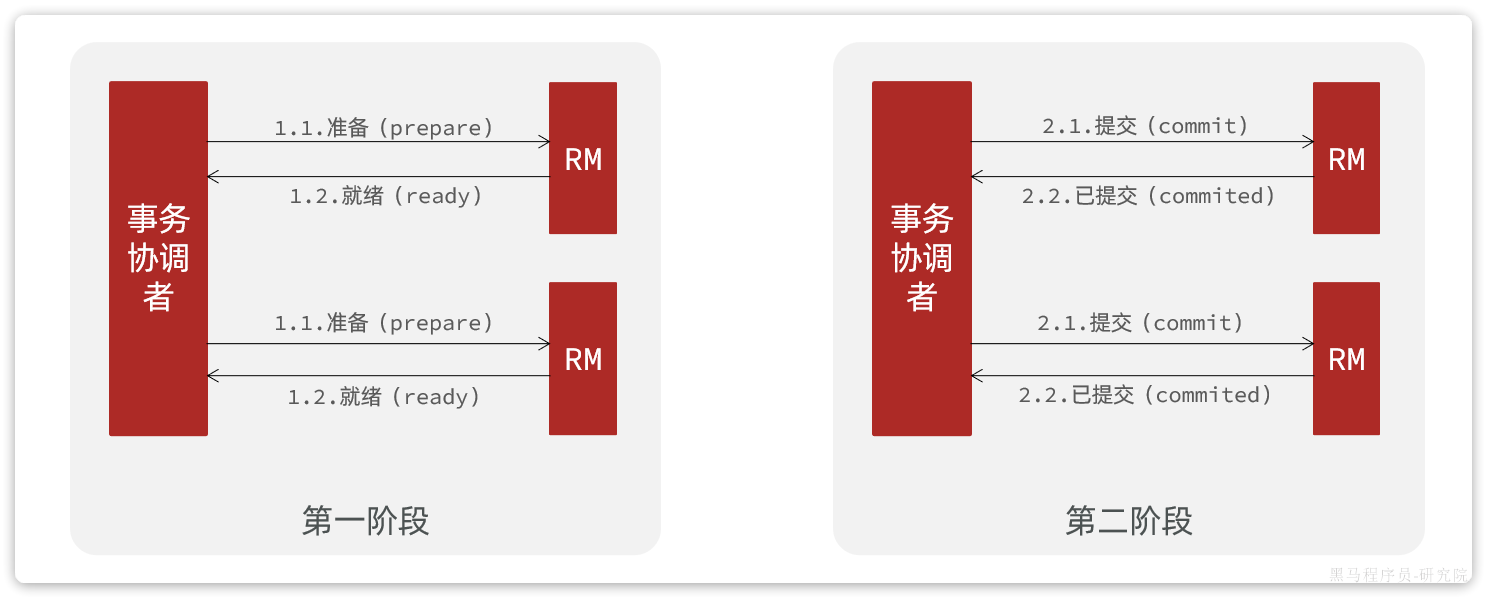
A是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
正常情况:
异常情况:
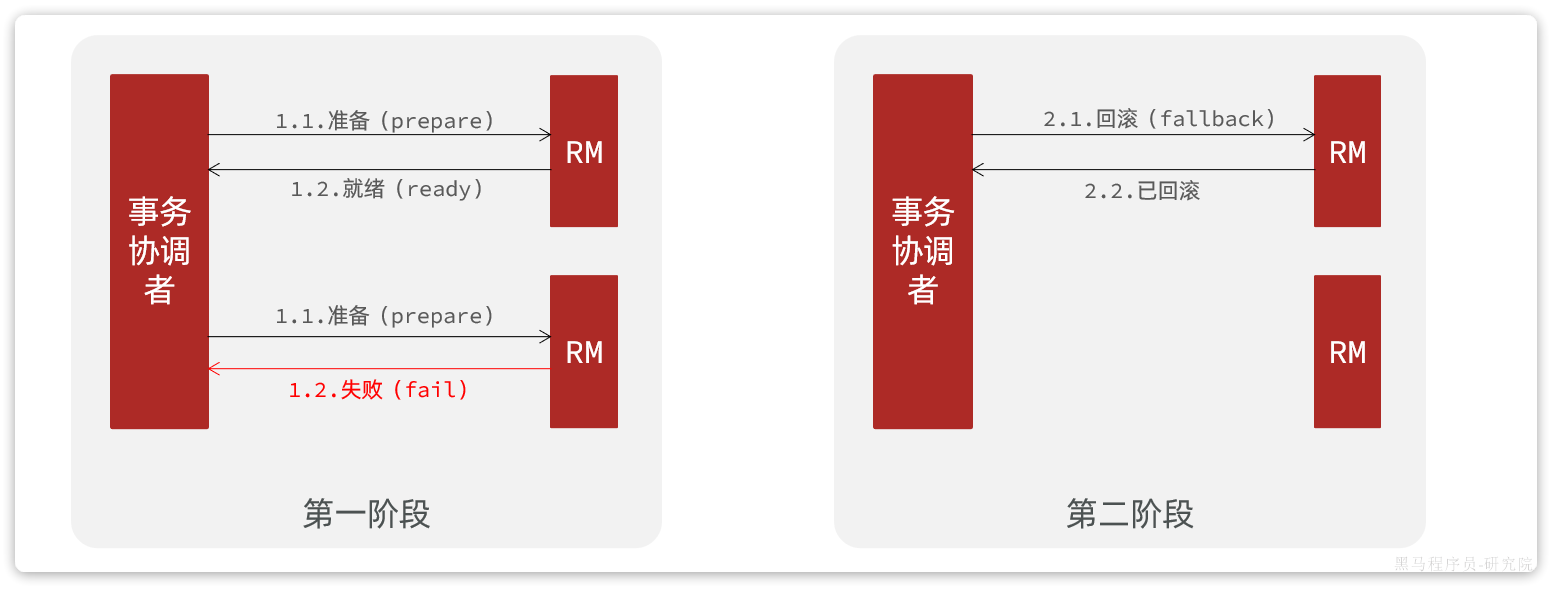
一阶段:
- 事务协调者通知每个事务参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务
Seata的XA模型
Seata对原始的XA模式做了简单的封装和改造,以适应自己的事务模型,基本架构如图:
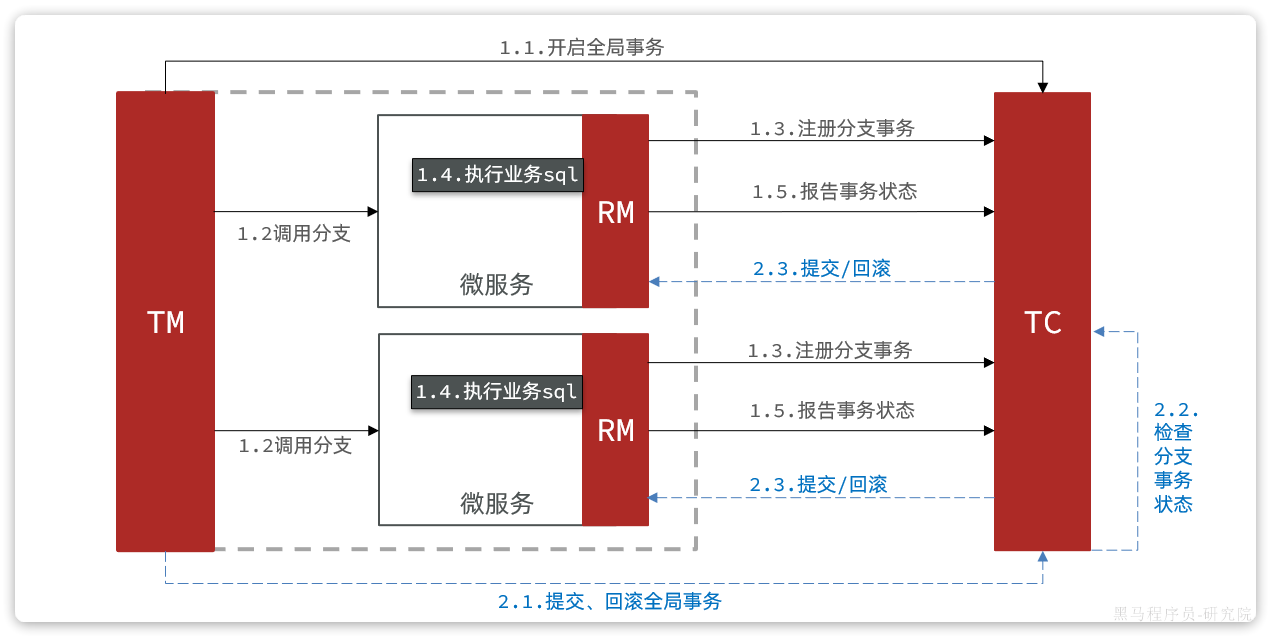
RM一阶段的工作:
- 注册分支事务到
TC - 执行分支业务sql但不提交
- 报告执行状态到
TC
TC二阶段的工作:
TC检测各分支事务执行状态- 如果都成功,通知所有RM提交事务
- 如果有失败,通知所有RM回滚事务
优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
实现步骤
首先,我们要在配置文件中指定要采用的分布式事务模式。我们可以在Nacos中的共享shared-seata.yaml配置文件中设置:
seata:data-source-proxy-mode: XA
其次,我们要利用@GlobalTransactional标记分布式事务的入口方法:
AT模式
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
Seata的AT模型
基本流程图:
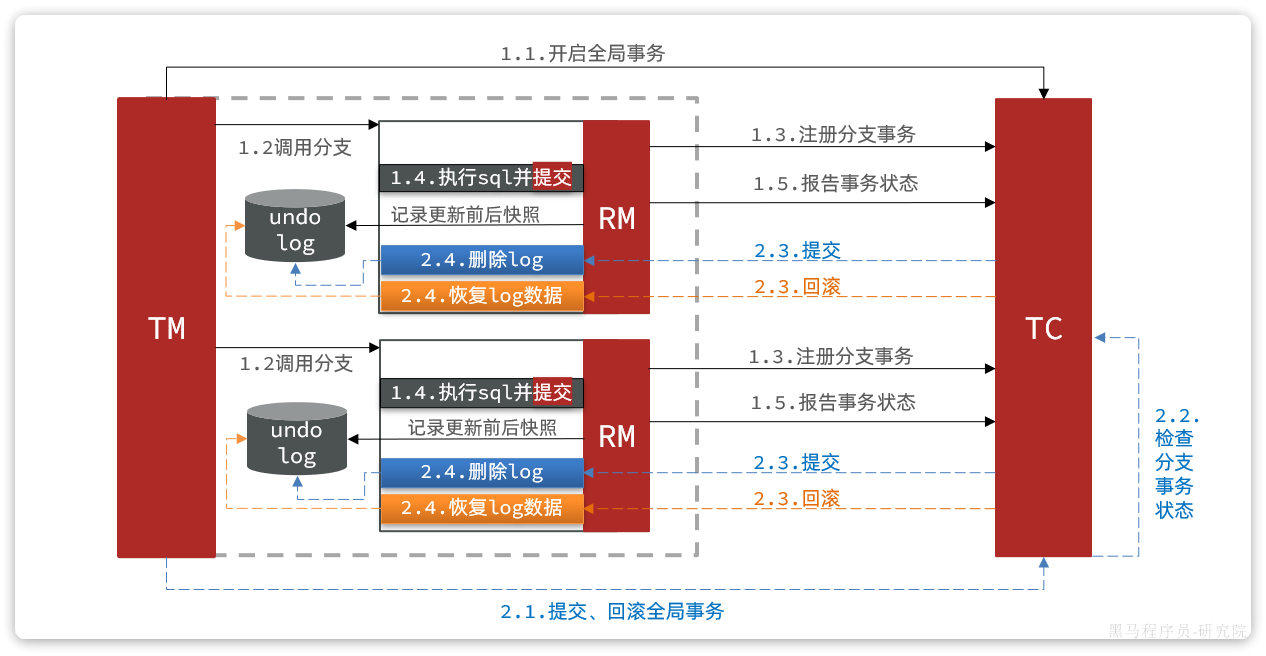
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
流程图:
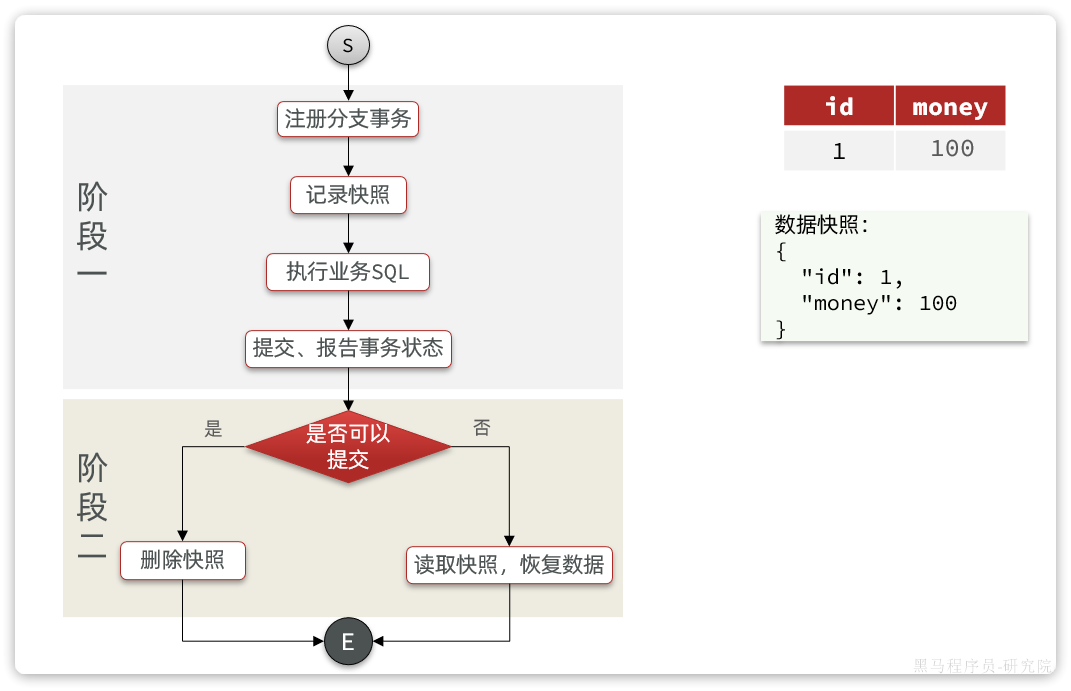
AT的脏写问题
但是AT在极端情况下,特别是多线程并发访问AT模式的分布式事务时,有可能出现脏写问题,如图:
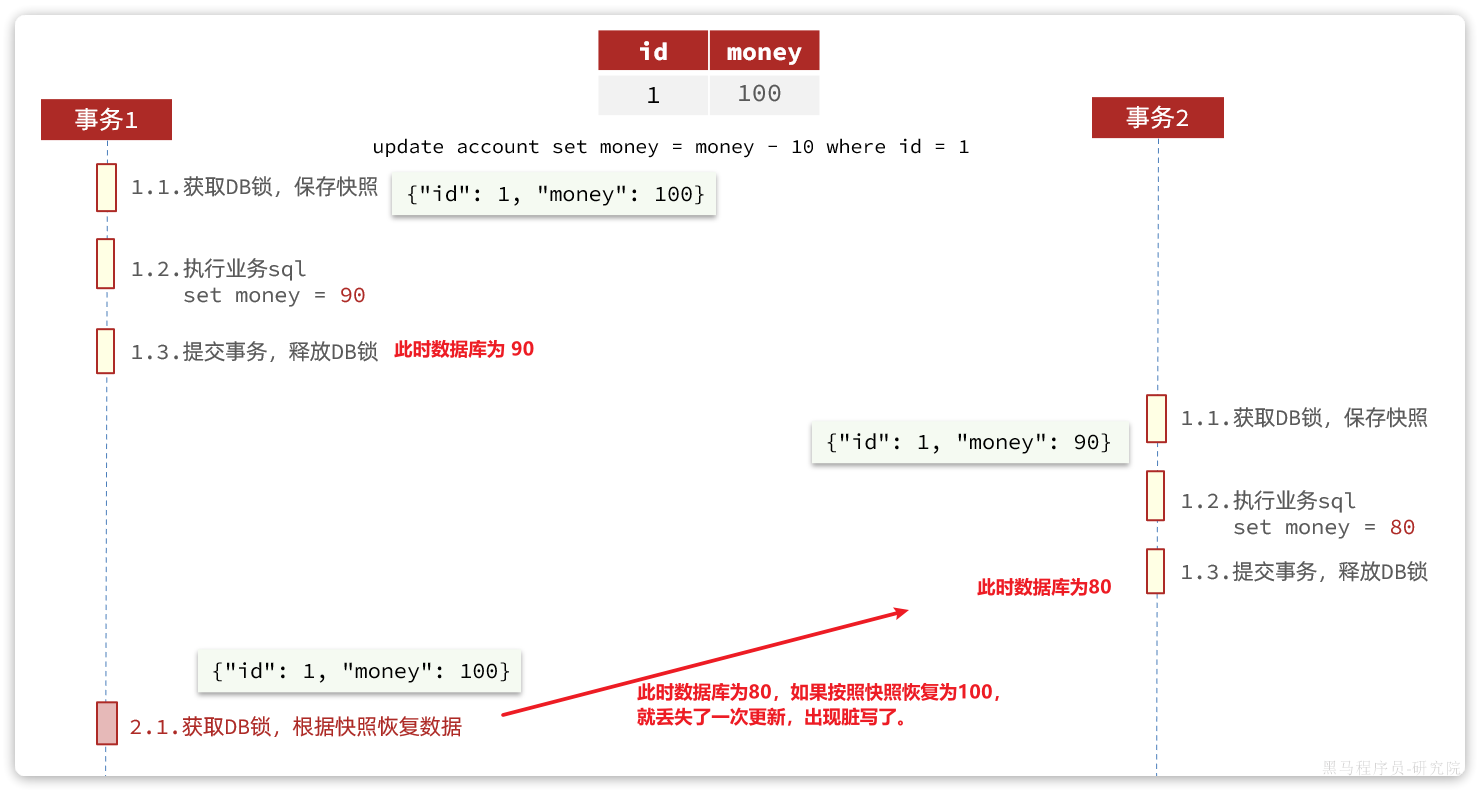
在一个全局事务处理的时候,另一个独立的事务如果操作同一个数据就会可能出现回滚后另一个事务白操作了情况。
解决思路就是引入了全局锁的概念。在释放DB锁之前,先拿到全局锁。避免同一时刻有另外一个事务来操作当前数据。

具体可以参考官方文档:
https://seata.io/zh-cn/docs/dev/mode/at-mode.html
除此之外,针对非seata管理的事务修改数据产生的影响,我们认为这个情况发生概率较小,但是还是要考虑,于是在产生快照时,设置两份快照,分别是修改前的快照和修改后的,修改前的用于回滚数据,修改后的用于回滚前的比较,若是比较不一致,说明在这个过程中数据被修改过了,不能回滚。
AT与XA的区别
简述AT模式与XA模式最大的区别是什么?
XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。XA模式强一致;AT模式最终一致
可见,AT模式使用起来更加简单,无业务侵入,性能更好。因此企业90%的分布式事务都可以用AT模式来解决。
TCC模式
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复(存在业务侵入)。需要实现三个方法:
try:资源的检测和预留;confirm:完成资源操作业务;要求try成功confirm一定要能成功。cancel:预留资源释放,可以理解为try的反向操作。
流程分析
举例,一个扣减用户余额的业务。假设账户A原来余额是100,需要余额扣减30元。采用新建一个包含冻结金额的数据表实现对应的冻结操作;
阶段一( Try ):检查余额是否充足,如果充足则冻结金额增加30元,可用余额扣除30
初始余额:

余额充足,可以冻结:

此时,总金额 = 冻结金额 + 可用金额,数量依然是100不变。事务直接提交无需等待其它事务。
阶段二(Confirm):假如要提交(Confirm),之前可用金额已经扣减,并转移到冻结金额。因此可用金额不变,直接冻结金额扣减30即可:

此时,总金额 = 冻结金额 + 可用金额 = 0 + 70 = 70元
阶段二(Canncel):如果要回滚(Cancel),则释放之前冻结的金额,也就是冻结金额扣减30,可用余额增加30

事务悬挂和空回滚
假如一个分布式事务中包含两个分支事务,try阶段,一个分支成功执行,另一个分支事务阻塞:
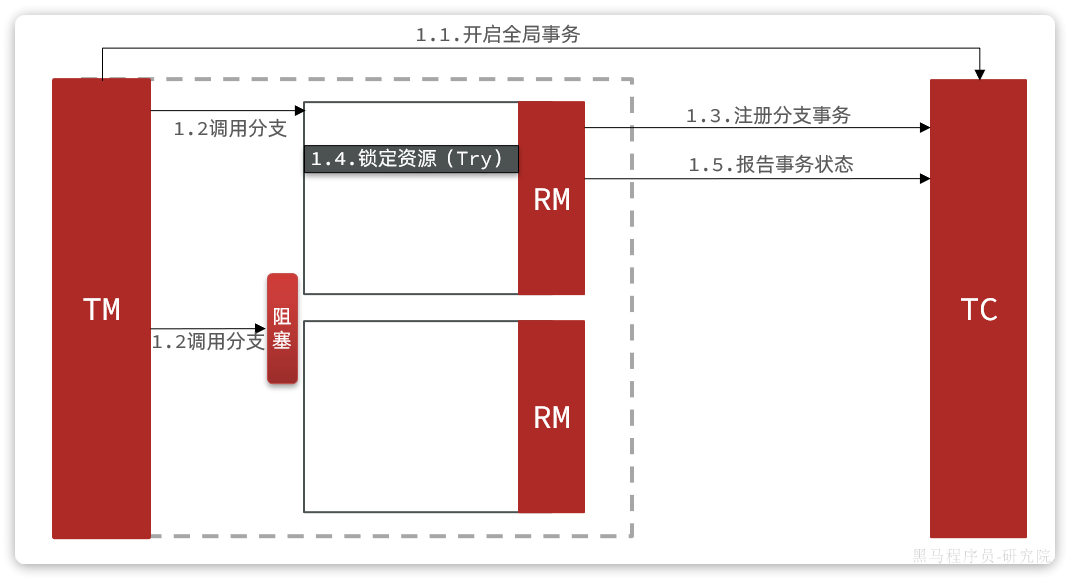
如果阻塞时间太长,可能导致全局事务超时而触发二阶段的cancel操作。两个分支事务都会执行cancel操作:
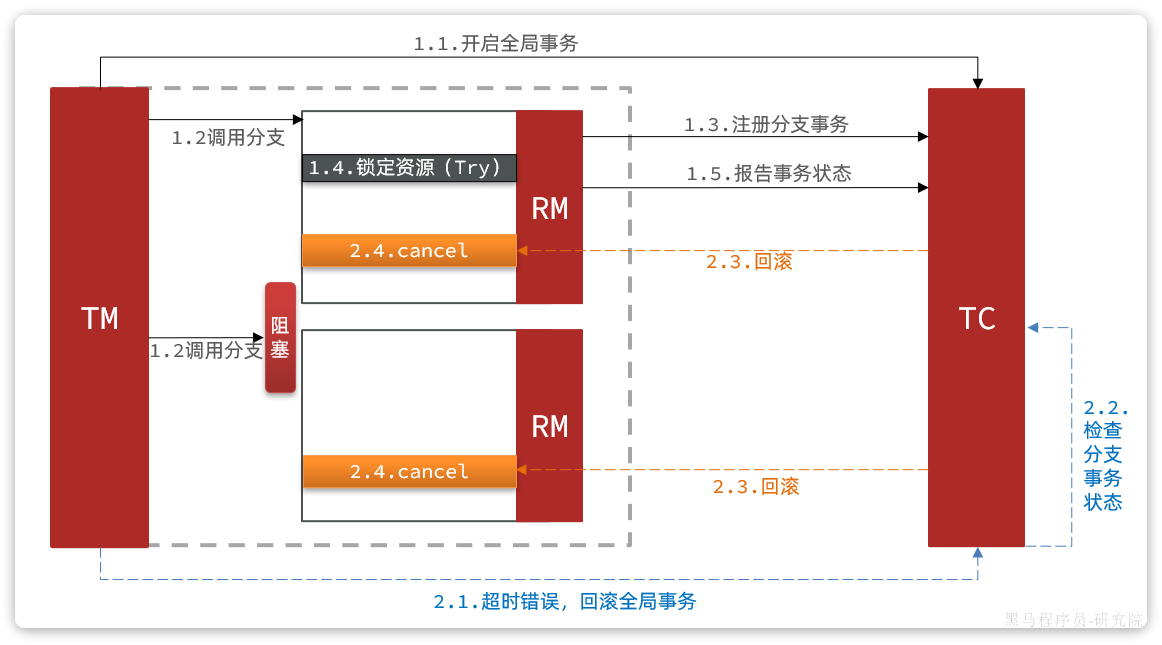
要知道,其中一个分支是未执行try操作的,直接执行了cancel操作,反而会导致数据错误。因此,这种情况下,尽管cancel方法要执行,但其中不能做任何回滚操作,这就是空回滚。
对于整个空回滚的分支事务,将来try方法阻塞结束依然会执行。但是整个全局事务其实已经结束了,因此永远不会再有confirm或cancel,也就是说这个事务执行了一半,处于悬挂状态,这就是业务悬挂问题。
以上问题都需要我们在编写try、cancel方法时处理。
总结
TCC模式的每个阶段是做什么的?
- Try:资源检查和预留
- Confirm:业务执行和提交
- Cancel:预留资源的释放
TCC的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模型,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC的缺点是什么?
- 有代码侵入,需要人为编写try、Confirm和Cancel接口,太麻烦
- 软状态,事务是最终一致
- 需要考虑Confirm和Cancel的失败情况,做好幂等处理、事务悬挂和空回滚处理
四种模式对比
| XA | AT | TCC | SAGA | |
|---|---|---|---|---|
| 一致性 | 强一致 | 弱一致 | 弱一致 | 最终一致 |
| 隔离性 | 完全隔离 | 基于全局锁隔离 | 基于资源预留隔离 | 无隔离 |
| 代码侵入 | 无 | 无 | 有,要编写三个接口 | 有,要编写状态机和补偿业务 |
| 性能 | 差 | 好 | 非常好 | 非常好 |
| 场景 | 对一致性、隔离性 有高要求的业务 | 基于关系型数据库的 大多数分布式事务场 景都可以 | 1、对性能要求较高的事务。 2、有非关系型数据库要参 与的事务。 | 1、业务流程长、业务流程多 2、参与者包含其它公司或遗留 系统服务,无法提供TCC 模式要求的三个接口 |
总结
核心问题:分布式事务挑战
在分布式系统(微服务架构)中,一个业务操作(全局事务)会调用多个服务,每个服务在其独立的数据库上执行操作(分支事务)。要保证所有分支事务要么全部成功,要么全部失败,是极其复杂的。单个数据库的 ACID 事务无法解决跨数据库、跨服务的数据一致性问题。
通用解决方案:事务协调者
核心思路是引入一个事务协调者 (Transaction Coordinator) 来统一调度和管理所有参与事务的资源。
- 角色:协调者像一个大项目的总指挥,它不干具体活,但负责掌握所有部分的进度,并最终下达“全部提交”或“全部回滚”的指令。
- 标准协议:最著名的协议是两阶段提交 (2PC),分为准备阶段(投票)和提交阶段(执行)。
Seata 的架构:三大角色
Seata 实现了上述思想,并将其抽象为三个角色:
| 角色 | 中文名 | 职责 | 部署方式 | 生动比喻 |
|---|---|---|---|---|
| TC (Transaction Coordinator) | 事务协调者 | 维护全局和分支事务的状态,驱动最终的全局提交或回滚。是大脑和中枢。 | 独立部署的 Server 端组件。 | 总经理办公室:负责决策和调度,不处理具体业务。 |
| TM (Transaction Manager) | 事务管理器 | 定义全局事务的边界(开始、结束),并最终向 TC 发起全局提交或回滚的决议。 | 嵌入在业务应用中。 | 部门经理:决定启动一个大项目,并在完成后向总经办汇报结果。 |
| RM (Resource Manager) | 资源管理器 | 管理分支事务,向 TC 注册分支状态、报告状态,并负责本地事务的提交和回滚。 | 嵌入在业务应用中。 | 一线员工:执行具体的业务操作(SQL),并向总经办汇报自己的工作状态。 |
核心关系:TM 和 RM 是集成在应用程序中的客户端,它们与独立部署的 TC 服务器进行通信,共同完成分布式事务。
重点模式详解
XA 模式(XA Transaction Mode)
- 工作原理:
基于数据库本身支持的 XA 协议(两阶段提交协议)。- 一阶段 (准备阶段):TM、RM注册全局事务,锁定资源不提交,RM向TC报告状态
- 二阶段 (提交/回滚阶段):
- 提交:若所有 RM 都报告“Ready”,TC 向所有 RM 发送 XA COMMIT 指令,各分支事务正式提交。
- 回滚:若有任何一个 RM 报告失败,TC 向所有 RM 发送 XA ROLLBACK 指令,所有分支事务回滚。
- 特点:
- 强一致性:在整个事务完成前,资源一直被数据库自身锁定,一致性最高。
- 性能较差:因为锁定时长覆盖整个分布式事务周期,并发性能低。
AT 模式(Auto Transaction Mode)
- 流程:
- 一阶段:RM 执行业务 SQL 并提交,同时将数据前后镜像生成
undo_log记录到同一数据库。 - 二阶段:
- 提交:TC 通知所有 RM 异步删除
undo_log。 - 回滚:RM 根据
undo_log生成反向 SQL 执行回滚,然后删除日志。
- 提交:TC 通知所有 RM 异步删除
- 一阶段:RM 执行业务 SQL 并提交,同时将数据前后镜像生成
- 脏写问题:因为一阶段已提交,其他事务可能修改数据,导致回滚失败。
- 解决方案:Seata 通过全局锁(一张内置表)来防止其他事务更新正在被全局事务处理的数据。回滚时会对比修改后的快照,若不一致则报警人工处理。
TCC 模式 (Try-Confirm-Cancel Mode)
- 工作原理:
TCC 是一种业务侵入性极强的模式,并没有和之前一样采用两阶段提交协议,他要求开发者将一个业务逻辑拆分为三个操作:- Try (尝试):资源检查和预留。完成所有业务的检查,并预留必须的资源。例如,将库存状态从“可用”改为“冻结”,而不是直接扣减。
- Confirm (确认):业务执行。真正执行业务操作,使用 Try 阶段预留的资源。要求 Try 成功 Confirm 一定能成功。例如,将“冻结”的库存状态改为“已扣减”。
- Cancel (取消):补偿回滚。释放 Try 阶段预留的资源。例如,将“冻结”的库存状态改回“可用”。
- 注意事项:
- 空回滚:Try 超时失败后,Cancel 可能会在一个从未执行过 Try 的分支上调用。Cancel 接口需要能识别并处理这种空回滚。
- 防悬挂:一个分支事务,Try 因网络阻塞姗姗来迟,在 Cancel 之后才执行。此时这个 Try 操作不应该成功,需要能判断并丢弃(悬挂)。
- 幂等性:网络原因可能导致重复调用,三个接口都需要保证幂等。
Seata有四种模式,其中的XA和AT比较常见,都是代码无侵入的模式。两者都是二阶段的;
其中XA在1阶段不提交事务,2阶段TC确认所有事务都成功后再提交;
AT需要在每个RM所在数据库都有一张undo_log辅助表;它在1阶段就提交,但是将相关的前后数据记录到undo_log快照当中,如果2阶段成功则删除快照,失败则依据快照恢复数据。
具体操作如下:
实现XA:Nacos设置共享seata配置,设置模式为XA;所有RM涉及的微服务导入依赖并拉取seata共享配置;在全局事务开启的位置添加注解@GlobalTransactional;分支事务所在位置添加@Transactional
实现AT:和XA不同的地方在于,设置模式为AT(默认);为分支事务所在微服务数据库添加undo_log表
XA模式一致性强,但是锁定资源性能较差;
AT模式性能较好但是一致性弱,可能存在读写问题,尤其在高并发的情况下,多个独立事务之间可能存在脏写的问题;
AT解决脏写问题的方案是:1、使用全局锁;2、保存修改前后的快照,修改前的用于回滚,修改后的用于最终的对比,二阶段的时候查看数据是否和刚修改完一样,不一样的报错申请人工介入;
TCC模式存在业务侵入,需要人为编写三个接口,而且需要做好业务幂等、考虑业务悬挂和空回滚的相关内容,依旧存在软连接,是最终一致;但是相比于AT,他无需生成快照,无需加全局锁,性能进一步提高;
Saga模式是SEATA提供的长事务解决方案。一阶段提交,二阶段失败则使用编写的补偿机制进行回滚,和TCC一样存在业务侵入
| XA | AT | TCC | SAGA | |
|---|---|---|---|---|
| 一致性 | 强一致 | 弱一致 | 弱一致 | 最终一致 |
| 隔离性 | 完全隔离 | 基于全局锁隔离 | 基于资源预留隔离 | 无隔离 |
| 代码侵入 | 无 | 无 | 有,要编写三个接口 | 有,要编写状态机和补偿业务 |
| 性能 | 差 | 好 | 非常好 | 非常好 |
| 场景 | 对一致性、隔离性 有高要求的业务 | 基于关系型数据库的 大多数分布式事务场 景都可以 | 1、对性能要求较高的事务。 2、有非关系型数据库要参 与的事务。 | 1、业务流程长、业务流程多 2、参与者包含其它公司或遗留 系统服务,无法提供TCC 模式要求的三个接口 |
RabbitMQ消息队列
为什么用消息队列
同步调用的问题
之前说过,我们现在基于OpenFeign的调用都属于是同步调用,那么这种方式存在哪些问题呢?
举个例子,我们以昨天留给大家作为作业的余额支付功能为例来分析,首先看下整个流程:
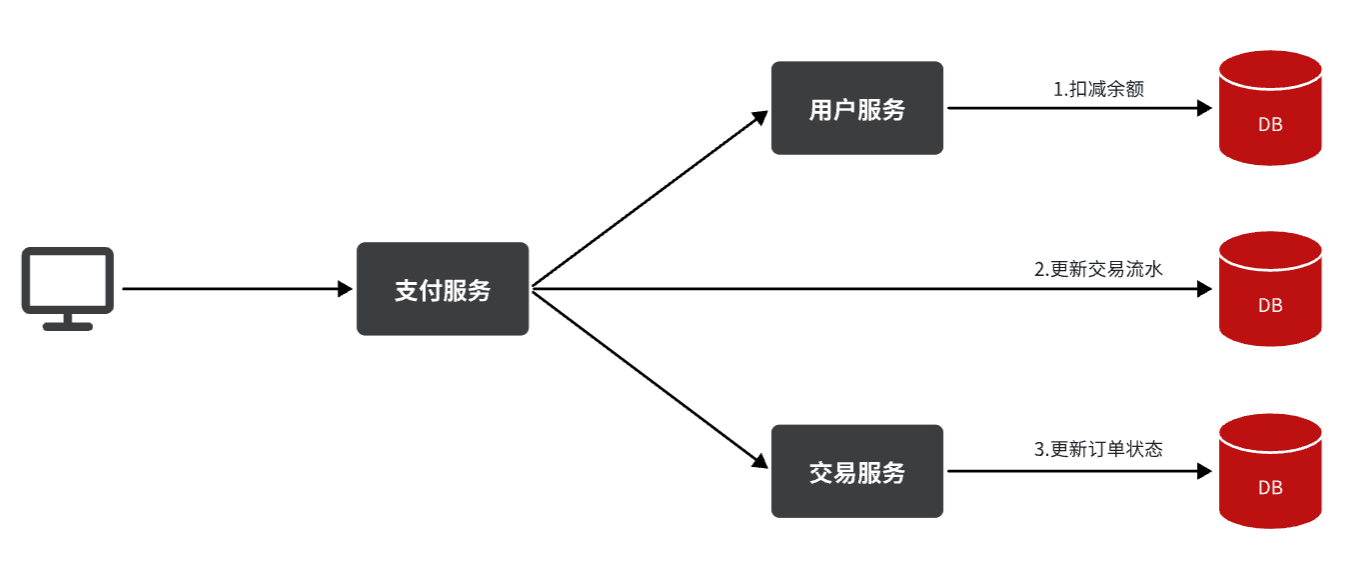
第一,拓展性差
我们目前的业务相对简单,但是随着业务规模扩大,产品的功能也在不断完善。
第二,性能下降
由于我们采用了同步调用,调用者需要等待服务提供者执行完返回结果后,才能继续向下执行,也就是说每次远程调用,调用者都是阻塞等待状态。最终整个业务的响应时长就是每次远程调用的执行时长之和:
第三,级联失败
由于我们是基于OpenFeign调用交易服务、通知服务。当交易服务、通知服务出现故障时,整个事务都会回滚,交易失败。
这其实就是同步调用的级联失败问题。
而要解决这些问题,我们就必须用异步调用的方式来代替同步调用。
异步调用
异步调用方式其实就是基于消息通知的方式,一般包含三个角色:
- 消息发送者:投递消息的人,就是原来的调用方
- 消息Broker:管理、暂存、转发消息,你可以把它理解成微信服务器
- 消息接收者:接收和处理消息的人,就是原来的服务提供方
在异步调用中,发送者不再直接同步调用接收者的业务接口,而是发送一条消息投递给消息Broker。然后接收者根据自己的需求从消息Broker那里订阅消息。每当发送方发送消息后,接受者都能获取消息并处理。
这样,发送消息的人和接收消息的人就完全解耦了。
综上,异步调用的优势包括:
- 耦合度更低
- 性能更好
- 业务拓展性强
- 故障隔离,避免级联失败
- 缓存消息,流量削峰填谷
当然,异步通信也并非完美无缺,它存在下列缺点:
- 完全依赖于Broker的可靠性、安全性和性能
- 架构复杂,后期维护和调试麻烦
- 不能立即得到调用结果,时效性差
技术选型
消息Broker,目前常见的实现方案就是消息队列(MessageQueue),简称为MQ.
目比较常见的MQ实现:
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
几种常见MQ的对比:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
RabbitMQ
安装
我们同样基于Docker来安装RabbitMQ,使用下面的命令即可:
docker run \-e RABBITMQ_DEFAULT_USER=itheima \-e RABBITMQ_DEFAULT_PASS=123321 \-v mq-plugins:/plugins \--name mq \--hostname mq \-p 15672:15672 \-p 5672:5672 \--network hm-net\-d \rabbitmq:3.8-management
可以看到在安装命令中有两个映射的端口:
- 15672:RabbitMQ提供的管理控制台的端口
- 5672:RabbitMQ的消息发送处理接口
安装完成后,我们访问 http://192.168.150.101:15672即可看到管理控制台。首次访问需要登录,默认的用户名和密码在配置文件中已经指定了。
登录后即可看到管理控制台总览页面:
RabbitMQ对应的架构如图:
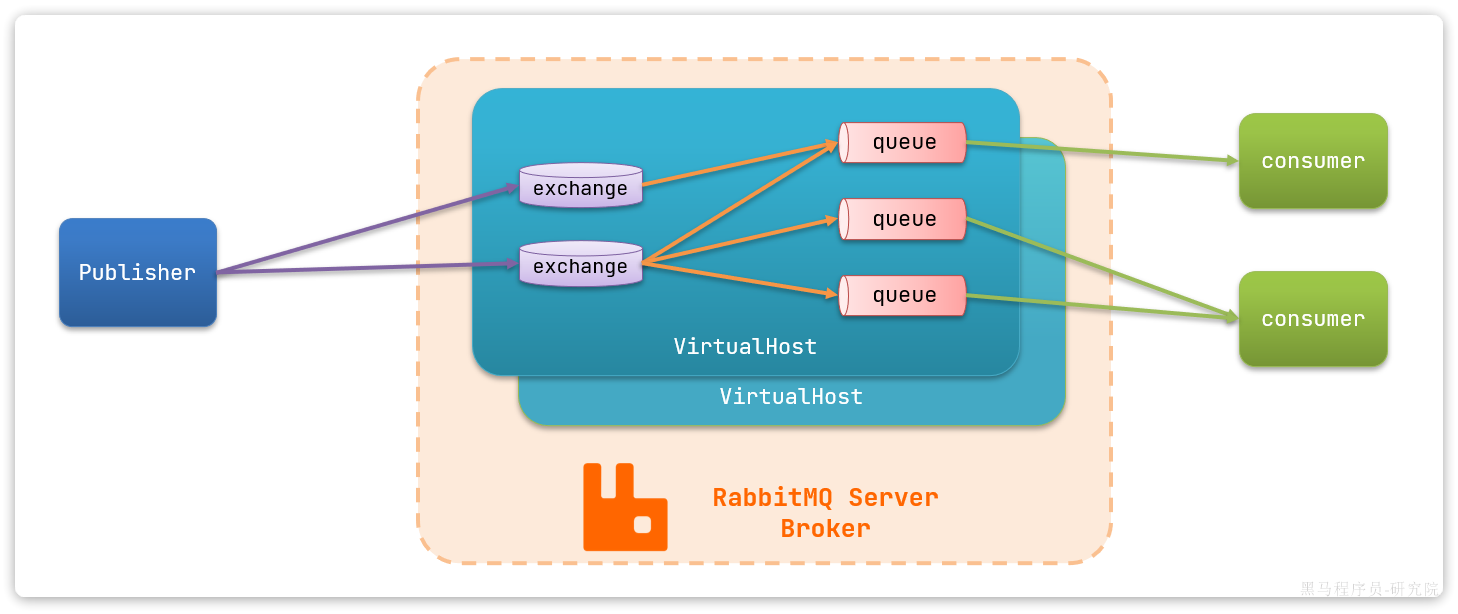
其中包含几个概念:
publisher:生产者,也就是发送消息的一方consumer:消费者,也就是消费消息的一方queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
上述这些东西都可以在RabbitMQ的管理控制台来管理,下一节我们就一起来学习控制台的使用。
收发消息
交换机
我们打开Exchanges选项卡,可以看到已经存在很多交换机:
我们点击任意交换机,即可进入交换机详情页面。仍然会利用控制台中的publish message 发送一条消息:
这里是由控制台模拟了生产者发送的消息。由于没有消费者存在,最终消息丢失了,这样说明交换机没有存储消息的能力。
队列
我们打开Queues选项卡,新建一个队列:
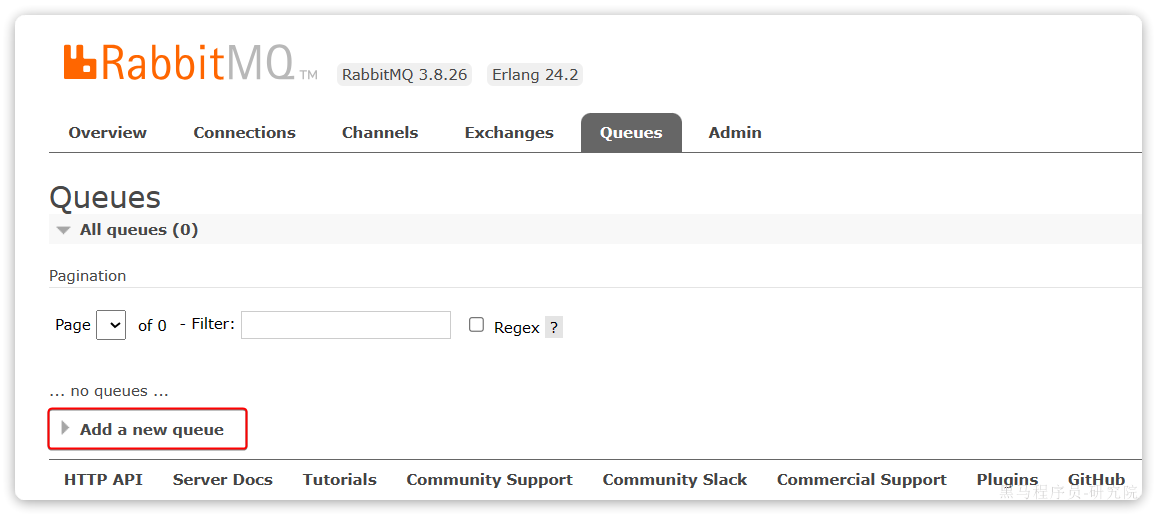
命名为hello.queue1:
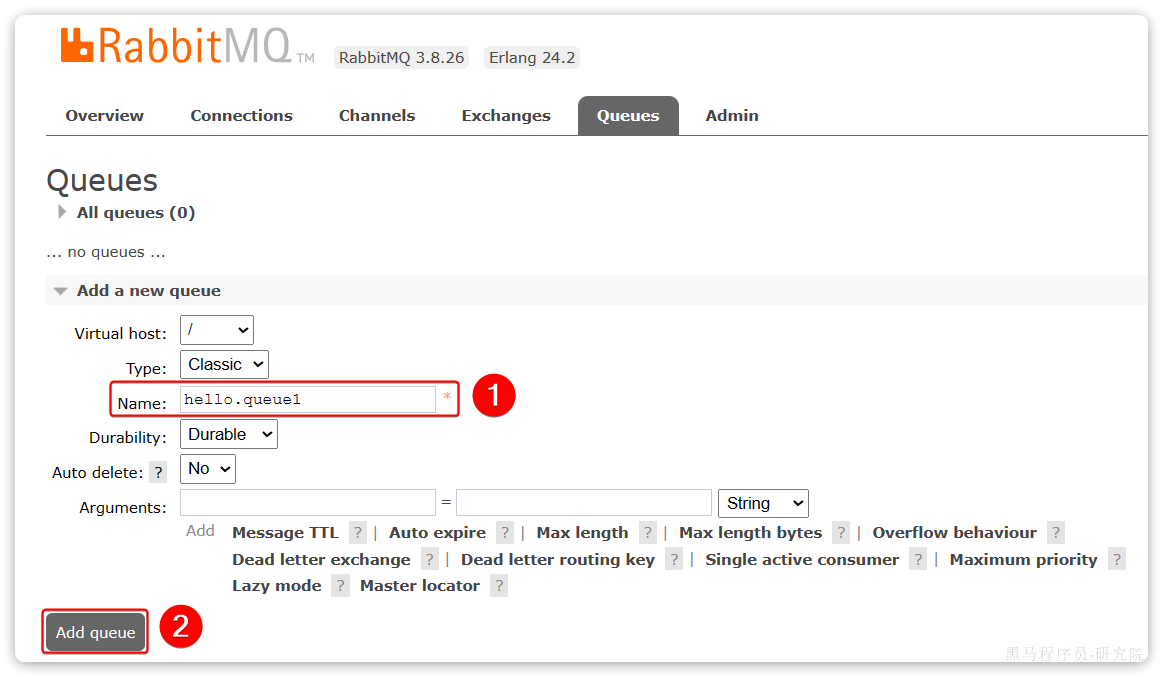
再以相同的方式,创建一个队列,密码为hello.queue2,最终队列列表如下:
此时,我们再次向amq.fanout交换机发送一条消息。会发现消息依然没有到达队列!!
怎么回事呢?
发送到交换机的消息,只会路由到与其绑定的队列,因此仅仅创建队列是不够的,我们还需要将其与交换机绑定。
绑定关系
点击Exchanges选项卡,点击amq.fanout交换机,进入交换机详情页,然后点击Bindings菜单,在表单中填写要绑定的队列名称:
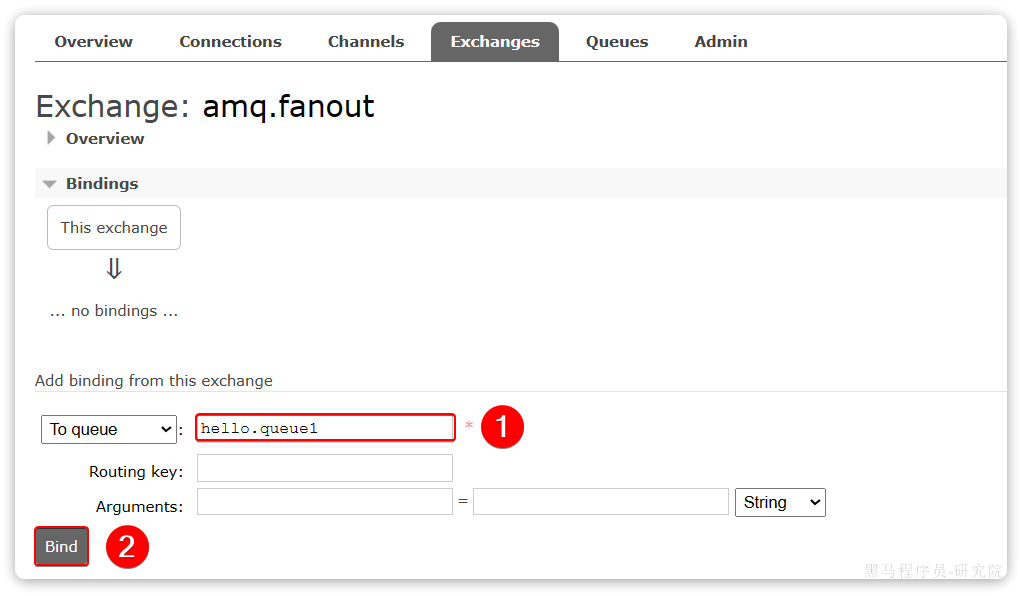
相同的方式,将hello.queue2也绑定到改交换机。
最终,绑定结果如下:
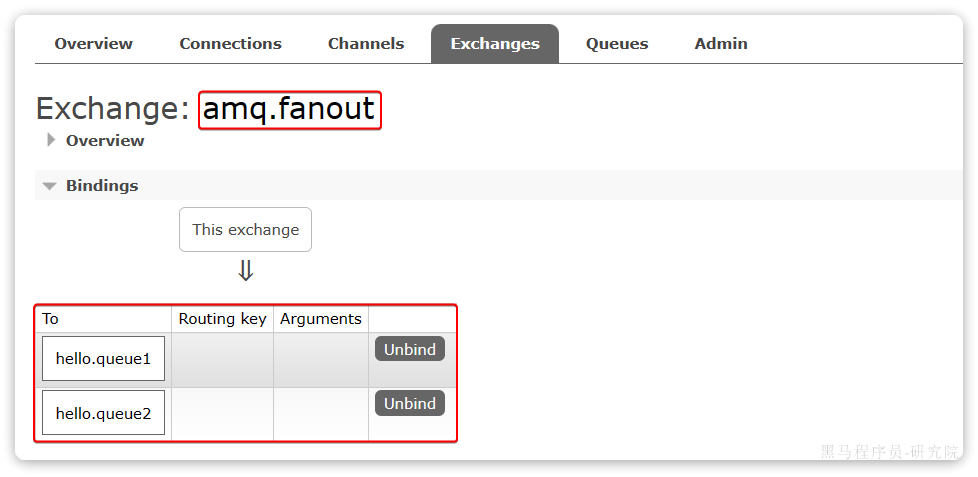
发送消息
再次回到exchange页面,找到刚刚绑定的amq.fanout,点击进入详情页,再次发送一条消息:
回到Queues页面,可以发现hello.queue中已经有一条消息了:
点击队列名称,进入详情页,查看队列详情,这次我们点击get message:
可以看到消息到达队列了:
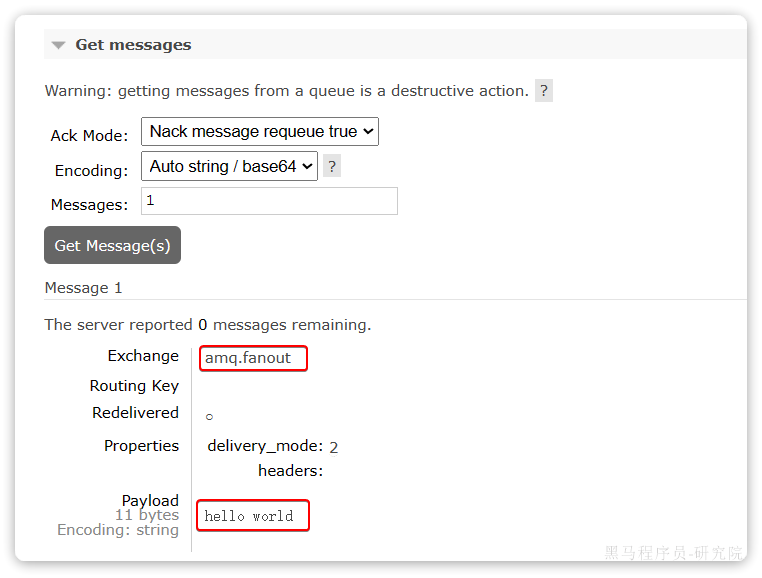
这个时候如果有消费者监听了MQ的hello.queue1或hello.queue2队列,自然就能接收到消息了。
数据隔离
用户管理
点击Admin选项卡,首先会看到RabbitMQ控制台的用户管理界面:
这里的用户都是RabbitMQ的管理或运维人员。目前只有安装RabbitMQ时添加的itheima这个用户。仔细观察用户表格中的字段,如下:
Name:itheima,也就是用户名Tags:administrator,说明itheima用户是超级管理员,拥有所有权限Can access virtual host:/,可以访问的virtual host,这里的/是默认的virtual host
对于小型企业而言,出于成本考虑,我们通常只会搭建一套MQ集群,公司内的多个不同项目同时使用。这个时候为了避免互相干扰, 我们会利用virtual host的隔离特性,将不同项目隔离。一般会做两件事情:
- 给每个项目创建独立的运维账号,将管理权限分离。
- 给每个项目创建不同的
virtual host,将每个项目的数据隔离。
比如,我们给黑马商城创建一个新的用户,命名为hmall:
你会发现此时hmall用户没有任何virtual host的访问权限:
别急,接下来我们就来授权。
virtual host
我们先退出登录:
切换到刚刚创建的hmall用户登录,然后点击Virtual Hosts菜单,进入virtual host管理页:
可以看到目前只有一个默认的virtual host,名字为 /。
我们可以给黑马商城项目创建一个单独的virtual host,而不是使用默认的/。
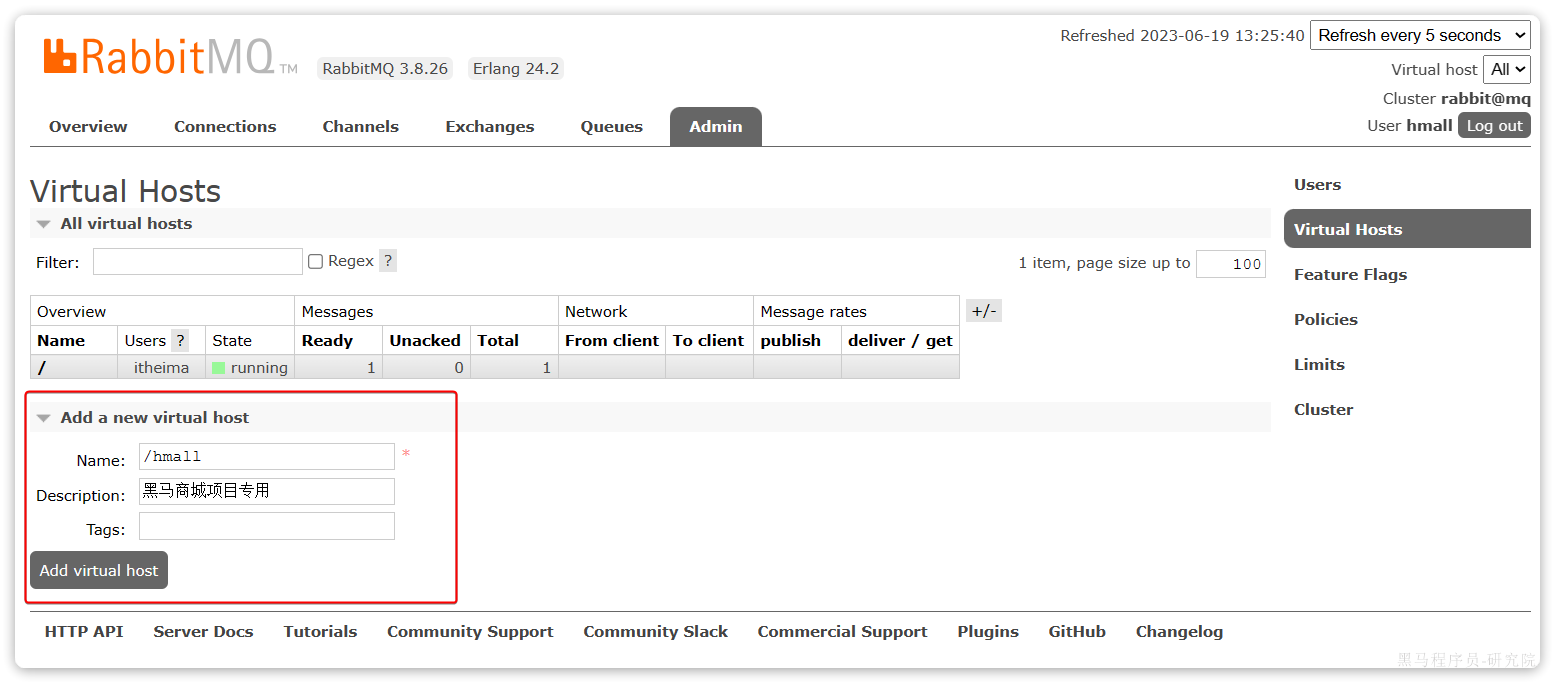
创建完成后如图:
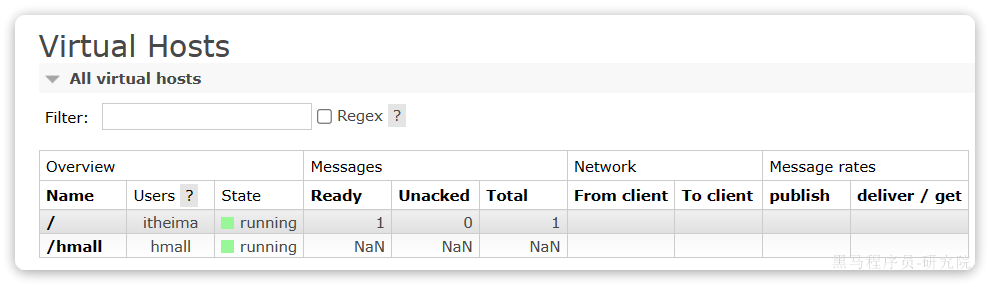
由于我们是登录hmall账户后创建的virtual host,因此回到users菜单,你会发现当前用户已经具备了对/hmall这个virtual host的访问权限了:
此时,点击页面右上角的virtual host下拉菜单,切换virtual host为 /hmall:

然后再次查看queues选项卡,会发现之前的队列已经看不到了:
这就是基于virtual host 的隔离效果。
SpringAMQP
Spring的官方基于RabbitMQ提供了这样一套消息收发的模板工具:SpringAMQP。并且还基于SpringBoot对其实现了自动装配,使用起来非常方便。
SpringAmqp的官方地址:
https://spring.io/projects/spring-amqp
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息
操作
导入相关依赖
<!--AMQP依赖,包含RabbitMQ--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>
配置MQ地址,在publisher服务的application.yml中添加配置:
spring:rabbitmq:host: 192.168.150.101 # 你的虚拟机IPport: 5672 # 端口virtual-host: /hmall # 虚拟主机username: hmall # 用户名password: 123 # 密码
在publisher服务中编写测试类SpringAmqpTest,并利用RabbitTemplate实现消息发送:
package com.itheima.publisher.amqp;
@SpringBootTest
public class SpringAmqpTest {@Autowiredprivate RabbitTemplate rabbitTemplate;@Testpublic void testSimpleQueue() {// 队列名称String queueName = "simple.queue";// 消息String message = "hello, spring amqp!";// 发送消息rabbitTemplate.convertAndSend(queueName, message);}
}
配置MQ地址,在consumer服务的application.yml中添加配置:
spring:rabbitmq:host: 192.168.150.101 # 你的虚拟机IPport: 5672 # 端口virtual-host: /hmall # 虚拟主机username: hmall # 用户名password: 123 # 密码
在consumer服务的com.itheima.consumer.listener包中新建一个类SpringRabbitListener,代码如下:
package com.itheima.consumer.listener;@Component
public class SpringRabbitListener {// 利用RabbitListener来声明要监听的队列信息// 将来一旦监听的队列中有了消息,就会推送给当前服务,调用当前方法,处理消息。// 可以看到方法体中接收的就是消息体的内容@RabbitListener(queues = "simple.queue")public void listenSimpleQueueMessage(String msg) throws InterruptedException {System.out.println("spring 消费者接收到消息:【" + msg + "】");}
}
WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
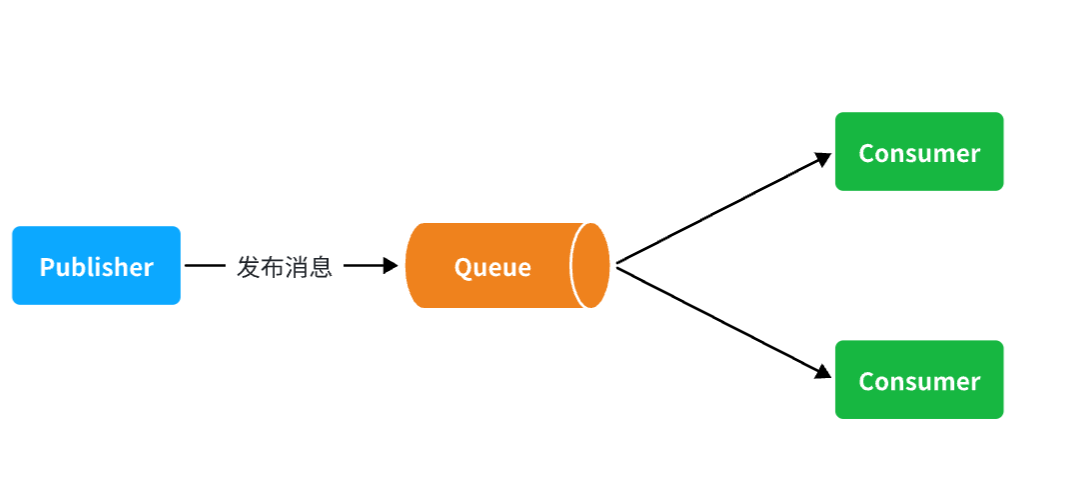
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
能者多劳
没有配置的时候,默认是平均分配给消费者的
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
当prefetch设置为n时,表示消费者每次只能从MQ获取n条消息,只有当这条消息处理完成后,才能获取下n条消息。这样,处理能力强的消费者会更快地处理完当前消息并获取下n条,从而承担更多的消息处理任务。
spring:rabbitmq:listener:simple:prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
交换机类型
在之前的两个测试案例中,都没有交换机,生产者直接发送消息到队列。而一旦引入交换机,消息发送的模式会有很大变化:
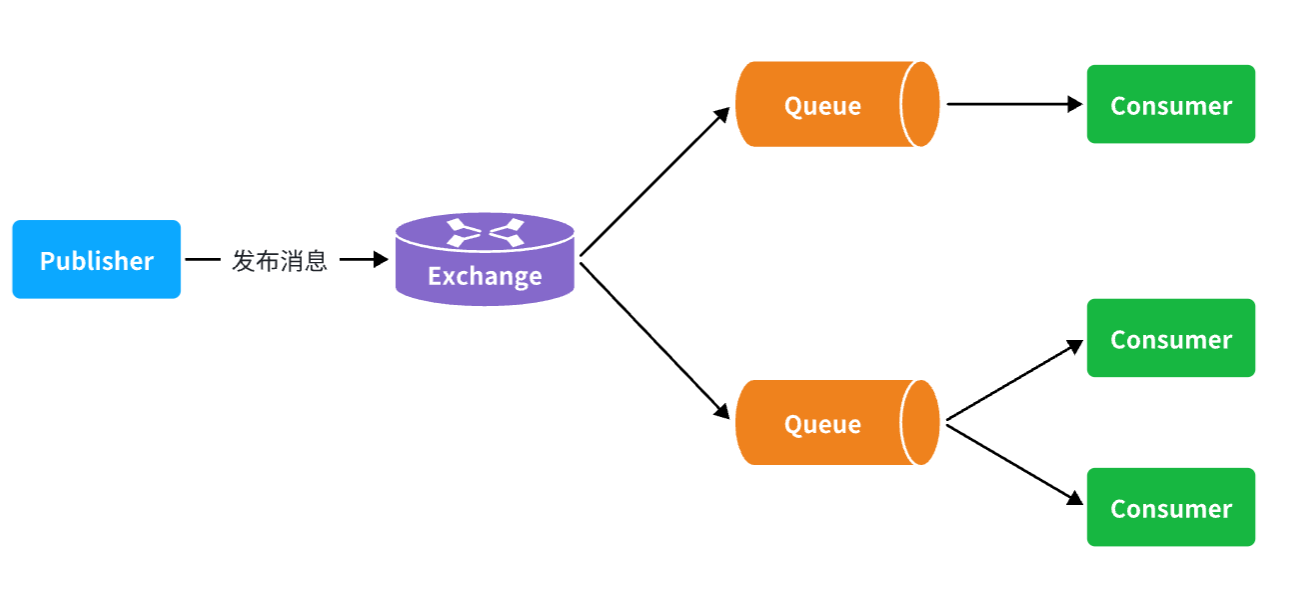
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,不再发送消息到队列中,而是发给交换机
- Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
- Queue:消息队列也与以前一样,接收消息、缓存消息。不过队列一定要与交换机绑定。
- Consumer:消费者,与以前一样,订阅队列,没有变化
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
交换机的类型有四种:
- Fanout:广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
- Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
- Topic:通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
- Headers:头匹配,基于MQ的消息头匹配,用的较少。
Fanout交换机
Fanout,英文翻译是扇出,我觉得在MQ中叫广播更合适。
在广播模式下,消息发送流程是这样的:
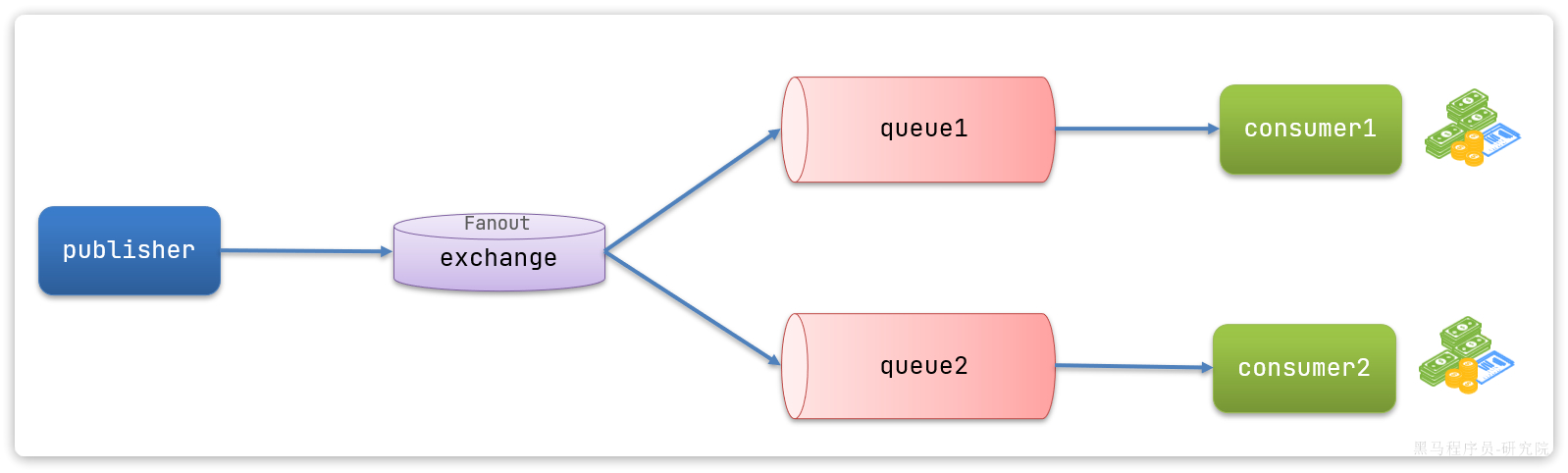
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
声明队列和交换机
在控制台创建队列fanout.queue1:
在创建一个队列fanout.queue2:
然后再创建一个交换机:
然后绑定两个队列到交换机:
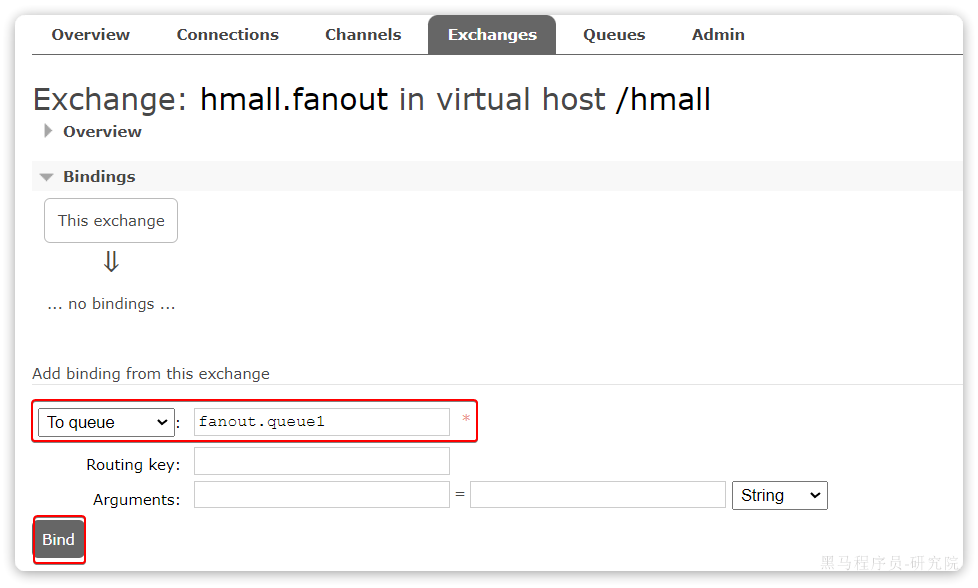
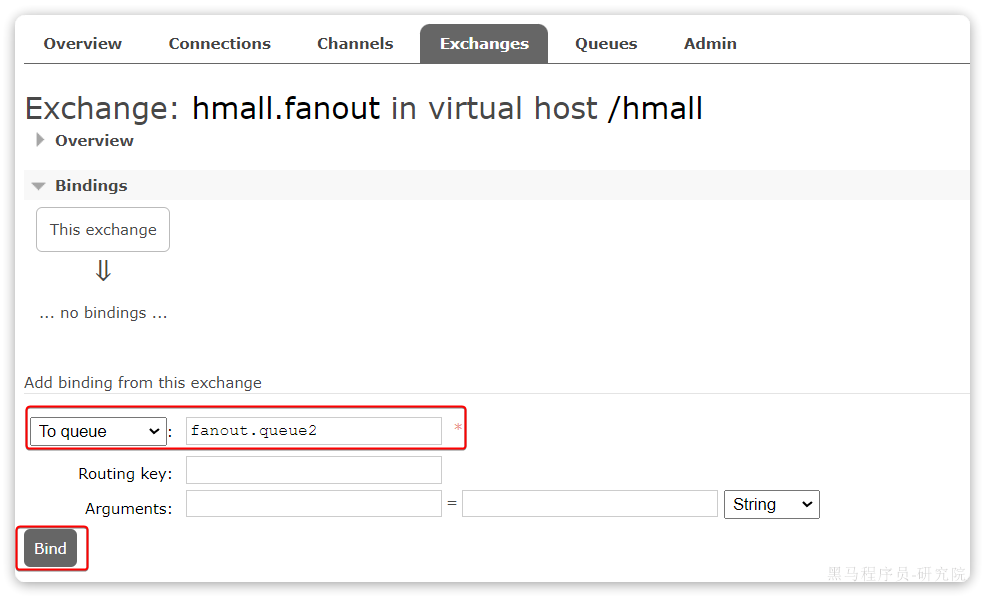
消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
public void testFanoutExchange() {// 交换机名称String exchangeName = "hmall.fanout";// 消息String message = "hello, everyone!";rabbitTemplate.convertAndSend(exchangeName, "", message);
}
息接收
在consumer服务的SpringRabbitListener中添加两个方法,作为消费者:
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) {System.out.println("消费者1接收到Fanout消息:【" + msg + "】");
}@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) {System.out.println("消费者2接收到Fanout消息:【" + msg + "】");
}
Direct交换机
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
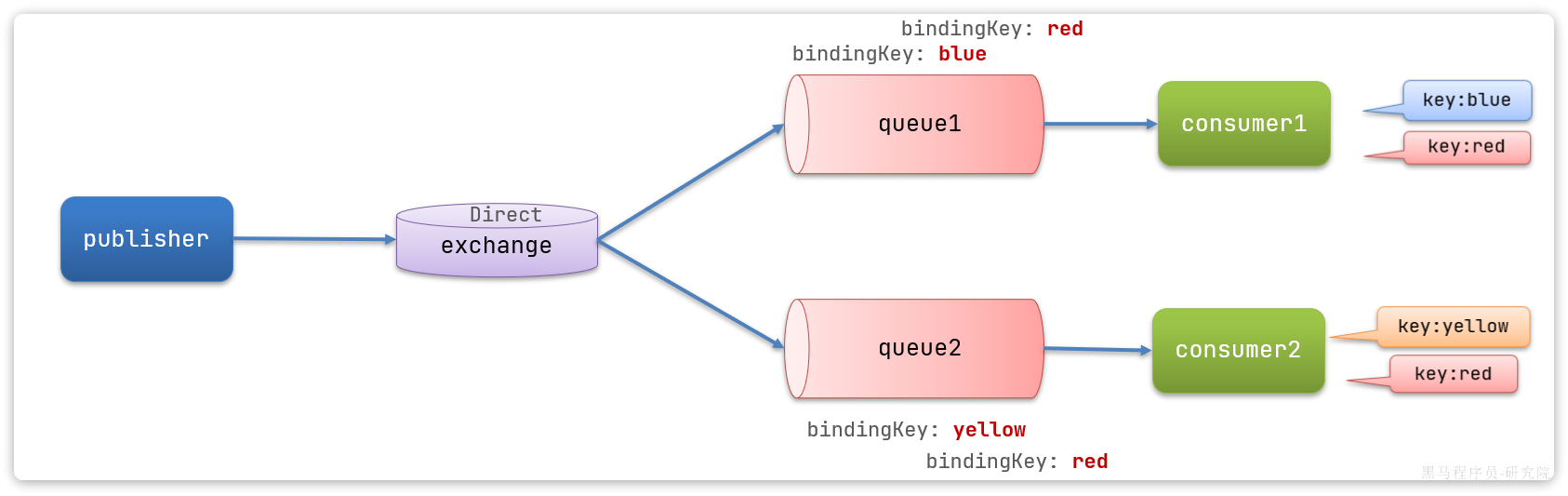
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 - Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
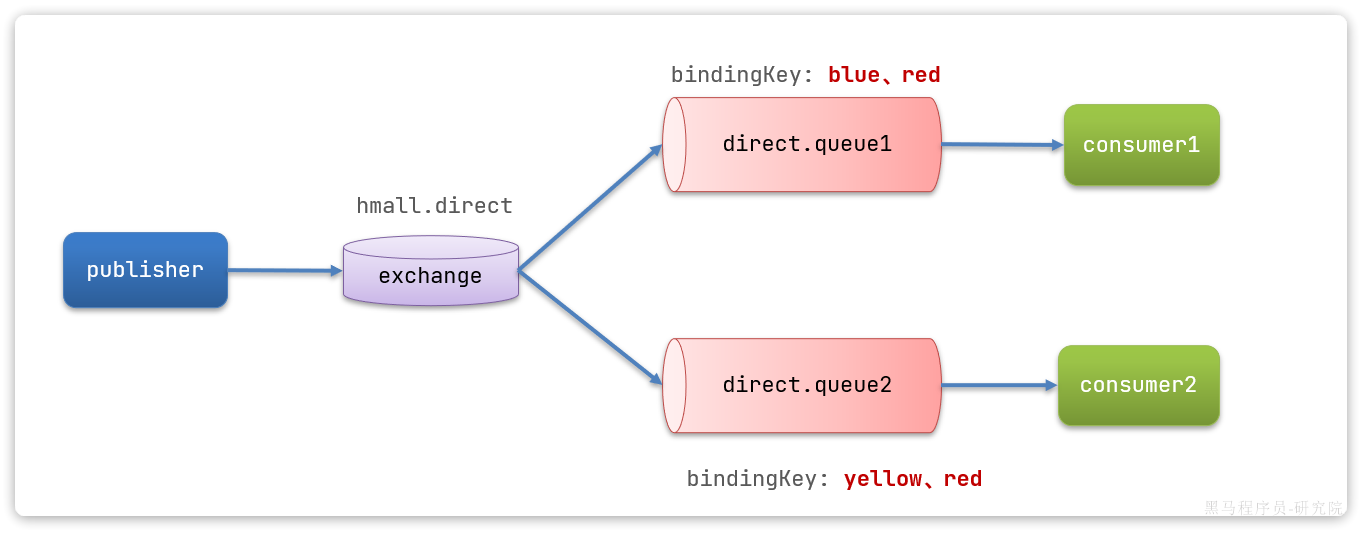
- 声明一个名为
hmall.direct的交换机 - 声明队列
direct.queue1,绑定hmall.direct,bindingKey为blud和red - 声明队列
direct.queue2,绑定hmall.direct,bindingKey为yellow和red - 在
consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2 - 在publisher中编写测试方法,向
hmall.direct发送消息
声明队列和交换机
首先在控制台声明两个队列direct.queue1和direct.queue2,这里不再展示过程:
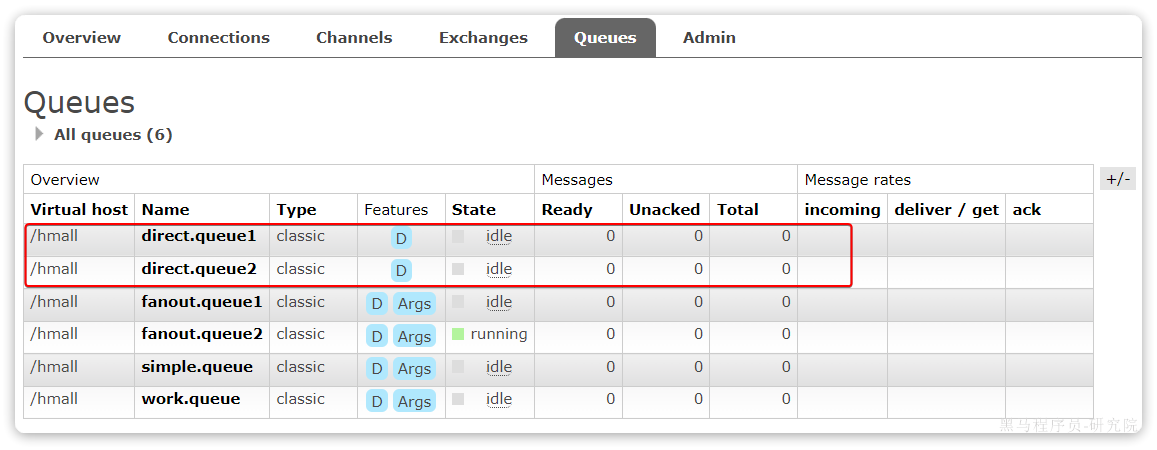
然后声明一个direct类型的交换机,命名为hmall.direct:
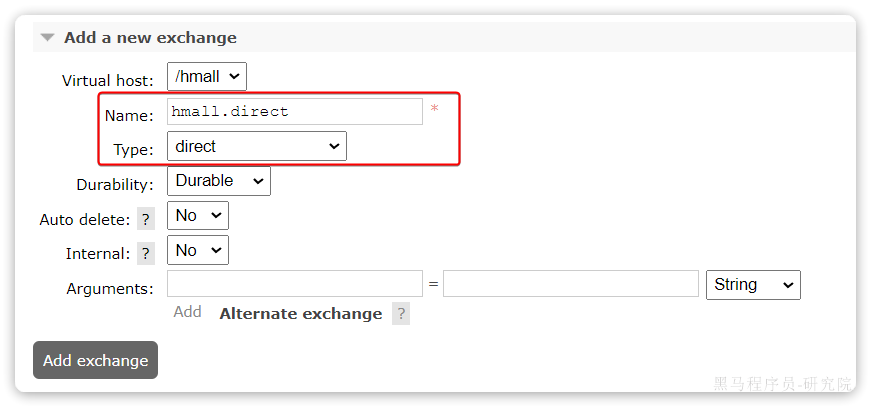
然后使用red和blue作为key,绑定direct.queue1到hmall.direct:
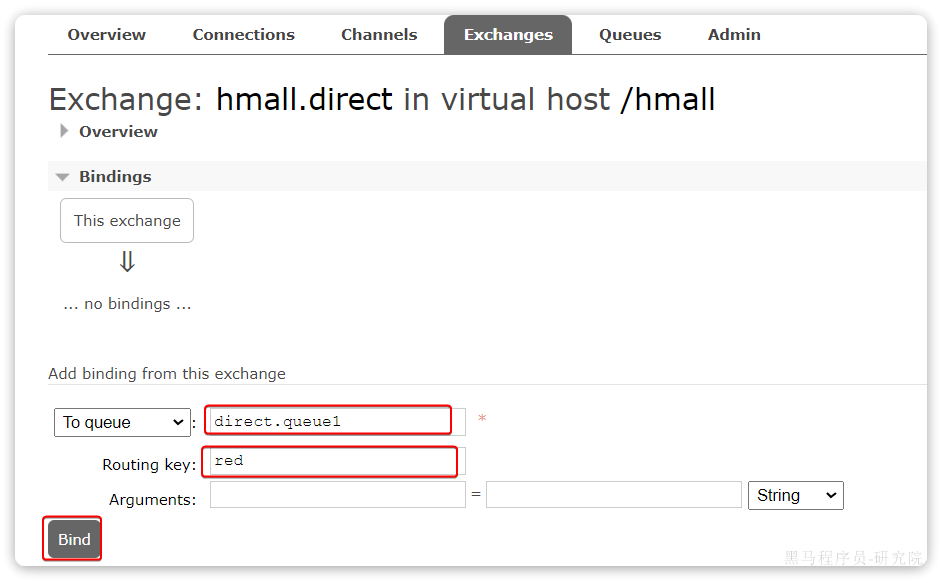
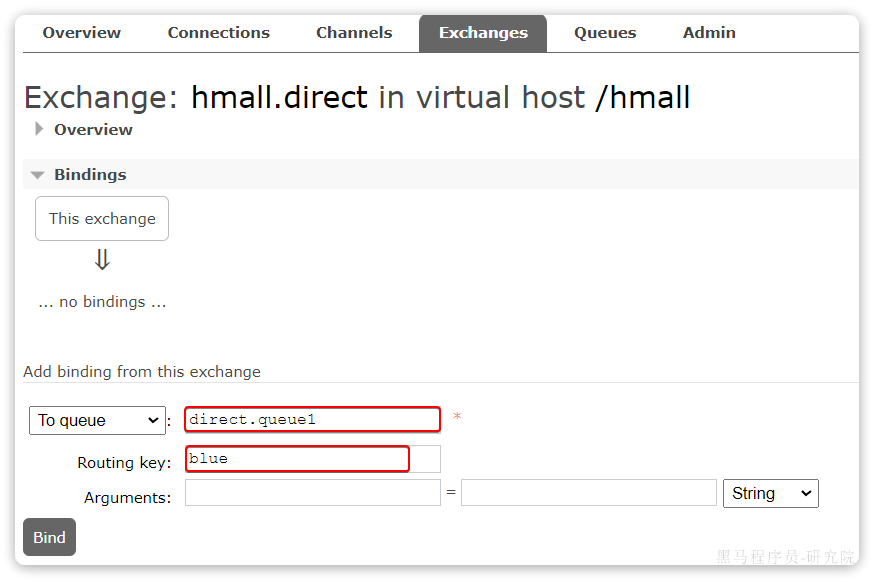
同理,使用red和yellow作为key,绑定direct.queue2到hmall.direct,步骤略,最终结果:
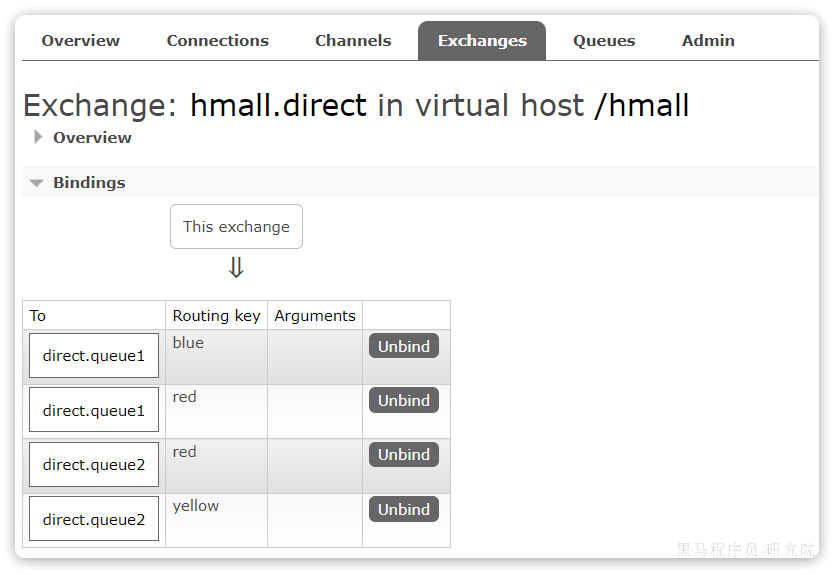
消息接收
在consumer服务的SpringRabbitListener中添加方法:
@RabbitListener(queues = "direct.queue1")
public void listenDirectQueue1(String msg) {System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】");
}@RabbitListener(queues = "direct.queue2")
public void listenDirectQueue2(String msg) {System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】");
}
消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
public void testSendDirectExchange() {// 交换机名称String exchangeName = "hmall.direct";// 消息String message = "红色警报!日本乱排核废水,导致海洋生物变异,惊现哥斯拉!";// 发送消息rabbitTemplate.convertAndSend(exchangeName, "red", message);
}
由于使用的red这个key,所以两个消费者都收到了消息:

我们再切换为blue这个key:
@Test
public void testSendDirectExchange() {// 交换机名称String exchangeName = "hmall.direct";// 消息String message = "最新报道,哥斯拉是居民自治巨型气球,虚惊一场!";// 发送消息rabbitTemplate.convertAndSend(exchangeName, "blue", message);
}
你会发现,只有消费者1收到了消息:

Topic交换机
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。
只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候使用通配符!
BindingKey` 一般都是有一个或多个单词组成,多个单词之间以`.`分割,例如: `item.insert
通配符规则:
#:匹配一个或多个词*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.spu.insert或者item.spuitem.*:只能匹配item.spu
图示:
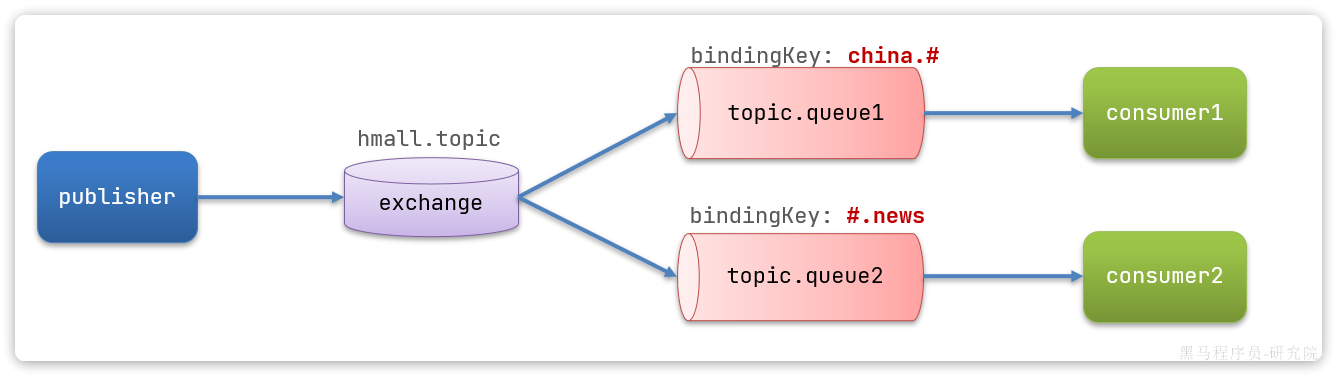
假如此时publisher发送的消息使用的RoutingKey共有四种:
china.news代表有中国的新闻消息;china.weather代表中国的天气消息;japan.news则代表日本新闻japan.weather代表日本的天气消息;
解释:
topic.queue1:绑定的是china.#,凡是以china.开头的routing key都会被匹配到,包括:china.newschina.weather
topic.queue2:绑定的是#.news,凡是以.news结尾的routing key都会被匹配。包括:china.newsjapan.news
接下来,我们就按照上图所示,来演示一下Topic交换机的用法。
首先,在控制台按照图示例子创建队列、交换机,并利用通配符绑定队列和交换机。此处步骤略。最终结果如下:
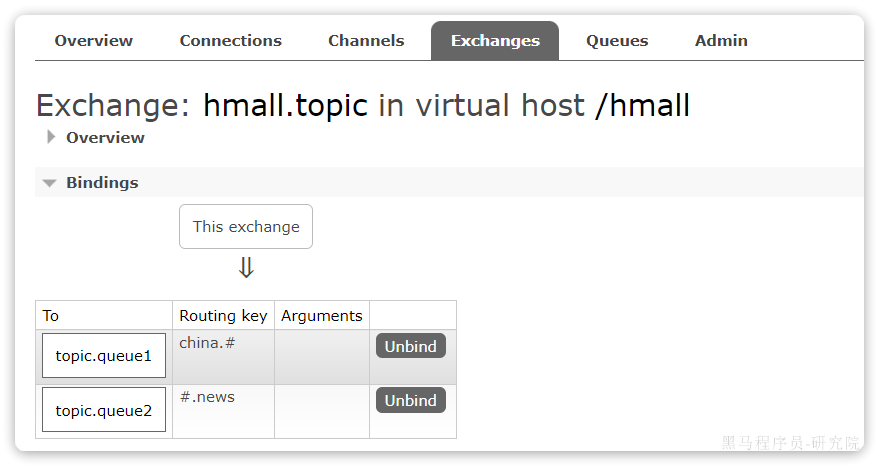
消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
/*** topicExchange*/
@Test
public void testSendTopicExchange() {// 交换机名称String exchangeName = "hmall.topic";// 消息String message = "喜报!孙悟空大战哥斯拉,胜!";// 发送消息rabbitTemplate.convertAndSend(exchangeName, "china.news", message);
}
消息接收
在consumer服务的SpringRabbitListener中添加方法:
@RabbitListener(queues = "topic.queue1")
public void listenTopicQueue1(String msg){System.out.println("消费者1接收到topic.queue1的消息:【" + msg + "】");
}@RabbitListener(queues = "topic.queue2")
public void listenTopicQueue2(String msg){System.out.println("消费者2接收到topic.queue2的消息:【" + msg + "】");
}
声明队列和交换机
在之前我们都是基于RabbitMQ控制台来创建队列、交换机。但是在实际开发时,队列和交换机是程序员定义的,将来项目上线,又要交给运维去创建。那么程序员就需要把程序中运行的所有队列和交换机都写下来,交给运维。在这个过程中是很容易出现错误的。
因此推荐的做法是由程序启动时检查队列和交换机是否存在,如果不存在自动创建。
基本API
SpringAMQP提供了一个Queue类,用来创建队列:

SpringAMQP还提供了一个Exchange接口,来表示所有不同类型的交换机:
我们可以自己创建队列和交换机,不过SpringAMQP还提供了ExchangeBuilder来简化这个过程:
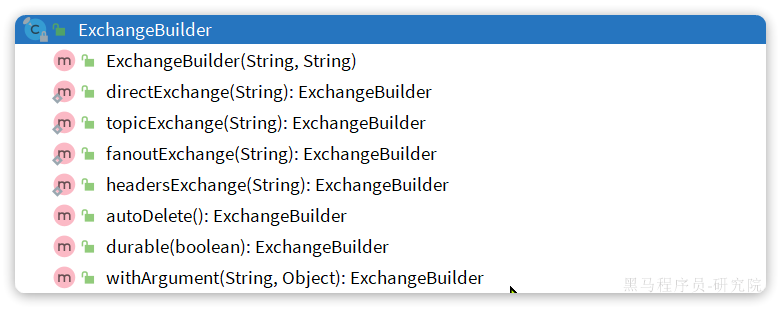
而在绑定队列和交换机时,则需要使用BindingBuilder来创建Binding对象:
fanout示例
在consumer中创建一个类,声明队列和交换机:
package com.itheima.consumer.config;import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.FanoutExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class FanoutConfig {/*** 声明交换机* @return Fanout类型交换机*/@Beanpublic FanoutExchange fanoutExchange(){return new FanoutExchange("hmall.fanout");}/*** 第1个队列*/@Beanpublic Queue fanoutQueue1(){return new Queue("fanout.queue1");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);}/*** 第2个队列*/@Beanpublic Queue fanoutQueue2(){return new Queue("fanout.queue2");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);}
}
direct示例
direct模式由于要绑定多个KEY,会非常麻烦,每一个Key都要编写一个binding:
package com.itheima.consumer.config;import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class DirectConfig {/*** 声明交换机* @return Direct类型交换机*/@Beanpublic DirectExchange directExchange(){return ExchangeBuilder.directExchange("hmall.direct").build();}/*** 第1个队列*/@Beanpublic Queue directQueue1(){return new Queue("direct.queue1");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue1WithRed(Queue directQueue1, DirectExchange directExchange){return BindingBuilder.bind(directQueue1).to(directExchange).with("red");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue1WithBlue(Queue directQueue1, DirectExchange directExchange){return BindingBuilder.bind(directQueue1).to(directExchange).with("blue");}/*** 第2个队列*/@Beanpublic Queue directQueue2(){return new Queue("direct.queue2");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue2WithRed(Queue directQueue2, DirectExchange directExchange){return BindingBuilder.bind(directQueue2).to(directExchange).with("red");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue2WithYellow(Queue directQueue2, DirectExchange directExchange){return BindingBuilder.bind(directQueue2).to(directExchange).with("yellow");}
}
基于注解声明
基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。
例如,我们同样声明Direct模式的交换机和队列:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "direct.queue1"),exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】");
}@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "direct.queue2"),exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】");
}
再试试Topic模式:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "topic.queue1"),exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),key = "china.#"
))
public void listenTopicQueue1(String msg){System.out.println("消费者1接收到topic.queue1的消息:【" + msg + "】");
}@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "topic.queue2"),exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),key = "#.news"
))
public void listenTopicQueue2(String msg){System.out.println("消费者2接收到topic.queue2的消息:【" + msg + "】");
}
消息转换器
Spring的消息发送代码接收的消息体是一个Object:
而在数据传输时,它会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。
只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
- 数据体积过大
- 有安全漏洞
- 可读性差
配置JSON转换器
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml</artifactId><version>2.9.10</version>
</dependency>
注意,如果项目中引入了spring-boot-starter-web依赖,则无需再次引入Jackson依赖。
配置消息转换器,在publisher和consumer两个服务的启动类中添加一个Bean即可:
@Bean
public MessageConverter messageConverter(){// 1.定义消息转换器Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter();// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息jackson2JsonMessageConverter.setCreateMessageIds(true);return jackson2JsonMessageConverter;
}
个人总结
消息队列的好处
使用消息队列可以做到
- 异步: 将非核心操作异步化,提升主流程响应速度。
- 扩展性好
- 性能高
- 不会出现级联失败
- 解耦: 通过消息通道实现服务间间接通信,消除直接依赖。
- 削峰: 缓冲突发流量,让下游服务按能力匀速消费,保障系统稳定。
virtual host隔离
利用virtual host的隔离特性,将不同项目隔离。一般会做两件事情:
- 给每个项目创建独立的运维账号,将管理权限分离。
- 给每个项目创建不同的
virtual host,将每个项目的数据隔离。
基本原理
一般会定义交换机转发发送者给出的原始消息给绑定的队列,但是交换机本身不存储消息,必须绑定队列。而队列可以绑定多个消费者一起处理消息,通过配置prefetch实现能者多劳;
交换机有几种常见类型
- Fanout广播:将收到消息发给所有绑定的队列
- Direct:通过RoutingKey将消息转发给RoutingKey与bingdingKey匹配的队列;这要求发送的消息携带RoutingKey,且绑定队列和交换机的时候指定bingdingKey
- Topic:使得bingdingKey可以使用通配符
实现方式
发送消息一般使用RabbitTemplate的convertAndSend(exchangeName, RoutingKey, message);
消息接收一般在消费者逻辑对应的方法上添加@RabbitListener(queues = “队列名称”)
其中消息发送的时候的message类型和接收的时候方法的参数类型保持一致
但是关于交换机和交换机与队列的绑定关系就有两种不一样的做法了,一种是交给运维人员通过RabbitMQ的控制台创建(不推荐);另一种就是代码实现;
代码实现也有两种方式:1、基于配置和Bean;2、基于注解
基于注解较复杂,一般更推荐在消费者当中使用注解。
@RabbitListener(bindings = @QueueBinding(// 设置队列和是否持久化value = @Queue(name = "topic.queue1", durable = "true"),// 设置交换机和是否持久化exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),// 设置key = "china.#"
))
public void listenTopicQueue1(String msg){System.out.println("消费者1接收到topic.queue1的消息:【" + msg + "】");
}可以通过配置JSON转化器替代默认的JDK序列化,减小数据体积、减少安全漏洞、增加可读性
RabbitMQ进阶
消息从生产者到消费者的每一步都可能导致消息丢失:
- 发送消息时丢失:
- 生产者发送消息时连接MQ失败
- 生产者发送消息到达MQ后未找到
Exchange - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue - 消息到达MQ后,处理消息的进程发生异常
- MQ导致消息丢失:
- 消息到达MQ,保存到队列后,尚未消费就突然宕机
- 消费者处理消息时:
- 消息接收后尚未处理突然宕机
- 消息接收后处理过程中抛出异常
综上,我们要解决消息丢失问题,保证MQ的可靠性,就必须从3个方面入手:
- 确保生产者一定把消息发送到MQ
- 确保MQ不会将消息弄丢
- 确保消费者一定要处理消息
发送者的可靠性
生产者重试机制
首先第一种情况,就是生产者发送消息时,出现了网络故障,导致与MQ的连接中断。
为了解决这个问题,SpringAMQP提供的消息发送时的重试机制。即:当RabbitTemplate与MQ连接超时后,多次重试。
修改publisher模块的application.yaml文件,添加下面的内容:
spring:rabbitmq:connection-timeout: 1s # 设置MQ的连接超时时间template:retry:enabled: true # 开启超时重试机制initial-interval: 1000ms # 失败后的初始等待时间multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multipliermax-attempts: 3 # 最大重试次数
注意:当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
生产者确认机制
一般情况下,只要生产者与MQ之间的网路连接顺畅,基本不会出现发送消息丢失的情况,因此大多数情况下我们无需考虑这种问题。
不过,在少数情况下,也会出现消息发送到MQ之后丢失的现象,比如:
- MQ内部处理消息的进程发生了异常
- 生产者发送消息到达MQ后未找到
Exchange - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue,因此无法路由
针对上述情况,RabbitMQ提供了生产者消息确认机制,包括Publisher Confirm和Publisher Return两种。在开启确认机制的情况下,当生产者发送消息给MQ后,MQ会根据消息处理的情况返回不同的回执。
具体如图所示:
总结如下:
- 当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常信息,同时返回ack的确认信息,代表投递成功
- 临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
- 持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
- 其它情况都会返回NACK,告知投递失败
其中ack和nack属于Publisher Confirm机制,ack是投递成功;nack是投递失败。而return则属于Publisher Return机制。
默认两种机制都是关闭状态,需要通过配置文件来开启。
实现生产者确认
开启生产者确认
在publisher模块的application.yaml中添加配置:
spring:rabbitmq:publisher-confirm-type: correlated # 开启publisher confirm机制,并设置confirm类型publisher-returns: true # 开启publisher return机制
这里publisher-confirm-type有三种模式可选:
none:关闭confirm机制simple:同步阻塞等待MQ的回执correlated:MQ异步回调返回回执
一般我们推荐使用correlated,回调机制。
定义ReturnCallback
每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置。我们在publisher模块定义一个配置类:
内容如下:
package com.itheima.publisher.config;import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.ReturnedMessage;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.annotation.Configuration;import javax.annotation.PostConstruct;@Slf4j
@AllArgsConstructor
@Configuration
public class MqConfig {private final RabbitTemplate rabbitTemplate;@PostConstructpublic void init(){rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {@Overridepublic void returnedMessage(ReturnedMessage returned) {log.error("触发return callback,");log.debug("exchange: {}", returned.getExchange());log.debug("routingKey: {}", returned.getRoutingKey());log.debug("message: {}", returned.getMessage());log.debug("replyCode: {}", returned.getReplyCode());log.debug("replyText: {}", returned.getReplyText());}});}
}
定义ConfirmCallback
由于每个消息发送时的处理逻辑不一定相同,因此ConfirmCallback需要在每次发消息时定义。具体来说,是在调用RabbitTemplate中的convertAndSend方法时,多传递一个参数:
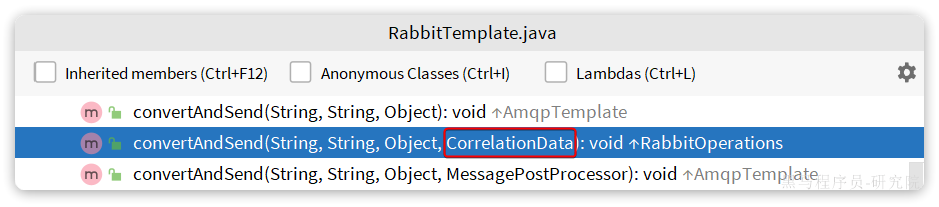
这里的CorrelationData中包含两个核心的东西:
id:消息的唯一标示,MQ对不同的消息的回执以此做判断,避免混淆SettableListenableFuture:回执结果的Future对象
将来MQ的回执就会通过这个Future来返回,我们可以提前给CorrelationData中的Future添加回调函数来处理消息回执:
我们新建一个测试,向系统自带的交换机发送消息,并且添加ConfirmCallback:
@Test
void testPublisherConfirm() {// 1.创建CorrelationDataCorrelationData cd = new CorrelationData();// 2.给Future添加ConfirmCallbackcd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {@Overridepublic void onFailure(Throwable ex) {// 2.1.Future发生异常时的处理逻辑,基本不会触发log.error("send message fail", ex);}@Overridepublic void onSuccess(CorrelationData.Confirm result) {// 2.2.Future接收到回执的处理逻辑,参数中的result就是回执内容if(result.isAck()){ // result.isAck(),boolean类型,true代表ack回执,false 代表 nack回执log.debug("发送消息成功,收到 ack!");}else{ // result.getReason(),String类型,返回nack时的异常描述log.error("发送消息失败,收到 nack, reason : {}", result.getReason());}}});// 3.发送消息rabbitTemplate.convertAndSend("hmall.direct", "q", "hello", cd);
}
注意:
开启生产者确认比较消耗MQ性能,一般不建议开启。而且大家思考一下触发确认的几种情况:
- 路由失败:一般是因为RoutingKey错误导致,往往是编程导致
- 交换机名称错误:同样是编程错误导致
- MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以了。
MQ的可靠性
消息到达MQ以后,如果MQ不能及时保存,也会导致消息丢失,所以MQ的可靠性也非常重要。
数据持久化
为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须配置数据持久化,包括:
- 交换机持久化
- 队列持久化
- 消息持久化
我们以控制台界面为例来说明
交换机持久化
在控制台的Exchanges页面,添加交换机时可以配置交换机的Durability参数:
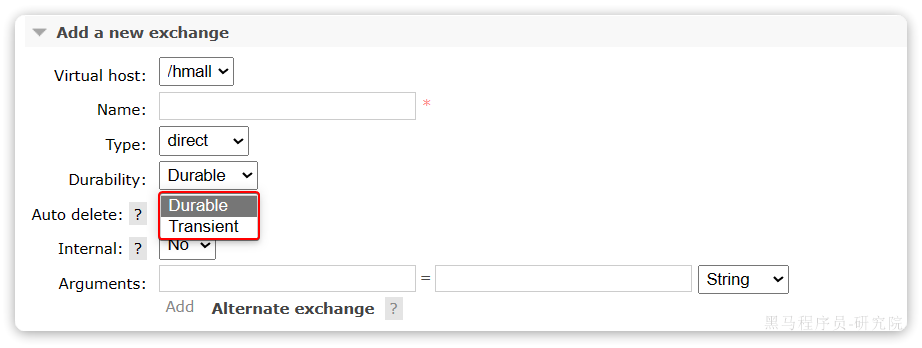
设置为Durable就是持久化模式,Transient就是临时模式。
队列持久化
在控制台的Queues页面,添加队列时,同样可以配置队列的Durability参数:
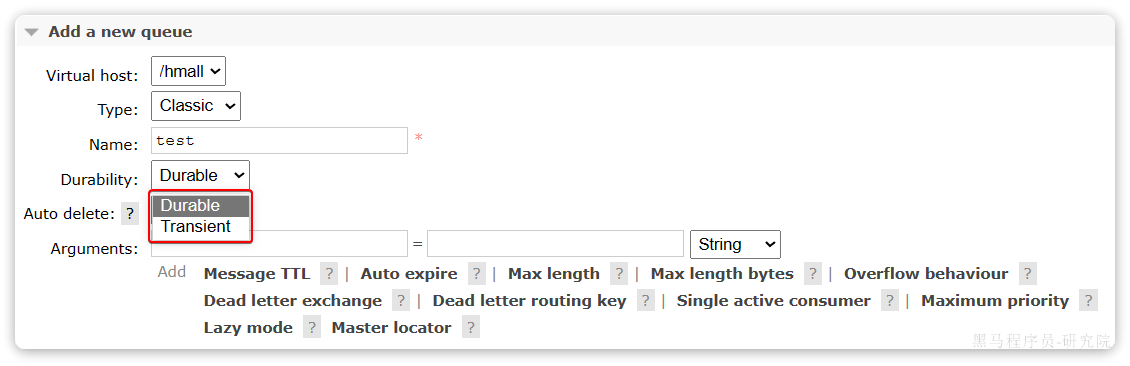
除了持久化以外,你可以看到队列还有很多其它参数,有一些我们会在后期学习。
消息持久化
在控制台发送消息的时候,可以添加很多参数,而消息的持久化是要配置一个properties:
说明:在开启持久化机制以后,如果同时还开启了生产者确认,那么MQ会在消息持久化以后才发送ACK回执,进一步确保消息的可靠性。
不过出于性能考虑,为了减少IO次数,发送到MQ的消息并不是逐条持久化到数据库的,而是每隔一段时间批量持久化。一般间隔在100毫秒左右,这就会导致ACK有一定的延迟,因此建议生产者确认全部采用异步方式。
LazyQueue
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。但在某些特殊情况下,这会导致消息积压,比如:
- 消费者宕机或出现网络故障
- 消息发送量激增,超过了消费者处理速度
- 消费者处理业务发生阻塞
一旦出现消息堆积问题,RabbitMQ的内存占用就会越来越高,直到触发内存预警上限。此时RabbitMQ会将内存消息刷到磁盘上,这个行为成为PageOut. PageOut会耗费一段时间,并且会阻塞队列进程。因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞。
为了解决这个问题,从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的模式,也就是惰性队列。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)
- 支持数百万条的消息存储
而在3.12版本之后,LazyQueue已经成为所有队列的默认格式。因此官方推荐升级MQ为3.12版本或者所有队列都设置为LazyQueue模式。
控制台配置Lazy模式
在添加队列的时候,添加x-queue-mod=lazy参数即可设置队列为Lazy模式:
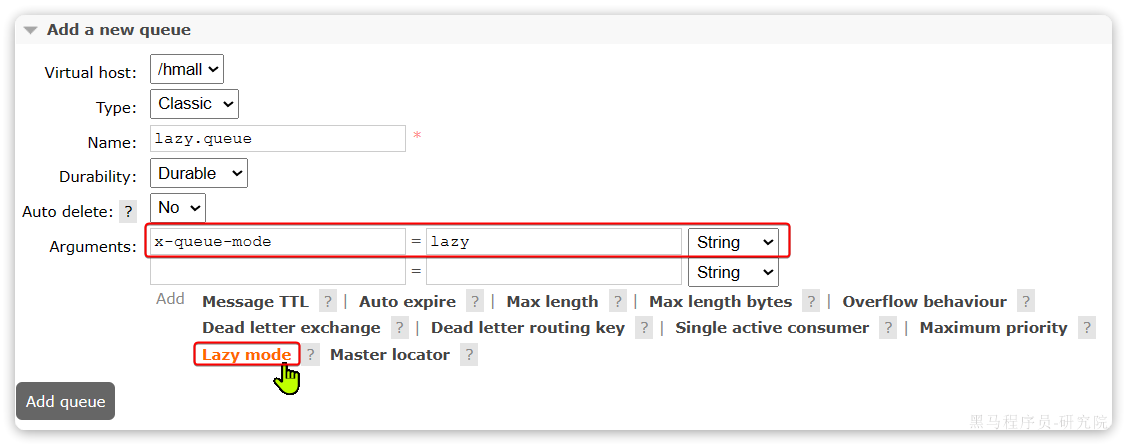
代码配置Lazy模式
在利用SpringAMQP声明队列的时候,添加x-queue-mod=lazy参数也可设置队列为Lazy模式:
@Bean
public Queue lazyQueue(){return QueueBuilder.durable("lazy.queue").lazy() // 开启Lazy模式.build();
}
这里是通过QueueBuilder的lazy()函数配置Lazy模式,底层源码如下:
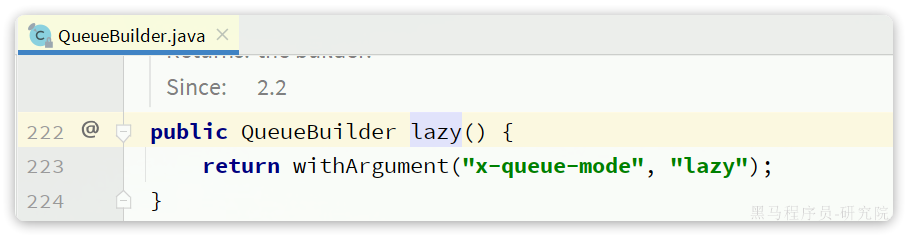
当然,我们也可以基于注解来声明队列并设置为Lazy模式:
@RabbitListener(queuesToDeclare = @Queue(name = "lazy.queue",durable = "true",arguments = @Argument(name = "x-queue-mode", value = "lazy")
))
public void listenLazyQueue(String msg){log.info("接收到 lazy.queue的消息:{}", msg);
}
更新已有队列为lazy模式
对于已经存在的队列,也可以配置为lazy模式,但是要通过设置policy实现。
可以基于命令行设置policy:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues
命令解读:
rabbitmqctl:RabbitMQ的命令行工具set_policy:添加一个策略Lazy:策略名称,可以自定义"^lazy-queue$":用正则表达式匹配队列的名字'{"queue-mode":"lazy"}':设置队列模式为lazy模式--apply-to queues:策略的作用对象,是所有的队列
当然,也可以在控制台配置policy,进入在控制台的Admin页面,点击Policies,即可添加配置:
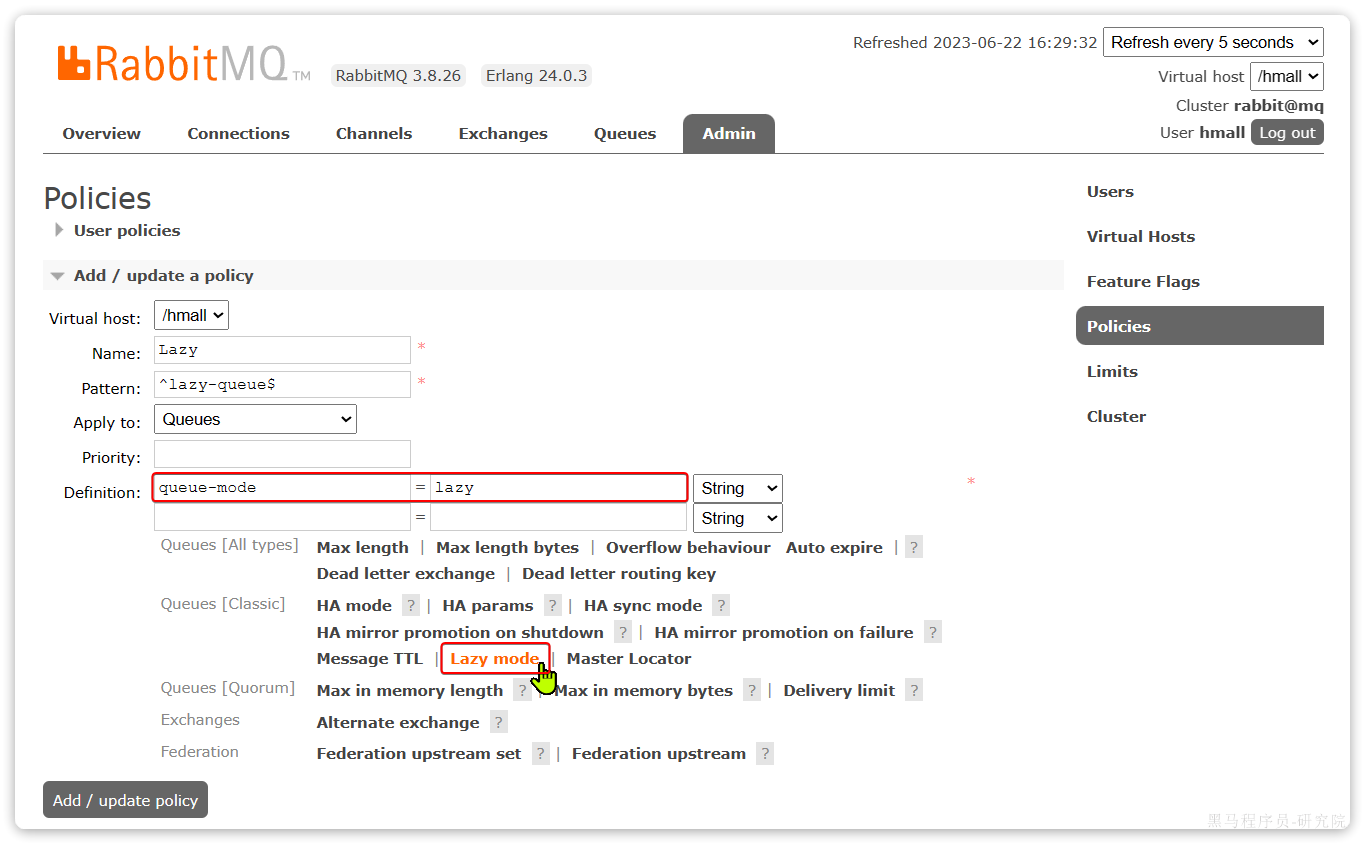
消费者的可靠性
当RabbitMQ向消费者投递消息以后,需要知道消费者的处理状态如何。因为消息投递给消费者并不代表就一定被正确消费了,可能出现的故障有很多,比如:
- 消息投递的过程中出现了网络故障
- 消费者接收到消息后突然宕机
- 消费者接收到消息后,因处理不当导致异常
- …
一旦发生上述情况,消息也会丢失。因此,RabbitMQ必须知道消费者的处理状态,一旦消息处理失败才能重新投递消息。
消费者确认机制
为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制(Consumer Acknowledgement)。即:当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。回执有三种可选值:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
一般reject方式用的较少,除非是消息格式有问题,那就是开发问题了。因此大多数情况下我们需要将消息处理的代码通过try catch机制捕获,消息处理成功时返回ack,处理失败时返回nack.
由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:- 如果是业务异常,会自动返回
nack; - 如果是消息处理或校验异常,自动返回
reject;
- 如果是业务异常,会自动返回
通过下面的配置可以修改SpringAMQP的ACK处理方式:
spring:rabbitmq:listener:simple:acknowledge-mode: none # 不做处理
失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。
极端情况就是消费者一直无法执行成功,那么消息requeue就会无限循环,导致mq的消息处理飙升,带来不必要的压力:

当然,上述极端情况发生的概率还是非常低的,不过不怕一万就怕万一。为了应对上述情况Spring又提供了消费者失败重试机制:在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
修改consumer服务的application.yml文件,添加内容:
spring:rabbitmq:listener:simple:retry:enabled: true # 开启消费者失败重试initial-interval: 1000ms # 初识的失败等待时长为1秒multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-intervalmax-attempts: 3 # 最大重试次数stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false
失败处理策略
在之前的测试中,本地测试达到最大重试次数后,消息会被丢弃。这在某些对于消息可靠性要求较高的业务场景下,显然不太合适了。
因此Spring允许我们自定义重试次数耗尽后的消息处理策略,这个策略是由MessageRecovery接口来定义的,它有3个不同实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
1)在consumer服务中定义处理失败消息的交换机和队列
@Bean
public DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");
}
2)定义一个RepublishMessageRecoverer,关联队列和交换机
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
业务幂等性
何为幂等性?
幂等是一个数学概念,用函数表达式来描述是这样的:f(x) = f(f(x)),例如求绝对值函数。
在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。例如:
- 根据id删除数据
- 查询数据
- 新增数据
但数据的更新往往不是幂等的,如果重复执行可能造成不一样的后果。比如:
- 取消订单,恢复库存的业务。如果多次恢复就会出现库存重复增加的情况
- 退款业务。重复退款对商家而言会有经济损失。
所以,我们要尽可能避免业务被重复执行。
然而在实际业务场景中,由于意外经常会出现业务被重复执行的情况,例如:
- 页面卡顿时频繁刷新导致表单重复提交
- 服务间调用的重试
- MQ消息的重复投递
因此,我们必须想办法保证消息处理的幂等性。这里给出两种方案:
- 唯一消息ID
- 业务状态判断
唯一消息ID
这个思路非常简单:
- 每一条消息都生成一个唯一的id,与消息一起投递给消费者。
- 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库
- 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理。
我们该如何给消息添加唯一ID呢?
其实很简单,SpringAMQP的MessageConverter自带了MessageID的功能,我们只要开启这个功能即可。
以Jackson的消息转换器为例:
@Bean
public MessageConverter messageConverter(){// 1.定义消息转换器Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息jjmc.setCreateMessageIds(true);return jjmc;
}
业务判断
业务判断就是基于业务本身的逻辑或状态来判断是否是重复的请求或消息,不同的业务场景判断的思路也不一样。
例如我们当前案例中,处理消息的业务逻辑是把订单状态从未支付修改为已支付。因此我们就可以在执行业务时判断订单状态是否是未支付,如果不是则证明订单已经被处理过,无需重复处理。
相比较而言,消息ID的方案需要改造原有的数据库,所以我更推荐使用业务判断的方案。
以支付修改订单的业务为例,我们需要修改OrderServiceImpl中的markOrderPaySuccess方法:
@Overridepublic void markOrderPaySuccess(Long orderId) {// 1.查询订单Order old = getById(orderId);// 2.判断订单状态if (old == null || old.getStatus() != 1) {// 订单不存在或者订单状态不是1,放弃处理return;}// 3.尝试更新订单Order order = new Order();order.setId(orderId);order.setStatus(2);order.setPayTime(LocalDateTime.now());updateById(order);}
上述代码逻辑上符合了幂等判断的需求,但是由于判断和更新是两步动作,因此在极小概率下可能存在线程安全问题。
我们可以合并上述操作为这样:
@Override
public void markOrderPaySuccess(Long orderId) {// UPDATE `order` SET status = ? , pay_time = ? WHERE id = ? AND status = 1lambdaUpdate().set(Order::getStatus, 2).set(Order::getPayTime, LocalDateTime.now()).eq(Order::getId, orderId).eq(Order::getStatus, 1).update();
}
兜底方案
虽然我们利用各种机制尽可能增加了消息的可靠性,但也不好说能保证消息100%的可靠。万一真的MQ通知失败该怎么办呢?
有没有其它兜底方案,能够确保订单的支付状态一致呢?
其实思想很简单:既然MQ通知不一定发送到交易服务,那么交易服务就必须自己主动去查询支付状态。这样即便支付服务的MQ通知失败,我们依然能通过主动查询来保证订单状态的一致。
流程如下:
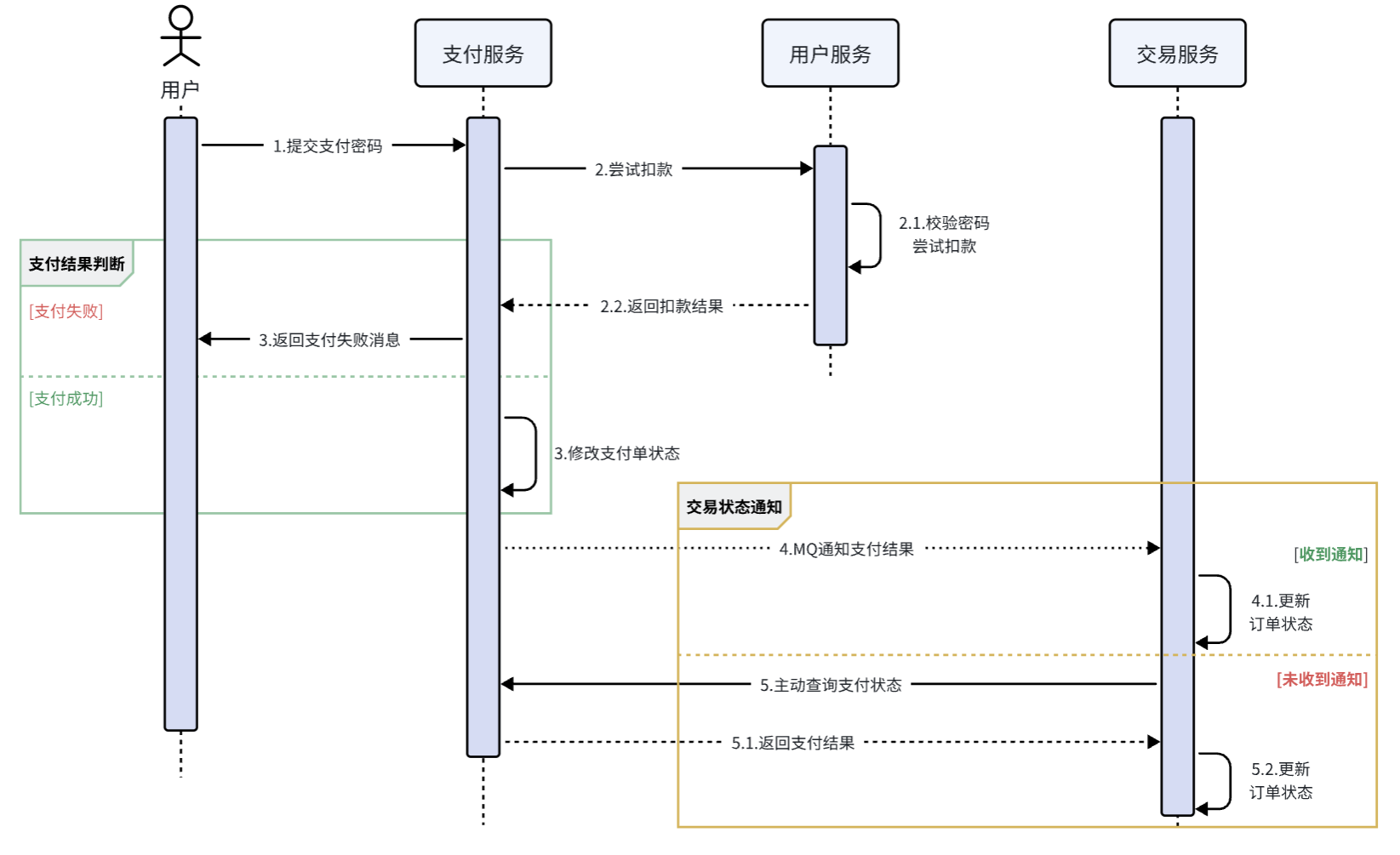
图中黄色线圈起来的部分就是MQ通知失败后的兜底处理方案,由交易服务自己主动去查询支付状态。
不过需要注意的是,交易服务并不知道用户会在什么时候支付,如果查询的时机不正确(比如查询的时候用户正在支付中),可能查询到的支付状态也不正确。
那么问题来了,我们到底该在什么时间主动查询支付状态呢?
这个时间是无法确定的,因此,通常我们采取的措施就是利用定时任务定期查询,例如每隔20秒就查询一次,并判断支付状态。如果发现订单已经支付,则立刻更新订单状态为已支付即可。
或者通过延迟消息进行查询
延迟消息
死信交换机和延迟消息
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
- 消费者使用
basic.reject或basic.nack声明消费失败,并且消息的requeue参数设置为false - 消息是一个过期消息,超时无人消费
- 要投递的队列消息满了,无法投递
如果一个队列中的消息已经成为死信,并且这个队列通过**dead-letter-exchange属性指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机就称为死信交换机**(Dead Letter Exchange)。而此时加入有队列与死信交换机绑定,则最终死信就会被投递到这个队列中。
死信交换机有什么作用呢?
- 收集那些因处理失败而被拒绝的消息
- 收集那些因队列满了而被拒绝的消息
- 收集因TTL(有效期)到期的消息
延迟消息
前面两种作用场景可以看做是把死信交换机当做一种消息处理的最终兜底方案,与消费者重试时讲的RepublishMessageRecoverer作用类似。
而最后一种场景,大家设想一下这样的场景:
如图,有一组绑定的交换机(ttl.fanout)和队列(ttl.queue)。但是ttl.queue没有消费者监听,而是设定了死信交换机hmall.direct,而队列direct.queue1则与死信交换机绑定,RoutingKey是blue:
假如我们现在发送一条消息到ttl.fanout,RoutingKey为blue,并设置消息的有效期为5000毫秒:
注意:尽管这里的ttl.fanout不需要RoutingKey,但是当消息变为死信并投递到死信交换机时,会沿用之前的RoutingKey,这样hmall.direct才能正确路由消息。
消息肯定会被投递到ttl.queue之后,由于没有消费者,因此消息无人消费。5秒之后,消息的有效期到期,成为死信:
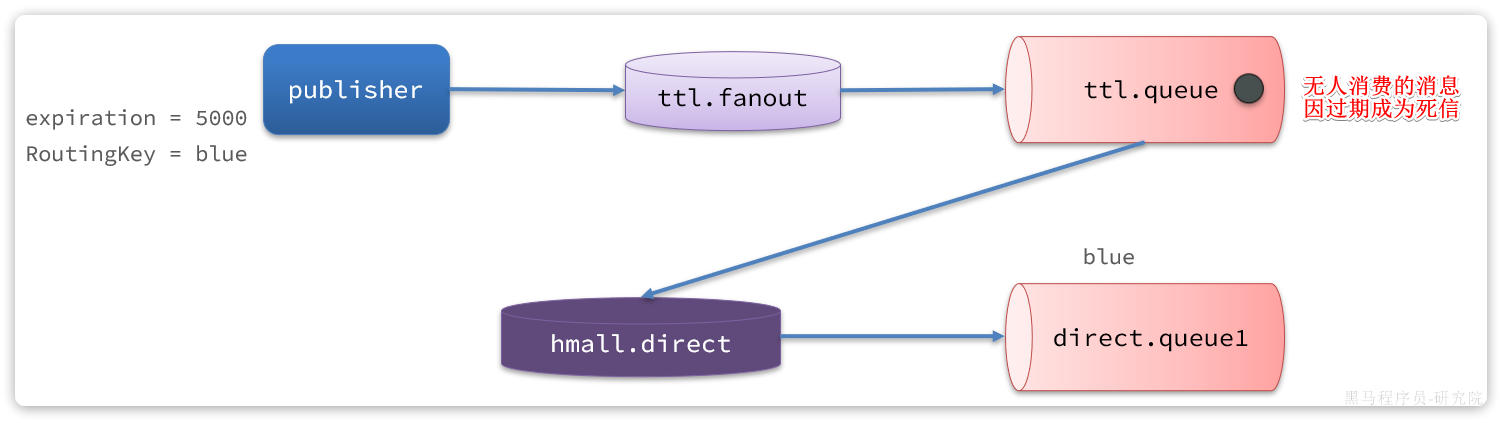
死信被再次投递到死信交换机hmall.direct,并沿用之前的RoutingKey,也就是blue:
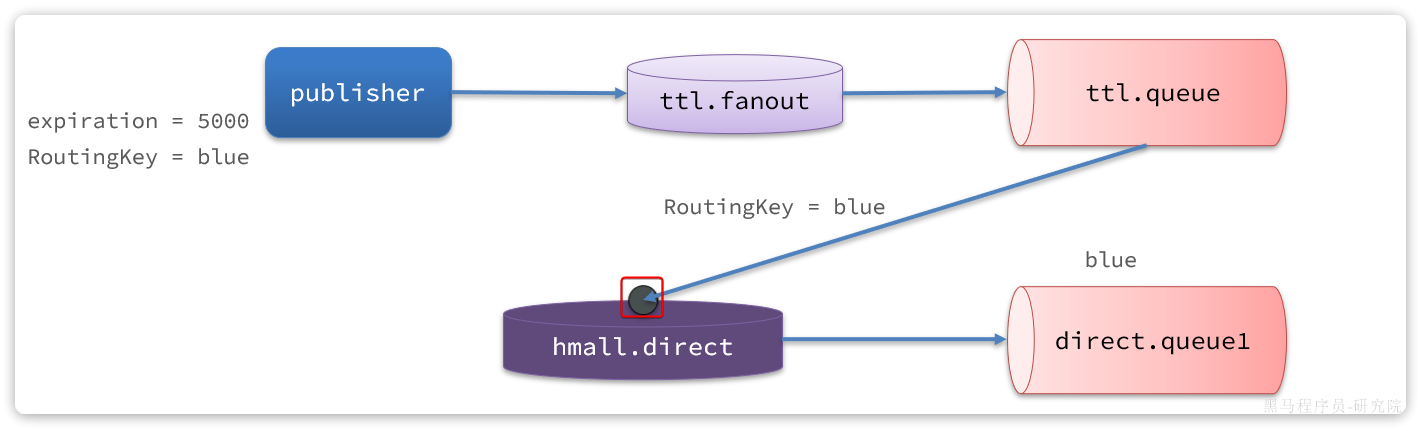
由于direct.queue1与hmall.direct绑定的key是blue,因此最终消息被成功路由到direct.queue1,如果此时有消费者与direct.queue1绑定, 也就能成功消费消息了。但此时已经是5秒钟以后了:
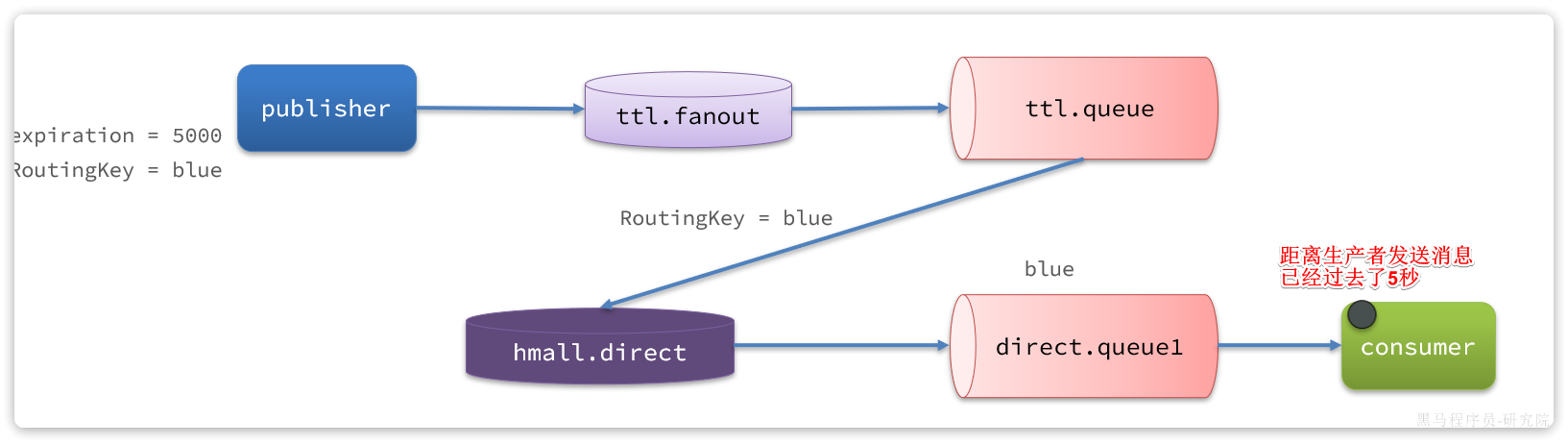
也就是说,publisher发送了一条消息,但最终consumer在5秒后才收到消息。我们成功实现了延迟消息。
注意:
RabbitMQ的消息过期是基于追溯方式来实现的,也就是说当一个消息的TTL到期以后不一定会被移除或投递到死信交换机,而是在消息恰好处于队首时才会被处理。
当队列中消息堆积很多的时候,过期消息可能不会被按时处理,因此你设置的TTL时间不一定准确。
DelayExchange插件
基于死信队列虽然可以实现延迟消息,但是太麻烦了。因此RabbitMQ社区提供了一个延迟消息插件来实现相同的效果。
官方文档说明:
https://blog.rabbitmq.com/posts/2015/04/scheduling-messages-with-rabbitmq
下载
插件下载地址:
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
安装
因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷。
docker volume inspect mq-plugins
结果如下:
[{"CreatedAt": "2024-06-19T09:22:59+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/mq-plugins/_data","Name": "mq-plugins","Options": null,"Scope": "local"}
]
插件目录被挂载到了/var/lib/docker/volumes/mq-plugins/_data这个目录,我们上传插件到该目录下。
接下来执行命令,安装插件:
docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange
运行结果如下:
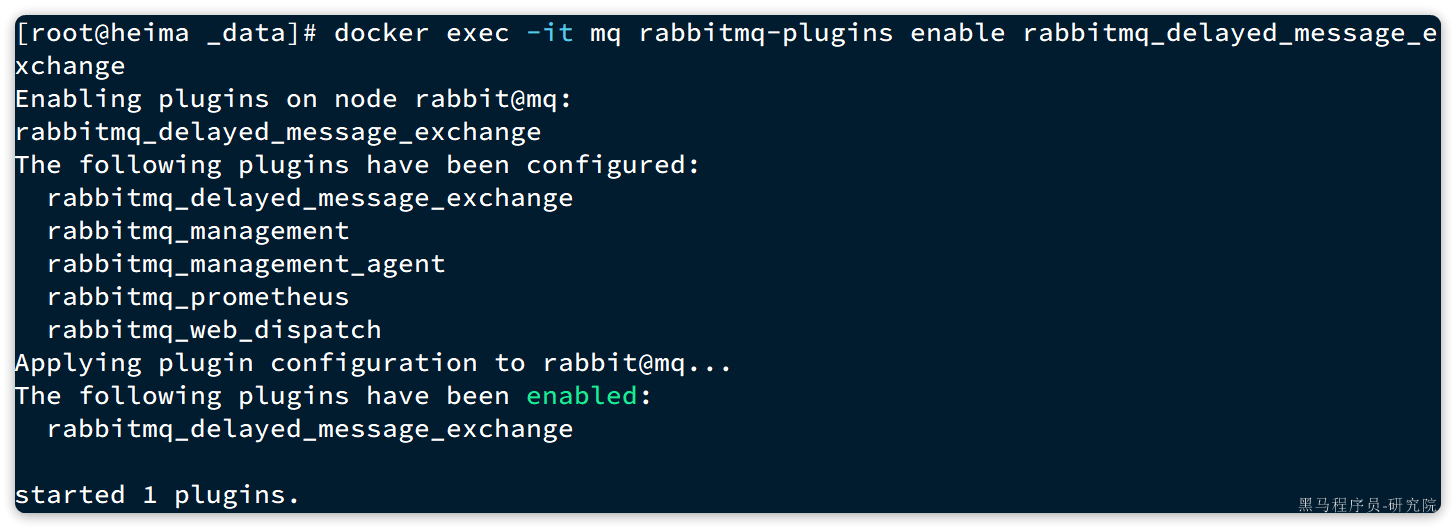
声明延迟交换机
基于注解方式:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "delay.queue", durable = "true"),exchange = @Exchange(name = "delay.direct", delayed = "true"),key = "delay"
))
public void listenDelayMessage(String msg){log.info("接收到delay.queue的延迟消息:{}", msg);
}
基于@Bean的方式:
package com.itheima.consumer.config;import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Slf4j
@Configuration
public class DelayExchangeConfig {@Beanpublic DirectExchange delayExchange(){return ExchangeBuilder.directExchange("delay.direct") // 指定交换机类型和名称.delayed() // 设置delay的属性为true.durable(true) // 持久化.build();}@Beanpublic Queue delayedQueue(){return new Queue("delay.queue");}@Beanpublic Binding delayQueueBinding(){return BindingBuilder.bind(delayedQueue()).to(delayExchange()).with("delay");}
}
发送延迟消息
发送消息时,必须通过x-delay属性设定延迟时间:
@Test
void testPublisherDelayMessage() {// 1.创建消息String message = "hello, delayed message";// 2.发送消息,利用消息后置处理器添加消息头rabbitTemplate.convertAndSend("delay.direct", "delay", message, new MessagePostProcessor() {@Overridepublic Message postProcessMessage(Message message) throws AmqpException {// 添加延迟消息属性message.getMessageProperties().setDelay(5000);return message;}});
}
注意:
延迟消息插件内部会维护一个本地数据库表,同时使用Elang Timers功能实现计时。如果消息的延迟时间设置较长,可能会导致堆积的延迟消息非常多,会带来较大的CPU开销,同时延迟消息的时间会存在误差。
因此,不建议设置延迟时间过长的延迟消息。
超时订单问题
接下来,我们就在交易服务中利用延迟消息实现订单超时取消功能。其大概思路如下:
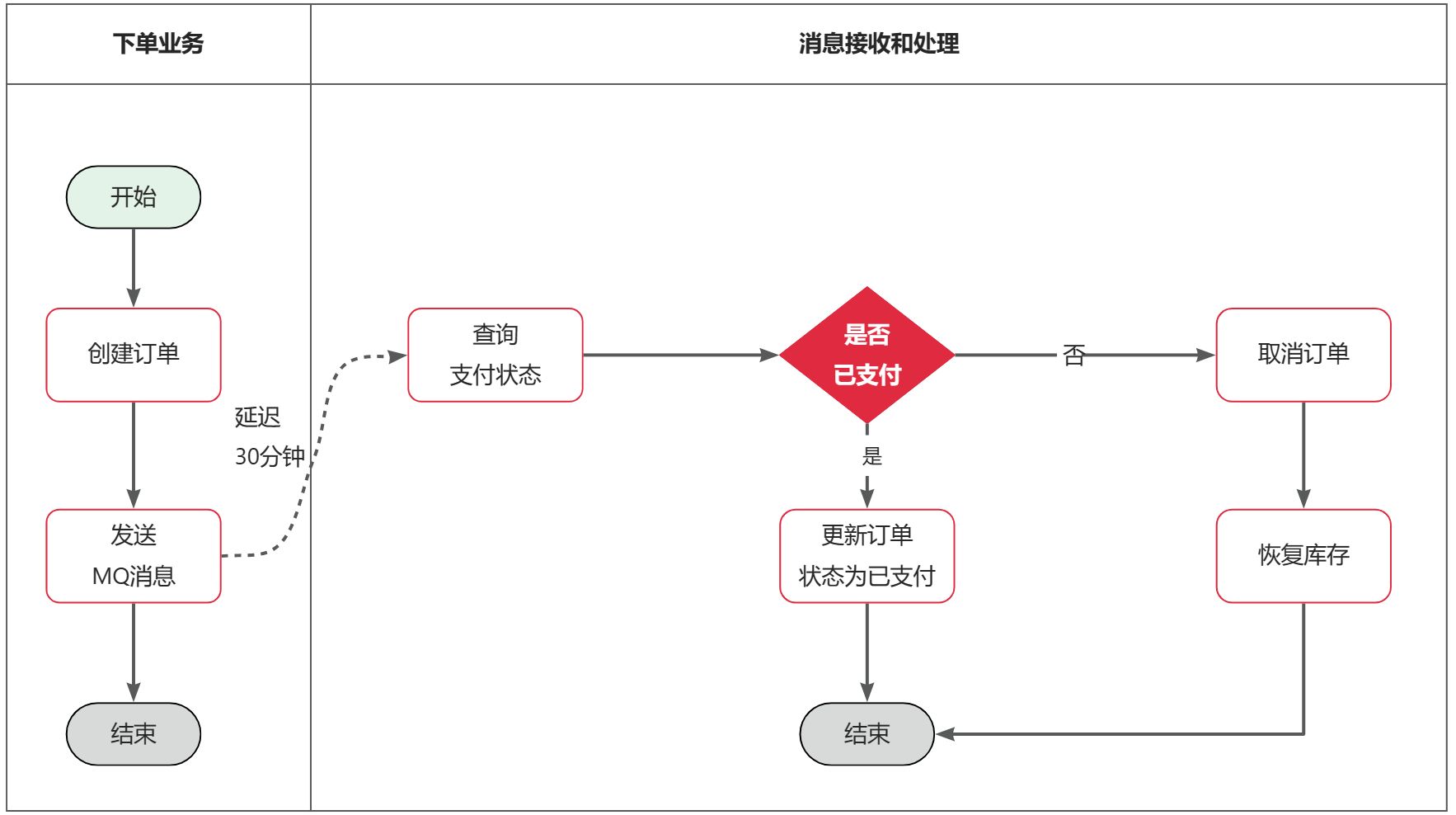
假如订单超时支付时间为30分钟,理论上说我们应该在下单时发送一条延迟消息,延迟时间为30分钟。这样就可以在接收到消息时检验订单支付状态,关闭未支付订单。
定义常量
无论是消息发送还是接收都是在交易服务完成,因此我们在trade-service中定义一个常量类,用于记录交换机、队列、RoutingKey等常量:
内容如下:
package com.hmall.trade.constants;public interface MQConstants {String DELAY_EXCHANGE_NAME = "trade.delay.direct";String DELAY_ORDER_QUEUE_NAME = "trade.delay.order.queue";String DELAY_ORDER_KEY = "delay.order.query";
}
配置MQ
在trade-service模块的pom.xml中引入amqp的依赖:
<!--amqp--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>
在trade-service的application.yaml中添加MQ的配置:
spring:rabbitmq:host: 192.168.150.101port: 5672virtual-host: /hmallusername: hmallpassword: 123
改造下单业务,发送延迟消息
接下来,我们改造下单业务,在下单完成后,发送延迟消息,查询支付状态。
修改trade-service模块的com.hmall.trade.service.impl.OrderServiceImpl类的createOrder方法,添加消息发送的代码:

这里延迟消息的时间应该是15分钟,不过我们为了测试方便,改成10秒。
编写查询支付状态接口
由于MQ消息处理时需要查询支付状态,因此我们要在pay-service模块定义一个这样的接口,并提供对应的FeignClient.
首先,在hm-api模块定义三个类:
说明:
- PayOrderDTO:支付单的数据传输实体
- PayClient:支付系统的Feign客户端
- PayClientFallback:支付系统的fallback逻辑
PayOrderDTO代码如下:
package com.hmall.api.dto;import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;import java.time.LocalDateTime;/*** <p>* 支付订单* </p>*/
@Data
@ApiModel(description = "支付单数据传输实体")
public class PayOrderDTO {@ApiModelProperty("id")private Long id;@ApiModelProperty("业务订单号")private Long bizOrderNo;@ApiModelProperty("支付单号")private Long payOrderNo;@ApiModelProperty("支付用户id")private Long bizUserId;@ApiModelProperty("支付渠道编码")private String payChannelCode;@ApiModelProperty("支付金额,单位分")private Integer amount;@ApiModelProperty("付类型,1:h5,2:小程序,3:公众号,4:扫码,5:余额支付")private Integer payType;@ApiModelProperty("付状态,0:待提交,1:待支付,2:支付超时或取消,3:支付成功")private Integer status;@ApiModelProperty("拓展字段,用于传递不同渠道单独处理的字段")private String expandJson;@ApiModelProperty("第三方返回业务码")private String resultCode;@ApiModelProperty("第三方返回提示信息")private String resultMsg;@ApiModelProperty("支付成功时间")private LocalDateTime paySuccessTime;@ApiModelProperty("支付超时时间")private LocalDateTime payOverTime;@ApiModelProperty("支付二维码链接")private String qrCodeUrl;@ApiModelProperty("创建时间")private LocalDateTime createTime;@ApiModelProperty("更新时间")private LocalDateTime updateTime;
}
PayClient代码如下:
package com.hmall.api.client;import com.hmall.api.client.fallback.PayClientFallback;
import com.hmall.api.dto.PayOrderDTO;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;@FeignClient(value = "pay-service", fallbackFactory = PayClientFallback.class)
public interface PayClient {/*** 根据交易订单id查询支付单* @param id 业务订单id* @return 支付单信息*/@GetMapping("/pay-orders/biz/{id}")PayOrderDTO queryPayOrderByBizOrderNo(@PathVariable("id") Long id);
}
PayClientFallback代码如下:
package com.hmall.api.client.fallback;import com.hmall.api.client.PayClient;
import com.hmall.api.dto.PayOrderDTO;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.openfeign.FallbackFactory;@Slf4j
public class PayClientFallback implements FallbackFactory<PayClient> {@Overridepublic PayClient create(Throwable cause) {return new PayClient() {@Overridepublic PayOrderDTO queryPayOrderByBizOrderNo(Long id) {return null;}};}
}
最后,在pay-service模块的PayController中实现该接口:
@ApiOperation("根据id查询支付单")
@GetMapping("/biz/{id}")
public PayOrderDTO queryPayOrderByBizOrderNo(@PathVariable("id") Long id){PayOrder payOrder = payOrderService.lambdaQuery().eq(PayOrder::getBizOrderNo, id).one();return BeanUtils.copyBean(payOrder, PayOrderDTO.class);
}
监听消息,查询支付状态
接下来,我们在trader-service编写一个监听器,监听延迟消息,查询订单支付状态:
代码如下:
package com.hmall.trade.listener;import com.hmall.api.client.PayClient;
import com.hmall.api.dto.PayOrderDTO;
import com.hmall.trade.constants.MQConstants;
import com.hmall.trade.domain.po.Order;
import com.hmall.trade.service.IOrderService;
import lombok.RequiredArgsConstructor;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;@Component
@RequiredArgsConstructor
public class OrderDelayMessageListener {private final IOrderService orderService;private final PayClient payClient;@RabbitListener(bindings = @QueueBinding(value = @Queue(name = MQConstants.DELAY_ORDER_QUEUE_NAME),exchange = @Exchange(name = MQConstants.DELAY_EXCHANGE_NAME, delayed = "true"),key = MQConstants.DELAY_ORDER_KEY))public void listenOrderDelayMessage(Long orderId){// 1.查询订单Order order = orderService.getById(orderId);// 2.检测订单状态,判断是否已支付if(order == null || order.getStatus() != 1){// 订单不存在或者已经支付return;}// 3.未支付,需要查询支付流水状态PayOrderDTO payOrder = payClient.queryPayOrderByBizOrderNo(orderId);// 4.判断是否支付if(payOrder != null && payOrder.getStatus() == 3){// 4.1.已支付,标记订单状态为已支付orderService.markOrderPaySuccess(orderId);}else{// TODO 4.2.未支付,取消订单,回复库存orderService.cancelOrder(orderId);}}
}
注意,这里要在OrderServiceImpl中实现cancelOrder方法,留作作业大家自行实现。
总结
MQ的用过程当中,从消息的发送到接收,每一步都有着消息丢失的风险,于是分成三种情况增强MQ的可靠性:增强发送者可靠性;增强MQ本身可靠性;增强接受者可靠性;
但是尽管如此还是可能出现不可靠的情况,所以需要一定的保底策略:主动查询消息结果,此时可以考虑使用延迟消息
增强发送者可靠性
发送者主要有两种情况可能导致消息丢失:1、发给MQ的时候因为网络等原因,MQ没收到。2、MQ收到了,但还是丢失了;
对于MQ没收到,考虑重新发一份消息,这就是生产者重试。通过配置开启后阻塞式等待重试。所以如果有性能需求,则谨慎开启
对于MQ收到还丢失:
- MQ内部处理消息的进程发生了异常
- 生产者发送消息到达MQ后未找到
Exchange - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue,因此无法路由
生产者消息确认机制,包括Publisher Confirm和Publisher Return两种。
- 当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常信息,同时返回ack的确认信息,代表投递成功
- 临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
- 持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
- 其它情况都会返回NACK,告知投递失败
其中ack和nack属于Publisher Confirm机制,ack是投递成功;nack是投递失败。而return则属于Publisher Return机制。
默认两种机制都是关闭状态,需要通过配置文件来开启。
在配置时的publisher-confirm-type有三种模式可选:
none:关闭confirm机制simple:同步阻塞等待MQ的回执correlated:MQ异步回调返回回执
一般我们推荐使用correlated,回调机制。
为了开启Publisher Return需要为RabbitTemplate设置一个ReturnCallback。
为了开启Publisher Confirm,需要在使用RabbitTemplate发送消息的时候增加一个CorrelationData参数
生产者确认比较消耗MQ性能,一般不建议开启。主要考虑编程的时候队列和交换机绑定、交换机名称、RoutingKey是否正确等。以及MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以了。
MQ的可靠性
主要考虑将数据持久化保存到本地以及使用LazyQueue。
数据持久化包括:交换机持久化、队列持久化、消息持久化
RabbitMQ默认会将信息存放在内存中,但是一旦出现消息堆积问题,过多信息触发内存上限,会刷新信息到磁盘上,此时队列进程会堵塞;LazyQueue是指将原本默认保存在内存当中的信息,先保存到磁盘中,消费者需要使用的时候再加载到磁盘中。
可代码配置Lazy模式,也可以控制台配置。也可以将已有的队列更新为Lazy模式。
消费者的可靠性
消费者确认
为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制。当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。回执有三种可选值:
- ack:成功处理,从队列中删除该消息
- nack:处理失败,再次投递消息
- reject:处理失败并拒绝该消息,从队列中删除
SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
none:不处理。投递后立刻ackmanual:手动模式。自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活auto:自动模式。AOP增强,业务正常执行ack. 当业务出现异常时,根据异常判断返回不同结果:- 业务异常,会自动nack;
- 消息处理或校验异常,自动reject;
失败重试与处理
在消费者确认中频繁nack会不断重新入队,过于频繁开销极大;可以配置失败重试,出现异常后先本地重试几次再做失败处理。失败处理有三种:返回reject并丢弃、返回nack并重入队、投递失败消息到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
业务幂等
在MQ消息处理中,由于网络波动、生产者重试或MQ重复投递等原因,消费者可能会收到重复的消息。如果消费者不对重复消息进行判断和处理,可能导致业务被重复执行,造成数据不一致或业务逻辑错误,因此需要保证业务幂等性。
业务幂等指的就是一个业务处理一次和处理多次的影响是一样的。
为了解决部分业务不幂等的问题:
- 可以在消息转换的时候为消息加上唯一id,消费者处理消息的时候在数据库当中查询已处理的唯一id列表,查询是否存在,存在不处理,不存在则处理后存id进数据库。但是会有业务侵入,且影响性能
- 还可以基于业务本身的逻辑或状态来判断是否是重复的请求或消息,比如在标记订单为已支付增加判断订单状态是否为未支付,只有未支付需要标记。
可靠性兜底-延迟消息
一种可靠性的兜底方案是消费者主动去查询支付状态,但是查询时机很重要,可以考虑定时任务或者延迟任务。
一段时间以后才执行的任务,我们称之为延迟任务,而要实现延迟任务,最简单的方案就是利用MQ的延迟消息了。
延迟消息指的是消费者不会立刻收到消息,而是指定时间之后收到消息。
默认情况下一个消息称为死信会被销毁,但是如果指定了死信交换机就会进入死信交换机(DLX) 。可以利用这一特性故意让消息过期称为死信,在与其绑定的队列中进行消息的处理,从而实现延迟消息;
但是更推荐使用延迟消息插件实现延迟消息,直接就能在注解当中添加属性实现延迟交换机的声明。发送消息时则,必须通过x-delay属性设定延迟时间。
ElasticSearch分布式搜索
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
- Elasticsearch:用于数据存储、计算和搜索
- Logstash/Beats:用于数据收集
- Kibana:用于数据可视化
整套技术栈被称为ELK,经常用来做日志收集、系统监控和状态分析等等:
整套技术栈的核心就是用来存储、搜索、计算的Elasticsearch
基础知识
安装elasticsearch
通过下面的Docker命令即可安装单机版本的elasticsearch:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network hm-net \-p 9200:9200 \-p 9300:9300 \elasticsearch:7.12.1
安装Kibana
通过下面的Docker命令,即可部署Kibana:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
倒排索引
elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。那么什么是倒排索引呢?
倒排索引的概念是基于MySQL这样的正向索引而言的。
正向索引
我们先来回顾一下正向索引。
例如有一张名为tb_goods的表:
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| … | … | … |
其中的id字段已经创建了索引,由于索引底层采用了B+树结构,因此我们根据id搜索的速度会非常快。但是其他字段例如title,只在叶子节点上存在。
因此要根据title搜索的时候只能遍历树中的每一个叶子节点,判断title数据是否符合要求。
比如用户的SQL语句为:
select * from tb_goods where title like '%手机%';
那搜索的大概流程如图:
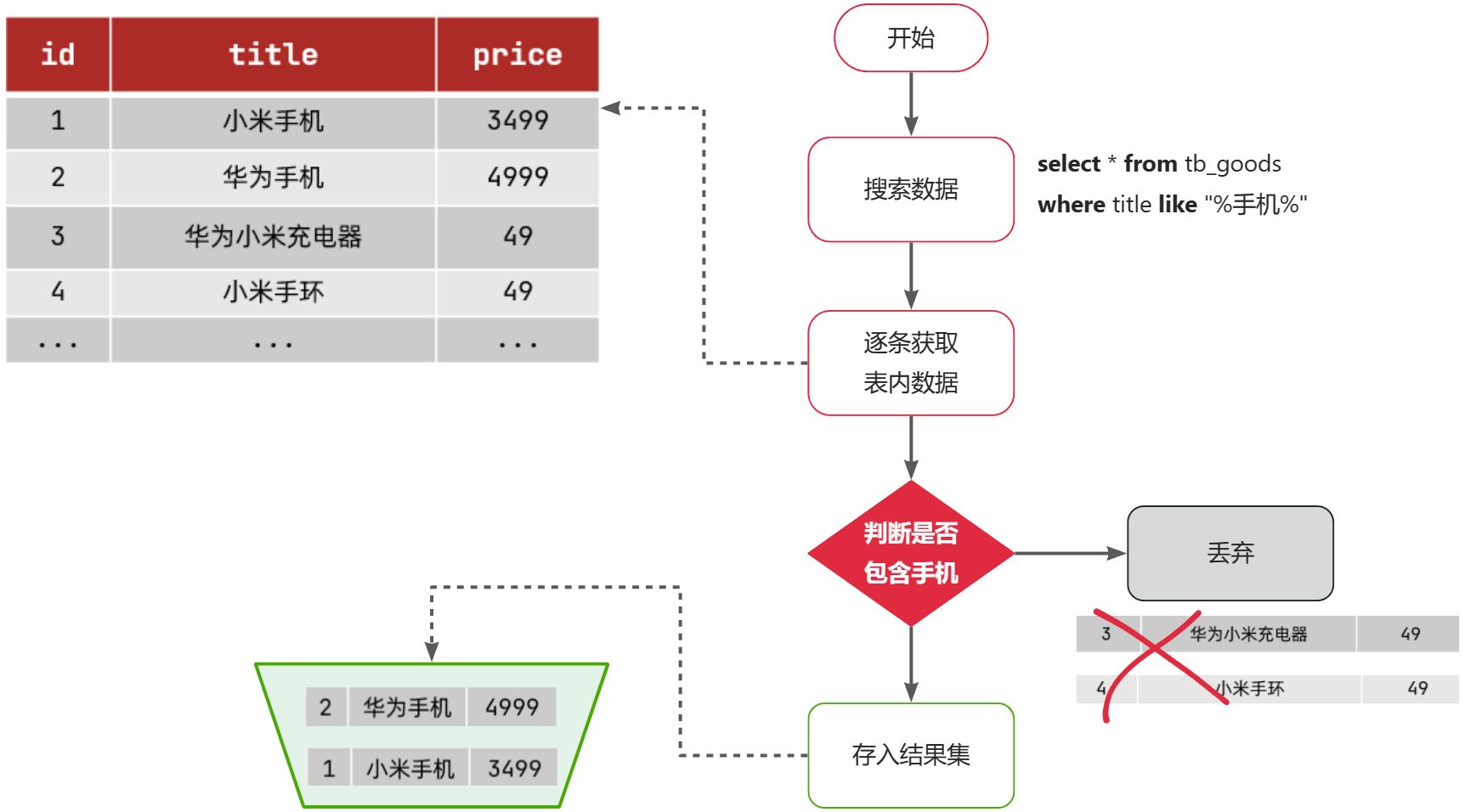
说明:
- 1)检查到搜索条件为
like '%手机%',需要找到title中包含手机的数据 - 2)逐条遍历每行数据(每个叶子节点),比如第1次拿到
id为1的数据 - 3)判断数据中的
title字段值是否符合条件 - 4)如果符合则放入结果集,不符合则丢弃
- 5)回到步骤1
综上,根据id精确匹配时,可以走索引,查询效率较高。而当搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下:
- 将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建正向索引
此时形成的这张以词条为索引的表,就是倒排索引表,两者对比如下:
正向索引
| id(索引) | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| … | … | … |
倒排索引
| 词条(索引) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
其实倒排索引还会记录词条在文档中出现的位置等信息;
索引的搜索流程如下(以搜索"华为手机"为例),如图:
流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
- 正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
- 而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
是不是恰好反过来了?
那么两者方式的优缺点是什么呢?
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
基础概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
文档和字段
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
{"id": 1,"title": "小米手机","price": 3499
}
{"id": 2,"title": "华为手机","price": 4999
}
{"id": 3,"title": "华为小米充电器","price": 49
}
{"id": 4,"title": "小米手环","price": 299
}
因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
索引和映射
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等:

所有文档都散乱存放显然非常混乱,也不方便管理。
因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:
商品索引
{"id": 1,"title": "小米手机","price": 3499
}{"id": 2,"title": "华为手机","price": 4999
}{"id": 3,"title": "三星手机","price": 3999
}
用户索引
{"id": 101,"name": "张三","age": 21
}{"id": 102,"name": "李四","age": 24
}{"id": 103,"name": "麻子","age": 18
}
订单索引
{"id": 10,"userId": 101,"goodsId": 1,"totalFee": 294
}{"id": 11,"userId": 102,"goodsId": 2,"totalFee": 328
}
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;
因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
如图:
那是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长之处:
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
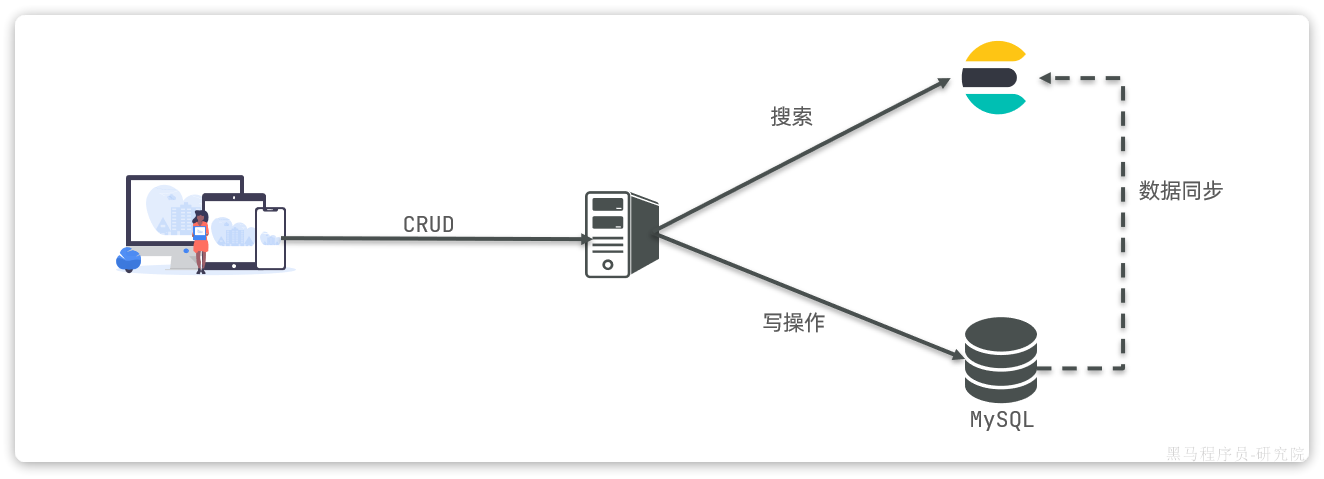
IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
安装IK分词器
方案一:在线安装
运行一个命令即可:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
然后重启es容器:
docker restart es
方案二:离线安装
如果网速较差,也可以选择离线安装。
首先,查看之前安装的Elasticsearch容器的plugins数据卷目录:
docker volume inspect es-plugins
结果如下:
[{"CreatedAt": "2024-11-06T10:06:34+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]
可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。我们需要把IK分词器上传至这个目录。
找到课前资料提供的ik分词器插件,课前资料提供了7.12.1版本的ik分词器压缩文件,你需要对其解压:
然后上传至虚拟机的/var/lib/docker/volumes/es-plugins/_data这个目录:
最后,重启es容器:
docker restart es
使用IK分词器
IK分词器包含两种模式:
ik_smart:智能语义切分ik_max_word:最细粒度切分
我们在Kibana的DevTools上来测试分词器,首先测试Elasticsearch官方提供的标准分词器:
POST /_analyze
{"analyzer": "standard","text": "黑马程序员学习java太棒了"
}
结果如下:
{"tokens" : [{"token" : "黑","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "马","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "程","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "序","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "员","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4},{"token" : "学","start_offset" : 5,"end_offset" : 6,"type" : "<IDEOGRAPHIC>","position" : 5},{"token" : "习","start_offset" : 6,"end_offset" : 7,"type" : "<IDEOGRAPHIC>","position" : 6},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "<ALPHANUM>","position" : 7},{"token" : "太","start_offset" : 11,"end_offset" : 12,"type" : "<IDEOGRAPHIC>","position" : 8},{"token" : "棒","start_offset" : 12,"end_offset" : 13,"type" : "<IDEOGRAPHIC>","position" : 9},{"token" : "了","start_offset" : 13,"end_offset" : 14,"type" : "<IDEOGRAPHIC>","position" : 10}]
}
可以看到,标准分词器智能1字1词条,无法正确对中文做分词。
我们再测试IK分词器:
POST /_analyze
{"analyzer": "ik_smart","text": "黑马程序员学习java太棒了"
}
执行结果如下:
{"tokens" : [{"token" : "黑马","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "程序员","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 1},{"token" : "学习","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 2},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "ENGLISH","position" : 3},{"token" : "太棒了","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 4}]
}
拓展词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“泰裤辣”,“传智播客” 等。
IK分词器无法对这些词汇分词,测试一下:
POST /_analyze
{"analyzer": "ik_max_word","text": "传智播客开设大学,真的泰裤辣!"
}
结果:
{"tokens" : [{"token" : "传","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "智","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "播","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 2},{"token" : "客","start_offset" : 3,"end_offset" : 4,"type" : "CN_CHAR","position" : 3},{"token" : "开设","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 4},{"token" : "大学","start_offset" : 6,"end_offset" : 8,"type" : "CN_WORD","position" : 5},{"token" : "真的","start_offset" : 9,"end_offset" : 11,"type" : "CN_WORD","position" : 6},{"token" : "泰","start_offset" : 11,"end_offset" : 12,"type" : "CN_CHAR","position" : 7},{"token" : "裤","start_offset" : 12,"end_offset" : 13,"type" : "CN_CHAR","position" : 8},{"token" : "辣","start_offset" : 13,"end_offset" : 14,"type" : "CN_CHAR","position" : 9}]
}
可以看到,传智播客和泰裤辣都无法正确分词。
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
注意,如果采用在线安装的通过,默认是没有config目录的,需要把课前资料提供的ik下的config上传至对应目录。
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--><entry key="ext_dict">ext.dic</entry>
</properties>
3)在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
传智播客
泰裤辣
4)重启elasticsearch
docker restart es# 查看 日志
docker logs -f elasticsearch
再次测试,可以发现传智播客和泰裤辣都正确分词了:
{"tokens" : [{"token" : "传智播客","start_offset" : 0,"end_offset" : 4,"type" : "CN_WORD","position" : 0},{"token" : "开设","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 1},{"token" : "大学","start_offset" : 6,"end_offset" : 8,"type" : "CN_WORD","position" : 2},{"token" : "真的","start_offset" : 9,"end_offset" : 11,"type" : "CN_WORD","position" : 3},{"token" : "泰裤辣","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 4}]
}
总结
分词器的作用是什么?
- 创建倒排索引时,对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
ik_smart:智能切分,粗粒度ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的
IkAnalyzer.cfg.xml文件添加拓展词典和停用词典 - 在词典中添加拓展词条或者停用词条
总结
ES的关键是倒排索引,倒排索引的建立依赖于分词器;分词器对文档分出一堆词条,给分词表添加文档的id、词条在文档中的位置等信息,每个词条包含多个文档id代表当前词条是哪些文档当中包含的。
搜索时也是分词后先找词条,依据词条的文档id找到所有文档,存入结果集。
ES将类型相同的文档集中在一起管理,称为索引(Index),这就好像MYSQL当中的表;文档就如一条记录;字段就如MYSQL的一列;Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema);DSL操控语句就和SQL语句一样
中文最好不要用默认的分词器,可以参考使用ik分词器,他有两种模式ik_smart和ik_max_word分别是粗粒度和细粒度的。IK分词器还可以主动扩展词条
ES基础操作
索引库操作
Index就类似数据库表,Mapping映射就类似表的结构。我们要向es中存储数据,必须先创建Index和Mapping
Mapping映射属性
Mapping是对索引库中文档的约束,常见的Mapping属性包括:
type:字段数据类型,常见的简单类型有:- 字符串:
text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址) - 数值:
long、integer、short、byte、double、float、 - 布尔:
boolean - 日期:
date - 对象:
object
- 字符串:
index:是否创建索引,默认为trueanalyzer:使用哪种分词器properties:该字段的子字段
例如下面的json文档:
{"age": 21,"weight": 52.1,"isMarried": false,"info": "黑马程序员Java讲师","email": "zy@itcast.cn","score": [99.1, 99.5, 98.9],"name": {"firstName": "云","lastName": "赵"}
}
对应的每个字段映射(Mapping):
| 字段名 | 字段类型 | 类型说明 | 是否参与搜索 | 是否参与分词 | 分词器 | |
|---|---|---|---|---|---|---|
| age | integer | 整数 | —— | |||
| weight | float | 浮点数 | —— | |||
| isMarried | boolean | 布尔 | —— | |||
| info | text | 字符串,但需要分词 | IK | |||
keyword | 字符串,但是不分词 | —— | ||||
| score | float | 只看数组中元素类型 | —— | |||
| name | firstName | keyword | 字符串,但是不分词 | —— | ||
| lastName | keyword | 字符串,但是不分词 | —— |
索引库的CRUD
由于Elasticsearch采用的是Restful风格的API,因此其请求方式和路径相对都比较规范,而且请求参数也都采用JSON风格。
我们直接基于Kibana的DevTools来编写请求做测试,由于有语法提示,会非常方便。
创建索引库和映射
基本语法:
- 请求方式:
PUT - 请求路径:
/索引库名,可以自定义 - 请求参数:
mapping映射
格式:
PUT /索引库名称
{"mappings": {"properties": {"字段1":{"type": "text","analyzer": "ik_smart"},"字段2":{"type": "keyword","index": "false"},"字段3":{"properties": {"子属性1": {"type": "keyword"}}},// ...略}}
}
查询索引库
基本语法:
- 请求方式:GET
- 请求路径:/索引库名
- 请求参数:无
格式:
GET /索引库名
修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
语法说明:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
删除索引库
语法:
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
格式:
DELETE /索引库名
总结
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 修改索引库,添加字段:PUT /索引库名/_mapping
文档操作
有了索引库,接下来就可以向索引库中添加数据了。
Elasticsearch中的数据其实就是JSON风格的文档。操作文档自然保护增、删、改、查等几种常见操作,我们分别来学习。
新增文档
语法:
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},
}
put也可以实现相关操作
查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法:
GET /{索引库名称}/_doc/{id}
删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值
修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 局部修改:修改文档中的部分字段
全量修改
全量修改是覆盖原来的文档,其本质是两步操作:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}
局部修改
局部修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}
批处理
批处理采用POST请求,基本语法如下:
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
其中:
index代表新增操作_index:指定索引库名_id指定要操作的文档id{ "field1" : "value1" }:则是要新增的文档内容
delete代表删除操作_index:指定索引库名_id指定要操作的文档id
update代表更新操作_index:指定索引库名_id指定要操作的文档id{ "doc" : {"field2" : "value2"} }:要更新的文档字段
示例,批量新增:
POST /_bulk
{"index": {"_index":"heima", "_id": "3"}}
{"info": "黑马程序员C++讲师", "email": "ww@itcast.cn", "name":{"firstName": "五", "lastName":"王"}}
{"index": {"_index":"heima", "_id": "4"}}
{"info": "黑马程序员前端讲师", "email": "zhangsan@itcast.cn", "name":{"firstName": "三", "lastName":"张"}}
批量删除:
POST /_bulk
{"delete":{"_index":"heima", "_id": "3"}}
{"delete":{"_index":"heima", "_id": "4"}}
批量更新:
POST /_bulk
{"index": {"_index":"heima", "_id": "3"}}
{"doc":{"info": "黑马程序员C++讲师", "email": "ww@itcast.cn", "name":{"firstName": "五", "lastName":"王"}}}
{"index": {"_index":"heima", "_id": "4"}}
{"doc":{"info": "黑马程序员前端讲师", "email": "zhangsan@itcast.cn", "name":{"firstName": "三", "lastName":"张"}}}
总结
文档操作有哪些?
- 创建文档:
POST /{索引库名}/_doc/文档id { json文档 } - 查询文档:
GET /{索引库名}/_doc/文档id - 删除文档:
DELETE /{索引库名}/_doc/文档id - 修改文档:
- 全量修改:
PUT /{索引库名}/_doc/文档id { json文档 } - 局部修改:
POST /{索引库名}/_update/文档id { "doc": {字段}}
- 全量修改:
RestAPI
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。
初始化RestClient
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
分为三步:
1)在item-service模块中引入es的RestHighLevelClient依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2)因为SpringBoot默认的ES版本是7.17.10,所以我们需要覆盖默认的ES版本:
<properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><elasticsearch.version>7.12.1</elasticsearch.version></properties>
3)初始化RestHighLevelClient:
初始化的代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")
));
创建索引库
由于要实现对商品搜索,所以我们需要将商品添加到Elasticsearch中,不过需要根据搜索业务的需求来设定索引库结构,而不是一股脑的把MySQL数据写入Elasticsearch.
创建索引
创建索引库的API如下:
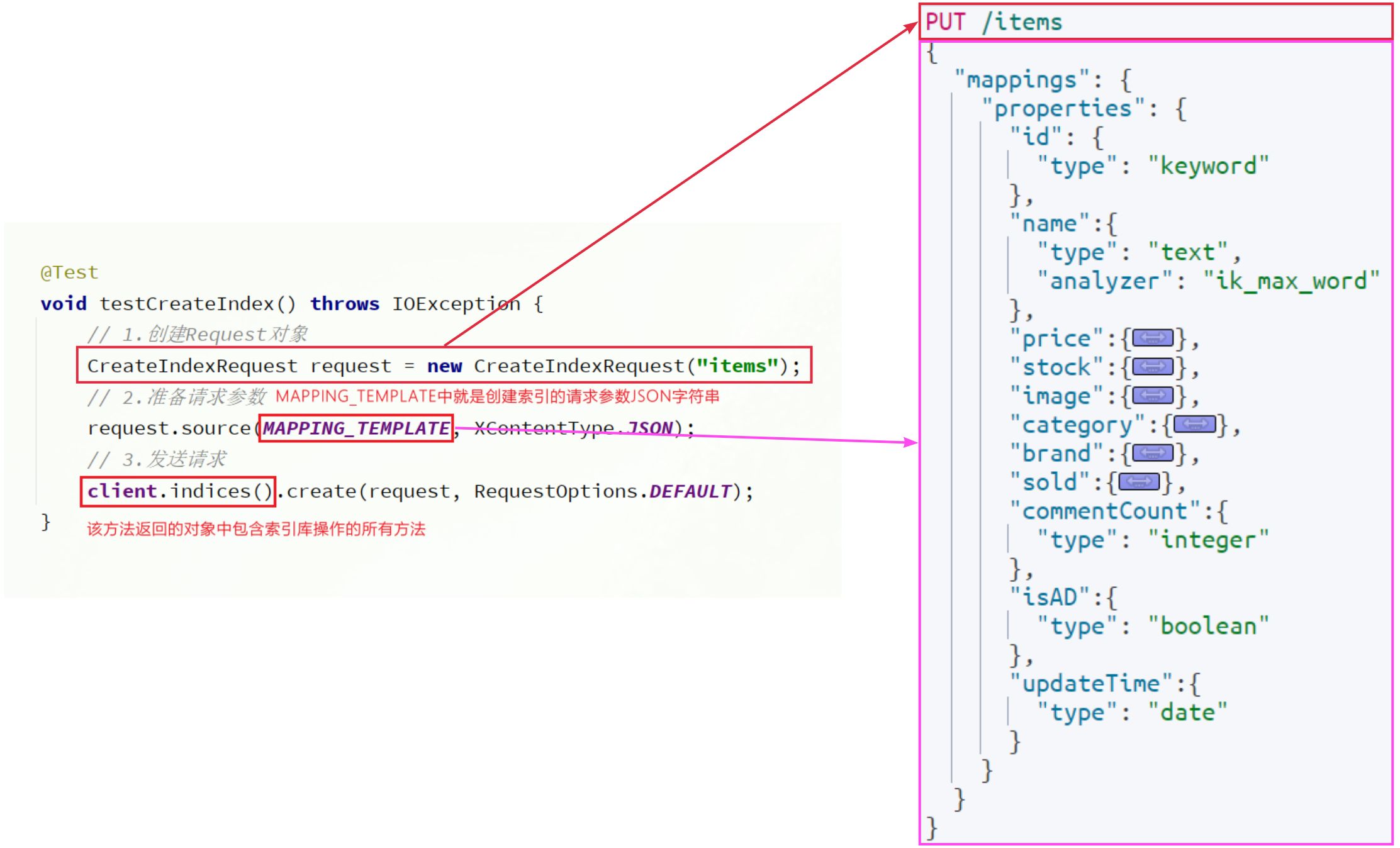
代码分为三步:
- 1)创建Request对象。
- 因为是创建索引库的操作,因此Request是
CreateIndexRequest。
- 因为是创建索引库的操作,因此Request是
- 2)添加请求参数
- 其实就是Json格式的Mapping映射参数。因为json字符串很长,这里是定义了静态字符串常量
MAPPING_TEMPLATE,让代码看起来更加优雅。
- 其实就是Json格式的Mapping映射参数。因为json字符串很长,这里是定义了静态字符串常量
- 3)发送请求
client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。例如创建索引、删除索引、判断索引是否存在等
在item-service中的IndexTest测试类中,具体代码如下:
@Test
void testCreateIndex() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("items");// 2.准备请求参数request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"stock\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"image\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"category\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"sold\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"commentCount\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"isAD\":{\n" +" \"type\": \"boolean\"\n" +" },\n" +" \"updateTime\":{\n" +" \"type\": \"date\"\n" +" }\n" +" }\n" +" }\n" +"}";
删除索引库
删除索引库的请求非常简单:
DELETE /hotel
与创建索引库相比:
- 请求方式从PUT变为DELTE
- 请求路径不变
- 无请求参数
所以代码的差异,注意体现在Request对象上。流程如下:
- 1)创建Request对象。这次是DeleteIndexRequest对象
- 2)准备参数。这里是无参,因此省略
- 3)发送请求。改用delete方法
在item-service中的IndexTest测试类中,编写单元测试,实现删除索引:
@Test
void testDeleteIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("items");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);
}
判断索引库是否存在
判断索引库是否存在,本质就是查询,对应的请求语句是:
GET /hotel
因此与删除的Java代码流程是类似的,流程如下:
- 1)创建Request对象。这次是GetIndexRequest对象
- 2)准备参数。这里是无参,直接省略
- 3)发送请求。改用exists方法
@Test
void testExistsIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("items");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
总结
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化
RestHighLevelClient - 创建XxxIndexRequest。XXX是
Create、Get、Delete - 准备请求参数(
Create时需要,其它是无参,可以省略) - 发送请求。调用
RestHighLevelClient#indices().xxx()方法,xxx是create、get、exists、delete
RestClient操作文档
索引库准备好以后,就可以操作文档了。
新增文档
我们需要将数据库中的商品信息导入elasticsearch中,而不是造假数据了。
API语法
新增文档的请求语法如下:
POST /{索引库名}/_doc/1
{"name": "Jack","age": 21
}
对应的JavaAPI如下:

可以看到与索引库操作的API非常类似,同样是三步走:
- 1)创建Request对象,这里是
IndexRequest,因为添加文档就是创建倒排索引的过程 - 2)准备请求参数,本例中就是Json文档
- 3)发送请求
变化的地方在于,这里直接使用client.xxx()的API,不再需要client.indices()了。
在item-service的DocumentTest测试类中,编写单元测试:
@Test
void testAddDocument() throws IOException {// 1.根据id查询商品数据Item item = itemService.getById(100002644680L);// 2.转换为文档类型ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);// 3.将ItemDTO转jsonString doc = JSONUtil.toJsonStr(itemDoc);// 1.准备Request对象IndexRequest request = new IndexRequest("items").id(itemDoc.getId());// 2.准备Json文档request.source(doc, XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);
}
查询文档
我们以根据id查询文档为例
查询的请求语句如下:
GET /{索引库名}/_doc/{id}
在item-service的DocumentTest测试类中,编写单元测试:
@Test
void testGetDocumentById() throws IOException {// 1.准备Request对象GetRequest request = new GetRequest("items").id("100002644680");// 2.发送请求GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.获取响应结果中的sourceString json = response.getSourceAsString();ItemDoc itemDoc = JSONUtil.toBean(json, ItemDoc.class);System.out.println("itemDoc= " + ItemDoc);
}
删除文档
删除的请求语句如下:
DELETE /hotel/_doc/{id}
在item-service的DocumentTest测试类中,编写单元测试:
@Test
void testDeleteDocument() throws IOException {// 1.准备Request,两个参数,第一个是索引库名,第二个是文档idDeleteRequest request = new DeleteRequest("item", "100002644680");// 2.发送请求client.delete(request, RequestOptions.DEFAULT);
}
修改文档
修改我们讲过两种方式:
- 全量修改:本质是先根据id删除,再新增
- 局部修改:修改文档中的指定字段值
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
- 如果新增时,ID已经存在,则修改
- 如果新增时,ID不存在,则新增
局部修改的请求语法如下:
POST /{索引库名}/_update/{id}
{"doc": {"字段名": "字段值","字段名": "字段值"}
}
在item-service的DocumentTest测试类中,编写单元测试:
@Test
void testUpdateDocument() throws IOException {// 1.准备RequestUpdateRequest request = new UpdateRequest("items", "100002644680");// 2.准备请求参数request.doc("price", 58800,"commentCount", 1);// 3.发送请求client.update(request, RequestOptions.DEFAULT);
}
批量导入文档
在之前的案例中,我们都是操作单个文档。而数据库中的商品数据实际会达到数十万条,某些项目中可能达到数百万条。
我们如果要将这些数据导入索引库,肯定不能逐条导入,而是采用批处理方案。常见的方案有:
- 利用Logstash批量导入
- 需要安装Logstash
- 对数据的再加工能力较弱
- 无需编码,但要学习编写Logstash导入配置
- 利用JavaAPI批量导入
- 需要编码,但基于JavaAPI,学习成本低
- 更加灵活,可以任意对数据做再加工处理后写入索引库
语法说明
批处理与前面讲的文档的CRUD步骤基本一致:
- 创建Request,但这次用的是
BulkRequest - 准备请求参数
- 发送请求,这次要用到
client.bulk()方法
BulkRequest本身其实并没有请求参数,其本质就是将多个普通的CRUD请求组合在一起发送。例如:
- 批量新增文档,就是给每个文档创建一个
IndexRequest请求,然后封装到BulkRequest中,一起发出。 - 批量删除,就是创建N个
DeleteRequest请求,然后封装到BulkRequest,一起发出
因此BulkRequest中提供了add方法,用以添加其它CRUD的请求:
可以看到,能添加的请求有:
IndexRequest,也就是新增UpdateRequest,也就是修改DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。示例:
@Test
void testBulk() throws IOException {// 1.创建RequestBulkRequest request = new BulkRequest();// 2.准备请求参数request.add(new IndexRequest("items").id("1").source("json doc1", XContentType.JSON));request.add(new IndexRequest("items").id("2").source("json doc2", XContentType.JSON));// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);
}
总结
文档操作的基本步骤:
- 初始化
RestHighLevelClient - 创建XxxRequest。
- XXX是
Index、Get、Update、Delete、Bulk
- XXX是
- 准备参数(
Index、Update、Bulk时需要) - 发送请求。
- 调用
RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
- 调用
- 解析结果(
Get时需要)
总结
数据库模糊查询效率较低,尤其在数据量大时不走索引,性能很差;功能单一,无法支持错字纠正、拼音搜索、同义词搜索等高级功能。而搜索引擎(如Elasticsearch)针对海量数据搜索和复杂搜索场景进行了优化,查询效率高,功能丰富。
ES高效检索的核心在于倒排索引;正向索引在模糊查询的时候只能全文检索;
但是倒排索引可以通过分词器将文档分成多个词条;存储时为已有词条新增该文档的id,以及出现位置等,没有的词条则新增词条之后新增文档id、出现位置等信息;检索时将检索内容分词,依据词条找文档id,之后找到所有文档;
分词器的好坏决定性能,中文常用IK分词器;
ES当中有很多和MYSQL相似的概念:
- ES是面向文档存储的,一个文档是包含多个字段和字段值的JSON字符串;类似于MYSQL的一条记录
- 索引(index)是文档的集合,类似于表
- 映射(Mapping)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema)
- SQL语言=DSL语言
操作
进行DSL操作的时候是REST风格的
索引相关
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 修改索引库,添加字段:PUT /索引库名/_mapping
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化
RestHighLevelClient - 创建XxxIndexRequest。XXX是
Create、Get、Delete - 准备请求参数(
Create时需要,其它是无参,可以省略) - 发送请求。调用
RestHighLevelClient#indices().xxx()方法,xxx是create、get、exists、delete
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")
));
@Test
void testCreateIndex() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("items");// 2.准备请求参数request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}
此外还有批量操作的见前文
文档相关
DSL有如下
- 创建文档:
POST /{索引库名}/_doc/文档id { json文档 } - 查询文档:
GET /{索引库名}/_doc/文档id - 删除文档:
DELETE /{索引库名}/_doc/文档id - 修改文档:
- 全量修改:
PUT /{索引库名}/_doc/文档id { json文档 } - 局部修改:
POST /{索引库名}/_update/文档id { "doc": {字段}}
- 全量修改:
文档操作的基本步骤:
- 初始化
RestHighLevelClient - 创建XxxRequest。
- XXX是
Index、Get、Update、Delete、Bulk
- XXX是
- 准备参数(
Index、Update、Bulk时需要) - 发送请求。
- 调用
RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
- 调用
- 解析结果(
Get时需要)
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")
));
@Test
void testUpdateDocument() throws IOException {// 1.准备RequestUpdateRequest request = new UpdateRequest("items", "100002644680");// 2.准备请求参数request.doc("price", 58800,"commentCount", 1);// 3.发送请求client.update(request, RequestOptions.DEFAULT);
}
此外还有批量操作的见前文
ES高级查询
DSL查询
Elasticsearch的查询可以分为两大类:
- 叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
- 复合查询(Compound query clauses):以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
查询的语法结构:
GET /{索引库名}/_search
{"query": {"查询类型": {// .. 查询条件}}
}
说明:
GET /{索引库名}/_search:其中的_search是固定路径,不能修改
例如,我们以最简单的无条件查询为例,无条件查询的类型是:match_all,因此其查询语句如下:
GET /items/_search
{"query": {"match_all": {}}
}
由于match_all无条件,所以条件位置不写即可。
虽然是match_all,但是响应结果中并不会包含索引库中的所有文档,而是仅有10条。这是因为处于安全考虑,elasticsearch设置了默认的查询页数。
叶子查询
叶子查询的类型也可以做进一步细分,详情大家可以查看官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/query-dsl.html
如图:
这里列举一些常见的,例如:
- 全文检索查询(Full Text Queries):利用分词器对用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条。例如:
match:multi_match
- 精确查询(Term-level queries):不对用户输入搜索条件分词,根据字段内容精确值匹配。但只能查找keyword、数值、日期、boolean类型的字段。例如:
idstermrange
- **地理坐标查询:**用于搜索地理位置,搜索方式很多,例如:
geo_bounding_box:按矩形搜索geo_distance:按点和半径搜索
- …略
全文检索查询
全文检索的种类也很多,详情可以参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/full-text-queries.html
以全文检索中的match为例,语法如下:
GET /{索引库名}/_search
{"query": {"match": {"字段名": "搜索条件"}}
}
示例:
与match类似的还有multi_match,区别在于可以同时对多个字段搜索,而且多个字段都要满足,语法示例:
GET /{索引库名}/_search
{"query": {"multi_match": {"query": "搜索条件","fields": ["字段1", "字段2"]}}
}
示例:
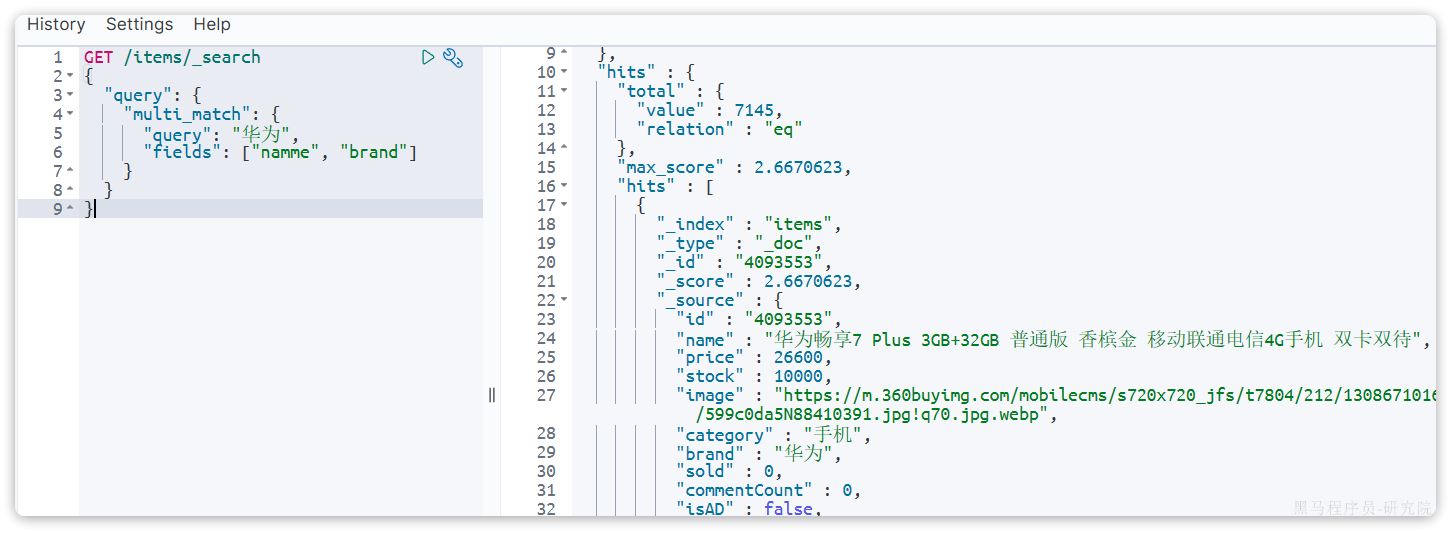
精确查询
精确查询,英文是Term-level query,顾名思义,词条级别的查询。也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配。因此推荐查找keyword、数值、日期、boolean类型的字段。例如:
- id
- price
- 城市
- 地名
- 人名
等等,作为一个整体才有含义的字段。
详情可以查看官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/term-level-queries.html
以term查询为例,其语法如下:
GET /{索引库名}/_search
{"query": {"term": {"字段名": {"value": "搜索条件"}}}
}
示例:
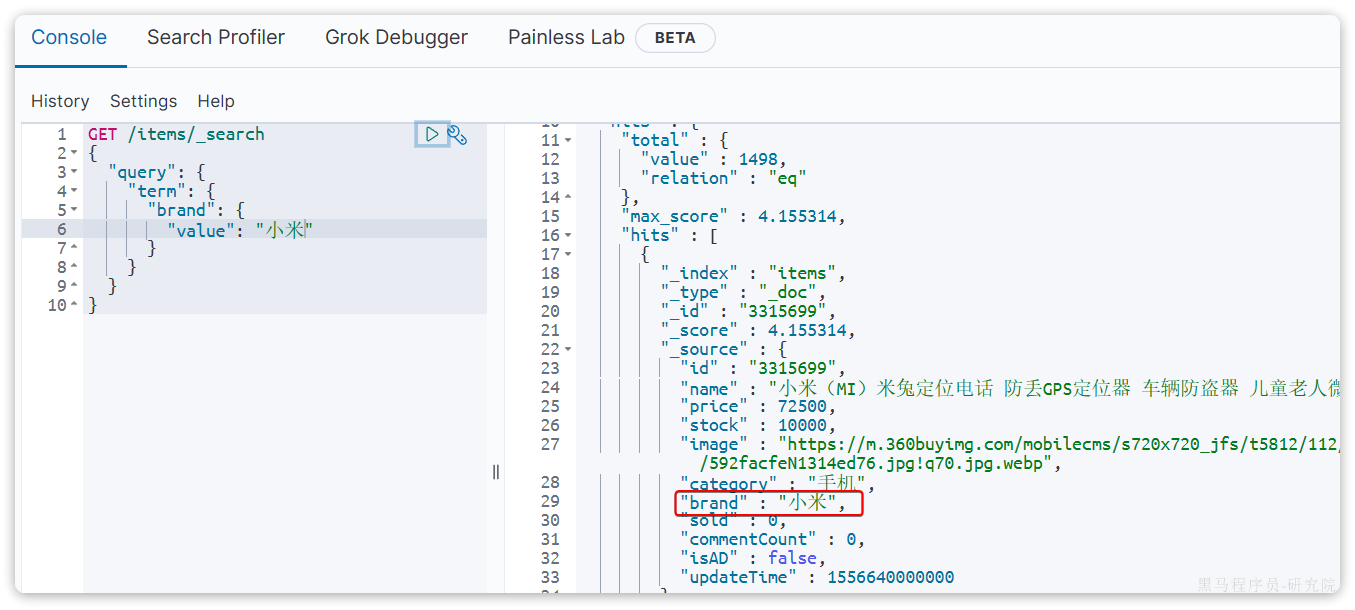
当你输入的搜索条件不是词条,而是短语时,由于不做分词,你反而搜索不到:
再来看下range查询,语法如下:
GET /{索引库名}/_search
{"query": {"range": {"字段名": {"gte": {最小值},"lte": {最大值}}}}
}
range是范围查询,对于范围筛选的关键字有:
gte:大于等于gt:大于lte:小于等于lt:小于
示例:
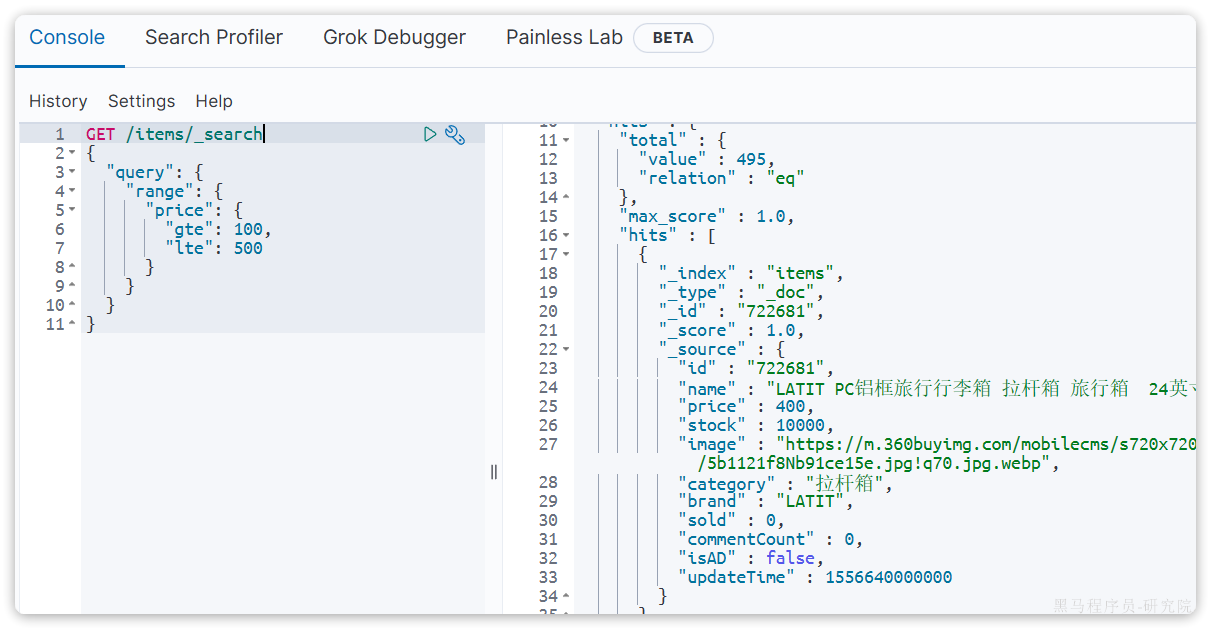
复合查询
复合查询大致可以分为两类:
- 第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
- bool
- 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
- function_score
- dis_max
其它复合查询及相关语法可以参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/compound-queries.html
算分函数查询(选讲)
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,我们搜索 “手机”,结果如下:
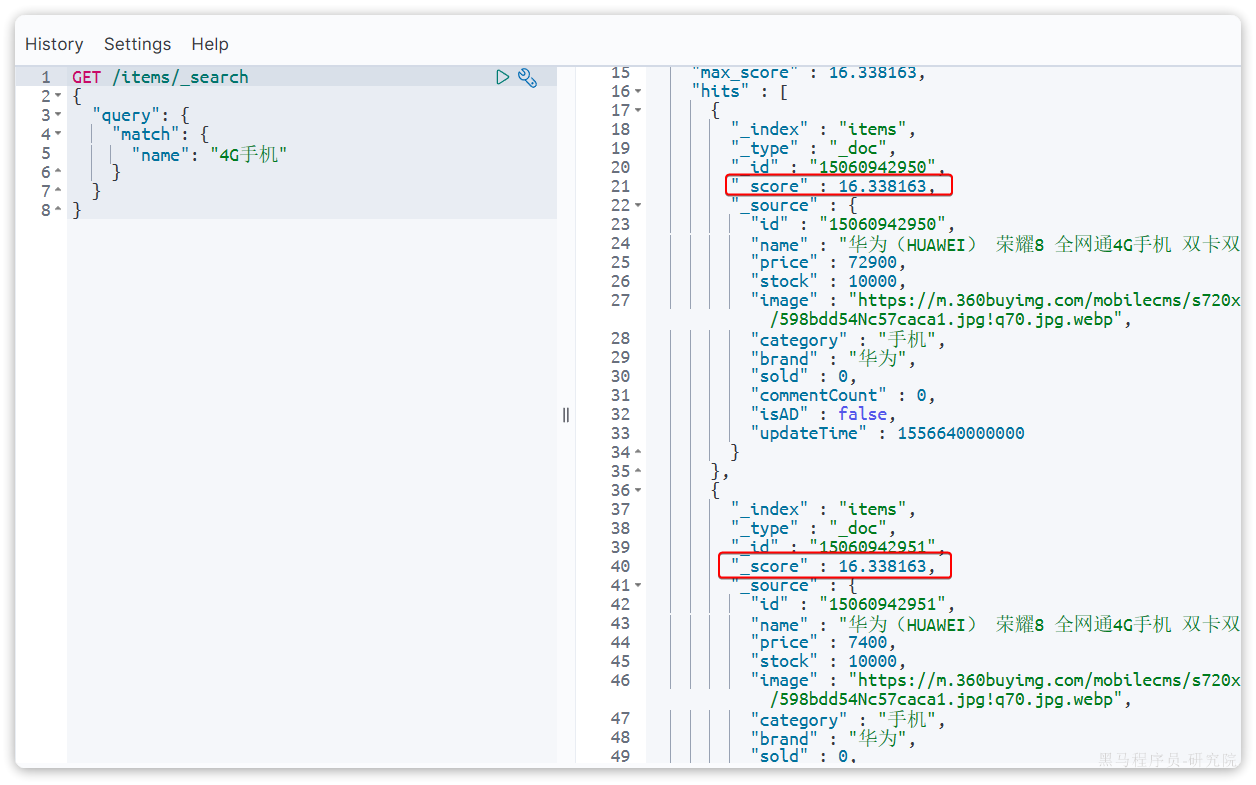
从elasticsearch5.1开始,采用的相关性打分算法是BM25算法,公式如下:

基于这套公式,就可以判断出某个文档与用户搜索的关键字之间的关联度,还是比较准确的。但是,在实际业务需求中,常常会有竞价排名的功能。不是相关度越高排名越靠前,而是掏的钱多的排名靠前。
要想为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
基本语法:
function score 查询中包含四部分内容:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
function score的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
示例:给IPhone这个品牌的手机算分提高十倍,分析如下:
- 过滤条件:品牌必须为IPhone
- 算分函数:常量weight,值为10
- 算分模式:相乘multiply
对应代码如下:
GET /hotel/_search
{"query": {"function_score": {"query": { .... }, // 原始查询,可以是任意条件"functions": [ // 算分函数{"filter": { // 满足的条件,品牌必须是Iphone"term": {"brand": "Iphone"}},"weight": 10 // 算分权重为2}],"boost_mode": "multipy" // 加权模式,求乘积}}
}
bool查询
bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool查询支持的逻辑运算有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
bool查询的语法如下:
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}}],"should": [{"term": {"brand": { "value": "vivo" }}},{"term": {"brand": { "value": "小米" }}}],"must_not": [{"range": {"price": {"gte": 2500}}}],"filter": [{"range": {"price": {"lte": 1000}}}]}}
}
出于性能考虑,与搜索关键字无关的查询尽量采用must_not或filter逻辑运算,避免参与相关性算分。
排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。不过分词字段无法排序,能参与排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
详细说明可以参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/sort-search-results.html
语法说明:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"排序字段": {"order": "排序方式asc和desc"}}]
}
分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
基础分页
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
from:从第几个文档开始size:总共查询几个文档
类似于mysql中的limit ?, ?
官方文档如下:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/paginate-search-results.html
语法如下:
GET /items/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 每页文档数量,默认10"sort": [{"price": {"order": "desc"}}]
}
深度分页
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
比如一个索引库中有100000条数据,分别存储到4个分片,每个分片25000条数据。现在每页查询10条,查询第99页。那么分页查询的条件如下:
GET /items/_search
{"from": 990, // 从第990条开始查询"size": 10, // 每页查询10条"sort": [{"price": "asc"}]
}
从语句来分析,要查询第990~1000名的数据。
从实现思路来分析,肯定是将所有数据排序,找出前1000名,截取其中的990~1000的部分。但问题来了,我们如何才能找到所有数据中的前1000名呢?
要知道每一片的数据都不一样,第1片上的第900~1000,在另1个节点上并不一定依然是900~1000名。所以我们只能在每一个分片上都找出排名前1000的数据,然后汇总到一起,重新排序,才能找出整个索引库中真正的前1000名,此时截取990~1000的数据即可。
如图:
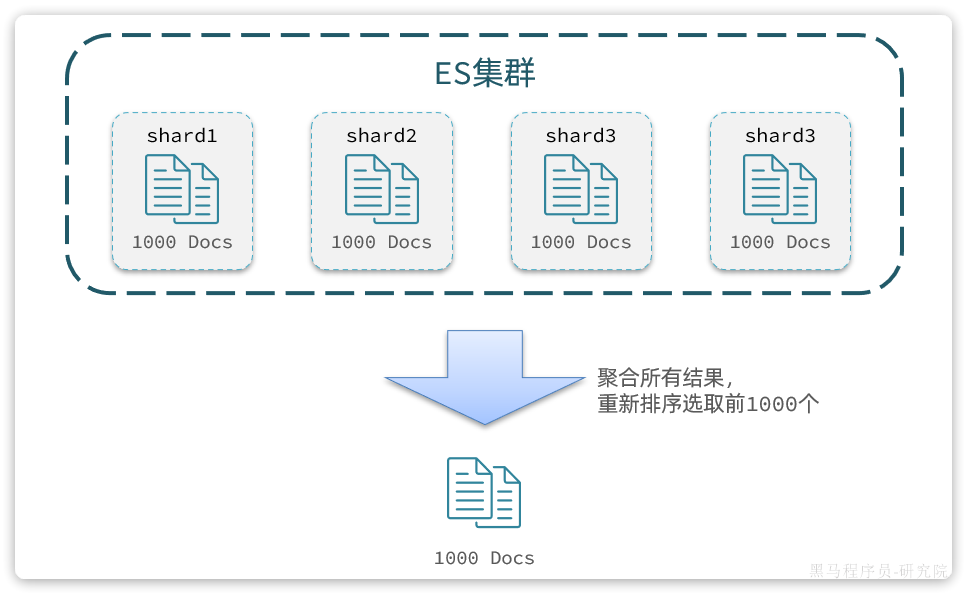
试想一下,假如我们现在要查询的是第999页数据呢,是不是要找第9990~10000的数据,那岂不是需要把每个分片中的前10000名数据都查询出来,汇总在一起,在内存中排序?如果查询的分页深度更深呢,需要一次检索的数据岂不是更多?
由此可知,当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力。
因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,elasticsearch提供了两种解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。scroll:原理将排序后的文档id形成快照,保存下来,基于快照做分页。官方已经不推荐使用。
详情见文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/paginate-search-results.html
总结:
大多数情况下,我们采用普通分页就可以了。查看百度、京东等网站,会发现其分页都有限制。例如百度最多支持77页,每页不足20条。京东最多100页,每页最多60条。
因此,一般我们采用限制分页深度的方式即可,无需实现深度分页。
高亮
高亮原理
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示:
因此词条的高亮标签肯定是由服务端提供数据的时候已经加上的。
因此实现高亮的思路就是:
- 用户输入搜索关键字搜索数据
- 服务端根据搜索关键字到elasticsearch搜索,并给搜索结果中的关键字词条添加
html标签 - 前端提前给约定好的
html标签添加CSS样式
实现高亮
事实上elasticsearch已经提供了给搜索关键字加标签的语法,无需我们自己编码。
基本语法如下:
GET /{索引库名}/_search
{"query": {"match": {"搜索字段": "搜索关键字"}},"highlight": {"fields": {"高亮字段名称": {"pre_tags": "<em>","post_tags": "</em>"}}}
}
注意:
- 搜索必须有查询条件,而且是全文检索类型的查询条件,例如
match - 参与高亮的字段必须是
text类型的字段 - 默认情况下参与高亮的字段要与搜索字段一致,除非添加:
required_field_match=false
RestClient查询
文档的查询依然使用昨天学习的 RestHighLevelClient对象,查询的基本步骤如下:
-
初始化RestHighLevelClient
-
1)创建
request对象,这次是搜索,所以是SearchRequest -
2)准备请求参数,也就是查询DSL对应的JSON参数
-
3)发起请求
-
4)解析响应,响应结果相对复杂,需要逐层解析
快速入门
之前说过,由于Elasticsearch对外暴露的接口都是Restful风格的接口,因此JavaAPI调用就是在发送Http请求。而我们核心要做的就是利用利用Java代码组织请求参数,解析响应结果。
这个参数的格式完全参考DSL查询语句的JSON结构,因此我们在学习的过程中,会不断的把JavaAPI与DSL语句对比。大家在学习记忆的过程中,也应该这样对比学习。
发送请求
首先以match_all查询为例,其DSL和JavaAPI的对比如图:

代码解读:
- 第一步,创建
SearchRequest对象,指定索引库名 - 第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等 query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL- 第三步,利用
client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),它构建的就是DSL中的完整JSON参数。其中包含了query、sort、from、size、highlight等所有功能:
另一个是QueryBuilders,其中包含了我们学习过的各种叶子查询、复合查询等:

解析响应结果
在发送请求以后,得到了响应结果SearchResponse,这个类的结构与我们在kibana中看到的响应结果JSON结构完全一致:
{"took" : 0,"timed_out" : false,"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "heima","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"info" : "Java讲师","name" : "赵云"}}]}
}
因此,我们解析SearchResponse的代码就是在解析这个JSON结果,对比如下:
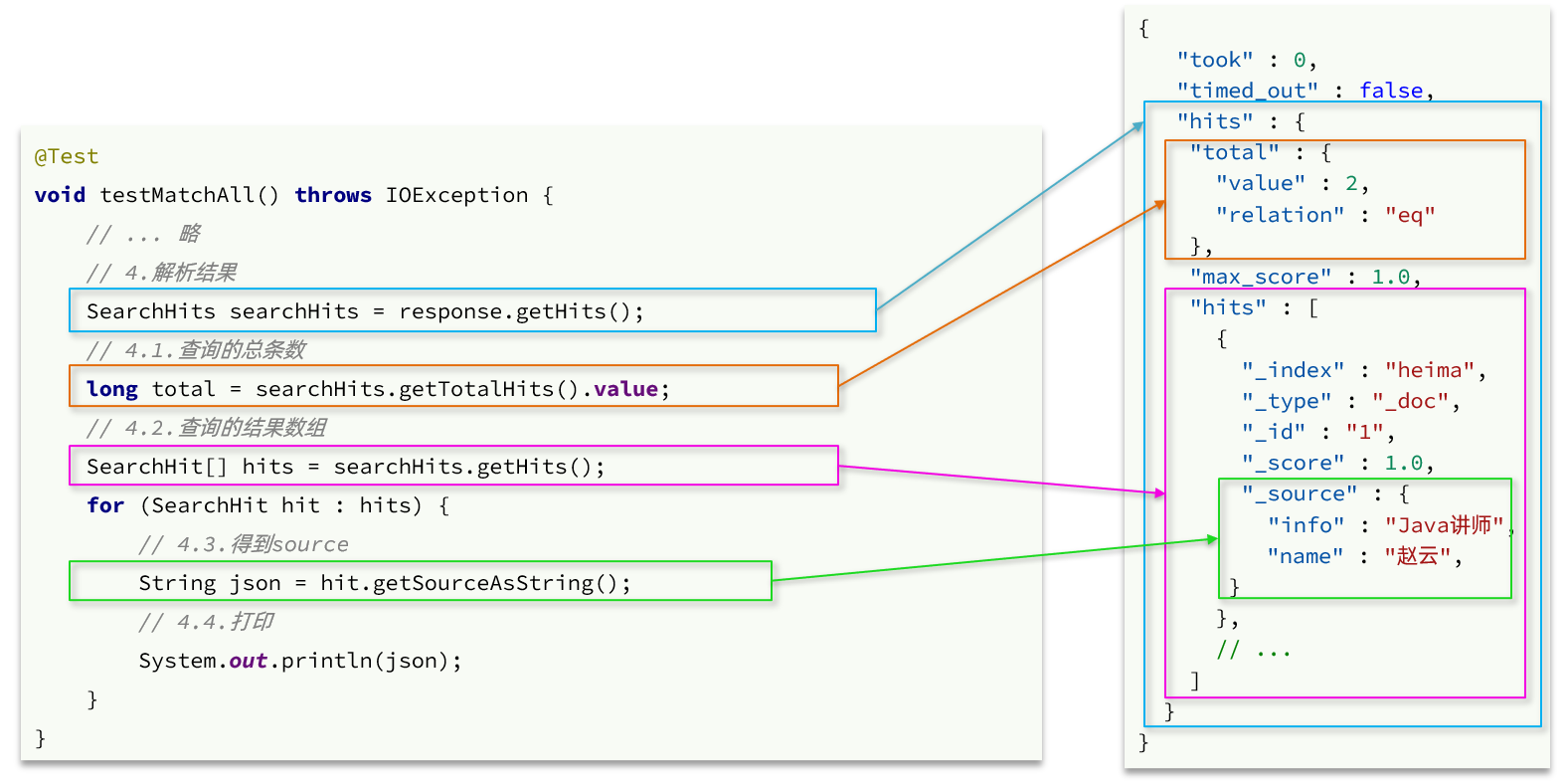
elasticsearch返回的结果是一个JSON字符串,结构包含:
hits:命中的结果total:总条数,其中的value是具体的总条数值max_score:所有结果中得分最高的文档的相关性算分hits:搜索结果的文档数组,其中的每个文档都是一个json对象_source:文档中的原始数据,也是json对象
因此,我们解析响应结果,就是逐层解析JSON字符串,流程如下:
SearchHits:通过response.getHits()获取,就是JSON中的最外层的hits,代表命中的结果SearchHits#getTotalHits().value:获取总条数信息SearchHits#getHits():获取SearchHit数组,也就是文档数组SearchHit#getSourceAsString():获取文档结果中的_source,也就是原始的json文档数据
总结
文档搜索的基本步骤是:
- 创建
SearchRequest对象 - 准备
request.source(),也就是DSL。QueryBuilders来构建查询条件- 传入
request.source()的query()方法
- 发送请求,得到结果
- 解析结果(参考JSON结果,从外到内,逐层解析)
完整代码如下:
@Test
void testMatchAll() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.matchAllQuery());// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化并打印ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);System.out.println(item);}
}
叶子查询
所有的查询条件都是由QueryBuilders来构建的,叶子查询也不例外。因此整套代码中变化的部分仅仅是query条件构造的方式,其它不动。
例如match查询:
@Test
void testMatch() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
再比如multi_match查询:
@Test
void testMultiMatch() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.multiMatchQuery("脱脂牛奶", "name", "category"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
还有range查询:
@Test
void testRange() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.rangeQuery("price").gte(10000).lte(30000));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
还有term查询:
@Test
void testTerm() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.termQuery("brand", "华为"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
复合查询
复合查询也是由QueryBuilders来构建,我们以bool查询为例,DSL和JavaAPI的对比如图:
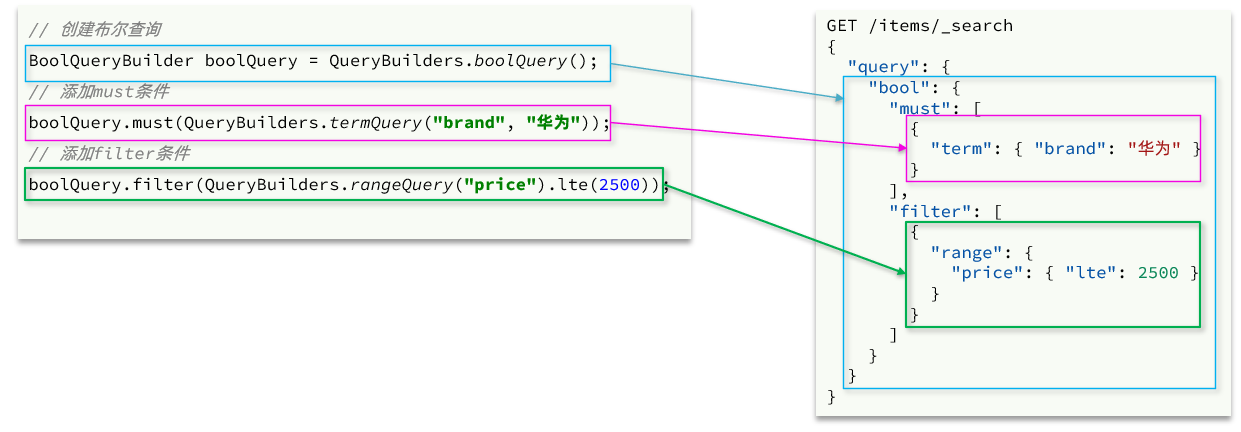
完整代码如下:
@Test
void testBool() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.准备bool查询BoolQueryBuilder bool = QueryBuilders.boolQuery();// 2.2.关键字搜索bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.3.品牌过滤bool.filter(QueryBuilders.termQuery("brand", "德亚"));// 2.4.价格过滤bool.filter(QueryBuilders.rangeQuery("price").lte(30000));request.source().query(bool);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
排序和分页
之前说过,requeset.source()就是整个请求JSON参数,所以排序、分页都是基于这个来设置,其DSL和JavaAPI的对比如下:
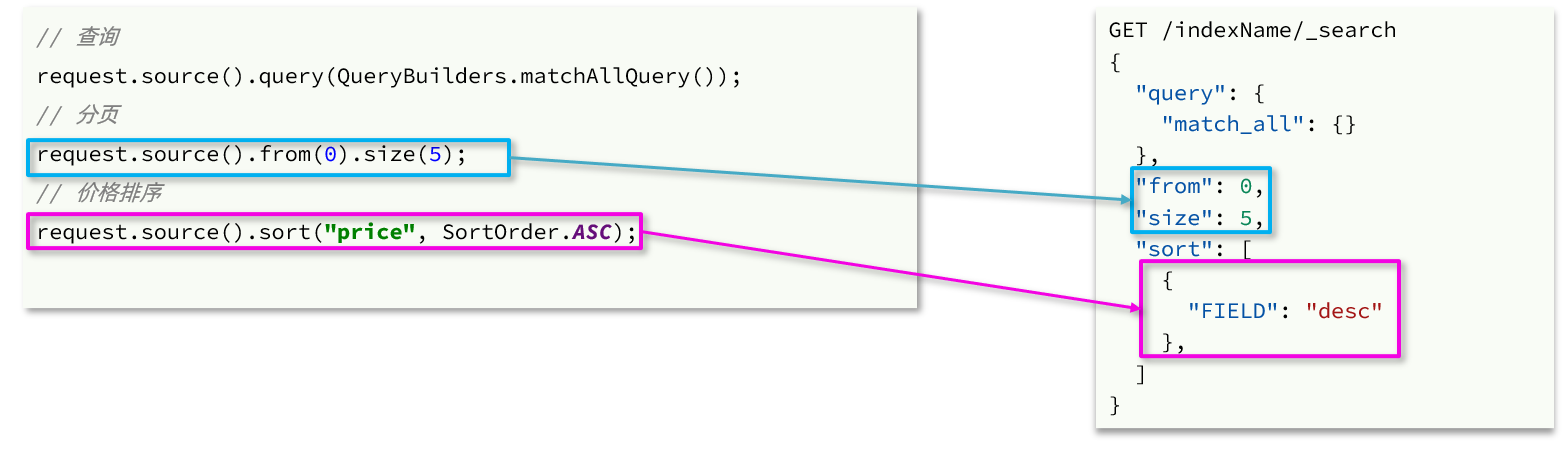
完整示例代码:
@Test
void testPageAndSort() throws IOException {int pageNo = 1, pageSize = 5;// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.搜索条件参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.排序参数request.source().sort("price", SortOrder.ASC);// 2.3.分页参数request.source().from((pageNo - 1) * pageSize).size(pageSize);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
高亮
高亮查询与前面的查询有两点不同:
- 条件同样是在
request.source()中指定,只不过高亮条件要基于HighlightBuilder来构造 - 高亮响应结果与搜索的文档结果不在一起,需要单独解析
首先来看高亮条件构造,其DSL和JavaAPI的对比如图:

示例代码如下:
@Test
void testHighlight() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.query条件request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.高亮条件request.source().highlighter(SearchSourceBuilder.highlight().field("name").preTags("<em>").postTags("</em>"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
再来看结果解析,文档解析的部分不变,主要是高亮内容需要单独解析出来,其DSL和JavaAPI的对比如图:
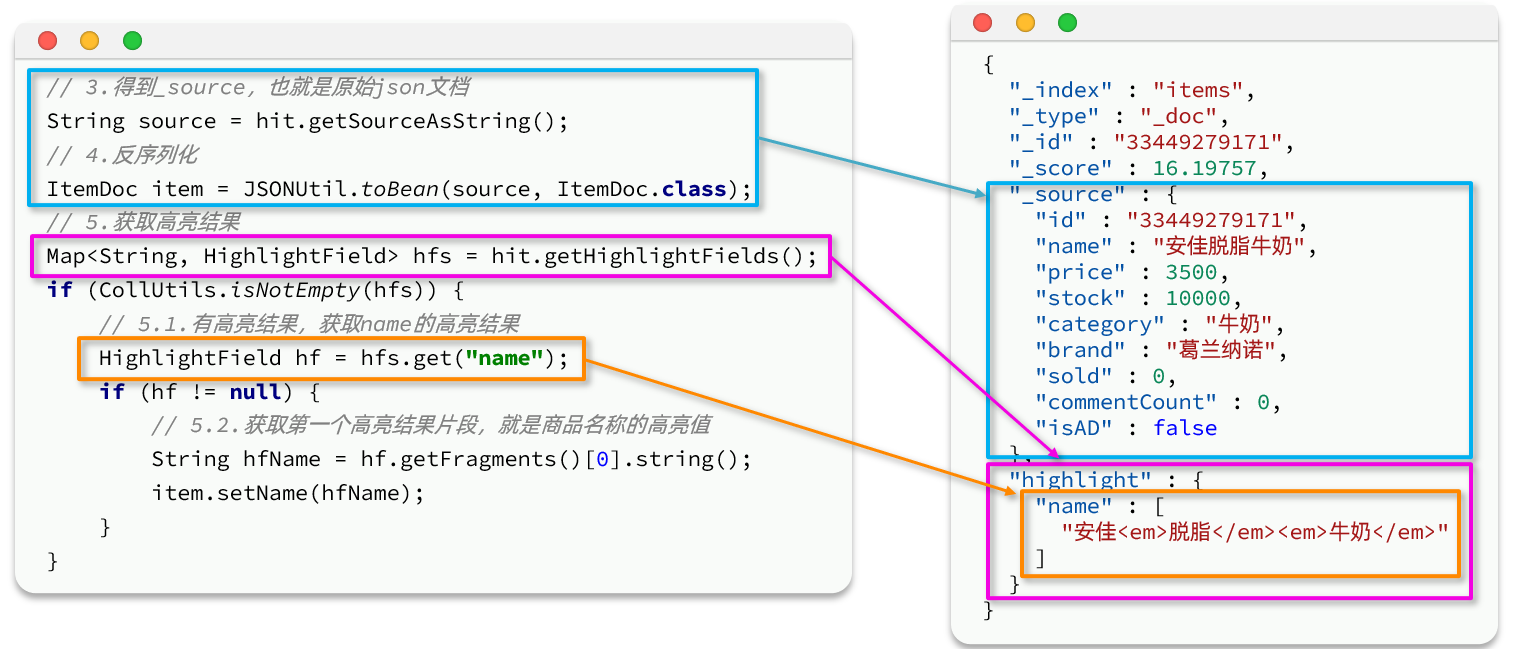
代码解读:
- 第
3、4步:从结果中获取_source。hit.getSourceAsString(),这部分是非高亮结果,json字符串。还需要反序列为ItemDoc对象 - 第
5步:获取高亮结果。hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值 - 第
5.1步:从Map中根据高亮字段名称,获取高亮字段值对象HighlightField - 第
5.2步:从HighlightField中获取Fragments,并且转为字符串。这部分就是真正的高亮字符串了 - 最后:用高亮的结果替换
ItemDoc中的非高亮结果
完整代码如下:
private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);// 5.获取高亮结果Map<String, HighlightField> hfs = hit.getHighlightFields();if (CollUtils.isNotEmpty(hfs)) {// 5.1.有高亮结果,获取name的高亮结果HighlightField hf = hfs.get("name");if (hf != null) {// 5.2.获取第一个高亮结果片段,就是商品名称的高亮值String hfName = hf.getFragments()[0].string();item.setName(hfName);}}System.out.println(item);}
}
数据聚合
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/search-aggregations.html
聚合常见的有三类:
- **桶(
Bucket)**聚合:用来对文档做分组 TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组- **度量(
Metric)**聚合:用以计算一些值,比如:最大值、最小值、平均值等 Avg:求平均值Max:求最大值Min:求最小值Stats:同时求max、min、avg、sum等- **管道(
pipeline)**聚合:其它聚合的结果为基础做进一步运算
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型
DSL实现聚合
与之前的搜索功能类似,我们依然先学习DSL的语法,再学习JavaAPI.
Bucket聚合
例如我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category值一样的放在同一组,属于Bucket聚合中的Term聚合。
基本语法如下:
GET /items/_search
{"query":{"match_all":{}},// 全查的时候可以省略"size": 0, "aggs": {"category_agg": {"terms": {"field": "category","size": 20}}}
}
语法说明:
size:设置size为0,就是每页查0条,则结果中就不包含文档,只包含聚合aggs:定义聚合category_agg:聚合名称,自定义,但不能重复terms:聚合的类型,按分类聚合,所以用termfield:参与聚合的字段名称size:希望返回的聚合结果的最大数量
来看下查询的结果:

带条件聚合
默认情况下,Bucket聚合是对索引库的所有文档做聚合,例如我们统计商品中所有的品牌,结果如下:
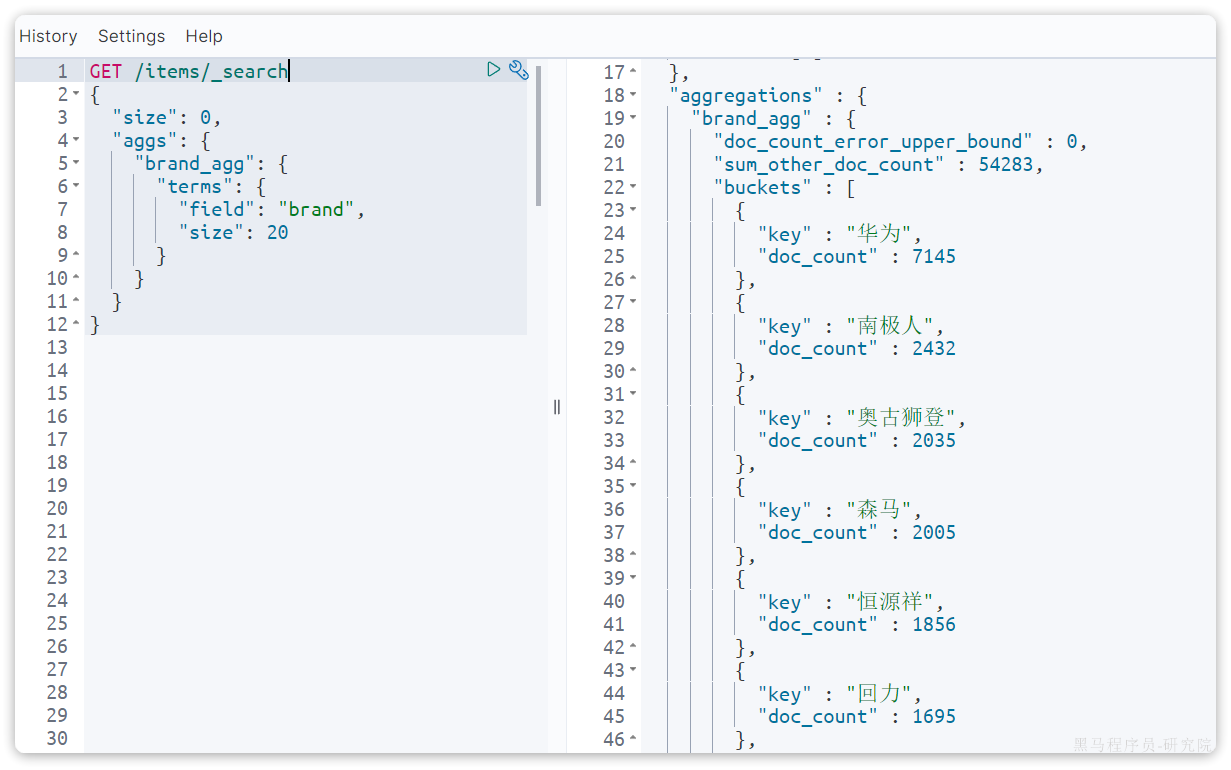
可以看到统计出的品牌非常多。
但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
例如,我想知道价格高于3000元的手机品牌有哪些,该怎么统计呢?
我们需要从需求中分析出搜索查询的条件和聚合的目标:
- 搜索查询条件:
- 价格高于3000
- 必须是手机
- 聚合目标:统计的是品牌,肯定是对brand字段做term聚合
语法如下:
GET /items/_search
{"query": {"bool": {"filter": [{"term": {"category": "手机"}},{"range": {"price": {"gte": 300000}}}]}}, "size": 0, "aggs": {"brand_agg": {"terms": {"field": "brand","size": 20}}}
}
聚合结果如下:
{"took" : 2,"timed_out" : false,"hits" : {"total" : {"value" : 13,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"brand_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "华为","doc_count" : 7},{"key" : "Apple","doc_count" : 5},{"key" : "小米","doc_count" : 1}]}}
}
Metric聚合
现在我们需要对桶内的商品做运算,获取每个品牌价格的最小值、最大值、平均值。
这就要用到Metric聚合了,例如stat聚合,就可以同时获取min、max、avg等结果。
语法如下:
GET /items/_search
{"query": {"bool": {"filter": [{"term": {"category": "手机"}},{"range": {"price": {"gte": 300000}}}]}}, "size": 0, "aggs": {"brand_agg": {"terms": {"field": "brand","size": 20},"aggs": {"stats_meric": {"stats": {"field": "price"}}}}}
}
query部分就不说了,我们重点解读聚合部分语法。
可以看到我们在brand_agg聚合的内部,我们新加了一个aggs参数。这个聚合就是brand_agg的子聚合,会对brand_agg形成的每个桶中的文档分别统计。
stats_meric:聚合名称stats:聚合类型,stats是metric聚合的一种field:聚合字段,这里选择price,统计价格
由于stats是对brand_agg形成的每个品牌桶内文档分别做统计,因此每个品牌都会统计出自己的价格最小、最大、平均值。
结果如下:

另外,我们还可以让聚合按照每个品牌的价格平均值排序:
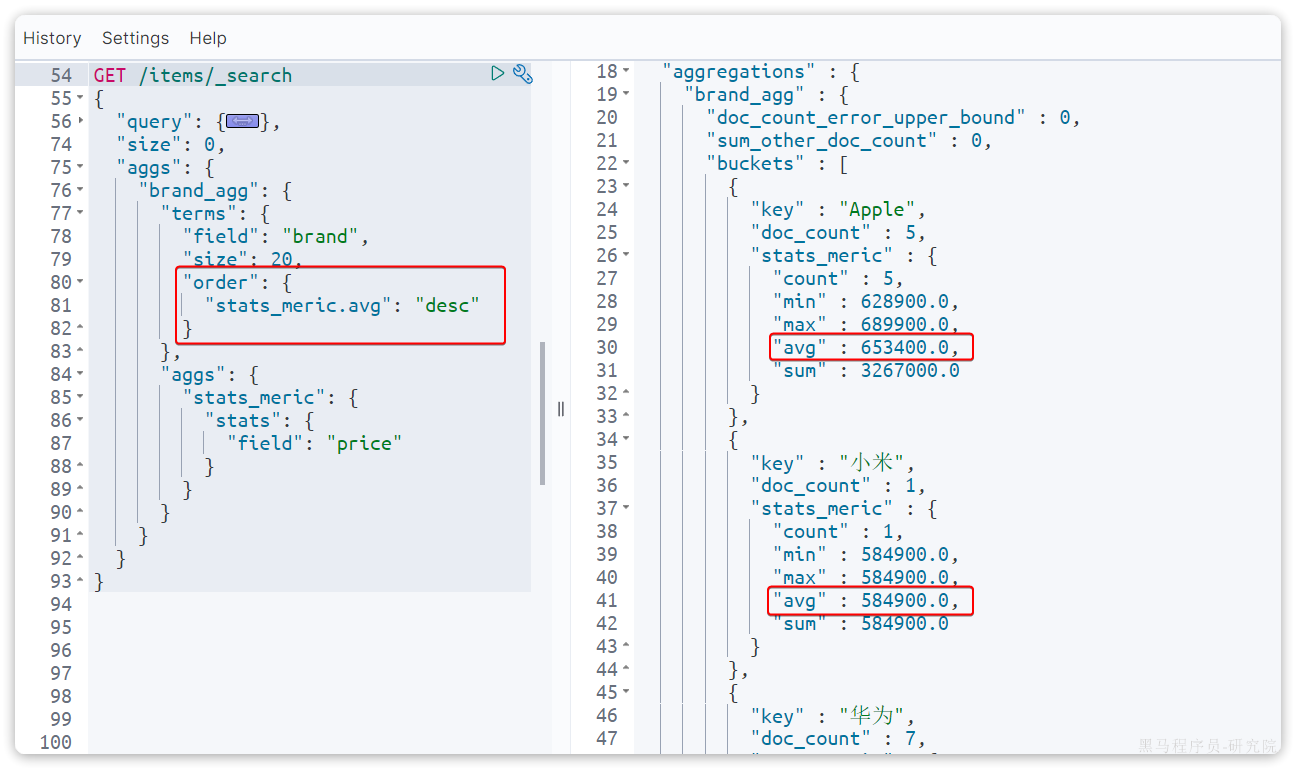
总结
aggs代表聚合,与query同级,此时query就是查询条件,也可以正常查找出内容
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
RestClient实现聚合
可以看到在DSL中,aggs聚合条件与query条件是同一级别,都属于查询JSON参数。因此依然是利用request.source()方法来设置。
不过聚合条件的要利用AggregationBuilders这个工具类来构造。DSL与JavaAPI的语法对比如下:
聚合结果与搜索文档同一级别,因此需要单独获取和解析。具体解析语法如下:
完整代码如下:
@Test
void testAgg() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.准备请求参数BoolQueryBuilder bool = QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("category", "手机")).filter(QueryBuilders.rangeQuery("price").gte(300000));request.source().query(bool).size(0);// 3.聚合参数request.source().aggregation(AggregationBuilders.terms("brand_agg").field("brand").size(5));// 4.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5.解析聚合结果Aggregations aggregations = response.getAggregations();// 5.1.获取品牌聚合// 注意解析聚合结果时,用什么类型聚合,就用什么类型的结果接口接收Terms brandTerms = aggregations.get("brand_agg");// 5.2.获取聚合中的桶List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 5.3.遍历桶内数据for (Terms.Bucket bucket : buckets) {// 5.4.获取桶内keyString brand = bucket.getKeyAsString();System.out.print("brand = " + brand);long count = bucket.getDocCount();System.out.println("; count = " + count);}
}
总结
原理
总的来说ES进行高级查询的时候不再只是使用文档id进行查询,而是可以综合查询多个条件。
查询的DSL是一个大的JSON对象,包含下列属性:
query:查询条件from和size:分页条件sort:排序条件highlight:高亮条件
示例:
一般会使用复合查询当中嵌套叶子查询的方式做核心查询,最后可以选用排序、分页、高亮等方式进行结果处理;
叶子查询中常见的有全文检索(match、多字段multi_match)、精准查询(ids、词条term、范围range)
复合查询最常见的就是bool查询,其次是算分函数查询。
bool查询当中包含参与算分的与、或;和不参与算分的非、筛选;默认按照算分进行排序,也可以通过sort指定排序方式;
选择分页的话,由于分布式存储的原因,要注意分页排序出现的深度分页问题:当查询靠后的前k个文档时要将每个分片的前k个文档全查询后合并,导致总文档数过量。
为了解决深度分页一种参考思路是多查几次,每次记录最后一条数据的排序值,之后的查询新增条件是排序值要小于这个值。同时ES也限制了分页的参数大小,一般是相加不超过1w;
高亮的实现是后端实现的,通过倒排索引找到文档,定位词条出现位置,返回时为高亮字段的词条环绕上高亮标签。
ES当中也提供了和Mysql聚合函数一样的实现对数据的统计、分析、运算的功能:聚合(aggregations)
聚合常见的有三类:
- **桶(
Bucket)**聚合:用来对文档做分组 ,类似Group By;可以实现字段分组,或者一段时间周期为单位分组 - **度量(
Metric)**聚合:用以计算一些值,比如:最大值、最小值、平均值 等 - **管道(
pipeline)**聚合:其它聚合的结果为基础做进一步运算
聚合是查询功能的一部分是针对query结果的计算、分组操作,类似于附加功能;如果一个_search没有query,只有aggs,说明是默认的match_all();
实操
ES进行高级查询的时候,DSL主要是
通过以下结构进行的查询
GET /{索引库名}/_search
{"query": {"查询类型": {// .. 查询条件}},"from": 990, // 从第990条开始查询"size": 10, // 每页查询10条"sort": [{"price": "asc"}],"highlight": {"fields": {"高亮字段名称": {"pre_tags": "<em>","post_tags": "</em>"}}},// 先按照brand分组,显示20条,按照最大价格降序排列"aggs": {"聚合名称1": {"terms": {"field": "brand","size": 20,"order":{"聚合名称2.max":"desc"}},// 每组内部信息显示价格的最大值最小值等内容// 没有这部分则是显示记录数目"aggs": {"聚合名称2": {"stats": {"field": "price"}}}}}
}
而使用RestClient则是
- 创建
SearchRequest对象 - 准备
request.source(),也就是DSL。QueryBuilders来构建查询条件- 传入
request.source()的query()方法
- 发送请求,得到结果
- 解析结果(参考JSON结果,从外到内,逐层解析)
示例代码如下:
@Test
void testHighlight() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.query条件1// request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.1.query条件2// 2.1.1.准备bool查询BoolQueryBuilder bool = QueryBuilders.boolQuery();// 2.1.2.关键字搜索bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.1.3.品牌过滤bool.filter(QueryBuilders.termQuery("brand", "德亚"));// 2.1.4.价格过滤bool.filter(QueryBuilders.rangeQuery("price").lte(30000));request.source().query(bool);// 2.2.排序参数request.source().sort("price", SortOrder.ASC);// 2.3.分页参数request.source().from((pageNo - 1) * pageSize).size(pageSize);// 2.4.高亮条件request.source().highlighter(SearchSourceBuilder.highlight().field("name").preTags("<em>").postTags("</em>"));// 3.聚合参数request.source().aggregation(AggregationBuilders.terms("brand_agg").field("brand").size(5));// 4.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5.解析响应数据+聚合结果// 注意解析聚合结果时,用什么类型聚合,就用什么类型的结果接口接收handleResponse(response);
}
响应数据
响应数据的格式如下