因表并行引发的血案【故障处理案例】
1 说明
某天值班,收到应用反馈说有个测试库最近每天都出现接口超时情况,请求排查。

虽说这个库是一个测试库,但承载着核心系统订单模块的回归测试、新功能验证等核心测试场景,最近系统很卡:
接口超时导致第三方无法完成每日既定的测试用例,可能影响后续版本的上线计划,用户体验极差,抱怨频繁。
2 处理措施1
2.1 检查进程数
根据该 11g RAC 集群的历史维护记录,此前曾因最大进程数设置过低(原设 2000)导致进程数满,进而引发接口超时,后来将节点 1 的processes调整为 5000。
查看参数设置情况:
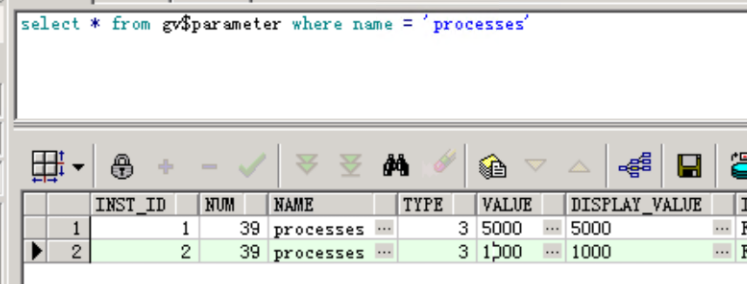
节点2的最大进程数只有1000,当时基于ASH判断节点 2 业务量低(峰值小于 1000),便未同步调整,保持 1000 不变。
查看近期节点1历史进程数:
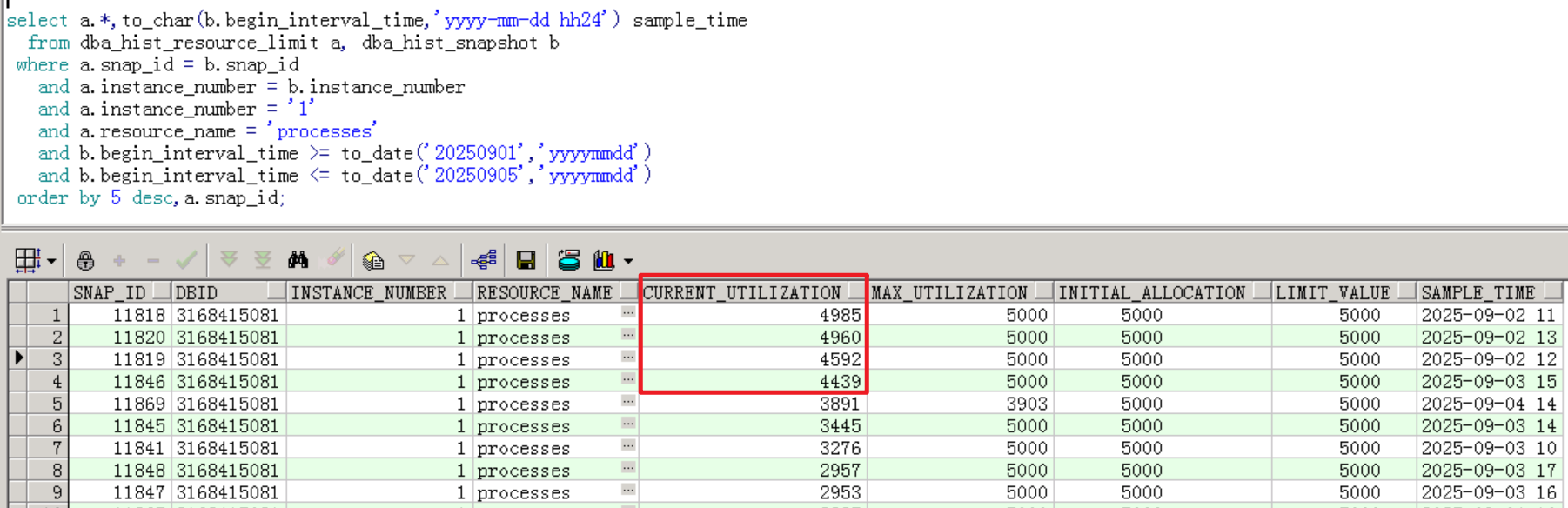
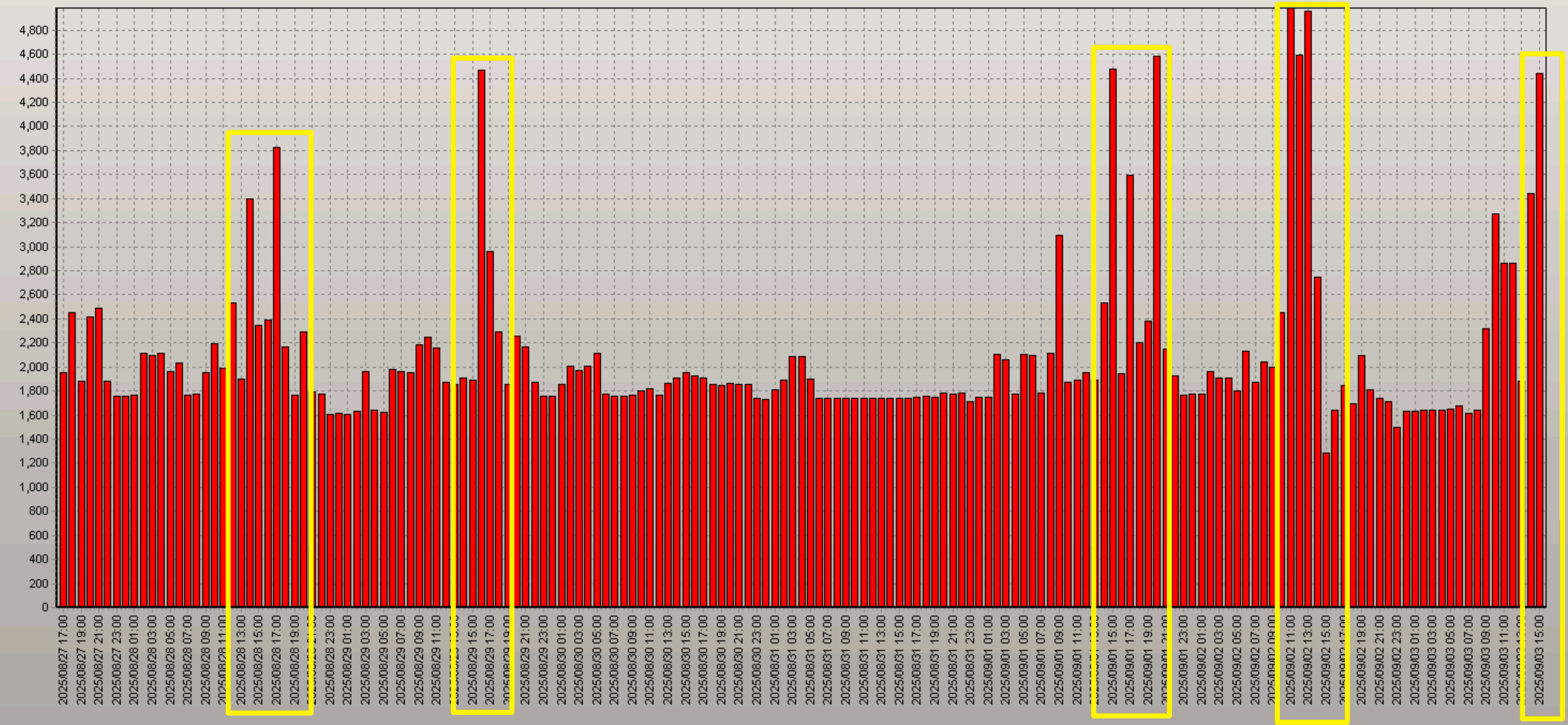
可以看到,节点 1 每天中午 12 点左右,当前进程数会都会超过 4000 左右,距离 5000 的上限仅差 几百,接近满负荷;而9月3日这天,当前进程数的峰值更是达到4985,这时候新进程完全是连不上节点1了,导致接口连接超时。
再查看节点2进程数:
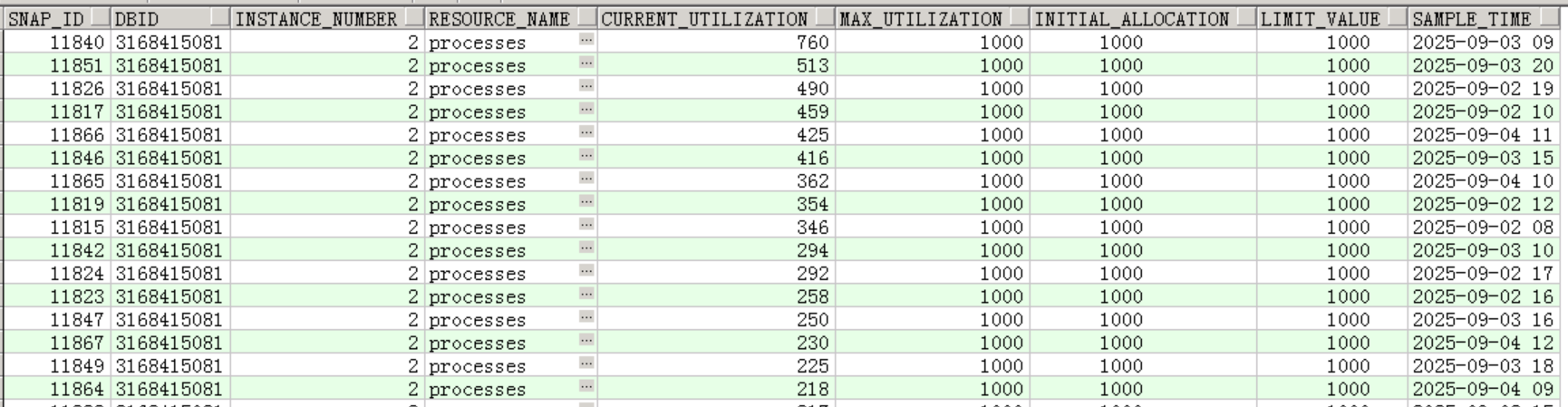
而节点 2 的进程数在相同时间峰值最高仅 760,远低于 1000 的上限,两个节点的负载差异悬殊,大量应用连接集中在节点 1,导致节点 1 进程数频繁接近阈值。
2.2 调整参数
既然节点 2 存在资源冗余,且节点 1 负载过高,决定将节点 2 的最大进程数同步调整为 5000,然后将节点1部分的业务连接分流到节点2,以提升整体资源承载能力。
修改参数:
# 关闭实例2
srvctl stop instance -d xxx -i xxx -o immediate# 启动实例2到nomount状态
srvctl start instance -d xxx -i xxx2 -o nomount# 修改参数
alter system set processes=5000 scope=both sid='xxx2';# 关闭实例2
srvctl stop instance -d xxx -i xxx -o immediate# 启动实例2
srvctl start instance -d xxx -i xxx2
由于processes是静态参数,需重启实例才能生效。
2.3 服务调整
调整参数后,如何快速把一部分应用连接分到节点2?
肯定不能让应用去改代码,最快的办法就是调整服务,修改主节点。用以下脚本可以直观看出各个服务的负载占比情况:
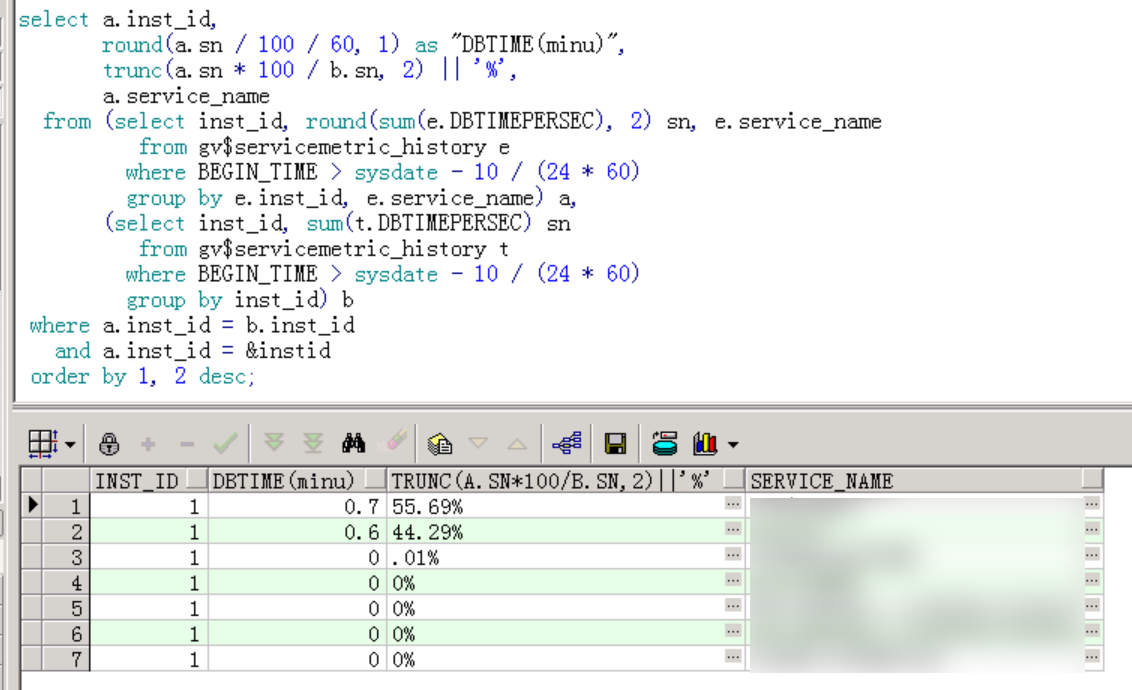
可以看到,节点 1 上有两个核心服务的DBTIME占比分别为 55.69% 和 44.29%,合计达 99.98%,几乎所有应用连接都集中在这两个服务上。
为分摊负载,决定将其中一个服务的主节点从节点 1 切换为节点 2,操作如下:
# 将服务改为主2备1
srvctl modify service -d xxx -s xxx -modifyconfig -preferred xxx2 -acailable xxx1# 把服务从xxx1节点切换到xxx2
srvctl relocate service -d xxx -s xxx -i xxx1 -t xxx2
操作完成后,让应用重启相关服务关联的应用进程,因应用端会复用旧连接,仅调整服务配置无法让现有连接切换,重启后新连接才会优先分配至节点 2。
3 处理措施2
然鹅,第二天相同的时间,应用侧还是反馈有超时情况,看来调整最大进程数和服务配置没有效果。
3.1 表收集统计信息
并且有一个很奇怪的现象,应用反馈说一些表不带任何条件查询就很慢,而表也是小表,只有1条数那种。
据开发反馈,收集相关表的统计信息后,系统短暂恢复正常,但仅过 2 小时,超时问题再次出现,这说明故障根源并非单纯的统计信息过期,需要展开更深入的排查。
这种不带条件查询很慢,第一反应就是高水位,但是去库里查看发现高水位并没有很严重,表的统计信息也未过期。难道是抽样比例太小了,统计信息不准?
重新收集了一次统计信息后,再次执行查询发现还是很慢,什么条件都不带竟然1分钟出不了结果,太奇怪了。
根据上述情况,感觉这个库已经完全用不了了。。。
3.2 异常等待事件
既然过往处理办法无法解决问题,那只能回归常规的问题解决思路了,查看awr、等待事件、TOPSQL等。
看ash高峰期时的等待事件如下:
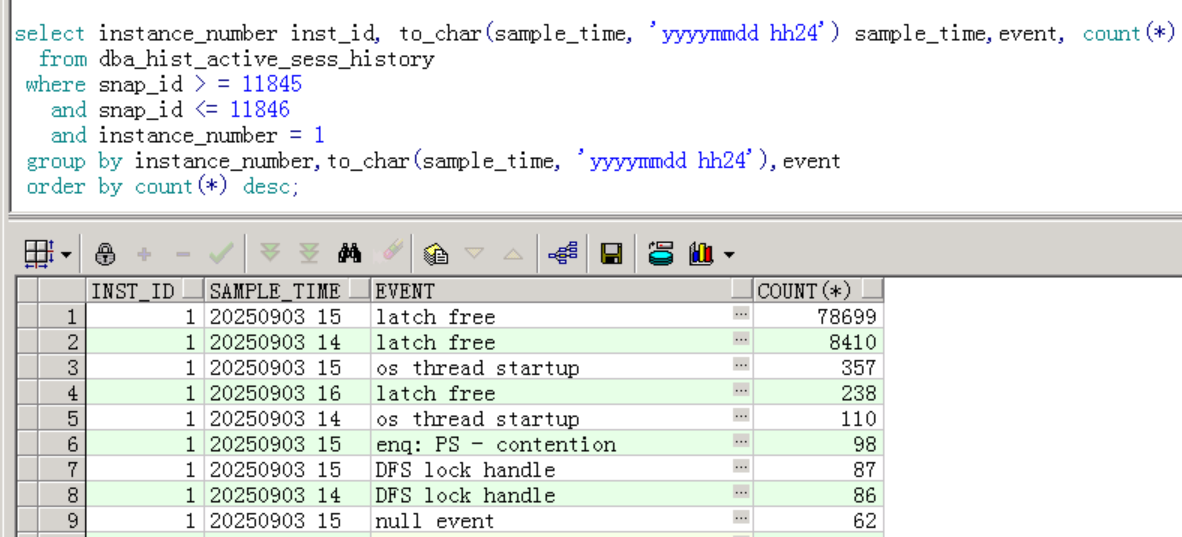
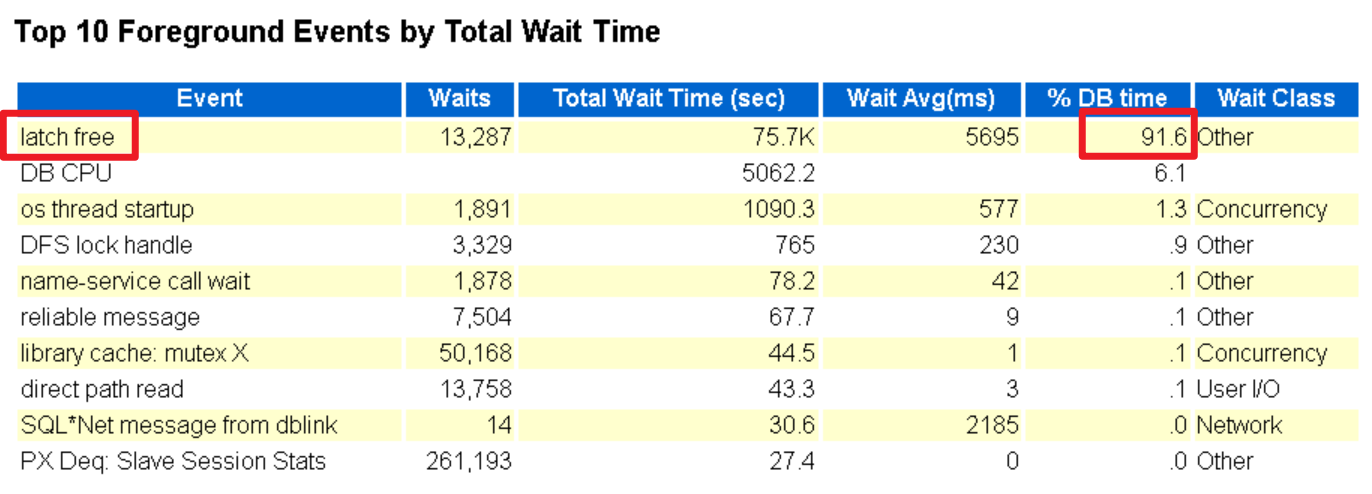
绝大部分是latch free等待事件,占总等待次数的 91% 以上。形成原因是共享池或Buffer Cache竞争,****常见于高并发 OLTP。
3.2.1 检查内存使用情况
既然是latch free等待事件,则检查一下shared pool和buffer cache的使用情况。
awr查看负载情况:
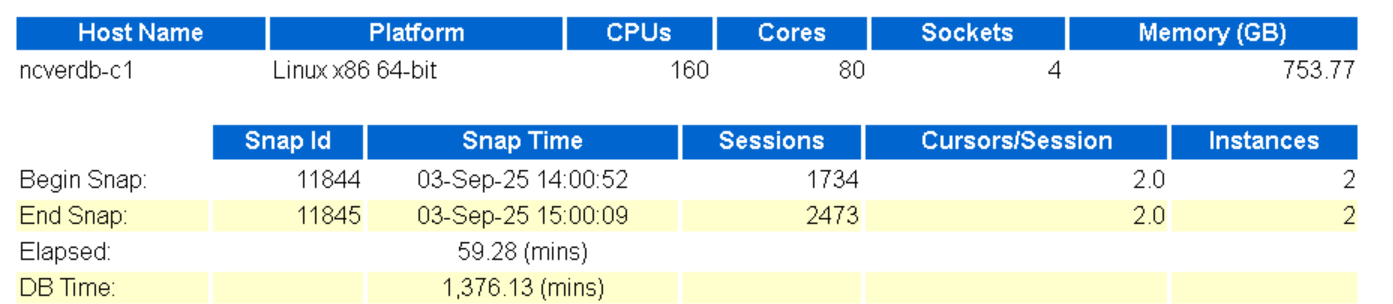
整个库一点也不忙。
查看共享池:
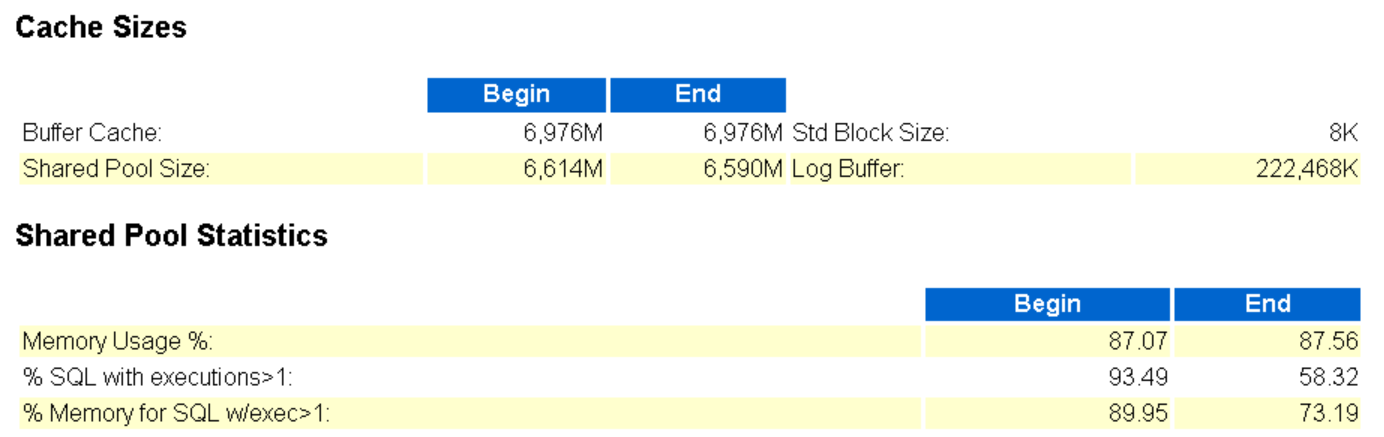
总体上,Buffer Cache 稳定,Shared Pool大小略减,内存使用率上升了一丢丢,执行次数大于1次的sql数量减少了30%左右。
根据上面的信息可以推断硬解析有可能增多?
查看硬解析:

硬解析很少,不到2%,正常。
3.2.2 分析 Latch 竞争的根源
内存资源无异常,说明latch free等待并非由内存不足引发,需进一步分析 Latch 的具体类型。
确定该 Latch 对应的名称和类型。看ash中的P2,找出latch id:
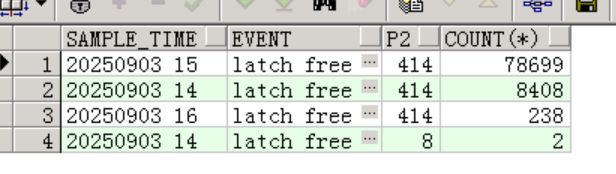
99% 以上的latch free等待对应的latch_id=414,查看latch name,根据hash值查看高峰期latch情况:

从结果看,query server process 相关闩锁存在严重争用,闩锁被频繁访问,总等待时间很长,大量会话在竞争该 Latch,导致 SQL 一直在等待。
在awr中得到验证,匹配这两个latch:
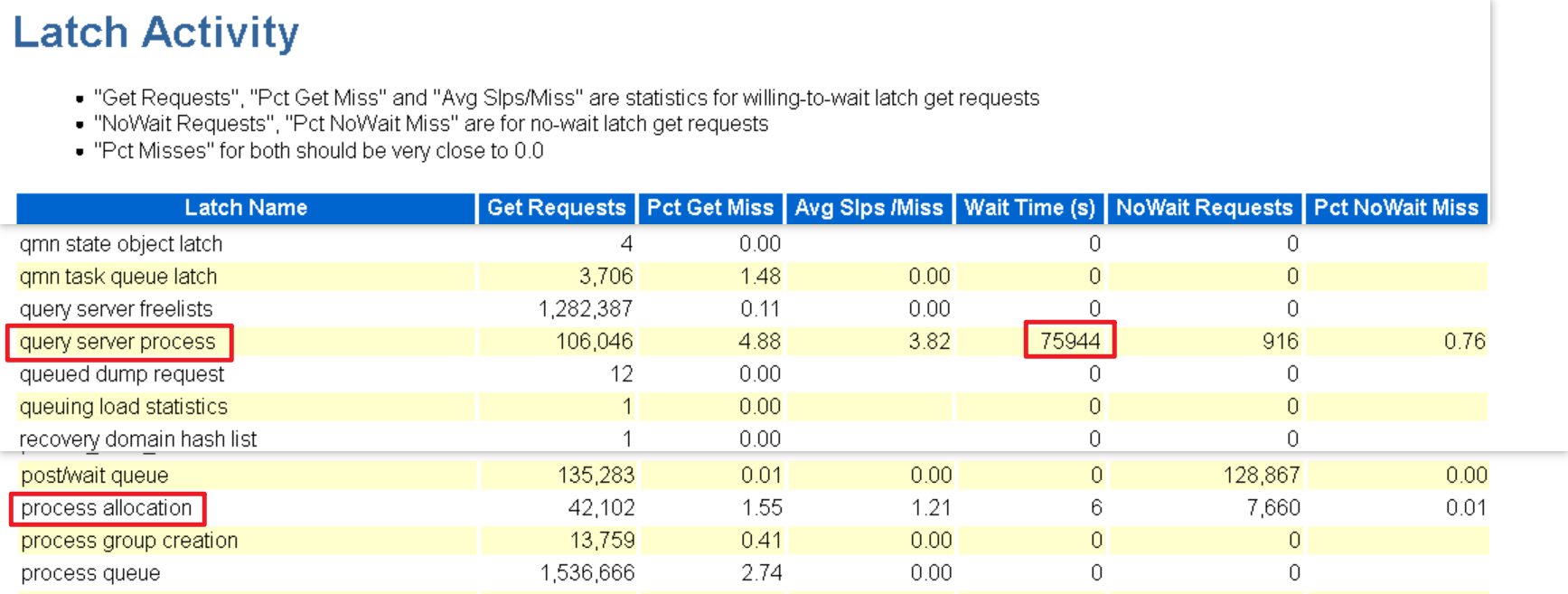
可以看到,`query server process相关闩锁等待时间达到了了75944秒,失败率有4.88%。
3.3 并行问题
上面已经查到latch free等待都是由于`query server process 相关latch引起的,而这个latch又是和并行相关的。
根据 Oracle 官方文档(Note 651060):

意思是:如果在并行进程执行期间有新的子进程产生,则query server process`闩锁会被保留。
回头看top 10 events:
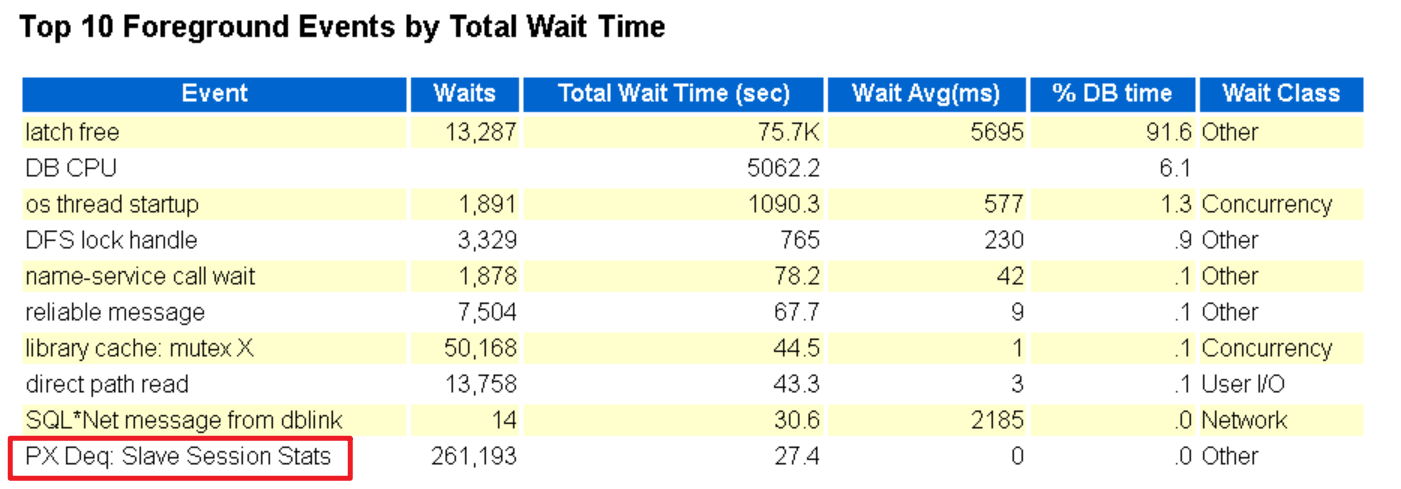
存在并行等待事件PX Deq: Slave Session Stats,等待次数很高,有26万次。
该等待事件在并行执行场景下常见,是并行子进程间的通信等待,该等待事件进入Top 5 等待事件,说明 数据库中存在大量不必要的并行执行。
查看latch free事件等待次数top sql:
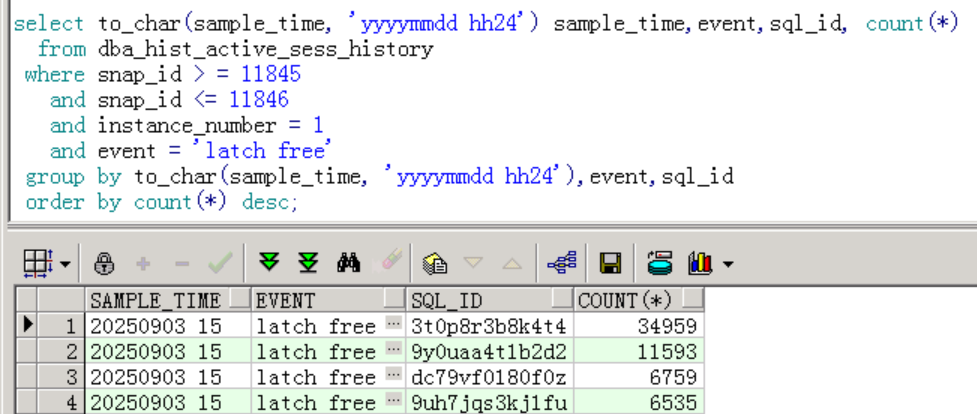
查看top1 sql的执行计划:
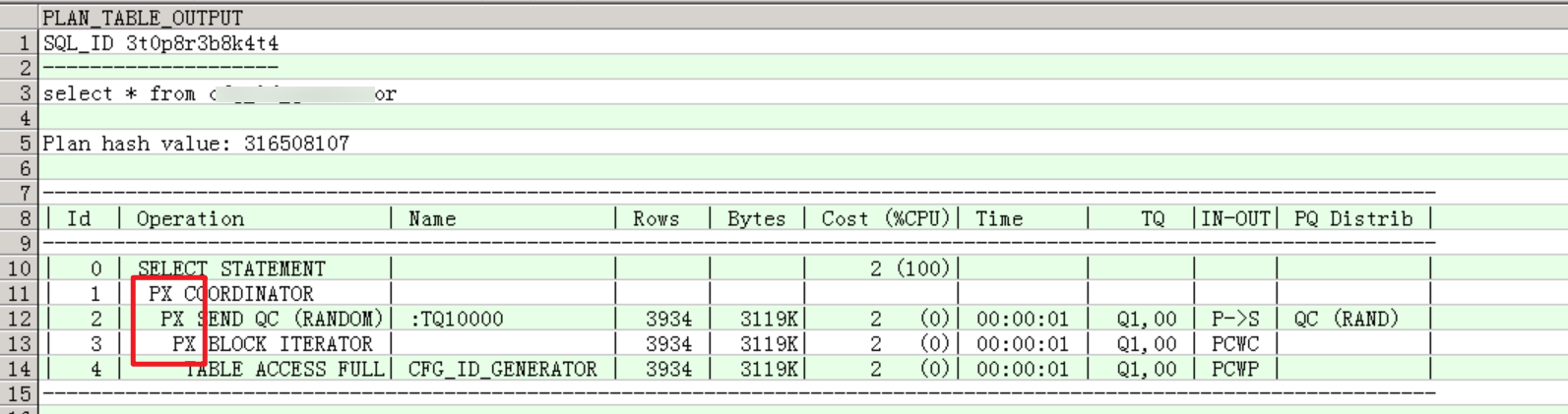
这个sql仅仅是select *,没有任何where条件,但执行计划却启用了并行执行:心中已有了答案:表开了并行。
查看开了并行的表:
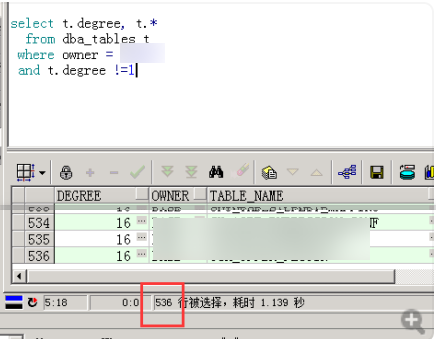
结果一共536张表开了并行,而生产库所有表都是不开的,而且这些表都是核心表,高频使用,并行不高才有鬼。。。
3.4 关闭表并行
让应用自行把这些表并行调整为1:
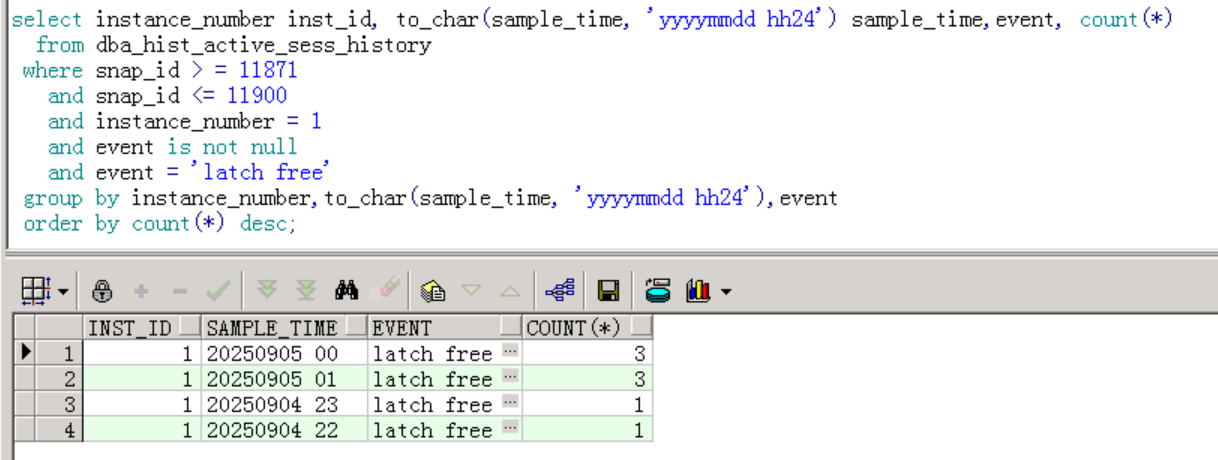
9月4日关闭并行后,往后2天观察到等待事件正常,latch free等待事件几乎没有了:
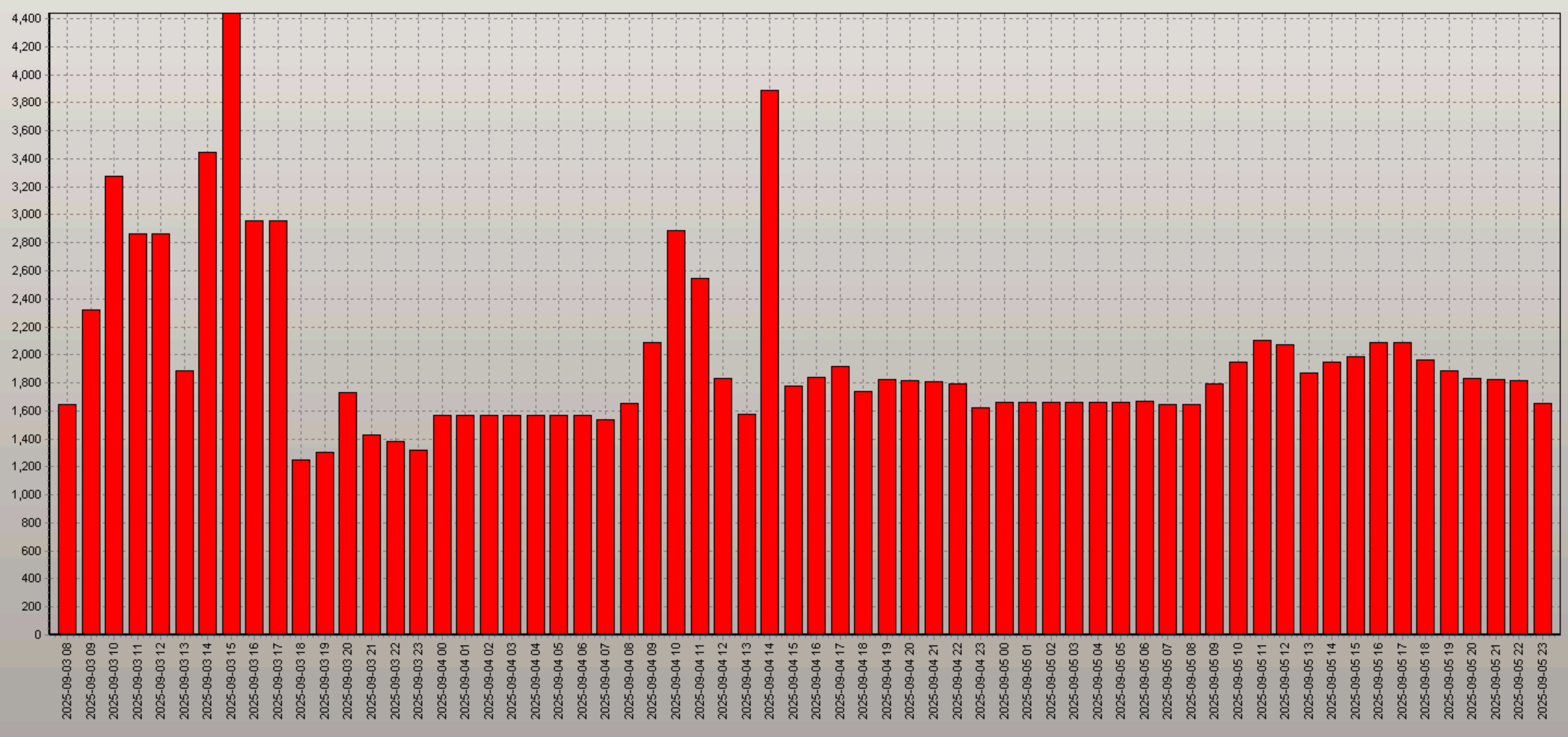
进程数维持稳定状态,节点1峰值小于2200:
问题解决。
4 总结
本次故障的核心根源是测试库中 五百多张表被错误开了表并行,在并行执行创建大量子进程,引发query server process Latch 激烈竞争,最终导致latch free等待事件爆发,导致接口超时与查询缓慢。