Java POI实现对docx文件搜索指定文本进行批注/评论
📄 使用 Apache POI 在 Word 文档中批量添加批注(支持跨 Run 匹配)
关键词:Apache POI、XWPFDocument、Word 批注、Java 操作 DOCX、跨 Run 文本匹配
在实际项目开发中,我们经常需要通过程序自动处理 Word 文档,比如插入批注、高亮关键词等。本文将介绍如何使用 Apache POI 实现一个强大的功能:根据指定文本,在 .docx 文件中精准定位并添加批注,支持跨 Run 的文本匹配与样式保留。
最终效果如下图所示:
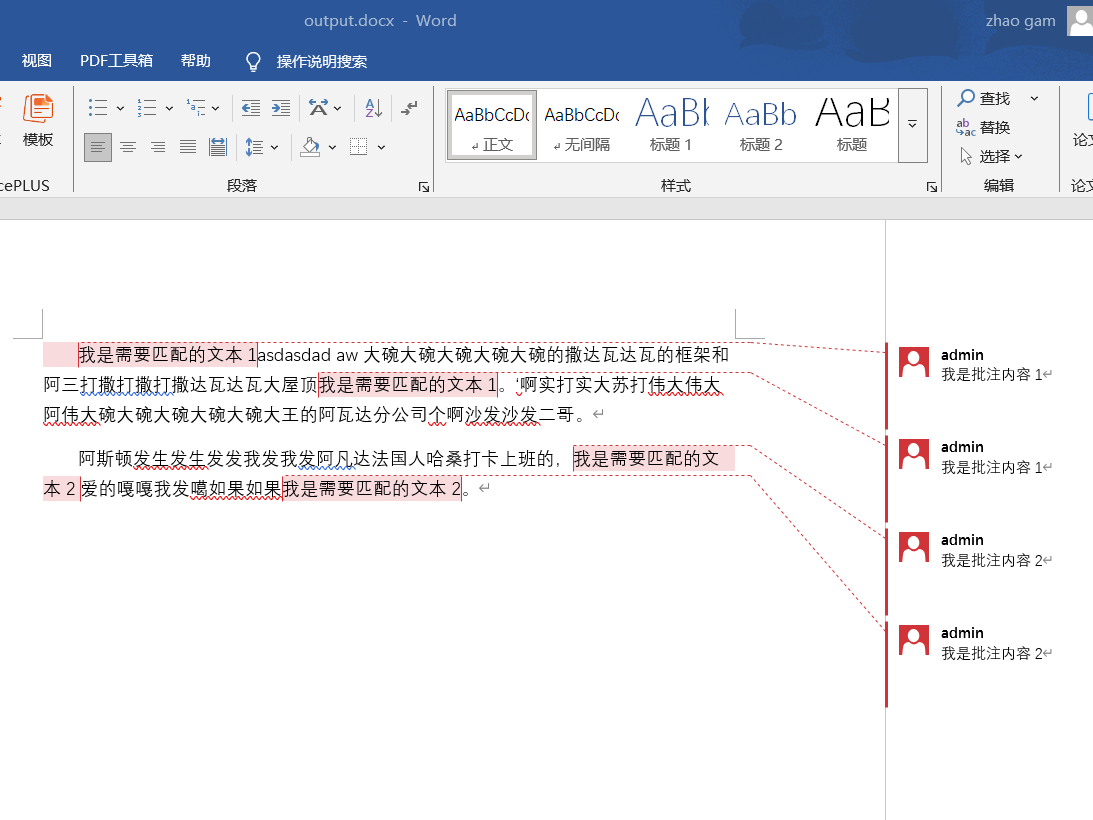
✅ 功能亮点
- 支持普通段落和表格中的文本查找
- 跨多个
XWPFRun的连续文本匹配(解决“一个词被拆分到两个 run”的问题) - 自动分割 Run 并保持原有字体样式
- 支持全量匹配或多处匹配控制
- 兼容中文及复杂格式文档
🔧 依赖配置(Maven)
<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.4.1</version>
</dependency>
<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml-full</artifactId><version>5.4.1</version>
</dependency>
⚠️ 注意:
poi-ooxml-full是必须的,用于支持更完整的 XML Schema 解析(如批注标签)。
🧱 核心逻辑设计
1. 数据模型定义
@Getter @Setter
public static final class CommentPayload {private String author; // 批注作者private CommentEntry[] entries; // 批注条目列表private Boolean isFullMatch; // 是否匹配所有出现位置
}@Getter @Setter @AllArgsConstructor
public static final class CommentEntry {private String target; // 要匹配的目标文本private String text; // 批注内容
}
每个 CommentEntry 表示一条“目标文本 → 批注内容”的映射规则。
2. 主流程入口
public static void call(CommentPayload payload, String location) throws IOException {try (FileInputStream fis = new FileInputStream(location);XWPFDocument doc = new XWPFDocument(fis)) {for (CommentEntry entry : payload.getEntries()) {List<CommentRunPair> foundRuns = findTargetRuns(doc, entry.getTarget(), payload.getIsFullMatch());if (foundRuns.isEmpty()) {System.out.println("----------------> 未找到匹配文本: " + entry.getTarget());continue;}// 添加批注foundRuns.forEach(pair -> addComment(doc, pair.getStart(), pair.getEnd(), entry.getText(), payload.getAuthor()));}// 输出文件String outPath = "C:\\Users\\sssss\\Desktop\\output.docx";try (FileOutputStream out = new FileOutputStream(outPath)) {doc.write(out);}}
}
🔍 关键实现细节
✅ 多 Run 连续文本匹配算法
由于 Word 中的文本可能被分成多个 XWPFRun(例如加粗部分单独成 run),所以我们不能简单地用 run.getText().contains() 来判断。
为此,我们采用 滑动窗口式字符串拼接匹配法,逐个遍历 Run,利用“重叠长度”来判断是否正在逐步匹配目标文本。
核心方法:findOverlapLength
private static int findOverlapLength(String runText, String remainingText) {if (remainingText.startsWith(runText)) return runText.length();int maxPossibleOverlap = Math.min(runText.length(), remainingText.length());for (int overlap = maxPossibleOverlap; overlap > 0; overlap--) {if (runText.endsWith(remainingText.substring(0, overlap))) {return overlap;}}return 0;
}
该函数返回当前 Run 文本与待匹配串开头的最大重叠字符数。
✅ 支持段落 & 表格双通道搜索
分别遍历文档中的段落和表格单元格内的段落:
private static List<CommentRunPair> findRunPairInParagraphs(...) { ... }
private static List<CommentRunPair> findRunPairInTables(...) { ... }
两者逻辑一致:维护一个 StringBuilder remainingText 表示尚未匹配的部分,当完全归零时即完成一次匹配。
✅ 拆分 Run 并保留样式
若匹配的起始/结束 Run 包含多余字符(如 "Hello World" 只想批注 "World"),需将其拆开。
private static List<XWPFRun> splitRunAt(XWPFRun run, int offset) {String text = run.getText(run.getTextPosition());if (offset <= 0) return Arrays.asList(null, run);if (offset >= text.length()) return Arrays.asList(run, null);// 1. 修改原 Run 为前半部分run.setText(text.substring(0, offset), 0);// 2. 插入新 Run 作为后半部分XWPFParagraph parent = (XWPFParagraph) run.getParent();int index = parent.getRuns().indexOf(run);XWPFRun newRun = parent.insertNewRun(index + 1);newRun.setText(text.substring(offset));// 3. 复制所有样式(包括未暴露 API 的属性)copyRunStyle(run, newRun);return Arrays.asList(run, newRun);
}
样式复制增强版
private static void copyRunStyle(XWPFRun src, XWPFRun dest) {dest.setFontSize(src.getFontSizeAsDouble());dest.setColor(src.getColor());dest.setBold(src.isBold());dest.setItalic(src.isItalic());dest.setUnderline(src.getUnderline());dest.setTextPosition(src.getTextPosition());dest.setStrikeThrough(src.isStrikeThrough());dest.setFontFamily(src.getFontFamily());// 关键:直接复制底层 CTR 的 RPr(避免遗漏隐藏样式)dest.getCTR().setRPr(src.getCTR().getRPr());
}
✅ 添加批注(commentRangeStart / commentReference)
Apache POI 原生不支持直接添加批注范围,需手动操作 OpenXML 结构。
private static void addComment(XWPFDocument document, XWPFRun start, XWPFRun end,String commentText, String author) {BigInteger commentId = getNextCommentId(document);CTComment ctComment = document.getDocComments().getCtComments().addNewComment();ctComment.setAuthor(author);ctComment.setInitials("");ctComment.setDate(new GregorianCalendar(Locale.CHINA));ctComment.addNewP().addNewR().addNewT().setStringValue(commentText);ctComment.setId(commentId);insertCommentRangeToRun(start, true, commentId); // 开始标记insertCommentRangeToRun(end, false, commentId); // 结束标记
}
获取唯一 ID
public static BigInteger getNextCommentId(XWPFDocument doc) {BigInteger maxId = BigInteger.ZERO;for (var comment : doc.createComments().getCtComments().getCommentArray()) {BigInteger id = comment.getId();if (id.compareTo(maxId) > 0) {maxId = id;}}return maxId.add(BigInteger.ONE);
}
插入 XML 标签(commentRangeStart / End)
private static void insertCommentRangeToRun(XWPFRun run, boolean start, BigInteger commentId) {String uri = CTMarkupRange.type.getName().getNamespaceURI();String localPart = start ? "commentRangeStart" : "commentRangeEnd";XmlCursor cursor = run.getCTR().newCursor();if (!start && !cursor.toNextSibling()) {cursor.toParent();cursor.toNextSibling();}cursor.beginElement(localPart, uri);cursor.toParent();CTMarkupRange markup = (CTMarkupRange) cursor.getObject();markup.setId(commentId);cursor.close();if (!start) {run.getCTR().addNewCommentReference().setId(commentId);}
}
✅ 文本预处理:去除空白干扰
因为 Word 中可能存在换行符、空格、全角空格等问题,统一标准化:
private static String normalizeText(String text) {if (text == null) return "";return text.replaceAll("\\s+", ""); // 合并所有空白字符
}
这样即使原文是 "我是 需要匹配的\n文本1",也能正确匹配 "我是需要匹配的文本1"。(之前模型生成的文档就会出现莫名其妙的好多空白字符)
🧪 使用示例
public static void main(String[] args) throws Exception {CommentPayload payload = new CommentPayload();payload.setAuthor("admin");payload.setIsFullMatch(true); // true=全部匹配;false=只匹配第一个payload.setEntries(new CommentEntry[]{new CommentEntry("我是需要匹配的文本1", "这是第一条批注"),new CommentEntry("我是需要匹配的文本2", "这是第二条批注")});call(payload, "C:\\Users\\sssss\\Desktop\\input.docx");
}
🛠️ 注意事项 & 优化建议
| 项目 | 说明 |
|---|---|
| ✅ 性能优化 | 若文档极大,可考虑加入中断机制或异步处理 |
| ⚠️ 内存占用 | 大文件注意使用流式读写,避免 OOM |
| 💡 扩展方向 | 支持正则匹配、高亮颜色标注、导出 HTML 预览等 |
| ❗ 异常处理 | 生产环境应增加 try-catch 和日志记录 |
📚 参考资料
- Apache POI 官方文档
- OpenXML SDK 文档
- GitHub 示例项目:https://github.com/apache/poi
📝 源码
可以把不需要的优化下,基本两百行搞定
package com.xxxs.commons.plugins;import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.Setter;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.xwpf.usermodel.*;
import org.apache.xmlbeans.XmlCursor;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTComment;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTMarkup;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTMarkupRange;import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.math.BigInteger;
import java.util.*;public class plunins {public static void main(String[] args) throws Exception {CommentPayload payload = new CommentPayload();payload.setAuthor("admin");// false场景返回匹配的第一个payload.setIsFullMatch(true);payload.setEntries(new CommentEntry[]{new CommentEntry("我是需要匹配的文本1", "我是批注内容1"),new CommentEntry("我是需要匹配的文本2", "我是批注内容2")});call(payload, "C:\\Users\\sssss\\Desktop\\input.docx");}public static void call(CommentPayload payload, String location) throws IOException {// 加载文档try (FileInputStream fis = new FileInputStream(location); XWPFDocument doc = new XWPFDocument(fis)) {// 处理每个任务for (CommentEntry entry : payload.getEntries()) {// 处理单行文本// 获取匹配文本的目标run集合List<CommentRunPair> foundRuns = findTargetRuns(doc, entry.getTarget(), payload.getIsFullMatch());if (foundRuns.isEmpty()) {// 没有匹配到System.out.println("----------------> 没有匹配到" + entry.getTarget());continue;}// 添加批注foundRuns.forEach(pair -> addComment(doc, pair.getStart(), pair.getEnd(), entry.getText(), payload.getAuthor()));}String outPath = "C:\\Users\\sssss\\Desktop\\output.docx";try (var out = new FileOutputStream(outPath)) {doc.write(out);}}}private static List<CommentRunPair> findTargetRuns(XWPFDocument document, String searchText, Boolean isFullMatch) {List<CommentRunPair> result = new ArrayList<>();// 匹配普通段落result.addAll(findRunPairInParagraphs(document, searchText, isFullMatch));// 匹配表格result.addAll(findRunPairInTables(document, searchText, isFullMatch));// 单个run内容不确定,需要重新分割。 比如某个run可能是 "s Hello World" 我们只需要"Hello World" 就需要分割for (CommentRunPair pair : result) {if (!StringUtils.startsWith(pair.getStart().getText(0), searchText)) {int pos = pair.getStart().getText(0).length() - findOverlapLength(pair.getStart().getText(0), searchText);pair.setStart(splitRunAt(pair.getStart(), pos).getLast());}if (!StringUtils.endsWith(searchText,pair.getEnd().getText(0))) {int pos = findOverlapLength(pair.getEnd().getText(0), searchText);pair.setEnd(splitRunAt(pair.getEnd(), pos).getFirst());}}return result;}private static List<CommentRunPair> findRunPairInTables(XWPFDocument document, String searchText, Boolean isFullMatch) {StringBuilder remainingText = new StringBuilder(normalizeText(searchText));List<CommentRunPair> result = new ArrayList<>();XWPFRun firstMatchedRun = null;for (XWPFTable table : document.getTables()) {for (XWPFTableRow row : table.getRows()) {for (XWPFTableCell cell : row.getTableCells()) {for (XWPFParagraph para : cell.getParagraphs()) {for (XWPFRun run : para.getRuns()) {String runText = normalizeText(run.getText(0));if (runText.isEmpty()) {continue;}// 检查是否有重叠部分(runText的结尾匹配remainingText的开头)int overlapLength = findOverlapLength(runText, remainingText.toString());if (overlapLength > 0) {// 如果匹配,截取remainingText已匹配的部分remainingText.delete(0, overlapLength);// 记录第一个匹配的Runif (firstMatchedRun == null) {firstMatchedRun = run;}// 如果remainingText被完全匹配,收集第一个runif (!remainingText.isEmpty()) {continue;}result.add(new CommentRunPair(firstMatchedRun, splitRunAt(run, overlapLength).getFirst()));if (Boolean.TRUE.equals(isFullMatch)) {remainingText = new StringBuilder(normalizeText(searchText));firstMatchedRun = null;} else {return result;}} else {// 如果不匹配,重置remainingText和firstMatchedRunremainingText = new StringBuilder(normalizeText(searchText));firstMatchedRun = null;}}}}}}return result;}private static List<CommentRunPair> findRunPairInParagraphs(XWPFDocument document, String searchText, Boolean isFullMatch) {// 数据来源不确定,比如我的文档和批注内容都是大模型生成的,格式会有点奇怪,所以需要使用normalizeText处理下StringBuilder remainingText = new StringBuilder(normalizeText(searchText));XWPFRun firstMatchedRun = null;List<CommentRunPair> result = new ArrayList<>();for (XWPFParagraph para : document.getParagraphs()) {for (XWPFRun run : para.getRuns()) {String runText = normalizeText(run.getText(0));if (runText.isEmpty()) {continue;}// 检查是否有重叠部分(runText的结尾匹配remainingText的开头)int overlapLength = findOverlapLength(runText, remainingText.toString());if (overlapLength > 0) {// 如果匹配,截取remainingText已匹配的部分remainingText.delete(0, overlapLength);// 记录第一个匹配的Runif (firstMatchedRun == null) {firstMatchedRun = run;}// 如果remainingText被完全匹配,收集第一个runif (!remainingText.isEmpty()) {continue;}result.add(new CommentRunPair(firstMatchedRun, run));if (Boolean.TRUE.equals(isFullMatch)) {remainingText = new StringBuilder(normalizeText(searchText));firstMatchedRun = null;} else {return result;}} else {// 如果不匹配,重置remainingText和firstMatchedRunremainingText = new StringBuilder(normalizeText(searchText));firstMatchedRun = null;}}}return result;}private static List<XWPFRun> splitRunAt(XWPFRun run, int offset) {String text = run.getText(run.getTextPosition());int len = text.length();if (offset <= 0) {// 不需要拆分,前面为空return Arrays.asList(null, run);}if (offset >= len) {// 不需要拆分,后面为空return Arrays.asList(run, null);}// 1. 修改原 Run 为左半部分run.setText(text.substring(0, offset), 0);// 2. 创建新 Run 放在后面XWPFParagraph parent = (XWPFParagraph) run.getParent();int currentIndex = parent.getRuns().indexOf(run);XWPFRun newRun = parent.insertNewRun(currentIndex + 1);// 3. 设置文本newRun.setText(text.substring(offset));// 4. 复制所有样式(关键!)copyRunStyle(run, newRun);return Arrays.asList(run, newRun);}private static void copyRunStyle(XWPFRun src, XWPFRun dest) {
// dest.setFontSize(src.getFontSize());dest.setFontSize(src.getFontSizeAsDouble());dest.setColor(src.getColor());dest.setBold(src.isBold());dest.setItalic(src.isItalic());dest.setUnderline(src.getUnderline());dest.setTextPosition(src.getTextPosition());dest.setStrikeThrough(src.isStrikeThrough());dest.setFontFamily(src.getFontFamily());// 更彻底的方式:复制 CTRaw XML 内容(保留所有未封装属性)dest.getCTR().setRPr(src.getCTR().getRPr());}private static void addComment(XWPFDocument document, XWPFRun start, XWPFRun end, String commentText, String author) {BigInteger commentId = getNextCommentId(document);CTComment ctComment = document.getDocComments().getCtComments().addNewComment();ctComment.setAuthor(author);ctComment.setInitials("");ctComment.setDate(new GregorianCalendar(Locale.CHINA));ctComment.addNewP().addNewR().addNewT().setStringValue(commentText);ctComment.setId(commentId);insertCommentRangeToRun(start, true, commentId);insertCommentRangeToRun(end, false, commentId);}public static BigInteger getNextCommentId(XWPFDocument doc) {BigInteger maxId = BigInteger.ZERO;for (var comment : doc.createComments().getCtComments().getCommentArray()) {BigInteger id = comment.getId();if (id.compareTo(maxId) > 0) {maxId = id;}}return maxId.add(BigInteger.ONE);}private static void insertCommentRangeToRun(XWPFRun run, boolean start, BigInteger commentId) {String uri = CTMarkupRange.type.getName().getNamespaceURI();String localPart;XmlCursor cursor = run.getCTR().newCursor();if (start) {// 批注的开始标签名, org.openxmlformats.schemas.wordprocessingml.x2006.main.impl.CTRImpl.PROPERTY_QNAMElocalPart = "commentRangeStart";} else {if (!cursor.toNextSibling()) {// 如果没有下一个兄弟节点 , 则跳到父节点的下一个兄弟节点添加结束标签cursor.toParent();cursor.toNextSibling();}// 批注的结束标签名localPart = "commentRangeEnd";}cursor.beginElement(localPart, uri);cursor.toParent();CTMarkupRange markup = (CTMarkupRange) cursor.getObject();cursor.close();markup.setId(commentId);if (!start) {// 结束标签设置批注引用CTMarkup ctMarkup = run.getCTR().addNewCommentReference();ctMarkup.setId(commentId);}}private static int findOverlapLength(String runText, String remainingText) {if (remainingText.startsWith(runText)) {return runText.length();}int maxPossibleOverlap = Math.min(runText.length(), remainingText.length());for (int overlap = maxPossibleOverlap; overlap > 0; overlap--) {// 检查runText的最后overlap个字符是否等于remainingText的前overlap个字符if (runText.substring(runText.length() - overlap).equals(remainingText.substring(0, overlap))) {return overlap;}}return 0;}private static String normalizeText(String text) {if (text == null) {return "";}return text.replaceAll("\\s+", "");}@Getter@Setterprivate static final class CommentRunPair {private XWPFRun start;private XWPFRun end;public CommentRunPair(XWPFRun start, XWPFRun end) {this.start = start;this.end = end;}}@Getter@Setterpublic static final class CommentPayload {/*** 作者*/private String author;/*** 批注内容*/private CommentEntry[] entries;/*** 全部匹配*/private Boolean isFullMatch;}@Getter@Setter@AllArgsConstructorpublic static final class CommentEntry {/*** 批注目标*/private String target;/*** 批注文本*/private String text;}
}
© 2025 YourName 版权所有|技术博客 · Office 自动化系列