make和Makefile细节补充
make和Makefile细节补充
本文主要补充4点细节:
- Makefile中的依赖关系,执行make指令的时候的具体行为细节。
- make执行时,Makefile生成的最终目标的确定机制
- make和Makefile如何判断何时需要重新编译
- 如何理解Linux文件属性中的时间属性
第一部分:依赖关系
说法一: “Makefile和make形成目标文件的时候,默认是从上到下扫描Makefile文件的”
基本正确,但“扫描”的目的需要澄清。
make 确实会从上到下读取和解析 Makefile 文件。但是,这个“扫描”过程的主要目的不是为了立即执行命令(recipe)来构建文件,而是为了:
- 建立依赖关系图:
make读取所有规则(target: prerequisites),在内存中构建一个完整的、所有目标之间的依赖关系图。它需要知道整个项目的依赖结构,然后才能决定做什么。 - 变量赋值:在解析过程中,它会处理所有的变量赋值(如
CC := gcc)。 - 处理指令:处理
include,ifeq等指令。
关键点:解析(从上到下扫描)和执行(运行命令构建目标)是两个独立的阶段。
- 解析阶段:从上到下扫描
Makefile,建立依赖图。 - 执行阶段:从命令行指定的目标(或默认目标)开始,根据依赖图,判断哪些目标需要重新构建,然后逆着依赖关系的方向(从叶子节点到根节点) 执行相应的命令。
示例:
# Makefile 内容(从上到下)
main.o: main.cgcc -c main.c -o main.outils.o: utils.cgcc -c utils.c -o utils.omyapp: main.o utils.ogcc main.o utils.o -o myapp
- 扫描:
make先看到main.o的规则,记录下来;然后看到utils.o的规则,记录下来;最后看到最终目标myapp的规则,记录下来。现在它知道了myapp依赖main.o和utils.o,而main.o又依赖main.c,等等。 - 执行(第一种情况):如果你只运行
make,make会选择第一个目标做为默认目标,即main.o。它会尝试构建main.o,所以它只会执行gcc -c main.c -o main.o这一条命令。 - 执行(第二种情况):如果你在命令行运行
make myapp,它会找到目标myapp。为了构建myapp,它发现需要先有main.o和utils.o。于是它逆着依赖关系,先去检查(并可能构建(这里可能构建的意思是得要先判断main.o和utils.o两个文件的依赖文件(main.c和utils.c)是否有更新,是否有内容上的变化,有则重新构建,无则不构建)具体看本文第三部分的内容)main.o和utils.o,最后才来执行链接命令生成myapp。
结论:说法一是正确的,make 确实从上到下扫描,但扫描的目的是建立依赖图,实际的执行顺序是从命令行指定的目标(或默认目标)开始,根据依赖图决定的,不一定是文件中的书写顺序。
说法二: “而且默认只形成一个目标文件。”
这个说法不完全准确,取决于您对“目标文件”和“形成”的理解。
-
默认只处理一个“终极目标”:这是绝对正确的。如果你在命令行只输入
make,而不指定任何目标,make会选择Makefile中定义的第一个目标(也称为默认目标)作为要构建的终极目标。它的一切努力都是为了生成这个终极目标。 -
但“形成一个目标文件”可能产生歧义:
-
歧义一:“目标文件”通常指
.o文件(Object File)。你的说法可能让人误解为“默认只生成一个.o文件”。这是错误的。终极目标可以是任何东西:一个可执行程序(如myapp)、一个库文件(如lib.a)、甚至是一个伪目标(如clean)。为了生成这个终极目标,make通常会先构建它所依赖的所有中间文件(例如多个.o文件),最后才生成终极目标。- 在上面的例子中,运行
make myapp的最终结果是生成了myapp这一个文件,但在这个过程中,它可能先后生成了main.o和utils.o两个目标文件。所以,它并非“只形成一个文件”,而是“只为了形成一个终极目标,但过程中可能会形成多个文件”。
- 在上面的例子中,运行
-
歧义二:如果你运行
make并指定一个目标,比如make clean,那么make就只尝试去完成clean这一个“目标”(task),不会去构建myapp或.o文件。
-
更精确的表述是:默认情况下,make 会尝试构建(make)且仅构建(make)Makefile 中的第一个目标。为了完成这个目标,它可能需要递归地先构建该目标所依赖的所有其他目标。
如何控制默认目标?
最佳实践是使用一个名为 all 的伪目标作为第一个目标,让它依赖于你真正想构建的所有东西。
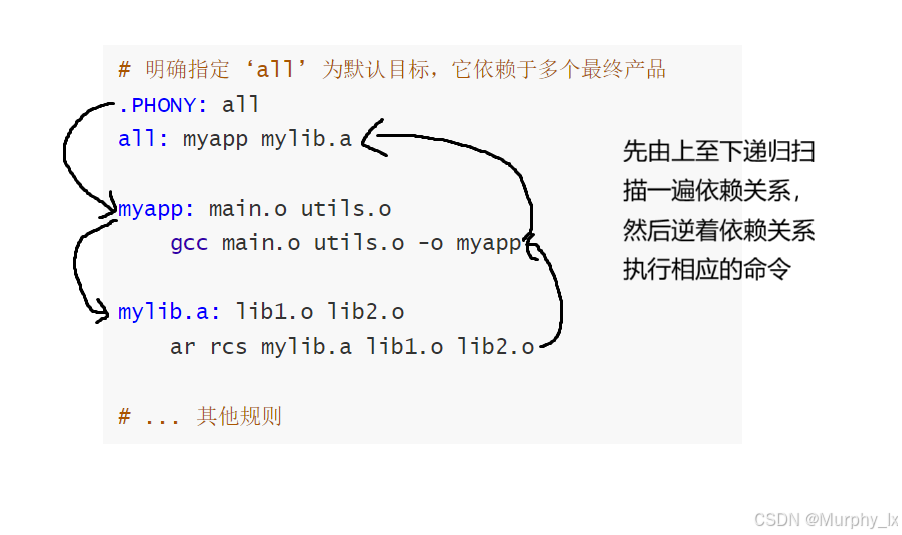
# 明确指定 ‘all’ 为默认目标,它依赖于多个最终产品
.PHONY: all
all: myapp mylib.amyapp: main.o utils.ogcc main.o utils.o -o myappmylib.a: lib1.o lib2.oar rcs mylib.a lib1.o lib2.o# ... 其他规则
这样,只输入 make 就会同时构建 myapp 和 mylib.a。
小点总结
| 说法 | 精确解释 |
|---|---|
| “从上到下扫描” | 正确。 make 从上到下解析 Makefile 以建立依赖关系图,但不按此顺序执行命令。命令执行顺序由命令行make的目标和依赖图决定。 |
| “默认只形成一个目标文件” | 需要澄清。 make 默认只致力于完成一个终极目标(即第一个目标或命令行指定目标)。但为了完成它,通常需要先形成多个依赖文件(如多个 .o 文件)。终极目标本身不一定是一个“.o”文件。 |
所以,更准确的结论是:
make 默认从上到下扫描 Makefile 来建立依赖图,并默认只构建第一个目标(以及它所需的所有依赖)。
第二部分:Makefile 目标确定机制详解
make 工具如何确定最终要生成的目标,遵循一个明确的规则:
默认目标规则
make 默认会选择 Makefile 中的第一个目标作为要构建的最终目标。
在下面这个示例中:
main.o: main.cgcc -c main.c -o main.outils.o: utils.cgcc -c utils.c -o utils.omyapp: main.o utils.ogcc main.o utils.o -o myapp
- 第一个目标是
main.o - 因此,当我们只输入
make命令而不指定任何参数时,make会尝试构建main.o
验证示例
让我们通过实际操作来验证这一点:
-
创建一个简单的测试环境:
echo "int main() { return 0; }" > main.c echo "void util() {}" > utils.c -
运行
make:make输出会是:
gcc -c main.c -o main.o这表明
make确实只执行了第一个目标main.o的规则。 -
如果想构建
myapp,需要明确指定:make myapp输出会是:
gcc -c main.c -o main.o # 如果 main.o 不存在 #或者main.o存在但是main.c更新了内容 gcc -c utils.c -o utils.o # 如果 utils.o 不存在 #或者utils.o存在但是utils.c更新了内容 gcc main.o utils.o -o myapp
最佳实践:明确指定默认目标
在实际项目中,通常不希望第一个目标是中间文件(如 .o 文件),而是希望是最终的可执行文件或库。有几种方法可以实现这一点:
方法1:调整目标顺序(最简单)
# 将最终目标放在第一位
myapp: main.o utils.ogcc main.o utils.o -o myappmain.o: main.cgcc -c main.c -o main.outils.o: utils.cgcc -c utils.c -o utils.o
方法2:使用 .DEFAULT_GOAL 特殊变量(GNU make 特性)
main.o: main.cgcc -c main.c -o main.outils.o: utils.cgcc -c utils.c -o utils.omyapp: main.o utils.ogcc main.o utils.o -o myapp# 明确指定默认目标是 myapp
.DEFAULT_GOAL := myapp
方法3:使用 all 伪目标(最常用、最推荐)
# 第一个目标是 all,它依赖于真正的最终目标
all: myappmain.o: main.cgcc -c main.c -o main.outils.o: utils.cgcc -c utils.c -o utils.omyapp: main.o utils.ogcc main.o utils.o -o myapp# 声明 all 为伪目标
.PHONY: all
使用 all 伪目标的好处是:
- 明确表明了构建意图
- 可以轻松扩展为构建多个目标
- 是大多数开源项目的标准做法
小点总结
在这个 Makefile 中:
main.o: main.cgcc -c main.c -o main.outils.o: utils.cgcc -c utils.c -o utils.omyapp: main.o utils.ogcc main.o utils.o -o myapp
- 默认最终目标是
main.o(因为它是第一个目标) - 要构建
myapp,需要明确指定:make myapp - 最佳实践是将最终目标放在第一位或使用
all伪目标
make 的这种设计允许您在一个 Makefile 中定义多个构建目标,并通过命令行参数选择要构建的具体目标,例如:
make clean(清理构建文件)make test(运行测试)make install(安装程序)
第三部分:make和Makefile如何判断何时需要重新编译
make 工具的核心就是一个基于时间戳的依赖关系检查系统。它通过比较文件的最后修改时间来判断目标是否需要重新构建。
核心原理:时间戳比较
make 遵循一个非常简单的逻辑规则:
如果“目标”文件不存在,或者任何一个“先决条件”文件(依赖文件)比“目标”文件更(更加的更)新(即修改时间更晚),那么就执行规则中的命令来重新生成这个“目标”。
这个过程是递归的:为了判断目标A是否需要更新,make 会先去检查A的所有先决条件(B, C, D…)是否需要更新,依此类推,直到依赖链的最底端。//这段话非常重要!!!!!!!
详细决策过程
让我们通过一个经典的例子来一步步拆解 make 的决策过程。(这个例子只是帮助大家浅层的理解,大家先往下看,我会在第五部分写一个简单的代码来给大家验证。)
假设我们有如下 Makefile 和文件结构:
myprogram: main.o utils.ogcc main.o utils.o -o myprogrammain.o: main.c utils.hgcc -c main.c -o main.outils.o: utils.c utils.hgcc -c utils.c -o utils.oclean:rm -f *.o myprogram
文件时间线(假设):
utils.h最后修改时间: 10:00utils.c最后修改时间: 10:05main.c最后修改时间: 09:00
现在,我们第一次运行 make。
场景一:首次构建(目标文件不存在)
make决定构建默认目标myprogram。- 它检查
myprogram是否存在?不存在。 - 结论:必须执行规则
gcc main.o utils.o -o myprogram。 - 但在执行之前,它必须先确保它的依赖
main.o和utils.o是最新的。 - 检查
main.o:- 存在?不存在。
- 结论:必须执行规则
gcc -c main.c -o main.o。执行后,main.o被创建,它的时间戳是当前时间(例如 10:30)。
- 检查
utils.o:- 存在?不存在。
- 结论:必须执行规则
gcc -c utils.c -o utils.o。执行后,utils.o被创建,它的时间戳是当前时间(例如 10:31)。
- 现在所有先决条件都已就绪,
make执行链接命令:gcc main.o utils.o -o myprogram。myprogram被创建,它的时间戳是当前时间(例如 10:32)。
构建完成。
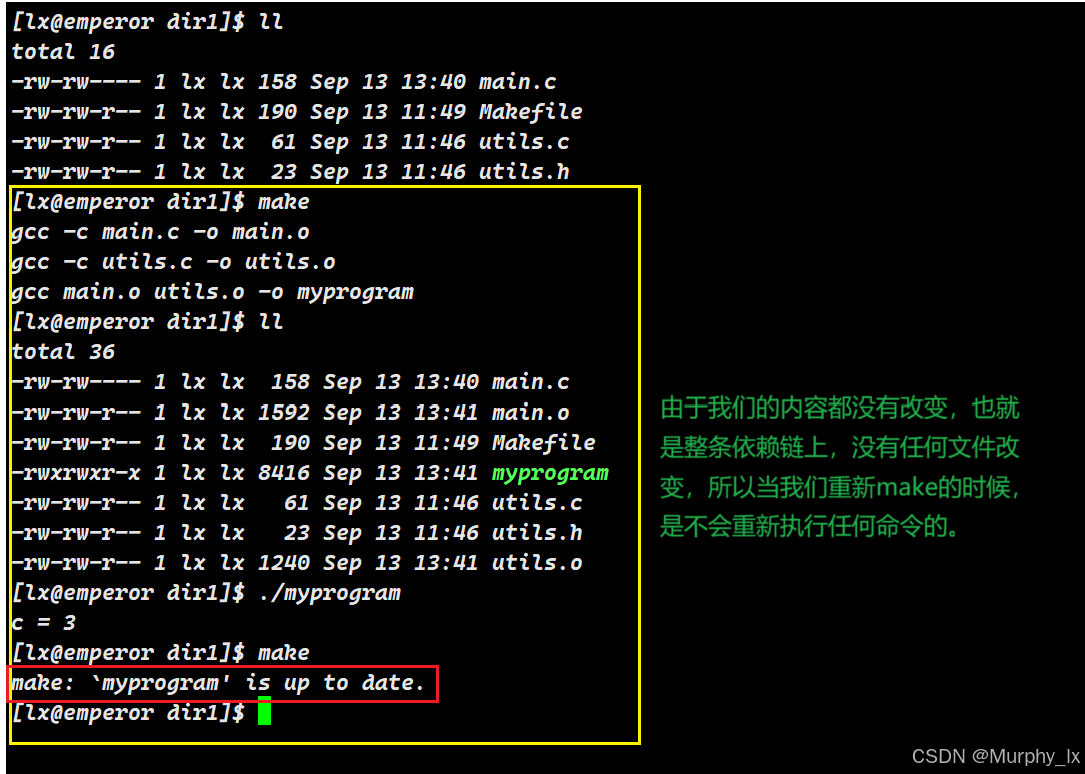
场景二:再次运行 make(无任何更改)
make 的递归依赖检查过程:
make 的工作方式是递归的和自底向上的。当决定是否需要重新构建一个目标时,make 会:
- 递归向下检查所有依赖项
- 自底向上执行必要的构建命令
在这个Makefile文件中:
myprogram: main.o utils.ogcc main.o utils.o -o myprogrammain.o: main.c utils.hgcc -c main.c -o main.outils.o: utils.c utils.hgcc -c utils.c -o utils.oclean:rm -f *.o myprogram
当运行 make 时:
-
make决定构建默认目标myprogram -
递归检查
myprogram的依赖:
a. 检查main.o是否需要更新:- 检查
main.o的依赖:main.c(09:00) 和utils.h(10:00) - 比较:
main.c(09:00) 比main.o(10:30) 旧? → 是 - 比较:
utils.h(10:00) 比main.o(10:30) 旧? → 是 - 结论:
main.o的所有依赖都比它旧(说明在首次构建main.o之后,main.c和utils.h中的内容都没有变化),不需要重新编译。
b. 检查
utils.o是否需要更新:- 检查
utils.o的依赖:utils.c(10:05) 和utils.h(10:00) - 比较:
utils.c(10:05) 比utils.o(10:31) 旧? → 是 - 比较:
utils.h(10:00) 比utils.o(10:31) 旧? → 是 - 结论:
utils.o的所有依赖都比它旧,不需要重新编译
- 检查
-
检查
myprogram本身:- 检查
myprogram的依赖:main.o(10:30) 和utils.o(10:31) - 比较:
main.o(10:30) 比myprogram(10:32) 旧? → 是 - 比较:
utils.o(10:31) 比myprogram(10:32) 旧? → 是 - 结论:所有依赖都比目标旧,不需要重新链接
- 检查
-
最终决定:
make输出make: 'myprogram' is up to date.并停止
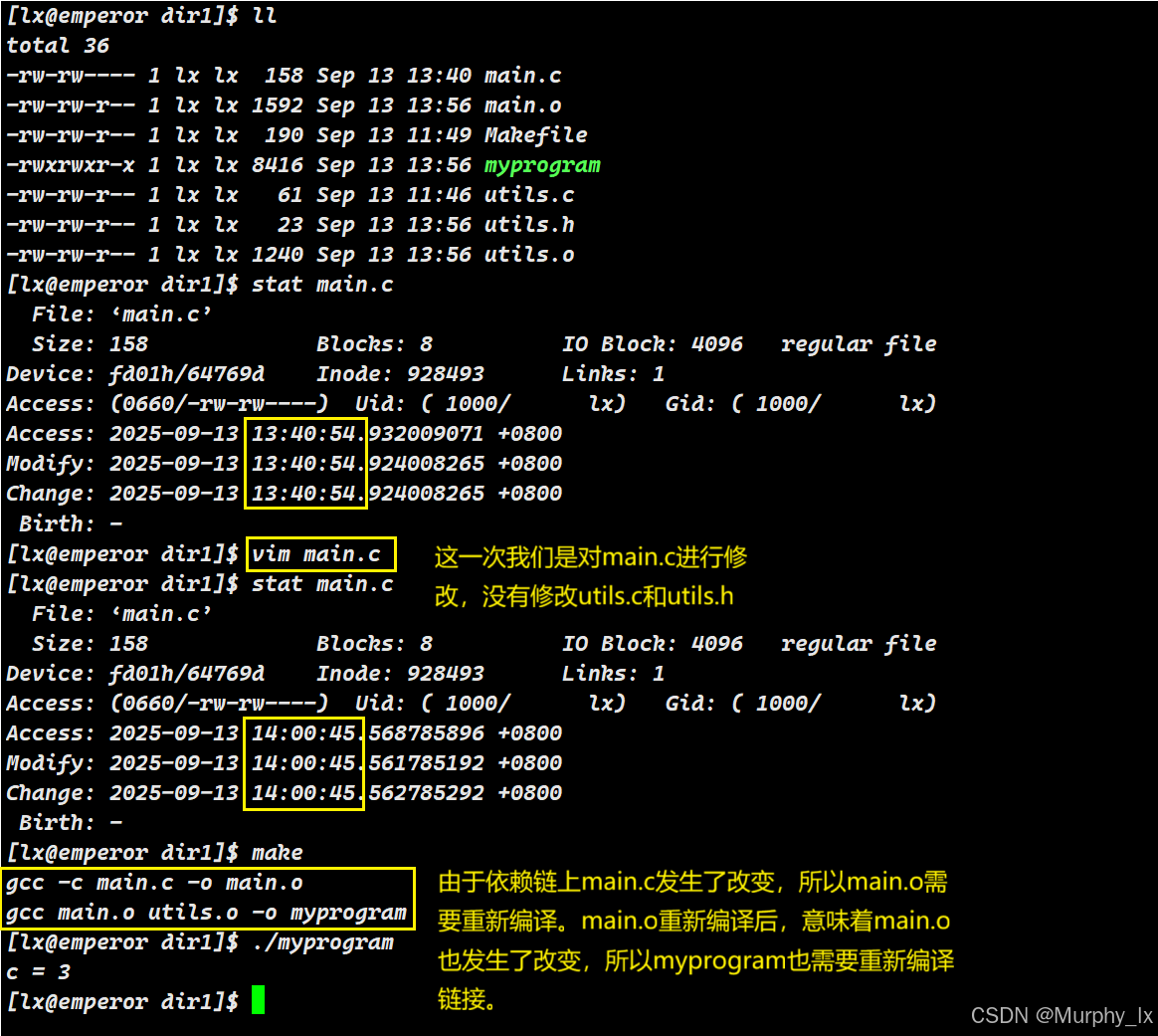
场景三:修改一个先决条件(例如 utils.h)
假设我们用编辑器修改并保存了 utils.h。它的时间戳更新为 11:00。
-
make决定构建默认目标myprogram -
递归检查
myprogram的依赖:
a. 检查main.o是否需要更新:- 检查
main.o的依赖:main.c(09:00) 和utils.h(11:00) - 比较:
main.c(09:00) 比main.o(10:30) 新? → 否 - 比较:
utils.h(11:00) 比main.o(10:30) 新? → 是! - 结论:有一个依赖比目标新,需要重新编译
main.o - 执行命令:
gcc -c main.c -o main.o(新时间戳:11:01)
b. 检查
utils.o是否需要更新:- 检查
utils.o的依赖:utils.c(10:05) 和utils.h(11:00) - 比较:
utils.c(10:05) 比utils.o(10:31) 新? → 否 - 比较:
utils.h(11:00) 比utils.o(10:31) 新? → 是! - 结论:有一个依赖比目标新,需要重新编译
utils.o - 执行命令:
gcc -c utils.c -o utils.o(新时间戳:11:02)
- 检查
-
检查
myprogram本身:- 检查
myprogram的依赖:main.o(11:01) 和utils.o(11:02) - 比较:
main.o(11:01) 比myprogram(10:32) 新? → 是! - 比较:
utils.o(11:02) 比myprogram(10:32) 新? → 是! - 结论:所有依赖都比目标新,需要重新链接(只要有一个依赖比目标新,就需要重新链接了)
- 执行命令:
gcc main.o utils.o -o myprogram(新时间戳:11:03)
- 检查
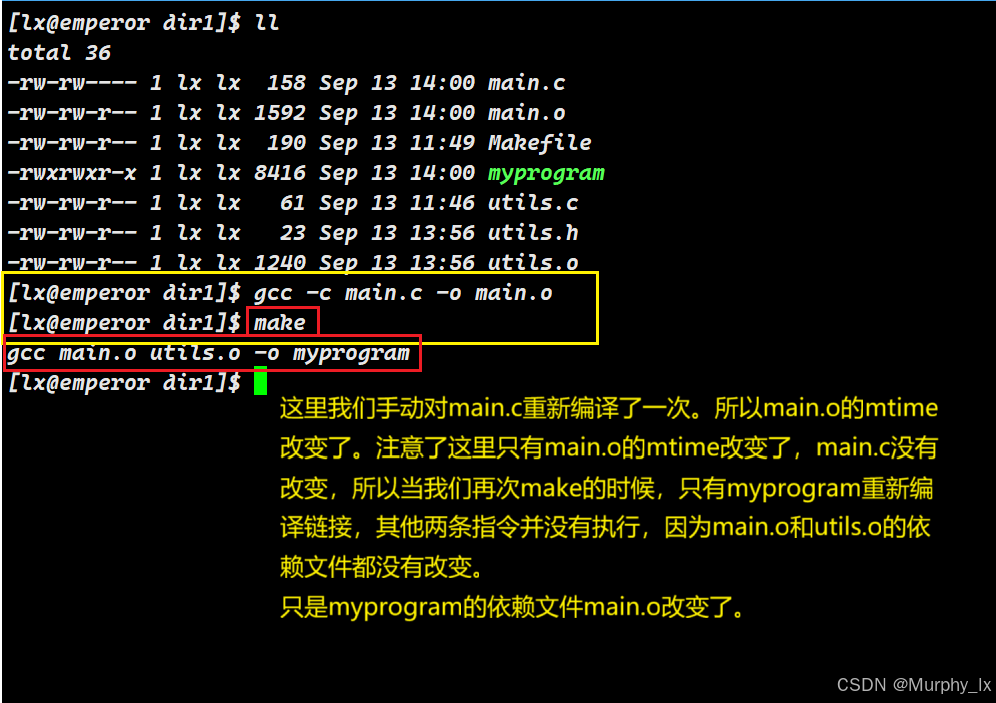
整个过程的关键:make 通过递归地比较文件系统中文件的 mtime(修改时间),自底向上地重建了整个依赖树上所有过时的节点。
依旧是这段话:这个过程是递归的:为了判断目标A是否需要更新,make 会先去检查A的所有先决条件(B, C, D…)是否需要更新,依此类推,直到依赖链的最底端。
小点总结
| 关键点 | 解释 |
|---|---|
| 决策机制 | make 通过递归地比较目标文件和先决条件文件的最后修改时间来决定是否需要重建。 |
| 触发条件 | 目标不存在或任何一个先决条件比目标“新”(时间戳更晚)。 |
| 递归过程 | 判断从最终目标开始,沿着依赖树向下检查,再从叶子节点向上执行重建命令。 |
| 自动化关键 | 使用编译器的 -MMD -MP 选项自动生成并包含依赖关系文件(.d),是管理头文件依赖的行业标准做法,避免了手动维护的繁琐和错误。 |
这就是 make 的智慧所在:用一个非常简单的规则(比较时间戳),配上一个定义良好的依赖关系图,就能高效、准确地管理整个复杂的构建过程。
第四部分:如何理解Linux文件属性中的时间属性
理解Linux 文件系统中的时间属性对于系统管理、开发(尤其是 make 这类工具)、数据恢复和审计都至关重要。
Linux 文件通常包含三个主要的时间戳属性,我们可以使用 stat 命令来查看它们:
stat filename
输出示例:
File: filenameSize: 1234 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 123456 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ user) Gid: ( 1000/ user)
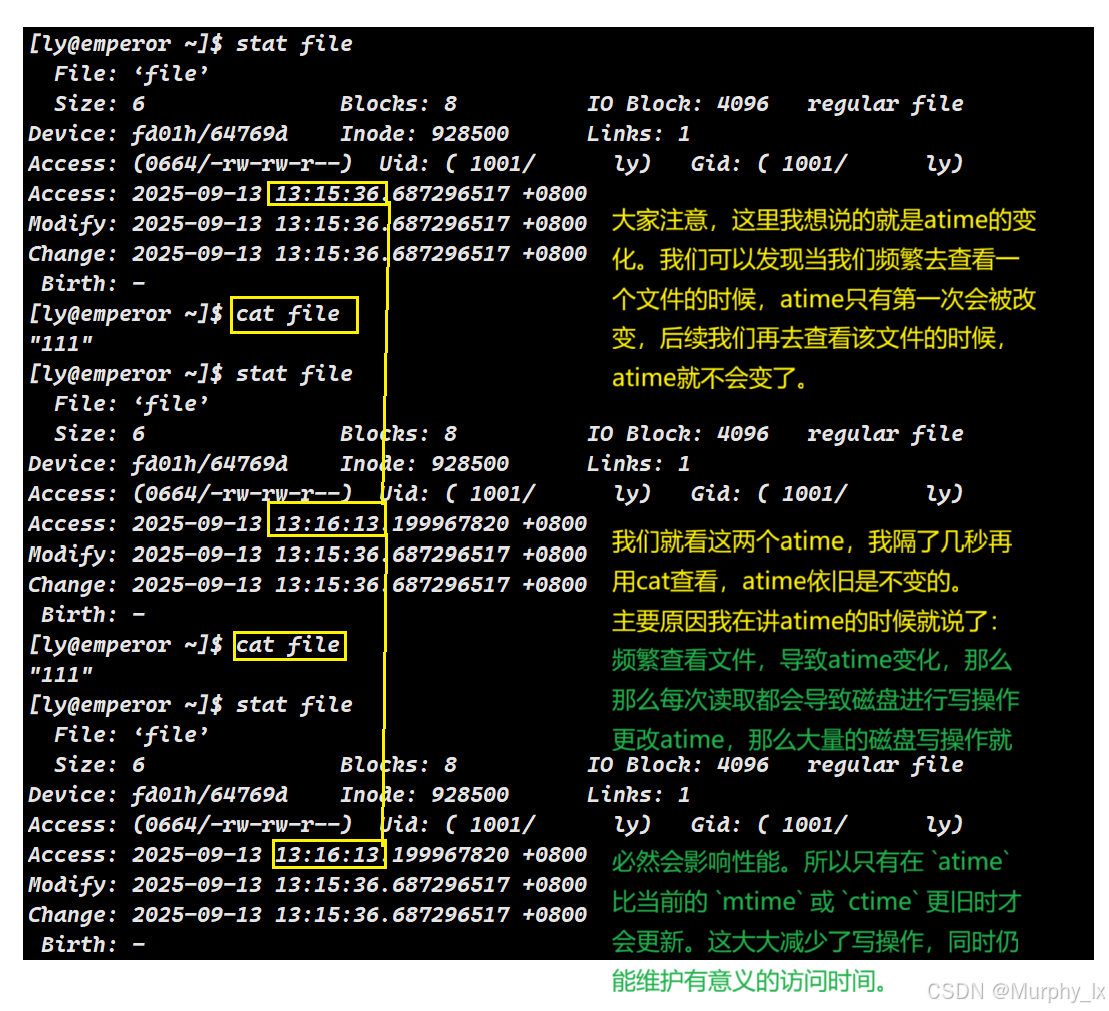
Access: 2023-10-27 14:30:00.000000000 +0800 # atime
Modify: 2023-10-27 15:45:00.000000000 +0800 # mtime
Change: 2023-10-27 16:15:00.000000000 +0800 # ctimeBirth: 2023-10-25 09:00:00.000000000 +0800 # btime (并非所有文件系统都支持)
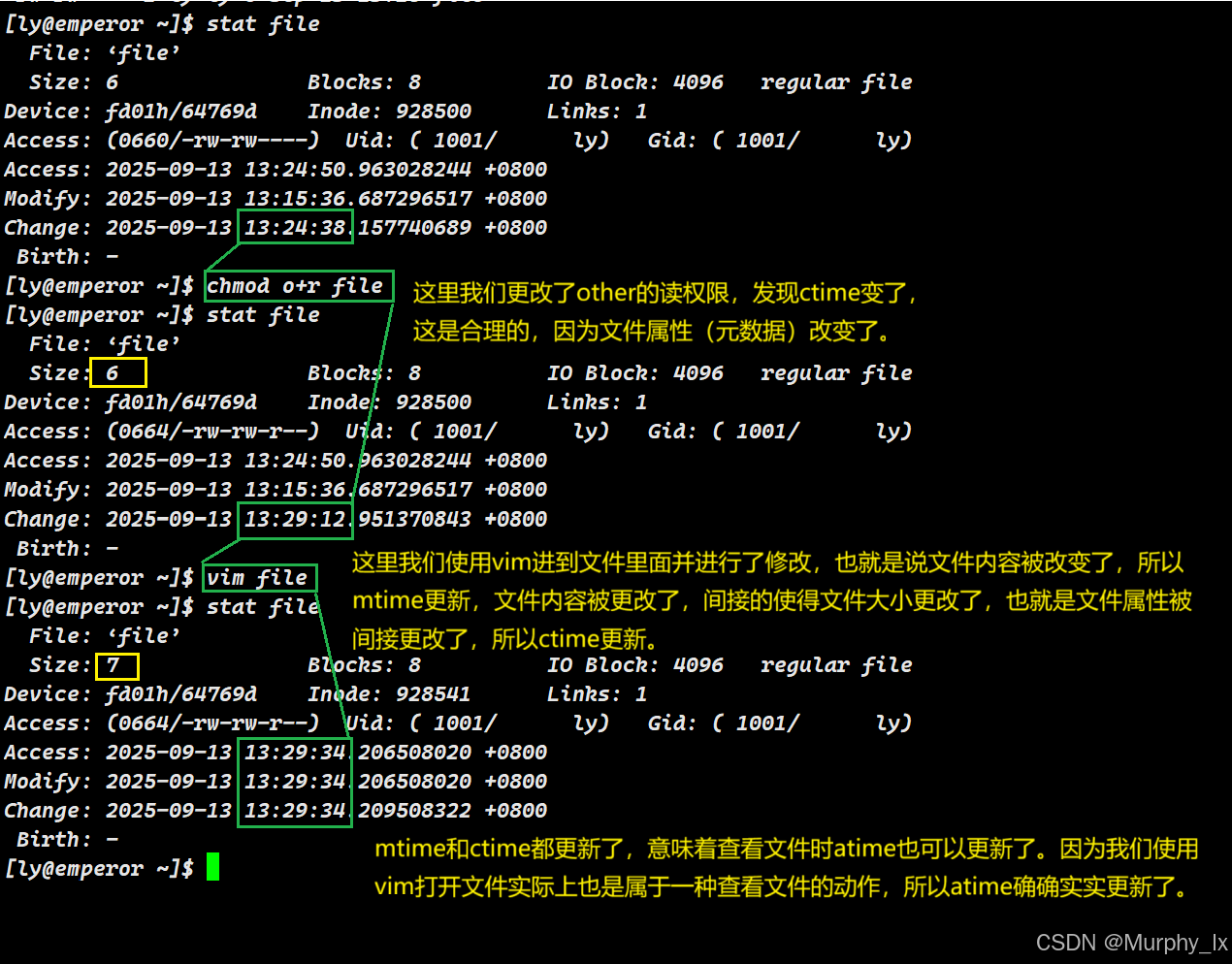
1. 修改时间 (Modification Time - mtime)
这是最常用和最容易理解的时间戳。
- 含义:文件内容最后一次被修改的时间。
- 触发更新的操作:
- 使用编辑器(如
vim,nano)修改并保存文件内容。 - 使用
echo "text" > file或cat > file重定向覆盖文件。 - 使用
sed -i或awk -i原地修改文件。 - 下载文件覆盖旧文件。
- 解压文件覆盖已存在的文件。
- 使用编辑器(如
- 不触发更新的操作:(只要不是文件中的内容修改,都不会触发更新操作)
- 更改文件权限或所有权。
- 重命名文件。
- 创建文件的硬链接。
- 主要用途:
make等构建工具:判断源文件是否比目标文件新,从而决定是否需要重新编译。//这点是最重要的。当我们使用make指令时,判断Makefile中的目标文件是否需要重新编译,就是:比较目标文件和依赖文件的修改时间。- 备份工具(如
rsync,tar):仅备份自上次备份后内容发生变化的文件(rsync -u,tar --newer-mtime)。 - 查找文件:查找最近更改过的文件(
find . -mtime -1查找一天内修改过的文件)。
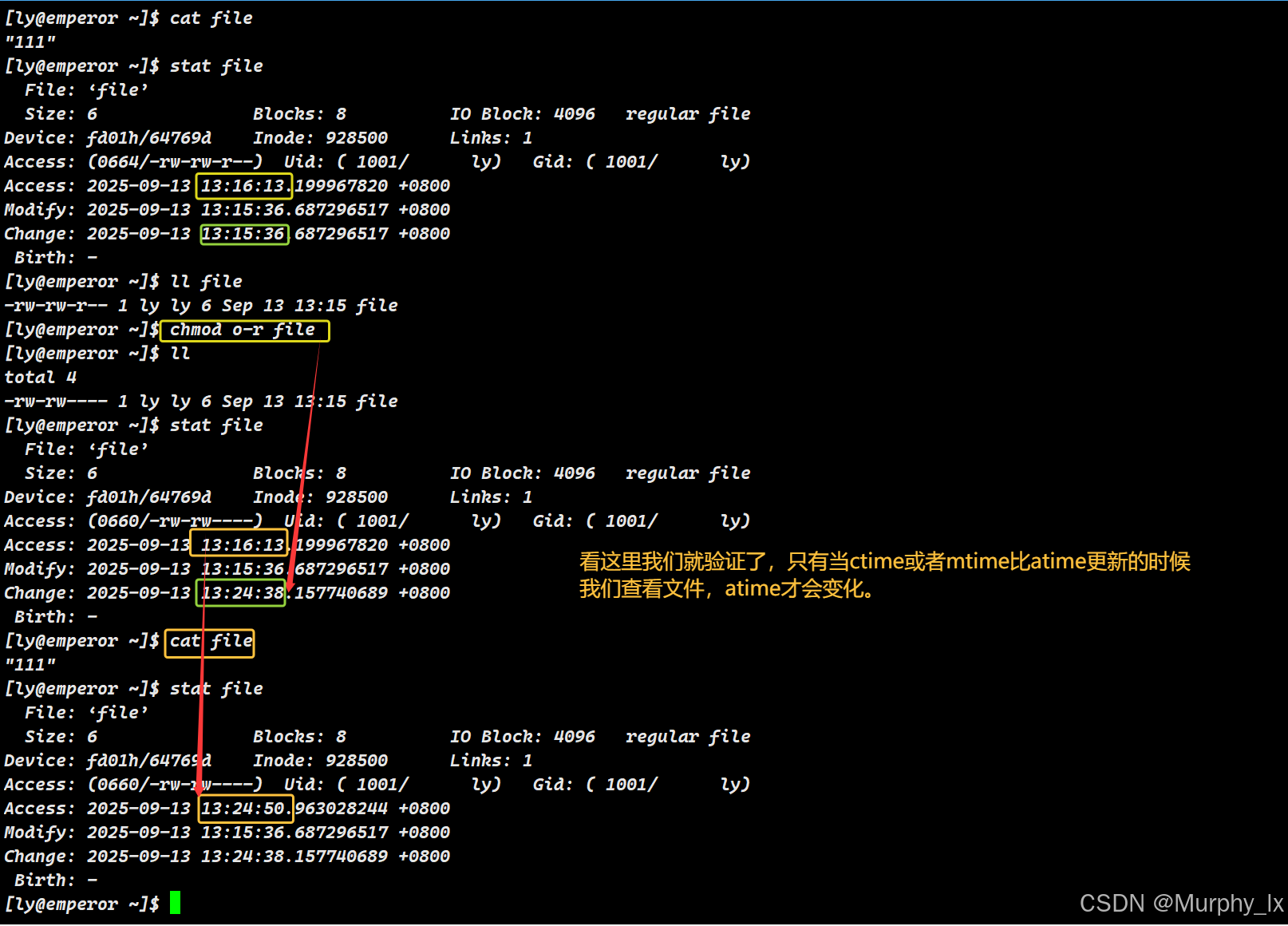
2. 状态更改时间 (Status Change Time - ctime)
这个时间戳容易被误解,它不是文件创建时间(creation time)。
- 含义:文件的元数据(metadata) 或称状态(文件属性)最后一次被改变的时间。元数据包括权限、所有权、硬链接计数、文件大小等,但不包括文件内容(但是修改文件内容会改变文件大小)。(这里大家把元数据简单理解为文件属性就ok)
- 触发更新的操作(任何改变
inode信息的操作):- 更改文件权限(
chmod)。 - 更改文件所有者或属组(
chown,chgrp)。 - 重命名或移动文件(因为这会改变其所在的目录项)。
- 创建文件的硬链接(因为增加了链接计数)。
- 也包括修改文件内容(因为文件大小、修改时间等元数据也改变了)。
- 更改文件权限(
- 关键点:任何导致
mtime更新的操作,也一定会导致ctime更新。但反过来不成立(例如只改权限不会更新mtime)。 - 主要用途:
- 系统审计:追踪文件属性何时被更改。
- 数据恢复/取证:了解文件状态发生变化的完整历史。
什么是inode信息
这是一个非常核心的Linux/Unix文件系统概念。用一句话概括:
Inode(索引节点)是文件系统中的一个数据结构,它存储了关于一个文件或目录的几乎所有元数据(metadata),但唯独不存储其名称。
你可以把 inode 理解为文件的身份证或户口本。操作系统不是通过文件名来识别文件,而是通过 inode 号码。
详细讲解
1. Inode 里面存储了什么信息?
当你使用 stat 命令时,显示的大部分信息都来自于文件的 inode:
stat myfile.txt
输出示例:
File: myfile.txtSize: 5632 Blocks: 16 IO Block: 4096 regular file
Device: 801h/2049d Inode: 260123 Links: 1 # <-- Inode 号码
Access: (0644/-rw-r--r--) Uid: ( 1000/ user) Gid: ( 1000/ user)
Access: 2023-10-27 14:30:00.000000000 +0800
Modify: 2023-10-27 15:45:00.000000000 +0800
Change: 2023-10-27 16:15:00.000000000 +0800Birth: -
一个 inode 通常包含以下信息:(只要更改以下这些信息,Change Time都会发生改变)
- 文件类型:是普通文件(
-)、目录(d)、符号链接(l)、块设备(b)还是字符设备(c)等。 - 文件权限(
rwxr-xr-x):谁可以读、写、执行这个文件。 - 所有者信息(UID, GID):文件属于哪个用户和用户组。
- 文件大小(以字节为单位)。
- 时间戳:
- atime:上次访问时间。
- mtime:上次修改内容的时间。
- ctime:上次修改inode本身(即元数据)的时间。(注意:
ctime不是创建时间!)
- 链接计数:有多少个文件名指向这个 inode(后面会详细解释)。
- 数据块指针:这是 inode 最核心的功能。它存储了指向磁盘上哪些数据块(Blocks) 包含了该文件实际内容的指针。没有这个,inode 就只是知道文件的所有信息,却不知道文件内容在哪。
2. 文件名和 Inode 的关系
这是理解 inode 的关键。整个过程可以分解为以下几步:
-
目录的本质:目录本身就是一个特殊文件,它的内容非常简单:一个表格,记录了文件名到 inode 号码 的映射。
/home/user/Documents/ 目录的内容大概像这样: +--------------------------+-----------+ | 文件名 (Name) | inode号码 | +--------------------------+-----------+ | report.txt | 260123 | | photo.jpg | 260124 | | projects | 260125 | (这是一个子目录) +--------------------------+-----------+ -
访问文件的过程:当你尝试打开
/home/user/Documents/report.txt时,系统会:- 在根目录
/中找到home目录对应的 inode。 - 从
home的 inode 找到其数据块,在数据块中找到user目录的 inode 号。 - 在
user目录的数据块中找到Documents目录的 inode 号。 - 最后,在
Documents目录的数据块中找到report.txt这个文件名对应的 inode 号(例如260123)。 - 系统然后通过 inode 号
260123找到文件的元信息,检查权限,最后通过 inode 中的数据块指针读取文件的实际内容。
- 在根目录
核心结论:文件名是给用户看的友好标识,而 inode 号码是操作系统用于查找和管理文件的真正凭据。
3. 硬链接(Hard Link)与 Inode
硬链接是理解 inode 的最佳例子。
- 创建硬链接:
ln file.txt hardlink_to_file.txt - 本质:硬链接不是一个独立的文件。它只是在另一个目录里创建了一个新的条目(文件名),这个新条目指向了与原始文件完全相同的 inode。
- 效果:
- 此时,
file.txt和hardlink_to_file.txt是完全平等的两个名字,指向同一份数据。 - 修改其中一个文件,另一个文件的内容也会同步改变,因为它们访问的是同一组数据块。
- 删除其中一个文件名,只是从目录中删除了一个指向该 inode 的条目。只要 inode 的链接计数还大于 0(即还有文件名指向它),文件数据就不会被真正删除。
- 此时,
4. 软链接(符号链接,Soft/Symbolic Link)与 Inode
软链接则完全不同。
- 创建软链接:
ln -s file.txt symlink_to_file.txt - 本质:软链接是一个独立的特殊文件,它拥有自己的 inode 和数据块。它的数据块里不存储文件内容,而是存储它指向的目标文件的路径。
- 效果:
- 如果你删除了原始文件
file.txt,软链接symlink_to_file.txt就会变成“断开的”或“悬空的”(dangling link),指向一个不存在的文件。 - 软链接的权限通常是
rwxrwxrwx,但实际操作时取决于它指向的文件的权限。
- 如果你删除了原始文件
硬链接 vs. 软链接
| 特性 | 硬链接 (Hard Link) | 软链接 (Soft Link) |
|---|---|---|
| inode | 与原始文件相同 | 是一个新的、独立的 inode |
| 跨文件系统 | 不行 | 可以 |
| 链接目录 | 通常不行(防止循环) | 可以 |
| 原始文件删除 | 数据仍在,直到所有链接删除 | 链接失效( dangling link) |
| 文件大小 | 与原始文件相同 | 很小(只存储路径字符串) |
ls -l 显示 | 看起来像普通文件 | 显示 -> 指向目标,权限为 lrwxrwxrwx |
5. 实际应用和命令
-
查看 inode 号码:
ls -i:在ls输出中显示第一列的 inode 号。stat filename:显示详细的 inode 信息。
-
磁盘空间已满,但
df显示还有空间?
这可能是 inode 耗尽了。每个文件(和目录)都会消耗一个 inode。文件系统创建时 inode 的总数是固定的。如果你有数百万个小文件,可能会在用完磁盘空间之前就用完所有 inode。- 检查 inode 使用情况:
df -i - 查找包含大量文件的目录:
find /path -xdev -type f | cut -d "/" -f 2 | sort | uniq -c | sort -n
- 检查 inode 使用情况:
小点总结
| 概念 | 解释 |
|---|---|
| Inode | 文件的元数据容器,是操作系统识别文件的唯一凭证。 |
| 文件名 | 存储在目录中,仅仅是用于映射到 inode 号码的友好标签。 |
| 硬链接 | 多个文件名指向同一个 inode。 |
| 软链接 | 一个独立的文件,其内容是另一个文件的路径名。 |
理解 inode 对于掌握 Linux 文件系统操作(如移动、删除、链接文件)、调试存储问题(inode 耗尽)以及理解系统如何运作都至关重要。它是 Linux/Unix 文件系统设计的基石。
3. 访问时间 (Access Time - atime)
- 含义:文件内容最后一次被访问(读取)的时间。
- 触发更新的操作:
- 使用
cat,less,more,head,tail等命令读取文件。 - 被编辑器或另一个程序(如编译器、脚本解释器)打开读取。
- 被另一个命令(如
grep,awk) 处理。
- 使用
- 性能问题:对于频繁被读取的文件(如系统日志、库文件),每次读取都要更新
atime意味着大量的磁盘写操作,这会严重影响性能。 - 解决方案:现代 Linux 系统通常默认使用
relatime或noatime选项挂载文件系统。relatime(relative atime):只有在atime比当前的mtime或ctime更旧时才会更新。这大大减少了写操作,同时仍能维护有意义的访问时间。noatime:完全禁止更新atime,以获得最佳性能。- 你可以在
/etc/fstab文件中查看或修改这些挂载选项。
4. 创建时间 (Birth Time / File Creation Time - btime)
- 含义:文件的创建时间。这是很多人期望但传统 Unix/Linux 文件系统(如
ext4)并不直接支持的属性。 - 现状:
btime并非 POSIX 标准的一部分。一些较新的文件系统开始支持它(例如btrfs,zfs,xfs,ext4在某些版本和内核中也记录了这一信息),但支持程度和访问方式不统一。 - 查看:如果你的文件系统和内核支持,
stat命令可能会显示Birth字段。但不要期望它在所有系统上都存在。
对比总结
| 属性 | 含义 | 触发更新的操作示例 | 关键点 |
|---|---|---|---|
mtime | 内容修改时间 | vim file && :w, echo > file | 构建工具的核心,最常用于判断文件是否更改 |
ctime | 状态更改时间 | chmod, chown, mv, 也包括修改内容 | 内容修改必导致状态改变。不是创建时间 |
atime | 访问时间 | cat file, ./script | 出于性能考虑,常被 relatime 选项抑制 |
btime | 创建时间 | 文件创建时设定 | 并非所有文件系统都支持,不可移植 |
常用命令与时间戳
-
查看时间戳:
stat filename:查看所有详细信息。ls -l:显示的是mtime(修改时间)。ls -lc:显示的是ctime(状态更改时间)。ls -lu:显示的是atime(访问时间)。
-
触摸时间戳:
touch命令
touch命令非常强大,可以精确修改文件的时间戳。touch filename:- 如果文件不存在,则创建空文件。
- 如果文件存在,则将其
atime和mtime更新为当前时间。
touch -m filename:只更新mtime为当前时间。touch -a filename:只更新atime为当前时间。touch -t 202310271530.45 filename:-t参数允许指定一个具体时间(格式:[[CC]YY]MMDDhhmm[.ss])。- 这个命令将文件的
atime和mtime设置为 2023年10月27日15点30分45秒。
touch -r reference_file file_to_change:将file_to_change的时间戳设置为和reference_file一模一样。
核心理解
你可以这样记忆:
mtime:“What” - 文件里的"什么"内容被改动了。ctime:“How” - 文件的"如何"状态(权限、归属等)被改变了。它也记录了"什么"被改变的历史。atime:“When” - 文件最后一次是"何时"被读取的。
mtime关注的是文件中的内容是否改变。ctime关注的是文件属性(文件状态)是否改变。atime关注的是文件最后一次被查看的时间。
第五部分:结合实践理解第三部分和第四部分
下面是我们实验用到的代码:
main.c
#include <stdio.h>
#include"utils.h"
int main()
{int a = 1;int b = 2;int c = 0;c = add(a,b);printf("c = %d\n" , c);return 0;
}
utils.h
int add(int a,int b);
utils.c
#include "utils.h"int add(int a,int b)
{return a+b;
}
Makefile
myprogram: main.o utils.ogcc main.o utils.o -o myprogrammain.o: main.c utils.hgcc -c main.c -o main.outils.o: utils.c utils.hgcc -c utils.c -o utils.oclean:rm -f *.o myprogram
我们先借助main.c这个文件来验证理解一下第四部分的文件时间属性:
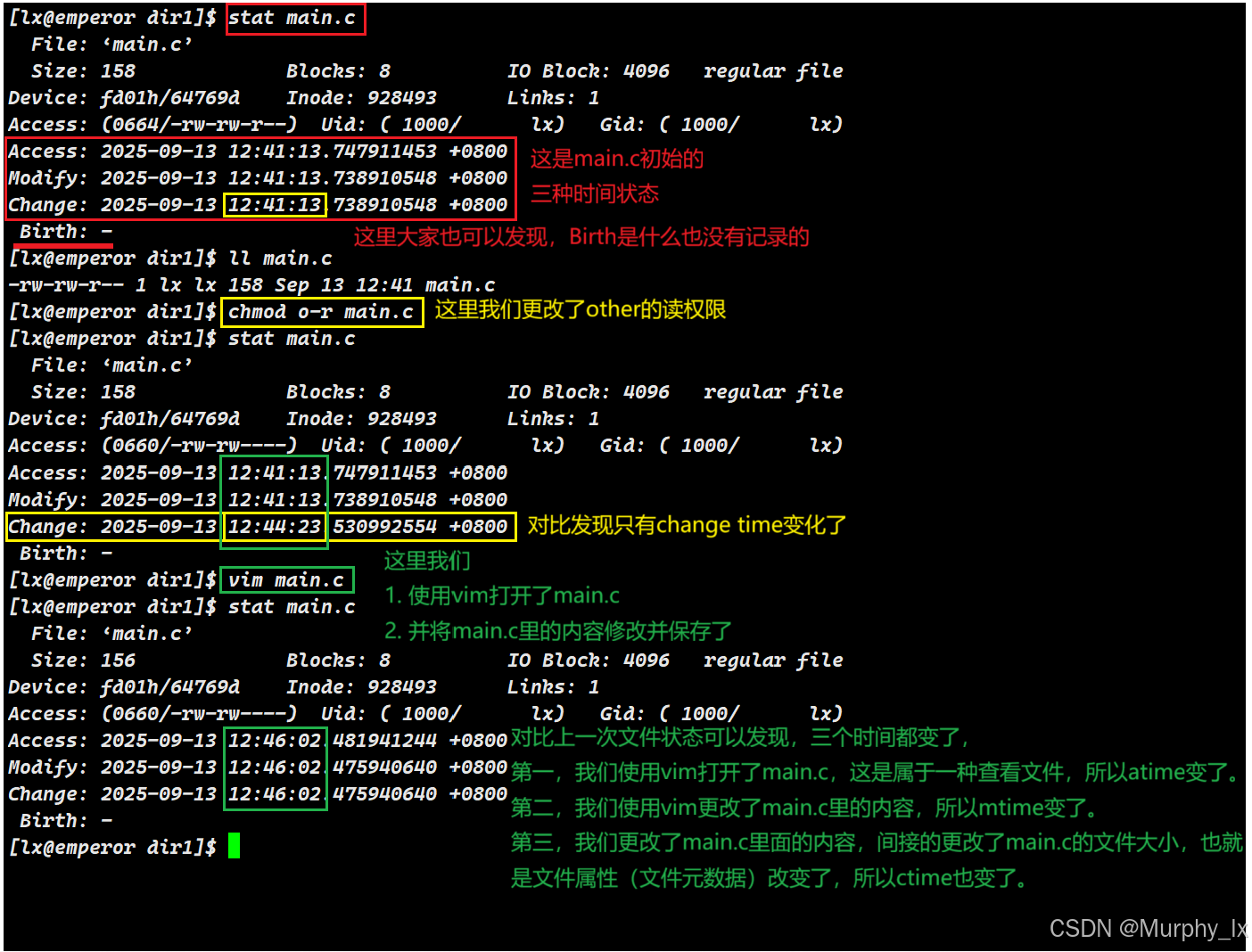
接下来我要进行一点补充就是:mtime的改变和你vim的配置有关。
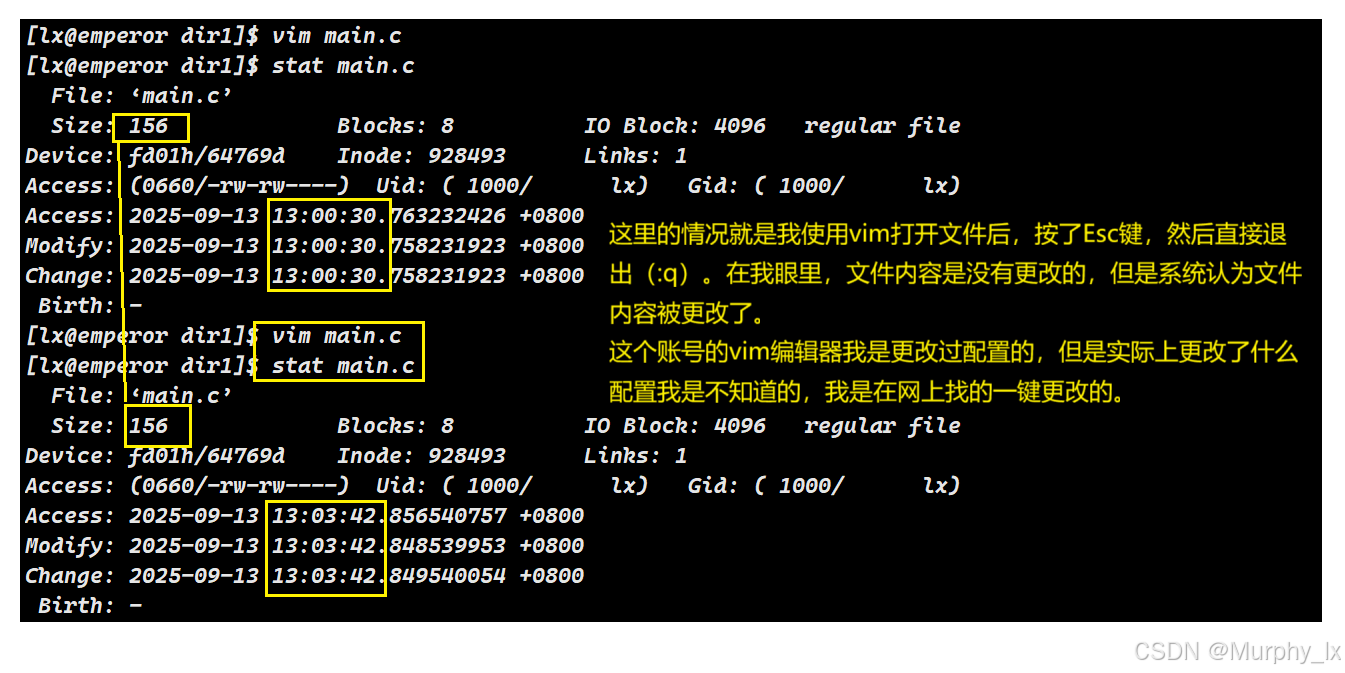
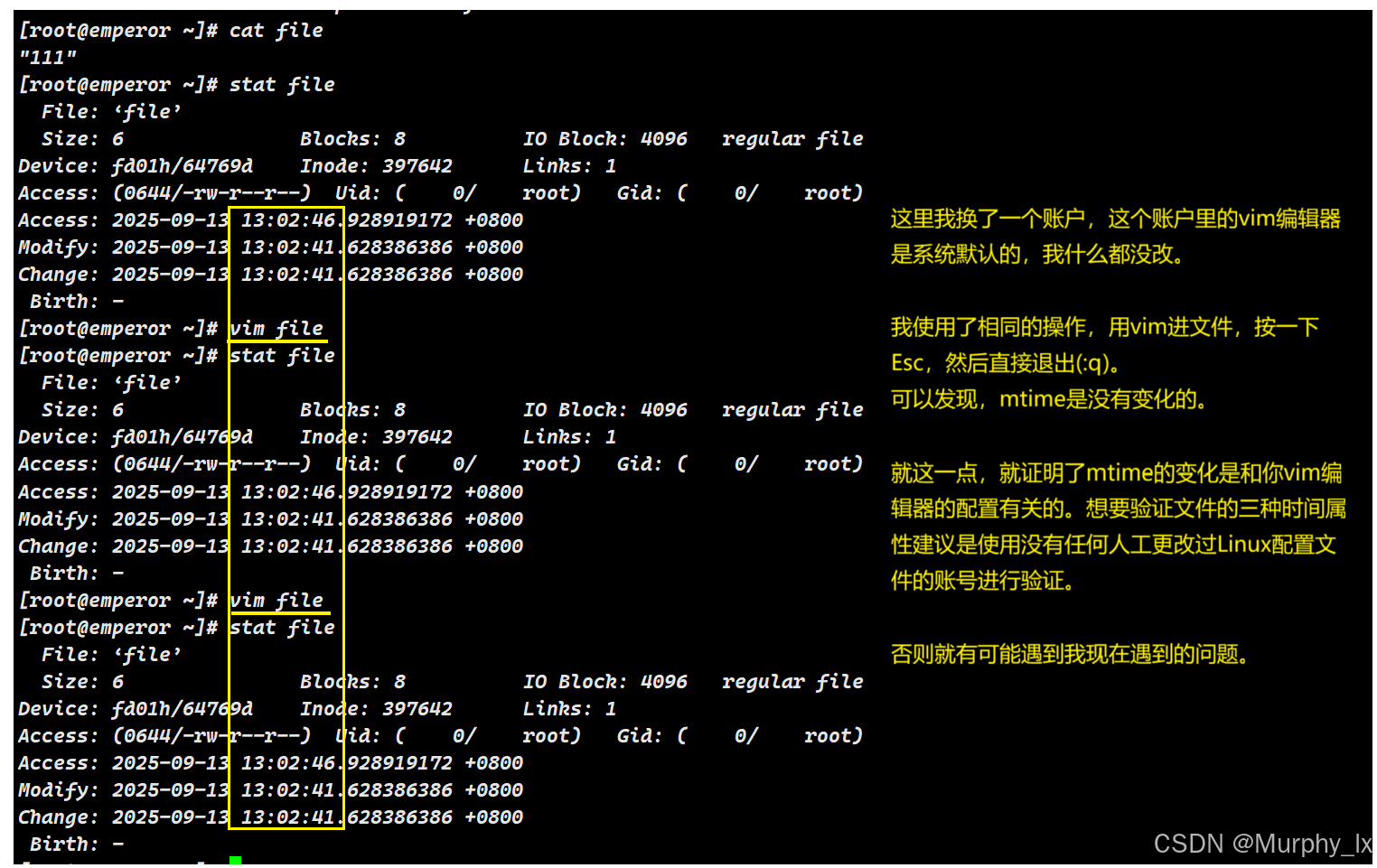
由于出现了上面的问题,我将重新使用新账号中的新文件来验证文件时间属性:
主要的时间属性验证已经做完了,如果大家还有别的验证想法可以自己创建一个简单的文件进行验证。
接下来就是验证理解第三部分了,也就是验证make和Makefile如何判断何时需要重新编译:
我们使用的就是上文提到的三个代码文件,main.c,utils.h,utils.c和Makefile。
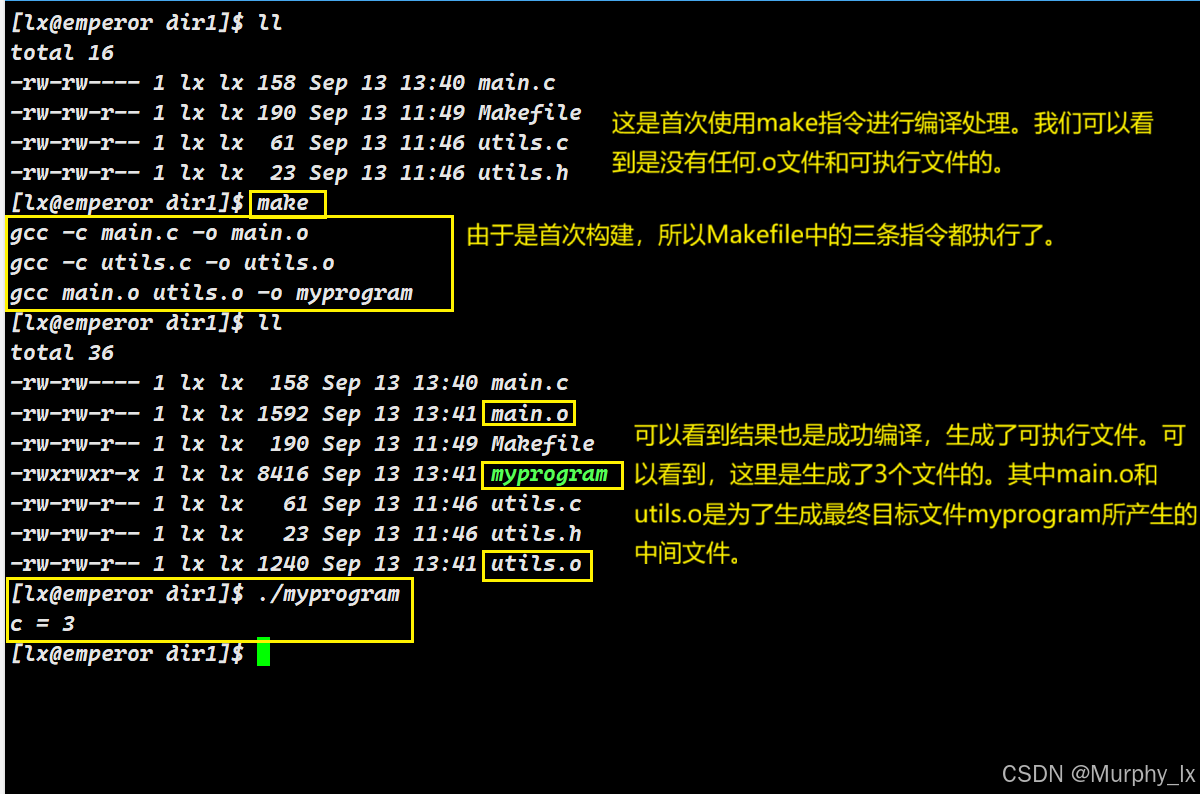
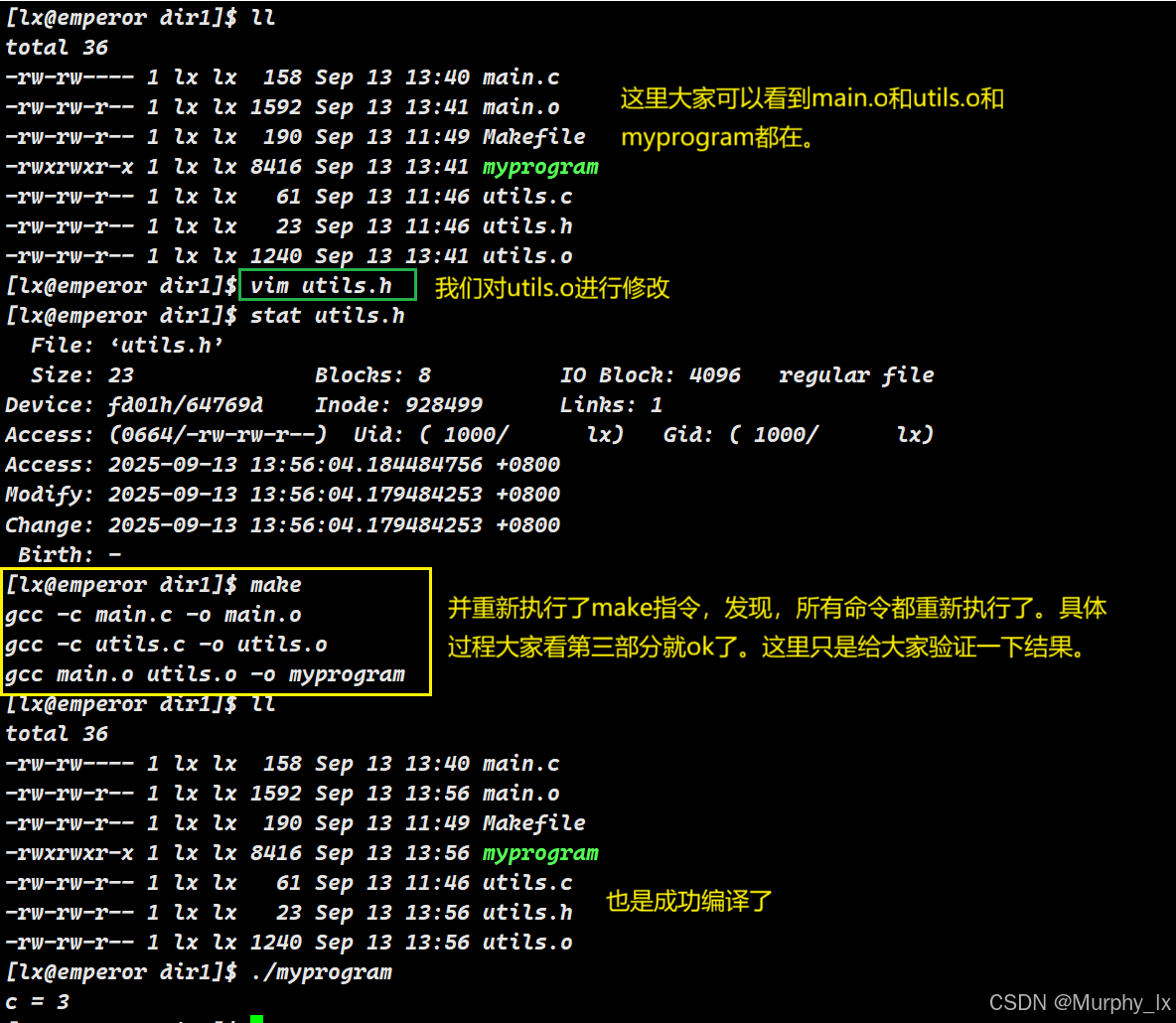
这里的图中有一个失误,“我们对utils.o进行了修改”这个是错的,应该是“我们对utils.h进行了修改”
那么到这里,make和Makefile的知识就已经讲差不多了。