JVM 运行时数据区详解:程序计数器、虚拟机栈、堆内存、方法区与直接内存
摘要:本文系统解析 Java 运行时数据区的核心组件,包括程序计数器、虚拟机栈、堆内存、方法区与直接内存。详细阐述各区域的作用、工作原理、内存溢出场景及调优参数,通过代码示例模拟栈与堆溢出,帮助开发者全面理解 JVM 内存管理机制。
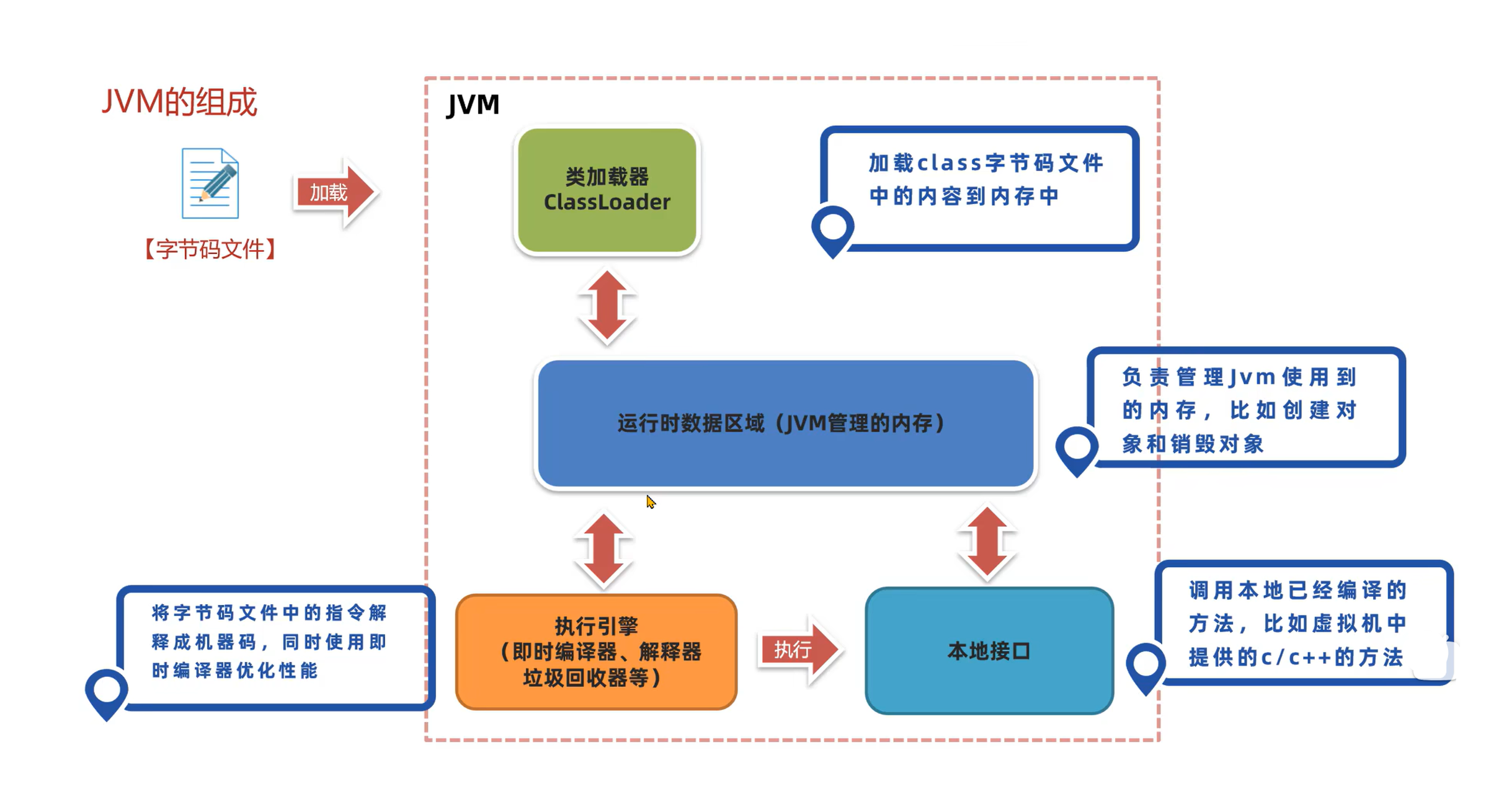

1. 运行时数据区
Java 虚拟机在运行 Java 程序过程中管理的内存区域,称之为运行时数据区。《Java 虚拟机规范》中规定了每一部分的作用。
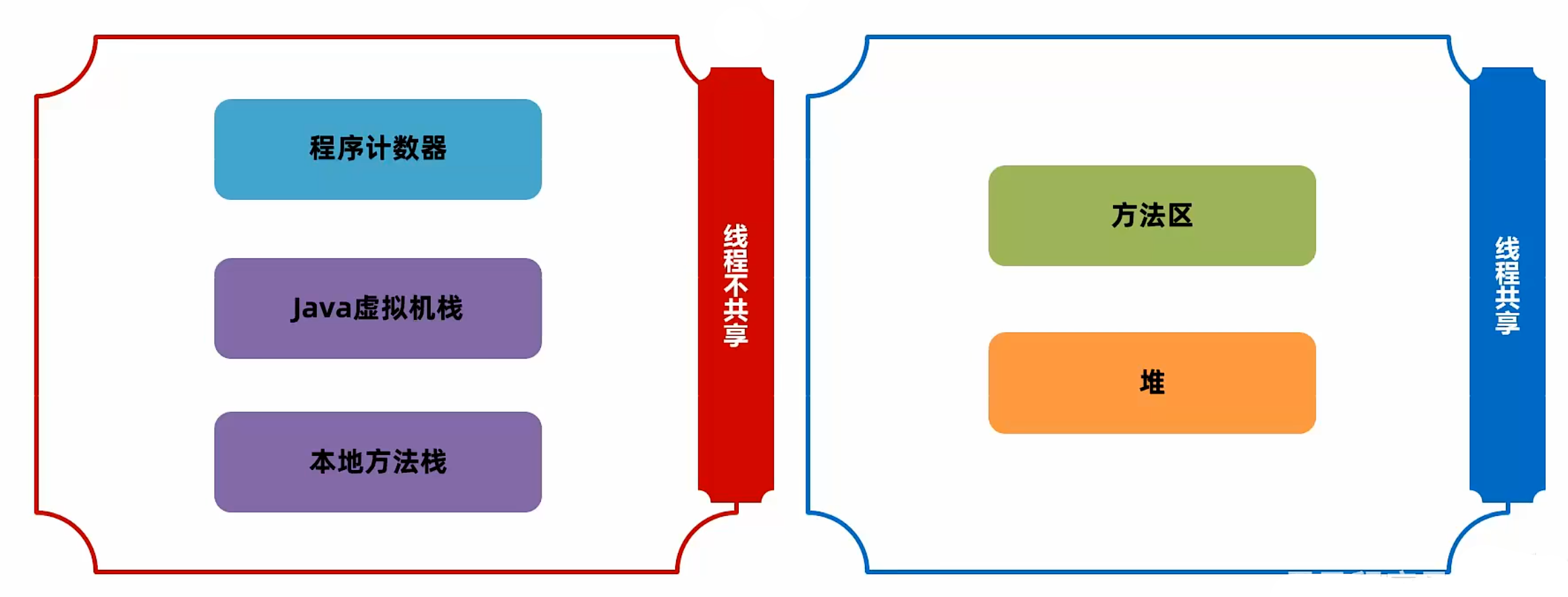
| 内存区域类型 | 包含区域 |
|---|---|
| 线程不共享 | 程序计数器、Java 虚拟机栈、本地方法栈 |
| 线程共享 | 堆内存、方法区 |
1.1 程序计数器
程序计数器也叫 PC 寄存器,每个线程会通过程序计数器记录当前要执行的字节码指令的地址。
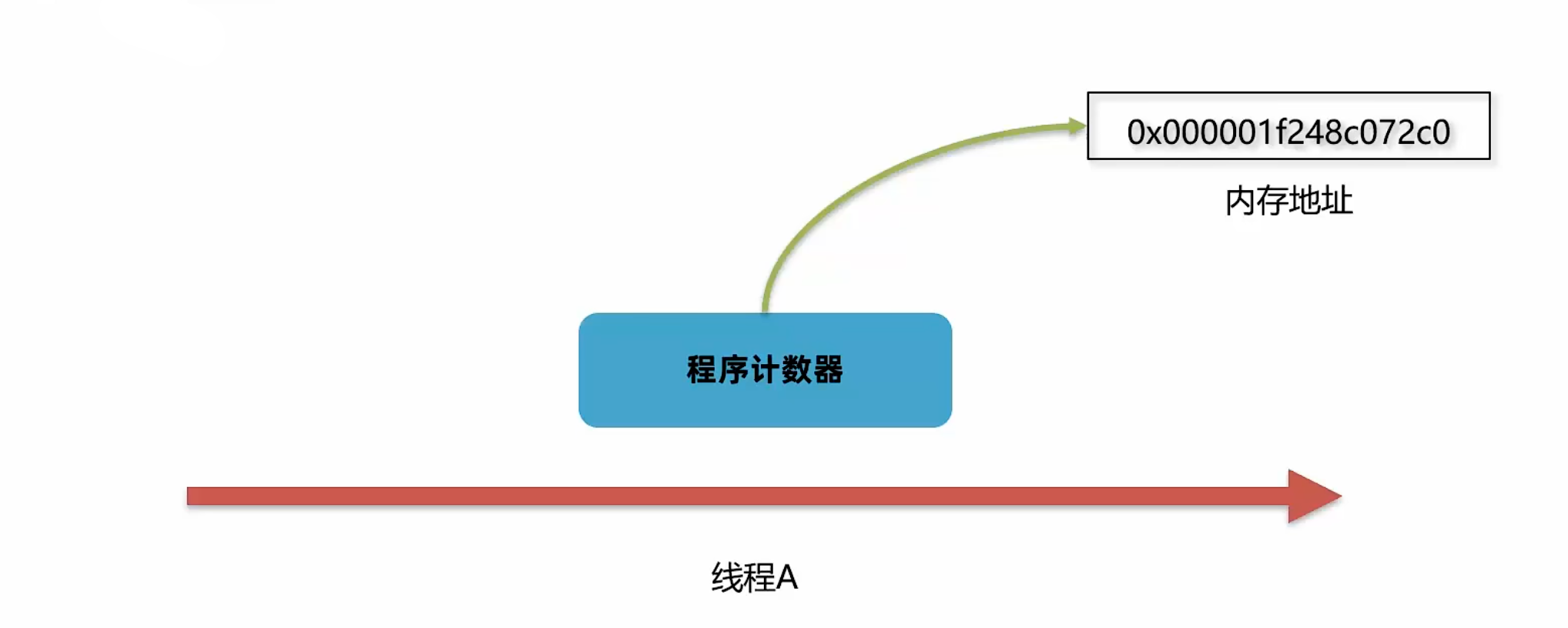
1.1.1 程序计数器的工作机制
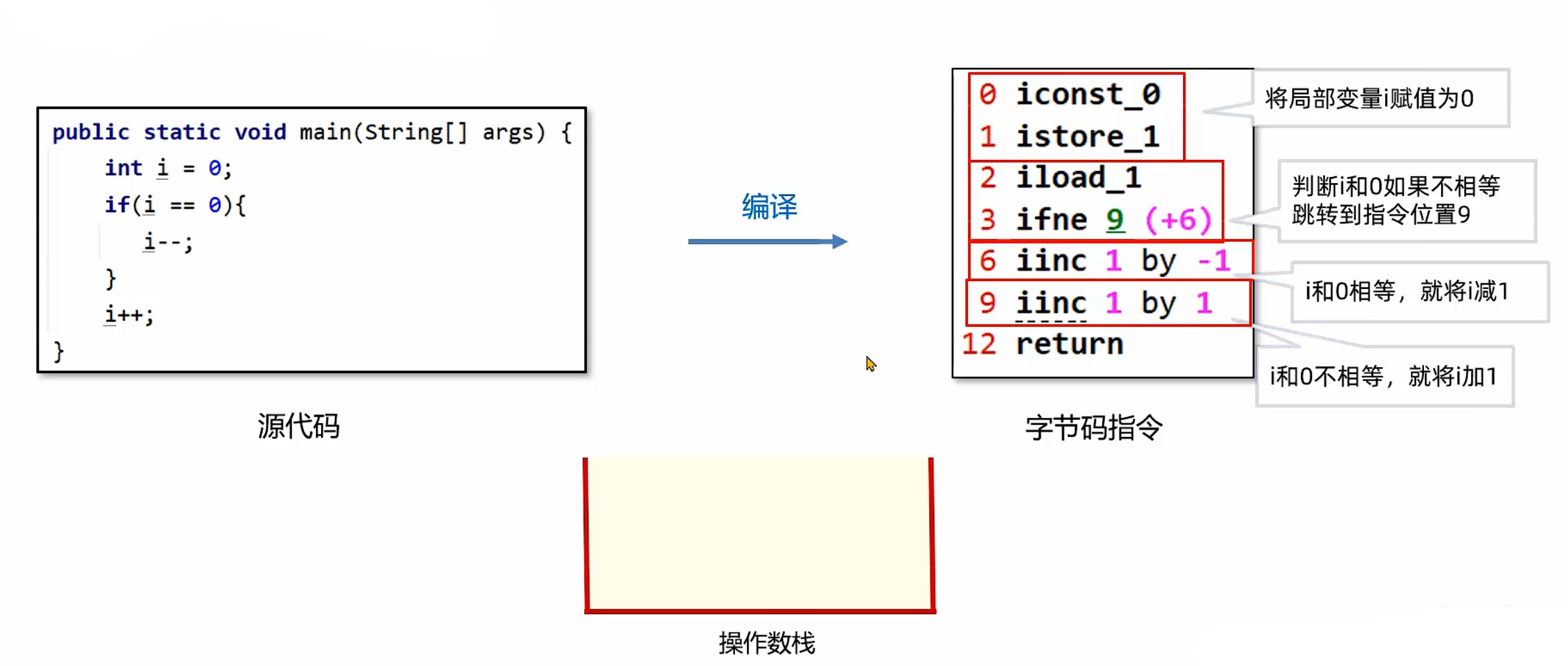
1. 地址记录:在加载阶段,虚拟机将字节码文件中的指令读取到内存之后,会将原文件中的偏移量转换成内存地址,每一条字节码指令都会拥有一个内存地址。
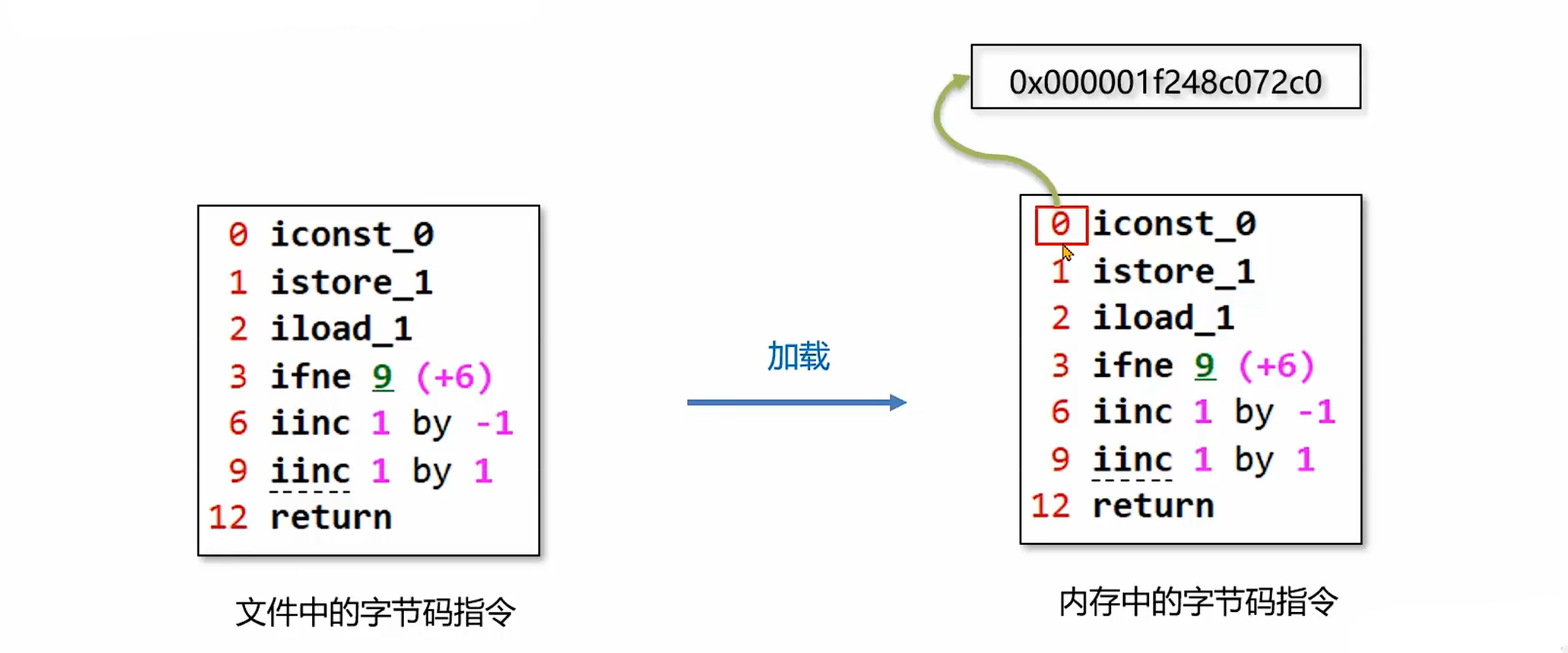
2. 指令执行控制:在代码执行过程中,程序计数器会记录下一行字节码指令的地址。执行完当前指令之后,虚拟机的执行引擎根据程序计数器执行下一行指令。例如当前执行偏移量为 0 的指令,程序计数器中保存的就是下一条指令的地址(偏移量 1);执行到方法最后一行指令(如return)时,程序计数器中会放入方法出口的地址(即回到调用该方法的上一级方法的下一条指令地址)。
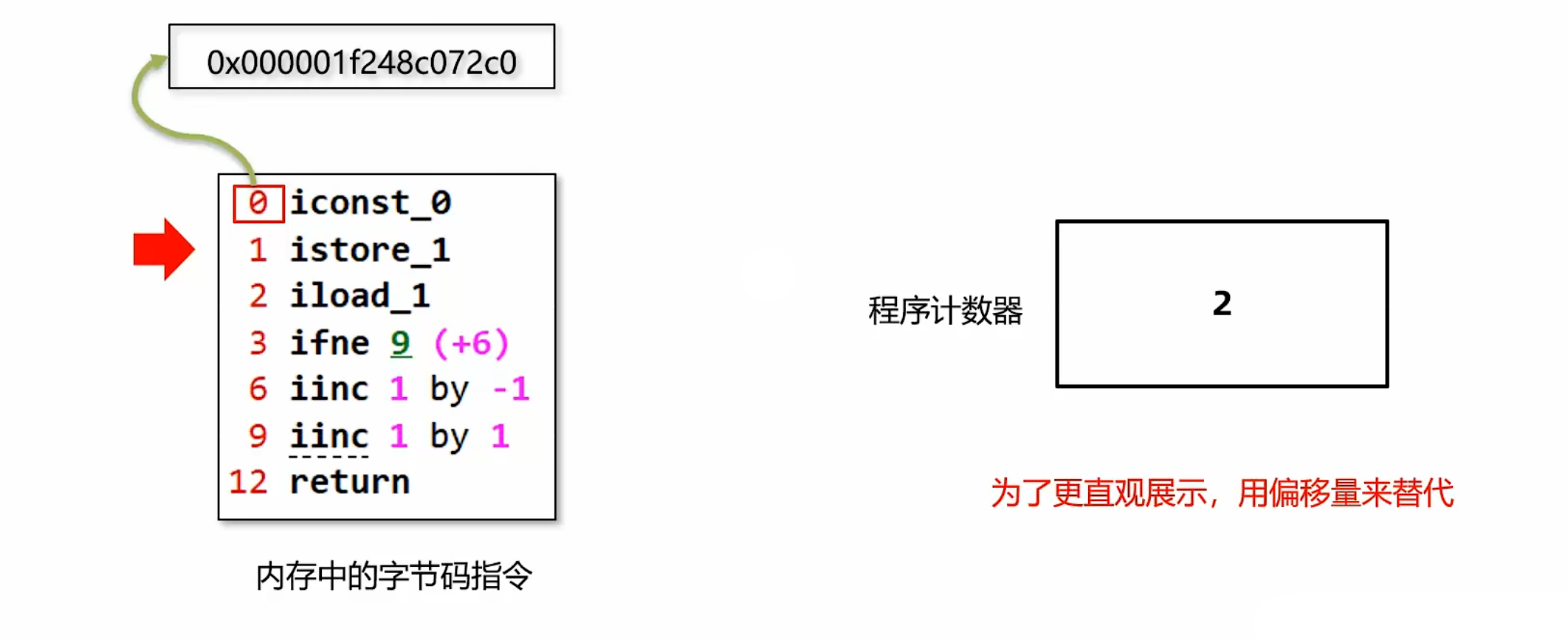
3. 多线程支持:在多线程执行情况下,Java 虚拟机需要通过程序计数器记录 CPU 切换前解释执行到的指令位置,待线程重新获得 CPU 资源时,可继续从该位置解释运行。
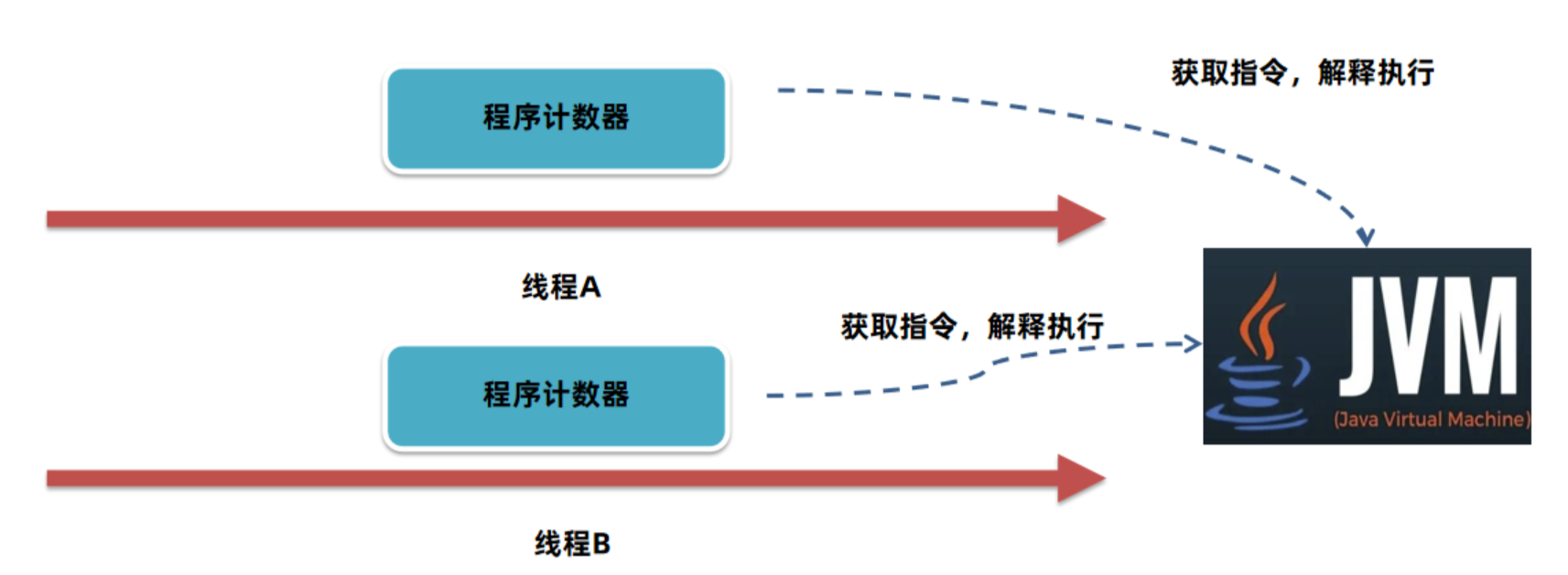
1.1.2 程序计数器的内存溢出问题
内存溢出指程序使用某块内存时,所需内存超过虚拟机能提供的上限。由于每个线程的程序计数器仅存储一个固定长度的内存地址,不会随着程序执行而动态扩容,因此程序计数器不会发生内存溢出,程序员无需对其做额外处理。

1.2 Java 虚拟机栈
Java 虚拟机栈采用栈的数据结构管理方法调用中的基本数据,遵循 "先进后出" 原则,每一个方法的调用对应一个栈帧的创建与销毁。
1.2.1 栈帧的生命周期
以以下代码为例,栈帧的创建与销毁过程如下:
public class MethodDemo { public static void main(String[] args) { study(); }public static void study(){eat();sleep();} public static void eat(){ System.out.println("吃饭"); } public static void sleep(){ System.out.println("睡觉"); }}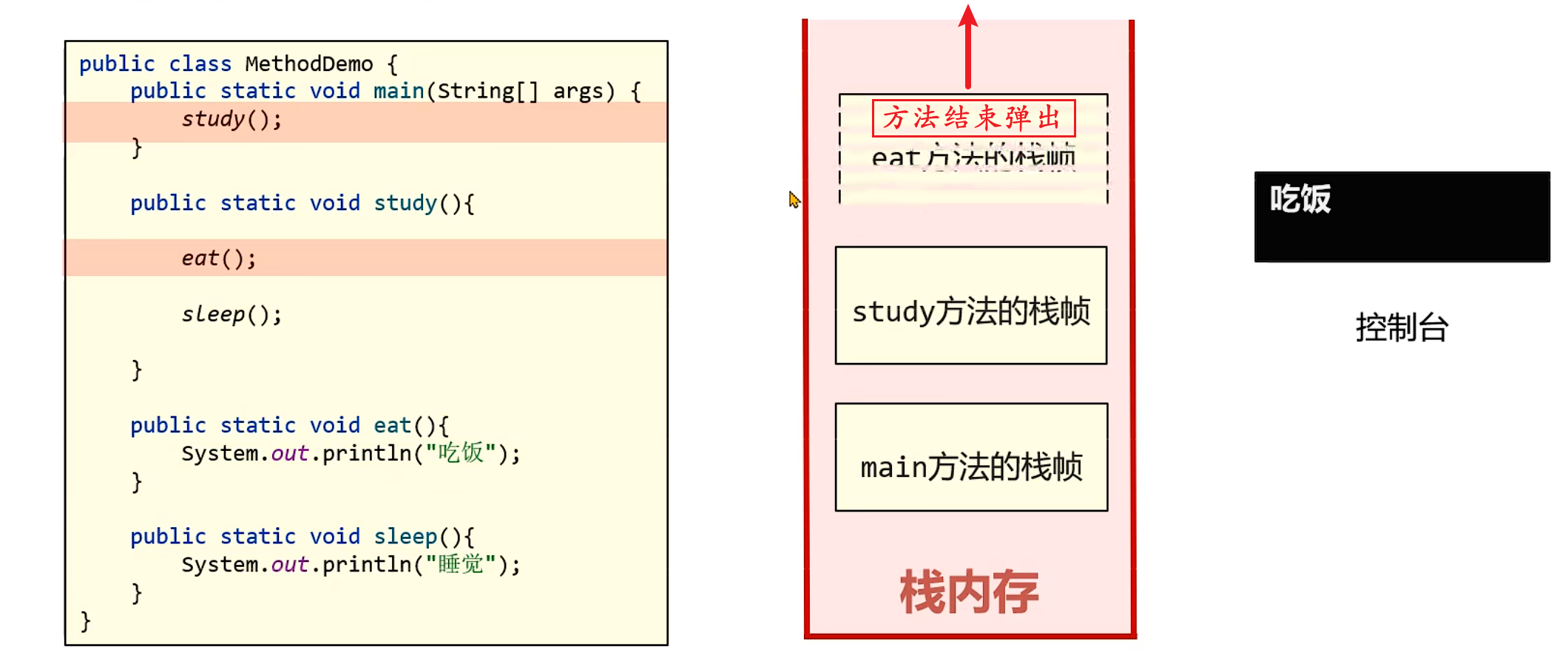
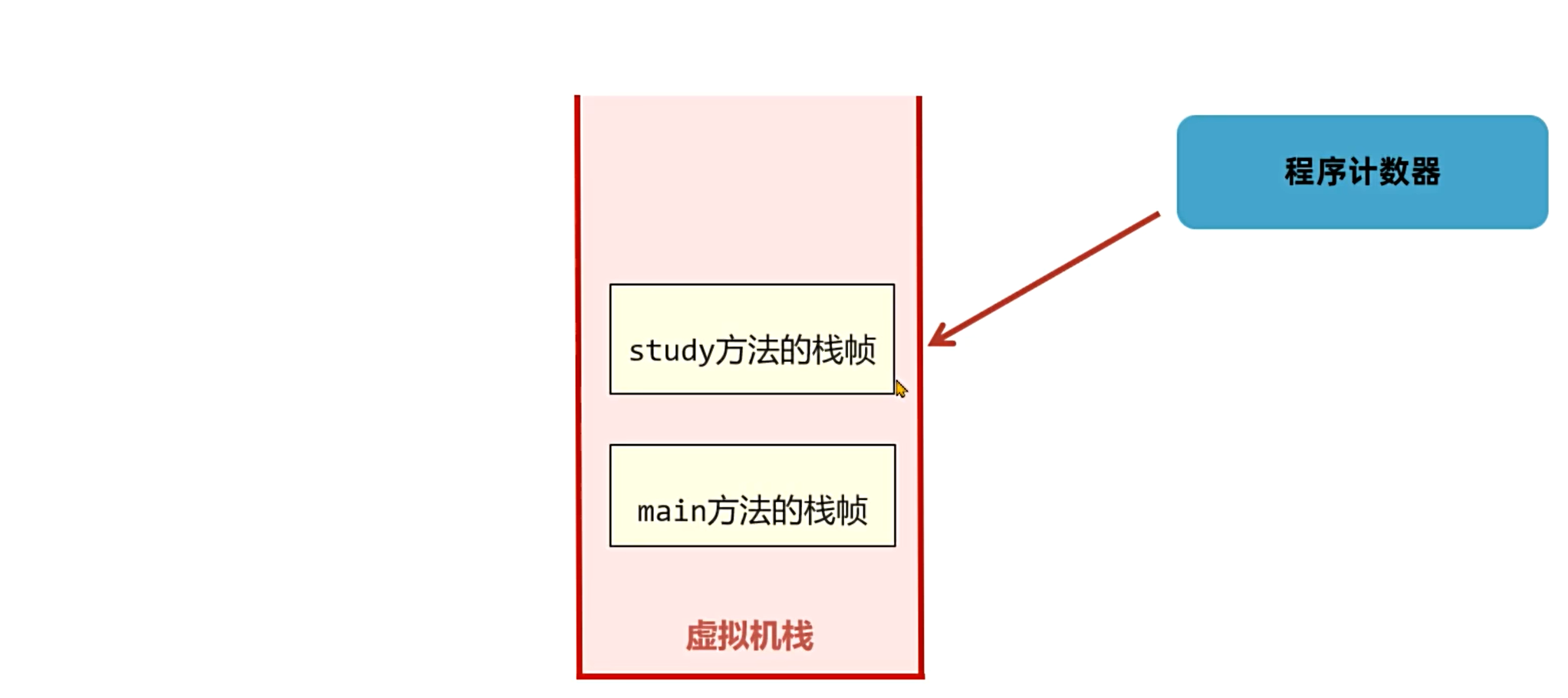
1. main方法执行时,创建main方法的栈帧并压入栈内存。

2. 执行study()方法,创建study方法的栈帧并压入栈内存(位于main栈帧之上)。

3. 执行eat()方法,创建eat方法的栈帧并压入栈内存(位于study栈帧之上)。
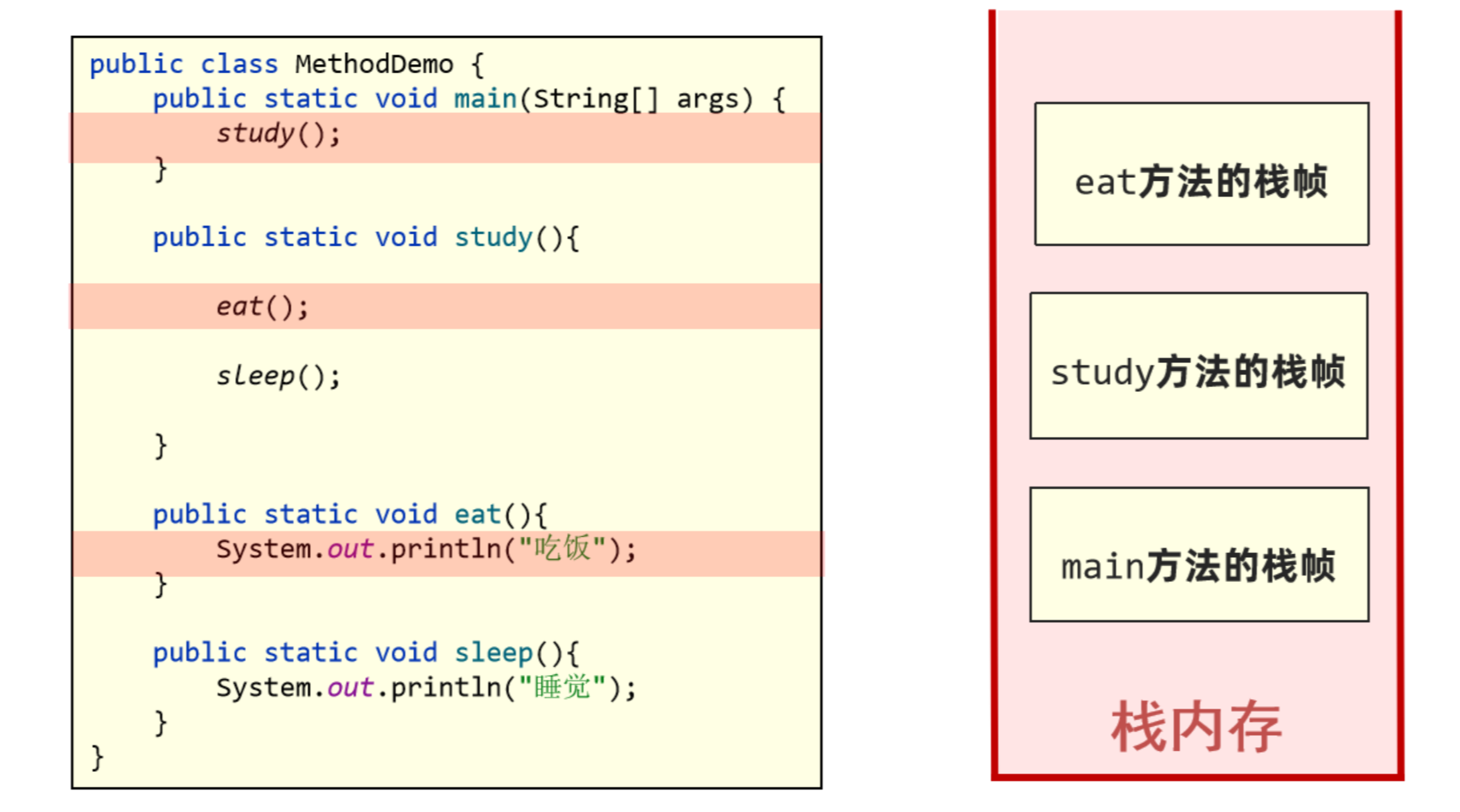
4. eat方法执行完毕,其栈帧弹出栈内存并释放。
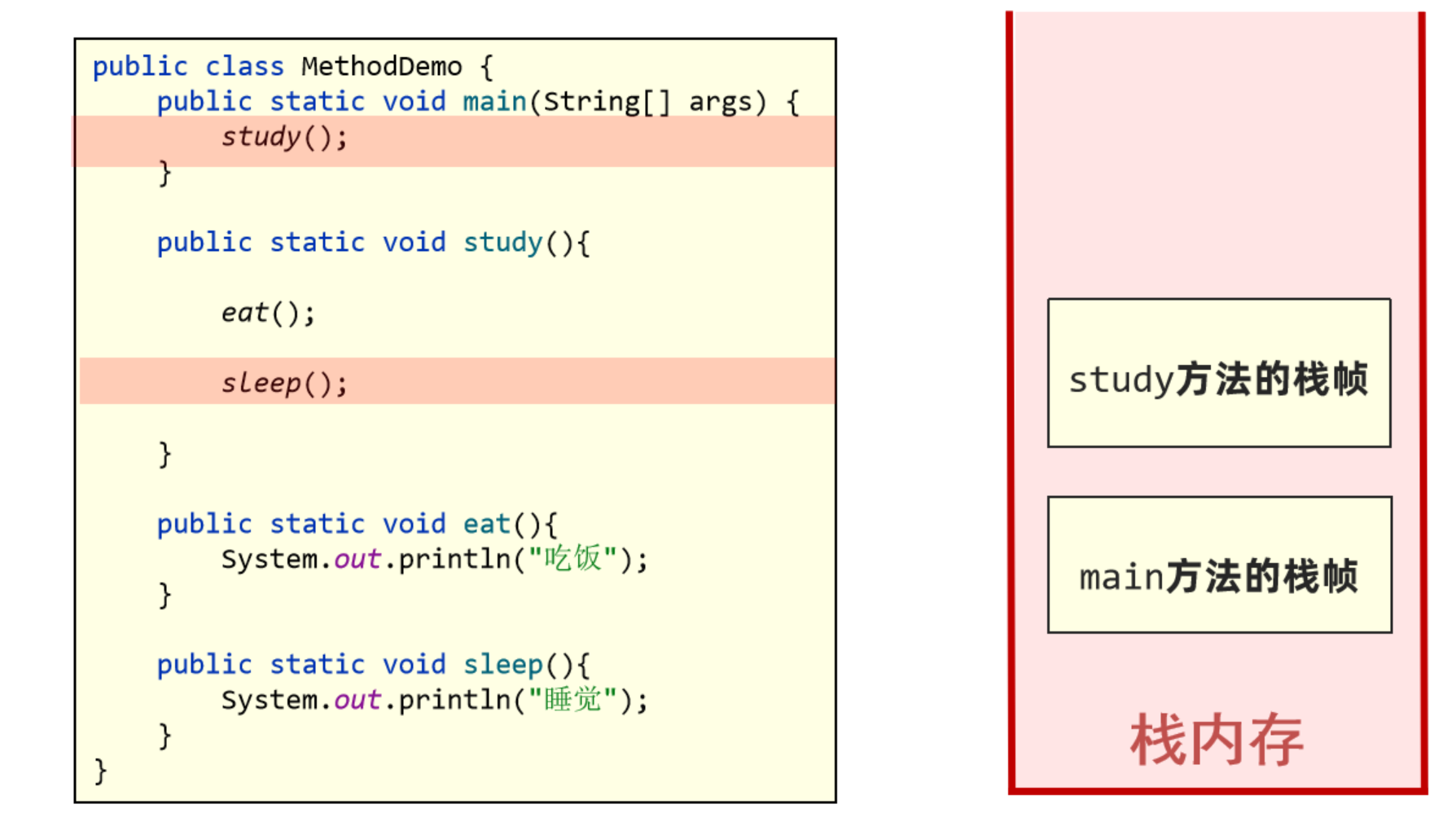
5. 执行sleep()方法,创建sleep方法的栈帧并压入栈内存。
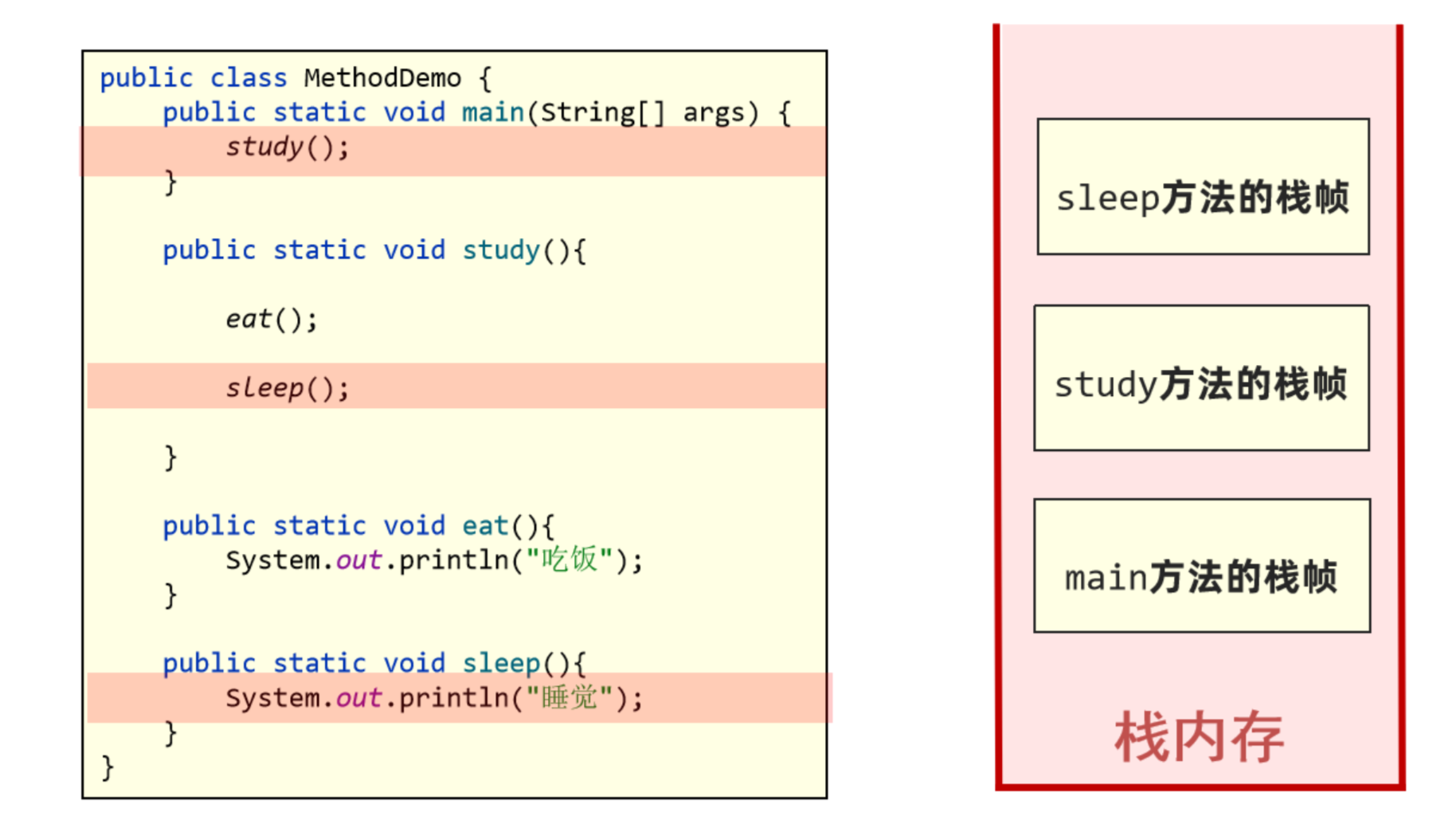
6. sleep方法执行完毕,其栈帧弹出栈内存并释放。
7. study方法执行完毕,其栈帧弹出栈内存并释放。
8. main方法执行完毕,其栈帧弹出栈内存并释放。
1.2.2 线程与虚拟机栈的关系
Java 虚拟机栈随线程的创建而创建,随线程的销毁而回收。每个线程都有独立的虚拟机栈,不同线程的栈帧互不干扰。例如main线程和自定义的 “线程 A” 会分别拥有各自的虚拟机栈,栈内存储对应线程中方法调用的栈帧。
1.2.3 栈帧的组成
栈帧主要包含三部分内容:局部变量表、操作数栈、帧数据。

1. 局部变量表

作用:在方法执行过程中存放所有局部变量,包括实例方法的
this对象、方法参数、方法体中声明的局部变量。槽的使用:局部变量表是一个数组,数组的每个位置称为 “槽(Slot)”。
long和double类型占用 2 个槽,其他基本数据类型和引用类型占用 1 个槽。槽的复用:为节省空间,局部变量表中的槽可复用。当某个局部变量超出生效范围(如代码块结束),其占用的槽可被后续局部变量使用。
编译期确定:局部变量表的内容(如槽的数量、变量生效范围)在编译成字节码文件时已确定,运行时仅需按此创建对应数组。
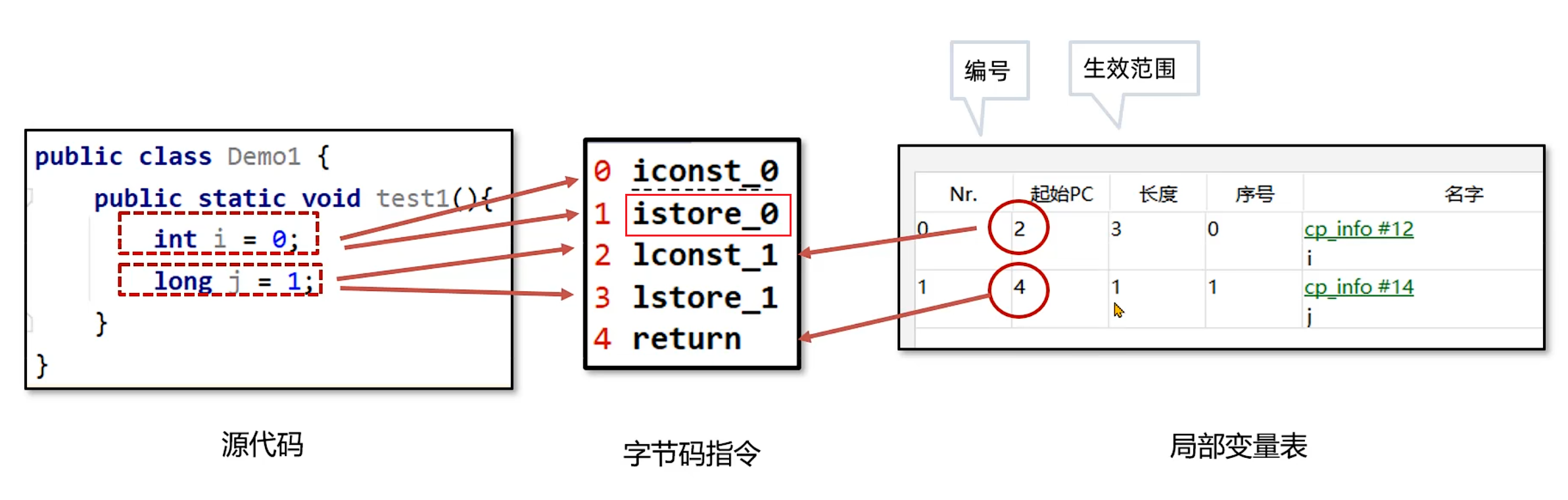
比如
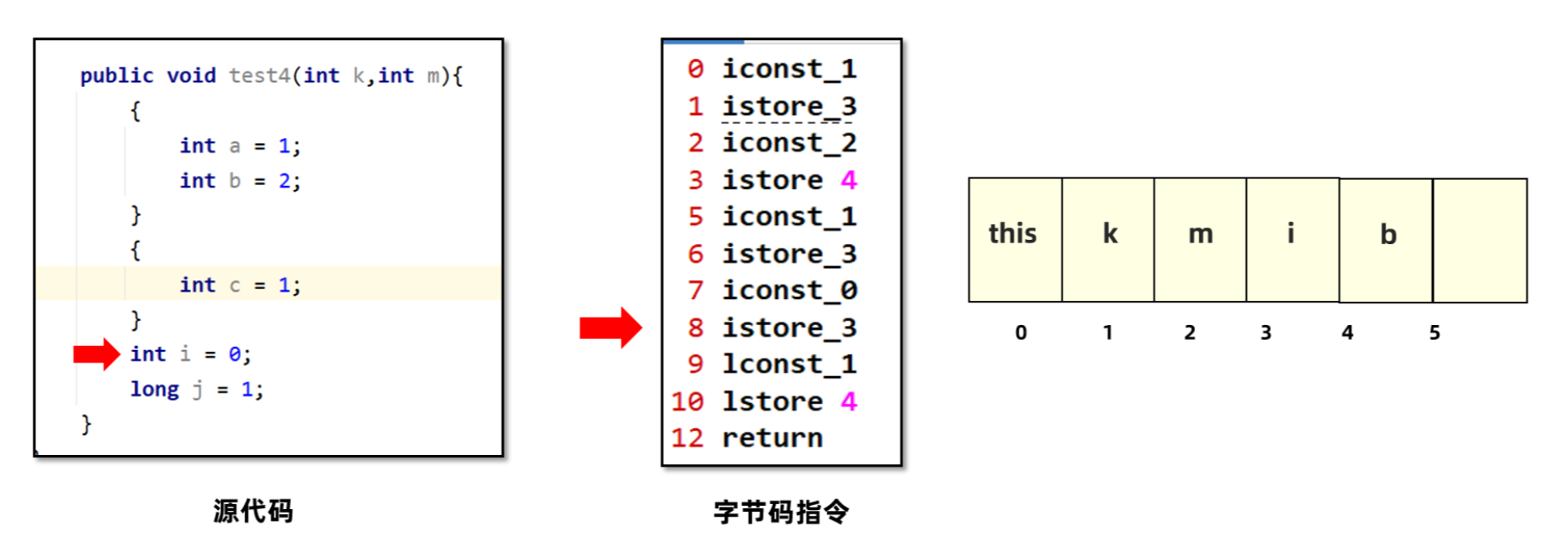
i这个变量,它的起始PC是2,代表从lconst_1这句指令开始才能使用i,长度为3,也就是2-4这三句指令都可以使用i。为什么从2才能使用,因为0和1这两句字节码指令还在处理int i = 0这句赋值语句。j这个变量只有等3指令执行完之后也就是long j = 1代码执行完之后才能使用,所以起始PC为4,只能在4这行字节码指令中使用。
示例:test4方法的局部变量表槽复用
public void test4(int k,int m){{int a = 1;int b = 2;}{int c = 1;}int i = 0;long j = 1;
}1. 方法执行时,实例对象this、k、m 会被放入局部变量表中,占用3个槽。

2. 将1的值放入局部变量表下标为3的位置上,相当于给a进行赋值。

3. 将2放入局部变量表下标为4的位置,给b赋值为2。
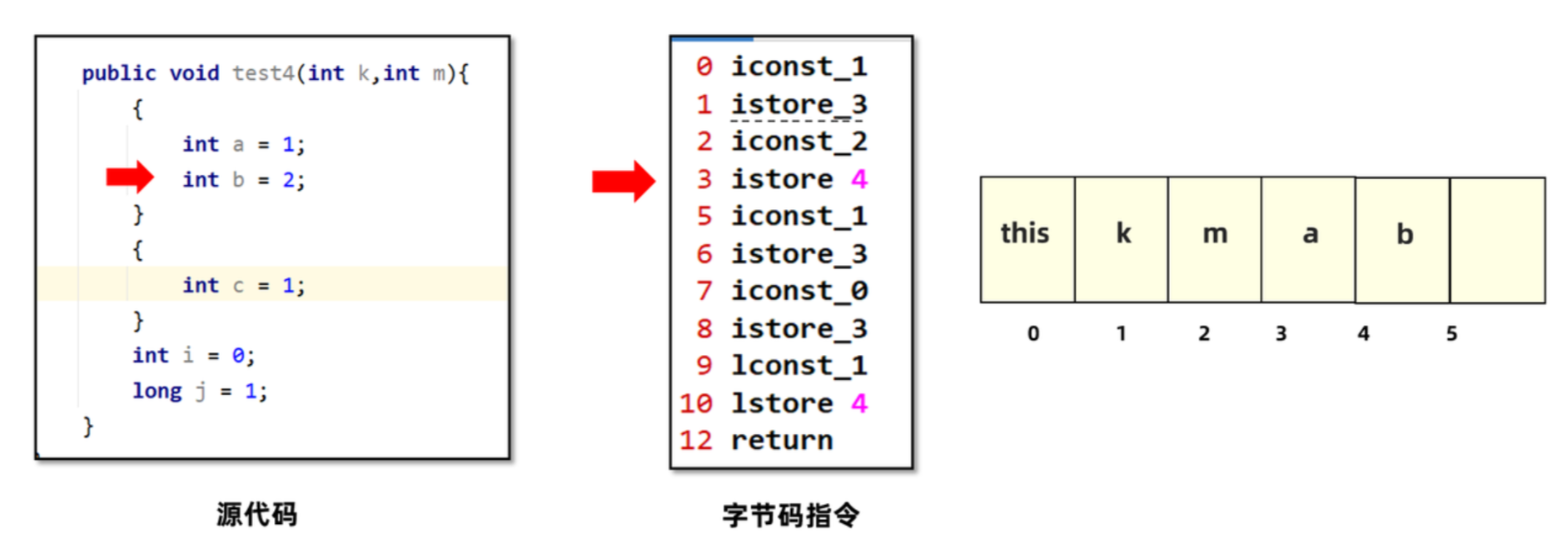
4. ab已经脱离了生效范围,所以下标为3和4的这两个位置可以复用。此时c的值1就可以放入下标为3的位置。
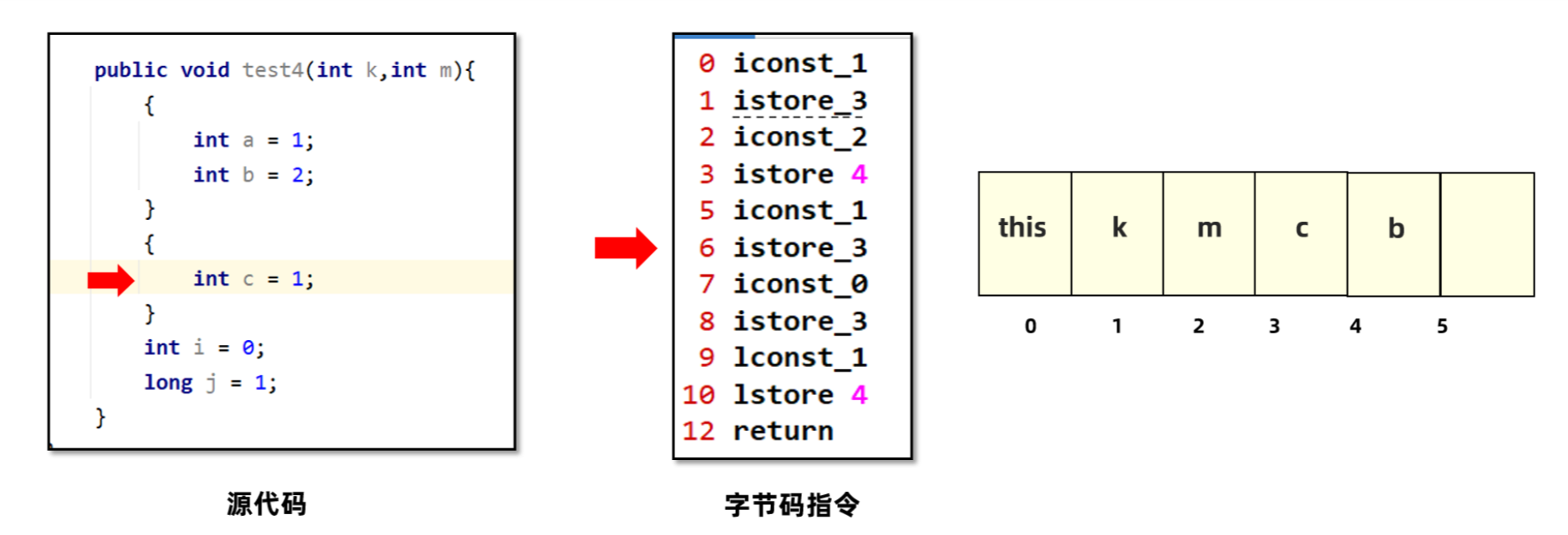
5. 脱离c的生效范围之后,给i赋值就可以复用c的位置。
6. 最后放入j,j是一个long类型,占用两个槽。但可复用b所在的位置,所以占用4和5这两个位置。
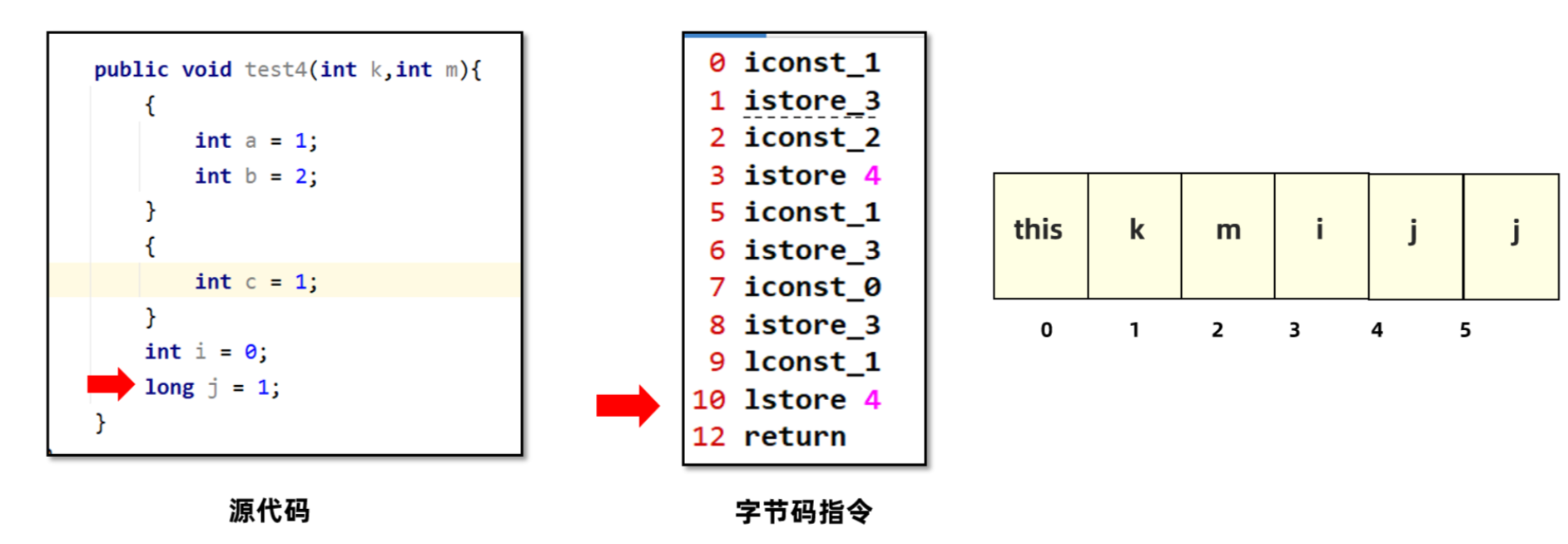
所以,局部变量表数值的长度为6。这一点在编译期间就可以确定了,运行过程中只需要在栈帧中创建长度为6的数组即可。
2. 操作数栈
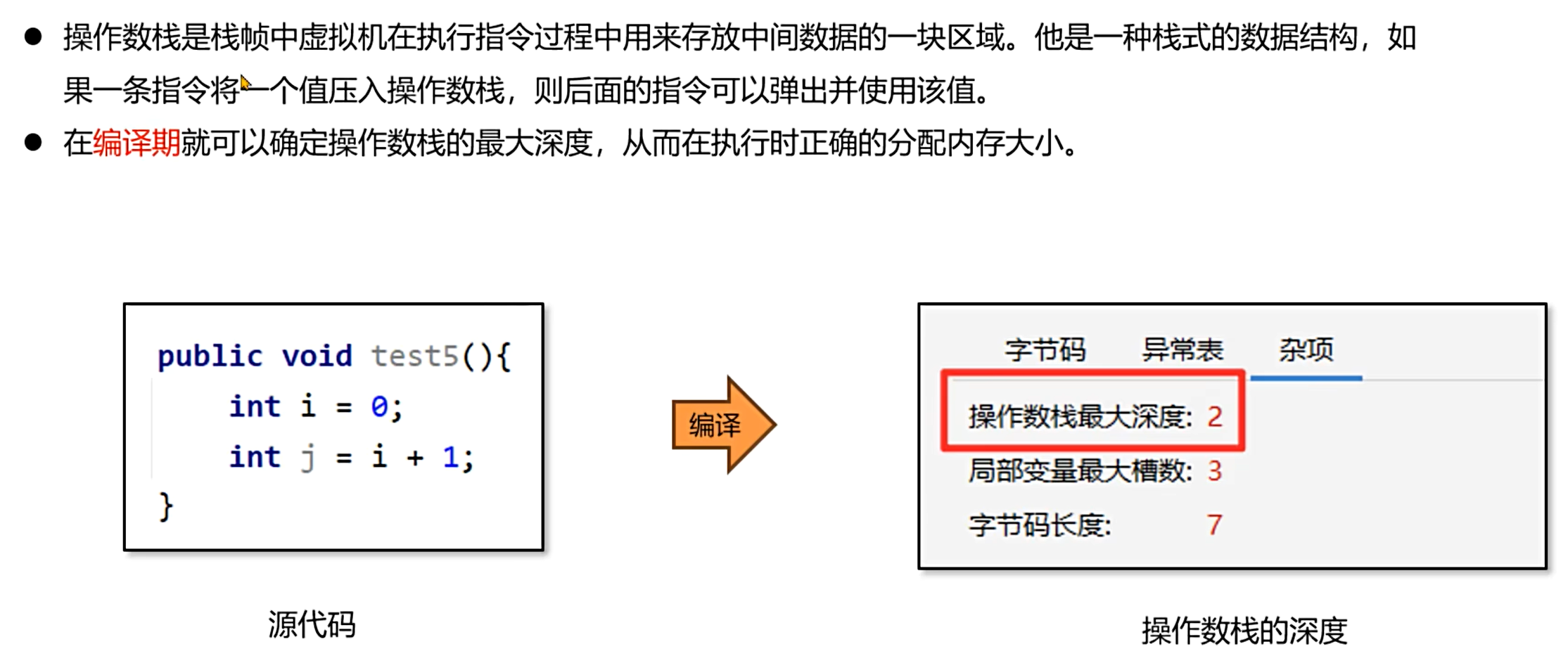
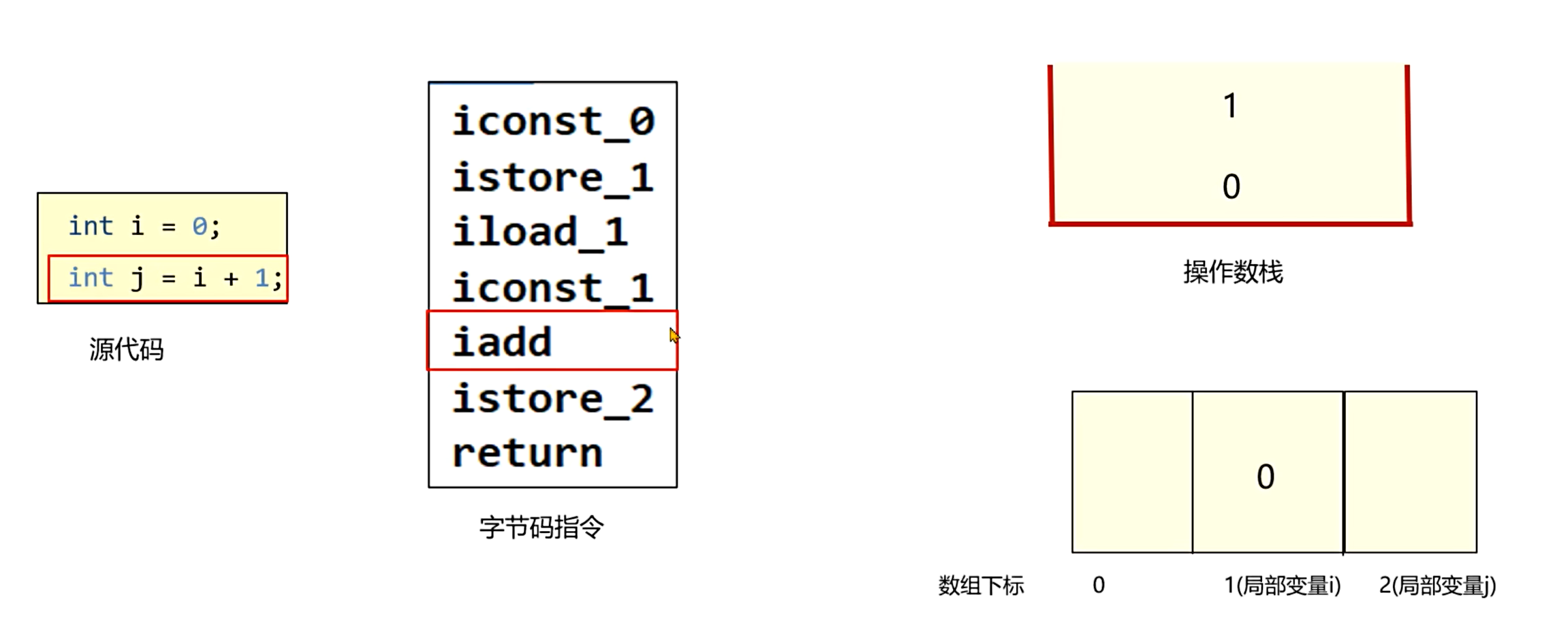
作用:栈帧中虚拟机执行指令时存放临时数据的区域,遵循 "先进后出" 原则。一条指令将值压入操作数栈后,后续指令可弹出并使用该值。
深度确定:操作数栈的最大深度在编译期已确定,运行时按此分配内存。例如代码int i=0; int j=i+1;的操作数栈最大深度为 2(需同时存放i的值和常量 1)。
3. 帧数据
帧数据主要包含动态链接、方法出口、异常表的引用
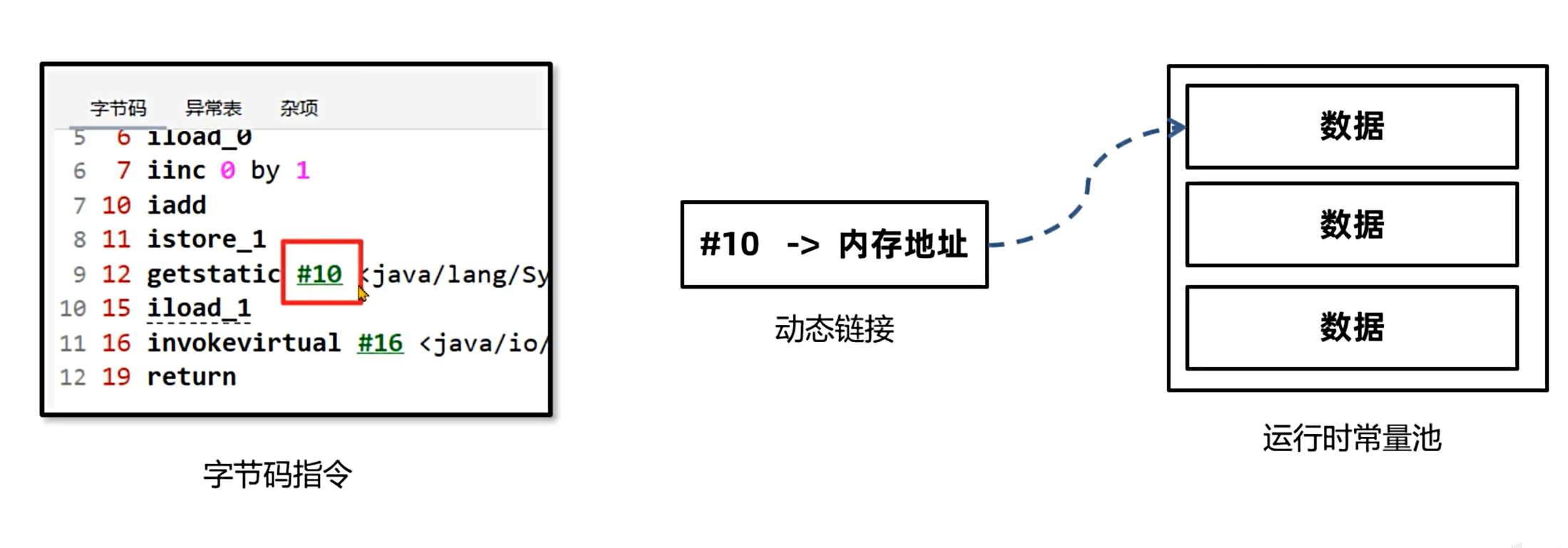
动态链接:保存字节码指令中符号引用(# 编号)到运行时常量池内存地址的映射关系。当指令引用其他类的属性或方法时,通过动态链接快速定位到目标数据。
方法出口:记录方法正常或异常结束时,程序计数器应指向的上一级栈帧的下一条指令地址,确保方法执行完毕后能正确回到调用处。
异常表:存放代码中异常的处理信息,包括异常捕获的生效范围(字节码指令偏移量区间)和异常发生后跳转的指令位置。

1.2.4 栈内存溢出
当 Java 虚拟机栈中栈帧过多,占用内存超过栈内存最大限制时,会抛出StackOverflowError错误。
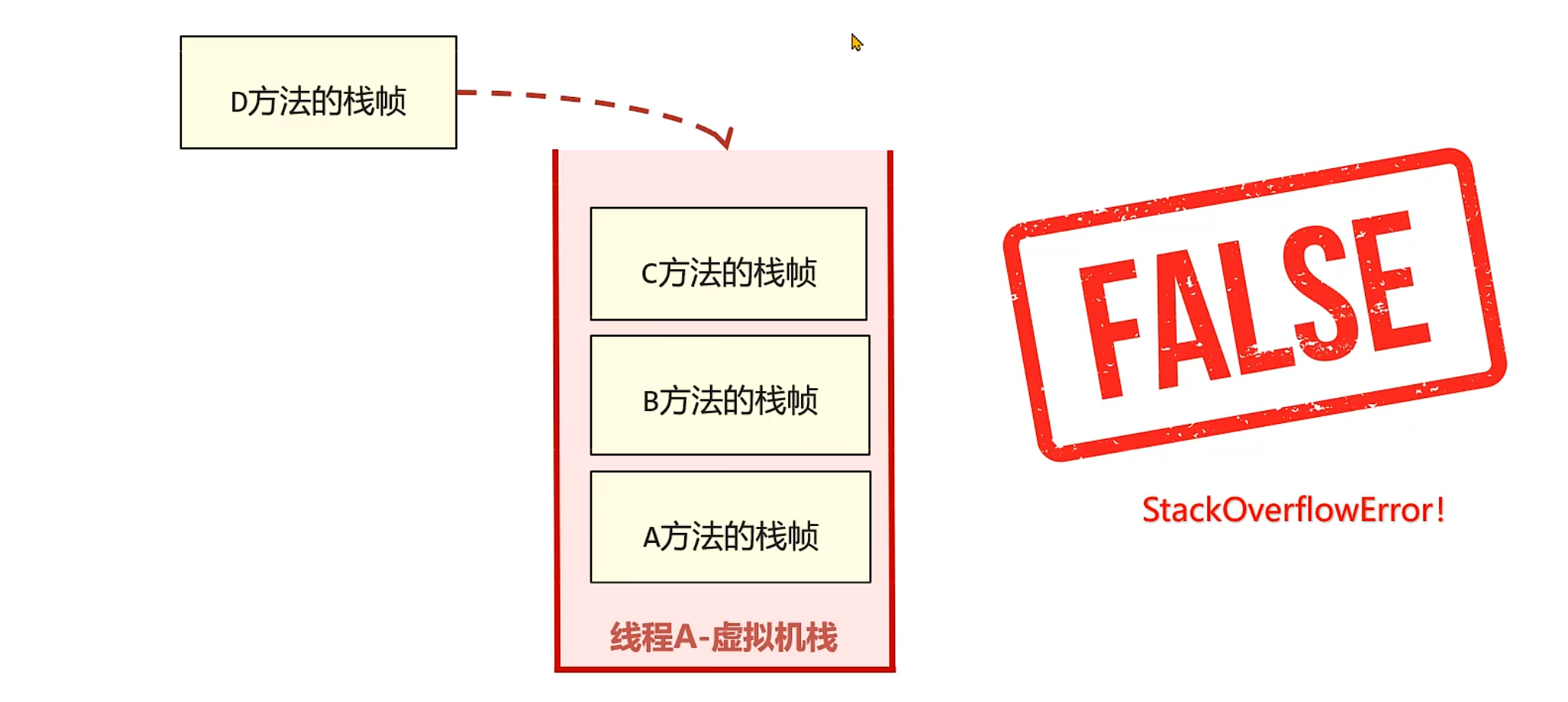
如果我们不指定栈的大小,JVM 将创建一个具有默认大小的栈。大小取决于操作系统和计算机的体系结构。

1. 模拟栈溢出

通过无退出条件的递归调用,可模拟栈溢出:
public static int count = 0;//递归方法调用自己public static void recursion(){System.out.println(++count);recursion();}
执行后会打印调用次数,最终抛出StackOverflowError。
2. 调整栈内存大小
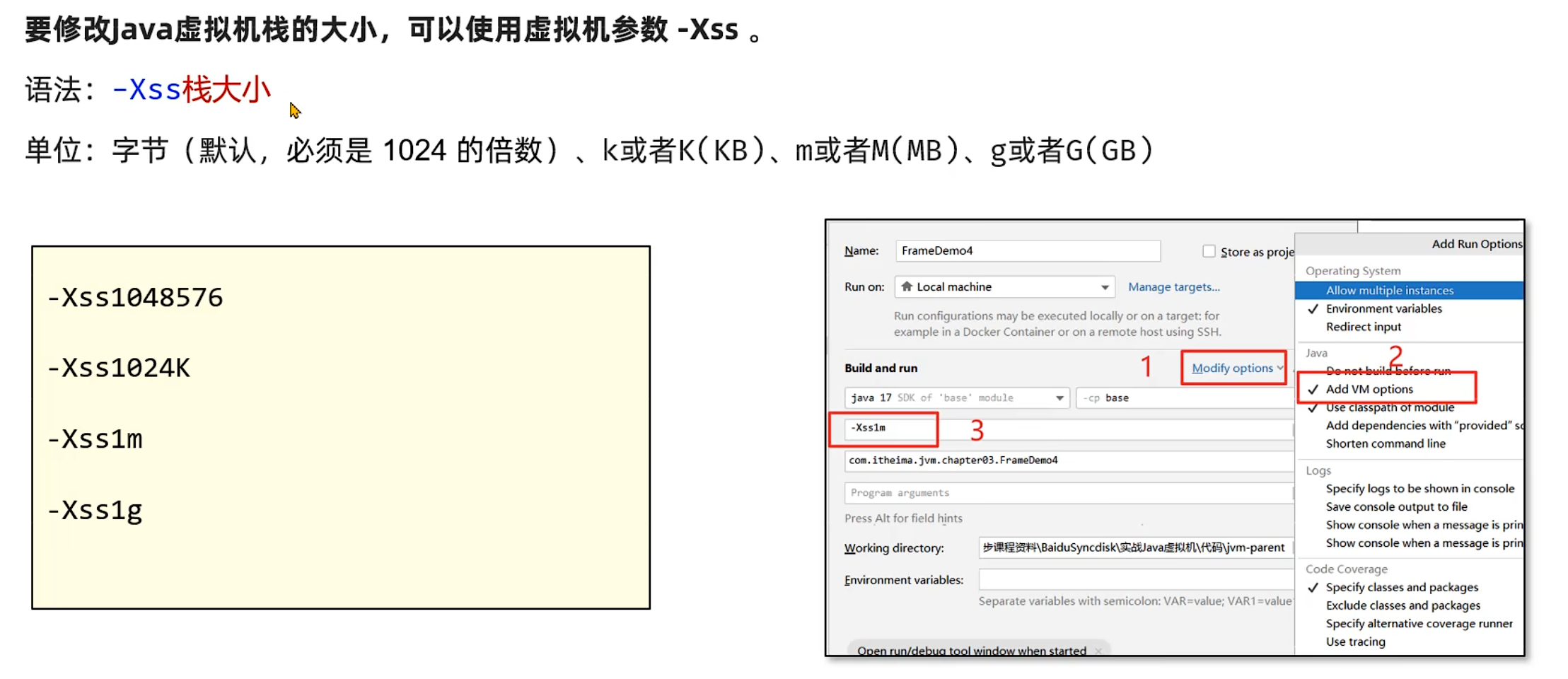
此外,也可使用 -XX:ThreadStackSize=<大小> 调整,如-XX:ThreadStackSize=1024(单位为 KB)。
3. 注意事项

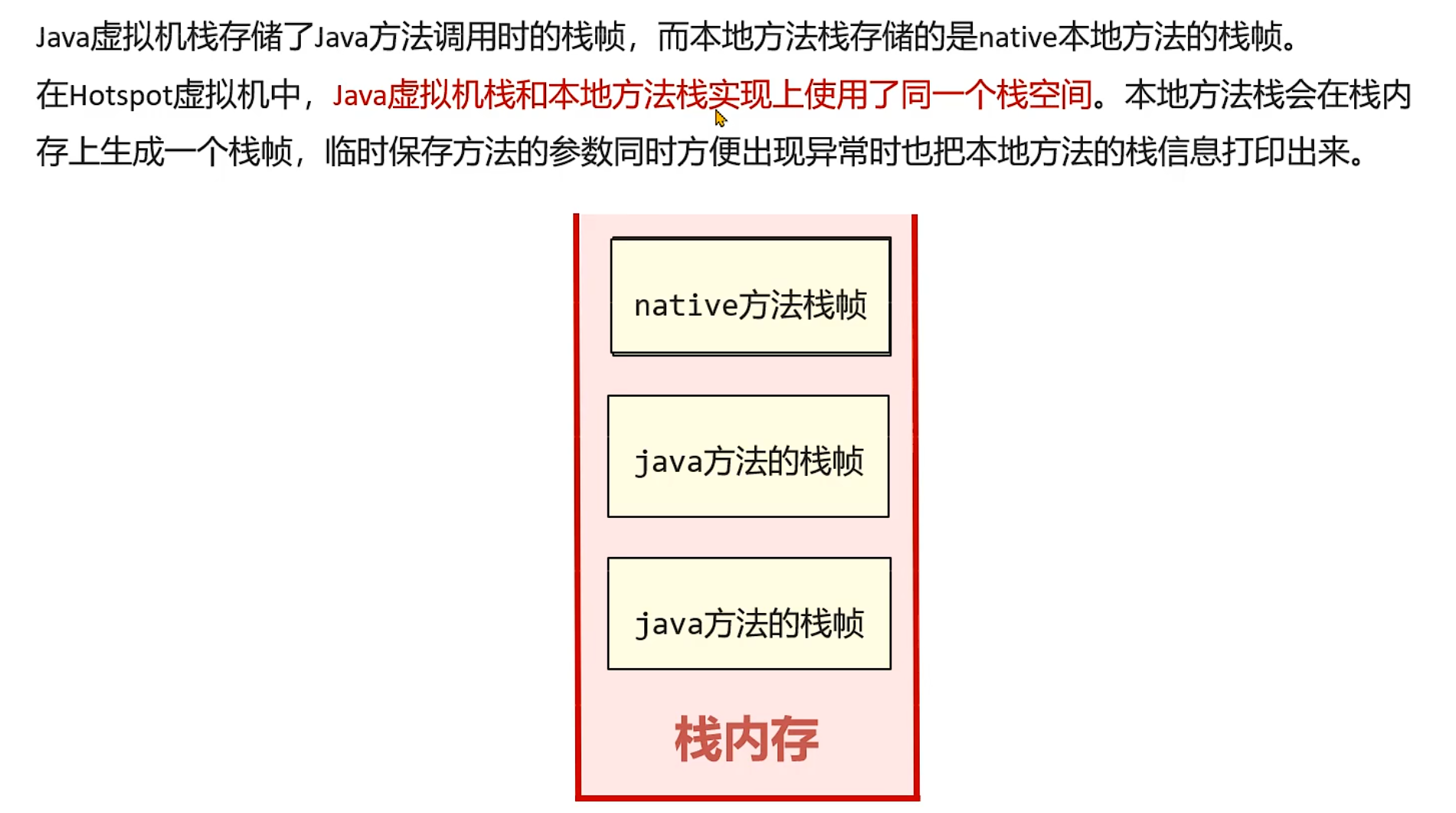
1.3 本地方法栈
1.4 堆内存
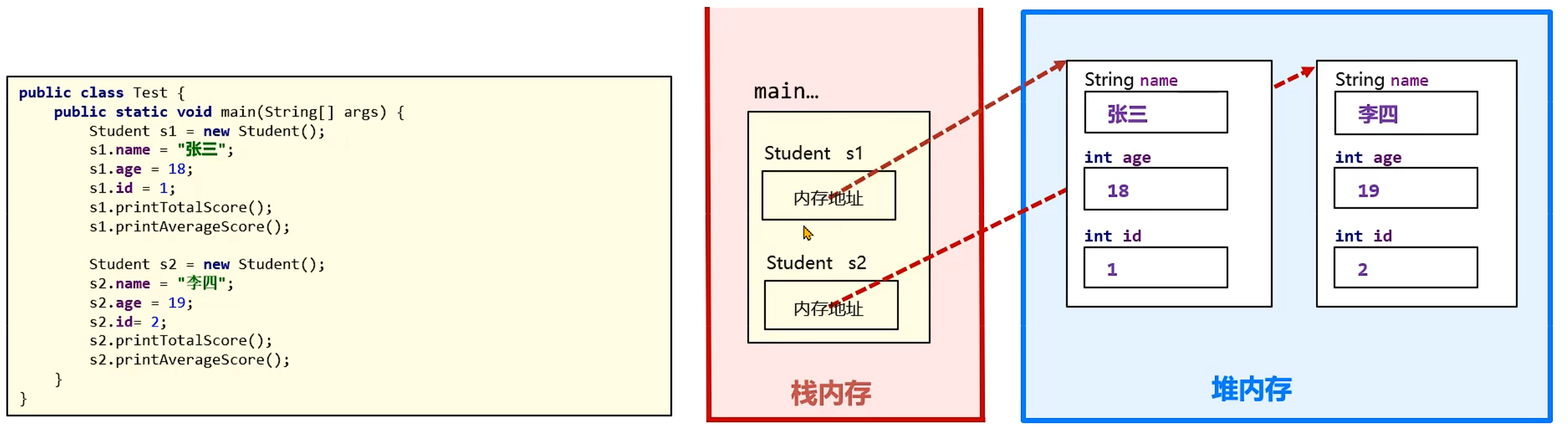
堆内存是 Java 程序中空间最大的线程共享内存区域,创建的对象均存储在堆上。栈上的局部变量表、方法区的静态变量可存放堆对象的引用,通过引用实现对堆对象的访问。
1.4.1 堆内存的溢出
当堆内存中对象持续创建且无法回收,最终超出堆内存上限时,会抛出OutOfMemoryError: Java heap space错误。
1. 模拟堆溢出
通过死循环创建对象并放入集合(避免对象被回收),可模拟堆溢出:
package chapter03.heap;import java.io.IOException;
import java.util.ArrayList;/*** 堆内存的使用和回收*/
public class Demo1 {public static void main(String[] args) throws InterruptedException, IOException {ArrayList<Object> objects = new ArrayList<Object>();System.in.read();while (true){objects.add(new byte[1024 * 1024 * 100]);Thread.sleep(1000);}}
}堆内存大小是有上限的,当对象一直向堆中放入对象达到上限之后,就会抛出OutOfMemory错误。在这段代码中,不停创建100M大小的字节数组并放入ArrayList集合中,最终超过了堆内存的上限。抛出如下错误:

1.4.1 堆内存的关键参数
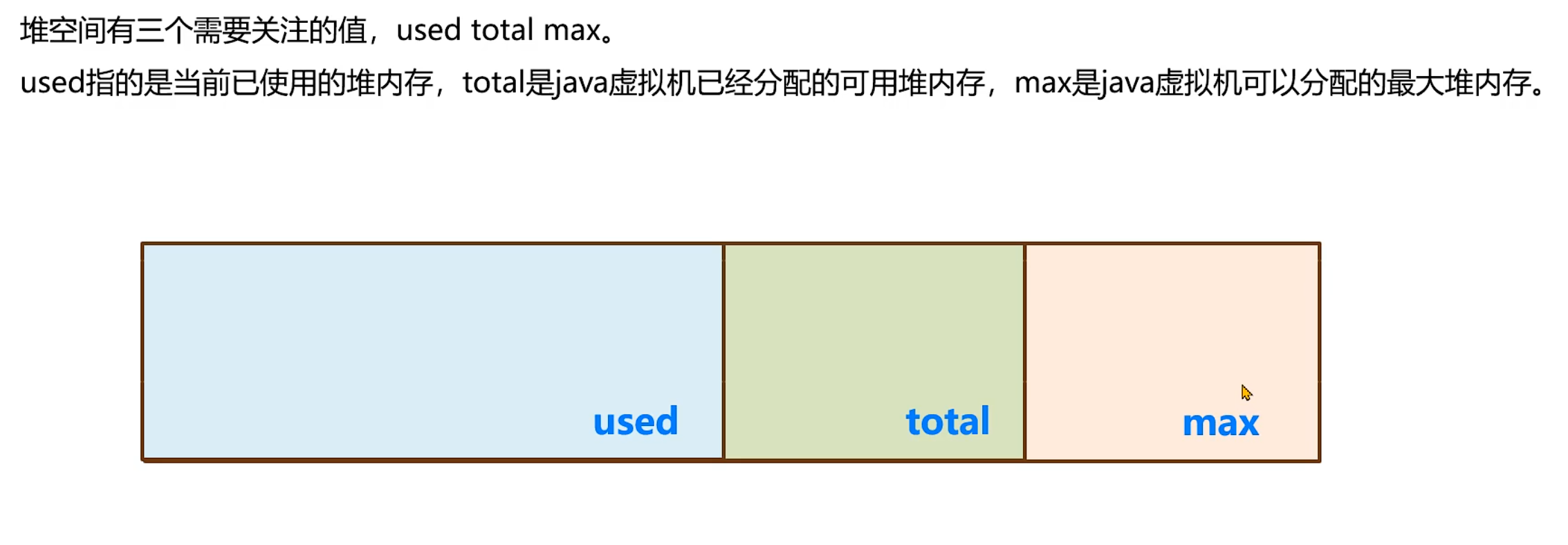
可通过 Arthas 的dashboard命令查看,示例如下:

| Memory | used | total | max | usage |
|---|---|---|---|---|
| heap | 153M | 981M | 981M | 15.68% |
| ps_eden_space | 100M | 266M | 266M | 37.59% |
| ps_survivor_space | 0K | 43520K | 43520K | 0.00% |
| ps_old_gen | 0K | 699392K | 699392K | 0.00% |
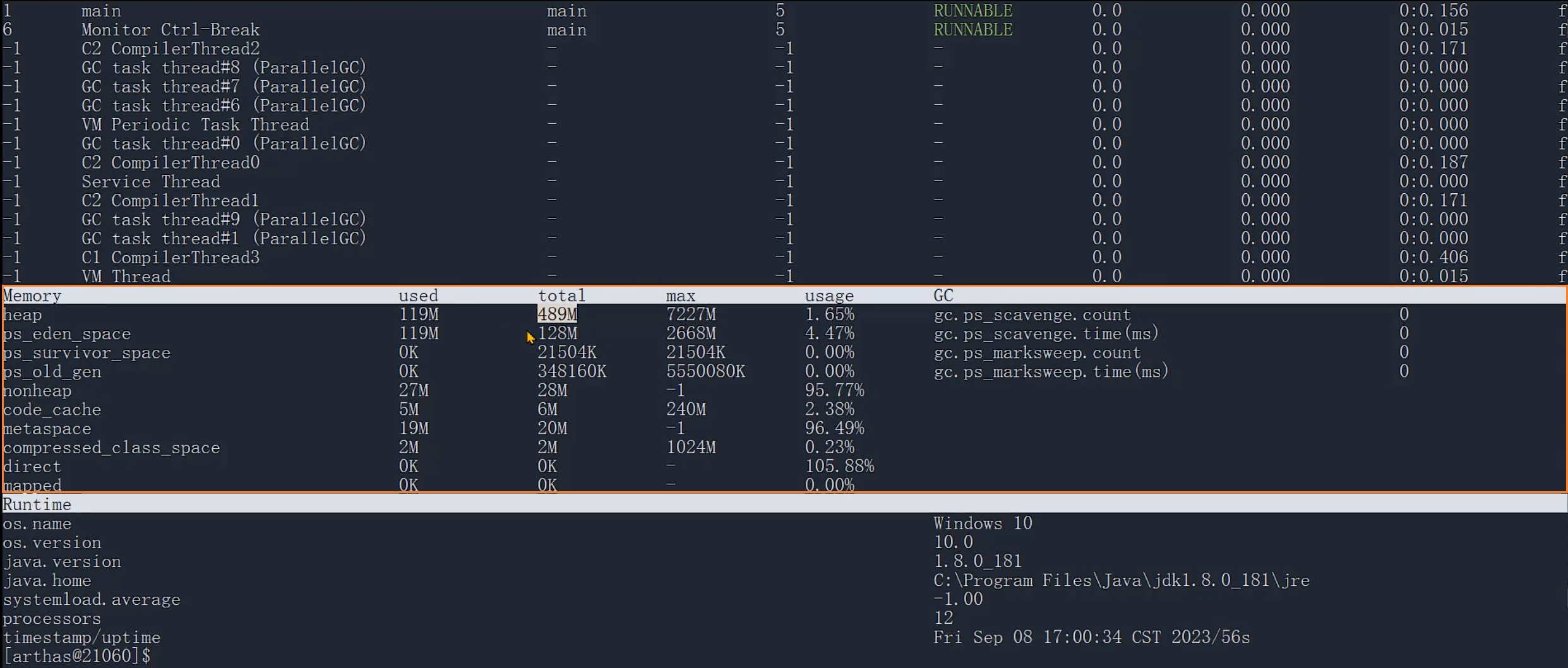
随着堆中的对象增多,当total可以使用的内存即将不足时,java虚拟机会继续分配内存给堆。

此时used达到了total的大小,Java虚拟机会向操作系统申请更大的内存。

但是这个申请过程不是无限的,total最多只能与max相等。


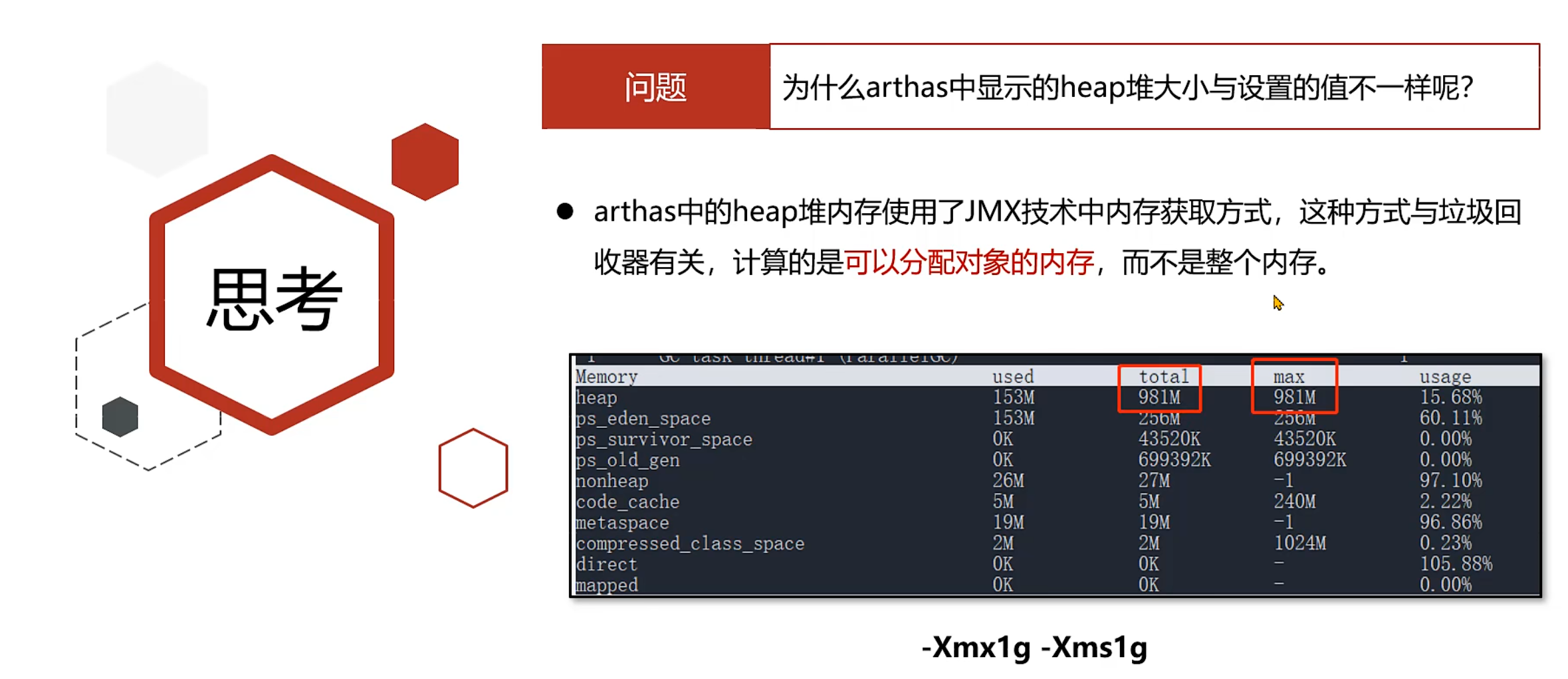
1. 参数默认值
如果不设置任何的虚拟机参数,max默认是系统内存的1/4,total默认是系统内存的1/64。在实际应用中一般都需要设置total和max的值。
2. 手动设置堆大小

3. 建议配置

1.5 方法区
方法区是存放基础信息的位置,线程共享,主要包含三部分内容:

类的元信息,保存了所有类的基本信息
运行时常量池,保存了字节码文件中的常量池内容
字符串常量池,保存了字符串常量
1.5.1 存储内容
1. 类的元信息
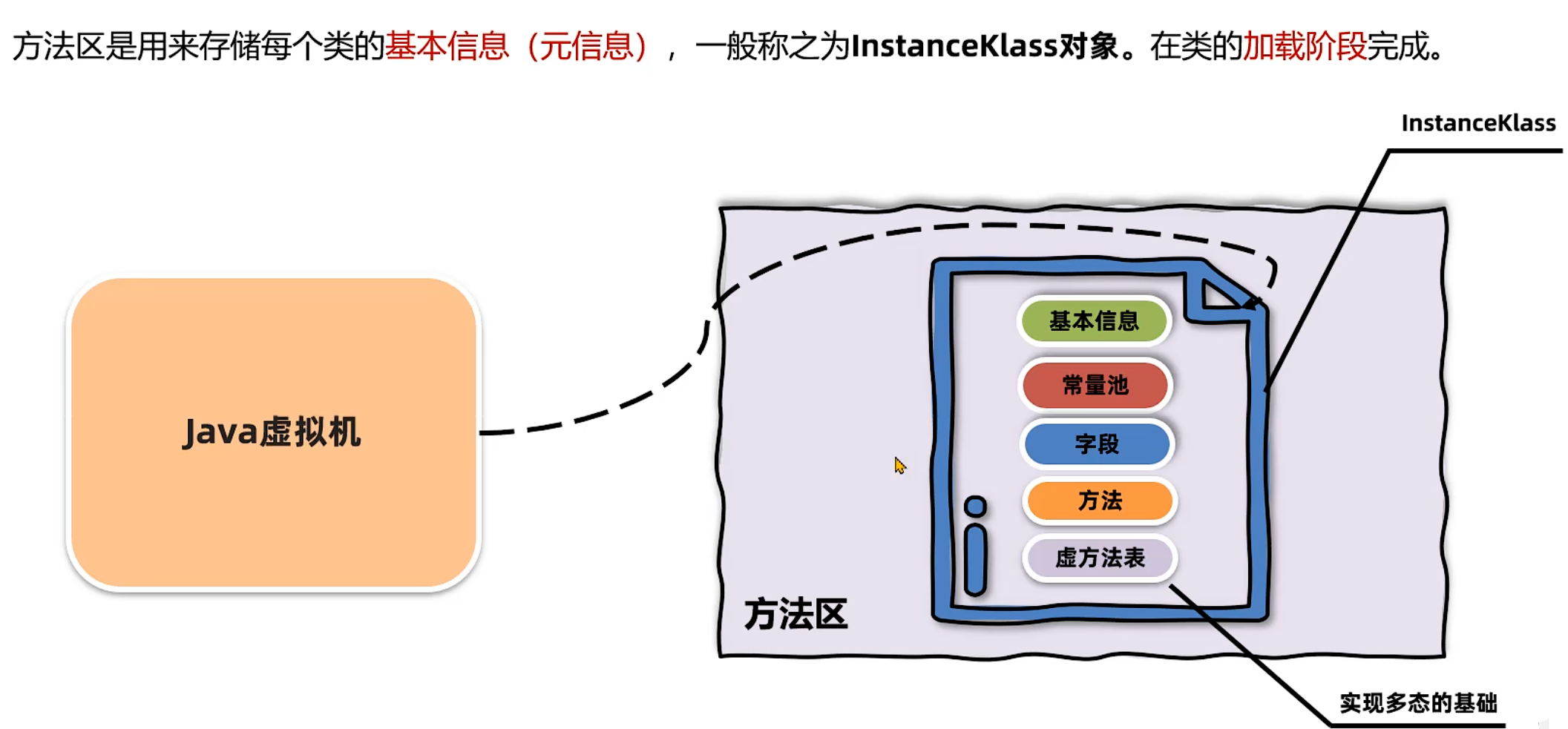
方法区是用来存储每个类的基本信息(元信息),一般称之为InstanceKlass对象。在类的加载阶段完成。其中就包含了类的字段、方法等字节码文件中的内容,同时还保存了运行过程中需要使用的虚方法表(实现多态的基础)等信息。
2. 运行时常量池
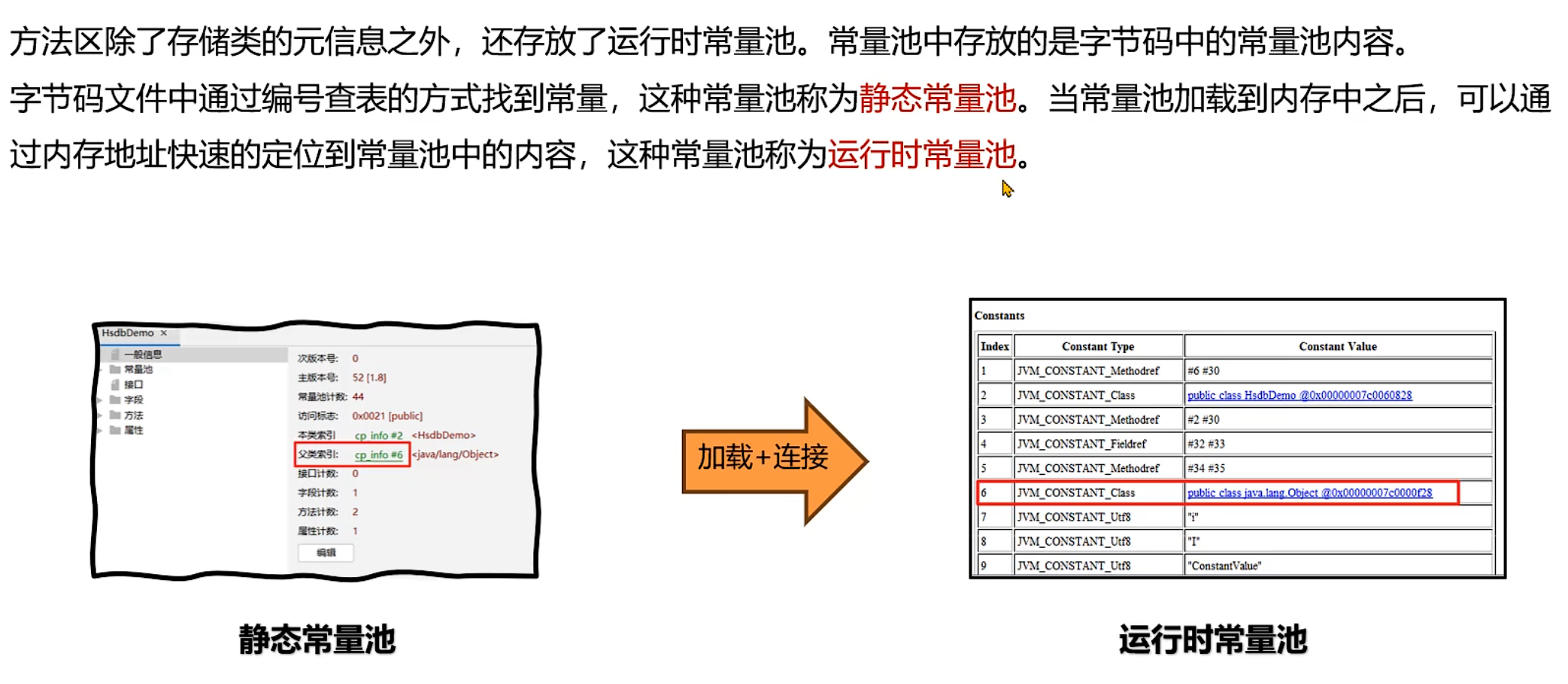
静态常量池与运行时常量池的关系:字节码文件中的常量池(静态常量池)通过编号查表访问常量;加载到内存后,静态常量池转换为运行时常量池,可通过内存地址直接定位常量,提升访问效率。
作用:存放字节码文件中常量池的内容,包括字符串常量、类或接口名、字段名、方法名等,供字节码指令引用。
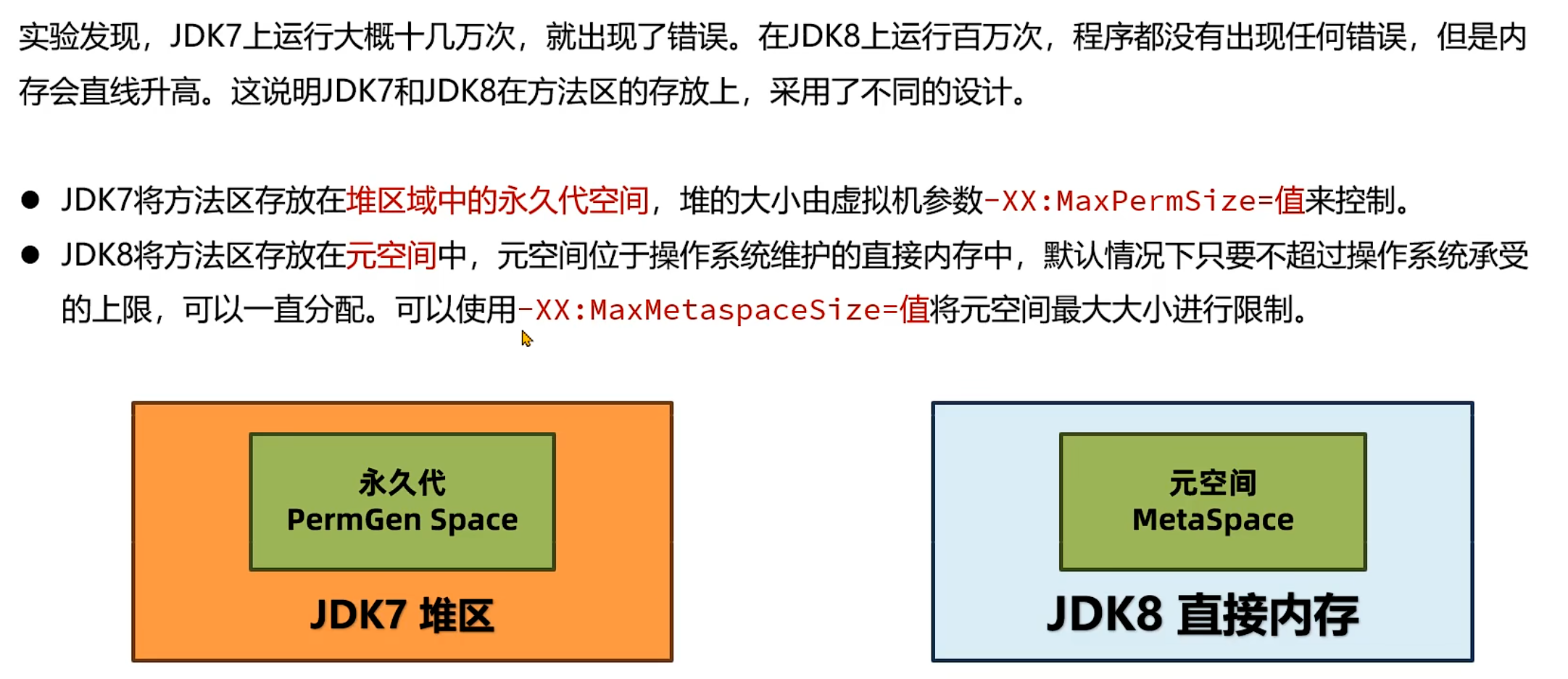
3. 方法区的溢出
4. 字符串常量池
方法区中除类的元信息、运行时常量池之外,还有一块区域叫字符串常量池(StringTable)。
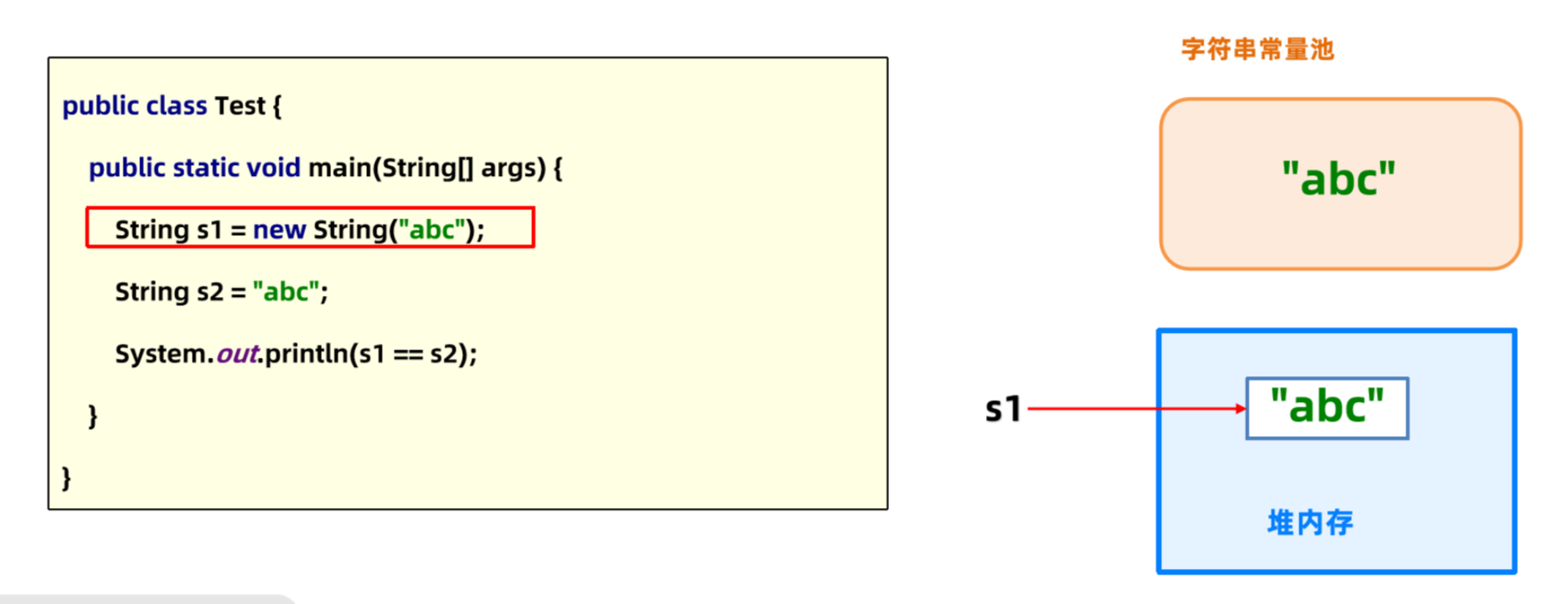
字符串常量池存储在代码中定义的常量字符串内容。如“123” 就会被放入字符串常量池。
如下代码执行时,代码中包含abc字符串,就会被直接放入字符串常量池。在堆上创建String对象,并通过局部变量s1引用堆上的对象。
接下来通过s2局部变量引用字符串常量池的abc。
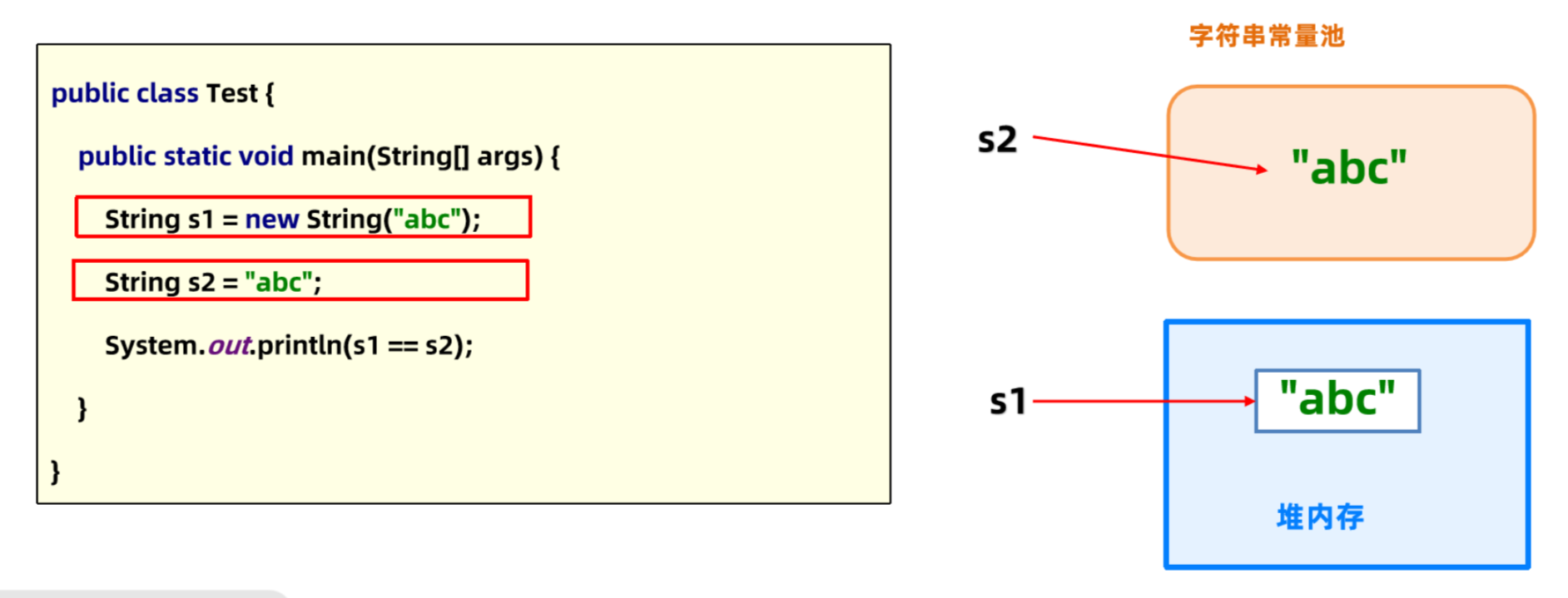
所以s1和s2指向的不是同一个对象,打印出false。
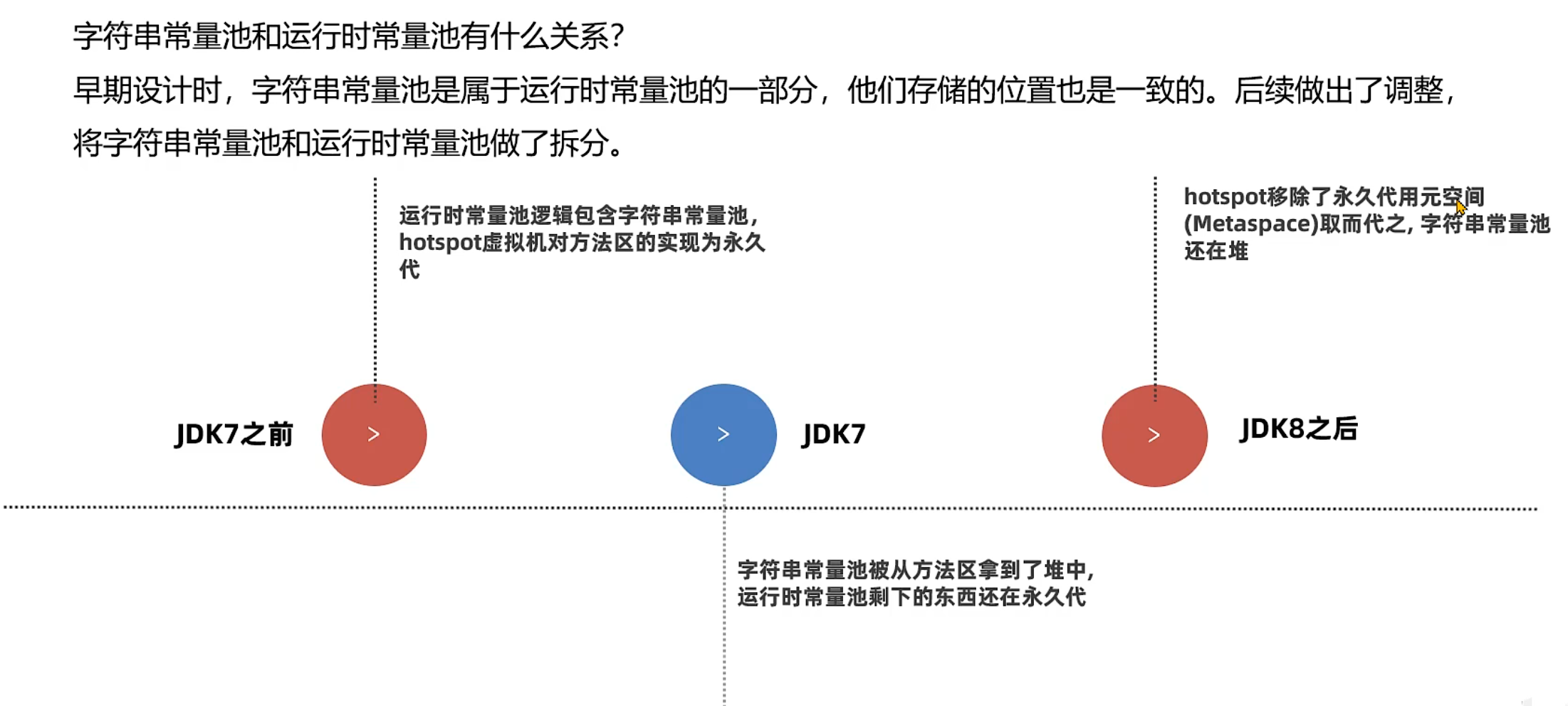
字符串常量池和运行时常量池有什么关系?
早期设计时,字符串常量池是属于运行时常量池的一部分,他们存储的位置也是一致的。后续做出了调整,将字符串常量池和运行时常量池做了拆分。
神奇的intern
1.使用StringBuilder的将think和123拼接成think123,转换成字符串,在堆上创建一个字符串对象。局部变量s1指向堆上的对象。

2. 调用s1.intern方法,会在字符串常量池中创建think123的对象,最后将对象引用返回。所以s1.intern和s1指向的不是同一个对象。打印出false。

3. 同理,通过StringBuilder在堆上创建java字符串对象。这里注意字符串常量池中本来就有一个java字符串对象,这是java虚拟机自身使用的所以启动时就会创建出来。

4. 调用s2.intern发现字符串常量池中已经有java字符串对象了,就将引用返回。所以s2.intern指向的是字符串常量池中的对象,而s2指向的是堆中的对象。打印结果为false。

接下来分析JDK7中,JDK7及之后版本中由于字符串常量池在堆上,所以intern () 方法会把第一次遇到的字符串的引用放入字符串常量池。
代码执行步骤如下:
1. 执行第二句代码时,由于字符串常量池中没有think123的字符串,所以直接创建一个引用,指向堆中的think123对象。所以s1.intern和s1指向的都是堆上的对象,打印结果为true。

2. s2.intern方法调用时,字符串常量池中已经有java字符串了,所以将引用返回。这样打印出来的结果就是false。

后续JDK版本中,如果Java虚拟机不需要使用java字符串,那么字符串常量池中就不会存放
java。打印结果有可能会出现两个true。
面试题:静态变量存储在哪里呢?
JDK6及之前的版本中,静态变量是存放在方法区中的,也就是永久代。
JDK7及之后的版本中,静态变量是存放在堆中的Class对象中,脱离了永久代。
1.6 直接内存
直接内存并不在《Java虚拟机规范》中存在,所以并不属于Java运行时的内存区域。
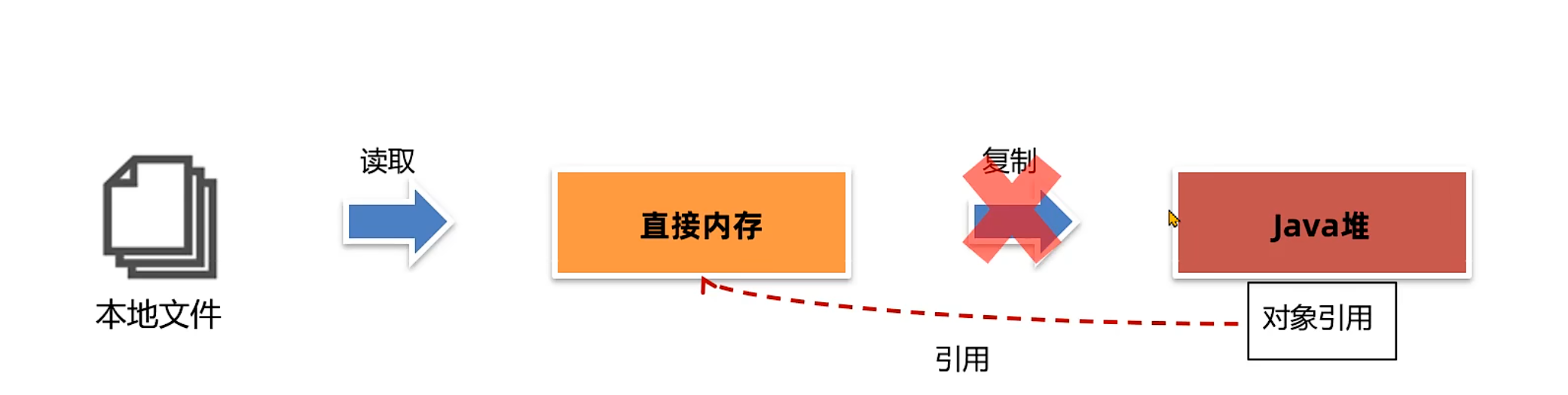
在 JDK 1.4 中引入了 NIO 机制,使用了直接内存,主要为了解决以下两个问题:
1. Java堆中的对象如果不再使用要回收,回收时会影响对象的创建和使用。
2. IO操作比如读文件,需要先把文件读入直接内存(缓冲区)再把数据复制到Java堆中。
现在直接放入直接内存即可,同时Java堆上维护直接内存的引用,减少了数据复制的开销。写文件也是类似的思路。
1.6.1 直接内存的使用
要创建直接内存上的数据,可以使用ByteBuffer。
语法: ByteBuffer directBuffer = ByteBuffer.allocateDirect(size);
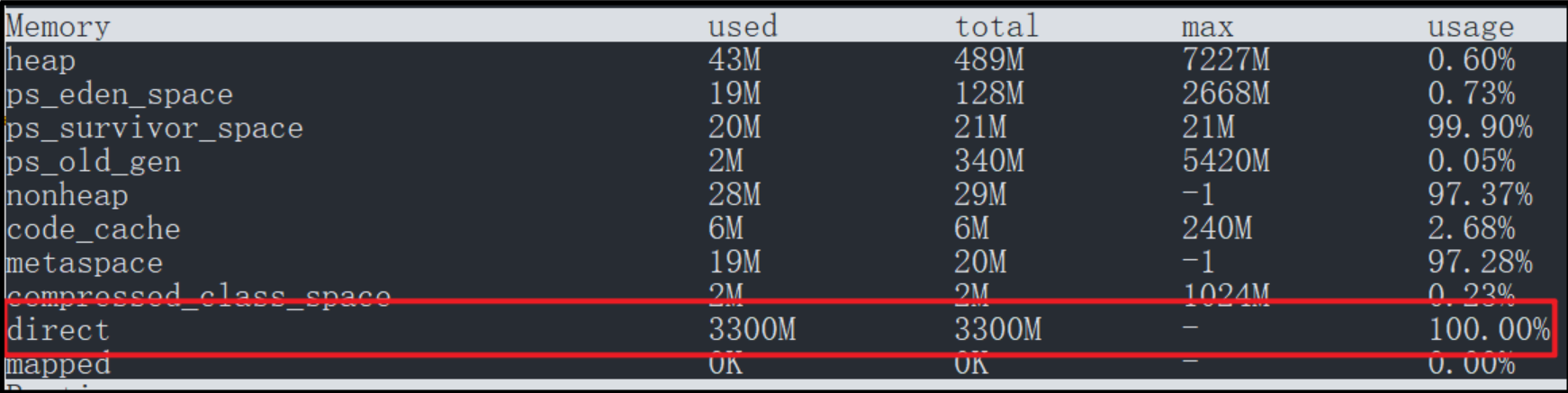
注意事项: arthas的memory命令可以查看直接内存大小,属性名direct。
代码:
package chapter03.direct;import java.io.IOException;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.List;/*** 直接内存的使用和回收*/
public class Demo1 {public static int size = 1024 * 1024 * 100; //100mbpublic static List<ByteBuffer> list = new ArrayList<ByteBuffer>();public static int count = 0;public static void main(String[] args) throws IOException, InterruptedException {System.in.read();while (true) {//1.创建DirectByteBuffer对象并返回//2.在DirectByteBuffer构造方法中,向操作系统申请直接内存空间ByteBuffer directBuffer = ByteBuffer.allocateDirect(size);//directBuffer = null;list.add(directBuffer);System.out.println(++count);Thread.sleep(5000);}}
}1.6.2 直接内存的溢出与参数设置
1. 溢出场景
若直接内存持续分配且无回收,超出操作系统内存上限时,会抛出OutOfMemoryError: Direct buffer memory错误。

2. 调整直接内存大小
通过 -XX:MaxDirectMemorySize=<大小> 设置直接内存最大值,单位支持 KB、MB、GB。例如:
-XX:MaxDirectMemorySize=1m
-XX:MaxDirectMemorySize=1024k
-XX:MaxDirectMemorySize=1048576-XX:MaxDirectMemorySize=1g:设置直接内存最大为 1GB
若不设置该参数,JVM 会自动选择最大分配大小(通常与堆max相近)。
大功告成!