IP验证概述
目录
前言
一、整体框架
二.transaction(sequence item)框架
三、agent框架
四. env框架
五.集成VIP和寄存器模型:
总结
前言
个人搭建UVM环境不需要太多的关心点,因为在验证工作的时候可能会共用一套UVM验证环境和脚本(除非你是自己玩,用AI可以解决大部分环境代码框架了。),作为入门读者搭建验证环境实也属有些难度。
刚入门的读者要先把心思花在如何编写case上去,至于整个UVM验证环境读者可以慢慢熟悉后再现有环境下做改动。
验证环境很多时候也是凑合着用就行,为了力图简单,搭建验证环境通常使用脚本生成验证环境,验证时还应该将注意力放到功能点的提取和corner完备性验证。
本文只是简单的入门基础,预备知识只需要读者对UVM的环境有个大概的了解即可。
参考:网络上常见的验证资料;有关验证的公众号。
一、观察IP
对于IP验证,拿到IP后搭建环境通常会关注四点:
数据流:查看一共有几路数据流,这些数据流决定了对应了环境中的有几个agent,同时还要区分输入和输出,这决定了agent中是否是active或者passive模式,该数据流的使用的协议是什么,这决定了agent的接口时序。
控制流:查看寄存器配置,存在寄存器配置的话需要在环境中加入对应的VIP或者agent。
模型检查:
C模型使用dpi导入环境中,python模型使用对应的方法或者使用dpi间接导入,如果没有模型也可以自己编写。
集成环境:考虑集成情况,一般分为:集成驱动sequence,集成checker ,集成整体env 三种情况。
在搭建环境的时候同功能性质的组件最好只出现一次,例如agent中通常会将driver和monitor都要用到的virtual interface放到agent_config中统一管理,上层环境env也是一样的道理,诸如此类,我们总是能在各种环境组件中看到config里有vif(virtual interface) 。
二.transaction(sequence item)框架
拿到DUT的第一步,首先需要查看各个数据流,例如上述的数据流,控制流等,这样可以划分出对应的各种接口,接着编写各式各样的transaction。
另外在查看设计文档时,重点关注寄存器的功能,从中提取出要验证的功能点。
这些transaction就是各种数据流或者控制流,搭建的时候需要大致了解它们的流向。
三、agent框架
编写agent时,需要考虑该agent具体需要哪些接口,哪些接口需要transaction发送 ,哪些接口需要采样。通常将同一种协议或者时序相同性质类似的放到同一个agent中。
考虑到是否需要driver的存在,这个配置同样可以在config里完成配置,如果考虑复用性的话通常会在顶层top里配置各个agent的模式,以求达到最大的复用性。
四. env框架
env在配置中主要使用env_config组件来传递接口,配置各个agent的模式,配置寄存器模型和参考模型等。
不过不建议将env_config例化到env中,为了保证纵向配置工作量最小,通常会和env一起要例化到basetest中去,再由顶层直接控制。
功能点的提取工作量很大,而提取完成后还要写case并给对应的case编写相应的seuqence。
在某些特定的环境下,我们使用VIP进行验证,例如使用SVT_VIP进行集成和验证,下面讲一下如何集成?
五.集成VIP和寄存器模型:
在集成VIP之前,首先要去查看对应的demo是怎么做集成的,进入到demo中的base_test里面看是如何配置sequence和config对应的组件。
再进入到vip里面env和congfig组件,查看如何配置下属环境以及查看VIP的属性。
总的集成方法归结为以下几步:
1.实例化vip里的env(agent) ,config等组件。
2.修改config里的配置。
3.实例化寄存器模型,并配置寄存器模型对应的seuqnecer,以便能够进行前门访问。
4.配置slave sequence ,主要是给slave做DUT的响应操作。
5.在顶层将interface配置到各层的接口上。
六.整合框架
在基本确定了组件框架后就可以整合起来,组成一个可用的测试环境。不过这一步按照人的惯性思维也会放在第一步,即先确定整体框架,再来整理细节。
不过由于整体框架基本类似,在大脑中很容易形成,所以我放到了文末来讲。
一个常见的整体框架如图:
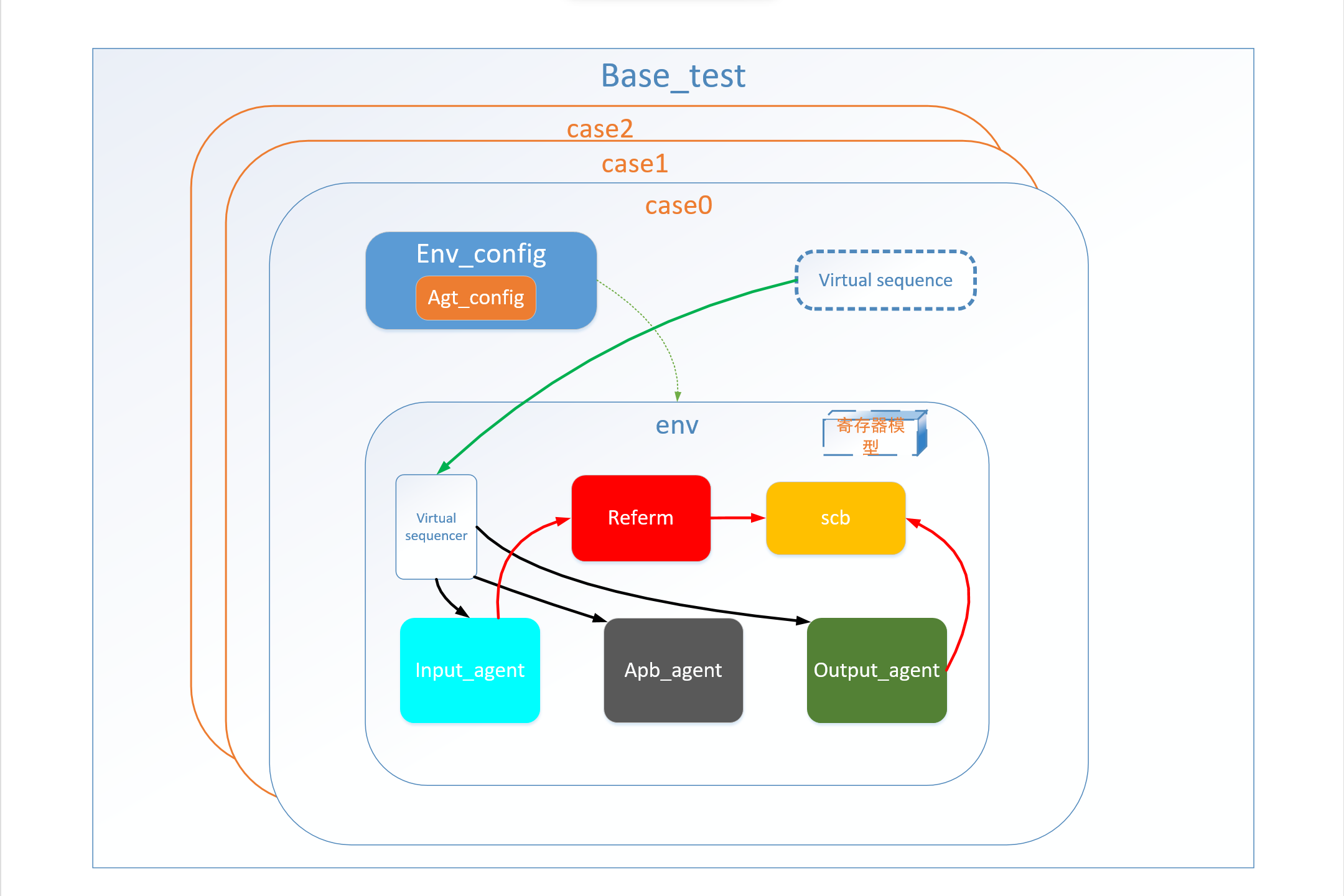
这是一个十分清晰的验证框架了,读者在看图可以大致理解UVM的控制框架和数据通路。需要理解的是在图中寄存器模型可以在env中例化,也可以上层test中例化。
因此图中寄存器模型并没有连线。