《堆的详解:结构、操作及堆排序算法》
目录
一.堆的概念与结构
1.1 堆的概念
1.2 堆性质:
1.3 堆的结构定义
二.堆的初始化和销毁
2.1 堆的初始化:
2.2 堆的销毁:
三.堆的插入数据(含向上调整算法的实现)
3.1 插入逻辑
3.2 插入函数
3.3 向上调整算法
三. 堆的删除数据(含向下调整算法)
3.1 删除逻辑
3.2 向下调整算法
3.3 删除栈顶
四.堆的取堆顶
五.堆排序的实现
5.1 借助数据结构实现排序
5.2 真正的堆排序算法
一.堆的概念与结构
堆(Heap)是一种特殊的完全二叉树,同时也是一种高效的数据结构,主要用于实现优先队列等场景。其核心特性是节点之间的数值关系满足严格的堆序性,具体可分为大堆(大顶堆) 和小堆(小顶堆)。
1.1 堆的概念
堆的本质
堆是一棵完全二叉树(结构特性),且每个节点的值必须满足:
- 若为大堆:每个节点的值大于等于其左右子节点的值(根节点是最大值)。
- 若为小堆:每个节点的值小于等于其左右子节点的值(根节点是最小值)。
1.2 堆性质:
- 堆中某个结点的值总是不大于或者不小于其父结点的值
- 堆总是一颗完全二叉树
- 堆顶是最值(最大值或最小值)
1.3 堆的结构定义
// 堆的结构体定义(大堆)
typedef int HPDataType; // 堆中元素的类型
typedef struct Heap {HPDataType* arr; // 存储堆元素的数组int size; // 当前堆中元素的个数int capacity; // 堆的最大容量
} Heap;二.堆的初始化和销毁
2.1 堆的初始化:
// 初始化空堆
void HeapInit(Heap* hp) {if (hp == NULL) {return; // 处理空指针}hp->arr = NULL;hp->size = 0;hp->capacity = 0;
}2.2 堆的销毁:
销毁之前先检查数组为不为空,不为空就释放掉然后置空,并把size和capacity赋值为0
//销毁
void HPDestory(HP* php)
{assert(php);if (php->arr)free(php->arr);php->arr = NULL;php->size = php->capacity = 0;
}三.堆的插入数据(含向上调整算法的实现)
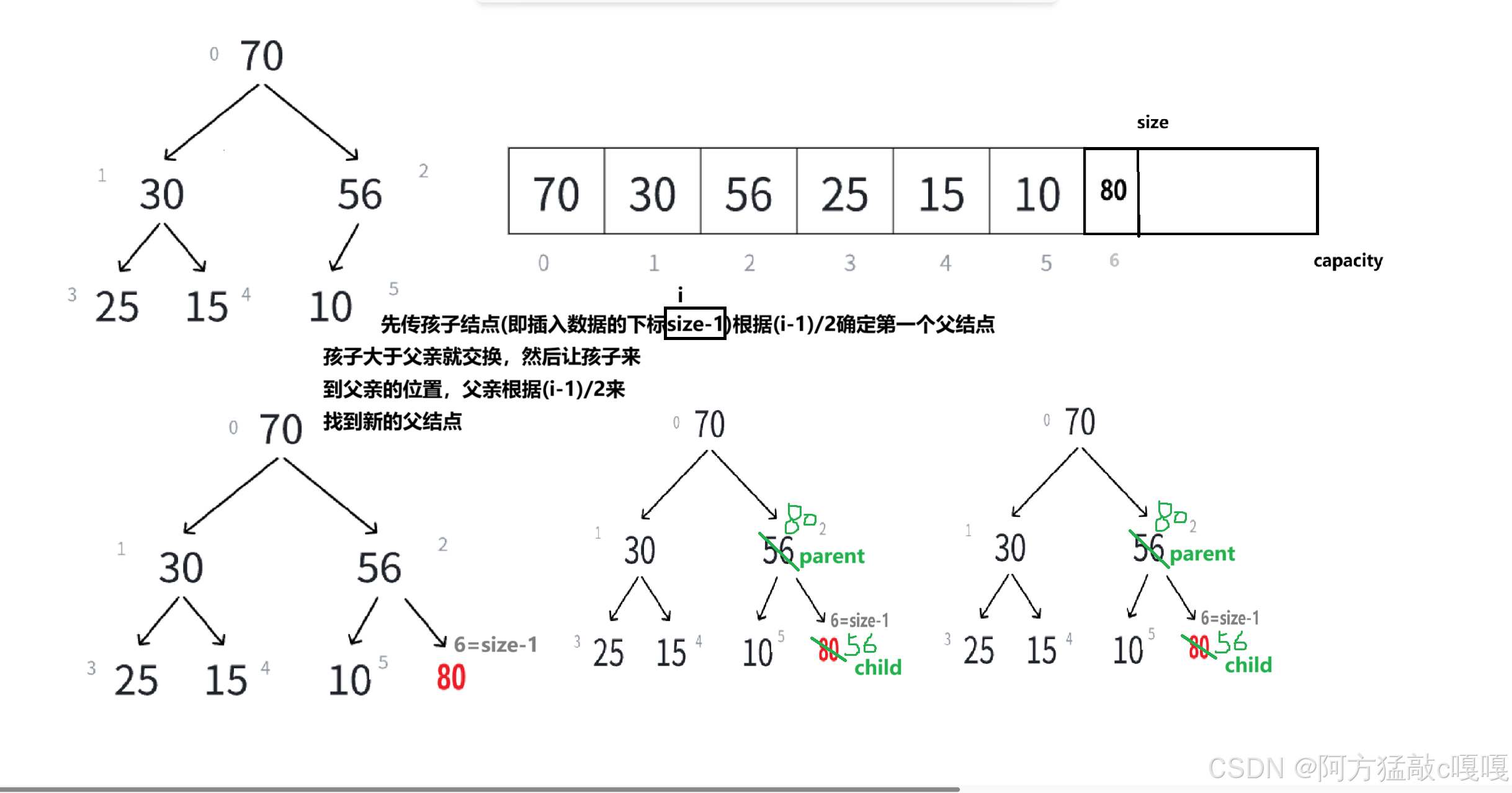
首先我们需要知道插入数据的逻辑 然后通过向上调整的方法来实现
向上调整算法
向上调整(也称 “上浮”)的核心是:新插入的元素从底部逐步向上移动,与父节点比较,若不满足堆序则交换,直到找到合适位置或到达根节点。
3.1 插入逻辑
- 空间检查:若堆已满,需扩容(类似动态数组扩容)。
- 添加元素:将新元素插入到堆的末尾(数组的最后一个位置)。
- 向上调整:从新元素位置开始,与父节点比较并交换,直至满足堆序性(大堆:子节点≤父节点;小堆:子节点≥父节点)。
如下图:
3.2 插入函数
首先插入时 我们需要判断空间是否足够 若不够的话就需要进行增容 代码如下
//往堆里面插入数据
void HPPush(HP* php, HPDataType x)
{//检查空间是否足够//不够就扩容if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* tmp = (HPDataType*)realloc(php->arr,newcapacity * sizeof(HPDataType));if (tmp == NULL){perror("realloc fail!");exit(1);}php->arr = tmp;php->capacity = newcapacity;}//够就直接插入php->arr[php->size++] = x;//向上调整AdjustUp(php->arr, php->size - 1);//因为前面size++了,所有传的是size-1
}3.3 向上调整算法
//交换
void swap(int* a, int* b)
{int temp = *a;*a = *b;*b = temp;
}
//向上调整
void AdjustUp(HPDataType*arr, int child)
{assert(arr);int parent = (child - 1) / 2;while (child > 0){//大堆:>//小堆:<if (arr[child] > arr[parent]){swap(&arr[child], &arr[parent]);child = parent;parent= (child - 1) / 2;}else{break;}}
}以大堆为例,步骤如下:
- 设新元素索引为
child,其父节点索引为parent = (child - 1) / 2(数组从 0 开始)。- 若
a[child] > a[parent](大堆条件),交换两者,更新child = parent,继续向上比较。- 重复上述步骤,直到
child = 0(根节点)或a[child] ≤ a[parent]
三. 堆的删除数据(含向下调整算法)
堆的删除操作通常指删除堆顶元素(根节点,即最大值或最小值),并通过向下调整算法重新维护堆的特性。以下是具体实现:
3.1 删除逻辑
- 替换堆顶:用堆的最后一个元素覆盖堆顶元素(避免直接删除堆顶导致结构破坏)。
- 缩减规模:堆的元素数量减 1(逻辑上移除最后一个元素)。
- 向下调整:从新的堆顶开始,与左右子节点中符合堆序的节点交换,直至满足堆的特性。
如下图

3.2 向下调整算法
向下调整(也称 “下沉”)的核心是:将替换后的堆顶元素逐步向下移动,与左右子节点中更符合堆序的节点(大堆选较大者,小堆选较小者)交换,直到找到合适位置或成为叶子节点。
以大堆为例,步骤如下:
- 设当前节点索引为
parent,左子节点索引为child = 2 * parent + 1(数组从 0 开始)。 - 若右子节点存在且大于左子节点,更新
child为右子节点索引。 - 若
a[parent] < a[child](大堆条件),交换两者,更新parent = child,继续向下比较。 - 重复上述步骤,直到
child超出堆的范围或a[parent] ≥ a[child]。
//向下调整
void AdjustDown(HPDataType* arr, int parent, int n)
{assert(arr);int child = 2 * parent + 1;while (child < n){//child+1也小于n//后面的小堆就是取小的,大堆取大的孩子if (child + 1 < n && arr[child] < arr[child + 1]){child++;}//大堆:> 小堆:<if (arr[child] > arr[parent]){swap(&arr[child], &arr[parent]);parent = child;child = 2 * parent + 1;}else{break;}}
}3.3 删除栈顶
首先我们需要一个判断是否为空的函数
//判空
bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}删除栈顶函数
//删除(堆顶操作)
void HPPop(HP* php)
{assert(!HPEmpty(php));//首尾交换swap(&php->arr[0], &php->arr[php->size - 1]);php->size--;//向下调整AdjustDown(php->arr, 0, php->size);
}先判断不为空,然后交换首尾,直接--size删掉,再通过向下调整算法把删除一个数据后的堆重新调整成大堆。
四.堆的取堆顶
首先判断是否为空 若不为空则直接返回栈顶元素arr[0]
//取堆顶
HPDataType HPTop(HP* php)
{assert(!HPEmpty(php));return php->arr[0];
}五.堆排序的实现
这里向大家介绍两种方式 但其实第一种并不是真正意义上的排序 只是达到了排序的目的而已
下面介绍第一种
5.1 借助数据结构实现排序
#include"Heap.h"//堆排序--这不是真正的堆排序,而是利用了堆这个数据结构来实现的排序
void HeapSort1(int* arr, int n)
{HP sp; // 定义一个堆结构体变量HPInit(&sp); // 初始化堆(创建空堆)// 1. 将数组所有元素插入堆中for (int i = 0; i < n; i++){HPPush(&sp, arr[i]); // 插入元素,内部会通过向上调整维护堆序}// 2. 从堆中提取元素,重构数组int i = 0;while (!HPEmpty(&sp)) // 当堆不为空时{HPDataType top = HPTop(&sp); // 获取堆顶元素(最小值或最大值)arr[i++] = top; // 将堆顶元素存入原数组,依次填充HPPop(&sp); // 删除堆顶元素,内部通过向下调整维护堆序}
}
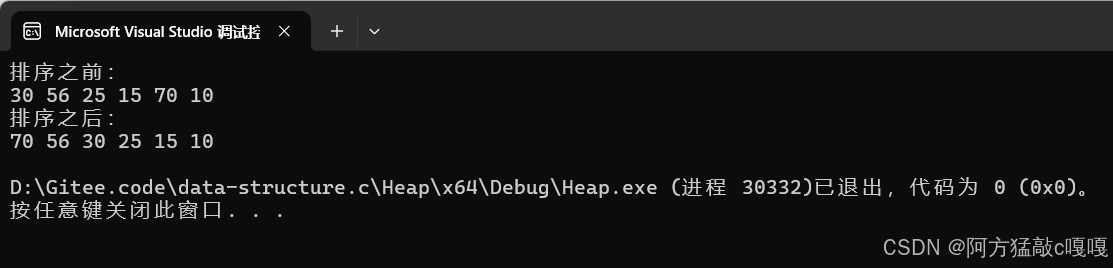
int main()
{int arr[6] = { 30,56,25,15,70,10 };printf("排序之前:\n");for (int i = 0; i < 6; i++){printf("%d ", arr[i]);}printf("\n");HeapSort1(arr, 6);printf("排序之后:\n");for (int i = 0; i < 6; i++){printf("%d ", arr[i]);}printf("\n");return 0;
}
核心思路
- 借助堆存储元素:将待排序数组的所有元素依次插入堆中(构建堆)。
- 提取最值并重构数组:反复从堆顶提取最小值(或最大值),按顺序存入原数组,最终得到有序数组。
为什么说 “这不是真正的堆排序”?
真正的堆排序(如之前实现的HeapSort)是原地排序,直接在原数组上通过构建堆和调整堆实现排序,不需要额外的堆结构,空间复杂度为O(1)。
而这段代码的本质是:
- 额外创建了一个堆(
HP sp),需要O(n)的额外空间存储元素; - 排序过程依赖于堆的插入和删除操作,本质是 “利用堆的特性进行排序”,而非严格意义上的原地堆排序。
5.2 真正的堆排序算法
通过构建大堆并反复提取最大值来实现数组的升序排序。其核心特点是原地排序(无需额外空间存储堆),充分利用堆的特性高效完成排序。以下是详细解释:
一、核心思路
构建大堆:将待排序数组转换为大堆(每个父节点的值 ≥ 子节点的值),此时堆顶(数组首位)是最大值。
排序过程:
交换堆顶(最大值)与当前堆的最后一个元素,将最大值放到数组末尾(最终位置)。
缩小堆的范围(排除已排好的末尾元素),对新堆顶执行向下调整,重新维护大堆特性。
重复上述步骤,直到所有元素排序完成。
二、代码逐段解析
1. HeapSort 函数(排序核心)
void HeapSort(int* arr, int n)
{// 1. 构建大堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, i, n); // 从最后一个非叶子节点开始向下调整}// 2. 执行排序int end = n - 1; // 标记当前堆的最后一个元素索引while (end > 0){// 交换堆顶(最大值)与当前堆的最后一个元素swap(&arr[0], &arr[end]);// 缩小堆范围(end减1),对新堆顶执行向下调整,重建大堆AdjustDown(arr, 0, end);end--; // 下一次排序的堆范围更小}
}
(1)构建大堆
关键代码:
for (int i = (n - 1 - 1) / 2; i >= 0; i--)计算最后一个非叶子节点的索引:
(n-1-1)/2(等价于(n-2)/2)。- 数组从 0 开始,最后一个元素索引为
n-1,其父亲节点索引为(n-1-1)/2。- 从下往上调整:从最后一个非叶子节点开始,依次向上对每个节点执行
AdjustDown(向下调整),最终将整个数组转换为大堆。
为什么从非叶子节点开始?
叶子节点没有子节点,无需调整;非叶子节点可能破坏堆序,需通过向下调整使其子树满足大堆特性。
(2)排序过程
-
交换堆顶与末尾元素:
swap(&arr[0], &arr[end])
大堆的堆顶(arr[0])是当前堆中的最大值,交换后最大值被放到数组末尾(arr[end]),即它的最终位置。 -
向下调整重建大堆:
AdjustDown(arr, 0, end)
交换后堆顶元素可能破坏堆序,需从堆顶开始向下调整,但此时堆的范围已缩小为[0, end-1](end位置已排好序)。 -
循环缩小范围:
end--
每次循环后,已排序的元素增加一个,堆的范围持续缩小,直到end=0(所有元素排序完成)。
2. main 函数(测试逻辑)
int main()
{int arr[6] = { 30,56,25,15,70,10 }; // 待排序数组printf("排序之前:\n");for (int i = 0; i < 6; i++){printf("%d ", arr[i]); // 输出:30 56 25 15 70 10}printf("\n");HeapSort(arr, 6); // 调用堆排序函数printf("排序之后:\n");for (int i = 0; i < 6; i++){printf("%d ", arr[i]); // 输出:10 15 25 30 56 70(升序)}printf("\n");return 0;
}
-
测试数组初始为
[30,56,25,15,70,10],经过堆排序后变为升序数组[10,15,25,30,56,70]。
三、关键辅助函数说明
AdjustDown(向下调整算法)
作用:当某个节点破坏大堆特性时,通过与左右子节点中较大的一个交换,逐步向下移动,直至子树重新满足大堆特性。
(代码中未显示实现,但核心逻辑是:选择左右子节点的最大值,与父节点比较,不满足大堆则交换并继续调整。)swap(交换函数)
作用:交换两个元素的值,用于将堆顶最大值移动到数组末尾。
四、为什么大堆能实现升序排序?
大堆的堆顶始终是当前堆中的最大值,每次将最大值放到数组末尾,相当于 “从后往前” 依次确定最大元素的位置。
经过
n-1次交换和调整后,数组从前往后依次递增,最终实现升序。
五、算法特性
-
时间复杂度:
O(n+logn)(构建堆O(n)+ 排序阶段O(nlog+n))。 -
空间复杂度:
O(1)(原地排序,仅需常数级额外空间)。 -
不稳定性:交换过程可能改变相等元素的相对顺序(例如
[2, 2, 1]排序后可能变为[1, 2, 2],但两个2的原始顺序可能改变)。
总结
这段代码是标准的堆排序实现,通过 “构建大堆→交换堆顶与末尾→调整堆” 的循环,高效完成升序排序。其原地排序的特性和 O(n+log n) 的时间复杂度,使其在大规模数据排序中表现优异。