Redis其他的数据类型及渐进式遍历
Redis其他的数据类型:
Streams数据类型:
Redis Stream是Redis 5.0版本后引入的一个新数据类型,他是一个可持久化,可查询的,可扩展的消息队列服务。
Stream数据类型类似于一个日志系统,数据被添加到Stream末尾,并且每个数据都会分配一个唯一的序列号,这个序列号是按照时间递增的,这使得Stream数据类型特别适合消息队列,事件驱动系统,数据流处理场景
Stream类型主要包括:
可持久性 :
redis的stream数据类型也可以像其他的数据类型一样,Stream数据类型的数据也可以被同步到磁盘上,即使Redis重启,数据也不会消失
消费者组:
Stream数据类型也支持消费者组的概念,多个消费者可以到同一个Stream中去读取数据,每个消费者都会读取自己未读取到的数据。
阻塞读取:
消费者可以选择阻塞的从Stream中进行读取数据,如果Stream中现在没有数据,则消费者可以选择等待,直到有新的数据到达。
可以读取历史数据:
消费者可以读取Stream中的历史数据,这意味着消费者在处理完当前的数据之后,还可以处理之前的数据。
Stream类型使用场景:
1.消息队列:
Redis Stream可以作为一个可持久化,可扩展的消息队列服务,用于在不同的应用组件之间进行消息传递。消费者可以实时从Stream中读取数据,还可以读取历史数据。
2.日志记录:
由于日志是按照时间顺序进行储存的,因此String非常适合用于记录日志,你可以将日志作为Stream的元素,包含日志级别,消息和时间戳等信息。
3.事件驱动系统:
在事件驱动系统中,可以用Stream类储存和传递事件,每个Stream可以是一个事件,其中记录着事件的一些内容。
4.数据流处理:
也可以将数据流作为一个Stream数据类型,然后使用消费者组来进行消费。
Geospatial数据类型:
Redis 在 3.2 版本中加入了地理空间以及索引半径查询的功能,主要用在需要地理位置的应用上。将指定的地理空间位置(经度、纬度、名称)添加到指定的 key 中,这些数据将会存储到 sorted set。这样的目的是为了方便使用 GEORADIUS 或者 GEORADIUSBYMEMBER 命令对数据进行半径查询等操作。也就是说,推算地理位置的信息,两地之间的距离,周围方圆的人等等场景都可以用它实现
HyperLogLog数据类型:
这个类型的应用场景只有一个,估算集合中的元素个数。
之前讲过set的一个应用场景,统计服务器的UV(用户访问的次数),使用Set可以满足统计UV,但是问题是,UV的数据量非常大,Set就会消耗大量的内存储空间。
因为Set中还会储存用户的userId,每个userId按照8字节算,1亿UV就会消耗800MB的内存,但是使用HyperLogLog最多12kb的空间就能实现上述效果。
HyperLogLog不储存元素的内容,但是能够记录元素的特征,从而在新增的元素的时候,能够知道当前新增的元素,是一个已经存在的数据,还是一个崭新的数据。
但是这个存在一定的误差。只不过误差在0.81%左右。
Bitmaps数据类型:
位图,使用bit位来表示整数,更加节省空间。
比如把10储存到位图中,把10储存到位图中,0000 0000 0000 0000 0010 0000 0000,通过在第十位存1,可以来储存10这个数据。
Redis bitfields数据类型:
位域,bitfields可以理解成一串二进制序列(字节数组),同时可以把这个数组中的某几位,赋予特定的含义,并且进行读取/修改/算术运算。
渐进式遍历:
keys一次性把整个Redis中的所有key都获取到,这是一个非常危险的操作。因为redis是单线程的,所以可能会阻塞redis的服务器。
但是通过渐进式遍历,就可以做到,既能获取所有的key,同时又不会卡死服务器。渐进式遍历,不是一个命令,把所有key拿到的,而是每一次执行一次命令,每一次执行的命令只能获取到其中一小部分,这样的话保证当前这一次操作不会太卡。如果想要得到更多的key就需要多次进行遍历。多次执行渐进式遍历命令。
scan cursor count 这是渐进式遍历命令。
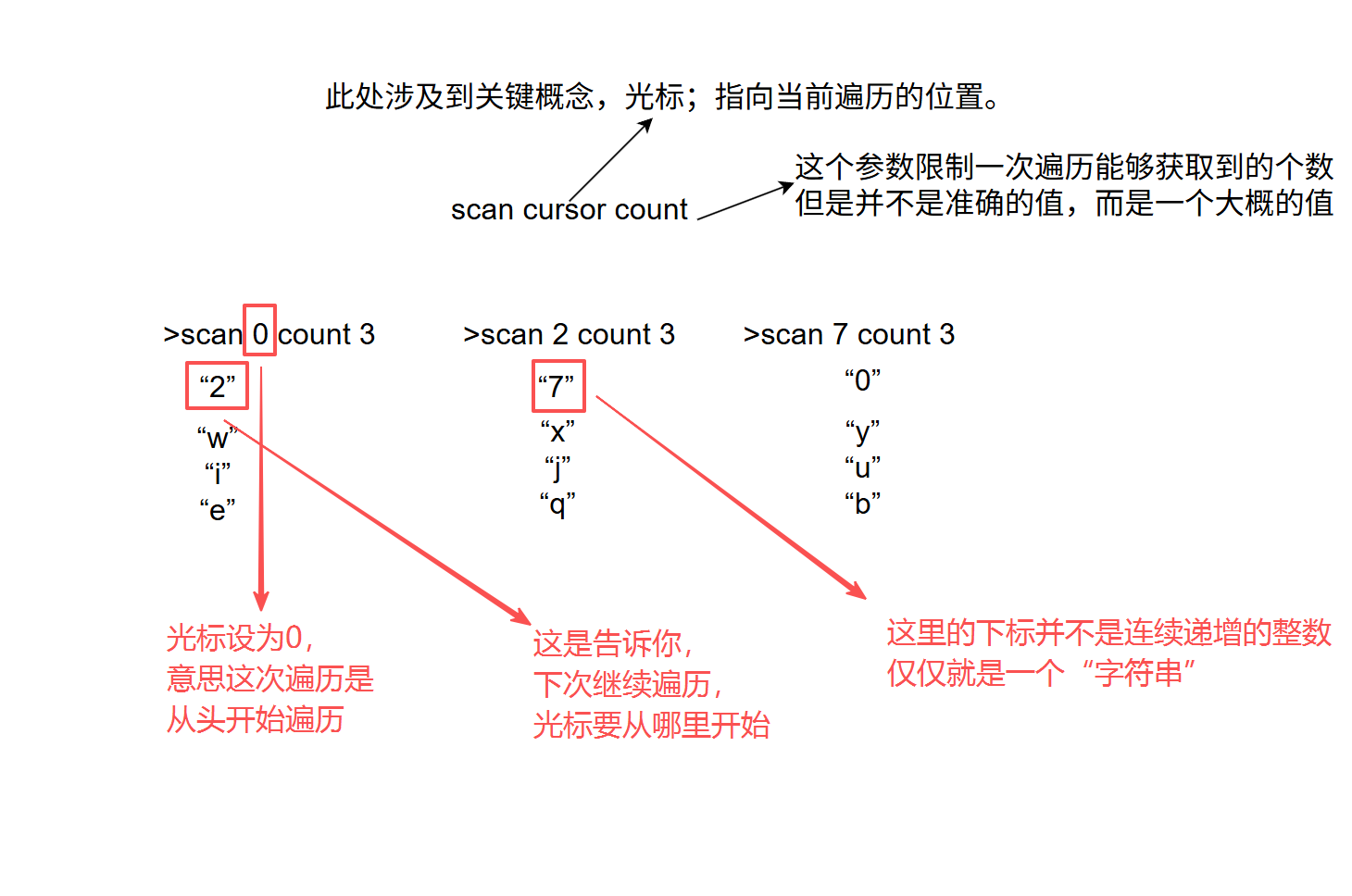
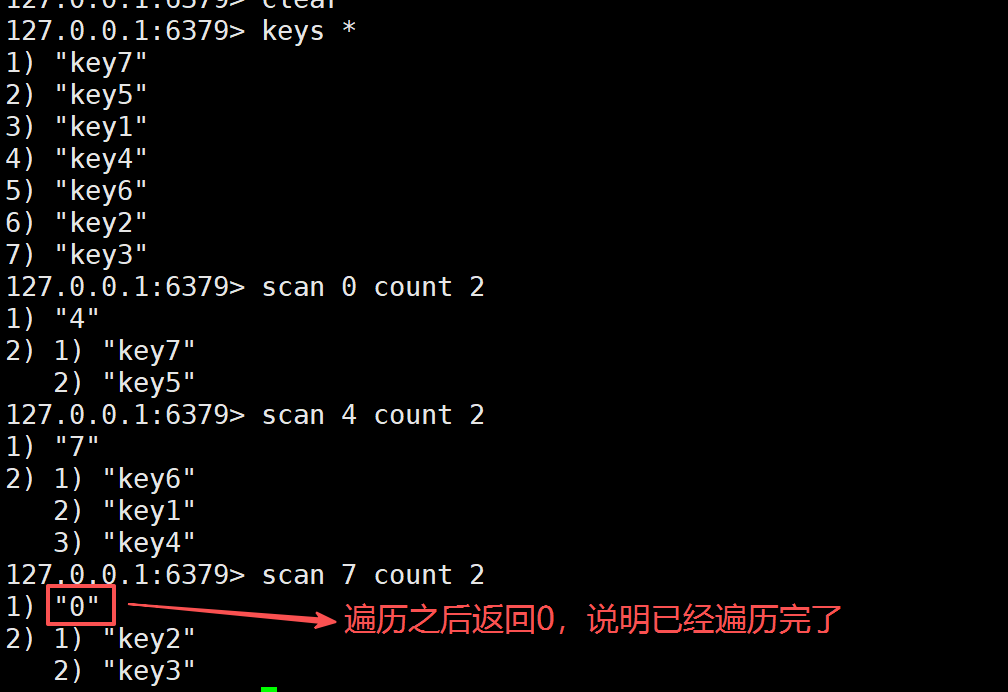
count这里的数字不是每次非得设置成一样的,这里可以根据实际情况来设置。这里的渐进式遍历,在遍历的过程中,在服务器这边不储存任何的状态信息,此处的遍历是随机可以终止的,不会对服务器产生任何副作用。
注意:渐进式命令scan虽然解决了阻塞的问题,但如果在遍历期间键有所变化,比如增加,删除,可能导致遍历时产生遗漏或者重复遍历,这点在实际开发中考虑。