大数据电商流量分析项目实战:可视化 数据分析(九)


✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:大数据、Java、测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨

前言&课程重点
大家好,我是程序员小羊!接下来一周,咱们将用 “实战拆解 + 技术落地” 的方式,带大家吃透一个完整的大数据电商项目 ——不管你是想靠项目经验敲开大厂就业门,还是要做毕业设计、提升技术深度,这门课都能帮你 “从懂概念到能落地”。
毕竟大数据领域不缺 “会背理论” 的人,缺的是 “能把项目跑通、能跟业务结合” 的实战型选手。咱们这一周的内容,不搞虚的,全程围绕 “电商业务痛点→数据解决方案→技术栈落地” 展开,每天聚焦 1 个核心模块,最后还能输出可放进简历的项目成果。
进入正题:
本项目是一门实战导向的大数据课程,专为具备Java基础但对大数据生态系统不熟悉的同学量身打造。你将从零开始,逐步掌握大数据的基本概念、架构原理以及在电商流量分析中的实际应用,迅速融入当下热门的离线数据处理技术。
在这门课程中,你将学会如何搭建和优化Hadoop高可用环境,了解HDFS存储、YARN资源调度的核心原理,为数据处理打下坚实的基础。同时,你将掌握Hive数据仓库的构建和数仓建模方法,了解如何将海量原始数据经过层次化处理,转化为高质量的数据资产。
课程还将引领你深入Spark SQL的世界,通过实际案例学习如何利用Spark高效计算PV、UV以及各类衍生指标,提升数据分析效率。此外,你还将学习Flume的安装与配置,实现Web日志的实时采集和ETL入仓,确保数据传输的稳定与高效。
为了贴近企业实际运作,本项目还包括定时任务的设置和自动化数据管道构建,教你如何编写Shell脚本并利用crontab定时调度Spark作业,让数据处理过程实现自动化与智能化。最后,通过可视化展示模块,你将学会用FineBI等工具将数据分析结果直观呈现
总之,这是一门集大数据基础、系统搭建、数据处理与智能分析于一体的全链路实战课程。无论你是初入大数据领域的新手,还是希望提升数据处理能力的开发者,都将在这里收获满满,掌握最前沿的大数据技术。
课程计划:
| 天数 | 主题 | 主要内容 |
|---|---|---|
| Day 1 | 大数据基础+项目分组 (ZK补充) | 大数据概念、数仓建模、组件介绍、分组;简单介绍项目。 |
| Day 2 | Hadoop初认识+ HA环境搭建 | 初认识Hadoop,了解HDFS 基本操作,YARN 资源调度,数据存储测试等,并且完成Hadoop高可用的环境搭建。 |
| Day 3 | Hive 数据仓库 | Hive SQL 基础、表设计、加载数据,搭建Hive环境并融入Hadoop实现高可用 |
| Day 4 | Spark SQL 基础 | 讲解Spark基础,DataFrame & SQL 查询,Hive 集成和环境的搭建 |
| Day 5 | Flume 数据采集及ETL入仓 | 安装Flume高可用,学习基础的Flume知识并且使用Flume 采集 Web 日志,存入 HDFS;数据格式解析,数据传输优化 |
| Day 6 | 数据入仓 & 指标计算 | 解析 PV、UV 计算逻辑,Hive 数据清洗、分层存储(ODS → DWD) |
| Day 7 | Spark 计算 & 指标优化 | 使用 Spark SQL 计算 PV、UV 及衍生指标(如跳出率、人均访问时长等) |
| Day 8 | 定时任务 & 数据管道 | 编写 Shell 脚本,使用 crontab 实现定时任务,调度 Spark SQL |
| Day 9 | 可视化 & 数据分析 | 搭建一个简单的项目使用 FineBI 进行数据展示,分析趋势。 |
| Day 10 | 项目答辩 | 小组演示分析结果,可以后台联系程序员小羊点评 |
今日学习重点(可视化 & 数据分析):
FineBI概述
FineBI是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品,其定位是一个大数据自助分析工具,旨在帮助企业的业务人员充分了解和利用他们的数据。
FineBI商业智能软件 - 自助大数据分析工具
FineBI商业智能软件 - 自助大数据分析工具
FineBI部署
FineBI 是一款纯 B/S 端的商业智能分析服务平台;支持通过 Web 应用服务器将其部署在服务器上,提供企业云服务器。用户端只需要使用一个浏览器即可进行服务平台的访问和使用。
软件分为免费试用版和商用版,免费试用版享有全部功能,不限制时间,但限制2个并发,而商业版无限制。

点击免费试用,注册并且登录账号。

注册登录后选择学习和竞赛方向用途即可。之后会出现一个激活码,先复制我们先安装软件:windows-x64_FineBI6_1-CN.exe https://cloud.189.cn/web/share?code=NzuA3aiiYNFf(访问码:fad9)
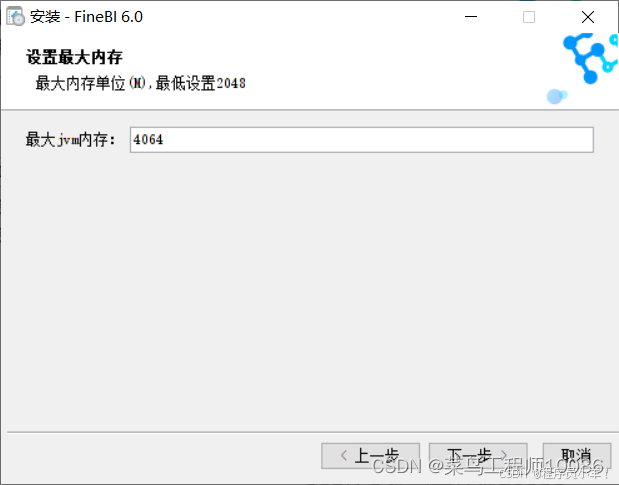
选择给予内存,根据电脑性能而定

正常安装后输入刚刚的激活码确定即可。最后打开软件等待之后会进入一个内部网页完成初始化选择内部数据库即可,软件安装和部署完成。

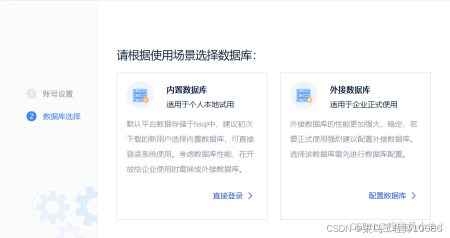
配置Hive连接驱动
-
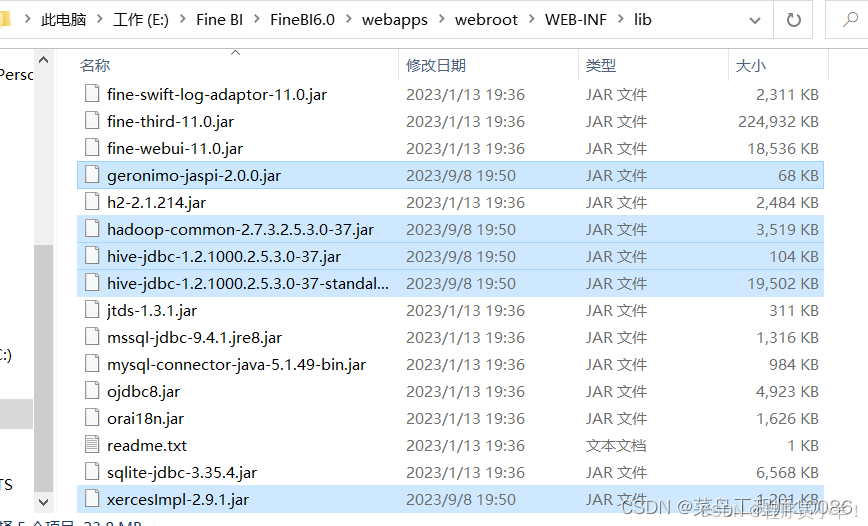
在FineBI安装目录进入FineBI6.0\webapps\webroot\WEB-INF\lib此文件夹(安装目录)
-
下载Jar包 粘贴jar包到里面即可,下载地址:Hadoop Hive(fineBI连接驱动) https://cloud.189.cn/web/share?code=NzuA3aiiYNFf(访问码:fad9)
-
安装插件 打开Fine BI管理系统、打开插件管理
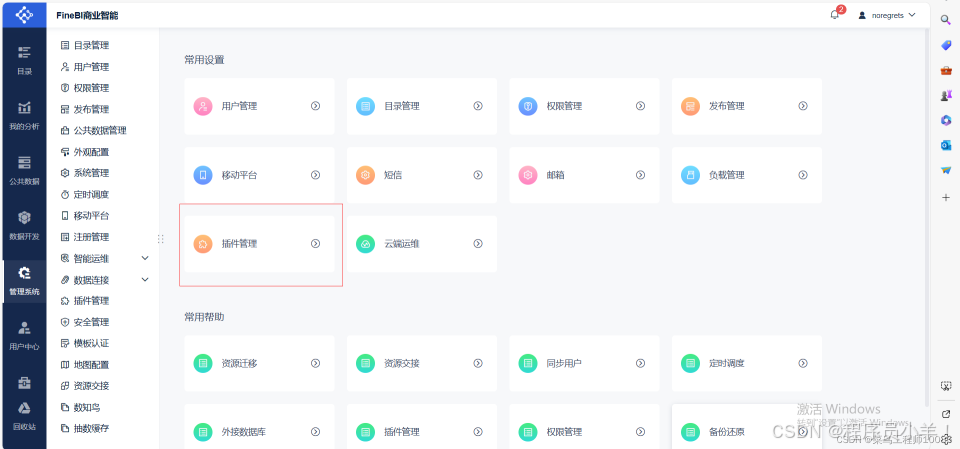
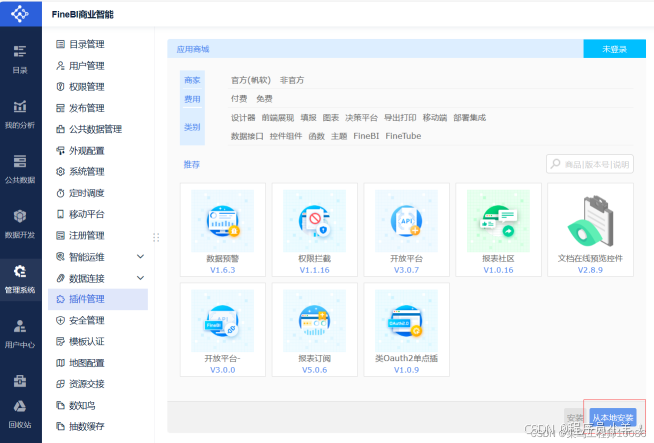
点击本地安装 安装插件包 安装成功后重启程序,重新登录即可。 (插件包名:fr-plugin-hive-driver-loader-3.0.zip) https://cloud.189.cn/web/share?code=NzuA3aiiYNFf(访问码:fad9) 安装完成后重启软件!重启软件!
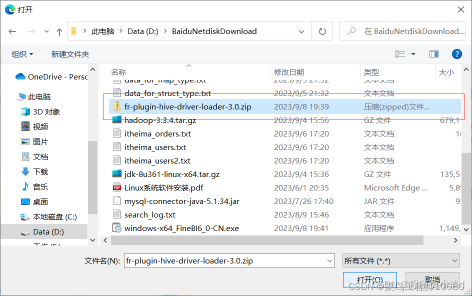
-
新建Hive连接 在数据连接里点击数据连接管理 选择新建连接;点击所有,找到Hadoop Hive
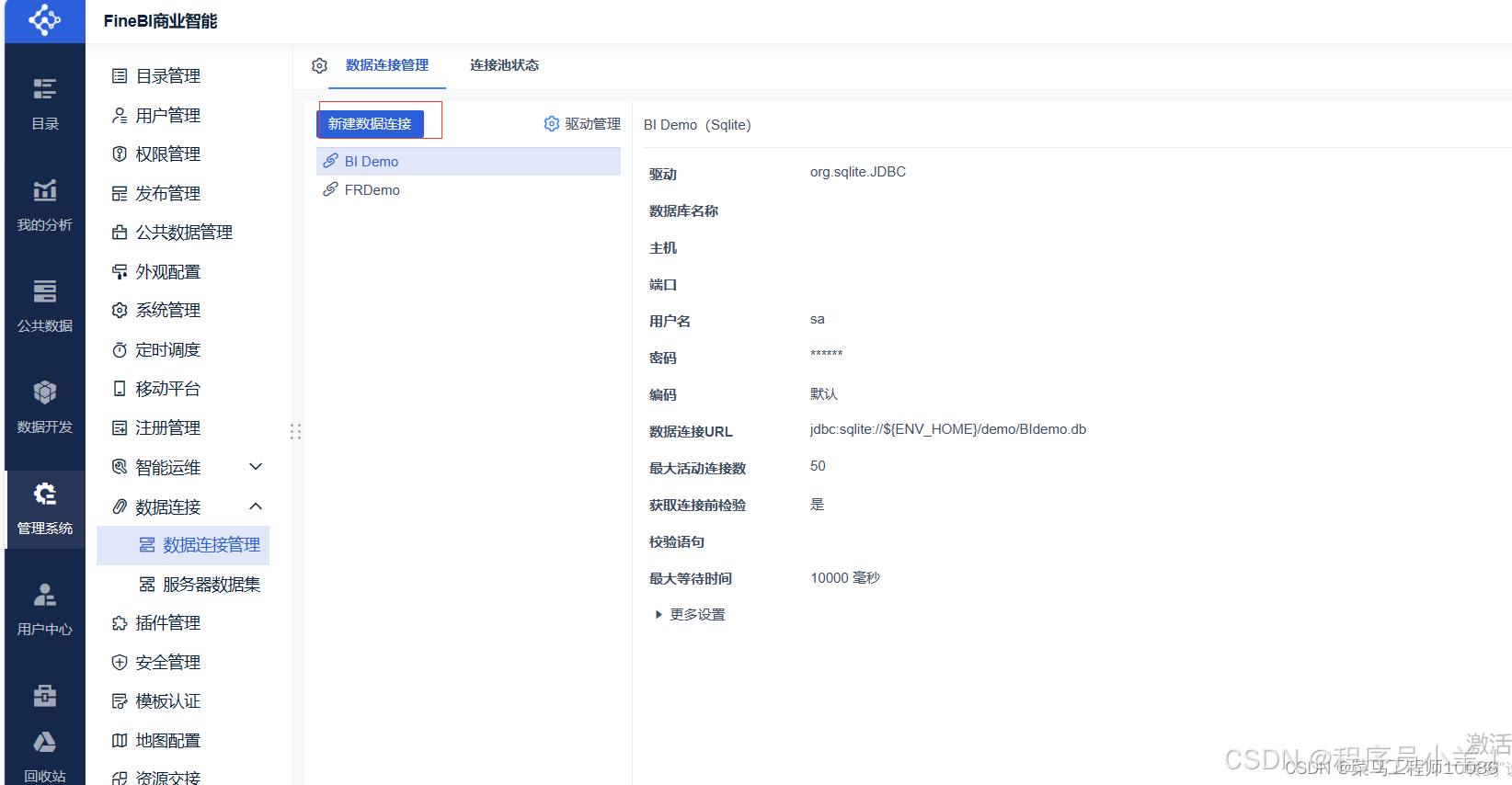

-
填写信息,密码不用填然后点击测试连接,注意数据库选择 ads,点击连接确定即可。
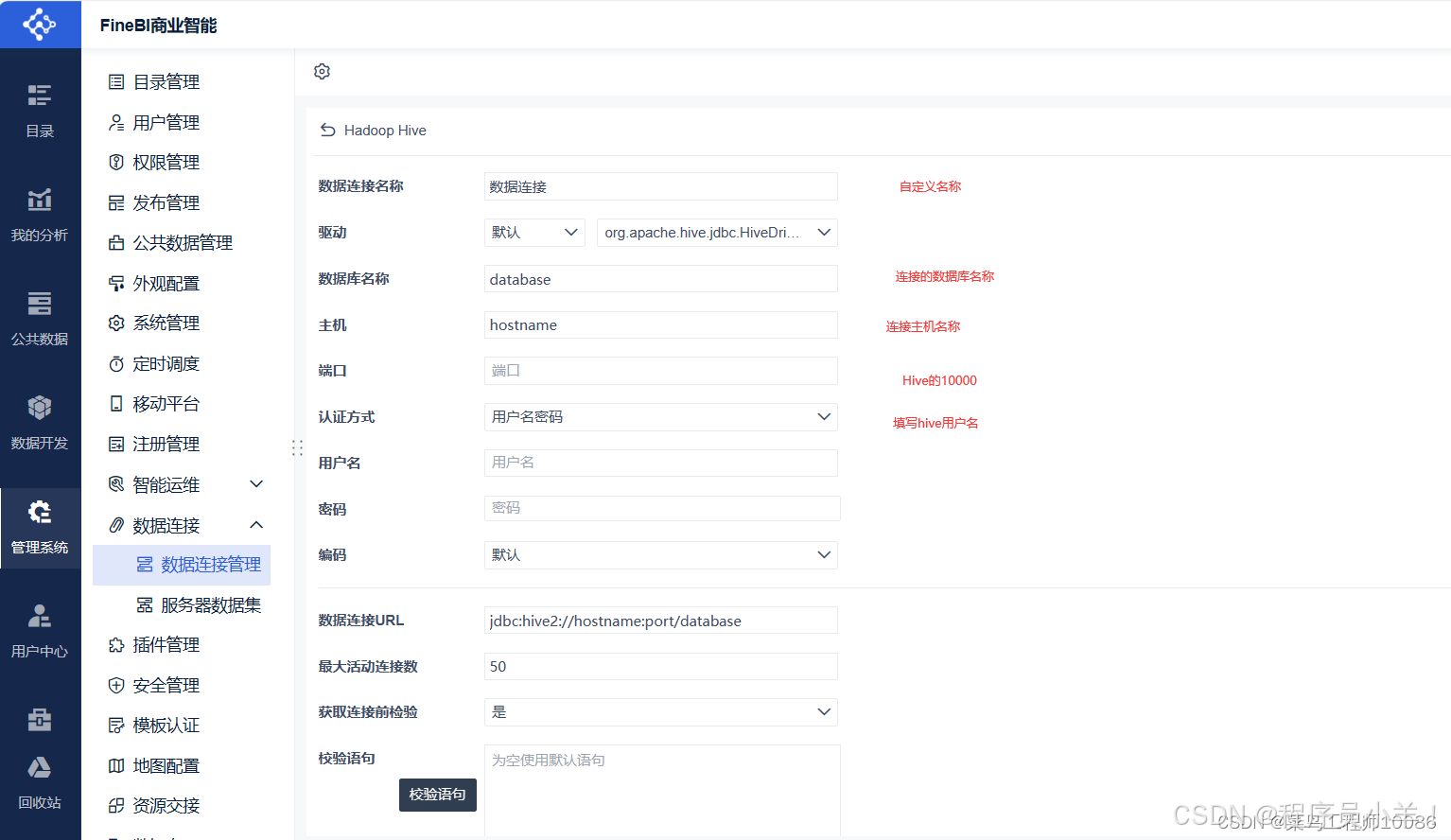
- 同样的原理,添加Spark 端口 10015 需要注意
步骤:
制作一个BI展示图
结尾:
本课程是一门以电商流量数据分析为核心的大数据实战课程,旨在帮助你全面掌握大数据技术栈的核心组件及其在实际项目中的应用。从零开始,你将深入了解并实践Hadoop、Hive、Spark和Flume等主流技术,为企业级电商流量项目构建一个高可用、稳定高效的数据处理系统。
在课程中,你将学习如何搭建并优化Hadoop高可用环境,熟悉HDFS分布式存储和YARN资源调度机制,为大规模数据存储与计算奠定坚实基础。随后,通过Hive数据仓库的构建与数仓建模,你将掌握如何将原始日志数据进行分层处理,实现数据清洗与结构化存储,从而为后续数据分析做好准备。
借助Spark SQL的强大功能,你将通过实战案例学会快速计算和分析关键指标,如页面浏览量(PV)、独立访客数(UV),以及通过数据比较获得的环比、等比等衍生指标。这些指标将帮助企业准确洞察用户行为和流量趋势,为优化营销策略提供科学依据。
同时,本课程还包含Flume数据采集与ETL入仓的实战模块,教你如何采集实时Web日志数据,并利用ETL流程将数据自动导入HDFS和Hive,确保数据传输和处理的高效稳定。
总体来说,这门课程面向希望提升大数据应用能力的技术人员和企业项目团队,紧密围绕公司电商流量项目的实际需求展开。通过系统的理论讲解与动手实践,你不仅能够构建从数据采集、存储、处理到可视化展示的完整数据管道,还能利用PV、UV、环比、等比等关键指标,全面掌握电商流量数据分析的核心技能。
今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文
