【数据结构】LRU Cache
目录
1.什么是LRU Cache
2.LRU Cache的实现
3.LRU Cache的OJ
1.什么是LRU Cache
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。 什么是
Cache?狭义的Cache指的是位于CPU和主存间的快速RAM, 通常它不像系统主存那样使用
DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种
硬件之间, 用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache, 内存与硬盘
之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或
网络内容缓存等。
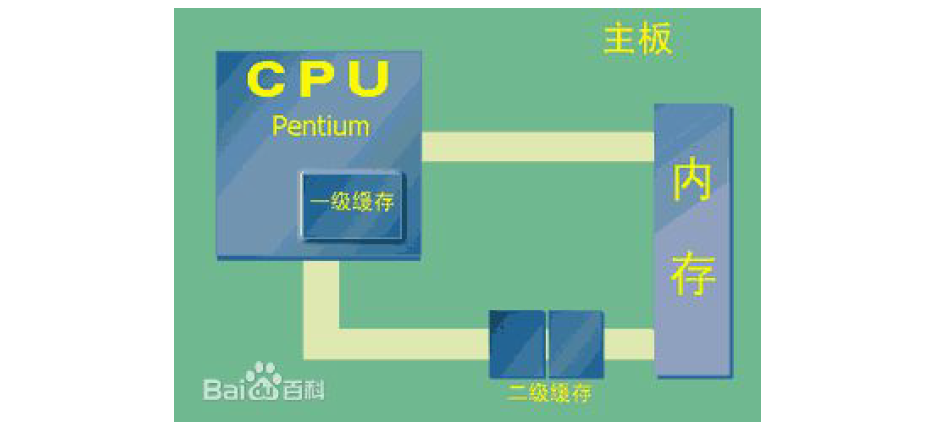
Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选
并舍弃原有的部分内容,从而腾出空间来放新内容。
LRU Cache 的替换原则就是将最近最少使用的内容替换掉。这是因为计算机中的二八原则:20%的数据承担80%的访问,因此当我们访问一个数据很多次,那么下一次再次访问该数据或者该数据周围的数据,可能性非常大,所以LRU算法每次替换掉的就是一段时间内最久没有使用过的内容。
其实,LRU译成最久未使用会更形象。
2.LRU Cache的实现
实现LRU Cache的方法和思路很多,但是要保持高效实现O(1)的put和get(插入、访问数据),那么使用双向链表和哈希表的搭配是最高效和经典的。
使用哈希表是因为哈希表的增删查改也是O(1),我们可以根据key值快速找到对应数据,但是由于哈希表本身的结构,我们无法很好的分别冷热数据,如果通过数组之类进行标记,效率反而下降,所以一个容器并不行,我们需要增加一个容器
而使用双向链表是因为双向链表可以实现任意位置O(1)的插入和删除,数据存储在节点中,并且我们可以将在链表前面的数据视作热数据,链表尾部视作冷数据,这样我们就很好的区分数据了,但是链表本身还存在一个问题,尽管双向链表的节点的插入删除是O(1),但是找到对应节点的位置,我们需要先遍历,针对这个问题,我们的哈希表就需要存储数据在链表中的位置,这样我们就可以通过哈希表O(1)地拿到数据在链表中的位置,再O(1)地删除链表中对应数据,
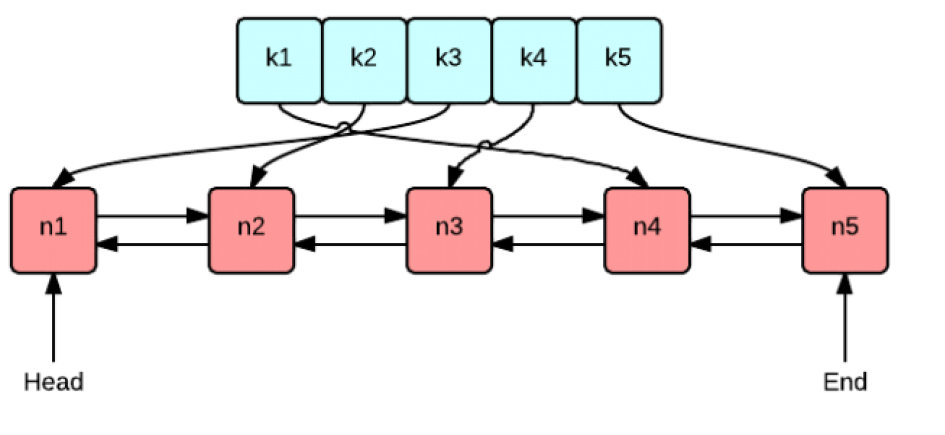
3.LRU Cache的OJ
LRU缓存

这一题中的实现机构就是之前哈希+链表的组合,这题需要注意的是无论对一个数据进行什么操作,那这个数据就相当于被使用了,就是热数据,我们需要将热数据放到链表前面,在链表后面的数据是冷数据,这样当数据量超过capacity,我们优先删冷数据。
class LRUCache {
public:LRUCache(int capacity) {_capacity = capacity;}int get(int key) {// 如果key对应的值存在,则listit取出,//这里就可以看出hashmap的value存的是list的iterator的好处://找到key也就找到key存的值在list中的iterator,也就直接删除,再进行头插,实现O(1)的数据//挪动。auto hashit = _hashmap.find(key);if (hashit != _hashmap.end()){auto listit = hashit->second;pair<int, int> kv = *listit;//erase+push_front的更新方式会导致//原有迭代器指向失效//所以更推荐list 的 splice接口_list.erase(listit);//插入要注意热数据放在前面_list.push_front(kv);_hashmap[key] = _list.begin();return kv.second;}else{return -1;}}void put(int key, int value) {// 1.如果没有数据则进行插入数据// 2.如果有数据则进行数据更新auto hashit = _hashmap.find(key);if (hashit == _hashmap.end()){// 插入数据时,如果数据已经达到上限,则删除链表头的数据和hashmap中的数据,两个//删除操作都是O(1)//需要注意的是这里不推荐通过_list.size()判断//因为_list.size不同版本不同,有的版本是通过O(n)的遍历得出的if (_hashmap.size() >= _capacity){_hashmap.erase(_list.back().first);_list.pop_back();}//插入要注意热数据放在前面_list.push_front(make_pair(key, value));_hashmap[key] = _list.begin();}else{// 再次put,将数据挪动list前面auto listit = hashit->second;pair<int, int> kv = *listit;kv.second = value;_list.erase(listit);_list.push_front(kv);_hashmap[key] = _list.begin();}}private:list<pair<int, int>> _list; // 将最近用过的往链表的投上移动,保持LRUsize_t _capacity; // 容量大小,超过容量则换出,保持LRUunordered_map<int, list<pair<int, int>>::iterator> _hashmap;// 使用unordered_map,让搜索效率达到O(1)// 需要注意:这里最巧的设计就是将unordered_map的value type放成list<pair<int,//int >> ::iterator,因为这样,当get一个已有的值以后,就可以直接找到key在list中对应的//iterator,然后将这个值移动到链表的头部,保持LRU。
};/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/