TGRS 2025 | DIA 模块:融合全局与局部特征的可变形交互注意力,即插即用,涨点起飞!
1. 基本信息

-
标题: An Adaptive Dual-Supervised Cross-Deep Dependency Network for Pixel-Wise Classification (一种用于像素级分类的自适应双监督交叉深度依赖网络)
-
论文来源:https://ieeexplore.ieee.org/document/10841446
2. 核心创新点
-
提出两阶段混合监督网络 (ADCD-Net):通过第一阶段的自监督学习生成相似性语义特征,作为先验知识指导第二阶段的监督分类任务,有效缓解多模态数据间的语义差异。
-
设计深度时序Mamba模块 (DTM-Module):将网络不同深度的特征图视为时序序列,利用Mamba模型捕捉跨层级的长距离依赖关系,使浅层信息能有效指导深层语义优化。
-
首创可变形交互注意力模块 (DIA-Module):通过动态调整不同属性特征(全局与局部)的梯度来重构注意力掩码,在去除通道冗余的同时,增强关键空间位置信息的表征能力。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/iIi0F7SpdUIQ4cEOjQDUZw
https://mp.weixin.qq.com/s/iIi0F7SpdUIQ4cEOjQDUZw
3. 方法详解
整体结构概述
ADCD-Net 是一个创新的两阶段训练框架,旨在融合多光谱(MS)和全色(PAN)遥感影像进行像素级分类。第一阶段(语义感知自监督),网络通过自监督的相似性损失,使MS和PAN影像的深层特征在语义上趋于一致,减少模态差异,并生成用于指导第二阶段的先验知识(特征权重和语义序列)。第二阶段(多分支监督),利用第一阶段的先验知识来优化主融合分支的监督学习,同时引入DTM模块捕捉网络内部不同深度特征间的依赖关系,并通过独立的分类分支增强模型性能。
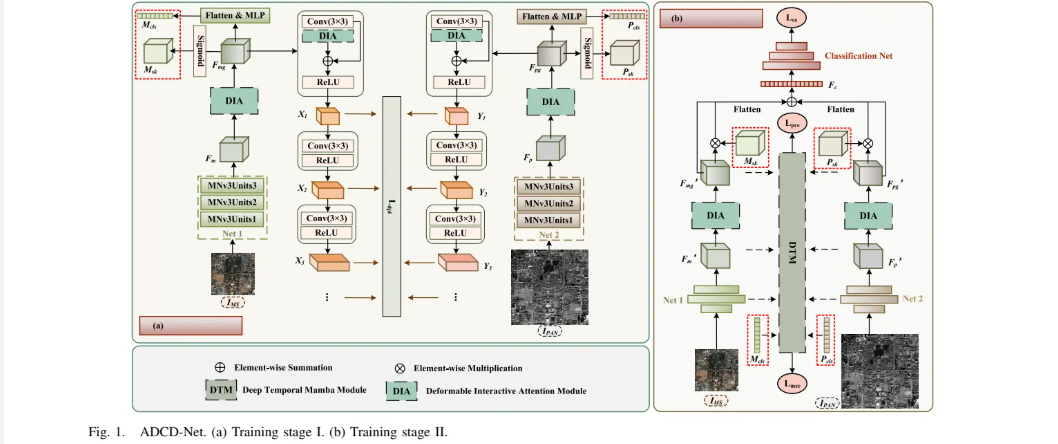
ADCD-Net整体架构图
步骤分解
-
阶段 I:语义感知自监督 (SPS)
-
特征提取: MS影像 () 和 PAN影像 () 分别通过基础卷积网络(MobileNetV3单元)提取初步特征 和 。
-
注意力优化: 初步特征输入到可变形交互注意力模块(DIA-Module)中,以去除冗余并增强空间信息,输出优化后的特征 和 。
-
先验知识生成: 将优化特征 和 通过Sigmoid函数生成权重掩码 和 ,同时展平后通过MLP生成语义序列 和 $这些都将用于第二阶段。
-
自监督损失计算: 和 经过多层感知特征提取后,计算它们在各层特征()之间的均方误差,形成自监督感知损失 ,旨在拉近两种模态的语义距离。
-
-
阶段 II:多分支监督学习
-
主干特征融合: 在第二阶段,重新提取MS和PAN的深层特征 和 。然后,利用第一阶段生成的权重掩码 和 对其进行加权,再与原始特征进行残差连接,最后融合得到特征 。
-
主损失计算: 融合特征 被送入全连接网络(CNet)进行分类,计算主要的分类交叉熵损失 。
-
辅助损失计算(DTM-Module): 网络中MS和PAN分支不同深度的特征图(如 )被展平并拼接,形成时序序列。将第一阶段生成的语义序列 (或 )作为先验知识拼接到序列末尾。该序列输入到**深度时序Mamba模块 (DTM-Module)**中,捕捉跨层特征的依赖关系。最后,DTM模块的输出被用于独立的分类任务,产生辅助损失 和 。
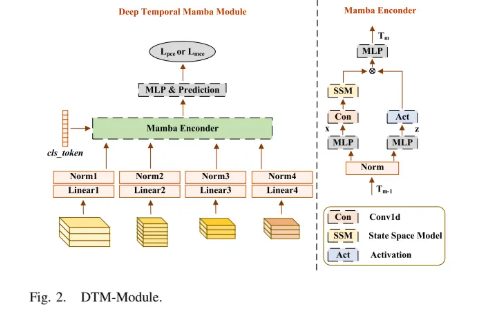
-
总损失: 模型的总损失由主损失和加权的辅助损失构成。
-
-
核心模块:可变形交互注意力模块 (DIA-Module)
-
双重池化: 对输入特征 同时进行全局平均池化(GAP)和全局最大池化(GMP),分别得到平滑的全局背景特征 和包含边缘纹理的局部特征 。
-
可变形交互: 对池化后的特征,通过一组相互依赖的调制系数进行重构。例如,在MS分支中,用全局特征 以较大的梯度缩放因子(如0.4)去调制局部特征 ,同时用局部特征以较小的梯度缩放因子(如0.1)去调制全局特征。这种非对称的梯度调整使得模块能自适应地强化主导特征并融合补充特征。
-
掩码生成: 重构后的特征经过拼接、卷积和Sigmoid激活函数,生成最终的空间注意力掩码 ,并作用于原始输入特征。
-
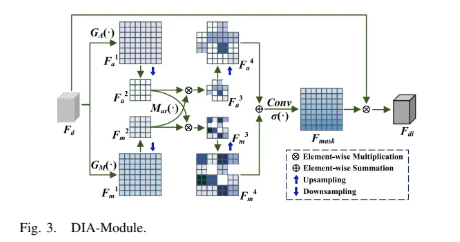
DIA-Module结构图
4. 即插即用模块作用
本报告选取 可变形交互注意力模块(DIA-Module) 和 深度时序Mamba模块(DTM-Module) 作为核心分析对象。
适用场景
- DIA-Module:
-
多模态特征融合: 适用于需要融合不同传感器数据(如光学与雷达、多光谱与全色)的场景,能自适应地平衡和增强各自的优势特征(如MS的全局光谱与PAN的局部纹理)。
-
特征去冗余: 可用于任何视觉任务的特征提取骨干网络中,替代传统的空间注意力模块,以更精细的方式压缩通道信息并突出关键空间区域。
-
遥감图像分类/分割: 特别适用于地物类别复杂、边界模糊的遥感影像分析任务。
-
- DTM-Module:
-
深度网络优化: 可应用于需要综合不同层级特征信息的深度学习模型中,如图像分类、目标检测等,以加强浅层细节对深层语义的引导。
-
时序数据分析: 虽然本文用于图像,但其核心思想可自然迁移到视频分析、医学信号处理等真正的时序数据建模任务中。
-
模型解释性增强: 通过建模层与层之间的依赖关系,为理解深层网络如何做出决策提供新的视角。
-
主要作用
- DIA-Module:
-
模拟/替代能力: 替代传统的空间注意力机制(如CBAM中的空间模块),提供一种更具适应性的空间信息筛选能力。
-
增强特征辨别性: 通过非对称的梯度调制和特征交互,使得生成的注意力掩码能够更好地捕捉和区分不同模态的优势信息(如光谱 vs. 纹理),避免信息偏置。
-
减少信息损失: 在对通道进行压缩以生成空间注意力图时,避免了标准最大池化或平均池化带来的信息单一化问题,保留了更丰富的特征多样性。
-
- DTM-Module:
-
增强全局依赖建模: 模拟了网络从浅到深的“演化”过程,通过状态空间模型捕捉了跨层级的全局特征依赖,弥补了CNN和Transformer在特定场景下对层级间互动建模的不足。
-
提升模型性能与鲁棒性: 确保了浅层的纹理、边缘等非语义信息能够有效传递并影响最终的分类决策,提高了模型在复杂场景下的分类表现。
-
利用先验知识: 巧妙地将第一阶段自监督学习到的语义序列作为Mamba的可学习参数,加速了收敛并提高了训练效率。
-
总结
-
DIA-Module 是一个 “特征重构师”,它通过智能的梯度控制和跨属性交互,动态地重塑特征图,生成一个既能突出重点又能兼顾全局的、信息更丰富的空间注意力掩码。
-
DTM-Module 是一个 “特征指挥家”,它将网络各层特征谱写成一曲时序乐章,利用Mamba模型指挥信息在不同深度间的流动与和谐互动,确保最终的决策融合了从底层细节到高层语义的完整信息。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/iIi0F7SpdUIQ4cEOjQDUZw
https://mp.weixin.qq.com/s/iIi0F7SpdUIQ4cEOjQDUZw
5. 即插即用模块
import torch
from torch import nn
import torch.nn.functional as Fclass DeformableInteractiveAttention(nn.Module):def __init__(self, stride=1, distortionmode=False):super(DeformableInteractiveAttention, self).__init__()# 定义卷积层,将输入通道数从 2 转换为 1self.conv = nn.Conv2d(2, 1, kernel_size=3, stride=1, padding=1)# 定义 Sigmoid 激活函数self.sigmoid = nn.Sigmoid()# 是否启用调制模式self.distortionmode = distortionmode# 上采样操作,scale_factor=2表示放大两倍self.upsample = nn.Upsample(scale_factor=2)# 两个下采样卷积层,用于减少特征图尺寸self.downavg = nn.Conv2d(1, 1, kernel_size=3, stride=2, padding=1)self.downmax = nn.Conv2d(1, 1, kernel_size=3, stride=2, padding=1)# 如果启用了调制模式ifdistortionmode:# 定义调制卷积层,并将其权重初始化为零self.d_conv = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=stride)nn.init.constant_(self.d_conv.weight, 0)# 注册后向传播钩子,设置学习率self.d_conv.register_full_backward_hook(self._set_lra)# 另一个调制卷积层,同样初始化权重为零self.d_conv1 = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=stride)nn.init.constant_(self.d_conv1.weight, 0)self.d_conv1.register_full_backward_hook(self._set_lrm)@staticmethoddef _set_lra(module, grad_input, grad_output):# 设置学习率大小,通过修改梯度来控制更新grad_input = [g * 0.4 if g is not None else None for g in grad_input]grad_output = [g * 0.4 if g is not None else None for g in grad_output]grad_input = tuple(grad_input)grad_output = tuple(grad_output)return grad_input@staticmethoddef _set_lrm(module, grad_input, grad_output):# 设置另一种学习率大小,控制不同卷积层的梯度更新grad_input = [g * 0.1 if g is not None else None for g in grad_input]grad_output = [g * 0.1 if g is not None else None for g in grad_output]grad_input = tuple(grad_input)grad_output = tuple(grad_output)return grad_inputdef forward(self, x):# 计算输入张量在第一个维度(通道维)上的均值和最大值avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)# 对均值和最大值进行下采样avg_out = self.downavg(avg_out)max_out = self.downmax(max_out)# 将下采样后的均值和最大值在通道维度拼接out = torch.cat([max_out, avg_out], dim=1)# 如果启用了调制模式ifself.distortionmode:# 对均值和最大值分别进行卷积,得到调制因子d_avg_out = torch.sigmoid(self.d_conv(avg_out))d_max_out = torch.sigmoid(self.d_conv1(max_out))# 调制最大值和均值out = torch.cat([d_avg_out * max_out, d_max_out * avg_out], dim=1)# 对拼接后的张量进行卷积操作out = self.conv(out)# 使用上采样操作放大结果,并应用 Sigmoid 激活mask = self.sigmoid(self.upsample(out))# 通过 mask 对输入张量进行加权att_out = x * mask# 返回 ReLU 激活后的结果return F.relu(att_out)if __name__ == '__main__':# 设置输入张量的尺寸B, C, H, W = 1, 32, 256, 256# 批量大小 B, 输入通道数 C, 高度 H, 宽度 Wx = torch.randn(B, C, H, W).cuda() # 创建输入张量,形状为 (B, C, H, W),并将其移到 GPU# 创建 DeformableInteractiveAttention 模型实例model = DeformableInteractiveAttention(stride=1, distortionmode=True).cuda()# 打印模型结构print(model)# 前向传播output = model(x)# 打印输入和输出的形状print(f"输入张量的形状: {x.shape}") # 打印输入张量的形状print(f"输出张量的形状: {output.shape}") # 打印输出张量的形状