Story2Board: A Training-Free Approach for Expressive Storyboard Generation论文
code:https://github.com/daviddinkevich/Story2Board
benchmark 100个故事的基准集,未开源
gpt-4o生成的。生成整体的剧本,包含丰富的背景等,然后拆分n个prompt,每个prompt具有相同的subject描述(reference)+其他(panel)
Scene Diversity Metric:
量化故事板中角色在不同画幅里的构图变化,包括其大小、位置和姿势的变化程度。
通过grounding DINO和vitpose计算不通panel的subject的框以及关键点,然后计算这些点的方差得到
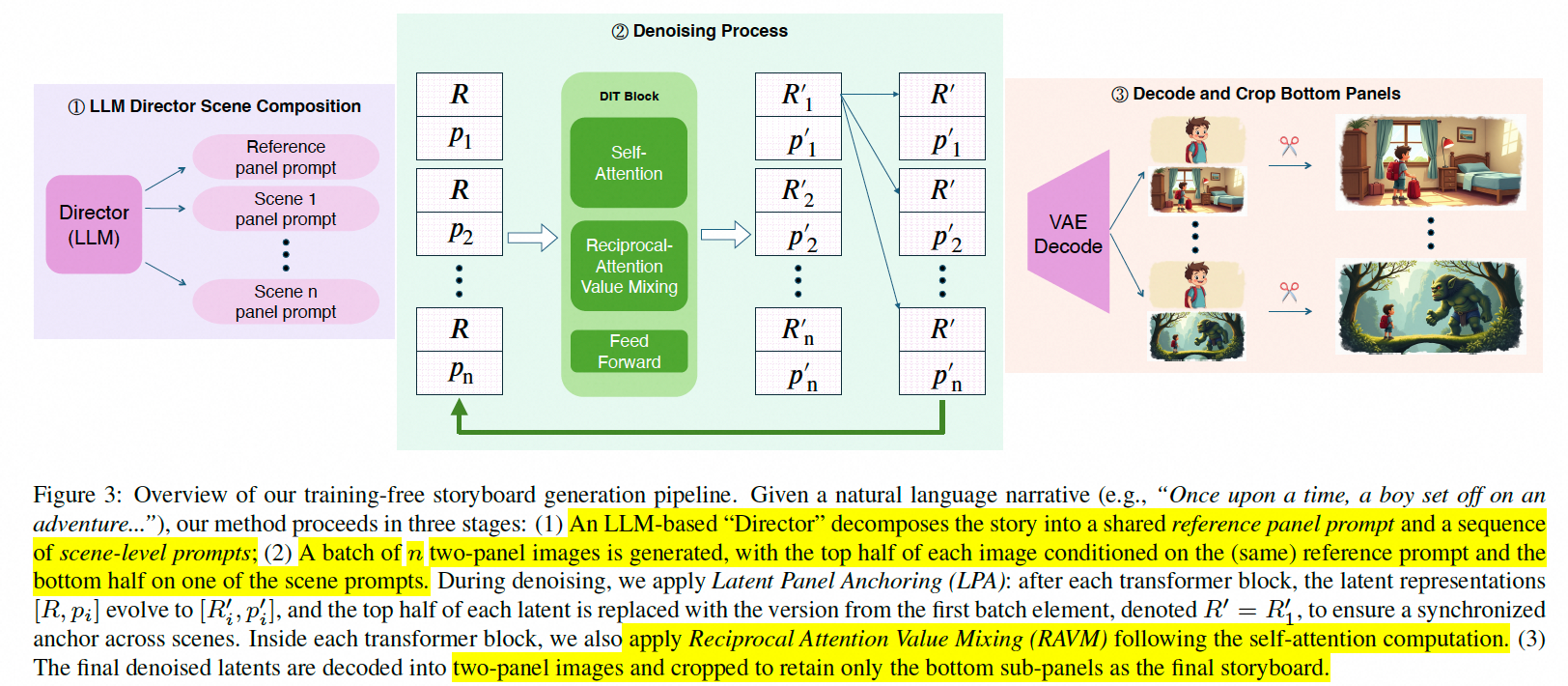
LPA
输入设置:通过LLM得到"A storyboard of [reference prompt] (top) and [scene prompt_i] (bottom)"
● 并行处理: n 个场景的 Latent Grid:[R_1, p_1], [R_2, p_2], …, [R_n, p_n]。
● 一步去噪:得到新的潜在表示:[R’_1, p’_1], [R’_2, p’_2], …, [R’_n, p’_n]。
● 锚定操作 (Anchoring):强制将所有潜在表示的上半部分,都替换为第一个潜在表示的上半部分:[R’_1, p’_1], [R’_1, p’_2], …, [R’_1, p’_n]。
● 循环往复:这个“去噪 -> 锚定”的过程在整个去噪循环中不断重复。
核心代码
hidden_states[1:, n_prompt_tokens : n_prompt_tokens + n_image_tokens // 2, :] = \hidden_states[0, n_prompt_tokens : n_prompt_tokens + n_image_tokens // 2, :]RAVM进一步增强人物的一致性

attention中,qk计算的的结果为attention score,影响的是图片的整体空间布局,v影响的是细节。
通过互惠注意力 (Reciprocal Attention)去找到bottom某些token对应的top中的token。
● 互惠注意力分数,获取注意力矩阵 M
● 筛选高置信度的对应关系,对M平滑、过滤、二值化,自适应取阈值、滤波等。
● value mix
备注:只作用于first_mixing_block(30)和last_mixing_block(57)之间,first_mixing_denoising_step(1)和last_mixing_denoising_step(21)之间。加权系数为0.5.同时对m矩阵做ema平滑。只会改变bottom的value,对top不作改变
# save: (H, k, D)save = value[i, :, n_prompt_tokens + n_panel_tokens + bottom_indices, :] # (H, k, D) paste = value[i, :, n_prompt_tokens + matched_top_indices, :] # (H, k, D)# Blend and assignblended = (1 - ravm_mixing_coef) * save + ravm_mixing_coef * pastevalue[i, :, n_prompt_tokens + n_panel_tokens + bottom_indices, :] = blended