基于 OpenCV 的眼球识别算法以及青光眼算法识别
在计算机视觉中,眼球识别(Eye Detection / Eye Tracking)是一个非常有趣且实用的方向。它广泛应用于 人机交互、智能驾驶(疲劳驾驶检测)、AR/VR 设备、医学影像分析 等领域。今天我们就用 Python + OpenCV 来实现一个基础的眼球识别算法。
算法背景
眼球识别的基本流程一般分为两步:
人脸检测(Face Detection)
首先定位人脸区域,缩小搜索范围。眼睛检测(Eye Detection)
在人脸区域内进一步检测眼睛位置,识别眼球轮廓,甚至追踪眼球运动。
常见的实现方法有:
Haar 特征级联分类器(Haar Cascade Classifier)
OpenCV 自带的经典方法,速度快,适合入门。DNN / CNN 深度学习方法
如使用 Dlib、Mediapipe 或自定义模型,准确率更高。
在这里我们用 OpenCV Haar 分类器 来实现一个简单的眼球识别系统。
2. 算法思路
使用 Haar 分类器加载人脸和眼睛的预训练模型。
将摄像头捕获的帧转换为灰度图,加快检测速度。
先检测人脸区域,再在该区域中检测眼睛。
在检测到的眼睛区域绘制矩形框,实现实时识别。
3. 实现步骤
导入依赖库(cv2、numpy)。
加载 Haar 分类器:
haarcascade_frontalface_default.xml(人脸检测)haarcascade_eye.xml(眼睛检测)
打开摄像头并逐帧处理。
在图像中检测并标注人脸和眼睛位置。
4. 代码示例
import cv2# 加载 Haar 特征分类器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_eye.xml")# 打开摄像头(0 为默认摄像头)
cap = cv2.VideoCapture(0)while True:ret, frame = cap.read()if not ret:break# 转为灰度图,加快检测速度gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)# 人脸检测faces = face_cascade.detectMultiScale(gray, 1.3, 5)for (x, y, w, h) in faces:# 绘制人脸框cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)# 获取人脸 ROI(Region of Interest)roi_gray = gray[y:y + h, x:x + w]roi_color = frame[y:y + h, x:x + w]# 在人脸区域内检测眼睛eyes = eye_cascade.detectMultiScale(roi_gray)for (ex, ey, ew, eh) in eyes:cv2.rectangle(roi_color, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 2)# 显示结果cv2.imshow("Eye Detection", frame)# 按 'q' 退出if cv2.waitKey(1) & 0xFF == ord('q'):breakcap.release()
cv2.destroyAllWindows()
5. 效果演示
运行后,你会看到摄像头画面中:
人脸会被蓝色矩形框标出
眼睛会被绿色矩形框标出
这样一个简单的眼球识别就完成了 🎉
6. 总结与扩展
上面的实现属于 传统视觉算法,优点是 实现简单、速度快,但在复杂场景(光照变化、眼镜遮挡、斜脸角度)下可能会检测不准。
如果想要更高的准确率,可以尝试:
使用 Dlib 的 68 个关键点检测 来定位眼睛。
使用 Mediapipe Face Mesh,可以检测 468 个面部关键点,追踪眼球位置。
基于 深度学习的 CNN 模型,实现更强大的眼球跟踪。
青光眼算法识别:
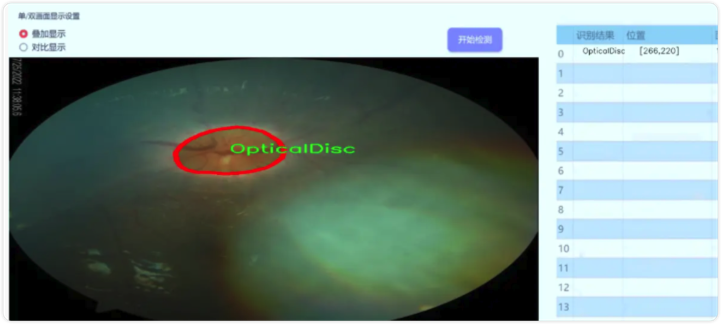
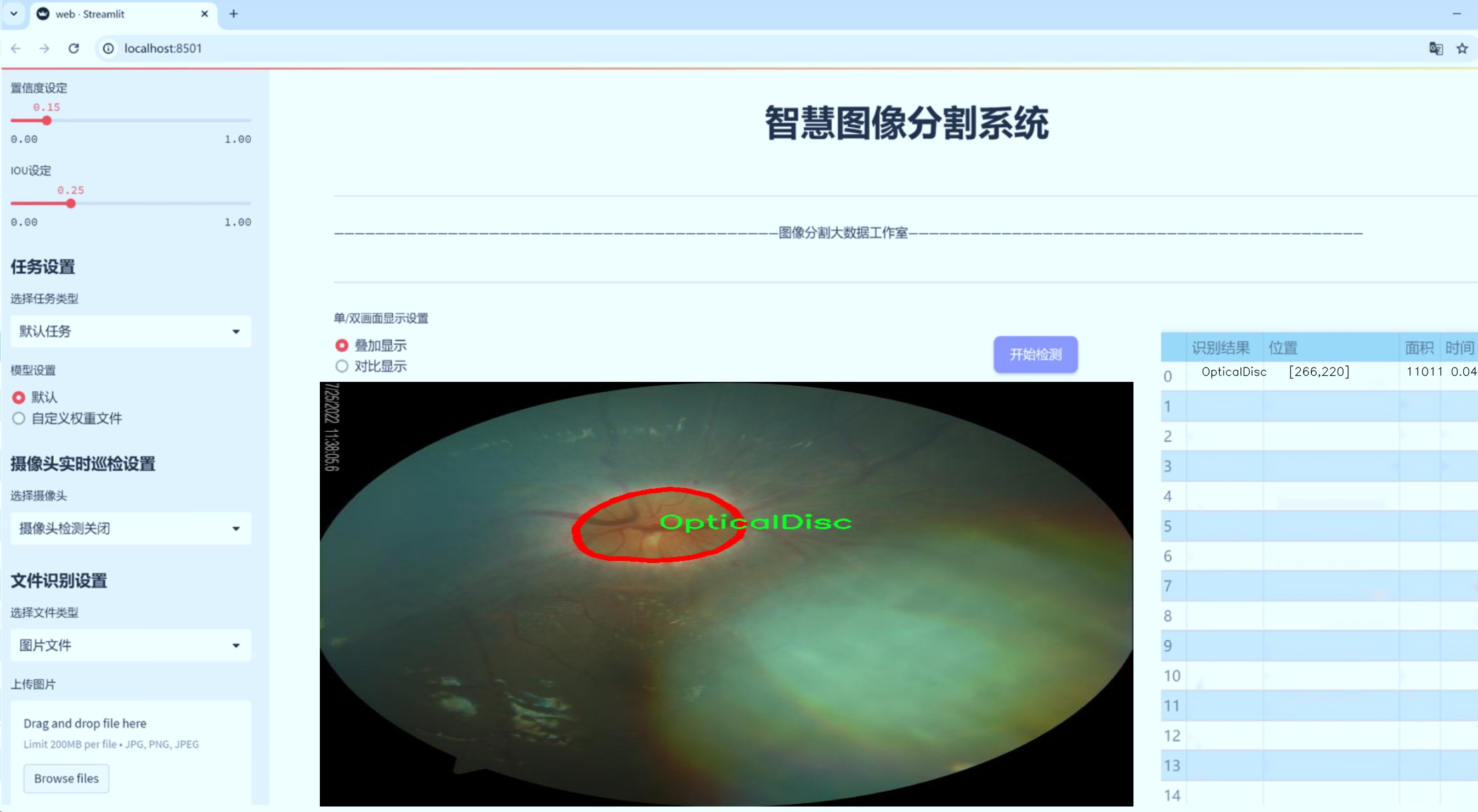
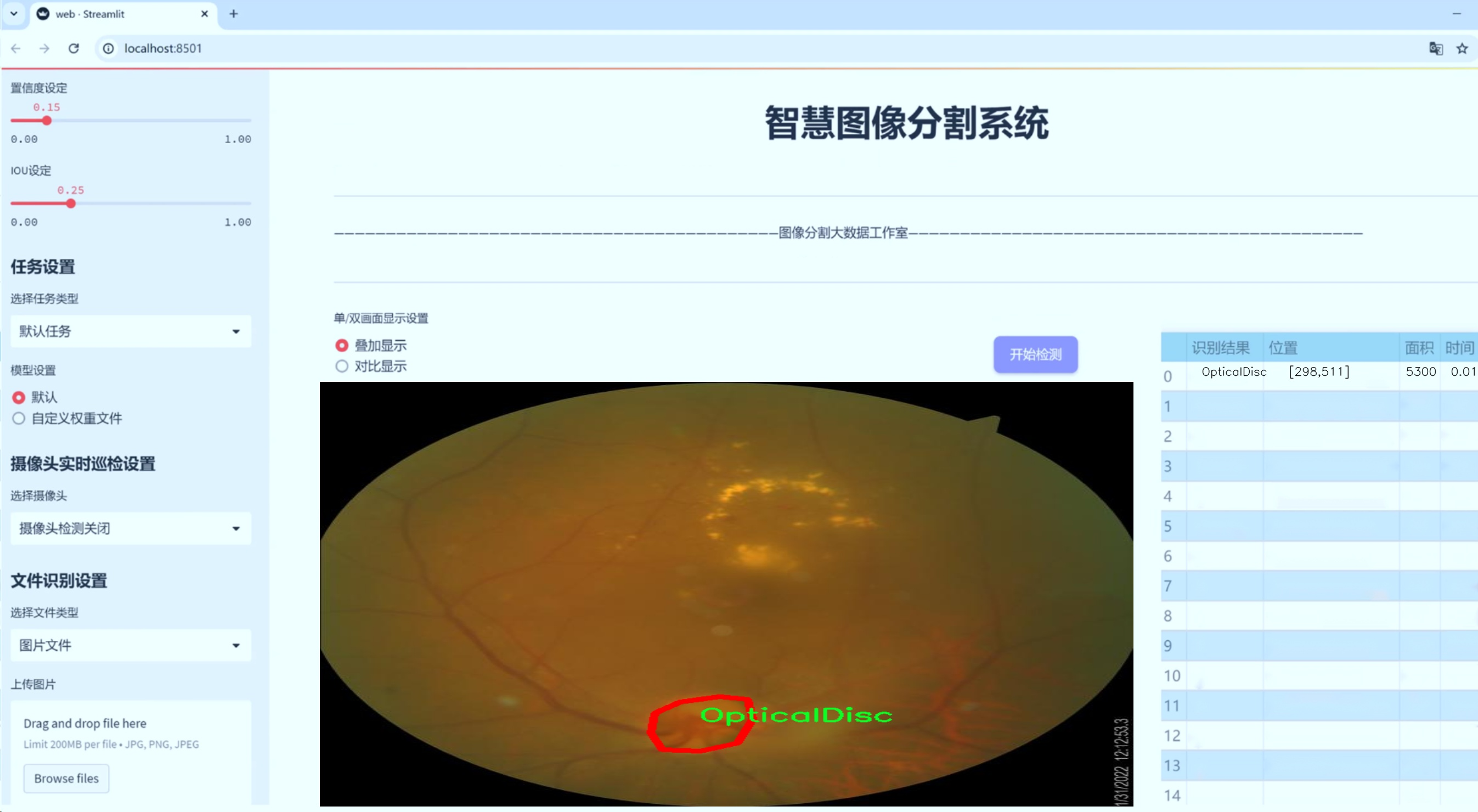
数据集信息展示
4.1 本项目数据集详细数据(类别数&类别名)
nc: 2 names: ['OpticalCup', 'OpticalDisc']
4.2 本项目数据集信息介绍
数据集信息展示
在本研究中,我们采用了名为“Segmentation-Sardjito”的数据集,以支持改进YOLOv8-seg的青光眼影像分割系统的训练与验证。该数据集专注于眼科影像的分割任务,特别是青光眼相关的关键结构——视神经盘(Optical Disc)和视杯(Optical Cup)。通过精确分割这些结构,我们能够更好地分析青光眼的特征,从而为临床诊断提供更为有效的支持。
“Segmentation-Sardjito”数据集包含了两类主要的目标,即“OpticalCup”和“OpticalDisc”。这两类的选择是基于青光眼的病理特征,视杯与视神经盘的比率(Cup-to-Disc Ratio, CDR)是评估青光眼的重要指标。视神经盘是眼底图像中可见的视神经的区域,而视杯则是视神经盘内部的凹陷部分。青光眼患者通常会表现出视杯的扩大,因此准确分割这两个区域对于疾病的早期检测和治疗方案的制定至关重要。
该数据集的构建经过了严格的标准化流程,确保每一幅图像的质量和标注的准确性。图像数据来源于多位患者的眼底检查,涵盖了不同阶段的青光眼病例,保证了数据的多样性和代表性。这种多样性不仅提高了模型的泛化能力,也为不同类型的青光眼提供了充分的样本支持。每幅图像都经过专业眼科医生的标注,确保了视杯和视神经盘的边界清晰且准确,从而为后续的深度学习模型训练提供了高质量的标签数据。
在数据集的使用过程中,我们将采用数据增强技术,以进一步提升模型的鲁棒性和适应性。通过旋转、翻转、缩放等操作,我们能够生成多样化的训练样本,从而减少模型对特定图像特征的依赖,增强其在真实场景中的表现。此外,数据集还将被划分为训练集、验证集和测试集,以便于对模型性能的全面评估。
在训练过程中,我们将重点关注模型在分割任务中的表现,尤其是对视杯和视神经盘的分割精度。我们将采用交叉熵损失函数和IoU(Intersection over Union)指标来评估模型的分割效果,确保模型不仅能够准确识别目标区域,还能在边界处保持高精度。通过不断迭代和优化,我们期望在青光眼影像分割领域取得显著的进展,为临床实践提供有力的技术支持。
总之,“Segmentation-Sardjito”数据集为本研究提供了坚实的基础,通过对视杯和视神经盘的精准分割,我们希望能够提升青光眼的早期诊断能力,为患者的治疗和管理提供更为科学的依据。随着研究的深入,我们期待这一数据集能够在青光眼影像分析领域发挥更大的作用,推动相关技术的进步与应用。
以下是经过简化和注释的核心代码部分:
import os
import re
import shutil
import socket
import sys
import tempfile
from pathlib import Pathdef find_free_network_port() -> int:"""查找本地主机上一个空闲的网络端口。在单节点训练时,当我们不想连接到真实的主节点,但必须设置`MASTER_PORT` 环境变量时,这个函数非常有用。"""with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:s.bind(('127.0.0.1', 0)) # 绑定到本地地址和随机端口return s.getsockname()[1] # 返回绑定的端口号def generate_ddp_file(trainer):"""生成一个 DDP 文件并返回其文件名。"""# 获取训练器的模块和类名module, name = f'{trainer.__class__.__module__}.{trainer.__class__.__name__}'.rsplit('.', 1)# 创建 DDP 文件的内容content = f'''overrides = {vars(trainer.args)} \nif __name__ == "__main__":from {module} import {name}from ultralytics.utils import DEFAULT_CFG_DICTcfg = DEFAULT_CFG_DICT.copy()cfg.update(save_dir='') # 处理额外的键 'save_dir'trainer = {name}(cfg=cfg, overrides=overrides)trainer.train()'''# 创建 DDP 目录(如果不存在)(USER_CONFIG_DIR / 'DDP').mkdir(exist_ok=True)# 创建临时文件并写入内容with tempfile.NamedTemporaryFile(prefix='_temp_',suffix=f'{id(trainer)}.py',mode='w+',encoding='utf-8',dir=USER_CONFIG_DIR / 'DDP',delete=False) as file:file.write(content) # 写入内容到临时文件return file.name # 返回临时文件的名称def generate_ddp_command(world_size, trainer):"""生成并返回用于分布式训练的命令。"""import __main__ # 本地导入以避免某些问题if not trainer.resume:shutil.rmtree(trainer.save_dir) # 如果不恢复训练,删除保存目录file = str(Path(sys.argv[0]).resolve()) # 获取当前脚本的绝对路径safe_pattern = re.compile(r'^[a-zA-Z0-9_. /\\-]{1,128}$') # 允许的字符和最大长度限制# 检查文件名是否安全且存在,并且以 .py 结尾if not (safe_pattern.match(file) and Path(file).exists() and file.endswith('.py')):file = generate_ddp_file(trainer) # 如果不安全,则生成 DDP 文件# 根据 PyTorch 版本选择分布式命令dist_cmd = 'torch.distributed.run' if TORCH_1_9 else 'torch.distributed.launch'port = find_free_network_port() # 查找空闲端口# 构建命令列表cmd = [sys.executable, '-m', dist_cmd, '--nproc_per_node', f'{world_size}', '--master_port', f'{port}', file]return cmd, file # 返回命令和文件名def ddp_cleanup(trainer, file):"""如果创建了临时文件,则删除它。"""if f'{id(trainer)}.py' in file: # 检查文件名中是否包含临时文件的后缀os.remove(file) # 删除临时文件代码说明:
- 导入必要的库:导入了PyTorch和其他相关模块,以便进行模型预测和图像处理。
- RTDETRPredictor类:这是一个预测器类,继承自
BasePredictor,用于处理RT-DETR模型的预测。 - postprocess方法:该方法对模型的原始预测结果进行后处理,生成边界框和置信度分数,并根据指定的置信度和类进行过滤。
- pre_transform方法:该方法对输入图像进行预处理,确保图像为正方形并适合模型输入。
这个程序文件 ultralytics\models\rtdetr\predict.py 实现了一个用于实时目标检测的预测器类 RTDETRPredictor,该类继承自 BasePredictor。它主要用于使用百度的 RT-DETR 模型进行目标检测,结合了视觉变换器的优势,能够在保持高精度的同时实现实时检测。该类支持高效的混合编码和 IoU(Intersection over Union)感知查询选择等关键特性。
在文件开头,导入了必要的库和模块,包括 PyTorch、数据增强工具、基本预测器、结果处理工具以及一些操作工具。接下来,定义了 RTDETRPredictor 类,并在类文档字符串中描述了其功能、使用示例和属性。
该类包含两个主要方法:postprocess 和 pre_transform。
postprocess 方法用于对模型的原始预测结果进行后处理,以生成边界框和置信度分数。它首先从模型的预测结果中分离出边界框和分数,然后根据置信度和类别进行过滤。对于每个边界框,方法将其坐标从中心点宽高格式转换为左上角和右下角格式,并根据置信度阈值和指定的类别进行筛选。最后,方法将处理后的结果封装为 Results 对象,并返回一个包含所有结果的列表。
pre_transform 方法则用于在将输入图像传递给模型进行推理之前进行预处理。它使用 LetterBox 类将输入图像调整为方形,并确保填充比例正确。该方法接受输入图像并返回经过预处理的图像列表,准备好进行模型推理。
整体而言,这个文件实现了一个高效的目标检测预测器,能够处理输入图像并生成检测结果,适用于需要实时处理的应用场景。
以下是代码中最核心的部分,并附上详细的中文注释:
import os
import re
import shutil
import socket
import sys
import tempfile
from pathlib import Pathdef find_free_network_port() -> int:"""查找本地主机上一个空闲的网络端口。在单节点训练时,当我们不想连接到真实的主节点,但必须设置`MASTER_PORT` 环境变量时,这个函数非常有用。"""with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:s.bind(('127.0.0.1', 0)) # 绑定到本地地址和随机端口return s.getsockname()[1] # 返回绑定的端口号def generate_ddp_file(trainer):"""生成一个 DDP 文件并返回其文件名。"""# 获取训练器的模块和类名module, name = f'{trainer.__class__.__module__}.{trainer.__class__.__name__}'.rsplit('.', 1)# 创建 DDP 文件的内容content = f'''overrides = {vars(trainer.args)} \nif __name__ == "__main__":from {module} import {name}from ultralytics.utils import DEFAULT_CFG_DICTcfg = DEFAULT_CFG_DICT.copy()cfg.update(save_dir='') # 处理额外的键 'save_dir'trainer = {name}(cfg=cfg, overrides=overrides)trainer.train()'''# 创建 DDP 目录(如果不存在)(USER_CONFIG_DIR / 'DDP').mkdir(exist_ok=True)# 创建临时文件并写入内容with tempfile.NamedTemporaryFile(prefix='_temp_',suffix=f'{id(trainer)}.py',mode='w+',encoding='utf-8',dir=USER_CONFIG_DIR / 'DDP',delete=False) as file:file.write(content) # 写入内容到临时文件return file.name # 返回临时文件的名称def generate_ddp_command(world_size, trainer):"""生成并返回用于分布式训练的命令。"""import __main__ # 本地导入以避免某些问题if not trainer.resume:shutil.rmtree(trainer.save_dir) # 如果不恢复训练,删除保存目录file = str(Path(sys.argv[0]).resolve()) # 获取当前脚本的绝对路径safe_pattern = re.compile(r'^[a-zA-Z0-9_. /\\-]{1,128}$') # 允许的字符和最大长度限制# 检查文件名是否安全且存在,并且以 .py 结尾if not (safe_pattern.match(file) and Path(file).exists() and file.endswith('.py')):file = generate_ddp_file(trainer) # 如果不安全,则生成 DDP 文件# 根据 PyTorch 版本选择分布式命令dist_cmd = 'torch.distributed.run' if TORCH_1_9 else 'torch.distributed.launch'port = find_free_network_port() # 查找空闲端口# 构建命令列表cmd = [sys.executable, '-m', dist_cmd, '--nproc_per_node', f'{world_size}', '--master_port', f'{port}', file]return cmd, file # 返回命令和文件名def ddp_cleanup(trainer, file):"""如果创建了临时文件,则删除它。"""if f'{id(trainer)}.py' in file: # 检查文件名中是否包含临时文件的后缀os.remove(file) # 删除临时文件- 查找空闲端口:
find_free_network_port函数用于查找本地的一个空闲网络端口,方便在分布式训练中设置MASTER_PORT环境变量。 - 生成 DDP 文件:
generate_ddp_file函数生成一个用于分布式数据并行(DDP)训练的 Python 文件,包含训练器的配置和训练逻辑。 - 生成分布式训练命令:
generate_ddp_command函数根据训练器的状态和当前脚本的路径生成分布式训练的命令,并返回命令和文件名。 - 清理临时文件:
ddp_cleanup函数用于删除在训练过程中生成的临时文件,以保持文件系统的整洁。
这个程序文件是用于处理分布式训练的工具,主要包含了几个函数,帮助用户在使用Ultralytics YOLO进行深度学习训练时,方便地设置和管理分布式训练的环境。
首先,文件导入了一些必要的模块,包括操作系统、正则表达式、文件处理、网络套接字、系统参数、临时文件以及路径处理等。接着,定义了一个函数find_free_network_port,它的作用是查找本地主机上一个可用的网络端口。这在单节点训练时非常有用,因为我们不想连接到真实的主节点,但又需要设置MASTER_PORT环境变量。
接下来是generate_ddp_file函数,该函数用于生成一个DDP(Distributed Data Parallel)文件,并返回其文件名。它首先获取训练器的模块和类名,然后构建一个Python脚本的内容,这个脚本会在主程序中运行。该脚本会导入训练器的类,并使用默认配置字典创建一个训练器实例,最后调用其train方法进行训练。生成的文件会被保存在用户配置目录下的DDP文件夹中。
然后是generate_ddp_command函数,它用于生成分布式训练的命令。函数首先检查训练器是否需要恢复训练,如果不需要,则删除保存目录。接着,它获取当前脚本的路径,并使用正则表达式检查该路径是否符合安全标准。如果不符合标准,则调用generate_ddp_file生成一个临时文件。之后,函数确定使用的分布式命令(根据PyTorch版本选择torch.distributed.run或torch.distributed.launch),并调用find_free_network_port获取一个可用的端口。最后,构建并返回一个命令列表和文件名。
最后,ddp_cleanup函数用于清理临时文件。如果生成的临时文件的后缀与训练器的ID匹配,则删除该文件,以避免文件堆积。
总体而言,这个文件提供了一系列工具函数,旨在简化Ultralytics YOLO在分布式环境下的训练过程,使得用户能够更方便地进行大规模训练。
图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list# 根据名称生成颜色
def generate_color_based_on_name(name):......# 计算多边形面积
def calculate_polygon_area(points):return cv2.contourArea(points.astype(np.float32))...
# 绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(image_pil)font = ImageFont.truetype("simsun.ttc", font_size, encoding="unic")draw.text(position, text, font=font, fill=color)return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)# 动态调整参数
def adjust_parameter(image_size, base_size=1000):max_size = max(image_size)return max_size / base_size# 绘制检测结果
def draw_detections(image, info, alpha=0.2):name, bbox, conf, cls_id, mask = info['class_name'], info['bbox'], info['score'], info['class_id'], info['mask']adjust_param = adjust_parameter(image.shape[:2])spacing = int(20 * adjust_param)if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area# 处理每帧图像
def process_frame(model, image):pre_img = model.preprocess(image)pred = model.predict(pre_img)det = pred[0] if det is not None and len(det)if det:det_info = model.postprocess(pred)for info in det_info:image, _ = draw_detections(image, info)return imageif __name__ == "__main__":cls_name = Label_listmodel = Web_Detector()model.load_model("./weights/yolov8s-seg.pt")# 摄像头实时处理cap = cv2.VideoCapture(0)while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理image_path = './icon/OIP.jpg'image = cv2.imread(image_path)if image is not None:processed_image = process_frame(model, image)......# 视频处理video_path = '' # 输入视频的路径cap = cv2.VideoCapture(video_path)while cap.isOpened():ret, frame = cap.read()......