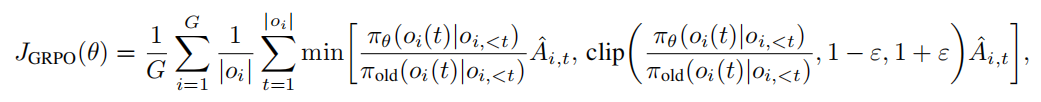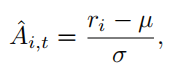Abstract
将大型语言模型(LLMs)训练为控制图形用户界面(graphical user interfaces, GUIs)的交互式智能体,面临着一个独特挑战:需要基于复杂环境中的多模态反馈来优化长周期动作序列[long-horizon action sequences]。尽管近期研究在推进LLMs的多轮强化学习(RL)以提升推理和工具使用能力方面取得了进展,但由于稀疏奖励[sparse rewards]、延迟反馈[delayed feedback]以及高成本轨迹生成[high rollout costs]等难题,这些方法在基于GUI的智能体上的应用仍相对未被充分探索。
本文中,我们研究了基于视觉-语言[vision-language-based]的GUI智能体[GUI agents]的端到端策略优化,旨在提升其在复杂、长周期计算机任务上的表现。我们提出了代理回放策略优化(Agentic Replay Policy Optimization, ARPO),这是一种端到端RL方法,通过在组相对策略优化(Group Relative Policy Optimization, GRPO)中引入回放缓冲区[replay buffer],以跨训练迭代复用成功经验。
为了进一步稳定训练过程,我们提出了一种任务选择策略,该策略基于基线智能体性能筛选任务,从而使智能体能够专注于从信息丰富的交互中学习。此外,我们将ARPO与离线偏好优化方法[offline preference optimization]进行对比,突出了基于策略的方法在GUI环境中的优势。在OSWorld基准测试上的实验表明,ARPO取得了具有竞争力的结果,为通过强化学习训练的基于LLM的GUI智能体建立了新的性能基线。
我们的研究结果强调了强化学习在训练能够管理复杂现实世界UI交互的多轮、视觉-语言GUI智能体方面的有效性。代码与模型:https://github.com/dvlab-research/ARPO.git。
1 Introduction
在各类智能体中,通过视觉感知和动作与计算机屏幕交互的GUI智能体长期以来备受关注[2,16,4]。现有研究大多依赖大规模轨迹数据的监督微调(supervised fine-tuning (SFT) SFT)。这些智能体通常通过大规模轨迹数据集进行SFT训练,模型基于当前屏幕截图和交互历史预测下一步动作来模仿人类行为。然而,这类智能体缺乏自我纠正能力,在工作轨迹[the working trajectory]中容易产生错误累积。
为解决这些局限,我们探索了GUI智能体的强化学习(RL)训练方法。与单轮RL或静态奖励优化不同,我们采用组相对策略优化(Group Relative Policy Optimization, GRPO)[5]——PPO[18]的最新变体,它无需价值函数,通过组间奖励归一化估算token级优势。
GRPO已在数学推理[19]和工具使用智能体[15]中展现出优异效果。因其高效处理长序列和多模态的能力,它天然适合视觉-语言智能体的训练。
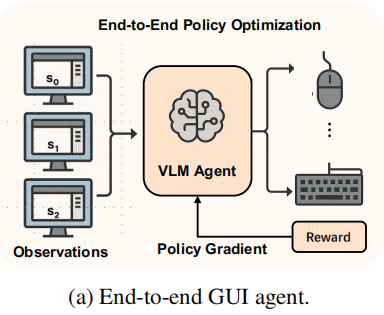
本文攻克GUI智能体端到端策略优化的挑战,特别关注多轮次、多模态的智能体设计(见图1a)。我们的目标是通过GRPO最大化环境基于规则的全程轨迹奖励[rule-based reward]。但GUI环境通常提供稀疏且延迟的奖励信号:智能体仅在任务完成时获得反馈,许多复杂任务在早期训练阶段可能完全无奖励。
此外,真实桌面环境中的轨迹生成成本不容忽视。GUI交互涉及操作系统级延迟,会显著拖慢数据收集过程。为克服这些障碍,我们开发了可扩展的分布式轨迹生成系统[a scalable distributed rollout system],支持与OSWorld[25]等真实桌面环境的并行交互。通过跨环境批量推理,我们降低了延迟并高效利用GPU资源,从而实现大规模轨迹收集。
为进一步提升训练稳定性和样本效率,我们提出了任务选择策略[a task selection strategy],筛选基线智能体下能生成成功轨迹的任务。这个精选子集提升了早期训练阶段的信号质量并加速收敛。我们还设计了专为GUI智能体学习的经验回放缓冲区。该缓冲区按任务存储成功轨迹,当某组所有采样轨迹失败时动态注入GRPO训练组。每组至少包含一条高奖励轨迹[one high-reward trajectory],确保有意义的奖励方差,这对计算token级优势至关重要。
我们在OSWorld基准测试上进行了广泛评估,发现强化学习能有效提升智能体性能。我们还发现一个有趣现象:RL训练对领域内任务带来显著提升,但对领域外任务几乎无益。
Our contributions are summarized as follows:
• 我们提出了一种端到端策略优化方法,利用GRPO在具有挑战性的多轮次、多模态环境中训练GUI智能体。
• 我们证明了精心选择训练任务对保持奖励多样性、确保策略优化稳定性至关重要。
• 我们提出了保留成功轨迹的经验回放缓冲区,在稀疏奖励场景中提升样本效率并稳定训练。
• 我们发现强化学习显著提升领域内任务表现,同时对领域外任务提供有限泛化改进。
2 Related Works
GUI Agents.
多模态模型的最新进展显著推动了GUI和基于Web的自动化技术进步。SeeClick[2]和ScreenAgent[14]利用具有视觉输入处理能力的大型视觉-语言模型(vision-language models, VLMs)执行用户界面交互任务。在此基础上,OmniAct[9]提出了专注于从视觉基础的自然语言指令生成可执行动作的基准测试。CogAgent[6]和UI-Tars[16]通过大规模网页和桌面界面数据扩展预训练,增强了屏幕理解和智能体行为。GUI-R1[24]探索了强化学习在提升基于VLM智能体的UI基础能力方面的应用。然而,当前研究中尚未探索以端到端策略优化方式直接优化GUI智能体的策略模型。
智能体强化学习[Reinforcement Learning for Agents]:基于规则的强化学习(Rule-based reinforcement learning, RL)已被证实在多个领域微调大语言模型(LLMs)方面具有显著效果。OpenAI的o1[8]和DeepSeek-R1[5]通过结构化奖励信号[structured reward signals],在数学推理[19]、代码生成[11]和多模态推理[7,12]等任务中展现出强大性能。ToolRL[15]通过为与外部工具交互的LLM智能体引入基于RL的训练,扩展了这一范式。Sweet-RL[29]提出了多轮DPO框架来增强长视野语言智能体行为。RAGEN[21]通过在实时、基于规则的环境中应用多轮RL进行自我进化智能体训练,进一步推动了该技术发展。
技术方向 | 代表性工作 | 核心突破 | 应用场景 |
|---|
视觉-语言模型 | SeeClick/ScreenAgent | 视觉输入处理能力 | GUI交互任务 |
基准测试体系 | OmniAct | 自然语言到可执行动作 | 智能体评估 |
预训练扩展 | CogAgent/UI-Tars | 大规模界面数据训练 | 屏幕理解 |
RL算法创新 | GUI-R1/RAGEN | 多轮次策略优化 | 自我进化智能体 |
尽管已有这些技术进步,现有研究大多集中于符号化任务[symbolic tasks]或静态工具使用[static tool use]场景。将强化学习应用于动态多模态GUI[multimodal GUI]环境中运行的视觉-语言智能体[vision-language agents]仍是一项具有挑战性的任务。本研究特别致力于利用实时桌面环境的基于规则奖励,实现多轮次GUI智能体的端到端策略优化。
维度 | 传统RL研究 | 本研究的创新 |
|---|
环境特性 | 静态符号空间 | 动态GUI界面 |
输入模态 | 单一文本输入 | 视觉-语言多模态 |
奖励机制 | 密集人工设计 | 实时环境规则反馈 |
训练周期 | 短周期决策 | 长序列多轮交互 |
3 Method
本节首先简要介绍组相对策略优化(GRPO)的基础原理。接着详细描述GUI智能体的架构设计和训练流程。该智能体基于视觉-语言模型(vision-language models,VLMs),通过扩展上下文窗口和延长图像-动作链[longer context windows and longer image, action chains]进行增强。这些改进对于使用GRPO等端到端强化学习算法训练复杂GUI任务至关重要。
3.1 Preliminary
群体相对策略优化(Group Relative Policy Optimization, GRPO)[19]是一种强化学习算法,旨在无需显式价值函数[explicit value function]或评论器[critic]的情况下高效优化语言模型。GRPO通过基于群体归一化奖励计算token-level 优势[advantages],改进了标准近端策略优化(Proximal Policy Optimization, PPO)的目标函数,使其特别适用于大型语言模型(LLM)。给定查询[query]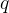 的一批
的一批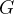 个响应[responses]
个响应[responses] ,每个响应由a sequence of tokens
,每个响应由a sequence of tokens 组成,GRPO的目标函数定义为:
组成,GRPO的目标函数定义为: 其中

表示标记[
token]

在响应[
response]
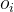
中的组归一化优势,其计算公式为:
和
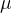
、
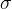
分别表示组内
奖励的平均值和标准差[
the mean and standard deviation of rewards]。
我们的设计实现了最多可处理15张输入图像、具有64K模型上下文长度的视觉-语言模型(VLM),能够准确解析1080P分辨率的完整GUI交互轨迹。不同于早期短上下文GUI智能体[2,4,26]需要截断轨迹、仅处理最近一两张屏幕截图的做法。
我们的方法充分利用完整轨迹历史[full trajectory history],使模型能够推理长期依赖关系,并优化整个交互序列的性能。


3.3 Distributed Trajectory Rollout
通过强化学习训练图形用户界面(GUI)代理需要在丰富的交互式桌面环境中实现可扩展且高效的轨迹采集。为满足这一需求,我们设计了一种专为OSWorld [25]等实时交互环境量身打造的分布式轨迹部署策略。该方案构建了由多个部署节点组成的系统,每个节点包含一个交互环境与对应的GUI代理,后者负责记录屏幕截图及其对应操作的历史数据(记作( ))。部署节点持续抓取当前GUI环境的屏幕截图,并将这些数据传输至一个由VLLM驱动的集中式语言模型推理服务器。
))。部署节点持续抓取当前GUI环境的屏幕截图,并将这些数据传输至一个由VLLM驱动的集中式语言模型推理服务器。 该策略模型采用并行处理方式,能够同步分析批量视觉观测数据,同时预测所有环境的下一步动作。与数学[19]或工具使用[15]场景不同,当面对OSWorld等实时图形界面时,由于操作系统级别的延迟问题,会产生显著的响应延迟。通过并行轨迹部署技术,不仅能高效利用推理服务器的GPU资源,还能有效降低每一步决策的延迟成本。
3.4 End-to-End Policy Optimization with GRPO
我们采用GRPO [19]作为强化学习算法来训练基于视觉的图形用户界面智能体。该算法通过组别奖励归一化[group-wise reward normalization]计算令牌级优势[token-level advantages],无需依赖价值函数,这一特性使其特别适合训练支持多图像输入和扩展上下文长度的视觉语言模型智能体。
Reward Design.
Reward Design. 为有效指导策略优化,我们设计了一个结构化的奖励函数,同时兼顾任务层面的成功率与动作格式的正确性。
- 轨迹奖励机制[Trajectory Reward]:针对每个任务,我们根据任务完成情况设定一个标量级轨迹奖励
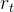 。当智能体成功完成OSWorld [25]定义的任务时,奖励值
。当智能体成功完成OSWorld [25]定义的任务时,奖励值 ;否则
;否则 。这种二元奖励机制为多轮次规划与执行的成功提供了高级训练信号。
。这种二元奖励机制为多轮次规划与执行的成功提供了高级训练信号。 - 行动格式奖励[Action Format Reward]:在任务执行过程中,VLM智能体的每个响应都会被解析为离散动作[discrete actions]。若响应不符合预设动作模式且无法解析,则会施加
 的惩罚系数[penalty]。该机制旨在促使模型生成语法正确且可执行的动作。
的惩罚系数[penalty]。该机制旨在促使模型生成语法正确且可执行的动作。
Training Objective.
我们将GUI交互建模为多轮次马尔可夫决策过程(MDP),其中智能体观察
屏幕截图序列[a sequence of screenshots]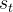
并生成
动作[actions]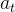
以完成指令

。
轨迹[trajectory]
由具备扩展上下文能力的VLM智能体编码,支持跨多步观察的长周期推理。我们的训练目标是最优化任务和轨迹的期望奖励:
我们采用GRPO优化该目标函数,通过组归一化轨迹奖励估算token-level advantages,无需价值函数即可实现高效可扩展的训练。
GRPO价值任务选择:尽管GRPO变体[28]取得进展,但训练GUI智能体仍面临挑战,主要源于OSWorld[25]等复杂桌面环境的稀疏奖励信号。
当前最先进智能体[16,4]即使多次尝试也难以可靠完成该基准测试中的多数任务。这导致这些任务在轨迹生成时反馈有限,阻碍GRPO的有效策略优化训练。为提高采样效率,我们提出任务过滤流程,筛选能由基线智能体生成成功轨迹的"价值任务"子集。
具体实施中,我们使用UI-Tars-1.5模型评估OSWorld每个任务,每个任务执行16次轨迹生成。智能体在至少一次尝试中成功完成的任务才会保留在GRPO训练集。
该方法最终生成128个精选任务,更适合早期学习,使策略优化能从信息丰富的奖励信号中受益。
3.5 Experience Replay Buffer
动态采样[28][Dynamic Sampling]通过移除奖励均匀的训练组[all rewards are uniform]来提高GRPO样本效率。但该策略在GUI交互场景效果受限,主要面临两大挑战:轨迹获取成本高和成功轨迹生成率低。
与遵循明确逻辑链的数学推理任务不同,GUI任务常需环境探索交互,导致奖励信号稀疏。(假如平均需9.3次探索才能发现有效操作路径)因此成功轨迹虽稀少但信息价值高,保存和复用它们对训练进展至关重要。为此我们引入按任务缓存成功轨迹[ successful trajectories]的经验回放缓冲区[experience replay buffer]。
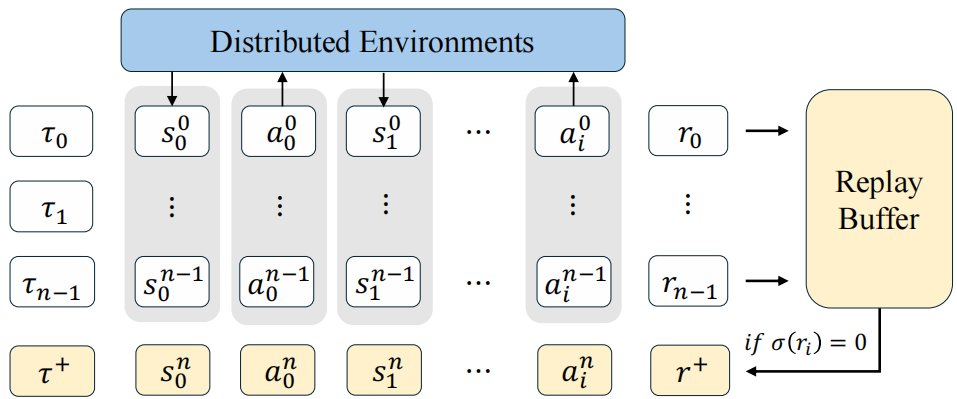
训练中当GRPO组全为失败轨迹时,随机替换为缓冲区中对应任务的既往成功轨迹。这确保只要智能体曾成功完成某任务,后续训练组将至少包含一个非零奖励轨迹[a non-zero reward signal](如图2)。
图2:多轮次图形界面智能体强化学习流程示意图。针对单一任务,我们采用n个并行环境进行环境部署,并通过轨迹回放收集各环境中的动作轨迹和奖励 。若所有环境的奖励均为零,则从回放缓冲区中提取一条正向轨迹
。若所有环境的奖励均为零,则从回放缓冲区中提取一条正向轨迹 ,以防止梯度消失。
,以防止梯度消失。
GUI代理[2,4,26]截断轨迹,只处理最近的一两张截图,而我们的方法利用完整的轨迹历史,使模型能够推理长期依赖关系,并在整个交互序列中优化性能。