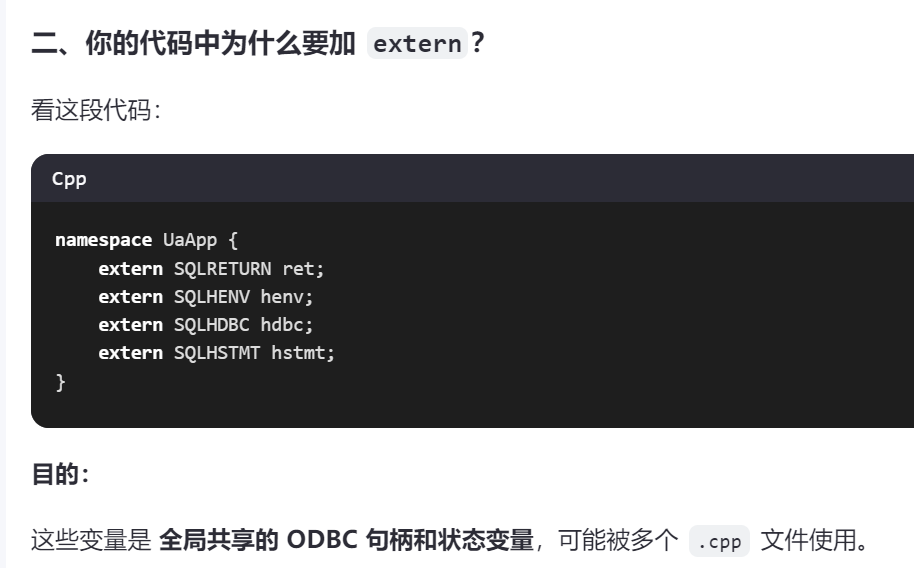
OPC Client第10讲:实现主界面;获取初始界面传来的所有配置信息config【C++读写Excel:xlnx;ODBC;缓冲区】
接前面代码内容:
OPC Client第6讲(wxwidgets):Logger.h日志记录文件(单例模式);登录后的主界面_wx.logger-CSDN博客
OPC Client第8讲:OPC UA;KEPServerEX创建OPC服务器;C#创建OPC客户端;OpcUaHelper库;OPC客户端(Softing Opc Client和UaExpert)_c# opcua客户端-CSDN博客
一、登录后的主界面:MainFrame::InitElement()
即实现下述界面,直接看void MainFrame::InitElement()代码及备注
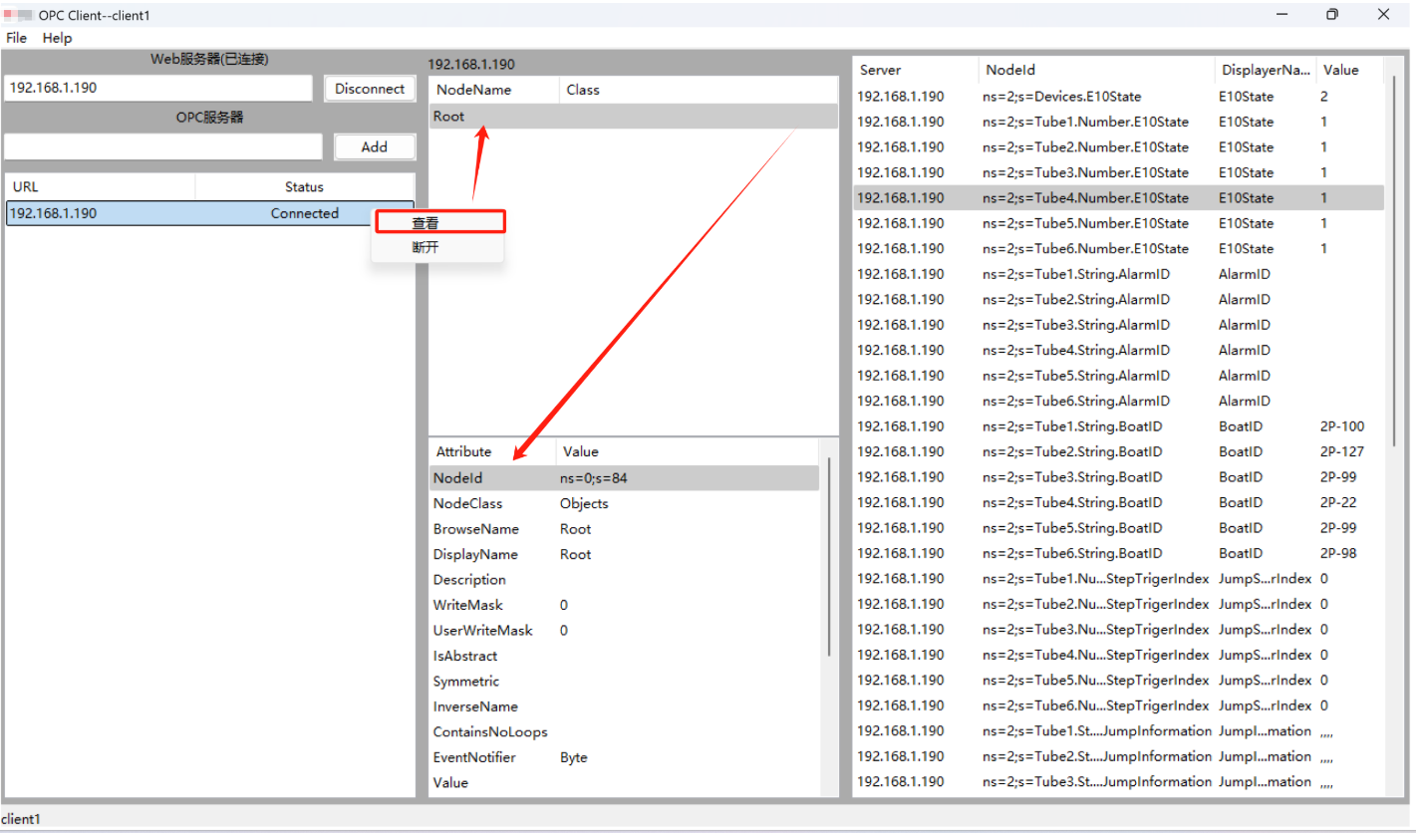
OPC Client第3讲(wxwidgets):wxFormBuilder;基础框架;事件处理-CSDN博客
OPC Client第4讲(wxwidgets):窗口布局基础知识;界面练习_wxwidgets wxstaticbitmap-CSDN博客
OPC Client第5讲(wxwidgets):实现项目的初始界面代码-CSDN博客
OPC Client第6讲(wxwidgets):初始界面的事件处理;按照配置文件初始化界面的内容_propcclient控件-CSDN博客
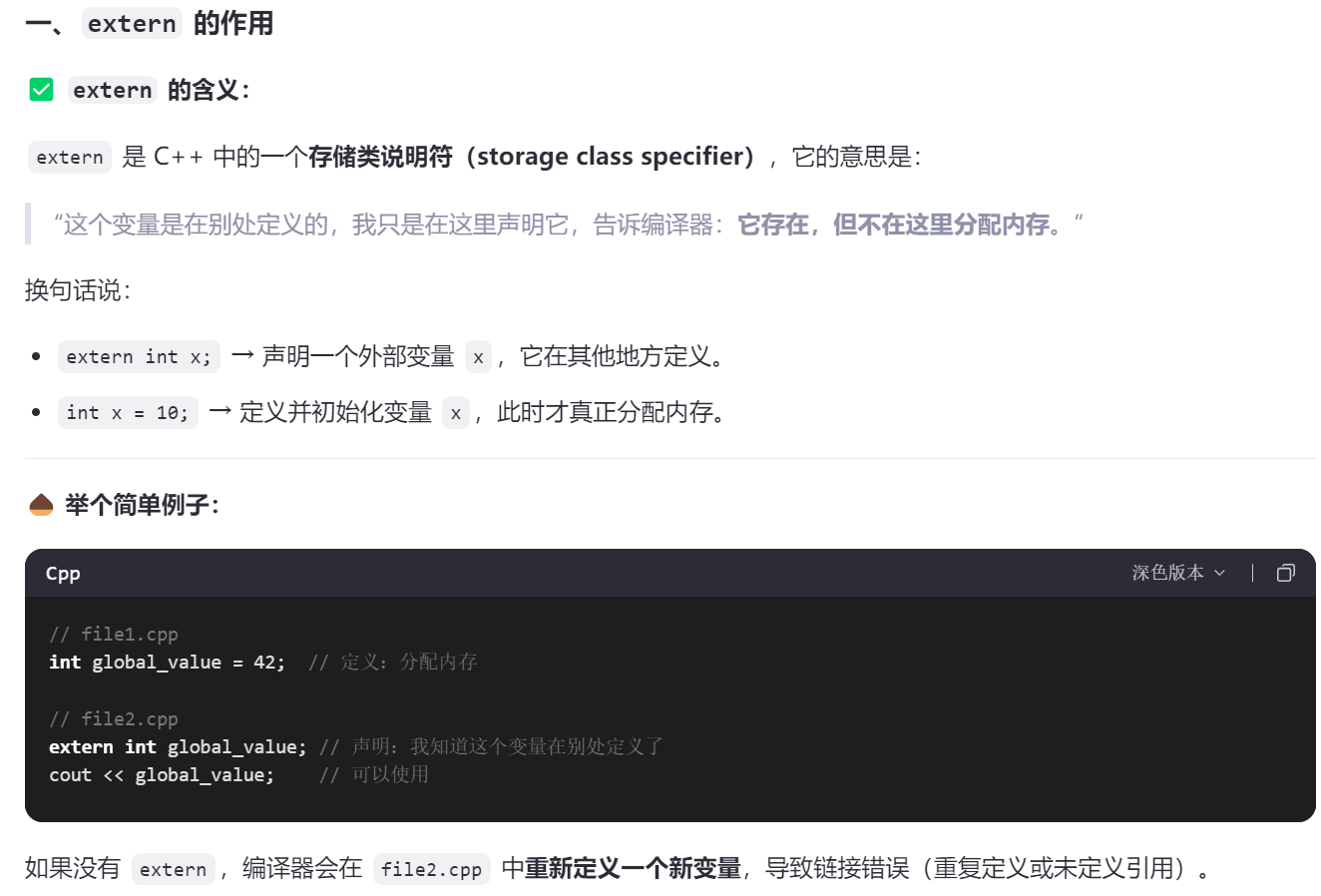
1、如果在.h文件中声明了变量,.cpp中再次声明且初始化,那么这是同一个变量吗?
它们可以是同一个变量 —— 但前提是使用了正确的语法(如
extern声明),否则就可能是重复定义或链接错误。
1>声明与定义 区别
声明:在头文件中,你通常会声明变量,这意味着你告诉编译器该变量的存在,但不分配内存空间。
定义:在源文件中,当你声明并初始化一个变量时,你实际上是在定义它,即为它分配内存空间。
2>正确做法:加extern
或者在.cpp文件中直接初始化:g_value = 42;(对比下图)

2、wxDataViewListCtrl:构建动态数据展示界面
wxDataViewListCtrl 提供了一种直观且高效的方法来展示和与列表数据进行交互,非常适合用来构建动态数据展示界面。
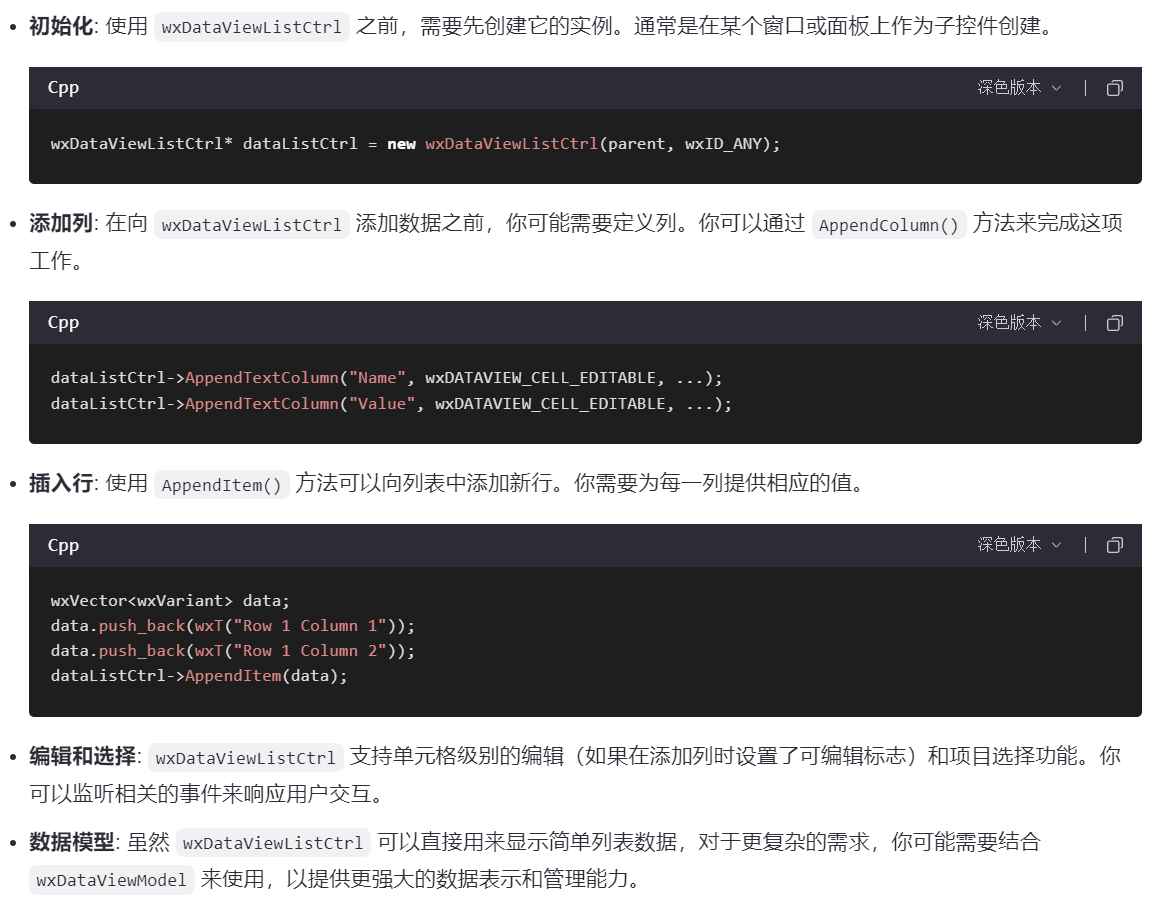
3、wxTreeListCtrl:显示层次结构数据的控件
wxTreeListCtrl是用于显示层次结构数据的控件,它结合了 wxTreeCtrl(树形控件)和 wxListCtrl(列表控件)的功能。
这个控件允许你以树的形式展示数据,并且每个节点可以有多列信息,而不仅仅是单一的标签。这使得 wxTreeListCtrl 成为需要展示具有多个属性的层次化数据的理想选择。
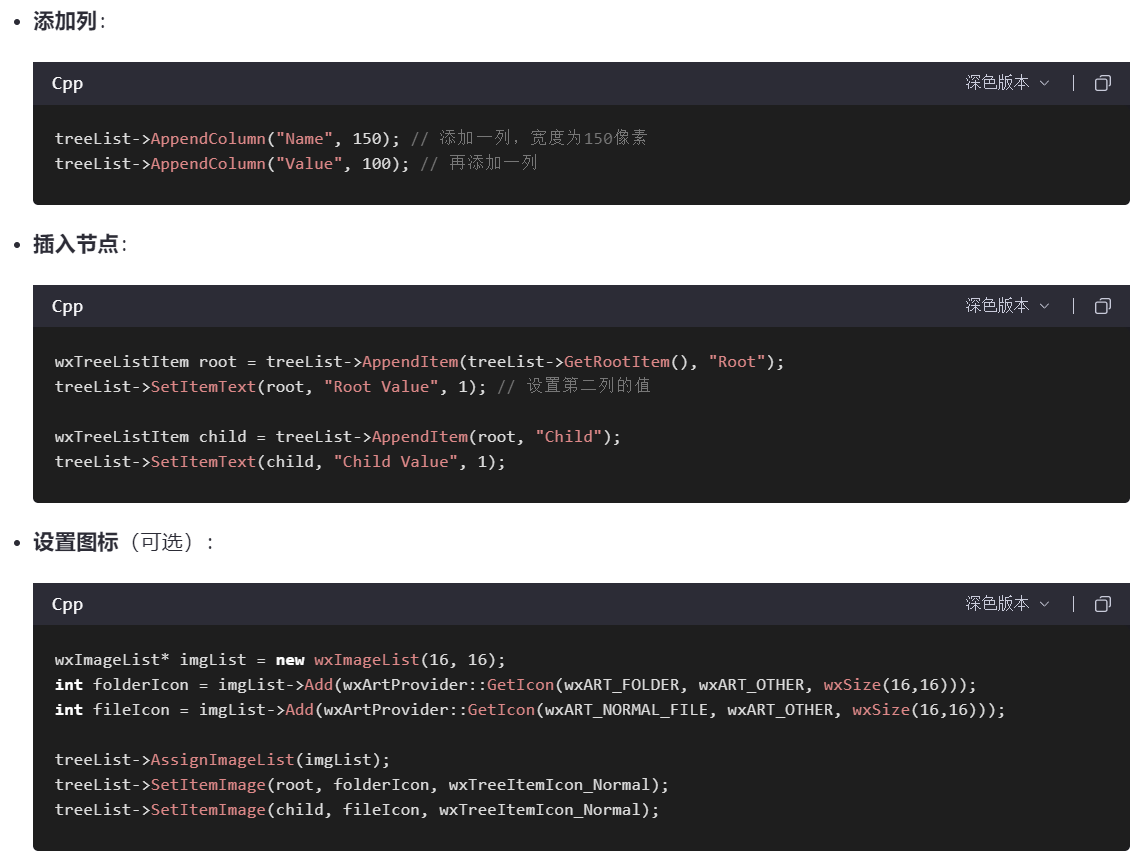
4、事件绑定处理??????????????????????
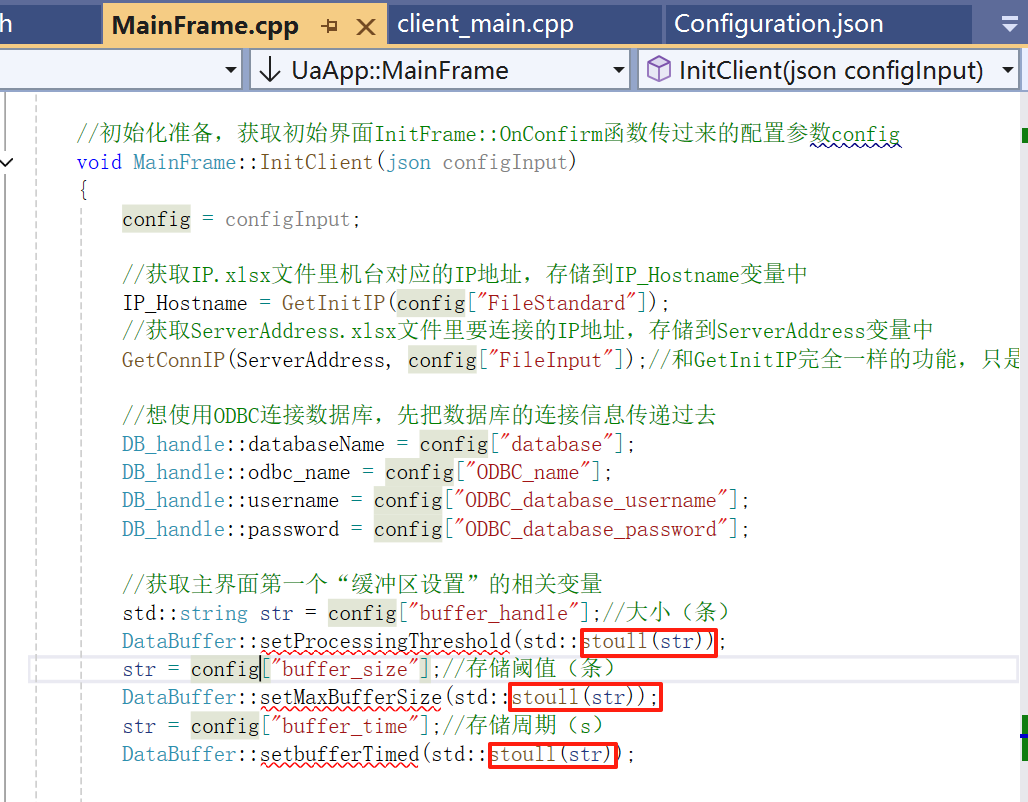
二、初始化准备:MainFrame::InitClient()
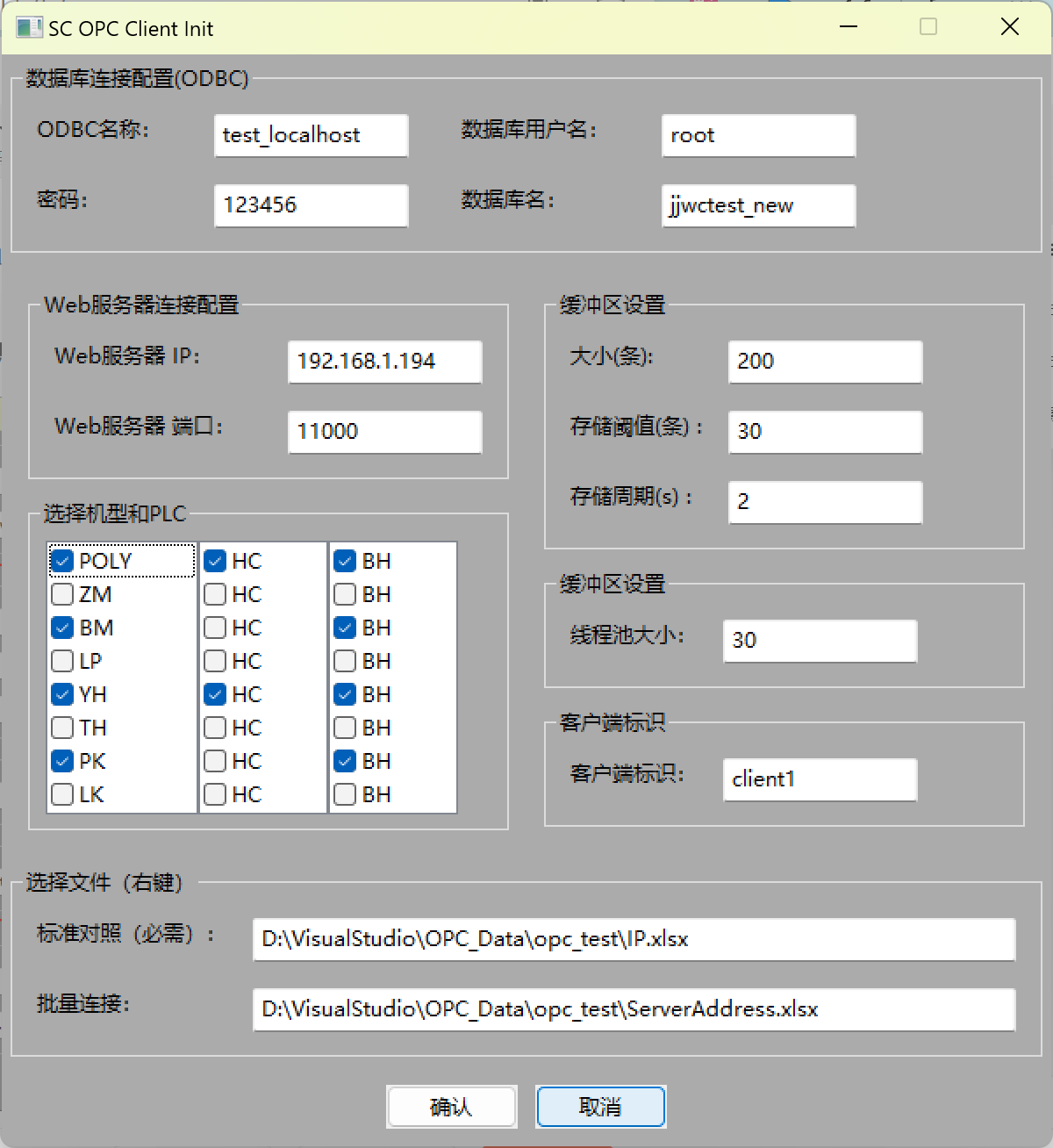
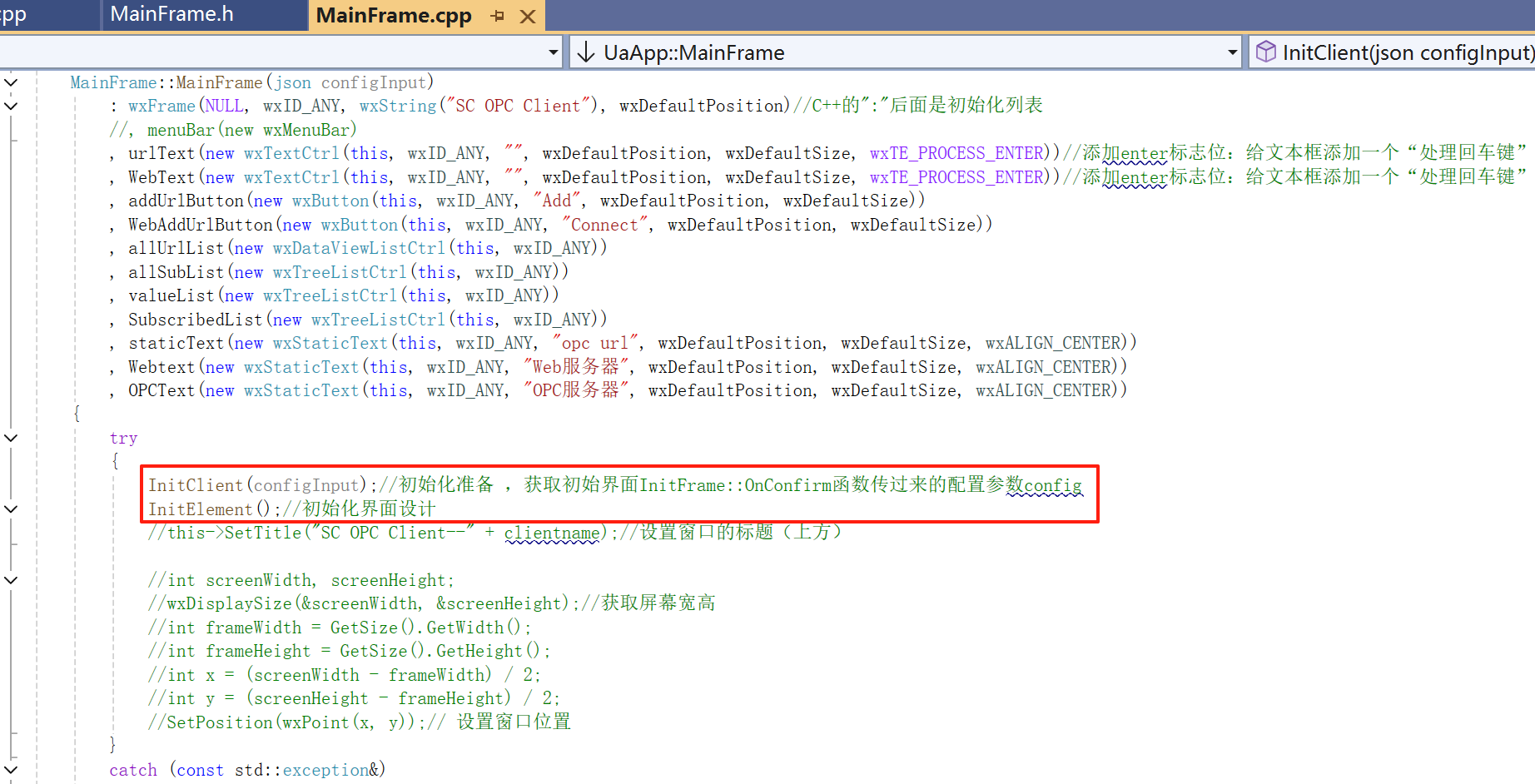
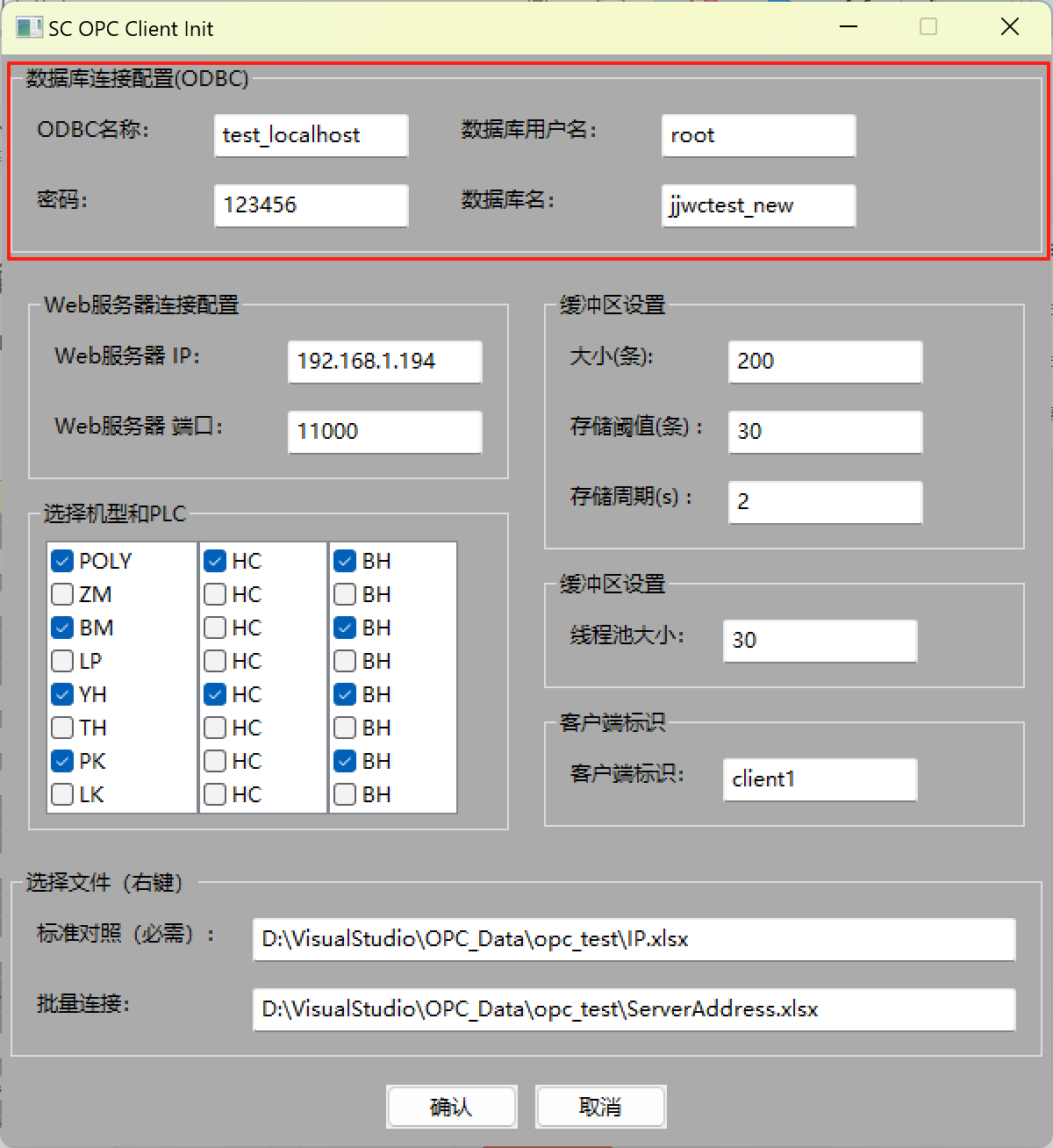
目的:获取初始界面InitFrame::OnConfirm函数传过来的配置参数config【如下图所有的初始化信息】。
这个函数是在一、之前进入的,如下图。
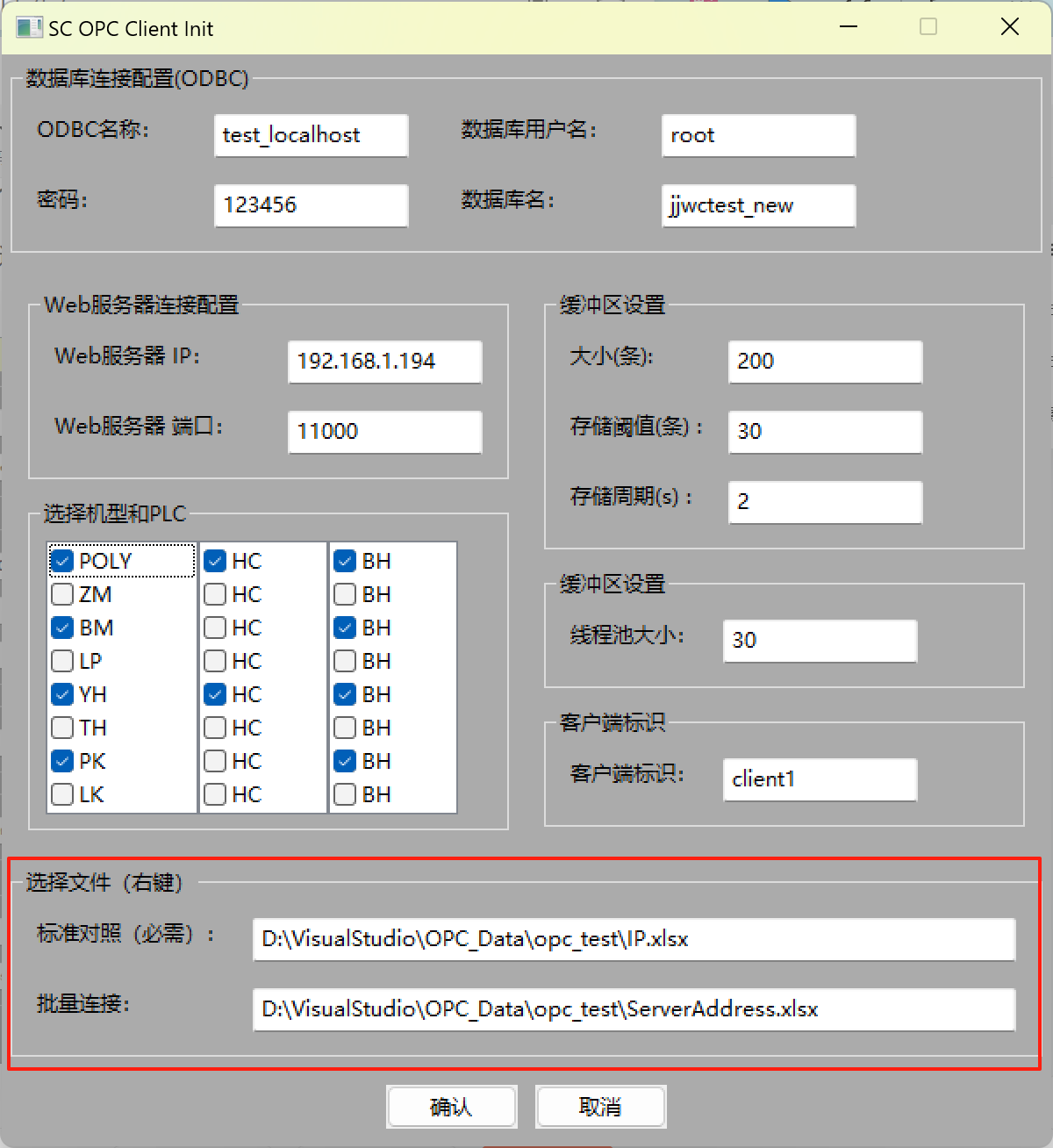
三、初始化准备1:“选择文件(右键)”——C++ 读写 Excel :利用开源库xlnt
二、的目的:获取初始界面InitFrame::OnConfirm函数传过来的配置参数config【如下图所有的初始化信息】。
这部分是实现二、的下图红框部分
C++ 读写 Excel :利用开源库xlnt
师傅是按照下述链接生成的xlnt文件夹,很奇怪。
1、利用CMake导入xlnt包
C++ 读写 Excel 在 vs2015 中实现(利用开源库xlnt)_xlnt读取中文-CSDN博客
【xlnt】入门级编译教程_xlnt编译-CSDN博客
按照上述链接的操作下载源代码等。
再在CMake文件中导入库,如下图。
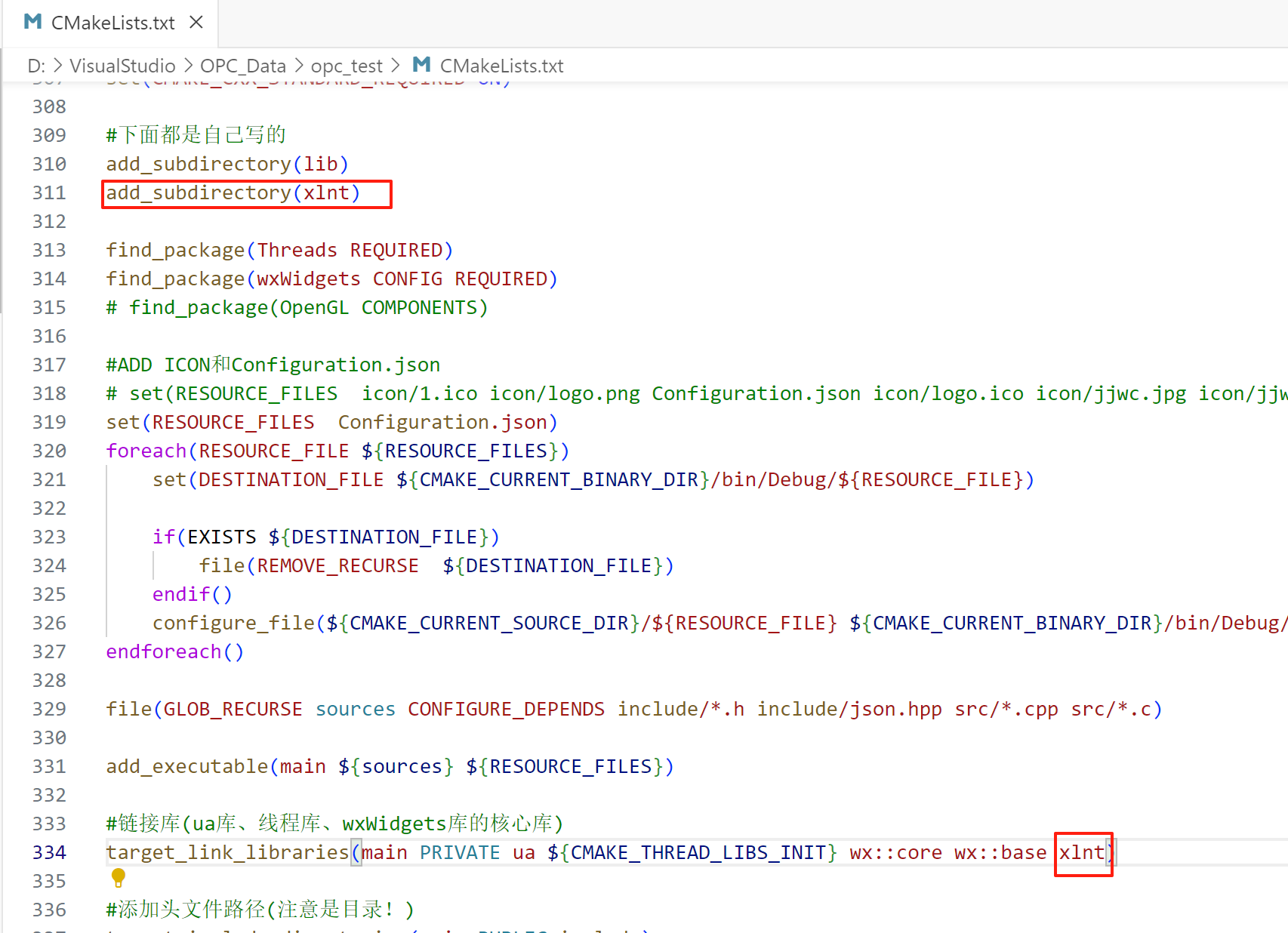
再用CMake重新生成
2、Vcpkg导入xlnt包【报错放弃了】
下面自己尝试利用Vcpkg导入xlnt包:
Vcpkg C/C++库管理工具安装和使用教程(链接VS2019)_vcpkg 安装-CSDN博客
不知道为什么报错(如下图)

询问AI排除了其它原因,提示问题如下图
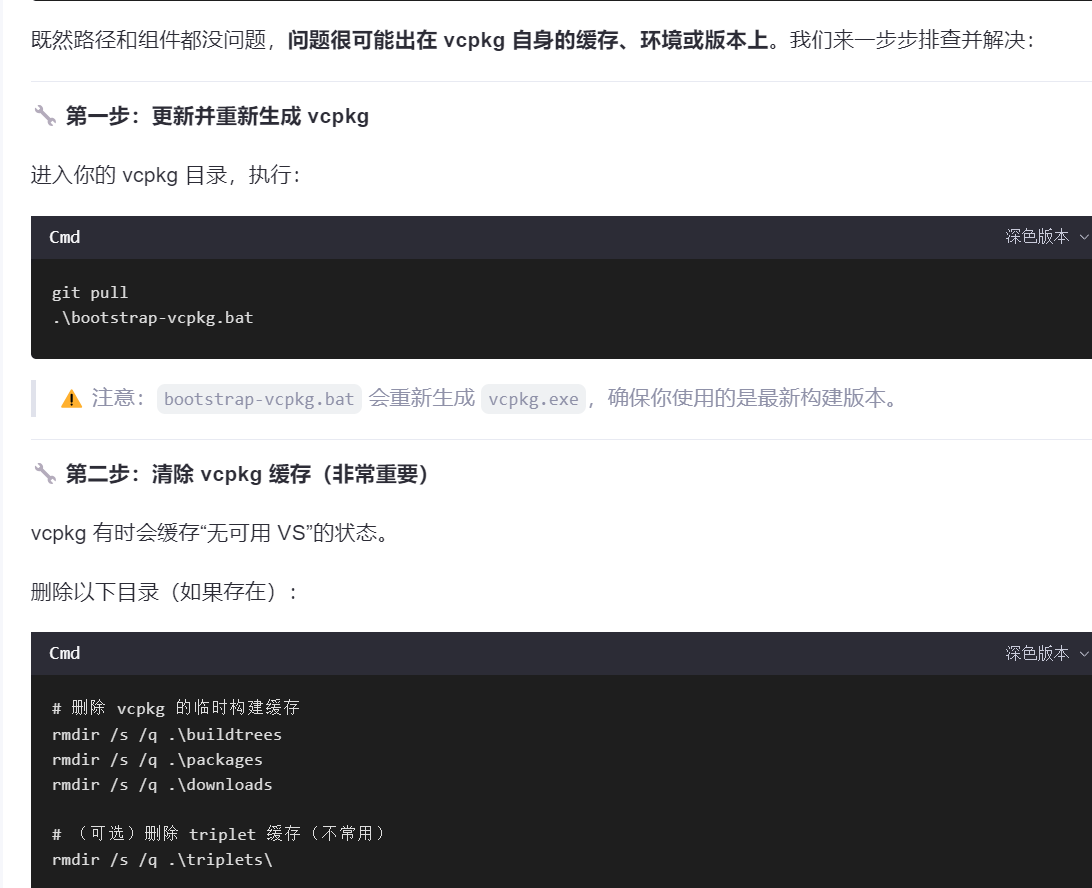
??????????????????/
下面一直显示不出来
3、xlnt详细操作:获取IP.xlsx和ServerAddress.xlsx文件里的表格数据
按照下述链接操作就行,具体看代码。
用XLNT库读写Excel文件 | 西加加斯基
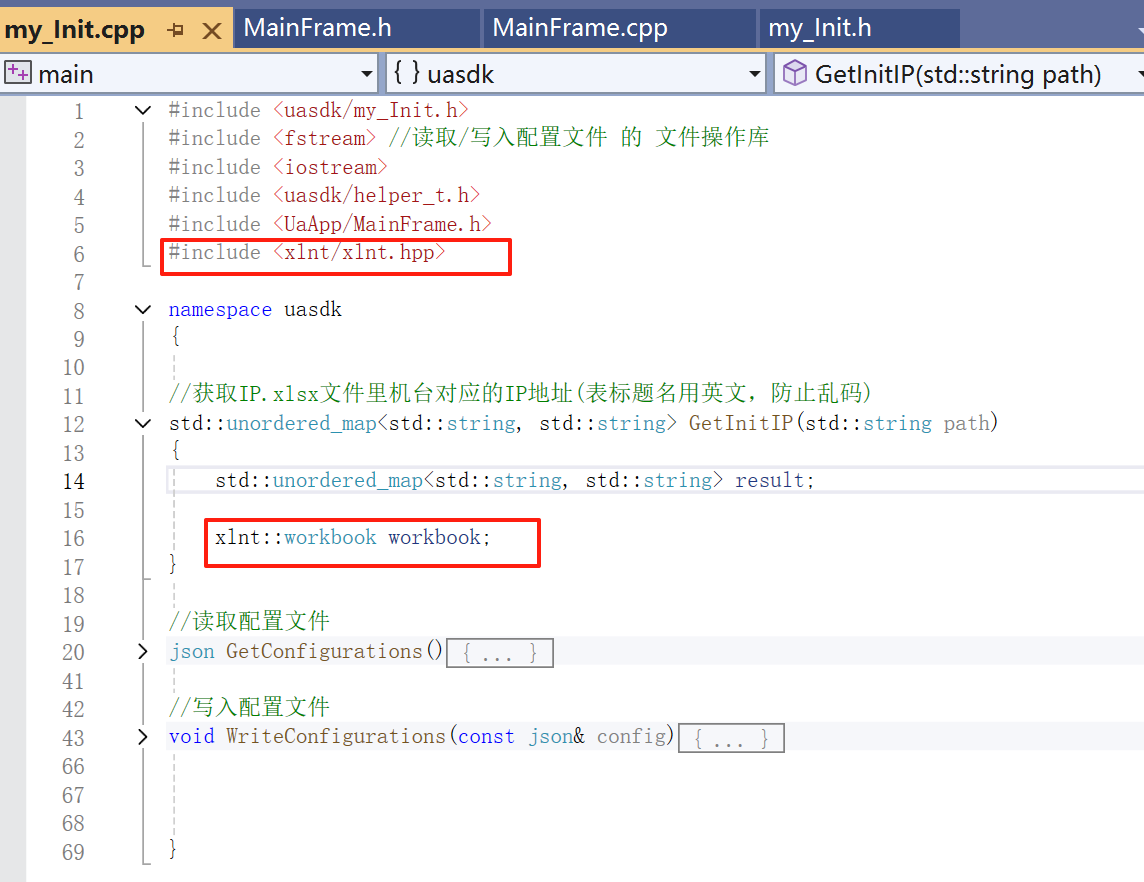
注意两个工作簿(IP.xlsx和ServerAddress.xlsx)里都是有多张表的,如下图
![]()
1>如何切换一个xlsx文件下不同的表格?
在 xlnt 库中,一个 .xlsx 文件对应一个 workbook(工作簿),而一个工作簿可以包含多个 worksheet(工作表/表格)。
你可以通过工作表的 名称(name) 或 索引(index) 来切换不同的表格。
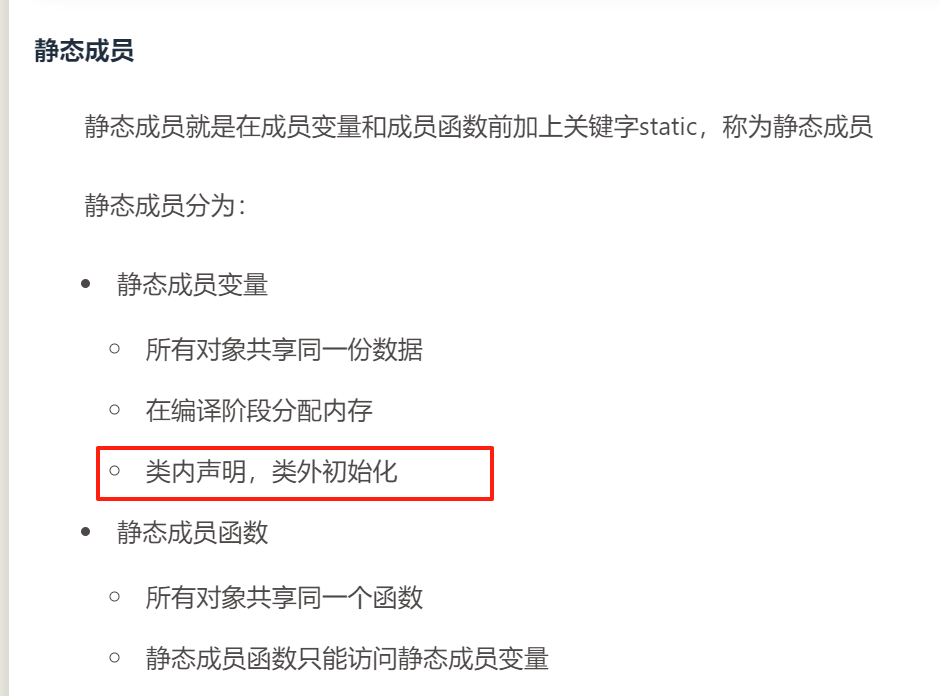
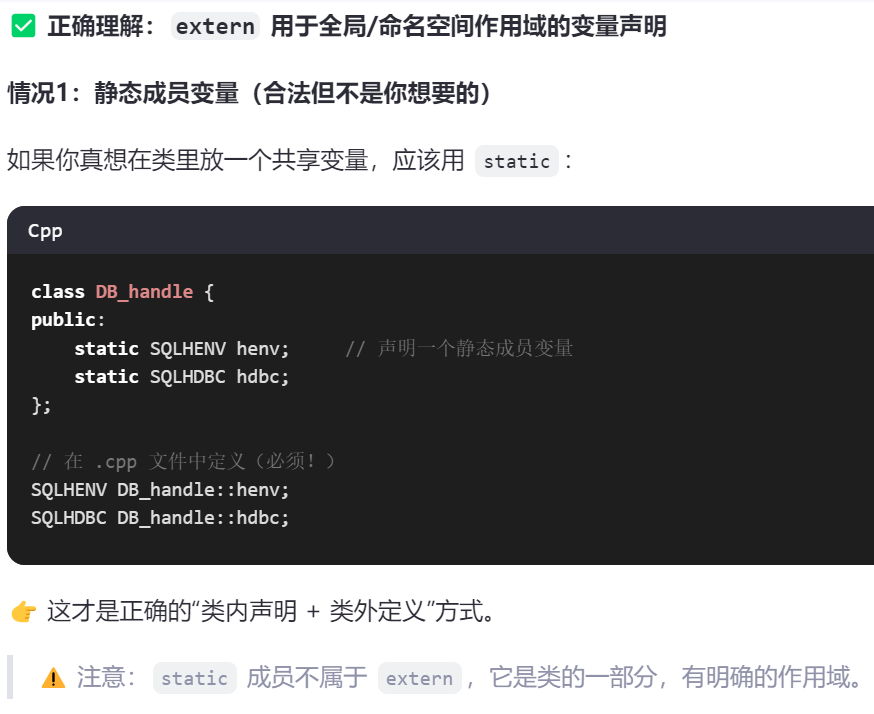
2>静态成员:类内声明,类外初始化

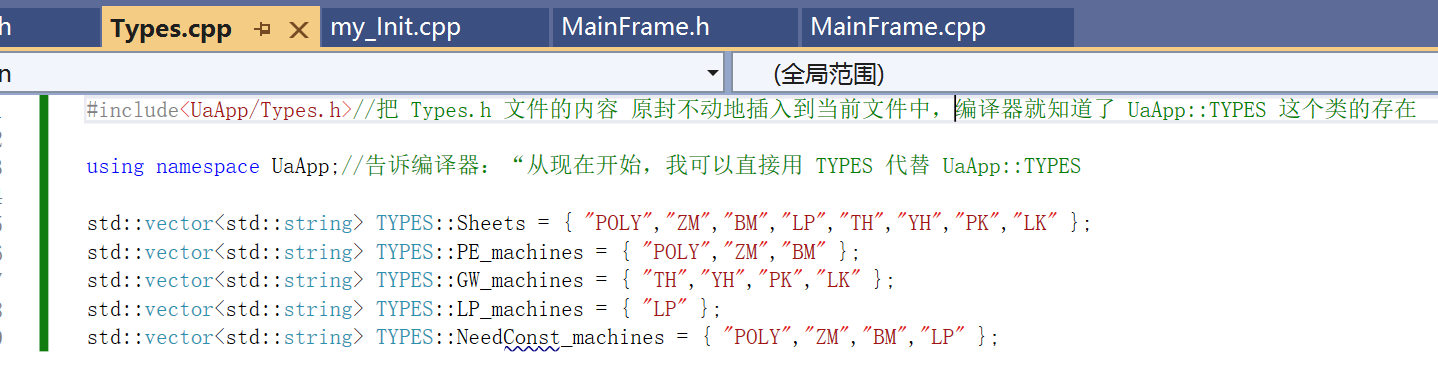
3>为什么代码中还要额外using namespace UaApp?不是已经#include<UaApp/Types.h>了吗?

4>auto&
例如:auto& x = some_variable;
“让编译器自动判断
some_variable是什么类型,并让x成为它的引用(即别名)。”

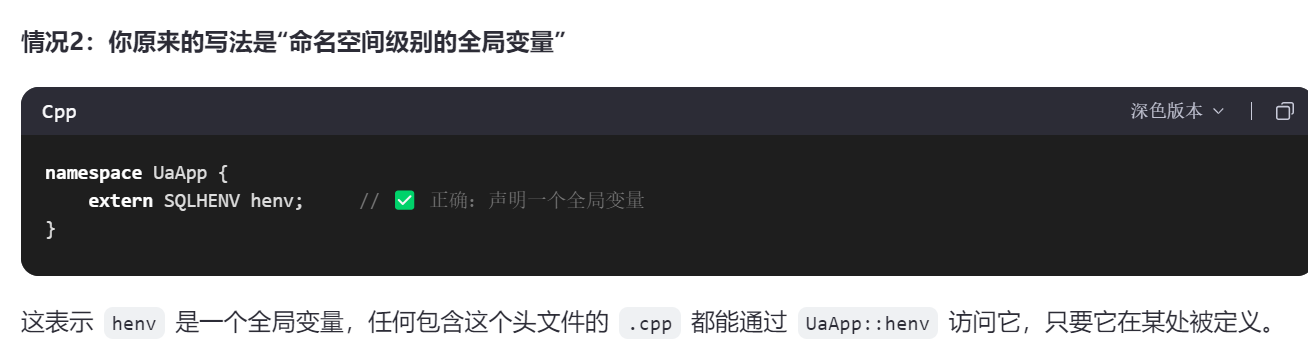
四、初始化准备2:“数据库连接配置(ODBC)”
二、的目的:获取初始界面InitFrame::OnConfirm函数传过来的配置参数config【如下图所有的初始化信息】。
这部分是实现二、的下图红框部分
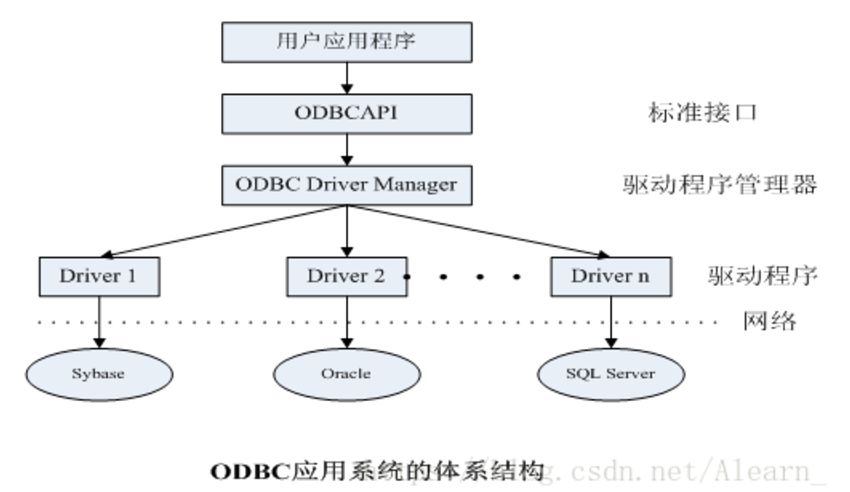
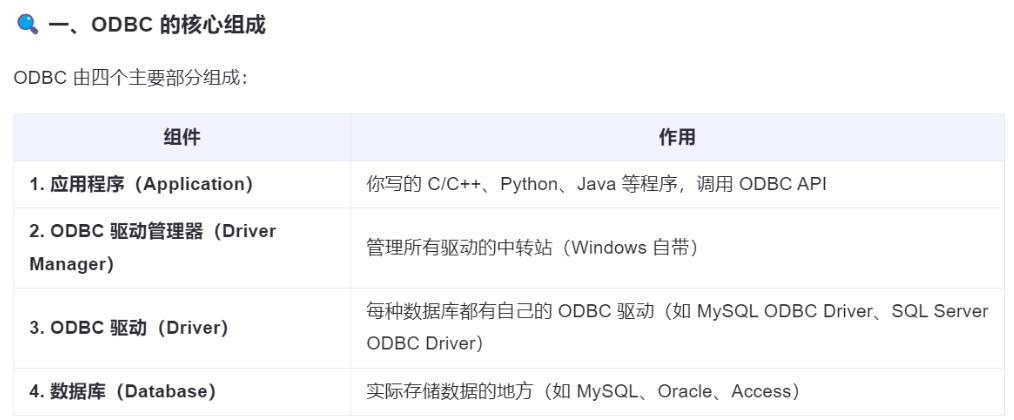
1、什么是ODBC?为什么用ODBC?
ODBC( Open Database Connectivity):开放数据库连接【=翻译官】
因为我们这个暂时没确定用哪种数据库,所以使用的ODBC。
它是一种由微软提出的标准数据库访问接口(API),目的是让应用程序能够以统一的方式访问各种不同的数据库系统,而不需要为每种数据库编写不同的代码。

2、ODBC写代码
1>前提条件【之前已经做完了,没有做任何其它的操作】:
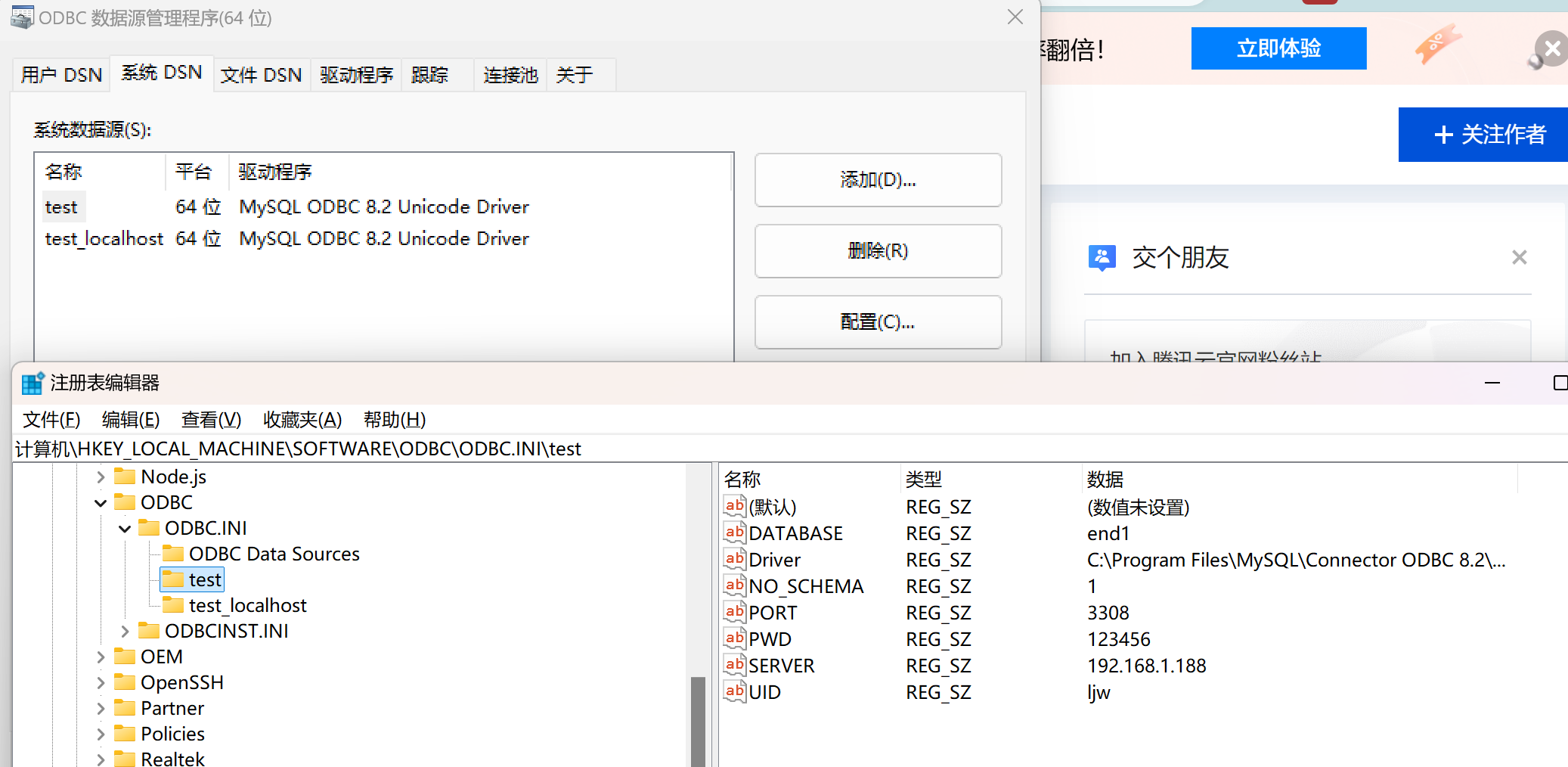
- 安装并配置好MySQL ODBC驱动(如MySQL Connector/ODBC)。
- 在“ODBC数据源管理程序”中配置一个系统DSN(数据源名称)
ODBC 安装/使用/编程-腾讯云开发者社区-腾讯云
- 为什么 电脑注册表(Windows Registry)中自带ODBC?
- ODBC作为微软主导的跨平台数据库连接标准,自Windows 95起就被深度集成到操作系统中。注册表作为Windows存储系统配置、驱动信息、应用程序参数的核心数据库,自然需要包含ODBC的配置项(如驱动路径、数据源定义等),以确保系统级功能(如数据源管理器、ODBC API调用)能正常工作。
2>ODBC理解+具体的代码写法:
【ODBC】ODBC连接数据库详细说明-CSDN博客
直接看上述链接
句柄还看下述《3》
henv-> Handle (句柄) to Environment- 这个句柄用于管理整个ODBC环境,例如设置ODBC版本(如SQL_OV_ODBC3)。
- 通常也只需一个
hdbc-> Handle to Database Connection- 这个句柄代表应用程序与特定数据库之间的连接。
hstmt-> Handle to Statement(语句)- 这个句柄用于准备和执行SQL语句,以及处理结果集。
- 可以有多个
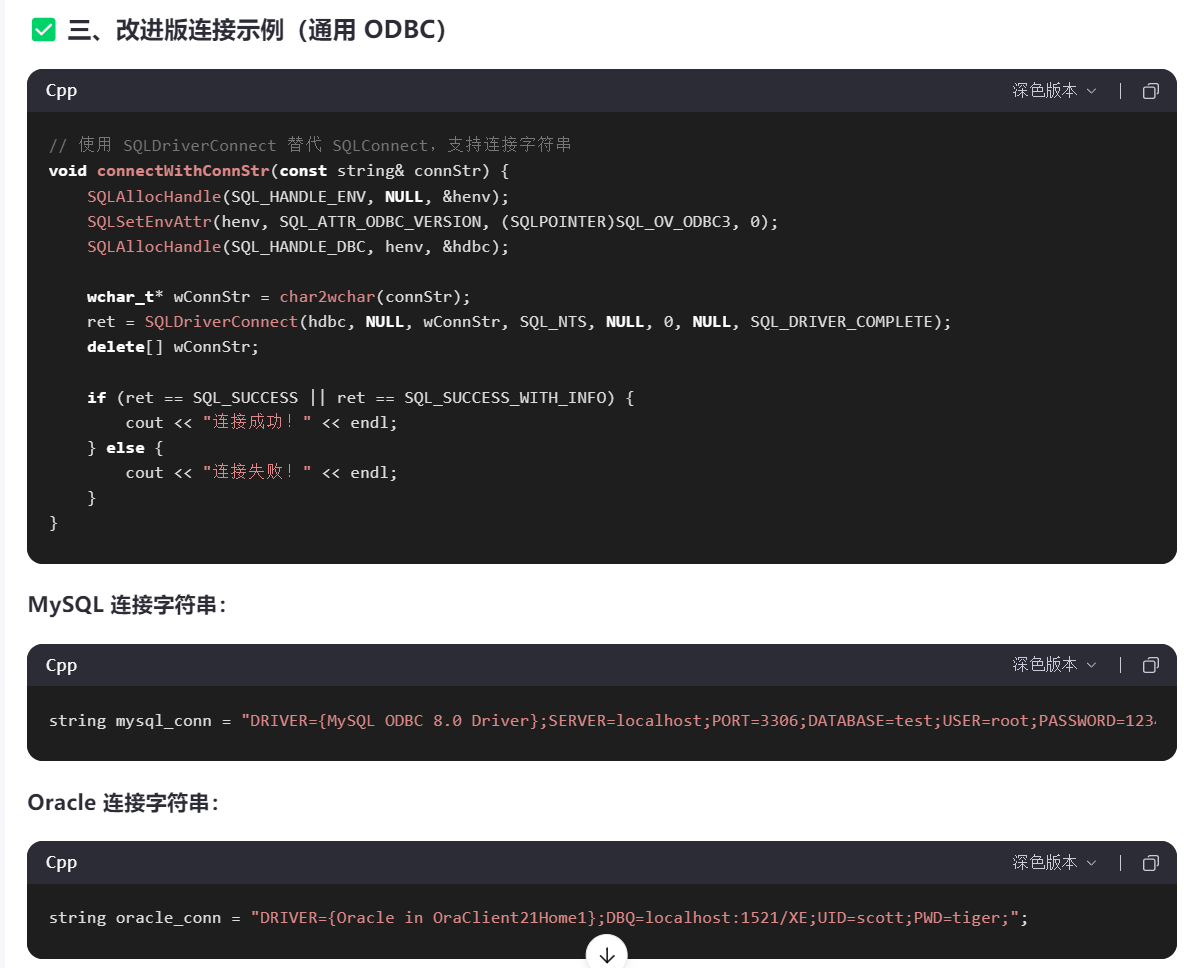
1》ODBC连接 Mysql 或者 Oracle 数据库的代码区别?

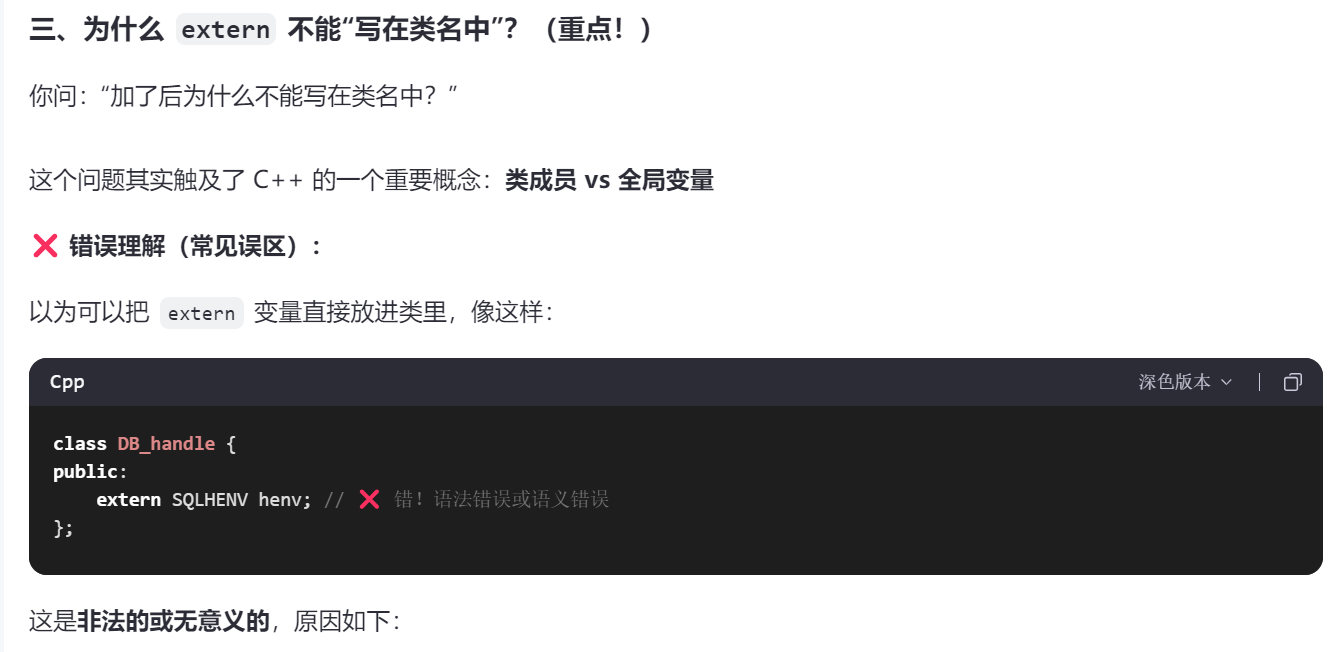
2》extern不能写在类定义内部作为成员变量
比如在Address_handle.h里面,还会通过ODBC执行SQL语句。

extern 和 static是语义上完全冲突的两个关键字。

3》为什么ODBC的句柄要设置为全局变量?——为了复用连接、简化调用、避免重复创建

4》数据类型转换【自己的代码做了改进,删去了冗余的代码,且正确delete了,避免了内存泄漏】
下述链接六、数据类型
【ODBC】ODBC连接数据库详细说明-CSDN博客
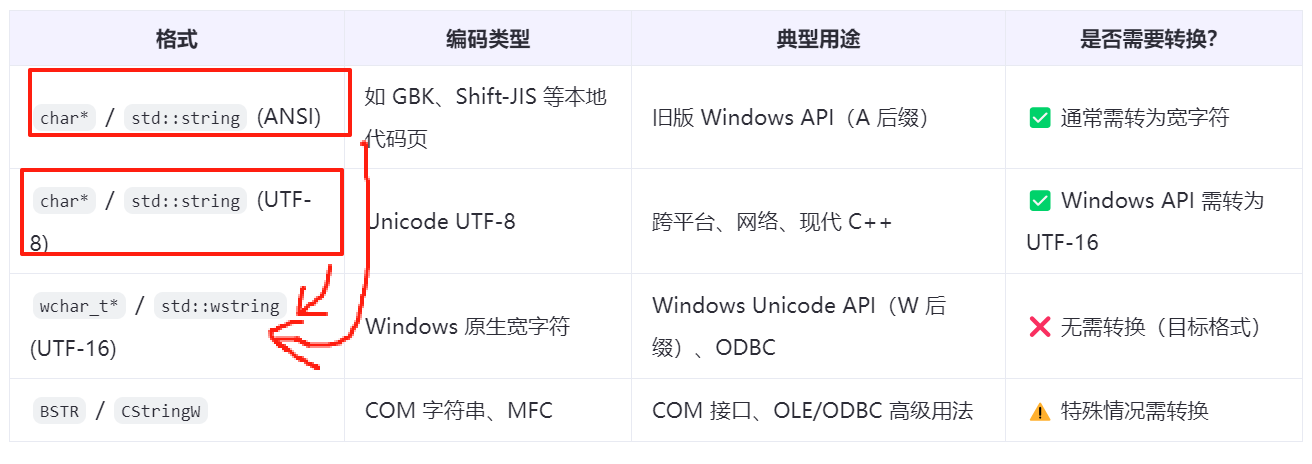
5》执行一条SQL语句
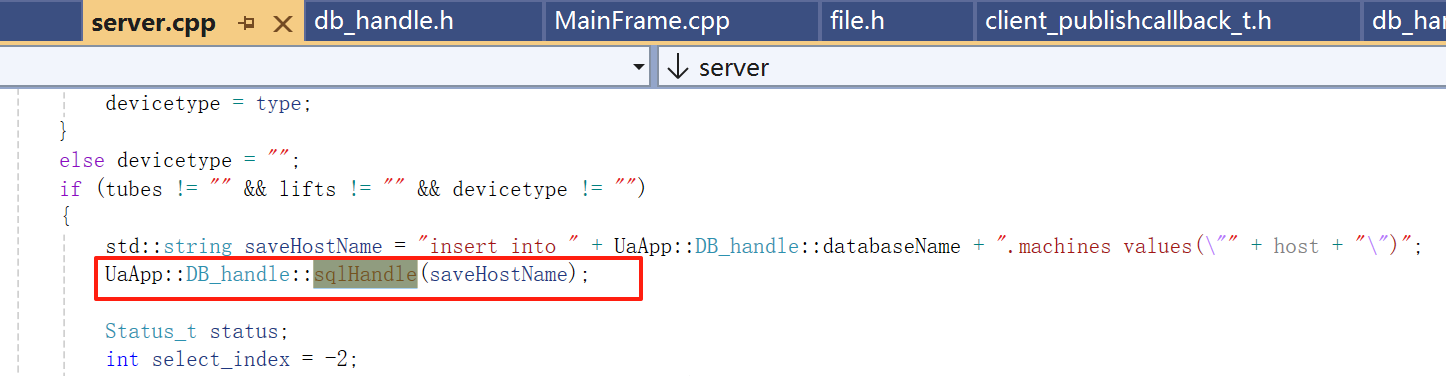
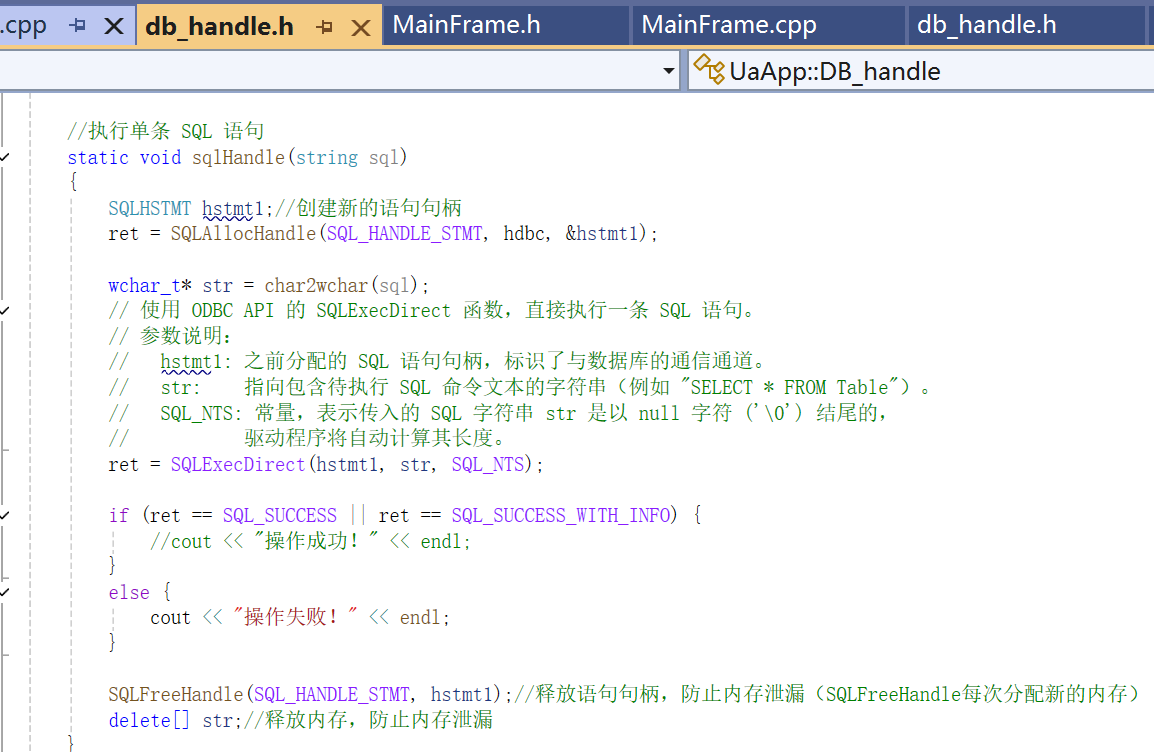
6》执行两条SQL语句:先切换为同一个连接下的其它数据库,再执行传入的 sql 语句
【这个函数没用上,而且写得有问题,考虑不完全【自己已经改好】】
切换数据库的关键是——构造一个像 "USE your_database_name;" 这样的完整 SQL 语句字符串,然后用 SQLExecDirect 去执行它。
五、初始化准备3:“缓冲区设置”【DataBuffer.h】
二、的目的:获取初始界面InitFrame::OnConfirm函数传过来的配置参数config【如下图所有的初始化信息】。
这部分是实现二、的下图红框部分
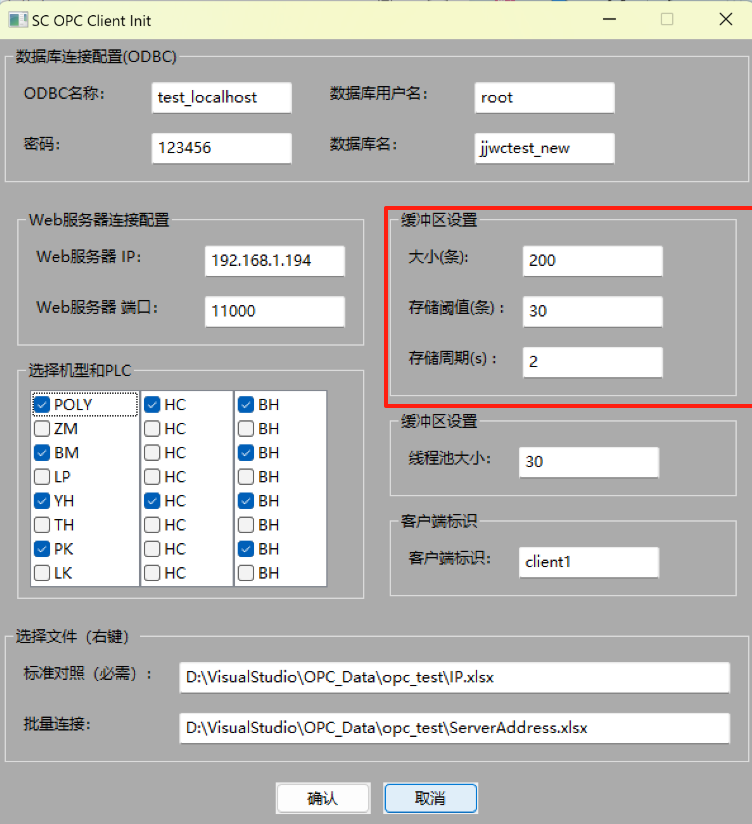
- 大小 (Size, 条):指缓冲区能容纳的最大数据条目数量。达到此上限时,可能需要丢弃旧数据或阻塞写入。
- 存储阈值 (Threshold, 条):指触发缓冲区刷新(如写入磁盘、发送)所需积累的数据条目数量。达到此数量时,立即处理缓冲区内容。
- 存储周期 (Storage Period, 秒):指缓冲区中数据的最长保留时间。超过这个时间的数据应该被“过期”或触发处理(如写入文件、发送网络)。
1、std::stoull
std::stoull:字面意思就是 "string to unsigned long long"(字符串转无符号长长整型)

2、函数的参数为什么是size_t 类型的?
1>size_t区别1、的unsigned long long

2>size_t
是一个无符号整数类型(通常是 unsigned int 或 unsigned long),它被设计用来表示:
- 对象的大小(例如
sizeof的返回值) - 容器的大小(例如
std::vector::size()) - 数组的索引
- 内存相关的计数
它的核心语义是:“非负的、用于表示大小或数量的整数”。
3>为什么 setProcessingThreshold 和 setMaxBufferSize 用 size_t 是合理的?
processingThreshold: 表示“多少条”数据触发存储。这是一个数量,必须是非负整数。size_t完美匹配其语义。maxBufferSize: 表示缓冲区能容纳的“最大条数”或“字节数”。这也是一个大小/容量,size_t非常合适。
4>师傅的代码有问题:为什么 setbufferTimed 用 size_t 是不合理的?
bufferTime: 表示“时间间隔(秒)”。- 问题1:精度丢失:时间间隔通常需要小数。例如,你可能希望轮询间隔是
0.5秒、1.2秒或0.1秒。size_t只能存储整数,setbufferTimed(0.5)会被截断为0,导致轮询间隔为0秒,这几乎等同于忙等待(busy-waiting),会耗尽CPU资源,是严重的性能问题。 - 问题2:语义不匹配:虽然时间间隔是一个“量”,但它本质上是一个物理量(时间),而不是一个“数量”或“大小”。
size_t的语义是“大小/数量”,而时间间隔的语义是“持续时间”。 - 问题3:灵活性差:无法设置亚秒级(sub-second)的轮询间隔,这在需要高响应速度的系统中是致命的。