shell脚本练习:文件检查与拷贝
本篇来学习shell脚本,通过一个文件检查与拷贝的实例,来学习shell脚本的一些语法。
1 功能说明
在Linux系统中,通过一个shell脚本,实现将一个目录中的所有文件(包括子目录中的),拷贝到顶一个指定的目录,要求:
- 在拷贝前,先检查两个目录中文件的MD5是否一样,不一样的才拷贝
- 若需要拷贝,先打印出需要拷贝文件数目,以及可能缺失的子目录数目,并提示是否执行拷贝
- 确认拷贝后,再执行拷贝,并打印详细的拷贝信息
2 脚本实现
下面分功能模块来讲解脚本。
2.1 源目录与目标目录
SRC_DIR="./curl-8.15.0" # 源目录路径
DEST_DIR="./curl-8.15.0-test2" # 目标目录路径# 确保目录路径不以斜杠结尾,避免路径处理问题
SRC_DIR=${SRC_DIR%/}
DEST_DIR=${DEST_DIR%/}# 检查源目录是否存在
if [ ! -d "$SRC_DIR" ]; thenecho "错误:源目录 $SRC_DIR 不存在!"exit 1
fi# 检查目标目录,不存在则创建
if [ ! -d "$DEST_DIR" ]; thenecho "目标目录 $DEST_DIR 不存在,正在创建..."mkdir -p "$DEST_DIR" || { echo "创建目标目录失败!"; exit 1; }
fi
2.2.1 确保目录路径不以斜杠结尾
移除变量SRC_DIR末尾可能存在的斜杠/,避免后续拼接路径时出现重复的斜杠
SRC_DIR=${SRC_DIR%/}
其语法为:
${变量%模式}
会从变量值的末尾开始匹配 “模式”,并删除最短的匹配部分(这里用到的模式就是那个斜杠)
- 如果
SRC_DIR的值本身不带斜杠(如src),则该操作不改变原变量 - 如果
SRC_DIR的值带斜杠(如src/或./src/),则会删除末尾的斜杠,变成src或./src
2.2.2 检查目录是否存在
在进行文件检查前,需要先检查对应的目录是否存在
if [ ! -d "$SRC_DIR" ]; then#...
fi
在 Shell 脚本中,-d是一个文件测试运算符,用于检查指定的路径是否为一个目录(directory),类似的常用文件测试运算符还有:
-f:检查是否为普通文件(不是目录)-e:检查路径是否存在(无论是文件还是目录)-r:检查是否有读权限-w:检查是否有写权限
再来看下if [ ! -d "$SRC_DIR" ]的语法:
[ ]是 Shell 的条件判断语法!表示取反-d "$SRC_DIR"检查变量$SRC_DIR对应的路径是否为一个存在的目录
2.2 统计源目录的总文件数和总目录数
这里使用Shell 脚本中的命令替换(Command Substitution)语法,来计算指定目录下的普通文件总数
# 统计源目录的总文件数和总目录数
TOTAL_FILES=$(find "$SRC_DIR" -type f | wc -l)
TOTAL_DIRS=$(find "$SRC_DIR" -type d | wc -l)
# 减去源目录本身
TOTAL_DIRS=$((TOTAL_DIRS - 1))echo "源目录总文件数: $TOTAL_FILES"
echo "源目录总目录数: $TOTAL_DIRS"
具体解释下这句
TOTAL_FILES=$(find "$SRC_DIR" -type f | wc -l)
find是用于查找文件和目录的命令"$SRC_DIR"是查找的起始目录(使用变量引用,双引号处理路径中的空格)-type f是find的参数,指定只查找普通文件(排除目录、链接等),除了f参数,还可以有d:目录(directory)l:符号链接(symbolic link)b:块设备文件(block special file),通常指存储设备(如硬盘分区)c:字符设备文件(character special file),通常指输入输出设备(如键盘、终端)p:管道文件(named pipe/FIFO),用于进程间通信的特殊文件s:套接字文件(socket),用于网络或进程间通信的特殊文件
|管道符,是将前一个命令(find)的输出作为后一个命令(wc -l)的输入wc是用于统计的命令(Word Count ),后面的参数可以为-l参数表示统计行数(每行对应一个文件路径)-w单词数-c字节数-m字符数
$(...)是命令替换语法,将括号内命令的输出结果作为字符串返回,给前面的TOTAL_FILES变量赋值
2.3 通过MD5对比文件是否一样
# 创建临时文件存储需要处理的项目
TMP_FILE=$(mktemp)# 递归遍历源目录下所有文件,使用临时文件解决子shell变量问题
find "$SRC_DIR" -type f | while read -r src_file; do# 计算相对路径rel_path="${src_file#$SRC_DIR/}"dest_file="$DEST_DIR/$rel_path"dest_dir=$(dirname "$dest_file")# 计算源文件MD5src_md5=$(md5sum "$src_file" | awk '{print $1}')# 计算目标文件MD5(如果存在)if [ -f "$dest_file" ]; thendest_md5=$(md5sum "$dest_file" | awk '{print $1}')elsedest_md5="不存在"fi# 比较MD5,不同则记录到临时文件if [ "$src_md5" != "$dest_md5" ]; thenecho "MD5不同: $rel_path"echo " 源文件: $src_md5"echo " 目标文件: $dest_md5"echo "----------------------------------"# 只记录不存在的目录if [ ! -d "$dest_dir" ]; thenecho "DIR:$dest_dir" >> "$TMP_FILE"fi# 记录需要复制的文件echo "FILE:$src_file:$dest_file:$rel_path" >> "$TMP_FILE"fi
done# 从临时文件读取数据并去重
NEED_CREATE_DIRS=($(grep "^DIR:" "$TMP_FILE" | sort -u | cut -d: -f2-))
NEED_COPY_FILES=($(grep "^FILE:" "$TMP_FILE" | sort -u))# 删除临时文件
rm -f "$TMP_FILE"
2.3.1 创建临时文件
TMP_FILE=$(mktemp)
解释含义:
mktemp:一个专门用于创建临时文件的命令,会在系统的临时目录(通常是/tmp)中生成一个唯一的临时文件,并返回该文件的完整路径$(...):命令替换语法,将mktemp命令的输出结果,即临时文件的路径,赋值给TMP_FILE变量
2.3.2 遍历每个文件
find "$SRC_DIR" -type f | while read -r src_file; do#...
done
解释含义:
find "$SRC_DIR" -type f用于查找$SRC_DIR目录下所有的普通文件(-type f),并输出每个文件的完整路径(一行一个路径)while循环:持续读取输入内容,直到没有更多内容为止read -r src_file:从输入中读取一行内容,并将其保存到变量src_file中-r选项用于防止read命令对输入中的反斜杠\进行转义,保证路径的完整性
2.3.3 计算路径
从源目录文件的完整路径中提取出相对路径,然后根据目标位置,组成目标文件的路径
rel_path="${src_file#$SRC_DIR/}"
dest_file="$DEST_DIR/$rel_path"
dest_dir=$(dirname "$dest_file")
解释一下:
${变量#模式},从变量值的开头开始匹配 “模式”,并删除最短的匹配部分src_file,存储着文件的完整路径,例如/home/user/src/docs/readme.txt$SRC_DIR/,作为匹配的前缀模式,例如/home/user/src/rel_path,最终得到docs/readme.txt
$DEST_DIR/$rel_path,拼接成目标文件的路径,例如/home/user/src2/docs/readme.txtdirname,从文件路径中提取其所在的目录部分,例如/home/user/src2/docs
2.3.4 计算MD5
# 计算源文件MD5
src_md5=$(md5sum "$src_file" | awk '{print $1}')# 计算目标文件MD5(如果存在)
if [ -f "$dest_file" ]; thendest_md5=$(md5sum "$dest_file" | awk '{print $1}')
elsedest_md5="不存在"
fi
解释一下这句:
md5sum "$src_file" | awk '{print $1}'
-
md5sum是一个计算文件 MD5 哈希值的命令,能生成一个唯一标识文件内容的 32 位十六进制字符串-
"$src_file"是要计算哈希值的文件路径 -
该命令的输出格式通常是:
[MD5值] [文件名]
-
-
awk是文本处理工具,$1表示取行中的第一个字段,即MD5的值
2.3.5 比较MD5
if [ "$src_md5" != "$dest_md5" ]; thenecho "MD5不同: $rel_path"echo " 源文件: $src_md5"echo " 目标文件: $dest_md5"echo "----------------------------------"# 只记录不存在的目录if [ ! -d "$dest_dir" ]; thenecho "DIR:$dest_dir" >> "$TMP_FILE"fi# 记录需要复制的文件echo "FILE:$src_file:$dest_file:$rel_path" >> "$TMP_FILE"
fi
解释下这句:
echo "DIR:$dest_dir" >> "$TMP_FILE"
echo用于输出字符串"DIR:$dest_dir"是要输出的内容,$dest_dir是目标目录路径>>,追加重定向运算符,用于将前面命令的输出追加到指定文件的末尾"$TMP_FILE",被写入的文件路径,之前用mktemp创建的临时文件
最终写入TMP_FILE中的需要复制的目录的信息如:DIR:./curl-8.15.0-test2/include/curl
类似的,最终写入TMP_FILE中的需要复制的文件的信息如:FILE:./curl-8.15.0/CMakeLists.txt:./curl-8.15.0-test2/CMakeLists.txt:CMakeLists.txt
2.3.6 从临时文件读取数据
# 从临时文件读取数据并去重
NEED_CREATE_DIRS=($(grep "^DIR:" "$TMP_FILE" | sort -u | cut -d: -f2-))
NEED_COPY_FILES=($(grep "^FILE:" "$TMP_FILE" | sort -u))# 删除临时文件
rm -f "$TMP_FILE"
解释下第一句:
grep "^DIR:" "$TMP_FILE":筛选出类似DIR:/home/user/output/utils这样的行grep用于从文件中筛选匹配特定模式的行^DIR:是匹配模式,^表示行首,即筛选所有以DIR:开头的行(这些行是之前用echo "DIR:$dest_dir" >> "$TMP_FILE"写入的)
sort -u:对筛选出的行进行排序-u表示去重(unique),确保相同的目录路径只保留一次
cut -d: -f2-:比如将DIR:/home/user/output/utils处理为/home/user/output/utilscut用于从行中提取指定部分-d:指定分隔符(delimiter,分隔符)为冒号:-f2-表示提取从第 2 个字段(field)开始到行尾的内容(去掉前面的DIR:前缀)- 前面的
-是cut命令的选项标志,用于标识f是一个命令选项 - 后面的
-紧跟在数字2之后,表示从第 2 个字段开始,直到行的末尾 - 如果只写
-f2(没有后面的-),则只会提取单个第 2 个字段,效果相同,但语义上更强调是到结尾
- 前面的
2.4 确认是否复制
# 检查是否有需要处理的内容
if [ ${#NEED_CREATE_DIRS[@]} -eq 0 ] && [ ${#NEED_COPY_FILES[@]} -eq 0 ]; thenecho "=== 所有文件MD5一致,无需复制 ==="exit 0
fi# 显示统计信息并确认,附加源目录总数量
echo -e "\n=== 准备操作汇总 ==="
echo "需要创建的目录数: ${#NEED_CREATE_DIRS[@]} (共 $TOTAL_DIRS 个目录)"
echo "需要复制的文件数: ${#NEED_COPY_FILES[@]} (共 $TOTAL_FILES 个文件)"
read -p "是否继续执行操作?(y/n):" confirmif [ "$confirm" != "y" ] && [ "$confirm" != "Y" ]; thenecho "操作已取消"exit 0
fi
解释一下:
if [ ${#NEED_CREATE_DIRS[@]} -eq 0 ]:判断NEED_CREATE_DIRS数组的长度是否为0${#数组名[@]}表示返回数组中元素的数量-eq是 Shell 中的比较运算符,表示等于(equal)
read -p "是否继续执行操作?(y/n):" confirm:用于获取用户输入的交互命令read:Shell 中的读取命令,用于从标准输入(通常是键盘)读取用户输入的内容-p是read命令的选项,用于指定一个提示信息(prompt),会在等待用户输入前显示这个提- 这里的提示信息是
是否继续执行操作?(y/n):
confirm:变量名,用于存储用户输入的内容。用户输入后按回车,输入的内容会被保存到这个变量中
2.5 复制有变化的文件
# 创建目录
for dir in "${NEED_CREATE_DIRS[@]}"; doecho "创建目录: $dir"mkdir -p "$dir" || echo "警告:创建目录 $dir 失败!"
done# 复制文件
total=${#NEED_COPY_FILES[@]}
current=0for item in "${NEED_COPY_FILES[@]}"; docurrent=$((current + 1))# 解析数据src_file=$(echo "$item" | cut -d: -f2)dest_file=$(echo "$item" | cut -d: -f3)rel_path=$(echo "$item" | cut -d: -f4)# 显示进度和文件名echo "[$current/$total] 复制: $rel_path"# 执行复制cp -pv "$src_file" "$dest_file" || echo "警告:复制 $rel_path 失败!"
done
2.5.1 创建目录
for dir in "${NEED_CREATE_DIRS[@]}"; doecho "创建目录: $dir"mkdir -p "$dir" || echo "警告:创建目录 $dir 失败!"
done
解释一下
for dir in "${NEED_CREATE_DIRS[@]}for是循环关键字,用于遍历后面指定的列表dir是循环变量,每次循环会将数组中的一个元素赋值给这个变量NEED_CREATE_DIRS是之前定义的数组,存储着需要创建的目录路径列表[@]表示获取数组中的所有元素
mkdir -p "$dir" || echo "警告:创建目录 $dir 失败!":确保目录存在,存在则忽略,不存在则创建,创建失败则提示失败mkdir是创建目录的命令-p选项表示递归(parents,父目录)创建目录:如果目录的父级目录不存在,会自动创建所有缺失的父目录||是 Shell 中的逻辑运算符,表示逻辑或,如果左边的命令执行失败,则执行右边的命令
2.5.2 需要复制的数量
total=${#NEED_COPY_FILES[@]}
${#数组名[@]}:是 Shell 中获取数组长度的语法#在这里用于获取变量(或数组元素)的长度 / 数量[@]表示引用数组中的所有元素
2.5.3 复制文件
current=0for item in "${NEED_COPY_FILES[@]}"; docurrent=$((current + 1))# 解析数据src_file=$(echo "$item" | cut -d: -f2)dest_file=$(echo "$item" | cut -d: -f3)rel_path=$(echo "$item" | cut -d: -f4)# 显示进度和文件名echo "[$current/$total] 复制: $rel_path"# 执行复制cp -pv "$src_file" "$dest_file" || echo "警告:复制 $rel_path 失败!"
done
解释下
src_file=$(echo "$item" | cut -d: -f2)从字符串中提取特定字段echo "$item",输出变量$item的内容cut -d: -f2,以冒号:作为字段的分隔符,指定提取第 2 个字段
cp -pv "$src_file" "$dest_file"cp:用于复制文件或目录-p选项,复制文件时保留(preserve)源文件的元数据信息,包括:- 文件的修改时间(mtime)、访问时间(atime)
- 文件的权限模式(如读写执行权限)
- 文件的所有者和所属组(在有足够权限的情况下)
-v选项,显示详细的(verbose)复制过程信息,即输出类似'源文件' -> '目标文件'的日志
3 完整的脚本
#!/bin/bashSRC_DIR="./curl-8.15.0" # 源目录路径
DEST_DIR="./curl-8.15.0-test2" # 目标目录路径# 确保目录路径不以斜杠结尾,避免路径处理问题
SRC_DIR=${SRC_DIR%/}
DEST_DIR=${DEST_DIR%/}# 检查源目录是否存在
if [ ! -d "$SRC_DIR" ]; thenecho "错误:源目录 $SRC_DIR 不存在!"exit 1
fi# 检查目标目录,不存在则创建
if [ ! -d "$DEST_DIR" ]; thenecho "目标目录 $DEST_DIR 不存在,正在创建..."mkdir -p "$DEST_DIR" || { echo "创建目标目录失败!"; exit 1; }
fiecho "源目录: $SRC_DIR"
echo "目标目录: $DEST_DIR"# 统计源目录的总文件数和总目录数
TOTAL_FILES=$(find "$SRC_DIR" -type f | wc -l)
TOTAL_DIRS=$(find "$SRC_DIR" -type d | wc -l)
# 减去源目录本身
TOTAL_DIRS=$((TOTAL_DIRS - 1))echo "源目录总文件数: $TOTAL_FILES"
echo "源目录总目录数: $TOTAL_DIRS"# 创建临时文件存储需要处理的项目
TMP_FILE=$(mktemp)echo "=== 开始MD5校验(包括子目录) ==="# 递归遍历源目录下所有文件,使用临时文件解决子shell变量问题
find "$SRC_DIR" -type f | while read -r src_file; do# 计算相对路径rel_path="${src_file#$SRC_DIR/}"dest_file="$DEST_DIR/$rel_path"dest_dir=$(dirname "$dest_file")# 计算源文件MD5src_md5=$(md5sum "$src_file" | awk '{print $1}')# 计算目标文件MD5(如果存在)if [ -f "$dest_file" ]; thendest_md5=$(md5sum "$dest_file" | awk '{print $1}')elsedest_md5="不存在"fi# 比较MD5,不同则记录到临时文件if [ "$src_md5" != "$dest_md5" ]; thenecho "MD5不同: $rel_path"echo " 源文件: $src_md5"echo " 目标文件: $dest_md5"echo "----------------------------------"# 只记录不存在的目录if [ ! -d "$dest_dir" ]; thenecho "DIR:$dest_dir" >> "$TMP_FILE"fi# 记录需要复制的文件echo "FILE:$src_file:$dest_file:$rel_path" >> "$TMP_FILE"fi
done# 从临时文件读取数据并去重
NEED_CREATE_DIRS=($(grep "^DIR:" "$TMP_FILE" | sort -u | cut -d: -f2-))
NEED_COPY_FILES=($(grep "^FILE:" "$TMP_FILE" | sort -u))# 删除临时文件
rm -f "$TMP_FILE"# 检查是否有需要处理的内容
if [ ${#NEED_CREATE_DIRS[@]} -eq 0 ] && [ ${#NEED_COPY_FILES[@]} -eq 0 ]; thenecho "=== 所有文件MD5一致,无需复制 ==="exit 0
fi# 显示统计信息并确认,附加源目录总数量
echo -e "\n=== 准备操作汇总 ==="
echo "需要创建的目录数: ${#NEED_CREATE_DIRS[@]} (共 $TOTAL_DIRS 个目录)"
echo "需要复制的文件数: ${#NEED_COPY_FILES[@]} (共 $TOTAL_FILES 个文件)"
read -p "是否继续执行操作?(y/n):" confirmif [ "$confirm" != "y" ] && [ "$confirm" != "Y" ]; thenecho "操作已取消"exit 0
fi# 创建目录
echo -e "\n=== 开始创建目录 ==="
for dir in "${NEED_CREATE_DIRS[@]}"; doecho "创建目录: $dir"mkdir -p "$dir" || echo "警告:创建目录 $dir 失败!"
done# 复制文件
echo -e "\n=== 开始复制文件 ==="
total=${#NEED_COPY_FILES[@]}
current=0for item in "${NEED_COPY_FILES[@]}"; docurrent=$((current + 1))# 解析数据src_file=$(echo "$item" | cut -d: -f2)dest_file=$(echo "$item" | cut -d: -f3)rel_path=$(echo "$item" | cut -d: -f4)# 显示进度和文件名echo "[$current/$total] 复制: $rel_path"# 执行复制cp -pv "$src_file" "$dest_file" || echo "警告:复制 $rel_path 失败!"
doneecho -e "\n=== 操作完成 ==="
4 测试结果
这里用curl的源码目录进行测试,拷贝一份到curl-8.15.0-test2目录,然后删除一些文件,进行测试:
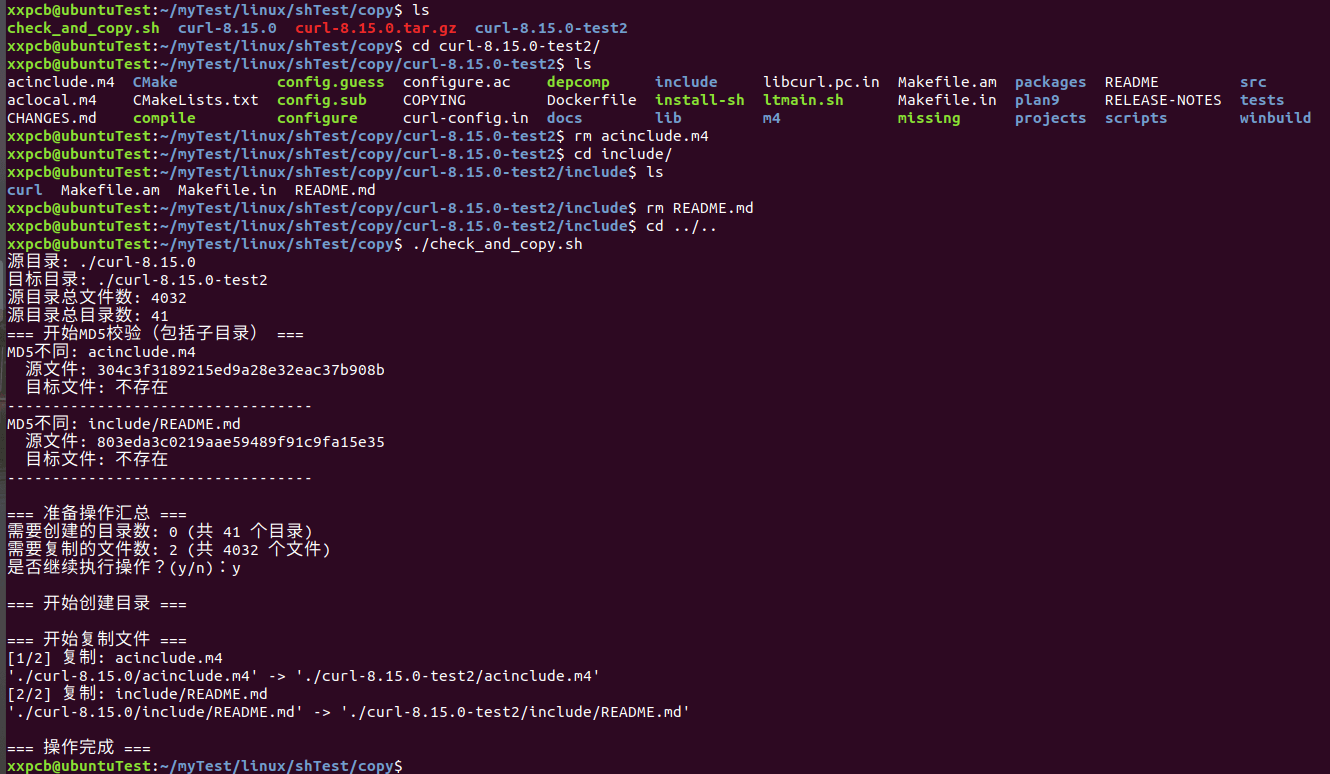
可以看到有检查到两个目录存在不一样的文件,在确认拷贝后,执行了拷贝。
再次执行脚本
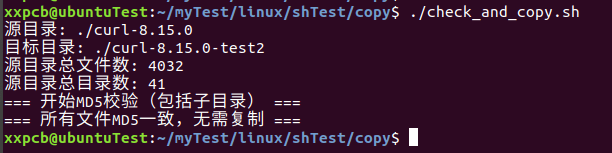
可以看到文件都完全一样了
5 总结
本篇通过一个文件检查与拷贝的实例,介绍了shell脚本的一些语法,并通过实际测试来验证脚本的功能。