基于CNN/CRNN的汉字手写体识别:从图像到文字的智能解码
在人工智能浪潮的推动下, handwriting recognition(手写识别)技术已成为连接传统书写与数字世界的重要桥梁。其中,汉字手写体识别因其字符集的庞大和结构的复杂性,被视为模式识别领域最具挑战性的任务之一。近年来,基于深度学习的技术成功突破了传统方法的瓶颈,将汉字识别的准确率和实用性推向了新的高度。

工作原理:从像素到语义的智能映射
深度学习模型,特别是卷积神经网络(CNN),是当前汉字手写体识别的核心技术。其工作流程可概括为以下几个步骤:
1.数据预处理:
- 图像归一化:将不同大小、分辨率和背景的手写图像调整为统一尺寸,并进行灰度化或二值化处理,以减少无关变量的干扰。
- 去噪与平滑:使用滤波器去除图像中的噪点、划痕,平滑笔画边缘,提升图像质量。
- 校正:对书写倾斜的图像进行旋转校正,使得文字处于水平位置。
2.特征提取(核心):
预处理后的图像被送入CNN模型。CNN通过多层卷积层、池化层和激活函数,自动学习汉字的层次化特征。
- 底层特征:最初的卷积层捕捉笔画边缘、角点、端点等局部特征。
- 中层特征:中间层将底层特征组合成更复杂的结构,如横、竖、撇、捺等基本笔画组件。
- 高层特征:深层网络最终将这些笔画组件整合,形成能够代表整个汉字或部首的抽象特征表示。这种自动学习特征的能力避免了传统方法中复杂且依赖专家知识的手工特征设计。
3.分类识别:
- 提取到的高层特征被“展平”并输入到全连接层。
- 最终,通过一个Softmax分类器输出一个概率分布向量,向量的每一个维度对应一个候选汉字(如3755个一级国标汉字或更庞大的字符集)。概率最高的那个汉字即为模型的识别结果。
- 对于更复杂的序列(如整行文本),汉字手写体识别通常会结合 CNN 与 循环神经网络(RNN),形成 CRNN 模型,其中CNN负责提取视觉特征,RNN(常用LSTM或GRU)负责处理序列上下文关系,最后通过连接主义时间分类(CTC) 损失函数进行对齐和翻译,实现高精度的整行识别。
技术难点与挑战
尽管深度学习取得了巨大成功,但汉字手写体识别依然面临诸多挑战:
- 类别数量极其庞大:与仅有几十个类别的拉丁字母识别不同,汉字识别是一个超大规模的分类问题。常用汉字有数千个,而总字符集可达数万个,这对模型的分类能力和计算资源提出了极高要求。
- 结构复杂,相似字多:许多汉字在结构上只有细微差别(如“己、已、巳”、“末、未”),模型必须能精准捕捉这些微小差异,对特征的判别性要求极高。
- 书写风格多变:不同人的书写风格千差万别,包括笔画粗细、倾斜度、连笔、简写等。同一人在不同时间、不同心境下的字迹也可能不同,要求模型具有强大的泛化能力。
- 数据采集与标注困难:要训练一个高性能的深度学习模型,需要海量、高质量且标注准确的手写汉字数据。大规模数据的采集、清洗和标注工作需要耗费巨大的人力物力。
- 脱机识别的固有难题:与“联机识别”(可获取笔序、笔压等动态信息)相比,“脱机识别”仅有一张静态图像,丢失了大量动态信息,使得识别任务更加困难。
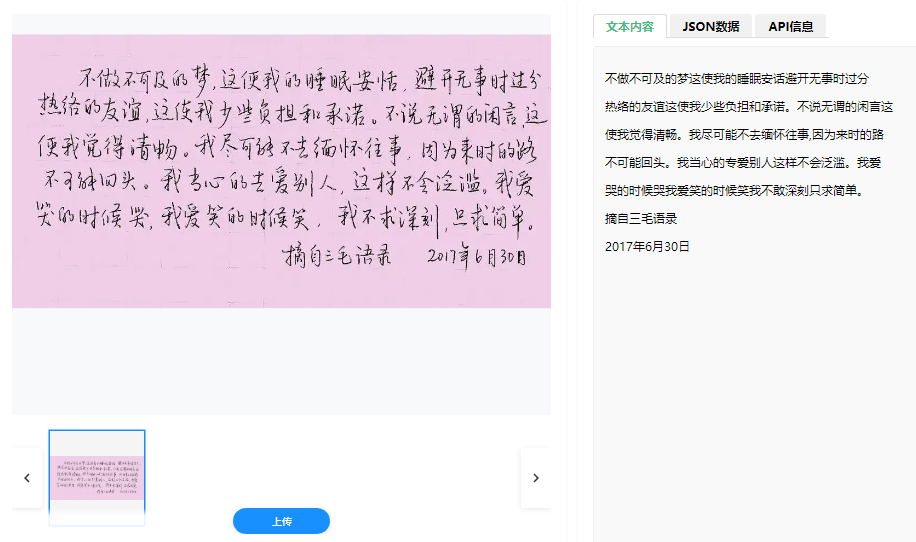
功能特点
基于深度学习的汉字手写体识别技术展现出以下突出特点:
- 高精度与高鲁棒性:在标准测试集上,对规整手写体的识别准确率可达98%以上,甚至超过人类水平。对不同程度的噪声、倾斜和光照变化具有较强的容错能力。
- 强大的泛化能力:经过充分训练的模型能够较好地识别未曾见过的书写风格,适应不同用户的字迹。
- 端到端学习:无需人工设计特征,模型直接从原始像素输入中学习并输出结果,简化了流程,提高了效率。
- 支持大规模字符集:能够同时识别数千甚至上万个汉字,满足实际应用的需求。
- 多模态融合:可与自然语言处理(NLP)技术结合,利用语言模型(如N-gram、神经网络语言模型)对识别结果进行后处理纠错,根据上下文语境提升识别准确率。
应用领域
汉字手写体识别技术的成熟为其在众多领域开辟了广阔的应用前景:
教育领域:
- 智能阅卷:自动批改作业和试卷中的主观题、作文题,减轻教师负担。
- 书法教学与评价:对学生的书写笔迹进行分析,给出结构、笔势等方面的改进建议。
- 在线学习:在手写板或平板电脑上实时识别书写内容,进行交互式教学。
金融服务:
- 银行票据处理:自动识别和录入支票、汇票、表单上的手写金额、日期、签名等信息。
办公与政务自动化:
- 文档数字化:将历史档案、手稿、纸质文件扫描并识别为可编辑的电子文本,便于存储和检索。
- 表单信息提取:自动处理各类调查问卷、申请表、报销单等。
智能终端与人机交互:
- 移动设备输入:在手机、平板等触摸屏设备上提供流畅的手写输入法。
- 智能穿戴设备:在小屏幕设备上,手写输入是一种高效的交互方式。
文化传承与研究:
- 古籍数字化:用于识别和数字化古代典籍、碑帖、书法作品,助力文化遗产的保护和研究。
基于深度学习的汉字手写体识别技术已经取得了令人瞩目的成就,但其研究远未止步。未来的发展方向包括:探索更高效轻量的网络模型以适应移动端部署;利用少样本学习、自监督学习等技术降低对标注数据的依赖;提升对极端潦草字迹、古文字的识别能力;以及深化与NLP的结合,实现更深层次的“理解”而非仅仅是“识别”。随着技术的不断演进,手写汉字识别必将更加无缝地融入我们的生活,进一步推动社会的智能化进程。