【完整源码+数据集+部署教程】航拍遥感太阳能面板识别图像分割
背景意义
随着全球对可再生能源的日益重视,太阳能作为一种清洁、可再生的能源形式,正逐渐成为各国能源结构转型的重要组成部分。太阳能面板的广泛应用不仅有助于减少温室气体排放,还能有效降低对化石燃料的依赖。然而,太阳能面板的安装、维护和监测过程中的效率提升,依赖于高效的图像识别与分析技术。航拍遥感技术因其高效、广域的特性,成为了太阳能面板监测的重要手段。通过对航拍图像的分析,可以快速、准确地识别和定位太阳能面板,从而为后续的维护和管理提供数据支持。
在这一背景下,基于改进YOLOv8的航拍遥感太阳能面板识别图像分割系统的研究显得尤为重要。YOLO(You Only Look Once)系列模型因其实时性和高准确率,已成为目标检测领域的主流算法之一。YOLOv8作为其最新版本,进一步提升了模型的性能,尤其在处理复杂场景和小目标检测方面展现出优越的能力。然而,传统的YOLOv8模型在处理航拍图像时,仍然面临着目标遮挡、光照变化和背景复杂等挑战。因此,针对航拍遥感图像的特性,对YOLOv8进行改进,构建一个专门用于太阳能面板识别的图像分割系统,具有重要的理论价值和实际意义。
本研究将利用“solar-antwerp”数据集,该数据集包含5400张航拍图像,专注于太阳能面板的实例分割任务。该数据集的单一类别(太阳能面板)使得模型训练更加专注,能够有效提升识别精度和分割效果。通过对数据集的深入分析与处理,结合改进的YOLOv8模型,我们期望能够实现对太阳能面板的高效、准确的识别与分割。这不仅能够为太阳能行业提供精准的监测手段,还能为相关政策的制定与实施提供数据支持,推动可再生能源的可持续发展。
此外,航拍遥感技术与深度学习的结合,能够为智能城市、环境监测等领域提供新的解决方案。通过对太阳能面板的精准识别与监测,能够为城市的能源管理提供重要依据,促进绿色建筑和可持续发展的理念落地。研究成果的推广应用,将有助于提升太阳能面板的使用效率,降低维护成本,从而推动太阳能行业的健康发展。
综上所述,基于改进YOLOv8的航拍遥感太阳能面板识别图像分割系统的研究,不仅具有重要的学术价值,也为实际应用提供了有力的技术支持。通过这一研究,我们希望能够为太阳能面板的高效监测与管理提供创新的解决方案,助力全球可再生能源的推广与应用。
图片效果
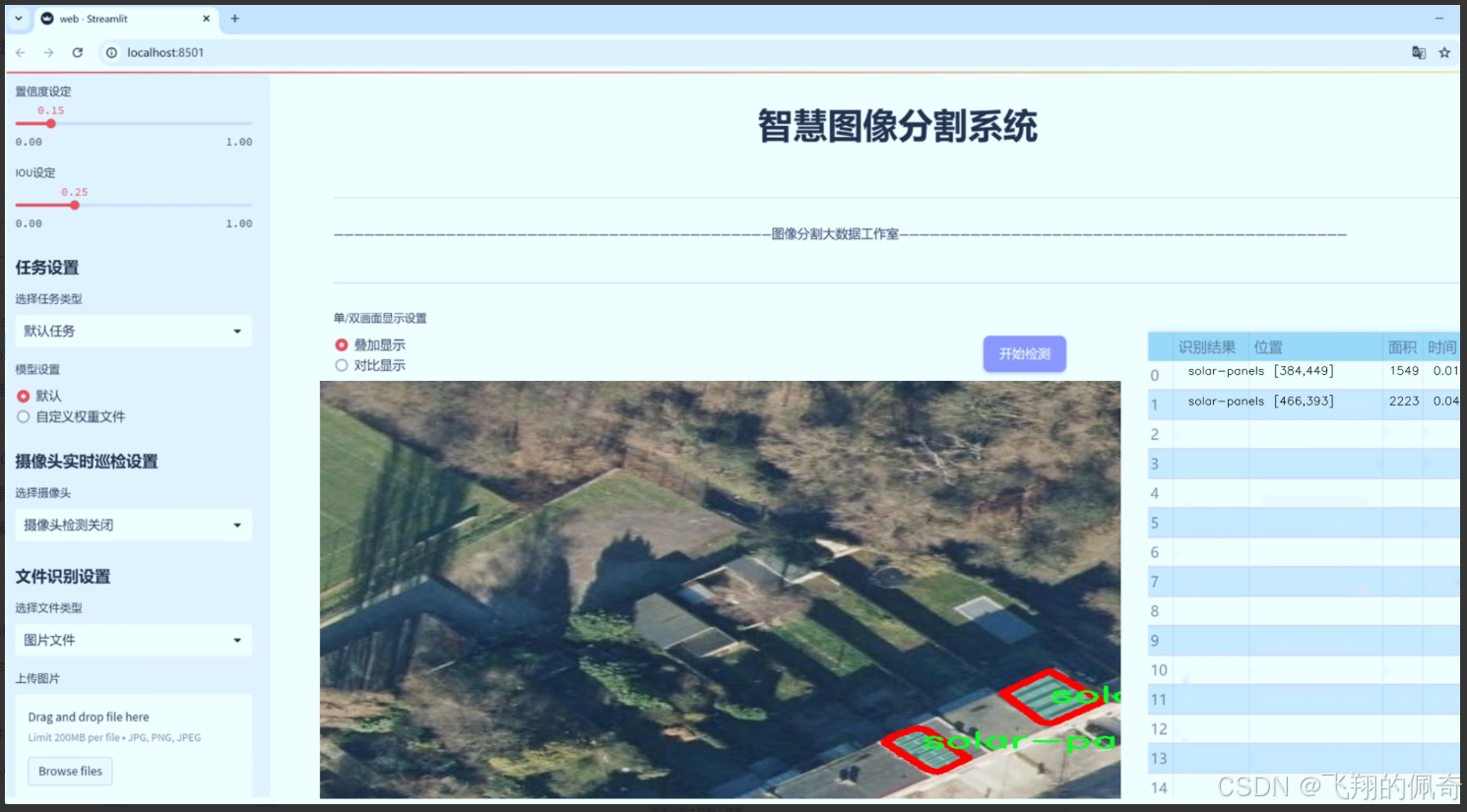
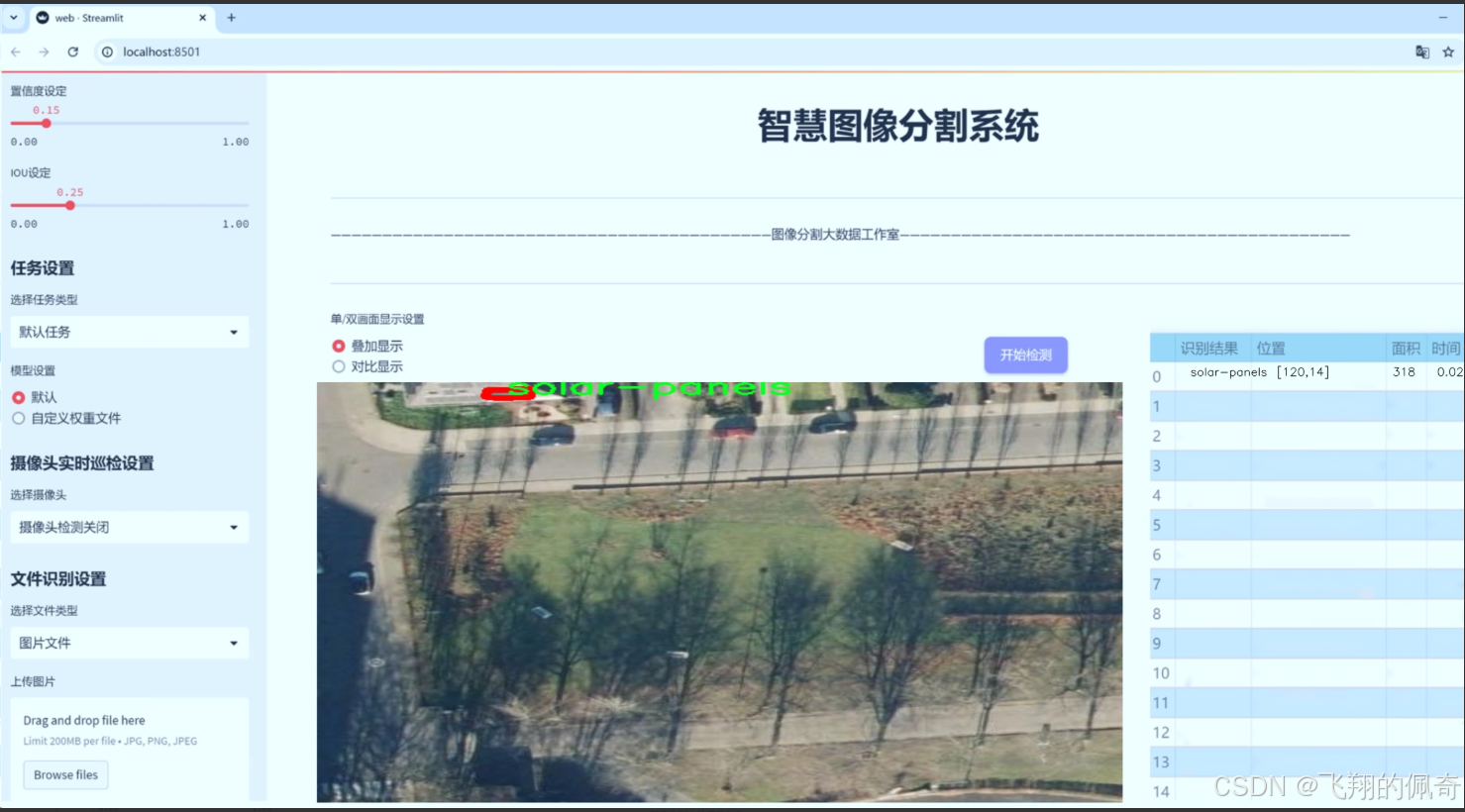
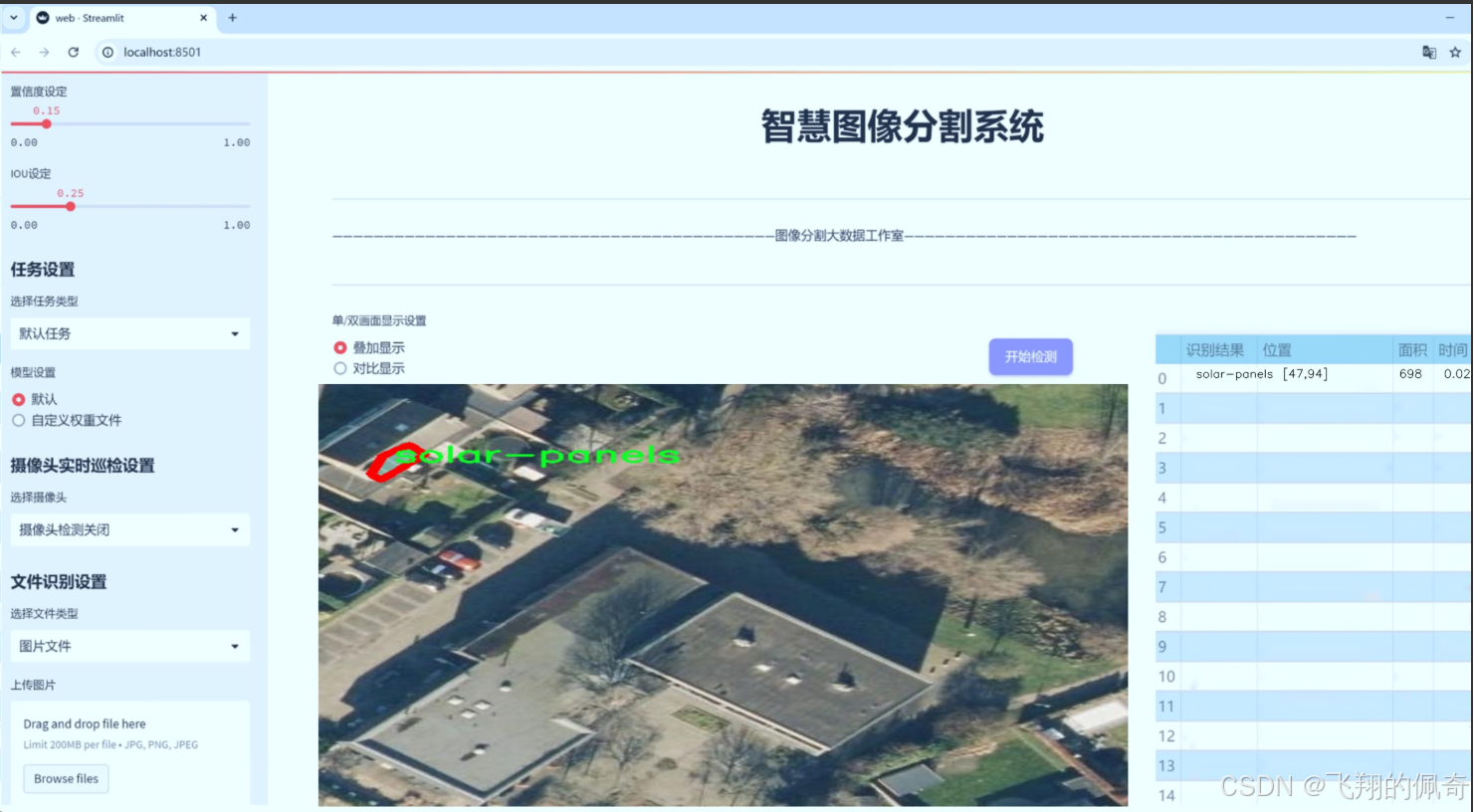
数据集信息
数据集信息展示
在现代遥感技术的迅速发展中,航拍图像的分析与处理成为了研究的热点之一。尤其是在太阳能面板的识别与分割领域,准确的图像处理技术对于提高太阳能资源的利用效率具有重要意义。本研究所使用的数据集名为“solar-antwerp”,专门用于训练改进版的YOLOv8-seg模型,以实现高效的航拍遥感太阳能面板识别图像分割。
“solar-antwerp”数据集的构建基于丰富的航拍图像,涵盖了多种不同环境下的太阳能面板。这些图像来源于不同的地理位置,确保了数据集的多样性和代表性。数据集中包含的类别数量为1,具体类别为“solar-panels”。这一类别的选择反映了本研究的重点,即聚焦于太阳能面板的检测与分割,而不涉及其他物体或类别的干扰,从而提高模型的专注度和识别精度。
在数据集的构建过程中,研究团队采用了高分辨率的航拍图像,确保每一幅图像都能清晰地展示太阳能面板的特征。图像的获取过程经过精心设计,涵盖了不同的天气条件、时间段和地理环境,以增强模型的泛化能力。通过这种方式,数据集不仅能够反映太阳能面板在各种实际应用场景中的表现,还能够帮助模型学习到不同环境下的特征变化。
数据集中的每一幅图像都经过了精确的标注,确保太阳能面板的边界被准确地框定。这一过程不仅依赖于人工标注的细致工作,还结合了先进的图像处理技术,以提高标注的准确性和一致性。通过这种高质量的标注,YOLOv8-seg模型能够在训练过程中获得丰富的特征信息,从而提升其在实际应用中的识别能力。
在数据集的使用过程中,研究者们将“solar-antwerp”数据集分为训练集和验证集,以便于模型的训练和性能评估。训练集用于模型的学习,而验证集则用于实时监测模型的性能,确保其在未见数据上的表现同样优秀。这种分割策略有助于避免过拟合现象的发生,从而提升模型的泛化能力。
通过对“solar-antwerp”数据集的深入分析与应用,研究团队希望能够在航拍遥感领域实现更高效的太阳能面板识别与分割。这不仅将推动相关技术的发展,也为未来的太阳能资源管理和优化提供了重要的数据支持。随着模型的不断改进与优化,预计将会在实际应用中取得显著的成果,为可再生能源的利用贡献力量。





核心代码
以下是经过简化并添加详细中文注释的核心代码部分,主要包括 KalmanFilterXYAH 类的定义和关键方法:
import numpy as np
import scipy.linalg
class KalmanFilterXYAH:
“”"
Kalman滤波器,用于在图像空间中跟踪边界框。
状态空间为8维 (x, y, a, h, vx, vy, va, vh),分别表示边界框中心位置 (x, y),宽高比 a,高度 h 及其对应的速度。
物体运动遵循恒定速度模型。
“”"
def __init__(self):"""初始化卡尔曼滤波器模型矩阵,设置运动和观测的不确定性权重。"""ndim, dt = 4, 1. # 状态维度和时间增量# 创建卡尔曼滤波器模型矩阵self._motion_mat = np.eye(2 * ndim, 2 * ndim) # 运动矩阵for i in range(ndim):self._motion_mat[i, ndim + i] = dt # 设置速度部分self._update_mat = np.eye(ndim, 2 * ndim) # 更新矩阵# 运动和观测的不确定性权重self._std_weight_position = 1. / 20self._std_weight_velocity = 1. / 160def initiate(self, measurement):"""从未关联的测量值创建跟踪。参数----------measurement : ndarray边界框坐标 (x, y, a, h)。返回-------(ndarray, ndarray)返回新跟踪的均值向量和协方差矩阵。"""mean_pos = measurement # 位置均值mean_vel = np.zeros_like(mean_pos) # 速度均值初始化为0mean = np.r_[mean_pos, mean_vel] # 合并位置和速度均值# 计算协方差矩阵的标准差std = [2 * self._std_weight_position * measurement[3], # 高度的标准差2 * self._std_weight_position * measurement[3], # 高度的标准差1e-2, # 宽高比的标准差2 * self._std_weight_position * measurement[3], # 高度的标准差10 * self._std_weight_velocity * measurement[3], # 速度的标准差10 * self._std_weight_velocity * measurement[3], # 速度的标准差1e-5, # 角速度的标准差10 * self._std_weight_velocity * measurement[3] # 速度的标准差]covariance = np.diag(np.square(std)) # 协方差矩阵return mean, covariancedef predict(self, mean, covariance):"""执行卡尔曼滤波器预测步骤。参数----------mean : ndarray先前时间步的状态均值向量。covariance : ndarray先前时间步的状态协方差矩阵。返回-------(ndarray, ndarray)返回预测状态的均值向量和协方差矩阵。"""# 计算运动协方差std_pos = [self._std_weight_position * mean[3], # 高度的标准差self._std_weight_position * mean[3], # 高度的标准差1e-2, # 宽高比的标准差self._std_weight_position * mean[3] # 高度的标准差]std_vel = [self._std_weight_velocity * mean[3], # 速度的标准差self._std_weight_velocity * mean[3], # 速度的标准差1e-5, # 角速度的标准差self._std_weight_velocity * mean[3] # 速度的标准差]motion_cov = np.diag(np.square(np.r_[std_pos, std_vel])) # 运动协方差矩阵# 预测均值和协方差mean = np.dot(mean, self._motion_mat.T) # 更新均值covariance = np.linalg.multi_dot((self._motion_mat, covariance, self._motion_mat.T)) + motion_cov # 更新协方差return mean, covariancedef update(self, mean, covariance, measurement):"""执行卡尔曼滤波器校正步骤。参数----------mean : ndarray预测状态的均值向量。covariance : ndarray状态的协方差矩阵。measurement : ndarray测量向量 (x, y, a, h)。返回-------(ndarray, ndarray)返回经过测量校正后的状态分布。"""projected_mean, projected_cov = self.project(mean, covariance) # 投影到测量空间# 计算卡尔曼增益chol_factor, lower = scipy.linalg.cho_factor(projected_cov, lower=True, check_finite=False)kalman_gain = scipy.linalg.cho_solve((chol_factor, lower),np.dot(covariance, self._update_mat.T).T,check_finite=False).Tinnovation = measurement - projected_mean # 计算创新# 更新均值和协方差new_mean = mean + np.dot(innovation, kalman_gain.T)new_covariance = covariance - np.linalg.multi_dot((kalman_gain, projected_cov, kalman_gain.T))return new_mean, new_covariance
代码说明
KalmanFilterXYAH 类:这是一个用于跟踪边界框的卡尔曼滤波器,处理的状态包括位置、宽高比、高度及其速度。
init 方法:初始化卡尔曼滤波器的运动和观测矩阵,以及不确定性权重。
initiate 方法:根据测量值创建新的跟踪对象,返回均值和协方差矩阵。
predict 方法:执行预测步骤,更新状态的均值和协方差。
update 方法:执行校正步骤,结合测量值更新状态的均值和协方差。
这个程序文件实现了一个简单的卡尔曼滤波器,用于在图像空间中跟踪边界框。主要包含两个类:KalmanFilterXYAH和KalmanFilterXYWH,分别用于处理不同的边界框表示形式。
KalmanFilterXYAH类使用8维状态空间,包括边界框的中心位置(x, y)、长宽比(a)、高度(h)及其对应的速度(vx, vy, va, vh)。该类的初始化方法中,创建了运动模型矩阵和观测模型矩阵,并设定了运动和观测的不确定性权重。
initiate方法用于从未关联的测量值创建跟踪对象,返回新的状态均值向量和协方差矩阵。predict方法执行卡尔曼滤波的预测步骤,计算下一时刻的状态均值和协方差。project方法将状态分布投影到测量空间,计算测量的均值和协方差。
multi_predict方法是predict的向量化版本,能够同时处理多个状态的预测。update方法则执行卡尔曼滤波的校正步骤,根据新的测量值更新状态均值和协方差。gating_distance方法计算状态分布与测量之间的门控距离,帮助判断测量是否与当前状态相关。
KalmanFilterXYWH类继承自KalmanFilterXYAH,主要区别在于状态空间的表示形式为(x, y, w, h),即边界框的宽度和高度。它重写了initiate、predict、project和multi_predict方法,以适应新的状态表示,但update方法则直接调用父类的实现。
整体而言,这个文件实现了一个灵活的卡尔曼滤波器,可以根据不同的边界框表示形式进行跟踪,适用于计算机视觉中的目标跟踪任务。
11.5 ultralytics\utils\callbacks\clearml.py
以下是代码中最核心的部分,并附上详细的中文注释:
导入必要的库
from ultralytics.utils import LOGGER, SETTINGS, TESTS_RUNNING
尝试导入 ClearML 相关的库并进行基本的检查
try:
assert not TESTS_RUNNING # 确保当前不是在运行测试
assert SETTINGS[‘clearml’] is True # 确保 ClearML 集成已启用
import clearml
from clearml import Task
from clearml.binding.frameworks.pytorch_bind import PatchPyTorchModelIO
from clearml.binding.matplotlib_bind import PatchedMatplotlib
assert hasattr(clearml, '__version__') # 确保 ClearML 包已正确安装
except (ImportError, AssertionError):
clearml = None # 如果导入失败,设置 clearml 为 None
def on_pretrain_routine_start(trainer):
“”“在预训练例程开始时运行;初始化并连接/记录任务到 ClearML。”“”
try:
task = Task.current_task() # 获取当前任务
if task:
# 确保自动的 PyTorch 和 Matplotlib 绑定被禁用
PatchPyTorchModelIO.update_current_task(None)
PatchedMatplotlib.update_current_task(None)
else:
# 初始化一个新的 ClearML 任务
task = Task.init(project_name=trainer.args.project or ‘YOLOv8’,
task_name=trainer.args.name,
tags=[‘YOLOv8’],
output_uri=True,
reuse_last_task_id=False,
auto_connect_frameworks={
‘pytorch’: False,
‘matplotlib’: False})
LOGGER.warning(‘ClearML 初始化了一个新任务。如果你想远程运行,请在初始化 YOLO 之前添加 clearml-init 并连接你的参数。’)
task.connect(vars(trainer.args), name=‘General’) # 连接训练参数
except Exception as e:
LOGGER.warning(f’警告 ⚠️ ClearML 已安装但未正确初始化,未记录此运行。{e}')
def on_train_epoch_end(trainer):
“”“在 YOLO 训练的每个 epoch 结束时记录调试样本并报告当前训练进度。”“”
task = Task.current_task() # 获取当前任务
if task:
# 仅在第一个 epoch 记录调试样本
if trainer.epoch == 1:
_log_debug_samples(sorted(trainer.save_dir.glob(‘train_batch*.jpg’)), ‘Mosaic’)
# 报告当前训练进度
for k, v in trainer.validator.metrics.results_dict.items():
task.get_logger().report_scalar(‘train’, k, v, iteration=trainer.epoch)
def on_train_end(trainer):
“”“在训练完成时记录最终模型及其名称。”“”
task = Task.current_task() # 获取当前任务
if task:
# 记录最终结果,包括混淆矩阵和 PR 曲线
files = [
‘results.png’, ‘confusion_matrix.png’, ‘confusion_matrix_normalized.png’,
*(f’{x}_curve.png’ for x in (‘F1’, ‘PR’, ‘P’, ‘R’))]
files = [(trainer.save_dir / f) for f in files if (trainer.save_dir / f).exists()] # 过滤存在的文件
for f in files:
_log_plot(title=f.stem, plot_path=f) # 记录图像
# 报告最终指标
for k, v in trainer.validator.metrics.results_dict.items():
task.get_logger().report_single_value(k, v)
# 记录最终模型
task.update_output_model(model_path=str(trainer.best), model_name=trainer.args.name, auto_delete_file=False)
定义回调函数
callbacks = {
‘on_pretrain_routine_start’: on_pretrain_routine_start,
‘on_train_epoch_end’: on_train_epoch_end,
‘on_train_end’: on_train_end} if clearml else {}
代码说明:
导入库:导入必要的库和模块,包括 clearml 和相关的 PyTorch 绑定。
任务初始化:在 on_pretrain_routine_start 函数中,初始化 ClearML 任务并连接训练参数。确保自动绑定被禁用,以便手动记录。
训练过程中的记录:在每个训练 epoch 结束时,使用 on_train_epoch_end 函数记录调试样本和训练进度。
训练结束时的记录:在 on_train_end 函数中,记录最终模型、混淆矩阵和其他指标。
回调函数:定义了一个回调字典,用于在训练过程中调用相应的函数。
这个程序文件 clearml.py 是用于与 ClearML 进行集成的回调函数实现,主要用于在训练 YOLO 模型时记录和管理训练过程中的各种信息。文件中首先导入了一些必要的模块和库,并进行了一些基本的检查,确保 ClearML 库的可用性和集成设置的启用。
在程序中,定义了几个重要的函数。_log_debug_samples 函数用于将调试样本(如图像)记录到当前的 ClearML 任务中。它接受一个文件路径列表和一个标题,遍历文件列表并将存在的文件作为图像记录到 ClearML 中,使用正则表达式提取批次信息。
_log_plot 函数则用于将图像作为绘图记录到 ClearML 的绘图部分。它读取指定路径的图像文件,并使用 Matplotlib 进行绘制,最后将绘制的图像记录到 ClearML 中。
on_pretrain_routine_start 函数在预训练例程开始时运行,负责初始化和连接 ClearML 任务。如果当前没有任务,它会创建一个新的任务,并将训练参数连接到任务中。这个函数还确保 PyTorch 和 Matplotlib 的自动绑定被禁用,以便手动记录。
on_train_epoch_end 函数在每个训练周期结束时运行,记录调试样本并报告当前的训练进度。在第一个周期结束时,它会记录训练样本的图像,并在每个周期结束时报告训练指标。
on_fit_epoch_end 函数在每个适应周期结束时运行,记录模型信息,包括每个周期的时间和其他相关信息。
on_val_end 函数在验证结束时运行,记录验证结果,包括标签和预测。
on_train_end 函数在训练完成时运行,记录最终模型及其名称,并记录最终的结果和指标,包括混淆矩阵和其他性能曲线。
最后,程序将这些回调函数组织成一个字典,便于在训练过程中调用。整个文件的设计旨在确保在训练 YOLO 模型时,能够有效地记录和管理训练过程中的重要信息,以便后续分析和调试。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是Ultralytics YOLO项目的一部分,主要用于目标检测和图像分割任务。整体架构由多个模块组成,每个模块负责特定的功能。以下是各个模块的主要功能:
数据处理与操作:包括图像预处理、边界框和掩膜的转换、非极大值抑制等。
模型构建与管理:定义了动态卷积模块,增强了模型的灵活性和性能。
目标跟踪:实现了卡尔曼滤波器,用于在视频序列中跟踪目标。
回调与监控:集成了ClearML,用于记录训练过程中的各种信息,方便后续分析和调试。
这些模块通过相互调用和组合,形成了一个完整的目标检测和跟踪系统,支持高效的训练和推理过程。
功能整理表格
文件路径 功能描述
ultralytics/utils/ops.py 提供图像处理和边界框操作的工具函数,包括NMS、坐标转换等。
ultralytics/models/sam/amg.py 实现图像分割和边界框处理的功能,包括裁剪、掩膜稳定性评估等。
ultralytics/nn/extra_modules/ops_dcnv3/modules/init.py 初始化模块,导入动态卷积相关的类和函数,简化模块使用。
ultralytics/trackers/utils/kalman_filter.py 实现卡尔曼滤波器,用于目标跟踪,支持不同的边界框表示形式。
ultralytics/utils/callbacks/clearml.py 集成ClearML进行训练过程监控和记录,支持调试样本和训练指标的记录。
这个表格总结了每个文件的主要功能,帮助理解Ultralytics YOLO项目的结构和各个模块之间的关系。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式