【Linux】面试常考!Linux 进程核心考点:写时拷贝优化原理 + 进程等待实战,一篇理清进程一生
前言:欢迎各位光临本博客,这里小编带你直接手撕**,文章并不复杂,愿诸君耐其心性,忘却杂尘,道有所长!!!!
 🔥 个人专栏:
🔥 个人专栏:《C语言》
《C++深度学习》
《Linux》
《数据结构》
《数学建模》
文章目录
- 一、进程创建:fork()
- 1. fork():一次调用,两次返回
- 2. 代码实战:区分父子进程
- 3. fork()啥时候会失败?
- 小拓展:为啥能跑多个系统?
- 二、写时拷贝
- 1. 先懂基础:虚拟内存
- 2. 写时拷贝的逻辑
- 3. 为啥要搞写时拷贝?
- 三、进程终止
- 1. 进程退出的3种场景
- 2. 3种常见的退出方法
- (1)main函数返回值
- (2)exit():任意地方退出
- (3)_exit():直接退出,不刷缓冲
- 四、退出码
- 1. 怎么看退出码?
- 2. 退出码转错误信息:strerror()
- 3. 异常终止:退出码无意义
- 五、进程等待:别让子进程变“僵尸”
- 1. 第一个工具:wait()
- 2. 更灵活的工具:waitpid()
- 非阻塞等待:父进程不用傻等
- 3. 解析status:子进程是正常还是异常?
- 六、异常终止:信号是“杀手”
- 1. 查看所有信号:kill -l
- 2. 代码实战:异常信号示例
- (1)野指针:触发SIGSEGV(11号信号)
- (2)除0:触发SIGFPE(8号信号)
- 七、回调函数:“你办事,成了叫我”
- 总结:进程的“一生”
大家好!这篇博客会用最通俗的话,带你搞懂Linux进程的核心逻辑——从怎么创建进程、如何高效复用内存,到进程怎么正常退出、出问题了怎么办,每个知识点都结合图片和代码,新手也能轻松看懂~
一、进程创建:fork()
用fork()实现
想让Linux同时干多个活?比如一边听歌一边写代码,本质是多个“进程”在跑。而创建进程的核心函数,就是 fork()。
1. fork():一次调用,两次返回
fork()的神奇之处在于:它只调用一次,却会返回两次——因为它会“复制”出一个和父进程几乎一样的子进程。
看这张图,能直观看到父子进程的关系:
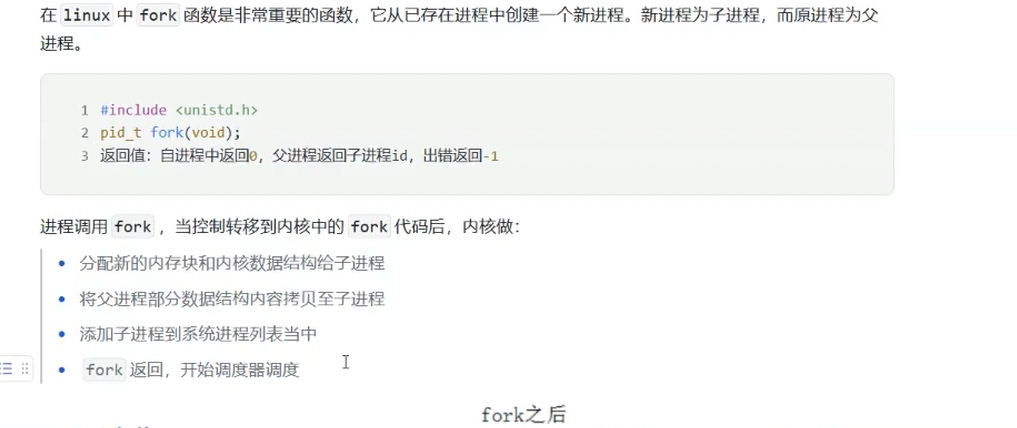
- 父进程调用fork()后,内核会给子进程分配新的PID(进程ID),并复制父进程的核心数据(比如进程控制块task_struct、虚拟内存映射);
- 父进程会收到子进程的PID(一个大于0的整数);
- 子进程会收到0;
- 若返回-1,说明创建失败。
2. 代码实战:区分父子进程
用一段简单代码,就能看出fork()的“分身”效果:
#include <stdio.h>
#include <unistd.h> // fork()和获取PID的头文件int main() {pid_t pid = fork(); // 调用fork创建子进程if (pid > 0) {// 父进程:返回值是子进程PIDprintf("我是父进程!PID=%d,子进程PID=%d\n", getpid(), pid);} else if (pid == 0) {// 子进程:返回值是0printf("我是子进程!PID=%d,父进程PID=%d\n", getpid(), getppid());} else {// fork失败perror("fork创建进程失败"); // 打印错误原因return 1;}return 0;
}
运行后会输出两行内容(顺序可能不同):父进程和子进程各自打印自己的ID——这就是fork()的核心作用:让一个进程变成两个,干不同的活。
3. fork()啥时候会失败?
看这张图里的场景,fork失败主要有两个原因:
- 内核没资源了:创建进程需要申请页表(虚拟内存用)和物理内存,这些不够时会失败;
- 超进程数限制:Linux对每个用户能创建的进程数有上限,超过就会失败。
小拓展:为啥能跑多个系统?
如果fork()创建的子进程是“操作系统”,那Linux就能同时跑四五个系统——这就是内核级虚拟机的核心原理(比如KVM)。
二、写时拷贝
刚说fork()会“复制”父进程内存,但如果父进程有1GB数据,直接复制岂不是又慢又浪费?别急,写时拷贝(Copy-On-Write) 就是解决这个问题的“聪明办法”。
1. 先懂基础:虚拟内存
每个进程都以为自己独占内存,其实它用的是虚拟地址,通过“页表”映射到真实物理内存。这里的“mm+vm_area”就是进程的内存描述:
- mm:进程的内存管理结构体;
- vm_area:划分虚拟内存的区间(比如代码段、数据段、栈段)。
操作系统通过vm_area,就能知道你访问的虚拟地址是代码段(只读)还是数据段(可读写)。
2. 写时拷贝的逻辑
- 没创建子进程时:父进程数据段的页表权限是“读写”,虚拟地址直接映射物理内存;
- 创建子进程后:内核不复制物理内存,而是让父子进程共享同一个物理页,同时把两者的页表权限改成“只读”;
- 当某一方要改数据(比如父进程改了一个变量):操作系统会检测到“只读页被写”,这时才复制一份物理页给写操作的进程,再把它的页表权限改回“读写”——这就是“写时拷贝”。
3. 为啥要搞写时拷贝?
- 快:创建子进程不用复制内存,秒启动;
- 省:如果父子进程都不改数据,就一直共享内存,不浪费空间;
- 精:只复制要修改的页,不是整个内存。
关键是:写完后,父子进程的数据权限都会恢复成读写,互不影响。
三、进程终止
进程不会一直跑,总有终止的时候。终止的核心是释放资源(比如内存、文件描述符),不然会变成“僵尸进程”,占着资源不放手。
1. 进程退出的3种场景
看这张图,进程退出就分三类情况:
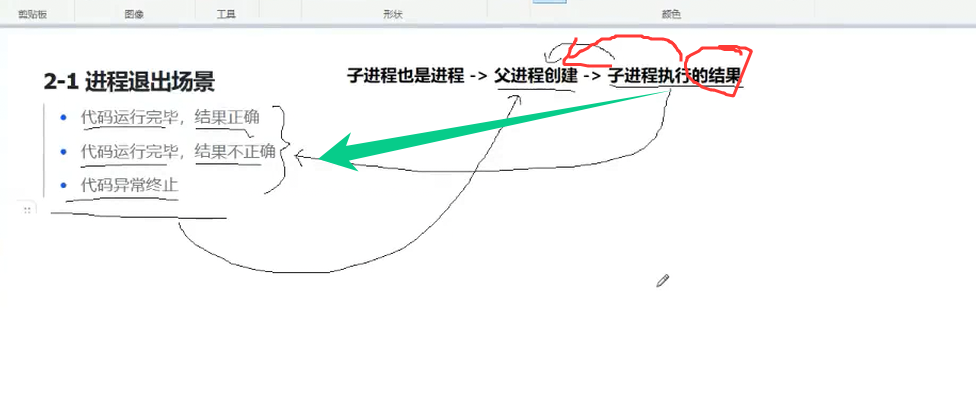
- 正常跑完:代码执行完了
- 结果对:比如算1+1得2;
- 结果错:比如算1+1得3;
- 异常终止:代码没跑完就崩了(比如访问不存在的内存、除0)。
2. 3种常见的退出方法
(1)main函数返回值
这是最常用的方式:return 0代表“正常退出”,return 非0(比如return 1)代表“结果错误”。
底层逻辑:返回值通过CPU寄存器(比如eax)传递,即使返回大型结构体,也会通过寄存器处理(编译时会转成mv指令)。
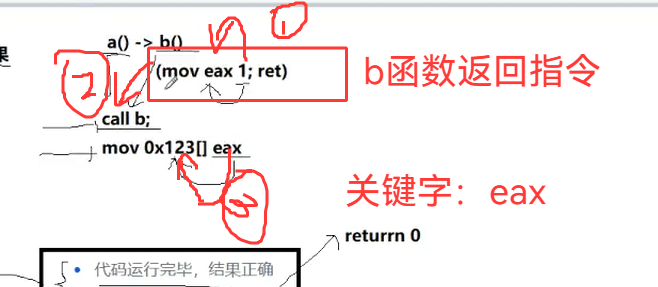
比如这段代码:
#include <stdio.h>int main() {int a = 1 + 1;if (a == 2) {return 0; // 正常退出} else {return 2; // 结果错误退出}
}
(2)exit():任意地方退出
exit(数字)可以在代码任意地方让进程退出,还会刷新C语言缓冲区(比如printf没换行的内容会输出)。
看这张图里的exit()效果:
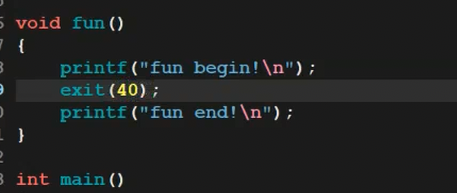
代码例子:
#include <stdio.h>
#include <stdlib.h> // exit()的头文件void test() {printf("我要退出了"); // 没换行,存在C缓冲区exit(0); // 刷新缓冲区,再退出
}int main() {test();return 1; // 这句不会执行
}
运行后会输出“我要退出了”——因为exit()刷新了缓冲区。
(3)_exit():直接退出,不刷缓冲
和exit()的核心区别:_exit(数字)不刷新C语言缓冲区,直接终止进程。
看这张图的对比:

把上面代码的exit(0)改成_exit(0),运行后不会输出“我要退出了”——因为缓冲区没被刷新。
注意:C语言缓冲区在“库层面”,不是操作系统内核的缓冲区;如果是内核缓冲区,系统调用后都会刷新。
四、退出码
进程退出时会返回一个“退出码”,就像考试成绩单:0代表“及格”(正常),非0代表“不及格”(错误)。
1. 怎么看退出码?
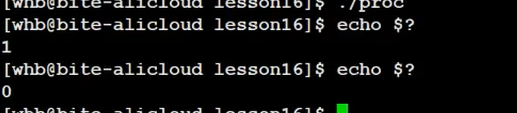
用Linux指令 echo $?,就能查看最近一个进程的退出码。
看这张图的效果:

- 进程的退出码会存在它的task_struct(进程控制块)里;
$?是Linux的环境变量,只存最近一次的退出码。
比如先运行./a.out(正常退出,return 0),再运行echo $?,会输出0;如果进程return 1,echo $?就输出1。
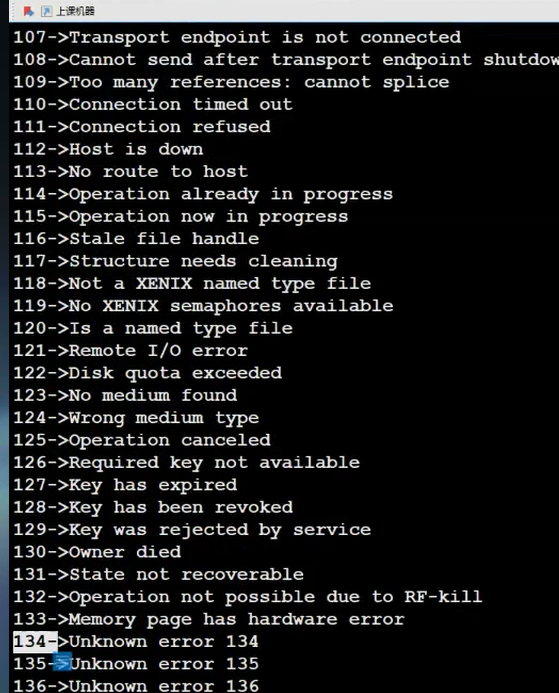
2. 退出码转错误信息:strerror()
如果退出码是错误码(比如打开文件失败),用strerror(错误码)能把它转成人类能看懂的文字。
C标准库一共定义了134个错误信息,看这张图:
代码例子(打开不存在的文件):
#include <stdio.h>
#include <string.h> // strerror()的头文件
#include <errno.h> // errno的头文件int main() {FILE *fp = fopen("不存在的文件.txt", "r");if (fp == NULL) {// errno:存最近一次系统调用的错误码printf("错误原因:%s\n", strerror(errno));return 1;}fclose(fp);return 0;
}
运行后会输出“错误原因:No such file or directory”(没有这个文件),对应这张图的效果:

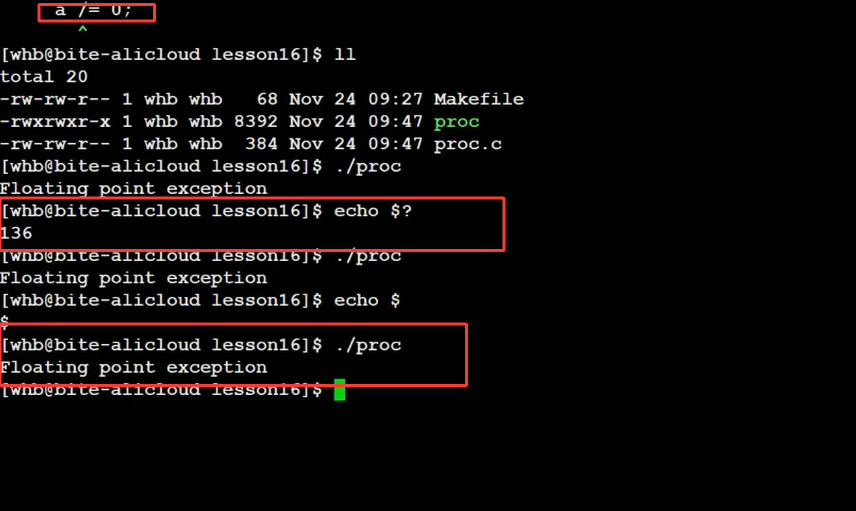
3. 异常终止:退出码无意义
如果进程是异常终止(比如被信号杀死),退出码就没用了。比如return 89,但实际退出码是136——这就是异常的信号导致的,看这张图:
五、进程等待:别让子进程变“僵尸”
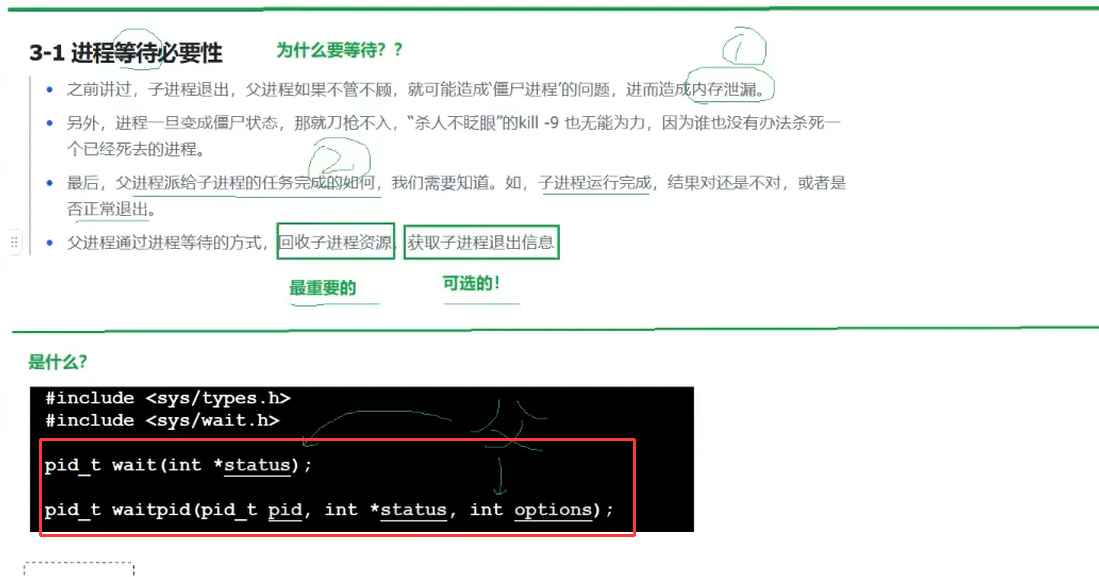
如果子进程先退出,父进程不管它,子进程就会变成僵尸进程(占着PID和task_struct,删不掉)。这时候就得用“进程等待”,回收子进程资源,还能拿到它的退出信息。
1. 第一个工具:wait()
wait(int *status)的作用:
- 阻塞父进程,直到有一个子进程退出;
- 回收子进程资源,解决僵尸问题;
- 把子进程的退出信息存到
status里; - 返回值:成功回收的子进程PID,失败返回-1。
看这张wait()的接口图:
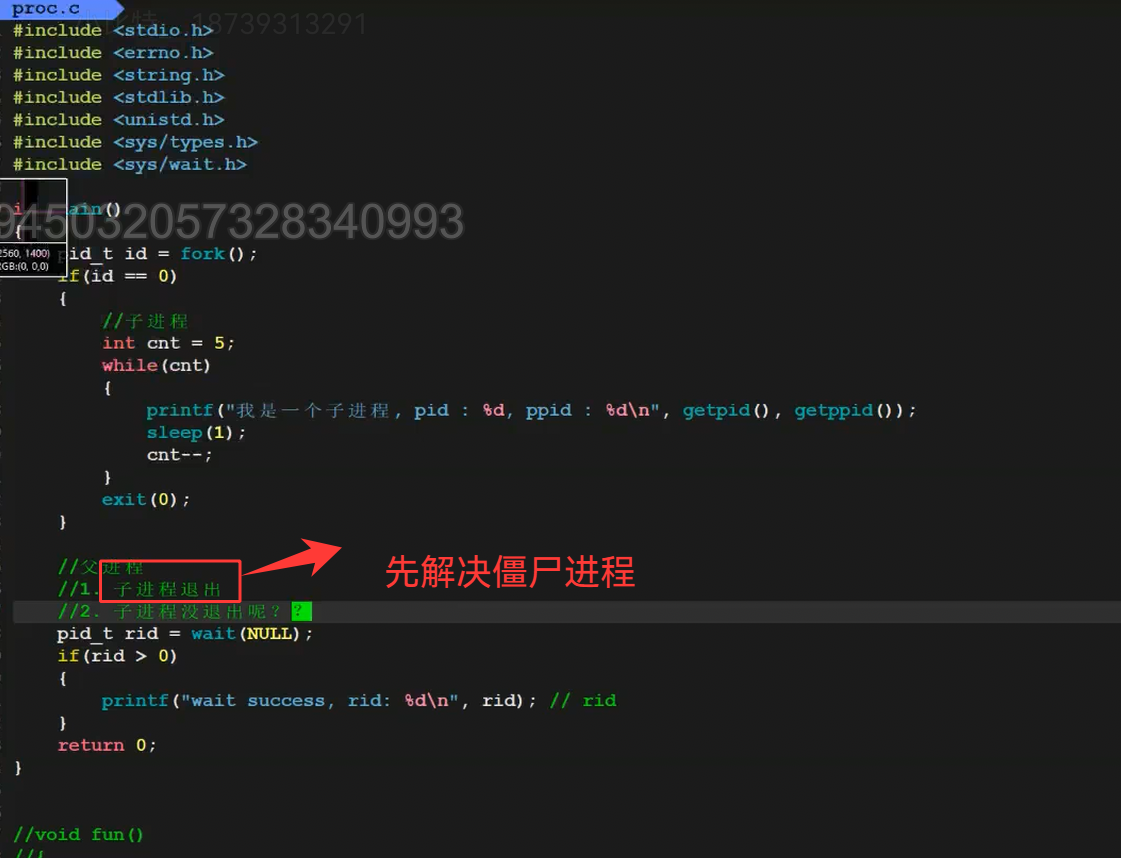
代码实战(解决僵尸问题):
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h> // wait()的头文件int main() {pid_t pid = fork();if (pid == 0) {// 子进程:睡2秒再退出,返回3sleep(2);printf("子进程退出,返回码3\n");return 3;} else if (pid > 0) {// 父进程:等待子进程int status;pid_t ret = wait(&status); // 阻塞等待printf("回收了子进程PID:%d\n", ret);// 解析退出码:status的8-15位是退出码(右移8位+与0xff)printf("子进程退出码:%d\n", (status >> 8) & 0xff);}return 0;
}
看这张图的运行效果,僵尸进程被解决了:
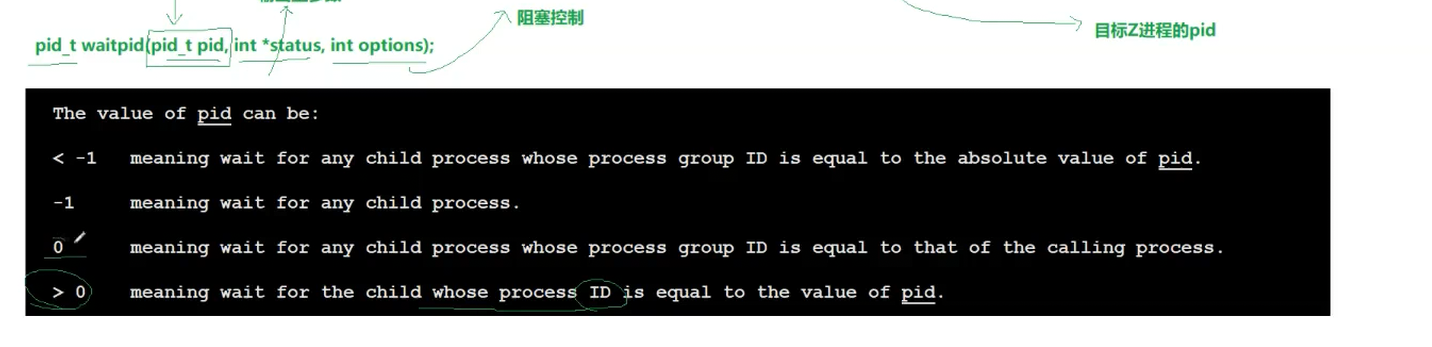
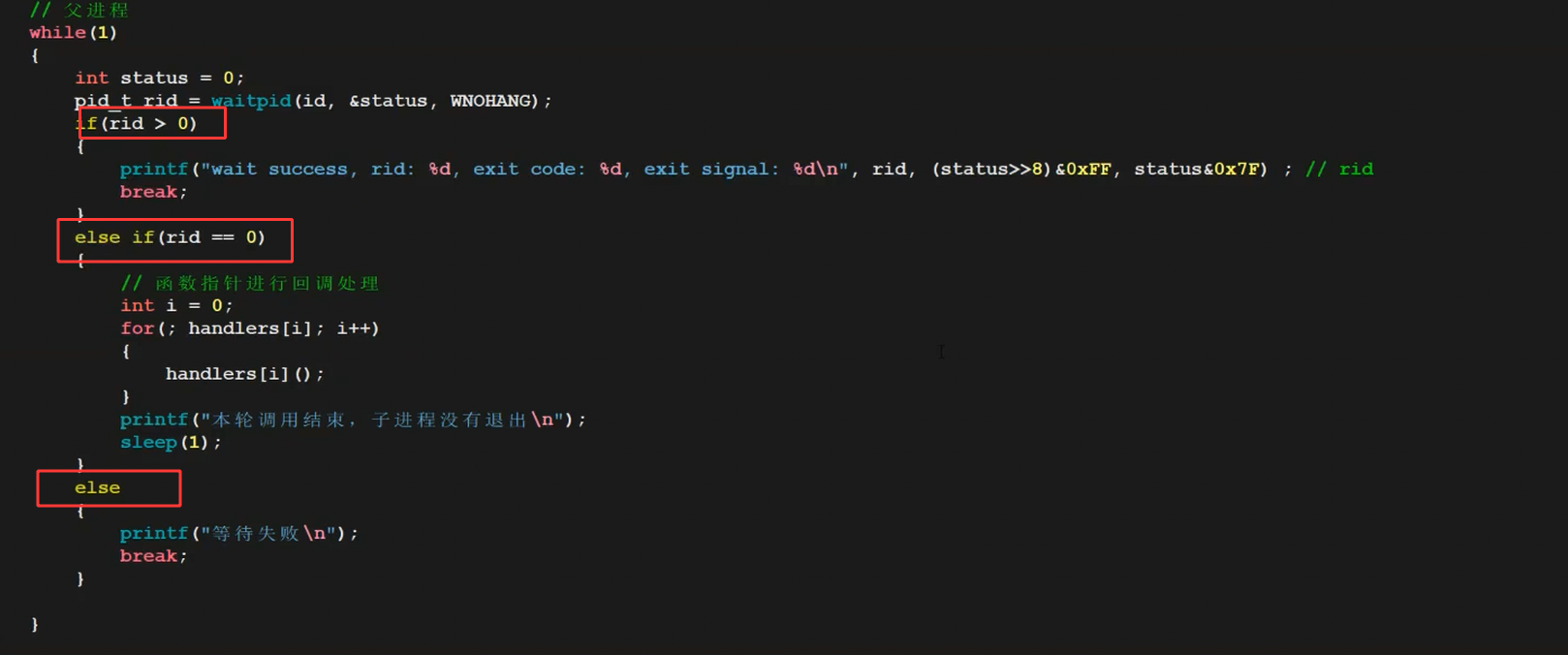
2. 更灵活的工具:waitpid()
waitpid(pid_t pid, int *status, int options)比wait()灵活,核心参数:
pid:指定等哪个子进程(-1=等任意子进程,和wait一样;>0=等指定PID的子进程);options:WNOHANG(非阻塞,子进程没退出就立即返回0,不卡父进程)。
看这张waitpid()的参数图:
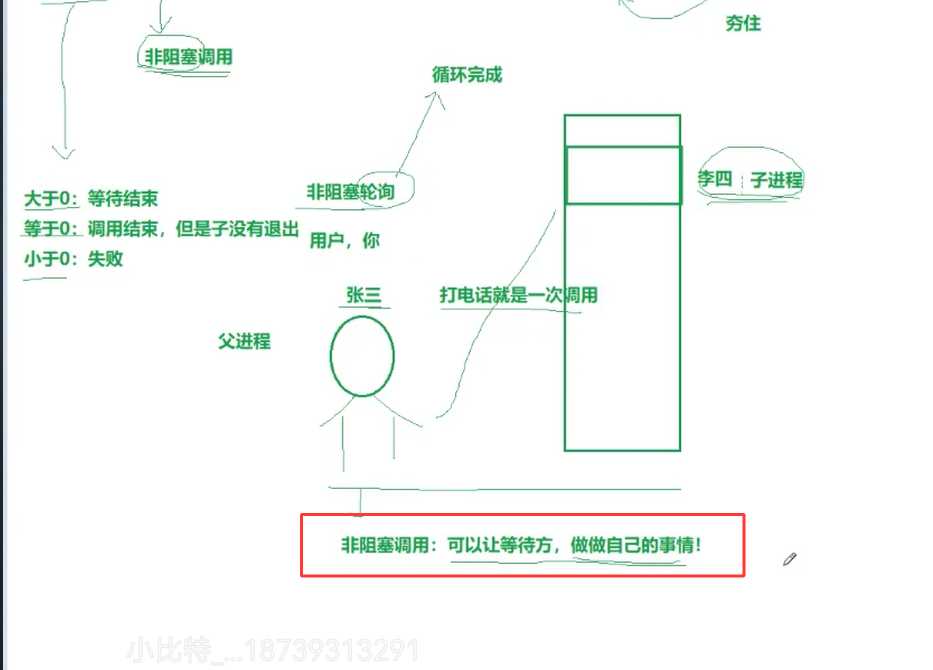
非阻塞等待:父进程不用傻等
代码例子(父进程等子进程时能做自己的事):
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>int main() {pid_t pid = fork();if (pid == 0) {// 子进程:睡3秒再退出sleep(3);printf("子进程退出\n");return 0;} else if (pid > 0) {int status;while (1) {// 非阻塞等待:子进程没退出就返回0pid_t ret = waitpid(pid, &status, WNOHANG);if (ret == 0) {// 子进程还在跑,父进程干自己的事printf("子进程没退出,我先刷会儿手机...\n");sleep(1);} else if (ret == pid) {// 回收成功printf("回收子进程!退出码:%d\n", (status>>8)&0xff);break;}}}return 0;
}
运行后会先输出3次“刷会儿手机”,再回收子进程,对应这张非阻塞的图:
3. 解析status:子进程是正常还是异常?
status不是简单的退出码,而是32位的“信息包”,看这张底层逻辑图:
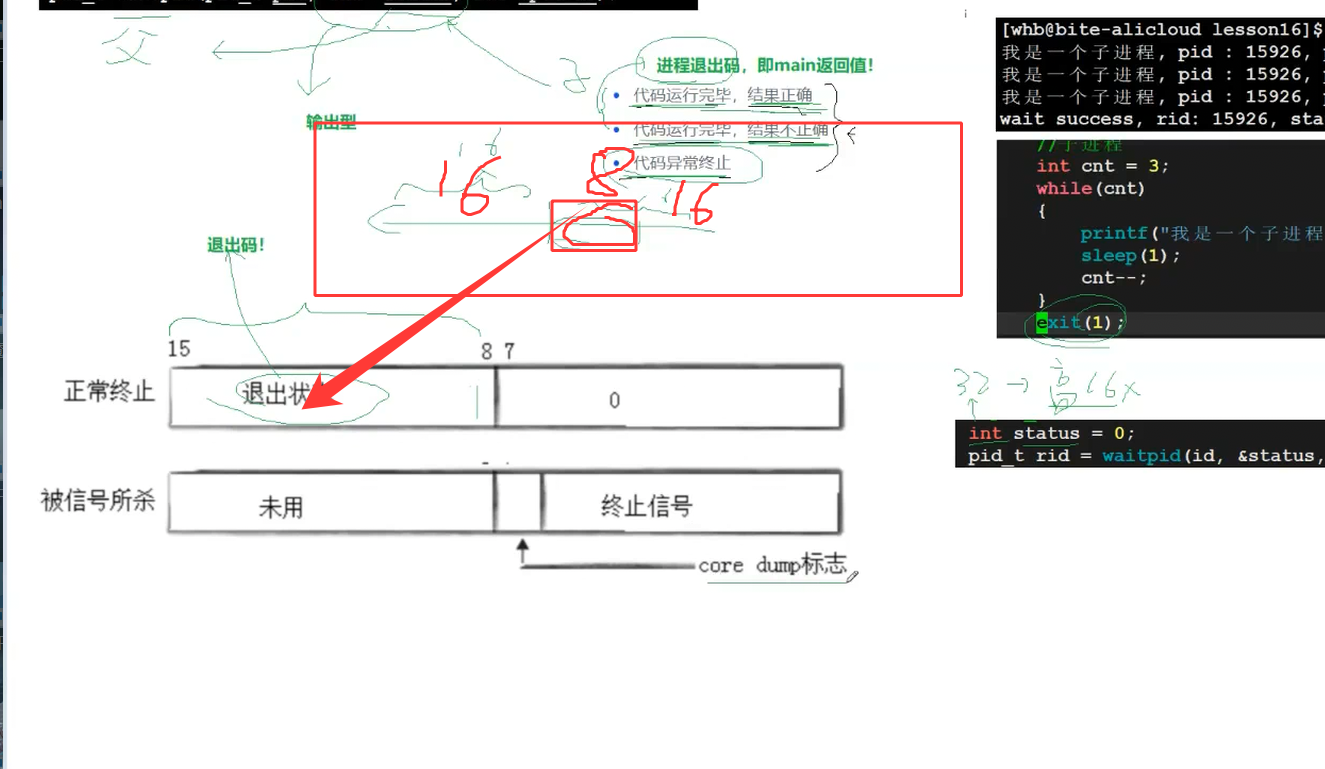
- 低7位:存“信号编号”——如果子进程异常终止(被信号杀死),这里非0;
- 8-15位:存“退出码”——只有正常退出时,这里才有意义(低7位为0)。
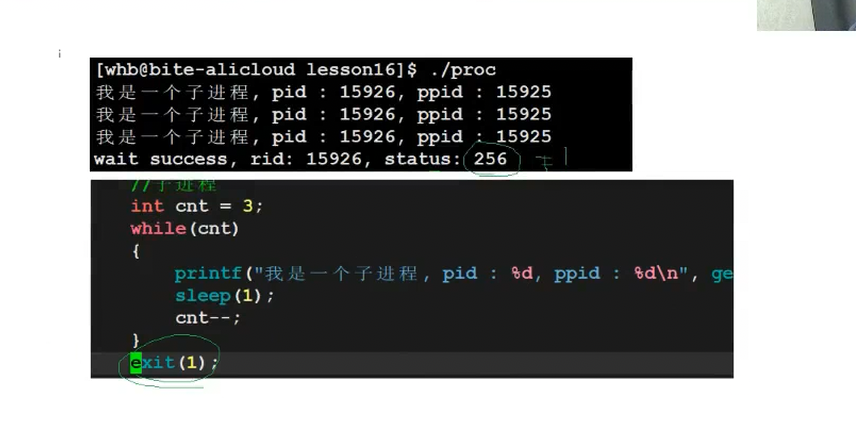
比如子进程return 1,status是256(二进制100000000),右移8位后是1,就是退出码:
六、异常终止:信号是“杀手”
进程异常终止,本质是收到了Linux的“信号”——信号是内核给进程的“命令”,比如“你出错了,赶紧退出”。
1. 查看所有信号:kill -l
用kill -l指令,能看到Linux的所有信号(共64个,没有0号):
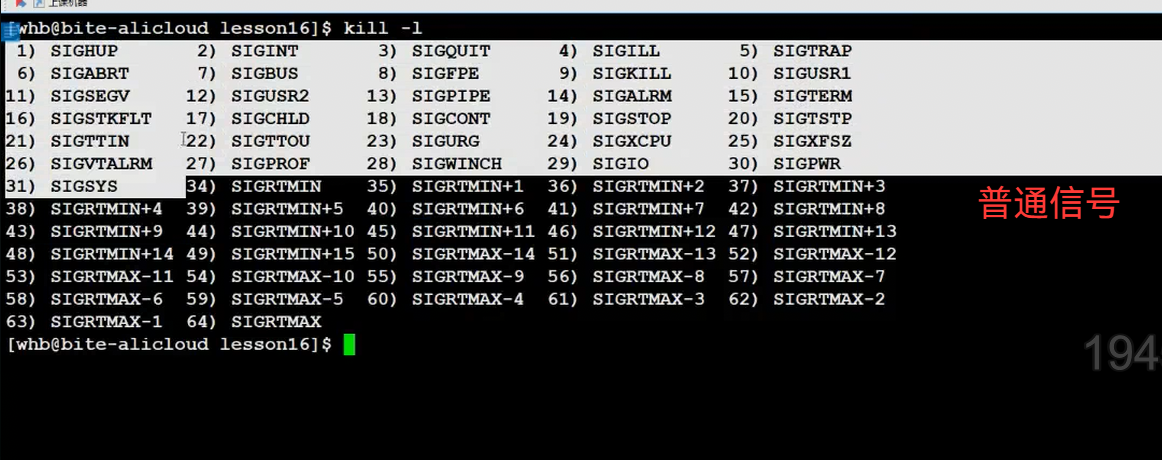
信号的本质是宏,比如SIGSEGV是11号信号,SIGFPE是8号信号:

2. 代码实战:异常信号示例
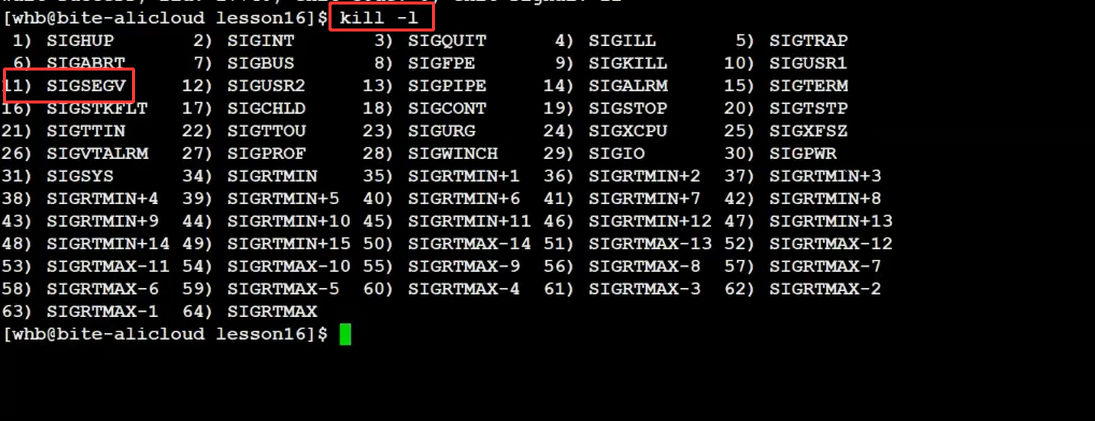
(1)野指针:触发SIGSEGV(11号信号)
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>int main() {pid_t pid = fork();if (pid == 0) {int *p = NULL; // 野指针(空指针)*p = 10; // 访问空指针,触发段错误return 0;} else if (pid > 0) {int status;wait(&status);// 低7位是信号编号printf("子进程收到信号:%d\n", status & 0x7f); // 输出11}return 0;
}
运行后输出信号11,用kill -l查得11是SIGSEGV(段错误),对应这张图:
(2)除0:触发SIGFPE(8号信号)
把上面代码的“野指针”改成“a/=0”:
int a = 10;
a /= 0; // 除0,触发浮点数异常
运行后输出信号8,对应这张图:
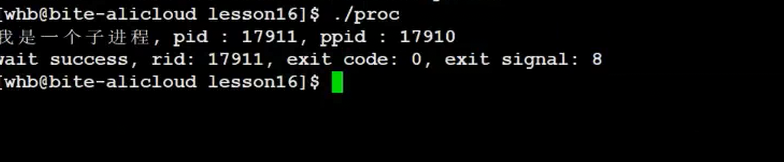
注意:异常时,退出码无意义,只有信号编号有用。
七、回调函数:“你办事,成了叫我”
回调函数的核心逻辑是:“我把函数传给你,你执行完自己的逻辑后,再调用我传的函数”——就像“你去买奶茶,买好后打电话叫我”。
看这张回调函数的示意图:
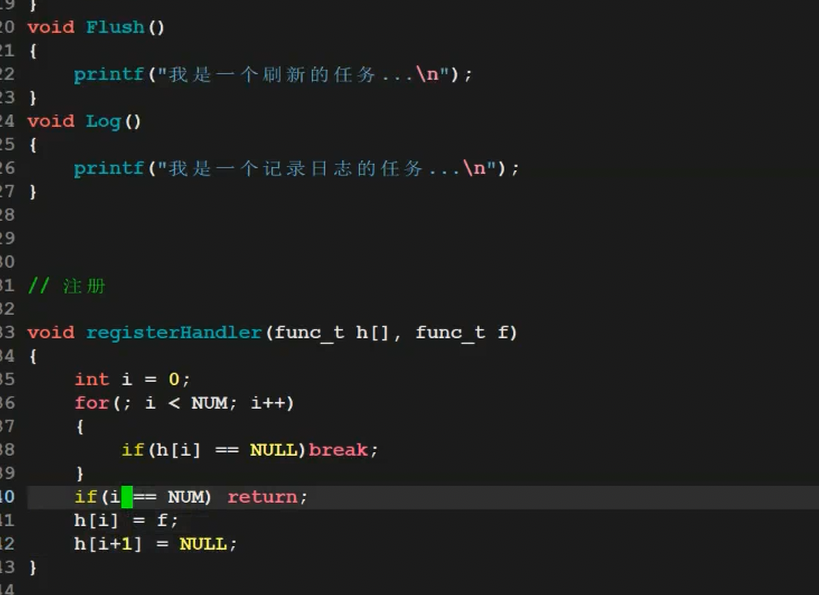
代码例子(按钮点击回调):
#include <stdio.h>// 回调函数:按钮点击后要执行的逻辑
void onButtonClick() {printf("按钮被点击了!\n");
}// 注册回调:把回调函数传给“按钮”
void registerCallback(void (*callback)()) {// 模拟按钮被点击printf("检测到按钮操作...\n");callback(); // 调用回调函数
}int main() {// 注册回调函数registerCallback(onButtonClick);return 0;
}
运行后输出:
检测到按钮操作...
按钮被点击了!
对应这张回调执行的图:
总结:进程的“一生”
- 创建:用fork()分身,写时拷贝让创建又快又省;
- 运行:父子进程通过fork()返回值区分,干不同活;
- 退出:main返回、exit(刷缓冲)、_exit(不刷缓冲);
- 等待:用wait/waitpid回收子进程,避免僵尸;
- 异常:信号是“杀手”,status低7位存信号编号。
掌握这些,就能搞懂Linux进程的核心逻辑啦~