Uber开发的QueryGPT:自然语言提示生成SQL查询系统演化
文章目录
- 1 引言
- 2 动机
- 3 架构
- 3.1 Hackdayz(版本1)
- 3.2 更好的RAG
- 3.3 理解用户意图
- 3.4 处理大型模式
- 4 当前设计
- 4.1 工作区
- 4.2 意图代理
- 4.3 表代理
- 4.4 列剪枝代理
- 4.5 输出
- 5 评估
- 5.1 评估集
- 5.2 评估流程
- 5.3 限制
- 6 经验总结
- 6.1 LLM是优秀的分类器
- 6.2 幻觉问题
- 6.3 用户提示不总是“上下文丰富”
- 6.4 对LLM生成SQL的高标准
- 7 结论

1 引言
SQL是Uber工程师、运营经理和数据科学家每天使用的重要工具,用于访问和操作海量数据。编写这些查询不仅需要扎实的SQL语法基础,还需要深入了解我们内部数据模型如何表示业务概念。QueryGPT旨在弥合这一差距,使用户能够通过自然语言提示生成SQL查询,从而显著提升工作效率。
QueryGPT利用大型语言模型(LLM)、向量数据库和相似度搜索,将用户输入的英文问题转换成复杂的SQL查询。
本文记录了我们过去一年多的开发历程以及目前实现的愿景。
2 动机
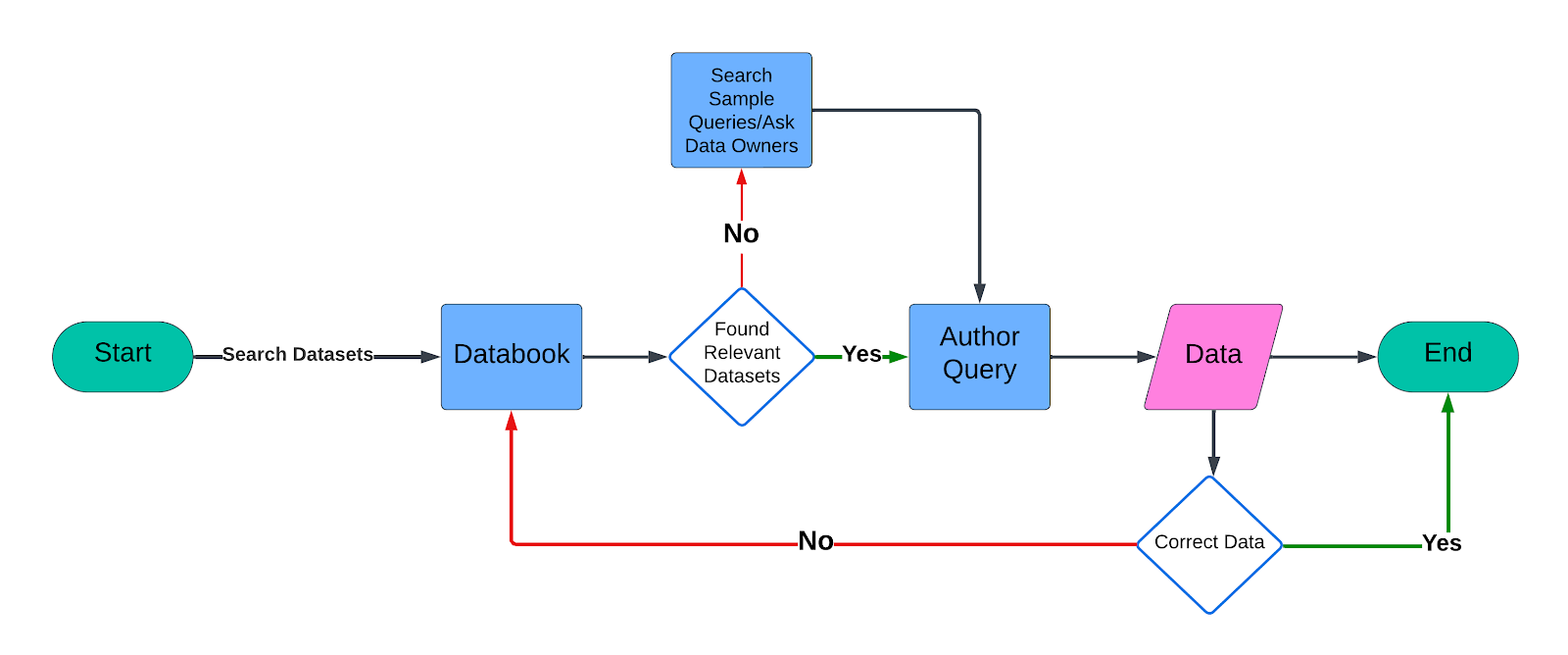
图1:查询创作流程。
在Uber,我们的数据平台每月处理约120万条交互式查询。运营组织作为最大的用户群体之一,贡献了约36%的查询量。编写这些查询通常需要花费相当多的时间,从查找相关数据集到在编辑器中编写查询。鉴于每条查询大约需要10分钟,QueryGPT的引入能够自动化此过程,并在约3分钟内生成可靠查询,极大提升生产效率。
保守估计,每条查询编写需10分钟,QueryGPT可将此时间缩短至约3分钟,为Uber带来显著的生产力提升。
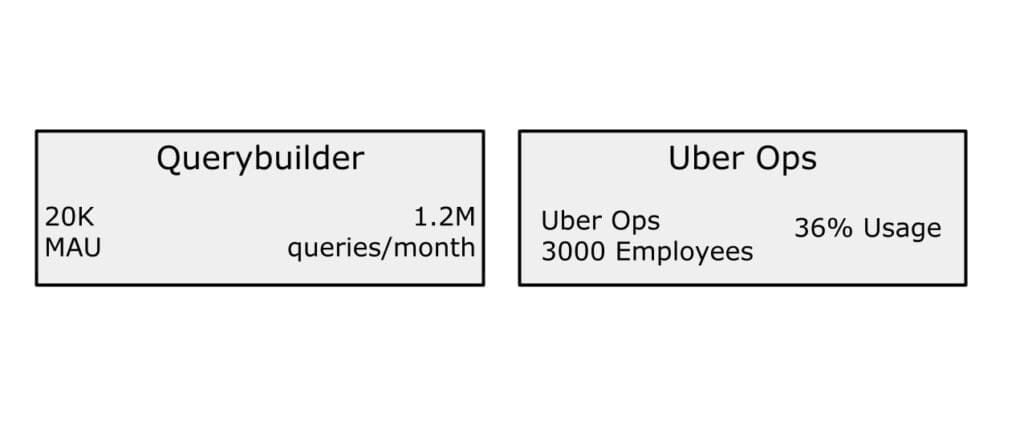
图2:Querybuilder使用情况。
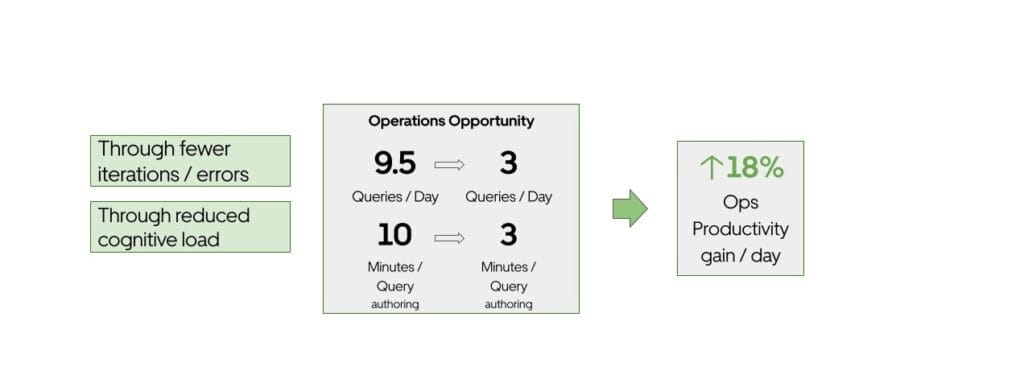
图3:QueryGPT影响力。
3 架构
QueryGPT起源于2023年5月Uber生成式AI Hackdays的提案。此后,我们不断迭代优化QueryGPT核心算法,将其从概念转变为生产级服务。以下详细介绍QueryGPT的发展历程及当前架构,重点突出关键改进。
当前版本经历了20多次算法迭代,若逐一详述,篇幅将远超安·兰德的《阿特拉斯耸耸肩》。
3.1 Hackdayz(版本1)
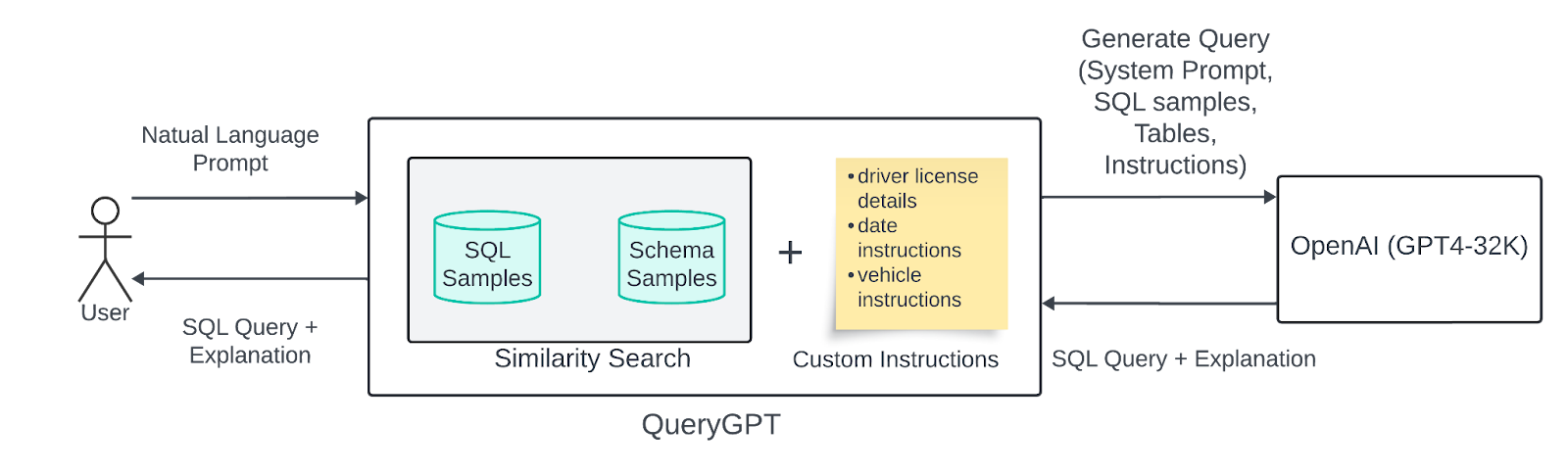
图4:QueryGPT Hackdayz版本。
第一版QueryGPT基于较简单的RAG(检索增强生成)机制,获取生成SQL查询所需的相关样本以调用LLM(少样本提示)。我们将用户的自然语言提示向量化,并在SQL样本和数据库模式中进行k近邻相似度搜索,获取3个相关表和7个相关SQL样本。
该版本使用7个一级表和20条SQL查询作为样本数据。SQL查询为LLM提供如何使用表结构的指导,表结构则提供表中列的信息。
例如,对于一级表_uber.trips_data_(非真实表),其模式如下:

图5:uber.trips_data表结构。
为了帮助LLM理解Uber内部术语和数据集,我们还在调用中加入了定制指令。下图展示了我们如何让LLM处理日期:

图6:处理Uber数据集中日期的定制指令。
我们将所有相关的表结构样本、SQL样本、用户自然语言提示和Uber业务指令包装在系统提示中,发送给LLM。
响应包含“SQL查询”和LLM生成查询的“解释”:
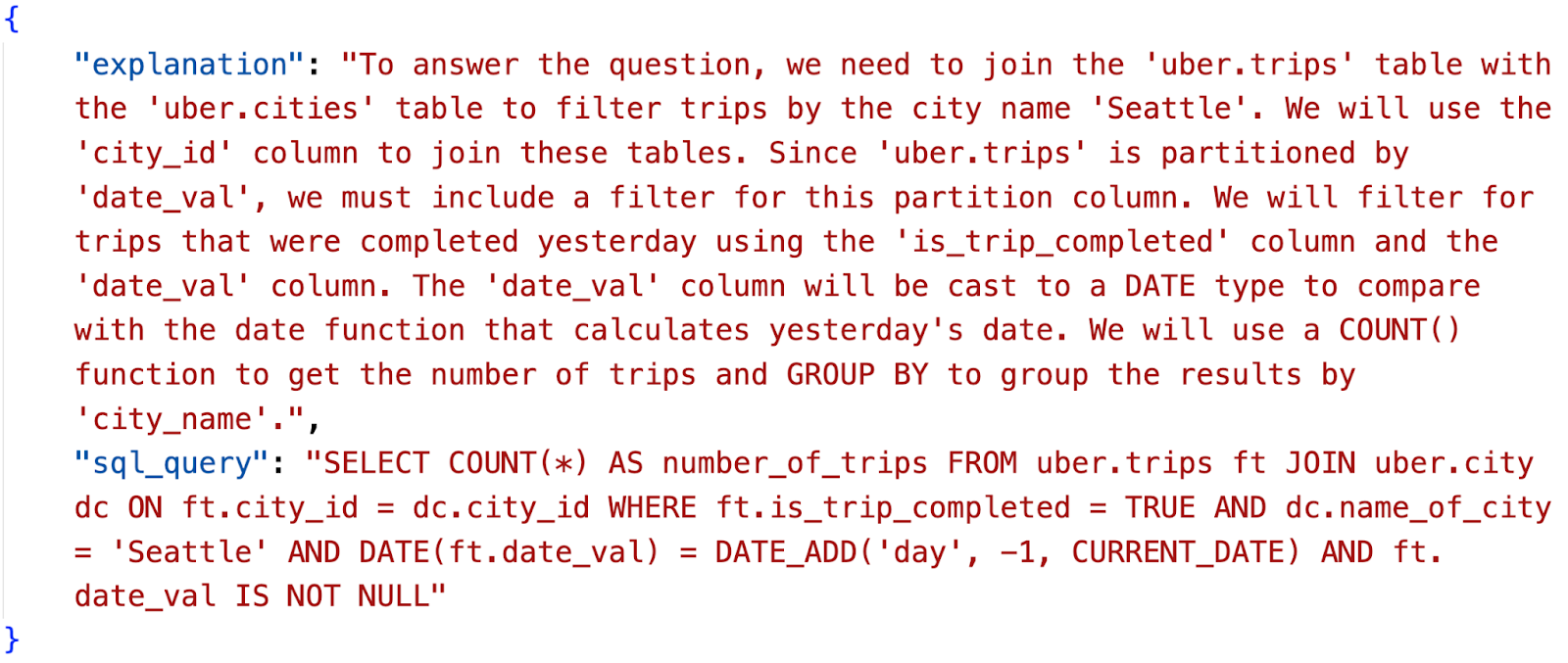
图7:生成的SQL及解释。
虽然该版本在小规模表结构和SQL样本上表现良好,但随着更多表及其SQL样本加入服务,生成查询的准确率开始下降。
3.2 更好的RAG
对用户自然语言提示(如“查找昨天在西雅图完成的行程数”)简单地在模式样本(CREATE TABLE…)和SQL查询(SELECT a, b, c FROM uber.foo…)中做相似度搜索,无法返回相关结果。
3.3 理解用户意图
另一个问题是,从用户自然语言提示直接找到相关模式极其困难。我们需要一个中间步骤,将用户提示分类为映射到相关模式和SQL样本的“意图”。
3.4 处理大型模式
Uber部分一级表的模式非常庞大,有些超过200列。这些大表在请求对象中可能占用4万到6万个token。一次请求中包含3个或更多此类表会超出当时最大模型(支持32K token)的限制,导致调用失败。
4 当前设计
下图展示了我们目前在生产环境中运行的QueryGPT设计。当前版本包含了大量从第一版迭代而来的改进。
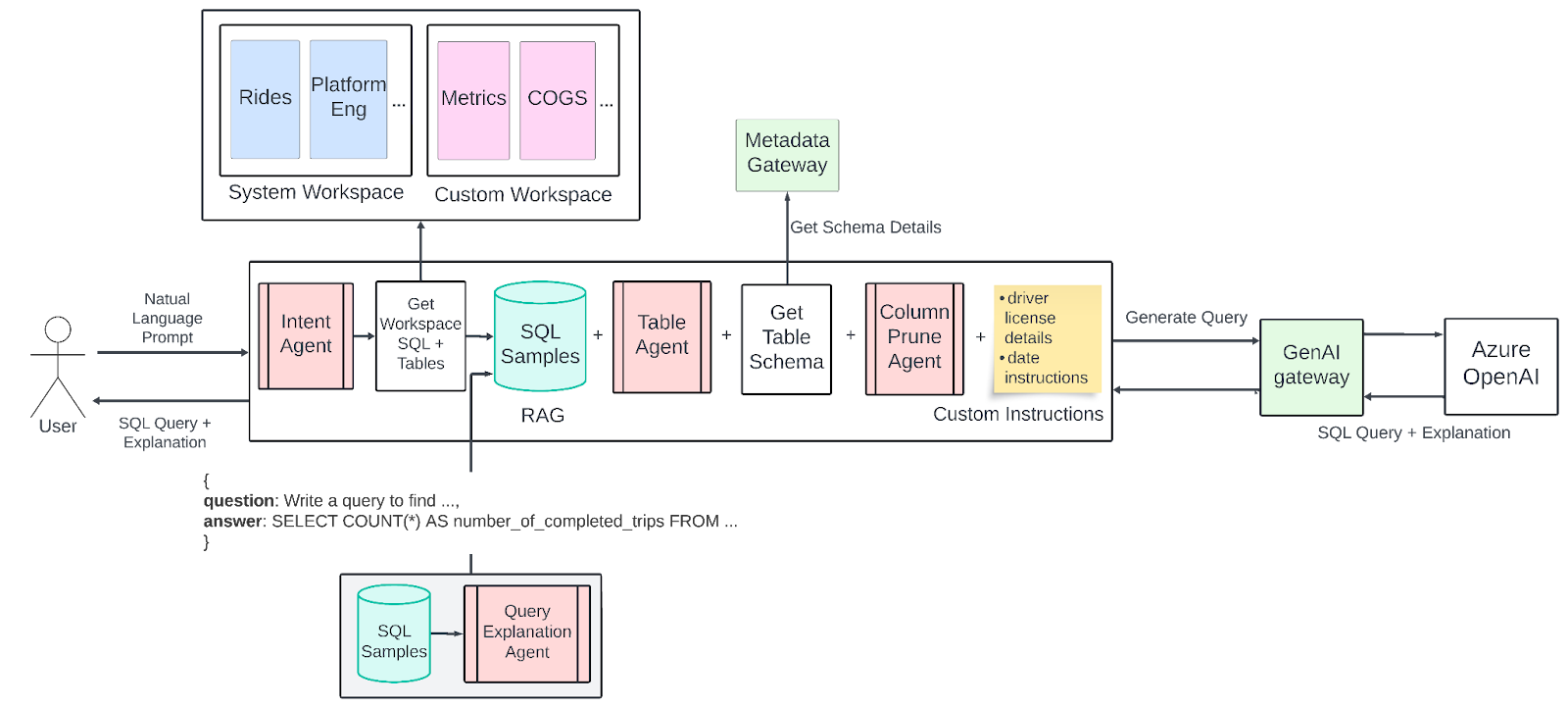
图8:QueryGPT当前架构。
4.1 工作区
我们引入了“工作区”,即针对特定业务领域(如广告、出行、核心服务)精心挑选的SQL样本和表集合。这些工作区帮助缩小LLM的关注范围,提高生成查询的相关性和准确度。
我们识别了一些Uber内较常见的业务领域,并在后端创建了“系统工作区”。出行(Mobility)是其中一个基础领域,用于查询包含行程、司机、文件详情等信息。
示例:
编写一个查询,查找昨天在西雅图由特斯拉完成的行程数。
此外,我们还发布了11个其他系统工作区,包括“核心服务”、“平台工程”、“IT”、“广告”等。
如果现有系统工作区不满足需求,用户还可以创建“自定义工作区”用于查询生成。
4.2 意图代理
每个用户输入的提示首先经过“意图代理”,其目的是将用户的问题映射到一个或多个业务领域/工作区(继而映射到该领域的SQL样本和表)。我们通过LLM调用推断意图,并映射到“系统”或“自定义”工作区。
业务领域的选择大幅缩小了RAG的搜索范围。
4.3 表代理
部分用户反馈QueryGPT最终选择的表不正确。为解决此问题,我们增加了另一个LLM代理(表代理),负责选择正确的表并反馈给用户,用户可“确认”或编辑修改表列表以确定用于查询生成的正确表。
下图展示了用户界面示例:
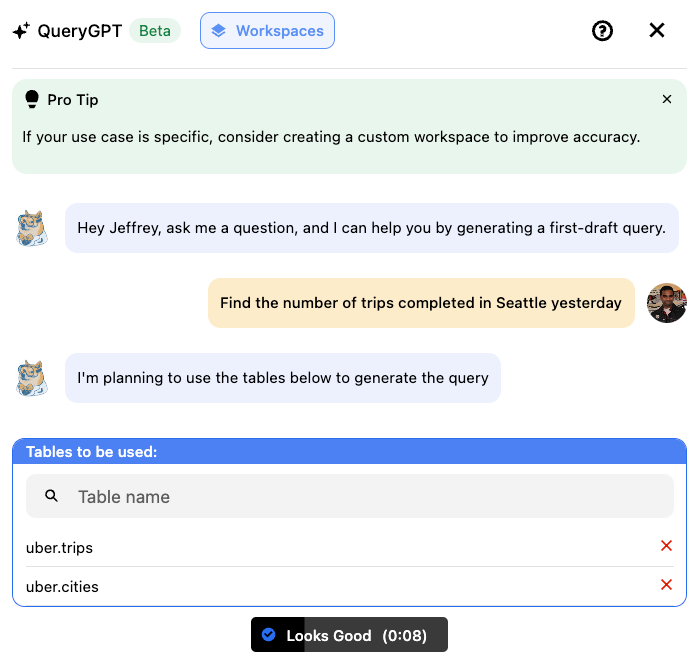
图9:表代理界面。
用户可点击“看起来不错”按钮,或编辑修改表列表。
4.4 列剪枝代理
在向更大范围用户推广QueryGPT后,我们遇到了查询生成时“间歇性”token大小问题。尽管使用了支持128K token限制的OpenAI GPT-4 Turbo模型(1106版本),某些请求仍因包含消耗大量token的表而触发限制。
为解决此问题,我们实现了“列剪枝”代理,利用LLM调用从提供给LLM的表结构中剪除无关列。
代理输出示例如下:

图10:列剪枝代理输出。
输出包含每个表的精简版本。此改进不仅大幅减少了token数量和调用成本,也降低了延迟。
4.5 输出
当前设计未对输出结构做改动。响应仍包含SQL查询及LLM对查询生成过程的解释,类似图7所示。
5 评估
为了跟踪QueryGPT性能的渐进提升,我们需要标准化评估流程。这有助于区分服务的反复性问题与偶发性缺陷,确保算法改进整体提升性能。
5.1 评估集
评估集由人工策划的黄金问题与SQL映射组成。我们从QueryGPT日志中选取真实问题,人工验证正确意图、所需模式及黄金SQL。问题涵盖多种数据集和业务领域。
5.2 评估流程
我们设计了灵活流程,能在生产和测试环境不同产品流程中捕捉查询生成过程的信号:
| 产品流程 | 目的 | 流程 |
|---|---|---|
| Vanilla | 测量QueryGPT基线性能 | 输入问题,QueryGPT推断意图和所需数据集,生成SQL,评估意图、数据集和SQL。 |
| Decoupled | 测量带人类介入的性能,支持组件级评估,消除对早期结果依赖 | 输入问题、意图和数据集,QueryGPT推断意图和数据集,用实际(非推断)意图和数据集生成SQL,评估意图、数据集和SQL。 |
对每个问题,我们捕获以下信号:
- 意图准确性:意图分配是否准确?
- 表覆盖率:通过搜索+表代理识别的表是否正确?以0到1的分数表示。例如,若问题需用[fact_trip_state, dim_city],而QueryGPT识别了[dim_city, fact_eats_trip_],覆盖分数为0.5。
- 执行成功率:生成的查询是否成功执行?
- 有无输出:查询执行是否返回大于0条记录。(有时QueryGPT会“幻觉”生成如WHERE status = “Finished”的过滤条件,实际应为“Completed”,导致执行成功但无输出)
- 查询相似度:生成查询与黄金SQL的相似度,使用LLM评分0到1,快速判断语法错误外是否在列、连接、函数等方面接近目标。
我们通过可视化跟踪进展,识别回归和改进点。
下图示例展示了问题级的运行结果,帮助发现重复性缺陷:

图11A:SQL查询评估。

图11B:不同环境下SQL查询评估。
以下示例问题生成的查询经常失败,原因是未在WHERE子句应用分区过滤。但根据基于LLM的定性评估,生成的SQL在其他方面与黄金SQL相似。

图12:SQL评估统计。
我们还汇总每次评估的准确率和延迟指标,跟踪性能趋势。

图13:SQL评估指标。
5.3 限制
由于LLM的非确定性,同一评估在无变更的情况下多次运行可能产生不同结果。通常,我们不会过度关注大约5%的指标波动,而是关注长期的错误模式,并针对性改进功能。
Uber拥有数十万个不同文档质量的数据集,不可能通过评估问题集覆盖所有业务问题。我们策划的问题集代表当前产品使用情况,随着准确率提升和新问题出现,评估集也会不断演进。
此外,问题往往没有唯一正确答案。同一问题可能通过不同表或不同风格的查询实现。通过对比黄金SQL与生成SQL及LLM评分,我们能判断生成查询是否风格不同但意图相似。
6 经验总结
过去一年与GPT及LLM等新兴技术共事,让我们尝试并学习了许多关于代理和LLM如何利用数据响应用户问题的细节。以下是部分经验:
6.1 LLM是优秀的分类器
我们在QueryGPT中使用的中间代理将用户自然语言提示拆解成更精准信号供RAG使用,显著提升了准确率。这得益于LLM在处理单一、专门任务时表现优异。
意图代理、表代理和列剪枝代理均表现出色,因为它们专注于单一任务,而非泛化的广泛任务。
6.2 幻觉问题
幻觉仍是我们持续攻关的难题。我们确实发现LLM有时生成包含不存在表或列的查询。
我们尝试通过提示优化减少幻觉,引入聊天式模式让用户迭代生成查询,并计划增加“验证”代理递归修正幻觉,但这一挑战尚未完全解决。
6.3 用户提示不总是“上下文丰富”
用户输入的问题从包含正确关键词的详细描述,到只有5个字(带错别字)且需跨多个表连接的宽泛问题不等。
仅依赖用户原始问题作为LLM输入导致准确率和可靠性问题。我们需要“提示增强器”或“提示扩展器”在发送给LLM前丰富用户问题的上下文。
6.4 对LLM生成SQL的高标准
虽然当前版本对广泛用户群有帮助,但许多用户期望生成的查询高度准确且“开箱即用”,标准很高。
我们的经验是,构建此类产品时,最好从合适的用户角色入手,针对其进行测试和调优。
7 结论
本文QueryGPT – Natural Language to SQL Using Generative AI来自Uber技术分享。
Uber的QueryGPT开发历程是一段变革之旅,大幅提升了从自然语言提示生成SQL查询的效率和准确性。借助先进的生成式AI模型,QueryGPT无缝整合Uber庞大数据生态,缩短查询编写时间,提升准确率,应对数据规模和复杂性的双重挑战。
尽管仍面临如处理大规模模式和减少幻觉等挑战,我们的迭代方法和持续学习推动了不断改进。QueryGPT不仅简化了数据访问,还实现了数据民主化,使Uber各团队更易获得强大数据洞察。
目前,我们已在运营和支持团队有限发布,日均活跃用户约300人,其中78%表示生成查询减少了从零编写的时间。
展望未来,更先进的AI技术和用户反馈将驱动持续优化,确保QueryGPT成为Uber数据平台的重要工具。