sVLMs之:《SmolVLM: Redefining small and efficient multimodal models》的翻译与解读
sVLMs之:《SmolVLM: Redefining small and efficient multimodal models》的翻译与解读
导读:这篇论文成功地挑战了“模型越大性能越好”的传统观念,通过一系列精巧的系统性优化,设计并实现了一组兼具高性能与高效率的紧凑型多模态模型(SmolVLM)。该研究不仅在理论上指明了构建高效小模型的关键设计方向,更在实践中证明了小至2.56亿参数的模型可以在极低的资源消耗下超越比其大数百倍的巨型模型。这项工作为多模态AI在移动设备、边缘计算等资源受限场景的广泛应用铺平了道路,对推动AI技术的普及和实用化具有重要意义。
>> 背景痛点
● 资源消耗巨大: 当前最先进的大型视觉语言模型(VLMs)虽然性能卓越,但需要大量的计算资源,特别是GPU内存,这极大地限制了它们在移动设备和边缘设备等资源受限环境中的实际部署。
● 小型模型的局限性: 现有的小型VLM在设计上通常只是简单模仿大型模型,例如采用复杂的图像分词(Tokenization)策略,这导致GPU内存使用效率低下,并未从根本上解决在端侧设备上应用的实际难题。
● 部署成本高昂: 大型模型的训练和推理成本高昂,使得许多需要AI能力的场景望而却步,尤其是在需要大规模、低能耗部署的实际应用中。
>> 具体的解决方案
● 提出SmolVLM系列模型: 论文介绍了一系列名为 SmolVLM 的紧凑型多模态模型,这些模型是专门为实现资源高效的推理而设计的。
● 系统性优化设计: 研究团队系统性地探索了多种优化策略,包括专为低计算开销优化的模型架构、分词策略以及数据筛选和管理方法。
● 推出不同规模的变体: 该系列包含多个不同参数规模的模型,例如最小的 SmolVLM-256M(2.56亿参数)和较大的2.2B(22亿参数)版本,以适应不同的性能和资源需求。 其中,小参数模型(如256M和500M)被明确设计用于端侧设备部署。
>> 核心思路步骤
● 探索高效架构: 研究人员对模型的架构配置进行了系统性探索,以找到在保持性能的同时能最大限度减少内存占用的关键设计方案。
● 优化分词策略: 论文强调了分词策略的重要性,采用了一种更积极且高效的视觉分词压缩方法。这种方法虽然可能牺牲部分需要精确定位的任务(如OCR)的性能,但通过减少视觉token数量,显著降低了注意力机制的开销,并改善了长上下文建模能力。
● 精心筛选训练数据: 通过对训练数据进行精心的策划和筛选,确保模型能够在较小的规模下学习到足够丰富和高质量的信息,从而提升多模态性能。
● 扩展上下文长度: 研究发现,即使是紧凑型的VLM也能从扩展的上下文长度中显著受益。因此,研究人员为不同大小的模型设定了优化的上下文长度限制(例如,为2.2B模型设置16k,为更小的变体设置8k)。
>> 优势
● 极高的资源效率: SmolVLM在性能上取得了巨大突破,同时资源消耗极低。其最小的256M模型在推理时仅使用不到1GB的GPU显存。
● 卓越的性能表现: 尽管模型尺寸极小,但性能却非常强大。SmolVLM-256M的表现甚至超过了比它大300倍的Idefics-80B模型。 其2.2B参数版本性能可与消耗其两倍GPU内存的SOTA(最先进)模型相媲美。
● 强大的视频理解能力: SmolVLM的能力不仅限于静态图像,还展示了稳健的视频理解能力,使其应用场景更加广泛。
● 促进实际应用部署: 该研究的成果使得在移动设备、消费级笔记本电脑甚至浏览器环境中直接进行高效的多模态推理成为可能,极大地降低了技术门槛和运营成本,促进了AI在现实世界中的实际部署。
>> 结论和观点(侧重经验与建议)
● 战略性优化优于盲目模仿: 论文的核心观点是,小型多模态模型的成功不在于简单地复制大型模型的设计,而在于进行战略性的、针对资源效率的系统性优化。
● 架构、分词和数据是关键: 研究证明,在模型架构、分词策略和训练数据管理这三个方面进行深思熟虑的优化,是实现小模型高性能的关键。
● 视觉分词压缩的权衡: 采用更激进的视觉分词压缩策略对小型VLM非常有益,可以显著降低计算开销。但需要认识到这可能影响那些需要精细空间定位的任务的性能。
● 扩展上下文长度对小模型同样重要: 研究发现,扩展上下文窗口对小型VLM的性能提升有显著的正面影响,这是一个在设计小模型时值得采纳的策略。
● 为端侧应用专门设计模型: 对于需要在移动或边缘设备上部署的应用,应当选择或设计像SmolVLM这样专为资源受限环境优化的模型,而不是试图压缩大型模型。
目录
《SmolVLM: Redefining small and efficient multimodal models》的翻译与解读
Abstract
Figure 1:Smol yet Mighty: comparison of SmolVLM with other state-of-the-art small VLM models. Image results are sourced from the OpenCompass OpenVLM leaderboard (Duan et al., 2024).图 1:小巧却强大:SmolVLM 与其他最先进的小型视觉语言模型的比较。图像结果来自 OpenCompass OpenVLM 领先榜(Duan 等人,2024 年)。
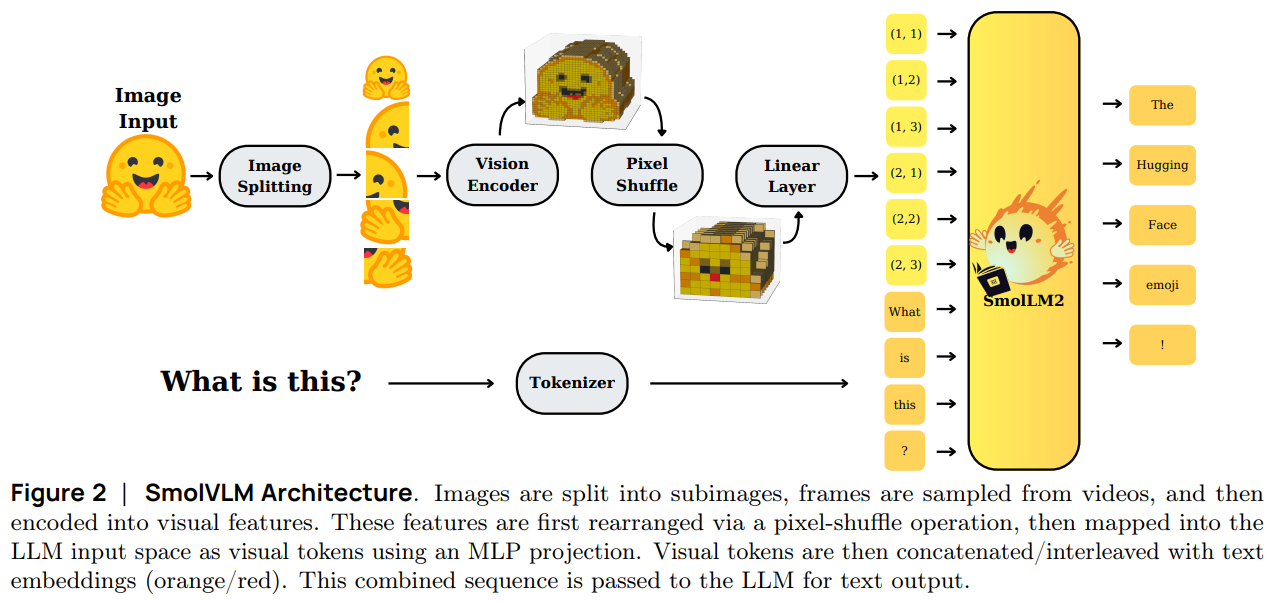
Figure 2:SmolVLM Architecture. Images are split into subimages, frames are sampled from videos, and then encoded into visual features. These features are first rearranged via a pixel-shuffle operation, then mapped into the LLM input space as visual tokens using an MLP projection. Visual tokens are then concatenated/interleaved with text embeddings (orange/red). This combined sequence is passed to the LLM for text output.图 2:SmolVLM 架构。图像被分割成子图像,从视频中抽取帧,然后编码为视觉特征。这些特征首先通过像素重排操作重新排列,然后使用多层感知机(MLP)投影映射到 LLM 的输入空间作为视觉标记。视觉标记随后与文本嵌入(橙色/红色)进行拼接/交错。这个组合序列被传递给 LLM 以生成文本输出。
1、Introduction
Conclusion
《SmolVLM: Redefining small and efficient multimodal models》的翻译与解读
| 地址 | https://arxiv.org/abs/2504.05299 |
| 时间 | 2025年4月7日 |
| 作者 | Hugging Face, Stanford |
Abstract
| Large Vision-Language Models (VLMs) deliver exceptional performance but require significant computational resources, limiting their deployment on mobile and edge devices. Smaller VLMs typically mirror design choices of larger models, such as extensive image tokenization, leading to inefficient GPU memory usage and constrained practicality for on-device applications. We introduce SmolVLM, a series of compact multimodal models specifically engineered for resource-efficient inference. We systematically explore architectural configurations, tokenization strategies, and data curation optimized for low computational overhead. Through this, we identify key design choices that yield substantial performance gains on image and video tasks with minimal memory footprints. Our smallest model, SmolVLM-256M, uses less than 1GB GPU memory during inference and outperforms the 300-times larger Idefics-80B model, despite an 18-month development gap. Our largest model, at 2.2B parameters, rivals state-of-the-art VLMs consuming twice the GPU memory. SmolVLM models extend beyond static images, demonstrating robust video comprehension capabilities. Our results emphasize that strategic architectural optimizations, aggressive yet efficient tokenization, and carefully curated training data significantly enhance multimodal performance, facilitating practical, energy-efficient deployments at significantly smaller scales. | 大型视觉语言模型(VLM)表现出色,但需要大量的计算资源,这限制了它们在移动设备和边缘设备上的部署。较小的 VLM 通常采用与大型模型相同的设计选择,例如广泛的图像标记化,导致 GPU 内存使用效率低下,限制了其在设备上的实际应用。 我们推出了 SmolVLM,这是一系列专门用于资源高效推理的紧凑型多模态模型。我们系统地探索了架构配置、标记化策略和数据整理,以优化低计算开销。通过这种方式,我们确定了关键的设计选择,这些选择在图像和视频任务中带来了显著的性能提升,同时内存占用极小。 我们的最小模型 SmolVLM-256M 在推理时使用的 GPU 内存不到 1GB,尽管与 Idefics-80B 相比开发时间晚了 18 个月,但其性能却优于 Idefics-80B(参数量是其 300 倍)。我们的最大模型拥有 22 亿参数,与占用两倍 GPU 内存的最先进的 VLM 相媲美。SmolVLM 模型不仅适用于静态图像,还展示了强大的视频理解能力。我们的研究结果表明,战略性的架构优化、积极而高效的标记化以及精心挑选的训练数据能够显著提升多模态性能,从而在规模大幅缩小的情况下实现实用且节能的部署。 |
Figure 1:Smol yet Mighty: comparison of SmolVLM with other state-of-the-art small VLM models. Image results are sourced from the OpenCompass OpenVLM leaderboard (Duan et al., 2024).图 1:小巧却强大:SmolVLM 与其他最先进的小型视觉语言模型的比较。图像结果来自 OpenCompass OpenVLM 领先榜(Duan 等人,2024 年)。
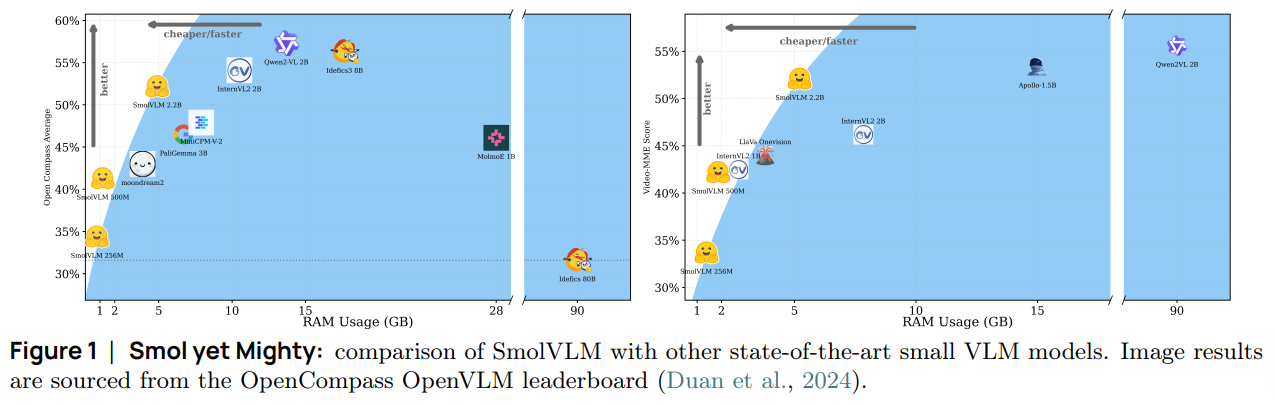
Figure 2:SmolVLM Architecture. Images are split into subimages, frames are sampled from videos, and then encoded into visual features. These features are first rearranged via a pixel-shuffle operation, then mapped into the LLM input space as visual tokens using an MLP projection. Visual tokens are then concatenated/interleaved with text embeddings (orange/red). This combined sequence is passed to the LLM for text output.图 2:SmolVLM 架构。图像被分割成子图像,从视频中抽取帧,然后编码为视觉特征。这些特征首先通过像素重排操作重新排列,然后使用多层感知机(MLP)投影映射到 LLM 的输入空间作为视觉标记。视觉标记随后与文本嵌入(橙色/红色)进行拼接/交错。这个组合序列被传递给 LLM 以生成文本输出。
1、Introduction
| Vision-Language Models (VLMs) have rapidly advanced in capability and adoption (Achiam et al., 2023; Bai et al., 2023; Beyer et al., 2024; Chen et al., 2024c; McKinzie et al., 2024), driving breakthroughs in cross-modal reasoning (Liu et al., 2024a, 2023) and document understanding (Appalaraju et al., 2021; Faysse et al., 2024a; Livathinos et al., 2025; Nassar et al., 2025a). However, these improvements typically entail large parameter counts and high computational demands. Since early large-scale VLMs like Flamingo (Alayrac et al., 2022a) and Idefics (Laurençon et al., 2023) demonstrated capabilities with 80 B parameters, new models have slowly appeared at smaller sizes. However, these models often retain high memory demands due to architectural decisions made for their larger counterparts. For instance, Qwen2-VL (Wang et al., 2024a) and InternVL 2.5 (Chen et al., 2024b) offer smaller variants (1B-2B), but retain significant computational overhead. Conversely, models from Meta (Dubey et al., 2024) and Google (Gemma 3) reserve vision capabilities for large-scale models. Even PaliGemma (Beyer et al., 2024), initially efficiency-focused, scaled up significantly in its second release (Steiner et al., 2024). In contrast, Moondream (Korrapati, 2024) keeps focusing on improving performance while maintaining efficiency, and H2OVL-Mississippi (Galib et al., 2024) explicitly targets on-device deployment. Efficient processing is particularly critical for video understanding tasks, exemplified by Apollo (Zohar et al., 2024b), where memory management is essential. Furthermore, reasoning LLMs generate more tokens during inference, compounding computational costs (DeepSeek-AI, 2025; OpenAI et al., 2024). Therefore, efficiency per token becomes vital to ensure models remain practical for real-world use. Our contributions are: | 视觉语言模型(VLMs)在能力提升和应用推广方面进展迅速(Achiam 等人,2023 年;Bai 等人,2023 年;Beyer 等人,2024 年;Chen 等人,2024 年 c;McKinzie 等人,2024 年),推动了跨模态推理(Liu 等人,2024 年 a,2023 年)和文档理解(Appalaraju 等人,2021 年;Faysse 等人,2024 年 a;Livathinos 等人,2025 年;Nassar 等人,2025 年 a)方面的突破。然而,这些改进通常伴随着庞大的参数数量和较高的计算需求。 自早期的大规模 VLM 模型如 Flamingo(Alayrac 等人,2022 年 a)和 Idefics(Laurencon 等人,2023 年)展示出 800 亿参数的能力以来,规模较小的新模型逐渐出现。然而,这些模型往往由于为更大规模的模型所作的架构决策而仍具有较高的内存需求。例如,Qwen2-VL(Wang 等人,2024 年 a)和 InternVL 2.5(Chen 等人,2024 年 b)提供了较小的变体(10 亿至 20 亿参数),但仍存在显著的计算开销。相反,Meta(Dubey 等人,2024 年)和谷歌(Gemma 3)的模型则将视觉能力保留给大规模模型。即使最初以效率为重的 PaliGemma(贝耶尔等人,2024 年),在其第二次发布时(施泰纳等人,2024 年)也大幅扩展了规模。相比之下,Moondream(科拉帕蒂,2024 年)持续专注于提升性能的同时保持高效,而 H2OVL-密西西比(加利布等人,2024 年)则明确将目标锁定在设备端部署。对于视频理解任务而言,高效处理尤为关键,以阿波罗(佐哈尔等人,2024 年 b)为例,其中内存管理至关重要。此外,推理型 LLM 在推理过程中生成更多标记,从而增加了计算成本(DeepSeek-AI,2025 年;OpenAI 等人,2024 年)。因此,每标记的效率变得至关重要,以确保模型在实际应用中保持实用性。我们的贡献在于: |
| • Compact yet Powerful Models: We introduce SmolVLM, a family of powerful small-scale multimodal models, demonstrating that careful architectural design can substantially reduce resource requirements without sacrificing capability. • Efficient GPU Memory Usage: Our smallest model runs inference using less than 1GB GPU RAM, significantly lowering the barrier to on-device deployment. • Systematic Architectural Exploration: We comprehensively investigate the impact of architectural choices, including encoder-LM parameter balance, tokenization methods, positional encoding, and training data composition, identifying critical factors that maximize performance in compact VLMs. • Robust Video Understanding on Edge Devices: We demonstrate that SmolVLM models generalize effectively to video tasks, achieving competitive scores on challenging benchmarks like Video-MME, highlighting their suitability for diverse multimodal scenarios and real-time, on-device applications. • Fully Open-source Resources: To promote reproducibility and facilitate further research, we release all model weights, datasets, code, and a mobile application showcasing inference on a smartphone. | • 紧凑而强大的模型:我们推出了 SmolVLM,这是一个强大的小型多模态模型系列,表明精心设计的架构能够在不牺牲能力的前提下大幅降低资源需求。 • 高效的 GPU 内存使用:我们的最小模型在推理时使用的 GPU 内存不到 1GB,显著降低了设备端部署的门槛。• 系统性架构探索:我们全面研究架构选择的影响,包括编码器 - 语言模型参数平衡、标记化方法、位置编码以及训练数据构成,确定了在紧凑型视觉语言模型中最大化性能的关键因素。 • 边缘设备上的强大视频理解:我们证明了 SmolVLM 模型能够有效地泛化到视频任务上,在诸如 Video-MME 这样的具有挑战性的基准测试中取得了具有竞争力的分数,突显了其在各种多模态场景和实时设备端应用中的适用性。 • 完全开源资源:为了促进可重复性并推动进一步的研究,我们发布了所有模型权重、数据集、代码以及一个在智能手机上展示推理过程的移动应用程序。 |
Conclusion
| We introduced SmolVLM, a family of memory-efficient Vision-Language Models ranging from 256M to 2.2B parameters. Remarkably, even our smallest variant requires less than 1GB of GPU memory yet surpasses state-of-the-art 80B-parameter models from just 18 months ago (Laurençon et al., 2023). Our findings emphasize a critical insight: scaling down large VLM architectures optimized under resource-rich conditions results in disproportionately high memory demands during inference with little advantage over specialized architectures. By contrast, SmolVLM’s design philosophy explicitly prioritizes compact architectural innovations, aggressive but careful tokenization methods, and efficient training strategies, enabling powerful multimodal capabilities at a fraction of the computational cost. All model weights, training datasets, and training code are publicly released to encourage reproducibility, transparency, and continued innovation. We hope SmolVLM will inspire the next generation of lightweight, efficient VLMs, unlocking new possibilities for real-time multimodal inference with minimal power consumption. | 我们推出了 SmolVLM,这是一系列参数量从 2.56 亿到 22 亿的高效内存视觉语言模型。令人瞩目的是,即使是最小的变体也只需不到 1GB 的 GPU 内存,却能超越 18 个月前最先进的 800 亿参数模型(Laurencon 等人,2023 年)。我们的研究结果强调了一个关键见解:在资源丰富的条件下优化的大规模 VLM 架构在推理时会带来不成比例的高内存需求,且相对于专门架构几乎没有优势。相比之下,SmolVLM 的设计理念明确优先考虑紧凑的架构创新、激进但谨慎的标记化方法以及高效的训练策略,从而以极低的计算成本实现强大的多模态能力。 所有模型权重、训练数据集和训练代码均已公开发布,以鼓励可重复性、透明度和持续创新。我们希望 SmolVLM 能够激发下一代轻量级、高效的 VLM 的发展,为低功耗实时多模态推理开辟新的可能性。 |