机器学习-探索性数据分析
美国加州房屋分析示例
导入要用的包
读取数据
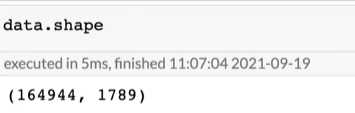
读取的表有几行几列

展示前几行数据
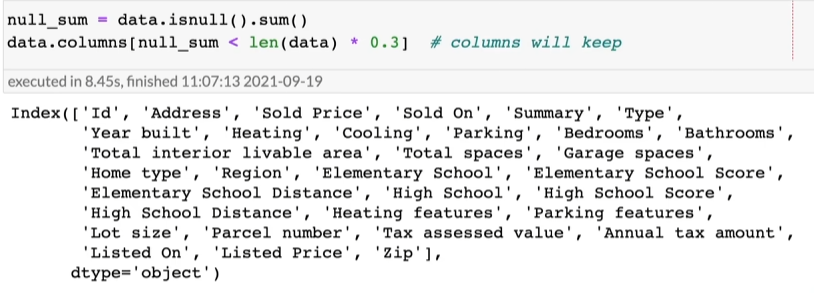
找出那些缺失数据量小于总数据量的30%的列

将那些缺失数据量大于总数据量30%的列删掉,inplace=True表示直接对数据进行修改(执行完一次后表里就没有那些删除的列了)
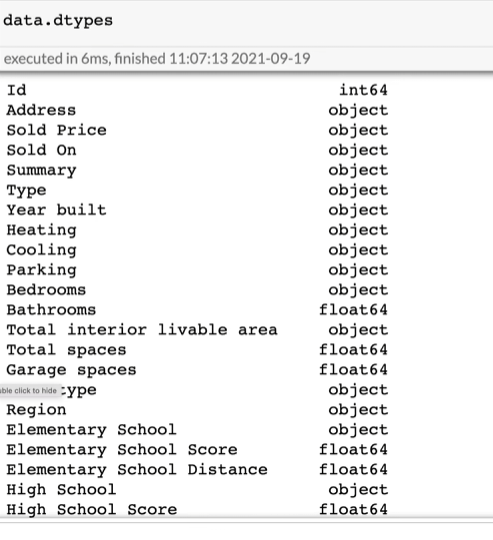
展示各个数据列的数据类型

将与钱相关的列加入currency数组,之后分别对这些列用正则表达式将"$“”,“”-"号全部删掉,下一个是若是空字符串,直接转成numpy的not a number,之后将这些列的数据都转成float类型的数据

修改占地面积的数据类型
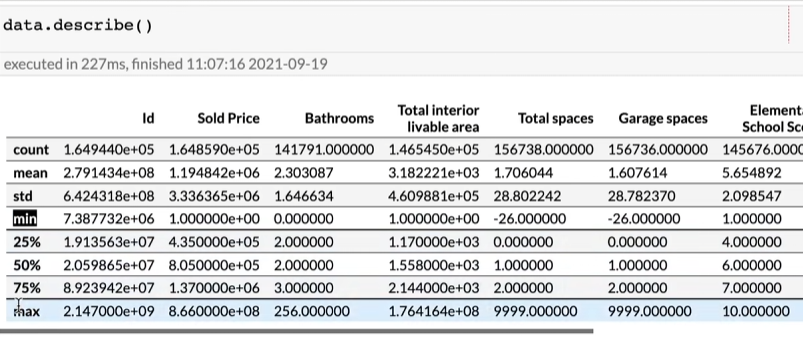
看各列数据的水平
可以发现有多个噪音(如最大总空间9999,最大卫生间数256等)
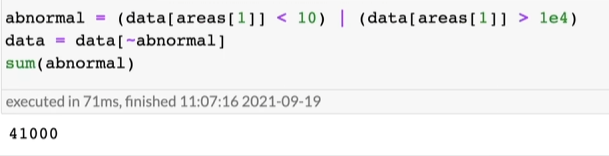
拿出房间面积小于10或大于10000的列(不正常的),第二行代码把除不正常数据之外的其他数据留下,再看有多少不正常的数据
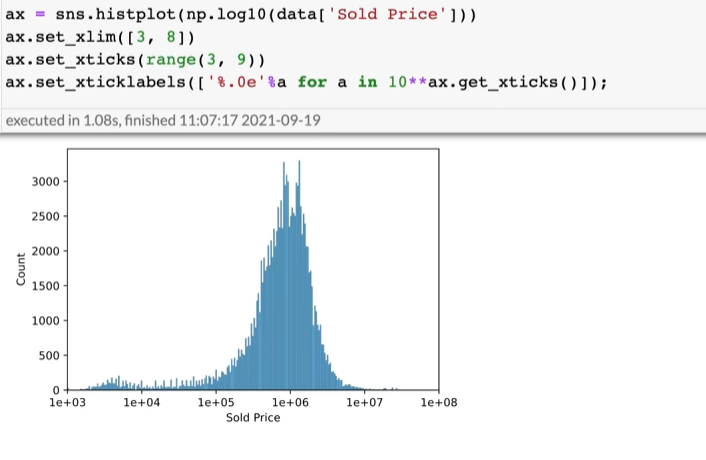
观测价格分布
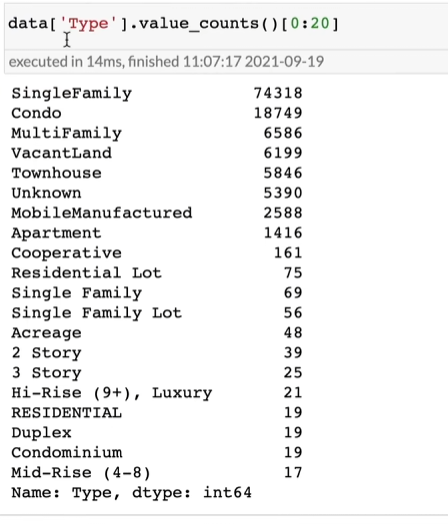
计数各个房子类型有多少个,这里只显示前20个
可以发现“SingleFamily”和“Single Family”未计数到一起,这也是噪音
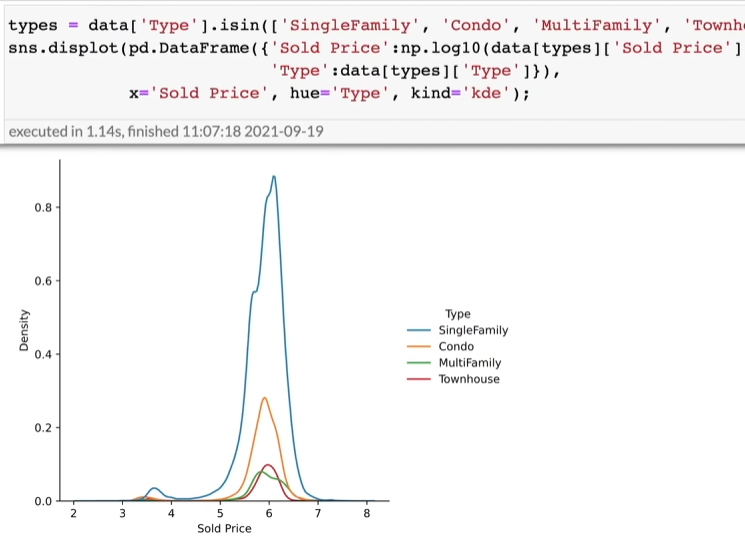
将四种类型的房子拿出来,观察各个类型的房价分布

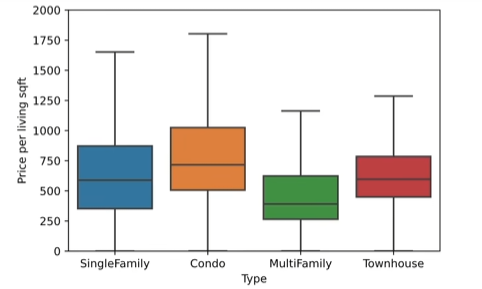
看各个类型房子的每平米的价格的分布,色块内的横线表示均值,色块上界和下界分别表示75%和25%的分位数
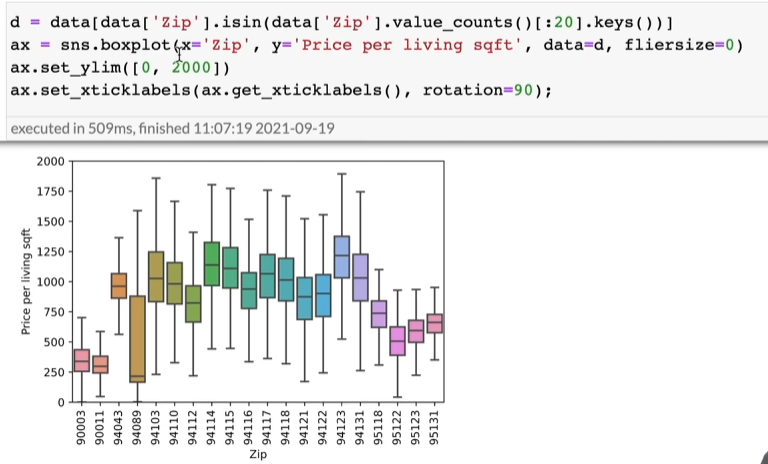
看不同邮政编码的房子的单位面积的均价分布

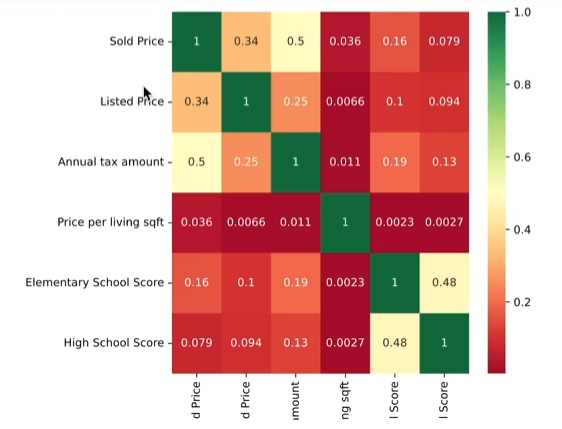
热力图观察各类变量之间的相关性