STL简介及string
目录
STL简介
1.2 STL的版本
1.3 STL的六大组件
1.4学习STL的目标
String
2.1string类使用
2.2 auto和范围for重温
2.3 string 类的常用接口说明
2.4string的常见构造
2.4.1容量操作
2.4.2string类对象的访问 及 遍历 操作
编辑
2.4.3string类对象的修改操作
2.4.4 string类非成员函数
STL简介
我们首先来看,什么是stl,我们常说stl是标准模板库。其实这样不对。
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且 是一个包罗数据结构与算法的软件框架。
什么意思呢?
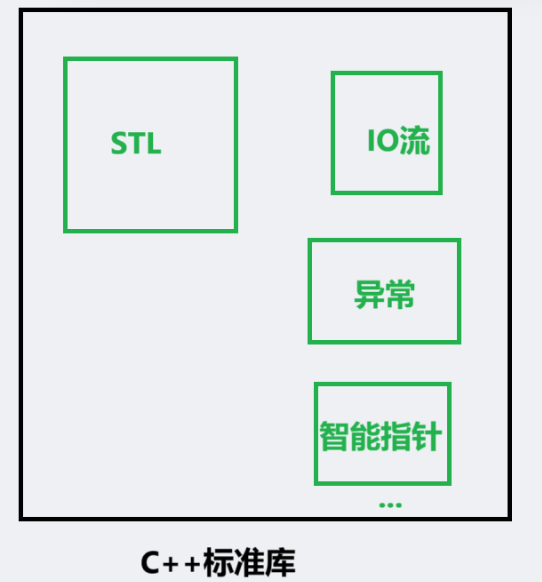
STL是标准库的一部分 !C++标准库还包括其他的库 ,比方如下:
当然IO流和智能指针我们后面讲,这里仅做列举。
1.2 STL的版本
原始版本
Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原始版本一样做开源使用。 HP 版本--所有STL实现版本的始祖。做一个小的知识扩展:(比较出名的闭源和开源有)
闭源 : windows mac os , Oracle
开源 : linux git
P. J. 版本
由P. J. Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。RW版本
由Rouge Wage公司开发,继承自HP版本,被C+ + Builder 采用,不能公开或修改,可读性一般。SGI版本
由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版 本。被GCC(Linux)采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程 风格上看,阅读性非常高。我们后面学习STL要阅读部分源代码,主要参考的就是这个版本。
1.3 STL的六大组件
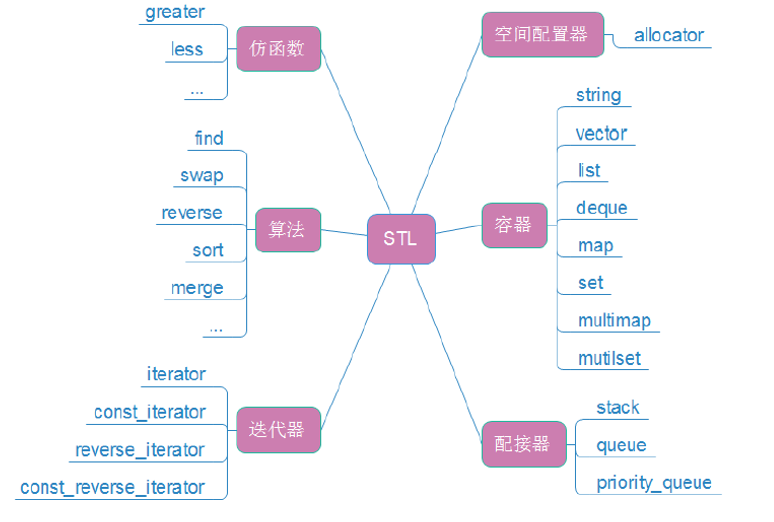
我们再来看STL的六大组件,这些就像我们的工具箱里面的扳手螺丝,各有各的用处。
所以网上有句话说:“不懂STL,不要说你会C++”。STL是C++中的优秀作品,有了它的陪伴,许多底层的数据结构以及算法都不需要自己重新造轮子,站在前人的肩膀上,健步如飞的快速开发。
1.4学习STL的目标

总结一下:学习STL的三个境界:能用,明理,能扩展 。这个我们后面也会在vector的扩容方面有提到。
1.5 STL的缺陷(了解)
1. STL库的更新太慢了。这个得严重吐槽,上一版靠谱是C++98,中间的C++03基本一些修订。C++11出来已经相隔了13年,STL才进一步更新。
2. STL现在都没有支持线程安全。并发环境下需要我们自己加锁。且锁的粒度是比较大的。
3. STL极度的追求效率,导致内部比较复杂。比如类型萃取,迭代器萃取。
4. STL的使用会有代码膨胀的问题,比如使用vector/vector/vector这样会生成多份代码,当然这是模板语法本身导致的。模板进阶的时候会有更深体会
好了解了这些时候,我们再来重温两个知识,直接进入string。
String
2.1string类使用
string 类的文档介绍 :string在c++官网的文档
在使用string 类时 , 必须包含 #include 头文件以及 using namespace std;
2.2 auto和范围for重温
这两个小语法可以极大减轻我们写代码的负担。之前已经见过了,在这里还是用思维导图和实例来带大家来提纲挈领一下。
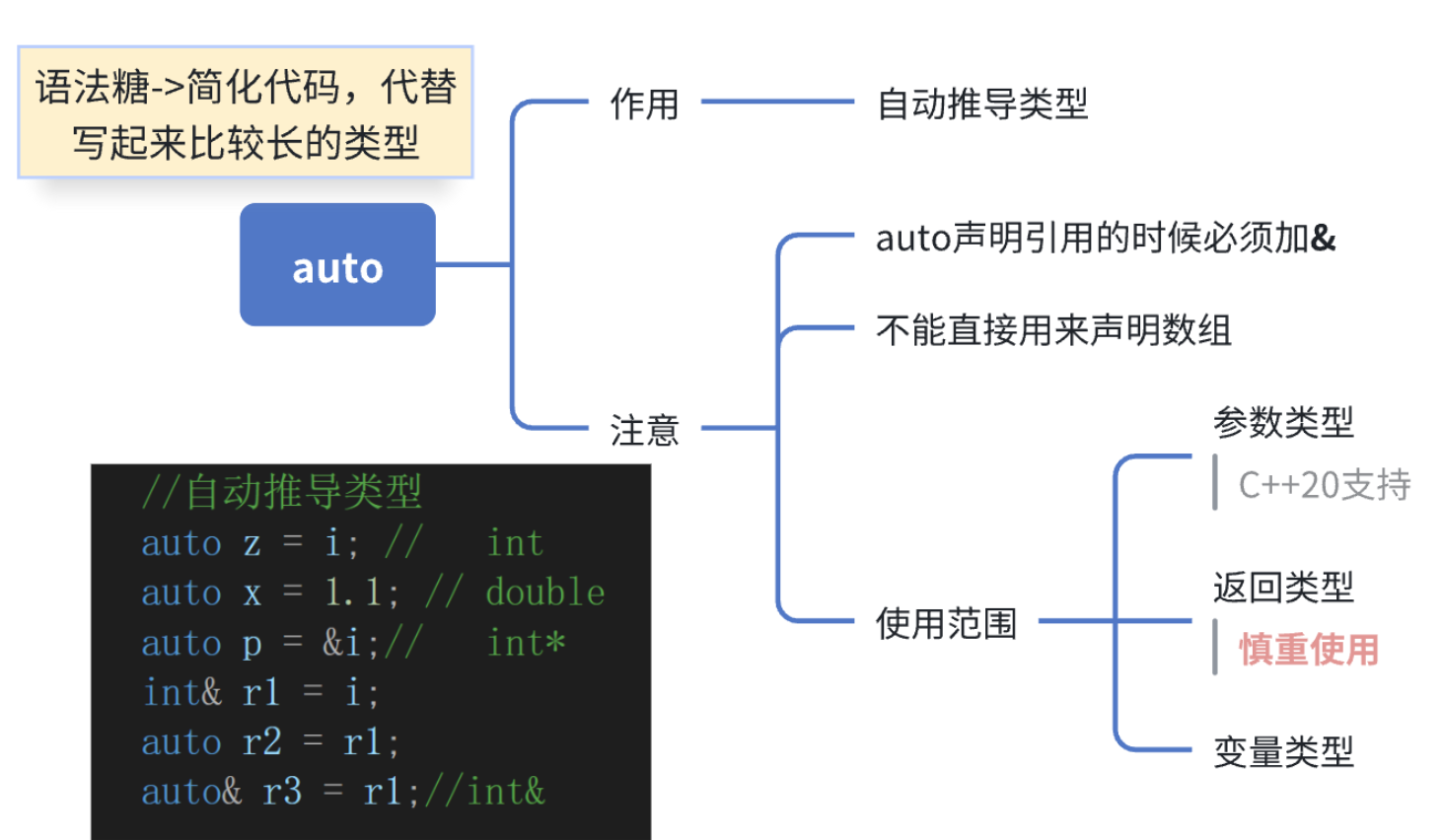

那么,什么时候用auto关键字呢?
#include<iostream>
#include <string>
#include <map>
using namespace std;
int main()
{std::map<std::string, std::string> dict = { { "apple", "苹果" },{ "orange","橙子" }, {"pear","梨"} };// auto的用武之地//std::map<std::string, std::string>::iterator it = dict.begin();auto it = dict.begin();while (it != dict.end()){cout << it->first << ":" << it->second << endl;++it;}return 0;
}范围for 的使用
#include<iostream>
#include <string>
#include <map>
using namespace std;
int main()
{int array[] = { 1, 2, 3, 4, 5 };// C++98的遍历for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i){array[i] *= 2;}for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i){cout << array[i] << " ";}cout << endl;//范围for//语法糖:自动++,自动判断,自动执行for (auto & e : array){e *= 2;}for (auto e : array){cout << e << " ";}cout << endl;return 0;
}这里需要格外注意一个const的使用:

2.3 string 类的常用接口说明
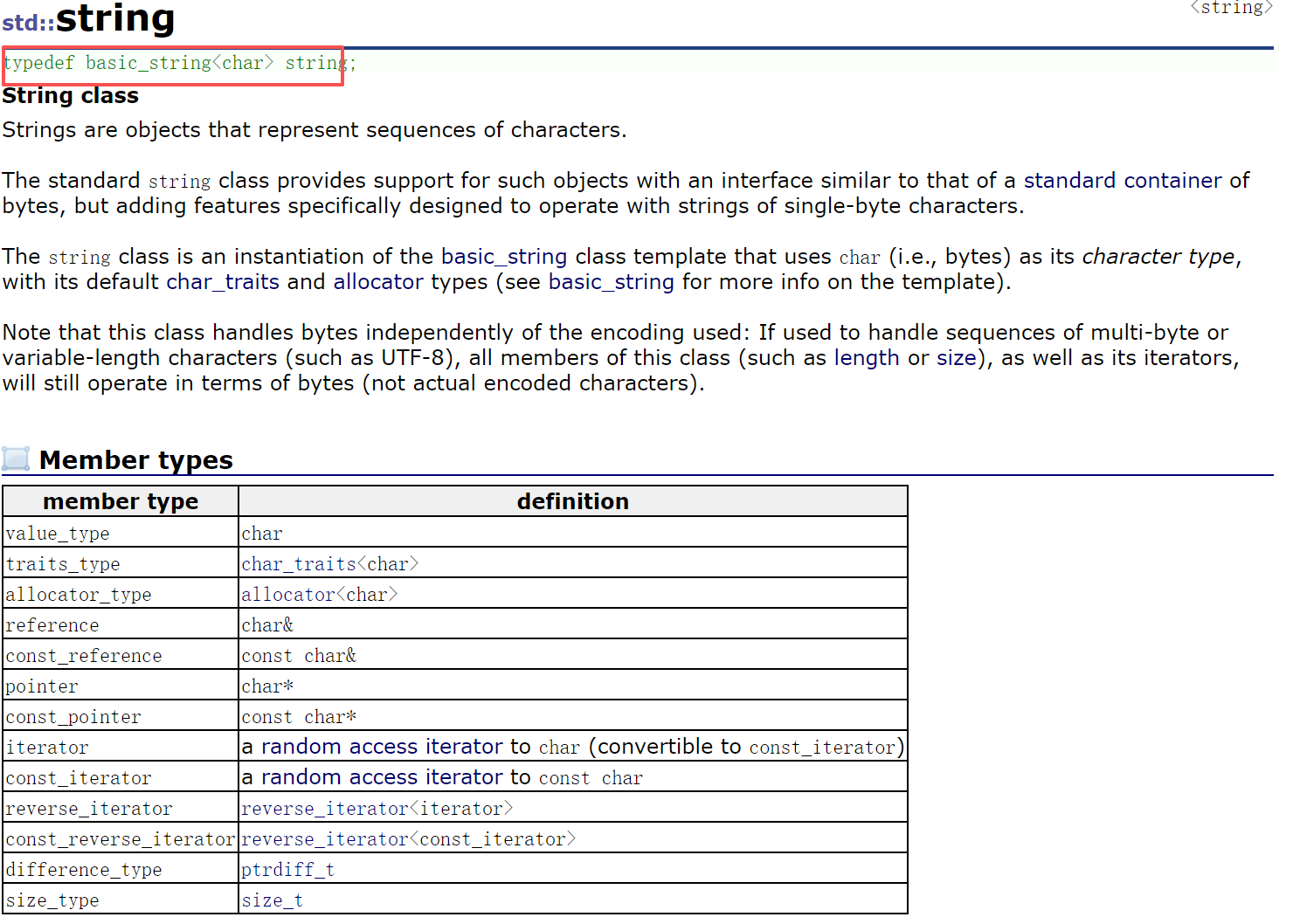
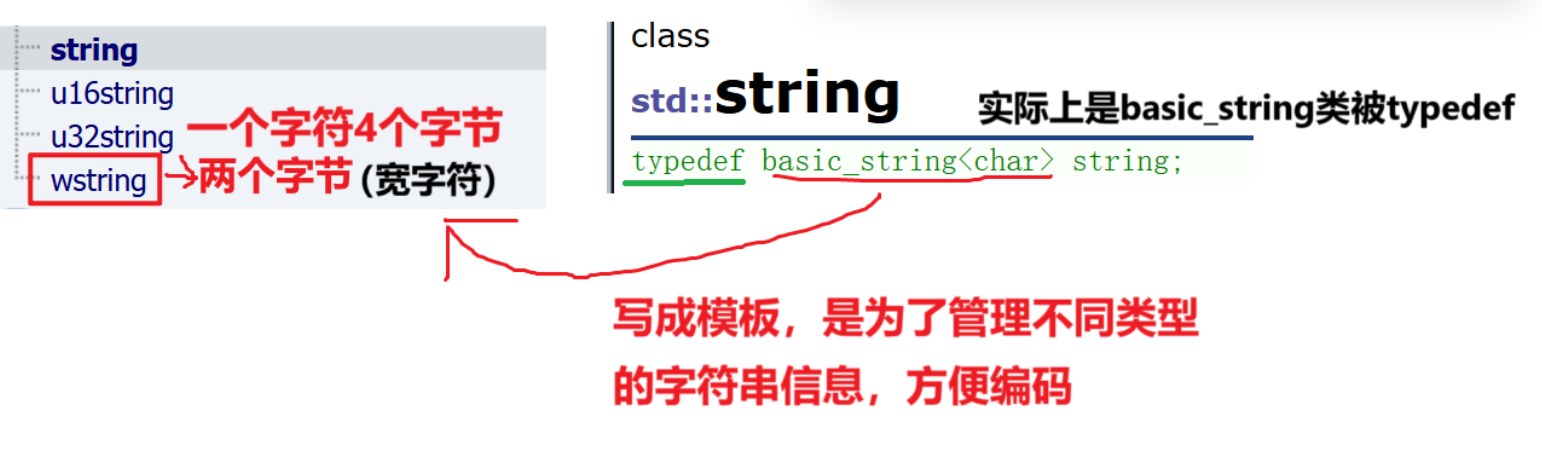
我们会发现string 没在containers , 这是由于历史的原因导致的 , string 出现比STL早 , 但是string 的功能角度看 , 可以把string 归纳到 containers。
我们接下去点开string 来看 , 发现string 实际上是basic_string 类被 typedef , 这里重点学string , 因为接口的高度相似,并且用的最多的是string , 因为string 方便存储在utf8。
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;int main()
{cout << sizeof(char) << endl;cout << sizeof(wchar_t) << endl;cout << sizeof(char16_t) << endl;cout << sizeof(char32_t) << endl;return 0;
}这里我们举例子来看一下,这段代码的输出结果应该是 1 2 2 4 。
2.4string的常见构造
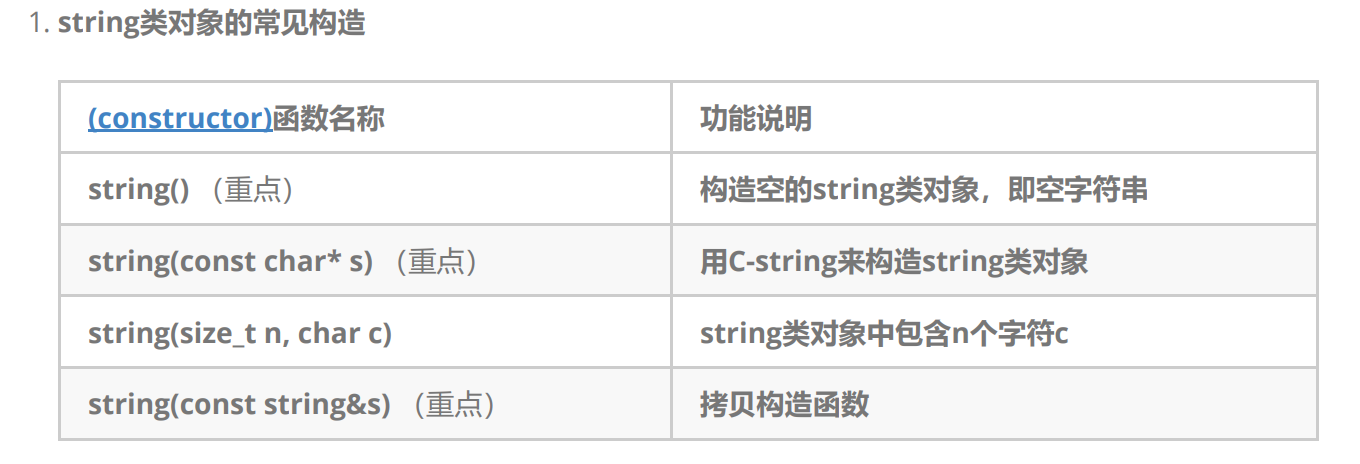

我们观看文档的时候要根据一定的单词半蒙半思考的去猜,string 的构造有很多 , 需要记住是无参构造,有参构造,拷贝构造,其他的了解即可,使用时忘记随时查阅文档 , 无需刻意记忆 , 多练
void Teststring()
{string s1; // 构造空的string类对象s1string s2("hello bit"); // 用C格式字符串构造string类对象s2string s3(s2); // 拷贝构造s3
}2.4.1容量操作
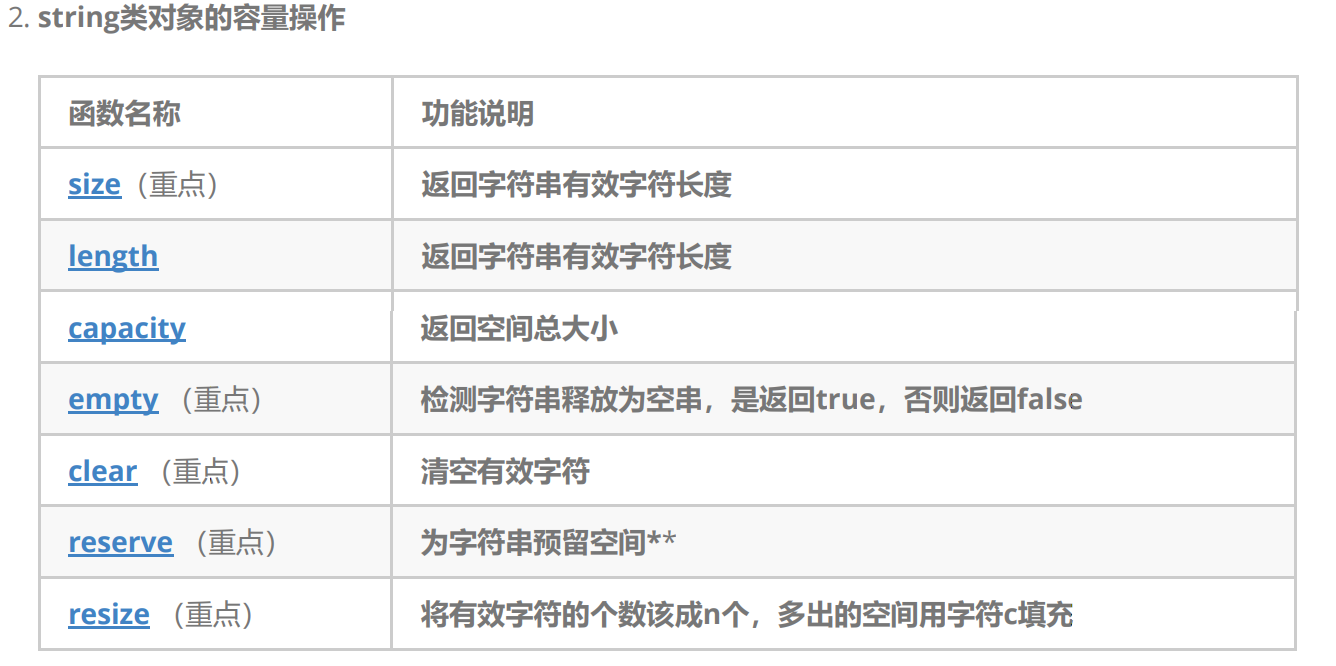
注意 :
1 . size() 与 length() : 方法底层实现原理完全相同 , 引入size()的原因 是为了与其他容器的接口保持一致 , 一般情况下基本都是用size()。
2 . max_size() : 没什么实际意义 ,因为实际中开不了这么大的空间 。
3 . clear() : 只是将string中有效字符清空 , 不改变底层空间大小
4 . capacity() : 返回容量 , 不包含'/0';
size和capacity都不含/0
5.reserve(size_t res_arg=0) : 为string 预留空间 , 不改变有效元素个数 , 当reserve 的参数小于string 的底层空间总大小时 , reserve 不会改变容量大小 。
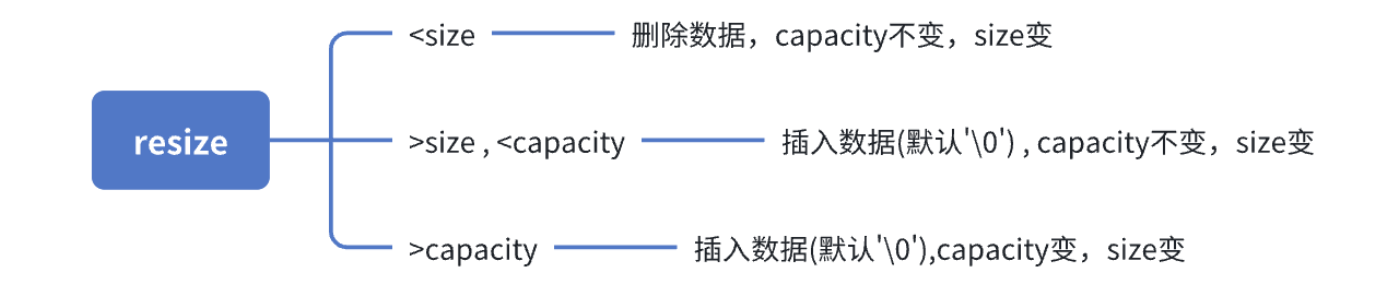
6.resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字 符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的 元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大 小,如果是将元素个数减少,底层空间总大小不变。
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <string>void Test_String1()
{string s("hello world!");cout << s.size() << endl;cout << s.capacity() << endl;//测试reserve是否会改变string中有效元素个数s.reserve(100);cout << s.size() << endl;cout << s.capacity() << endl;//测试reserve参数小于string的底层空间大小时,是否会将空间缩小s.reserve(5);cout << s.size() << endl;cout << s.capacity() << endl;//利用reserve提高插入数据的效率,避免增容带来的开销
}
int main()
{Test_String1();return 0;
}注意:reserve不改变容器的size,一般不用来缩容,一般不确定是否缩容成功,一般用来扩容,提高插入数据的效率,避免增容带来的开销。
再看resize

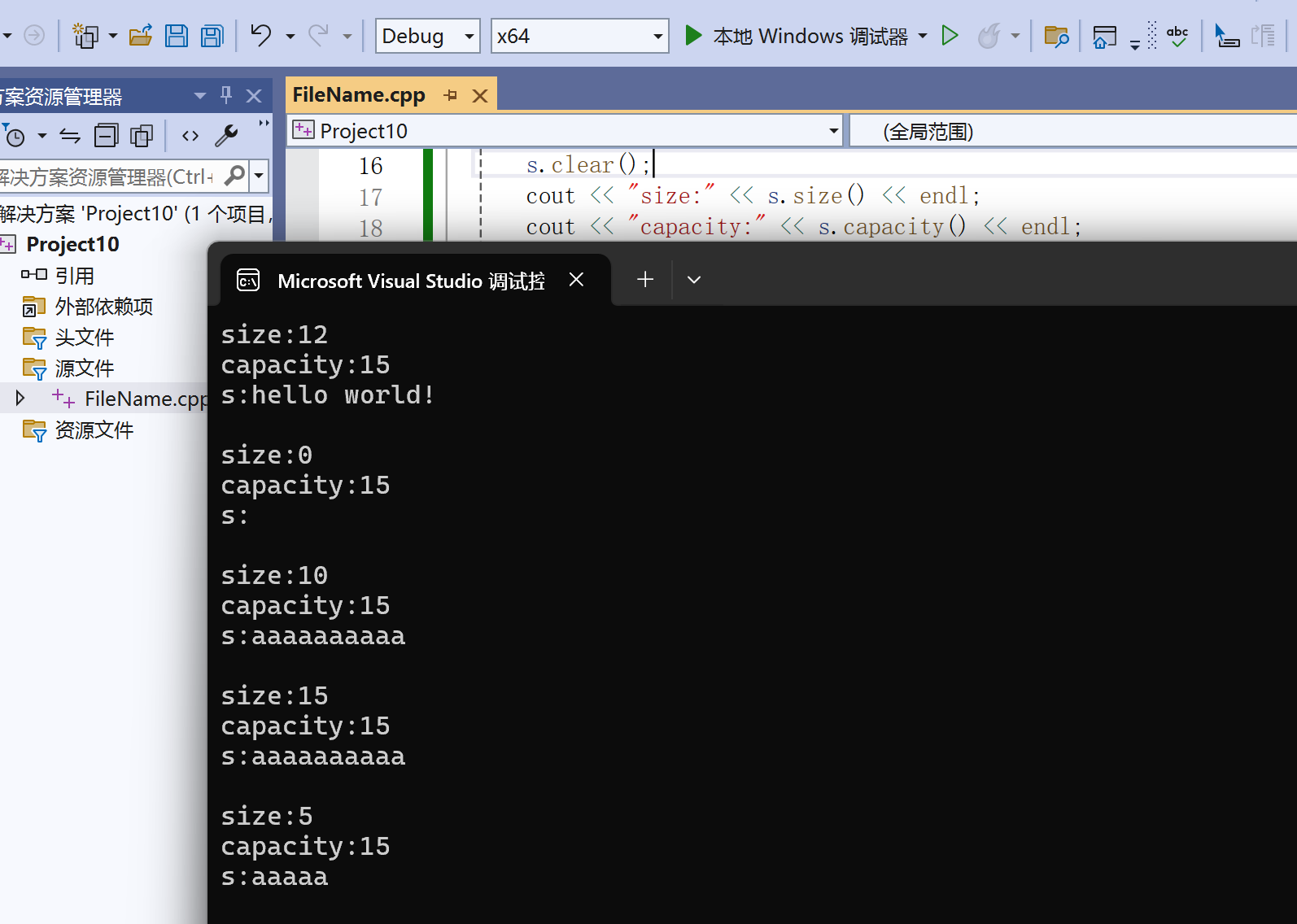
void Test_String2()
{string s("hello world!");cout << "size:"<< s.size() << endl;cout << "capacity:"<<s.capacity() << endl;cout << "s:" << s << endl;cout << endl;//将s中的字符串清空,注意清空时只是将size清0,不改变底层空间s.clear();cout << "size:" << s.size() << endl;cout << "capacity:" << s.capacity() << endl;cout << "s:" << s << endl;cout << endl;//将s中有效字符个数增加到10个,多出位置用'a'进行填充s.resize(10, 'a');cout << "size:" << s.size() << endl;cout << "capacity:" << s.capacity() << endl;cout << "s:" << s << endl;cout << endl;//将s中有效字符个数增加到15个,多出位置用缺省值'\0'进行补充s.resize(15);cout << "size:" << s.size() << endl;cout << "capacity:" << s.capacity() << endl;cout << "s:" << s << endl;cout << endl;//将s中有效字符个数缩小到5个s.resize(5);cout << "size:" << s.size() << endl;cout << "capacity:" << s.capacity() << endl;cout << "s:" << s << endl;cout << endl;
}
2.4.2string类对象的访问 及 遍历 操作

1 )string 类访问对象 : 使用 [] , 或者at

不同点就是 访问失败 的时候返回形式不同 ,at 访问失败会抛异常(程序还会继续跑,比较温和的方式) , [] 访问失败,断言(直接结束程序运行,比较暴力的方式)
2 ) 遍历string 对象的方式 :
1 . 下标 + [ ] : 运算符重载operaror[]
2 . 迭代器
3 . 范围 for
先来看 下标 + [] 的遍历方式 :
#include <string>
int main()
{//无参的构造string st1;//带参的构造string st2("Hello World!");//拷贝构造string st3(st2);string st4(st2, 6, 1000);cout << st1 << endl;cout << st2 << endl;cout << st3 << endl;cout << st4 << endl;//1.下标+[] for (size_t i = 0; i < st2.size(); i++){st2[i] += 1;}for (size_t i = 0; i < st2.size(); i++){cout << st2[i] << " ";}cout << endl;return 0;
}实际上是重载了[] 运算符 , 能够使string 能像数组一样被访问 , 底层的operator[] 如下 :
namespace cyh
{class string{public:char& operator[](size_t pos){assert(pos < _size);return _str[pos];}private:char* _str;size_t _size;size_t _capacity;};
}这里我们就能明白 引用&作为返回值 的意义:减少拷贝,同时可以修改返回值。
再来看 迭代器遍历 :
//2 .迭代器// [ )string::iterator it = st2.begin();while (it != st2.end()){cout << *it << " ";++it;}cout << endl;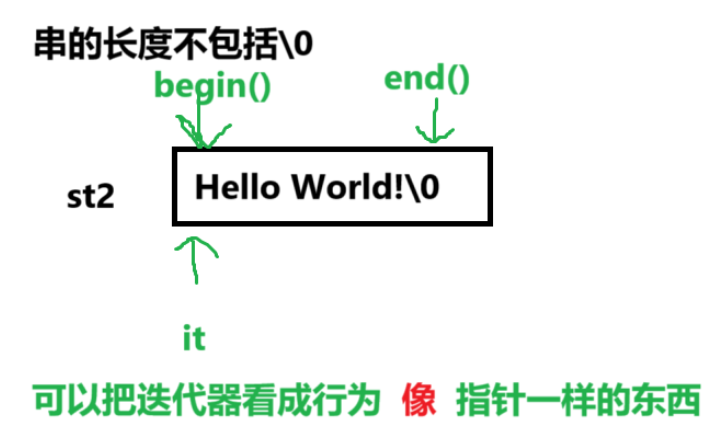 (it != st2.end())
(it != st2.end())
我们这里注意到这里写的是不等于,但是对于string来说,可以改为<,因为底层是数组,前后元素有大小关系但是对于链表等数据结构来说,空间不连续,不能使用,所以建议都写!=。
思考 : 为什么有了 下标 + [] 的遍历方式还需要有 迭代器 呢 ? 前者明明用到更顺。
因为下标 + [] 限制底层必须是数组,像链表就被限制了 , 但迭代器是通用的!
那么有正向迭代器,就一定有反向迭代器,倒着遍历的就是反向迭代器(链表不一定有反向迭代器)后面vector等再深入了解。
string::reverse_iterator rit = st2.rbegin();while (rit != st2.rend()){cout << *rit << endl;++rit;}cout << endl;所以,表面上从上层看有三种遍历方式:下标+[] , 迭代器,返回for , 但是底层就只有两种遍方式 : 下标+[] 和迭代器!(范围for底层就是迭代器)
2.4.3string类对象的修改操作

1 ) push_back() / append() / opeartor+=() 都是在 字符串后追加 (尾插)
2) insert 从某个位置开始插入 : 谨慎使用,头插数据时候 , 后面的数据需要全部往后挪
时间复杂度为O(n)!谨慎使用。
void Test_String3()
{string s("hello world!");s.insert(0, "xxx,");cout << "s:" << s << endl;s.insert(0, 1, 'a');cout << "s:" << s << endl;}注意 :
1 . 在string 尾部追加字符时 , s.push_back(c) / s.append(1,c) / s+='c' 三种的实现方式差不多,一般情况下string类的+=操作用的比较多 , +=操作不仅可以连接单个字符 , 还可以连接字符串 。
2 . 对string 操作时 , 如果能够预估到放多少个字符 , 可以先通过 reserve 把空间预留好 。
3 ) erase: 删除数据

4)c_str : 返回底层的字符串
这个很奇怪,为什么要有c_呢?
其实这个关键字就是为了和C语言保持兼容。 有的时候C++会和 C 进行混合编程 (在写C++的时候 , 必不可少的需要调用的C 的 库 ,C++并不是纯粹的面向对象)。还有一些库可能不会提供C++的接口,仅提供C的接口,有一些数据库就是。

5)find : 查找字符 , 查找成功 , 返回对应位置 。 查找失败 , 返回 npos (无效位置)。

那么这里有问题,如果我想要查找空格并替换字符可以吗?
int main()
{//查找到空格,并且替换成"%%"//方法一:string s1("hello world hello linux!");cout << s1 << endl;size_t i = s1.find(' ');while (i != string::npos){s1.replace(i, 1, "%%");i = s1.find(' ',i+2);}cout << s1 << endl << endl;//方法二:string s2("hello world!");string s3;cout << s2 << endl;for (auto ch : s2){if (ch != ' ')s3 += ch;elses3 += "%%";}cout << s3 << endl;return 0;
}这里给了两种方法,方法一使用 repalce 对找到的有空格的位置替换成 "%%" , 但是会把后面的字符都往后挪动 ,时间复杂度最差为 O(N^2) 。 方法二为遍历一遍,遇到空格再进行替换,时间复杂度为O(N)。
6)rfind : 倒着查找

用的较少,看一下使用场景就行:
2.4.4 string类非成员函数
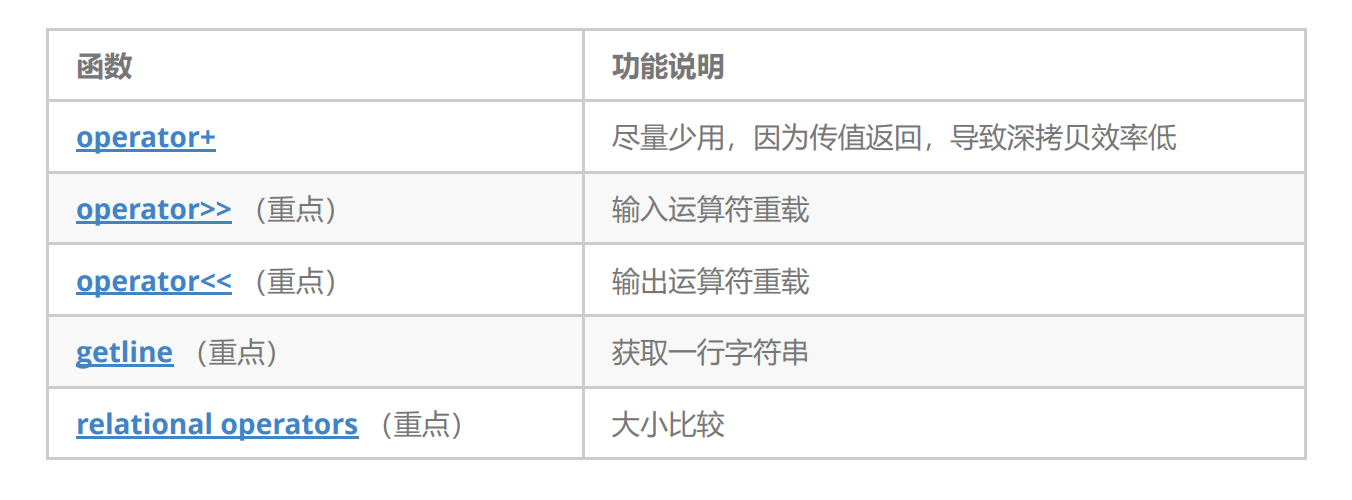
6. find_first_of : 任意一个出现在字符串的字符
这里再补充一类函数
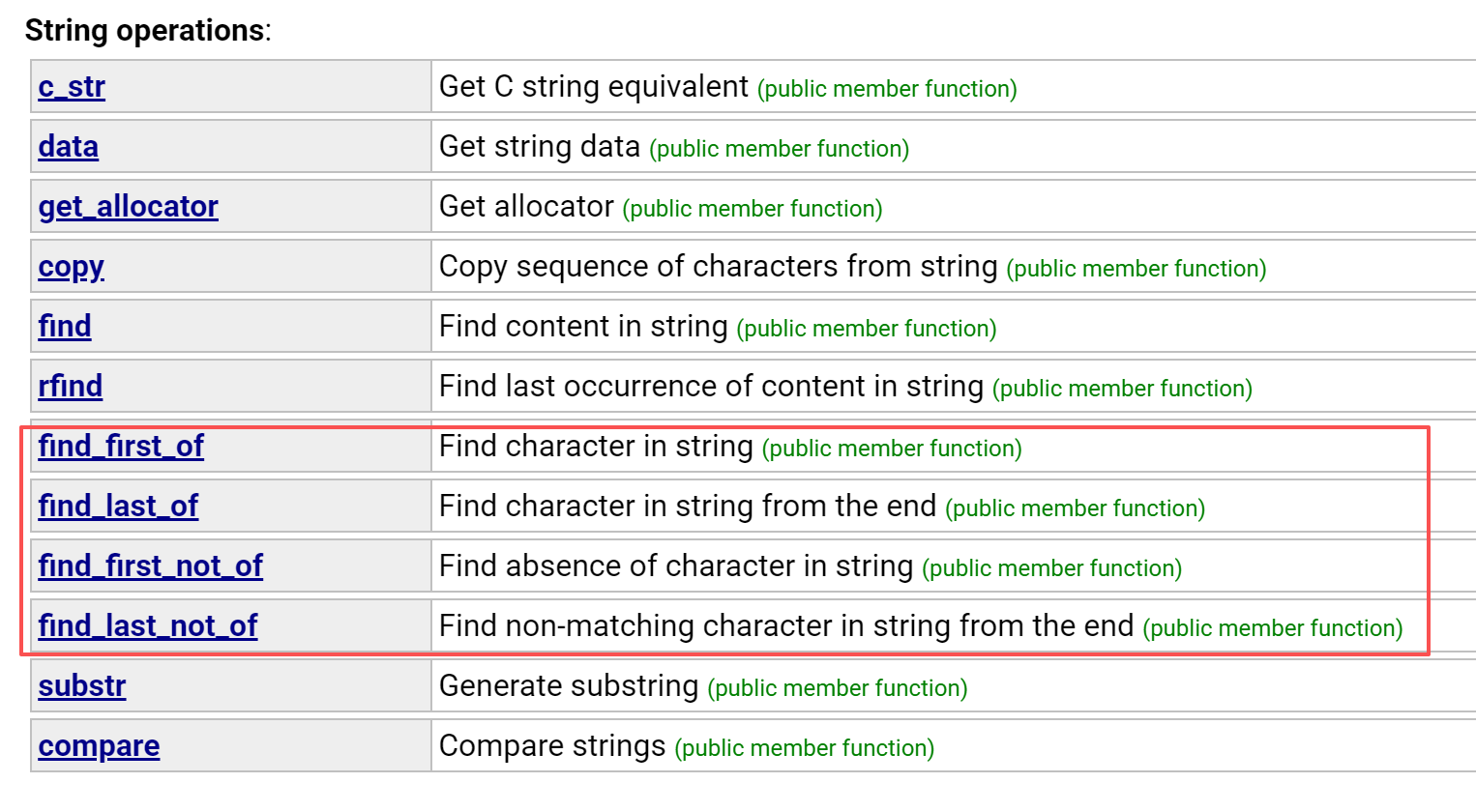 我们看一下 find_first_of 的用法, 类比就行。
我们看一下 find_first_of 的用法, 类比就行。
函数原型:
template <class ForwardIt1, class ForwardIt2>
ForwardIt1 find_first_of(ForwardIt1 first1, ForwardIt1 last1, // 搜索范围 [first1, last1)ForwardIt2 first2, ForwardIt2 last2 // 要查找的元素范围 [first2, last2)
);// C++11 起支持自定义比较函数
template <class ForwardIt1, class ForwardIt2, class BinaryPredicate>
ForwardIt1 find_first_of(ForwardIt1 first1, ForwardIt1 last1,ForwardIt2 first2, ForwardIt2 last2,BinaryPredicate p // 自定义比较规则
);使用实例
#include <algorithm>
#include <vector>
#include <iostream>int main() {std::vector<int> data = {1, 2, 3, 4, 5, 6};std::vector<int> targets = {10, 3, 5}; // 要查找的元素// 在 data 中查找 targets 里的任意元素auto it = std::find_first_of(data.begin(), data.end(),targets.begin(), targets.end());if (it != data.end()) {std::cout << "第一个匹配的元素是: " << *it << std::endl;std::cout << "位置在: " << std::distance(data.begin(), it) << std::endl;} else {std::cout << "没有找到匹配的元素" << std::endl;}return 0;
}