KingbaseES读写分离集群架构解析
一套为企业关键业务而生的数据库架构
在当今数字化转型的浪潮中,KingbaseES推出了基于WAL流复制技术的读写分离集群方案。据了解,这套架构通过JDBC驱动程序实现了智能化的读写分离——写操作交给主库处理,读操作则分散到备库执行,让数据库系统的响应速度和吞吐量都得到了显著提升。
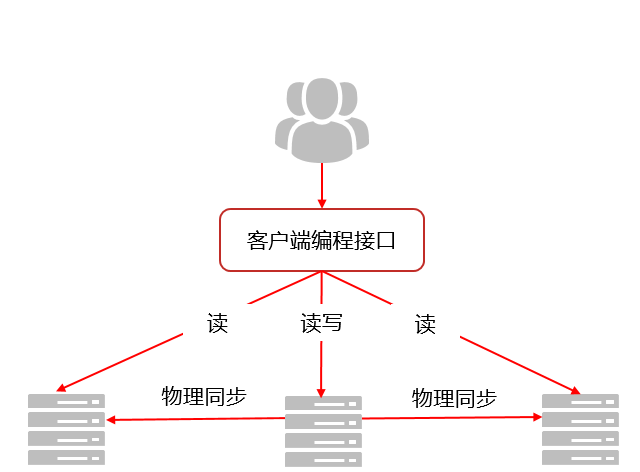
两个"管家"守护着整个集群
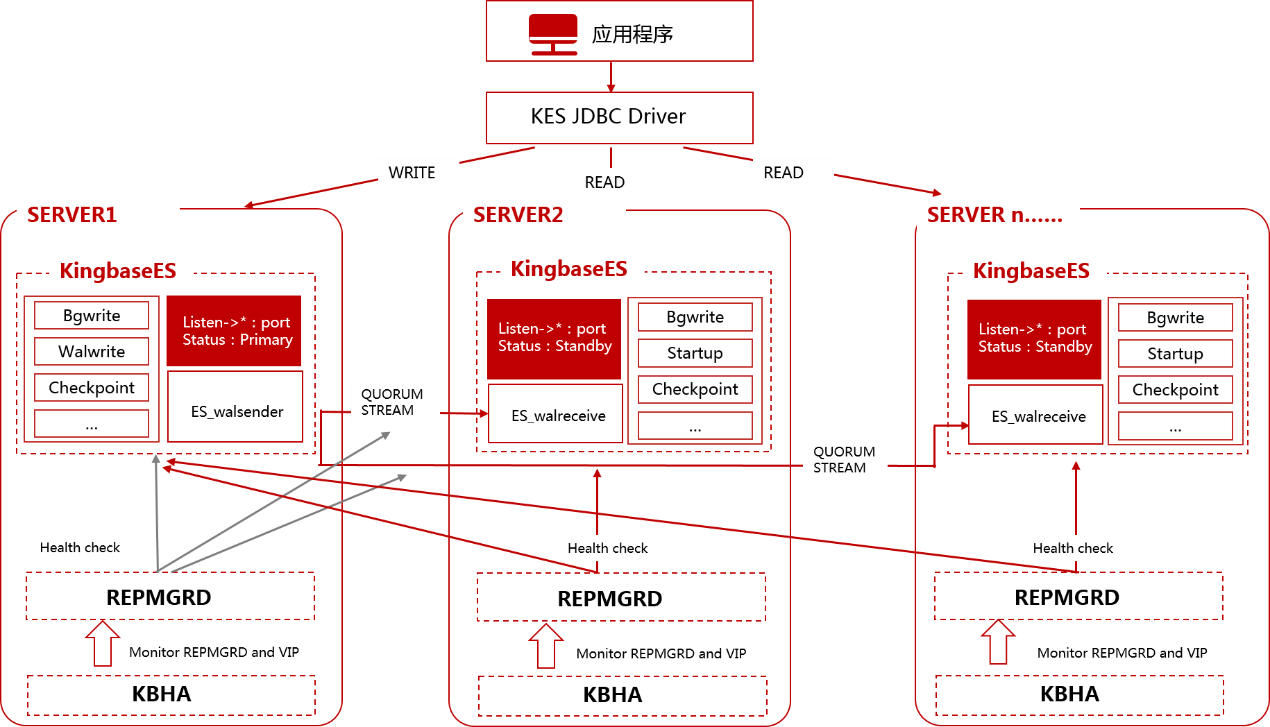
KingbaseES的技术负责人介绍说,集群的稳定运行主要依靠两个核心进程来保障。
首先是repmgrd进程,它就像集群的"大管家"。在主节点上,它随时关注着本地数据库的健康状况;在备节点上,它不仅要看好自己家,还要时刻留意主库那边的动静。通过定期检查和sys_stat_replication视图,它能实时掌握数据同步的进展。一旦发现异常,立即启动应急预案。
其次是kbha进程,这是环境监控的"守护神"。它的主要职责是保护repmgrd进程正常运行,同时监控磁盘、网络等基础设施的状态。有意思的是,系统还通过crond服务来保护kbha自己,形成了"守护者的守护者"这样一个巧妙的设计。
数据是如何在主备库之间"传递"的
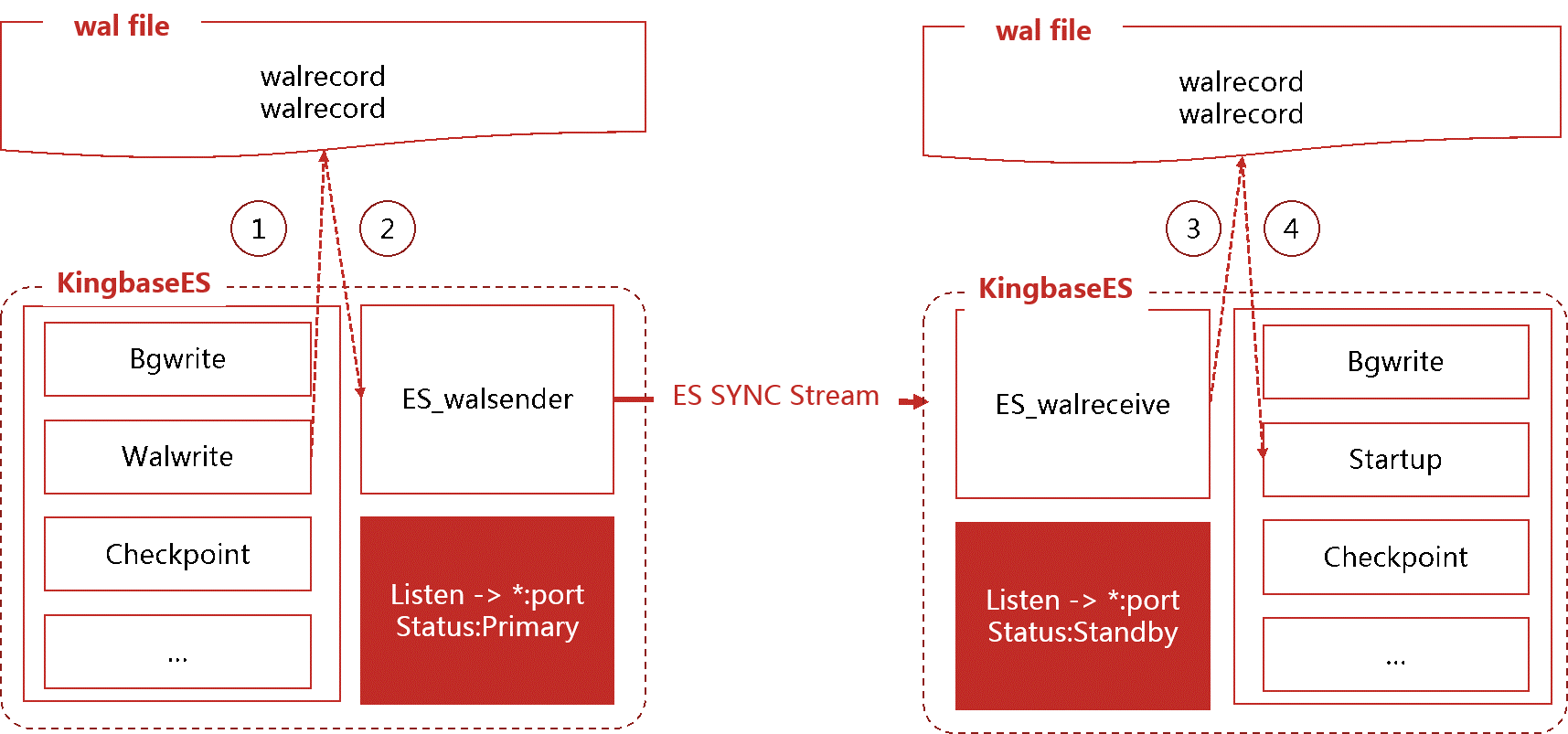
数据同步的过程其实并不复杂,主要分为三个步骤:
第一步,当主库接收到数据更新请求后,walwriter进程会把变更记录(也就是WAL日志)写入磁盘保存起来。
第二步,walsender进程读取这些WAL日志,通过网络流式传输给备库。这个过程就像快递员把包裹送到目的地一样。
第三步,备库的walreceiver进程接收到WAL日志后,先存储在本地,然后由startup进程重新执行这些操作,完成数据的同步更新。
企业可以根据需要选择不同的同步模式
技术人员表示,通过调整repmgr.conf配置文件中的synchronous参数,企业可以灵活选择适合自己业务特点的同步模式:
- async模式:所有备库都采用异步复制,速度最快但存在数据丢失风险
- sync模式:第一个连接的备库同步复制,其他作为候选,兼顾性能和安全
- quorum模式:任意一个备库完成同步即可,在容错性和性能间找到平衡
- all模式:所有备库必须同步完成,数据一致性最强但容错性较低
- custom模式:允许用户自定义同步策略,灵活性最高
据介绍,生产环境通常推荐使用remote_apply级别的同步,这样能确保主备库之间的强一致性。当然,不同的业务场景需要在数据安全性和系统性能之间做出权衡。
当故障来临时,系统如何自救
一套完整的自动恢复体系
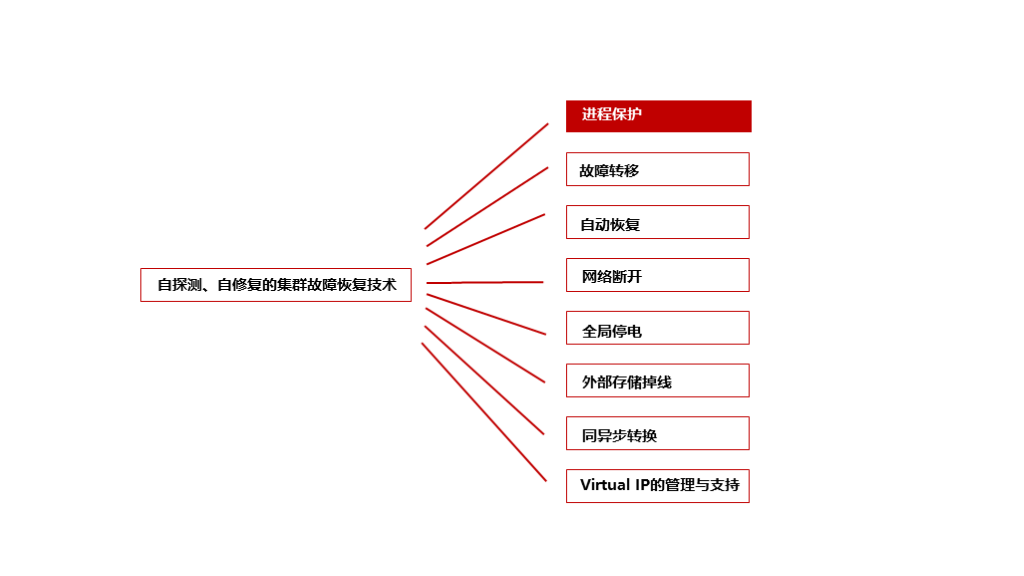
双层保护确保管理进程不掉线
为了确保高可用功能始终在线,系统采用了双层守护进程保护架构。kbha进程每3秒检查一次repmgrd的运行状态,发现异常立即重启;而系统的crontab则每分钟检查kbha进程,确保守护进程本身也不会失效。
主库故障后的四步切换流程
当主库发生故障时,备库的repmgrd进程会启动一套精心设计的四阶段切换流程:
第一阶段,先尝试重新连接主库。这是为了避免因为网络抖动造成的误判,毕竟"冤枉"一个正常运行的主库代价太大。
第二阶段,如果确认主库真的出问题了,系统会关闭所有备库的数据接收进程,让大家都"冷静"下来,确保状态一致。
第三阶段,多个备库开始"竞选"新主库。竞选的规则很明确:先看谁的数据最新(通过LSN比较),再看优先级设置,最后看节点ID。为了防止出现"脑裂"(两个主库同时存在),系统还会执行半数节点存活检查。
第四阶段,竞选成功的备库开始升级为主库。这个过程包括检查网络连通性、强制停止原主库(如果还在运行)、挂载VIP地址、执行promote命令升主,最后执行checkpoint确保数据持久化。
切换时间到底需要多久
根据实际测试,故障切换的总时间由5个部分组成:监控检测延迟、故障确认时间、进程处理时间、网络检查时间和VIP切换时间。在最理想的情况下,切换可能只需要几秒钟;而在最坏的情况下,可能需要几分钟。影响切换时间的主要因素包括监控间隔设置、重连参数配置以及网络和VIP的切换速度。
故障节点如何重新加入集群
当一个故障的备库恢复后,主库的repmgrd进程会自动发现并启动恢复流程。整个过程分为7个步骤,从远程调用恢复命令开始,经过状态检查、数据同步(使用sys_rewind工具)、配置复制槽,最后重新启动并注册为备库。如果恢复失败,系统最多会重试3次。
智能的同异步转换机制
集群还具备一个很聪明的功能:根据实际情况自动在同步和异步模式间切换。当发现没有可用的流复制时,系统会自动转为异步模式,避免主库被阻塞;当流复制恢复且主备数据差异小于设定阈值(默认16M)时,又会自动切回同步模式,保证数据一致性。这个过程由主库的repmgrd进程每2秒检查一次,实现了高可用性和数据一致性的智能平衡。
全部宕机后的自启动能力
即使遇到极端情况——集群所有节点都发生故障,只要网络正常且kbha守护进程还在运行,系统也能自动恢复。原主库节点会在确认自己是唯一的主库后,自动启动数据库并触发故障恢复流程,逐步重建整个集群。这个功能通过auto_cluster_recovery_level参数控制,默认是开启状态。
几项提升用户体验的高级功能
VIP让故障切换对应用透明
VIP(虚拟IP)功能让应用程序不需要关心实际连接的是哪个数据库节点。当发生故障切换时,VIP会自动"漂移"到新的主库上,应用程序完全感知不到底层的变化。VIP的变化会在主库注册、故障切换、主备切换等多个时机自动触发,确保业务连续性。
在线修复损坏的数据块
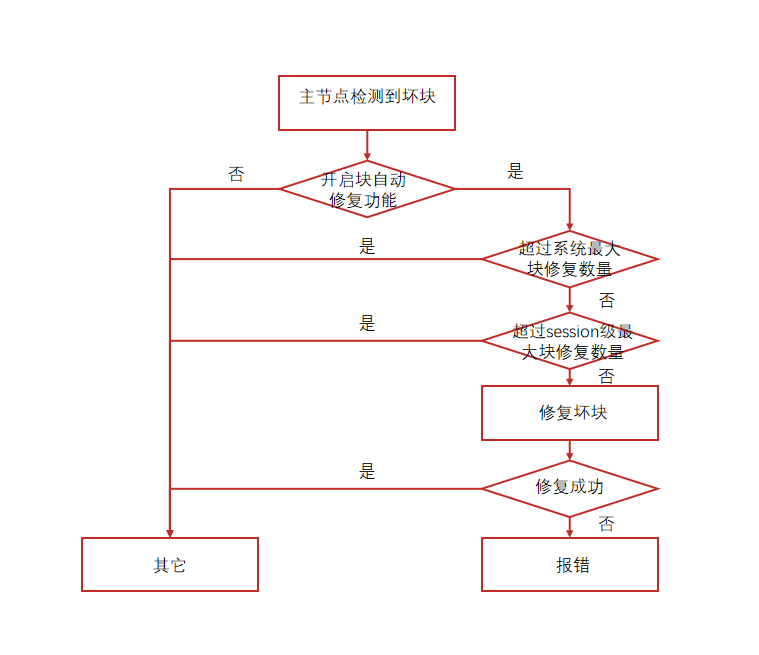
这是一项很有特色的功能。当主数据库在访问数据时检测到坏块,系统会自动从备节点获取正常的数据副本进行修复,整个过程对业务完全透明。系统提供了会话级和系统级的修复数量限制,防止大量坏块影响系统性能。使用这个功能需要先创建auto_bmr扩展,并确保开启了数据校验功能。
网络和存储的健康监测
系统还具备完善的基础设施监测能力。通过配置信任网关,kbha进程会持续ping测网关的连通性,一旦发现网络故障,会接管部分管理功能但禁用自动故障转移,防止出现脑裂问题。
对于存储健康,kbha每60秒会对配置的存储路径进行读写测试——创建临时文件、写入8KB数据、读取验证后删除。如果检测到存储异常,会根据配置决定是否关闭数据库,确保数据安全。
写在最后
通过这套完整的高可用架构设计,KingbaseES读写分离集群实现了从数据同步、故障检测、自动切换到故障恢复的全链路自动化管理。无论是双层守护进程的巧妙设计,还是灵活的同步策略选择,亦或是快速的故障切换机制和数据块级别的修复能力,都体现了国产数据库在高可用技术上的成熟度。
对于那些对可靠性、性能和数据一致性有严格要求的关键业务系统来说,这样一套经过精心设计和充分验证的数据库集群方案,无疑提供了一个值得信赖的选择。