Hadoop简介:分布式系统的基石与核心架构详解
Hadoop简介:分布式系统的基石与核心架构详解
Hadoop 作为 Apache 基金会开发的分布式系统基础架构,彻底改变了海量数据的存储与处理方式。它允许用户在不深入了解分布式底层细节的情况下,轻松开发分布式程序,充分利用集群的算力和存储能力。本文将从 Hadoop 的核心组成、架构原理、配置实践到适用场景进行全面解析,帮你快速掌握 Hadoop 的核心知识。
Hadoop 核心价值:为什么选择 Hadoop?
在大数据时代,传统单机系统无法应对 PB 级甚至 EB 级数据的存储和计算需求。Hadoop 的出现解决了三大核心问题:
- 分布式存储:通过 HDFS 实现海量数据的分布式存储,突破单机存储上限;
- 分布式计算:通过 MapReduce 框架将复杂任务分解为并行子任务,利用集群算力高效处理;
- 易用性:屏蔽分布式底层细节,开发者只需关注业务逻辑,无需手动管理节点通信、数据分片等问题。
Hadoop 核心组件:HDFS 与 MapReduce
Hadoop 最核心的设计是 HDFS(分布式文件系统) 和 MapReduce(分布式计算框架),二者分别负责数据的存储与计算,构成了 Hadoop 的基石。
一、HDFS:高容错的分布式文件系统
HDFS(Hadoop Distributed File System)是 Hadoop 的分布式存储核心,专为大规模数据存储设计,具有高容错性、高吞吐量的特点。
1. HDFS 核心架构
HDFS 采用 主从架构(Master-Slave),由三个核心组件构成:NameNode、DataNode 和 SecondaryNameNode。
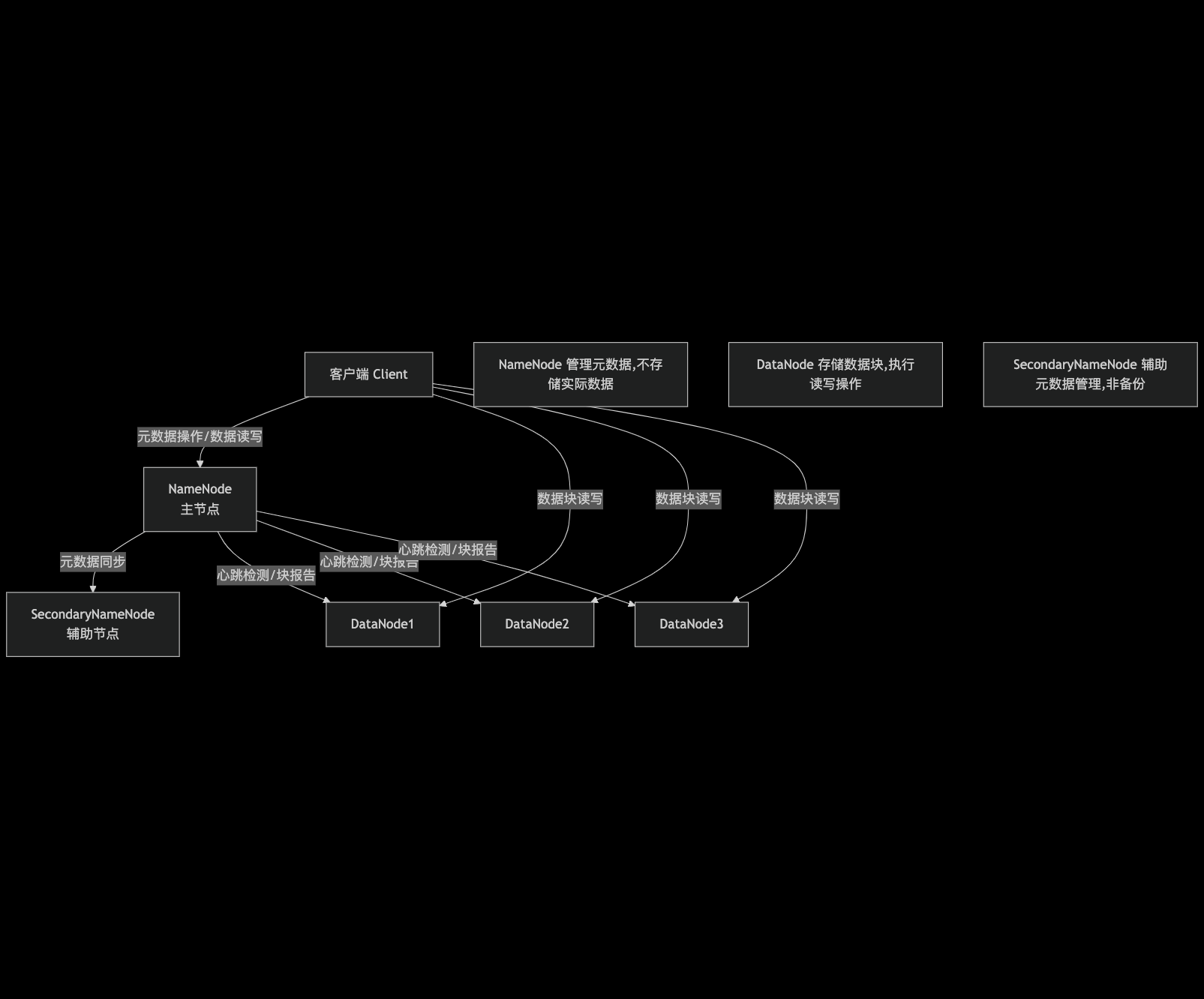
2. 核心组件功能详解
| 组件 | 角色与核心功能 |
|---|---|
| NameNode | - 存储 HDFS 元数据(文件目录结构、文件与数据块的映射关系、权限等); - 管理文件系统命名空间(创建、删除、移动文件 / 文件夹); - 接收 DataNode 的心跳(Heartbeat)和块报告(Blockreport),监控节点健康状态; - 决定数据块的副本分配策略。 |
| DataNode | - 存储实际数据(以固定大小的 数据块(Block) 为单位,默认 128MB,可配置); - 执行 NameNode 下达的文件操作命令(如创建、删除、复制数据块); - 定时向 NameNode 发送心跳(证明节点存活)和块报告(汇报本地数据块状态)。 |
| SecondaryNameNode | - 定期合并 NameNode 的元数据镜像(fsimage)和编辑日志(editlog),生成新的 fsimage 并同步给 NameNode; - 缓解 NameNode 的元数据管理压力,注意:并非 NameNode 的备份节点,无法直接替代故障的 NameNode。 |
合并时间根据配置文件来进行配置
fs.checkpoint.period时间间隔,默认3600sfs.checkpoint.sizeedits log大小,默认64M
3. HDFS 核心机制
- 数据块(Block):HDFS 将文件分割为固定大小的块(默认 128MB),每个块会在多个 DataNode 上存储副本(默认 3 个),提高可靠性。
- 副本机制:通过
dfs.replication配置副本数(如单机测试设为 1,生产环境通常设为 3),确保某节点故障时数据不丢失。 - 元数据管理:NameNode 存储元数据在内存中,同时通过
fsimage(元数据快照)和editlog(操作日志)持久化到磁盘,SecondaryNameNode 定期合并二者以优化性能。
二、MapReduce:分布式计算框架
MapReduce 是 Hadoop 的分布式计算引擎,基于 “分而治之” 思想,将大规模计算任务分解为可并行执行的子任务,在集群节点上分布式运行。
1. MapReduce 核心流程
MapReduce 任务分为两个阶段:Map 阶段和Reduce 阶段,中间通过 Shuffle 过程连接:
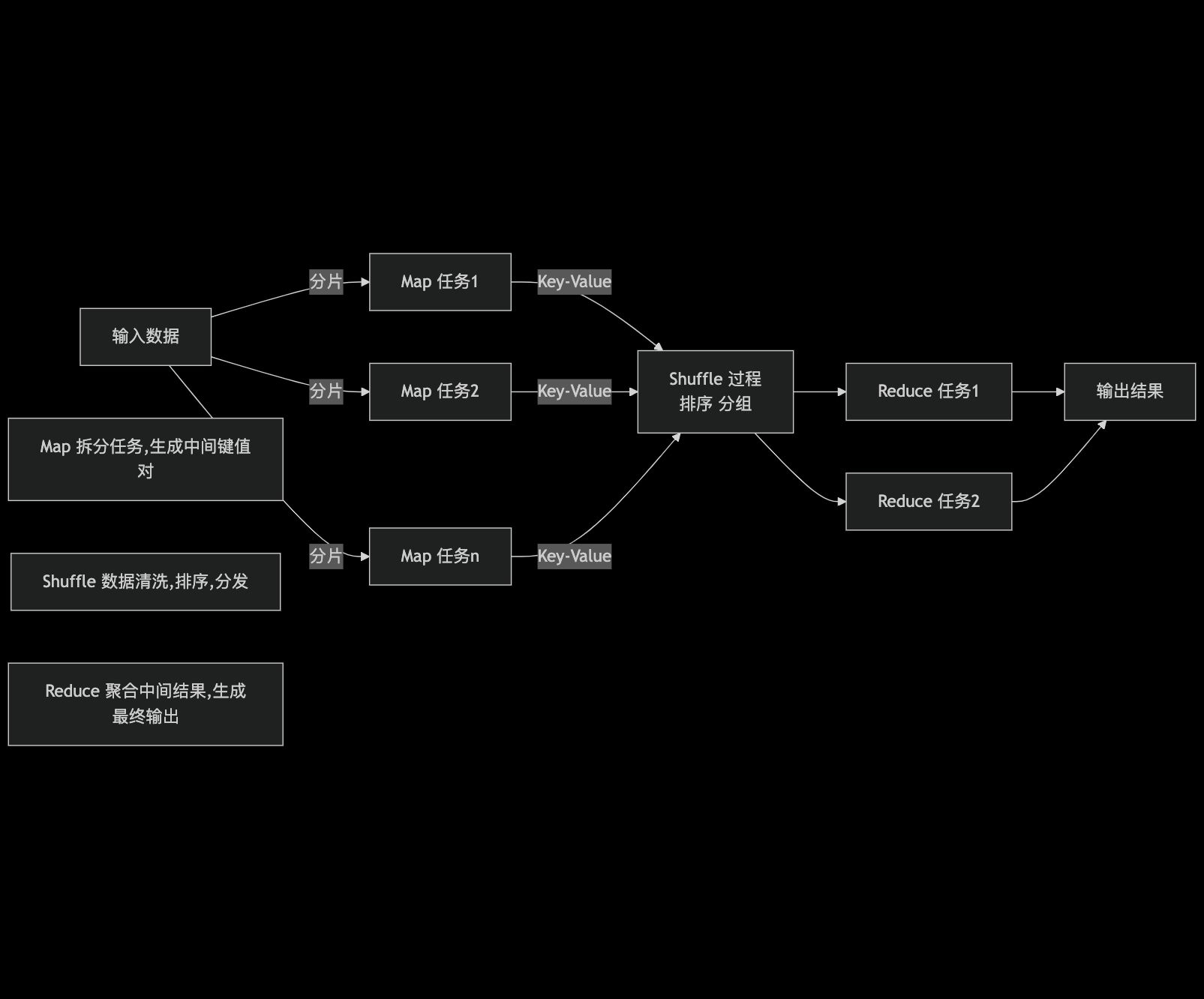
2. 核心组件
- Map 阶段:将输入数据分片(Split),每个分片由一个 Map 任务处理,输出 <Key, Value> 形式的中间结果;
- Shuffle 阶段:对 Map 输出的中间结果进行排序、分组、合并,按 Key 分发到对应的 Reduce 任务;
- Reduce 阶段:接收 Shuffle 后的中间结果,聚合计算并输出最终结果。
Hadoop 发行版本:选择适合你的版本
Hadoop 有多个发行版本,各版本在稳定性、生态工具集成和商业支持上存在差异,选择时需结合场景需求:
| 发行版本 | 特点与优势 | 适用场景 |
|---|---|---|
| Apache Hadoop | - 最基础、最原始的版本,开源免费; - 社区活跃,更新频繁; - 需自行搭建和维护生态工具(如 Hive、Spark)。 | 技术研究、定制化需求高的场景,或有专业运维团队的企业。 |
| Cloudera CDH | - 基于 Apache Hadoop 优化,稳定性高; - 集成丰富生态工具(Hive、Impala、Spark 等),开箱即用; - 提供商业支持和运维工具(Cloudera Manager)。 | 企业级生产环境,尤其是对稳定性和商业支持有需求的场景。(收费) |
| Hortonworks HDP | - 文档丰富,易用性强; - 完全开源,专注于企业级部署; - 后与 Cloudera 合并为 CDP 平台。 | 注重文档和开源生态的企业,或需要低成本企业级解决方案的场景。 |
Hadoop 核心优势:四大特性支撑大规模应用
Hadoop 之所以成为分布式系统的标杆,源于其四大核心优势:
- 高可用性(High Availability)
HDFS 通过多副本机制存储数据,即使部分 DataNode 故障,数据仍可通过其他副本访问;MapReduce 支持任务失败重试,确保计算任务最终完成。 - 高扩展性(High Scalability)
集群可通过横向扩展(增加节点)轻松提升存储和计算能力,无需重构系统架构,理论上支持数千甚至数万个节点。 - 高效性(High Efficiency)
HDFS 读写数据时可并行访问多个 DataNode 的副本,MapReduce 将任务分布式并行处理,充分利用集群算力,大幅提升处理效率。 - 高容错性(High Fault Tolerance)
- 节点故障自动检测(通过心跳机制);
- 数据块自动复制(当副本数不足时,NameNode 会触发复制);
- 任务失败自动重试(MapReduce 框架负责重新调度失败任务)。
Hadoop 适用场景与局限性
Hadoop 并非万能解决方案,需根据数据特性和业务需求判断是否适用:
适合的场景
- 大规模数据存储与处理:PB 级以上数据的离线批处理(如日志分析、数据挖掘);
- “写一次,读多次” 的数据:适合数据一旦写入后很少修改的场景(如历史日志归档、数据备份);
- 非实时性需求:批处理任务(如每日 / 每小时数据汇总),而非毫秒级实时响应场景。
不适合的场景
- 低延时数据访问:HDFS 为高吞吐量设计,读写延迟较高,不适合实时查询(如 OLTP 数据库场景);
- 大量小文件存储:HDFS 元数据存储在 NameNode 内存中,过多小文件会消耗大量内存,降低性能;
- 频繁修改文件:HDFS 设计为 “一次写入,多次读取”,不支持高效的随机修改,仅支持追加写操作。
Hadoop 常用端口:版本差异与访问方式
Hadoop 2.x 和 3.x 的核心端口存在差异,需注意区分:
| 服务 / 功能 | Hadoop 2.x 端口 | Hadoop 3.x 端口 | 访问方式(示例) |
|---|---|---|---|
| NameNode 内部通信 | 8020 / 9000 | 8020 / 9000 / 9820 | 用于程序访问 HDFS(如 hdfs://localhost:9000) |
| NameNode HTTP UI | 50070 | 9870 | http://localhost:9870 |
| YARN ResourceManager UI | 8088 | 8088 | http://localhost:8088(查看任务) |
| 历史服务器 UI | 19888 | 19888 | http://localhost:19888(查看历史任务) |
参考文献
- hadoop简介