Java IO流(字节流和字符流)
目录
一、IO流的基本概念
1.1 核心特点
1.2 流的两大分类
1.3 前置知识:File 类的使用
场景 1:创建单个文件(无父目录)
场景 2:创建文件(含多级父目录)
场景 3:遍历目录下的文件(递归遍历子目录)
场景4:过滤文件(函数式接口)
二、字节流:处理所有类型文件
2.1 基础字节流:FileInputStream 与 FileOutputStream
案例 1:读取文本文件(使用缓冲区)
案例 2:复制文件(文本 / 二进制通用)
2.2 缓冲字节流:BufferedInputStream 与 BufferedOutputStream
案例:用缓冲流复制大文件(如 MP3)
2.3 对象流:ObjectInputStream 与 ObjectOutputStream
案例:对象的序列化与反序列化
三、字符流:高效处理文本文件
3.1 基础字符流:FileReader 与 FileWriter
案例 1:写入文本文件(追加模式)
案例 2:读取文本文件
3.2 缓冲字符流:BufferedReader 与 BufferedWriter
案例 1:逐行读取文本文件
3.3 转换流(字节流转字符流)
3.4 高级字符流:PrintWriter
四、随机读写流:RandomAccessFile
4.2 随机读取文件内容
4.3 随机写入文件(覆盖指定位置)
一、IO流的基本概念
IO流是Java中用于处理输入输出操作的抽象概念。可以将流想象成一条"数据管道",数据从一个源(如文件、网络连接)通过这条管道流向目标位置。
1.1 核心特点
-
单向性:输入流(InputStream/Reader)只能读数据,输出流(OutputStream/Writer)只能写数据。
-
顺序性:数据按顺序传输,不能随机访问(除非使用随机读写流)。
-
缓冲优化:通过缓冲区(字节数组)减少 I/O 次数,提高读写性能(类比 “用瓢舀米比一粒粒拿起米更快”)。
1.2 流的两大分类
| 对比维度 | 字节流(Byte Stream) | 字符流(Character Stream) |
|---|---|---|
| 处理单位 | 1 个字节(8 位) | 1 个字符(如 UTF-8 中 1 个汉字占 3 字节) |
| 核心 API | InputStream/OutputStream(抽象类) | Reader/Writer(抽象类) |
| 适用场景 | 二进制文件(图片、音频、视频)+ 文本文件 | 仅文本文件(.txt、.java 等) |
| 性能特点 | 文本文件读写性能低于字符流 | 文本文件读写性能更高(适配字符编码) |
1.3 前置知识:File 类的使用
File类并非流的一部分,而是用于封装文件 / 目录路径,是流操作的 “入口”(如指定读写的文件位置)。以下是File类的核心实战场景:
场景 1:创建单个文件(无父目录)
直接指定文件路径,调用createNewFile()创建文件(需处理IOException)。
package com.demo11;import java.io.File;
import java.io.IOException;public class Test {public static void main(String[] args) {// 仅封装文件路径,不创建实际文件File f = new File("d:\\abc.txt");try {// 创建文件(若文件已存在,返回false) boolean isCreated = f.createNewFile();System.out.println("文件是否创建成功: " + isCreated);} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}
}运行效果:

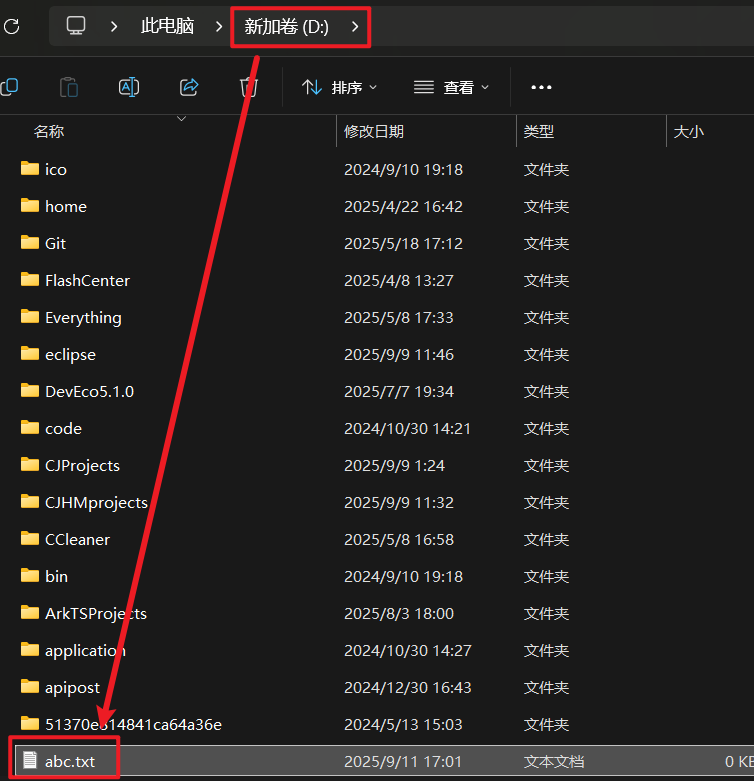
场景 2:创建文件(含多级父目录)
若文件的父目录(如d:/abc/cccc)不存在,直接创建文件会失败,需先通过getParentFile().mkdirs()创建多级目录。
mkdirs()创建多级目录,mkdir()仅创建单级目录。
package com.demo12;import java.io.File;
import java.io.IOException;public class Test {public static void main(String[] args) {File f = new File("d://abc//qq//a1.txt");// 检查父目录是否存在,不存在则创建(mkdirs()创建多级目录,mkdir()仅创建单级目录)if(!f.getParentFile().exists()) {f.getParentFile().mkdirs();}// 创建文件try {f.createNewFile();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}
}
运行效果:
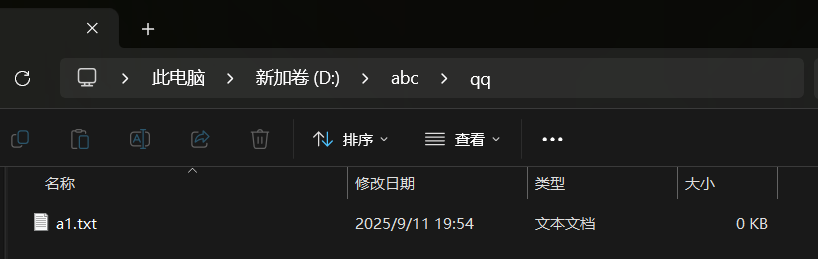
场景 3:遍历目录下的文件(递归遍历子目录)
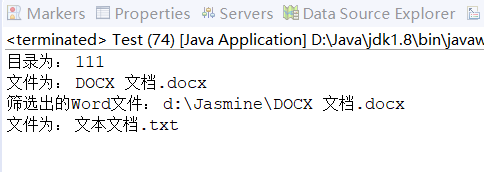
通过listFiles()获取目录下所有文件 / 子目录,结合递归实现 “深度遍历”,甚至可以筛选特定后缀的文件(如.docx)。
package com.demo15;import java.io.File;public class Test {// 递归遍历目录的方法public static void selectFile(File f) {// 1. 获取目录下所有文件/子目录File[] fs = f.listFiles();if (fs == null) return; // 避免空指针(如目录不存在)// 2. 遍历每个文件/子目录for(File cf : fs) {// 判断是否为文件if(cf.isFile()) {System.out.println("文件为: " + cf.getName());// 筛选后缀为.docx的文件if(cf.getName().endsWith(".docx")) {System.out.println("筛选出的Word文件: " + cf.getPath());}}else { System.out.println("目录为: " + cf.getName());selectFile(cf); // 若为目录,递归调用}}}public static void main(String[] args) {// File f = new File("d://Jasmine");
// selectFile(f);selectFile(new File("d://Jasmine"));}}
运行效果:

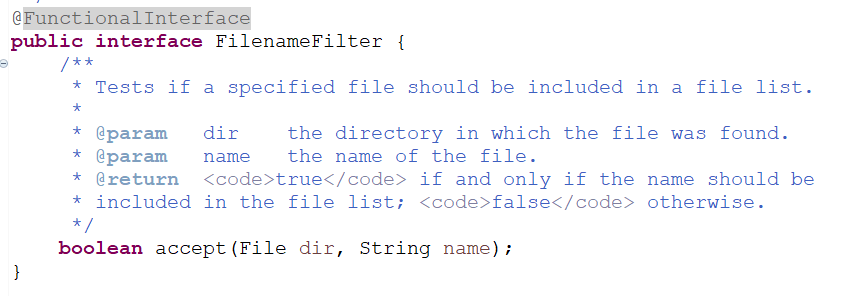
场景4:过滤文件(函数式接口)
list() 会返回 字符串数组(String[]),数组里是每个子项的名字(不含路径)。如果想把过滤逻辑一次性传进去,就重载了带 FilenameFilter 的版本。该方法对目录中每个条目都会回调一次 accept(File dir, String name),只有返回 true 的名字才会被收进结果数组。
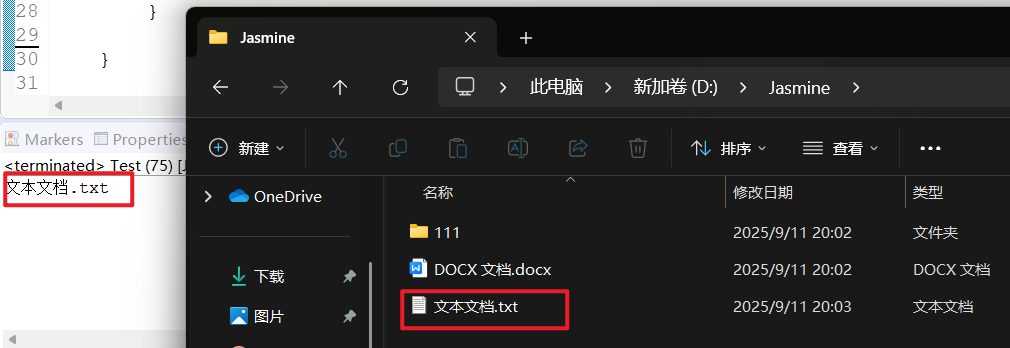
package com.demo16;import java.io.File;
import java.io.FilenameFilter;public class Test {public static void main(String[] args) {// 把 d:\Jasmine 中所有以 .txt 结尾的文件名筛选并输出File f = new File("d://Jasmine");String[] str = f.list((File dir, String name)->{if(name.endsWith(".txt")){
// System.out.println(name);return true; // 告诉 list 把它收进结果数组}return false;}); // 遍历结果数组for(String s : str) {System.out.println(s);}}}运行结果:
二、字节流:处理所有类型文件
字节流以字节(byte) 为单位读写数据,是 Java I/O 的 “基础流”,可处理所有类型的文件(二进制 + 文本)。核心抽象类为InputStream(输入)和OutputStream(输出),常用实现类包括:
- 文件操作:
FileInputStream/FileOutputStream - 缓冲优化:
BufferedInputStream/BufferedOutputStream 对象序列化:ObjectInputStream/ObjectOutputStream
2.1 基础字节流:FileInputStream 与 FileOutputStream
FileInputStream用于从文件读取字节,FileOutputStream用于向文件写入字节,二者均无内置缓冲区,需手动通过字节数组优化性能。
案例 1:读取文本文件(使用缓冲区)
通过字节数组byte[] buffer减少 I/O 次数,避免逐字节读取(性能极低)。
package com.demo17;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;public class Test {public static void main(String[] args) {// 存储读取的文本内容StringBuilder sb = new StringBuilder();// 声明输入流(放在try外,确保finally可访问)InputStream in = null;try {in = new FileInputStream("./a.txt");byte[] buffer = new byte[1024]; // 定义缓冲区int len = 0; // 记录每次读取的字节数// 循环读取:read(buffer)返回读取的字节数,-1表示读取完毕while ((len = in.read(buffer)) != -1) { //read()方法:将数据读入缓冲区,返回读取的字节数// sb.append(new String(buffer)); //会包含缓冲区中的残留数据sb.append(new String(buffer,0,len)); // 将字节数组转为字符串(注意:仅取前len个字节,避免读取残留数据)System.out.println("len为: " + len);}System.out.println("文件的内容为: " + sb.toString());} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();} finally {// 关闭流(必须!避免资源泄漏)if (in != null) {try {in.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}
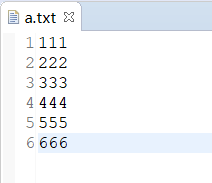
运行结果:

为什么输出结果中 len 的长度为 28?
len 为 28 是因为 文件中的文本内容 + 换行符 总共占用了 28 个字节。在Windows系统中,换行符实际上是 \r\n(回车+换行),而不是单纯的 \n。数字字符每个占1字节,换行符每个占2个字节。
案例 2:复制文件(文本 / 二进制通用)
通过 “输入流读 + 输出流写” 实现文件复制,支持图片、音频等二进制文件。
package com.demo17;import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
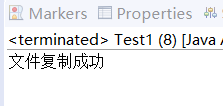
import java.io.OutputStream;public class Test1 {public static void main(String[] args) {InputStream in = null;OutputStream out = null;try {// 输入流:读取源文件(./a.txt)in = new FileInputStream("./a.txt");// 输出流:写入目标文件(./aaa/b.txt,父目录不存在则创建)File targetFile = new File("./aaa/b.txt");if (!targetFile.getParentFile().exists()) {targetFile.getParentFile().mkdirs();}out = new FileOutputStream(targetFile); // 若文件已存在,会覆盖byte[] buffer = new byte[1024];int len = 0;while ((len = in.read(buffer)) != -1) {out.write(buffer, 0, len); // 把读取的字节写入到输出流}System.out.println("文件复制成功");} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();} finally {if (in != null) {try {in.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}if (out != null) {try {out.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}
运行结果:
2.2 缓冲字节流:BufferedInputStream 与 BufferedOutputStream
BufferedInputStream和BufferedOutputStream是带内置缓冲区的字节流(默认缓冲区大小 8192 字节 = 8KB),无需手动定义字节数组,性能比基础字节流更高。
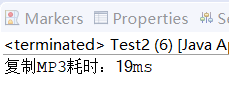
案例:用缓冲流复制大文件(如 MP3)
package com.demo17;import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;public class Test2 {public static void main(String[] args) {// 1. 缓冲输入流(包装基础输入流)BufferedInputStream bis = null;// 2. 缓冲输出流(包装基础输出流)BufferedOutputStream bos = null;try{bis = new BufferedInputStream(new FileInputStream("./a0.mp3"));bos = new BufferedOutputStream(new FileOutputStream("./aaa/b1.mp3"));long startTime = System.currentTimeMillis(); // 记录开始时间int len = 0;// 3. 读取字节(缓冲流自动处理缓冲区,无需手动定义byte[])while ((len = bis.read()) != -1) {bos.write(len);}// 4. 刷新输出流(确保缓冲区数据写入文件)bos.flush();long endTime = System.currentTimeMillis();System.out.println("复制MP3耗时:" + (endTime - startTime) + "ms");} catch (IOException e) {e.printStackTrace();}finally {if(bis != null) {try {bis.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}if(bos != null) {try {bos.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}
运行结果:
2.3 对象流:ObjectInputStream 与 ObjectOutputStream
对象流用于实现对象的序列化与反序列化:(前提条件:对象类实现 Serializable 接口)
-
序列化:将 Java 对象转换为字节序列(二进制),可写入文件或网络传输。
-
反序列化:将字节序列恢复为 Java 对象。
案例:对象的序列化与反序列化
- 定义可序列化的 User 类:
package com.demo19;import java.io.Serializable;// 实现Serializable接口,标记为可序列化
public class User implements Serializable {private int uid;private String username;private transient String userpwd; // 被transient修饰的字段不会被序列化// 无参构造(反序列化时需要)public User() {}public User(int uid, String username, String userpwd) {super();this.uid = uid;this.username = username;this.userpwd = userpwd;}public int getUid() {return uid;}public void setUid(int uid) {this.uid = uid;}public String getUsername() {return username;}public void setUsername(String username) {this.username = username;}public String getUserpwd() {return userpwd;}public void setUserpwd(String userpwd) {this.userpwd = userpwd;}}
- 序列化与反序列化操作:
package com.demo19;import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;public class Test {public static void main(String[] args) {try {// 序列化(将对象转换为字节序列保存到文件)
// ObjectOutputStream out =new
// ObjectOutputStream(new FileOutputStream(new File("./aaa/user.data")));
//
// User u = new User();
// u.setUid(100);
// u.setUsername("茉莉");
// u.setUserpwd("123456");
//
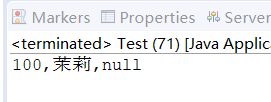
// out.writeObject(u); //User对象 → ObjectOutputStream → FileOutputStream → File → 磁盘文件// 反序列化(从文件读取字节序列重建对象)ObjectInputStream oin = new ObjectInputStream(new FileInputStream("./aaa/user.data"));User u = (User) oin.readObject();System.out.println(u.getUid() + "," + u.getUsername() + "," + u.getUserpwd());} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}}}
运行结果:
三、字符流:高效处理文本文件
字符流以字符(char) 为单位读写数据,专门用于处理文本文件。它会自动适配字符编码(如 UTF-8、GBK),避免字节流读取文本时出现乱码问题。核心抽象类为Reader(输入)和Writer(输出),常用实现类包括FileReader/FileWriter(文件操作)、BufferedReader/BufferedWriter(缓冲优化)。
3.1 基础字符流:FileReader 与 FileWriter
FileReader用于从文本文件读取字符,FileWriter用于向文本文件写入字符,内置小缓冲区,但性能仍低于缓冲字符流。
案例 1:写入文本文件(追加模式)
package com.demo20;import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
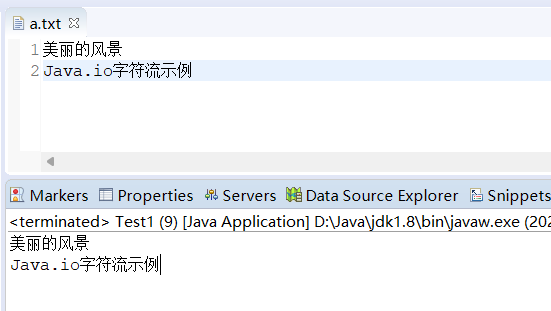
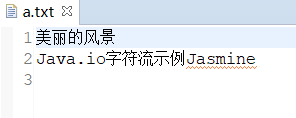
import java.io.Writer;public class Test {public static void main(String[] args) {// 目标文件:./user/a.txt(父目录不存在则创建)File targetFile = new File("./user/a.txt");if (!targetFile.getParentFile().exists()) {targetFile.getParentFile().mkdirs();}Writer writer = null;try {// 1. 创建FileWriter(第二个参数true表示追加写入,默认false覆盖)writer = new FileWriter(targetFile, true);// 2. 写入字符/字符串writer.write("美丽的风景\n"); writer.write("Java.io字符流示例");// 3. 刷新缓冲区(字符流需主动刷新,否则数据可能留在缓冲区)writer.flush();System.out.println("文本写入成功");} catch (IOException e) {e.printStackTrace();} finally {// 4. 关闭流if (writer != null) {try {writer.close();} catch (IOException e) {e.printStackTrace();}}}}
}案例 2:读取文本文件
package com.demo20;import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;public class Test1 {public static void main(String[] args) {Reader reader = null;try {// 1. 创建FileReaderreader = new FileReader("./user/a.txt");int len = 0;// 2. 逐字符读取:read()返回单个字符的ASCII码,-1表示读取完毕while ((len = reader.read()) != -1) {// 将ASCII码转为字符并输出System.out.print((char) len);}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (reader != null) {try {reader.close();} catch (IOException e) {e.printStackTrace();}}}}
}运行结果:
3.2 缓冲字符流:BufferedReader 与 BufferedWriter
BufferedReader和BufferedWriter是带大缓冲区的字符流(默认缓冲区 8192 字符),性能远超基础字符流,且提供了实用方法(如BufferedReader.readLine()逐行读取文本),是处理文本文件的首选。
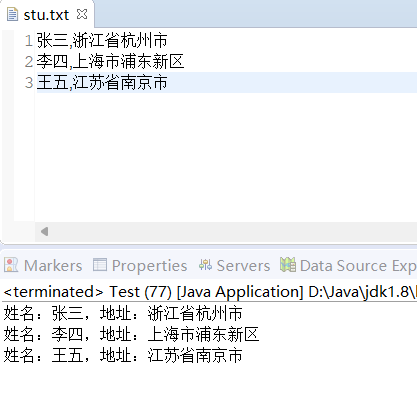
案例 1:逐行读取文本文件
package com.demo21;import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;public class Test {public static void main(String[] args) {try {BufferedReader br = new BufferedReader(new FileReader("./user/stu.txt"));String line = "";// 逐行读取:readLine()返回一行文本,null表示读取完毕(自动忽略换行符)while ((line = br.readLine()) != null) {// 按逗号分割String[] info = line.split(",");if (info.length == 2) { // 确保格式正确String name = info[0];String address = info[1];System.out.println("姓名:" + name + ",地址:" + address);}}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}
}
运行结果:
3.3 转换流(字节流转字符流)
System.in键盘输入是字节流(InputStream),若要读取键盘输入的字符串,需用InputStreamReader将其转为字符流,再包装为BufferedReader提升性能:
package com.demo21;import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;public class Test1 {public static void main(String[] args) {// 字节流:System.in(键盘输入)InputStream in = System.in;// 转换流:将字节流转为字符流InputStreamReader inReader = new InputStreamReader(in);// 缓冲字符流:提升读取性能BufferedReader br = new BufferedReader(inReader);try {// 缓冲输出流:写入文件BufferedWriter bw = new BufferedWriter(new FileWriter("./user/a.txt", true));System.out.print("请输入内容:");// 读取键盘输入的一行内容String input = br.readLine();System.out.println("你输入的内容:" + input);// 写入文件并换行(newLine()自动适配系统换行符)bw.write(input + "\n");bw.flush();System.out.println("内容已写入文件");} catch (IOException e) {e.printStackTrace();}}
}运行结果:

3.4 高级字符流:PrintWriter
PrintWriter是高级字符流,既可以构造字节流,也可以构造字符流,且自带缓冲,无需手动flush(关闭时自动刷新)。
package com.demo21;import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;public class Test2 {public static void main(String[] args) {try {//高级流 属于字符流 PrintWriter pw = new PrintWriter(new FileOutputStream("./user/a1.txt"));PrintWriter pw1 = new PrintWriter(new FileWriter("./user/a2.txt"));} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}四、随机读写流:RandomAccessFile
RandomAccessFile是 Java 中唯一支持随机访问的流(不属于字节流 / 字符流体系),可直接跳转到文件任意位置读写数据,常用于大文件分段读写。
- 支持两种模式:
r(只读)、rw(读写)。 - 通过
seek(long pos)方法设置文件指针位置(从文件开头计算,单位:字节)。 - 可读取 / 写入基本数据类型(如
readInt()、writeLong())和字节数组。
4.2 随机读取文件内容
package com.demo21;import java.io.FileNotFoundException;
import java.io.IOException;
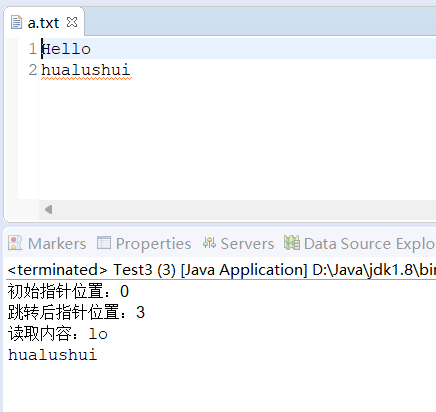
import java.io.RandomAccessFile;public class Test3 {public static void main(String[] args) {try {RandomAccessFile raf = new RandomAccessFile("./user/a.txt", "r");// 1. 获取初始文件指针位置(默认0,即文件开头)System.out.println("初始指针位置:" + raf.getFilePointer());// 2. 跳转到指针位置3(从第4个字节开始读取)raf.seek(3);System.out.println("跳转后指针位置:" + raf.getFilePointer());// 3. 读取数据(缓冲读取)byte[] buffer = new byte[40];int len = 0;while ((len = raf.read(buffer)) != -1) {System.out.println("读取内容:" + new String(buffer, 0, len));}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}
}运行结果:
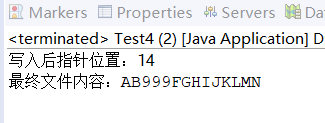
4.3 随机写入文件(覆盖指定位置)
package com.demo21;import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;public class Test4 {public static void main(String[] args) {File targetFile = new File("./user/a1.txt");try {RandomAccessFile raf = new RandomAccessFile(targetFile, "rw");// 1. 写入初始内容raf.write("ABCDEFGHIJKLMN".getBytes());System.out.println("写入后指针位置:" + raf.getFilePointer()); // 输出14(共14个字节)// 2. 跳转到指针位置2(覆盖第3个字节开始的内容)raf.seek(2);raf.write("999".getBytes()); // 覆盖CDE为999// 3. 验证结果:跳回文件开头读取raf.seek(0);byte[] buffer = new byte[(int) raf.length()];raf.read(buffer);System.out.println("最终文件内容:" + new String(buffer));} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}
}
运行结果: