C++学习记录(8)list
前言
学习了string类,初次领略了STL库,到后来学习动态数组vector的库函数以及模拟实现,可以体会到,充分将类与对象、内存管理、模板的只是糅合在一起实现容器,简单理解就是类似于汽车制造商其实不可能说凡事亲力亲为,零部件分布全球各地制造,STL就相当于提前给我们造好的零件,我们想要写一个完善的程序就得写一段合适的代码将这些容器的特点结合起来实现。
string和vector的底层实现的数据结构都可以认为是顺序表,或者说动态管理的数组,而此次我们学习的容器list是我们C语言阶段学习数据结构的时候学习的双向链表,当然,全称是带头双向循环链表。
一、初步了解list
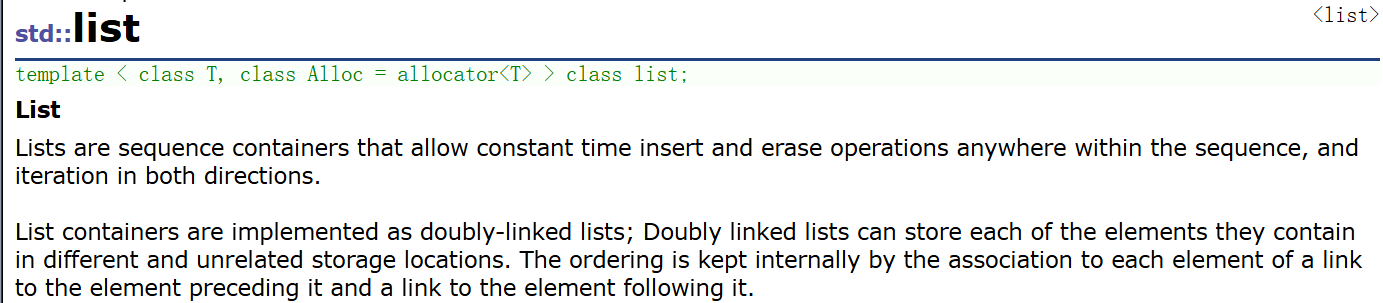
也不一句一句翻译了,大致意思就是底层用双向量表来存储每一个数据,元素的顺序用指向前驱节点的prev指针和指向后驱结点的next指针来维护。
其实就当成我们学过的带头双向循环链表来使用和实现即可。
需要注意的是,容器一般都是可以存储任意类型的,所以设计的时候仍旧设计成模板:
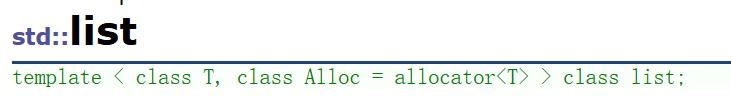
二、list的构造析构
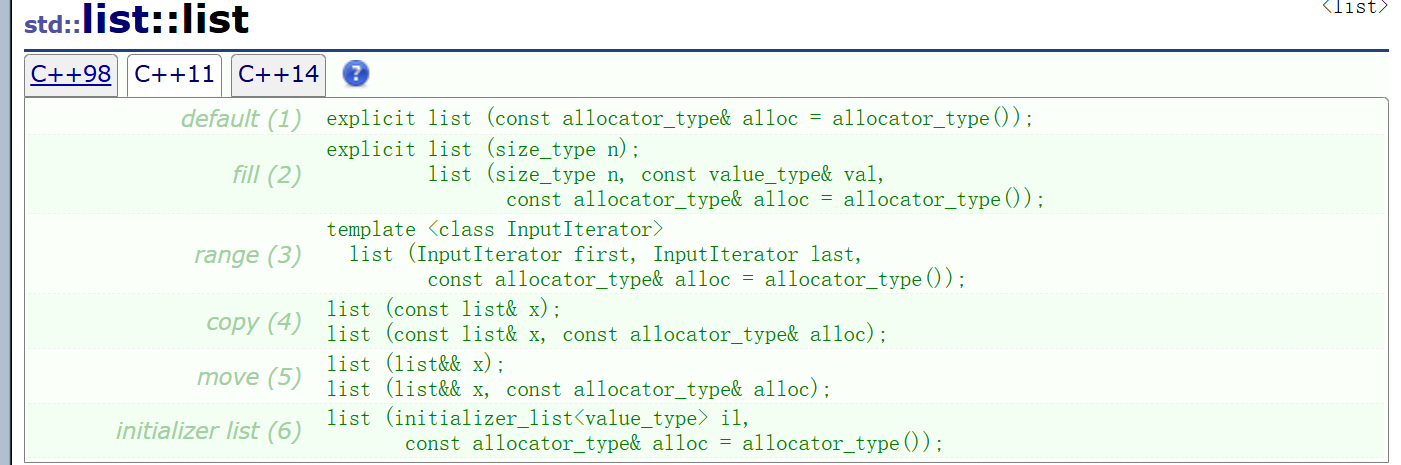
1.default
默认构造啥都不传,使用角度不用多在意。
2.fill
用n个值填充,不用多讲,使用角度其实跟vector完全一样。
3.iterator区间初始化
还是不用多说,直接用就行了。
4.拷贝构造
传list对象即可。
5.initializer_list构造
初始化列表构造。
6.测试大部分构造函数
其实这些都没啥可讲的,因为其实接口设计跟vector完全一样,底层实现肯定不一样,但是站在使用的角度一模一样的。

其实基本上没什么可说的了,但是这里涉及到一个问题,我们传vector的迭代器初始化没啥毛病,毕竟vector这个容器人家本身就是有迭代器嘛,那我问你,为什么传数组指针也可以呢?这个问题我们先放一放。
看一看另一个方面的问题,如果是数组可以有:

但是传链表迭代器试试呢:
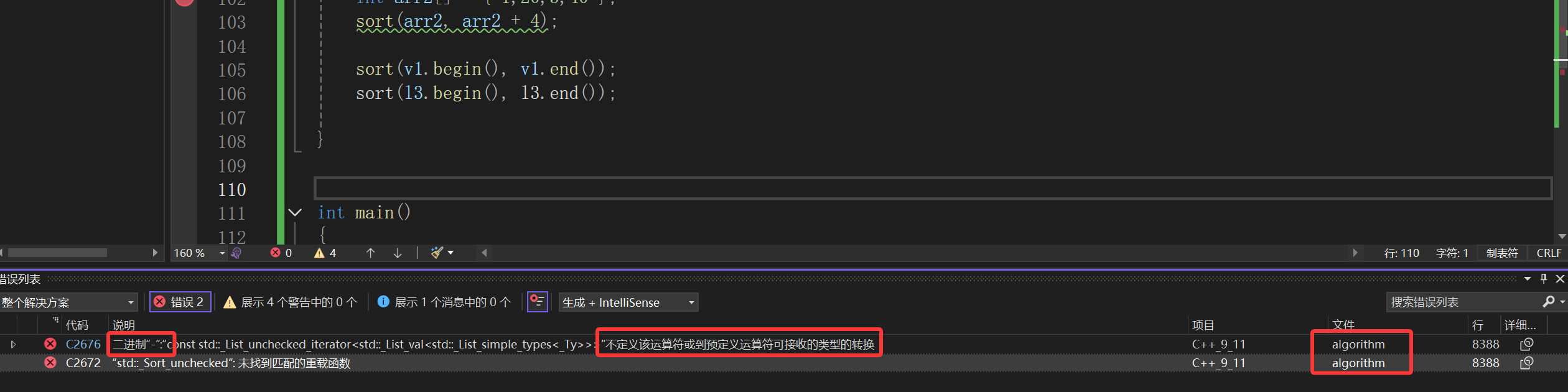
报的什么玩意的错啊这是?
迭代器分类问题
在list中可以找到:

在vector中可以找到:

另外在forward_list中可以找到:

这个所谓的forward_list实际上就是单链表。
点进去就可以找到这样一张图:

问了问ai这是什么玩意以后:

自己理解就是这样的:

input迭代器就是用来遍历读的,而单向双向随机迭代器都属于input迭代器。
单向双向随机都是可以多次遍历读,input迭代器遍历读一次。
空说其实根本理解不了:

算法库里的find方法就是inputiterator,想想也是啊,find方法遍历一遍找不到就算了,所以这里的迭代器需要能够具备遍历一次的本事,也就是++ *。

库里的remove函数是用来删除我们给定迭代器范围的val的值的,需要遍历完整个范围,所以也就是要求支持++ *。

其实也好理解,我们自己实现过reverse算法,一个指针在前,一个指针在后,每次就把这两个指针指向的值swap一下,然后++--,直至两个指针相遇,所以这个时候的迭代器需要双向的,这个也能理解。

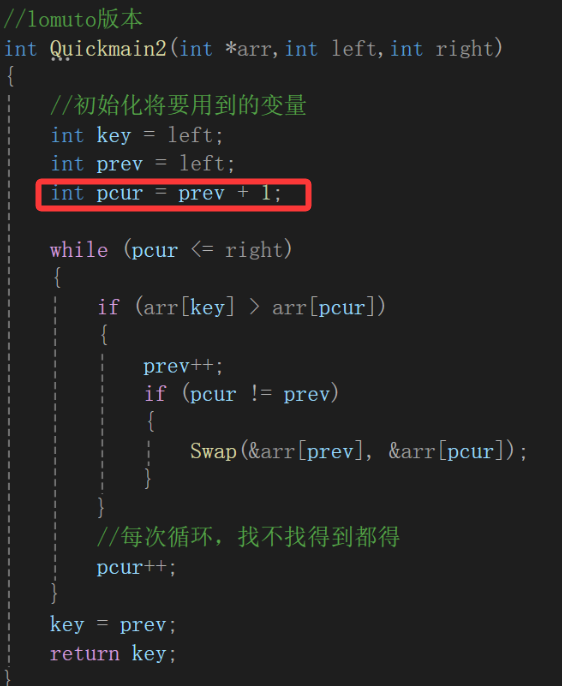
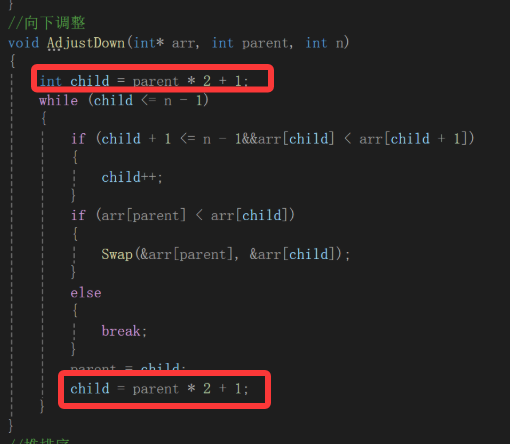
然后就是sort算法了,底层我搜了搜,大概率是快排+堆排+插入排,基本上时间复杂度就当成nlogn来看待,这个倒是无所谓,我们把C语言阶段的代码拿过来:
随便截两张图,指针不仅得++ --,还得支持+ - 这些运算,所以必须是随机迭代器。
看了这么多迭代器和算法库函数,其实核心就是一个点,迭代器为什么要分类,因为算法库里底层实现需要用到迭代器的某些特性,人家算法模板里写的类型名就是迭代器类型其实就是为了提醒你传合适的迭代器,比如你敢用算法库里的sort传list的迭代器嘛?
底层代码根本没实现,根本用不了。
当然,只读迭代器input其实实际容器里根本没有,只不过是算法里可能只需要遍历一次就不再用了,所以就写的input迭代器,其它同理。
它们这几种迭代器的关系就是:

目前我们就认为是包含关系,随机迭代器能实现++ -- + -,所以它肯定能充当双向迭代器使用;同理双向迭代器可以当成单向迭代器使用,重点是迭代器这些名字就是为了契合底层代码。
这就是为什么最开始编译器会给我们报错报个list用不了-。
当然,再多嘴一句,就拿list来说,难道它没本事实现iterator的+/-操作符吗,答案很显然,只要记着数然后往后遍历对应次数的结点就行了,但是有必要吗?
双向链表两端插入删除其实也是个小事,但是你要是给定下标去访问,那不是遭老罪了嘛,不是不实现,是效率太低了,索性标准库就不再设计了,你真闲的没事就想用这种低效率的玩意,那简单,自己写就行。
7.析构
站在使用角度其实都懒得说,想析构你直接调就完了呗。

模拟实现当然得好好写,因为一个链表析构意味着需要一个结点一个结点释放。
三、list的iterator
其实使用就不用多说,用就完了,迭代器就那几种:

但是为了模拟实现的时候我们好接受,所以在这里先行解释一下上面的现象。
string和vector的迭代器使用的时候我们想的都是当成指针来使用,即使是模拟实现也是用指针typedef一下,因为迭代器要求的功能用指针就能实现。
包括我们写的arr数组,其实相当于是未包装的数组的迭代器,功能上其实跟string和vector的迭代器可以说一模一样。
但是list的迭代器真的就仅仅是指针吗?
我们学过双向链表的数据结构,其实是非常清楚的,不是,如果只拿到链表结点的指针,比如就叫Node*,你直接解引用就是Node这个结构体,还是得不到里面的数据,难道++ --就能在双链表里随意游走了吗?其实我们都很清楚不是。
说这么多,重点就是,用迭代器的时候当成指针用就行了,但是迭代器可不都是指针,有了list其实就能理解了这个说法,具体到后面模拟实现再来见识。
四、容量相关操作

empty判断链表是否为空,size返回链表结点个数,max_size依旧无用,代表list理论能存的元素个数。
至于capacity等接口,链表哪有capacity的概念,你要插入数据,它就申请结点,要删除数据,它就释放结点,反正都是对size动手。
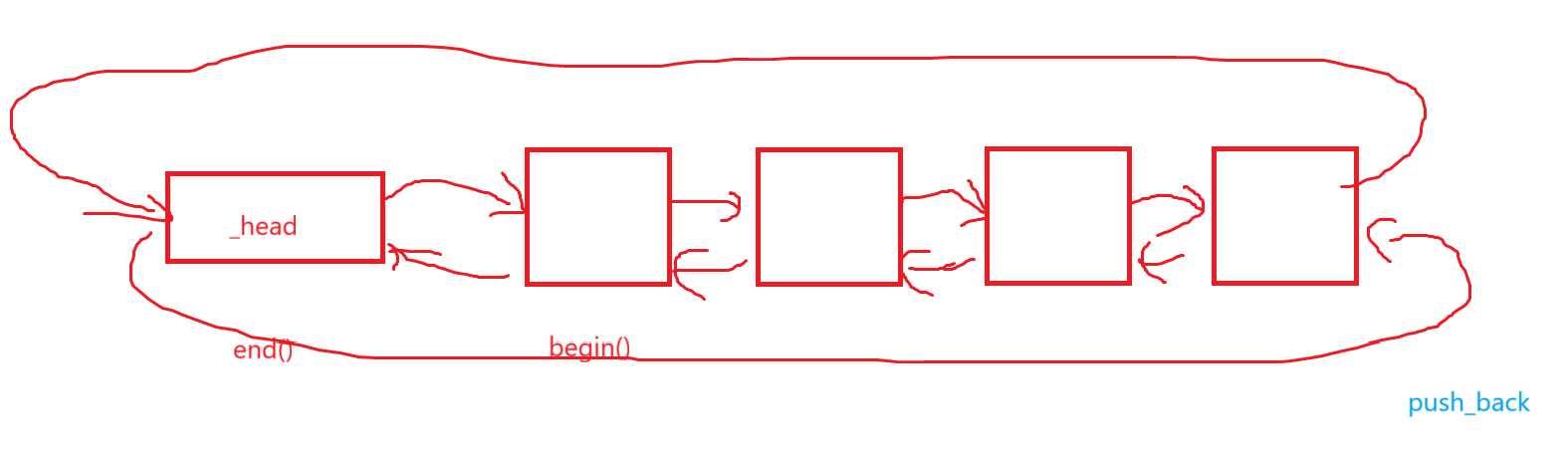
五、获取头尾元素操作

看这个接口其实有点似曾相识,我们学数据结构的时候,栈写过top方法,队列也写过front和back方法,因为这些地方的数据最好获取了。
同理,毕竟是个双向循环链表,而且我们一般认为它是带头的,你想象一下,phead->prev->data得到back位置数据,phead->next->data得到front位置数据。
不过当然,肯定传引用:


六、修改链表结构/数据相关操作
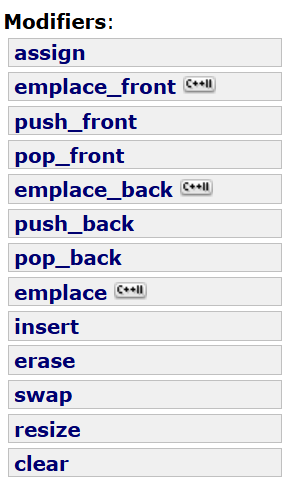
大致上这么多玩意,其实看着吓人。
push_front和pop_front、push_back和pop_back、emplace_front和emplace_back、insert和erase、emplace其实我们都非常熟悉这些玩意是干啥的了,就不再bb了。
1.assign
这个单词大概意思就是分配,只不过到我们这里编程的话,很明显就是赋值的意思,只不过它这个赋值有点强硬:
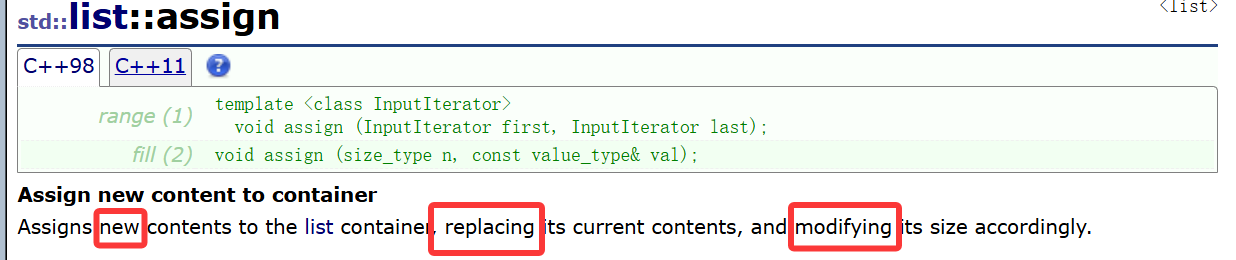
参数有两种,一种是传迭代器区间,一种是直接用n个val的值初始化,这俩跟构造函数老像了,所以重点不是这,重点是对这个函数的介绍。
给链表赋新值,根据参数改容量,改大小。简单来说就是,在原有的申请的链表结点的基础上根据迭代器区间遍历完,或者把n个val的结点安排好,原有结点不够就新开结点;多了就删点结点。
可以看出来,如果不是怕内存的浪费,我感觉他连原来的链表结点都不想要了,其实跟直接删了原有的结点再重申请大概率也就是原有空间的不同。
2.resize
刚模拟实现完vector的resize,我现在不看库的介绍,肯定是你如果n<size,那就保留前n个结点,如果n>size,会根据你给的val补原size后的结点。

人家设计容器就是方便使用者使用,肯定接口设计的都一样一样的,这样用起来就方便的很。
3.clear
这个方法我粘都不粘了,还用说啥吗。
七、其它相关操作
1.sort
上面已经了解了,由于链表的迭代器不支持+ -也就是不是随机迭代器,那么算法库里的sort就是不能用的,所以它就在自己类里面写了个sort:

也不需要传参,直接.sort用就完了。
为什么单独拿出来讲呢?
因为这个sort实际上没啥用。
为什么这么说呢,看这样的代码:
#define N 1000000
void test_cmp1()
{srand(time(NULL));list<int> lt;vector<int> v;for (size_t i = 0; i < N; i++){auto e = rand() + i;lt.push_back(e);v.push_back(e);}int begin1 = clock();lt.sort();int end1 = clock();cout <<"list sort:" << end1 - begin1 << endl;int begin2 = clock();sort(v.begin(), v.end());int end2 = clock();cout << "algorithm sort :"<< end2 - begin2 << endl;
}因为排序我们最关注的是运行效率嘛,你要运行效率低了我肯定不满意的,所以写了这样一段代码,大致意思就是同样的数据(1000000个),放在list里用list的sort和放在vector利用算法库的sort到底哪个更加高效。
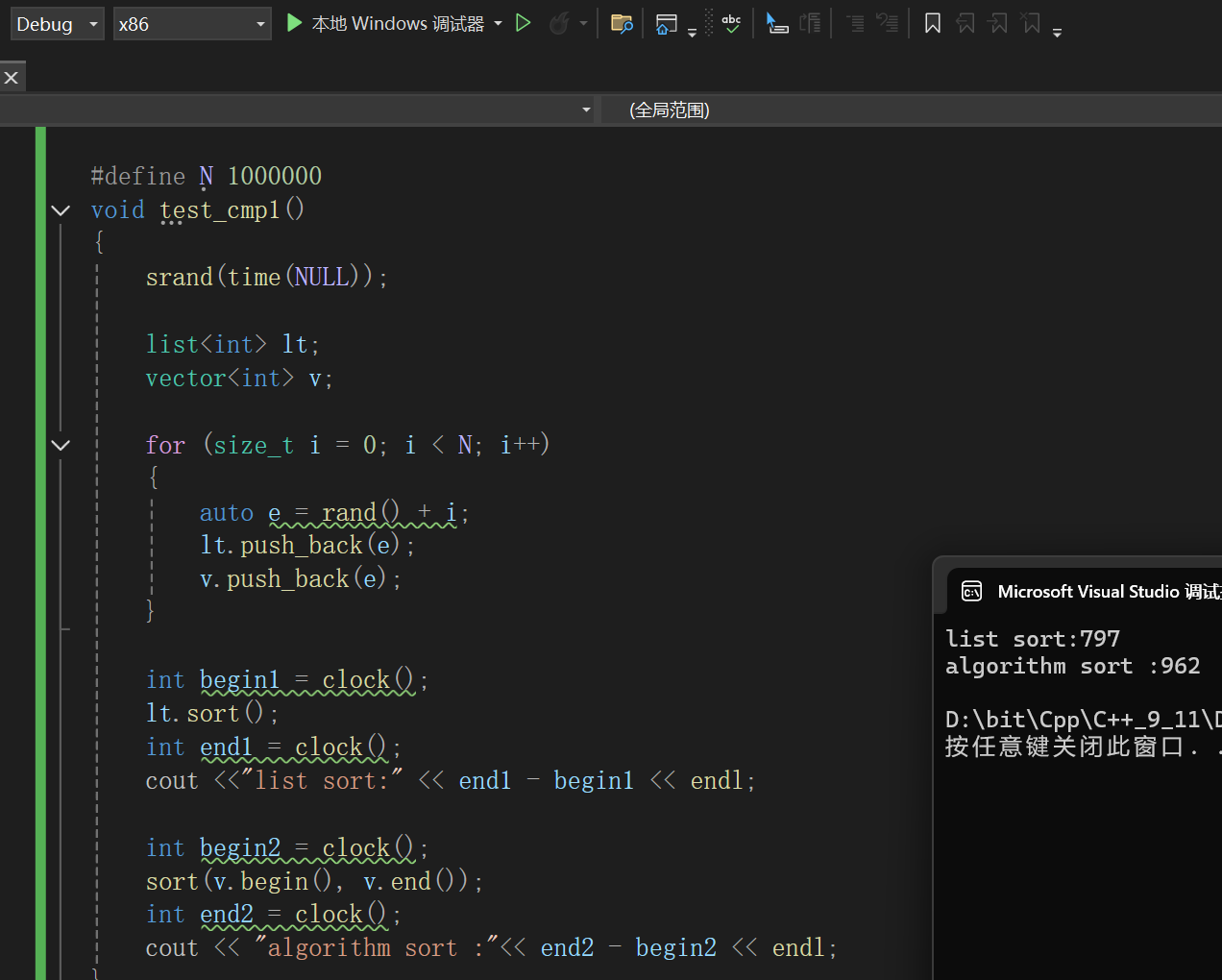
看起来大概是list类的sort更加高效,list难道夹带私货了?当然,如果注意到的话,其实我这次截屏截的很多,把工具栏都搞到里面了,重点是突出这是在Debug版本下执行的。
如果切换到release版本:

明显库里面的sort更加高效,基本上快一倍,我大概查了查,算法库底层快排实现的时候,用的是递归,递归就肯定免不了大量的创建函数栈帧,而Debug版本下由于为了方便调试,所以函数栈帧创建的时候很麻烦,因为免不了插入点调试信息,不过一旦release以后,其实就没事了,因为release以后,不会弄一大堆调试信息,函数栈帧创建就会更加高效。
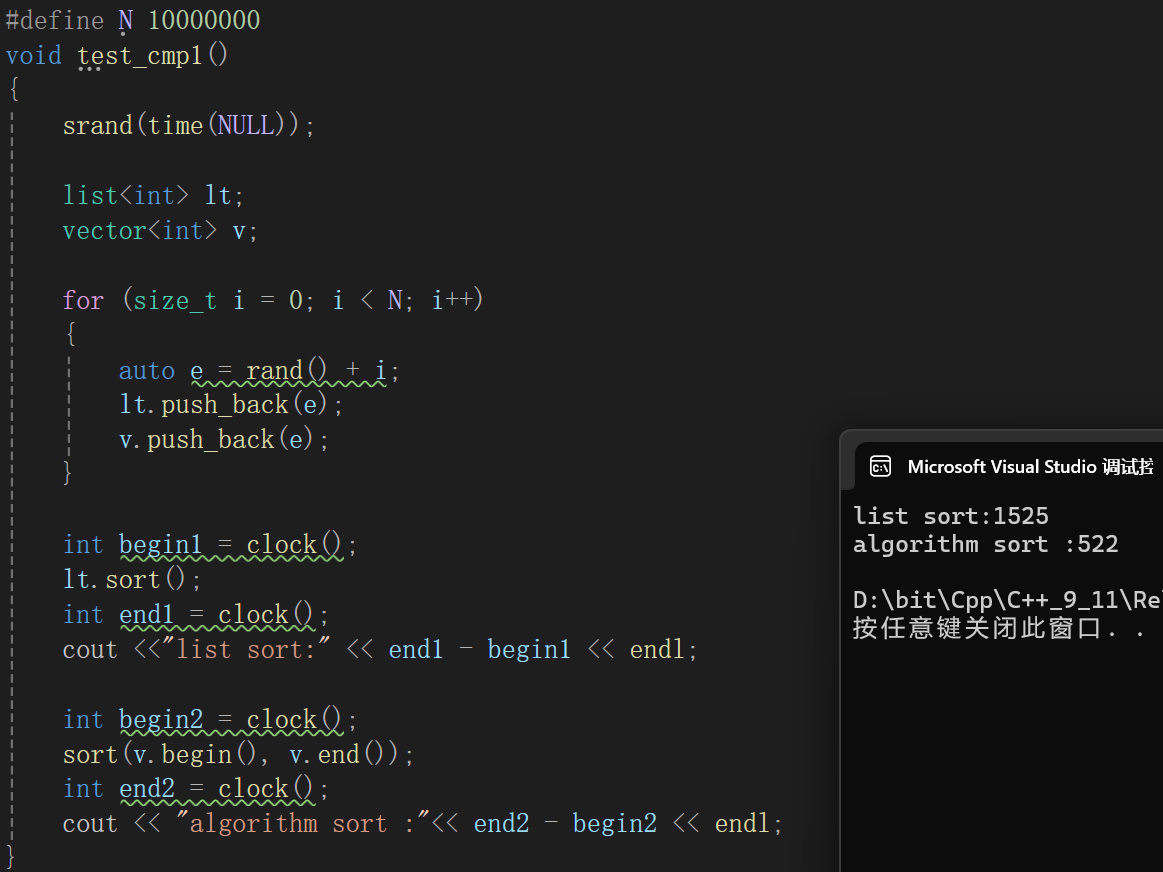
数据越多差异量越明显,这次直接干到一千万个数据了。
list底层sort大概也查了,用的归并排序:

但是如果没记错的话,其实归并排序和快速排序的时间复杂度都是O(nlogn)啊,为什么这里还有这么大的差异呢?
我们C语言阶段写排序算法用的是什么比较,全都是数组,这里vector当成数组,,但是list是链表啊,不信来看这样一段代码:
void test_cmp2()
{srand(time(NULL));list<int> lt1;list<int> lt2;for (size_t i = 0; i < N; i++){auto e = rand() + i;lt1.push_back(e);lt2.push_back(e);}int begin1 = clock();lt1.sort();int end1 = clock();cout << "list sort:" << end1 - begin1 << endl;int begin2 = clock();vector<int> v(lt2.begin(), lt2.end());sort(v.begin(), v.end());lt2.assign(v.begin(), v.end());int end2 = clock();cout << "algorithm sort :" << end2 - begin2 << endl;
}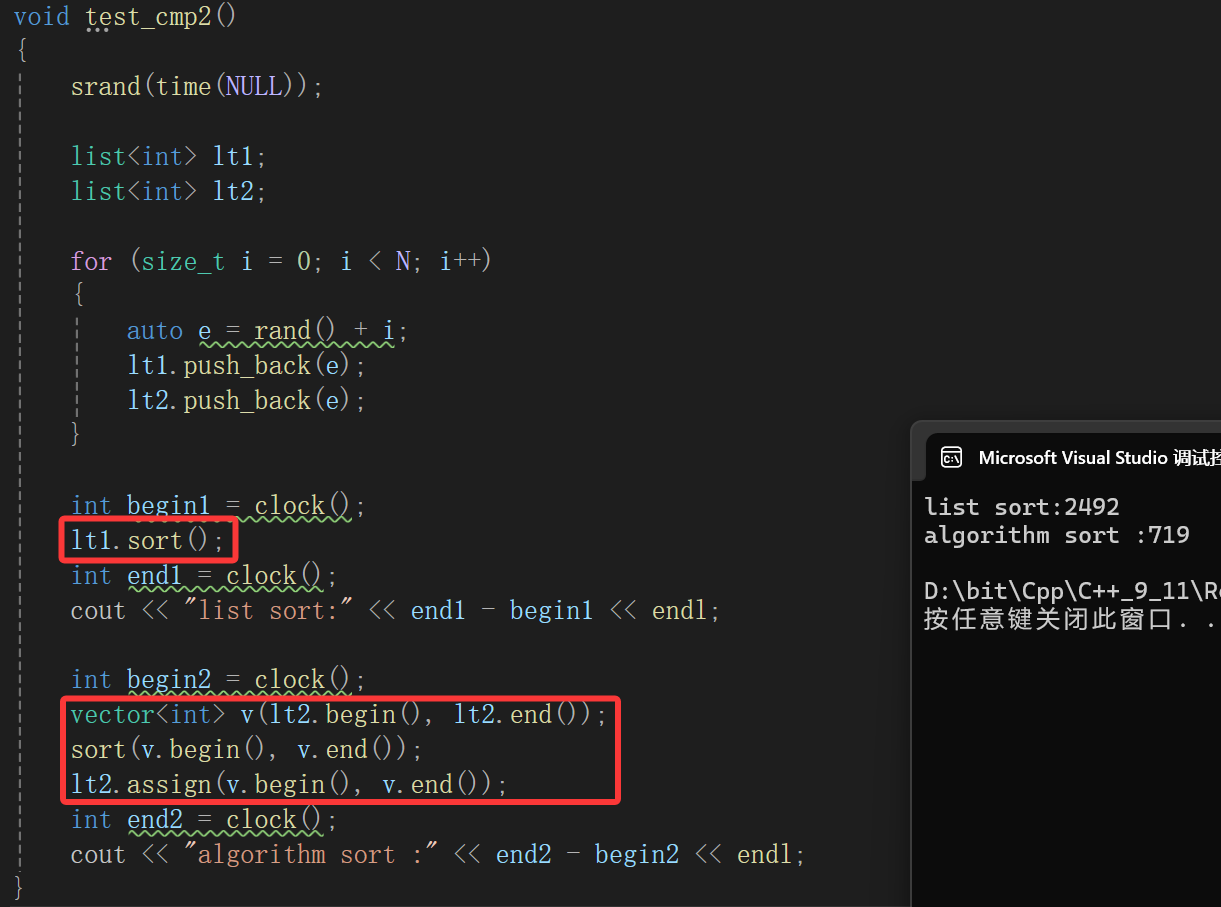
简单来说还是同样多的数据,只不过这次让一个链表直接用list类的sort方法,一个将链表数据拷贝给vector以后让,利用vector的迭代器调用算法库里的sort,很明显,即使有两次拷贝的时间消耗,算法库里面的sort依旧高效。
所以这里给我们了一个启示,如果数据量足够大(数据量小,比如就10个20个几百个,两个差异也不会太大),那么就不要再用list的sort,想办法拷贝用算法库里的吧。
那么为什么这种容器的差异就会造成同样时间复杂度的排序算法的时间差异这么多倍呢?
CPU高速缓存命中率问题
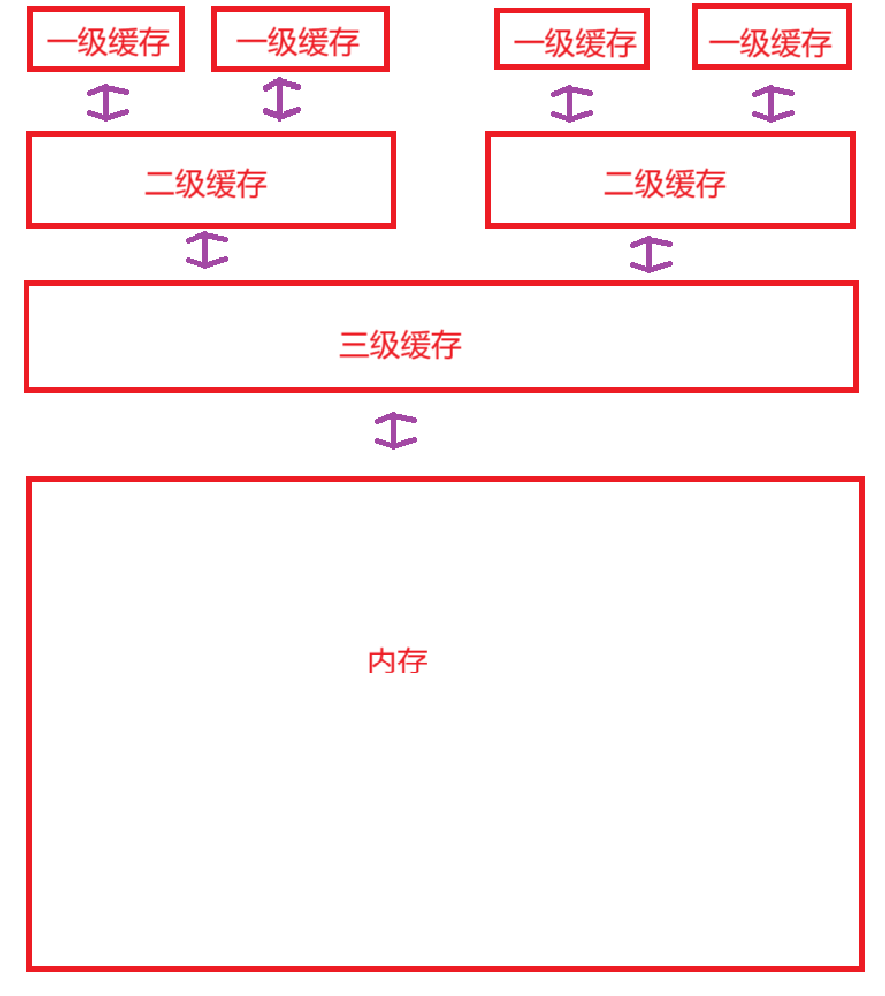
现代CPU都有缓存这个空间,大概步骤就是从缓存先连续的从内存中读取数据,CPU再从缓存中读取数据。这个机制的核心就是为了提高CPU读取的效率。
什么叫缓存命中率呢?
就拿数组和链表对比,在数据量非常大的情况下:
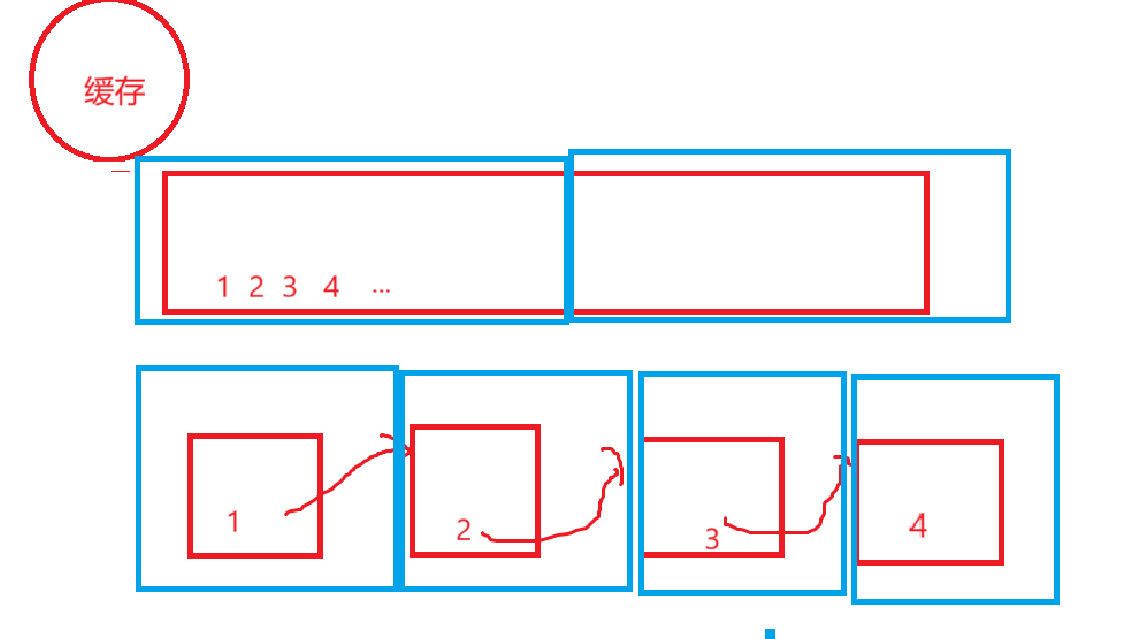
CPU要读数据不是从缓存里读嘛,缓存里没有它就会指挥着缓存去内存读,缓存一次可能就读几十个字节的样子,如果是数组的话,数据都是连续存放的,缓存读一次,很多数据都是有效的,所以基本每次CPU从缓存中读取想要的数据(CPU从缓存中读可就是想要啥读啥了),基本每次都能在缓存中找到,这就是缓存命中率高。
如果对于链式结构,我这里画的夸张了一点,可能缓存读一次的数据给CPU读,只有一个结点的数据被读到了,后面的都没读到,又得让缓存从内存中读数据,反复好多次,这样每次CPU去一大批一大批的读,只能找到零星的几个读,那么这就是缓存命中率低。
懂了这个问题以后,就知道为什么相同的时间复杂度下,不同容器的排序时间差异会很大。
2.reverse

list里面reverse这个接口其实也有点鸡肋吧,描述就是直接把整个list给reverse。
但是算法库里的:

人家还能根据你传的迭代器区间来reverse,还是设计上可能存在什么历史遗留问题吧,不然真就有点诡异了。
3.unique
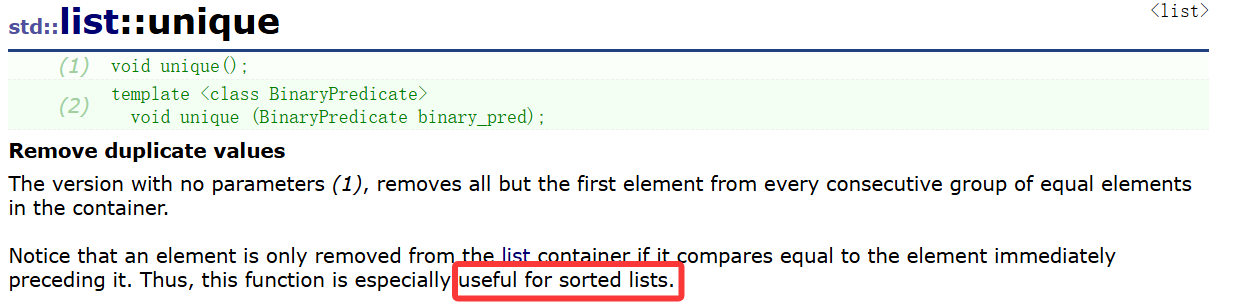
就看这个无参的unique版本昂,unique不是独特的;独一无二的意思嘛,无参版本的意思就是所有元素只保留第一个,其它重复的全部删去。
需要注意的是在使用unique前要先保证list有序。
这个测试一下就是:
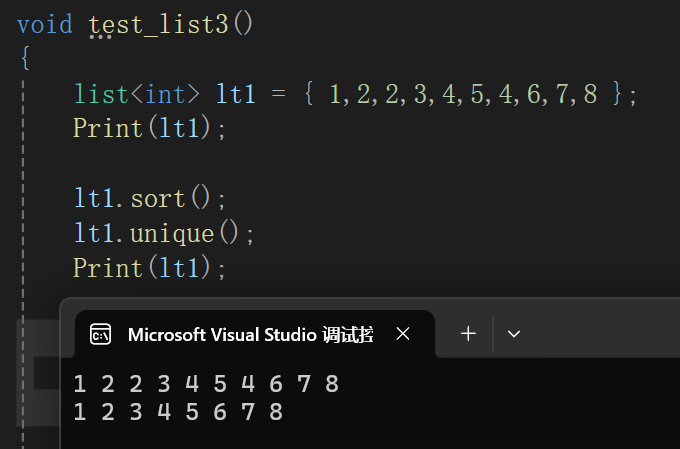
所有元素只保留顺序上的第一个。
4.merge

这个函数是用来合并两个存储数据相同的两个链表的,需要注意的是参数列表那个链表是会被全部转移走,最后直接清空。
另外就是注意调用这两个函数前,默认两个链表都是有序的:

测试可知:
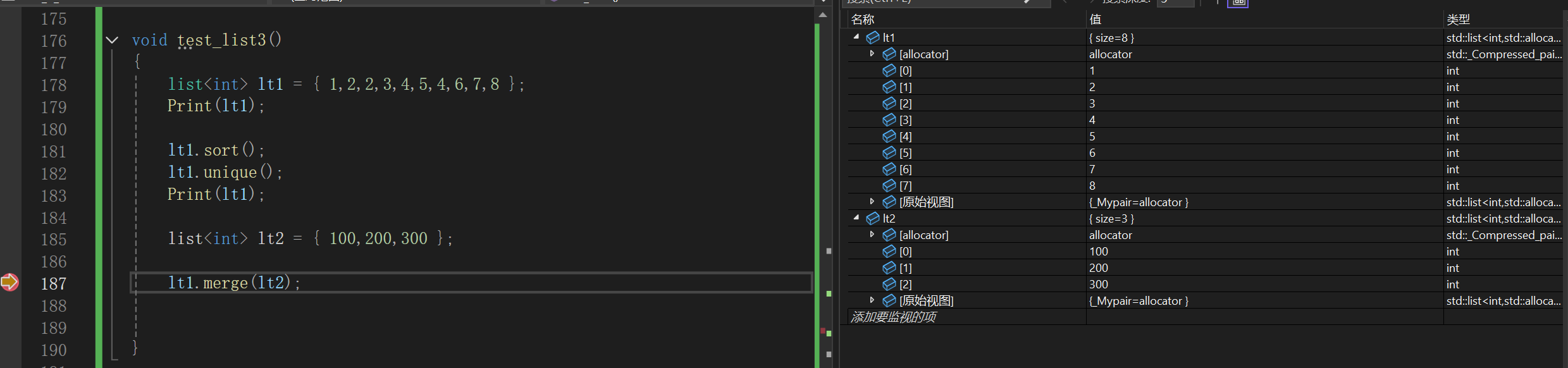
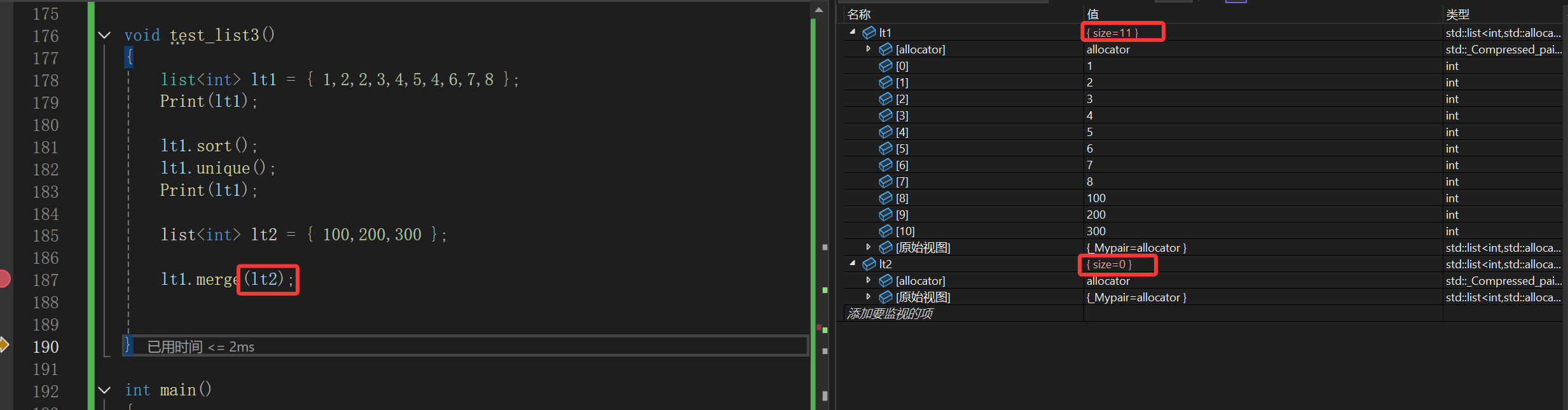
没有任何的开辟释放空间,仅仅是改变了底层结点的指针朝向。
5.remove

list的remove函数是用来删除list中所有存储值val的结点:
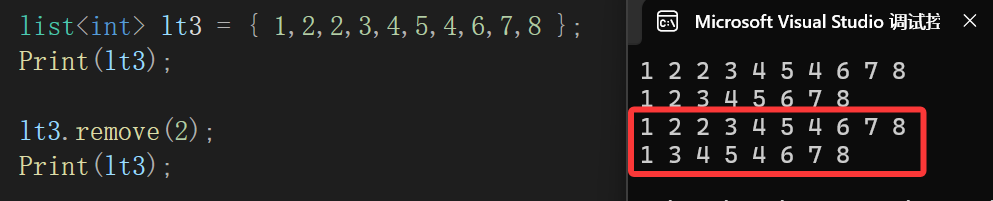
而算法库给的remove是:

删除的是所给迭代器区间内的所有存储val值的结点。
6.splice
本意是粘接的意思。

在库里面其实有种剪切的意思,因为函数的介绍又用了transfer,就是把指定的整个链表了,链表里的某个迭代器位置的值了,链表的迭代器区间的值了,插入到pos位置。
主要就是这样:

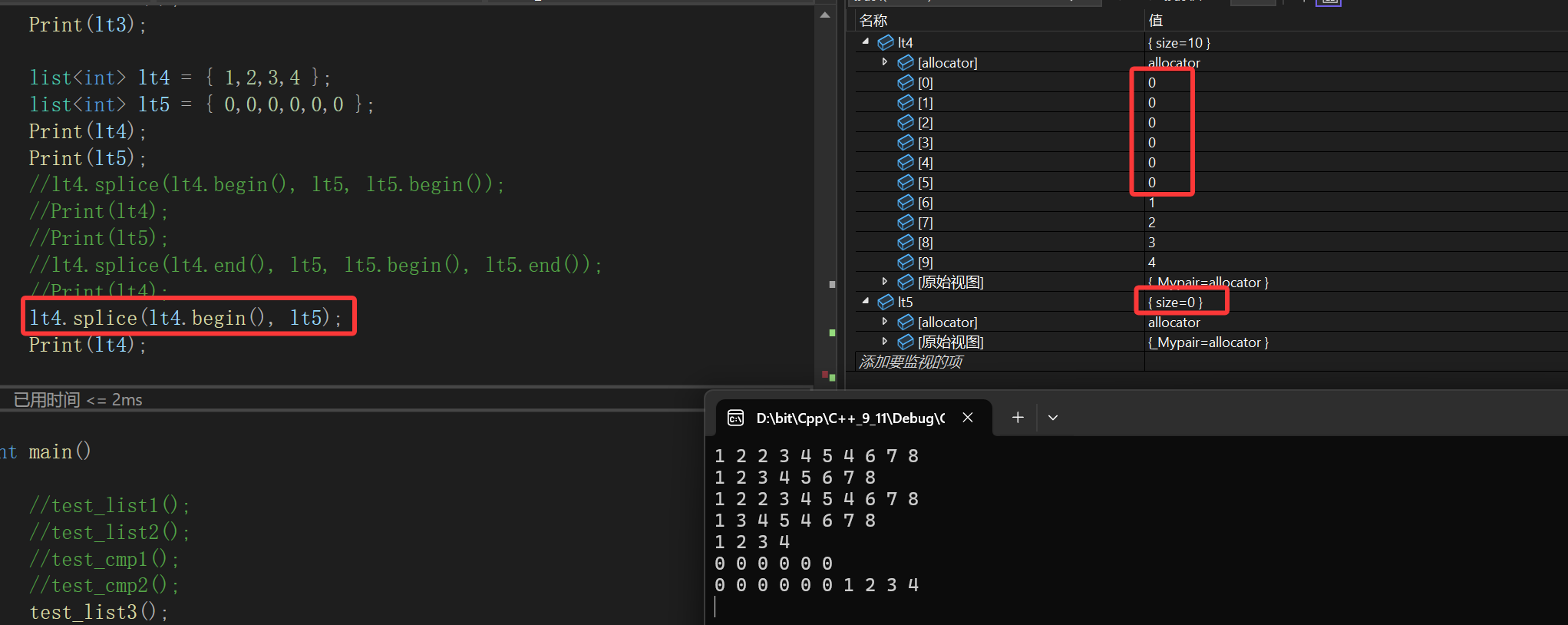
所以才说其实splice有点剪切的意味,但是说来又说去,这个接口还是了解即可,某些情况下会调用,因为毕竟不是像push_back那些常见,真不会直接查库就行。
八、list的成员变量
拜读源代码有这样的认知:
![]()
![]()

从list类中疯狂的找成员变量,最后就找到个link_type node的,再那一系列typedef往上疯狂的找,就能看到最终的这个struct。
其实struct的内容我们可以说是非常熟悉了,双向链表的结点经典配置,一个data存储值,next指向后继结点,prev指向前驱结点。
等于设计者理念大概是这样的,链表的基本元素是不是就是一个个链表的结点,没毛病吧,所以链表的成员变量就应该是一个结点相关的,为什么说是相关的呢,因为如果直接用结点做成员变量就类似于这样:
struct ListNode
{
struct ListNode next;struct ListNode prev;
T data;
};
这就成啥了,成无穷递归了,因为这样的话,结点存的是结点,编译器怎么算结点的大小,根本算不了好吧,逻辑上过的去吗,你可以想象一下一个结点包含一个结点在无穷包含下去。
所以存的就是链表结点的指针,用指针来管理,->来访问。
namespace xx
{template <class T>struct _list_node{struct _list_node* _next;struct _list_node* _prev;T _data;};template <class T>class list{public:typedef _list_node<T> Node;private:Node* _head;};
}- 设计在命名空间内防止与标准库list冲突
- 利用struct设计结点目的在于(struct默认public),一般来说,我们list这个类需要频繁的访问_data、_next、_prev,如果设计成class(默认private/protected),那还得弄成友元,那干脆直接搞成公有的不就行了
- list底层数据结构是双向链表,底层其实只需要暴露头结点这个哨兵结点就够了,并且这么做的话,我们后续的接口其实都是通过Node* _head实现的,那么也就不用担心_list_node结点成员变量被访问了,因为唯一暴露出来的Node* head被private修饰了
- 为了容器可以容纳任意类型的数据,把list及其结点都弄成类模板
最令人瞩目的就是用struct来封装list结点,看起来好像结点就能被随机访问,但是链表只暴露出来头结点_head,_head被private修饰,又暴露不出来了,唯一能访问的结点还被隐藏了。
九、list相关操作的模拟实现
1.list无参构造
站在list的角度,那么很明显,结点就是成员变量,所以构造函数初始化就是对结点进行处理,而可知,带头双向循环链表的处理应当是:
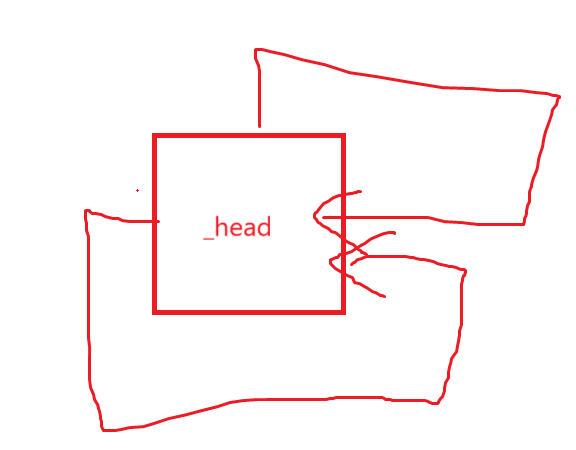
list(){_head = new Node;_head->_next = _head;_head->_prev = _head;}2.push_back
为什么我们写完默认构造啥都不管了,上来就写push_back,原因其实也很简单,那就是如果我们想要扩充构造函数,后续的构造函数比如什么迭代器区间、initializerlist,其实都是一个一个从这里面读取并一个一个尾插,想想是不是,所以写好尾插到后面丰富构造就非常简单;并且有了尾插以后,我们可以初步的见识list。
push_back的逻辑肯定就是先申请一个结点,把结点存储值给好,然后改链表与新结点的指针朝向,也就是:
道理就这么简单,代码表达:
void push_back(const T& x){Node* newnode = new Node(x);Node* tail = _head->_prev;tail->_next = newnode;newnode->_prev = tail;newnode->_next = _head;_head->_prev = newnode;}不过这段代码其实还是有问题的,Node类型是我们typedef _list_node<T>,所以直接new Node(x)的话,没有对应的构造函数对应,还得补一下:
_list_node(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}- 能走初始化列表就尽量直接走初始化列表初始化,真走不了(如string类c-str的构造函数)再和函数体结合
- 站在push_back的角度,node的构造函数不需要给T()的缺省值,但是站在默认构造的角度,如果给个默认构造缺省值确实是比较合适的
3.iterator
①实现list遍历
编译器把std里的list监视窗口经过特殊处理的,我们自己写的list想要从监视窗口直观看到其实很难,还是得打印啊,而遍历list就得有迭代器,所以我们先来写个迭代器。
如果我们还类比string和vector的模拟实现,真的能完成任务吗?
它们都是将所管理的数据类型T*直接typedef,因为迭代器要求你得实现++ * == !=它们还都是随机迭代器,还得满足-- + -这些,不过直接用原生指针(不经包装的指针变量)就能实现。
list的Node*就说最通用的功能* ++,Node*解引用是Node,能够做到访问这个结点存储的值吗?Node++也是同样道理,访问不到下一个结点。
所以直接typedef就不能完成迭代器的功能了,因此我们依旧用一个类来封装迭代器的行为:
template <class T>struct _list_iterator{typedef _list_node<T> Node;Node* _node;_list_iterator(Node* node):_node(node){}T& operator* (){return _node->_data;}_list_iterator<T>& operator++(){_node = _node->_next;return *this;}bool operator!=(const _list_iterator<T>& it){return _node != it._node;}};迭代器指向的都是容器的元素,而list的元素就是node,所以iterator唯一的属性就是Node*,只不过原生功能不够用:
- operator*重载解引用操作符,解引用操作符就是为了拿到当前结点的值,故return _node->_data,我们大多数时候不仅仅是希望拿到这个值,更期望能够修改,所以传引用返回
- operator++旨在实现迭代器后移的行为,不给int就是前置++,前置++是先++再返回,我们写代码的逻辑就是先++(往后遍历),再返回
- 再来就是实现!=
迭代器简单行为已经写完了,但是如果想要实现下面一段代码:
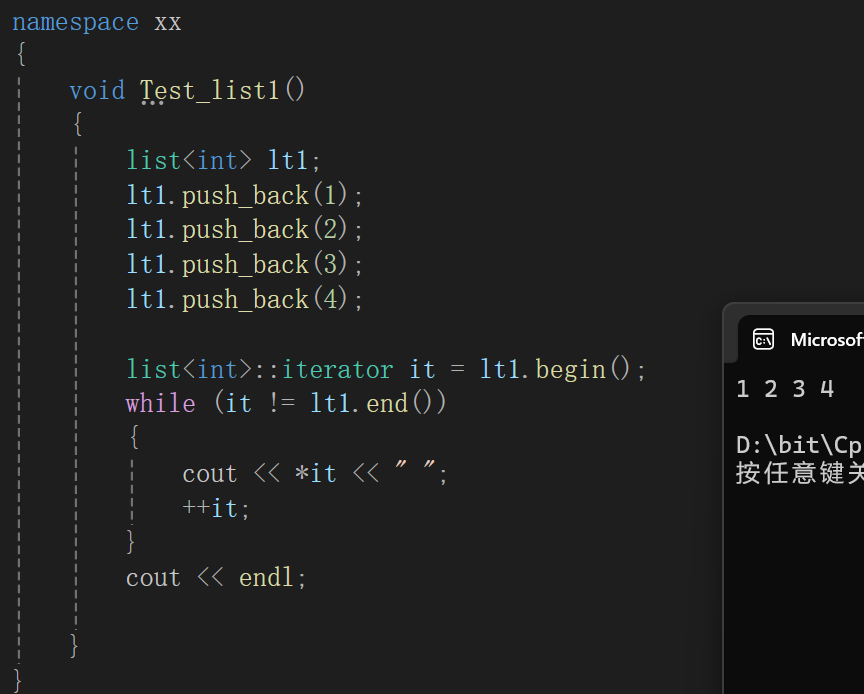
list<int>::iterator it = lt1.begin();while (it != lt1.end()){cout << *it << " ";++it;}cout << endl;
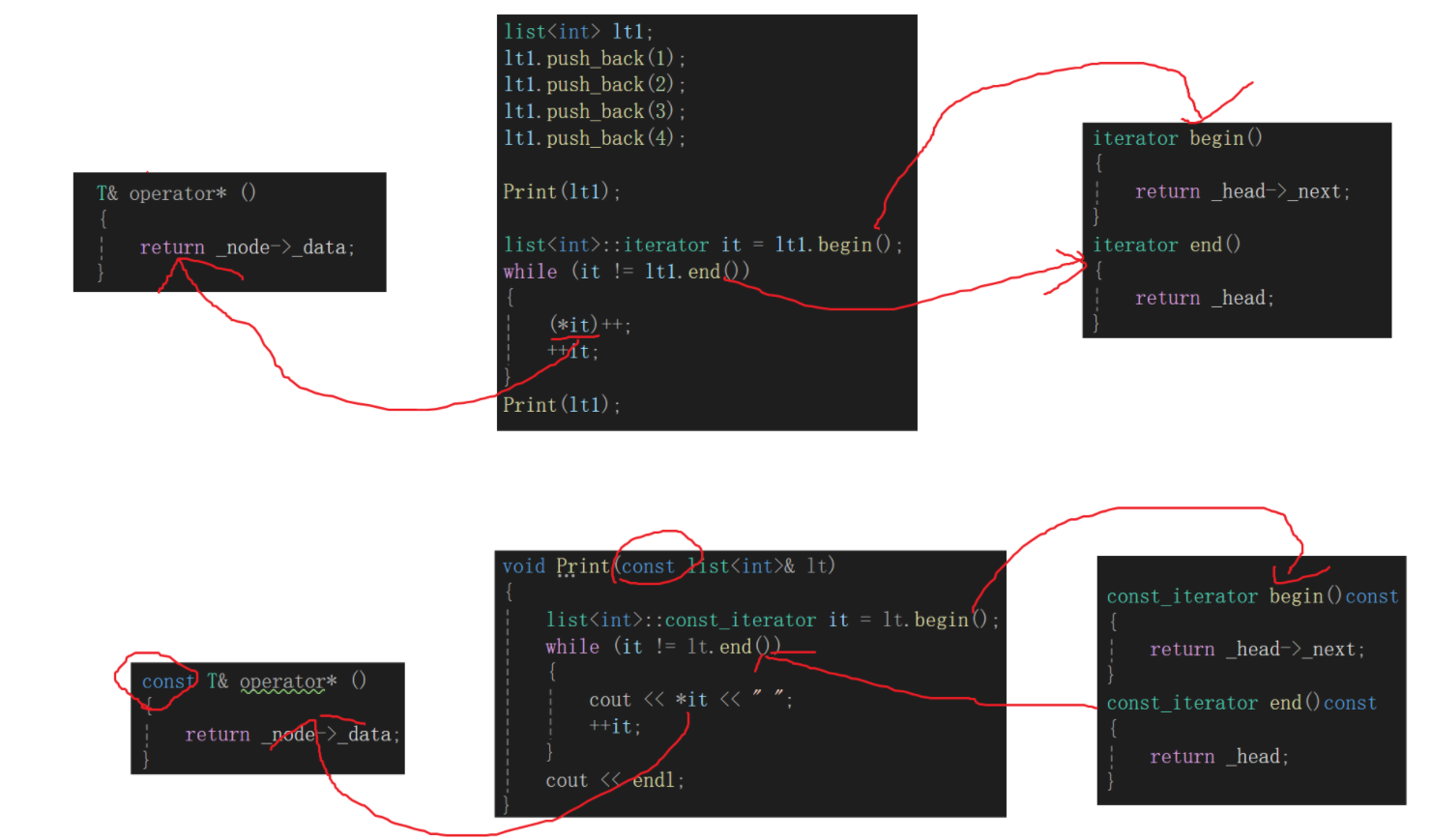
很明显还得写几个函数,并且这个时候应该是在list类里写,原因也很简单,这是list的begin和end的指向:
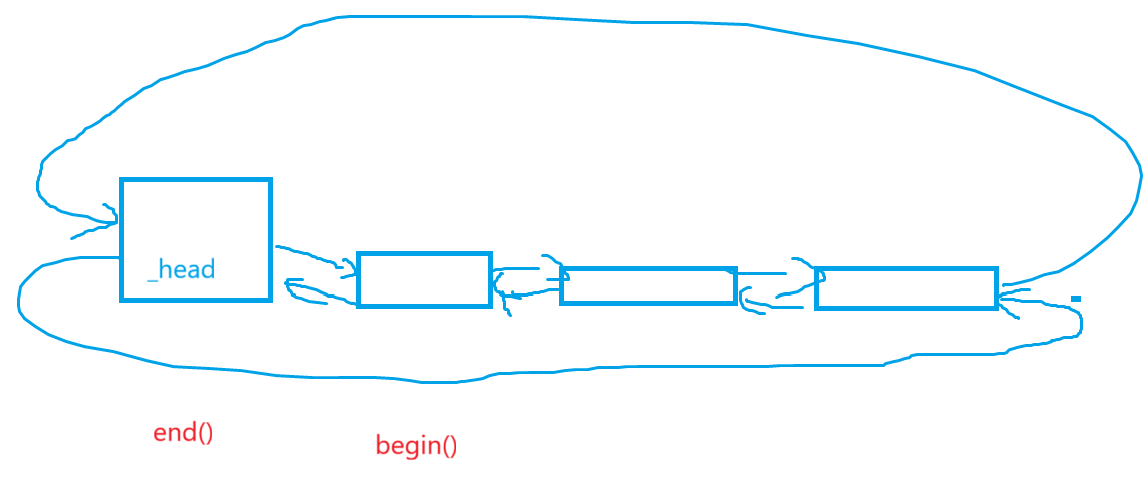
begin返回链表有效元素开始的位置,end返回链表有效元素的下一个位置。
从结果上看,想要拿到begin和end的返回值,必须借助头结点_head,因此在list内部执行:
//class list内部完成typedef _list_iterator<T> iterator;//必须public修饰iterator begin(){return _head->_next;}iterator end(){return _head;}
iterator其实就是我们写的_list_iterator这个类的实例化对象的typedef结果,return Node*类型给iterator实际上又是走了隐式类型转换。
最后效果:
总结:
list遍历借助的是iterator的行为,但是iterator的行为复杂,而且实际上跟list本身没有关系,而是对此次遍历到的结点的指针负责,因此单独用一个类封装这些行为,而迭代器行为有了,要想用出来迭代器遍历list,还需要list实现相关方法使得有遍历的起点和终点。
②完善iterator行为
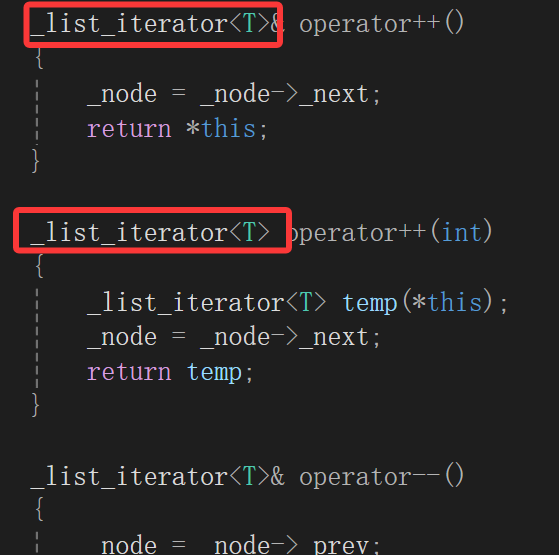
list的迭代器使用阶段我们就知道是双向迭代器,双向迭代器因为着迭代器的方向不止一个;除了迭代器前置++还有后置++;逻辑运算符==/!=等行为都需要完善。
template <class T>struct _list_iterator{typedef _list_node<T> Node;Node* _node;_list_iterator(Node* node):_node(node){}T& operator* (){return _node->_data;}_list_iterator<T>& operator++(){_node = _node->_next;return *this;}_list_iterator<T> operator++(int){_list_iterator<T> temp(*this);_node = _node->_next;return temp;}_list_iterator<T>& operator--(){_node = _node->_prev;return *this;}_list_iterator<T> operator--(int){_list_iterator<T> temp(*this);_node = _node->_prev;return temp;}bool operator!=(const _list_iterator<T>& it)const{return _node != it._node;}bool operator==(const _list_iterator<T>& it)const{return _node == it._node;}};还是得解释,毕竟我自己写的时候还是挺迟疑的:
- 实现后置++,语法格式肯定还是operator++重载,但是为了与前置++区分,在参数列表要以int作占位符,表示这是后置的运算符
- 可以观察到,前置++的逻辑是先后移再使用,所以直接返回后移后的迭代器的引用即可;后置++的逻辑是先使用再后移,在运算符重载中实现就是保存++前的值做返回值,因为使用用的就是返回值,但是最终迭代器确实要实现后移
这里还有一个细节就是_list_iterator不用写拷贝构造,因为这里就是为了保存原始的*this,是浅拷贝场景,如果写拷贝构造搞个深拷贝就找不到链表里的那个结点 - 前置++返回引用是因为返回的迭代器实际存在,减少拷贝;后置++返回值是因为返回值是临时保存的迭代器的值,出了作用域就会销毁,不能引用绑定
- --和++的区别就是一个是往前移,一个往后移
- !=/==的核心逻辑就是判断这两个迭代器指向的是否是同一个结点,核心就是比较两个迭代器存的指针是否相等
③const_iterator的实现
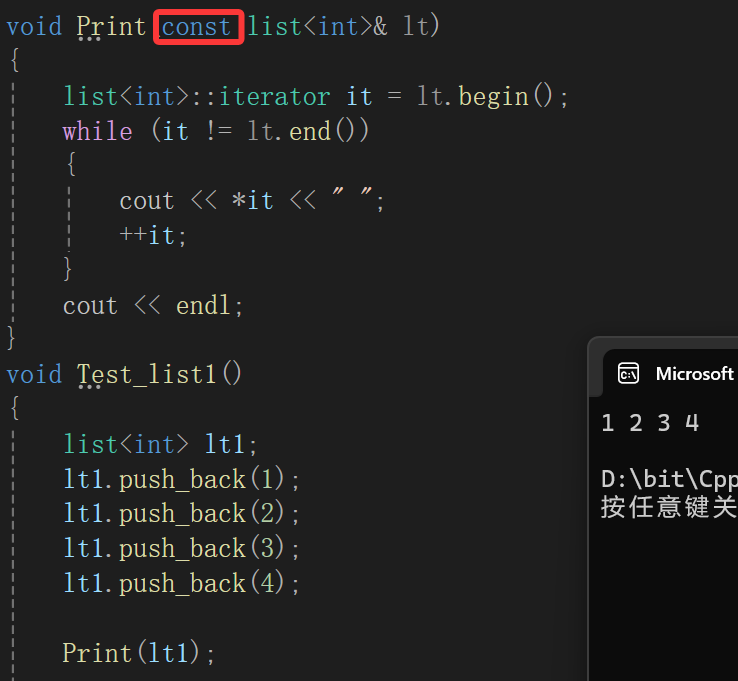
假设我们现在就要写一个独属于list<int>的print函数:
void Print(const list<int>& lt){list<int>::iterator it = lt.begin();while (it != lt.end()){cout << *it << " ";++it;}cout << endl;}其实这段代码是有问题的噢:

我们知道const对象就得用const迭代器原理。
误区1
按照我自己对const的理解,突然就想不通,或者说string vector道理很简单我就没有深究/没有问题,为什么const对象就得用const迭代器。
刚开始我是这么想的,const不是修饰的list嘛,那list的内容就不能修改了,list的内容只有一个_head,那它内容不能修改其实不就是Node* const _head嘛,那这不对啊,等于Node的内容没管住啊,相当于
_head->next;
_head->prev;
T data;
不用const迭代器看着也没毛病啊,但是我们都心知肚明,其实const对象就该用const迭代器。
那当然是我们自己逻辑推理有问题了,最简单的,const修饰相当于只读,那么一个链表如果只读,肯定不希望你再修改里面的数据和结构,如果还用普通迭代器不坏事了嘛。
不妨从宏观角度看一遍:
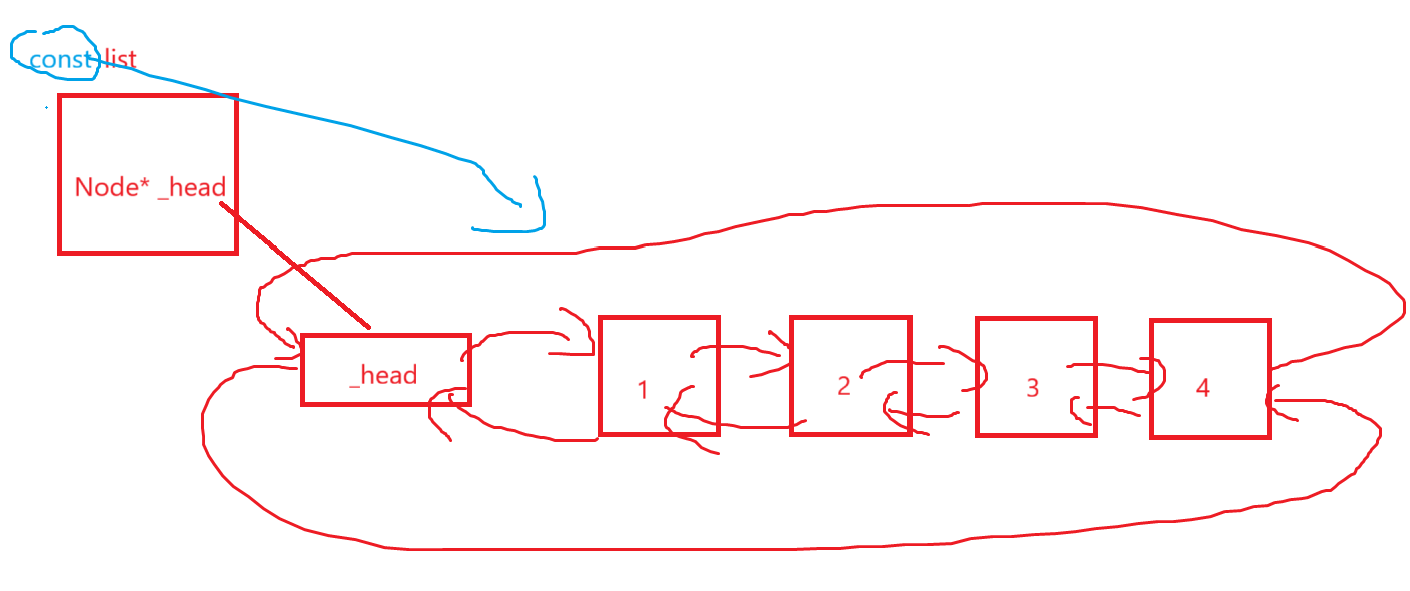
最根本就是const相当于一个承诺,保证list里面一根毫毛都不会动,不然怎么能做到只读呢?我们推的Node* const _head实际上应该是const Node* const _head,这样总能说通了。
实现const迭代器其实也好说,其实看iterator实现的代码:
template <class T>
struct _list_iterator
{typedef _list_node<T> Node;Node* _node;_list_iterator(Node* node):_node(node){}T& operator* (){return _node->_data;}_list_iterator<T>& operator++(){_node = _node->_next;return *this;}_list_iterator<T> operator++(int){_list_iterator<T> temp(*this);_node = _node->_next;return temp;}_list_iterator<T>& operator--(){_node = _node->_prev;return *this;}_list_iterator<T> operator--(int){_list_iterator<T> temp(*this);_node = _node->_prev;return temp;}bool operator!=(const _list_iterator<T>& it)const{return _node != it._node;}bool operator==(const _list_iterator<T>& it)const{return _node == it._node;}
};其实只有
T& operator* ()
{
return _node->_data;
}
才涉及到数据能不能修改,其它的又没动list里的东西,人家单纯在移动迭代器而已,那又不犯const的毛病。
所以直接:
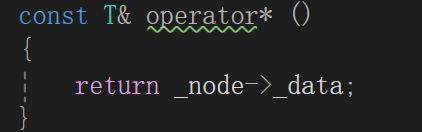
同时:
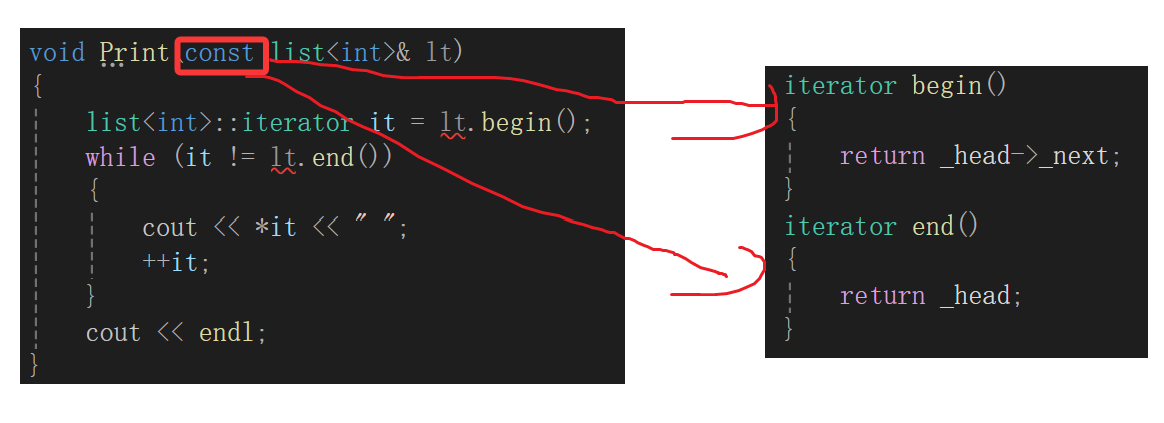
我们讲类与对象的知识的时候讲过这样的事,为什么实例化对象去调成员函数使用成员属性的时候每次都能一一对应呢?
原因是成员函数默认第一个形参会是类型*const this的指针,成员函数传实参的时候会直接把实例化对象的地址作为第一个实参传过去,比如这里调用begin和end函数就会:
iterator begin(list* const this)
{
return this->_head->next;}
iterator end(list* const this)
{
return this->_head;}
那我问你,你是不是给我整成const list对象传给list对象的事了。
误区2
注意,在C的环境下:
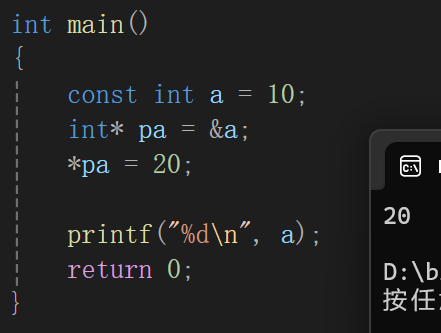
如果你把一个const int的地址传给int*是没毛病的啊,C的情况下是能走的,而且不仅能走,还能通过指针修改。
但是在C++的环境下:

我大概查了查这个行为,ai是这么跟我说的:C语言的const更像是一种建议或者说一种君子协议,明着不让你弄,但是你要是不要脸非得弄其实它也管不了你;
C++这个它说的什么符号表啥的,我也看不懂。

反正我觉得最重要的就是记住const 修饰保护范围更宽了
为什么突然提上面那种情况,因为
iterator begin(list* const this)
{
return this->_head->next;}
iterator end(list* const this)
{
return this->_head;}
我们传实参传的就是&(const list),跟&(const int)其实异曲同工,只不过因为C++相当于在C的基础上对const进行升级,间接的潜在的风险也会直接编译报错。
所以如果是const实例化对象,还必须用const成员函数也就是:
iterator begin(const list* const this)const
{
return this->_head->next;}
iterator end(const list* const this)const
{
return this->_head;}
这样就相当于将(&const list)传给const list*,这样编译器就不会找事了。

所以这个时候:
误区3
我下意识的其实并没有通过去操纵迭代器内部行为来实现const迭代器,就像走捷径。
比如:
![]()
但是我一想,这不就相当于const iterator,我要的是const_iterator,迭代器肯定是可以修改的,只不过迭代器指向的内容不能修改。
又有,我没想动脑子,因为其实vector模拟实现做的是:

我顺手就:

这不跟第一个错误一个道理嘛,因为_list_iterator<T>不就是iterator嘛,不是等于还是const iterator嘛。
最后,我对operator*起歪心思了:

纯粹没细想,我就想的是,哦,那就加const呗,不让修改就不修改,但是我仔细想想,相当于是const iterator* const this,而且这玩意不纯脱裤子放屁嘛,我解引用本来就没想修改迭代器,我要的是迭代器指向的内容不能被修改,这么写不等于白干嘛。
误区总结
一次是对const对象即使不用const迭代器应该也可以,因为按照我的推理,其实最根本的结点的属性没有被保护;另一次就是对const成员为什么非得用const成员函数产生疑问。
总得就是以C的角度对const关键字进行理解,而不是C++,上面我们已经看到了,C++的const从深度上将一系列与const修饰的对象能够产生关系的所有属性进行const修饰;从广度上直接禁止非const引用/指针与const对象产生关系。
其实之前没有思考到这一层,之前也不少见const,只不过这一次相当于是压死骆驼的最后一根稻草了,所有问题都因为list的类型太多,我从最底层思考就都暴露出来了。
无脑实现
既然已经没啥问题,而且也知道const_iterator相比于一般的iterator需要在哪里找补了,这次就在普通迭代器的基础上实现const迭代器:
template <class T>struct _list_iterator{typedef _list_node<T> Node;Node* _node;_list_iterator(Node* node):_node(node){}T& operator* (){return _node->_data;}_list_iterator<T>& operator++(){_node = _node->_next;return *this;}_list_iterator<T> operator++(int){_list_iterator<T> temp(*this);_node = _node->_next;return temp;}_list_iterator<T>& operator--(){_node = _node->_prev;return *this;}_list_iterator<T> operator--(int){_list_iterator<T> temp(*this);_node = _node->_prev;return temp;}bool operator!=(const _list_iterator<T>& it)const{return _node != it._node;}bool operator==(const _list_iterator<T>& it)const{return _node == it._node;}};
template <class T>struct _const_list_iterator{typedef _list_node<T> Node;Node* _node;_const_list_iterator(Node* node):_node(node){}const T& operator* (){return _node->_data;}_const_list_iterator<T>& operator++(){_node = _node->_next;return *this;}_const_list_iterator<T> operator++(int){_const_list_iterator<T> temp(*this);_node = _node->_next;return temp;}_const_list_iterator<T>& operator--(){_node = _node->_prev;return *this;}_const_list_iterator<T> operator--(int){_const_list_iterator<T> temp(*this);_node = _node->_prev;return temp;}bool operator!=(const _const_list_iterator<T>& it)const{return _node != it._node;}bool operator==(const _const_list_iterator<T>& it)const{return _node == it._node;}};专门搞了一个类来代表const_iterator的行为。
并且:
typedef _list_iterator<T> iterator;typedef _const_list_iterator<T> const_iterator;iterator begin(){return _head->_next;}iterator end(){return _head;}const_iterator begin()const{return _head->_next;}const_iterator end()const{return _head;}这样就能实现:
大致意思就是,调用函数的时候根据list对象的性质,调用合适的begin/end函数,返回合适的迭代器类型,迭代器合适了,将来调用的操作符重载就行为正确。
优化版本
其实我们无脑实现就是把类名换了一下,operator*返回值类型变了一下,其它的根本就没有变,这个时候我们做这样的操作:
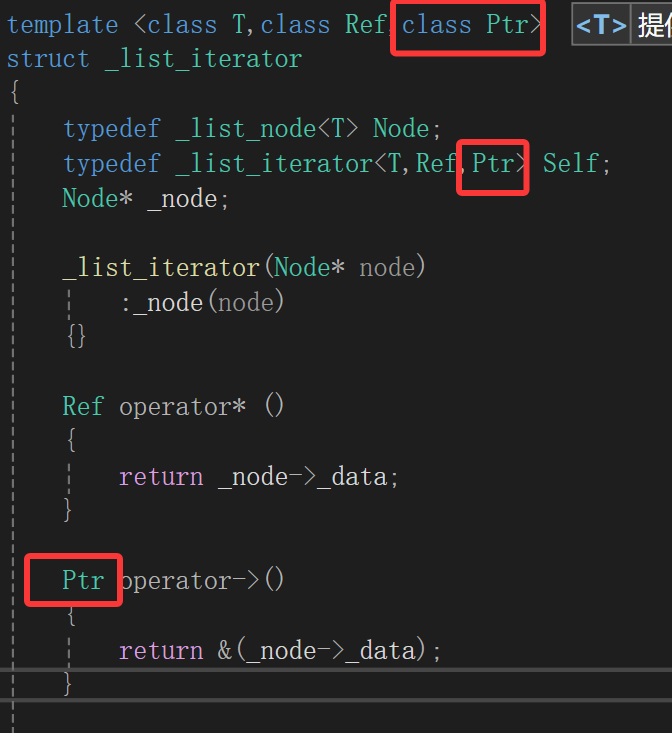
template <class T,class Ref>struct _list_iterator{typedef _list_node<T> Node;Node* _node;_list_iterator(Node* node):_node(node){}Ref operator* (){return _node->_data;}_list_iterator<T>& operator++(){_node = _node->_next;return *this;}_list_iterator<T> operator++(int){_list_iterator<T> temp(*this);_node = _node->_next;return temp;}_list_iterator<T>& operator--(){_node = _node->_prev;return *this;}_list_iterator<T> operator--(int){_list_iterator<T> temp(*this);_node = _node->_prev;return temp;}bool operator!=(const _list_iterator<T>& it)const{return _node != it._node;}bool operator==(const _list_iterator<T>& it)const{return _node == it._node;}};

在模板中多加一个类型,专门代表operator*的返回值,因为其它部分的逻辑根本就不变嘛,直接当模板参数传过去得了。
依据传过去的模板参数不同,形成不同的类,用哪个调哪个。
最终版本
其实如果试了的话,优化版本是编译不过去的,这一点有点抽象,比如:
![]()
普通迭代器不是这个模板类嘛,类型名可以说就是这个,实例化对象的类型就也会是类名,类似于class A,这个类叫A,实例化对象的类型是A。
所以对于这些函数:
因为返回的都是迭代器类型的对象嘛,而现在普通迭代器迭代器这个类类名是_list_iterator<T,T&>,等于实例化对象的类型是_list_iterator<T,T&>,这些函数返回值都是普通迭代器类的实例化对象,所以都得写成_list_iterator<T,T&>,但是写这个玩意太累,所以干脆:
![]()
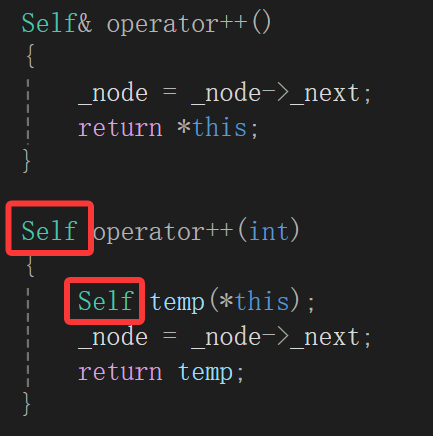
template <class T,class Ref>struct _list_iterator{typedef _list_node<T> Node;typedef _list_iterator<T,Ref> Self;Node* _node;_list_iterator(Node* node):_node(node){}Ref operator* (){return _node->_data;}Self& operator++(){_node = _node->_next;return *this;}Self operator++(int){Self temp(*this);_node = _node->_next;return temp;}Self& operator--(){_node = _node->_prev;return *this;}Self operator--(int){Self temp(*this);_node = _node->_prev;return temp;}bool operator!=(const Self& it)const{return _node != it._node;}bool operator==(const Self& it)const{return _node == it._node;}};
4.小结
实话说,写这个玩意,哪怕是让现在的我抄一遍都是非常大的冲击了,我得发,vector/string的模拟实现就写个template <class T>,剩下的地方只要用到所存储数据类型全部都是T就行了,但是list的模拟实现实现真是磨人啊我的老天爷,所以下面我简述一下到目前为止的心路历程:
private:Node* _head;站在list的角度,我的元素很简单,就是结点,因为实际上的数据结构是带头双向循环链表,索性我直接只实现头结点,其实除了头结点其它结点设立起来有什么意义呢?
list的接口都站在头结点的角度考虑。
但是结点肯定也不是个简单的int、double啊,最少包含三个元素,所存数据data、后继结点指针next、前驱节点指针prev。
所存数据由于是list的结点所以也应该是可以存储任意类型的结点,那么根据C++的特性,又得设计成模板了,同时由于我们需要在list类里频繁使用结点的成员变量,面临如下三个选项:
1.设计成struct类,与list类分为两个类(实际上最后效果上这种方式使得这个类成为了list的子类)
2.设计成class类,在内部声明成list类的友元
3.设计成list类的子类
首先3就排除了,我们C++不太喜欢内部类这种玩法,很少能用的到。
第二种其实全然有种脱裤子放屁的美感,设计成私有的然后又让list随便访问,贱不贱啊,而且唯一一个隐藏结点成员变量的作用其实也多余了,list设计的时候直接把唯一可能暴露出来的头结点设成私有了,完全没必要,所以我们就使用struct当结点类,最终实现:
template <class T>struct _list_node{struct _list_node* _next;struct _list_node* _prev;T _data;};list的成员变量设计完毕以后就涉及到一系列方法,容器的类,上来肯定得考虑构造函数,毕竟容器是动态开辟的手动管理的,使用前必须初始化。
根据双向链表的结构,很容易就能得到:
list()
{_head = new Node;_head->_next = _head;_head->_prev = _head;
}默认构造嘛,简简单单的。
之后就写了push_back,原因也很简单,我们后续多种构造函数的实现其实都可以借助push_back来实现,所以实现push_back非常有必要。
至于push_back,其实还是根据双向链表的结构实现一下就行:
void push_back(const T& x){Node* newnode = new Node(x);Node* tail = _head->_prev;tail->_next = newnode;newnode->_prev = tail;newnode->_next = _head;_head->_prev = newnode;}
唯一剩下的问题就是,因为插入值嘛,申请链表结点的时候就new Node(x),我们说了,C++这套动态内存开辟,不管什么类型都要调对应的构造函数(内置类型int double在C++中同样被升级成类,并且具有类有的构造等方法),所以现在需要补实现Node类的构造函数:
_list_node(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}接下来就到了最让人崩溃的list最高的山,迭代器的实现,事情的起因就是我们想要遍历打印,看看push_back的效果,结果就一去不复返了:
普通迭代器实现的时候麻烦的点就是发现原生的指针做不到我们经常使用的迭代器效果,即模仿数组指针的方式,但是说归说闹归闹,类比list结点的设计,其实迭代器的行为也是需要单独包装的,所以写成:
template <class T>
struct _list_iterator
{typedef _list_node<T> Node;Node* _node;_list_iterator(Node* node):_node(node){}T& operator* (){return _node->_data;}_list_iterator<T>& operator++(){_node = _node->_next;return *this;}_list_iterator<T> operator++(int){_list_iterator<T> temp(*this);_node = _node->_next;return temp;}_list_iterator<T>& operator--(){_node = _node->_prev;return *this;}_list_iterator<T> operator--(int){_list_iterator<T> temp(*this);_node = _node->_prev;return temp;}bool operator!=(const _list_iterator<T>& it)const{return _node != it._node;}bool operator==(const _list_iterator<T>& it)const{return _node == it._node;}
};真正的二战转折点就是实现const迭代器。
以实现const迭代器跟瘟疫爆发了一样问题一个接着一个:
- 为什么const list必须使用const迭代器
- 为什么const list必须使用const成员函数
- 为什么偷懒版的直接加const与设计成const成员函数实现不了const迭代器
最后也就是最最抽象的地方:

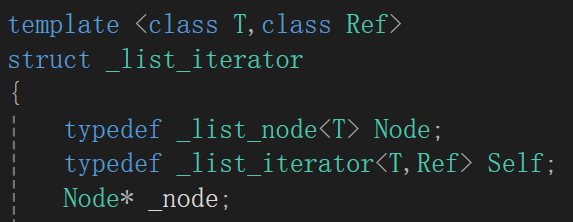
这个类型实例化对象的类型是_list_iterator<T,Ref>。
5.iterator小点补充
比如这样的场景:
struct pos{int _x;int _y;pos() = default;pos(int x, int y):_x(x),_y(y){}};void Test_list2(){list<pos> lt1;lt1.push_back({ 1,1 });lt1.push_back({ 2,2 });lt1.push_back({ 3,3 });lt1.push_back({ 4,4 });list<pos>::iterator it = lt1.begin();while (it != lt1.end()){cout << (*it)._x << ":" << (*it)._y << endl;++it;}cout << endl;}我们实现完所有的迭代器行为以后,设计了这样一个结构体,代表坐标,如果想要对其遍历打印,借助迭代器,而*it得到的是:
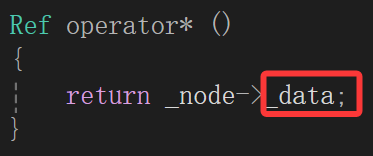
也就是该结点存储的pos这个结构体,所以如果想要访问结构体成员变量_x_y,还得继续用.成员变量访问操作符。
最后结果很显然:

但是往往我们看见*.就像直接转化成->用,只不过:

不管是提示还是我们自己想,其实都不能用,因为迭代器又不是指针,只是一个存储结点指针的结构体,所以如果想要用这个操作符我们总得拿到这个位置的地址,也就是做到:

但是实际上这个操作符用起来非常古怪,我们迭代器运算符重载最终拿到的是啥,是pos*,等于说it-> == pos*,那不还得pos*->_x,pos*->_y吗,但是:
 这种现象我问了问ai:
这种现象我问了问ai:

等于为了当成指针叫你用,隐式自己添加一个->,所以就好像直接能访问最底层的数据一样。
想要显式调用当然也是可以的:
最后,为了不破坏阵型:

6.list操作完善
也不整花里胡哨的,我们现代写代码要求代码复用而不是重复的代码复制粘贴,双向链表的一大特点就是能在任意位置随意的插入删除结点,宏观上看就是能在任意位置插入和删除数据,所以我们现在核心思想就是实现insert和erase。
首先是insert:
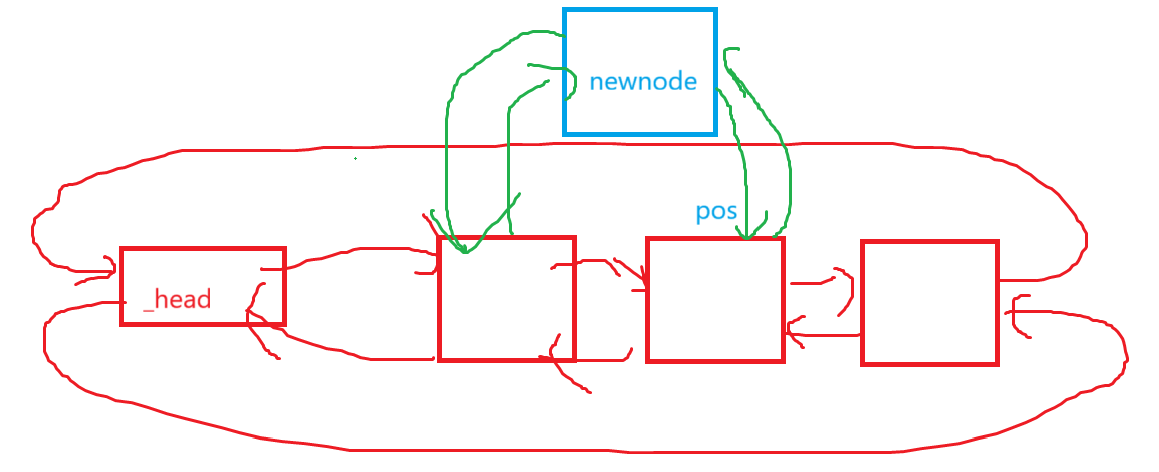 insert的大致逻辑就是这样,等于如果想在pos位置插入,需要照顾到的结点是链表里pos位置的结点和pos的前驱结点。
insert的大致逻辑就是这样,等于如果想在pos位置插入,需要照顾到的结点是链表里pos位置的结点和pos的前驱结点。
void insert(iterator pos,const T& x){Node* pcur = pos._node;Node* newnode = new Node(x);Node* prev = pcur->_prev;//prev newnode pcurprev->_next = newnode;newnode->_prev = prev;newnode->_next = pcur;pcur->_prev = newnode;}再来是erase:
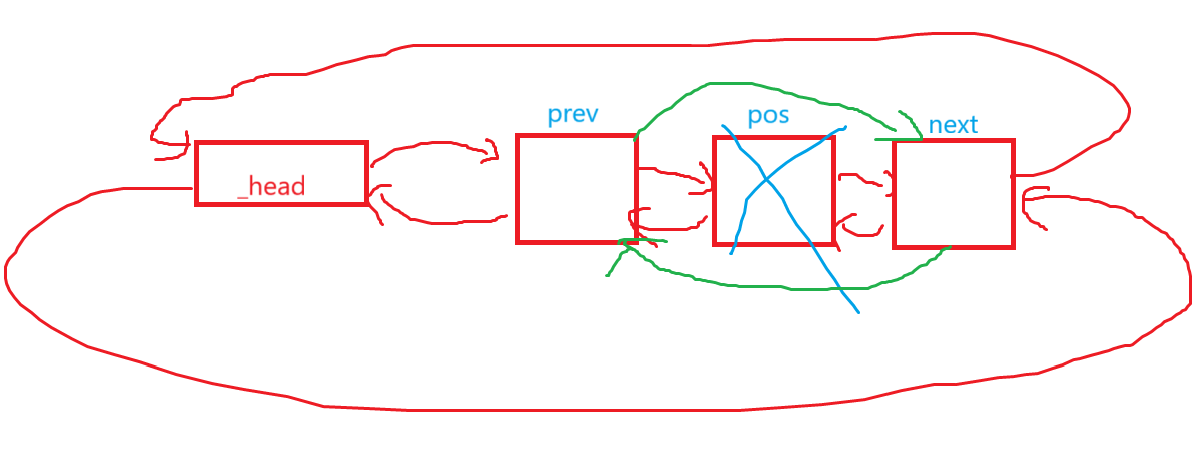
管好pos前驱结点和后继结点以后,直接释放掉pos位置的结点就行:
void erase(iterator pos){Node* pcur = pos._node;Node* prev = pcur->_prev;Node* next = pcur->_next;prev->_next = next;next->_prev = prev;delete pcur;pcur = nullptr;}但是这里的delete就有点疑问了,delete对于内置类型直接释放资源就行,自定义类型的行为是先调用自定义类型的析构函数,再用operator delete释放自定义类型申请的资源。
Node类并没有准备对应的析构函数,它有资源需要释放吗?
其实是没有的,_data就不用说了,就算存的自定义类型,delete也会把它的资源全部释放,_data就像空壳一样,没有资源需要释放了;另外两个指针_next和_prev存储的是结点的值并不是申请的资源,那还是不需要释放资源。所以总得来说根本不需要析构函数释放资源。
list的迭代器失效问题
谈到容器的插入删除数据,我们不仅就想到了,vector的插入和删除数据造成的迭代器失效问题,简单来说就是vector插入数据扩容会直接导致失效,删除数据迭代器不再指向有效元素的位置了。
类比过来想,list的insert有这样的问题吗?
其实是没有的,我们没有扩容,毕竟链表的结点是一个一个申请出来的,不过参考库里的设计:

还是会传迭代器返回,给予更新迭代器的效果,不过按照它的描述,直接返回pos位置的迭代器就行:
iterator insert(iterator pos,const T& x){Node* pcur = pos._node;Node* newnode = new Node(x);Node* prev = pcur->_prev;//prev newnode pcurprev->_next = newnode;newnode->_prev = prev;newnode->_next = pcur;pcur->_prev = newnode;return newnode;}erase呢?画个图很容易就能看到:

pos指向的结点已经被释放了,外部如果原来使用pos位置的迭代器一定是失效了的,所以这里必须添加更新迭代器的行为,标准库定义为:

被删除的元素的下一个元素的位置。
iterator erase(iterator pos){Node* pcur = pos._node;Node* prev = pcur->_prev;Node* next = pcur->_next;prev->_next = next;next->_prev = prev;delete pcur;pcur = nullptr;return next;}当然,这里两个函数的返回值设计都被我弄成隐式类型转换返回了。
有了insert和erase,完善
就跟玩一样:
void push_back(const T& x){insert(end(), x);}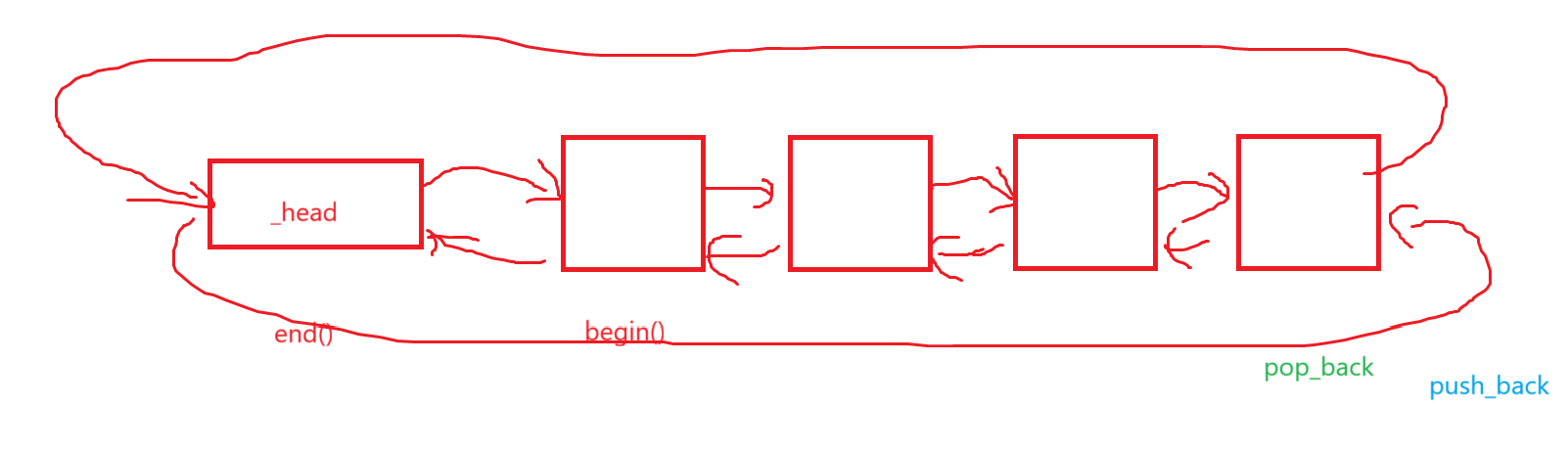
void pop_back(){erase(end()--);}
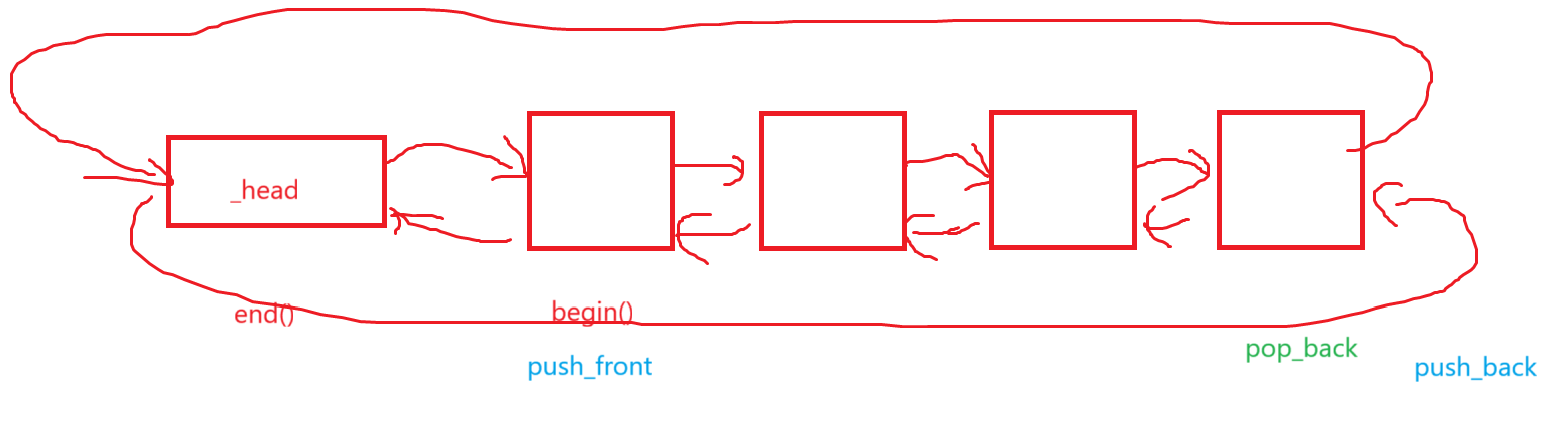
void push_front(const T& x){insert(begin(),x);}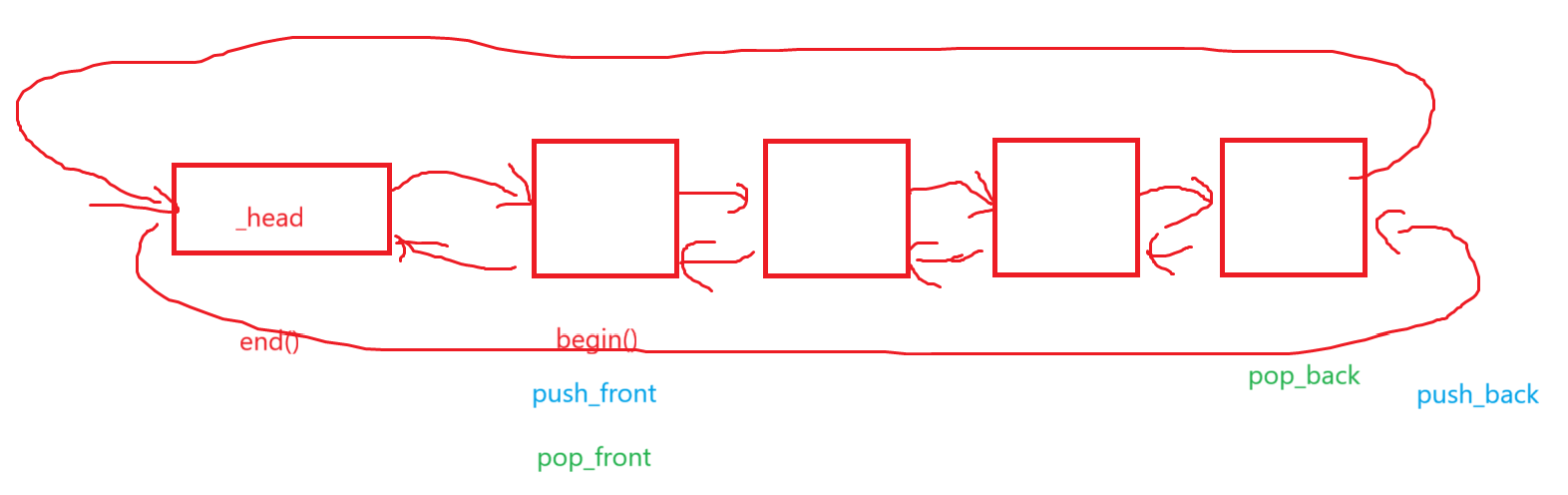
测试代码:

除了这些另外再搞个clear:
void clear(){iterator it = begin();while(it != end()){it = erase(it);}}
利用erase迭代器指向被删元素下一个元素的更新代替自主变更迭代器。
测试代码:
7.list构造函数完善

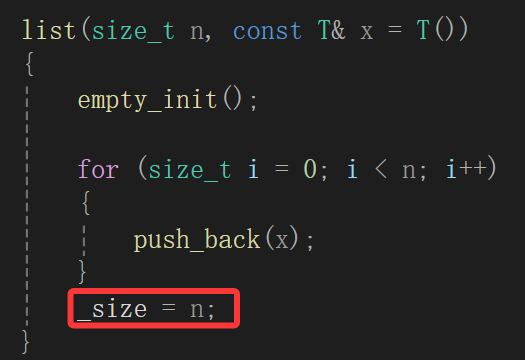
list(size_t n, const T& x = T()){empty_init();for (size_t i = 0; i < n; i++){push_back(x);}_size = n;}
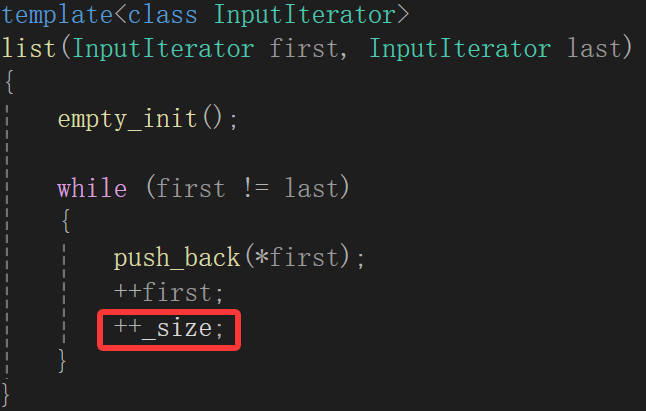
template<class InputIterator>list(InputIterator first, InputIterator last){empty_init();while (first != last){push_back(*first);++first;++_size;}}
list(initializer_list<T> il){empty_init();for (auto& e : il){push_back(e);++_size;}}
拷贝构造和赋值运算符重载
拷贝构造和赋值运算符重载是每个容器实现的关键,因为每个容器都需要对管理的资源做考虑,深拷贝还是浅拷贝合适。
拷贝构造拷贝构造,肯定是通过已有的对象来创建一个新的对象,这样的话这个对象应该先进行资源的申请,资源的初始化再考虑拷贝。
而这个过程:

其实跟默认构造可以说是完全一样,干脆直接:
void empty_init(){_head = new Node;_head->_next = _head;_head->_prev = _head;}list(){empty_init();}list(const list<T>& lt){empty_init();}
不过逻辑没啥难的:
list(const list<T>& lt){empty_init();for (auto& e : lt){push_back(e);}}
赋值运算符重载的实现其实大概想了想,不用初始化了,但是还得一个一个push_back,这个方式我就不写了,直接:
void swap(list<T>& lt){std::swap(_head, lt._head);}list<T>& operator=(const list<T>& lt){list<T> temp(lt);swap(temp);return *this;}8.list类及其子类析构函数
①list类
看了半天,发现自己还没写析构,list的析构就是把结点全部释放,再释放头结点(哨兵结点)。
~list(){clear();delete _head;_head = nullptr;}clear的逻辑其实超级符合析构要求的把结点全部释放。
②Node类
delete调的是Node的析构,而Node:
template <class T>struct _list_node{struct _list_node* _next;struct _list_node* _prev;T _data;_list_node(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}};已经分析过了,没有资源需要释放,简述一下吧再,对于指针,默认生成的析构函数的行为就是类似于_next = _prev = nullptr;也就是摧毁指针,对于_data,存的是类类型的话调用其对应的析构函数,内置类型不做处理。默认行为已经够用。
③iterator类
Node* _node;
iterator类就这么一个成员变量,而且咋说呢,iterator难道还得delete _node嘛,按理来说迭代器只有使用这个指针的权利,毕竟iterator类实际上也没有申请资源,只是替list类管理资源而已,默认析构的行为是直接摧毁指针,其实已经够用了。
同样多说几句,既然没有资源的申请,我们说过,一般析构 拷贝构造 赋值重载是绑在一起的,不妨验证一下:
拷贝构造一般在这里能见到:
但是仔细想想,这里不都要的是最底层的Node*的值嘛,总不会说根据底层的结点的值重新申请一个结点再返回一个Node*吧,这里其实就是要浅拷贝。
赋值运算符重载同理。
九、补充小知识
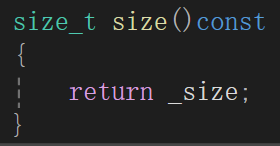
1.size方法
库里面有size方法,这个毋庸置疑
其实真实现大概率就是把链表遍历一遍再计数呗,但是这个方法还是太吃时间复杂度了,我的处理方式也很简单,加一个成员变量_size,专门来记录链表结点个数:

大概思路就是给个缺省值,这样的话不管走哪个构造函数都能将其初始化为0,这个方法省了时间复杂度就苦了我们写代码的了,因为这样的话:
剩下的就不一一展示了,就是看哪些方法会影响_size的值,你对应写点操作就行,重点还是增删查改那里。
不过付出总归还是会有回报的:
至少时间复杂度大降,其实这也有点小智慧在里面,颇有众人拾柴火焰高的意味。
2.typename在模板中的特殊用法

这个Print不太契合我们接下来要讲的场景,所以专门写成给list用的函数模板:

思路也很简单,不再以容器为参数,改为以list所存放的类型做参数,并且内部显式写用迭代器遍历打印,这个时候就碰到事了,说什么iterator类型必须以typename为前缀,也就是:
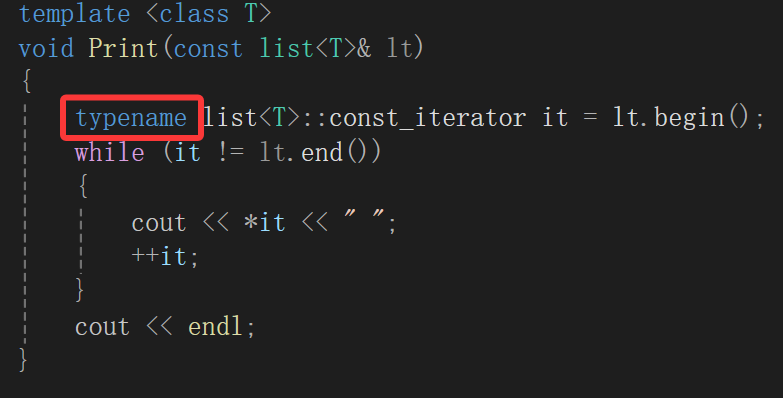
原因大概是这样的,因为这里函数模板内碰见了一个const_iterator,这个玩意还是一个模板list<T>类域里的,我们知道,类型里面除了类型需要这样用类域声明,还有静态成员变量,如果不加typename的话,编译器默认就当成变量来用了,毕竟编译的时候模板又没有被传参初始化,编译器也不能顺着类型去检查,加typename相当于给编译器打了强心剂,告诉它这就是个类型,放心用吧,出了问题我负责。
所以此时随便一个list容器:
