人工智能学习:Transformer结构中的编码器层(Encoder Layer)
Transformer结构中的编码器层(Encoder Layer)

一、编码器层介绍
-
概念
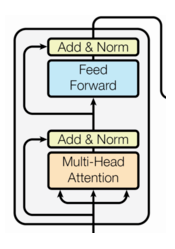
编码器层(Encoder Layer)是Transformer编码器的基本构建单元,它重复堆叠形成整个编码器,负责逐步提取输入序列的特征。每个编码器层由两个核心子层组成:
- 多头自注意力机制(Multi-Head Self-Attention):用于捕捉输入序列中每个位置与其他位置的关系。
- 前馈全连接层(Feed-Forward Neural Network, FFN):用于对每个位置的表示进行非线性变换。
每个子层后都有残差连接(Residual Connection)和层归一化(Layer Normalization),以增强模型的训练稳定性和性能。
-
结构/工作流程
-
输入:
- 每个编码器层的输入是上一层编码器层的输出,或者对于第一层编码器层来说,是输入嵌入向量加上位置编码向量,形状为
[batch_size, seq_len, d_model]。
- 每个编码器层的输入是上一层编码器层的输出,或者对于第一层编码器层来说,是输入嵌入向量加上位置编码向量,形状为
-
多头自注意力机制:
- 将输入x传递给多头自注意力层,得到输出Attention(x)。
- 多头自注意力层会捕捉输入序列中各个token之间的依赖关系,每个注意力头关注不同的特征,然后将多个头的输出拼接。
- Q, K, V三个矩阵都来自于相同的输入x,这是“自”注意力的含义。
-
残差连接与层归一化:
-
将多头自注意力的输入x与输出Attention(x) 相加,形成残差连接:
x+Attention(x)
-
对残差连接的结果进行层归一化,得到第一部分的输出:
LayerNorm(x+Attention(x))
-
-
前馈全连接层:
- 将经过残差连接和层归一化的输出传递给前馈全连接网络,得到输出FFN(x)。
- 前馈全连接网络会对每个token的表示进行非线性变换,并提取更高级的特征。
-
残差连接与层归一化:
-
将前馈全连接网络的输入(即上一层的输出)与输出FFN(x)相加,形成残差连接:
LayerNorm(x+Attention(x))+FFN(x)
-
对残差连接的结果进行层归一化,得到第二部分的输出,也是编码器层的最终输出:
LayerNorm(LayerNorm(x+Attention(x))+FFN(x))
-
-
输出:
-